
2
Evolution of Information Security Algorithms
Anurag Jagetiya1* and C. Rama Krishna2†
1 Department of Information Technology, MLV Textile and Engineering College, Bhilwara, Rajasthan, India
2 National Institute of Technical Teachers Training and Research, Chandigarh, India
Abstract
The chapter begins with the classical encryption techniques namely substitution cipher and transposition cipher. It covers popular substitution ciphers like Caesar, mono-alphabetic, Playfair, poly-alphabetic, and vignere cipher. Transposition-based ciphers like Rail Fence and Simple Columnar are also discussed with example.
Modern security algorithms, designed using both substitution and transposition based approaches, are categorized as stream cipher and block cipher. The chapter explores popular stream cipher algorithms like one-time pad (Vernam cipher), RC4, and A5/1. The key concepts of block cipher algorithms like key expansion method, Shannon’s theory of confusion and diffusion, and the basic Feistel structure are covered elegantly. Later, the chapter covers block cipher algorithms like DES, 3DES, IDEA, Blowfish, and CAST-128 and analyzes them with respect to their key generation methods, S-box designs, and vulnerabilities, etc.
Keywords: Classical encryption techniques, stream cipher, block cipher, A5/1, 3DES, IDEA, Blowfish, CAST-128
2.1 Introduction to Conventional Encryption
Over the decades many protocols and mechanism were invented to achieve information security. Information stored on magnetic disks and transmitted via wired/wireless links can be copied and altered. The need for information security for today’s internet-savvy generation requires fast and efficient methods of information security that cannot be penetrated by any intruder. Information security is the study of hiding useful and sensitive information from the illegitimate audience. It is the art of secret writing to thwart unauthorized access to someone’s secret information. In Cryptography, word “Cryptos” is taken from Greek that means “hidden” and graphy means “study”. Modern Cryptography is better described as the science of using mathematical techniques to scramble the data and transmit through a public network like the Internet in a way that is only readable by its intended recipient. In this chapter, human-readable information is termed as plaintext while scrambled information is termed as ciphertext. Scrambling of human-readable information into unintelligent text using mathematical formula or a well-defined procedure is referred as encipherment or encryption, while the reverse of encryption is termed as decipherment or decryption. Well-defined and proved algorithms are used for encryption and decryption purposes. For example, web traffic is secured by a protocol named Hyper Text Transfer Protocol over Transport Layer Security (HTTPS), wireless traffic is secured by protocol Wireless Protected Access-2 (WPA2), files stored on disk are also encrypted by Encrypting File System (EFS) or TrueCrypt software, and content of DVDs is encrypted with the Content Scramble System (CSS).
The principle of symmetric key cryptography states that two or more legitimate parties involved in the communication share a confidential piece of information termed as secret key among them. The sender encrypts the plaintext using an encryption algorithm and secret key. It, then, transfers the ciphertext to the receiver through a communication channel. Receiver, on the other hand, deciphers the ciphertext to get the plaintext using the same algorithm and the secret key. The key must remain secret to thwart against any kind of attack to reveal the secret key or compromise the information. Symmetric key cryptography involves only a single shared secret key to encrypt and decrypt the message between a pair, therefore, it is also known as a secret key or single key encryption. Generally, the encryption algorithm is having a reversible structure, i.e., the same algorithm is used in the decryption process, given the key in reverse order. A most common form of communication network used to transmit the information is publicly available internet. But, the internet cannot be trusted enough to share sensitive information. Therefore, this chapter will discuss the algorithms and practices used to protect the sensitive information over insecure networks. Figure 2.11 shows the principle of symmetric encryption between a sender and receiver. Intruder’s aim here is to discover the shared secret key. Because, once the key is known, all the ciphertext exchanged between legitimate parties can be decrypted using the same algorithm available publically.
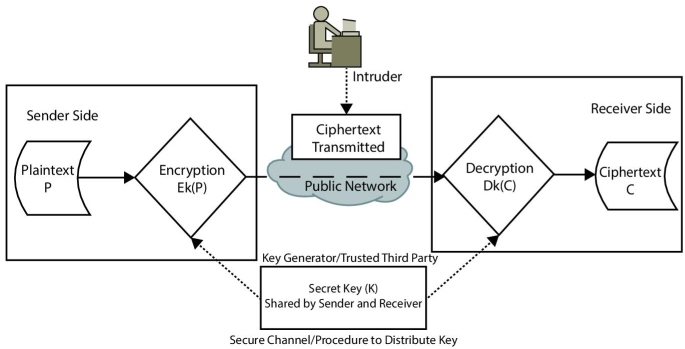
Figure 2.1 Conventional cryptography.
In symmetric key cryptography, encryption algorithms are well known and documented. Therefore, it should be strong that if intruder possesses some pairs of plaintext and corresponding ciphertext, he/she cannot decipher the ciphertext in order to discover the secret key. As shown in Figure 2.1 that symmetric key procedure is safe unless intruder obtains the shared secret key. Therefore, the key distribution must be a secure process. The symmetric key encryption process takes very less time to encrypt/decrypt as there is no heavy mathematics involved. Nevertheless, if opponent obtains the key, it can compromise the message as the algorithm is known already. In fact, a large number of keys will be required if the symmetric key procedure is used among many machines.
2.2 Classical Encryption Techniques
Classical encryption techniques are the elderly ciphers used to protect the information. Most of the classical ciphers are based upon substitution or permutation based approach [1].
2.2.1 Substitution Based
In substitution, each individual element of plaintext is mapped onto some different element of the given set of elements to produce ciphertext. In one of the most basic approaches of the substitution cipher, each alphabet in English is assigned a number ranging from 0 to 25.
The terminology used in this book to represent plaintext and ciphertext is shown below.
Plaintext “P” consist of individual elements so

- Encryption - C = Ek(P) = (P + k) mod Z
- Decryption - P = Dk(C) = (C − k) mod Z
In the case of English alphabets, the value of Z is 26, and k is the secret key (ranging from 1 to 25). For example, a plaintext letter “E” and key value 25 will be substituted to ciphertext letter “D”
2.2.1.1 Caesar Cipher
It was the ancient example of substitution based ciphers and it was believed to be applied in practice by ancient king Julius Caesar. In Caesar cipher, the smallest unit of a message is replaced by a unit three position next in its alphabet set. Therefore, plaintext message “How are you” will be transformed into “Kru duh brx”.
Caesar cipher is quite easy to implement but prone to brute force attack. Trying all the possible key space to deduce the plaintext from ciphertext is termed as Brute Force attack or exhaustive key search method. The approach is useful only when the key size is smaller otherwise for a larger key size this approach is quite impractical. Therefore, Caesar cipher can be easily decrypted by trying all the 25 keys.
2.2.1.2 Monoalphabetic Cipher
The problem of smaller key space of Caesar cipher was rectified in Monoalphabetic cipher. In Monoalphabetic cipher substitution characters are a random permutation of 26 alphabets. It means B can be replaced by alphabets A to Z, other than B. Furthermore there is no relation among replacement of each character. In other words replacement of A by D (i.e., A + 3 = D) does not mandate replacement of B by E.
Generally, the plaintext is written in well-known language therefore its statistical properties are easily available that can lead to statistical analysis attack on the ciphertext. It is not easy to apply brute force method in this case as it will take a lot more time trying 26! possible combinations of keys1 or even half of them. But, the frequency of occurrence of characters may lead to statistical analysis attack, i.e., same plaintext symbols always map to same ciphertext symbols [2].
Statistical analysis techniques provide good results if the length of the analyzed text is large. Therefore, good ciphers must hide the statistical properties of plaintext i.e., generates a random sequence of ciphertext symbols. Alternatively, plaintext available can be compressed before encryption to thwart against such attacks. Mathematician Carl Friedrich Gauss suggested an idea of using homophones i.e., multiple occurrences of a symbol will be replaced with different symbols. But, the biggest challenge of occurrence of combinations of two letters known as digraph cannot be removed.
An enhancement to the Monoalphabetic cipher is made by Polygram substitution cipher where a group of plaintext letters is encrypted with a group of ciphertext letters. It may be applied to a group of two (termed bigram or digraph) to N letters (N-gram). For example plaintext block “HIJ” may be encrypted to “KTQ” while “HIK” may be encrypted to “CDS”. This hides the frequency of individual letters.
2.2.1.3 Playfair Cipher
It has been seen that all the previously discussed ciphers were majorly suffering from the occurrence of a digraph in the text. Sir Charles Wheatstone suggested a method to treat diagrams as a single unit. He analyzed that ciphertext generated by one character substitution methods are more likely to preserve much of the plaintext syntax. However, substituting multiple plaintext letters i.e., treating them as a unit will wipe out some of that plaintext. Playfair Cipher is a popular cipher for multiple-letter substitution. This Cipher treats digraphs (i.e., the combination of two letters) of plaintext syntax as a single unit and substitutes them into equivalent cipher digraphs.
Playfair cipher requires a 5 * 5 matrix of letters of a keyword. For example, if the keyword is: Cryptography then the corresponding matrix will be as per Table 2.1:
This matrix is constructed by filling the alphabets of keyword: Cryptography left to right without writing duplicates (r and p). Rest of the matrix is filled by the remaining of the alphabets (a to z) in their actual order. Letters I and J considered as a single letter. Two letters of alphabets are translated at a time as per the following rules:
- A pair of same alphabets will be separated by a filler letter, for example say Z. So “Collect” will be treated in digraphs as “Colzlect”.
- Plaintext letter that comes in the same row will be replaced by their immediate right letter of the same row in a circular manner. So PT will be translated as TC.
- Plaintext letter of the same column will be replaced by the letter beneath from top to down in a circular manner of the same column. So RV will be translated as GR.
- Else, every plaintext character is swapped by the character found at the intersection of its row and remaining plaintext character’s column position. E.g., plaintext unit GQ will be changed to HM, similarly, BN will be changed to AS.
Playfair remains robust cipher for a long time and popularly used during World War I and II. But, the cryptanalysis of the Playfair cipher is also aided by the fact that a digraph and its reverse will encrypt in a similar fashion. It means that if the encryption of MN will be AJ, then encryption of NM will be JA. So by looking for words like: receiver, departed, repairer that begin and end in reversed digraphs may lead intruder to apply frequency analysis method to reveal plaintext.
Table 2.1 Playfair matrix.
| C | R | Y | P | T |
| O | G | A | H | B |
| D | E | F | I/J | K |
| L | M | N | Q | S |
| U | V | W | X | Z |
2.2.1.4 Polyalphabetic Cipher
Monoalphabetic cipher uses the same substitution rule for each substitution but in Polyalphabetic cipher rule changes with each letter or alphabet according to key value as per Table 2.2.
An early example of Polyalphabetic cipher is Vigenere cipher. Each letter of plaintext substituted into cipher as per the corresponding key value. For example, key: abracadabra and plaintext: “Can you meet me at midnight”, then corresponding ciphertext will be as shown in Table 2.3.
Generally, the key string is shorter than the message length like “abracadabra” is the key in the above example, so a same key string is appended and repeated for entire message length, or as an alternate, plaintext may be appended to the key. It is quite difficult to implement a frequency analysis method on Polyalphabetic cipher as the output is having multiple ciphertext letters corresponding to the same plaintext letter. For a key length N; Cipher consists of N monoalphabetic substitution cipher and the plaintext letters at positions 1, N, 2N, etc., will be encrypted by same monoalphabetic substitution cipher. This may be useful to decrypt each monoalphabetic cipher. The same cipher will be produced if two same sequence of plaintext appears at a distance that is an integer multiple of keyword length e.g., plaintext “hello to hell” and key “welcome” will produce ciphertext dIqkcfsdIqk.
Table 2.2 Polyalphabetic cipher.
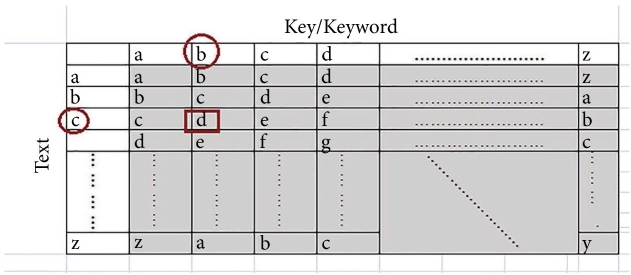
Table 2.3 Polyalphabetic cipher example.
| Key | abracadabraabracadabra |
| Plaintext | canyoumeetmeatmidnight |
| Ciphertext | CBEYQUPEFKME……… |
It is not difficult for the intruder to steal the information for a shorter key length. Therefore, it is recommended that length of key and plaintext should be same, and key should be a random permutation of 26 letters of the alphabet.
2.2.2 Transposition Based
Transposition is a technique to rearrange the order of plaintext elements to produce ciphertext. This technique is based upon permutation of the plaintext, i.e., SECURITY can be transposed to SCRYEIUT. Some popularly used transposition ciphers namely Simple Columnar and Rail Fence are discussed for better understanding of the approaches.
2.2.2.1 Simple Columnar
In this approach plaintext message is written in the rows of a certain size matrix and cipher is produced by reading its contents column-wise. The order to read the column is determined by the secret keyword shared among the communicating parties. If the keyword is given in alphabets, then, it is to be first converted into numbers according to their alphabetic order. For example, if the keyword is “BASH”, then the corresponding key will be 2143. For example, to encipher the plaintext “I AM SENDING YOU A MESSAGE” with keyword “SECRET, a two-dimensional matrix of 4 rows and 6 (keyword length) column is required. Number of rows (M) can be calculated as ⌈Length (plaintext)/Length (keyword) ⌉2.
Thus, the final matrix is as per Table 2.4.
Three places of the matrix left vacant after filling the matrix with plaintext. These vacant places should be filled with random letters instead of filling with a single padding character (for example “X”). The ciphertext will be written in the blocks of five to avoid guessing of keyword length. Thus, the cipher text is MNMEA IAGEY SPSGE QIDUA NOSJ.
Table 2.4 Simple columnar example.
| Keyword | S | E | C | R | E | T |
| Key | 5 | 2 | 1 | 4 | 3 | 6 |
| Plaintext | I | A | M | S | E | N |
| D | I | N | G | Y | O | |
| U | A | M | E | S | S | |
| A | G | E | Q | P | J |
Double Columnar:
The cipher produced by simple columnar can be made more secure by applying another round of the same permutation where ciphertext of above example is treated as intermediate plaintext to produce final ciphertext that is more secure.
2.2.2.2 Rail Fence Cipher
In Rail Fence transposition technique, plaintext characters are arranged diagonally and processed row by row to produce ciphertext. The number of rows is termed as the depth of the cipher. For example, plaintext “this is secret” will be arranged in depth of 2 as shown in Table 2.5. Depth is also known as ‘rail’ justifying its name as ‘Rail Fence’.
The corresponding ciphertext is produced by reading the characters row by row, therefore ciphertext is:
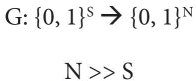
The number of rows (rails) can be more than two to enhance the robustness of the cipher. The strength of the cipher can be judged on the basis that the intruder can simply start assuming that there are two rows hence letters 1, 3, 5, … of the message are from the same row and 2,4,6, … are from another. If this is not the case then intruder will assume three rows hence letters 1,5,9, ... are in the first row, letters 2,4,6,8, … are in second and 3,7,11 are in row number three.
Table 2.5 Rail fence cipher example.
| Row1: | t | i | i | s | c | e | ||||||
| Row2: | h | s | s | E | r | T |
Generally, many modern security algorithms achieve information security by applying multiple rounds of substitution and transportation in a combined fashion [3].
2.3 Evolutions of Modern Security Techniques
As discussed in earlier chapters that there are two methods to convert plaintext into ciphertext namely block cipher and stream cipher. Block cipher works upon a chunk of plaintext bytes at a time and convert it into ciphertext. The size of the block depends upon the underlying algorithm used for encryption. A generally acceptable size of a block is 64-bit. Contrary to this, in stream cipher mode, a symbol is encrypted at a time; symbol can be a character or a bit. The below sections discuss both the modes in detail.
2.3.1 Stream Cipher Algorithms
Stream cipher encrypts symbols of plain text one at a time into corresponding ciphertext symbol with the help of a pseudo-random key value. Generally, stream cipher works on byte level i.e., it encrypts one byte at a time. The pseudo-random key in stream cipher is generated from an initial random secret key. The generator function is described as:
It indicates that generator function G maps initial seed value in seed space S to a pseudo-random value in space N. Here the value of N is very large than S, i.e., a seed value of around hundreds of bit might be mapped to a Gigabyte long pseudo-random value. Here, generator G should be efficiently computable through a deterministic function. The only randomness lies in the initial seed value. However, the output of generator G must look random. Figure 2.2 show that the generator produces a large value from a fixed length small seed value. In stream ciphers, this large value acts as an internal state for the generator from which it can produce a 1-byte key value per iteration. This key value is XOR’d with plain text byte to produce ciphertext byte.
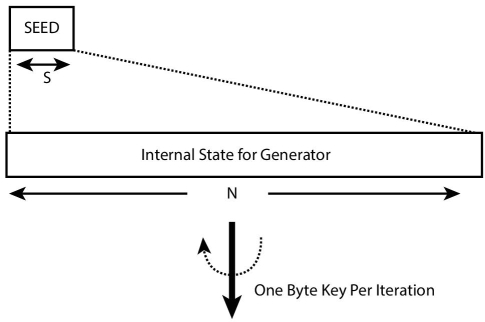
Figure 2.2 Generator function in stream cipher.
Most of the stream ciphers are based upon Linear Feedback Shift Register (LFSR). It is a shift register in which input is determined by XORing some of its existing bit-values called ‘taps’. LFSR is used to produce pseudo-random numbers; therefore, it can act as a generator in stream ciphers. It is chosen for this purpose due to ease of its development in both software and hardware. Figure 2.3 shows a LFSR, whose rightmost bit is taken as output and an initial bit is XOR’d to feedback into the register as input after every clock cycle. LFSR operation starts from an initial state determined by a seed value.
The length of LFSR is fixed. It means it has a limited number of input values which will be feedback to the register. Therefore, ultimately, LFSR will be stuck in a repeating cycle of output bit which makes it vulnerable to attacks. However, if the feedback function is chosen carefully, this cycle can be extended to some more time. There are many stream ciphers based upon LFSR viz. Content Scrambling System (CSS) used to encrypt DVD data uses two LFSRs, A5 (1/2) algorithm used in GSM system uses four LFSRs, E0 algorithm used to secure Bluetooth communication uses five LFSRs. Following subsections discusses popular stream ciphers One-Time Pad, RC-4, and A5/1.

Figure 2.3 Linear feedback shift register.
2.3.1.1 One Time Pad (OTP)
To begin with the simplest approach of a stream cipher, we illustrate the One Time Pad (OTP) invented by Vernam in 1917. The OTP cipher considered to be first secured stream cipher. In OTP, plaintext, ciphertext, and key value consist of binary numbers:
- Plaintext := Ciphertext := {0,1}n
- Key value :=.{0,1}n
Key value is a random stream of bits whose length is equal to the length of plaintext message and the cipher is defined as:
In OTP, the encryption process is simply XOR3 of key and plaintext message, so
XOR operation is also termed as modulo two additions as the results of modulo-two additions are exactly same as of XOR operations.
Based upon the properties of XOR, decryption of the ciphertext is:
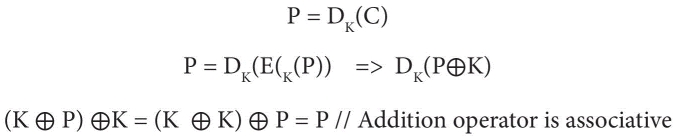
OTP approach is efficient and fast to encrypt and decrypt plaintext. However, it requires a large key size to thwart against attacks. If plaintext P and its OTP encryption C are given, it is possible to find out the OTP key K.
Now, XOR both the side by P
Readers must note that encryption process is often randomized while decryption process is always deterministic.
2.3.1.2 RC-4
RC-4 (Rivest Cipher) is a stream cipher algorithm that uses variable length secret key ranging from 1 to 256-bytes. It was developed in 1987 by Ron Rivest. RC-4 generates a keystream in the form of a bit which is XOR’d with the plaintext to produce ciphertext.
Working of RC-4 is divided into two parts namely: initialization of state vector and key generation. Initialization phase uses a key K as a seed value to populate state vector (array) S, and the key generation phase produces key in the form of pseudo-random bit streams. The idea of the key generation phase is to use a key value as a seed to generate a look-up table that can be used to produce pseudo-random bit streams, which act as key values. Array S is basically a 256-byte long state vector, which is populated using the small pseudo-code given below:

As the key length is variable, it can be less than 256 bytes, therefore, a temporary array T of size 256 bytes is used to copy the key value. If key length is less than 256 bytes, key values will be repeated to fill the array T.
The code is permuting the initial values of state vector S which were initialized from 0 to 255 in the beginning. The second loop which takes key values to produce the value of index j indicates that the values of state vector S are dependent upon key K. Once this code is over, the second phase, i.e., key generation starts. The pseudo code of the key generation phase is shown below:
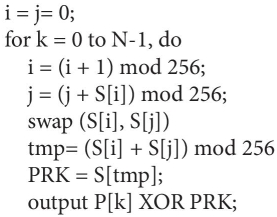
In the pseudo code, PRK stands for Pseudo-Random Key and P [0: N-1] denotes to plaintext. The code suggests that the value of index i is incremented in each iteration, and the value at that index is used to compute next index value j. Then, values at both the indexes in the state vector S are swapped. It means every iteration will make changes in the state look-up table. Values of S[i] and S[j] are added and ‘modulo 256’ operator is used to limit the result in the range of 0 to 255. Finally, the value at this index which is shown as tmp” in the code is used to fetch the value from state vector S. This value is the key for this iteration. The key value is XOR’d with the plaintext and this process is repeated for next byte of plaintext and so on. RC-4 generates pseudo-random bytes of the key at a time, which can be XOR’d with the byte of plaintext to produce ciphertext byte, i.e., operations of RC-4 are byte oriented. Figure 2.4 illustrates the operations of RC-4 graphically.
RC-4 is a simple and easy to implement encryption algorithm that works fast in software. HTTPS and WEP (Wired Equivalence Privacy) incorporates RC-4. However, WEP protocol is no longer considered secure due to the way of implementing RC-4 in it. Nevertheless, the problem is not with RC-4, but the way it is implemented.
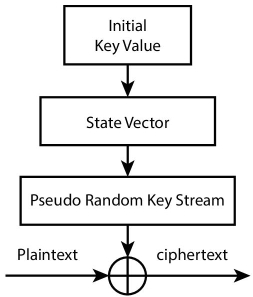
Figure 2.4 RC-4 operations.
2.3.1.3 A5/1
A5/1 is a stream cipher algorithm used to encrypt the telephonic conversations. It was first used by the Global System of Mobile (GSM) based mobiles as a built-in support to provide confidentiality to their users. Initially, A5/1 remained secret by GSM service providers, but, later, it was reverse engineered and analyzed by cryptanalysts.
A5/1 uses a secret key of size 64-bit and an initialization vector (IV) of size 22-bit. IV is obtained from a publically known frame number of 22-bit. The key component of A5/1 stream encryption is a linear feedback shift register (LFSR). It incorporates three LFSRs namely R1, R2, and R3 of size 19-bit, 22-bit, and 23-bit, respectively. LFSRs uses their bit number 8, 10, and 10, respectively, as clocking bit, i.e., LFSRs are clocked regularly as per the value of their corresponding clocking bit. Clocking decision involves all the three registers. Clocking bit of all the three LFSRs are used to compute majority value using the following formula:
In Figure 2.5, a clock controlling unit is indicated that controls the clocking decision of A5/1. LFSRs whose clocking bit agrees with the computed majority are clocked i.e., LFSR R1 will be clocked if its 8th bit (clocking bit) agrees with the majority. In every clock cycle, LFSRs updates according to their primitive polynomial as shown in Table 2.6, Only last bit of LFSRs contributes to the output which is calculated by XORing the values of Most Significant Bit (MSB) of R1, R2, and R3. Following expression summarizes the output:
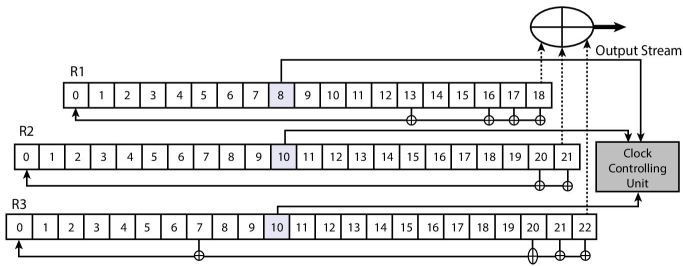
Figure 2.5 A5/1 structure.
Table 2.6 A5/1 parameters.
| Register | Length | Primitive Polynomial | Clock Bit | Bits XOR’d |
| R1 | 19 | X19 + X5 + X2 + X + 1 | 8 | 18,17,16,13 |
| R2 | 22 | X22 + X +1 | 10 | 20,21 |
| R3 | 23 | X23 + X15 + X2 + X +1 | 10 | 22,21,20,7 |
Using one bit per clock cycle, A5/1 produces a 228-bit output stream. The first half of the output stream is used to encrypt uplink data while the remaining half is used to encrypt downlink data.
With only 64-bit of key size, A5/1 seems weak using today’s modern day computer systems. However, A5/1 is used in many countries to protect their GSM networks. Many countries also use A5/2 which is also a similar kind of stream cipher but it is designed to be weaker than A5/1 [4].
2.3.2 Block Cipher Algorithms
Unlike stream cipher, block cipher coverts a chunk of plaintext byte at a time into ciphertext. Most commonly used size of a block is 64-bits, but it is not fixed and depends upon the nature of the security algorithm used. Block cipher is based upon the fact that entire plaintext message is partitioned into blocks of similar size to be encrypted using a secret key. It is clear that every block of plaintext is encrypted individually, moreover, inside in a single block; every smallest element of a block is encrypted with keystream. So it gives a glimpse of stream cipher inside block cipher. Popular block cipher algorithms are Advanced Encryption Standard (AES), Triple Data Encryption Standard (TDES or 3DES), etc.
Block ciphers are built by iterations, i.e., the plaintext is supplied as input and ciphertext are generated after several rounds of iterations. As shown in Figure 2.6 that a single secret key is expanded to produce multiple unique keys for multiple iterations also called rounds of encryption.
Here R(K, P) is known as a round function that accepts two arguments namely key and the current message state. Figure shows that initially plaintext P is fed into first round function and then the output of this round function is fed as input to another round function with a different key value. The ultimate output of all the round functions is the ciphertext. The reader might be thinking that is there any generally accepted number of round functions. Actually, it depends upon the algorithm, for example, 1 DES uses 16 rounds, 3DES uses 48 rounds, and AES uses 10 rounds. The idea behind using multiple rounds of encryption is to generate a strong cipher that will not exhibit any relationship between plaintext and secret key. More details of rounds will be discussed in subsequent sections of this chapter. It is found that block cipher may generate same ciphertext block for repeating plaintext block if the key is same, hence cryptanalyst can make a guess of part or pattern of plaintext. With some more efforts, cryptanalyst may also reveal much part of the plaintext which leads to harmful consequences.
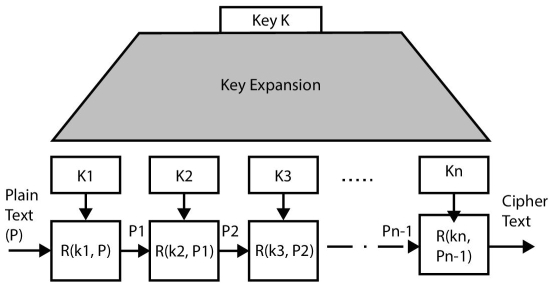
Figure 2.6 Key expansion method in a block cipher.
Claude Shannon in one of his research publication suggested two primitive operations namely confusion and diffusion in order to perform strong encryption and decryption. The idea was to make a strong cipher such that cryptanalyst cannot deduce key easily from ciphertext and plaintext pair. He also thought of a strong cipher that fulfills the strict avalanche effect, i.e., a single bit change in plaintext will affect several bits in the ciphertext. Shannon suggested that these properties of a strong cipher can be achieved with the help of confusion and diffusion methods [4].
Confusion:
Confusion is intended to conceal the relationship between plaintext and ciphertext. In easier words, it is a technique to make sure that ciphertext does not reveal the pattern of plaintext. The process of confusion uses the key in a complex manner that even when an intruder knows the statistics; it is still difficult to infer the key. Confusion means that every bit of ciphertext depends upon many bits of the key. Therefore, changing a single bit in the key will drastically change the cipher.
Diffusion: It spreads the statistical properties of plaintext while producing ciphertext. Thus, diffusion dissipates the statistical structure of plaintext over most of the ciphertext. Diffusion complicates the statistics of the ciphertext, so it is difficult to discover plaintext through ciphertext. Shannon suggested a network of substitution and permutation to achieve confusion and diffusion in a strong cipher. An algorithm will be known for good diffusion if each of its plaintext bits and key bits affects half of the output bits. A good degree of avalanche effect is a major requirement of any cryptographic algorithm. Otherwise, the cryptanalyst can find out plaintext given some ciphertext or cryptanalyst can figure out key having a pair of plaintext and ciphertext. In order to illustrate the avalanche effect, an example of hash algorithm SHA-1 is shown in Table 2.7.
So, it is clear that in the second string only “hello” word is replaced with “hell” but there is a significant change in their corresponding hash value. This is a good example of the avalanche effect in the hash function. In order to achieve a strong avalanche effect most of the modern cryptographic algorithms combine both confusion and diffusion methods.
2.3.2.1 Feistel Cipher Structure
In the early 1970s, IBM realized that the customers are demanding some form of encryption to protect their information stored or transferred digitally. Therefore, IBM formed a group called crypto group and the head of the group was German-born physicist and cryptographer Horst Feistel. His first designed algorithm called Lucifer that accepts a secret key length and block length of 128 bit.
The design of Horst Feistel is popularly known as Feistel network. Feistel network is a symmetric structure used to design most of the block cipher algorithms (except AES). The goal behind building the Feistel network was to develop an invertible function, i.e., a structure that can be used in both encryption and decryption with the change in parameters only. In Feistel network, plaintext passes through a sequence of N-iterations of a round function whose working will be more precisely discussed successively. In each round, 2w-bit plaintext is divided into two equal halves and transformed with the help of secret key and round function. Working of round function remains the same in every iteration and every round produces 2w-bit output. It is worth mention here that the structure of each round is exactly identical, but, input parameters like intermediate ciphertext, secret key value, etc., are quite different. In each round, a unique key value is produced with the help of a key generating function. Finally, the ciphertext is generated after performing final permutation to the output of the last round.
Table 2.7 SHA-1 avalanche effect in hash function SHA-1.
| Input text | The hash value of SHA-1 |
| hello how are you | BA6A9C00C87E2AA5F02C2085214383FE256529BA |
| hell how are you | 3490BB27F976D61A6EDD5CF799D2519D0AB1DB3E |
For example, plaintext of size 2w-bit is divided into two equal halves portions termed left and right. As shown in Figure 2.7, right half of first round (R0) is fed directly into the left half of second round (L1) and processed with a secret key (K) in round function (F). Whereas, left half of first round (L0) is XOR’d with the processed output of round function. This procedure is repeated up to a total number of rounds (N) and the final combined value of left and right portions is treated as ciphertext.
Transformations made at each round are summarized through the following equations
Value of i = 1, 2…..n
In the Feistel network, encryption and decryption process are structurally identical. Therefore, in decryption process, ciphertext is used as input and the sub-key Ki is used in reverse sequence of encryption, i.e., Kn will be used in the first round, Kn-1 in the next and so on.
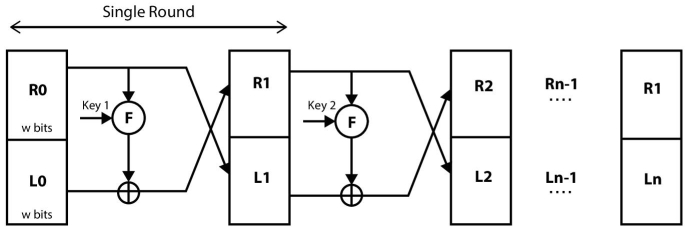
Figure 2.7 Feistel cipher structure.
In order to prove the Feistel network is really reversible, let’s construct inverse of Feistel network’s round, i.e., if we are given Ri + 1 and Li + 1, we need to find out Ri and Li and so on. With the help of Figure 2.8, it can be said that: Ri = Li + 1 and Li = Ri+1 XOR F (Li + 1). The inverse of a round function in Feistel structure is shown in Figure 2.9.
It is clear that the inverse of a Feistel round is much similar to its original round or it can be said that they are the mirror image of each other. Thus, putting together the inverse of all these rounds, the inverse of the entire Feistel structure can be obtained.
2.3.2.2 Data Encryption Standard (DES)
Data Encryption Standard used to be the most popularly used symmetric block cipher algorithm. The purpose of DES was to provide a standard method for protecting sensitive commercial information. Feistel’s suggestion was to keep the key length to 128-bit. But, NBS decided to reduce the key length to be 56-bit. Reduction in size of key length proved as a fatal decision and in the year 1997, DES was broken by exhaustive search method. In the year 2000 Advanced Encryption Standard (AES) was finalized as the next-generation encryption algorithm. Nevertheless, DES was widely deployed in banking and commerce industry before being replaced by AES. These days, the successor of DES known as Triple Data Encryption Standard (TDES) is widely used conventional encryption algorithms. DES operates on a block of 64-bit plaintext and uses a 56-bit key. As shown macroscopically in Figure 2.10, DES has 16 Feistel rounds of encryption. Each round requires a different key (K1-K16) of 48-bit produced through a key generator. Key generation mechanism accepts the initial 56-bit key and subsequently generates unique keys of 48-bit for all the iterations of round function by performing some transformations. Due to reversible design, decryption in DES uses the same structure and key (reverse order).
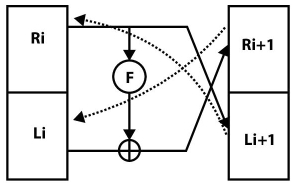
Figure 2.8 Reversibility of Feistel cipher structure.
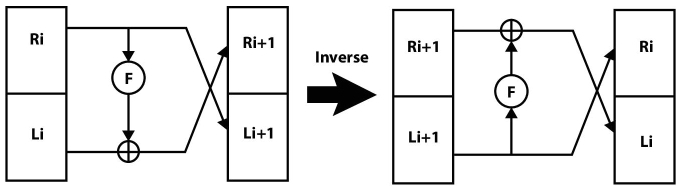
Figure 2.9 Inverse of Feistel cipher structure.
DES is based upon Feistel network; therefore, its working is similar to Feistel network. The output of an ith iteration in a round can be summarized as:
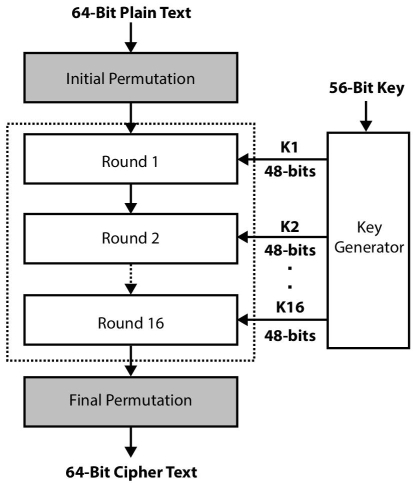
Figure 2.10 General model of DES.
An initial and final permutation is used to add permutations in DES. Working of each portion of DES is discussed subsequently.
Initial and final permutation:
Initial Permutation (IP) and final permutation (IP-1) are used to permute the input plaintext according to a predetermined rule4. This is achieved with the help of Permutation (P)-box in DES.
Round Function:
Figure 2.11 illustrates the accurate working of a single round function (left) with key generator (right) used in the DES algorithm. In DES, plaintext block is divided into two equal halves of 32-bit each namely left and right. Right value is entered into a core function F whose working is as follows:
- The input 32-bit value is expanded into 48-bit through Expansion Permutation and XOR’d with the 48-bit key value produced by the key generator.
- The resultant 48-bit value is feed into Substitution Box (S-Box) that again converts it into 32-bit and passed into Permutation function P.
Expansion Permutation:
Expansion permutation expands 32-bit right half value (Ri-1) to 48-bit so that it can be XOR’d with 48-bit sub-key. In order to do so, Ri-1 is divided into 8 equal parts of 4-bit each. Now every 4-bit part will be expanded into 6-bit to make it a total 48-bit. This will be done by simply copying certain values of 4-bit input using a predetermined rule of expansion permutation table (Appendix). Numbers in the table indicate bit positions and each row in the table is having six values out of which border values are highlighted, and these highlighted values are added in each row of 4-bit to convert to 6-bit. The first row shows that the bit at positions 1, 2, 3, and 4 in the input will be copied at positions 2, 3, 4, and 5 in the output. The first position of output will be filled by the 32-bit value of the input and 6th position of output will be filled by 5th-bit value. Thus remaining rows of 4-bit will also be transformed into 6-bit. Figure 2.12 further demystify the approach used to convert the 32-bit value of the right half into 48-bit.
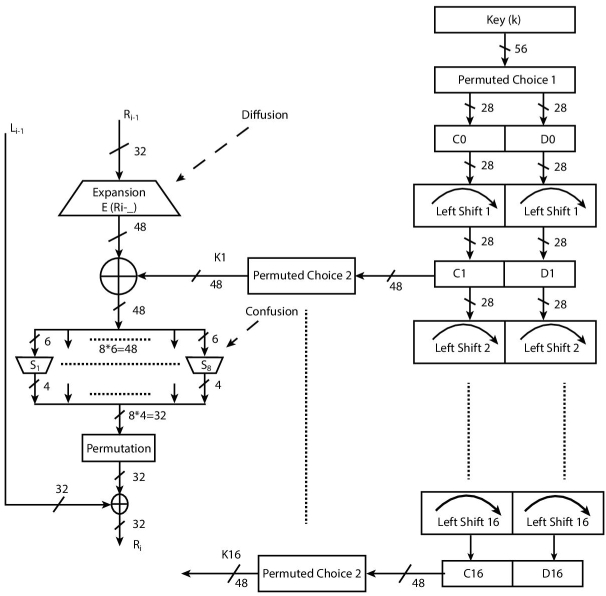
Figure 2.11 DES round structure (left) and key generator (right).
Substitution (S) Boxes:
This is a very important part of DES and adds the Shannon’s suggested confusion phenomena into it. S-boxes again convert the 48-bit value to 32-bit.
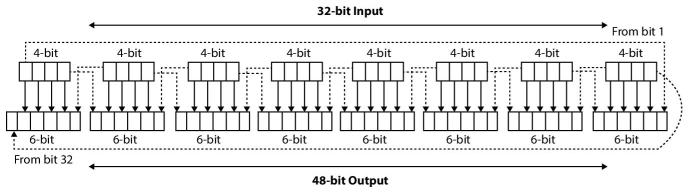
Figure 2.12 DES 32-bit to 48-bit expansion.
DES uses eight S-boxes having 6-bit input and 4-bit output. The substitution is based upon the predetermined table of 4 rows and 16 columns. This table is different for every S-box and contained 64 (4 * 16) random values which can be represented with 4-bit, i.e., 0 to 15. In order to choose a value from 64 values, 6-bit input is used. As shown in Figure 2.13 that first and last bit of the 6-bit input determines the particular row and bit ranging from 2 to 5 (4 bit) is used to find the column number of the table. Thus, the entry corresponding to the given row and column is taken as a 4-bit value corresponding to the given 6-bit value.
To further clarify the working of S-box, take an example whose graphical representation is shown in Figure 2.14. Suppose the 6-bit input for S-box-1 is: 101010, it means an entry in the table of S-box 1 corresponding to row 10 (2 in decimal) and column 0101 (5 in decimal) is-06 (binary equivalent 0110). Thus string 101010 will be converted to 0110. Each S-box is having a different Table that is shown in the Appendix 2.8.
P-box permutation table:
The 32-bit output of eight S-boxes is fed into a permutation box that again permutes the bit according to the predetermined table shown in Appendix 2.7.
Key Generator:
Actual key size in DES is 64-bit, but before the process starts, every 8th bit of key, i.e., 8, 16, 24, 32, 40, 48, 56, 64, is discarded. These bits can be used for parity checking to ensure that the key does not contain any error. Key generator as shown in Figure 2.11, divides input 56-bit key into two equal halves of 28-bit each, namely, C0 and D0 and then pass through Permutation Choice-1 (PC-1) function for permutation. Every iteration performs Left Circular Shift on these 28-bit values. Schedule of left circular shift is also fixed in every round and is shown in Appendix 2.5. These shifted values fulfill the following two purposes:
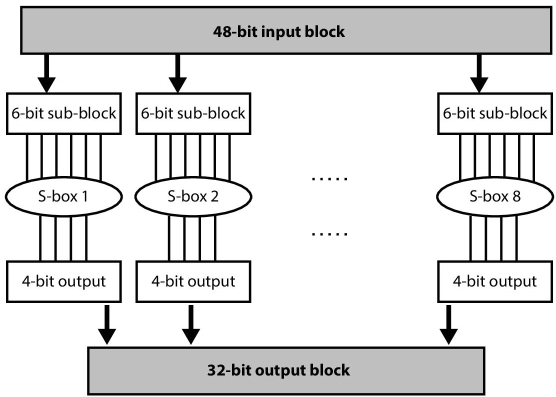
Figure 2.13 DES 48-bit to 32-bit substitution.
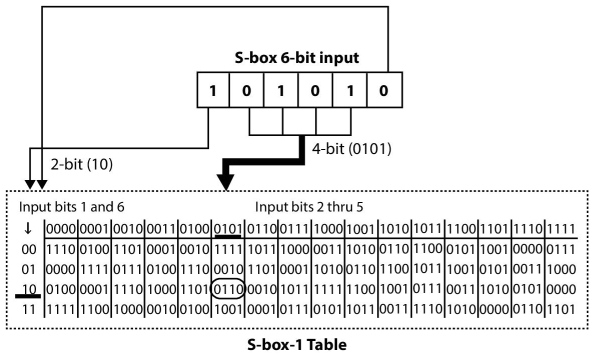
Figure 2.14 DES S-box substitution.
- Serve as input for the next iteration, i.e., C1 and D1
- Serve as input to Permutation Choice-2 (PC-2) function resulting in a 48-bit key Ki. Permutation choice-2 function is basically a compression permutation as it compresses 56-bit key into 48-bit. This 48-bit key is used as the key for round function and process continued for remaining 15 rounds. Tables of PC-1 and PC-2 are predefined and shown in Appendix 2.3 and 2.4 respectively.
It is to be mentioned again that in the very beginning, 64-bit plaintext is divided into two equal halves namely left and right halves. All the transformations discussed so far are applicable to the only the right half. As depicted in Eq. (2.4), 32-bit output of function F mentioned above is XOR’d with 32-bit left half and produces the 32-bit right half for next round. 32-bit right half portion of previous round is copied directly into 32-bit left half of next round as per Eq. (2.3). The process is repeated for 16 iterations of round structure. The right and left output of 16th round are swapped and it is termed as pre-output. Pre-output is delivered to Final Permutation (also called Inverse Initial Permutation) to produces the final 64-bit ciphertext output.
The decryption process in DES is same as of encryption. The difference is only in the sequence of the key, which is reversed key. It means key will be used as K16, K15, K14, ... K1 for all 16 rounds of decryption process respectively [1].
Analysis of DES:
DES is robust against analytical attacks as it is based upon avalanche effect i.e., small changes in plaintext or key bit results into drastic changes in ciphertext and changes increase with the number of round functions. DES is very fast in computation, compact in hardware, and easy to adapt in diverse applications. However, as mentioned earlier, DES is vulnerable to brute-force method. But, there are two more methods namely differential and linear cryptanalysis discovered to break DES in less than 256 times, i.e., lesser than brute-force attack on DES.
Differential cryptanalysis:
Differential cryptanalysis is a chosen plaintext attack. In chosen plaintext attack, an intruder is able to obtain some ciphertext corresponding to some chosen-plaintext by him. Differential cryptanalysis is the method to measure the differences in the output ciphertext when corresponding input plaintext is changed. The idea is that the cipher of any plaintext may look random but this is not true on a differential basis. This method uses plaintext pairs with a constant difference and the attacker compares the differences in the corresponding ciphertext with the purpose to find out statistical patterns in the cipher to discover the key. Therefore it is termed as differential cryptanalysis. Readers must note that statistical properties depend upon the S-box used for encryption. Input difference of two plaintexts M1 and M2 is wisely chosen such that the difference of their corresponding ciphers C1 and C2 will provide an idea about the statistical properties of some of the key bit. Differential cryptanalysis has become a design concern of modern algorithm as its knowledge is increasing; as a result, Advanced Encryption Standard (AES) has proven secure against this attack.
Linear Cryptanalysis:
Linear cryptanalysis is a known plaintext attach based upon the linear calculations of parity bit of all the three entities namely plaintext, ciphertext, and key. It requires 243 known plaintexts and ciphertext pairs to discover the key. The goal of linear cryptanalysis is to find out the secret key in less than 256 time, i.e., less time than the brute force attack. It is assumed that during linear cryptanalysis attacker possess many input and output pairs of plaintext and corresponding ciphertext.
Let C= DES (K, M), suppose for random K, M, there is dependence among message, ciphertext and plaintext such that if we XOR a subset of plaintext with a subset of ciphertext, it produces a subset of the key bit with a probability of ½.
If this probability is ½, it means both the sides are completely independent, i.e., given many pairs of message and cipher, an attacker cannot figure out the key bit. But, due to a bug in the design of 5th S-box of DES, this probability is actually ½ + epsilon (Ɛ), not exactly ½. Tiny linearity in the 5th S-box generates liner equations as given below through entire circuit:
For, DES, this Ɛ is very low (i.e., 1/221 ~ 0.0000000477), but there is a bias that leads to a linear attack on DES. A theorem suggests that given 1/Ɛ2 random pair of plaintext and corresponding ciphertext, the probability that the above relationship will be correct for more than ½ of the time is more than 97.7%. It is mentioned that for DES, Ɛ =1/221, so with 242 (i.e., 1/Ɛ2) pairs of plaintext and ciphertext, an attacker can find out XOR of some of the key bit. Therefore, around 14 key bit can be predicted using this relationship once by going through a backward direction and once by going through forwarding direction. When 14 bits are predicted, the brute force method can be applied to remaining 42 bits (56 − 14 = 42). Brute force on 42 bits will take 242 time or roughly 243, which is very less than 256
Therefore, in linear cryptanalysis total attack time is 243 with 242 random plaintext and ciphertext pairs [6].
2.3.2.3 Triple Data Encryption Standard (TDES)
As the computational capacity of modern machines is increasing tremendously, it is not difficult to brute force a 56-bit long key. Therefore to achieve more security a variation of DES named Triple DES (TDES) is in use. The term variation is used because TDES is not a new algorithm and is based upon DES algorithm differing only in key length.
As per its name, it applies DES algorithm three times on a single block of plaintext with a different key each time. Parameters of 3DES are 64-bit block size, 48 rounds (3 * 16), and key size 3 * 56 = 168-bit. TDES was standardized in 1999 and is in use of the electronic payment industry. The layout of 3DES is shown in Figure 2.15.
TDES uses three keys each of 56 bit length and follow the sequence of Encryption-Decryption-Encryption that is summarized as:
Where Ek denotes encryption of plaintext using key k and Dk denotes decryption using key k.
Readers might be wondering why its Encryption, Decryption, Encryption instead of Encryption, Encryption, Encryption. So, to justify this, suppose all three keys are the same, i.e., k1 = k2 = k3 = k, then the above-stated formula becomes:
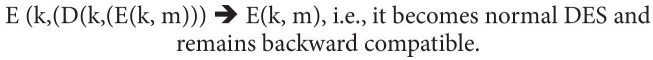
Key options in TDES:
TDES algorithm uses three consecutive keys viz. k1, k2, k3 so keying option can be described in Table 2.8. Option 1 is TDES with total key size 168-bit. Option 2 uses two keys with key size 112 also known as double DES and option 3 is simple DES.
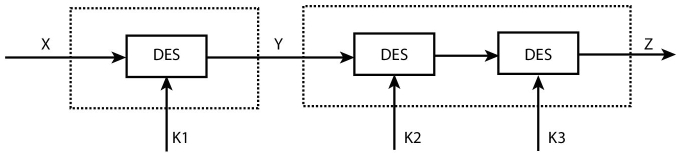
Figure 2.15 Block diagram of 3DES.
Table 2.8 TDES key option.
| Option | Description | Key size | Security level |
| 1. | All keys are independent | 56 * 3 = 168 | High |
| 2. | k1, k2 are independent while k3=k1 | 56 * 2 = 112 | More than DES |
| 3. | All three keys are same | 56 | Equal to DES |
Analysis of 3DES:
As the key size is 168, any exhaustive search has to try 2168 possible keys, that is really a very huge number and practically impossible. But, the number of rounds will definitely slow down the performance of 3DES. It is almost three times slower than DES. Then, Why not use double DES if triple DES is slower?
Defining double DES as 2E((k1,k2),m) = E(k1, E(k2,m)), and key length is: 2 * 56 = 112 that is sufficiently large and its speed will be two times slower than DES. Then, it should be a good choice, but this structure can’t be used due to its vulnerability of meet-in-the-middle attack.
Meet-In-The-Middle attack (MITM) on 2DES:
Suppose, given a pair of message M = {m1, m2,….m10} and corresponding ciphertext C = {c1,c2…c10}, and the goal is to find out key pairs {k1, k2} such that
If we apply decryption with key k1 on both the side of this equation, then:
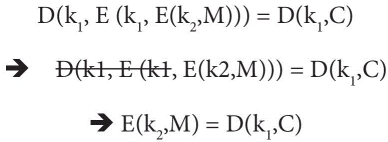
This final equation says that key k2 encrypts plaintext M to a value, which is same to the decryption of cipher C by key k1. As shown in Figure 2.16, this attack is called “meet in the middle” and it will take time lesser than exhaustive search.
Total time taken by “meet-in-the-middle” attack on 2DES is around 263 that is very less than 2112 of exhaustive search. 263 is really very less time and approximately equal to the time taken by an exhaustive search on DES. Therefore, 2DES is not a recommended block cipher. What if the same attack is applied to 3DES? Figure 2.17 indicates the point where “meet-in-the-middle” attack can be applied to 3DES.
In the forward direction, a table of 256 entries of encryptions of plaintext is to be created, and then try to decrypt cipher with all 2112 possible key values until a collision in the encryption table is found. But, this leads to an approximate 2112 time that is still much-much larger to brute force. Therefore, 3DES is the NIST standard and DES is no more used in its original form.
2.3.2.4 International Data Encryption Algorithm (IDEA)
IDEA is eight rounds, 64-bit symmetric block cipher using 128-bit key size. This algorithm provides full protection of information from unauthorized access by intruders. IDEA is far better in security than 56-bit key based widely used Data Encryption Standard (DES). Instead of look-up tables or S-Box used in DES, IDEA uses a complex transform by the combination of XOR, binary addition and multiplication of 16-bit integers.
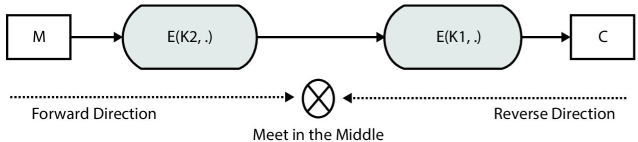
Figure 2.16 Meet in the middle attack in double DES.
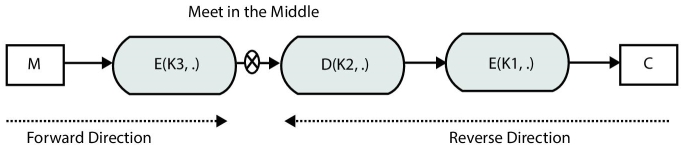
Figure 2.17 Meet in the middle attack in triple DES.
The IDEA algorithm depicted graphically in Figure 2.18 begins by dividing 64-bit Input block into four equal words of 16-bit each, namely A, B, C, and D. IDEA uses eight rounds of computation and each requires six subkeys (16-bit each). After eight rounds of computations, the output transformation process uses four subkeys. Thus, entire IDEA encryption process uses 52 number of (i.e., 8 * 6 + 4) 16-bit subkeys that are generated by an initial 128-bit master key.
Key Management:
Master key (128-bit) is initially divided into eight 16-bit words and is used as first eight subkeys out of 52 sub keys as mentioned above. Subsequent subkeys (52 – 8 = 44) for the next rounds are generated by rotating 25-bit left to an initial 128-bit master key. The starting process of dividing master key into eight sub keys is again repeated for the next rounds.
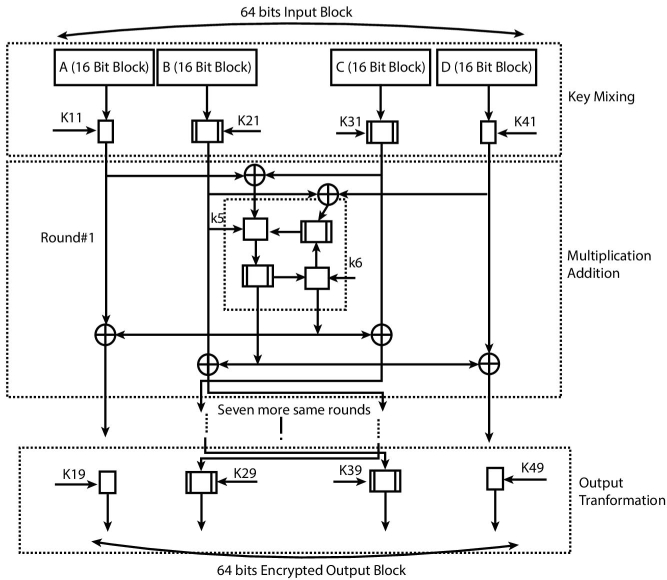
Figure 2.18 IDEA encryption process.
Encryption:
Each round of IDEA encryption is divided into two parts viz. key mixing layer and a multiplication-addition structure.
- Key mixing layer performs parall el operations (multiplication and addition) to combine each input word (A, B, C, and D) with first four subkeys (K1, K2, K3, and K4).
- The multiplication-addition (MA) structure takes the output of the key mixing layer as input and combines with two next subkeys (K5 and K6). Finally MA structure exchanges two middle words (B and C).
The last step consists of output transformation which uses last four subkeys (e.g., K19, K29, K39, K49) and generates four blocks (each of 16-bit) of ciphertext, these blocks are combined to produce 64-bit ciphertext. The process of decryption remains the same while the inverse of sub keys used during encryption is used. IDEA has several advantages like worldwide presence and fast algorithm, provides high-level security with a 128-bit key (Double of DES), cost effective implement IDEA in hardware chips, etc. IDEA was first used with Pretty Good Privacy (PGP) and later used in various areas like finance, telecom, etc.
2.3.2.5 Blowfish
Blowfish is publically available general-purpose symmetric block cipher encryption algorithm which is based upon Feistel structure. Blowfish was proposed as a replacement to DES which was getting older and slower. It was proposed as a software encryption algorithm that could work easily on 32-bit machines.
The similarity of Blowfish with its predecessor is the use of 64-bit block size of the plain text. However, Blowfish uses a variable key length ranging from 32 to 448-bit. Normally, Blowfish uses 16 rounds of Feistel structure.
Key Management:
Blowfish uses a large 448-bit long key that is used to generate sub-keys of 576-bit. Due to a larger key size, Blowfish calculates keys before performing encryption and decryption. It uses 14 K arrays each of capacity to store 32-bit resulting in the 448-bit long key. While 18 P arrays each of capacity to stores 32-bit resulting in 576-bit long sub-key.
Encryption:
The 64-bit input plaintext is divided into two equal halves, namely, RE and LE. Then, following operations are repeated for each round function, i.e., repeated 16 times.
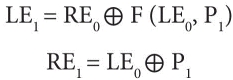
The above expressions can be generalized as:
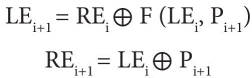
Here ⊕ denotes bitwise exclusive-OR, F is the function used in each round, and P denotes that array holding sub-keys.
As shown in Figure 2.19 the output of the 16th round is to generate final encryption in the following way:
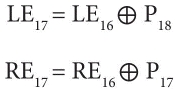
Basically, the output of the 16th round is swapped again to produce LE17 and RE17, which are merged to produce final 64-bit ciphertext. Figure 2.19 indicates that function F in a round is having four S-boxes and each S-box takes 8-bit input and produces a 32-bit output which is XOR’d and added to produce 32-bit output.
Decryption process in Blowfish uses encryption structure with reverse oder key. But, first P17 and P18 are XOR’d with ciphertext, then, remaining sub-keys are used in reverse order.
Blowfish uses a very large key which makes it more robust toward any security attack. Generation of a key in advance makes it suitable for applications, which do not need new key often. Blowfish was designed to run in software-based encryption so its encryption speed is fast. Moreover, it is not patented that makes it more easy to use in many applications.
However, producing key is a slow and intensive task in Blowfish that might be a limitation of the same in many areas. It is also found that the first four rounds of Blowfish can be compromised by second order differential attack. Therefore, the creator of Blowfish proposed its successor Twofish encryption algorithm.
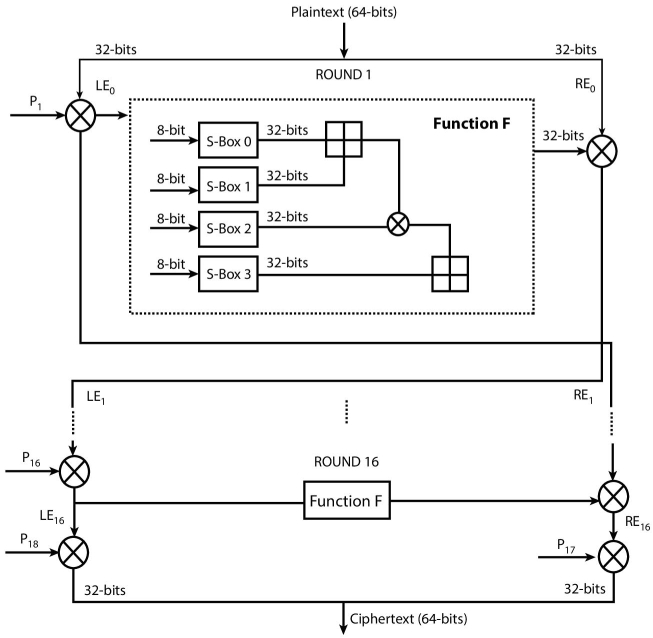
Figure 2.19 Blowfish encryption.
2.3.2.6 CAST-128
In order to thwart against linear and differential cryptanalysis, Carlise Adams and Stafford Tavares proposed CAST encryption algorithms in 1996. CAST is a basically a family of symmetric key encryption/decryption algorithms and CAST-128 is a prevalent algorithm of this family that uses a 128-bit long key. Like DES, CAST-128 is also based upon the well-proven design principles of Feistel structure, but, it provides strict avalanche criteria which was absent in DES. Interestingly, it provides better performance by using lesser rounds than DES. CAST incorporates certain changes in round function and key schedule that makes it more suitable for software implementation too. The main idea of CAST algorithm is to use large S-box to thwart against linear and differential cryptanalysis, i.e., it uses 8 × 32 size S-box rather than 6 × 4 size of DES. It uses exclusive OR, addition and subtraction modulo 232 operations. It uses eight S-boxes from which four are used in key scheduling while four are used in round function.
CAST-128 seems structurally identical to Blowfish. But, CAST-128 uses fixed length S-boxes while Blowfish uses key-dependent S-boxes unlike.
The similarity of CAST-128 with its predecessor is the use of 64-bit block size of plaintext. However, CAST-128 uses a variable key length ranging from 40 to 128-bit (128-bit key size is recommended). Key range increments in octets, i.e., 48-bit will be the next possible key size after 40-bit. Normally, CAST-128 uses 12 rounds of Feistel structure if key length is lesser than 80-bit, otherwise, CAST-128 uses all 16 rounds. In case of shorter key lengths than 128-bit, the key is padded with zero bytes. Example shown in Table 2.9 illustrates the padding of key and sample plaintexts (in octets).
Key Management:
Like Feistel structure, CAST-128 uses a primary key to generate sub-keys for subsequent rounds. But, it has been found and proved by many researchers that key generation procedure of DES suffers from certain issues like lack of strict avalanche, bit independent criteria, etc. Therefore, in order to overcome such issues, CAST-128 uses special substitution boxes for the creation of subkeys from the primary key. This feature of CAST is different from the subkeys generation method of DES. It uses two 32-bit sub-keys, namely, Kmi and Kri per round, where Kri is responsible for rotation, i.e., rotations in CAST-128 are dependent upon the key and Kmi performs masking in each round.
Encryption:
Input plaintext block of 64-bit is divided into two equal halves of 32-bit each, namely, L0 and R0. Following iterations are calculated for all the 16 rounds of CAST encryption:
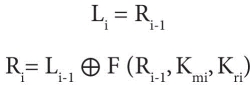
Table 2.9 Example of key-padding in CAST-128.
| 40-bit key | 12 32 26 89 67 |
| Padded 128-bit key | 12 32 26 89 67 00 00 00 00 00 00 00 00 00 00 |
| 64-bit plain text | AB EF 24 01 34 13 |
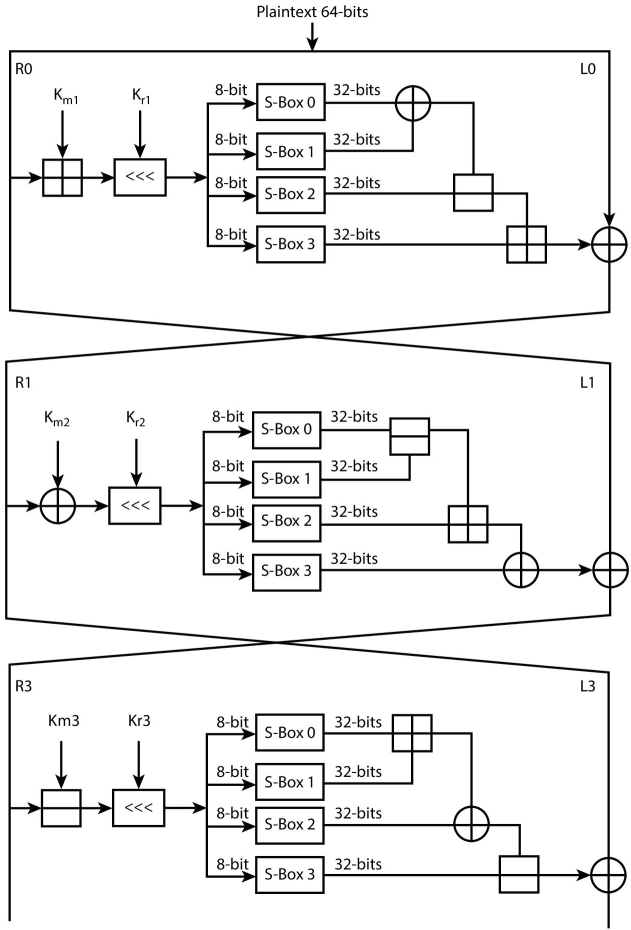
Figure 2.20 CAST-128 encryption (NOTE: right and left halves of plaintext are drawn on opposite sides in Figure 2.20 to indicate the similarity of CAST-128 with Blowfish algorithm).
Here F is the round function and CAST-128 uses three structurally identical round functions having a basic difference in the choice of operations as shown in Figure 2.20. The major difference in round functions is the change in the position of basic operations viz. addition modulo 232, subtraction modulo 232, and exclusive OR. Figure 2.20 shows only the first three rounds of CAST-128 to indicate that three types of functions are used one after another. Then, this pattern is repeated for remaining rounds of CAST-128.
Function F consists of four S-boxes having 8-bit input and 32-bit output. To understand the working of function F in a round function, an intermediate variable X is used to store the result of keys masking and rotations with the right half of plaintext/intermediate ciphertext. Thus, the value of X for the first round is:
This intermediate value X is divided into four equal parts each of 8-bit and fed into four S-boxes respectively to add non-linearity. The output of S-boxes is combined using three different ways in all the three types of functions in the round. The final output of the function in round 1 in the form of intermediate value X is as follows:
Here S0, S1, S2, and S3 are the 32-bit output of four S-boxes used in the function and ⊕ is eXclusive OR, − is subtraction modulo 232, and, + is addition modulo 232.
Similarly, a reader can derive the expressions for rounds 2 and 3. After the end of the 16th round, both halves are swapped and merged to produce 64-bit ciphertext.
Decryption process in CAST-128 uses the same encryption structure with key in reverse sequence.
Although CAST-128, which is also known as CAST5 is patented by Entrust, it can be used for profitable and non-profitable use without any royalty. Mostly 3DES is used to secure the communication of multimedia objects in an e-mail through Secure/Multipurpose Internet Mail Extensions (S/MIME). But, 3DES is found slow in many cases; therefore, according to internet drafts, use of CAST-128 in securing S/MIME provides good speed with security. E-mail encryption standard Pretty Good Privacy (PGP) and open source based GNU Public Guard (BPG) also makes use of CAST-128.
CAST-128 is vulnerable to linear cryptanalysis through known plaintext attack. Therefore, CAST-256 is proposed as a robust successor of CAST-128 in RFC 2612. Table 2.10 summarizes the differences between CAST-128 and Blowfish encryption algorithm [7].
2.4 Conclusion
Internet is a dominant medium of transmitting information in today’s era. But, it is a public network that cannot be relied upon. Therefore, scientists and researchers have been discovering many approaches, methods, and algorithms to protect our sensitive information from illegitimate audience. Elderly encryption algorithm based upon either substitution or transposition approaches cannot withstand the robust cyber attacks. Therefore, modern encryption algorithms intelligently use the combination of both substitution and transposition approaches. Claude Shannon’s theory of confusion and diffusion further assisted cryptographers to design robust algorithms. Horst Feistel’s initial design “lucifer” paved the path for block cipher designers and many modern day algorithms are based upon it. Increasing computational capabilities indicates that more insights are required to develop futuristic encryption algorithm. Vulnerabilities in DES encouraged for the development of 3DES and AES kind of algorithms. Developments in the field of VLSI and ULSI made the fabrication of algorithms easy and cost-effective. Growing usage of mobile devices encouraged the development of stream cipher based algorithms which are fast and secure. It can be undoubtedly stated that the there is a great scope for new algorithms for ever-changing world of technology.
Table 2.10 Differences between CAST-128 and Blowfish algorithms.
| Factors | CAST-128 | Blowfish |
| Key length | 128-bit | 448-bit |
| Security | Moderate | Secure Enough |
| No. of rounds | 12–16 | 16 |
| No. of S-boxes | 8 | 4 |
References
- 1. Stallings, W., Cryptography and Network Security: Principles and Practice, 6e, Prentice Hall Press Upper Saddle River, NJ, USA, 2013.
- 2. Paar, Christof, Lecture Notes Applied Crytography and Data Security, Chair for Communication Security, Department of Electrical Engineering and Information Sciences, Ruhr-Universit¨at Bochum, Germany, version 2.5, January 2005.
- 3. Kahate, A., Cryptography andNetwork Security, Tata McGraw-Hill Education, India, 2013.
- 4. Eli Biham, O.D., Cryptanalysis of the A5/1 GSM Stream Cipher. Indocrypt 2000, 2000.
- 5. Shannon, C., A Mathematical Theory of Communication. Bell Syst. Tech. J., 28, 4, 656–715, 1948.
- 6. Matsui, M., A new method for known plaintext attack of FEAL cipher. Advances in Cryptology. EUROCRYPT, 1992.
- 7. Adams, C.M., Constructing Symmetric Ciphers Using the CAST Design Procedure, Kluwer Academic Publishers, Boston, 1997.
Practice Set
Summary
- ✓ Block Cipher encrypts a block of plaintext at a time
- ✓ Block cipher approach is quite faster than its counterpart stream cipher and used in computer-based cryptographic algorithms.
- ✓ Shannon suggested two primitive operations namely confusion and diffusion perform strong encryption and decryption.
- ✓ Confusion makes the relationship of key and ciphertext more complex so that the ciphertext does not reveal the pattern of plaintext
- ✓ Diffusion refers to rearranging or spreading out the bit in the message so that any repetition in the plaintext is spread out over the ciphertext.
- ✓ Block cipher has three modes of operations namely electronic code book, cipher block chaining, and cipher feedback mode to process blocks of plaintext into ciphertext.
- ✓ Electronics codebook mode produces unique ciphertext for every 64-bit block of plaintext given the same key.
- ✓ In cipher block, chaining encryption is performed in 64-bit blocks with the ciphertext output of encrypting block n being XORed with the plaintext input of block n + 1.
- ✓ Bit Padding is a technique to add some extra bit to the original message to make it a positive multiple of the block length.
- ✓ Cipher feedback makes block cipher into stream cipher Like CBC, but do XOR after encryption.
- ✓ Feistel Cipher is a symmetric structure that used in the development of block cipher. This Feistel Network works as the basic building block of DES algorithm.
- ✓ Feistel Cipher structure is affected by parameters like block size, key length, number of rounds, etc. There is a trade-off between security level and encryption speed with the increase in these parameters.
- ✓ Data Encryption Standard is widely used, symmetric block cipher technique, it uses 64-bit block length and 56-bit key with 16 rounds of a cryptographic function.
- ✓ Expansion creates diffusion and Substitution box provides confusion in DES.
- ✓ Avalanche effect causes small changes in the plaintext to lead to significant changes in the cipher.
- ✓ DES with 56-bit key is more prone to be broken by brute-force approach.
- ✓ Differential cryptanalysis is the method to measure the differences in the output ciphertext when corresponding input plaintext is changed.
- ✓ In Liner cryptanalysis, some linear equations are derived relating plaintext, Ciphertext and the key bit. Then these linear equations are used in conjunction with known plain-text-ciphertext pairs to derive key bit.
- ✓ Triple Data Encryption Standard uses three keys each of 56-bit length and follows the sequence of Encryption-Decryption-Encryption.
- ✓ IDEA is eight rounds, 64-bit symmetric block cipher using 128-bit key size.
- ✓ IDEA is far better in security than 56-bit key based widely used DES.
- ✓ IDEA produces a complex transform by the combination of XOR, Binary addition and multiplication of 16-bit integers Instead of look-up tables or S-Box used in DES.
- ✓ In link, encryption data is encrypted just before the system places it on the physical communication links. Either Physical or data link layer in OSI or TCP/IP protocol suites are responsible for link encryption.
- ✓ Link encryption is faster, easier for the user. It also eliminates traffic analysis by the attacker as the entire message is encrypted.
- ✓ Encryption is performed by the Application or presentation layer opposite to link encryption.
- ✓ Traffic flow analysis is based upon the variation of a load of traffic to determine the type of communication.
- ✓ A padding approach is used to insert spurious data into the network to balance the traffic load thus prevent traffic flow analysis.
- ✓ A trusted server symmetric Key-Distribution Center (KDC) is used to provide temporary session-keys to its authorized hosts.
- ✓ Front End Processor (FEP) also known as communication processor is responsible for end to end encryption and asks the KDC to release the session key.
- ✓ Denial of Service is a threat to the entire key distribution system.
- ✓ The secrecy of the cryptographic algorithm is determined by the pure random and unpredictable key values generated by a random number generator.
- ✓ Random bit generator is a system whose output consists of the completely unpredictable bit.
- ✓ Hardware-based random value generator is preferred over software-based because they are having a clearer model of the source and its possible interaction with the outside world.
Review Questions and Exercises
A. Multiple Choice Questions
Q.1 3DES uses ______________ rounds
- 48
- 10
- 15
- 46
Q.2 AES uses _______________ rounds
- 10
- 12
- 13
- 48
Q.3 In ECB data is divided into _______ bit blocks
- 64
- 32
- 68
- 48
Q.4 Bit padding is done in
- CFB
- ECB
- BCE
- All of above
Q.5 Key length used in Feistel cipher
- 128
- 64
- 32
- 56
Q.6 Key length in DES
- 56
- 64
- 128
- 32
Q.7 Plaintext passes through a sequence of ____ iterations of a round function in DES
- 16
- 8
- 10
- 12
Q.8 S-boxes again convert the ____ value to ____ bit in DES
- 48 to 32
- 32 to 48
- 48 to 46
- None of the above
Q.9 IDEA uses 8 rounds of computation and each requires ____ subkeys
- 6
- 8
- 4
- 3
Q.10 Master key in IDEA __bit
- 128
- 32
- 64
Q.11 Link encryption is performed in
- Layer 1
- Layer 2
- TCP
- DLL
Q.12N users require ____keys in asymmetric cryptography.
- N*(N-1)/ 2
- N*(N-1)
- N
- N2
Q.13 Bit-values which are XOR’d in a Linear Feedback Shift Register to produce an output are called:
- Bit-values
- Special Bit
- Taps
- Tokens
Q.14 What limitation of LFSR makes it vulnerable to security attacks?
- Feedback Function
- Fixed Length of LFSR
- Design of LFSR
- All of the above
Q.15 Which of these protocol incorporates RC-4
- HTTPS
- WEP
- Both (A) and (B)
- None of the above
Q.16 Size of secret key and initialization vector (IV) in A5/1 are
- 128-bit, 22-bit
- 64-bit, 22-bit
- 128-bit, 64-bit
- 64-bit, 64-bit
B. Subjective Questions
- Q.1 Discuss Claude Shannon’s principles of Confusion and Diffusion.
- Q.2 Explain block cipher modes of operations in details.
- Q.3 Discuss Feistel cipher structure, parameters affecting its performance, and reversibility of the structure.
- Q.4 Describe the DES algorithm in details. Discuss the strength and limitation of the DES algorithm.
- Q.5 Explain the parameters affecting the realization of Feistel Cipher architecture.
- Q.6 Which operations of DES provide confusion and diffusion?
- Q.7 Explain Differential cryptanalysis and Liner cryptanalysis attack on DES.
- Q.8 Elaborate TDES algorithm with reference to DES algorithm.
- Q.9 Explain International Data Encryption Standard algorithm.
- Q.10 State the differences between DES and IDEA.
- Q.11 List the differences between link encryption and an end to end encryption.
- Q.12 Explain the key distribution process.
- Q.13 What is the use of a random number in cryptography? Explain the Random Number Generator.
- Q.14 What will be the result of Denial of Service attack on a KDC?
- Q.15 If a plain message P and its OTP encryption C is given, is it possible to figure out the OTP key K using P and C?
- Q.16 Is Feistel network is really reversible?
- Q.17 Draw the inverse diagram of entire Feistel structure.
- Q.18 Why not use fewer rounds than 16 in DES?
- Q.19 Is there any attack possible on 3DES that takes time lesser than 2168?
- Q.20 Why not use double DES if triple DES is slower?
C. Numerical Problems
- Q.1 Given a plaintext, P = 1001001 and key K is: 0101101 then find the value of ciphertext C using One Time Pad approach. Decrypt cipher using the same key and confirm your answer.
- Q.2 What will be the 4-bit output of S-box-1 when the 6-bit input is: 101010.
D. Lab/Programming Assignments
- Q.1 Implement 1-DES algorithm using any of your favorite programming languages.
- Q.2 Explain the working of rand() and srand()function of C language.
- Q.3 Write a program to generate random numbers between 0 to N numbers.
APPENDIX A: Tables of Data Encryption Standard [1]
Table 2.1 Initial permutation.
| 58, | 50, | 42, | 34, | 26, | 18, | 10, | 2, | 60, | 52, | 44, | 36, | 28, | 20, | 12, | 4 |
| 62, | 54, | 46, | 38, | 30, | 22, | 14, | 6, | 64, | 56, | 48, | 40, | 32, | 24, | 16, | 8 |
| 57, | 49, | 41, | 33, | 25, | 17, | 9, | 1, | 59, | 51, | 43, | 35, | 27, | 19, | 11, | 3 |
| 61, | 53, | 45, | 37, | 29, | 21, | 13, | 5, | 63, | 55, | 47, | 39, | 31, | 23, | 15, | 7 |
Table 2.2 Final permutation or IP inverse.
| 40, | 8, | 48, | 16, | 56, | 24, | 64, | 32, | 39, | 7, | 47, | 15, | 55, | 23, | 63, | 31 |
| 38, | 6, | 46, | 14, | 54, | 22, | 62, | 30, | 37, | 5, | 45, | 13, | 53, | 21, | 61, | 29 |
| 36, | 4, | 44, | 12, | 52, | 20, | 60, | 28, | 35, | 3, | 43, | 11, | 51, | 19, | 59, | 27 |
| 34, | 2, | 42, | 10, | 50, | 18, | 58, | 26, | 33, | 1, | 41, | 9, | 49, | 17, | 57, | 25 |
Table 2.3 Permutation choice-1.
| 57 | 49 | 41 | 33 | 25 | 17 | 9 |
| 1 | 58 | 50 | 42 | 34 | 26 | 18 |
| 10 | 2 | 59 | 51 | 43 | 35 | 27 |
| 19 | 11 | 3 | 60 | 52 | 44 | 36 |
| 63 | 55 | 47 | 39 | 31 | 23 | 15 |
| 7 | 62 | 54 | 46 | 38 | 30 | 22 |
| 14 | 6 | 61 | 53 | 45 | 37 | 29 |
| 21 | 13 | 5 | 28 | 20 | 12 | 4 |
Table 2.4 Permutation choice-2.
| 14 | 17 | 11 | 24 | 1 | 5 | 3 | 28 |
| 15 | 6 | 21 | 10 | 23 | 19 | 12 | 4 |
| 26 | 8 | 16 | 7 | 27 | 20 | 13 | 2 |
| 41 | 52 | 31 | 37 | 47 | 55 | 30 | 40 |
| 51 | 45 | 33 | 48 | 44 | 49 | 39 | 56 |
| 34 | 53 | 46 | 42 | 50 | 36 | 29 | 32 |
Table 2.5 Key schedule of left shifts.
| Round number | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 | 16 |
| Bits rotated | 1 | 1 | 2 | 2 | 2 | 2 | 2 | 2 | 1 | 2 | 2 | 2 | 2 | 2 | 2 | 1 |
Table 2.6 Expansion table.
| 32 | 1 | 2 | 3 | 4 | 5 |
| 4 | 5 | 6 | 7 | 8 | 9 |
| 8 | 9 | 10 | 11 | 12 | 13 |
| 12 | 13 | 14 | 15 | 16 | 17 |
| 16 | 17 | 18 | 19 | 20 | 21 |
| 20 | 21 | 22 | 23 | 24 | 25 |
| 24 | 25 | 26 | 27 | 28 | 29 |
| 28 | 29 | 30 | 31 | 32 | 1 |
Table 2.7 P-box permutation.
| 16 | 7 | 20 | 21 | 29 | 12 | 28 | 17 | 1 | 15 | 23 | 26 | 5 | 18 | 31 | 10 |
| 2 | 8 | 24 | 14 | 32 | 27 | 3 | 9 | 19 | 13 | 30 | 6 | 22 | 11 | 4 | 25 |
Table 2.8 S-box table (1–8).
| S-Box 1: | |||||||||||||||
| 14, | 4, | 13, | 1, | 2, | 15, | 11, | 8, | 3, | 10, | 6, | 12, | 5, | 9, | 0, | 7 |
| 0, | 15, | 7, | 4, | 14, | 2, | 13, | 1, | 10, | 6, | 12, | 11, | 9, | 5, | 3, | 8 |
| 4, | 1, | 14, | 8, | 13, | 6, | 2, | 11, | 15, | 12, | 9, | 7, | 3, | 10, | 5, | 0 |
| 15, | 12, | 8, | 2, | 4, | 9, | 1, | 7, | 5, | 11, | 3, | 14, | 10, | 0, | 6, | 13 |
| S-Box 2: | |||||||||||||||
| 15, | 1, | 8, | 14, | 6, | 11, | 3, | 4, | 9, | 7, | 2, | 13, | 12, | 0, | 5, | 10 |
| 3, | 13, | 4, | 7, | 15, | 2, | 8, | 14, | 12, | 0, | 1, | 10, | 6, | 9, | 11, | 5 |
| 0, | 14, | 7, | 11, | 10, | 4, | 13, | 1, | 5, | 8, | 12, | 6, | 9, | 3, | 2, | 15 |
| 13, | 8, | 10, | 1, | 3, | 15, | 4, | 2, | 11, | 6, | 7, | 12, | 0, | 5, | 14, | 9 |
| S-Box 3: | |||||||||||||||
| 10, | 0, | 9, | 14, | 6, | 3, | 15, | 5, | 1, | 13, | 12, | 7, | 11, | 4, | 2, | 8 |
| 13, | 7, | 0, | 9, | 3, | 4, | 6, | 10, | 2, | 8, | 5, | 14, | 12, | 11, | 15, | 1 |
| 13, | 6, | 4, | 9, | 8, | 15, | 3, | 0, | 11, | 1, | 2, | 12, | 5, | 10, | 14, | 7 |
| 1, | 10, | 13, | 0, | 6, | 9, | 8, | 7, | 4, | 15, | 14, | 3, | 11, | 5, | 2, | 12 |
| S-Box 4: | |||||||||||||||
| 7, | 13, | 14, | 3, | 0, | 6, | 9, | 10, | 1, | 2, | 8, | 5, | 11, | 12, | 4, | 15 |
| 13, | 8, | 11, | 5, | 6, | 15, | 0, | 3, | 4, | 7, | 2, | 12, | 1, | 10, | 14, | 9 |
| 10, | 6, | 9, | 0, | 12, | 11, | 7, | 13, | 15, | 1, | 3, | 14, | 5, | 2, | 8, | 4 |
| 3, | 15, | 0, | 6, | 10, | 1, | 13, | 8, | 9, | 4, | 5, | 11, | 12, | 7, | 2, | 14 |
| S-Box 5: | |||||||||||||||
| 2, | 12, | 4, | 1, | 7, | 10, | 11, | 6, | 8, | 5, | 3, | 15, | 13, | 0, | 14, | 9 |
| 14, | 11, | 2, | 12, | 4, | 7, | 13, | 1, | 5, | 0, | 15, | 10, | 3, | 9, | 8, | 6 |
| 4, | 2, | 1, | 11, | 10, | 13, | 7, | 8, | 15, | 9, | 12, | 5, | 6, | 3, | 0, | 14 |
| 11, | 8, | 12, | 7, | 1, | 14, | 2, | 13, | 6, | 15, | 0, | 9, | 10, | 4, | 5, | 3 |
| S-Box 6: | |||||||||||||||
| 12, | 1, | 10, | 15, | 9, | 2, | 6, | 8, | 0, | 13, | 3, | 4, | 14, | 7, | 5, | 11 |
| 10, | 15, | 4, | 2, | 7, | 12, | 9, | 5, | 6, | 1, | 13, | 14, | 0, | 11, | 3, | 8 |
| 9, | 14, | 15, | 5, | 2, | 8, | 12, | 3, | 7, | 0, | 4, | 10, | 1, | 13, | 11, | 6 |
| 4, | 3, | 2, | 12, | 9, | 5, | 15, | 10, | 11, | 14, | 1, | 7, | 6, | 0, | 8, | 13 |
| S-Box 7: | |||||||||||||||
| 4, | 11, | 2, | 14, | 15, | 0, | 8, | 13, | 3, | 12, | 9, | 7, | 5, | 10, | 6, | 1 |
| 13, | 0, | 11, | 7, | 4, | 9, | 1, | 10, | 14, | 3, | 5, | 12, | 2, | 15, | 8, | 6 |
| 1, | 4, | 11, | 13, | 12, | 3, | 7, | 14, | 10, | 15, | 6, | 8, | 0, | 5, | 9, | 2 |
| 6, | 11, | 13, | 8, | 1, | 4, | 10, | 7, | 9, | 5, | 0, | 15, | 14, | 2, | 3, | 12 |
| S-Box 8: | |||||||||||||||
| 13, | 2, | 8, | 4, | 6, | 15, | 11, | 1, | 10, | 9, | 3, | 14, | 5, | 0, | 12, | 7 |
| 1, | 15, | 13, | 8, | 10, | 3, | 7, | 4, | 12, | 5, | 6, | 11, | 0, | 14, | 9, | 2 |
| 7, | 11, | 4, | 1, | 9, | 12, | 14, | 2, | 0, | 6, | 10, | 13, | 15, | 3, | 5, | 8 |
| 2, | 1, | 14, | 7, | 4, | 10, | 8, | 13, | 15, | 12, | 9, | 0, | 3, | 5, | 6, | 11 |
Notes
- * Corresponding author: [email protected]
- † Corresponding author: [email protected]
- 1 26! > 4 * 1026 that is almost equal to 288 and remember that this keyspace is much larger than the key space of DES algorithm.
- 2 ⌈ ⌉ is a ceiling operator.
- 3 XOR operation outputs 1 on dissimilar inputs and 0 otherwise.
- 4 However, it is argued that initial and final permutation has no significance in DES, and the actual reason behind the use of them by the designers of DES is unknown. However, it is believed that these operations are very computation intensive while implementing in software and reduces the chances of software simulation of DES.