
Chapter 3. The Apache Portable Runtime
The Apache Portable Runtime (APR) and Utilities (APR-UTILS or APU) are a pair of libraries used by the Apache httpd, but autonomously developed and maintained within the ASF. Although many core developers are involved in both httpd (the webserver) and APR, the projects are separate. These libraries provide core functions that are not specific to webserving but are also useful in more general applications.
Apart from the webserver, the best-known APR application is Subversion, a revision and change control management system. Another is Site Valet, a suite of software for QA and accessibility audit on the Web; Site Valet was developed by this book’s author.
This chapter discusses the APR as it applies to Apache modules. It does not go into subjects such as application initialization, which are necessary but are handled internally by the Apache core code. For developers working outside the webserver context, this usage is documented clearly within APR itself, and it is covered in the tutorial at http://dev.ariel-networks.com/apr/apr-tutorial/html/apr-tutorial.html.
3.1. APR
The main purpose of APR is to provide a portable, platform-independent layer for applications. Functions such as filesystem access, network programming, process and thread management, and shared memory are supported in a low-level, cross-platform library. Apache modules that use exclusively APR instead of native system functions are portable across platforms and can expect to compile cleanly—or at worst with a trivial amount of tidying up—on all platforms supported by Apache.
Each APR module comprises an application programming interface (API) shared between all platforms, together with implementations of the functions defined in the API. The implementations are often wholly or partly platform-specific, although this issue is of no concern to applications.
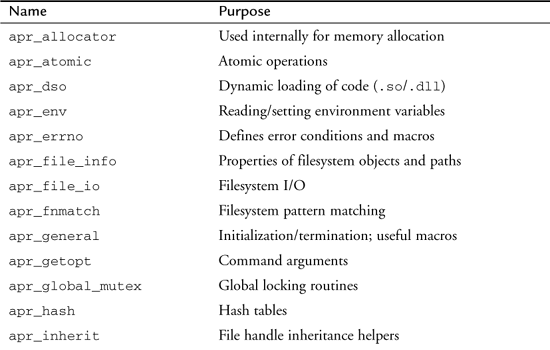
At the core of APR is Apache’s resource management (pools), which are discussed in more detail later in this chapter. Table 3-1 provides a full list of the APR modules.
Table 3-1. APR Modules

3.2. APR-UTIL
APR-UTIL (also known as APU) is a second library in the APR project. It provides a small set of utilities, based on the APR and with a unified programming interface. APU doesn’t have separate per-platform modules, but it does adopt a similar approach to some other commonly used resources, such as databases.
Table 3-2 provides a complete list of APU modules.
Table 3-2. APU Modules

3.3. Basic Conventions
APR and APR-UTIL adopt a number of conventions that give them a homogenous API and make them easy to work with.
3.3.1. Reference Manual: API Documentation and Doxygen
All of APR/APU is very well documented at the code level. Every public function and data type is documented in the header file that defines it, in doxygen[1]-friendly format. The header files themselves, or the doxygen-generated documentation, provide a full API reference for programmers. If you have doxygen installed, you can generate your own copy of the APR reference manual from the source code with the command make dox.
3.3.2. Namespacing
All APR/APU public interfaces are prefixed with the string “apr_” (data types and functions) or “APR_” (macros). This defines APR’s “reserved” namespace.
Within the APR namespace, most of the APR and APU modules use secondary namespacing. This convention is often based on the name of the module in question. For example, all functions in module apr_dbd are prefixed with the string “apr_dbd_”. Sometimes an obviously descriptive secondary namespace is used. For example, socket operations in module apr_network_io are prefixed with “apr_socket_”.
3.3.3. Declaration Macros
Public functions in APR/APU are declared using macros such as APR_DECLARE, APU_DECLARE, and APR_DECLARE_NONSTD. For example:
APR_DECLARE(apr_status_t) apr_initialize(void);
On most platforms, this is a null declaration and expands to
apr_status_t apr_initialize(void);
On platforms such as Windows with Visual C++, which require their own nonstandard keywords such as _dllexport to enable other modules to use a function, these macros will expand to the required keywords.
3.3.4. apr_status_t and Return Values
A convention widely adopted in APR/APU is that functions return a status value indicating success or an error code to the caller. The type is apr_status_t, which takes integer values defined in apr_errno.h. Thus the usual prototype for an APR function is
APR_DECLARE(apr_status_t) apr_do_something(…function args…);
Return values should routinely be tested, and error handling (recovery or graceful failure) should be implemented. The return value APR_SUCCESS indicates success, and we can commonly handle errors using constructs such as

Sometimes we may do more. For example, if do_something was a nonblocking I/O operation and returned APR_EAGAIN, we will probably want to retry the operation.
Some functions return a string value (char* or const char*), a void*, or void. These functions are assumed to have no failure conditions or to return a null pointer on failure as appropriate.
3.3.5. Conditional Compilation
By their very nature, a number of features of APR may not be supported on every platform. For example, prior to version 5.x, FreeBSD had no native thread implementation considered suitable for Apache; hence threads were not supported in APR (unless the relevant options were set manually for compilation).
To enable applications to work around this issue, APR provides APR_HAS_* macros for such features. When an application is concerned with such a feature, it should use conditional compilation based on these macros. For example, a module performing an operation that could lead to a race condition in a multithreaded environment might want to use something like this:

3.4. Resource Management: APR Pools
The APR pools are a fundamental building block that lie at the heart of APR and Apache; they serve as the basis for all resource management. The pools allocate memory, either directly (in a malloc-like manner) or indirectly (e.g., in string manipulation), and, crucially, ensure that memory is freed at the appropriate time. But they extend much further, to ensure that other resources such as files or mutexes can be allocated and will always be properly cleaned up. They can even deal with resources managed opaquely by third-party libraries.
Note
It is common practice in Apache to assume that pool memory allocation never fails. The rationale for this assumption is that if the allocation does fail, then the system is not recoverable, and any error handling will fail, too.
3.4.1. The Problem of Resource Management
Every programmer knows that when you allocate a resource, you must ensure that it is released again when you’ve finished with it. For example:
![]()
or
![]()
Clearly, failure to free buf or to close f is a bug. In the context of a long-lasting program such as Apache, it would have serious consequences, up to and including bringing the entire system down. Obviously, it is important to get resource management right.
In trivial cases, this is straightforward. In a more complex case with multiple error paths, in which even the scope of a resource is uncertain at the time it is allocated, ensuring that cleanup takes place in every execution path is much more challenging. In such circumstances, we need a better way to manage resources.
Constructor/Destructor Model
One method of resource management is exemplified by the C++ concept of objects having a constructor and a destructor. Many C++ programmers make the destructor responsible for cleanup of all resources allocated by the object. This approach works well provided all dynamic resources are clearly made the responsibility of an object. But, as with the simple C approach, it requires a good deal of care and attention to detail—for example, where resources are conditionally allocated or shared between many different objects—and it is vulnerable to programming bugs.
Garbage Collection Model
A high-level method of resource management, typified by Lisp and Java, is garbage collection. This approach has the advantage of taking the problem away from the programmer and transferring it to the language itself, thereby completely removing the danger of crippling programming errors. The drawback is that garbage collection incurs a substantial overhead even where it isn’t necessary, and it deprives the programmer of useful levels of control, such as the ability to control the lifetime of a resource. It also requires that all program components—including third-party libraries—be built on the same system, which is clearly not possible in an open system written in C.
3.4.2. APR Pools
The APR pools provide an alternative model for resource management. Like garbage collection, they liberate the programmer from the complexities of dealing with cleanups in all possible cases. In addition, they offer several other advantages, including full control over the lifetime of resources and the ability to manage heterogeneous resources.
The basic concept goes like this: Whenever you allocate a resource that requires cleanup, you register it with a pool. The pool then takes responsibility for the cleanup, which will happen when the pool itself is cleaned. In this way, the problem is reduced to one of allocating and cleaning up a single resource: the pool itself. Given that the Apache pools are managed by the server itself, the complexity is, therefore, removed from applications programming. All the programmer has to do is select the appropriate pool for the required lifetime of a resource.
Basic Memory Management
The most basic application of pools is for memory management. Instead of
![]()
we use
mytype* myvar = apr_palloc(pool, sizeof(mytype)) ;
The pool automatically takes responsibility for freeing this resource, regardless of what may happen in the meantime. A secondary benefit is that pool allocation is faster than malloc on most platforms!
Basic memory management takes many forms in APR and Apache, where memory is allocated within another function. Examples include string-manipulation functions and logging, where we gain the immediate benefit of being able to use constructs such as the APR version of sprintf() without having to know the size of a string in advance:
char* result = apr_psprintf(pool, fmt, …) ;
APR also provides higher-level abstractions of pool memory—for example, in the buckets used to pass data down the filter chain.
Generalized Memory Management
APR provides built-in functions for managing memory, as well as a few other basic resources such as files, sockets, and mutexes. However, programmers are not required to use these functions and resources. An alternative is to use native allocation functions and explicitly register a cleanup with the pool:
![]()
or
![]()
This code delegates responsibility for cleanup to the pool, so that no further action from the programmer is required. However, native functions may be less portable than the APR equivalents from apr_pools and apr_file_io, respectively, and malloc on most systems will be slower than using the pool.
This method of memory management generalizes to resources opaque to Apache and APR. For example, to open a MySQL database connection and ensure it is closed after use, you would write the following code:
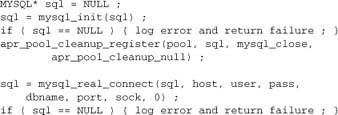
Note that apr_dbd (which is discussed in Chapter 11) provides an altogether better method for managing database connections.
As a second example, consider XML processing:

Integrating C++ destructor-cleanup code provides yet another example. Suppose we have

We define a C wrapper:
void myclassCleanup(void* ptr) { delete (myclass*)ptr ; }
We then register this wrapper with the pool when we allocate myclass:

Implicit and Explicit Cleanup
Suppose we want to free our resource explicitly before the end of the request—for example, because we’re doing something memory intensive but have objects we can free. We may want to do everything according to normal scoping rules and just use pool-based cleanup as a fallback to deal with error paths. However, because we registered the cleanup, it will run regardless of our intentions. In the worst-case scenario, it could possibly lead to a double-free and a segfault.
Another pool function, apr_pool_cleanup_kill, is provided to deal with this situation. When we run the explicit cleanup, we unregister the cleanup from the pool. Of course, we can be a little more clever about how we go about this task.
Here’s the outline of a C++ class that manages itself based on a pool, regardless of whether it is explicitly deleted:

If you use C++ with Apache (or APR), you can derive any class from poolclass. Most APR functions do something equivalent to this, conducting register and kill operations whenever resources are allocated or cleaned up.
In simple C, we would use the following generic form:

We can also streamline this form by running the cleanup and unregistering it with the pool using a single function:
apr_pool_cleanup_run(pool, my_res, my_res_free) ;
3.4.3. Resource Lifetime
When we allocate resources by using a pool, we automatically ensure that they get cleaned up at some point. But when? We need to make sure the cleanup happens at the right time—that is, neither while the resource is still in use, nor long after the resource is no longer required.
Apache Pools
Fortunately, Apache makes this process quite easy, by providing different pools for different types of resource. These pools are associated with relevant structures of the httpd, and they have the lifetime of the corresponding struct. Four general-purpose pools are always available in Apache:
- The request pool, with the lifetime of an HTTP request
- The process pool, with the lifetime of a server process
- The connection pool, with the lifetime of a TCP connection
- The configuration pool
The first three, which are associated with the relevant Apache structs, are accessed as request->pool, connection->pool, and process->pool, respectively. The fourth, process->pconf, is also associated with the process, but differs from the process pool in that it is cleared whenever Apache rereads its configuration.
The process pool is suitable for long-lived resources, such as those that are initialized at server start-up. The request pool is suitable for transient resources used to process a single request.
The connection pool has the lifetime of a connection, which normally consists of one or more requests. This pool is useful for transient resources that cannot be associated with a request—most notably, in a connection-level filter, where the request_rec structure is undefined, or in a non-HTTP protocol handler.
In addition to these standard pools, special-purpose pools may be created for other purposes, such as configuration and logging, or may be created privately by modules for their own use.
Using Pools in Apache: Processing a Request
All request-processing hooks take the form
![]()
This hook puts the request pool r->pool at our disposal. As discussed earlier, the request pool is appropriate for the vast majority of operations involved in processing a request. We pass it to Apache and APR functions that need a pool argument as well as our own.
The process pool is available as r->server->process->pool for operations that need to allocate long-lived resources—for example, caching a resource that should be computed once and subsequently reused in other requests. However, this process is a little more complex, and it is generally preferable to derive a subpool from the process pool, as discussed in Chapters 4 and 10.
The connection pool is r->connection->pool.
Using Pools in Apache: Initialization and Configuration
The internal workings of Apache’s initialization are complex. As far as modules are concerned, however, the initialization can normally be treated as a simple procedure: Just set up a configuration, and everything is permanent. Apache makes that easy, because most of the relevant hooks have prototypes that pass the relevant pool as their first argument.
Configuration Handlers
static const char* my_cfg(cmd_parms* cmd, void* cfg, /* args */ )
Use the configuration pool, cmd->pool, to give a configuration the lifetime of the directive.
Pre-configuration and Post-configuration Hooks
These hooks are unusual in having several pools passed:
![]()
For most purposes, just use the first pool argument. ptemp is suitable for resources used during configuration, but will be destroyed before Apache goes into operational mode. plog remains active for the lifetime of the server, but is cleaned up each time the configuration is read.
Child init
static void my_child_init(apr_pool_t* pool, server_rec* s).
The child pool is the first argument.
Monitor
static int my_monitor(apr_pool_t* pool)
The monitor is a special case: It runs in the parent process and is not tied to any time-limited structure. For this reason, resources allocated in a monitor function should be explicitly freed. If necessary, a monitor may create and free its own subpool and manage it as discussed in Chapter 4. Few applications will need to use the monitor hook.
Using Pools in Apache: Other Cases
Most Apache modules involve the initialization and request processing we have already discussed. There are two other cases to deal with, however: connection functions and filter functions.
Connection Functions
The pre_connection and process_connection connection-level hooks pass a conn_rec object as their first argument; they are directly analogous to request functions as far as pool resources are concerned. The create_connection connection-initialization hook passes the pool as its first argument. Any module implementing this hook takes responsibility for setting up the connection.
Filter Functions
Filter functions receive an ap_filter_t as their first argument. This object ambiguously contains both a request_rec and a conn_rec as members, regardless of whether it is a request-level or a connection-level filter. Content filters should normally use the request pool. Connection-level filters will get a junk pointer in f->r (the request doesn’t exist outside the protocol layer; see Chapter 8) and must use the connection pool. Be careful: This can be a trap for the unwary.
3.4.4. Limitations of Pools
So far, we have seen the advantages of using pools for resource management. Naturally, there are also some limitations:
- Managing resources that have a lifetime that doesn’t correspond to any of Apache’s main objects requires more work. This issue is discussed further in Chapter 4.
- Allocating resources from a pool is not thread safe. This is rarely an issue, because most pool allocation by modules when Apache is running on a multithreaded basis uses a pool owned by an object (HTTP request or TCP connection) that is thread private at the time of use. Chapter 4 discusses some cases where thread safety is an issue.
- APR pools never return memory to the operating system until they are destroyed (they do, of course, reuse memory, so pool-based applications don’t grow indefinitely). Thus it may sometimes make sense to use
mallocrather than pools when allocating very large blocks of memory. Conversely, usingmallocin your code may affect binary compatibility. On Windows, it may prevent your code from being linked with a binary compiled using a different version of Visual C++, due to incompatibilities in the runtime libraries.
3.5. Selected APR Topics
APR provides a direct alternative to functions that are familiar and almost certain to be available on your system without any need for APR. Nevertheless, there are good reasons to use the APR versions of these functions:
- APR functions are platform independent and provide for better portability.
- APR functions get the benefit of APR’s pool-based resource management for free.
We won’t go into detail here. For more information, see the excellent documentation in the header files.
3.5.1. Strings and Formats
The apr_strings module provides APR implementations of
- Common string functions: comparisons, substring matches, copying, and concatenation
stdio-like functions:sprintfand family, including vformatters- Parsing, including thread-safe
strtok - Conversion to and from other data types (e.g.,
atoi)
APR string handling is based on pools. This scheme brings with it a substantial simplification, as we very rarely need to worry about the size of a buffer. For example, to concatenate an arbitrary number of strings, we can use
result = apr_pstrcat(pool, str1, str2, str3, …, NULL);
without the need to compute the length of result and allocate a buffer in advance. Similarly,
result = apr_psprintf(pool, fmt, …) ;
requires altogether less tedious housekeeping than
![]()
There is no regular expression support in APR (although there is in Apache), but the apr_strmatch module provides fast string matching that deals with the issues of case-insensitive (as well as case-sensitive) searches and non-null-terminated strings.
3.5.2. Internationalization
The apr_xlate module provides conversion between different character sets.
At the time of this book’s writing, apr_xlate on the Windows platform relies on a third APR library, apr_iconv, because Windows lacks (or lacked) native internationalization support. This dependency is expected to be removed in the future.
3.5.3. Time and Date
The apr_time module provides a microsecond timer and clock. Because APR works in microseconds, its fundamental data type apr_time_t is a 64-bit integer and is not interchangeable with time_t. Macros provided for conversion include the following:

Other data types include time intervals and a “struct tm” -like type apr_time_exp_t. APR time functions include
- Time now
- Any time as Greenwich Mean Time (GMT), local time, or a selected time zone
- Time arithmetic
- Sleep
- Time formatted as a
ctimeor RFC822 string
The apr_date module provides additional functions for parsing commonly used time and date formats.
3.5.4. Data Structs
Apache provides four data struct modules:
apr_tableprovides tables and arrays.apr_hashprovides hash tables.apr_queueprovides first in, first out (FIFO) queues.apr_ringprovides a ring struct, which is also the basis for APR bucket brigades.
3.5.4.1. Arrays
APR arrays are provided by the apr_array_header_t type, and can hold either objects or pointers. The array data type also serves as a stack. An array has a default size that is set when the array is created. Although it works most efficiently when it remains within that size, the array can grow as required. The most common operations supported are append (push) and iteration:

Other array operations include the pop stack operation, copying (shallow copy), lazy copy, concatenation, append, and conversion to a string value (the latter is obviously meaningful only when the contents of the array are string values).
3.5.4.2. Tables
The apr_table_t is an intuitive, higher-level data type built on the array for storing key/value pairs. It supports adding elements (several variants), deleting elements (not efficient), lookup, iteration, and clearing an entire table. It also supports merge and overlay operations, and merging or elimination of duplicate entries.
Table keys are always case insensitive (in contrast to the keys in APR hash tables).

Variants on apr_table_set include apr_table_setn, apr_table_add, apr_table_addn, apr_table_merge, and apr_table_mergen:
apr_table_setnsets a value, overwriting any existing value for the key.apr_table_addnadds a new value, leaving duplicate keys if there was an existing value for the key.apr_table_mergenadds a new value, merging it with any existing value for the key.apr_table_setcopies the data as they are entered in the table;apr_table_setndoesn’t (and is therefore more efficient when the values are persistent or allocated on the same pool as the table). The same applies to the other functions.

The high-level API and the availability of functions such as apr_table_merge and apr_table_overlap provide the ideal foundations for manipulation of HTTP headers and environment variables in Apache.
3.5.4.3. Hash Tables
apr_hash_t also stores key/value pairs, but is a lower-level data type than apr_table_t. It has two advantages:
- Keys and values can be of any data type (and, unlike with tables, are case sensitive).
- Hash tables scale more efficiently as the number of elements grows.
Unlike the array and table, the hash table has no initial size. The most commonly used operations are insertion and lookup. Other operations supported include iteration, copy, overlay, and merge.

There is one special case we commonly encounter: where the key is a character string. To ensure the proper string comparison semantics are used, we should use the macro APR_HASH_KEY_STRING in place of the size argument.
3.5.4.4. Queues
The apr_queue_t is a thread-safe, FIFO bounded queue. It is available only in threaded APR builds, and it enables multiple threads to cooperate in handling jobs. A queue has a fixed capacity, as set in apr_queue_create. The main queue operations are blocking and nonblocking push and pop.
3.5.4.5. Rings
APR_RING is not, in fact, a data type, but rather a collection of macros somewhat like a C++ template; these macros implement cyclic, doubly linked lists. The main ring example in Apache is the bucket brigade, which we’ll introduce in Section 3.5.5 and discuss at length in Chapter 8. The bucket is an element in the ring, while the brigade is the ring structure itself. The following declarations implement the ring structure:

3.5.5. Buckets and Brigades
Here’s a one-sentence, buzzword-laden overview: Bucket brigades represent a complex data stream that can be passed through a layered I/O system without unnecessary copying.
Buckets and brigades form the basis of Apache’s data handling, I/O, and filter chain (which are really three ways of saying the same thing). Use and manipulation of these is fundamental to filter modules, as is discussed in detail in Chapter 8.
A bucket brigade is a doubly linked list (ring) of buckets, so we aren’t limited to inserting elements at the front and removing them at the end. Buckets are passed around only as members of a brigade, although singleton buckets can occur for short periods of time.
Buckets are data stores of various types. They can refer to data in memory, or part of a file or mmap area, or the output of a process, among other things. Buckets also have some type-dependent accessor functions:
The read function returns the address and size of the data in the bucket. If the data isn’t in memory, then it is read in and the bucket changes type so that it can refer to the new location of the data. If all of the data cannot fit in the bucket, then a new bucket is inserted into the brigade to hold the rest of it.
The split function divides the data in a bucket into two regions. After a split, the original bucket refers to the first part of the data and a new bucket inserted into the brigade after the original bucket refers to the second part of the data. Reference counts are maintained as necessary.
The setaside function ensures that the data in the bucket has an adequate lifetime. For example, sometimes it is convenient to create a bucket referring to data on the stack in the expectation that it will be consumed (e.g., output to the network) before the stack is unwound. If that expectation turns out not to be valid, the setaside function is called to move the data somewhere safer.
The copy function makes a duplicate of the bucket structure as long as it’s possible to have multiple references to a single copy of the data itself. Not all bucket types can be copied.
The destroy function maintains the reference counts on the resources used by a bucket and frees them if necessary.
Note
All of these functions have wrapper macros [apr_bucket_read(), apr_bucket_destroy(), and so on]. The wrapper macros should be used rather than using the function pointers directly.
To write a bucket brigade, we first turn the data into an iovec, so that we don’t write too little data at one time. If we really want good performance, then we need to compact the buckets before we convert the data to an iovec, or possibly while we are converting to an iovec.
The following bucket types are supported natively in APR:
- File—bucket contents are a file. Commonly used when serving a static file.
- Pipe—bucket contents are a pipe (filesystem FIFO).
- Socket—bucket contents are a socket. Most commonly used by the network filters.
- Heap—bucket contents are heap memory. Used for
stdio-like buffered I/O. - Mmap—bucket contents are an mmapped file.
- Immortal—bucket contents are memory, which is guaranteed to be valid for at least the lifetime of the bucket.
- Pool—bucket contents are allocated on a pool.
- Transient—bucket contents may go out of scope and disappear.
- Flush (metadata)—the brigade’s contents should be flushed before continuing. In Apache, that means passing whatever data is available to the next filter in the chain.
- EOS (metadata)—end of data.
Other types may also be implemented—indeed, additional metadata types are used internally in Apache. This author has implemented bucket types for SQL queries (using apr_dbd) and for script fragments; both of these types execute and convert data to another bucket type when read. A third-party library implementing a wide range of bucket types is serf.[2]
3.5.6. Filesystem
APR modules related to filesystems include the following:
apr_file_ioprovides standard file operations: open/close,stdio-style read/write operations, locking, and create/delete/copy/rename/chmod. This module supports ordinary files, temporary files, directories, and pipes.apr_file_infoprovides filesystem information (stat), directory manipulation functions (e.g., open, close, read), file path manipulation, and relative path resolution.apr_fnmatchprovides pattern matching for the filesystem, to support wildcard operations.apr_mmapmmaps a file.
We will see examples of these modules in later chapters.
A third-party extension is apvfs,[3] a library that implements a common, APR-based front end to a wide range of different (virtual) filesystems such as standard files, APR buckets, archives IPC, and databases.
3.5.7. Network
APR provides two modules related to networks:
apr_network_iois a socket layer supporting IPv4, IPv6, and the TCP, UDP, and SCTP protocols. It supports a number of features subject to underlying operating system support, and will emulate them where not available. These features include send file, accept filters, and multicast.apr_pollprovides functions for polling a socket (or other descriptor).
3.5.8. Encoding and Cryptography
APR does not provide a cryptographic library, and Apache’s mod_ssl relies on the external OpenSSL package for implementation of transport-level security. APR does support a number of data encoding and hashing techniques in its apr_base64, apr_md4, apr_md5, and apr_sha1 modules.
3.5.9. URI Handling
The apr_uri module defines a struct for URIs/URLs, and provides parsing and unparsing functions:

The main functions provided are apr_uri_parse and apr_uri_unparse, which convert between a string and the apr_uri struct.
3.5.10. Processes and Threads
apr_thread_procprovides process and thread management functions: creation, parent–child relationships including environment propagation, pipes, rendezvous, and wait.apr_signalprovides basic signal handling.apr_global_mutexprovides global locks that protect the calling thread both-from other threads and processes.
Processes
apr_proc_mutexprovides locks for the calling process against other processes.apr_shmprovides shared memory segments.
Threads
apr_thread_mutexandapr_thread_rwlockprovide thread locks/mutexes.apr_thread_condprovides thread conditions for synchronization of different threads in a process.
Modules should be able to run in a multiprocess and/or multithreaded environment. Although they will rarely need to create a new thread, they may need to use mutexes, shared memory, or other techniques to share resources and avoid race conditions. Techniques for working with threads and processes in Apache are discussed in Chapter 4.
3.5.11. Resource Pooling
The apr_reslist module manages a pool of persistent resources.
A database is a fundamental component of many web applications. Unfortunately, connecting to it incurs an overhead that affects traditional application architectures such as CGI and the environment commonly known as LAMP (Linux, Apache, MySQL, [Perl|PHP|Python]). Using apr_reslist (APR’s resource pooling module) with Apache 2’s threaded MPMs, we can achieve significant improvements in performance and scalability in applications using “expensive” resources such as databases, or back-end connections when proxying an application server.
Chapter 11 presents the DBD framework, which is one of the main applications of connection pooling.
3.5.12. API Extensions
The following modules serve to enable new APIs:
apr_hooksprovides Apache’s hooks, a mechanism for exporting an API where an extension (module) can insert its own processingapr_optional_hooksprovides optional hooks, enabling different modules to use each other’s APIs when both are present without creating a dependency.apr_optionalprovides optional functions, so that a module can use functions exported by another module without creating a dependency.
These extensions are discussed in depth in Chapter 10.
3.6. Databases in APR/Apache
Readers of a certain age will recollect a time in the 1980s when every application for the PC came bundled with hundreds of different printer drivers on ever-growing piles of floppy disks. Eventually, the operating system implemented the sensible solution: a unified printing API, so that each printer had a single driver, and each application had a single print function that works with any driver.
The history of database support in Apache echoes this evolutionary path. At first, Apache had no database support, so every module needing it had to implement it. Apache 1.3 offered separate, yet virtually identical modules for authentication with NDBM and Berkeley DB, and a whole slew of different (third-party) authentication modules for popular SQL databases such as MySQL. Similarly, every scripting language—such as Perl, PHP and Python—had its own database management.
In time for the release of Apache 2.0, the apr_dbm module was developed to provide a unified interface for the DBM (simple key/value lookup) class of databases. Most recently, the apr_dbd module has been introduced, providing an analogous API for SQL databases. Just as with the printer drivers, the APR database classes eliminate the need for duplication and, as such, are the preferred means of database support for new applications in APR and Apache.
3.6.1. DBMs and apr_dbm
DBMs have been with us since the early days of computing, when the need for fast keyed lookups was recognized. The original DBM is a UNIX-based library and file format for fast, highly scalable, keyed access to data. It was followed (in order) by NDBM (“new DBM”), GDBM (“GNU DBM”), and the Berkeley DB. This last is by far the most advanced, and the only DBM under active development today. Nevertheless, all of the DBMs from NDBM onward provide the same core functionality used by most programs, including Apache. A minimal-implementation SDBM is also bundled with APR, and is available to applications along with the other DBMs.
Although NDBM is now old—like the city named New Town (“Neapolis”) by the Greeks in about 600 B.C. and still called Naples today—it remains the baseline DBM. NDBM was used by early Apache modules such as the Apache 1.x versions of mod_auth_dbm and mod_rewrite. Both GDBM and Berkeley DB provide NDBM emulations, and Linux distributions ship with one or other of those emulations in place of the “real” NDBM, which is excluded for licensing reasons. Unfortunately, the various file formats are totally incompatible, and there are subtle differences in behavior concerning database locking. These issues led a steady stream of Linux users to report problems with DBMs in Apache 1.x.
Apache 2 replaces direct access to a DBM with a unified wrapper layer, apr_dbm. There can be one or more underlying databases; this determination is made at build time, either through a configuration option or by being detected automatically by the build scripts (the default behavior). The database to be used by an application may be passed as a parameter whenever a DBM is opened, so it is under direct programmer control (or administrator control, if the database is configurable) and can be trivially switched if that ever becomes necessary. Alternatively, for cases like authentication that are known to work well with any DBM, it can use a system default. Apache has to support only a single DBM interface, so, for example, a single DBM authentication module serves regardless of the underlying DBM used.
The apr_dbm layer, which is similar to the DBM APIs, is documented in apr_dbm.h. When programming with it, one should not assume any locking, although update operations are safe if the DBM is either GDBM or the original NDBM. Using a mutex for critical updates makes it safe in all cases.
The DBM functions supported in APR are basically the same as those common to all of the DBMs—namely, an API essentially equivalent to NDBM, GDBM, and early versions of Berkeley DB. Advanced capabilities of recent Berkeley DB versions, such as transactions, are not supported, so applications requiring them have to access DB directly.
Example
The function fetch_dbm_value in mod_authn_dbm looks up a value in a DBM database.

3.6.2. SQL Databases and apr_dbd
Note
The apr_dbd module is not available in APR0.x and, therefore, Apache 2.0. It requires APR 1.2 or higher, or the current version of CVS.
SQL is the standard for nontrivial database applications, and many such databases are regularly used with Apache in web applications. The most popular option is the lightweight open-source MySQL, but it is merely one choice among many possibilities.
SQL databases are altogether bigger and more complex than DBMs, and are not in general interchangeable, except where applications are explicitly designed to be portable (or in a limited range of simple tasks). Nevertheless, a unified API for SQL applications brings benefits analogous to the printer drivers.
The apr_dbd module is a unified API for using SQL databases in Apache and other APR applications. The concept is similar to Perl’s DBI/DBD framework or libdbi for C, but apr_dbd differs from these in that APR pools are used for resource management. As a consequence, it is much easier to work with apr_dbd in APR applications.
The apr_dbd module is also unusual within APR in terms of its approach. Whereas the apr_dbd API is compiled into libaprutil, the drivers for individual databases may be dynamically loaded at runtime. Thus, when you install a new database package, you can install an APR driver for it without having to recompile the whole of APR or APR-UTIL.
At the time of this writing, apr_dbd supports the MySQL, PostgreSQL, SQLite, and Oracle databases. Drivers for other databases will likely be contributed in due course.
The MySQL Driver
Apache views MySQL as a special case. Because it is licensed under the GNU General Public License (GPL), a driver for MySQL must also be distributed under the GPL (or not at all). This requirement is incompatible with Apache licensing policy, because it would impose additional restrictions on Apache users.
The author has dealt with this issue by making a MySQL driver available separately[4] and licensing it under the GPL. Users requiring this driver should download it into the apr_dbd directory or folder and build it there. If MySQL is installed in a standard location, it should then be automatically detected and built by the standard APR-UTIL configuration process.
Usage
Apache modules should normally use apr_dbd through the provider module mod_dbd.
3.7. Summary
This chapter presented a brief overview of the APR and APR-UTIL (APU), focusing on those modules most likely to be of interest to developers of Apache applications. Many of the topics introduced here are discussed in more depth in later chapters where they become relevant—indeed essential—to the techniques presented there.
Specifically, this chapter identified the principal roles of APR:
- A platform-independent operating system layer
- A solution to resource management issues
- A utilities and class library
We took a detailed look at the following topics:
- APR conventions and style
- APR pools and resource management in Apache
- The APR database classes
- The principal APR types
We also engaged in a brief tour of other APR modules.
An appreciation of the APR is fundamental to all C programming in Apache, and the remainder of this book will use it extensively. For further reading on the APR, you can refer to the excellent API documentation generated automatically from the header files (available for browsing at apr.apache.org) and to INOUE Seiichiro’s tutorial.[5]