
Chapter 6. Request Processing Cycle and Metadata Handlers
Before returning contents to the client, Apache needs to examine the HTTP request with reference to the server configuration. Much of the Apache standard code is concerned with this task, and sometimes we may need to write a new module to support different behavior. Such modules work by hooking into the early parts of request processing, before any content generator is invoked, and sometimes by diverting or aborting the entire request.
In this chapter, we will first review the metadata sent to the server in an HTTP request. We will then see how the standard modules in Apache deal with this in handling a request. Finally, we will develop a new module.
Note that there is no universally agreed-upon nomenclature here. Modules directly relevant to this chapter are classified into various categories in the Apache distribution:
- Mappers (modules that map from a request URL to the internal structure of the server and/or the filesystem)
- Metadata (modules that explicitly manipulate HTTP headers and/or Apache’s internal state)
- AAA (access, authentication, and authorization modules—the most popular class of metadata modules; discussed in detail in Chapter 7)
This chapter deals with general issues concerning the request processing cycle and metadata handling. Of course, many modules with a different primary purpose (e.g., handlers) may include metadata hooks alongside other functions.
A great deal of folklore has arisen concerning certain uses of metadata and request handling—for example, methods for presenting different types of content to different visitors. At worst, adhering to these myths can lead to broken reimplementations of standard features (reinventing the wheel, but the new one isn’t round)! Professional developers as well as hobbyists may be guilty of this. This chapter warns you about some of the more common misconceptions.
6.1. HTTP
To discuss HTTP request processing, we first need to understand some basics about the Hypertext Transfer Protocol (HTTP).
6.1.1. The HTTP Protocol
HTTP is one member of a broad family of networking protocols for passing messages, whose roots go back to the early days of the Internet. The oldest of these protocols still in general use today is SMTP, the e-mail standard known as RFC822 that dates from 1983. The protocol of the Web is HTTP, which is specified in RFC1945 (HTTP 1.0) and RFC2616 (HTTP/1.1, the current protocol version—see Appendix C). These protocols share some common overall characteristics, designed for the exchange of messages.
Envelopes, Cover Notes, Letters, and Enclosures
Before the Internet, we had other means of communicating over a distance. For those communication strategies to work, we needed two things:
- The contents of the communication: the letter, telegram, fax, or telephone conversation.
- The addressing information: the envelope, phone number, or fax number and cover sheet. This information ensures that the contents can be correctly sent to the intended recipient.
When the Internet messaging protocols were designed, a similar approach was adopted. A modern Internet message comprises an envelope, cover note, and message contents. The contents may be a single letter, a letter with enclosures, or empty.
Metadata Versus Data
When applying the letter metaphor to the Internet, we speak of data and metadata (information about the data). That is, a letter is data, or the contents of a message; the envelope and cover sheet are metadata, or information about the message.
HTTP metadata can be quite extensive. We will encounter examples of it in this chapter, though we will not present a detailed or thorough overview of it here. The authoritative specification dealing with HTTP metadata is RFC2616, which is included in this book as Appendix C.
Request and Response
One important characteristic of the RFC822 family of Internet protocols, including all versions of HTTP, is that all messages are two-way. In other words, every transaction includes both a request sent from the client to the server, and a response sent from the server to the client. A complete message comprising metadata and (optionally) data passes each way.
6.1.2. Anatomy of an HTTP Request
The first thing Apache must do upon receiving a request is to check the cover sheet (metadata) and decide how to deal with the request. The server configuration, together with HTTP rules, will determine how it proceeds.
In HTTP, we must deal with two sets of request metadata:
- The request line (envelope)
- The request headers (cover sheet)
The request line is a single line that specifies the request method and the resource requested. The request headers provide supplementary metadata that may be of relevance to the server in generating a response or in carrying out secondary tasks such as logging and analyzing usage patterns.
Let’s consider a hypothetical request:
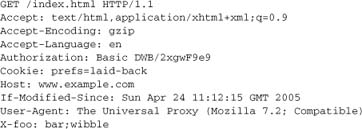
Note
The Host: header is available in both HTTP/1.0 and 1.1. The fact that it’s (technically) optional in HTTP/1.0 is a red herring: Support has been almost universal in both HTTP/1.0 and 1.1 clients since 1995.
The first line indicates a GET request for /index.html on the server. Combined with the Host header, it identifies the requested resource as http://www.example.com/index.html (which is necessary if and only if the server is running more than one virtual host on the IP address and port that the request came on).
The remaining headers, all of which are optional, illustrate the kind of metadata Apache may wish to deal with. No single module is likely to be concerned with all of the request headers, but many modules are concerned with at least some of these tasks:
- Mapping
/index.htmlto the filesystem or to a custom handler from the server configuration forwww.example.com. - Selecting a response acceptable to the browser based on the various
Accept-*headers. - Checking whether the user is permitted to access the resource requested (
Authorizationheader). - Checking whether, from the information supplied, the client already has an up-to-date copy in cache (
If-Modified-Since). If so, we just confirm that with a “304 Not Modified” response and save the bandwidth of returning the entire response body. - Identifying private application data passed between this server and this particular client (
CookieandX-anythingheaders). - Logging data (
User-Agent).
To deal effectively with all these issues, Apache implements several request processing phases before content generation. Modules can hook into any of these phases to adjust, or take full control of, different aspects of request processing, just as our HelloWorld module hooked a content generator in Chapter 5.
6.2. Request Processing in Apache
We have already introduced the request processing cycle. A module can hook into this cycle in the following ways:
post_read_request— General-purpose hook that runs immediately on creating therequest_recobject.translate_name— Map the request URL to the filesystem.map_to_storage— Apply per-directory configuration.header_parser— Check the HTTP request headers. Another general-purpose hook after the configuration is fully available but before more specific phases begin.access_checker— Check whether access is permitted to the remote host.check_user_id— Authenticate the remote user (where applicable).auth_checker— Check whether the remote user is authorized to perform the attempted operation.type_checker— Apply configuration rules that determine the handler and response headers.fixups— General-purpose hook at the end of request preparation but before the handler is called.insert_filter— Insert content filters.handler— Handle the request and generate a response.logger— Log the transaction.
These can also be grouped into phases:
- The
post_read_requestphase marks the transition from the protocol to the request processing. Therequest_recobject is valid, but many of its fields are not yet set. - The phases from
translate_nametofixupsare collectively known as the request preparation phase. - The
insert_filterandhandlerhooks represent the handler (content generator) phase. - The
loggeris the final phase, being called after the request has run.
The request preparation phase can be further subdivided:
translate_nameandmap_to_storageresolve the request to the filesystem and/or logical URL space defined for the server. The per-directory configuration doesn’t exist at this point.header_parseris the first hook where the per-directory configuration is available and enables early processing that relies on it.access_checker,check_user_id, andauth_checkerare the security phase; they determine whether the user is permitted to carry out the attempted operation.type_checkerandfixupsare the last part of the request and occur before the content generator is run.
Let’s consider in more detail how the standard modules in Apache deal with our request.
6.2.1. Mapping to the Filesystem
The first task we identified was to map /index.html to the filesystem. By default, the Apache core will handle this task by appending the request in the path to the DocumentRoot (a configuration setting) at the end of the translate_name phase. Thus, if /var/www/example.com/htdocs is our DocumentRoot for www.example.com, then the default is to map that location to a file /var/www/example.com/htdocs/index.html. A second default handler, at the end of map_to_storage, cross-references the file to <Directory> and <Files> configuration and, if .htaccess files are enabled, merges them into the configuration.
Warning
Don’t confuse URLs with filesystem paths. Although they may correspond (and do, by default, in Apache), this is never more than a matter of convention.
Use <Directory> and <Files> with your filesystem paths to configure them for local contents. Use <Location> with URLs for virtual or nonlocal contents.
A standard module that can change the default behavior is mod_alias. The Alias configuration directive is used to specify a different mapping to the filesystem for selected request paths. Alias uses a translate_name hook that replaces the default action of appending the request URL path to the document root. Subsequent processing, including the default map_to_storage handler, remains unchanged.
Here’s the translate_name hook from mod_alias:

This code calls the function try_alias_list twice: first to apply the Redirect directive and then to apply the Alias directive. If a directive matches, try_alias_list will return the redirected URL or pathname. An Alias directive will then simply set r->filename, whereas a Redirect directive will divert request processing into a separate processing path, using the error document mechanism described in Section 6.3.1.
6.2.2. Content Negotiation
Our second task was to select a response that will be acceptable to the browser, according to the Accept-* headers sent.
![]()
These conditions may be ignored, and will be if we use default processing without multiviews. This task may also be handled in other ways. For example, for dynamic contents, gzip encoding is determined by an output filter (mod_deflate), rather than by a metadata handler. Likewise, an XSLT output filter could deal with selection of content types. But a regular case we should consider (not least because it’s a wheel that’s been reinvented badly by many organizations that should know better) is standard content negotiation, in which Apache selects an appropriate static file from several available options.
Note
Take the time to read about content negotiation in the HTTP specification (Appendix C) and look at Apache’s mod_negotiation module. This extra effort could save you and your clients or employers the embarrassment of a broken reinvention—some bad blunders are distressingly widespread!
Wrong: Sniff a user’s hostname or IP address, look up a country based on that information, and serve the language you think someone in that country would like.
Right: Serve the language selected by the user in the browser preferences and supplied to the server in Accept-Language.
Wrong: Serve different contents to users by inferring client capabilities from a User-Agent string.
Right: Infer what a browser is capable of rendering from an Accept: header. But take care: Some browsers may lie. MS Internet Explorer (MSIE) is the main culprit. For example, it claims to accept all compressed contents and works fine with compressed HTML, yet chokes on other formats when they are compressed.
The module of interest here is mod_negotiation, which is typically used for the following purposes:
- For multilingual sites, to select a language specified in the user’s browser preferences
- For sites supporting different devices (e.g., desktop PCs versus WAP devices), to select between HTML and XML variants, or between SVG and bitmap images.
The simplest use of mod_negotiation is just to create a choice of resources. For example, if we supply the files
index.html.en (English)index.html.fr (French)index.html.de (German)index.html.it (Italian)
together with appropriate AddLanguage directives and MultiViews, then mod_negotiation will select one of the preceding files according to the Accept-Language header sent by the browser (and configured by the user in a preferences menu, or as supplied to the user localized by an ISP or other network administrator). mod_negotiation uses a type_checker handler to map index.html to one of the available variants. When a variant is chosen, it overwrites the request state with one that is identical except in that a new file has been selected.
Don’t forget to set the Vary response header when your module serves negotiated contents, so that caches know there may be other variants better suited to another client requesting the same URL!
6.2.3. Security
The third task was to check that the user is authorized to access the resource. The access, authentication, and authorization phases of request processing check the client’s credentials (if any) supplied in the request headers, together with the client’s IP address, against any policies for the requested resource defined in httpd.conf or an applicable .htaccess file. This phase, which is a traditional favorite with module developers, will be discussed in detail in Chapter 7.
6.2.4. Caching
The fourth task was to check when the resource was last modified, so we don’t have to resend the data if they are older than the version the client has cached, as indicated in the If-Modified-Since header. This is one of several HTTP headers concerned with caching and efficiency. By default, caching is dealt with only in the handler/content generator phase. Nevertheless, a module that is not concerned with the possible effects of another module’s fixups operation could check this earlier.
6.2.5. Private Metadata
The fifth task was to deal with application-specific data, including cookies and any private HTTP extensions (X-anything headers). This task is entirely application-specific and cannot be generalized. Applications should always be sure to implement fallback behavior for clients that don’t supply a cookie or a private header. A major blunder sometimes seen on websites is to redirect any client without a cookie to a page that sets one and then send the client into an infinite loop.
6.2.6. Logging
The final task is to log the request. Logging a request is the only appropriate use for a User-Agent string. One of the most common errors on the Web today is to attempt to infer client characteristics or capabilities from a User-Agent string. This behavior is wrong for many reasons. First, many browsers spoof their User-Agent strings to avoid being excluded from MSIE-only sites (ironically, MSIE still uses the Mozilla keyword, which is itself a spoof introduced originally to keep MSIE users from being excluded from Netscape-enhanced sites in the mid-1990s). Second, it fails to account for caching, including the likelihood that a single cache may serve many different user agents. Third, and most importantly, it is at best a poor reinvention of HTTP content negotiation, based on the preferences and capabilities stated in the Accept-* headers.
6.3. Diverting a Request: The Internal Redirect
The request processing cycle may be diverted at any point using a mechanism known as an internal redirect. An internal redirect replaces the current request with a new request for the new (redirected) resource.
The internal redirect mechanism emulates HTTP redirection (such as an HTTP 302 response), but without requiring an additional request from the browser. This behavior mirrors the distinction made through the dual nature of the CGI Location header:
Location: http://www.example.com/foo/
This causes Apache to send an HTTP redirection to the browser, including the HTTP Location header.
By contrast, a relative URL—which is illegal in HTTP—is allowed in CGI:
Location: /foo/
This generates an internal redirect, without involving the browser.
A module can divert request processing using one of the two internal redirection functions defined in http_request.h:
void ap_internal_redirect(const char *new_uri, request_rec *r)
This is the canonical internal redirection function, and the mechanism to use if you have no strong reason to make another choice. This function creates a new request object for the new URL, and then runs the new request as if new_uri had been requested in the first place.void ap_internal_fast_redirect(request_rec *new_req, request_rec *r)
This function clones an existing request structure new_req into the running request r, so it can be used to set up a new request and simulate passing control to it. This mechanism is sometimes used to promote a subrequest (as discussed later in this chapter) to a main request.
Internal redirection can occur anywhere in the request processing cycle, provided that no data have been returned to the client as yet. The most common form of internal redirection is the error document, as described in Section 6.3.1.
Note that Apache’s normal processing, including—where appropriate—functions implemented by your modules, will run within an internal redirect. Bear in mind that the configuration applied is that of the redirected URL, not the original URL. Your handlers can determine whether they are running in an internal redirect by examining the r->prev field. Normally, its value will be NULL; in an internal redirect, however, it contains the original request_rec from before the redirection. An internal redirection will also have an environment variable REDIRECT_STATUS set to the status code of the original request at the time of redirection.

6.3.1. Error Documents
In Chapter 5, we mentioned that if our handler returned an HTTP status code (or, indeed, any value other than OK or DECLINED), this would divert the entire request processing into an error path. Any function implementing an earlier hook in the request cycle may likewise return an HTTP status code. At that point, Apache sets up an internal redirection to the error document for the HTTP status code in question.
An error document is, by default, a predefined document that presents the user with a brief explanation of the error. A server administrator can change this document by using the ErrorDocument directive. Because an error document is treated internally as a different request, it can be served by any handler (such as a CGI or PHP script). To avoid going into an error loop, this functionality is not recursive: An error document will not divert the path to another error document by returning an HTTP status code itself. If that happens, it generates a predefined server error.
A special case involves error documents for HTTP 3xx status codes. These codes are not errors, but rather redirections and similar messages. Thus, in addition to an internal redirection, they generate an HTTP redirection. This operation is straight-forward and perfectly normal, as illustrated by our earlier example in which mod_alias handles the Redirect directive.
6.3.2. Dealing with Malformed and Malicious Requests
A fundamental principle of security on the Web is always to exercise caution in what you accept from any unknown source. That includes HTTP requests coming from anywhere on the Web. Most of these requests will be legitimate, being generated by human-driven browsers, spiders such as Googlebot, proxy cache agents, QA tools such as Site Valet, and so on. Unfortunately, a significant number of HTTP requests represent attempts to exploit security vulnerabilities. Traces of some rather old IIS worms (e.g., Nimda, Code Red) are routinely seen in Apache logs, in which automated attacks attempt to use IIS bugs to take control of Windows servers. Although Apache has not suffered a comparable attack, it is every module developer’s business to keep Apache clean! The basic rule is to determine which inputs, or pattern of inputs, an application will accept, and then to reject any request that fails to match an acceptable pattern.
Apache offers a ready-made solution that allows any module to deal with bad requests: Simply abort by returning HTTP status code 400 (Bad Request) or, where applicable, a more specific HTTP 4xx status code, as soon as you encounter the bad inputs. Don’t even try to deal with the bad request directly—that way complexity and security vulnerabilities lie.
6.4. Gathering Information: Subrequests
A second form of diversion from normal request processing is the subrequest. A subrequest is a diversion to a new request. Unlike with internal redirection, however, processing returns to the original request after the subrequest completes.
Subrequests constituted an important tool in Apache 1.x, where they could be used to improvise a primitive form of filtering in which a module sets up a handler to run another handler in a subrequest, and intercepts incoming and/or outgoing data. In Apache 2.x, this kind of hack is no longer necessary. The main role of the subrequest now is to run a fast partial request, to gather information: “What would happen if we ran this request?” For example, mod_autoindex runs a subrequest to each file in a directory, producing a list of only those files that are accessible to the server. Of course, at the system level, we could achieve the same goal with a simple stat, but running a subrequest means that we can also ascertain whether the server configuration permits access.
The subrequest API in Apache 2 comprises four methods to create a subrequest from a request
ap_sub_req_lookup_uriap_sub_req_lookup_fileap_sub_req_lookup_direntap_sub_req_method_uri
together with a method to run it
ap_run_sub_req
and a method to dispose of it when done
ap_destroy_sub_req
When we create a subrequest using one of the first four methods, Apache goes through the request preparation phase (up to the fixups hook). This may be sufficient if the purpose of the subrequest is to gather information on “What would happen if we request this URL?” Running a subrequest is optional.
Destroying the subrequest can be a more complex issue. It is always required, whether or not the request was run. Modules can either run ap_destroy_sub_req explicitly or leave it to the pool cleanup when the parent request is destroyed. Take care when destroying a subrequest, as anything allocated on the subrequest’s pool will die along with it!
Like the internal redirect and the error document, a subrequest will invoke functions from all modules hooked into the processing cycle, as appropriate. Your functions can tell when they are invoked in a subrequest by looking at the r->main field of the request_rec; its value is normally NULL, but in the context of a subrequest it holds the parent request_rec.

6.4.1. Example
The mod_include module demonstrates both forms of subrequests. The SSI <!—#include virtual="…"--> directive is implemented by a full subrequest to the included resource, whereas other directives such as <!--#fsize …--> and <!--#flastmod …--> use only a lookup to find information about the resource (metadata), without actually serving the resource to the client.
Here’s the relevant subrequest code for processing <!--#include virtual…--> and <!--#include file …--> directives in mod_include:

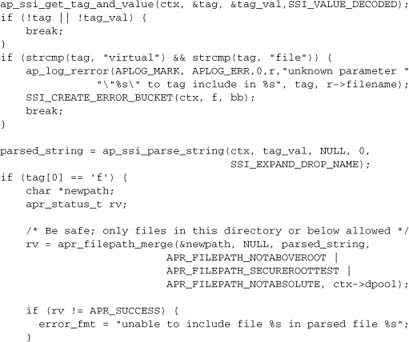
The next two else clauses create the subrequest: the first for <!--#include file-->, and the second for <!--#include virtual-->.
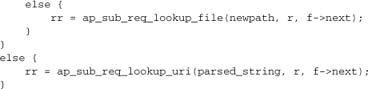
At this point, the subrequest has not been run, but the lookup alone takes us through the process of constructing the subrequest and running it, up to and including the fixups phase. As a consequence, we know quite a lot about the subrequest: We know if it has failed or been denied (except for the case in which an error in its content generator causes it to fail), and we’ve got the file information we’d need for <!--#fsize--> or <!--#flastmod-->. But the subrequest has not (yet) touched the data, only the metadata.
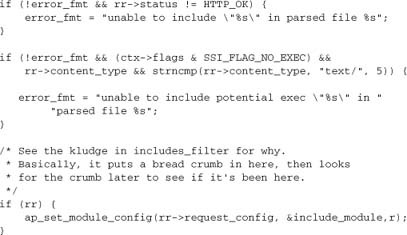
The second phase of the subrequest processing is to run the content generator. The subrequest’s output will then be sent to the client. Other SSI directives such as <!--#flastmod--> and <!--#fsize> omit this step.

The comment is noting that at this point, we would normally call ap_destroy_sub_req. The memory leak isn’t really important, because it lasts only until the main request is itself destroyed.

6.5. Developing a Module
So far, we have breezed through a brief overview of the earlier phases of request processing. In the remainder of this chapter, we will develop a real example module.
6.5.1. Selecting Different Variants of a Document
The author’s Site Valet product includes a facility through which users can publish reports to the server. These reports are part of a QA/audit process. As such, they are important but will be accessed infrequently, so system performance is not a major issue with the report generation process.
Reports are generated and stored on the server in an XML format used within Site Valet. Not surprisingly, the reports need to be accessible in other formats: HTML for web browsers and human readers, and EARL (RDF) for the Semantic Web. This reformatting is accomplished by applying an XSLT transformation on the fly when a document is served to anyone other than the Valet tools. The XSLT transformation is performed by mod_transform, which is a prerequisite for this module.
The problem we have to address here is, in a sense, the opposite of content negotiation. Instead of selecting one of many static resources according to the request headers, we must respond to the user’s explicit request for a different URL.
Put explicitly, if an XML report is stored at {DOCUMENT_ROOT}/reports/example, then we need to map requested URLs as follows:

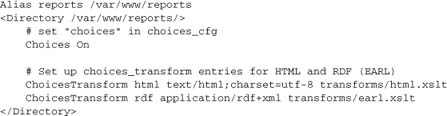
For additional flexibility, our module enables users to define other formats by introducing their own XSLT stylesheets. Let’s call this module mod_choices.
The core of mod_choices is a type_checker hook. To set the scene for it, we need to define the relevant data structs. First, we define the module configuration:

Second, we note that each “extension” is a record describing how to handle itself:

To implement .html and .rdf as described above, we will set up entries in the transforms table. The configuration will look something like this:
Now we can present the main function:


All we need to do now is to hook in the handler, together with its configuration. We’ll show the remainder of the module here for completeness, but defer an explanation of it to Chapter 9, where we describe module configuration. We use APR_HOOK_FIRST to hook this handler in ahead of standard type checkers such as mod_mime.

6.5.2. Error Handling and Reusability
The preceding module is adequate for our application. Anyone using this code will be accessing a URL generated by the application, so how we deal with failure to find a resource is unimportant. Of course, if we want to generalize our module a little, we could make a few changes. There’s no problem with reusing it as is; it’s just that the module is specific to a single project, so it is not very likely to be used on a more widespread basis.
There are three points at which we return an HTTP status of 404 (Not Found), thereby diverting processing into an error document. Points 1 and 3 indicate cases in which we fail to find any resource. Point 2 indicates the case in which we find the file but don’t know what to do with the extension.
Now, mod_choices implements one scheme for dealing with variants on a resource; mod_negotiation implements another scheme; and another third-party module might provide an altogether different mapping. At points 1 and 3, we could return DECLINED instead of HTTP_NOT_FOUND to enable those modules to work alongside mod_choices.[1] At point 3, we would also need to restore r->filename to its original value first! If we do that, we can let Apache apply several different schemes until it finds one that works (or gives up).
We could do the same at point 2, but this failure is probably due to a server configuration that doesn’t quite meet the client’s expectations. As an example, suppose that the client requested
http://server/reports/example.html
but the ChoicesTransform line for html is missing from httpd.conf. In this scenario, a better option is to return HTTP_MULTIPLE_CHOICES, which will divert us into an error document. To be useful, our error document should tell the client which options are available, so we’ll have to write our own handler for it, too. This handler needs the mod_choices configuration, so it’ll be easiest to implement it in the same module.
Here’s a minimal implementation:


Now we just need to add this function to our hooks:
![]()
Finally, we configure it:

6.6. Summary
This chapter presented an overview of the HTTP request processing cycle in Apache, covering both the standard processing path and diversions from it. As with content generators, the primary building blocks for metadata modules are callback functions attached to Apache’s hooks. Specifically, we examined the following topics:
- The anatomy of an HTTP request
- Mapping the request to the server
- Handling HTTP request headers (metadata), including content negotiation
- The roles of the request processing phases, and hooking into them
- Diverting the request from the normal cycle
- Processing errors
Apache’s hooks are explained in detail in Chapter 10, and configuration is addressed more fully in Chapter 9. Next, Chapter 7 offers a detailed look at the security phase of request processing.