
Chapter 8. Filter Modules
In terms of application development, the most important innovation in Apache 2 is the filter architecture and the ability to chain multiple different data processing operations at will. In this chapter, we will take a detailed look at the filter chain and develop several illustrative filter modules.
Before going into details, let’s review a few basics. In Chapter 2, we saw that filters operate on a “data” axis, orthogonal to the processing axis familiar from Apache 1 and other webservers (Figure 8-1). But this is not the whole story. Strictly speaking, it is really accurate only for content filters—that is, for those filters that operate on the body of an HTTP request or response. If your application is not concerned directly with processing HTTP requests, you may need to use filters that are not so clearly associated with the content generator.
Figure 8-1. The filter axis
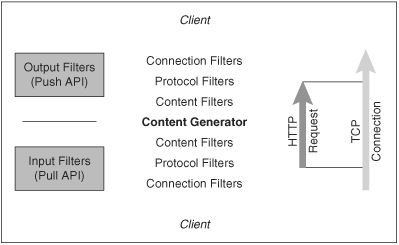
Let’s take a closer look at the filter chain. Filters are classified in two ways, as described in the following sections.
8.1. Input and Output Filters
Filters that process request data coming from a client are known as input filters. Filters that process response data as it is sent out to the client are known as output filters.
We will deal with the APIs for input and output filters in detail in this chapter.
8.2. Content, Protocol, and Connection Filters
Each filter chain (input and output) passes through predefined stages. Thus the same filter architecture can be used for different kinds of operation. In brief, from the content generator to the client, we have the following classes of filters:
- Content filters, which process document contents within a request. These are the filters most commonly relevant to applications programming.
- Protocol filters, which deal with details of the protocol but treat the contents as opaque. These filters are concerned with translating between HTTP data (as defined in RFC2616) and Apache’s internal representation in the
request_recand associated structures. - Connection filters, which process a TCP connection without reference to HTTP (either the protocol or contents). These filters are concerned with interfacing Apache with the network; they operate entirely outside the scope of HTTP or of any
request_rec.
Although these filters have very different functions, moving from an applications level in the inner layers to a system level farther out, the API is the same throughout. There is just one important difference: The inner filters, working on HTTP, have a valid request_rec object, whereas connection-level filters have none. All filters have a conn_rec for the TCP connection.
In more detail, the output chain comprises the following stages in an enumeration in util_filter.h (the input chain is an exact mirror image of this sequence, and uses the same definitions):
AP_FTYPE_RESOURCEis for content filters. These filters are the first to see content as it is produced by the content generator, and they serve to examine, modify, or even completely rewrite it. This is the most common form of application filter, and encompasses markup processing (such as SSI or XML filtering), image processing, or content assembly/aggregation. Resource filters may completely change the nature of the contents. For example, an XSLT filter might change the contents from XML to HTML or PDF.AP_FTYPE_CONTENT_SETis a second stage of content filtering. It is intended for operations concerned with packaging the contents, such asmod_deflate(which applies gzip compression).
Filters of type RESOURCE or CONTENT_SET operate on an HTTP response entity—that is, the body contents being returned to the client. The HTTP headers don’t pass through these filters. The headers can be accessed in exactly the same way as in a content generator, via the headers tables in the request_rec.
AP_FTYPE_PROTOCOLis the third layer of filtering. The normal function here is to insert the HTTP headers ahead of the data emerging from the content filters. This is dealt with by a core filterHTTP_HEADER(functionap_http_header_filter), so applications can normally ignore it. Apache also handles HTTP byte ranges[1] using a protocol filter.
AP_FTYPE_TRANSCODEis for transport-level packaging. Apache implements HTTP chunking[2] (where applicable) at this level.
AP_FTYPE_CONNECTIONfilters operate on connections, at the TCP level (HTTP requests no longer exist). Apache (mod_ssl) uses it for SSL encoding. Another application is throttling and bandwidth control.AP_FTYPE_NETWORK, the final layer, deals with the connection to the client itself. This layer is normally dealt with by Apache’sCOREoutput filter (functionap_core_output_filter).
The examples presented in detail in this chapter are all content filters, of types AP_FTYPE_RESOURCE and AP_FTYPE_CONTENT_SET. The essential principles of writing a filter are no different for other filters, with a few exceptions.
Protocol
Protocol filters are responsible for converting the input data from a byte stream to an HTTP request, and the output data back again. The input protocol filter populates r->headers_in, while the output protocol filter converts r->headers_out to a byte stream.
Headers and Entities
Filters of types AP_FTYPE_RESOURCE and AP_FTYPE_CONTENT_SET only see an HTTP request or response entity (body). The request and response headers may be accessed through the r->headers_in and r->headers_out tables, respectively.
Caution
r->headers_out will be converted to a set of response headers the first time the output HTTP protocol filter is invoked. Any changes made later will have no effect!
By contrast, filters outside the protocol layer will not have r->headers_in and headers_out, but just a stream of bytes or lines. In fact, they won’t have a request_rec at all, just an undefined pointer in f->r.
Metadata Buckets
Inner filters will rarely see metadata buckets (except for EOS) and can commonly ignore them, although technically, flush buckets should be flushed immediately, and ignoring them may make a filter unsuitable for streaming media. Outer filters should respect all metadata buckets.
8.3. Anatomy of a Filter
8.3.1. Callback Function
The heart of a filter module is a callback function. How it is called differs between input and output filters:
- The input filter chain runs whenever the handler requests data from the client. Apache will call the callback function to request (pull) a chunk of data from it. Our filter must, in turn, pull a chunk of data from the next filter in the chain, process it, and return the requested data to the caller.
- The output filter chain runs whenever the handler sends a chunk of data to the client. This may be triggered explicitly by the handler (with
ap_pass_brigade), or implicitly when a handler using thestdio-like APIs has filled a default (8K) buffer. Our filter should process the data, and send (push) a chunk to the next filter in the chain.
Apart from the callback, there is an optional initialization function. Also, filter modules may independently use other parts of the Apache API where necessary.
8.3.2. Pipelining
The basic principle of pipelining is that we should not have to wait for one stage of processing to complete before starting on the next stage (Figure 8-2). In the context of a webserver, where I/O commonly takes far more time than processing a request, this is an important performance issue.
Figure 8-2. Linear versus pipelined processing
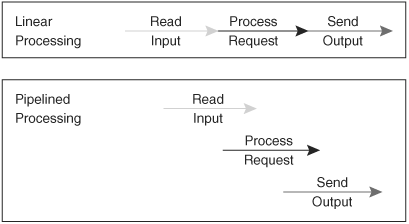
In the Apache 2.x filter architecture, we don’t have just the three stages to processing data—every filter is itself a stage. Thus there is still more to be gained by pipelining. As far as possible, we want to run the filters in parallel. To run filters on large documents without introducing scalability problems, we must avoid having to load an entire document into memory at once. Apache’s filters, therefore, work on chunks of data rather than entire documents, and any general-purpose filter must deal with that behavior. Filters should always endeavor to cooperate with this pipelining. Ideally, a filter should always process a chunk of data and pass it on before the callback returns. Sometimes this is not possible, and a filter needs to buffer data over more than one call. For example, running an XSLT transform requires that the entire document be parsed into an in-memory structure, so an XSLT filter can’t avoid breaking the pipeline.
Pipelining can be an important consideration when designing a module. If you are planning to use an external library, it’s worth reviewing how well it will work with the pipeline. In the case of an input filter, that’s usually straightforward: It can just pull in more data from the pipeline on demand. For an output filter, however, you need to look for an API that can accept arbitrary chunks of data. This author has written a number of XML- and HTML-parsing filters, and working with the Apache pipeline has a profound effect on the choice of a parser. Among markup processing libraries, expat and libxml2 have parseChunk APIs and work well with Apache, but Tidy, OpenSP, and Xerces-C have no such APIs, and so cannot be used without breaking the pipeline.
8.4. The Filter API and Objects
As discussed in Section 8.3.2, the filter callback function differs between input and output filters. Let’s deal with each case in turn.
8.4.1. Output Filters
The callback prototype for output filters is
![]()
Here f is the filter object, and bb is a bucket brigade containing an arbitrary chunk (zero or more bytes) of data in APR buckets. The filter function should process the data in bb, and then pass the processed data to the next filter in the chain, f->next. We will see how to do this when we develop filter examples later in this chapter.
8.4.2. Input Filters
The input filter callback is a little more complex:
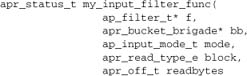
The first two arguments are the same as the output filter arguments, although the usage differs. This is a pull API, and our function is responsible for fetching a chunk of data from the next filter in the input chain, putting that data into the bucket brigade, and returning to the caller. Let’s look at the other arguments.
mode is one of an enumeration:

Clearly, not all of these modes are relevant to every filter. A filter that cannot support the mode it is called with is inappropriate, and may indicate a misconfiguration. It should normally remove itself from the filter chain and log a warning message for the administrator. A filter may often call the next filter using the same mode that it was called with, but this behavior is not always appropriate and a filter is free to do otherwise.
The block argument takes the value APR_BLOCK_READ or APR_NONBLOCK_READ. It determines whether the filter should block if data are not immediately available. Where set, readbytes is an indication of the (maximum) number of bytes the filter should return to its caller.
8.5. Filter Objects
The filter object (like others discussed in this chapter) is defined in util_filter.h.
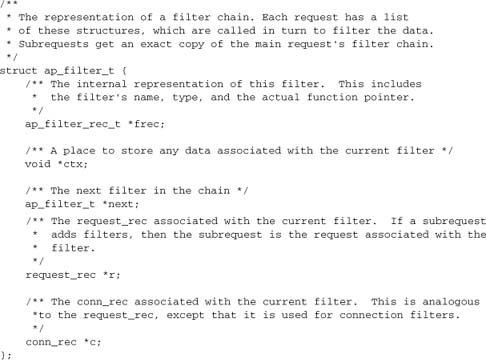
The fields that most filter modules will use here are ctx, to store application data for the filter between calls, and request_rec, to access all the normal request data. (In the case of connection-level filters, there is no valid request_rec field, and the conn_rec serves a similar purpose.) The next field will be used to push data to the next filter in the output chain or to pull data from the next filter in the input chain.
The frec field can normally be treated as opaque by applications, but is necessary to our understanding of filter internals. Here it is:

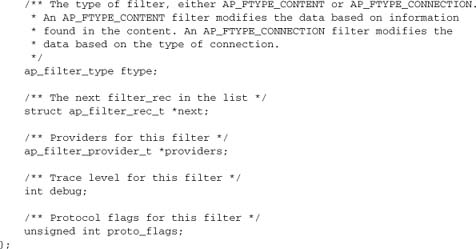
The name is just an identifier for the filter configuration, which will be discussed in Chapter 9. The filter_func is the main callback we’ve already introduced, and the filter_init_func is a seldom-used initialization function that is called when the filter is inserted and before the first data are available.
The final three fields were introduced with the smart filtering architecture in Apache 2.2, as described in Section 8.7.
8.6. Filter I/O
Data passes through the filter chain on the bucket brigade. There are several strategies for dealing with the data in a filter:
- If the filter merely looks at the data but doesn’t change anything, it can pass the brigade on as is.
- If the filter makes changes but preserve content length (e.g., a case filter for ASCII text), it can replace bytes in place.
- A filter that passes through most of the data intact but makes some changes can edit the data by direct bucket manipulation.
- A filter that completely transforms the data will often need to replace the data completely, by creating an entirely new brigade and populating it. It can do so either directly or by using
stdio-like functions. Two families ofstdio-like functions are available: APR providesapr_brigade_puts/apr_brigade_write/etc., whileutil_filterprovidesap_fwrite/ap_fputs/ap_fprintf/etc.
Management of I/O lies at the heart of filtering. It will be demonstrated at length when we develop example filters later in this chapter.
The key concepts in managing data are the bucket and the brigade. We have already encountered them in Chapter 3 and elsewhere. In this chapter, our examples will explore them in depth.
8.7. Smart Filtering in Apache 2.2
The original Apache 2.0 filter architecture presents problems when used with unknown content—whether in a proxy or with a local handler that generates different content types to order. The basic difficulty derives from the Apache configuration. Content filters need to be applied conditionally. For example, we don’t want to pass images through an HTML filter. Apache 2.0 provides four generic configuration directives for filters:
SetOutputFilter: Unconditionally insert a filter.AddOutputFilter,RemoveOutputFilter: Insert or remove a filter based on “extension.”AddOutputFilterByType: Insert a filter based on content type. This directive is implemented in theap_set_content_typefunction, and has complex side effects.
In the case of a proxy, extensions are meaningless, as we cannot know what conventions an origin server might adopt. Likewise, when the server generates content dynamically—or filters it dynamically with, for example, XSLT—it can be difficult or even impossible to configure the filter chain using the preceding directives. Instead, we have to resort to the unsatisfactory hack of inserting a filter unconditionally, checking the response headers from the proxy, and then having the filter remove itself where appropriate. Examples of filters that follow this approach include mod_deflate, mod_xmlns, mod_accessibility, and mod_proxy_html.
8.7.1. Preprocessing and Postprocessing
As with an origin server, it may be necessary to preprocess data before the data go through the main content-transforming filter and/or to postprocess the data afterward. For example, when dealing with gzipped content, we need to uncompress it for processing and then recompress the processed data. Similarly, in an image-processing filter, we need to decode the original image format and re-encode the processed data.
This may involve more than one phase. For example, when filtering text, we may need both to uncompress gzipped data and to transcode the character set before the main filter.
Potentially, then, we have a large multiplicity of filters: transformation filters, together with preprocessing and postprocessing for different content types and encodings (see Figures 8-3 and 8-4). To repeat the hack of each filter being inserted and determining whether to run or remove itself in such a setup goes beyond simple inelegance and into the absurd. An alternative architecture is required.
Figure 8-3. Apache 2.0 filter chain
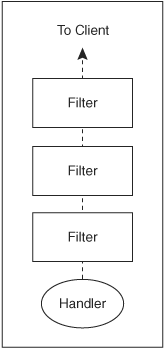
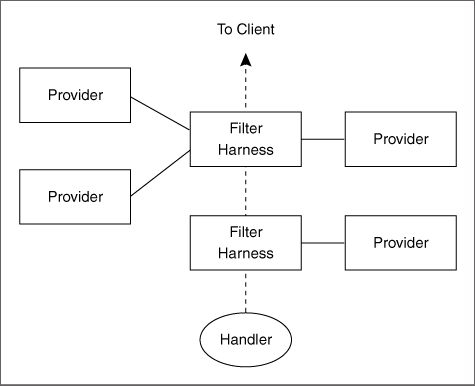
Figure 8-4. Apache 2.2 smart filtering
8.7.2. mod_filter
The solution to this problem is implemented in Apache 2.2 in mod_filter. This module works by introducing indirection into the filter chain. Instead of inserting filters in the chain, we insert a filter harness, which in turn dispatches conditionally to a filter provider. Any content filter may be used as a provider to mod_filter; no change to existing filter modules is required (although it may be possible to simplify them). There can be multiple providers for one filter, but no more than one provider will run for any single request.
A filter chain comprises any number of instances of the filter harness, each of which may have any number of providers. A special case is that of a single provider with unconditional dispatch—this is equivalent to inserting the provider filter directly into the chain.
mod_filter is implemented only for output filters: The configuration problems it deals with are not relevant to the input chain. And although it can be applied anywhere in the output filter chain, it is really relevant only to content (application) filters. Neither the old nor the new filter configuration directives are generally used for the outer filters. For example, SSL (both input and output) is activated by mod_ssl’s own configuration directives instead.
8.7.3. Filter Self-configuration
In addition to using the standard filter configuration provided by the core and mod_filter, a filter may be self-configuring.
The insert_filter Hook
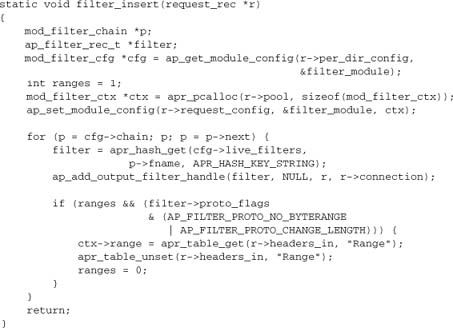
A hook for inserting filters is provided in the content-handling phase of request processing, immediately before the content generator. mod_filter uses this hook to insert the filter harness for dynamically configured filters, but the same hook may also be used by other modules. Here is mod_filter’s hook, which inserts all entries in the filter chain (as configured by the FilterChain directive) in order:
![]()
When other modules may use this hook, they should consider carefully where their filter should be inserted into the chain. They can explicitly run their filter_insert before or after mod_filter, to determine their position in the chain.
Configuration Using Environment Variables and Notes
Another strategy available to filters is to examine the request details themselves to determine whether to run or uninsert themselves. This approach was widely used in Apache 2.0 before mod_filter became available, and it may still be required when the configuration is more complex than can be delegated to mod_filter.
An example is the compression filter in mod_deflate. Since it is older than mod_filter, this module provides explicitly for control by environment variables (which could be set either in httpd.conf with SetEnv or similar or by another module). However, mod_deflate also provides some more complex logic that is better handled internally than in httpd.conf. Relevant code from mod_deflate.c is provided here:

8.7.4. Protocol Handling
In Apache 2.0, each filter is responsible for ensuring that whatever changes it makes are correctly represented in the HTTP response headers, and that it does not run when it would make an illegal change. This requirement imposes a burden on filter authors to reimplement some common functionality in every filter. For example:
- Many filters will change the content, invalidating existing content tags, checksums, hashes, and lengths.
- Filters that require an entire, unbroken response in input need to ensure that they don’t get byte ranges from a back end.
- Filters that transform output in a proxy need to ensure that they don’t violate a
Cache-Control: no-transformheader from the back end. - Filters may make responses uncacheable.
mod_filter aims to offer generic handling of these details of filter implementation, reducing the complexity required of content filter modules. At the same time, mod_filter should not interfere with a filter that wants to handle all aspects of the protocol. By default (i.e., in the absence of any explicit instructions), mod_filter will leave the headers untouched.
Thus you as a filter developer have two options. If you handle all protocol considerations within your filter, then it will work with any Apache 2.x. However, if you are not concerned with backward compatibility, you can dispense with this approach and leave protocol handling to mod_filter. If you take advantage of this opportunity, please note that (at the time of this book’s writing) mod_filter’s protocol handling is considered experimental: You should be prepared to verify that it works correctly with your module.
The API for filter protocol handling is simple. The protocol is defined in a bit field (unsigned int), which is passed as an argument when the filter is registered (in function ap_register_output_filter_protocol) or later in function ap_filter_protocol.
The following bit fields are currently supported:
AP_FILTER_PROTO_CHANGE: filter changes the contents (thereby invalidating content-based metadata such as checksums)AP_FILTER_PROTO_CHANGE_LENGTH: filter changes the length of the contentsAP_FILTER_PROTO_NO_BYTERANGE: filter requires complete input and cannot work on byte rangesAP_FILTER_PROTO_NO_PROXY: filter cannot run in a proxy (e.g., it makes changes that would violate mandatory HTTP requirements in a proxy)AP_FILTER_PROTO_NO_CACHE: filter output is non-cacheable, even if the input was cacheableAP_FILTER_PROTO_TRANSFORM: filter is incompatible withCache-Control: no-transform
8.8. Example: Filtering Text by Direct Manipulation of Buckets
Our first example is a simple filter that manipulates buckets directly. It passes data straight through, but transforms it by manipulating pointers.
The purpose of this module is to display plain text files as HTML, prettified and having a site header and footer. So what the module has to do is this:
- Add a header at the top
- Add a footer at the bottom
- Escape the text as required by HTML
The header and footer are files specified by the system administrator who is responsible for the site.
8.8.1. Bucket Functions
First we introduce two functions to deal with the data insertions: one for the files and one for the simple entity replacements.
Creating a file bucket requires an open file handle and a byte range within the file. Since we’re transmitting the entire file, we just stat its size to set the byte range. We open the file with a shared lock and with sendfile enabled for maximum performance.
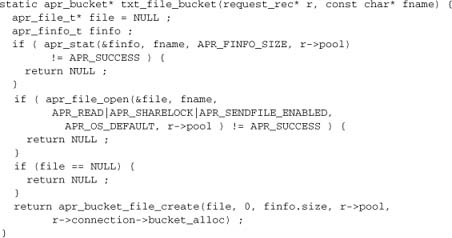
Creating the simple text replacements, we can just make a bucket of a string. By making the strings static, we avoid having to worry about their lifetime.

8.8.2. The Filter
The main filter itself is largely straightforward, albeit with a number of interesting and unexpected points to consider. Since this function is a little longer than the utility functions given earlier, we’ll comment it inline instead.
The txt_cfg struct used here is the module’s configuration; it contains just the filenames for the header and footer. Given that this may be used concurrently by many threads, we access it on a read-only basis and use a second, private, txt_ctxt object to maintain our own state.

The filter context f->ctx is used to hold module variables over multiple calls to a filter. It is common practice to initialize it on the first call to the filter function, which is detected by checking for a NULL value (which our function then sets, as in this example). We could also initialize f->ctx in a filter initialization function, but that’s rare in real filters.

The main loop here iterates over the incoming data in a manner common among filter functions:

As in any filter, we need to check for EOS. When we encounter it, we insert the footer in front of it. We shouldn’t get more than one EOS, but just in case we do we’ll note having inserted the footer. That means we’re being error-tolerant.

We can ignore other metadata buckets. If we get a flush bucket, it should be the last in our brigade, so we’ll automatically exit the loop and pass it down the chain, thereby handling it correctly. If it’s not the last bucket, then any damage we could have done by ignoring it has already been done by whatever sent us the brigade.
![]()
The main case is a bucket containing data. We can get it as a simple buffer, whose size is specified in bytes:

Now we can search for characters that need replacing, and replace them:
![]()
Here comes the tricky bit—replacing a single character inline:

Now we insert the header if it hasn’t already been inserted.
Be aware of the following points:
- This insertion has to come after the main loop, to avoid the header itself getting parsed and HTML-escaped.
- This approach works because we can insert a bucket anywhere in the brigade. In this case, we put it at the head.
- As with the footer, we save the state to avoid inserting the header more than once.
![]()
Note that we created a new bucket every time we replaced a character. Couldn’t we have prepared four buckets in advance—one for each of the characters to be escaped—and then reused those buckets whenever we encounter the character?
The problem here is that each bucket is linked to its neighbors. Thus, if we reuse the same bucket, we lose the links, so that the brigade now jumps over any data between the two instances of it. Hence we do need a new bucket every time, which means this technique becomes inefficient when a high proportion of input data has to be changed.
Now we’ve finished manipulating data, we just pass it down the filter chain:
return ap_pass_brigade(f->next, bb) ;
}
mod_txt was written one idle afternoon, after someone had asked on IRC whether such a module existed. It seemed such an obvious thing to do, and it is a great example to use here. Working with buckets and brigades is one of the most challenging parts of the Apache API, and it needs such a simple demonstrator module!
8.9. Complex Parsing
The parsing in the filter we just looked at is essentially trivial, in that each byte is treated as independent of its neighbors. A more complex task is to parse data where a pattern we want to match may span more than one bucket, or even more than one call to the filter function. Even a simple search-and-replace filter that matches words will need to save some context between calls, so as to avoid missing words that are split up. As an aside, this is a nontrivial task in general: Witness the number of spam messages that get past spam filters by breaking up words that might otherwise trigger their detection.
The simplest way to deal with this task is to collect the entire document body into memory. Unfortunately, this strategy is inefficient: It breaks Apache’s pipelining architecture, and it scales very badly as document size grows. We should avoid it wherever possible.
A module that faces exactly this task is mod_line_edit,[3] a filter that provides text search-and-replace based on string or regular expression matching. This module works by rearranging its input into complete lines of text before editing it (the definition of a “line” is somewhat flexible, but it defaults to parsing normal lines of text). Let’s look at this module for an example of more advanced bucket manipulation. For the purposes of this discussion, we’ll present a simplified version that supports only the UNIX-family “
” line-end character. The guiding principle of this filter is that it manipulates buckets and brigades at will (pointers are cheap), but moves or copies data only where unavoidable. This demonstrates some new techniques:
- Creating new bucket brigades for our own purposes
- Saving data between calls to the filter
- Flattening data into a contiguous buffer
Using this approach, we will need to rearrange any lines spanning more than one bucket, and save any partial lines between calls to the filter.




8.10. Filtering Through an Existing Parser
An alternative to parsing data ourselves is to feed it to an existing parser, typically from a third-party library. This author’s various markup-aware modules, including his most popular module, mod_proxy_html, work like this: The filter just reads each bucket and passes it to the library. This scheme works well because the library itself supports processing data in arbitrary chunks, so we don’t have to worry about troublesome breaks in the input data disrupting the parse. Here’s an example from mod_xmlns, which uses the expat library to parse XML. The core filter here is very simple, so we’ll give it in full:


This code takes the form of the now-familiar loop over input buckets, retrieving the bucket data (where applicable) into a buffer, and making a special case of EOS. But instead of parsing the data ourselves, we feed it to expat’s chunk-parsing function XML_Parse. And we don’t pass anything at all to the next brigade! So how does that work?
When we use the XML parser here, we basically lose the input data altogether. Our module must set up handlers with the library, but these receive XML events such as startElement, endElement, characters, cdata, and comment, rather than our input data. The filter has no option except to generate a new output stream from scratch. Of course, the expat library has no notion of Apache concepts such as buckets, brigades, requests, or filters, so whatever we do has to be done from scratch.
In this case, we could create a new bucket brigade and populate it with new buckets for each XML event.[4] But this is not an attractive option, for several reasons:
- Most markup events—for example, elements and attributes—involve generating just a few bytes of output per event. Creating new buckets for every few bytes becomes inefficient.
- We have no natural point at which to pass a brigade to the next filter. Either we have to break streaming or we have to do extra work to manage this ourselves.
- Creating buckets is an unduly awkward way to perform simple I/O.
This final reason alone could be considered compelling!
8.11. stdio-Like Filter I/O
Fortunately, the filter API provides an alternative, stdio-like way to write data and pass it down the chain. We still need to create a bucket brigade for output, but all we need to do with it is to pass it to the stdio-like calls, along with the filter we’re writing to, in the manner of a file descriptor. The stdio-like functions are defined in util_filter.h:

Internally, the first time you use any of these calls, Apache creates a heap bucket (normally of size 8K) and writes your data to it. Subsequent writes append to the heap while sufficient space is available. When the heap space is exhausted, a second bucket of type transient is appended containing the data over and above the size of the heap bucket, and the two are flushed down the chain. This approach is the same as that followed by the ap_rwrite/etc. stdio-like API, and is the reason for the 8K default stream buffer size seen by many applications.
How does mod_xmlns use stdio-like I/O? Because it’s a SAX2 filter, it has to generate all output from the SAX2 event callbacks. Let’s look at the essentials of some of these callbacks. Our examples use two #define statements, which define the next filter in the chain and our output bucket brigade, respectively:
![]()
The simplest callback is the default callback—an expat callback that gets any data not passed to any other callback. Since we’re registering callbacks for everything we need to process, anything passed to the default callback goes straight to the output:
![]()
The most complex handler is that for the startElement event. We’ll quote it in full to show use of the API to simplify a lot of small, fiddly writes:

The next section is the heart of the module. mod_xmlns exports an API for other modules to register handlers for namespace events, of which the most important is startElement. So lookup_ns will return a non-null value if and only if another module has registered a handler for the namespace and it is marked as active.

The remainder of this function is just default behavior that reconstructs the element as is when no handler has handled it. It serves to demonstrate filter stdio-style output.

The advantage that this API offers here is clear. We have lots of writes of just a few bytes, so direct manipulation of buckets would be insanely complex to write, not to mention inefficient. Classic buffered I/O is the ideal solution. And we lose nothing, because there simply isn’t an input stream we could pass through without copying data.
Warning
Mixing stdio-like I/O with direct bucket manipulation in the same filter is not advisable. The buffering in the stdio-like API will cause the data to reach the next filter in an unexpected order, and it could cause data to be flushed at the wrong time. You would have to take great care to flush everything explicitly before switching modes, and you effectively get the worst of both worlds. Hence, although the function xdefault could explicitly create a new bucket (of type transient) to contain its data, it doesn’t.
8.12. Input Filters and the Pull API
The input filter API differs from the output filter API we discussed earlier in several ways. As with the output filter, the heart of the input filter is a callback function, but the role of this function is different. Whereas the output filter accepts a chunk of data, processes it, and passes it to the next filter, the input filter requests data from the next filter in the chain, processes the data, and returns it to the caller. The basic form of an input filter can be demonstrated with a trivial, do-nothing filter:

We’ve already introduced the filter arguments. The first two are the same as for an output filter. The others will often be irrelevant to any particular filter, but are handled by Apache’s core input filter and may be of use elsewhere.
8.12.1. Mode
ap_input_mode_t mode
Most filters will not want to support all input modes. For example, mod_deflate’s input filter, which serves to uncompress input that arrives compressed at the server, is entirely inappropriate to line-mode data. The correct behavior for an input filter called in an inappropriate mode is either to pass the data straight through or to remove itself from the chain:
![]()
As a rule of thumb, a content filter will normally be called with AP_MODE_READBYTES. A connection filter will be called with AP_MODE_GETLINE until the HTTP headers are consumed by the protocol handler, and AP_MODE_READBYTES thereafter. But this behavior may vary, and cannot be relied on: Another filter or (more commonly) a content generator may use a different mode—hence the simple check in mod_deflate. MPMs may also use different input modes.
A module that supports multiple modes and modifies the data will typically need to use a switch statement or similar construct.
8.12.2. Block
apr_read_type_e block
Blocking versus nonblocking reads are only relevant to bucket types such as sockets where blocking is an issue. A filter should normally honor the block request and use the same value to retrieve data from the next filter. With due caution, however, it may override the request.
8.12.3. readbytes
apr_off_t readbytes
This is relevant to mode AP_MODE_READBYTES. A filter should not return more data than readbytes. In practice, it is sometimes treated as advisory: It is honored by the core input filter, but content filters sometimes ignore it. It may serve to optimize throughput of data by selecting a block size such as the widely used 8K default.
A filter to which readbytes may be highly relevant is mod_deflate, where the output data returned to the caller will often be many times greater than the input data from the next filter. mod_deflate deals with this issue by keeping a bucket brigade proc_bb in its filter context, and using the following logic:

8.12.4. Input Filter Example
To conclude this chapter, let’s present the mod_deflate input filter we’ve drawn on for the preceding illustrations, with additional comments inserted where appropriate. The filter has been slightly reduced by replacing some of the detail relevant to zlib (the compression library used), but not to Apache, with comments.




8.13. Summary
Filters are one of the most powerful and useful innovations in Apache 2, and are the single biggest architectural change that helps transform Apache from a mere webserver to a powerful applications platform. Programming filters is not straightforward, but is essential to applications development with Apache. Note that there is a section on filter debugging in Chapter 12.
This chapter discussed the following topics:
- The data axis and filter chain
- Input and output filters
- Content, protocol and connection filters, with examples
- The filter APIs: principal objects and callbacks
- The importance of pipelining in filters
- Techniques for working with streamed data in the output chain push API
- Managing I/O in a filter
- Smart filtering,
mod_filter, and self-configuration - Filters and the HTTP protocol
- Working with buckets and brigades, including an example
- Filtering through a parser, and using a
stdio-like buffer - Input filtering: the pull API, with an example
This chapter completes the discussion of processing HTTP requests we started in Chapter 5. We are now ready to move on to the deferred discussion of Apache configuration in Chapter 9.