
Chapter 5. Writing a Content Generator
In principle, one can do anything with the Common Gateway Interface (CGI).[1] But the range of problems for which CGI provides a good solution is much smaller!
The same is true of a content generator in Apache. It lies at the heart of processing a request and of building a web application. Indeed, it can be extended to do anything that the underlying system permits the webserver to do. The content generator is the most basic kind of module in Apache.
All of the major traditional applications normally work as content generators. For example, CGI, PHP, and application servers proxied by Apache are content generators.
5.1. The HelloWorld Module
In this chapter, we will develop a simple content generator. The customary HelloWorld example demonstrates the basic concepts of module programming, including the complete module structure, and use of the handler callback and request_rec.
By the end of the chapter, we will have extended our HelloWorld module to report the full details of the request and response headers, the environment variables, and any data posted to the server, and we will be equipped to write content generator modules in situations where we might otherwise have used a CGI script or comparable extension.
5.1.1. The Module Skeleton
Every Apache module works by exporting a module data structure. In general, an Apache 2.x module takes the following form:

The STANDARD20_MODULE_STUFF macro expands to provide version information that ensures the compiled module will load into a server build only when it is fully binary compatible, together with the filename and reserved fields. Most of the remaining fields are concerned with module configuration; they will be discussed in detail in Chapter 9. For the purposes of our HelloWorld module, we need only the hooks:

Having declared the module structure, we now need to instantiate the hooks function. Apache will run this function at server start-up. Its purpose is to register our module’s processing functions with the server core, so that our module’s functions will subsequently be invoked whenever they are appropriate. In the case of HelloWorld, we just need to register a simple content generator, or handler,[2] which is one of many kinds of functions we can insert here.
![]()
Finally, we need to implement helloworld_handler. This is a callback function that will be called by Apache at the appropriate point in processing an HTTP request. It may choose to handle or ignore a request. If it handles a request, the function is responsible for sending a valid HTTP response to the client and for ensuring that any data coming from the client are read (or discarded). This is very similar to the responsibilities of a CGI script—or, indeed, the responsibilities of the webserver as a whole.
Here’s our simplest handler:
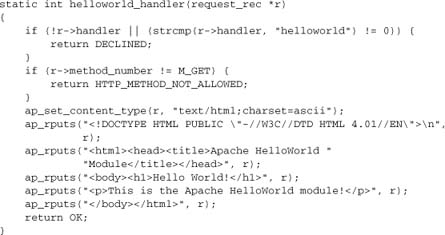
This callback function starts with a couple of basic sanity checks. First, we check r->handler to determine whether the request is for us. If the request is not for us, we ignore it by returning DECLINED. Apache will then pass control to the next handler.
Second, we want to support only the HTTP GET and HEAD methods. We check for those cases and, if appropriate, return an HTTP error code indicating that the method is not allowed. Returning an error code here will cause Apache to return an error page to the client. Note that the HTTP standard (see Appendix C) defines HEAD as being identical to GET except for the response body, which is omitted in HEAD. Both methods are included in Apache’s M_GET, and content generator functions should treat them as identical.
The order in which these checks are performed is important. If we reversed them, our module might cause Apache to return an error page in cases such as POST requests intended for another handler, such as a CGI script that accepts them.
Once we are satisfied that the request is acceptable and is meant for this handler, we generate the actual response—in this case, a trivial HTML page. Having done so, we return OK to tell Apache that we have dealt with this request and that it should not call any other handler.
5.1.2. Return Values
Even this trivial handler has three possible return values. In general, handlers provided by modules can return
OK, to indicate that the handler has fully and successfully dealt with the request. No further processing is necessary.DECLINED, to indicate that the handler takes no interest in the request and declines to process it. Apache will then try the next handler. The default handler, which simply returns a file from the local disk (or an error page if that fails), never returnsDECLINED, so requests are always handled by some function.- An HTTP status code, to indicate an error. The handler has taken responsibility for the request, but was unable or unwilling to complete it.
An HTTP status code diverts the entire processing chain within Apache. Normal processing of the request is aborted, and Apache sets up an internal redirect to an error document, which may either be one of Apache’s predefined defaults or be a document or handler specified by the ErrorDocument directive in the server configuration. Note that this diversion works only if Apache hasn’t already started to send the response down the wire to the client—this can be an important design consideration in handling errors. To ensure correct behavior, any such diversion must take place before writing any data (the first ap_rputs statements in our case).
Where possible, it is good practice to deal with errors earlier in the request processing cycle. This consideration is discussed further in Chapter 6.
5.1.3. The Handler Field
Having to check r->handler may seem counterintuitive, but this step is generally necessary in all content generators. Apache will call all content generators registered by any module until one of them returns either OK or an HTTP status code. Thus it’s up to each module to check r->handler, which tells the module whether it should process the request.
This scheme is made necessary by the implementation of Apache’s hooks, which are designed to enable any number of functions (or nothing) to run on a hook. The content generator is unique among Apache’s hooks in that exactly one content generator function must take responsibility for every request. Other hooks that share the implementation have different semantics, as we will see in Chapters 6 and 10.
5.1.4. The Complete Module
Putting it all together and adding the required headers, we have a complete mod_helloworld.c source file:

And that’s all we need! Now we can build the module and insert it into Apache. We use the apxs utility, which is bundled with Apache and serves to ensure the compilation flags and paths are correct:
Compile the module
$ apxs -c mod_helloworld.c
and (working as root) install it:
# apxs -i mod_helloworld.la
Now configure it as a handler in httpd.conf:
![]()
This code causes any request to /helloworld on our server to invoke this module as its handler.
Note that the helloworld_hooks and helloworld_handler functions are both declared as static. This practice is typical—though not quite universal—in Apache modules. In general, only the module symbol is exported, and everything else remains private to the module itself. As a consequence, it is good practice to declare all functions as static. Exceptions may arise when a module exports a service or API for other modules, as discussed in Chapter 10. Another case arises when a module is implemented in multiple source files and needs some symbols to be common to those files. A naming convention should be adopted in such cases, to avoid symbol space pollution.
5.1.5. Using the request_rec Object
As we have just seen, the single argument to our handler function is the request_rec object. The same argument is used for all hooks involved in request processing.
The request_rec object is a large data structure that represents an HTTP request and provides access to all data involved in processing a request. It is also an argument to many lower-level API calls. For example, in helloworld_handler, it serves as an argument to ap_set_content_type and as an I/O descriptor-like argument to ap_rputs.
Let’s look at another example. Suppose we want to serve a file from the local filesystem instead of a fixed HTML page. To do so, we would use the r->filename argument to identify the file. But we can also use file stat information to optimize the process of sending the file. Instead of reading the file and sending its contents with ap_rwrite, we can send the file itself, allowing APR to take advantage of available system optimizations:

5.2. The Request, the Response, and the Environment
Setting aside this little diversion into the filesystem, what else can a HelloWorld module usefully do?
Well, the module can report general information, in the manner of programs such as the printenv CGI script that comes bundled with Apache. Three of the most commonly used (and useful) sets of information in Apache modules are the request headers, the response headers, and the internal environment variables. Let’s update the original HelloWorld module to print them in the response page.
Each of these sets of information is held in an APR table that is part of the request_rec object. We can iterate over the tables to print the full contents using apr_table_do and a callback. We’ll use HTML tables to represent these Apache tables.
First, here’s a callback to print a table entry as an HTML row. Of course, we need to escape the data for HTML:

Second, we provide a function that uses the callback to print an entire table:

Now we can wrap this functionality in our HelloWorld handler:

5.2.1. Module I/O
Our HelloWorld module generates output using a stdio-like family of functions: ap_rputc, ap_rputs, ap_rwrite, ap_rvputs, ap_vrprintf, ap_rprintf, and ap_rflush. We have also seen the “send file” call ap_send_file. This simple, high-level API was inherited originally from earlier Apache versions, and it remains suitable for many content generators. It is defined in http_protocol.h.
Since the introduction of the filter chain, the underlying mechanism for generating output has been based on buckets and brigades, as discussed in Chapters 3 and 8. Filter modules employ different mechanisms for generating output, and these are also available to—and sometimes appropriate for—a content handler.
There are two fundamentally different ways to process or generate output in a filter:
- Direct manipulation of bucket and brigades
- Use of another
stdio-like API (which is a better option than theap_r*API, as backward compatibility isn’t an issue)
We will describe these mechanisms in detail in Chapter 8. For now, we will look at the basic mechanics of using the filter-oriented I/O in a content generator.
There are three steps to using filter I/O for output:
- Create a bucket brigade.
- Populate the brigade with the data we are writing.
- Pass the brigade to the first output filter on the stack (
r->output_filters).
These steps can be repeated as many times as needed, either by creating a new brigade or by reusing a single brigade. If a response is large and/or slow to generate, we may want to pass it down the filter chain in smaller chunks. The response can then be passed through the filters and to the client in chunks, giving us an efficient pipeline and avoiding the overhead of buffering the entire response. Working properly with the pipeline whenever possible is an extremely useful goal for filter modules.
For our HelloWorld module, all we need to do is to create the brigade and then replace the ap_r* family calls with the alternative stdio-like API defined in util_filter.h: ap_fflush, ap_fwrite, ap_fputs, ap_fputc, ap_fputstrs, and ap_fprintf. These calls have a slightly different prototype: Instead of passing request_rec as a file descriptor, we have to pass both the destination filter we are writing to and the bucket brigade. We’ll see examples of this scheme in Chapter 8.
5.2.1.1. Output
Here is our first trivial HelloWorld handler using filter-oriented output. This lower-level API is a little more complex than the simple stdio-like buffered I/O, and it may sometimes enable optimizations of the module (though in this instance, any difference will be negligible). We can also take advantage of slightly finer control by explicitly processing output errors.

5.2.1.2. Input
Module input is slightly different. Once again, we have at our disposal a legacy method inherited from Apache 1.x, but it is now treated as deprecated by most developers (although the method is still supported). In most cases, we would prefer to use the input filter chain directly in new code:
- Create a bucket brigade.
- Pull data into the brigade from the first input filter (
r->input_filters). - Read the data in our buckets, and use it.
Both input methods are commonly found in existing modules, including modules for Apache 2.x. Let’s introduce each in turn into our HelloWorld module. We’ll update the module to support POSTs and count the number of bytes POSTed (note that this operation will usually—but not always—be available in a Content-Length request header). We won’t decode or display the actual data; although we could do so, this task is usually best handled by an input filter (or by a library such as libapreq). The functions we use here are documented in http_protocol.h:


Here, finally, is check_postdata using the preferred method of direct access to the input filters, using functions documented in util_filter.h.
We create a brigade and then loop until EOS, filling the brigade from the input filters. We will see this technique again in Chapter 8.


5.2.1.3. I/O Errors
What happens when we get an I/O error?
Filters (covered in Chapter 8) indicate an error to us by returning an APR error code; they may also set r->status. Our handler can detect such an event, as in the preceding examples, by checking the return values from ap_pass_brigade and ap_get_brigade. Normal behavior is to stop processing and return an appropriate HTTP error code. This behavior causes Apache to send an error document (discussed in Chapter 6) to the client. We should also log an error message, thereby helping the systems administrator diagnose the problem.
But what if the error was that the client connection was terminated? It’s a waste of time trying to send an error document to a client that’s gone away. We can detect this disconnection by checking r->connection->aborted, as demonstrated in the default handler found at the end of this chapter.
5.2.2. Reading Form Data
We now have the basis for reading input data. But the data are useful only if we know what to do with them. The most common form of data we need to handle on the Web is data sent to us by a web browser submitting an HTML form. Such data follow one of two standard formats supported by general-purpose browsers and controlled by the enctype attribute to the <form> element in HTML:
application/x-www-form-urlencoded(normal web forms submitted either byPOSTorGET)multipart/form-data(Netscape’s multipart format for file upload forms)
Historically, decoding form data in either of these formats is the responsibility of applications. For example, any CGI library or scripting module contains code for handling this task. Apache itself doesn’t include this capability as standard, but it is provided by third-party modules such as mod_form and mod_upload.
Parsing Form Data
The format for standard form data (application/x-www-form-urlencoded) is a series of key/value pairs, separated by ampersands (“&”). Any character may be escaped using a %nn sequence, where nn is the hex representation of a byte, and some characters must be escaped. Parsing the data is complicated by the fact that keys are not always unique; for example, an HTML <select multiple> element may submit several values for a key.
The natural structure representing these data is a table of bags. This structure can be represented in Apache as an apr_hash_t* (hash table) of apr_array_header_t* (array) values. We can parse input data into this representation as follows:


This scheme is based on parsing the entire input data from a single input buffer. It works well where the total size of a form submission is reasonably small, as is generally the case with normal web forms. We should guard against denial of service (DoS) attacks by limiting the size of inputs accepted this way (the maximum size of data to accept being specified by a server administrator). Alternative methods involving streamed parsing may be appropriate for larger forms, particularly those involving file upload that could involve megabytes or even gigabytes of data. The mod_upload[3] module provides a parser that is better suited to large uploads.
We can use the function we just defined to parse data submitted by GET:
![]()
Parsing data submitted by POST is more work, because we have to read the data:
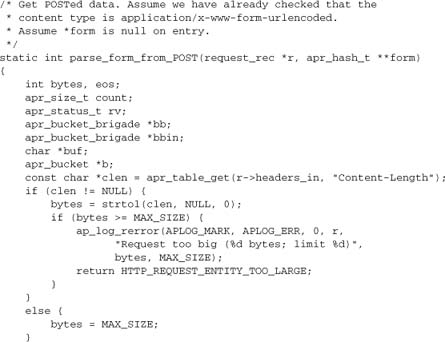


At this point, we have laid the groundwork to ensure easy access to form data, and we can provide some accessor functions. mod_form performs a similar function, but uses techniques we haven’t encountered yet to offer a cleaner API wherein the handler module need not concern itself with the hash.
The following example shows a function that returns all values for a key as a comma-separated string, a representation that will be familiar to users of scripting environments such as Perl (with CGI.pm) or PHP. Other high-level accessors are now similarly straightforward to write.

Combining these functions, we can update our HelloWorld handler to display form data. We’ll assume that the form data consist of ASCII input, and substitute question marks for any non-ASCII characters:


5.3. The Default Handler
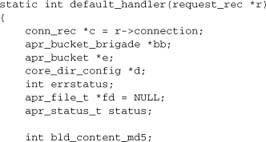
So far, we’ve presented simple variants on a simple handler, and highlighted the tools required to develop a content handler equivalent to a normal CGI or PHP script. To conclude this chapter, we’ll present Apache’s default handler. Although it serves a file from the server’s filesystem, this handler differs from our earlier functions in that it does quite a lot more housekeeping, illustrating more of the core API. Apache’s default handler is more advanced than the handlers shown in the previous examples, and you may prefer to skip it on a first reading.

ap_get_module_config retrieves the module’s configuration (Chapter 9):
![]()
We can compute an MD5 hash if our system is configured to do so, but only if there isn’t a filter that will transform the contents and invalidate our hash.
![]()
Because this is the handler of last resort, we can’t just return DECLINED if we don’t want the request.
![]()
This next check performs housekeeping tasks. It’s not really necessary, because Apache will perform these tasks for us if unused input remains when it destroys the request.
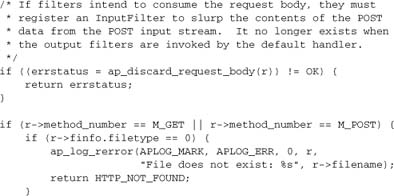
This handler serves only normal files; Apache handles directories differently. If a request for a directory reaches this handler, it’s a configuration error.
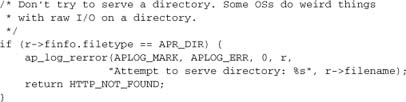
Deal with any extra junk on the end of the request URI.
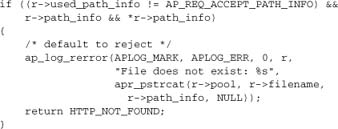

Now we set a few more standard headers:

ap_meets_conditions carries out some useful checks, cross-referencing the file information to the request headers to determine whether we really need to send the file or just to confirm the validity of a client’s cached copy. In exceptional circumstances, it may determine that our file is useless to the client and should be discarded.

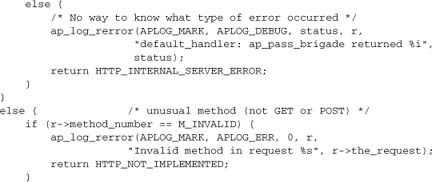
Another API call supports the OPTIONS method:

5.4. Summary
This chapter dealt with content generators and related topics:
- It introduced the Apache module structure.
- It showed how a module can register a handler function with the core.
- It described the basic handler API.
- It described the role of content generator modules and developed a simple module.
- It showed how a content generator works with the
request_recobject to obtain information such as headers and environment variables, to perform I/O, and to access form data. - It demonstrated basic error handling.
- It described basic housekeeping commonly encountered in modules.
- It introduced Apache’s default handler, demonstrating slightly more advanced techniques to serve static files efficiently and with proper attention to the HTTP protocol.
At this point, you should be able to write an application as a module or rewrite a CGI script as a module. While we have introduced the overall structural skeleton of a module, our coverage has been punctuated with several blanks. The remaining parts of the module structure are concerned with configuration; they will be discussed in Chapter 9. The meaning of hooks and their registration are covered in Chapter 10. Next, Chapters 6, 7, and 8 complete our discussion of request handling fundamentals by introducing the request processing cycle, access and authentication, and the filter chain.