
Chapter 4. Programming Techniques and Caveats
Before we start actually developing modules, we need to discuss matters of good practice for safe, efficient, and portable programming. There are a number of “gotchas” for the unwary, including thread safety and resource sharing between processes, that arise from the behavior of different MPMs. Some of the techniques in this chapter may be considered advanced, and the code examples will be easier to follow after reading some further relevant background in the following chapters, particularly Chapters 5, 6, and 9.
4.1. Apache Coding Conventions
A number of coding conventions apply within the Apache source code to ensure consistency and facilitate readability and review. These conventions are, of course, purely optional for third-party code, and examples used in this book may not always follow them.
4.1.1. Lines
- Lines of code should not exceed 80 characters, including any leading whitespace. Where necessary, continuation lines are used.
- Continuation lines are indented to align with the first term in a continued expression or the first entry in a continued list.
- Separators (commas) appear in a continued line, but other binary operators appear in the continuation.
- No whitespace appears before the final semicolon.
- Whitespace is used within lines where appropriate and not prohibited.

4.1.2. Functions
- Functions are always declared with ANSI-C style arguments.
- No whitespace is used before or after the brackets around the argument list.
- Arguments are separated by a comma and a single space.
- The function’s opening and closing braces occupy their own lines, flush left.
![]()
4.1.3. Blocks
- Blocks are indented by four spaces from their surrounding blocks. Tabs are not permitted.
- Braces are always used, even where optional. Opening braces appear at the end of the line introducing a block. Closing braces appear in a line of their own, aligned with the code outside the block.

4.1.4. Flow Control
- Flow control elements follow blocking rules.
casestatements are not indented in aswitch, but their code is indented.

4.1.5. Declarations
- Declarations may include variable initialization where appropriate.
- Pointers are declared with the asterisk attached to the variable name, not to the type.
![]()
4.1.6. Comments
- Comments always use C
/* … */style. - Multiline comments have a
*aligned at the start of each line, including the closing line of the comment. - Comments are aligned with the block they are in.
![]()
4.2. Managing Module Data
When you first start programming, you learn about the scope of data. Typically (in C and most other lexically scoped languages), a variable declared within a function or block remains in scope until the end of the function or block, but thereafter is undefined. Variables may also have global scope and remain defined throughout the program. Of course, in terms of simple C programming, variables in Apache follow these rules.
4.2.1. Configuration Vectors
Apache modules are based on callbacks. C does not provide a mechanism to share data over two or more separate callback functions, other than global scope, which is, of course, not appropriate in a multithreaded environment. Apache provides an alternative means of managing data: the configuration vector (ap_conf_vector_t). The primary purpose of such vectors is, as the name suggests, to hold configuration data. They also serve a more general purpose.
4.2.2. Lifetime Scopes
The Apache architecture naturally defines a different kind of scope for data—namely, the core objects of process, server, connection, and request. Most data are naturally associated with one of these objects (or some subobject such as a filter). The Apache configuration vectors together with APR pools provide a natural framework for module data to be tied to an appropriate object. This deals nicely with two problems:
- Using an appropriate configuration vector deals with the scoping issue, making data available wherever they are required.
- Using an appropriate pool deals with the lifetime of resources, ensuring that they are properly cleaned up after use.
These techniques gives us three simple and useful associations: Variables and data can be associated with the server, the connection, or the request objects.
4.2.2.1. Configuration Data
Configuration data (Chapter 9) are set at server start-up, but can be accessed later by looking them up on the configuration vectors from request_rec or server_rec:
![]()
When the server is running, configuration data should be treated as strictly readonly. Any changes will affect not only the current request, but also any other requests running concurrently or later in the same process.
4.2.2.2. Request Data
Apart from the configuration, the most common nontrivial case we have to deal with is where data need to be created in the course of processing a request, but scoped over more than one hook. Apache provides a pool and a configuration vector that are explicitly intended to enable modules to give variables the scope and lifetime of a request:
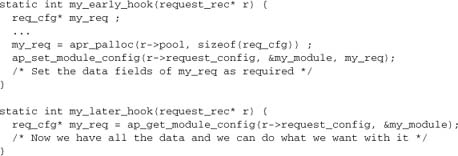
And if we have a hook where the req_cfg may or may not be already set:

The lesson here is to get into the habit of using the request configuration vector whenever we have data that need to be scoped over more than one hook. The configuration struct itself is, of course, completely defined by the module, and it contains exactly what the module needs it to contain. If the module is complex and has multiple different hooks, each of which needs to set variables for later use, the different data should be combined in the configuration vector—for example, by giving each function its own substructure.
Note the standard use of the request pool to allocate the request configuration vector. The request configuration vector, therefore, will be freed at the end of the request, which is exactly what we want. Any data members that involve dynamic resource allocation should similarly use the request pool or register a cleanup on it, as discussed in Chapter 3 and illustrated in examples throughout this book. The request pool and request configuration solve the problem of resource management in request processing.
4.2.2.3. Connection Data
The connection is the other transient core object in Apache. It, too, presents a pool and a configuration vector for management of connection data. Use of the connection configuration and pool is exactly analogous to their use with the request.
4.2.2.4. Persistent Data
A more complex case arises where a module needs to manage persistent but non-constant data. Such data may be held on the server_rec object (separate from any configuration data fields), or even given global scope. In either case, thread-safety becomes an issue, and we need to use a mutex for any critical operations. We usually also need to define a pool for our module, as we should normally only use the process pool at server startup. The mutex and the pool will have the same scope and lifetime as the variable data. We’ll discuss this in detail below.
4.3. Communicating Between Modules
Modules can communicate and interact in various ways. Chapter 10 presents a range of advanced methods for exporting an API and providing a service. For simpler needs, the request_rec object provides some straightforward methods we should look at first.
r->subprocess_env
r->subprocess_env is an apr_table that has the lifetime of a request and is shared by all modules. It was originally Apache’s internal representation of the CGI environment; as such, it would be set whenever CGI or SSI was in use. It has subsequently acquired a much wider range of uses—in advanced configuration such as mod_rewrite and mod_filter, and in all the embedded scripting languages.
Any module can set values in the subprocess_env. Two, in particular, are noteworthy: mod_env and mod_setenvif are configuration modules whose purpose is to enable system administrators to determine environment variables.
In addition to the standard CGI/scripting environment, modules can define their own variables to enable another module or a system administrator to control some aspect of module behavior. Examples in the core distribution include mod_deflate responding to environment variables such as no-gzip and force-gzip to override default behavior, and even the core HTTP protocol module responding to nokeepalive. These environment variables are commonly determined using the Browsermatch directive, which is implemented by mod_setenvif.
Finally, mod_rewrite’s E flag sets an environment variable in a RewriteRule. Modules can take advantage of this capability by using an environment variable to determine aspects of behavior. This gives system administrators access to the full power of mod_rewrite to configure the system dynamically.
r->notes
r->notes is another apr_table_t having the lifetime of a request. Its purpose is explicitly to enable modules to leave notes for each other. Unlike subprocess_env, it serves no other purpose. We’ll see an example of its use in Chapter 6, where we use r->notes to set an error message that can be displayed in an error page returned to a user.
r->headers_in
r->headers_in holds the request headers; it is available to all modules. A module may “fake” request headers by manipulating them. For example:
mod_headersreads “faked” headers set in the Apache configuration, and sets them in this internal table.mod_auth_cookie[1] sets a fakedAuthorizationheader from a cookie, so that Apache can authenticate the user using standard HTTP basic authentication.
r->headers_out
r->headers_out holds the response headers. Since these response headers describe exactly what Apache is returning to the client, modules should set them whenever they do something that affects the protocol. They are converted from the apr_table_t to simple text in the HTTP protocol core output filter.
r->err_headers_out
r->err_headers_out also holds response headers. However, whereas r->headers_out is discarded if request processing is diverted into an internal redirect or error document (Chapter 6), r->err_headers_out is preserved. As a consequence, it is suitable for tasks such as setting headers when redirecting a client.
4.4. Thread-Safe Programming Issues
For the most part, thread safety in Apache is the same as in any other software environment:
- Don’t use global or static data (except for constants). Global data may be set during configuration or in a pre-configuration or post-configuration hook, but should not be modified thereafter. In almost all nontrivial situations, you should use the configuration vectors in preference to global variables.
- Don’t call functions that are not themselves thread-safe and reentrant.
- If you ever need to violate either of the preceding guidelines, use a mutex to do so in a critical section, and prevent concurrent modifications by multiple threads.
One more rule applies in Apache: Don’t change values of configuration data. Treat configuration variables with the same respect as you treat global variables. Stated in general terms, apply the same principles of thread safety in Apache as you would in any other environment.
Now let’s formulate these rules for Apache in terms of dos rather than don’ts:
- When processing a request, use the fields of the
request_rec—in particular, the request pool and the request configuration vector. Treat everything else as read-only. - When processing a connection, use the fields of the
conn_rec—in particular, the connection pool and the connection configuration vector. Treat everything else as read-only. - Use configuration functions or functions hooked to
post_configto initialize constant module data, including values determined by the configuration. - Use module-private resources to manage data that outlive a request or connection yet cannot be treated as constant. Use a
child_inithook to initialize such resources.
The last rule is the only one that requires us to do anything nontrivial. Let’s take a closer look at it.
4.5. Managing Persistent Data
When we discussed data scoping with pools and configuration vectors earlier, we deferred our discussion of managing persistent data. Chapter 10 presents one important example: mod_dbd managing a pool of database connections. But in that case, all of the hard work is delegated to apr_reslist. How do we deal with this situation more generally? Let’s consider a typical case where we’re managing a dynamic cache in a hash table. We must deal with two issues in this scenario: providing thread safety and avoiding memory or other resource leaks.
4.5.1. Thread Safety
The crucial step is to use a child_init hook to set up the dynamic resource:

The MPM code calls the child_init hook, after forking the child process but before entering operational mode and (in a threaded MPM) before creating threads. The pchild pool is created by the MPM as a process-wide subpool of the process pool itself (s->process->pool).
Now, when we want to add to the cache later, we are equipped to do so safely:


If we want to change an existing value, we similarly need to use the mutex to protect our critical code.
4.5.2. Memory/Resource Management
As we saw in Chapter 3, APR pools provide a full and elegant solution to most resource management problems in Apache. Persistent resources are an exception, however, because they bring up a new problem: Are we leaking memory (or any other resource)? In the preceding code, if cache entries are ever deleted, the APR pool mechanism for managing resources fails us, because the pool lives on. This becomes a bug, which a server administrator will have to work around by limiting MaxRequestsPerChild to prevent an indefinite leak.
Several approaches are available to deal with this problem.
Garbage Collection
Instead of terminating the entire child, it is more efficient overall just to terminate our own resource from time to time and reclaim any possibly leaked resources. We can do so by tearing down the pool we’ve been using and starting anew. We’ll need to make provision for this in our child_init function. In summary:
- Add
pchildto themy_svr_cfgstruct. - Add a counter or a timeout to the
my_svr_cfgstruct. - Now we can clear garbage by winding up the module’s pool, creating a new pool from
pchild, and starting again. This activity must, of course, take place in a critical section, which is why the mutex needs to outlive the pool.
Let’s take a look at a function to add garbage collection to our hash example. We call this function whenever an operation might leak, and we maintain a counter so that it does the real work only when it’s got a decent amount of real work to do. Of course, any operation that might leak will be happening under mutex anyway.

Sometimes we can get away with much less. For example, if we have a hash of objects that time out, and re-creating them is not too expensive, we could dispense with copying anything at all. Then the preceding code reduces to the much simpler function shown here:

This is the “clean” alternative to leaking and using MaxRequestsPerChild as a workaround.
Use of Subpools
A variant on the garbage collection scheme is to use a subpool for every hash entry. With this approach, we can delete the subpool and reclaim resources whenever the entry itself is deleted. Because the subpools themselves incur overhead, this strategy is most likely to be appropriate when the number of resources is modest, but their size and complexity is such that they dominate relative to the overhead associated with the pools themselves.
Given that the subpools are allocated from the main pool, they are themselves a resource that needs to be managed and a potential source of memory leaks. Subpools offer a partial solution to the problem, but should be used in conjunction with one of the other solutions—for example, clearing and reusing the subpools.
Reuse of Resources
When the objects we are managing are of fixed size, we can manage the memory ourselves within the module:
- We can allocate an array of objects, together with an indexing array of free/in-use flags.
- When we need an object, we can claim it from the array. When we’ve finished with it, we can mark it as “free.”
We can use this strategy with variable-sized objects by using subpools and managing the subpools themselves as the fixed-sized objects in the array. When we finish with an object, we run apr_pool_clear, but keep the pool itself for reuse.
Use of a Reslist
The apr_reslist serves to manage a pool of resources for reuse, providing a fully managed solution for us. It is most appropriate where the resources themselves carry a high cost. mod_dbd (see Chapter 10) is a usage example. For a case like our cache example, we could either use a reslist of subpools or manage blocks of memory and thereby avoid any dynamic allocation.
4.6. Cross-Platform Programming Issues
Provided we use the APR, cross-platform programming is basically straightforward. The problem, in this case, is equivalent to that seen with cross-MPM programming:
For example:
- The
apr_file_io,apr_file_info, andapr_fnmatchmodules provide a platform-independent filesystem layer. - The
apr_timemodule deals with timing issues. - The
apr_usermodule provides a platform-independent implementation of system users and groups. - The
apr_*_mutexmodules provide cross-platform locks.
The lesson here: Avoid nonportable system calls and use these APR modules wherever they exist.
4.6.1. Example: Creating a Temporary File
Working on a UNIX or UNIX-like platform, we can create a temporary file, avoiding the widely deprecated tmpfile() system call:
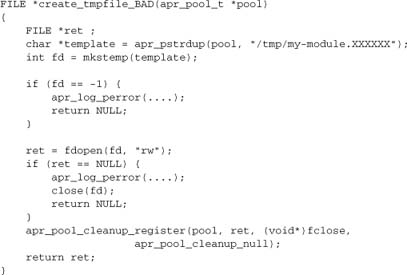
This code is fully correct and complete. We’ve created a temporary file using the standard secure mechanism, handled errors, and registered a cleanup to tie our temporary file to the lifetime of the pool. But it may not be fully portable:
- The
/tmp/directory is only valid in a UNIX or UNIX-like filesystem. fdopenrelies on POSIX.- The
FILE*type, while valid across platforms, may support different and nonportable operations on some platforms.
Here’s an APR-based version guaranteed to be portable across all supported platforms:

A second reason for using APR functions here is to avoid binary compatibility issues, which may potentially arise when the module is compiled in a different environment to Apache/APR. For example, different versions of Microsoft’s Visual C++ reportedly generate binary-compatible code if and only if the module avoids a wide range of native system calls, which it can do by delegating the system layer to APR.
4.7. Cross-MPM Programming Issues
As already hinted at, the MPM is really the platform for Apache. Because the APR deals with native platform issues such as the filesystem, the remaining MPM issues are the difficult ones. Principally, we have to deal with the consequences of running single or multiple processes, and implementing single or multiple threads within a process. This is not an “either/or” situation, however: Apache may also run with both multiple processes and multiple threads per process.
We’ve already discussed thread safety in Apache. The other major issue we need to deal with is coordinating between different processes. This coordination is generally expensive, and the types of interprocess interactions we can implement within the context of the standard Apache architecture are limited. Fortunately, such coordination is rarely necessary: While few modules need to concern themselves proactively with thread safety or resource management, fewer still need to concern themselves with interprocess issues.
There are two basic requirements you commonly have to consider:
- Global locks
- Shared memory
The APR provides Apache with support for both of these requirements.
4.7.1. Process and Global Locks
We’ve seen how using an APR thread mutex protects a critical section of code managing a server-based resource shared between threads. But APR provides two further mutexes: the process mutex apr_proc_mutex and the global mutex apr_global_mutex. When a module updates a globally shared resource (other than one with its own protection, such as an SQL database, or another server we are merely proxying), we need to use the latter mutex to protect critical sections of code. A case in which such a need often arises is when we are creating or updating files on the server.
The APR global mutex is more complex and more expensive than the thread mutex. The complexity lies in the initial setup of the mutex. First, it must be created in the parent process in the post_config phase. Second, each child has to attach to it in the child_init phase:

Now we’ve shown the two stages of global mutex creation and hooked an additional function: the content generator my_handler. A content generator is the most likely place in Apache to need a global mutex. Having set up our mutex in the server initialization, we can use it in the same manner as our thread mutex in any of our handlers:

4.7.2. Shared Memory
Many applications designers identify a shared resource as a requirement. Sometimes—as in the example case of editing a file—the shared resource has an independent existence. In other cases, the resource is internal to the webserver, as in a situation involving shared memory.
Consider, for example, the cache we examined earlier in this chapter. If our data are worth caching, presumably it’s more expensive to compute them than to maintain a cache. So wouldn’t it be better to share the cache over all processes, rather than duplicate it for every process?
The answer to this question is commonly “no.” Shared memory is computationally expensive and too inflexible for the task of maintaining such a cache without incurring much more work. At the most fundamental level, there is no mechanism for memory allocation, and C pointers cannot meaningfully be shared. For all these reasons, you may want to avoid shared memory in your design.
Of course, sometimes you really do need shared memory. As usual, APR provides support for it.
Shared Memory: apr_shm
The APR shared memory module apr_shm serves well to share fixed-size data such as simple variables or structs comprising data members but no pointers.
Pointers in Shared Memory: apr_rmm
As mentioned earlier, pointers in apr_shm shared memory are meaningless, because the address space they point to is not shared. It is possible to implement pointers in shared memory by using another APR module, apr_rmm, to manage a block of memory allocated by apr_shm. As an example, mod_ldap uses this combination to manage a shared cache with dynamic allocation:

Now mod_ldap can use the apr_rmm functions (including versions of malloc, calloc, realloc, and free) and obtain pointers in shared memory. However, we are still working with a fixed-sized block, and our apr_rmm operations will be substantially slower than normal apr_pool allocation.
Fully Generic Shared Memory
If we wish to implement other APR and Apache data types in shared memory, we might want to implement an APR pool based on our apr_rmm functions. This is not possible in the APR as it stands, but such a strategy could, in principle, be made to work with modest modifications based on an alternative apr_allocator that uses the apr_rmm memory block and functions. Unfortunately, handling errors and managing pool lifetime are unlikely to be straightforward operations with this approach.
Persistent/Unlimited Shared Resources: apr_dbm and apr_memcache
DBM files are keyed lookup databases, typically based on hashing and fast lookup. They are (usually) held on the filesystem, so they can be used to share arbitrary data between processes. These databases, which represent an alternative to apr_shm/apr_rmm, are better suited to management of larger shared resources or resources whose sizes cannot be set in the Apache configuration. They are also persistent, meaning that they will survive a restart of Apache.
The apr_memcache module is functionally similar (though by no means identical) to apr_dbm, but uses a (possibly remote) memcached[2] server instead of the local filesystem.
4.8. Secure Programming Issues
Warning
This section is not intended to serve as a general discussion of web and application security, nor even of programming modules for security-related tasks. Full coverage of these issues is beyond the scope of this book. Instead, we offer general good-practice tips and describe a few specific issues concerning programming for a sometimes-hostile environment. For further reading, two books this author has reviewed and can recommend are Ryan C. Barnett’s Preventing Web Attacks with Apache and Ivan Ristic’s Apache Security.[3]
If you are responsible for running a server and are uncertain of the security of applications running on it, you should probably also consider deploying the web application firewall module mod_security.[4] However, matters of server administration fall outside the scope of this book.
4.8.1. The Precautionary Principle: Trust Nothing
Validate Inputs Proactively
Perl provides a superb aid to application security: taint checking. Taint checking causes external inputs to be treated as untrusted, so Perl will prevent them from being used in an unsafe operation. For example, you can print tainted data out to a browser, but you cannot use them in any exec or filesystem operation, as the tainted data might enable malicious input to compromise the system. Before you can use any input data in a potentially unsafe operation, it must first be untainted. That means proactively matching inputs to patterns—such as regular expressions—that determine exactly which inputs the application permits, and rejecting anything that doesn’t match the specified patterns.
For example, an input representing a filename might be matched to a regular expression [w-_]{1-16}.w{3}. That matching criterion is, of course, far more restrictive than is necessary under any modern filesystem. But this tougher standard is not a critical issue: It just means that the application is a little more restrictive, in an unimportant area, than is strictly necessary. More importantly, it prevents an attacker from using a carefully crafted filename to compromise system security—for example, reading “../../../../../etc/passwd” or executing a command with “do_something_bad|” [in Perl, the | turns open() into popen()].
Although no equivalent enforcement mechanism is available in C, the same principles apply whenever an Apache module uses input data, whether from request headers, request entities (bodies), or any other source. Decide exactly what form the input data can take. Err on the side of caution where necessary. Check every input for conformance to allowed patterns. Refuse the request, typically by returning HTTP status 400 (bad request) if anything fails to match. To keep the input process reasonably user-friendly in case a legitimate user makes an honest mistake, you may want to construct an explanatory error page; of course, you can also delegate that task to system administrators by advising them to use an appropriate ErrorDocument.
Use Inputs Safely
An important principle of security is not to rely on a single method of enforcement. No matter how carefully validated your inputs, it’s worth using any means at your disposal to ensure they cannot be abused.
For example, consider authentication by SQL lookup with a statement like
statement = "SELECT password FROM authn WHERE user = '%s'"
together with a user value coming from the client.
If our module used something like
![]()
it would expose us to attacks such as an intruder adding himself to our database
user = "evil'; INSERT INTO authn VALUES (evil, password_for_evil);'"
or simply wiping the database in a similar manner.
In this case, the solution is obvious: Prepare the original statement, and pass the username as a parameter, so that the database treats the input as a string literal, eliminating this risk. In general, apply the same principle wherever possible: Ensure that inputs can never be treated as commands, only as data.
Apart from dbd, we must apply similar precautionary principles to logging, printing to the client, and—above all—system calls.
Don’t Cut Corners!
Sloppy programming creates fertile ground for would-be security exploits. Ensure that your code is free of such vulnerabilities:
- Check the error status of all system calls and APR calls. Don’t just ignore a return code. If there’s no simple way to recover, abort request processing and return
HTTP_INTERNAL_SERVER_ERRORto divert the request to anErrorDocument. An internal error has occurred, and it’s far better to admit that a problem exists than to cover it up and risk something far worse happening. - Avoid buffer overflows. Never write to an already-allocated buffer without first checking that the data being written fit within the buffer.
Don’t Be Afraid of Errors!
Sometimes you may be unsure what to do, as when dealing with an unexpected event in a complex situation. Your module should handle all events that you anticipate, but should also deal with events that seem unlikely or even impossible when the module is first written (maybe your impossible event will become possible in a future update). If it is not reasonable to think through every eventuality, just bail out with an error. With this approach, you’ve got a limitation, but you’ve also closed a potential security hole. Log an error message to help identify and fix it, should that ever become necessary.
4.8.2. Denial of Service: Limit the Damage
A denial of service (DoS) occurs when your server becomes too overloaded to manage its normal functions. Of course, it’s very easy to initiate a DoS yourself: From the pure fork bomb to the elusive memory leak, programming bugs or deliberate misuse can bring a server to its knees. Unfortunately, it’s almost as easy to initiate a DoS from a third-party server over the Internet. Causes can range from a targeted malicious attack to something perfectly innocent like the “slashdot effect,” in which a site is suddenly inundated with higher levels of legitimate traffic than the server and network can handle. The worst form of attack is the distributed denial of service (DDoS), which occurs when an attacker has access to thousands of different machines around the world[5] and cobbles all of them together to mount a brute force attack.
The primary responsibility for protecting against DoS lies with system administrators, who may choose to deploy explicit DoS protection such as special-purpose modules. Modules for Apache include the following:
mod_evasive[6] (formerlymod_dosevasive) is a sophisticated module that limits the amount of traffic per client IP the server will accept.
mod_cband[7] is a general-purpose module that shapes traffic and manages bandwidth and numbers of connections.
mod_load_average[8] is a simple module that avoids taking on heavy processing tasks when the server is already heavily loaded. Apache will return HTTP status503(the server is too busy) when processing the request normally would demand more of the system’s resources.
mod_robots[9] is a very simple module that denies access to badly behaved robots. It can also be used against spambots identifiable byuser-agent.
For normal modules—those whose primary purpose isn’t concerned with protecting the server—there is little you can or should do to protect them against DoS attacks. The main issue is to limit your module’s total resource consumption:
- Manage expensive resources using
apr_reslistor a similar means, so that the system administrator can set limits on the number of concurrent users. - Use timeouts on client I/O, including network-level filters.
- Stream all I/O. If that is not possible, ensure that a system administrator can set limits on I/O size. Note that this approach may directly conflict with the use of
mod_securityto protect vulnerable applications such as PHP, because some uses ofmod_securityprevent I/O streaming. - If your module supports large/long transactions (e.g., streaming media), reclaim memory and other resources regularly. This may mean using local pools and clearing them regularly and/or performing explicit cleaning of brigades in the filter chain.
4.8.3. Help the Operating System to Help You
It is up to system administrators to set up Apache securely, including using the protections provided by operating systems. The role of the application developer is to make as few demands as possible on the operating system that would be incompatible with security measures.
Privileges
Assume that Apache has no system privileges, such as a shell or ownership of any files or directories. If your module requires anything, it inevitably compromises best practices with regard to security.
Avoid requiring the identity or privileges of any system user, especially root. If your module absolutely must do something that requires root privileges,[10] it should run the privileged operations in a separate, ultra-simple, single-purpose process, so that Apache httpd doesn’t have to be given privileges. The same guideline applies, albeit a little less strongly, to other users. CGI with suexec[11] is a good sandbox for applications requiring medium-level privileges.
Networking
Work with a firewall. If your module needs to perform its own network I/O, make sure that the system administrator can fix the ports and IP addresses used (subject to the constraints of your application), so that the firewall can be kept simple and tight.
Protect yourself from broken or malicious input from your own network I/O just as you would with incoming HTTP requests.
Filesystem
Use the precautionary principle in accessing the filesystem. Let the system administrator define (in httpd.conf) areas of the filesystem you will access, and never stray outside those areas.
Flags to enforce this restriction are available in the apr_filepath calls. For example, the following function from mod_include prevents SSI inclusion of unauthorized and possibly sensitive files. First we resolve the filename passed, rejecting anything that takes us out of the permitted area of the filesystem (e.g., paths such as “../../../../etc/passwd”). Then we perform a subrequest lookup (see Chapter 6) to check that the file really is available to Apache (and that it is found where we expect it to be), before allowing it to be served. If find_file returns a nonzero value, the directive accessing the file will fail.

write and exec
The most serious exploits to have hit Apache servers in real life have involved saving an executable file to /tmp, and running it. It is not Apache itself, but rather applications (running under PHP) that give rise to this problem. Apache cannot prevent buggy applications from running, but you can and should protect against such serious consequences. The best advice to system administrators is to use filesystem security:
- Use file permissions and ownership to limit the Apache user’s write access to designated areas.
- Ensure that those designated areas are on a device mounted with a
noexecflag, so that the operating system prevents execution of a malicious file.
The role of the application developer here is, as usual, to avoid doing anything that could cause problems with this security. For example, do not write data anywhere that’s not specified by the system administrator and that might therefore be inconvenient or impossible to have mounted with noexec.
chroot
Avoid doing anything that would prevent a system administrator from running Apache chroot. In other words, avoid making any assumptions about how the filesystem will look from Apache’s perspective.
Running chroot is a relatively complex task for a system administrator, but has little relevance to most developers. Try this trick instead: Set up a minimal Apache installation to run in a chrooted test environment, and then add your module to the test server. If anything breaks, trace what caused the problem and try to fix it.
4.9. External Dependencies and Libraries
4.9.1. Third-Part Libraries
Administrators of many systems, including Apache, sometimes insist that more modules mean more complexity, and hence more trouble. Of course, more modules always mean a greater risk of bugs, simply because there’s more code. The real problem, however, is the possibility that two modules will be mutually incompatible and cause each other to fail. This should never happen!
Third-party libraries are fertile ground for this kind of trouble, because two or more modules may access a library in mutually incompatible ways. Following some basic rules of good practice can help ensure that your module doesn’t become the cuckoo in the nest that causes Apache to fail when it is used together with other modules from different sources.
4.9.2. Library Good Practice
Libraries, like modules, should always follow some basic rules of good practice. The most basic rule states that library functions should always return control to the caller in an orderly and properly documented manner. In particular, exit() is not an acceptable way to handle errors.
Unfortunately, some libraries—particularly older ones that may have been intended only for command line programs—may violate this principle. Examples are common in graphics libraries such as libjpeg.[12] Changing the library may pose a problem, but the conflict can be worked around by using setjmp/longjmp:
![]()
We need to set libjpeg to use longjmp rather than exit() when it encounters a fatal error:

We also need to register a function to generate error messages from the library:

Now we need our handler to set up its own error handler with libjpeg:

C++ throw/catch is superficially a more elegant solution that accomplishes the same thing, but in this author’s experience it doesn’t work so well in Apache. Your mileage may vary.
Thread Safety
When using third-party libraries, the module developer is responsible for ascertaining whether the libraries are thread safe. If they are not, then your module will need to use a thread mutex for every library call (which may be prohibitively expensive). Alternatively, you can document the module as not being thread safe, and limit its use to the Prefork MPM. The best-known example that uses the latter approach is PHP.
Some libraries—for example, the MySQL client library libmysqlclient—come as more than one version: a “standard” version that is not thread safe, and an alternative that is fully thread safe and reentrant. When using such a library, you should ensure your users always select the thread-safe version.
Initialization and Termination
Some libraries may require per-process initialization and termination. These tasks can be handled in various places in Apache, including the module hooks function. Unfortunately, the double start-up followed by forking of children makes this strategy complex and sometimes unsuitable. A library that is initialized before configuration will first be initialized, then terminated, then initialized a second time, after which child processes will be forked. If that behavior is acceptable with your library, then it’s a convenient way to handle initialization, because it makes the library available to the configuration functions.
Naturally, you will also need to register any termination function on the pool. If the library has a function whose signature is not compatible with a pool cleanup, you’ll need to write a wrapper for it. Here’s a typical outline for initialization:
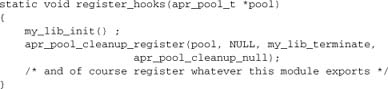
When the start-stop-restart-fork process will cause trouble, the safest place to handle library initialization may be a function hooked to child_init. In this case, initialization happens after the fork but before entering operational mode. As with the other strategy, you’ll need to call library initialization and register the termination function, this time on the child pool. If any configuration functions require the library, however, you may need to do something more complex, such as saving the configuration data “raw” in the configuration phase and then running any necessary library functions on the raw input data after initializing the library in the child_init phase.
Caution!
Bear in mind that your module may not be the only one to use the library. For most libraries, running initialization and global cleanup more than once does not pose a problem, so your module need not concern itself with this issue. If running either initialization or cleanup more than once will complicate life for the library, your module needs to be sensitive to whether another module is independently doing the same thing. One potential solution to this problem is to write a separate minimodule that specifically ensures that library functions are run exactly once.
Future Apache releases may provide a more elegant solution to this dilemma.
Library State Changes
If a library has global variables, any use of them is not thread safe.
A similar, more general issue arises when a library allows an application to change its state with global scope—for example, by registering callback functions for library events. This possibility is actually more than just a thread-safety issue, as it affects even the nonthreaded Prefork MPM.
To see how this problem arises, let’s consider a real-life example. The XML (and HTML) parsing library libxml2 allows an application to register handlers for parse errors. If your module uses such handlers, they should always be registered in the context of a parser that is owned by your module. However, mod_php skimped on this requirement and registered the handlers globally.[13]
Now, when another module uses libxml2 in processing a request and encounters a parse error, the registered error handler is called. But that is PHP’s handler! Because it wasn’t a PHP request, there is no PHP context, and Apache will crash (segfault). PHP has become a cuckoo in the nest, and other modules had to take extra trouble to work around the bug if using the XML parser in a manner that might generate XML parse errors.
4.9.3. Building Modules with Libraries
When your module relies on a third-party library, it needs that library at runtime. You can provide the library by any of three means:
- Link the library when building the module.
- Use
LoadFileto load the library into Apache. - Open the library from within your module code, using
apr_dso.
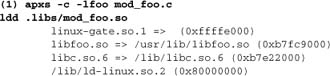
If you are contemplating the third option, you are probably doing something unusual and have a good reason for making this choice. Options 1 and 2, by contrast, are largely interchangeable. Consider a module mod_foo that relies on an external library libfoo. Here’s how it might look. These details are from an up-to-date Linux system, but the same principles apply on other platforms:
versus

In example 1, the library is linked directly into the module. This approach is superficially simpler for end users: A single LoadModule directive suffices to load the module (we can even insert the directive within the build procedure, using the -a option to apxs). Some developers prefer this strategy, for this reason.
In example 2, the single LoadModule is no longer sufficient. Apache will try to load mod_foo, but will encounter unresolved symbols (from libfoo) and refuse to start. In this case, we need an additional LoadFile directive:
![]()
Although superficially more complicated, this second approach has a number of advantages, which are discussed next.
Flexibility
If a module is built on one computer but intended to run on another computer (e.g., a developer supplying binaries to a client), the linked library may be in a different place in the filesystem on the target computer. This becomes a headache for the system administrator to sort out, particularly when the libraries are controlled by a package manager. When the developer uses LoadFile, the filesystem layout is immaterial; all that matters is that libfoo is available somewhere on the system.
Side Effects (Stealth Libraries)
When a module links a third-party library, that library is imported into Apache with the module. This approach may have side effects for other modules that use the library, causing the library to load or fail according to the ordering of the LoadModule directives. Such behavior is, in this author’s opinion, a clear violation of the principles of modularity. In some cases, it can also cause a module to load apparently successfully only to fail later, generating errors that are far more challenging to trace than an undefined symbol at start-up.
Versioning
When two or more modules link to a library, there is a risk of them linking to different versions of it. Even if the versions are fully binary compatible, this possibility causes major trouble: The overloading of the symbol table may lead to inexplicable, hard-to-trace segfaults. When a system administrator complains that supporting modules leads to trouble, this behavior is very likely to be the culprit.
In summary, it is recommended that you try to avoid linking any libraries into modules, and rely on LoadFile instead. If the setup is complex, shipping a configuration example with the module may be worthwhile. This tactic preserves modularity, leaves the system administrator in control, and makes conflicts and other serious problems both far less likely to happen and hugely easier to trace.
Note
Expert opinion is not unanimous on this subject, and even the core Apache distribution diverges from the principles of good practice suggested here. Your mileage may vary.
4.10. Modules Written and Compiled in Other Languages
Although all module examples in this book are written in C, it’s entirely possible to write modules in other languages:
- Any language that can be compiled to relocatable object code with C linkage can be used on exactly the same basis as C, with the C API. For example, C++, modern versions of FORTRAN, Modula 2/3, and a raft of obsolete languages can be used in this manner.
- Scripting languages such as Perl, PHP, Python, Ruby, and Tcl are supported by their respective language modules, which expose the Apache API to support module programming. Perl’s implementation of the API is probably the most complete of these options.
- Any language can be supported as an external programming—for example, with CGI or a proxied back end such as Java’s JSP and servlet APIs.
Only the first of these possibilities falls within the scope of this discussion. How do we compile and link a module written against the C API, given that apxs is fully compatible only with C?
This question is actually a platform-specific issue. On Windows, there is no apxs, and you can import a C++ module into VC++ exactly as you would a C module (I cannot speak for other languages on Windows). In our discussion here, we’ll deal with UNIX-family platforms, where apxs is the usual build tool.
Building and loading are simple:
- Export the C-compatible module symbol from your code, as you would in any module.
- Compile the module for position-independent code and with Apache and APR include paths.
- Link it as a shared object.
- Copy it to your Apache modules directory.
- Load it in
httpd.conf.
For example, with gcc’s options for C++, this process could be written as follows (don’t forget to declare the module symbol with extern "C" to ensure C linkage):
![]()
If our module uses any of the API features implemented as macros, it will need a C-compatible preprocessor, which may not be compatible with the language. Two workarounds are possible in this case: expand the macros explicitly, or use C stubs.
Expanded Macros
When our use of macros is sufficiently simple, we may just expand the macros within our module code. Configuration directives (covered in Chapter 9) are easy to expand, for instance. An example is mod_validator, in which
![]()
becomes
![]()
when expanded to work with a C++ compiler without a C99 preprocessor. (This step was required in Apache 2.2.0, but should no longer be necessary in future versions, as the C99 requirement shouldn’t have affected C++ source.)
C Stubs
For complex macros, such as those that implement optional functions or hooks (covered in Chapter 10), we can again expand them inline. Sometimes, however, it may be more convenient to implement the macros in a C stubs file and then to link that file with our non-C module. Let’s say we have a module written in language x, compiled with xcompile:

4.11. Summary
In this chapter, we discussed a number of important topics related to good practice and safe programming:
- The Apache
httpdproject’s code style guidelines - Management of transient and persistent module data, with regard to scope and lifetime
- Basic methods for communicating between modules
- Thread-safe and cross-process programming techniques
- Programming for security, and supporting the server administrator
- Working with third-party libraries and with languages other than C
We are now ready to move on to the more practically oriented section of the book and to develop real modules.