
At some point, you have to jump out of the plane under the assumption that you can get the parachute sewn together in time to deploy it. | ||
| --Jack Rickard | ||
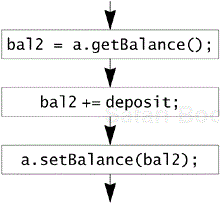
We usually write programs that operate one step at a time, in a sequence. In the following picture, the value of a bank balance is fetched, it is increased by the value of the deposit, and then it is copied back into the account record:

Real bank tellers and computer programs go through similar sequences. In a computer, a sequence of steps executed one at a time is called a thread. This single-threaded programming model is the one most programmers use.
In a real bank, more than one thing happens at a time:


Inside a computer, the analogue to having multiple real-world bank tellers is called multithreading. A thread, like a bank teller, can perform a task independent of other threads. And just as two bank tellers can use the same filing cabinets, threads can share access to objects.
This shared access is simultaneously one of the most useful features of multithreading and one of its greatest pitfalls. This kind of get–modify–set sequence has what is known as a race hazard or race condition. A race hazard exists when two threads can potentially modify the same piece of data in an interleaved way that can corrupt data. In the bank example, imagine that someone walks up to a bank teller to deposit money into an account. At almost the same time, a second customer asks another teller to handle a deposit into the same account. Each teller

goes to the filing cabinet to get the current account balance (assuming this is an old-fashioned bank that still uses paper files) and gets the same information. Then the tellers go back to their stations, add in the deposit, and return to the filing cabinet to record their separately calculated results. With this procedure, only the last deposit recorded actually affects the balance. The first modification is lost.
A real bank can handle this problem by having the first teller put a note into the file that says, “I'm working on this one, wait until I'm finished.” Essentially the same thing is done inside the computer: A lock is associated with an object to tell when the object is or is not being used.
Many real-world software problems can best be solved by using multiple threads of control. For example, an interactive program that graphically displays data often needs to let users change display parameters in real time. Interactive programs often obtain their best dynamic behavior by using threads. Single-threaded systems usually provide an illusion of multiple threads either by using interrupts or by polling. Polling mixes the display and user input parts of an application. In particular, the display code must be written so it will poll often enough to respond to user input in fractions of a second. Display code either must ensure that display operations take minimal time or must interrupt its own operations to poll. The resulting mixture of two unrelated functional aspects of a program leads to complex and often unmaintainable code.
These kinds of problems are more easily solved in a multithreaded system. One thread of control updates the display with current data, and another thread responds to user input. If user input is complex—for example, filling out a form— display code can run independently until it receives new data. In a polling model, either display updates must pause for complex input or complicated handshaking must be used so that display updates can continue while the user types data into the form. Such a model of shared control within a process can be directly supported in a multithreaded system instead of being handcrafted for each new polling case.
This chapter describes the basic constructs, classes, and methods that control multithreading in the Java programming language, but it cannot teach you effective multithreaded program design. The package java.util.concurrent and its subpackages provide higher-level concurrency utilities to ease the task of writing sophisticated multithreaded programs, but again the detailed use of such tools is beyond the scope of this book—an overview is given in Section 25.9.1 on page 733. You can read Concurrent Programming in Java™, Second Edition, a book in this series, to get advice on how to create well-designed multithreaded programs. “Further Reading” on page 755 has other useful references to give you a background in thread and synchronization design.
To create a thread of control, you start by creating a Thread object:
After a Thread object is created, you can configure it and then run it. Configuring a thread involves setting its initial priority, name, and so on. When the thread is ready to run, you invoke its start method. The start method spawns a new thread of control based on the data in the Thread object, then returns. Now the virtual machine invokes the new thread's run method, making the thread active. You can invoke start only once for each thread—invoking it again results in an IllegalThreadStateException.
When a thread's run method returns, the thread has exited. You can request that a thread cease running by invoking its interrupt method—a request a well-written thread will always respond to. While a thread is running you can interact with it in other ways, as you shall soon see.
The standard implementation of Thread.run does nothing. To get a thread that does something you must either extend Thread to provide a new run method or create a Runnable object and pass it to the thread's constructor. We first discuss how to create new kinds of threads by extending Thread. We describe how to use Runnable in the next section.
Here is a simple two-threaded program that prints the words “ping” and “PONG” at different rates:
public class PingPong extends Thread {
private String word; // what word to print
private int delay; // how long to pause
public PingPong(String whatToSay, int delayTime) {
word = whatToSay;
delay = delayTime;
}
public void run() {
try {
for (;;) {
System.out.print(word + " ");
Thread.sleep(delay); // wait until next time
}
} catch (InterruptedException e) {
return; // end this thread
}
}
public static void main(String[] args) {
new PingPong("ping", 33).start(); // 1/30 second
new PingPong("PONG", 100).start(); // 1/10 second
}
}
We define a type of thread called PingPong. Its run method loops forever, printing its word field and sleeping for delay milliseconds. PingPong.run cannot throw exceptions because Thread.run, which it overrides, doesn't throw any exceptions. Accordingly, we must catch the InterruptedException that sleep can throw (more on InterruptedException later).
Now we can create some working threads, and PingPong.main does just that. It creates two PingPong objects, each with its own word and delay cycle, and invokes each thread object's start method. Now the threads are off and running. Here is some example output:
ping PONG ping ping PONG ping ping ping PONG ping ping PONG ping ping ping PONG ping ping PONG ping ping ping PONG ping ping PONG ping ping ping PONG ping ping PONG ping ping ping PONG ping ping PONG ping ping ping PONG ping ping PONG ping ping ping PONG ping ping PONG ping ping ping PONG ping ping ...
You can give a thread a name, either as a String parameter to the constructor or as the parameter of a setName invocation. You can get the current name of a thread by invoking getName. Thread names are strictly for programmer convenience—they are not used by the runtime system—but a thread must have a name and so if none is specified, the runtime system will give it one, usually using a simple numbering scheme like Thread-1, Thread-2, and so on.
You can obtain the Thread object for the currently running thread by invoking the static method Thread.currentThread. There is always a currently running thread, even if you did not create one explicitly—main itself is executed by a thread created by the runtime system.
Exercise 14.1: Write a program that displays the name of the thread that executes main.
Threads abstract the concept of a worker—an entity that gets something done. The work done by a thread is packaged up in its run method. When you need to get some work done, you need both a worker and the work—the Runnable interface abstracts the concept of work and allows that work to be associated with a worker—the thread. The Runnable interface declares a single method:
public void run();
The Thread class itself implements the Runnable interface because a thread can also define a unit of work.
You have seen that Thread can be extended to provide specific computation for a thread, but this approach is awkward in many cases. First, class extension is single inheritance—if you extend a class to make it runnable in a thread, you cannot extend any other class, even if you need to. Also, if your class needs only to be runnable, inheriting all the overhead of Thread is more than you need.
Implementing Runnable is easier in many cases. You can execute a Runnable object in its own thread by passing it to a Thread constructor. If a Thread object is constructed with a Runnable object, the implementation of Thread.run will invoke the runnable object's run method.
Here is a Runnable version of the PingPong class. If you compare the versions, you will see that they look almost identical. The major differences are in the supertype (implementing Runnable versus extending Thread) and in main.
class RunPingPong implements Runnable {
private String word; // what word to print
private int delay; // how long to pause
RunPingPong(String whatToSay, int delayTime) {
word = whatToSay;
delay = delayTime;
}
public void run() {
try {
for (;;) {
System.out.print(word + " ");
Thread.sleep(delay); // wait until next time
}
} catch (InterruptedException e) {
return; // end this thread
}
}
public static void main(String[] args) {
Runnable ping = new RunPingPong("ping", 33);
Runnable pong = new RunPingPong("PONG", 100);
new Thread(ping).start();
new Thread(pong).start();
}
}
First, a new class that implements Runnable is defined. Its implementation of the run method is the same as PingPong's. In main, two RunPingPong objects with different timings are created; a new Thread object is then created for each object and is started immediately.
Five Thread constructors enable you to specify a Runnable object:
publicThread(Runnable target)Constructs a new
Threadthat uses therunmethod of the specifiedtarget.
publicThread(Runnable target, String name)Constructs a new
Threadwith the specifiednameand uses therunmethod of the specifiedtarget.
publicThread(ThreadGroup group, Runnable target)Constructs a new
Threadin the specifiedThreadGroupand uses therunmethod of the specifiedtarget. You will learn aboutThreadGrouplater.
publicThread(ThreadGroup group, Runnable target, String name)Constructs a new
Threadin the specifiedThreadGroupwith the specifiednameand uses therunmethod of the specifiedtarget.
publicThread(ThreadGroup group, Runnable target, String name, long stacksize)Constructs a new
Threadin the specifiedThreadGroupwith the specifiednameand uses therunmethod of the specifiedtarget. ThestackSizeparameter allows a stack size for the thread to be suggested. The values appropriate for a stack size are completely system dependent and the system does not have to honor the request. Such a facility is not needed by the vast majority of applications, but like most things of this nature, when you do need it, it is indispensable.
Classes that have only a run method are not very interesting. Real classes define complete state and behavior, where having something execute in a separate thread is only a part of their functionality. For example, consider a print server that spools print requests to a printer. Clients invoke the print method to submit print jobs. But all the print method actually does is place the job in a queue and a separate thread then pulls jobs from the queue and sends them to the printer. This allows clients to submit print jobs without waiting for the actual printing to take place.
class PrintServer implements Runnable {
private final PrintQueue requests = new PrintQueue();
public PrintServer() {
new Thread(this).start();
}
public void print(PrintJob job) {
requests.add(job);
}
public void run() {
for(;;)
realPrint(requests.remove());
}
private void realPrint(PrintJob job) {
// do the real work of printing
}
}
When a PrintServer is created, it creates a new Thread to do the actual printing and passes itself as the Runnable instance. Starting a thread in a constructor in this way can be risky if a class can be extended. If it becomes extended, the thread could access fields of the object before the extended class constructor had been executed.
The requests queue takes care of synchronizing the different threads that access it—those calling print and our own internal thread—we look at such synchronization in later sections and define the PrintQueue class on page 356.
You may be wondering about the fact that we don't have a reference to the thread we created—doesn't that mean that the thread can be garbage collected? The answer is no. While we didn't keep a reference to the thread, when the thread itself was created, it stored a reference to itself in its ThreadGroup—we talk more about thread groups later.
The work that you define within a run method is normally of a fairly private nature—it should be performed only by the worker to whom the work was assigned. However, as part of an interface, run is public and so can be invoked indiscriminately by anyone with access to your object—something you usually don't desire. For example, we definitely don't want clients to invoke the run method of PrintServer. One solution is to use Thread.currentThread to establish the identity of the thread that invokes run and to compare it with the intended worker thread. But a simpler solution is not to implement Runnable, but to define an inner Runnable object. For example, we can rewrite PrintServer as follows:
class PrintServer2 {
private final PrintQueue requests = new PrintQueue();
public PrintServer2() {
Runnable service = new Runnable() {
public void run() {
for(;;)
realPrint(requests.remove());
}
};
new Thread(service).start();
}
public void print(PrintJob job) {
requests.add(job);
}
private void realPrint(PrintJob job) {
// do the real work of printing
}
}
The run method is exactly the same as before, but now it is part of an anonymous inner class that implements Runnable. When the thread is created we pass service as the Runnable to execute. Now the work to be performed by the thread is completely private and can't be misused.
Using Runnable objects you can create very flexible multithreaded designs. Each Runnable becomes a unit of work and each can be passed around from one part of the system to another. We can store Runnable objects in a queue and have a pool of worker threads servicing the work requests in the queue—a very common design used in multithreaded server applications.
Exercise 14.2: Modify the first version of PrintServer so that only the thread created in the constructor can successfully execute run, using the identity of the thread as suggested.
Recall the bank teller example from the beginning of this chapter. When two tellers (threads) need to use the same file (object), there is a possibility of interleaved operations that can corrupt the data. Such potentially interfering actions are termed critical sections or critical regions, and you prevent interference by synchronizing access to those critical regions. In the bank, tellers synchronize their actions by putting notes in the files and agreeing to the protocol that a note in the file means that the file can't be used. The equivalent action in multithreading is to acquire a lock on an object. Threads cooperate by agreeing to the protocol that before certain actions can occur on an object, the lock of the object must be acquired. Acquiring the lock on an object prevents any other thread from acquiring that lock until the holder of the lock releases it. If done correctly, multiple threads won't simultaneously perform actions that could interfere with each other.
Every object has a lock associated with it, and that lock can be acquired and released through the use of synchronized methods and statements. The term synchronized code describes any code that is inside a synchronized method or statement.
A class whose objects must be protected from interference in a multithreaded environment usually has appropriate methods declared synchronized( “appropriate” is defined later). If one thread invokes a synchronized method on an object, the lock of that object is first acquired, the method body executed, and then the lock released. Another thread invoking a synchronized method on that same object will block until the lock is released:
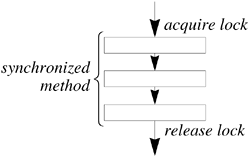
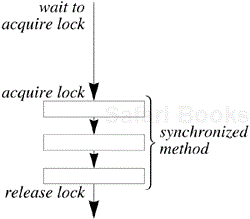
Synchronization forces execution of the two threads to be mutually exclusive in time. Unsynchronized access does not wait for any locks but proceeds regardless of locks that may be held on the object.
Locks are owned per thread, so invoking a synchronized method from within another method synchronized on the same object will proceed without blocking, releasing the lock only when the outermost synchronized method returns. This per-thread behavior prevents a thread from blocking on a lock it already has, and permits recursive method invocations and invocations of inherited methods, which themselves may be synchronized.
The lock is released as soon as the synchronized method terminates—whether normally, with a return statement or by reaching the end of the method body, or abnormally by throwing an exception. In contrast to systems in which locks must be explicitly acquired and released, this synchronization scheme makes it impossible to forget to release a lock.
Synchronization makes the interleaved execution example work: If the code is in a synchronized method, then when the second thread attempts to access the object while the first thread is using it, the second thread is blocked until the first one finishes.
For example, if the BankAccount class were written to live in a multithreaded environment it would look like this:
public class BankAccount {
private long number; // account number
private long balance; // current balance (in cents)
public BankAccount(long initialDeposit) {
balance = initialDeposit;
}
public synchronized long getBalance() {
return balance;
}
public synchronized void deposit(long amount) {
balance += amount;
}
// ... rest of methods ...
}
Now we can explain what is “appropriate” in synchronizing methods.
The constructor does not need to be synchronized because it is executed only when creating an object, and that can happen in only one thread for any given new object. Constructors, in fact, cannot be declared synchronized.
The balance field is defended from unsynchronized modification by the synchronized accessor methods. If the value of a field can change, its value should never be read at the same time another thread is writing it. If one thread were reading the value while another was setting it, the read might return an invalid value. Even if the value were valid, a get–modify–set sequence requires that the value not change between being read and being set, otherwise the set value will be wrong. Access to the field must be synchronized. This is yet another reason to prefer accessor methods to public or protected fields: Using methods, you can synchronize access to the data, but you have no way to do so if the fields can be accessed directly outside your class.
With the synchronized declaration, two or more running threads are guaranteed not to interfere with each other. Each of the methods will execute in mutual exclusion—once one invocation of a method starts execution, no other invocations of any of the methods can commence until the original has completed. However, there is no guarantee as to the order of operations. If the balance is queried about the same time that a deposit occurs, one of them will complete first but you can't tell which. If you want actions to happen in a guaranteed order, threads must coordinate their activities in some application-specific way.
You can ask whether the current thread holds the lock on a given object by passing that object to the Thread class's static holdsLock method, which returns true if the current thread does hold the lock on that object. This is typically used to assert that a lock is held when needed. For example, a private method that expects to be invoked only from synchronized public methods might assert that fact:
You will also occasionally find it important that a certain lock not be held in a method. And in some rare circumstances you might want to choose whether or not to acquire a given lock depending on whether or not another lock is held.
When an extended class overrides a synchronized method, the new method can be synchronized or not. The superclass's method will still be synchronized when it is invoked. If the unsynchronized method uses super to invoke the superclass's method, the object's lock will be acquired at that time and will be released when the superclass's method returns. Synchronization requirements are a part of the implementation of a class. An extended class may be able to modify a data structure such that concurrent invocations of a method do not interfere and so the method need not be synchronized; conversely the extended class may enhance the behavior of the method in such a way that interference becomes possible and so it must be synchronized.
Static methods can also be declared synchronized. Associated with every class is a Class object—see “The Class Class” on page 399. A static synchronized method acquires the lock of the Class object for its class. Two threads cannot execute static synchronized methods of the same class at the same time, just as two threads cannot execute synchronized methods on the same object at the same time. If static data is shared between threads then access to it must be protected by static synchronized methods.
Acquiring the Class object lock in a static synchronized method has no effect on any objects of that class. You can still invoke synchronized methods on an object while another thread holds the Class object lock in a static synchronized method. Only other static synchronized methods are blocked.
The synchronized statement enables you to execute synchronized code that acquires the lock of any object, not just the current object, or for durations less than the entire invocation of a method. The synchronized statement has two parts: an object whose lock is to be acquired and a statement to execute when the lock is obtained. The general form of the synchronized statement is
synchronized (expr) { statements }
The expression expr must evaluate to an object reference. After the lock is obtained, the statements in the block are executed. At the end of the block the lock is released—if an uncaught exception occurs within the block, the lock is still released. A synchronized method is simply a syntactic shorthand for a method whose body is wrapped in a synchronized statement with a reference to this.
Here is a method to replace each element in an array with its absolute value, relying on a synchronized statement to control access to the array:
/** make all elements in the array non-negative */ public static void abs(int[] values) { synchronized (values) { for (int i = 0; i < values.length; i++) { if (values[i] < 0) values[i] = -values[i]; } } }
The values array contains the elements to be modified. We synchronize values by naming it as the object of the synchronized statement. Now the loop can proceed, guaranteed that the array is not changed during execution by any other code that is similarly synchronized on the values array. This is an example of what is generally termed client-side synchronization—all the clients using the shared object (in this case the array) agree to synchronize on that object before manipulating it. For objects such as arrays, this is the only way to protect them when they can be shared directly, since they have no methods that can be synchronized.
The synchronized statement has a number of uses and advantages over a synchronized method. First, it can define a synchronized region of code that is smaller than a method. Synchronization affects performance—while one thread has a lock another thread can't get it—and a general rule of concurrent programming is to hold locks for as short a period as possible. Using a synchronized statement, you can choose to hold a lock only when it is absolutely needed—for example, a method that performs a complex calculation and then assigns the result to a field often needs to protect only the actual field assignment not the calculation process.
Second, synchronized statements allow you to synchronize on objects other than this, allowing a number of different synchronization designs to be implemented. Sometimes you want to increase the concurrency level of a class by using a finer granularity of locking. It may be that different groups of methods within a class act on different data within that class, and so while mutual exclusion is needed within a group, it is not needed between groups. Instead of making all the methods synchronized, you can define separate objects to be used as locks for each such group and have the methods use synchronized statements with the appropriate lock object. For example:
class SeparateGroups {
private double aVal = 0.0;
private double bVal = 1.1;
protected final Object lockA = new Object();
protected final Object lockB = new Object();
public double getA() {
synchronized (lockA) {
return aVal;
}
}
public void setA(double val) {
synchronized (lockA) {
aVal = val;
}
}
public double getB() {
synchronized (lockB) {
return bVal;
}
}
public void setB(double val) {
synchronized (lockB) {
bVal = val;
}
}
public void reset() {
synchronized (lockA) {
synchronized (lockB) {
aVal = bVal = 0.0;
}
}
}
}
The two lock references are protected so that an extended class can correctly synchronize its own methods—such as a method to set aVal and bVal to the same value. Also notice how reset acquires both locks before modifying both values.
Another common use of the synchronized statement is for an inner object to synchronize on its enclosing object:
public class Outer {
private int data;
// ...
private class Inner {
void setOuterData() {
synchronized (Outer.this) {
data = 12;
}
}
}
}
Like any other object, an inner object is independently synchronized—acquiring the lock of an inner object has no effect on its enclosing object's lock, nor does acquiring the lock of an enclosing object affect any enclosed inner objects. An inner class that needs to synchronize with its enclosing object must do so explicitly and a synchronized statement is a perfect tool—the alternative is to declare a synchronized method in the enclosing class just for the inner class to use.
If you need a synchronized statement to use the same lock used by static synchronized methods, you can use the class literal for your class (see example below). This also applies if you need to protect access to static data from within non-static code. For example, consider the Body class. It maintains a static field, nextID, to hold the next identifier for a new Body object. That field is accessed in the Body class's no-arg constructor. If Body objects were created concurrently, interference could occur when the nextID field is updated. To prevent that from happening you can use a synchronized statement within the Body constructor that uses the lock of the Body.class object:
Body() {
synchronized (Body.class) {
idNum = nextID++;
}
}
The synchronized statement in the constructor acquires the lock of the Class object for Body in the same way a synchronized static method of the class would. Synchronizing on this would use a different object for each invocation and so would not prevent threads from accessing nextID concurrently. It would also be wrong to use the Object method getClass to retrieve the Class object for the current instance: In an extended class, such as AttributedBody, that would return the Class object for AttributedBody not Body, and so again, different locks would be used and interference would not be prevented. The simplest rule is to always protect access to static data using the lock of the Class object for the class in which the static data was declared.
In many cases, instead of using a synchronized statement you can factor the code to be protected into a synchronized method of its own. You'll need to use your own experience and judgment to decide when this is preferable. For example, in the Body class we could encapsulate access to nextID in a static synchronized method getNextID.
Finally, the ability to acquire locks of arbitrary objects with synchronized statements makes it possible to perform the client-side synchronization that you saw in the array example. This capability is important, not only for protecting access to objects that don't have synchronized methods, but also for synchronizing a series of accesses to an object. We look more at this in the next section.
Designing the appropriate synchronization for a class can be a complex matter and it is beyond the scope of this book to delve too deeply into these design issues. We can take a brief look at some of the issues involved.
Client-side synchronization is done by having all the clients of a shared object use synchronized statements to lock the object before using it. Such a protocol is fragile—it relies on all of the clients doing the right thing. It is generally better to have shared objects protect access to themselves by making their methods synchronized (or using appropriate synchronized statements inside those methods). This makes it impossible for a client to use the object in a way that is not synchronized. This approach is sometimes termed server-side synchronization, but it is just an extension of the object-oriented perspective that objects encapsulate their own behavior, in this case synchronization.
Sometimes a designer hasn't considered a multithreaded environment when designing a class, and none of the class's methods are synchronized. To use such a class in a multithreaded environment, you have to decide whether to use client-side synchronization via synchronized statements or to create an extended class to override the appropriate methods, declare them synchronized, and forward method calls through the super reference.
If you are working with an interface instead of a class, you can provide an alternate implementation that wraps the methods of the interface in synchronized methods that forward the calls to another unsynchronized object that implements the same interface. This will work with any implementation of the interface, and is therefore a better solution than extending each class to use super in a synchronized method. This flexibility is another reason to use interfaces to design your system. You can see an example of this synchronized wrapper technique in the collections classes; see “The Synchronized Wrappers” on page 602.
The synchronization you have learned about so far is the simplest notion of “thread safety”—the idea that methods on objects can be invoked by multiple threads concurrently and each thread will have the method perform its expected job. Synchronization, however, has to extend to more complex situations involving multiple method invocations on an object, or even method invocations on multiple objects. If these series of invocations must appear as an atomic action you will need synchronization. In the case of multiple method invocations, you can encapsulate the series of invocations within another method and synchronize that method, but generally this is impractical—you can't define all combinations of the basic methods as methods themselves, nor are you likely to know at the time the class is designed which method combinations may be needed. In the case of operations on multiple objects, where could you put a synchronized method?
In these situations, the ability to use client-side synchronization through synchronized statements is often the only practical approach. An object can have its lock acquired, which prevents any of its synchronized methods from being invoked except by the lock holder performing the series of invocations. Similarly, you can acquire the locks of each of the objects involved and then invoke the series of methods on those objects—but watch out for deadlock (see Section 14.7 on page 362). As long as the object's methods are already synchronized on the current object's lock, then other clients of the object need not use client-side synchronization.
The way that synchronization is enforced in a class is an implementation detail. The fact that it is enforced is an important part of the contract of the class and must be clearly documented—the presence of the synchronized modifier on a method might only be an implementation detail of the class, not part of a binding contract. Additionally, the synchronization mechanism used within a class may need to be documented and made accessible to users of the class and/or to extended classes. An extended class needs to adhere to the synchronization policy enforced by its superclass and it can do that only if the programmer knows what that policy is and has access to the mechanisms that enforce it. For example, a class that uses a private field as a lock object prevents an extended class from using the same synchronization mechanism—the extended class would have to define its own lock object (perhaps this) and override every method of the superclass to use this new synchronization mechanism. Users of a class may need to know what synchronization mechanism is used so that they can safely apply client-side synchronization to invoke multiple methods on an object, without needing all users of that object to apply client-side synchronization.
Exercise 14.3: Write a class whose objects hold a current value and have a method that will add to that value, printing the new value. Write a program that creates such an object, creates multiple threads, and invokes the adding method repeatedly from each thread. Write the class so that no addition can be lost.
Exercise 14.4: Modify your code from Exercise 14.3 to use static data and methods.
Exercise 14.5: Modify your code from Exercise 14.4 so that threads can safely decrement the value without using a static synchronized method.
The synchronized locking mechanism suffices for keeping threads from interfering with each other, but you also need a way to communicate between threads. For this purpose, the wait method lets one thread wait until some condition occurs, and the notification methods notifyAll and notify tell waiting threads that something has occurred that might satisfy that condition. The wait and notification methods are defined in class Object and are inherited by all classes. They apply to particular objects, just as locks do.
There is a standard pattern that is important to use with wait and notification. The thread waiting for a condition should always do something like this:
synchronized void doWhenCondition() {
while (!condition)
wait();
… Do what must be done when the condition is true …
}
A number of things are going on here:
Everything is executed within synchronized code. If it were not, the state of the object would not be stable. For example, if the method were not declared
synchronized, then after thewhilestatement, there would be no guarantee that the condition remainedtrue: Another thread might have changed the situation that the condition tests.One of the important aspects of the definition of
waitis that when it pauses the thread, it atomically releases the lock on the object. Saying that the thread suspension and lock release are atomic means that they happen together, indivisibly. Otherwise, there would be a race hazard: A notification could happen after the lock is released but before the thread is suspended. The notification would have no effect on the thread, effectively getting lost. When a thread is restarted after being notified, the lock is atomically reacquired.The condition test should always be in a loop. Never assume that being awakened means that the condition has been satisfied—it may have changed again since being satisfied. In other words, don't change the
whileto anif.
On the other side, the notification methods are invoked by synchronized code that changes one or more conditions on which some other thread may be waiting. Notification code typically looks something like this:
synchronized void changeCondition() {
… change some value used in a condition test …
notifyAll(); // or notify()
}
Using notifyAll wakes up all waiting threads, whereas notify picks only one thread to wake up.
Multiple threads may be waiting on the same object, possibly for different conditions. If they are waiting for different conditions, you should always use notifyAll to wake up all waiting threads instead of using notify. Otherwise, you may wake up a thread that is waiting for a different condition from the one you satisfied. That thread will discover that its condition has not been satisfied and go back to waiting, while some thread waiting on the condition you did satisfy will never get awakened. Using notify is an optimization that can be applied only when:
All threads are waiting for the same condition
At most one thread can benefit from the condition being met
This is contractually true for all possible subclasses
Otherwise you must use notifyAll. If a subclass violates either of the first two conditions, code in the superclass that uses notify may well be broken. To that end it is important that waiting and notification strategies, which include identifying the reference used (this or some other field), are documented for use by extended classes.
The following example implements the PrintQueue class that we used with the PrintServer on page 343. We reuse the SingleLinkQueue class that we defined in Chapter 11 to actually store the print jobs, and add the necessary synchronization:
class PrintQueue {
private SingleLinkQueue<PrintJob> queue =
new SingleLinkQueue<PrintJob>();
public synchronized void add(PrintJob j) {
queue.add(j);
notifyAll(); // Tell waiters: print job added
}
public synchronized PrintJob remove()
throws InterruptedException
{
while (queue.size() == 0)
wait(); // Wait for a print job
return queue.remove();
}
}
In contrast to SingleLinkQueue itself, the methods are synchronized to avoid interference. When an item is added to the queue, waiters are notified; and instead of returning null when the queue is empty, the remove method waits for some other thread to insert something so that take will block until an item is available. Many threads (not just one) may be adding items to the queue, and many threads (again, not just one) may be removing items from the queue. Because wait can throw InterruptedException, we declare that in the throws clause—you'll learn about InterruptedException a little later.
Looking back at the PrintServer example, you can now see that although the internal thread appears to sit in an infinite loop, continually trying to remove jobs from the queue, the use of wait means that the thread is suspended whenever there is no work for it to do. In contrast, if we used a queue that returned null when empty, the printing thread would continually invoke remove, using the CPU the whole time—a situation known as busy-waiting. In a multithreaded system you very rarely want to busy-wait. You should always suspend until told that what you are waiting for may have happened. This is the essence of thread communication with the wait and notifyAll/notify mechanism.
There are three forms of wait and two forms of notification. All of them are methods in the Object class, and all are final so that their behavior cannot be changed:
public final voidwait(long timeout)throws InterruptedExceptionThe current thread waits until one of four things happens:
notifyis invoked on this object and this thread is selected to be runnable;notifyAllis invoked on this object; the specifiedtimeoutexpires; or the thread has itsinterruptmethod invoked.timeoutis in milliseconds. Iftimeoutis zero, the wait will not time out but will wait indefinitely for notification. During the wait the lock of the object is released and is automatically reacquired beforewaitcompletes—regardless of how or whywaitcompletes. AnInterruptedExceptionis thrown if the wait completes because the thread is interrupted.
public final voidwait(long timeout, int nanos)throws InterruptedExceptionA finer-grained
wait, with the time-out interval as the sum of the two parameters:timeoutin milliseconds andnanosin nanoseconds, in the range 0–999999).
public final voidwait()throws InterruptedExceptionEquivalent to
wait(0).
public final voidnotifyAll()Notifies all the threads waiting for a condition to change. Threads will return from the
waitinvocation once they can reacquire the object's lock.
public final voidnotify()Notifies at most one thread waiting for a condition to change. You cannot choose which thread will be notified, so use this form of
notifyonly when you are sure you know which threads are waiting for what at which times. If you are not sure of any of these factors, you should usenotifyAll.
If no threads are waiting when either notifyAll or notify is invoked, the notification is not remembered. If a thread subsequently decides to wait, an earlier notification will have no effect on it. Only notifications that occur after the wait commences will affect a waiting thread.
You can invoke these methods only from within synchronized code, using the lock for the object on which they are invoked. The invocation can be directly made from the synchronized code, or can be made indirectly from a method invoked in such code. You will get an IllegalMonitorStateException if you attempt to invoke these methods on an object when you don't hold its lock.
When a wait completes because the time-out period expires, there is no indication that this occurred rather than the thread being notified. If a thread needs to know whether or not it timed out, it has to track elapsed time itself. The use of a time-out is a defensive programming measure that allows you to recover when some condition should have been met but for some reason (probably a failure in another thread) has not. Because the lock of the object must be reacquired, the use of a time-out cannot guarantee that wait will return in a finite amount of time.
It is also possible that some virtual machine implementations will allow so-called “spurious wakeups” to occur—when a thread returns from wait without being the recipient of a notification, interruption, or time-out. This is another reason that wait should always be performed in a loop that tests the condition being waited on.
Exercise 14.6: Write a program that prints the elapsed time each second from the start of execution, with another thread that prints a message every fifteen seconds. Have the message-printing thread be notified by the time-printing thread as each second passes by. Add another thread that prints a different message every seven seconds without modifying the time-printing thread.
Threads perform different tasks within your programs and those tasks can have different importance levels attached to them. To reflect the importance of the tasks they are performing, each thread has a priority that is used by the runtime system to help determine which thread should be running at any given time. Programs can be run on both single- and multiprocessor machines and you can run with multiple threads or a single thread, so the thread scheduling guarantees are very general. On a system with N available processors, you will usually see N of the highest-priority runnable threads executing. Lower-priority threads generally run only when higher-priority threads are blocked (not runnable). But lower-priority threads might, in fact, run at other times to prevent starvation—a feature generally known as priority aging—though you cannot rely on it.
A running thread continues to run until it performs a blocking operation (such as wait, sleep, or some types of I/O) or it is preempted. A thread can be preempted by a higher-priority thread becoming runnable or because the thread scheduler decides it's another thread's turn to get some cycles—for example, time slicing limits the amount of time a single thread can run before being preempted.
Exactly when preemption can occur depends on the virtual machine you have. There are no guarantees, only a general expectation that preference is typically given to running higher-priority threads. Use priority only to affect scheduling policy for efficiency. Do not rely on thread priority for algorithm correctness. To write correct, cross-platform multithreaded code you must assume that a thread could be preempted at any time, and so you always protect access to shared resources. If you require that preemption occur at some specific time, you must use explicit thread communication mechanisms such as wait and notify. You also can make no assumptions about the order in which locks are granted to threads, nor the order in which waiting threads will receive notifications—these are all system dependent.
A thread's priority is initially the same as the priority of the thread that created it. You can change the priority using setPriority with a value between Thread's constants MIN_PRIORITY and MAX_PRIORITY. The standard priority for the default thread is NORM_PRIORITY. The priority of a running thread can be changed at any time. If you assign a thread a priority lower than its current one, the system may let another thread run because the original thread may no longer be among those with the highest priority. The getPriority method returns the priority of a thread.
Generally, if you are to worry about priorities at all, the continuously running part of your application should run in a lower-priority thread than the thread dealing with rarer events such as user input. When users push a “Cancel” button, for example, they expect the application to cancel what it's doing. If display update and user input are at the same priority and the display is updating, considerable time may pass before the user input thread reacts to the button. If you put the display thread at a lower priority, it will still run most of the time because the user interface thread will be blocked waiting for user input. When user input is available, the user interface thread will typically preempt the display thread to act on the user's request. For this reason, a thread that does continual updates is often set to NORM_PRIORITY-1 so that it doesn't hog all available cycles, while a user interface thread is often set to NORM_PRIORITY+1.
Using small “delta” values around the normal priority level is usually preferable to using MIN_PRIORITY or MAX_PRIORITY directly. Exactly what effect priorities have depends on the system you are running on. In some systems your thread priorities not only assign an importance relative to your program, they assign an importance relative to other applications running on the system.[1] Extreme priority settings may result in undesirable behavior and so should be avoided unless their effects are known and needed.
Some algorithms are sensitive to the number of processors available to the virtual machine to run threads on. For example, an algorithm might split work up into smaller chunks to take advantage of more parallel processing power. The availableProcessors method of the Runtime class (see Chapter 23) returns the number of processors currently available. Note that the number of processors can change at any time, so you want to check this number when it is important rather than remember the number from a previous check.
Several methods of the Thread class allow a thread to relinquish its use of the CPU. By convention, static methods of the Thread class always apply to the currently executing thread, and since you can never take the CPU from another thread, these voluntary rescheduling methods are all static:
public static voidsleep(long millis)throws InterruptedExceptionPuts the currently executing thread to sleep for at least the specified number of milliseconds. “At least” means there is no guarantee the thread will wake up in exactly the specified time. Other thread scheduling can interfere, as can the granularity and accuracy of the system clock, among other factors. If the thread is interrupted while it is sleeping, then an
InterruptedExceptionis thrown.
public static voidsleep(long millis, int nanos)throws InterruptedExceptionPuts the currently executing thread to sleep for at least the specified number of milliseconds and nanoseconds. Nanoseconds are in the range 0–999999.
public static voidyield()Provides a hint to the scheduler that the current thread need not run at the present time, so the scheduler may choose another thread to run. The scheduler may follow or ignore this suggestion as it sees fit—you can generally rely on the scheduler to “do the right thing” even though there is no specification of exactly what that is.
The following program illustrates how yield can affect thread scheduling. The application takes a list of words and creates a thread for each that is responsible for printing that word. The first parameter to the application says whether each thread will yield after each println; the second parameter is the number of times each thread should repeat its word. The remaining parameters are the words to be repeated:
class Babble extends Thread {
static boolean doYield; // yield to other threads?
static int howOften; // how many times to print
private String word; // my word
Babble(String whatToSay) {
word = whatToSay;
}
public void run() {
for (int i = 0; i < howOften; i++) {
System.out.println(word);
if (doYield)
Thread.yield(); // let other threads run
}
}
public static void main(String[] args) {
doYield = new Boolean(args[0]).booleanValue();
howOften = Integer.parseInt(args[1]);
// create a thread for each word
for (int i = 2; i < args.length; i++)
new Babble(args[i]).start();
}
}
When the threads do not yield, each thread gets large chunks of time, usually enough to finish all the prints without any other thread getting any cycles. For example, suppose the program is run with doYield set to false in the following way:
Babble false 2 Did DidNot
The output may well look like this:
If each thread yields after each println, other printing threads will have a chance to run. Suppose we set doYield to true with an invocation such as this:
Babble true 2 Did DidNot
The yields give the other threads a chance to run, and the other threads will yield in turn, producing an output more like this:
The output shown is only approximate—perhaps you expected the words to alternate? A different thread implementation could give different results, or the same implementation might give different results on different runs of the application. But under all implementations, invoking yield can give other threads a more equitable chance at getting cycles.
Two other factors affect the behavior of this program (and many like it that try to demonstrate scheduling behavior). The first is that println uses synchronization, so the different threads must all contend for the same lock.
The second factor is that there are three threads in the program, not two. The main thread has to create and start the two Babble threads and that means that it contends with them for scheduling as well. It is entirely possible that the first Babble thread will run to completion before the main thread even gets the chance to create a second Babble thread.
Exercise 14.7: Run Babble multiple times and examine the output: Is it always the same? If possible, run it on different systems and compare.
Whenever you have two threads and two objects with locks, you can have a deadlock, in which each thread has the lock on one of the objects and is waiting for the lock on the other object. If object X has a synchronized method that invokes a synchronized method on object Y, which in turn has a synchronized method invoking a synchronized method on object X, two threads may wait for each other to complete in order to get a lock, and neither thread will be able to run. This situation is also called a deadly embrace. Here's a Friendly class in which one friend, upon being hugged, insists on hugging back:
class Friendly {
private Friendly partner;
private String name;
public Friendly(String name) {
this.name = name;
}
public synchronized void hug() {
System.out.println(Thread.currentThread().getName()+
" in " + name + ".hug() trying to invoke " +
partner.name + ".hugBack()");
partner.hugBack();
}
private synchronized void hugBack() {
System.out.println(Thread.currentThread().getName()+
" in " + name + ".hugBack()");
}
public void becomeFriend(Friendly partner) {
this.partner = partner;
}
}
Now consider this scenario, in which jareth and cory are two Friendly objects that have become friends:
Thread number 1 invokes
synchronizedmethodjareth.hug. Thread number 1 now has the lock onjareth.Thread number 2 invokes
synchronizedmethodcory.hug. Thread number 2 now has the lock oncory.Now
jareth.huginvokessynchronizedmethodcory.hugBack. Thread number 1 is now blocked waiting for the lock oncory(currently held by thread number 2) to become available.Finally,
cory.huginvokessynchronizedmethodjareth.hugBack. Thread number 2 is now blocked waiting for the lock onjareth(currently held by thread number 1) to become available.
We have now achieved deadlock: cory won't proceed until the lock on jareth is released and vice versa, so the two threads are stuck in a permanent embrace.
We can try to set up this scenario:
public static void main(String[] args) {
final Friendly jareth = new Friendly("jareth");
final Friendly cory = new Friendly("cory");
jareth.becomeFriend(cory);
cory.becomeFriend(jareth);
new Thread(new Runnable() {
public void run() { jareth.hug(); }
}, "Thread1").start();
new Thread(new Runnable() {
public void run() { cory.hug(); }
}, "Thread2").start();
}
And when you run the program, you might get the following output before the program “hangs”:
Thread1 in jareth.hug() trying to invoke cory.hugBack() Thread2 in cory.hug() trying to invoke jareth.hugBack()
You could get lucky, of course, and have one thread complete the entire hug without the other one starting. If steps 2 and 3 happened to occur in the opposite order, jareth would complete both hug and hugBack before cory needed the lock on jareth. But a future run of the same application might deadlock because of a different choice of the thread scheduler. Several design changes would fix this problem. The simplest would be to make hug and hugBack not synchronized but have both methods synchronize on a single object shared by all Friendly objects. This technique would mean that only one hug could happen at a time in all the threads of a single application, but it would eliminate the possibility of deadlock. Other, more complicated techniques would enable multiple simultaneous hugs without deadlock.
You are responsible for avoiding deadlock. The runtime system neither detects nor prevents deadlocks. It can be frustrating to debug deadlock problems, so you should solve them by avoiding the possibility in your design. One common technique is to use resource ordering. With resource ordering you assign an order on all objects whose locks must be acquired and make sure that you always acquire locks in that order. This makes it impossible for two threads to hold one lock each and be trying to acquire the lock held by the other—they must both request the locks in the same order, and so once one thread has the first lock, the second thread will block trying to acquire that lock, and then the first thread can safely acquire the second lock.
Exercise 14.8: Experiment with the Friendly program. How often does the deadlock actually happen on your system? If you add yield calls, can you change the likelihood of deadlock? If you can, try this exercise on more than one kind of system. Remove the deadlock potential without getting rid of the synchronization.
A thread that has been started becomes alive and the isAlive method will return true for that thread. A thread continues to be alive until it terminates, which can occur in one of three ways:
The
runmethod returns normally.The
runmethod completes abruptly.The application terminates.
Having run return is the normal way for a thread to terminate. Every thread performs a task and when that task is over the thread should go away. If something goes wrong, however, and an exception occurs that is not caught, then that will also terminate the thread—we look at this further in Section 14.12 on page 379. By the time a thread terminates it will not hold any locks, because all synchronized code must have been exited by the time run has completed.
A thread can also be terminated when its application terminates, which you'll learn about in “Ending Application Execution” on page 369.
There are often occasions when you create a thread to perform some work and then need to cancel that work before it is complete—the most obvious example being a user clicking a cancel button in a user interface. To make a thread cancellable takes a bit of work on the programmer's part, but it is a clean and safe mechanism for getting a thread to terminate. You request cancellation by interrupting the thread and by writing the thread such that it watches for, and responds to, being interrupted. For example:
Thread 1

Thread 2
Interrupting the thread advises it that you want it to pay attention, usually to get it to halt execution. An interrupt does not force the thread to halt, although it will interrupt the slumber of a sleeping or waiting thread.
Interruption is also useful when you want to give the running thread some control over when it will handle an event. For example, a display update loop might need to access some database information using a transaction and would prefer to handle a user's “cancel” after waiting until that transaction completes normally. The user-interface thread might implement a “Cancel” button by interrupting the display thread to give the display thread that control. This approach will work well as long as the display thread is well behaved and checks at the end of every transaction to see whether it has been interrupted, halting if it has.
The following methods relate to interrupting a thread: interrupt, which sends an interrupt to a thread; isInterrupted, which tests whether a thread has been interrupted; and interrupted, a static method that tests whether the current thread has been interrupted and then clears the “interrupted” state of the thread. The interrupted state of a thread can be cleared only by that thread—there is no way to “uninterrupt” another thread. There is generally little point in querying the interrupted state of another thread, so these methods tend to be used by the current thread on itself. When a thread detects that it has been interrupted, it often needs to perform some cleanup before actually responding to the interrupt. That cleanup may involve actions that could be affected if the thread is left in the inter rupted state, so the thread will test and clear its interrupted state using interrupted.
Interrupting a thread will normally not affect what it is doing, but a few methods, such as sleep and wait, throw InterruptedException. If your thread is executing one of these methods when it is interrupted, the method will throw the InterruptedException. Such a thrown interruption clears the interrupted state of the thread, so handling code for InterruptedException commonly looks like this:
void tick(int count, long pauseTime) {
try {
for (int i = 0; i < count; i++) {
System.out.println('.'),
System.out.flush();
Thread.sleep(pauseTime);
}
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
}
}
The tick method prints a dot every pauseTime milliseconds up to a maximum of count times—see “Timer and TimerTask” on page 653 for a better way to do this. If something interrupts the thread in which tick is running, sleep will throw InterruptedException. The ticking will then cease, and the catch clause will reinterrupt the thread. You could instead declare that tick itself throws InterruptedException and simply let the exception percolate upward, but then every invoker of tick would have to handle the same possibility. Reinterrupting the thread allows tick to clean up its own behavior and then let other code handle the interrupt as it normally would.
In general any method that performs a blocking operation (either directly or indirectly) should allow that blocking operation to be cancelled with interrupt and should throw an appropriate exception if that occurs. This is what sleep and wait do. In some systems, blocking I/O operations will respond to interruption by throwing InterruptedIOException (which is a subclass of the general IOException that most I/O methods can throw—see Chapter 20 for more details on I/O). Even if the interruption cannot be responded to during the I/O operation, systems may check for interruption at the start of the operation and throw the exception—hence the need for an interrupted thread to clear its interrupted state if it needs to perform I/O as part of its cleanup. In general, however, you cannot assume that interrupt will unblock a thread that is performing I/O.
Every method of every class executes in some thread, but the behavior defined by those methods generally concerns the state of the object involved, not the state of the thread executing the method. Given that, how do you write methods that will allow threads to respond to interrupts and be cancellable? If your method can block, then it should respond to interruption as just discussed. Otherwise, you must decide what interruption or cancellation would mean for your method and then make that behavior part of the methods contract—in the majority of cases methods need not concern themselves with interruption at all. The golden rule, however, is to never hide an interrupt by clearing it explicitly or by catching an InterruptedException and continuing normally—that prevents any thread from being cancellable when executing your code.
The interruption mechanism is a tool that cooperating code can use to make multithreading effective. Neither it, nor any other mechanism, can deal with hostile or malicious code.
One thread can wait for another thread to terminate by using one of the join methods. The simple form waits forever for a particular thread to complete:
class CalcThread extends Thread {
private double result;
public void run() {
result = calculate();
}
public double getResult() {
return result;
}
public double calculate() {
// ... calculate a value for "result"
}
}
class ShowJoin {
public static void main(String[] args) {
CalcThread calc = new CalcThread();
calc.start();
doSomethingElse();
try {
calc.join();
System.out.println("result is "
+ calc.getResult());
} catch (InterruptedException e) {
System.out.println("No answer: interrupted");
}
}
// ... definition of doSomethingElse ...
}
First, a new thread type, CalcThread, is defined to calculate a result. We start a CalcThread, do something else for a while, and then join that thread. When join returns, CalcThread.run is guaranteed to have finished, and result will be set. If CalcThread is already finished when doSomethingElse has completed, join returns immediately. When a thread dies, its Thread object doesn't go away, so you can still access its state. You are not required to join a thread before it can terminate.
Two other forms of join take time-out values analogous to wait. Here are the three forms of join:
public final voidjoin(long millis)throws InterruptedExceptionWaits for this thread to finish or for the specified number of milliseconds to elapse, whichever comes first. A time-out of zero milliseconds means to wait forever. If the thread is interrupted while it is waiting you will get an
InterruptedException.
public final voidjoin(long millis, int nanos)throws InterruptedExceptionWaits for this thread to finish, with more precise timing. Again, a total time-out of zero nanoseconds means to wait forever. Nanoseconds are in the range 0–999,999.
public final voidjoin()throws InterruptedExceptionEquivalent to
join(0).
Internally, join is defined in terms of isAlive and can be logically considered to act as if written as
while (isAlive())
wait();
with the understanding that the runtime system will invoke notifyAll when the thread actually terminates.
Each application starts with one thread—the one that executes main. If your application creates no other threads, the application will finish when main returns. But if you create other threads, what happens to them when main returns?
There are two kinds of threads: user and daemon. The presence of a user thread keeps the application running, whereas a daemon thread is expendable. When the last user thread is finished, any daemon threads are terminated and the application is finished. This termination is like that of invoking destroy—abrupt and with no chance for any cleanup—so daemon threads are limited in what they can do. You use the method setDaemon(true) to mark a thread as a daemon thread, and you use isDaemon to test that flag. By default, daemon status is inherited from the thread that creates the new thread and cannot be changed after a thread is started; an IllegalThreadStateException is thrown if you try.
If your main method spawns a thread, that thread inherits the user-thread status of the original thread. When main finishes, the application will continue to run until the other thread finishes, too. There is nothing special about the original thread—it just happened to be the first one to get started for a particular run of an application, and it is treated just like any other user thread. An application will run until all user threads have completed. For all the runtime system knows, the original thread was designed to spawn another thread and die, letting the spawned thread do the real work. If you want your application to exit when the original thread dies, you can mark all the threads you create as daemon threads.
You can force an application to end by invoking either the System or Runtime method exit. This method terminates the current execution of the Java virtual machine and again is like invoking destroy on each thread. However, an application can install special threads to be run before the application shuts down—the methods for doing this are described in “Shutdown” on page 672.
Many classes implicitly create threads within an application. For example, the Abstract Window Toolkit (AWT), described briefly in Chapter 25, provides an event-based graphical user-interface and creates a special thread for dealing with all associated events. Similarly, Remote Method Invocation, also mentioned in Chapter 25, creates threads for responding to remote method invocations. Some of these threads may be daemons and others may not, so use of these classes can keep your application running longer than you may intend. In these circumstances the use of the exit method becomes essential if there is no other way to terminate the threads.
Any mutable (that is, changeable) value shared between different threads should always be accessed under synchronization to prevent interference from occurring. Synchronization comes at a cost, however, and may not always be necessary to prevent interference. The language guarantees that reading or writing any variables, other than those of type long or double, is atomic—the variable will only ever hold a value that was written by some thread, never a partial value intermixing two different writes. This means, for example, that an atomic variable that is only written by one thread and read by many threads need not have access to it synchronized to prevent corruption because there is no possibility of interference. This does not help with get–modify–set sequences (such as ++), which always require synchronization.
Atomic access does not ensure that a thread will always read the most recently written value of a variable. In fact, without synchronization, a value written by one thread may never become visible to another thread. A number of factors affect when a variable written by one thread becomes visible to another thread. Modern multiprocessing hardware can do very strange things when it comes to the way in which shared memory values get updated, as can dynamic compilation environments at runtime. Further, in the absence of synchronization the order in which variables are seen to be updated by different threads can be completely different. To the programmer these things are not only strange, they often seem completely unreasonable and invariably not what the programmer wanted. The rules that determine how memory accesses are ordered and when they are guaranteed to be visible are known as the memory model of the Java programming language.
The actions of a thread are determined by the semantics of the statements in the methods that it executes. Logically, these statements are executed in the order the statements are written—an order known as program order. However, the values of any variables read by the thread are determined by the memory model. The memory model defines the set of allowed values that can be returned when a variable is read. In this context variables consist only of fields (both static and non-static) and array elements. From a programmer's perspective this set of values should only consist of a single value: that value most recently written by some thread. However, as we shall see, in the absence of proper synchronization, the actual set of values available may consist of many different values.
For example, suppose you had a field, currentValue, that was continuously displayed by a graphics thread and that could be changed by other threads using a non-synchronized method:
public void updateCurrent() {
currentValue = (int) Math.random();
}
The display code might look something like this:
currentValue = 5; for (;;) { display.showValue(currentValue); Thread.sleep(1000); // wait 1 second }
When the loop is first entered (assuming no calls to updateCurrent have occurred in other threads) the only possible value for currentValue is 5. However, because there is no synchronization, each time a thread invokes updateCurrent the new value is added to the set of possible values to be read. By the time currentValue is read in the loop, the possible values might consist of 5, 25, 42, and 326, any of which may be returned by the read. According to the rules of the memory model any value written by some thread (but not some “out of thin air” value) may be returned by the read. In practical terms, if there is no way for showValue to change the value of currentValue, the compiler can assume that it can treat currentValue as unchanged inside the loop and simply use the constant 5 each time it invokes showValue. This is consistent with the memory model because 5 is one of the available values and the memory model doesn't control which value gets returned. For the program to work as desired we have to do something such that when currentValue is written, that written value becomes the only value that the memory model will allow to be read. To do that we have to synchronize the writes and the reads of variables.
Certain actions a thread performs are defined as synchronization actions, and the order in which these actions are executed is termed the synchronization order of the program—the synchronization order is always consistent with the program order. These synchronization actions synchronize reads and writes of variables.
The most familiar synchronization action is the use of synchronized methods and blocks to ensure exclusive access to shared variables. The release of a monitor lock is said to synchronize with all subsequent acquisitions and releases of that monitor lock. If all reads and writes to a variable occur only when a specific monitor is held, then each read of the variable is guaranteed by the memory model to return the value that was most recently written to it.
There is a second synchronization mechanism that doesn't provide the exclusive access of monitors, but that again ensures that each read of a variable returns the most recently written value—the use of volatile variables. Fields (but not array elements) can be declared with the volatile modifier. A write to a volatile variable synchronizes with all subsequent reads of that variable. If currentValue was declared as volatile then the example code we showed would be correctly synchronized and the latest value would always be displayed. The use of volatile variables is seldom a replacement for the use of synchronized methods or statements on its own, because they don't provide atomicity across different actions. Rather, volatile variables are most often used for simple flags to indicate something has occurred, or for writing lock-free algorithms that incorporate use of the atomic variables mentioned in Section 25.9.1 on page 733.
An additional effect of making a variable volatile is that reads and writes are guaranteed to be atomic. This extends the basic atomicity guarantee to cover long and double variables.
A few other synchronization actions help make multithreading work nicely:
Starting a thread synchronizes with the first action performed by that thread when it executes. This ensures that a newly started thread sees any data that was initialized by the creating thread—including the thread's own fields.
The final action of a thread synchronizes with any action that detects that the thread has terminated—such as calling
isAliveor invokingjoinon that thread. This ensures, for example, that if you join a thread you can see all data written by that thread before it terminated—such as the results of its computation.Interrupting a thread synchronizes with any other action that determines that the thread has been interrupted, such as the thread throwing
InterruptedExceptionor another thread invokingisInterruptedon the thread.The write of the default value (zero, null, or false) to any field synchronizes with the first action in any thread. This ensures that even in incorrectly synchronized programs a thread will never see arbitrary values in fields—either a specific value written by some thread will be seen or the default value of the field will be seen.
We described in Section 2.2.3 on page 46 how final fields are used to define immutable values; indeed you can use final fields to define immutable objects. There is a common misconception that shared access to immutable objects does not require any synchronization because the state of the object never changes. This is a misconception in general because it relies on the assumption that a thread will be guaranteed to see the initialized state of the immutable object, and that need not be the case. The problem is that, while the shared object is immutable, the reference used to access the shared object is itself shared and often mutable—consequently, a correctly synchronized program must synchronize access to that shared reference, but often programs do not do this, because programmers do not recognize the need to do it. For example, suppose one thread creates a String object and stores a reference to it in a static field. A second thread then uses that reference to access the string. There is no guarantee, based on what we've discussed so far, that the values written by the first thread when constructing the string will be seen by the second thread when it accesses the string.
The memory model defines the semantics for multithreaded programs and tells you what you need to do to correctly synchronize your programs. But additionally, you need safeguards that ensure that incorrectly synchronized programs cannot violate the integrity of the language, or the virtual machine implementation, or the security architecture that prevents sensitive APIs from being misused—see “Security” on page 677. These safeguards come in the form of additional rules in the memory model covering the use of final fields.
The first rule for final fields covers the situation we described with the shared string. Basically, the rule states that if a reference to an object is stored after the object has been constructed, then any thread that reads that reference is guaranteed to see initialized values for the object's final fields. Note that there is no guarantee concerning non-final fields of the object that are read without synchronization.
The second rule expands on the first to apply transitively to objects reachable via final fields. There is little point being guaranteed to see a reference stored in a final field, if the fields of that object are not guaranteed to be seen. What the second rule states, in general terms, is that if you read a reference from a final field, then any non-final fields in the referenced object will have a value at least as recent as the value they had when the reference was written. For example, this means that if one thread constructs an object and uses methods on that object to set its state, then a second thread will see the state set by the first thread if the reference used to access the object was written to a final field after the state changes were made. Any final fields in such objects are covered by the first rule.
To preserve the integrity of the system, classes must use final fields appropriately to protect sensitive data, if correct synchronization cannot be relied on. For this reason, the String class uses final fields internally so that String values are both immutable and guaranteed to be visible.
The description of synchronizations actions above is a simplification of the operation of the memory model. The use of synchronized blocks and methods and the use of volatile variables provide guarantees concerning the reading and writing of variables beyond the volatile variables themselves or the variables accessed within the synchronized block. These synchronization actions establish what is called a happens-before relationship and it is this relationship that determines what values can be returned by a read of a variable. The happens-before relationship is transitive, and a statement that occurs ahead of another in program order happens-before that second statement. This allows actions other than synchronization actions to become synchronized across threads. For example, if a non-volatile variable is written before a volatile variable, and in another thread the same volatile variable is read before reading the non-volatile variable, then the write of the non-volatile variable happens-before the read of that variable and so the read is guaranteed to return the value written. Consider the following:

If the read of dataReady by thread-2 yields true, then the write of dataReady by thread-1 happened-before that read. Since the write to data by thread-1 happens-before the write to dataReady by thread-1, it follows that it also happens-before the read of dataReady by thread-2, hence the read of data by thread-2. In short, if thread-2 sees dataReady is true then it is guaranteed to see the new Data object created by thread-1. This is true because dataReady is a volatile variable,[2] even though data is not itself a volatile variable.
Finally, note that the actual execution order of instructions and memory accesses can be in any order as long as the actions of the thread appear to that thread as if program order were followed, and provided all values read are allowed for by the memory model. This allows the programmer to fully understand the semantics of the programs they write, and it allows compiler writers and virtual machine implementors to perform complex optimizations that a simpler memory model would not permit.
This discussion gives you an idea of how the memory model interacts with multithreading. The full details of the memory model are beyond the scope of this book. Fortunately, if you pursue a straightforward locking strategy using the tools in this book, the subtleties of the memory model will work for you and your code will be fine.
When you're programming multiple threads—some of them created by library classes—it can be useful to organize them into related groups, manage the threads in a group as a unit, and, if necessary, place limitations on what threads in different groups can do.
Threads are organized into thread groups for management and security reasons. A thread group can be contained within another thread group, providing a hierarchy—originating with the top-level or system thread group. Threads within a group can be managed as a unit, for example, by interrupting all threads in the group at once, or placing a limit on the maximum priority of threads in a group. The thread group can also be used to define a security domain. Threads within a thread group can generally modify other threads in that group, including any threads farther down the hierarchy. In this context “modifying” means invoking any method that could affect a thread's behavior—such as changing its priority, or interrupting it. However, an application can define a security policy that prevents a thread from modifying threads outside of its group. Threads within different thread groups can also be granted different permissions for performing actions within the application, such as performing I/O.
Generally speaking, security-sensitive methods always check with any installed security manager before proceeding. If the security policy in force forbids the action, the method throws a SecurityException. By default there is no security manager installed when an application starts. If your code is executed in the context of another application, however, such as an applet within a browser, you can be fairly certain that a security manager has been installed. Actions such as creating threads, controlling threads, performing I/O, or terminating an application, are all security sensitive. For further details, see “Security” on page 677.
Every thread belongs to a thread group. Each thread group is represented by a ThreadGroup object that describes the limits on threads in that group and allows the threads in the group to be interacted with as a group. You can specify the thread group for a new thread by passing it to the thread constructor. By default each new thread is placed in the same thread group as that of the thread that created it, unless a security manager specifies differently. For example, if some event-handling code in an applet creates a new thread, the security manager can make the new thread part of the applet thread group rather than the system thread group of the event-processing thread. When a thread terminates, the Thread object is removed from its group and so may be garbage collected if no other references to it remain.
There are four Thread constructors that allow you to specify the ThreadGroup of the thread. You saw three of them on page 343 when looking at Runnable. The fourth is:
publicThread(ThreadGroup group, String name)Constructs a new thread in the specified thread group with the given name.
To prevent threads from being created in arbitrary thread groups (which would defeat the security mechanism), these constructors can themselves throw SecurityException if the current thread is not permitted to place a thread in the specified thread group.
The ThreadGroup object associated with a thread cannot be changed after the thread is created. You can get a thread's group by invoking its getThreadGroup method. You can also check whether you are allowed to modify a Thread by invoking its checkAccess method, which throws SecurityException if you cannot modify the thread and simply returns if you can (it is a void method).
A thread group can be a daemon group—which is totally unrelated to the concept of daemon threads. A daemon ThreadGroup is automatically destroyed when it becomes empty. Setting a ThreadGroup to be a daemon group does not affect whether any thread or group contained in that group is a daemon. It affects only what happens when the group becomes empty.
Thread groups can also be used to set an upper limit on the priority of the threads they contain. After you invoke setMaxPriority with a maximum priority, any attempt to set a thread priority higher than the thread group's maximum is silently reduced to that maximum. Existing threads are not affected by this invocation. To ensure that no other thread in the group will ever have a higher priority than that of a particular thread, you can set that thread's priority and then set the group's maximum priority to be less than that. The limit also applies to the thread group itself. Any attempt to set a new maximum priority for the group that is higher than the current maximum will be silently reduced.
static synchronized void maxThread(Thread thr, int priority) { ThreadGroup grp = thr.getThreadGroup(); thr.setPriority(priority); grp.setMaxPriority(thr.getPriority() - 1); }
This method works by setting the thread's priority to the desired value and then setting the group's maximum allowable priority to less than the thread's priority. The new group maximum is set to one less than the thread's actual priority—not to priority- 1 because an existing group maximum might limit your ability to set the thread to that priority. Of course, this method assumes that no thread in the group already has a higher priority.
ThreadGroup supports the following constructors and methods:
publicThreadGroup(String name)Creates a new
ThreadGroup. Its parent will be theThreadGroupof the current thread. LikeThreadnames, the name of a group is not used by the runtime system—but it can benull.
publicThreadGroup(ThreadGroup parent, String name)Creates a new
ThreadGroupwith a specifiednamein theThreadGroupparent. ANullPointerExceptionis thrown ifparentisnull.
public final StringgetName()Returns the name of this
ThreadGroup.
public final ThreadGroupgetParent()Returns the parent
ThreadGroup, ornullif it has none (which can only occur for the top-level thread group).
public final voidsetDaemon(boolean daemon)Sets the daemon status of this thread group.
public final booleanisDaemon()Returns the daemon status of this thread group.
public final voidsetMaxPriority(int maxPri)Sets the maximum priority of this thread group.
public final intgetMaxPriority()Gets the current maximum priority of this thread group.
public final booleanparentOf(ThreadGroup g)Checks whether this thread group is a parent of the group
g, or is the groupg. This might be better thought of as “part of,” since a group is part of itself.
public final voidcheckAccess()Throws
SecurityExceptionif the current thread is not allowed to modify this group. Otherwise, this method simply returns.
public final voiddestroy()Destroys this thread group. The thread group must contain no threads or this method throws
IllegalThreadStateException. If the group contains other groups, they must also be empty of threads. This does not destroy the threads in the group.
You can examine the contents of a thread group using two parallel sets of methods: One gets the threads contained in the group, and the other gets the thread groups contained in the group.
public intactiveCount()Returns an estimate of the number of active threads in this group, including threads contained in all subgroups. This is an estimate because by the time you get the number it may be out of date. Threads may have died, or new ones may have been created, during or after the invocation of
activeCount. An active thread is one for whichisAlivereturns true.
public intenumerate(Thread[] threadsInGroup, boolean recurse)Fills the
threadsInGrouparray with a reference to every active thread in the group, up to the size of the array, and returns the number of threads stored. Ifrecurseisfalse, only threads directly in the group are included; If it istrue, all threads in the group's hierarchy will be included.ThreadGroup.enumerategives you control over whether you recurse, butThreadGroup.activeCountdoes not. You can get a reasonable estimate of the size of an array needed to hold the results of a recursive enumeration, but you will overestimate the size needed for a non-recursiveenumerate.
public intenumerate(Thread[] threadsInGroup)Equivalent to
enumerate(threadsInGroup,true).
public intactiveGroupCount()Like
activeCount, but counts groups, instead of threads, in all subgroups. “Active” means “existing.” There is no concept of an inactive group; the term “active” is used for consistency withactiveCount.
public intenumerate(ThreadGroup[] groupsInGroup, boolean recurse)Like the similar
enumeratemethod for threads, but fills an array ofThreadGroupreferences instead ofThreadreferences.
public intenumerate(ThreadGroup[] groupsInGroup)Equivalent to
enumerate(groupsInGroup,true).
You can also use a ThreadGroup to manage threads in the group. Invoking interrupt on a group invokes the interrupt method on each thread in the group, including threads in all subgroups. This method is the only way to use a ThreadGroup to directly affect threads—there used to be others but they have been deprecated.
There are also two static methods in the Thread class to act on the current thread's group. They are shorthands for invoking currentThread, invoking getThreadGroup on that thread, and then invoking the method on that group.
public static intactiveCount()Returns the number of active threads in the current thread's
ThreadGroup.
public static intenumerate(Thread[] threadsInGroup)Equivalent to invoking the method
enumerate(threadsInGroup)on theThreadGroupof the current thread.
The ThreadGroup class also supports a method that is invoked when a thread dies because of an uncaught exception:
public void uncaughtException(Thread thr, Throwable exc)
We'll look at this in more detail in the next section.
Exercise 14.9: Write a method that takes a thread group and starts a thread that periodically prints the hierarchy of threads and thread groups within that group, using the methods just described. Test it with a program that creates several short-lived threads in various groups.
Exceptions always occur in a specific thread, due to the actions of that thread—for example, trying to perform division by zero, or explicitly throwing an exception. Such exceptions are synchronous exceptions and always remain within the thread. If a “parent” thread wants to know why a “child” terminated, the child will have to store that information somewhere the “parent” can get it. Placing a thread start invocation in a try-catch block does not catch exceptions that may be thrown by the new thread—it simply catches any exception thrown by start.
When an exception is thrown it causes statements to complete abruptly and propagates up the call stack as each method invocation completes abruptly. If the exception is not caught by the time the run method completes abruptly then it is, by definition, an uncaught exception. At that point the thread that experienced the exception has terminated and the exception no longer exists. Because uncaught exceptions are usually a sign of a serious error, their occurrence needs to be tracked in some way. To enable this, every thread can have associated with it an instance of UncaughtExceptionHandler. The UncaughtExceptionHandler interface is a nested interface of class Thread and declares a single method:
public voiduncaughtException(Thread thr, Throwable exc)Invoked when
thrterminated due toexcbeing thrown.
A thread's uncaught exception handler can be set, if security permissions allow it, using its setUncaughtExceptionHandler method.
When a thread is about to terminate due to an uncaught exception, the runtime queries it for its handler by invoking the getUncaughtExceptionHandler method on it, and invokes the returned handler's uncaughtException method, passing the thread and the exception as parameters.
The getUncaughtExceptionHandler method will return the handler explicitly set by the thread's setUncaughtExceptionHandler method, or if no handler has been explicitly set, then the thread's ThreadGroup object is returned. Once a thread has terminated, and it has no group, getUncaughtExceptionHandler may return null.
The default implementation of the ThreadGroupuncaughtException method invokes uncaughtException on the group's parent group if there is one. If the thread group has no parent, then the system is queried for a default uncaught exception handler, using the static Thread class method getDefaultUncaughtExceptionHandler. If such a default handler exists, its uncaughtException method is called with the thread and exception. If there is no default handler, ThreadGroup's uncaughtException method simply invokes the exception's printStackTrace method to display information about the exception that occurred (unless it is an instance of ThreadDeath in which case nothing further happens).
An application can control the handling of uncaught exceptions, both for the threads it creates, and threads created by libraries it uses, at three levels:
At the system level, by setting a default handler using the static
Threadclass methodsetDefaultUncaughtExceptionHandler. This operation is security checked to ensure the application has permission to control this.At the group level, by extending
ThreadGroupand overriding it's definition ofuncaughtException.At the thread level, by invoking
setUncaughtExceptionHandleron that thread.
For example, if you were writing a graphical environment, you might want to display the stack trace in a window rather than simply print it to System.err, which is where the method printStackTrace puts its output. You could define your own UncaughtExceptionHandler that implement uncaughtException to create the window you need and redirect the stack trace into the window.
We mentioned in Chapter 12 that two forms of asynchronous exceptions are defined—internal errors in the Java virtual machine, and exceptions caused by the invocation of the deprecated Thread.stop method.
As a general rule we don't discuss deprecated methods in this book, but stop is special—partly because of what it does, but mostly because it is, as they say, “out there” and you may well come across code that uses it (or tries to).
The stop method causes an asynchronous ThreadDeath exception to be thrown in the thread on which it is invoked. There is nothing special about this exception—just like any other exception it can be caught, and if it is not caught it will propagate until eventually the thread terminates. The exception can occur at almost any point during the execution of a thread, but not while trying to acquire a lock.
The intent of stop was to force a thread to terminate in a controlled manner. By throwing an exception that was unlikely to be caught, it allowed the normal cleanup procedure of using finally clauses to tidy up as the thread's call stack unwound. But stop failed to achieve this in two ways. First, it couldn't force any thread to terminate because a thread could catch the exception that was thrown and ignore it—hence it was ineffective against malicious code. Second, rather than allowing a controlled cleanup, it actually allowed the corruption of objects. If stop was invoked while a thread was in a critical section, the synchronization lock would be released as the exception propagated, but the object could have been left in a corrupt state due to the partial completion of the critical section. Because of these serious flaws stop was deprecated. Instead, interrupt should be used for cooperative cancellation of a thread's actions.
A second form of stop took any Throwable object as an argument and caused that to be the exception thrown in the target thread—this is even more insidious because it allows “impossible” checked exceptions to be thrown from code that doesn't declare them.
Any thread that is alive, can be queried for its current execution stack trace. The getStackTrace method returns an array of StackTraceElement objects—as described in “Stack Traces” on page 294—where the zeroth element represents the currently executing method of the thread. If the thread is not alive then a zero-length array is returned.
You can access the stack traces of all threads in the system using the static Thread class method getAllStackTraces, which returns a map from each thread to its corresponding StackTraceElement array.
Stack trace information is generally used for debugging and monitoring purposes—for example, if your application “hangs,” a monitoring thread might display all the stack traces, showing you what each thread is doing. Of course, if your application hangs because of an error in your code, any such monitoring thread may itself not get a chance to execute. The virtual machine is not required to produce non-zero-length stack traces for any given thread, and it is also allowed to omit some methods from the stack trace information.
The ThreadLocal class allows you to have a single logical variable that has independent values in each separate thread. Each ThreadLocal object has a set method that lets you set the value of the variable in the current thread, and a get method that returns the value for the current thread. It is as if you had defined a new field in each thread class, but without the need to actually change any thread class. This is a feature you may well never need, but if you do need it ThreadLocal may simplify your work.
For example, you might want to have a user object associated with all operations, set on a per-thread basis. You could create a ThreadLocal object to hold each thread's current user object:
public class Operations {
private static ThreadLocal<User> users =
new ThreadLocal<User>() {
/** Initially start as the "unknown user". */
protected User initialValue() {
return User.UNKNOWN_USER;
}
};
private static User currentUser() {
return users.get();
}
public static void setUser(User newUser) {
users.set(newUser);
}
public void setValue(int newValue) {
User user = currentUser();
if (!canChange(user))
throw new SecurityException();
// ... modify the value ...
}
// ...
}
The static field users holds a ThreadLocal variable whose initial value in each thread will be User.UNKNOWN_USER. This initial value is defined by overriding the method initialValue, whose default behavior is to return null. The programmer can set the user for a given thread by invoking setUser. Once set, the method currentUser will return that value when invoked in that thread. As shown in the method setValue, the current user might be used to determine privileges.
You can clear the value in a ThreadLocal by invoking its remove method. If get is invoked again, then initialValue will again be used to determine what to return.
When a thread dies, the values set in ThreadLocal variables for that thread are not reachable, and so can be collected as garbage if not otherwise referenced.
When you spawn a new thread, the values of ThreadLocal variables for that thread will be the value returned by its initialValue method. If you want the value in a new thread to be inherited from the spawning thread, you can use the class InheritableThreadLocal, a subclass of ThreadLocal. It has a protected method childValue that is invoked to get the child's (spawned thread's) initial value. The method is passed the parent's value for the variable and returns the value for the child. The default implementation of childValue returns the parent's value, but you can subclass to do something different, such as cloning the parent's value for the child.
Use of ThreadLocal objects is an inherently risky tool. You should use them only where you thoroughly understand the thread model that will be used. The problems arise with thread pooling, a technique that is sometimes used to reuse threads instead of creating new ones for each task. In a thread pooling system a thread might be used several times. Any ThreadLocal object used in such an environment would contain the state set by the last code that happened to use the same thread, instead of an uninitialized state expected at the beginning of a new thread of execution. If you write a general class that uses ThreadLocal objects and someone uses your class in a thread pool, the behavior might be dangerously wrong.
For example, the users variable in the Operations example above could have just this problem—if an Operations object was used in multiple threads, or different Operations objects were used in the same thread, the “current user” notion could easily be wrong. Programmers who use Operations objects must understand this and only use the objects in threading situations that match the assumptions of the class's code.
A few Thread methods are designed to help you debug a multithreaded application. These print-style debugging aids can be used to print the state of an application. You can invoke the following methods on a Thread object to help you debug your threads:
public StringtoString()Returns a string representation of the thread, including its name, its priority, and the name of its thread group.
public longgetId()Returns a positive value that uniquely identifies this thread while it is alive.
public Thread.StategetState()Returns the current state of this thread.
Thread.Stateis a nested enum that defines the constants:NEW,RUNNABLE,BLOCKED,WAITING,TIMED_WAITING, andTERMINATED. A newly created thread has stateNEW, until it is started, at which time it becomesRUNNABLEuntil it terminates and becomesTERMINATED. While a thread is runnable, but before it terminates it can switch between beingRUNNABLEand beingBLOCKED(such as acquiring a monitor lock),WAITING(having invokedwait), orTIMED_WAITING(having invoked a timed version ofwait).
public static voiddumpStack()Prints a stack trace for the current thread on
System.err.
There are also debugging aids to track the state of a thread group. You can invoke the following methods on ThreadGroup objects to print their state:
public StringtoString()Returns a string representation of the
ThreadGroup, including its name and priority.
public voidlist()Lists this
ThreadGrouprecursively toSystem.out. This prints thetoStringvalue for each of the threads and thread groups within this group.
I'll play it first and tell you what it is later. | ||
| --Miles Davis | ||