
Chapter 19. Information Architecture for the Enterprise
| What the goal of EIA is (it’s not centralization) |
| Practical EIA design techniques for top-down and bottom-up navigation, search, and emergent or “guerrilla” approaches |
| How in-house EIA competency can and often does grow, both strategically and operationally |
| What EIA work needs to get done, and what kinds of people should do it |
| How to pay for and position an in-house EIA group |
| What EIA services should be provided |
| How to grow an EIA group over time |
Information Architecture, Meet the Enterprise
What’s enterprise information architecture (EIA)? Quite simply, the practice of information in the enterprise setting.
Sorry, that definition was accurate but not too helpful. Let’s back up and make sure we understand what an enterprise is. Most would say that it’s a large, physically distributed organization—usually a corporation or a government agency, but we’d also count substantial academic institutions and nonprofits. Enterprises suffer from problems big and complicated enough to merit serious, expensive solutions. (Hence, software marketers have found that prepending the term “enterprise-class” to their products’ names is a reasonably reliable path to a condo in Aspen.)
But “large” and “physically distributed” aren’t what really defines an enterprise. In fact, the most telling attribute is a place where “one hand doesn’t know what the other one’s doing.” Or, one hand ignores or doesn’t care what the other’s doing. Or that first hand absolutely despises the second hand, and will do anything to undermine it. Interestingly, these attributes can be found in just about any organization, regardless of size or physical distribution. So while you might not work at ExxonMobil, Thomson, or the UN, it’s likely that you’re dealing with enterprise-class IA challenges.
Enterprises have been characterized by a constant tug-of-war between forces of centralization and autonomy. A new management regime comes in, finds wasteful duplication of effort and expense, and discovers a lack of coordination and collaboration among business units. The new managers try to reign things in by centralizing as much as they possibly can. Typically this process fails to have its intended impact and even creates some unintended negative consequences, such as choking off local innovation. Then a new regime enters the picture, sees a new set of problems, and in its hurry to leave its mark, swings the pendulum hard the other way: “let a thousand flowers bloom.” Staff in far-flung units are empowered to take things into their own hands but may do so in a wasteful, duplicative, uncoordinated manner. And we’re back where we started.
This constant tug-of-war impacts an organization’s web presence, whether public or internal. In fact, the Web, by dint of its democratizing ways, actually aggravates the naturally innate tension between local and central. The end result is, typically, a web environment consisting of hundreds or even thousands of separate mini-web sites that don’t work together in any coherent way, or failed efforts to enforce compliance with common design standards and platforms. Designing a successful information architecture against this insane backdrop is perhaps the biggest challenge we face today. And if it’s hard for us as designers, consider the even more horrible experience users face.
Finding Your Way Through an Enterprise Information Architecture
Let’s say that you work for a global consulting firm. You just returned from a client trip with a wad of receipts in your wallet or purse. Now you want to get repaid. It’s a common task, so it should be feasible to complete using your company’s intranet. But where do you begin?
Unfortunately, like many intranets, the company’s information architecture mirrors its organization chart and is structured like Figure 19-1. Do you know how your company is organized? (Grab a sheet of paper right now and try jotting it down. Not so easy, is it?) Imagine how confused you’d be if you were a new employee. And considering the “constant revolution” of ongoing reorgs that churn so many enterprises, even long-timers might not have a clue.
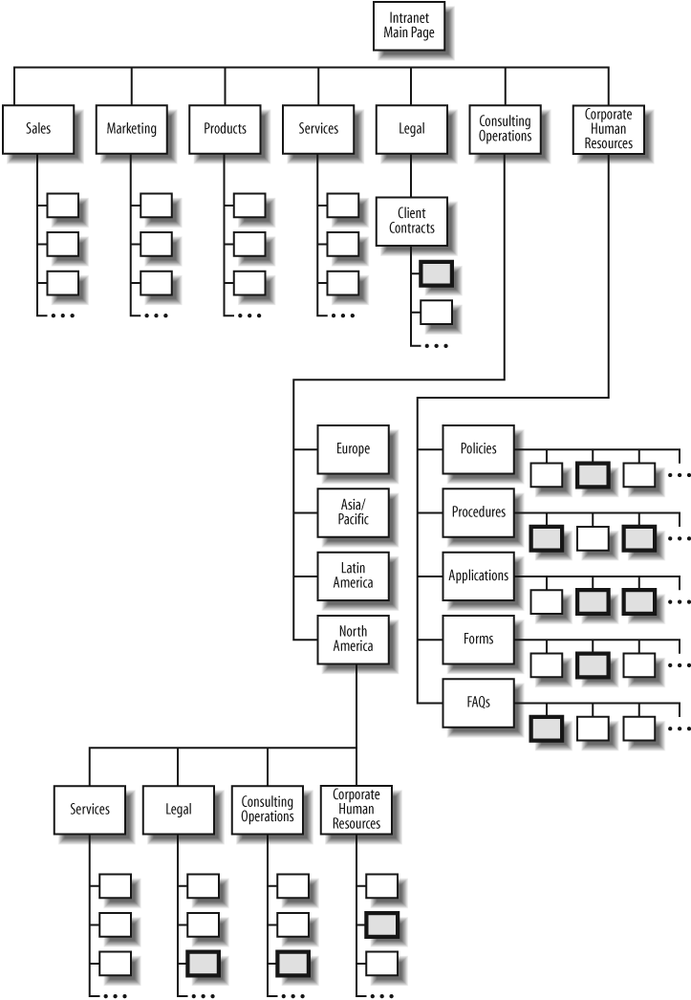
So you begin to poke around the intranet. The legal department might or might not have some information on how much your client’s contract allows you to be compensated for. But HR has various policies and procedures that you’ll need to take into account as well. They point to tools, forms, and other materials that might or might not help you get reimbursed.
Of course, if you work for the North American division, there might (or might not) be a similar array of contractual information, policies, tools, and so forth that only pertain to doing business in North American countries.
You’ll probably become tired of guessing and hunting. So what happens?
Maybe you give up, making your employer happy because they’ve just saved the expenses you’ll eat. But in the long run, they won’t be well served by the according decline in employee loyalty.
Or, more typically, you’ll go ask someone who you think can help. Now you’ve thrown the intranet—which hasn’t been exactly cheap for your company to build and maintain—out the window, and you’ll go bother an expensive human “expert,” who’s got other work to do and isn’t by any means guaranteed to give you the correct information.
Either way, it’s a bad outcome, and it’s why we’re devoting a chapter to enterprise IA. It may not be the most interesting or exciting of topics—most of us in the field would probably prefer to spend our time poking around at the intersection of Web 2.0, design patterns, and semantic webs (with a little Ajax thrown in for good measure). But more and more of us find ourselves thrust into the role of balancers—not of budgets, but of centralized and autonomous content, and the motivations, urges, people, and egos behind those conflicting forces. And we have precious little to go on to help us address information architecture challenges in this setting. Our goal in this chapter is to provide you with at least a little practical advice on improving an enterprise’s information architecture.
What’s the Goal of EIA?
We haven’t yet encountered an enterprise site that didn’t suffer from problems associated with decentralization. Put another way, it’s the rare site that is too centralized. Now that the Web’s novelty has started to wear off, and web sites are recognized as a foundational component of doing business in the 21st century, many early sources of resistance to centralization are wearing down. Business units are beginning to understand the benefits of shared resources and coherent user experience, for their sites’ users as much as for their own bottom lines.
Getting Everyone on the Same Page
But it’s still not clear to everyone why some measure of centralization is worth pursuing. So the following list of benefits of centralization might come in handy:
- Increased revenues
Especially in e-commerce situations, customers don’t want to be exposed to the enterprise’s org chart as they try to navigate the site. They want to make a purchase and go on with their lives. A centralized information architecture will help users focus on their needs, not your organization’s politics and structure.
- Reduced costs
Centralization helps the enterprise save money in so many ways. One is that you can avoid purchasing multiple and redundant licenses for such technologies as search engines, and can instead collectively negotiate for a single enterprise-wide license. Another is that pooling resources may allow the enterprise to afford the development of customized tools (or customization of shrink-wrapped tools) and specialized staff. Yet another is that duplication of effort, such as having two research teams working on the same project, can be eliminated. And, of course, reducing the time needed to find information can really add up when that time is paid for by the enterprise.
- Clearer communication
Whether they’re employees who access the intranet or investors wondering about new acquisitions, all users can expect a consistent and accurate message on behalf of the enterprise if centralization is in place.
- Shared expertise
Centralization implies that there is some means for cooperating and reaching decisions as a group. Besides indicating an organization with a healthy attitude toward communicating and sharing knowledge in a general sense, it also means that the organization is collectively learning about information architecture and other areas that will help “glue” together content from its disparate silos. Which, of course, can only be a good thing.
- Reduced likelihood of corporate reorganization
Perhaps it’s a stretch, but if poor communication and coordination are major causes of corporate reorganizations, then having a strong centralized information architecture will reduce the need for reorgs. Reorgs are often the most painful and expensive event that organizations face, so anything that reduces their likelihood should be considered valuable.
- Centralization is inevitable anyway
Most enterprises have already begun the process of centralizing their information architectures, consciously or not. Why not acknowledge this reality, tap it, and if possible, shape, hasten, and direct it with a conscious, intelligent strategy?
Centralization Above All?
Considering all those good outcomes, it’s tempting to consider centralization as the ultimate goal of enterprise IA (which, admittedly, we did in this book’s second edition). It does sound like a nice way to deal with the problematic intranet described in the example above. Just design an information architecture that knits together all units’ content silos in a rational, usable way, and then implement across the organization.
This kind of thinking is common in many enterprises. And anyone who’s been through such an exercise knows just how difficult it is to force business units to comply with common standards. It’s not completely impossible—for example, IBM.com’s pages now all use standard templates, which is quite an impressive achievement considering the size of the site and diversity of its numerous owners—but many aspects of a centralized IA are more difficult to understand and, therefore, to comply with. For example, while common page templates are a tangible aspect of the user experience, the more abstract concepts, like shared metadata, are not quickly grasped— much less adopted—by many enterprise decision-makers.
So What Is the Goal?
The goal of enterprise IA is not to centralize everything you see. In fact, the goal of EIA is no different than any other flavor of IA: identify the few most efficient means of connecting users with the information they need most. That often might involve adopting some centralizing measures, but it could also mean a highly decentralized approach, such as enabling employees to use a social bookmarking tool to tag intranet content (as the aforementioned IBM is doing). The point, as always, is to apply whatever approach makes the most sense given your organization, its users, content, and context.
Naturally, this is a more thoughtful approach than simply seeking to centralize the information architecture; put another way, it’s more work. But don’t dismay: patterns are emerging to describe common enterprise IA challenges and solutions. In the remainder of this chapter, we’ll describe how an EIA typically evolves in terms of design, strategy, and operations, and how you can have a positive impact in each case.
Designing an Enterprise Information Architecture
As with any other flavor of information architecture, there’s no “right way” to design an enterprise information architecture. However, over time certain IA design approaches, when pursued in the appropriate sequence, have emerged as making the most sense in the enterprise setting.[1] In this section, we’ve broken the wide range of possible IA design components into four categories, and for each we provide a few nuggets of practical advice on what to do and what not to do. We could fill up an entire book on enterprise IA design, but we hope you’ll find this tip of the iceberg to be useful.
Top-Down Navigation and EIA
Thanks to improved search engines and the advent of RSS syndication, users are finding more ways to bypass top-down navigation. But top-down navigation isn’t going away any time soon, and top-down elements provide ample opportunities for you to improve EIA.
Bypass the main page
You read it right. Many large IA projects get completely derailed by this one page among the millions that comprise your site. Granted, there are an increasing number of other ways to reach your site’s content, such as via a web-wide search engine, an RSS feed, and your advertisements. Still, you know that the main page is the single most important page on your site; the problem is that everyone else in your organization knows that, too. The result: design meetings where senior vice presidents joust over dozens of main-page pixels.
Of course, you could try to shepherd such a meeting to a productive end—a place where the main-page design is conceived with the needs of the enterprise as a whole and the users it serves, rather than the setting where interdepartmental strife plays out. But that might take years, and you’ve got other fish to fry. So we advise you to be prepared to step away from your normal urge to care about the main page. Consider it an unfortunate chunk of real estate that could be so nice if only the warring gangs would cease and desist. You’ll have a chance to rehabilitate it later; for now, move on...
Repurpose your sitemap
...to other pieces of real estate that might be quite useful if only anyone bothered to pay attention to them. For example, your sitemap (aka table of contents, as discussed in Chapter 7) may already be linked to throughout your site. That makes it a property with considerable value. And yet, it’s often something of an orphan; it may not be clear whose responsibility it is, and few people bother to use it. Can you blame them? Most sitemaps simply mirror the site’s main organization system, and in many enterprise sites, that’s the org chart. Not very useful.
Normally, your attention would be focused on improving the organization system, weaning your enterprise from an org-chart-driven self-view. But that’s quite difficult to pull off in an enterprise setting, and requires considerable agreement and coordination.
If you want to get things done in the enterprise, it’s often better to ask forgiveness than to beg permission. So you should consider sneaky, Machiavellian means for improving your organization’s information architecture. One trick is to redesign the sitemap so that it stops mirroring what is, and instead suggests what could be. In other words, use the sitemap as a sandbox to try out a new, more user-centered organization system. Chances are, few will complain, and you may be able to monitor traffic to this page to see how well your changes have gone over. This might help you build a case for eventually revising the site’s organization system; or, when your enterprise is ready to seriously consider improving site-wide navigation, you can point to a readily available model for how to do it. This whole messy undertaking may leave you feeling a little impure, but what the heck: life is short, and besides, no lives will be lost or damaged by your noodling around with your enterprise’s sitemap.
Slim down your site index
Another prime piece of real estate is the site index (also covered in Chapter 7). Like the sitemap, an index ties together content from silos all over your enterprise, thereby making it a great EIA tool. But indices are expensive to develop and maintain. And, in fact, site indices are often superseded by search systems; both support known-item searching, but search is more automated and comprehensive.[2]
Does this mean you should throw out your site’s index? Generally, no. Many search systems aren’t well designed, so users might still need to rely upon an index as a backup. What can you do to make that backup effective while cutting back on its maintenance costs?
Consider a specialized site index. Instead of trying to index everything in your site, focus on one critical type of information. For example, the Centers for Disease Control’s index, shown in Figure 19-2, doesn’t include directions to its campus or biographies of its directors. Instead, it provides an A–Z list of health topics and issues—the primary kind of content that users come to the site for.
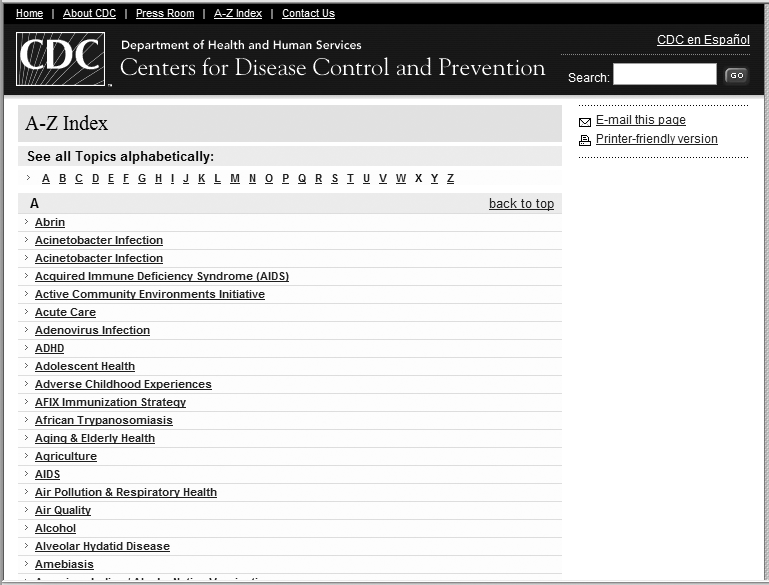
A specialized index is far simpler to maintain than a soups-to-nuts version, and because it’s focused on the important content type, it can provide value to a wide array of your enterprise site’s users.
As an alternative, you might consider another variety of less-than-comprehensive site index. Michigan State University builds its site index, shown in Figure 19-3, automatically, using the same common keywords derived from search-log analysis that have been assigned Best Bet results. Essentially, if the query is good (common) enough to merit a Best Bet, it’s good enough to be included in the site index. Note that each entry links directly to its Best Bet result:
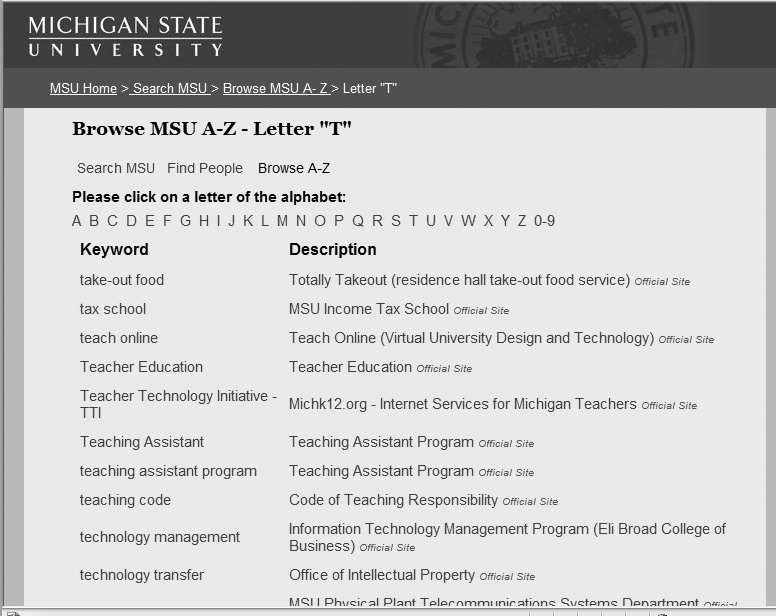
Develop guides
Guides, also covered in Chapter 7, are different from other forms of supplementary navigation. While they can link to content from any silo, guides don’t offer comprehensive coverage of your site’s content like sitemaps and traditional site indices do. Guides, like the one in Figure 19-4, are selective—they’re something of an enterprise FAQ—and for that reason they’re ideal “glue” for your enterprise site.
We recommend developing a handful of guides that address users’ top information needs and tasks. What do users really want and need from your site? Here’s your opportunity to serve those needs in an especially simple and low-tech way; guides are simply single pages of HTML code, and therefore don’t require specialized technical expertise or applications to implement. And you can use a variety of methods to determine common needs, such as search-log analysis (discussed in Chapters 6 and 10), persona development, and even talking to your organization’s switchboard operators.
We’re especially enthusiastic about guides in the enterprise context because they scale well. You can develop as many guides as your resources allow. The largest bottleneck typically comes from identifying subject matter experts. But in many cases, the expert—in the example above, the poor person besieged by requests for help processing travel expenses—will often be glad to encapsulate his knowledge so he doesn’t have to answer the same question over and over.
Guides are also a good reminder of how you should think about allocating your EIA resources. Let’s face it: you could spend decades trying to develop the ideal information architecture to serve all of your content to all of your users. No one has that luxury—or patience—as far as we know. Prioritization is the only viable alternative, and guides are an ideal tool to aid in efforts to prioritize your EIA development. Build a few guides to address common tasks and information needs, and you’ll see how a little effort can go a very long way.
Bottom-Up Navigation and EIA
While top-down navigation offers a few quick win opportunities, bottom-up navigation is much trickier. It’s difficult to integrate the upper layers of several separate information architectures, but because there are so many more “moving parts,” it can be far more difficult to integrate the more granular content from the collection of sites that make up an enterprise intranet or public web environment.
Build single-silo content models
To build momentum toward ambitious content-integration projects, you’ve got to start with baby steps. First among them is building a handful of content models (which we’ve introduced in Chapter 12).
Think back to the common information needs and tasks that we discussed earlier. Each might require navigating deep into the guts of your site; strong contextual navigation requires strong content models. Of course, some of the most critical tasks and information needs will require content models that cross departmental silos; set those aside for now and focus on the ones that can be served from within a single business unit’s web site. These will be easier to tackle, because 1) they involve fewer people, and 2) they won’t run into some of the metadata challenges that we’ll describe shortly.
Your goals are to get other people in your enterprise familiar with the idea and execution of content models, which is already a lot to ask of them. So focus on simple tasks and needs that can be addressed by content within a single silo. What useful content model could you build within Human Resources? Marketing? Within your staff directory? Or for each of your products? Your site’s users will benefit from even limited contextual-navigation improvements, and your organization will benefit in the long run from both the experience with content modeling that it gathers, and, ultimately, the ability to connect those content models across silos.
Limit dependence on metadata
As much as we’d like to build interconnected semantic webs throughout the guts of our enterprise’s content, metadata keeps getting in our way. Figure 19-5 shows a simple illustration, using the BBC content model. Here we want to connect our model with relevant content—let’s say events from a concert calendar and TV listings—from other silos within the BBC.
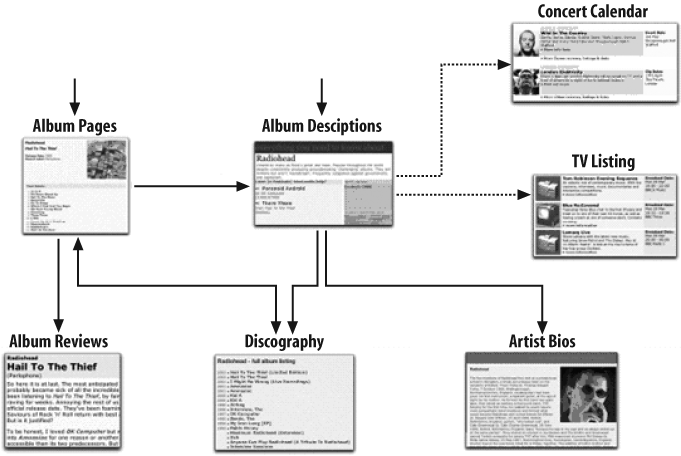
This should work—if we’ve got the same metadata to use to make the connection. Unfortunately, this isn’t always the case. For example, let’s assume that the artist’s name is the metadata that connects “artist descriptions” and “TV listings.” If the people who maintain the TV listings use a different version of an artist’s name—say, an abbreviated or all-caps version, and you list artist names differently, it can be tricky to automate the creation of a link between those two chunks of content.
Usually, software can be taught to understand and deal with simple differences like these. But as metadata becomes more descriptive, even the best artificial intelligence falls flat. For example, if one unit at the BBC classifies Johnny Cash’s music as “country,” while another unit deems it “Americana,” genre metadata wouldn’t be very useful or usable for automating connections between content models. Achieving agreement—such as on a standard usage of controlled vocabulary terms—is quite difficult, often for political reasons. And expensive efforts to retrospectively reclassify content might serve as yet another roadblock to relying on shared metadata across the enterprise.
It’s not all gloom and doom, though. Whenever you create a content model, you’re forced to select the most useful metadata attributes to build from a wide variety of possibilities. The same is true when you connect content models across silo boundaries—this exercise reveals the few types of metadata that you should focus your efforts on across the enterprise. So efforts to build enterprise-wide content models will have a useful byproduct: in the process, you’ll identify the few most important varieties of metadata to invest in.
“Telescoped” metadata development
In the above example from the BBC, you can see that some metadata types are easier to standardize than others. Because EIA is an expensive, long-term undertaking, you’ve got to prioritize whenever possible, taking on the easy wins first while building momentum toward tougher challenges. In the case of metadata, some varieties are indeed easier than others, though nothing’s ever easy.
Use content model exercises to help you choose which types of metadata to develop or acquire. But also keep in mind that, in general, the less ambiguous the metadata, the cheaper and easier you’ll find it to develop or acquire, and maintain. Table 19-1 orders some common (but by no means comprehensive) types of metadata attributes, from least to most difficult.
| Level of difficulty | Metadata attribute | Comments |
| Easy | Business unit names | These are typically already available and standardized |
| Easy to Moderate | Chronology | Variations in formats (e.g., 12/31/07 versus 31/12/07) usually can be addressed by reasonably intelligent software |
| Moderate to Difficult | Place names | Although many standards exist (e.g., state abbreviations and postal codes), many enterprises (and their business units) use custom terms for regions (such as sales territories) |
| Moderate to Difficult | Product names | Product granularity can vary greatly; marketing may think in terms of product families; sales in terms of items with SKU numbers, and support in terms of product parts that can be sold individually |
| Difficult | Audiences | Audiences, such as customers or types of employees, vary widely from unit to unit |
| Difficult | Topics | The most ambiguous type of metadata; difficult for individuals, much less business units, to come to agreement on topical metadata |
Similarly, as we know from examining thesauri in Chapter 9, metadata can support a complexity of semantic relationships, ranging from synonyms to broader/narrower terms to related terms (see Table 19-2). Consider beginning your enterprise metadata journey by relying on simpler vocabularies that provide only synonyms, rather than full-blown (and more expensive) thesauri.
| Level of difficulty | Type of relationship | Examples |
| Hard | Synonymous | Synonym rings and authority lists |
| Harder | Hierarchical | Classification schemes |
| Hardest | Associative | Thesauri |
Simpler vocabularies mean simpler information architectures. You might be able to assemble the metadata you’ll need for the top few layers of a site-wide navigation system before politics and your own lack of expertise with local content get in the way of going deeper. And your architecture almost certainly won’t be able to take advantage of “see alsos” and other related terms in any substantial way until your organization achieves some measure of “EIA maturity.”
It’s amazing that, after years of kicking around in the backwaters of corporate consciousness, “metadata” has suddenly emerged as a buzzword. Yet many senior decision-makers now see it as a panacea in much the same way they held out hopes for portals, personalization, and search in the past. We should all realize that there’s no such thing as a silver bullet, especially when it comes to information architecture; each interesting approach, new or not, comes with many hidden costs. Understanding the varying degrees of difficulty involved with metadata implementation will help you—and your enterprise—scale up its investment in metadata-driven solutions in a reasonable and ultimately successful manner.
Search Systems and EIA
As pessimistic as we are about instituting descriptive metadata across the enterprise, we see great potential for enterprise search systems. They’re the closest thing to a killer application for enterprise information architectures. Search systems can provide access to most or all of your enterprise content, regardless of silo. The query logs they create generate valuable data that can help you diagnose and fix your information architecture’s biggest problems. And because, typically, the same retrieval algorithm is applied to all of your enterprise’s content, search is as apolitical as things can get in the enterprise environment. Put another way, you might have a product manager scream at you about your design of your site’s navigation, organization, and labeling systems, but we’d be surprised that she’d come after you for reasons related to search.
That said, we don’t advise purchasing the latest and best enterprise search engine, installing it, and simply walking away. Small modifications can go a long way toward improving the interface. We’ve already covered many search system improvements in Chapter 8, but we’ll reiterate a few here, recast for enterprise consumption.
Simple consistent interface
If it’s important anywhere, it’s especially important in the enterprise: a simple search interface—“The Box”—should behave consistently and be consistently located on each page, like the one shown in Figure 19-6, regardless of who owns that page. Thankfully, this is becoming a convention, partly due to the advent of content management systems and their use of standard templates, which can be customized to include a simple search interface.
Perhaps your enterprise isn’t able or willing to provide a standard interface. Don’t let that stop you; simple search is a good cause around which you can build a campaign for some measure of enterprise centralization. Not only is it everywhere (you don’t have to look far to see how it’s emerged as a convention), but you can find good supporting data; for example, you can always cite a guru like Jakob Nielsen, who makes the point[3] that roughly 50 percent of all users begin their sessions on any given site by searching. Very few people can muster a strong case against ubiquitous simple search interfaces, and once you succeed with this particular battle, you’ll have momentum to take on bigger challenges that require some measure of coordination across the enterprise.
Analyze those logs
If search systems are the killer app for enterprise sites, then search-log analysis is the killer enterprise diagnostic tool. You don’t need to spend months analyzing your query data to reveal some critical problems with your search system and content. Common examples: users’ preponderance to misspell and mistype queries (fix it by implementing a spell-checker to your search system), frequent entry of acronyms and jargon (address with a glossary), searches for product codes (make sure your product pages include those codes!), and so on.
Prioritize your queries
Additionally, search-log analysis is a means for revealing which are the most commonly searched queries on your site. You can use this data to prioritize your efforts at developing Best Bet search results (covered in Chapter 8) and in a similar vein, guides, which could be considered Best Bets for main pages.
The numbers are really in your favor here: let’s say you create Best Bet results for the 200 most common queries. These 200 queries account for 25 percent of your all queries executed on your site. If, as Jakob Nielsen suggests, 50 percent of your site’s users start by searching, multiply that 50 percent by 25 percent; the result is an improvement in the user experience for 12.5 percent of all users. These numbers, like all IA-related numbers, can be easily challenged, but the message behind the numbers—improved performance—still rings loud and true.
While you’re at it, look over those top queries, identify which have zero results, and plug those content gaps. Might that bring you another three to five percent improvement in the user experience? Not bad. Add in some percentage for users who’d previously been defeated by spelling errors and typos, and the numbers start to add up.
Reverse-engineering content and metadata
No matter what you do to improve your enterprise search system, poor content and metadata can conspire to derail your efforts. Garbage in, garbage out. And in a distributed environment, it’s hard to even find authors, much less to convince them to do a better job preparing their content for consumption via the web site or intranet.
When you do have the opportunity to bend an author’s ear, you’ll need a good tool to help convince him to do a better job authoring content, applying metadata tags to it, and titling documents. Whether this comes up in the context of an enterprise style guide or a face-to-face meeting, come prepared with an example of poor search results—which include some of his own documents—to demonstrate just how much his work impacts users down the line.
For example, a search for “financing” on the DaimlerChrysler site returns poorly formatted, poorly titled results, as shown in Figure 19-7.

You now have the opportunity to show authors of these documents the importance of well-considered document titles. Conversely, you could show content authors how their documents don’t show up as highly as they should in search results, and explain to them how they might improve their rankings by following the enterprise’s guidelines on writing titles and good copy, and assigning metadata.
Poor search results are an effective way to communicate to authors just what happens when they fail to see their content, and their work, as part of something much larger—namely, an enterprise web site or intranet that serves thousands of users. “Reverse-engineering” search results uncovers opportunities for authors to do better, makes the case for doing so quite clear, and provides you with a way to accomplish “organizational change” in a small but important way: author by author.
“Guerrilla” EIA
The three tracks described so far all have to do with overlaying existing content from different silos with user-oriented ways to navigate and search. Increasingly, these approaches are being complemented with newer, often emergent methods of connecting users and content in the enterprise setting. One “ guerrilla” approach is predicated on enabling the creation of content that is, by definition, cross-departmental (mostly through the use of blogs and wikis). Another is the growing use of folksonomic tagging to provide access to content. Both guerrilla approaches make sense primarily on intranets.
Klogs for internal experts
Remember the person who knew so much about filing expense reports at our fictional consulting firm? She’s an SME (Subject Matter Expert) whose expertise spans multiple business units’ content. It serves the goal of EIA to enable her knowledge to be captured and shared more broadly within the enterprise. To that end, many companies are providing simple blog tools to their SMEs—sometimes describing them as “klogs,” or knowledge blogs[4]—to help them share what they know.
Implementing klogs internally is technically fairly simple; however, identifying SMEs—especially ones with valuable cross-departmental knowledge—may be a bit difficult. Even more challenging, your enterprise’s culture may not support its employees sharing their knowledge. It’s an unfortunate fact that many organizations encourage its opposite: knowledge hoarding. Additionally, many SMEs aren’t willing to share what they know simply to protect their job security. So klogs aren’t a slam dunk, especially in settings where there is little incentive to share information. But their technical barrier to entry is low, and they at least merit consideration. Many individuals already do share their knowledge, especially if it raises their personal visibility as an expert within the enterprise (and if it helps them to avoid answering the same questions over and over again).
Wikis for groups
Just as klogs enable individuals to capture and share their cross-departmental knowledge, wikis and other shared-authoring tools have similar potential for groups. Every enterprise has projects that require collaboration from multiple business units; these are typically tackled by temporarily constituted committees and working groups.
Wikis can make it relatively easy for these committees to capture their work—which, by definition, has cross-departmental value. In many cases, the content these groups develop will eventually receive official blessing and be published in a more traditional format, perhaps as a Word document or a PDF. But even in its relatively fluid and unfinished state, such content can have significant value to enterprise users. Additionally, wiki-based content is more likely to be accessible via search systems than Word or PDF files.
Accessing internal expertise through the staff directory
In so many cases, we search intranets for people rather than content. As cross-departmental information systems, staff directories are already excellent demonstrations of the value of EIA. We can extend their value by linking directory entries to corresponding klog and wiki content. The result: users can find out more about coworkers than their email addresses; they can learn about colleagues’ expertise, what projects they’ve served on, and who they served with. Users can also search a topic and ultimately find a person.
Traditional directories can also be expanded to include more relationships between coworkers, such as reporting relationships. For example, it can be useful to know what to expect from the new boss by grilling a few of his past supervisees. Look to social-network services like LinkedIn (shown in Figure 19-8) and Ryze for models of how staff directories can be expanded and enhanced.

Aggregating staff expertise...and everything else
If your enterprise does begin investing in blogs and other means for capturing cross-departmental content, the good news is that most of these new publishing tools generate RSS or Atom feeds for recently posted content (blogs especially, of course). The better news is that there are many tools, both web-based[5] and standalone, that allow users to aggregate the feeds they’ve subscribed to. Imagine in-house researchers relying on aggregators to easily monitor the findings of their colleagues from research centers throughout the enterprise as soon as they’re published.
The even better news is that, as feeds become common for just about any type of web site, your enterprise’s users could subscribe to feeds from a variety of departmental subsites. The aggregator becomes the means for accessing an enterprise’s new content—regardless of originating silo—in one window. Imagine aggregating news releases from their many sources within your enterprise so you can keep up with what your own employer is actually doing—or enabling a public site’s users to do the same.
Social bookmarking in the enterprise
Social bookmarking applications like del.icio.us have succeeded at helping users tag and return to visited content from across the Web. And by seeing what others have tagged with the same tags, del.icio.us subscribers also benefit from the wisdom of the hive, learning about other relevant documents (and who shares a similar interest).
Could the same approach work in the enterprise? Although it’s too soon to say, large enterprises like IBM are hoping to find out.[6] Enterprise environments are obviously smaller than the Web as a whole, but they certainly exhibit web-like characteristics, such as overwhelming growth, frustrating organization, and swirling change. Bookmarking tools could help enterprise users benefit from one another’s tagging efforts, and as an additional benefit, find like-minded colleagues. Collectively, tags also provide excellent fodder for helping improve traditional controlled vocabularies and bring them up-to-date.
EIA Strategy and Operations
We’ve described EIA design work that focuses on small steps and quick wins that don’t necessarily require a huge outlay of resources, time, or staff. Because so many of these improvements can be made “under the radar,” they often can take hold without requiring management sign-off up and down the chain of command.
Of course, there are far more ambitious designs that you can tackle within each of the four areas we covered above. But whether the focus is on short- or long-term goals, someone has to be responsible for design, implementation, maintenance, and governance of an enterprise information architecture. And management will ultimately have to be involved in setting policies, finding funding, and settling the political disputes that will inevitably arise.
Unfortunately, most enterprises have not dedicated staff to this work, or if they have, those staff are buried inside other business units that distract them from their primary goals. And management, despite its talking the talk of “information is our most strategic commodity” doesn’t yet walk the walk. How does ownership of an enterprise information architecture evolve?
A Common Evolutionary Path
The following table charts a common path for both operational and strategic aspects of EIA. Strategic work focuses on the growth, positioning, funding, and governance of EIA resources and staff, while the operational side addresses who actually does the work of developing and maintaining an EIA. This table shows how both tracks can evolve side by side over time, often in concert, in a “typical” enterprise environment.
| Operational EIA | Strategic EIA |
| Individuals recognize that EIA issues existA handful of people “in the trenches” responsible for some aspect of their business units’ respective information architectures independently become aware that there are IA challenges that affect the entire enterprise. They may see the need for their own work (e.g., managing a search engine, developing product metadata or a style guide) to be coordinated or shared with others, but have little or no contact with like-minded peers within the enterprise. Nor do they have incentive to coordinate efforts. | Managers stuck in redesign modeManagement is mostly unaware of and disinterested in EIA issues, although it may occasionally grapple with other relevant enterprise issues, such as branding. Typically, the enterprise web site is in the hands of the marketing function, and the enterprise intranet is managed by IT. Efforts to improve either site tend to be of the one-shot comprehensive “redesign” variety; accordingly, momentum quickly dissipates, and little institutional knowledge is retained.At this point, there is little value in attempting to engage decision-makers in the process of developing a coordinated EIA. However, some managers may begin to emerge as possible future champions of EIA projects. |
| Community of interest emergesAs IA becomes more accepted throughout the enterprise, more people assume the job title “information architect”; it becomes easier to find similarly titled peers. Other triggers for bringing IA peers together include external events, such as attending local professional meetings and IA conferences, or the installation of an enterprise-class application (e.g., CMS, portal, or enterprise search engine), which requires significant configuration by internal staff.An informal community of shared interest within the enterprise emerges, typically through the efforts of one or a few instigators, and is usually managed via an email discussion list and regular brown-bag lunches. At this point, few efforts are made to coordinate IA activities; it’s more typical to compare notes on “how we did it” (e.g., how best bets are being implemented locally), as well as sharing external best practices gleaned at conferences. | Friendly managers lend tacit supportA few “enlightened” managers emerge; their recognition of EIA issues often comes directly from analyzing the failures of past redesigns. These enlightened managers aren’t yet in a position to provide resources or to allocate a portion of staff time to EIA efforts, but are supportive (or at least don’t disapprove) of their staff who wish to participate in the informal activities of the community of interest. |
| Community of practice achieves formal recognitionThe community of interest becomes one of practice, with IAs from different units quietly coordinating efforts with enterprise implications. Examples include developing user-centered requirements for inclusion in functional specifications when new enterprise applications are being selected, and sharing budgets to cover software licenses or consulting from IA specialists (e.g., taxonomists). A semi-formal leadership structure emerges within the community of practice, mostly to manage communications within the group (rather than activities or resources). Local business units’ respective IA activities still trump EIA work for all involved. | Advisory Committee emergesFormalization of an in-house EIA community comes in the form of an official “blessing” on the part of managers. These managers are often drawn from a combination of friendly managers and “squeaky wheels” (vocal managers responsible for major content areas, product groups, or user constituencies), and they take on a semi-official role as an Advisory Committee. Meetings are irregular and often draw attendance from a different subset of managers each time. Official Advisory Committee responsibilities are minimal. At this point, its chief role is to serve as a means for communicating about EIA and related issues between departments and, occasionally, to advocate to senior managers on behalf of the community of practice when it identifies specific needs or requires help dealing with policy issues and internal politics. |
| Distributed teams assigned to specific EIA projectsGrowth in demand for better EIA coordination leads to formal allocation of IA staff to specific enterprise projects, especially around the implementation and configuration of enterprise-class applications, as well as metadata and interface design guidelines. IAs from business units continue to work primarily on local projects, but their enterprise allocation continues to increase—even if only for temporary projects—and they begin to take on formal responsibility for EIA-related projects.EIA teams that are initially constituted for specific projects increasingly become permanently established. External IA specialists are more commonly brought in to assist in EIA efforts. | Advisory Committee matures; Strategic Board backs it up The Advisory Committee becomes a formal decision-making group, advising EIA teams, formulating EIA policy and strategy, and paving the way for projects when EIA teams need more senior-level assistance. The Committee meets more regularly, and its membership becomes increasingly representative of important constituencies and internal units (extending especially beyond IT and Marketing).The Advisory Committee recognizes that its growing scope of responsibility requires additional authority and funding; it advocates for the creation of a very senior Strategic Board (akin to a company’s Board of Directors) to put at least the appearance of teeth into proposed policies through visible support (even if this support takes the form of rubber-stamping new policies). The Board, which meets every few months, also helps identify sources of funding for major EIA-related projects. |
| Business unit dedicated to EIA in placeA permanent EIA unit, usually drawn from internal staff, are now in place, with its own management structure. Team size varies, often based on scope (some units are more broadly focused on enterprise user experience or knowledge management). As team size reaches double digits, specialists in such areas as metadata development, user testing, search systems, and metrics are brought on as full-time staff. Though their primary responsibility is the enterprise architecture, both generalists and specialists also provide IA consulting to local business units on an as-needed basis. The EIA team also takes on a leadership role in training local IA staff and with EIA “intellectual property,” such as the enterprise-wide style guide and metadata standards. | Strategic players formalize and expand their rolesSeeing the strategic nature of enterprise information, the Strategic Board takes on a greater role, paving the way for the creation of a new cost center, a business unit dedicated to EIA and related areas. Other groups that have a role in EIA strategy begin to form, such as a user-advocacy board (useful for maintaining an enterprise-wide pool of users for testing and evaluation purposes).The Advisory Committee also takes on a more formal, active role as the primary decision-making group, serving as executive managers of the EIA business unit. |
This isn’t how it always happens, but it’s a relatively close approximation of the mean. (Another common path toward in-house EIA competence involves the migration of an e-commerce team or web development group to a group that addresses EIA as well.) More importantly, this evolution will provide you ideas and, if nothing else, a straw man that you can react to as you chart your own course.
The EIA Group’s Ideal Qualities and Makeup
As with an actual information architecture, you should consider assembling an in-house EIA group from both the top down and bottom up. Think of the top-down approach as the strategy end of things, where senior people figure out the big picture of where the EIA unit should be headed and how it will get there. The bottom-up side is comprised of the operational tasks involved in actually doing the work at hand. As much as possible, separate these two areas; their respective missions, tasks, and members will be quite different.
The strategists
The strategists—members of the Advisory Committee and Strategic Board—focus on the role of the EIA unit within the broader enterprise. Their mission is to ensure that the enterprise benefits from a quality information architecture through the efforts of the EIA group. Their goals are to:
Understand the strategic role of information architecture within the enterprise
Promote information architecture services as a permanent part of the enterprise’s infrastructure
Align the EIA operations team and its services with the enterprise’s goals
Ensure the financial and political viability
Inform EIA operations of changes in strategic direction that may impact the enterprise’s information architecture plans
Help develop EIA operating policies
Support the EIA team’s management
Assess the EIA team’s performance
In effect, strategists are responsible for the success of EIA operations. That means navigating politics, getting buy-in from management across the enterprise, and acquiring funding and other resources. It also requires the development of metrics to help judge the success of the enterprise information architecture broadly, and EIA operations specifically.
People who would be effective and available in the director’s role exhibit these qualities:
Have been in the enterprise long enough to have wide visibility, an extensive network, and the ability to draw on years of institutional memories and experiences
Are entrepreneurial; can read and even write a business plan
Have a track record of involvement with successful enterprise initiatives
Have experience with centralized efforts, successful or not (failures are as informative as successes)
Can navigate political situations
Can “sell” a new, abstract concept; have experience finding internal funding
Resemble or can at least understand your clients in terms of outlook, position within the org chart, personality, and golf handicap
Have experience with consulting operations, either as a provider or a purchaser
Have experience negotiating licensing agreements with vendors
Operations People
The EIA operations team takes on the tactical work of information architecture: researching and analyzing factors related to content, users, and business context; designing information architectures that address those factors; and implementing that design. Besides delivering the EIA Unit’s services, the operations unit follows (and upholds) policies and procedures for content management and architectural maintenance.
How should this team be staffed? There are many roles that would be nice to have on your team, including:
Strategy Architect
Thesaurus Designer
Interaction Architect
Technology Integration Specialist
Information Architecture Usability Specialist
Search Analyst
Controlled Vocabulary Manager
Indexing Specialist
Content Modeling Architect
Ethnographer
Project Manager
Of course, staffing each of these areas is a fantasy for most of us, but this ideal gives you something to shoot for. More importantly, it helps you line up outside consulting expertise. Don’t have a usability specialist on staff? Your entrepreneurial business model might allow you to pass a consultant’s costs to your clients.
When you do get around to hiring staff for your interdisciplinary operations team, look for these qualities:
Entrepreneurial mindset
Ability to consult (i.e., do work and justify IA and navigate difficult political environments)
Willingness to acknowledge ignorance and seek help
Ability to communicate with people from other fields
Experience within the organization
Experience of prior enterprise-wide centralization efforts
Sensitivity to users’ needs
Knowledge about information architecture and related fields (of course)
Finally, consider what gaps your EIA unit is filling within the enterprise. You may find that you want to broaden your scope, branching toward conventional IT services such as hosting, or toward visual design, editorial, or other areas under the broader umbrella of experience design. Select your staff and consultants accordingly to fit the needs of the enterprise.
Doing the Work and Paying the Bills
The evolutionary path described earlier ends with the seemingly optimistic outcome of a separate EIA business unit, independent of the baggage of IT, Marketing, Corporate Communication, or other parent groups. Why are we fans of the go-it-alone approach?
Efforts to knit together an enterprise’s information architecture naturally require extensive cross-departmental communication and involvement. And business units typically don’t trust other business units to do the right thing. An effort to centralize an enterprise-wide architecture will be tough enough without including the baggage of that effort’s foster parent, Department X. And if Department X’s mission in life is operating the corporate WAN or maintaining the corporate brand, its managers won’t typically understand—much less fully support—EIA efforts; they’re not likely to fit any existing department’s core mission and goals. So why force it?
Additionally, because efforts to centralize are long-term and ongoing, and information architecture and content management have become a permanent part of the scene, a support infrastructure for these efforts is a necessity. Enterprises simply can’t afford to “re-do” their information architectures every year or two; the direct costs are high, and no organizational learning is retained. For these reasons, EIA is ideally owned and operated by an independent infrastructural unit with its own budget and managers.
Interestingly, when the second edition of this book (published in 2002) suggested standalone EIA groups, the idea wasn’t popular; it seemed too optimistic given both the lack of acceptance of IA in many enterprises and the economic conditions of the time. Yet today this model is becoming widespread, because many organizations find it impossible to make progress with EIA unless it’s the responsibility of an (at least somewhat) autonomous and baggage-free business unit. There really are few viable alternatives.
Build a New Business Unit
The idea of a standalone business unit begs the question: how will it be funded? New cost centers do get established from time to time—at some point, IT, HR, and other groups found the funding they needed to address the needs of the entire enterprise. But, admittedly, such events are infrequently witnessed in the enterprise landscape. So where will the money come from?
Nothing is impossible, and there are a variety of potential sources of income that merit consideration. Here are five possibilities:
- Seed capital
In some cases, organizations see enough value in a new project to at least grant it an initial investment. Seed money is a fixed financial injection, usually to be used over a predetermined block of time and intended to support the new business unit until it can stand on its own feet. It should be carefully budgeted to cover the initial years of a project, gently winding down as revenues projected from other sources begin to grow.
- Operating expenses
Central funding can also come in the form of operating expenses that all business units (including new ones and especially cost centers) can count on to pay for the basics, like desks, roofs, and possibly administrative staff. These funds aren’t typically available to cover much else beyond a business unit’s basic “cost of living.”
- Flat tax
Some cost centers derive income from client business units to cover the cost of basic services and shared services that address the needs of the entire enterprise. A good example in the EIA context is the ongoing maintenance and tuning of a search system that provides access to the enterprise’s entire body of content, regardless of its originating business units.
- Income for special enterprise-wide projects
Occasional big-ticket items, like a new content management platform and content migration, are also costs likely to be borne by all business units. These are usually assessed as one-time fees, requiring agreement from all other business units; alternatively, the bill is footed by the enterprise’s central administration, which sees such projects as being important to the success of the enterprise as a whole.
- Income for services rendered
The standard “chargeback” model; services are paid for by client business units just as they’d pay external vendors. In an ideal world, the EIA unit ensures its independence by sustaining itself on the fees of a loyal in-house clientele; unfortunately, this model often runs counter to certain organizational cultures, especially those in the nonprofit and academic sectors.
Figure 19-9 shows how these sources of income might vary over the first few years in the life of an EIA business unit.
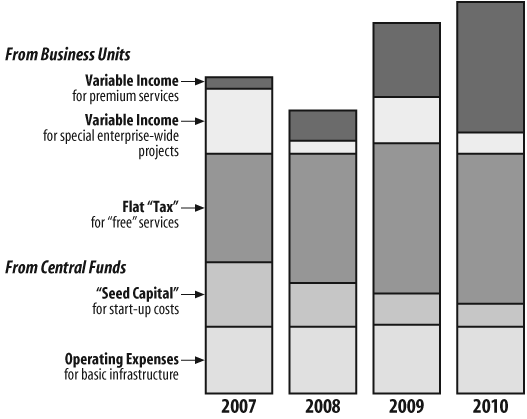
Which (if any) of these revenue sources makes sense for you depends on how business gets done internally within your organization. For example, some organizations live and die by the chargeback model, while it wouldn’t even receive 10 seconds of consideration in other settings. Clearly, the best approach is to try to “diversify your revenue stream” and not place too many eggs in one basket. And, hopefully, your Advisory Committee and Strategic Board (or equivalent thereof) will take the lead in determining the appropriate revenue model; ideally, they have prior experience doing so within your enterprise.
Build an Entrepreneurial Business Unit
We especially advocate reliance on one of the above-mentioned revenue streams: billing internal “clients” for services rendered. Obviously, a standalone cost center will be better off if it becomes responsible for its own income. Seeing the enterprise environment as a local economy, and seeking to function as a service provider in that environment, acknowledges a critical truth of the enterprise: nothing succeeds without trust and incentive.
We’ve already discussed how business units don’t tend to trust other business units, and how the new and baggage-free EIA unit might fly under the radar. It may not achieve trust, but at least it might avoid mistrust. A more important way to achieve trust is to behave in a way that’s familiar to your “clients.” In other words, if they’re operating within the corporate economy—functioning with budgets, costs, and revenues—then you should, too. If they see you operating by the same rules, they’ll understand and trust you more than if you appear to be some vice president’s ephemeral pet project. By acting as an entrepreneurial service provider to the enterprise, you will craft a menu of services catered to your clients’ true needs (more on these services shortly).
In terms of trust, people can’t trust what they don’t understand. So, like any entrepreneurial organization, a standalone EIA team needs to take seriously the role of marketing its efforts. We’ve found that one of the best ways to market an abstract concept like information architecture is through education. A program of introductory information architecture seminars, repeated regularly throughout the year, can help potential clients understand that their problems aren’t unique, that there is a nomenclature they can use to express these problems, that a field (information architecture) exists to guide them, that others within the enterprise suffer similar pain, and, ultimately, that the EIA group is there to provide real assistance with such problems.
Where does incentive fit in? Simply put, a self-funded business unit has greater incentive to do good work, especially because it often faces competition from external service providers. Self-support means that the EIA group will become better at listening to clients and discerning their pain, developing appropriate services, and communicating the benefits of its own services versus those of competitors.
Incentive is a two-way street. Should the EIA unit not justify its budget to clients, those clients will not have a good sense of what value information architects bring. They often don’t know what these services cost, never having purchased them before. Divorcing level and quality of service from some monetary equivalent muddies the waters, leading to relationships between the EIA team and its clients that are more likely to be fraught with misunderstandings and miscommunication. In effect, other business units don’t have incentive to be good clients.
Provide Modular Services to Clients
What types of services should you sell to clients? Naturally, they will be limited by the EIA team’s expertise. Basic market-research techniques will help you understand what exactly your clients need, whether it’s help configuring that search engine or designing better navigation systems. The important thing is to delineate services that are concrete and modular. By doing so, you are in effect making information architecture itself more concrete and less of an intimidating unknown. Therefore, it’s more likely to be an attractive and justifiable purchase for your clients.
Table 19-3 shows just some of the services the EIA unit might provide to clients around the enterprise.
| Content acquisition | Content archiving |
| Content authoring | Content management tool acquisition |
| Quality control and editing | Content management tool maintenance |
| Link checking | Search engine acquisition |
| HTML validation | Search engine maintenance |
| Designing templates | Autoclassification tool acquisition |
| Applying templates | Autoclassification tool maintenance |
| Overall information architecture design | Training of business unit staff in IA/CM |
| Overall information architecture maintenance | Publicity of new and changed content |
| Indexing (manual) | Standards development |
| Indexing (automated) | User testing and feedback evaluation |
| Controlled vocabulary/thesaurus creation | Search-log evaluation |
| Controlled vocabulary/thesaurus maintenance | Interaction with visual-design staff |
| Content development policy creation | Interaction with IT staff |
| Content development policy maintenance | Interaction with vendors |
| Content weeding and ROT removal |
This list of services is focused on information architecture and, to a lesser degree, content management. It could be expanded to include other aspects of the user experience, such as visual design, interaction design, application development, media production, copyrighting, hosting, and publicity.
Developing a list of potential services is also a useful exercise to help you determine just what your team can and can’t do. Don’t have anyone on staff who can develop a thesaurus? Now you know that you’ll need to find that expertise, whether in-house or from external vendors. This exercise helps you begin the process of resolving your team’s strengths and weaknesses, and points out expertise gaps that could be filled with external talent. In effect, you’ll now have the answers to your questions regarding when to bring in outside expertise, as well as what kind of staff to hire in-house once there’s sufficient demand. (This is a much better method for incorporating external expertise than is typical; outside contractors and consultants are often brought in at the wrong time and for the wrong reasons.)
Consider creating two versions of each service: a free “loss leader,” and a premium version that clients pay for. Because IA is still so new to so many within your enterprise, you should provide them a chance to dip their toes in and try your offerings. Ideally, they’ll like what they see, find it indispensable, and eventually “upgrade” to the premium version. Table 19-4 shows an example of one such item on the menu.
| Service: Content Acquisition | ||||
| Basic-level service description | Basic service pricing | Premium-level service description | Premium service pricing | Client requirements |
| Interview client and no more than 5 users to determine content needs. Identify free and proprietary sources of content. | First 25 hours free; then $125/hr. | Same as basic level, plus: interview 15 users total, and develop plan for integrating new and existing content, including plan for metadata integration. | $5,000 for 60 hours; then $125/hr. | Client agrees to identify, contact, and arrange meetings with content stewards and sample users for interviews regarding content needs. |
Aside from free versus fee, consider other ways of making your fee structure attractive. For example, clients may appreciate the opportunity to pay for certain service charges as fixed, such as a retainer fee for weekly spidering of content, versus flexible, such as an hourly charge for occasional search engine configuration.
Finally, you might also consider incentive programs; for example, you might reward a business unit with a discount for frequently updating its content or religiously following certain manual-tagging guidelines. There are whole information economies, like evolt.org (described in Chapter 21), that manage to inspire broad community participation and exchange of information without a single penny ever changing hands. Blogs and wikis are increasingly being explored as knowledge management tools within enterprise contexts. It’s worth reviewing such innovative approaches when considering how your own business model will function.
Before determining service fees, consider the models already in place within your enterprise. Are there organizations that already provide centralized services? The IT department is one logical place to look; others include the library or research center, the division that manages the enterprise’s office space, human resources, and so on.Your goal is to find out how they provide their services. How do they study market demand, how do they publicize their services, and how are they funded? What works and what doesn’t?
Timing Is Everything: A Phased Rollout
EIA efforts are often tripped up by efforts to work with everyone and to do so all at once. Obviously, this is a recipe for disaster, but what’s the alternative? It’s pretty simple, really: choose your battles wisely, and take your time. Here’s our advice.
Identifying Potential Clients
You don’t want to work with all clients. Some are simply too stuck in “cowboy” mode, playing the rugged individualist to your information architecture communalist. Some are too busy to work with you. Some are too cautious when it comes to new things. Some would like to work with you but don’t have the resources, or perhaps they don’t have particularly valuable content. Some, frankly, just don’t get this information architecture stuff, regardless of your best educational efforts. And don’t forget: some will actually have a much more sophisticated understanding of information architecture than you do.
In such a mixed environment—with both ends of the evolutionary spectrum coexisting on the same floor of the corporation—you must accept the reality that you’ll be working with only the few clients with whom success is immediately likely, and waiting for the others to catch up over time.
Some clients shouldn’t be using your information architecture at all; they may be better suited to managing the information that lives within their department. You need to figure out how to pull out that information and integrate it with other information. For example, HR data is probably never going to be something you have control over, but it is exposed through various interfaces (web, database, etc.). You can work with HR to extract the information you need and integrate it with your architecture, but you’ll have to build a bridge to HR to keep this functioning. Your task is to integrate all these scenarios into an overall strategy, and accommodate the different needs and requirements in your information architecture.
So who are the “right” clients? Once again, use the three-circle Venn diagram of information architecture to guide you. The right clients exhibit the following characteristics:
- Content
What’s the “killer” content within the organization? It might be the stuff that’s used the most broadly and therefore has the highest visibility within the enterprise. A great example, at least for enterprise intranets, is the staff directory; not only does it have high value, but everyone uses it. For public sites, the product catalog is a good candidate. Both are often examples of excellent information architecture design. So whoever owns it is potentially an excellent client. Also, who has content that already comes with reasonably good metadata, or that is well structured? This stuff has already undergone at least some information architecture design, and therefore is ripe for inclusion in your architecture.
- Users
The clients you want to work with are trying to please the most important and influential audiences within the enterprise. These users may already be complaining about some information architecture-related issue and pushing for change. Aside from throwing their weight around the enterprise, these users might also have the deepest pockets, which is always a good thing. A great example of a key audience is the Research and Development group—they’re influential within the enterprise, and they live and die by quality access to quality content. The clients who cater to them are probably already knowledgeable about information architecture (even if they call it something else) and are less likely to require “missionary” sales efforts on your part.
- Context
Where’s the money (and the good technology and the knowledgeable staff)? Ultimately, you want a paying client; you can’t be doing charity work for too long. Which clients do you think will present the fewest headaches to work with? How far along is each on the autonomy/centralization evolutionary path? Who will be in the best position to provide testimonial support as you approach other potential clients throughout the enterprise? If your prized client is infamous and unpopular throughout the enterprise, its support may actually be counterproductive.
In your quest to find the best clients to work with, consider these issues as part of your market research and selection process. Also keep in mind that your initial round of projects is a marketing tool, providing models of your work and work style to longer-term potential clients.
After your first pass at assessing who’s out there, you might go a level deeper in your analysis. Using the list we devised earlier, create a checklist for your “sales” staff to use as they delve deeper into each business unit’s needs. This will help to determine how “information architecture-ready” each business unit is, and to assess the market for your EIA unit’s services. The following checklist addresses the services listed in Table 19-1.
| Service | What are they doing now? | Do they have in-house expertise in this area? | Do they have tools or applications available in this area? | Other considerations |
| Content acquisition | ||||
| Content authoring | ||||
| Quality control and editing | ||||
| Link checking | ||||
| HTML validation | ||||
| Designing templates | ||||
| Applying templates | ||||
| Overall information architecture design | ||||
| Overall information architecture maintenance | ||||
| Indexing (manual) | ||||
| Indexing (automated) | ||||
| Controlled vocabulary/thesaurus creation | ||||
| Controlled vocabulary/thesaurus maintenance | ||||
| Content development policy creation | ||||
| Content development policy maintenance | ||||
| Content weeding and ROT removal | ||||
| Content archiving | ||||
| Content management tool acquisition | ||||
| Content management tool maintenance | ||||
| Search engine acquisition | ||||
| Search engine maintenance | ||||
| ...and so on |
Interestingly, this exercise is also beneficial in determining what each unit has to offer to centralization efforts. For example, you might learn that a far-flung, little-known unit has acquired an expensive license for a new search engine. Perhaps it can bring this tool to the table? Sharing license fees helps the unit, and the enterprise as a whole may benefit by using the technology at a lower cost.
Phasing in Centralization
Of course, the best potential client in Q3 of 2007 could be very different from the best in Q2 of 2009. If the previous section is about helping you identify the “low-hanging fruit” that is ready to be plucked right now, then this one is about being ready to catch the next batch as it ripens.
There is a natural evolution toward greater centralization among the enterprise’s business units. The modularization of information architecture services is the perfect way to tap this evolution because you can hook clients for basic “must-have” services right away, and sign them up for additional services over time. The idea is that today’s basic-service clients will evolve into clients of higher-end services as their needs become more sophisticated and their aversion to centralization wanes.
Strive for a plan that’s built upon a “timed release” of your services throughout the enterprise. For example, your market research may allow you to come up with projections like those shown in the following table. This worksheet tracks the evolution of demand for more and more sophisticated services over time, allowing the EIA Unit to make a case for additional headcount.
| BUSINESS UNITS (16 total): service usage (past and projected) | ||||||||
| Historical Performance → | Projected Performance → | |||||||
| 2007 Q3 | 2006 Q4 | 2008 Q1 | 2008 Q2 | 2008 Q3 | 2008 Q4 | 2008 Q1 | 2008 Q2 | |
| Designing templates | ||||||||
| No service | 11 | 11 | 10 | 10 | 9 | 9 | 8 | 7 |
| Basic service | 4 | 4 | 5 | 4 | 4 | 4 | 5 | 5 |
| Premium service | 1 | 1 | 1 | 2 | 3 | 3 | 3 | 4 |
| Indexing (manual) | ||||||||
| No service | 14 | 6 | 1 | 1 | 0 | 0 | 0 | 0 |
| Basic service | 2 | 8 | 11 | 11 | 10 | 10 | 8 | 8 |
| Premium service | 0 | 2 | 4 | 4 | 6 | 6 | 8 | 8 |
| Controlled vocabularymaintenance | ||||||||
| No service | 8 | 3 | 3 | 3 | 3 | 1 | 0 | 0 |
| Basic service | 4 | 7 | 6 | 5 | 4 | 5 | 6 | 4 |
| Premium service | 4 | 6 | 7 | 8 | 9 | 10 | 10 | 12 |
A glimpse at future demand will help you allocate the EIA unit’s resources more effectively, enabling you to develop a phased plan to approach each tier of potential clients over time and ensuring that the EIA unit’s services are ready to meet the demand. The predictive power of this approach will give you a better idea of when to bring in outside specialists and other types of help. Perhaps most importantly, realistic projections of demand will be quite useful as you approach senior management for additional investment.
Finally, phasing in modular services allows various business units to have differing levels of centralization. In other words, cavemen can coexist with the highly evolved folks down the hall. What might result is something like the following “snapshot” of the enterprise, where the three business units are at very different points on the spectrum of autonomy/centralization. A flexible framework supports the unique needs of each. The following table once again deals with the items in Table 19-1.
| Business Unit | |||
| Service | Human Resources | Corporate Communications | Procurement and Supply |
| Content acquisition | - | Premium | - |
| Content authoring | - | - | Basic |
| Quality control and editing | - | Basic | - |
| Link checking | Basic | Basic | - |
| HTML validation | Basic | Premium | - |
| Designing templates | - | Premium | Basic |
| Applying templates | - | Basic | - |
| Overall information architecture design | Basic | - | - |
| Overall information architecture maintenance | Basic | - | - |
| Indexing (manual) | - | Basic | Basic |
| Indexing (automated) | Basic | Basic | - |
| Controlled vocabulary/thesaurus creation | Basic | - | - |
| Controlled vocabulary/thesaurus maintenance | Basic | - | - |
| Content development policy creation | Basic | Basic | - |
| Content development policy maintenance | Basic | Basic | - |
| Content weeding and ROT removal | - | - | - |
| Content archiving | Basic | - | Basic |
| Content management tool acquisition | Basic | Basic | - |
| Content management tool maintenance | Basic | Basic | - |
| Search engine acquisition | - | Premium | Basic |
| Search engine maintenance | - | Basic | Basic |
| Autoclassification tool acquisition | - | - | - |
| ...and so on |
A Framework for Moving Forward
In this chapter, we’ve mapped out a loose and ambitious framework that, even if you don’t agree with our specific recommendations, will provide you with ideas to mull over and react to as you develop your own approach. By breaking up overwhelming problems into digestible pieces, we hope that this framework will ensure that information architecture becomes a permanent fixture within enterprises that need it. By taking a phased approach, we believe this framework can stand the test of time. And by staying true to an entrepreneurial approach, this framework might defuse the urge to “force” autonomous business units to comply with centralizing efforts.
Ideally, this framework will be flexible enough to roll with the inevitable punches of corporate mergers, spin-offs, and reorganizations. We hope that it helps you and your organization avoid the waste and frustration of developing elegant information architectures on paper that can never be implemented in the unruly distributed information environments that have proliferated within the modern enterprise.
[1] Lou Rosenfeld’s Enterprise Information Architecture Roadmap represents an effort to capture what makes sense to do and when; you can download the latest version (in PDF) from http://louisrosenfeld.com/publications/index.html#enterpriseia.
[2] Our former company, Argus Associates, was once hired by a Fortune 500 company to develop a custom A–Z index for its public site. We’d recommended investing in search improvements, but the search engine was off-limits at the time, so we began work on the index. Many months and $250,000 later, a comprehensive index was built and launched, and a team of indexers trained to maintain it. And two years later, it was thrown away, as the IT department acceded to improvements to the search system. So it goes in the enterprise environment.
[3] Jakob Nielsen, “Search and You May Find.” AlertBox, July 15, 1997. http://www.useit.com/alertbox/9707b.html.
[4] It should be noted that many public-facing web sites increasingly feature blogs from their employees as a way to positively influence customers. This is especially the case in technical areas where it is beneficial to showcase in-house technical expertise.
[5] If you’re not familiar with aggregators, we recommend kicking the tires of the excellent and free web-based service Bloglines (http://www.bloglines.com).
[6] David Millen, Jonathan Feinberg, and Bernard Kerr, “Social Bookmarking in the Enterprise” in ACM Queue, vol. 3, no. 9. Nov. 2005 (http://acmqueue.com/modules.php?name=Content&pa=showpage&pid=344&page=1).