
XSLT Stylesheets
In Listing 17.2, you saw a simple XSLT stylesheet that used default transformation rules to remove everything except the text from an XML document. You will now look at how to define your own rules for transforming an XML document.
Rules are based on matching elements in the XML document and transforming the elements into a new document. Text and information from the original XML document can be included or omitted. Components from the XML document are matched using the XPath notation defined by the W3C. You will learn more about XPath in the “Using XPath with XSLT” section later in today's lesson, after you have looked at some simple XSLT templates.
Template Rules
The most common XSLT template rules are those for matching and transforming elements. The following simple example matches the root node of a document and transforms it into an outline for an HTML document.
<xsl:template match="/"> <HTML> <HEAD> <TITLE>Job Details</TITLE> </HEAD> <BODY> </BODY> </HTML> </xsl:template>
The <xsl:template> defines a new template rule and its match attribute specifies which parts of the XML document will be matched by this rule. The root of a document is matched by the forward slash (/); other matching patterns are discussed later in the “Using XPath with XSLT” section.
The body of the <xsl:template> element is output in place of the matched element in the original document. In this case, the entire document is replaced by a blank HTML document. No other elements in the document will be matched.
If you want to transform other elements in the original document, you must define additional templates and apply those templates to the body of the matched element. The following text adds an <xsl:apply-templates/> element to the rule matching the XML document root at the point where additional transformed text should be placed:
<xsl:template match="/"> <HTML> <HEAD> <title>Job Details</title> </HEAD> <BODY> <xsl:apply-templates/> </BODY> </HTML> </xsl:template>
When this rule is applied to the transformed root element, the body of the root element is scanned for further template matches. The output from the other rules is inserted at the point where the <xsl:apply-templates/> element occurred.
Listing 17.6 shows an XSLT stylesheet that transforms all of the XML elements into HTML <STRONG> elements.
Listing 17.6. Full Text of basicHTML.xsl
In Listing 17.6, the second template rule match="*" matches every element in the XML document, replaces it with a <STRONG> element, and applies all the templates recursively to the body of the XML element.
CAUTION
An XSLT stylesheet is an XML document, and you must ensure that the XML remains valid when outputting HTML. In Listing 17.6 the <STRONG> text is enclosed inside an HTML paragraph to ensure that the stylesheet remains valid. Many authors of HTML simply insert the paragraph <P> tag at the end of the paragraph. This will not work with stylesheets because the un-terminated <P> tag is not well-formed XML. Other HTML tags, such as <BR> and <IMG>, must be treated in a similar manner. You must also quote all HTML attributes as shown in the <A> tag in Listing 17.6 in order for the XSLT stylesheet to be valid XML. And, HTML tags must use consistent letter case for both the start and end tags.
Listing 17.7 shows the HTML output from applying the basicHTML.xsl stylesheet to the jobs.xml file shown in Listing 17.3. (Because the layout includes all the original whitespace it is not easy to read. For this reason it may not initially appear to be well-formed HTML, careful inspection will nevertheless show that it is. You will see later how to strip leading and trailing whitespace from the original document.)
Listing 17.7. Applying basicHTML.xsl to jobs.xml
In Listing 17.7, the HTML body starts with two HTML <STRONG> elements corresponding to the <jobSummary> root element and the first <job> element. The nested XML elements <location> and <skill> are also output inside <STRONG> tags.
If you studied Listing 17.7 carefully, you will have seen a <META> element inserted into the output in the HTML <HEAD> element. This element was not added by the rules in basicHTML.xsl stylesheet; in this case the XSL processor has identified the output as an HTML document and, on recognizing the HTML <HEAD> element, has inserted the <META> element to identify the contents of the Web page.
Now that you have seen how the templates are applied to the body of a tag, you might be wondering how not to apply the templates but still output the text of an element. You do this by using the <xsl:value-of select='.'/> tag. This tag outputs the text of the currently selected XML element without applying any more templates either to this element or any of its descendents.
You will use the <xsl:value-of> element when you want to output the text of an XML tag rather than transform it in some way. Listing 17.8 shows a more useful and realistic stylesheet for the jobs.xml example file, and Listing 17.9 shows the transformed document.
Listing 17.8. Full Text of textHTML.xsl
In Listing 17.8, the leaf elements of <description>, <location>, and <skill> are output as text rather than expanded using the template rules.
NOTE
Listing 17.8 includes a template for the document root (match="/") and the root element (match="jobSummary"). On Day 16, you learned that the document root is the entire XML document, including the processing instructions and comments outside of the root element.
Listing 17.9. Applying textHTML.xsl to jobs.xml
Using the <xsl:value-of> tag raises two questions:
What is the text value of an XML element?
What does the select attribute do?
These questions are answered in the next two sections.
Text Representation of XML Elements
Every XML node has a textual representation that is used when the <xsl:value-of> tag is defined within a template rule. Table 17.1 shows how the textual equivalent of each of the seven XML nodes is obtained.
| Element Type | Description |
|---|---|
| Document root | The concatenation of all the text in the document |
| Elements | The concatenation of all the text in the body of the element |
| Text | The text value of the node, including whitespace |
| Attributes | The text value of the attribute, including whitespace |
| Namespaces | The namespace URI that is bound to the namespace prefix associated with the node |
| Processing Instructions | The text of the processing instruction following the target name and including any whitespace |
| Comments | The text of the comment between the <!-- and --> delimiters |
As you can see from Table 17.1, every node has a textual equivalent. The default rules for an XSLT stylesheet only include the text values for the document root, elements, and all text nodes. By default, the other four nodes (attributes, namespaces, processing instructions, and comments) are not output. Before you can understand the default rules, you will need to study the XPath notation for matching nodes in an XML document.
Using XPath with XSLT
XPath is a means of identifying nodes within an XML document. The W3C identified several aspects of XML that required the ability to identify nodes, for example,
Pointers from one XML document to another called XPointer (the equivalent of href in HTML)
Template rules for XSLT stylesheets
Schemas
To ensure that the two requirements for identifying nodes share a common syntax, the XPath notation was defined as a separate standard.
An XPath is a set of patterns that can be used to match nodes within an XML document. There are a large number of patterns that can be used to match any part of an XML document. Rather than reproduce the entire XPath specification in today's lesson, you will just study some examples that will help you understand how to use XPath. Further information about XPath can be obtained from the WC3 Web site.
XPath uses the concept of axes and expressions to define a path in the XML document:
Axes define different parts of the XML document structure.
Expressions refer to specific objects within an axis.
Some of the most frequently used axes have special shortcuts to reduce the amount of typing needed. Consider the XSLT stylesheet rule you used to match a skill element in the jobs.xml file:
<xsl:template match="skill"> Skill: <xsl:value-of select="."/><P></P> </xsl:template>
This matches a child skill element using a simple abbreviation. The full XPath notation for this is
<xsl:template match="child::skill">
The axis is child and the expression is an element with the name skill (the double colon separates the axis from the expression). The current node from which a path is defined is called the context node.
The child axis is used to identify all nodes that are immediate children of the context node. Related axes are
descendent Immediate children of the context node, all the children of those nodes, their children, and so on
descendent-or-self All descendent nodes and the current context node
ancestor Any node higher up the node tree that contains a context node
There are other axes defined in the XPath notation not listed here as they will not be discussed in today's lesson.
The match="." attribute in the example <xsl:value-of> element, shown previously, is another example of a shortcut. The full notation is as follows:
Skill: <xsl:value-of select="self::node()"/><P></P>
The function node() refers to the current context node. Additional functions are
name() The name of the context node instead of the body of the node
processing-instruction() Selects a processing instruction node
Some simple XPath expressions are as follows:
child::text() All the text nodes in the immediate child nodes
descendent-or-self::skill All the nodes named skill below the current node, including the current node
Expressions can be more complex and specify a node hierarchy:
XPath expressions can be arbitrarily long and can contain the following special expressions:
These patterns can be used to identify any node as illustrated by the following examples:
jobSummary//skill Nodes called skill defined anywhere below the jobSummary node
jobSummary/*/skill skill nodes defined as children of children of the jobSummary node
parent::comment()|child::text() Comment nodes in the immediate parent and text nodes in the immediate child
Attributes can be selected using the attribute axis (this can be abbreviated to @). For example,
attribute::customer The attribute called customer of any node (not the node itself)
job/@reference An attribute called reference that is associated with a job node
In addition to these basic features, XPath supports a powerful matching language supporting variable-like constructs, expressions, and additional functions.
Now that you have a basic understanding of Xpath, you can look at the default rules for a stylesheet.
Default Stylesheet Rules
There are some default stylesheet rules that apply to the whole XML document unless overridden by specific template rules.
The first default rule that ensures all elements are processed is as follows:
<xsl:template match="*|/"> <xsl:apply-templates/> </xsl:template>
A second rule is used to output the text of text nodes and attributes:
<xsl:template match="text()|@*"> <xsl:value-of select="."/> </xsl:template>
A third rule suppresses comments and processing instructions:
<xsl:template match="processing-instruction()|comment()"/>
If an XML element in the source document matches more than one rule, the most specific rule is applied. Consequently, rules defined in an XSLT stylesheet will override any default rules.
The second default rule specifies that the text value of attributes should be output, but if you use this template on the attributes in jobs.xml (Listing 17.3), you will not see the attributes. This is because there is an extra requirement for processing attributes, which is described next.
Processing Attributes
Attributes of XML elements are not processed unless a specific rule is defined for those attributes.
An attribute is processed by using the <xsl:apply-templates> rule selecting one or more attributes. The third line in the following fragment applies templates to all attributes:
<xsl:template match="*"> <xsl:apply-templates/> <xsl:apply-templates select="@*"/> </xsl:template>
This <xsl:template> rule matches all elements and applies templates to the child elements and then that element's attributes. It is the second <xsl:apply-templates> rule with the select="@*" attribute that ensures that all attributes are output, but only because the node itself was matched with the previous <xsl:apply-templates> rule. If you only defined the second <xsl:apply-templates select="@*"> rule, no output would be produced because the node itself would not have been matched and hence no attributes found.
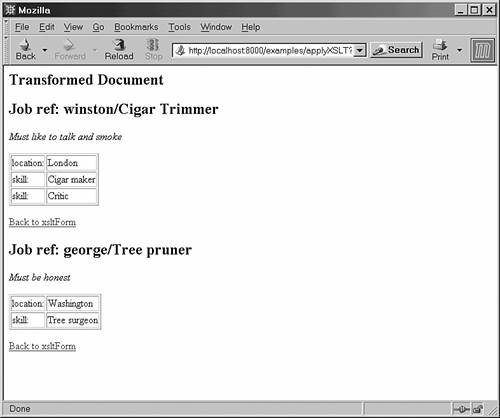
With this extra information, you can now revisit the jobs.xml file and define an XSLT stylesheet that will display the job information in an HTML table as shown in Listing 17.10.
Listing 17.10. Full Text of table.xsl
Listing 17.10 brings together several features of XSLT stylesheets that have been described previously. The rule matching a <job> element inserts the values of the customer and reference attributes and the job description child element is output in its own paragraph.
Note that the HTML table border attribute is enclosed in quotes so that it is valid XML (the same is also true for the colspan attribute). Even though HTML does not require these attributes to be quoted, XML does, and this XSLT stylesheet is an XML document.
Figure 17.2 shows the result of applying the table.xsl stylesheet from Listing 17.10 to the jobs.xml file.
XSL supports significantly more complex transformation rules than those shown so far. The next section will provide an overview of some of the additional XSL features.