
Implementing a BMP Entity Bean
Implementing an Entity bean involves providing an implementation for the methods of the javax.ejb.EntityBean, and corresponding methods for each method in the local-home and local interfaces.
Implementing javax.ejb.EntityBean
The setEntityContext() method is the preferred place to perform JNDI lookups, for example to acquire a JDBC DataSource reference. Listing 6.5 shows how this is done for the JobBean code.
Listing 6.5. JobBean.setEntityContext() Method
The unsetEntityContext() method (not shown) usually just sets the member variables to null.
The ejbLoad() and ejbStore() methods are responsible for synchronizing the bean's state with the persistent data store. Listing 6.6 shows these methods for JobBean.
Listing 6.6. JobBean's ejbLoad() and ejbStore() Methods
In the ejbLoad() method, the JobBean must load its state from both the Job and JobSkill tables To do this it uses the data in the JobSkill table to populate the skills field. In the ejbStore() method, the equivalent updates to the Job and JobSkill tables occur.
Of course, there is the chance that when the bean comes to save itself, the data could have been removed from the database. There is nothing in the EJB specification to require that an Entity bean “locks” the underlying data. In such a case, the bean should throw a javax.ejb.NoSuchEntityException; in turn, this will be returned to the client as some type of java.rmi.RemoteException.
CAUTION
To keep the case study as small and understandable as possible, the error handling in JobBean has been simplified. In Listing 6.6, the code will throw an EJBException (rather than NoSuchEntityException) from ejbLoad() if the data has been removed. In ejbStore(), it doesn't actually check to see if any rows were updated, so no exception would be thrown.
More complex beans can perform other processing within the ejbLoad() and ejbStore() methods. For example, the data might be stored in some de-normalized form in a relational database, perhaps for performance reasons. The ejbStore() method would store the data in this de-normalized form, while the ejbLoad() methods would effectively be able to re-normalize the data on-the-fly. The client need not be aware of these persistence issues.
Examples of other actions that could be performed in the include ejbLoad() and ejbStore() methods include:
Compressing and decompressing text fields to reduce network traffic to a remote database
Replacing keywords within the text by tokens
Converting Plain text into XML format, or vice versa
Expanding addresses from zip (or postal) codes for use by the client
As noted earlier today, there is usually very little to be done when an Entity bean is passivated or activated. Listing 6.7 shows the instance variable references being set to null during passivation to aid garbage collection.
Listing 6.7. JobBean's ejbActivate() and ejbPassivate() Methods
Implementing the Local-Home Interface Methods
The implementation of ejbCreate() and ejbPostCreate() for the JobBean is shown in Listing 6.8.
Listing 6.8. JobBean's ejbCreate() and ejbPostCreate() Methods
This particular implementation validates that the customer exists (jobs are identified by the customer and by a unique reference), and that the primary key does not already exist in the database. If the primary key does exist, the bean throws a CreateException; if it doesn't (represented by the ejbFindByPrimaryKey() call throwing a FinderException), the method continues.
An alternative implementation would have been to place a unique index on the Job table within the database and then to catch the SQLException that might be thrown when an attempt is made to insert a duplicate record.
CAUTION
There is a race condition here. It's possible that another user could insert a record between the check for duplicates and the actual SQL INSERT. If the ejbCreate() method is called within a transaction; changing the database isolation level (in a manner specified by the EJB container) would eliminate this risk, although deadlocks could then occur.
Note that the skills field is set to an empty ArrayList. This list will contain SkillLocal references (this being the local interface to the Skill bean), but of course, for a newly created Job bean, this list is empty. The decision for the skills field to hold references to SkillLocal objects rather than, say, just String variables holding the skill names, was taken advisedly. If the skill name had been used (that is, the primary key of a skill), finding information about the skill would require extra steps. Perhaps more compellingly, this is also the approach taken for CMP beans and container-managed relationships, discussed in detail tomorrow.
Also noteworthy is the customerObj field. The Job, when created, is passed just a String containing the customer's name. In other words, this is a primary key to a customer. The customerObj field contains a reference to the parent customer bean itself by way of its CustomerLocal reference.
Both the skills and the customerObj fields illustrate (for want of a better phrase) bean-managed relationships. For the skills field, this is a many-to-many relationship, from Job to Skill. For the customerObj field, this is a many-to-one relationship from Job to Customer.
The ejbCreate() and ejbPostCreate() methods both correspond to a single method called create() in the bean's local-home interface. The list of arguments to both methods must correspond exactly. It is, however, possible for there to be more than one create method with different sets of arguments using overloaded createXXX(), ejbCreateXXX() and ejbPostCreateXXX() methods.
The ejbRemove() method is the opposite of the ejbCreate() method; it removes a bean's data from the persistent data store. Its implementation for JobBean is shown in Listing 6.9.
Listing 6.9. JobBean's ejbRemove() Method
Each of the finder methods of the local-home interface must have a corresponding method in the bean. By way of example, Listing 6.10 shows two (of the three) finder methods for the JobBean.
Listing 6.10. JobBean's Finder Methods
The implementation of the ejbFindByPrimaryKey() method might seem somewhat unusual; it receives a primary key, and then returns it. Of course, what it has also done is validate that an entity exists for the given primary key; if there were none, a javax.ejb.ObjectNotFoundException would be thrown.
The implementation of ejbFindByCustomer() is straightforward; it simply returns a Collection of primary key objects.
The Job bean defines a home method, namely deleteByCustomer(), and the corresponding method in the JobBean class is ejbHomeDeleteByCustomer(), as shown in Listing 6.11.
Listing 6.11. JobBean.ejbHomeDeleteByCustomer() Home Method
Implementing the Local Interface Methods
Each of the methods in the local interface has a corresponding method in the bean itself. The corresponding methods for JobBean are shown in Listing 6.12.
Listing 6.12. Business Methods of JobBean Correspond to the Methods of the Local Interface
The getSkills() and setSkills() methods bear closer inspection. The getSkills() method returns a copy of the local skills field, because, otherwise, the client could change the contents of the skills field without the JobBean knowing. This isn't an issue that would have arisen if the interface to JobBean was remote, because a copy would automatically have been created. Turning to the setSkills() method, this checks to make sure that the new collection of skills supplied is a list of SkillLocal references. This is analogous to the setLocation() method that was discussed earlier; the Job Entity bean is enforcing referential integrity with the Skill Entity bean.
Generating IDs
Sometimes an Entity bean already has a field, or a simple set of fields, that can be used to represent the primary key. But at other times, the set of fields required may simply be too large. Or possibly, the obvious primary key may not be stable in the sense that its value could change over the lifetime of an entity—something prohibited by the EJB specification. For example, choosing a key of (lastname, firstname) as a means of identifying an employee may fail if an employee gets married and chooses to adopt the spouse's surname.
In these cases, it is common to introduce an artificial key, sometimes known as a surrogate key. You will be familiar with these if you have ever been allocated a customer number when shopping online. Your social security number, library card number and your driver's license number are all guaranteed to be unique and stable. These are all surrogate keys.
With BMP Entity beans, the responsibility for generating a surrogate key is yours. Whether numbers and letters or just numbers are used is up to you, although just numbers are often used in an ascending sequence (that is, 1, 2, 3, and so on). If you adopt this strategy, you could calculate the values by calling a stateless Session bean—a number fountain, if you will. A home method could perhaps encapsulate the lookup of this NumberFountainBean.
The implementation of such a NumberFountainBean can take many forms. There will need to be some persistent record of the maximum allocated number in the series, so a method such as getNextNumber("MyBean") could return a value by performing an appropriate piece of SQL against a table held in an database:
begin tran update number_fountain set max_value = max_value + 1 where bean_name = 'MyBean' select max_value from number_fountain where bean_name = 'MyBean' commit
One disadvantage with this approach is that the NumberFountainBean—or rather, the underlying database table—can become a bottleneck. A number of strategies have been developed to reduce this. One is to make the getNextNumber() method occur in a different transaction from the rest of the work. You will learn more about transactions on Day 8; for now, you only need to know that while this will increase throughput, there is the possibility of gaps occurring in the sequence (not usually a problem).
If non-contiguous sequences are acceptable, even better throughput can be achieved by implementing a stateless Session bean that caches values in memory. Thus, rather than incrementing the maximum value by 1, it can increment by a larger number, perhaps by 100. Only every 100th call actually performs SQL update, and the other 99 times, the number is allocated from memory.
A final enhancement, that improves scalability further and also improves resilience, is to arrange for there to be a number of beans, each with a range of values. For example, these might be allocated using a high-order byte/low-order bytes arrangement.
One advantage of implementing a Session bean, such as NumberFountainBean, is that it isolates the dependency on the persistent data store that is holding the maximum value. Also, the SQL to determine the next available number is easily ported across databases. On the other hand, many organizations use only a single database, so such portability is not needed. In these cases, the database may have built-in support for allocating monotonically increasing numeric values, and this can be used directly. For example, a SEQUENCE can be used in Oracle, while both Microsoft SQL Server and Sybase provide so-called identity columns and the @@identity global variable. So, for BMP Entity beans, another way to obtain the next value is to perform the SQL INSERT, obtaining the value from the back-end database. Note that most of these tools have the same scalability issues as the home-grown NumberFountainBean, and most also provide optimizations that can result in gaps in the series.
There is an alternative to using numbers for ID values, namely to generate a value that must be unique. A quick search on the Web should throw up some commercial products and free software that will generate unique keys. For example, one algorithm will generate values unique to the millisecond, the machine, the object creating the ID, and the top-most method of the call stack.
Granularity Revisited
A recurrent theme when developing Entity beans is selecting an appropriate granularity for the bean. Prior to EJB 2.0, Entity beans could only provide a remote interface, which meant that a relatively coarse grained interface was required to minimize the client-to-bean network traffic. Indeed, this is still the recommendation made for Session beans in EJB 2.0 that have a remote interface.
With EJB 2.0, Entity beans can have a local interface, meaning that the cost of interaction with the client is reduced. If the cost of interaction of the Entity bean to the persistent data store is not too high, fine-grained Entity beans are quite possible. This may be true, either because the EJB container can optimize the database access in some way (true only for CMP Entity beans) or if the data store resides on the same computer as the EJB container and, ideally, within the same JVM process space.
NOTE
Running a persistent data store in the same process space as the EJB container is quite possible; a number of pure Java databases provide an “embedded mode.”
Under BMP however, the advice is generally not to use fine-grained Entity beans, principally because the EJB container will be unable to perform any database access optimization. Choosing the granularity is then best determined by focusing on the identity and lifecycle of the candidate Entity beans. Hence, order and order-detail could and probably should be a single Order bean, but customer and order, while related, should be kept separate.
In the case study, you will find that the Job bean writes to both the Job table and also the JobSkill table (to record the skill(s) needed to perform the job).
Beware Those Finder Methods!
As you now have learned, Entity beans can be created, removed, and found through their home interface. While these all seem straightforward enough operations, there's danger lurking in the last of these; finder methods can cripple the performance of your application if used incorrectly.
This may not be immediately obvious, but if you consider the interplay between the EJB container (implementing the local-home interface) and the bean itself, the problems are easier to see:
Say for example, the local-home interface's findManyByXxx() method is called. For the purposes of this discussion, this finder method returns a Collection of local proxy objects to the client. The local-home interface delegates to a pooled bean, calling its ejbFindManyByXxx() method. This performs a SQL SELECT statement (or the equivalent), and returns back a Collection of primary keys to the local-home interface. The local-home interface instantiates a Collection the same size as was obtained from the bean and populates it with local proxies. Each local proxy is assigned a primary key.
So far so good; the client receives a Collection of proxies. Suppose now that the client iterates over this collection, calling some getter method getXxx().
The client calls getXxx() on the first proxy in its Collection. The proxy holds a primary key, but there is no corresponding bean actually associated with the proxy. Therefore, the EJB container activates a bean from the pool, calls its ejbLoad() lifecycle method, and then finally delegates the getXxx() business method. After the method has completed, the ejbStore() method is called. This process continues for all of the proxies in the collection.
Here lies the problem: The persistent data store will be hit numerous times. First, it will be hit as a result of the ejbFindManyByXxx() method; this will return a thin column of primary key values. Then, because ejbLoad() is called for each bean, the rest of the data for that row is returned. This is shown in Figure 6.8.
Figure 6.8. Finder methods can result in poor performance under BMP.
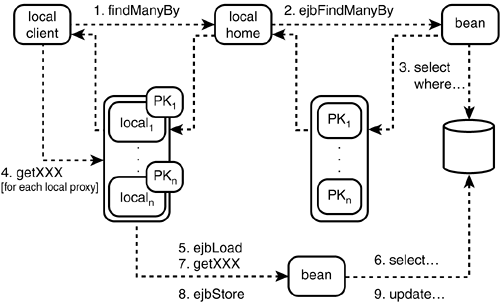
Consequently, if 20 primary keys were returned by the bean following the initial ejbFindManyByXxx(), the network would be traversed 21 times, and the database will be hit in all 41 times—once for the initial SELECT and two times each for each of the beans.
There are a number of techniques that can eliminate this overhead, each with pros and cons:
The most obvious solution is to not use finder methods that return a Collection of many beans. Instead, use stateless Session beans that perform a direct SQL SELECT query against the database, iterate over the ResultSet, and return back a Collection of serializable value objects that mirror the data contained in the actual entity. This technique is called the Fast-lane Reader pattern.
Another technique that can be used is to alter the definition of the primary key class. As well as holding the key information that identifies the bean in the database, it also holds the rest of the bean's data as well. When the original finder bean returns the Collection of primary keys, the local proxies hold these primary keys. When the beans are activated, the ejbLoad() methods can obtain their state from the proxy by using entityContext.getLocalObject().getPrimaryKey(); obviating the need to load the data from the persistent store. This technique has been dubbed the Fat Key pattern, for obvious reasons.
Last, you may be able to remove the performance hit by porting the bean to use container managed persistence. Because under CMP the EJB container is responsible for all access to the persistent data store, it may obtain all the required information from the data store during the first findManyByXxx method call, and then eagerly instantiate beans using this information. You will be learning more about CMP tomorrow.
EJB Container Performance Tuning
Many organizations are wary of using Entity beans because of the performance costs that are associated with them. You have already seen the performance issues arising from using finder methods, but even ignoring this, any business method to an Entity bean will require two database calls—one resulting from the ejbLoad() that precedes the business method and one from the ejbStore() to save the bean's new state back to the data store.
Of course, these database calls may be unnecessary. If a bean hasn't been passivated since the last business call, the ejbLoad() need not do anything, provided the data has not been updated. Also, if the business method called did not change the state of the bean, the ejbStore() has nothing to do.
Another case where multiple database calls may be unnecessary is where a bean is interacted with several times as part of a transaction. You will be learning more about transactions on Day 8, so for now, just appreciate that when a bean is modified through the course of a transaction, either all of its changes or none of them need to be persisted. In other words, there is really only the requirement to call ejbStore() just once at the end of the transaction.
Although not part of the EJB specification, many EJB containers try to alleviate this performance problem by providing proprietary mechanisms to prevent unnecessary ejbLoad() or ejbStore() calls. Of course, the use of these mechanisms will make your bean harder to port to another EJB container, but you may well put up with the inconvenience for the performance gains realized. Indeed, if you are in the process of evaluating EJB containers, as many companies are, you may even have placed these features on your requirements list.
Self-Encapsulated Fields
In the case study BMP beans, the private fields that represent state are accessed directly within methods. For example, the following is a fragment of the JobBean.ejbCreate() method:
public JobPK ejbCreate (String ref, String customer) throws CreateException {
// database access code omitted
this.ref = ref;
this.customer = customer;
this.description = description;
this.location = null;
this.skills = new ArrayList();
// further code omitted
}
Some OO proponents argue that all access to fields should be through getter and setter methods, even for other methods within the same class. In other words, the principle of encapsulation should be applied everywhere. Using such an approach, the ejbCreate() method would be as follows:
public JobPK ejbCreate (String ref, String customer) throws CreateException {
// database access code omitted
setRef(ref);
setCustomer(customer);
setDescription(description);
setLocation(null);
setSkills(new ArrayList());
// further code omitted
}
When developing CMP Entity beans (discussed tomorrow) this approach has to be adopted due to the implementation mechanism of CMP Entity bean properties.
Some people find this overly dogmatic, and, indeed, the code in the case study takes the more direct approach. However, you may want to consider self-encapsulation because it makes BMP beans easier to convert to CMP. As you will see tomorrow, all accessing to the Entity bean's state must be through accessor methods.