
Chapter 10 Programming for eDirectory
In previous chapters, you’ve learned how to use a number of Novell-supplied and third-party directory services (DS) data recovery applications. Because every network environment is unique in its own way, however, you might not be able to find one off-the-shelf utility that totally fulfills your requirements. This chapter offers you an overview on how you can use a basic programming background to develop some complex data recovery tools for your own network. Please note, however, that this chapter does not discuss programming in detail and expects you to already have that knowledge.
NOTE
If you are interested in NDS /eDirectory and/or Lightweight Directory Access Protocol (LDAP) programming, we suggest that you take a look at, respectively, Novell’s NDS Developer’s Guide (Novell Press) and Novell’s LDAP Developer’s Guide (Novell Press).
Programming for NDS disaster recovery need not always involve the Novell Developer Kit (NDK) or any form of NDS or the NetWare application programming interface (API) set. Some of the most effective programming techniques available are nothing more than text file manipulations. This type of manipulation is good for data conversions such as converting NList output to a format suitable for UImport or ICE to use for input.
Several programming languages include text (or string) manipulation. BASIC, C, Pascal, Perl, and even assembly language include interfaces and libraries for performing string manipulation. One of the best languages for this sort of work, however, is a programming language called awk.
The awk language was developed in 1977 by Alfred Aho, Brian Kernighan, and Peter Weinberger at AT&T Bell Labs; the name of the language comes from the last-name initials of the three authors. The original development of awk was done in a Unix environment, and because of this, many of the concepts are familiar if you have had exposure to utilities such as grep or sed. grep is very similar to the Windows find utility because it searches one or more input files for lines containing a match to a specified pattern. By default, grep prints the matching lines. sed (stream editor) is a non-interactive editor that works from a command line; it’s not a GUI Windows application. sed changes blocks of text on-the-fly, without requiring you to open a screen, push a cursor around, and press Delete, Insert, Enter, or function keys.
awk is an interpreted scripting language; this means that there is no compiler or other means to turn an awk program into a self-sufficient executable program as you would a C or Pascal program.
NOTE
The examples in this book are all interpreted using the GNU version of awk (called gawk), available from the Free Software Foundation. (GNU is a recursive acronym for “GNU’s Not Unix”; it is pronounced “guh-noo.”) The discussion presented in this section is based on version 3.0.3, but newer versions are available for DOS, Windows 32-bit operating systems, Unix/Linux, and other operating system platforms. An updated list of sites that maintain awk source code and binaries is available from the comp.lang.awk FAQ at ftp://rtfm.mit.edu/pub/usenet/comp.lang.awk/faq.
You might be wondering why we recommend awk for string manipulation.
There are several reasons awk might be a better choice than other languages for the sort of rapid development that may be necessary in a disaster situation:
![]()
awk interpreters are available for many operating system platforms, including DOS, Windows 32-bit operating systems, and Linux.
![]()
awk interpreters do not require any sort of special memory manager. Many Intel-platform Perl interpreters require DOS extenders of different sorts.
![]()
awk is not a compiled language; therefore, you can readily read and modify its script.
![]() The
The awk interpreter is very small (typically around 30KB or so), and it can be put on a disk along with a number of standard scripts for disaster recovery purposes.
![]() Unlike C or C++,
Unlike C or C++, awk does not require that you understand pointers when manipulating strings.
![]() The
The awk user interface is very straightforward. If you are recovering from a very serious disaster, a minimal workstation configuration can be used—DOS 6.22 with a Novell Client installed is sufficient to start parsing NList outputs.
![]()
awk’s regular expression parsing capabilities exceed the capabilities of many of the traditional programming languages, such as C and Pascal.
An awk program takes input a line at a time, parses and processes the input, and produces an output file. This is usually done through command-line pipes or redirection. Normally, this process involves the use of three files: an awk script, an input file, and an output file.
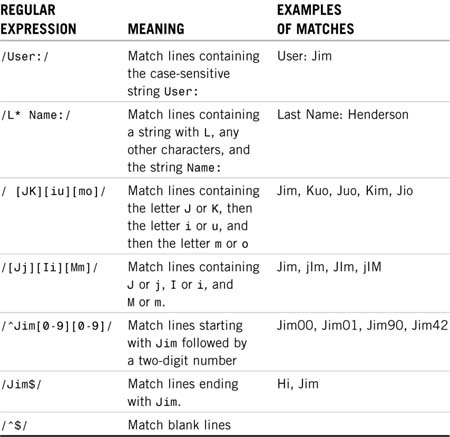
The awk script itself is a set of rules for processing lines of text from the input file. These rules are written using a pattern-matching technique that is common in the Unix world, called a regular expression (regex). Regex pattern matching enables you to specify the format of a line of text in the input file; if a line matches the regex, the text is processed in a manner described by that portion of the script.
Regex pattern matching uses this basic format:
/pattern/
where pattern is replaced by a string that represents an input format. Table 10.1 shows special sequences of characters that can be used in the pattern.
For example, if you execute this command:
NLIST USER SHOW Name /S /R /C > OUTPUT.TXT
and use the file OUTPUT.TXT as the input file to the script:
/User:/ { print "Found a user ID" }
awk searches the input file for the case-sensitive string User:, and if this text is found, it prints the string “Found a user ID.”
awk supports two special commands: BEGIN and END. These are not really patterns but are used to include special instructions—such as variable initialization and final output options—in the script. Here’s an example:
BEGIN { count = 0 }
/User:/ { count++ }
END { printf("Total users found: %d
", count) }
NOTE
If you are familiar with the C/C++, Perl, or Java programming languages, resist the urge to put a semicolon (;) at the end of each statement line as it is not required by awk!
This script searches for instances of the case-sensitive string User: (as in the previous example), but rather than print a string, it increments the variable count, and when it finishes that, it prints a total count of the user objects listed in the input file.
An awk script parses the input line based on a field separator. By default, the field separator is whitespace. Whitespace includes any number of spaces or tabs between the data. The line is then split out into internal variables based on the field separator found.
For example, this line consists of a total of four fields:
Full Name: Jim Henderson
These fields are referred to by the names $1, $2, $3, and $4, with these values:
|
Field |
Value |
|
|
|
|
|
|
|
|
|
|
|
|
The entire line of text is referred to by the variable $0. This variable always represents the entire line up to the record separator, which is typically a carriage return.
TIP
Another special value is the NF value. This value reports the number of fields in the line. If you are uncertain about the number of fields but need the last value from the line, you can reference this as $NF. In the preceding example, $4 has the value Henderson, as does $NF; therefore, NF would have the value 4.
You can change the defaults for the various separators, such as field separator and record separator. For example, if you have a tab-delimited file, you would want the field separator (FS) to be the tab character rather than a space. You typically make this change in the beginning of the script, in the BEGIN segment:
BEGIN { FS = " " }
NOTE
As with C, C++, and other programming languages, awk uses escaped characters for nonprintable characters. The sequence refers to the tab character, the
sequence refers to the newline character, and so on.
The output field separator (OFS) denotes the character used to separate the fields when awk prints them. The default is a blank or space character. To output a comma-separated variable (CSV) formatted file, you can change the OFS to a comma as follows:
BEGIN { OFS = "," }
You can also change the record separator (RS) by using the RS variable:
BEGIN { RS = " " }
Typically, you do not want to change this, but at times it might make sense to do so.
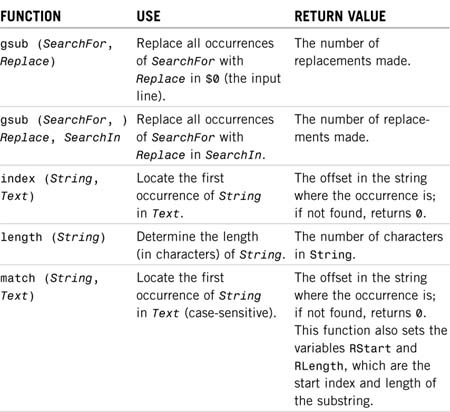
awk also has a number of string manipulation functions. Table 10.2 shows some of the commonly used functions and what they can be used for.
TABLE 10.2 awk String Manipulation Functions

In addition to doing string manipulation, you can also use awk for numeric manipulation. This type of manipulation of data is done in the same manner as C/C++ numeric manipulation. If you need to manipulate a number with an initial value, you can initialize it in the BEGIN section of the script.
When you’re scanning a line and breaking it into the initial subcomponents ($1 through $NF), or when you’re breaking it down using the split() function, if a numeric value is found, it is automatically treated as a number.
However, if you need to perform string manipulations on it, you are also able to do this. In this respect, awk provides greater flexibility than most other programming languages.
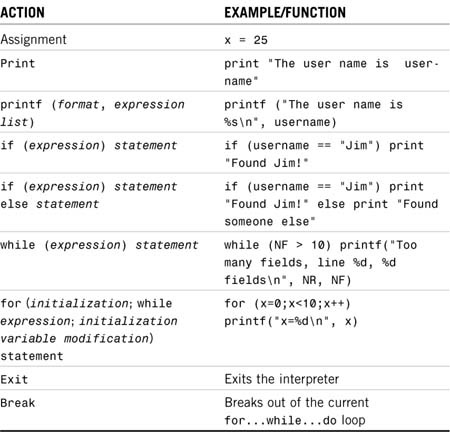
awk also supports the use of several other statements and structures. Table 10.3 lists the most common of these.
TIP
awk uses the pound sign (#) to indicate the start of a comment. Anything after a # will be ignored. Therefore, you can include inline comments anywhere within your script.
NOTE
awk resources and documentation are available on the Internet, and the following are two examples of good Web sites for this type of information: www.ling.ed.ac.uk/facilities/help/gawk/gawk_13.html#SEC97 and www.sunsite.ualberta.ca/Documentation/Gnu/gawk-3.1.0/html_chapter/gawk_10.html.
An additional feature of the awk language that is occasionally useful is the capability to create specialized functions for repeated operations. If you are coding an involved script, you can package the code so as to minimize your coding time. However, in disaster recovery situations, you will generally find that the scripts you write will perform very specific manipulations, and as a general rule, you do not need to reuse code within such scripts.
Creating functions within awk is a simple matter. For example, the following would be a function to return the minimum value of two passed-in parameters:
function min(a, b){
if (a < b)
return a
else
return b
}
Because awk supports the abbreviated if structure that C provides, the preceding can also be coded as follows:
function min(a, b){
return a < b ? a : b
}
This code sample provides the same functionality as the previous sample.
After you have written awk script, you need to give it an input file. When you’re using the gawk interpreter, you do this by using a command in the following format:
gawk awkfile.awk < inputfile [> outputfile]
This tells gawk to use awkfile.awk as the script and to pipe the contents of inputfile into the script. The input file can be left out, but if it is, you must type the input file by hand. The output file contains the results of the script; if an output file is not specified, the output is written to the screen.
TIP
Writing the output to the screen can be very useful during the development process. By exiting the script with the exit command after processing the first line of text, you can get an idea as to whether the program is working the way you want it to work without processing the entire input file.
In a disaster-recovery situation, it is not absolutely necessary that the script work completely correctly when you finish it. Using awk with a combination of other tools may get you to the end you need more quickly. Consider this example. Say you have an awk script that outputs a UImport file with group membership information in it. It is missing a few of the members because of an extra embedded space for those entries. Instead of trying to perfect the script to handle that small number of exceptions, you can use your favorite text editor to either remove those entries from the file or to make the correction using a search-and-replace function. Remember that during disaster recovery, it doesn’t matter if your script is elegant or pretty; it just matters that you get the job done quickly and correctly.
The example in this section shows a full awk program designed to convert the output from the NLIST command into a format suitable for importing into a spreadsheet or database program. For simplicity, the scope of this example is limited to a single context. (Chapter 11, “Examples from the Real World,” examines a case study that builds a UImport file based on information from the entire tree.)
For this example, the input file is generated by using the following command:
NLIST USER SHOW SURNAME, "FULL NAME", "GIVEN NAME" > USERS.TXT
The output file USERS.TXT contains the same information you would normally see on the screen. The contents of the file in this example are as follows:
Object Class: User
Current context: east.xyzcorp
User: JimH
Last Name: Henderson
Full Name: Jim Henderson
Given Name: Jim
User: PeterK
Last Name: Kuo
Full Name: Peter Kuo
Given Name: Peter
User: PKuo
Last Name: Kuo
Full Name: Peter Kuo
Given Name: Peter
User: JHenderson
Full Name: Jim Henderson
Given Name: Jim
Last Name: Henderson
A total of 4 User objects was found in this context.
A total of 4 User objects was found.
From this information, we want to generate a comma-delimited file with the fields User ID, Context, First Name, Last Name, and Full Name. The output file also contains a header line with the field names in it.
This awk script performs the conversion to a comma-delimited file:
BEGIN { flag = 0
printf(""User ID","Context","First Name",
"Last Name","Full Name"
")
}
/User:/ {
if (flag == 1) {
printf(""%s","%s","%s","%s","%s"
",
user, context, gn, ln, fn)
gn = ""
ln = ""
fn = ""
}
user = $2
gsub(" ", "", user)
flag = 1
}
/Full Name:/ { gsub(/Full Name: /,"")
gsub(/ /, "")
fn = $0
# Cleans up leading blanks (ONLY)
# from the full name
nfn = length(fn)
for (i=1;i<nfn;i++) {
if ( match(fn, " ") == 1 )
sub(" ", "", fn)
else
break
}
}
/Last Name:/ { gsub(/Last Name: /,"")
gsub(/ /, "")
ln = $0
gsub(" ", "", ln)
}
/Given Name:/ { gsub(/Given Name: /,"")
gsub(/ /, "")
gn = $0
gsub(" ", "", gn)
}
/Current context:/ { gsub(/Current context: /, "")
context = $0
gsub(" ", "", context)
}
END { printf(""%s","%s","%s","%s","%s"
",
user, context, gn, ln, fn)
}
The script starts with the BEGIN statement. It executes before any lines of the input file USERS.TXT are read. It sets a flag value to 0 in order to avoid printing a blank first line. The field headers are then printed to the output device.
Next, the first line is read. This line contains the object class information. Each line in the script that performs a pattern match on the data file is evaluated, in order. First, the line is checked for the presence of the User: string. This line, however, does not contain that specific string, so the next pattern is evaluated. That line also does not contain the other specified strings (Full Name:, Last Name:, Given Name:, or Current context:). As a result, the line is not processed and is not sent to output.
The second line contains the string Current context:, so the code written to handle that is used to process the line. The first line of code (the gsub line) replaces the string Current context: with nothing, effectively removing it from the $0 variable. The variable context is then assigned to the string contained in the line, which contains the actual context. This variable is preserved from one line to the next and is printed each time a new user is read in and at the end of the script.
After that line is processed, the next line is processed similarly. It contains a user ID and assigns the value. It also sets the flag variable to 1, but because the variable was 0 when the script started, the information gathered is not printed out. As soon as the flag is set to 1, each subsequent time a user ID is found, the previous user information is printed, and all variables except context are reset to empty strings.
After the last line of the file is read, the last user’s information is printed. The reason for using a BEGIN/END block is because NLIST may return the attributes in arbitrary order; therefore, you should not print out the results until the script has encountered the next User: data block.
The result of this script, using the output from the earlier NLIST command, is as follows:
"User ID","Context","First Name","Last Name","Full Name"
"JimH","east.xyzcorp","Jim","Henderson","Jim Henderson"
"PeterK","east.xyzcorp","Peter","Kuo","Peter Kuo"
"PKuo","east.xyzcorp","Peter","Kuo","Peter Kuo"
"JHenderson","east.xyzcorp","Jim","Henderson","Jim Henderson"
The C programming language has been, and still is, the programming language of choice for systems programming. It is, therefore, not a surprise that Novell’s initial Software Developer Kit (SDK; now known as the NDK) efforts were placed in C libraries. Even today, the NetWare Loadable Module (NLM) libraries are still C based, and workstation application developers now have more options in their choice of programming language (see the “Other Programming and Scripting Languages” section, later in this chapter).
NOTE
From a performance viewpoint, NLMs work better than workstation-based applications because in many cases, NLMs do not generate network traffic as they run on the servers. However, because of the error exception handling routines used by C++ compilers, C++ generally is not suitable for NLM development. If you want to use C++ for NLMs, consider using the Metrowerks CodeWarrior compiler. Visit http://developer.novell.com/ndk/cwpdk.htm for more information.
When you’re programming for NDS, there are a number of operations that your application must perform locally when accessing DS information. The operations include the following:
![]() Working with naming conventions
Working with naming conventions
![]() Maintaining directory context data
Maintaining directory context data
![]() Initializing Unicode tables
Initializing Unicode tables
![]() Managing local buffers
Managing local buffers
As mentioned previously, a DS object may be referenced in multiple ways: using its relative distinguished name (RDN) or its distinguished name (DN) in typeful or typeless naming syntax. DS operates on canonical names only—that is, names that include full naming paths, with a type specification for each naming component (typeful DNs). Because it’s not always convenient or practical to store or use canonical names, APIs enable you to use partial names and enable the underlying library routines to handle the conversion.
Most DS API calls that involve character data or interact with the NDS/eDirectory tree require additional information to be supplied. This is to indicate the default context and whether the character data should be translated to Unicode. This information is collectively held in a structure called the directory context and is used to pass the following details:
![]() The default context
The default context
![]() Whether alias objects should be dereferenced
Whether alias objects should be dereferenced
![]() Whether character data should be translated to and from Unicode
Whether character data should be translated to and from Unicode
![]() Whether object names should be given in canonical form
Whether object names should be given in canonical form
![]() Whether object names should be given in typeless form
Whether object names should be given in typeless form
When a directory context (which is essentially a memory pointer) is created, the default context is the same as the workstation’s current context, and the four operations listed previously are performed. The directory context should be freed when it is no longer needed (normally when the application terminates).
You can read and modify the information in a directory context. You need to be careful when changing the default context. You can set it to an arbitrary string, unlike with the CX command-line utility, which does not set the default context to an illegal value. If the default context is set to an illegal value, any API calls that rely on the directory context will fail.
The same object-naming conventions apply to the NDS API calls as to the NetWare command-line utilities. That is, leading and trailing periods can be used to modify the default context, and the type qualifiers, such as C=, can be inserted into the name to override the default typing.
The Unicode conversion tables have to be loaded before a workstation application can access NDS (this is not necessary for NLMs), and they should be released prior to an application’s terminating. These tables are used to convert character data between the general Unicode format used by the NDS and the local format used by the application. You load the Unicode tables by executing the Unicode API NWInitUnicodeTables() and specifying the local code page. You can obtain the local code page by executing the Internationalization Services APIs NWLsetlocale() and NWLlocaleconv().
DS API functions use buffers for sending and receiving data between the application and NDS/eDirectory. For example, a typical sequence in reading an object’s attribute values would be to initialize an input buffer, load the buffer with the list of desired attributes, execute the read object command, and unload the attribute values from an output buffer. Given that the output buffer is finite, it is sometimes necessary to call the read function repeatedly to get subsequent values. This protocol of using input and output buffers provides a general interface for transferring data.
Memory for directory buffers is allocated using an DS API call. The suggested amount of memory to allocate is given by the constant DEFAULT_MESSAGE_LEN that is set to 4096 bytes. This value is normally more than sufficient for a typical DS application. The only exception under normal circumstances would be when there is a single attribute value (such as a stream file) that will not fit in the buffer (thus resulting in a -119 error [buffer too small]). If you are unsure, you can consider using MAX_MESSAGE_LEN, which has a 63KB value, or using your own setting. Directory buffers should be freed when they are no longer needed (normally when the application terminates); otherwise, memory leaks result.
The directory buffer management tasks make DS-aware applications more complex than bindery-based programs; don’t let that discourage you from developing DS utilities, however, because it only looks harder than it is.
The following is an example of C source code that enables you to change a user’s telephone attribute from a command line. Error checking has been removed to simplify the example:
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#define N_PLAT_DOS
#include <nwcalls.h>
#include <nwnet.h>
#include <nwlocale.h>
void main (int argc, char *argv[])
{
NWDSContextHandle Cx;
NWDS_BUFFER *inBuf;
LCONV lconvInfo;
if ( argc < 4 ) {
printf ("Usage: ");
printf ("Newnumber objectname oldTnum newTnum
");
exit (1);
}
// Needed for workstation-based APIs only.
NWCallsInit (NULL, NULL);
// Unicode table must be loaded in order to use DS calls.
NWLlocaleconv (&lconvInfo);
NWInitUnicodeTables (lconvInfo.country_id,
lconvInfo.code_page);
// Create directory context
Cx = NWDSCreateContext ();
// Allocate local buffers
NWDSAllocBuf (DEFAULT_MESSAGE_LEN, &inBuf);
NWDSInitBuf (Cx, DSV_MODIFY_ENTRY, inBuf);
// First delete the old value and then add the new one
// (Can not use DS_OVERWRITE_VALUE because Telephone Number
// is multi-valued and the API would not know which value
// to overwrite, if there is more than one)
// The two actions can be combined into the same "buffer"
NWDSPutChange (Cx, inBuf, DS_REMOVE_VALUE,
"Telephone Number");
NWDSPutAttrVal (Cx, inBuf, SYN_CI_STRING, argv[2]);
NWDSPutChange (Cx, inBuf, DS_ADD_VALUE,
"Telephone Number");
NWDSPutAttrVal (Cx, inBuf, SYN_CI_STRING, argv[3]);
if ( NWDSModifyObject (Cx, argv[1], NULL, (NWFLAGS)0,
inBuf) == 0 ) {
printf ("%s’s old telephone number [%s] has been
",
argv[1], argv[2]);
printf ("replaced by a new number [%s]
", argv[3]);
}
else
printf ("Unable to change telephone number.
");
// Free allocated resources.
NWDSFreeBuf (inBuf);
NWDSFreeContext (Cx);
NWFreeUnicodeTables ();
exit(0);
}
If you have an external database that contains up-to-date user information, you can use a modified version of this example to read the telephone number (or other attribute values) from this database and repopulate the user objects with the information when needed.
You might be interested in knowing that when you modify eDirectory data via LDAP, you do not need to deal with allocating buffers, directory context, and so on (as is the case when using DS calls). You do, however, have to set up the necessary code to connect and bind to the LDAP server (where a workstation-based DS utility would not require but an NLM would require additional code to authenticate to NDS prior to changes being made). The following is a sample C code snippet (based on Novell’s modattrs.c example) that changes the telephone number:
#include <stdio.h>
#include <stdlib.h>
#include <ldap.h>
int main( int argc, char **argv)
{
int version, ldapPort, rc;
char *ldapHost, *loginDN, *password, *modifyDN;
char *phoneValues[2];
LDAP *ld;
LDAPMod modPhone, *modify[2];
// 10-second connection timeout
struct timeval timeOut = {10,0};
if (argc != 6) {
printf( "
Usage: modattrs <host name> ");
printf ("<port number> <login dn> <password>
");
printf ("
<modify dn>
");
printf ("
Example: modattrs acme.com 389 ");
printf ("cn=admin,o=acme secret
");
printf ("
cn=admin,ou=demo,o=testing
");
return(1);
}
// Set up connection and binding info
ldapHost = argv[1];
ldapPort = atoi(argv[2]);
loginDN = argv[3];
password = argv[4];
modifyDN = argv[5];
// Set LDAP version to 3 and set connection timeout
version = LDAP_VERSION3;
ldap_set_option ( NULL, LDAP_OPT_PROTOCOL_VERSION,
&version);
ldap_set_option ( NULL, LDAP_OPT_NETWORK_TIMEOUT,
&timeOut);
// Initialize the LDAP session
if (( ld = ldap_init ( ldapHost, ldapPort )) == NULL) {
printf ( "
LDAP session initialization![]() failed
");
failed
");
return( 1 );
}
printf ("
LDAP session initialized
");
// Bind to the server
rc = ldap_simple_bind_s( ld, loginDN, password );
if (rc != LDAP_SUCCESS ) {
printf ("ldap_simple_bind_s: %s
",
ldap_err2string( rc ));
ldap_unbind_s ( ld );
return( 1 );
}
printf ("
Bind successful
");
/*
* To modify the attributes of an entry
* 1 Specify the modify actions
* 2. Specify the attribute name to be modified
* 3. Specify the value of the attribute
* 4. Add to an array of LDAPMod structures
* 5. Call ldap_modify_ext_s
*/
// LDAP_MOD_REPLACE succeeds whether the value
// already exists or not
modPhone.mod_op = LDAP_MOD_REPLACE
modPhone.mod_type = "telephoneNumber";
phoneValues[0] = "1 234 567 8910";
phoneValues[1] = NULL;
modPhone.mod_values = phoneValues;
// If you have more than one modifications to make, increase
// the array size of modify[] and add more "&mod*" entries
modify[0] = &modPhone;
modify[1] = NULL;
// Modify the attributes
rc= ldap_modify_ext_s (ld, // LDAP session handle
modifyDN, // the object to
// modify
modify, // array of LDAPMod
// structures
NULL, // server controls
NULL); // client controls
if ( rc != LDAP_SUCCESS ) {
printf ("ldap_modify_ext_s: %s
",
ldap_err2string( rc ));
ldap_unbind_s( ld );
return(1);
}
printf ("
%s modified successfully.
", modifyDN);
ldap_unbind_s( ld );
return( 0 );
}
As you can see, although the LDAP code is longer than the DS-based code presented earlier in this chapter, about half of it actually has to deal with connecting and binding to the LDAP server. The actual code necessary for updating the attribute value is less than 10 lines, and most of it is just setup code.
Although the amount of work involved in using DS calls instead of LDAP calls seem about the same, the big advantage of using LDAP is that your application will also work with directories other than NDS. If you have to update a number of different directories with the same data and they all support LDAP, using LDAP calls would be the better way to go.
To help you quickly develop applications for NDS and NetWare without having to fully understand the underlying complexity, Novell Developer Support has several tools available. For example, you can build successful network-ready applications and utilities by using your favorite rapid application development (RAD) Windows programming tool, such as Visual Basic.
Visual Basic Libraries for Novell Services gives programmers full access to all the low-level NetWare APIs that have traditionally been available only to C programmers. The libraries are provided in the form of a single text file and a set of helper functions in a .BAS file. The text file (NETWARE.BAS) contains declarations for most of the NetWare APIs. (The libraries are for the 32-bit Novell Client DLLs and do not support the old 16-bit library.) All the constants, types, and function declarations are in NETWARE.BAS to make it easier to include them in a project. The following is a Visual Basic code snippet that illustrates how to remove an attribute value whose syntax type is SYN_CI_STRING:
Private objName As String
Private attrName As String
Private objType As Integer
Private Sub RemoveValueFromAttribute(objName As String,
attrName As String,
attrValue As String)
Dim inBuf As Long
Dim byteName(127) As Byte
retCode = NWDSAllocBuf(DEFAULT_MESSAGE_LEN, inBuf)
If retCode Then
MsgBox "NWDSAllocBug returned E=" + Str(retCode),
vbCritical
Exit Sub
End If
retCode = NWDSInitBuf(contextHandle, DSV_MODIFY_ENTRY,
inBuf)
If retCode Then
MsgBox "NWDSInitBuf returned E=" + Str(retCode),
vbCritical
GoTo exit1
End If
’defined in NETWARE.BAS
Call StringToByteArray(byteName, attrValue + Chr(0))
retCode = NWDSPutChangeAndVal(contextHandle, inBuf,
DS_REMOVE_VALUE,
attrName + Chr(0),
SYN_CI_STRING,
VarPtr(byteName(0)))
retCode = NWDSModifyObject(contextHandle,
objName + Chr(0),
-1, 0, inBuf)
exit1:
retCode = NWDSFreeBuf(inBuf)
End Sub
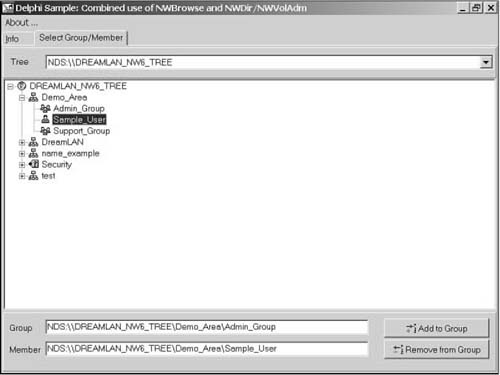
Alternately, you can use ActiveX Controls for Novell Services, which supports full access to NDS, as well as administration capabilities for NetWare servers, print queues, and volumes. All this functionality is packaged so it can be used quickly and easily in a Windows visual builder and other development tools, such as Visual Basic, Delphi (see Figure 10.1), PowerBuilder, Active Server Pages for Internet Information Server (IIS), Windows Scripting Host, and the Internet Explorer Web browser. ActiveX Controls for Novell Services contains controls that are divided into the following three categories:
![]() Novell Directory Access Protocol (NDAP; that is, NCP-based) controls:
Novell Directory Access Protocol (NDAP; that is, NCP-based) controls:
![]() Application Administration (
Application Administration (NWAppA)
![]() Browser (
Browser (NWBrowse)
![]() Directory (
Directory (NWDir)
![]() Directory Administration (
Directory Administration (NWDirA)
![]() Directory Authenticator (
Directory Authenticator (NWDirAuth)
![]() Directory Query (
Directory Query (NWDirQ)
![]() NDPS Printer Administration (
NDPS Printer Administration (NWDPPrtA)
![]() NDS Corporate Edition Domain (
NDS Corporate Edition Domain (NDSDomain)
![]() Network Selector (
Network Selector (NWSelect)
![]() SecretStore (
SecretStore (NWSecStr)
![]() Server Administration (
Server Administration (NWSrvA)
![]() Session Management (
Session Management (NWSess)
![]() User Group (
User Group (NWUsrGrp)
![]() Volume Administration (
Volume Administration (NWVolA)
![]() LDAP controls (to access NDS/eDirectory or any LDAP-complaint directory via LDAP):
LDAP controls (to access NDS/eDirectory or any LDAP-complaint directory via LDAP):
![]() Internet Directory (
Internet Directory (NWIDir)
![]() Internet Directory Authenticator (
Internet Directory Authenticator (NWIDirAuth)
![]() Internet Directory Entries (
Internet Directory Entries (NWIDirE)
![]() Internet Directory Query (
Internet Directory Query (NWIDirQ)
![]() Internet Directory Schema (
Internet Directory Schema (NWIDirS)
![]() Socket controls (to develop applications that communicate by using either TCP or SPX protocols):
Socket controls (to develop applications that communicate by using either TCP or SPX protocols):
![]() Client and Server Socket (
Client and Server Socket (NWCliSkt and NWSvrSkt)
![]() Peer Socket (
Peer Socket (NWPrSkt)
TIP
After installing the core components for ActiveX Controls for Novell Services, you need to also install the necessary LDAP/NDAP/Socket component to get the necessary controls. These controls use the .DLL extension and not the .OCX extension that you expect for ActiveX controls.
NOTE
Although ActiveX Controls for Novell Services provides broad coverage of the most popular features of the NetWare C APIs, the controls do not wrap 100% of the available API set.
If you are a Delphi developer, you can use Delphi Libraries for Novell Services, which includes the DCU and PAS files needed to call the NetWare APIs from Delphi, instead of using ActiveX Controls for Novell Services.
Java fans will be glad to know that Novell has classes for Java and Java Naming and Directory Interface (JNDI) providers, as well as JavaBeans, available to use. Java applications can access NDS through the JNDI APIs, with or without Novell client software installed. If you’re more comfortable with scripting languages, such as VBScript, you’ll be happy to hear that Novell has support for them, too. For example, using the Novell Script for NetWare (NSN), which is a VBScript-compatible language for script automation and Web development on the Netscape FastTrack Server for NetWare platform, you can use Novell Script’s prebuilt components to access NetWare and integrate eDirectory, Oracle, Microsoft Access, MySQL, and Pervasive (previously Btrieve) databases into your Web applications.
NOTE
You install and configure Novell Script for NetWare when you install a NetWare 5.1 or later server. You can find the latest at http://developer.novell.com/ndk/nscript.htm.
More traditional Web page designers can use Perl 5 for NetWare with the Apache Web Server for NetWare or the NetWare Enterprise Web Server. Perl 5 support enables you to enhance and continue your investment in Perl scripts and Perl applications. At the time of this writing, Perl 5 for NetWare is at Perl 5.8 and provides system administration and common gateway interface (CGI) scripting functionality. You can use the Perl_LDAP modules to access NDS/eDirectory. However, the standard Perl_LDAP modules available from Comprehensive Perl Archive Network (CPAN; www.cpan.org) do not support eDirectory-specific extensions such as those related to partition operations. However, the version from Novell, which can be found at http://developer.novell.com/ndk/perl5.htm, includes a set of functions for performing extended operations (such as ChangeReplicaType) on eDirectory.
With the release of NetWare 6.5, Novell introduced PHP scripting support (used in conjunction with Apache Web Server) to NetWare 6.x servers. (PHP is a recursive acronym for PHP: Hypertext Preprocesser.) PHP for NetWare is based on open-source PHP (www.php.net). On NetWare, PHP supports standard extensions and extensions for LDAP, XML, and MySQL. It also has a UCS extension (PHP2UCS) that can be used to access various Novell services, such as eDirectory, file I/O, server management, and volume administration. Through UCS, PHP can use UCX components, JavaBeans and classes, and remote ActiveX controls.
NOTE
For information on how to set up a NetWare 6 server to take advantage of Apache, MySQL, and PHP/Perl scripting—generally referred to as AMP—see the white paper about NetWare AMP at http://developer.novell.com/ndk/whitepapers/namp.htm.
Full access to eDirectory and other NetWare services is available through the use of APIs published in the NDK. You can obtain the NDK by signing up with Novell’s DeveloperNet program. There are four levels in the program:
![]() Online or electronic level—You can sign up at this level at no charge. At this level, you can download the necessary NDK components from the DeveloperNet Web site and have access to all online documentation and Web-based training courses.
Online or electronic level—You can sign up at this level at no charge. At this level, you can download the necessary NDK components from the DeveloperNet Web site and have access to all online documentation and Web-based training courses.
![]() Professional level—In addition to getting all the benefits of the electronic level, at the professional level, you also receive one set of Novell Software Evaluation and Development Library (SEDL; formally known as the Software Evaluation Library [SEL]) CDs or DVDs, which also includes the NDK. In addition, you get two free Developer support incidents as part of this package. The cost of the professional level is $395 per year.
Professional level—In addition to getting all the benefits of the electronic level, at the professional level, you also receive one set of Novell Software Evaluation and Development Library (SEDL; formally known as the Software Evaluation Library [SEL]) CDs or DVDs, which also includes the NDK. In addition, you get two free Developer support incidents as part of this package. The cost of the professional level is $395 per year.
![]() Advantage and premier levels—Subscriptions to these two levels are by contract only. These levels are generally for companies that require direct hands-on support from Novell engineering. Advantage and premier memberships were designed with corporate developers, independent software vendors, independent hardware vendors, value-added resellers, and consultants in mind. The benefits of these two levels include everything available at the professional level plus more, as determined by the contract.
Advantage and premier levels—Subscriptions to these two levels are by contract only. These levels are generally for companies that require direct hands-on support from Novell engineering. Advantage and premier memberships were designed with corporate developers, independent software vendors, independent hardware vendors, value-added resellers, and consultants in mind. The benefits of these two levels include everything available at the professional level plus more, as determined by the contract.
TIP
Unless you have specific needs, the electronic level is probably sufficient for you. By signing up as an electronic-level member of DeveloperNet, you get no-charge, Web-based access to the NDK, DeveloperNet resources, DeveloperNet support forums (http://developer-forums.novell.com), and co-marketing opportunities. Visit http://developer.novell.com for more information about the DeveloperNet program.
This chapter provides a quick overview of how you can develop your own NDS disaster recovery and reporting utilities, using various programming and scripting languages, such as awk, C, and Perl.
In Chapter 11, you’ll learn how to apply the various troubleshooting techniques and utilities discussed so far to some commonly encountered real-world scenarios.