

When most people think about computer clustering, they’re reminded of large machines in datacenters processing immense amounts of data. In these pictures, large, well-funded organizations employ men in white jackets who must always carry around clipboards and nod solemnly before entering a mark of some sort on the clipboard. And it’s obvious, of course, that all these billions of dollars are being spent on some seemingly insurmountable task, such as where to go out to eat for dinner.
Linux clustering refers to many different types of situations where computers act in unison with each other, passing data and acting on it. You’ve already seen how load balancing is one of the simplest forms of clustering, in which one computer segregates data that is based on a certain rule set and passes it off to other computers. You’ve seen how high-availability type clusters use a simple heartbeat to make each computer aware of each other and how one computer can take over when another computer fails. You’ve also seen a greater amount of communication take place in distributed computing and its ability to solve jobs and pass them back onto a master node.
Parallel computing, although similar to distributed computing, in its simplest form distributes tasks between processors and returns a result. Of course, that’s the abridged definition. What actually happens behind the scenes is much more complex.
There are literally hundreds of books written on parallel computing, and thousands of documents and web pages devoted to every task imaginable on the subject. In this chapter, you won’t be looking at programming the cluster, or even optimizing the code for it. As part of a book written for system administrators, this chapter focuses on the theories behind parallel computing, the background behind it, and how to think about getting a parallel computer up and working quickly.
As discussed in Chapter 1, “Clustering Fundamentals,” parallel computing allows you to take data or processes and spread them across processors or nodes. This comes in handy for organizations or people who have large amounts of data that they need to process, and who can benefit from having their data run in parallel.
Running several computers in parallel isn’t enough to guarantee that your application benefits from running on several different nodes or processors at once. The data that you process must be appropriate for the parallel cluster. The setup program might be serial, instead of parallel, as it’s composed of gathering data and is being set up for processing. However, the data resulting from the setup program might be applicable for a parallel cluster.
Let’s say that you have an application that you want to run on a parallel cluster. The first thing to do is ask yourself if it will benefit from being run in parallel. The logic goes that if one computer can run a program well enough, why can’t several? If Quake is great on a single processor system, it should be absolutely wicked on a cluster. Unfortunately, this is seldom the case. The program has to be optimized for the environment. These first person shooter games are designed for single processor environments because of the fact that they don’t benefit from having a second CPU take the load off of a decent game. However, it does benefit from offloading a good deal of the graphic work onto a separate video chip, which is parallelism at its most basic level. One chip does the graphics processing, while the CPU on the motherboard handles the game engine.
What does benefit from a parallel cluster is an application that offloads much of the same thing to many different processors. If you had a search engine, and the search engine was designed to access data from millions, if not billions, of pages, the master node offloads each request that is being generated to each node in the cluster; however, each node in the cluster performs the exact same task, which is churning through the exact same algorithms to bring up each relevant web page.
Many mathematical applications benefit from being run in parallel mode, as they have components that are parallel. Take a program that parses the movement of quarks. Large subsections of space-time are mapped out on a lattice, with the behavior of quarks mapped on this grid. Remembering that there are six types of quarks with different physical properties, you want to map the behavior of the quarks not only across three dimensions, but a fourth as they move across time. Because there’s a lot of space-time to cover, and numerous quarks, this type of application is best served by a parallel cluster.
Here’s how it works: The master node houses the data and results. It transfers the data to and from storage, and distributes the data across each of the nodes or CPUs. Because there are potentially thousands of lattices to run data against, each node in the cluster is given the same formula, but different data to run against. Each node returns the result to the master node, which stores the result in a different database. The database is composed of data from many different sites that are doing the exact same thing. This other cluster takes the results of all these different clusters, and by project end, returns the answer to life the universe and everything, which is close to forty-two.
The problem with parallel code is that to achieve solid results the code has to be optimized for the cluster in which it’s intended. This is why, as a general rule, there’s no commodity software available for parallel computing environments. What works for one cluster is most likely not optimized for another because of network design and hardware. When designing your parallel cluster you have to take into consideration the number of nodes, if they’re symmetric multiprocessor (SMP) machines, if you’re using hubs or switches, if you’re using one master node or more, or perhaps a single Network File System (NFS) server or more. And the code has to be fine-tuned to work over the specific network topology.
To some, the term Beowulf is synonymous with parallel computing. The work that the original team did to promote supercomputer-like performance with commodity parts is now almost legendary. It needs to be said, however, that parallel computing had been around for some time, and vector computing even longer. The Beowulf project broke new ground by doing so with Linux and on commodity hardware.
Thomas Sterling and Don Becker started the project in 1994 at NASA-Goddard (CESDIS, The Center of Excellence in Space Data and Information Sciences) under the sponsorship of the ESS project, which comprised 16 486 DX4 processors connected by channel bonded Ethernet (www.beowulf.org/intro.html), for which he wrote the drivers. The project grew into what they called Beowulf. It was built primarily because of the dissatisfaction of established vendors and the lack of support. Today, Don Becker sits on the board of Scyld Corporation, still writes many of the drivers for Linux Ethernet, and contributes code to the Linux kernel.
Typically, a Beowulf computer is composed of a cluster of commodity network components. There’s been strict religious debate over this on the Beowulf mailing lists; some say that a cluster is only a Beowulf if it meets the following requirements:
The nodes are composed of strictly open-source software.
The nodes and network are dedicated to the cluster and are used only for high-performance computing (parallel computing).
The nodes are composed of only commodity, off-the-shelf components.
Some take this to mean that a Beowulf cluster can only run on Linux. However, there are other open-source operating systems that run on commodity hardware, such as FreeBSD. Why open-source software? Cluster development requires a good deal of custom code, and open kernels allow the freedom to change whatever doesn’t work. Closed source monolithic kernels, such as those on Windows NT, don’t allow for changes, so you’re limited in what you can do. Seeing what’s happening in the kernel allows you to rule out problems and to fine tune the existing code. If you’re not familiar with the kernel tweaks, it’s more than likely that someone on the Beowulf list or a fellow parallel programmer can help modify this. Programs such as Mosix have been written specifically through the ability to work with custom kernels.
The low cost of commodity hardware and the high cost of supercomputers helped to make projects such as Beowulf succeed. The availability of free software such as Linux, Parallel Virtual Machine (PVM), and Message Passing Interface (MPI), and a decent compiler such as gcc also served to make this type of computing readily accessible.
Scyld Linux and its Beowulf roots aren’t the only parallel software available. Many other models and software programs exist. What makes their software attractive is that they make installation, configuration, and monitoring a snap with their distributions. You can make your own high-performance cluster simply by adding the right network, hardware topology, and message-passing software, such as LAM, MPICH or PVM. Or you can take the same shell script and run it over each node a few thousand times.
PVM and MPI are software packages that allow you to write parallel programs that run on a cluster. These extensions allow you to write in Fortran or C. PVM was the de facto standard in parallel development until MPI came along, although both are still widely used. MPI is standardized and has now taken the lead in portable programs across all parallel computers. More information on these are covered in Chapter 9, “Programming a Parallel Cluster.”
The theory behind a cluster is that messages (data) are passed back and forth between nodes so that it is appraised of what each node is doing, and it can send data to be processed. These message-passing nodes are handled like letters sent by the post office. It tries to pass letters to the nodes through the most effective means necessary. It tries to pass a message to the node that it’s destined for, and it doesn’t tie up any routes in getting the message through the nodes, or router, if it’s on a different subnet. If most of your nodes are internal and happen to be composed of CPUs, the only thing stopping the system is the speed of the bus and the speed of the processors. When the server contains 20 or so processors, you have an effective and robust medium to pass messages between.
When each CPU lies on a different server, a more effective method has to be devised to pass data or messages between them. Instead of the bus being the primary means of transport between the CPUs, the network takes its place. The speed on the bus is much faster than the network, which becomes the primary bottleneck. Way before managed switches were common and affordable (not to mention certain parts of the world where they’re not so accessible), the nodes of a cluster had to be specially pieced together so that they benefited from the most performance to pass messages back and forth to each other. This was done primarily through means of a hypercube or mesh diagram configuration. Nowadays, with fast Ethernet (FE) and switches being so common and inexpensive, these old topologies are outdated.
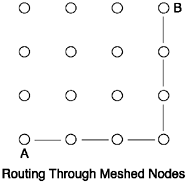
Some parallel machines have been designed in a mesh that you can visualize as lines on a sheet of graph paper. Each node is laid out with nodes spread to on right angles to each other. To pass messages to different nodes across the grid, each node in turn must relay messages through other nodes to get their message through. It’s not all that effective, but it gets the job done.
Figure 8.1 shows a grid of nodes and the route that the messages are supposed to take. Machine A has to pass messages through three nodes before Machine B can get them. Imagine what it takes to similarly design this in a Linux environment with commodity parts? It’s not impossible, but it is a wiring nightmare, with some of the machines in the grid requiring quad Ethernet cards to talk to their neighbors more effectively. The trick here is to get the nodes to talk to each other directly.
A more reasonable fully meshed node takes some of those quad Ethernet cards out and places hubs on the network. This is more cost effective and much less of a wiring nightmare, but you still have the problem of getting the nodes to talk directly to each other, and there is still plenty of hub cross talk. Remember that the network is the single greatest bottleneck. You’re not achieving optimal results with 16 computers on one hub.
Enter the hypercube. The hypercube tried to solve the problem of excess chatter in the design level by eliminating the need for hubs, yet not need the overhead of so many network interfaces. Each node in a hypercube only needs up to three interfaces. Figure 8.2 shows an example of a simple four-node cluster. In this example, each node needs only two network interfaces for direct communication with their neighbors. When four more nodes are added, direct communication becomes more difficult. A third network interface needs to be added for direct communication; however, messages still must be passed between nodes. This is more useful than the flat approach, as seen in Figure 8.1, because of the three dimensional design. You don’t have to pass through as many nodes.
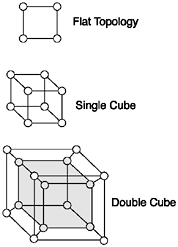
Adding eight more nodes to the hypercube gives you a box within a box, yet you still need only three network interfaces on each node. The number of messages passing increases, as does the complexity of the cube, although you still don’t have the issues of a flat topology. In a worst-case scenario with a flat topology, you have a maximum of 6 hops for a 16-node cluster, where you can get a maximum of 4 hops with a hypercube. Similarly, with a 256-node cluster, you have a maximum of 30 hops between nodes as opposed to 8 with a hypercube (High Performance Computing, O’Reilly & Associates, June 1993).
Enter the switch. Although in the past, it was common to design parallel clusters with a mesh or hypercube topology, switches are becoming extremely common and the prices are within reach of most budgets. With an initial out-lay of a little extra cash, you save yourself a lot of time, effort, and planning. The switch plays traffic director, which makes routing nightmares a thing of the past. The maximum number of hops is dependent now only on the number of switches that you have strung together for the single network. If you can afford it, drop fast ethernet all together, and go with Myrinet. It’s becoming the standard in gigabit networking for clustering, and although it is still the bottleneck in your cluster, it definitely won’t seem as bad. Myrinet, as you might remember, is a 1.28 Gbps full-duplex interconnection network that was designed by Myricom corporation. Myrinet uses a proprietary interface and switches that result in low latency. You might also consider straight gigabit cards. Although these don’t provide the bandwidth of Myrinet, they are less expensive than the Myrinet setup. They do suffer from more latency, although they’re still much faster than standard FE cards. If you can afford it, go for the higher bandwidth because it lessens the bottleneck pinch.
Up until now you’ve seen the best practices on how to build a cluster. You’ve gone over cluster installation and support, how to lay out the datacenter and network, and how to build mass quantities of machines from the ground up. Using tools such as Kickstart, SystemImager, and imaging programs such as Ghost for unix, you can deploy an unlimited number of machines for a parallel cluster in a manner of hours, as opposed to doing it by hand, which takes days.
If you’re doing everything from scratch, you must build the network and cluster infrastructure yourself or hire consultants to do it at exorbitant prices. You also need storage, such as a NFS server, storage area network (SAN), Parallel Virtual File System (PVFS), network access server (NAS), or even Internet Small Computer Systems Interface (iSCSI) to serve data and optionally home directories. You need a recommended gateway server to the outside network to shield the cluster, and as many nodes as your budget allows. Your gateway can also serve as the NFS server. Don’t forget the switches and cabling. Without connectivity, you’re going to have a hard time getting the machines to talk to each other. Power is always another good feature. Now that you have the infrastructure in place and have successfully imaged all the nodes in your cluster (complete with source hashing scheduling [SSH], .rhosts if you like living dangerously, Dynamic Host Configuration Protocol [DHCP], and host table information for all the nodes in your cluster), it’s time to incorporate the programming environment. What is a cluster without a programming environment? A POP (Pile of PCs), that’s what. Although you can install programs such as Mosix or Condor, as talked about in Chapter 7, “Distributed Computing,” a do-it-yourself cluster typically requires either PVM or some sort of MPI (LAM/MPI or MPICH).
Next, you need management software. This is covered in Chapter 10, “Cluster Management.” This enables you to view how your systems are doing at a glance. Applying workflow management software helps you to determine who gets access to which resource and when.
You can now either show your friends that you’re the most technologically inclined on your block (geek) or hand the system over to your boss with the satisfaction that it didn’t take much effort at all to build a parallel cluster.
The other option is to build your hardware infrastructure from the beginning and add a pre-built distribution that is specifically for parallel clustering. There are several pre-built distributions for you to choose from, which contain most of these tools.
The Scyld Linux Beowulf distribution is based on Red Hat Linux 6.2 with a custom kernel.
The setup for the Scyld Linux distribution is similar to the Red Hat installation. Scyld Linux needs the creation of a master node. It makes sense that this master node needs to be installed first. From there, you run the beosetup and it creates slave nodes for you.
The Scyld Linux distribution is designed to work as a switch setup as opposed to a hypercube where the nodes transmit information. The cluster needs to be set up first with the master node having two interfaces, a public subnet so that it can reach the outside world, and a private subnet that is hooked up to all the nodes in the cluster.
Scyld sells their professional product with varied pricing, depending on the number of CPUs in your cluster. For several thousand dollars, you get a nifty web interface, Alpha processor support, monitoring software, PVFS support, Preboot Execution Environment (PXE) support and a year’s support. Or you can buy the basic version from http://linuxcentral.com for $2.95 US.
Scyld Linux is nothing more than a custom Red Hat installation with a few extra packages that specifically refer to parallel clustering. The following is a list of packages that you can install upon setup, according to the install screens:
NAMD—. A parallel, object-oriented molecular dynamics code that is designed for the high-performance simulation of large biomolecular systems.
Atlas—. Part of the NetLib series of Linear Algebra libraries for high performance computing.
Beompi—. MPICH for Beowulf.
Beompi-devel—. Static libraries and header files for MPI.
Beonss—. glibc nss routines for Beowulf.
HPL (High-Performance Linpack)—. Part of the NetLib series of Linear Algebra libraries for high-performance computing. HPL is a software package that solves a (random) dense linear system in double precision (64 bits) arithmetic on distributed–memory computers.
MPIBLACS (MPI Basic Linear Algebra Communication Subprograms)—. Part of the NetLib series of Linear Algebra libraries for high-performance computing.
Mpirun—. Parallel job launcher for Beowulf-2 systems.
Npr—. Demonstration coscheduler that uses the beostatus library.
PARPACK—. Part of the NetLib series of Linear Algebra libraries for high-performance computing. PARPACK is a collection of Fortran77 subroutines that are designed to solve large-scale eigenvalue problems.
Scalapack—. Part of the NetLib series of Linear Algebra libraries for high-performance computing.
Insert the Scyld CD-ROM and boot from it. Scyld runs the typical Red Hat setup, but gives you three options: You can boot install Beowulf with Gnome, use a controlling, text-only machine, or boot with a custom configuration. Installing with Gnome gives you all the features of a normal workstation, including things such as printer support, synergy advanced multipurpose bus arbiter (SAMBA), and freecell. The only other way that the install differs from the Red Hat default install is that it offers to configure the internal interface and DHCP ranges for the subsequent slave nodes. The Scyld setup program recommends initially that you set up the internal interface on the 192.168 subnet, but of course that’s up to you. The install file puts the resulting entries in /etc/beowulf/config, so if you mess up, or need to change things, you can edit this file. At boot, this is called /etc/rc.d/init.d/beowulf.
Select what you want installed, optionally create a boot disk, configure X support, and reboot. You’re done installing the master node. If you get stuck, the documentation is on the master node in /usr/doc/beowulf-doc.
Installing the slave nodes of Scyld is slightly more difficult. Log into the master node as root, and run the beosetup gui. This allows you to make a boot disk for the slave nodes. Run /usr/bin/beosetup on the master node. All configuration is done on the master node, as the main distribution also installs the boot kernel for the slave nodes.
You can either use the CD-ROM to create slave nodes, or create a floppy to get an address and register itself with the master node. After the remote systems are booted, they register themselves with the master node. Drag the node to the configured nodes middle listing, where they register themselves with the cluster and start accepting jobs. Figure 8.3 shows a node being created with beosetup.
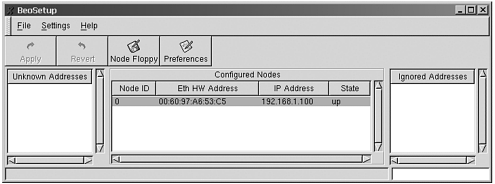
Create a floppy so that you can install the nodes, and get them to boot up so that you can indeed drag them with beosetup and register them. Creating a floppy is done by inserting a floppy in the drive, clicking the Node Floppy button, and pointing the destination path to the correct floppy drive, which is usually /dev/fd0.
After beosetup has finished the floppy installations, insert them into the slave computers and boot. The (Media Access Control (MAC) addresses register into the Unknown Addresses section of the beosetup upon startup. Drag these into the Configured Nodes section where they can register themselves into the database. After these are registered, it’s time to partition your nodes. If the slaves have a problem coming up, check the error logs on the master node, in /var/log/Beowulf/ node.<node>. If you haven’t partitioned the disks yet, you automatically get an error. Don’t worry about that, unless you’ve already partitioned and you’re still drawing errors.
If your nodes are already partitioned, record the information into /etc/beowulf/fstab on the master node. If not, you’ve got two choices: Either you can install default partitioning on the slave nodes, or you can manually partition the slave nodes however you wish. All partitioning is done from the master node. Following is how to quickly partition the slave nodes with a default setup:
#/usr/sbin/beofdisk –q #/usr/sbin/beofdisk –w #/usr/bin/beoboot-install –a /dev/hda <or /dev/sda, or default boot device> #/usr/sbin/bpctl –S all –s reboot
The first line tells beofdisk to query partitions for the slave nodes. The second line creates default partitions for the nodes. The third line writes the partition table to the drives. The fourth line installs the kernel on /dev/hda (or /dev/sda) and sets the partition as bootable so that you don’t have to boot off the floppy each time you bring the cluster up. You can select which node you write to with the beofdisk –n <node> option. Remember that the nodes start at n-1,so that the first node is always node 0.
The default partition includes three partitions: a boot partition of 2MB, SWAP Space consisting of twice the amount of physical memory, and the rest is put in as a default root partition.
Note
It’s interesting that you can bring up each node in the cluster with just a floppy with the Scyld kernel on it. If you have a notebook with the Scyld distribution installed and a handful of floppies, you can walk right into a lab or classroom, jack into the network, install floppies into the lab machines, and reboot them all. Voila—instant parallel cluster.
If you’re not comfortable with the beofdisk installing a default partition on each node in your cluster, partition the cluster yourself using beofdisk. This is a neat little utility that lets you partition everything at once from the master node.
You can manually partition the disks from the master node with the bpsh utility. Running bpsh <node number> fdisk lets you run the fdisk utility on the remote node. Setting your own partition is reflected in /etc/beowulf/fdisk by the disk type, position, and geometry (disktype:position:geometry).
And don’t forget to reboot with the following:
#/usr/sbin/bpctl –S all –s reboot
You now have a working copy of Scyld Linux after you install the kernel on the slave nodes and reboot. These should all boot easily and register themselves with the master node, ready to accept jobs, assuming that you’ve registered them as configured nodes.
One of the benefits of the Scyld Linux distribution is the ifenslave command, which is designed to scale network bandwidth. In its simplest term, channel bonding allows you to take multiple networks and trunk them together as a single network with more bandwidth. The use of the resulting bandwidth is transparent to the cluster, except for the resulting speed gain.
The ifenslave program works similar to the ifconfig command, although it bonds higher networks to lower ones. For example, it bonds eth1 and eth2 to eth0. This program doesn’t allow for general trunking, however you’re not limited to using ifenslave on Scyld Linux computers. All computers that talk through this method also must be connected to others that talk through this method. If you’re using channel bonding with one node, you must implement it on all nodes, or it doesn’t work.
The ifenslave program comes standard with the Scyld Linux distribution, or you can build it for other applications at www.beowulf.org/software/bonding.html
For example, if you have an eight-node cluster, you’re going to implement channel bonding throughout on two channels. Each node in the cluster has two network cards (except for the master node, which needs an extra to talk to the outside network). You also need two different networks, which means two different hubs, switches, or one switch with segregated virtual local-area networks (VLANs).
To start, type
#modprobe bonding #ifconfig bond0 192.168.0.1 netmask 255.255.0.0 #ifenslave bond0 eth0 eth1
which first creates bond0 and then slave eth0 and eth1 to bond0. You have to bond the slave nodes before the master node. Be careful when using this command; channel bonding the master when the slaves aren’t configured correctly can result in the slaves rebooting and being unable to pick up an arp request to register themselves back on the cluster.
After your cluster is set up, you’re ready to start launching remote jobs from the master node. You’ll most likely want to look at programming solutions such as an MPI running code that’s distributed with Scyld. MPI and PVM concepts are covered in the next chapter. Have fun; you’ve got a working Beowulf cluster.
You can use many different software distributions with clustering. The Scyld distribution happens to be one of the more common distributions, as is PVM. Environments such as these give the user a handy means of running parallel applications across many environments.
With the right planning for your network and hardware topology, you can come up with a decent cluster in no time. And you don’t need a dedicated clustered environment to work from, as you see in the next chapter.