
In many real deployment scenarios, endpoints are located behind Network Address Translation (NAT) devices. The NAT functionality was designed sometime ago, when most of the Internet traffic was client to server. At that time, clients were just opening TCP connections to web or email servers in the public network, and the NAT device performed address translation and let the responses flow back to the client. Today, NAT devices are deployed everywhere—in enterprises connected to Internet, in end users who share the same public IP address among several devices, and so on. In this landscape, the new peer-to-peer multimedia services come into play, and we then find that NAT has pernicious effects on SIP and media traffic. There is no option to modify the NAT devices—they are already there. So we have to invent some ingenious mechanisms to overcome the problem. This chapter gives an overview of the problems caused by NAT, related specifically to SIP signaling and media transfer, and presents several possible solutions.
We start by reviewing the NAT fundamentals. Then we try to categorize the different NAT behaviors encountered in real deployments. This will help us to better address the NAT traversal problem. We will then focus on the issues associated with NAT traversal of SIP, and propose some solutions. After that, we will touch upon the issues and solutions for the media traversal problem. We will base our analysis of the previous topics on the work that is currently being conducted in several IETF WGs. We then, in the last section, present the Session Border Controllers, which represent the industry’s response to solve, among others, the NAT traversal problem.
Network Address Translation is a mechanism to connect an isolated internal realm with private IP addresses to an external realm with globally unique registered addresses. The NAT functionality is typically implemented in a private domain’s edge router that connects to the public domain. This is shown in Figure 22.1.

There are various types of NAT,[1] though the most widely deployed, by far, is the so-called Traditional NAT. Figure 22.2 shows the different types of NAT.

In this book, we will consider only Traditional NAT, and we will refer to it simply as NAT. Traditional NAT (or simply NAT) is further split into two types:
Basic NAT
Network Address and Port Translation (NAPT)
In Basic NAT, whenever an internal host sends a packet to an external host, the NAT device translates the internal (private) source IP address in the outgoing IP packet into an external (public) IP address owned by the NAT device. Similarly, for IP packets in the return path, the NAT device translates the public destination IP address in the incoming IP packet into the host’s private address. This is depicted in Figure 22.3.

The mapping rule between private and public addresses can be static or can be dynamically created when the first packet from private address A to public address B traverses the NAT.
The mapping rule in the NAT could be expressed as:
For outgoing packets (Table 22.1)
For incoming packets (Table 22.2)
NAPT is similar to Basic NAT, except for the fact that it also translates TCP/UDP ports. In this way, an NAPT device with only one public IP address can map all the internal private IP addresses and ports to the same external public IP address, but with different ports, which allows for a significant saving in public IP addresses to be owned by this NAPT device. Figure 22.4 shows:
Internal host with private IP address “A” using source port “a” to communicate with port “b” in external host with IP address “B”
Internal host with private IP address “C” using source port “c” to communicate with port “d” in external host with IP address “D”
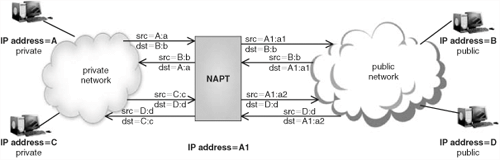
As can be seen in Figure 22.4, the NAPT device uses the same public source IP address (A1), though with different ports (a1, a2) for the packets from A and C, respectively.
The mapping rule in the NAPT device could be expressed as follows—where uppercase letters represent IP addresses, and lowercase letters indicate ports:
For outgoing packets (Table 22.3)
For incoming packets (Table 22.4)
NAT and NAPT functionalities may be combined in a single device that can manage a pool of IP addresses (instead of one), and can perform translations of both addresses and ports. During the rest of the chapter, we will use the term “NAT device” (or simply NAT) to refer to a device that supports both Basic NAT and NAPT functionalities (and their combination).
We have just described the very basic principles of NAT. Nevertheless, existing NAT devices, although fulfilling the basic functions, may exhibit different types of behaviors. Understanding these possible behaviors is crucial in order to successfully address the problems that NATs pose to peer-to-peer traffic (e.g., SIP and media).
NAT traversal of UDP traffic is particularly challenging, so it is important to understand what the NAT observed behavior for UDP traffic is with respect to two aspects:
Address mapping
Filtering
Filtering refers to the NAT’s capability to block incoming traffic. Filtering behavior defines the security characteristics provided by the NAT.
The observed NAT behavior for UDP traffic is described in [RFC 4787].
As we saw previously, when a first packet goes from A:a to B:b, a mapping is created in the NAT that maps the internal address A:a to the external one A1:a1. All subsequent packets from A:a to B:b will use this mapping.
Now, assume that a new packet is generated from A:a to a new destination C:c. What mapping will the NAT apply? Will it reuse the existing mapping, or will it create a new one? Different NATs behave differently regarding this point. More specifically, three different kinds of behaviors have been observed:
Endpoint-independent mapping:
The NAT reuses the same mapping for subsequent packets from the same internal IP address and port (A:a) to any external IP address and port (C:c).
Address-dependent mapping:
The NAT reuses the same mapping only for subsequent packets from the same internal IP address and port (A:a) to the same external IP address, irrespective of the destination port.
Address- and port-dependent mapping:
The NAT reuses the same mapping only for subsequent packets from the same internal IP address and port (A:a) to the same external IP address and port.
When a mapping is created in the NAT, a filtering rule is associated with the mapping. The filtering rule defines the criteria used by the NAT to filter incoming packets from specific external endpoints. Three different behaviors have been observed:
Endpoint-independent filtering:
The NAT filters out only packets not destined to the internal address and port (A:a), regardless of the external source IP address and port.
Address-dependent filtering:
The NAT filters out packets not destined to the internal address and port (A:a). Additionally, it also filters out packets destined to the internal address (A:a) if they are not coming from B (that is, from the address to which A:a previously sent packets).
Address- and port-dependent filtering:
The NAT filters out packets not destined to the internal address and port (A:a). Additionally, it also filters out packets destined to the internal address (A:a) if they are not coming from B:b (that is, from the address and port to which A:a previously sent packets).
NAT devices that exhibit both endpoint-independent mapping and endpoint-independent filtering behavior are typically called endpoint-independent NATs.
Likewise, NAT devices that exhibit both address- and port-dependent mapping and address- and port-dependent filtering behavior are typically called address-and port-dependent NATs.
We will now see an example of a couple of different NAT behaviors for UDP traffic. For the time being, we will not refer to a particular application protocol—we will refer just to generic UDP packet exchange between different parties (these packets might represent, for instance, SIP or RTP traffic).
Figure 22.5 depicts how this type of NAT behaves in different scenarios.

First, John sends to Alice a UDP packet (0) that opens a pinhole in the NAT.[2] The different scenarios shown in Figure 22.5 are:
Alice sends a packet to John with the same source address and port as the destination address in the received packet. The packet traverses NAT. Whatever the type of NAT is, this packet would always traverse the NAT because it is part of the virtual bidirectional UDP channel established in the NAT with the first outgoing packet.
Alice sends a packet to John with a source port that does not coincide with the destination port in the received packet. The packet traverses the NAT because the NAT exhibits an endpoint-independent filtering behavior—that is, whoever sends packets to John’s destination address and port is sure to traverse the NAT.
Robert sends a packet to John from a different address and port. Again, the packet traverses the NAT.
John sends a new packet from the same IP address and port to Robert. Because the NAT exhibits an endpoint-independent addressing behavior, the previously created mapping is reused.
Figure 22.6 depicts how this type of NAT behaves in different scenarios.
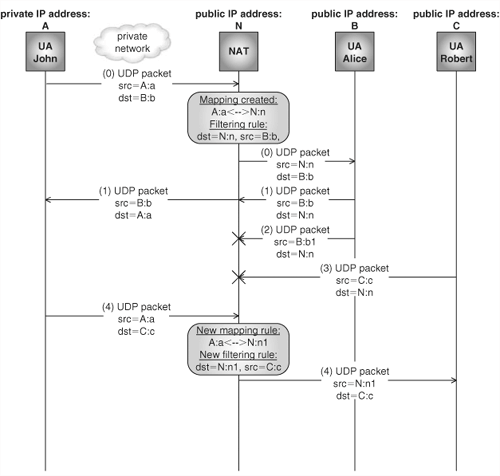
First, John sends to Alice a UDP packet (0) that opens a pinhole in the NAT. The different scenarios shown in Figure 22.6 are:
Alice sends a packet to John with the same source address and port as the destination address in the received packet. The packet traverses NAT. Whatever the type of NAT is, this packet would always traverse the NAT because it is part of the virtual bidirectional UDP channel established in the NAT with the first outgoing packet.
Alice sends a packet to John with a source port that does not coincide with the destination port in the received packet. The packet fails to traverse the NAT because the NAT exhibits an address- and port-independent filtering behavior, and, in this case, the port was changed.
Robert sends a packet to John from a different address and port. Again, the packet fails to traverse the NAT because neither port nor address coincides with the destination ones in the received packet (in this type of NAT, it would be sufficient that either the IP address or the port is changed so as to cause the packet to be filtered out in the NAT).
John sends a new packet from the same IP address and port to Robert. Because the NAT exhibits an address- and port-dependent addressing behavior, a new mapping is created in the NAT.
There are two main issues posed by NATs to SIP traversal:
Routing of SIP responses
Routing of incoming requests
First we will tackle the case where UDP is used.
Let us recall from Chapter 7 how routing of responses in SIP works irrespective of the presence of NATs. This is depicted in Figure 22.7. In this figure, “src” and “dst” refer, respectively, to the source and destination addresses and ports present in the packet at the IP and UDP headers. When John wants to send a SIP request to Alice, he would set the sent-by field in the Via header to his own IP address (A) and port (5060) where he wants to receive the response to the request. This port may or may not coincide with the actual source UDP port (a) in the actual IP packet.
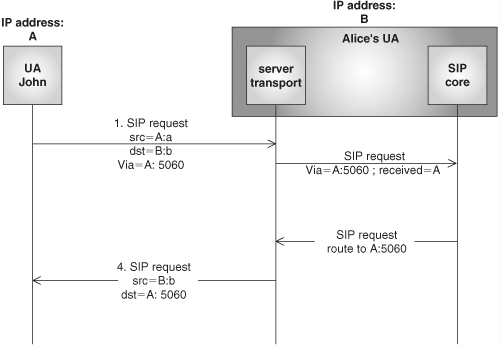
When the request gets to Alice’s UA, her UA examines the origin IP address (in the IP header), and sets the “received”[3] parameter in the Via header to that value (A).
In order to send back a response, Alice directs it to the IP address in the “received” parameter (A) and to the port in the sent-by field (5060). As a consequence, the message is routed back to John.
Let us assume now that John is in a private domain behind a NAT device, whereas Alice is in the public Internet. When John’s request reaches the NAT, the NAT will replace the internal origin IP address and port with an external IP address and port. When Alice now tries to send the response back to John, the response will be directed to the address in the received parameter—which coincides with the external address allocated by the NAT, but to a port that was selected by John (different from the source port in the request). This port is not open in the NAT. Therefore, the response will be rejected by the NAT. Figure 22.8 shows this scenario.
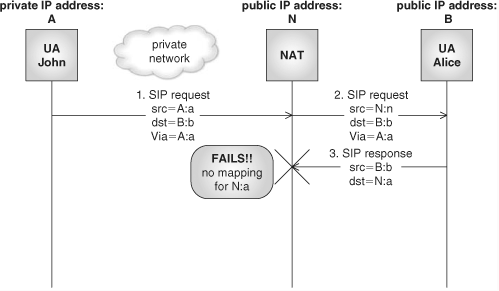
If John uses TCP, this problem would not occur because Alice would send the response back through the TCP connection in which the request was sent. This connection is open in the NAT. This is shown in Figure 22.9.

The second issue refers to the routing of incoming requests. Let us assume that John is in a private domain behind a NAT device. In order to be able to receive calls, he first needs to register with his SIP server. So John generates a REGISTER message in which he indicates a contact address. The contact address contains John’s private IP address and a port where he desires to receive incoming requests. Such a port in principle does not coincide with the source port used to send the REGISTER.
When an incoming request reaches the SIP server, it will retrieve the contact address and attempt to route the request toward a private IP address, which will fail.
This problem exists irrespective of the transport protocol that is used (UDP or TCP). This is shown in Figure 22.10.

The first of the previous problems (routing of responses) can be solved with a new SIP extension called “Symmetric response routing,” described in [RFC 3581].
A client that supports this extension performs, when sending the request, two additional actions:
Includes an “rport” parameter in the Via header. The parameter must have no value.
Prepares itself to receive the response on the same IP address and port it used to populate the source IP address and source port of the request.
Likewise, a server that supports this extension will, when receiving the request, set the value of the “rport” parameter to the source port of the request. Moreover, in order to send the response back, it will:
Send the response to the IP address indicated in the “received” parameter, and to the port indicated in the “rport” parameter.
Send the response from the same IP address and port that the corresponding request was received on.
If both John and Alice support the previously described extension, routing of SIP responses through any type of NAT does not pose any problem. Effectively, the response will always be sent to an address that is open in the NAT and that is routed to John. Moreover, given that the source IP address and port of the response are the same as the destination IP address and port in the original request, the request will not be filtered out by “address-dependent” or “address-and port-dependent” NATs. This is depicted in Figure 22.11.
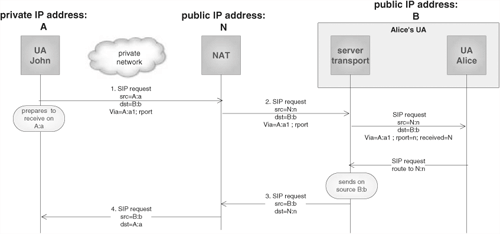
A solution to the second problem (routing of incoming requests) might be based on slightly modifying the core SIP registration process [draft-ietf-sip-outbound].
If UDP is used when a REGISTER is received, the SIP server might store the “flow” (that is, source IP/port and destination IP/port) on which the REGISTER was sent, and associate it with the AOR. The sending of the REGISTER would cause the NAT to open a pinhole for that flow. When a new request is received, the server will send the request within the same flow, therefore assuring that the request will traverse the NAT. This is shown in Figure 22.12.

If TCP is used, the TCP connection used for the registration opens a pinhole in the NAT. This connection should be kept open so that incoming requests can reuse it to traverse the NAT and reach the UA.
A problem associated with the mechanism described before refers to the fact that the mappings in the NAT expire after periods of inactivity. An incoming request might come a long time after the registration is done, so there is a need for a refresh mechanism that keeps the pinhole open. This might be done by having the client issue REGISTER requests after some timer expires or by sending other protocol messages (e.g., STUN messages[4]).
A best current practices (BCP) document for NAT traversal for SIP is actually in progress in the IETF [draft-ietf-sipping-nat-scenarios].
Let us consider that both John and Alice are located in private network domains behind respective NAT devices. Both domains are connected to the public Internet. The scenario is depicted in Figure 22.13.

Now John wants to call Alice. We will assume that the SIP signaling traverses NAT without problems, based on the solutions discussed before. During the SDP offer/response exchange, an IP address and port combination are specified by each UA for sending and receiving RTP media. Given that the endpoints are located in private domains, the IP addresses specified in the SDP are also private. Therefore, once the SDP exchange is completed, John and Alice will try to send packets to private addresses that are not resolvable in the Internet; thus, the submissions will fail. This situation is depicted in Figure 22.14.

Though the RTP problem when traversing NAT is quite obvious, the solutions to overcome it are not so simple. Furthermore, different NAT topologies and different NAT behaviors increase the difficulty of proposing a single solution. We will now examine some NAT scenarios and their solutions. The focus of the scenarios is on the RTP traffic, so we will assume that the SIP signaling traversal of NAT has already been resolved.
In order to start with a simple scenario, let us assume that John is behind a NAT and wants to communicate with Alice, who is on the public Internet (and who definitively knows that she is on the public network).
The SDP offered by John contains a private address that is not routable, therefore no audio will flow from Alice to John. On the other hand, Alice’s IP address in the SDP response is a public address, thus RTP packets can flow from John to Alice.
A possible mechanism to overcome this problem is to use “Symmetric RTP.” This technique implies that John will transmit and receive RTP packets from the same IP address and port combination. Symmetric RTP is described in [RFC 4961].
Let us assume that both John’s UA and Alice’s UA support symmetric RTP. When John receives Alice’s SDP, which contains a public IP address, John’s UA will start transmitting RTP packets to that destination. Let us assume that the source IP address and port that he uses for sending the RTP packets are A:a. If John’s UA supports symmetric RTP, it will then prepare itself to receive incoming packets in that same address and port (A:a).
When the outgoing RTP packet from John reaches the NAT, the NAT will select an external IP address and port (A1:a1), and will forward the packet to Alice. A pinhole has been created in the NAT. When the packet reaches Alice, there is an extra intelligence needed in Alice’s UA such that, if her UA knows that it resides in the public Internet, the UA is able to detect that the source IP address and port of the received RTP packet do not coincide with the IP address and port indicated in the received SDP. Alice’s UA will ignore the SDP information and start sending RTP packets to that address (A1:a1). Because Alice’s UA also supports symmetric RTP, the source address and port of the packets that she sends back match the destination address and port of the incoming RTP packets. Therefore, when the RTP packets that she generates reach the NAT, there already exists a pinhole that lets the packets flow back to John.
This technique works for all the possible behaviors of NATs. This scenario is depicted in Figure 22.15.
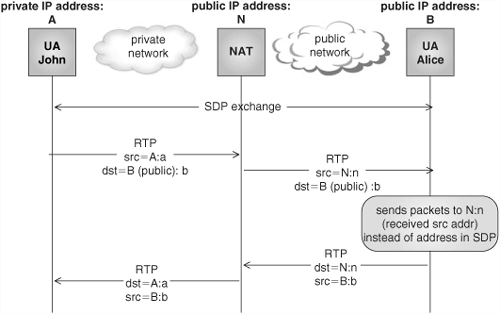
We will consider now a more complex scenario in which both John and Alice are located in private networks behind respective NATs. Both networks are connected to a public network.
In this scenario, if both NATs exhibit an endpoint-independent behavior, there is a relatively simple way to overcome the NAT traversal problem. Such a solution consists of using the STUN protocol.
The STUN (Simple Traversal Utilities for NAT) protocol is a lightweight protocol that offers several tools to assist in NAT traversal. The different tools or functionalities that STUN offers are realized by using the protocol in specific ways, so-called STUN usages.
STUN was specified in [RFC 3489], though it is now under revision in [draft-ietf-behave-rfc3489bis]. Several STUN usages are being currently defined for STUN, such as:
the binding discovery usage [draft-ietf-behave-rfc3489bis]
the binding keep-alive usage [draft-ietf-behave-rfc3489bis]
the short-term password usage [draft-ietf-behave-rfc3489bis]
the relay usage [draft-ietf-behave-turn]
the NAT-behavior discovery usage [draft-ietf-behave-nat-behavior-discovery]
the connectivity check usage [draft-ietf-mmusic-ice]
In order to cope with Scenario 2, the STUN binding usage may be used. The STUN binding usage represents the classical usage of STUN. It allows a client behind a NAT device to learn what are the public address and port that the NAT will assign, as a source address, to the packets generated by the client. Once the client has obtained that information, it can then include the public address in whatever application-level (e.g., SDP) fields are required in order to achieve NAT traversal. This procedure allows the client to obtain its public address (the so-called “reflexive transport address”) if the NAT is endpoint independent. If the NAT is endpoint dependent, this STUN usage is not helpful, as we will see in Scenario 3.
The simple architecture for STUN binding usage is depicted in Figure 22.16.

The client sends a STUN Binding request message to the STUN server, whose address is somehow known by the client (e.g., preconfigured). When the STUN request traverses the NAT, the STUN server changes the source address to A1:a1. The STUN server receives the request, and copies the source transport address into the MAPPED ADDRESS parameter of the STUN response. It sends back the message to the client to destination address A1:a1. The message traverses the NAT through the previously created pinhole, and is received by the client, who looks at the MAPPED ADDRESS parameter and learns its reflexive transport address.
Let us see now how the STUN binding discovery usage is used in the end-toend scenario between John and Alice. Both UAs need to implement a STUN client. The way it works is quite simple. Before sending the SDP offer or SDP response, John and Alice just need to use STUN in order to obtain their respective reflexive transport addresses, which they will then include in the corresponding SDP offer and answer.
The addresses contained in the SDP offer/answer would now be a routable public address for which, moreover, there is a pinhole in the NAT that was opened during the STUN transaction. Therefore, RTP traffic can flow in both directions. This scenario is shown in Figure 22.17.
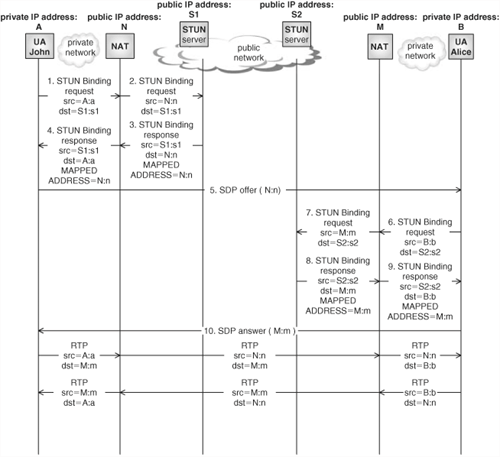
The flow shown before is purposely oversimplified so that the reader can focus on the crucial STUN functionality. More specifically, the flow does not show the STUN authentication process, which is a necessary aspect of the protocol. Another aspect that is not shown is the STUN Binding request, which is needed to obtain the client’s reflexive transport address for RTCP traffic. In the picture, we showed only the Binding request for obtaining the RTP address, but it is also necessary to get the RTCP one. Because there is a NAT in between, it cannot be assumed that the RTCP port selected by the NAT will always be RTP port + 1; thus, RTP and RTCP transport addresses need to be separately specified in the SDP. [RFC 3605] defines an extension attribute to SDP that can be used to carry the transport information for RTCP.
The scenario previously described is useful only to traverse endpoint-independent NATs.
A more complex scenario occurs when both John and Alice are located behind address-dependent or address- and port-dependent NATs. In this case, the STUN binding usage does not help because the NAT would block all incoming packets that are not coming from the STUN server (after the sending of the STUN message, the client has only a bidirectional virtual UDP channel with the STUN server). In these cases, the only way to resolve the scenario is to use the STUN server as an RTP relay. For such purpose, the STUN relay usage has been defined, which allows the STUN client to obtain a “relay address” from the STUN server. The STUN request used to obtain a relay address is called “Allocate request.” Both John’s UA and Alice’s UA will include such relay address in their respective SDPs, thus forcing the RTP traffic to traverse the STUN servers. Because all the RTP traffic traverses the STUN servers, it will use the pinhole open in the NAT for the virtual bidirectional UDP channel created in the first STUN transaction between UA and STUN server.
This scenario is depicted in Figure 22.18. When John sends media, the RTP packets are targeted at M:m, but they are encapsulated in a STUN message targeted at S1:s1, so that the NAT can be traversed. When the message arrives at John’s STUN server, the server extracts the RTP packet and sends it to M:m, which is a relay address in Alice’s STUN server.

Again, the diagram does not show either the STUN authentication or the Allocate request needed for the RTCP traffic.
Because the relay function consumes a lot of resources in the STUN server, it is recommended that this approach is used just where there are no other possible solutions—that is, only in case of endpoint-dependent NATs.
We have so far seen that RTP traversal through NAT is not a simple task. Moreover, different solutions are required depending on the scenario. What is needed is a kind of umbrella mechanism that can automatically discover what the NAT scenario is, and apply the right tool in order to solve it. An attempt to provide such a mechanism is being conducted in IETF. The mechanism is called ICE (Interactive Connectivity Establishment), and is an extension to the SDP offer/answer model that allows UAs to discover and agree on the right mechanism to use for NAT traversal.
The ICE mechanism is quite complex, and will not be analyzed in depth here. Interested readers are referred to the Internet draft where it is currently being defined [draft-ietf-mmusic-ice].
In essence, ICE works as follows. Before the SDP exchange takes place, both John’s UA and Alice’s UA employ the STUN binding and relay usages in order to obtain a mapped and a relay address. They then initiate the SDP exchange, including these addresses in the SDP body as CANDIDATE addresses (these are carried in new SDP attributes). Candidates are ordered in highest to lower priority, and the UAs form pairs between their candidates and those of their peers. Once this is done, both UAs make use of the STUN connectivity check usage [draft-ietf-mmusic-ice] that allows them to determine which pairs of addresses permit NAT traversal. Once a pair is selected, John and Alice start sending traffic to those addresses. This scenario is depicted in Figure 22.19.
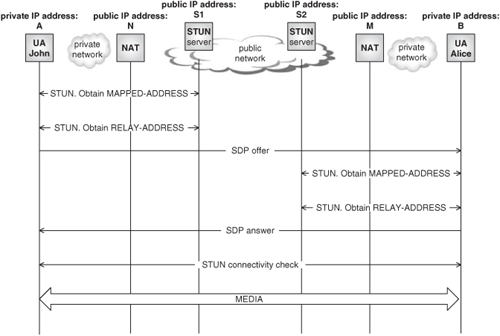
We have seen that the traversal of SIP and SDP traffic through NAT devices is not a simple task. In particular, traversal of SDP does not have an easy solution, and the ICE protocol is really complex. Furthermore, ICE imposes extra requirements in User Agents who have to implement a full-fledged STUN client.
A different solution for NAT traversal proposed by the industry is currently very successful. It consists of making the NAT traversal function reside in a piece of equipment called a Session Border Controller (SBC).
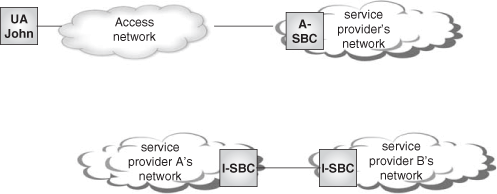
The term SBC has been coined by the industry to refer to signaling and media intermediaries that implement generic border control functions. Border control functions are functions needed at the border of IP-based communication networks. Two scenarios for SBC deployment exist:
Interconnect scenario: The SBC sits between two service provider networks in a peering environment. In this case, SBCs are typically referred to as I-SBC (Interconnect SBC) or N-SBC (Network SBC).
Access scenario: The SBC is placed at the border between the access network and the service provider’s network. In this case, SBCs are typically referred to as A-SBC (Access SBC).
Both scenarios are shown in Figure 22.20.
SBCs typically handle both signaling and media. Regarding the SIP signaling, they act as Back-to-Back User Agents (B2BUAs). See Figure 22.21.

The most common border control functions implemented by SBCs[5] are:
Topology hiding: They can implement the header privacy service that we discussed in Chapter 20, thus avoiding the fact that the information in some headers (e.g., Via, Record-Route, and so on), which can give information about the network topology, is provided to the other network. Additionally, they can also provide session privacy.
DOS protection: SBCs can protect from denial of service or other malicious attacks.
Access control: SBCs can be used to block traffic from unauthorized parties or from traffic that does not meet specific policies. For instance, the SBC can ensure that only media from authorized sessions is allowed to pass through the SBC.
Media traffic control: SBCs can implement a variety of functions related to controlling the media traffic—such as bandwidth control (checking that used bandwidth corresponds with what was negotiated in the SDP), bearer detection (detecting if media has stopped flowing, and consequently terminating the session), and so forth.
Protocol repair: So as to maximize interoperability, SBCs can repair protocol messages generated by clients that are not fully standard.
Protocol interworking: Allows us to bridge between different flavors of SIP (e.g., IETF and 3GPP). SIP extensions or methods that implement the same function differently can be interworked.
Media encryption: In those cases where encryption is required in the access network but not in the core network, an A-SBC can perform encryption/decryption at the edge of the network.
Lawful interception: In some scenarios, this may be necessary due to regulatory constraints (especially in telecom operators’ deployments of SIP infrastructure).
In addition to these functions, SBC vendors also incorporate NAT traversal functions in the Session Border Controllers. Moreover, SBCs represent the most common solution taken by service providers in order to resolve the NAT traversal problem for SIP and RTP traffic.
Using SBCs to solve the NAT traversal issue has the advantage that it does not require the clients to support more or less complex STUN and ICE functionality. Moreover, it is able to resolve NAT traversal for all types of deployed NATs. Also, given that SBCs are already in both the signaling and the media path of the communications traffic in order to resolve other functions, using SBCs does not imply an extra intermediary.
For SBC-assisted NAT traversal to work properly, the endpoints must support the following extensions, which were mentioned previously in the chapter:
In the next section, we will describe in detail the SBC operation for NAT traversal.
Let as assume that the endpoints are located behind a NAT, and are connected to a service provider’s network. The service provider would deploy an access SBC at the border between its public network and the private network. The A-SBC may implement several border control functions, including NAT traversal. The basic architecture is shown in Figure 22.22.
In order to assist in NAT traversal, the SBC acts as a B2BUA that is in the path of all signaling originated or terminated in the UA. The solution to NAT traversal is based in the following principles:
Both client and SBC will maintain open the TCP connection created to deliver the REGISTER message. The SBC will transmit any incoming SIP request toward the UA through that TCP connection.
The SBC will change the Expires header in the 200 OK response to the REGISTER request so as to force the UA to generate traffic that keeps the binding in the NAT alive. The SBC does not need to relay all the REGISTER requests received from the UA to the registrar. The SBC will instead respond autonomously to those requests until its own registration timer expires, at which point it will send the REGISTER to the registrar again.
In this case, both UA and SBC have to support symmetric SIP so as to create a virtual bidirectional channel.
Just as with TCP, the SBC will reduce the value in the Expires header in the 200 OK response that it sends to the UA so as to assure that the binding in the NAT is kept open.
Let us now see in more detail how this works. The call flow is depicted in Figure 22.23.
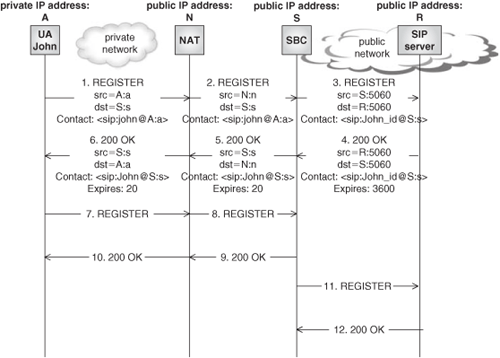
We will assume that the client is using UDP, but the flow for TCP is identical. Both John and SBC must support symmetric SIP.
1. | John sends the REGISTER request to the SBC (configured as its outbound proxy). The REGISTER is intercepted by the NAT device, which will change the source IP address and port number, and forward the REGISTER to the SBC. |
2. | When the SBC receives the REGISTER request, it checks the address set by the UA in the Via header against the packet’s source IP address. If they do not match, it means that there is a NAT between the UA and the SBC. Therefore, the SBC decides to assist the UA in NAT traversal.[6] |
3. | The B2BUA in the SBC creates a new REGISTER message setting the contact address to its own, and sends the REGISTER to the service provider’s registrar. It will also store context information that maps the UA’s received contact address with its own contact address. |
4. | The registrar sends back a 200 OK response including an Expires header set to 3600 (which is a typical value). The SBC changes the value of the “expires” parameter to 20 seconds, and forwards the response to the UA. By changing the “expires” value, the SBC forces the UA to generate frequent reregistrations (every 20 s) that will keep the NAT binding open. |
The 200 OK response reaches the NAT, and traverses it through the pin hole opened when the REGISTER was received. | |
6. | The 200 OK reaches the UA. |
7–10. | When the registration timer expires in the UA, it will send a new REGISTER message, but it will not cause the SBC to relay this message to the registrar. |
11. | The SBC maintains its own registration timer. When this timer expires, the SBC sends a new REGISTER request to the registrar. |
[6] If the client uses TCP, and the SBC determines that the UA is not behind a NAT (because the Via header and source IP address match), then the SBC would close the TCP connection after the REGISTER transaction is completed because there is no need for assisting with NAT traversal. | |
Once the UA is registered, it can receive incoming requests through the bidirectional UDP channel (or TCP connection), for which there exists a pinhole in the NAT. This is shown in Figure 22.24.

The problems posed by NAT traversal of RTP traffic might be overcome by:
Having the SBCs act as relays for both the incoming and the outgoing RTP traffic.
Having the endpoints support symmetric RTP.
Effectively, if the SBC assisting a UA receives the outgoing RTP traffic from the endpoint, it may store the source IP address and port. Later, when the incoming RTP traffic is received, the SBC would set the destination address to the stored address, and then forward it to the endpoint. In that way, the incoming traffic would traverse the NAT through the pinhole created by the outgoing RTP traffic, and the endpoint would accept the incoming RTP packets because it supports symmetric RTP.
It is important to highlight the fact that until the SBC has received the first RTP packet in the uplink direction (i.e., from the local endpoint), it would not know how to route the incoming RTP packets in the downlink direction (i.e., from the remote endpoint) because the local endpoint’s source address would not be stored in the SBC. Therefore, the SBC has to wait to start sending RTP packets to the local endpoint until it has received packets from the local endpoint. In order to facilitate this process, the local endpoint might send a first, “empty” RTP packet, even if no media has yet been produced, so that the SBC can learn the source address.
All in all, the problem boils down to forcing the RTP traffic (both outgoing and incoming) through the assisting SBC. Also, the SBC needs to be able to correlate the outgoing and incoming traffic so that it can perform the address manipulation explained above.
Given that the SBCs are in the path of the signaling, and that they are acting as B2BUAs, this can be easily achieved. When an SBC receives an SDP offer or response, it:
Stores the SDP connection addresses and ports in an information context. This would allow the SBC to correlate the incoming and outgoing RTP streams.
Sets the transport address in the outgoing SDP to its own address. The SBC addresses are public, so they can be conveyed in the SDP and then be used by the endpoints to send RTP traffic (i.e., they are routable addresses).
We can now look at the end-to-end scenario between John and Alice. Both of them are behind a NAT device, and both of them must support symmetric RTP. In this example, we will focus just on the traversal of RTP traffic, and will assume that the traversal of SIP traffic is already coped with by the SBCs based on the procedures discussed in the previous section.
This is depicted in Figure 22.25.

John offers an SDP containing its own private address. SBC1 stores the received SDP address, replaces that address with its own, and forwards the SDP to the network.
The SIP provider’s network will route the SDP offer to SBC2, which will perform an action similar to that of SBC1 in step 1.
SBC2 forwards the SDP offer to Alice.
Alice’s UA generates an SDP response and sends it to SBC2.
SBC2 stores the received SDP address, replaces that address with its own, and forwards the SDP answer to the network. The SIP provider’s network will route the SDP answer to SBC1, which will perform an action similar to that of SBC2 in step 5.
SBC1 will send the SDP answer to John.
John and Alice start sending RTP to their respective assisting SBCs. When the traffic traverses the NAT, a pinhole is created.
The SBCs store the source IP address and port in the received RTP packets, and forward the packets to the remote SBCs.
The SBCs receive the RTP packets. They replace the destination IP address with the source address received in step 8.
The SBCs forward the RTP packet to the endpoint. It traverses the NAT through the pinhole created in step 8.
The RTP packets are received by the endpoints.
As the reader will have perceived, the NAT traversal topic is extremely complex. However, its relevance has been acknowledged by the IETF community, and that accounts for the hectic activity in this remit. In this area, we have also witnessed how the industry has been faster than the standards in proposing solutions; the proprietary, industry-coined SBC approach is, by far, the one more extensively used in order to overcome the NAT traversal issue.
At this point, we have covered most of the key advanced topics related to SIP. We are now in an ideal position to examine how some of the concepts learned so far can be applied in order to offer multimedia services not just in an Internet environment, but also in a controlled network environment. In the next chapter, we will look at the undefined, though thoroughly implemented, concept of “SIP network.” We will set the basic ideas that will allow us to understand, in the last chapter of the book, the architecture of a particular instantiation of the “SIP network” concept, the IP Multimedia Subsystem (IMS).
[1] See [RFC 2663] for a description of all the NAT types. Traditional NAT is described in [RFC 3022].
[2] In the industry jargon, the expression “open a pinhole” is frequently used to refer to the creation of a policy in the NAT that allows packets in a specific flow (internal IP address/port; external IP address/port) to traverse the NAT. As we have already seen, sending the first packet from internal IP address/port to external IP address/port would create a mapping in the NAT (together with its associated filtering rule) that would allow incoming packets in the flow to traverse the NAT.
[4] More specifically, the STUN binding keep-alive usage could be used for this purpose. STUN will be presented in subsequent sections.
[5] A detailed description of SBC’s functions is given in [draft-ietf-sipping-sbc-funcs].