
Chapter 18
An Introduction to C++ AMP
Chapter Outline
18.1 Core C++ Amp Features
18.2 Details of the C++ AMP Execution Model
18.3 Managing Accelerators
18.4 Tiled Execution
18.5 C++ AMP Graphics Features
18.6 Summary
18.7 Exercises
C++ Accelerated Massive Parallelism, or C++ AMP, is a programming model for expressing data-parallel algorithms and exploiting heterogeneous computers using mainstream tools. C++ AMP was designed to offer productivity, portability, and performance. Developed initially by Microsoft, C++ AMP is defined by an open specification which takes input from multiple sources, including from AMD and NVIDIA. In this chapter we provide an overview of C++ AMP.
The focus of C++ AMP is to express the important data-parallel algorithm pattern while providing minimum new language features and shielding common scenarios from the intricacies of today’s GPU programming. This provides a foundation of portability for applications written in C++ AMP across a range of different hardware. This portability creates future-proofing to preserve investment as hardware continues to evolve, as well as improving reusability of code across different devices and different manufacturers. At the same time, the full C++ AMP feature set includes advanced mechanisms for achieving performance when system intricacies must be addressed. In this chapter, we discuss first the most straightforward examples of C++ AMP, and then we more lightly address these advanced features.
C++ AMP is a small extension to the current C++ 11 standard and is dependent on some of the core features of that standard. In particular, we will assume readers are familiar with modern C++, including the use of lambda expressions to build function closures, the use of templates for type-generic programming, the use of namespaces to control visibility of names, and the standard template library (STL). The common patterns are simple, so a deep understanding is not a prerequisite to use C++ AMP. Unlike CUDA and OpenCL, C++ AMP allows a rich subset of C++ inside data-parallel computations as well as using C++ for the host. C++ AMP has the same base compilation model as C++ with header files for interface specification and separate compilation units combined into a single executable.
C++ AMP does rely on two extensions to the language. The first places restrictions on the C++ operations that may be used in bodies of functions, and the second supports a form of limited cross-thread data sharing within data-parallel kernels. Both of these will be illustrated in Section 18.1. All other aspects of C++ AMP are delivered as a library accessed via a few header files.
C++ AMP shares many concepts with CUDA. In the following text we will illustrate this by showing C++ AMP equivalents for CUDA examples from earlier chapters. C++ AMP terminology differs from CUDA in small ways and we will highlight those differences as they arise.
18.1 Core C++ AMP Features
We describe the core features of C++ AMP by translating an example used in Chapter 3 from CUDA into C++ AMP. Figure 18.1 is the CUDA code for performing vector addition on host vectors using a CUDA device.

Figure 18.1 CUDA vector addition from Chapter 3.
The corresponding C++ AMP code is shown in Figure 18.2. Line 1 includes the C++ AMP header, amp.h, which provides the declarations of the core features. The C++ AMP classes and functions are part of the concurrency namespace. The using directive on the next line makes the C++ AMP names visible in the current scope. It is optional but avoids the need to prefix C++ AMP names with a concurrency:: scope specifier.

Figure 18.2 Vector addition in C++ AMP.
The function vecAdd on line 4 in Figure 18.2 is functionally identical to the same function starting in line 6 in Figure 18.1. This function is executed by a thread running on the host and it contains a data-parallel computation that may be accelerated. The term host has the same meaning in C++ AMP documentation as in CUDA. While CUDA uses the term device to refer to the execution environment used for accelerated execution, C++ AMP uses the term accelerator, which is discussed more in Section 18.3.
In C++ AMP, the primary vehicle for reading and writing large data collections is the class template array_view. An array_view provides a multidimensional reference to a rectangular collection of data locations. This is not a new copy of the data but rather a new way to access the existing memory locations. The template has two parameters: the type of the elements of the source data, and an integer that indicates the dimensionality of the array_view. Throughout C++ AMP, template parameters that indicate dimensionality are referred to as the rank of the type or object. In this example, we have a 1D array_view (or an array_view of rank 1) of C++ float values.
The constructor for array views of rank 1, such as CV on line 7 in Figure 18.2, takes two parameters. The first is an integer value that is the number of data elements. In general, the set of per-dimension lengths is referred to as an extent. To represent and manipulate extents, C++ AMP provides a class template, extent, with a single-integer template parameter that captures the rank. For objects with a low number of dimensions, various constructors are overloaded to allow specification of an extent as one or more integer values as is done for CV. The second parameter to the CV constructor is a pointer to the host data. In vecAdd the host data is expressed as a C-style pointer to contiguous data. An array_view may also overlay STL containers (see Section 16.1) such as std::vector when they support a data method to access underlying contiguous storage.
The CUDA code explicitly allocates memory (Figure 18.1, lines 9–13) that is accessible by the device and copies host data into it. These actions are implicit in C++ AMP by creating the association between an array_view and host data and subsequently accessing the data through the array_view on the accelerator. The method array_view::discard_data optimizes data transfers for some accelerators and is discussed in the next section. In this example, it is used when existing data values are immaterial because they are about to be overwritten.
Line 9 in Figure 18.2 illustrates the parallel_for_each construct that is the C++ AMP code pattern for a data-parallel computation. This corresponds to the kernel launch in CUDA (Figure 18.1, line 14). In CUDA terminology (as in Figure 3.3), the parallel_for_each creates a grid of threads. In C++ AMP the set of elements for which a computation is performed is called the compute domain and is defined by an extent object. Like in CUDA, each thread will invoke the same function for every point and threads are distinguished only by their location in the domain (grid). Unlike CUDA, this domain need not be treated as an array of thread blocks (as in Figure 3.12). The index parameter combines information needed for common cases from the separate CUDA keyword blockIdx.x, blockDim.x, and threadIdx.x.
Similar to the standard C++ STL algorithm for_each, the parallel_for_each function template specifies a function to be applied to a collection of values. The first argument to a parallel_for_each is a C++ AMP extent object that describes the domain over which a data-parallel computation is performed. In this example, we perform an operation over every element in an array_view and so the extent passed into the parallel_for_each is the extent of the CV array view. In the example, this is accessed through the extent property of the array_view type. This is a 1D extent and the domain of the computation consists of integer values 0..(n − 1).
The second argument to a parallel_for_each is a C++ function object (or functor). In these examples we use the C++ 11 lambda syntax as a convenient way to build such an object. The core semantics of a parallel_for_each is to invoke the function defined by the second parameter exactly once for every element in the compute domain defined by the extent argument.
The leading [=] indicates that variables declared inside the containing function but referenced inside the lambda are “captured” and copied into data members of the function object built for the lambda. In this case, this will be the three array_view objects. The function invoked has a single parameter that is initialized to the location of a thread within the compute domain. This is again represented by a class template, index, which represents a short vector of integer values. The rank of an index is the length of this vector and is the same as the rank of the extent. The index parameter conveys the same information as the explicitly computed value i in the CUDA code (see Figure 18.1, line 3). These index values can be used to select elements in an array view as illustrated on line 11 of Figure 18.2.
A key extension to C++ is shown in this example: the restrict(amp) modifier. In C++ AMP, the existing C99 keyword restrict is borrowed and allowed in a new context: it may trail the formal parameter list of a function (including lambda functions). The restrict keyword is then followed by a parenthesized list of one or more restriction specifiers. While other uses are possible, in C++ AMP there are only two such specifiers defined: amp and cpu.
The function object passed to parallel_for_each must have its call operator annotated with a restrict(amp) specification. Any function called from the body of that operator must similarly be restricted. The restrict(amp) specification is analogous to the __device__ keyword in CUDA. It identifies functions that may be invoked on a hardware accelerator. Analogously, restrict(cpu) corresponds to the CUDA __host__ keyword and indicates functions that may be invoked on the host. When no restriction is specified, the default is restrict(cpu). C++ AMP has no need for an analog to the CUDA __global__ keyword. A function may have both restrictions, restrict(cpu,amp), in which case it may be called in either host or accelerator contexts and must satisfy the restrictions of both contexts.
The restrict modifier allows a subset of C++ to be defined for use in a body of code. In the first release of C++ AMP, the restrictions reflect current common limitations of GPUs when used as accelerators of data-parallel code. The set of restrictions includes:
• No reference may be made to global or static variables except when they have a const type qualification and can be reduced to an integer literal value that is only used as an rvalue.
• A lambda expression used in a parallel_for_each must capture most variables by value with the exception of C++ AMP array and texture objects, each described later.
• Targets of function calls may not be virtual methods, pointers to functions, or pointers to member functions.
• Functions may not be recursively invoked and must be inlineable.
• Only bool, int, unsigned int, long, unsigned long, float, double, and void may be used as C++ primitive types.
• C++ compound user-defined types are generally permitted but may not have virtual base classes or bit fields, and all data members and base classes must be 4-byte aligned.
• No use of dynamic_cast or typeid is permitted.
• No use of goto statements is permitted.
These restrictions reflect a common set of limitations for the GPU-based accelerators broadly available today. Over time we expect these restrictions to be lifted, and the open specification for C++ AMP includes a possible roadmap of future versions that are less restrictive. The restrict(cpu) specifier, of course, permits all of the capabilities of C++ but, because some functions that are part of C++ AMP are accelerator-specific, they do not have restrict(cpu) versions and so they may only be used in restrict(amp) code.
The restriction specifiers for a function are part of the type of the function, and function names may be overloaded when they have different restrictions. Thus, two functions may have identical signatures except one has the restrict(amp) specification and the other has the restrict(cpu) specification. This allows context-specific implementations of functions to be created. A function that has two overloads, one for each context, may be called from a restrict(amp,cpu) function, and the appropriate overload will be invoked that corresponds to whether the function is being invoked on the host or on an accelerator. In particular, this capability is used within C++ AMP to allow context-specific implementations of mathematic operations, but it is also available to application and library developers.
Inside the body of the restrict(amp) lambda (Figure 18.2, lines 10-12), there are references to the array_view objects declared in the containing scope. These are “captured” into the function object that is created to implement the lambda. Other variables from the function scope may also be captured by value. Each of these other values is made available to each invocation of the function executed on the accelerator. As for any C++ 11 nonmutable lambda, variables captured by value may not be modified in the body of the lambda. However, the elements of an array_view may be modified and those modifications will be reflected back to the host. In this example, any changes to CV made inside the parallel_for_each will be reflected in the host data C before the function vecAdd returns.
The final statement on line 13 in Figure 18.2 uses the array_view::synchronize method to ensure the underlying host data structure is updated with any changes. This is also discussed in the next section. This operation is not needed if the host accesses the data through the array view CV, but is needed to reliably access the data through the host pointer C. The central purpose of the array_view is to allow coherent access to data from both the host and the accelerator without the need for explicit synchronization or data copies.
Figure 18.3 is a more complex example borrowed from Chapter 12 and Figure 12.3. It performs a calculation on a slice of a 3D data structure. We use it to illustrate the handing of higher-dimensional array_view objects and compute domains. The function interface is essentially identical to the source where the CUDA dim3 type is replaced with a C++ AMP extent<3> for the grid parameter. The contiguous data pointed to by energygrid is overlaid with a 3D array_view (named energygrid_view). C++ AMP follows a row-major storage layout so higher-numbered dimensions are less significant in the linear storage order. C++ AMP has mechanisms to create an array_view that is a section of another array_view and also to project down to select a lower-dimensional slice. This operation is used on line 6 of Figure 18.3 to select the portion of the data actually defined by the kernel. As before, we use the discard_data method to avoid copying the immaterial existing values to the GPU. We overlay the atoms data with the 2D array_view named atom_view to simplify the expression of the accesses. This does not fundamentally change how the actual addressing arithmetic is performed, but seems to model the problem more accurately.

Figure 18.3 Base coulomb potential calculation code for a 2D slice.
The data-parallel computation is then over the extent of the slice where the original sequential loop indices j and i are translated into the index<2> ji. Except for the indexing of atom_view, and the indexing into energy_slice, the body of the loop is largely unchanged.
C++ AMP provides a set of basic math operations for use in restrict(amp) contexts. These functions are accessed by including amp_math.h (which is not shown). The concurrency::fast_math and concurrency::precise_math names spaces respectively declare faster and more precise versions of functions. In the example, we chose to use precise_math::sqrtf for illustration. In restrict(cpu) code, both of these namespaces establish aliases to std:: implementations of these functions, so a function that is declared restrict(cpu,amp) can still reference math functions and get the best implementation for the target.
To summarize this section, the core C++ AMP concepts include an array_view, which provides a multidimensional view into rectangular data; an extent, which is the shape of such a view and also the shape of a data-parallel computation; an index, which is used to select elements of an array_view or a data-parallel computation; the parallel_for_each, which launches a data-parallel computation; and restrict(amp) modified functions, which are evaluated at each point in that computation.
18.2 Details of the C++ AMP Execution Model
The core C++ AMP features noted in the previous section focus on expressing data parallelism essentially as a concurrent invocation of a collection of threads that access multidimensional arrays of data. Many accelerators today run in a separate memory and cannot directly access host data. Furthermore, these accelerators run concurrently with the continuing execution of host code. While minimizing the impact of these concerns, these aspects are part of the execution model of C++ AMP.
Explicit and Implicit Data Copies
C++ AMP provides the class template array to allocate storage on an accelerator. Similar to an array_view and with a nearly identical interface, an array has element type and rank template parameters. The constructor includes extent information. Unlike an array_view, an array allocates new storage on an accelerator. The data elements of an array may only be accessed from that accelerator and all operations that copy data between an array and host memory are explicit.
To illustrate this, consider Figure 18.4, which rewrites Figure 18.2 to use explicit array operations. Each array_view is replaced with an array declaration of the same extent. Lines 5 and 6 show explicit copies from host data to an array using the C++ AMP copy function template. The lambda is changed slightly to capture array variables by reference rather than the default mode of capturing variables by value as in the other examples. C++ AMP array objects must be captured by reference while array_view objects must be captured by value for the lambda used in a parallel_for_each. Line 12 specifies the data to be copied back to the host after completion of the computation.

Figure 18.4 Explicit memory and copy management.
On an accelerator that cannot access host memory, all of the operations in Figure 18.4 also happen for the code in Figure 18.2 but they are performed transparently either when the parallel_for_each is launched or when array_view::synchronize is called. The intended use of the explicit mechanisms is to provide more control of memory management and allow copy operations to be initiated earlier and overlapped with other computations (although overlapped copies can be achieved through other means).
When an array_view overlays storage on the host but is accessed on the accelerator, the data is copied to an unnamed array on that accelerator and the access is made to that array. This copy of the host data may persist for the remainder of the lifetime of the array_view. This allows the C++ AMP runtime to avoid redundant copies of the same data to the accelerator. C++ AMP provides operations to influence how and when data is copied between these implicit copies and the source storage. Line 8 of Figure 18.2 shows the use of array_view::discard_data. This method is an assertion that the values stored in the host storage are immaterial, for example, because they are about to be overwritten. The effect of this assertion is that when the array_view is subsequently used in a parallel_for_each, no copy is performed from the source data to the implicit array created for accelerator access.
When an unnamed array is created to hold a copy of data associated with an array_view, and that array may be modified, the C++ AMP runtime system is permitted to copy the values back to the host storage immediately or leave them on the accelerator. If the array_view is destructed or an element is accessed on the host, then values will be copied promptly to make sure host accesses get the most recent definition. The method array_view::synchronize is available to force any such copies to be performed by a particular program point. The method array_view::refresh indicates to the C++ AMP runtime that all cached copies of the host data should be discarded. Generally, this method would be used when the underlying host data is modified directly without accessing through the array_view. This coherence between implicit cached copies and the underlying host data is the responsibility of the programmer.
An array_view may also refer to an array. This allows data allocated on an accelerator to be accessed by the host. Again, where necessary, this may involve creating copies of the data that are accessible by the host. The copies of data values between the source storage on the accelerator and the copies on the host are controlled using the same mechanisms and functions as before.
Asynchronous Operation
Most C++ AMP operations that initiate work on an accelerator, including operations to copy data to the accelerator, are asynchronous. This means that the host operation returns and the host thread continues to the next statement before the work completes. We illustrate this in Figure 18.5, which shows three strands of concurrent activity where time logically flows from the top to the bottom of the figure. On the left is the sequence of host operations that initiate accelerator operations. In the middle, we indicate three copy operations that take some duration each. On the right, we show the actual data-parallel computation that begins after the two copies to the accelerator complete and finishes before the final copy back to the host begins. On the host, the final copy-out is called before the data is ready and that operation blocks until the copy completes. When it returns, the return statement executes and the function returns with updated host data.
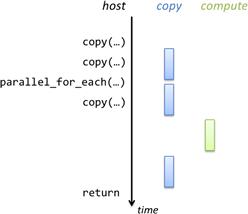
Figure 18.5 Concurrent host/accelerator execution.
To provide finer-grain notification on which operation on the accelerator is complete, C++ AMP provides the completion_future class. This class is analogous to std::shared_future, the C++ standard method for coordination with asynchronous operations. In particular, it provides the completion_future::get method that blocks the calling thread until the asynchronous operation completes. C++ AMP has variants of the methods discussed here that are nonblocking and return a completion_future. In particular there are array_view::synchronize_async and various overloads of copy_async. These will initiate the data transfer implied and return a synchronization object immediately rather than blocking the thread until the operation has completed. Figure 18.6 provides a simple illustration where we assume that following the vector add computation there is some other computation involving the unmodified host data A and B. Upon completion of that other processing, the host then waits for the results from the parallel_for_each to be available on the host by using the completion_future::get call on the object returned from the array_view::synchronize_async method. After the get call returns, the host vector C will hold the results.

Figure 18.6 Overlapped accelerator and host processing.
As discussed in Chapter 3, CUDA has an explicit notion of global memory, which is accessible by all threads in a kernel. In C++ AMP this concept is only available by having array objects associated with an accelerator. C++ AMP does not provide a facility for having file-scope objects accessible by functions running on the accelerator the way CUDA interprets __device__ as a qualification on file-scope object declarations. Similarly, C++ AMP does not expose a concept of constant memory although values captured in the top-level lambda passed to a parallel_for_each may be stored in constant memory. The differences between CUDA and C++ AMP represent conscious design choices for C++ AMP to simplify the programming model. Some elements of CUDA reflect specifics of current GPU architectures that are not necessarily present in other forms of accelerators or may be significantly less common in the future. C++ AMP chose to leave these as implementation details rather than part of the model.
Section Summary
In this section we have discussed the features of C++ AMP that support a discrete accelerator that does not share memory with the host and runs concurrently with host computations. The key features are the array data container, explicit copy operations, and explicit asynchronous work mechanisms. We also indicated when and where such copies are made when the more flexible array_view is used when targeting discrete accelerators. We discussed the relationship of CUDA memory types with that of C++ AMP.
18.3 Managing Accelerators
A computer system may include multiple accelerators suitable for implementing C++ AMP data-parallel computations. This includes both specialized hardware accelerators such as GPUs and simply the use of multicore CPUs with SIMD instructions. A system may also have multiple GPUs that may or may not have similar hardware characteristics. C++ AMP has mechanisms to enumerate available accelerators and to manage how work is mapped to those accelerators.
The class accelerator is the C++ AMP abstraction used for a specific mechanism for implementing data parallelism. As shown in Figure 18.7, the accelerator::get_all static method returns a vector of available accelerators in the system. A few properties associated with each accelerator may be used to select one when special requirements are required. For example, support of double-precision data types is an optional feature. For compute-intensive applications, it may be desirable to avoid placing work on the GPU that is used to drive an interactive display. Other properties include the amount of memory dedicated to the accelerator (accelerator::dedicated_memory) and a std::wstring that uniquely identifies the device (accelerator::device_path). The example uses the STL std::find algorithm to capture this search.

Figure 18.7 Example of finding an accelerator.
In addition to finding a specific accelerator, a system may support multiple suitable accelerators. C++ AMP enables off-loading work from one or more host threads to multiple accelerators. All such accelerator instances are returned by the call to accelerator::get_all and they may be used concurrently by an application.
In C++ AMP, an accelerator_view is an object that refers to a specific underlying accelerator and can be used to specify that accelerator for the purpose of indicating where an array is allocated and where work for a particular parallel_for_each should be executed. Similar to a CUDA stream, (cudaStream_t), various operations performed against a particular accelerator_view are performed in order but operations on different accelerator_views have no defined order.
In C++ AMP there is a default accelerator that is automatically selected by the runtime but can be explicitly set using the accelerator::set_default static method, which takes a device path string parameter. Each accelerator has a default accelerator_view (accelerator::default_view). The default view of the default accelerator is used for allocating an array when none is specified. A parallel_for_each may also have an explicit accelerator_view. Figure 18.8 is a variant of the vector add sample that makes use of defaults explicit. It is not necessary to use explicit arrays to direct work using an accelerator_view. Even when all data is accessed with array_view objects that overlay host data, a parallel_for_each may have an explicit accelerator_view indicating where the work should be performed.

Figure 18.8 Explicit accelerator use.
Figure 18.9 is another illustration of explicit use of an accelerator_view. Here we provide a modified vector add operation that is parameterized by an accelerator_view that identifies where the work should be performed. The function determines the memory available on the accelerator, converted from kilobytes to bytes and used to determine the largest block size (block) where three blocks may be stored concurrently. Line 8 then loops over the input vectors in chunks of this size. For each chunk, a computation is launched as was done in Figure 18.2 but here the accelerator is explicitly specified by the first parameter, acc, to the parallel_for_each. On line 17, we initiate an asynchronous transfer of the results back to the host data structure. The completion_future returned by this operation is moved into a vector of such results. After all operations are started, lines 19 and 20 iterate over the vector of results using C++ STL methods and wait for each one to complete by calling the get method before the function returns to the caller.

Figure 18.9 Explicit accelerator with asynchronous transfers.
18.4 Tiled Execution
This section touches on a topic important for some scenarios. We discuss a “tiled” version of data parallelism and the additional tools for optimizing memory available in that model.
As described earlier, a data-parallel computation has an associated computational domain defined by a C++ AMP extent object. A computational domain of rank 3 or less may also be blocked into regular, rectangular subdomains called tiles. The widths of these tiles must be compile-time constants. The threads that are associated with the same tile may share variables and participate in barrier synchronization. In CUDA, the term block is used to describe these groups of threads. A new storage class is also added to C++ AMP, tile_static, to indicate a variable that has a single instance per-tile that is shared by all threads (in CUDA this is indicated with the __shared__ keyword). Chapter 5 discusses the motivation for using tiling and tile-shared variables to optimize memory bandwidth. Objects with this storage class may only be accessed in restrict(amp) code.
We illustrate tiling as was done in Chapter 5 by using matrix multiplication. Figure 5.12 shows a CUDA kernel that we expand here into a host function (Figure 18.10) containing the kernel, as well as assuming host pointers are used to refer to dense arrays following the interface from Chapter 5. As before, we overlay array_view objects on top of the host data and discard the output data that is about to be overwritten so it is not copied to the accelerator.

Figure 18.10 Tiled matrix multiplication; compare Figure 5.12.
A tiled_extent is a form of extent that captures tile dimensions as template parameters. C++ AMP only supports tiling for one, two, and three dimensions, and the rank of a tiled_extent object is inferred from the number of tile dimensions specified. In this case, the tiled_extent has rank 2 (line 6).
The parallel_for_each method has an overload for tiled_extent. The structure is the same as before and the lambda function will be invoked once for each element in the compute domain. C++ AMP requires that the extent of the compute domain must be evenly divisible by the tile size. In this example, Width must be multiples of TILE_WIDTH. When this condition is not met, a runtime exception is thrown.
In the case of a parallel_for_each for a tiled_extent, the parameter to the lambda must be a tiled_index instead of an index. The tiled_index is a class template where again the tile sizes are captured as template parameters. The tiled_index (t_idx in Figure 18.10) provides both a mapping for each thread into the compute domain (t_idx.global) as well as the relative position of a thread within its tile (t_idx.local).
Line 9 declares a tile_static array named Mds that is shared by all threads in a tile. It will hold a copy of the values in M that are needed to perform a sub-block matrix multiplication computation for all of the threads in the tile. Similarly, line 10 declares analogous Nds to hold sub-blocks of N.
As in Figure 5.12, the loop on Figure 18.10, line 14, multiplies a block-row times a block column in tile-size chunks. The variable Width is used uniformly by all threads and is captured from the containing function scope for reuse in the lambda automatically. The threads in the tile cooperatively copy blocks of M and N into tile_static storage. Line 17 is the barrier synchronization point where all threads in the tile wait for the stores into shared variables to complete. A second barrier on line 20 makes sure all of the reads from shared variables are completed before writes on the next iteration begin. In C++ AMP, the object of type tile_index includes a tile_barrier object as a data member and that object provides methods to perform barriers. C++ AMP provides different forms of barriers that indicate whether the barrier applies to just tile_static data, global data, or both. Here we only need to protect tile_static data and so could use wait_with_tile_static_memory_fence, but chose to use the wait method to match the source from Chapter 5.
Figure 18.11 illustrates some details of C++ AMP tiling. It shows a 20×20 compute domain as a grid of small squares and the variable e in the code fragment. Rows (dimension 0) are shown as numbered from top to bottom and columns (dimension 1) from left to right. This domain might be blocked into 8×8 tiles. These tiles are illustrated with the larger black squares and the variable te or alternately the variable te2, which shows the extent::tile method template for creating a tiled_extent. We also illustrate the use of C++ 11 auto keyword to infer types of variables from their initializers.

Figure 18.11 Illustration of tiling 20×20 compute domain.
Note that the tile size in this example does not evenly divide the dimensions of the compute domain. A tiled parallel_for_each requires the extent be a multiple of the tile size in each dimension, and the developer must explicitly handle the boundary cases when this is not the case. The tiled_extent class template provides methods to either pad or truncate the underlying extent. In the example, variable pte corresponds to the padded extent, extent<2>(24,24), while the variable tte corresponds to the truncated extent, extent<2>(16,16).
The tiled_index parameter supports a variety of members to facilitate tiled computations. The global member is an index<2> holding the position in the underlying compute domain. The solid square in the figure corresponds to position (9,6) in the compute domain. The set of tiles (large squares) forms a domain, extent<2>(3,3) in this case, which is returned by the tile_extent member. The tile member is an index<2> holding the position of a point projected into this domain. The highlighted point (9,6) is in tile (1,0). The single lightly shaded square at the left edge is the first element in each dimension in the same tile as point (9,6). This is available as tile_origin and in this example corresponds to the global index (8,0). Finally, the points within a tile can be thought of as a small domain and the local member returns the position in this space (1,6) formed basically by subtracting tile_origin from global.
18.5 C++ AMP Graphics Features
The primary motivation for C++ AMP is to support data parallelism as an important algorithm pattern for general computing. Rendering and imaging processing are very important mainstream workloads for which C++ AMP includes some more specialized support, discussed briefly in this section. These facilities include normalized floating points, short vector types, textures, and, optionally on Microsoft platforms, interoperations with DirectX. Many of these features are segregated into a separate namespace, concurrency::graphics. Figure 18.12 illustrates some of the types defined in that namespace and discussed in this section.
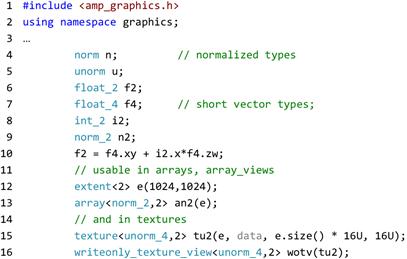
Figure 18.12 Example of types from concurrency::graphics.
C++ AMP provides two types, norm and unorm, which provide arithmetic that is floating point in nature but of bounded range. The norm type holds signed values with magnitude no more than one while the unorm type holds non-negative values with magnitude no more than one. Common arithmetic operations are defined on these types where result values that would exceed the range are forced to the extreme value (“clamped”). These types may be mixed with C++ types and convert to float. They may also be used as element types for C++ AMP composite types array, array_view, and the texture objects described in the following.
Graphics programs frequently manipulate short vectors of primitive types. C++ AMP supports graphics programming by including definitions of these. For C++ AMP types, int, unsigned int (as uint), float, double, norm, and unorm, and for each vector length 2, 3, and 4, there exist types such as int_2, uint_3, and float_4. Each of these holds a number of component values that are accessed by name. The names supported are x, y, z, and w, or alternately r, g, b, and w. Thus, given the declarations in Figure 18.12, we might access a component f4.z, which is a single float that can be used as either an rvalue or an lvalue. Certain compound patterns are also supported, such as f4.xy, which corresponds to a short vector of suitable length, float_2 in this case, that may be used as either an rvalue or lvalue. Assignment and arithmetic on short vectors is done in a component-wise style with scalar arguments promoted to vectors with that value in each component.
A texture is a special form of array that allows data-parallel code to access values that are stored using reduced precision. This is a common representation for image data and is the only method in the first version of C++ AMP to access partial word data types in a restrict(amp) context. Like an array, a texture is a class template that is parameterized by an element type and a rank. The set of allowed element types is constrained to be a subset of the restrict(amp) compatible primitive types and their short vector variants.
When a texture is constructed, in addition to the extent and a data source, a final unsigned integer argument indicates the number of bits per primitive data value used to store the value. Line 15 shows an example texture with a four-wide vector of unsigned normalized floating-point values. The 16U passed to the constructor indicates each of these values is stored with only 16 bits of information. Not all combinations of data type, vector length, and storage width are supported (details in the specification are listed in the C++ AMP open specification, http://blogs.msdn.com/b/nativeconcurrency/archive/2012/02/03/c-amp-open-spec-published.aspx).
A texture is a storage container like an array and may be associated with a particular accelerator_view. A texture is also indexed like an array with overloads of the index operator with an index instance of suitable rank as a parameter. As for array, these operations are restrict(amp) and may not be used in the host code. Overloads of the function template copy support transfers to and from host data structures.
A subset of textures may be written to directly and this is done explicitly via a texture::set method. For texture formats for which writing is not directly supported by hardware accelerators, C++ AMP provides the writeonly_texture_view class template illustrated with the variable named wotv (line 16 of Figure 18.12). The set method on this object may be used in a restrict(amp) context that is defining values in a texture.
Beyond support for these types, C++ AMP on Microsoft platforms includes specific features to enable interoperation with the DirectX framework. These interfaces are available in two namespaces : concurrency::direct3d contains make_array, get_buffer and create_accelerator_view while concurrency::graphics::direct3d contains make_texture. They include the following capabilities:
• Treating an existing Direct 3D device interface pointer as a C++ AMP acclerator_view.
• Treating an existing Direct 3D buffer interface pointer as a C++ AMP array.
• Treating an existing Direct 3D texture interface pointer as a C++ AMP texture.
These capabilities allow C++ AMP to provide a C++ language solution for GPU compute scenarios that integrates smoothly with the DirectX rendering framework.
Figure 18.13 illustrates the interop features. Function my_rotate consumes a vector of vertex data that is located on the host. Parameter d3ddevice is the existing DirectX interface that is used to first construct an accelerator_view and then an array. The parallel_for_each performs a rotation of the vertices where the result is left on the accelerator. Since the array instance vertices is located on a particular accelerator_view, the parallel_for_each will be executed on that same accelerator_view. We extract the underlying buffer object (typed only as IUnknown) and return this to the caller for subsequent use in scene rendering.
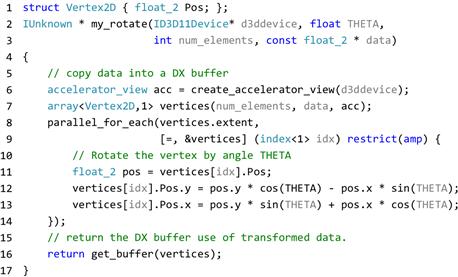
Figure 18.13 Example DirectX interop—rotate vertex list.
18.6 Summary
This chapter has presented an overview of C++ AMP, a small extension to C++ 11 to support hardware acceleration of data-parallel computations. The discussion is not complete, but the full specification is available at http://blogs.msdn.com/b/nativeconcurrency/archive/2012/02/03/c-amp-open-spec-published.aspx. The focus of C++ AMP is to create features that integrate well into modern C++ and leverage features such as templates, lambdas, and futures to provide a highly productive set of abstractions that compose with other aspects of C++ and parallelism. The features are layered to allow use by a very broad set of developers with limited knowledge of computer architecture, as well as providing access to the rich execution model needed for the most performance-critical scenarios. Lowering the barrier to expressing data parallelism and ensuring portability across hardware platforms will help more applications deliver the benefits of hardware acceleration and heterogeneous computing.
18.7 Exercises
18.1. Translate the simple, untiled version of matrix multiplication into C++ AMP. The CUDA kernel is shown in Figure 4.7. Write a host function that applies this computation to three array_view<float,2> inputs. Rather than implementing C = A∗B, accumulate in the output and implement C += A∗B.
18.2. Given an array view of rank 2, X, index<2> ij, and extent<2> e, the operation X.section(ij,e) returns a new array_view that overlays the same data as X. If we denote this new view as S, then for all valid indices idx of S we have S[idx] is the same location as X[idx+ij].
Assume now there are three array_view<float,2> objects, A, B, and C. Assume they will not fit simultaneously in the dedicated_memory of the accelerator in the system. Use the array_view::section method, explicit array objects, and the matrix multiply building block from the first exercise to implement matrix multiplication for the large arrays.
18.3. Assume std::vector gpu holds two elements of type accelerator_view that refer to different but similar GPUs in a system. Modify the solution to Exercise 18.3 to use both accelerators to implement the work.
18.4. Translate the tiled version of matrix transpose from Exercise 4.2 into C++ AMP.
18.5. The inner loop in Figure 18.3 redundantly loads data through atom_view that is used in multiple threads and these references are not coalesced (see Section 6.2). Rewrite the function in Figure 18.3 to use tile_static memory to improve the memory efficiency for accessing the data in atom_view.