
Theoretical foundations
A.1 Matrix Algebra
Basic Manipulations and Properties
A column vector x with d dimensions can be written

where the transpose operator, superscript T, allows it be written as a transposed row vector—which is useful when defining vectors in running text. In this book, vectors are assumed to be row vectors.
The transpose AT of a matrix A involves copying all the rows of the original matrix A into the columns of AT. Thus a matrix with m rows and n columns becomes a matrix with n rows and m columns:

The dot product or inner product between vector x and vector y of the same dimensionality yields a scalar quantity,
For example, the Euclidean norm can be written as the square root of the dot product of a vector x with itself, ![]() .
.
The tensor product or outer product ⊗ between an m-dimensional vector x and an n-dimensional vector y yields a matrix,

Given an N row and K column matrix A, and a K row and M column matrix B, if we write each row of A as ![]() and each column of B as bm, the matrix product AB (i.e., matrix multiplication) can be written
and each column of B as bm, the matrix product AB (i.e., matrix multiplication) can be written
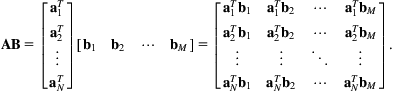
If we write each column of A as ak and each row of B as ![]() , the matrix product AB can also be written in terms of tensor products
, the matrix product AB can also be written in terms of tensor products
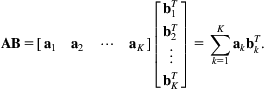
The elementwise product or Hadamard product of two matrices that are of the same size is

A square matrix A with n rows and n columns is invertible if there exists a square matrix B=A−1 such that AB=BA=I, where I is the identity matrix consisting of all zeros except that all diagonal elements are one. Square matrices that are not invertible are called singular. A square matrix A is singular if and only if its determinant, det(A), is zero. The following equation for the inverse shows why a zero determinant implies that a matrix is not invertible:
where det(A) is the determinant of A and C is another matrix known as the cofactor matrix. Finally, if a matrix A is orthogonal, then A−1=AT.
Derivatives of Vector and Scalar Functions
Given a scalar function y of an m-dimensional column vector x,

This quantity is known as the gradient, g. We have defined it here as a column vector, but it is sometimes defined as a row vector. Defining the gradient as a column vector implies certain orientations for the other quantities defined below, so keep in mind that the derivatives that follow are sometimes defined as the transposes of those given here. Using the definition and orientation above we can write the types of parameter updates frequently used in algorithms like gradient descent in vector form with expressions such as ![]() , where θ is a parameter (column) vector.
, where θ is a parameter (column) vector.
Given a scalar x and n-dimensional vector function y,
For an m-dimensional vector x and an n-dimensional vector y, the Jacobian matrix is given by

The Jacobian is sometimes defined as the transpose of this quantitiy even given the other definitions above. Watch out for the implications. The derivative of a scalar function y=f(X) with respect to an m×n dimensional matrix X is known as a gradient matrix and is given by

Our choice for the orientations of these quantities means that the gradient matrix has the same layout as the original matrix, so updates to a parameter matrix X take the form ![]() .
.
While many quantities can be expressed as scalars, vectors, or matrices, there are many that cannot. Inspired by the tabular visualization of Minka (2000), the scalar, vector, matrix, and tensor quantities resulting from taking the derivatives of different combinations of quantities are shown in Table A.1.
Table A.1
Quantities That Result From Various Derivatives (After Minka, 2000)
| Scalar |
Vector |
Matrix | |
| Scalar |
Scalar: |
Vector: |
Matrix: |
| Vector |
Vector: |
Matrix: |
Tensor: |
| Matrix |
Matrix: |
Tensor: |
Tensor: |

The Chain Rule
The chain rule for a function z, which is a function of y, which is a function of x, all of which are scalars, is
where the two terms could be reversed, because multiplication is commutative. Now, given an m-dimensional vector x, an n-dimensional vector y, and an o-dimensional vector z, if z=z(y(x)), then

where each entry in the m×n matrix can be computed using
The vector form could be viewed as

which yields the chain rule for vectors, where chains extend toward the left as opposed to the right as is often done with the scalar version. For the special case when the final function evaluates to a scalar—which is frequently encountered when optimizing a loss function, we have

The rule generalizes, so that if there were yet another vector function w that is a function of x, through z, then
To find the derivative of a matrix that is the function of another matrix, the chain rule generalizes. For example, for a matrix X if matrix Y=f(X), the derivative of a function g(Y) is

Computation Graphs and Backpropagation
Computation networks help to show how the gradients required for deep learning with backpropagation can be computed. They also provide the basis for many software packages for deep learning, which partially or fully automate the computations involved.
We begin with an example that computes intermediate quantities that are scalars, and then extend it to networks involving vectors that represent entire layers of variables at each node. Fig. A.1 gives a computation graph that implements the function z1(y1,z2(y2(y1),z3(y3(y2(y1))))), and shows how to compute the gradients. The chain rule for a scalar function a involving intermediate results b1,…,bk that are dependent on c is

In the example, the partial derivative of z1 with respect to y1 therefore consists of three terms

The sums needed to compute this involve following back along the flows of the subcomputations that were performed to evaluate the original function. These can be implemented efficiently by passing them between nodes in the graph, as Fig. A.1 shows.
This high-level notion of following flows in a graph generalizes to deep networks involving entire layers of variables. If Fig. A.1 were drawn using a scalar for z1 and vectors for each of the other nodes, the partial derivatives could be replaced by their vector versions. It is necessary to reverse the order of the multiplications, because in the case of partial derivatives of vectors with respect to vectors, computations grow to the left, yielding
To see this, consider (1) the chain rule for the partial derivative of a scalar function z with a vector x as argument, but involving the computation of an intermediate vector y:

and (2) the chain rule for the same scalar function z(x), but involving the computation of an intermediate matrix Y:

Derivatives of Functions of Vectors and Matrices
Here are some useful derivatives for functions of vectors and matrices. Petersen and Pedersen (2012) gives an even larger list.

Notice that the first identity above would be equal to simply A, had we defined the Jacobian to be the transpose of our definition above.
For a symmetric matrix C (e.g., an inverse covariance matrix),

Vector Taylor Series Expansion, Second-Order Methods, and Learning Rates
The method of gradient descent, the interpretation of learning rates, and more sophisticated second-order methods can be viewed through the lens of the Taylor series expansion of a function. The approach presented below is also known as Newton’s method.
The Taylor expansion of a function near point xo can be written
Using the approximation up to the second-order (squared) terms in x, taking the derivative, setting the result to zero, and solving for x, gives

This generalizes to the vector version of a Taylor series for a scalar function with matrix arguments, where

Using the identities given in the previous section, taking the derivative with respect to the parameter vector θ, setting it to zero and then solving for the point at which the quadratic approximation to the function would be zero, yields

This means that for the update ![]() , the learning rate used for gradient descent can be thought of in terms of a simple diagonal matrix approximation to the inverse Hessian matrix in a second-order method. In other words, using a simple learning rate is analogous to making an approximation, so that
, the learning rate used for gradient descent can be thought of in terms of a simple diagonal matrix approximation to the inverse Hessian matrix in a second-order method. In other words, using a simple learning rate is analogous to making an approximation, so that ![]() .
.
Full-blown second-order methods take more effective steps at each iteration. However, they can be expensive because of the need to compute this quantity. For convex problems like logistic regression, a popular second-order method known as L-BFGS builds an approximation to the Hessian. Here, L stands for limited memory and BFGS stands for the inventors of the approach, Broyden–Fletcher–Goldfarb–Shanno. Another family of approaches are known as the conjugate gradient algorithms and involve working with the linear system of equations associated with ![]() when solving for
when solving for ![]() as opposed to computing the inverse of
as opposed to computing the inverse of ![]() .
.
One needs to keep in mind that when solving nonconvex problems (e.g., learning for multilayer neural networks) the Hessian is not guaranteed to be positive definite, which means that it may not even be invertible. Consequently the use of heuristic adaptive learning rates and momentum terms remain popular and effective for neural network methods.
Eigenvectors, Eigenvalues, and Covariance Matrices
There is a strong connection between eigenvectors, eigenvalues and diagonalization of a covariance matrix, and the method of principal component analysis. If λ is a scalar eigenvalue of a matrix A, there exists a vector x called an eigenvector of A such that Ax=λx. Define a matrix Φ to consist of eigenvectors in each column, and define Λ as a matrix with the corresponding eigenvalues on the diagonal, then the matrix equation ![]() defines the eigenvalues and eigenvectors of A.
defines the eigenvalues and eigenvectors of A.
Many numerical linear algebra software packages (e.g., Matlab) can determine solutions to this equation. If the eigenvectors in Φ are orthogonal, which they are for symmetric matrices, the inverse of Φ equals its transpose, which implies that we could equally well write ![]() . To find the eigenvectors of a covariance matrix, set A=Σ, the covariance matrix. This yields the definition of the eigenvectors of a covariance matrix Σ as the set of orthogonal vectors stored in a matrix Φ and normalized to have unit length, such that
. To find the eigenvectors of a covariance matrix, set A=Σ, the covariance matrix. This yields the definition of the eigenvectors of a covariance matrix Σ as the set of orthogonal vectors stored in a matrix Φ and normalized to have unit length, such that ![]() . Since Λ is diagonal matrix of eigenvalues, the operation
. Since Λ is diagonal matrix of eigenvalues, the operation ![]() has been used to diagonalize the covariance matrix.
has been used to diagonalize the covariance matrix.
While these results may seem esoteric at first glance, their use is widespread. For example, in computer vision an eigenanalysis-based principal component analysis for face recognition yields what are known as “eigenfaces.” The general technique is widely used in numerous other contexts, and classic, well-cited eigenanalysis-based papers appear in many diverse fields.
The Singular Value Decomposition
The singular value decomposition is a type of matrix factorization that is widely used in data mining and machine learning settings and is implemented as a core routine in many numerical linear algebra packages. It decomposes a matrix X into the product of three matrices such that X=USVT, where U has orthogonal columns, S is a diagonal matrix containing the singular values (normally) sorted along the diagonal, and V also has orthogonal columns. By keeping only the k largest singular values, this factorization allows the data matrix to be reconstructed in a way that is optimal in a least squares sense for each value of k. For any given k, we could therefore write ![]() . Fig. 9.10 illustrates how this works visually.
. Fig. 9.10 illustrates how this works visually.
In our discussion earlier on eigendecompositions we developed an expression for diagonalizing a covariance matrix Σ using ![]() , where Φ holds the eigenvectors and Λ is a diagonal matrix of eigenvalues. This amounts to seeking a decomposition of the covariance matrix that factorizes into
, where Φ holds the eigenvectors and Λ is a diagonal matrix of eigenvalues. This amounts to seeking a decomposition of the covariance matrix that factorizes into ![]() . This reveals the relationship between principal component analysis and the singular value decomposition applied to data stored in the columns of matrix X. We will use the fact that the covariance matrix Σ for mean centered data stored as vectors in the columns of X is simply
. This reveals the relationship between principal component analysis and the singular value decomposition applied to data stored in the columns of matrix X. We will use the fact that the covariance matrix Σ for mean centered data stored as vectors in the columns of X is simply ![]() . Since orthogonal matrices have the property that UUT=I, through the following substitution we can see that the matrix Φ, known as the right singular vectors of X, corresponds to the eigenvectors of the covariance matrix. In other words, to factorize a covariance matrix into
. Since orthogonal matrices have the property that UUT=I, through the following substitution we can see that the matrix Φ, known as the right singular vectors of X, corresponds to the eigenvectors of the covariance matrix. In other words, to factorize a covariance matrix into ![]() , mean center the data and perform an singular value decomposition on X. Then the covariance matrix is
, mean center the data and perform an singular value decomposition on X. Then the covariance matrix is ![]() , so
, so ![]() and
and ![]() —in other words, the so-called singular values are the square roots of the eigenvalues.
—in other words, the so-called singular values are the square roots of the eigenvalues.
A.2 Fundamental Elements of Probabilistic Methods
Expectations
The expectation of a discrete random variable X is
where the sum is over all possible values for X. The conditional expectation for discrete random variable X given random variable Y=y has a similar form
Given a probability density function p(x) for a continuous random variable X,
The empirical expectation of a continuous-valued variable X is obtained by placing a Dirac delta function on each empirical observation or example, and normalizing by the number of examples, to define p(x). The expected value of a matrix is defined as a matrix of expected values.
The expectation of a function of a continuous random variable X and a discrete random variable y is
Expectations of sums of random variables are equal to sums of expectations, or
If there is a scaling factor s and bias or constant c, that
The variance is defined as

The expectation of the product of continuous random variables X and Y with joint probability p(x,y) is given by
The covariance between X and Y is given by

Therefore ![]() , and X and Y are said to be uncorrelated. Clearly Cov[X,X]=Var[X]. The covariance matrix for a d-dimensional continuous random variable x is obtained from
, and X and Y are said to be uncorrelated. Clearly Cov[X,X]=Var[X]. The covariance matrix for a d-dimensional continuous random variable x is obtained from

Conjugate Priors
In more fully Bayesian methods one treats both variables and parameters as random quantities. The use of prior distributions over parameters can provide simple and well justified ways to regularize model parameters and avoid overfitting. Applying the Bayesian modeling philosophy and techniques can lead to simple adjustments to traditional maximum likelihood estimates. In particular, the use of a conjugate prior distribution for a parameter in an appropriately defined probability model means that the posterior distribution over that parameter will remain in the same form as the prior. This makes it easy to adapt traditional maximum likelihood estimates for parameters using simple weighted averages of the maximum likelihood estimate and the relevant parameters of the conjugate prior. We will see how this works for the Bernoulli, categorical, and Gaussian distributions below. Other more sophisticated Bayesian manipulations are also simplified through the use of conjugacy.
Bernoulli, Binomial, and Beta Distributions
The Bernoulli probability distribution is defined for binary random variables. Suppose ![]() , the probability of x=1 is given by π and the probability of x=0 is given by 1−π. The probability distribution can be written in the following way
, the probability of x=1 is given by π and the probability of x=0 is given by 1−π. The probability distribution can be written in the following way
The binomial distribution generalizes the Bernoulli distribution. It defines the probability for a certain number of successes in a sequence of binary experiments, where the outcome of each experiment is governed by a Bernoulli distribution. The probability of exactly k successes in n experiments under the binomial distribution is
and defined for k=0, 1, 2,…, n where
is the binomial coefficient. Intuitively, the binomial coefficient is needed to account for the fact that the definition of this distribution ignores the order of the results of the experiments—the k results where x=1 could have occurred anywhere in the sequence of the n experiments. The binomial coefficient gives the number of different ways in which one could have obtained the k results where x=1. Intuitively, the term πk is the probability of exactly k results where x=1, and πn−k is the probability of having exactly n−k results where x=0. These two terms are valid for each of the possible ways in which the sequence of outcomes could have occurred, and we therefore simply multiply by the number of possibilities.
The Beta distribution is defined for a random variable π where ![]() . It uses two shape parameters
. It uses two shape parameters ![]() such that
such that
(A.1)
where ![]() is the beta function and serves as a normalization constant that ensures that the function integrates to one. The Beta distribution is useful because it can be used as a conjugate prior distribution for the Bernoulli and binomial distributions. Its mean is
is the beta function and serves as a normalization constant that ensures that the function integrates to one. The Beta distribution is useful because it can be used as a conjugate prior distribution for the Bernoulli and binomial distributions. Its mean is
and it can be shown that if the maximum likelihood estimate for the Bernoulli distribution is given by πML then the posterior mean ![]() of the Beta distribution is
of the Beta distribution is
where
and n is the number of examples used to estimate πML. The use of the posterior mean value ![]() as the regularized or smoothed estimate, replacing πML in a Bernoulli model, is therefore justified under Bayesian principles by the fact that the mean value of the posterior predictive distribution of a Beta-Bernoulli model is equivalent to plugging the posterior mean parameters of the Beta into the Bernoulli, i.e.
as the regularized or smoothed estimate, replacing πML in a Bernoulli model, is therefore justified under Bayesian principles by the fact that the mean value of the posterior predictive distribution of a Beta-Bernoulli model is equivalent to plugging the posterior mean parameters of the Beta into the Bernoulli, i.e.
This supports the intuitive notion of thinking of α and β as imaginary observations for x=1 and x=0, respectively, and justifies it in a Bayesian sense.
Categorical, Multinomial, and Dirichlet Distributions
The categorical distribution is defined for discrete random variables with more than two states; it generalizes the Bernoulli distribution. For K categories one might define ![]() or
or ![]() ; however, the order of the integers used to encode the categories is arbitrary. If the probability of x being in state or category k is given by πk, and if we use a one hot encoding for a vector representation x in which all the elements of x are zero except for exactly one dimension that is equal to 1, representing the state or category of x, then the categorical distribution is
; however, the order of the integers used to encode the categories is arbitrary. If the probability of x being in state or category k is given by πk, and if we use a one hot encoding for a vector representation x in which all the elements of x are zero except for exactly one dimension that is equal to 1, representing the state or category of x, then the categorical distribution is
The multinomial distribution generalizes the categorical distribution. Given multiple independent observations of a discrete random variable with a fixed categorical probability πk for each class k, the multinomial distribution defines the probability of observing a particular number of instances of each category. If the vector x is defined as the number of times each category has been observed, then the multinomial distribution can be expressed as
The Dirichlet distribution is defined for a random variable or parameter vector π such that ![]() ,
, ![]() ,
, ![]() , which is precisely the form of π used to define the categorical and multinomial distributions above. The Dirichlet distribution with parameters
, which is precisely the form of π used to define the categorical and multinomial distributions above. The Dirichlet distribution with parameters ![]() ,
, ![]() is
is
where B(α), the multinomial beta function, serves as the normalization constant that ensures that the function integrates to one:
where ![]() is the gamma function.
is the gamma function.
The Dirichlet distribution is useful because it can be used as a conjugate prior distribution for the categorical and multinomial distributions. Its mean (vector) is

And it generalizes the case of the Bernoulli distribution with a Beta prior. That is, it can be shown that if the traditional maximum likelihood estimate for the categorical distribution is given by πML, then the posterior mean ![]() of a model consisting of a categorical likelihood and a Dirichlet prior has the form of a Dirichlet distribution with mean
of a model consisting of a categorical likelihood and a Dirichlet prior has the form of a Dirichlet distribution with mean
where
and where n is the number of examples used to estimate πML. The use of the posterior mean value ![]() as the regularized or smoothed estimate to replace πML in a categorical probability model is therefore justified under Bayesian principles by the fact that the mean value of the posterior predictive distribution of a categorical model with a Dirichlet prior is equivalent to plugging the posterior mean parameters of the Dirichlet posterior into the categorical probability model, i.e.,
as the regularized or smoothed estimate to replace πML in a categorical probability model is therefore justified under Bayesian principles by the fact that the mean value of the posterior predictive distribution of a categorical model with a Dirichlet prior is equivalent to plugging the posterior mean parameters of the Dirichlet posterior into the categorical probability model, i.e.,
Again the intuitive notion of thinking of each of the elements αk of the parameter vector α for the Dirichlet as imaginary observations is justified under a Bayesian analysis.
Estimating the Parameters of a Discrete Distribution
Suppose we wish to estimate the parameters of a discrete probability distribution—of which the binary distribution is a special case. Let the probability of a variable being in category k be πk, and write the parameters of the distribution as the length–k vector π. Encode each example using a one hot vector xi, i=1,…, N, which is all zero except for one dimension that corresponds to the observed category, where xi,k=1. The probability of a dataset can be expressed as
If nk is the number of times that each class k in the data has been observed, the log-likelihood of the data is
To ensure that the parameter vector defines a valid probability, the log-likelihood is augmented with a term involving a Lagrange multiplier λ that enforces the constraint that the probabilities sum to one:
Taking the derivative of this function with respect to λ and setting the result to zero tells us that the sum over the probabilities in our model should be 1 (as desired). We then take the derivative of the function with respect to each parameter and set it to zero, which gives
We can solve for λ by summing both sides over k:
Therefore we can determine that the gradient of the augmented objective function is zero when
This simple result should be in line with your intuition about how to estimate probabilities.
We discussed above how specifying a Dirichlet prior for the parameters can regularize the estimation problem and compute a smoothed probability ![]() . The regularization can equivalently be viewed as imaginary data or counts αk for each class k, to give an estimate
. The regularization can equivalently be viewed as imaginary data or counts αk for each class k, to give an estimate
which can also be written
This also follows from the analysis above that expressed the smoothed probability vector ![]() as a weighted combination of the prior probability vector πD and the maximum likelihood estimate πML,
as a weighted combination of the prior probability vector πD and the maximum likelihood estimate πML, ![]() .
.
The Gaussian Distribution
The one-dimensional Gaussian probability distribution has the following form:
where the parameters of the model are its mean μ and variance σ2 (the standard deviation σ is simply the square root of the variance). Given N examples xi=1,…, N, the maximum likelihood estimates of these parameters are
When estimating the variance, the equation above is sometimes modified to use N–1 in place of N in the denominator to obtain an unbiased estimate, giving the standard deviation as

especially with sample sizes less than 10. This is known as the (corrected) sample standard deviation.
The Gaussian distribution can be generalized from one to two dimensions, or indeed to any number of dimensions. Consider a two-dimensional model consisting of independent Gaussian distributions for each dimension, which is equivalent to a model with a diagonal covariance matrix when written using matrix notation. We can transform from scalar to matrix notation for a two-dimensional Gaussian distribution:

where the covariance matrix of the model is given by Σ, the vector x=[x1 x2]T, and the mean vector μ=[μ1 μ2]T. This progression of equations is true because the inverse of a diagonal matrix is simply a diagonal matrix consisting of one over each of the original diagonal elements, which explains how the scalar notation converts to the matrix notation for an inverse covariance matrix. The covariance matrix is the matrix with this entry on row i and column j:
where E[.] refers to the expected value and ![]() . The mean can be computed in vector form:
. The mean can be computed in vector form:
The equation for estimating a covariance matrix is
In general the multivariate Gaussian distribution can be written
When a variable is to be modeled with a Gaussian distribution with mean μ and covariance matrix Σ, it is common to write P(x)=N(x; μ, Σ). Notice the semicolon: this implies that the mean and covariance will be treated as parameters. In contrast, the “|” (or “given”) symbol is used when the parameters are treated as variables and their uncertainty is to be modeled. Treating parameters as random variables is popular in Bayesian techniques such as latent Dirichlet allocation.
Useful Properties of Linear Gaussian Models
Consider a Gaussian random variable x with mean μ and covariance matrix A, ![]() , and a random variable y whose conditional distribution given x is Gaussian with mean Wx+b and covariance matrix B,
, and a random variable y whose conditional distribution given x is Gaussian with mean Wx+b and covariance matrix B, ![]() . The marginal distribution of y and conditional distribution of x given y can be written
. The marginal distribution of y and conditional distribution of x given y can be written
respectively, where ![]() .
.
Probabilistic PCA and the Eigenvectors of a Covariance Matrix
When explaining principal component analysis in Section 9.6 we discussed the idea of diagonalizing a covariance matrix Σ and formulated this in terms of finding a matrix of eigenvectors Φ such that ![]() , a diagonal matrix. The same objective could be formulated as finding a factorization of the covariance matrix such that
, a diagonal matrix. The same objective could be formulated as finding a factorization of the covariance matrix such that ![]() . Recall that in our presentation of probabilistic PCA in Chapter 9 we saw that the marginal probability for P(x) under principal component analysis involves a covariance matrix given by
. Recall that in our presentation of probabilistic PCA in Chapter 9 we saw that the marginal probability for P(x) under principal component analysis involves a covariance matrix given by ![]() . Therefore, when
. Therefore, when ![]() we can see that if
we can see that if ![]() we would have precisely the same W that one could obtain from matrix factorization methods based on eigendecomposition. Importantly, for
we would have precisely the same W that one could obtain from matrix factorization methods based on eigendecomposition. Importantly, for ![]() it can be shown that maximum likelihood learning will produce Ws that are not in general orthogonal (Tipping and Bishop, 1999a, 1999b); however, some more recent work has shown how to impose orthogonality constraints during a maximum likelihood–based optimization procedure.
it can be shown that maximum likelihood learning will produce Ws that are not in general orthogonal (Tipping and Bishop, 1999a, 1999b); however, some more recent work has shown how to impose orthogonality constraints during a maximum likelihood–based optimization procedure.
The Exponential Family of Distributions
The exponential family of distributions includes Gaussian, Bernoulli, Binomial, Beta, Gamma, Categorical, Multinomial, Dirichlet, Chi-squared, Exponential and Poisson, among many others. In addition to their commonly used forms, these distributions can all be written in the standardized exponential family form that makes them easy to work with algebraically:
where θ is a vector of natural parameters, T(x) is a vector of sufficient statistics, A(θ) is known as cumulant generating function, and h(x) is an additional function of x. As an example, for the 1D Gaussian distribution these parameters are ![]() ,
, ![]() ,
, ![]() , and
, and ![]() .
.
Variational Methods and the EM Algorithm
With a complex probability model for which the posterior distribution cannot be computed exactly, a method called variational EM can be used. This involves manipulating approximations to the model’s true posterior distribution during an EM optimization procedure. The following variational analysis also helps to show why and how the EM algorithm involving exact posterior distributions works.
Before we begin, when using variational methods with approximate distributions it is helpful to make a distinction between the parameters used to build an approximation to the true posterior distribution and the parameters of the original model. Consider a probability model with a set of hidden variables H and a set of observed variables X. The observed values are given by ![]() . Let
. Let ![]() be the model’s exact posterior distribution, and
be the model’s exact posterior distribution, and ![]() be a variational approximation, with a set Φ of variational parameters.
be a variational approximation, with a set Φ of variational parameters.
To understand how variational methods are used in practice, we first examine the well-known “variational bound.” This is created using two tricks. The first is to divide and multiply by the same quantity; the second is to apply an inequality known as Jensen’s inequality. These allow the construction of a variational lower bound L(q) on the log marginal likelihood:

Here, H(q) is the entropy of q, which is
The bound L(q) becomes an equality when q=p. In the case of “exact” EM, this confirms that each M-step will increase the likelihood of the data. However, to make the lower bound tight again in preparation for the next M-step, the new exact posterior must be recomputed with the updated parameters as a part of the subsequent E-step.
When q is merely an approximation to p, the relationship between the marginal log-likelihood and the expected log-likelihood under distribution q can be written with an equality as opposed to an inequality:
KL(q||p) is known as the Kullback–Leibler (KL) divergence, a measure of the distance between distributions q and p. It is not a true distance in the mathematical sense, but rather a quantity that always exceeds zero and only becomes zero when q=p. Here it is given by
The difference between the log marginal likelihood and the variational bound is given by the KL divergence between the approximate q and the true p. This means that if q is approximate, the bound can be tightened by improving the quality of the approximation q to the true posterior p. So, as we also saw above, when q is not an approximation but equals p exactly, ![]() and
and
Variational inference techniques are often used to improve the quality of an approximate posterior distribution within an EM algorithm, and the term “variational EM” refers to this general method. However, the result of a variational inference procedure is sometimes useful in itself. A key feature of variational methods arises from the existence of the variational bound and the fact that algorithms can be formulated that iteratively bring q closer to p in the sense of the KL divergence.
The mean-field approach is one of the simplest variational methods. It minimizes the KL divergence between an approximation, which consists of giving each variable its own separate variational distribution (and parameters), and the true joint distribution. This is known as a “fully factored variational approximation” and could be written
Given some initial parameters for the separate distributions for each variable qj=qj(hj), one proceeds to update each variable iteratively, given expectations of the model under the current variational approximation for the other variables. These updates take this general form:
where the expectation is performed using the approximate qs for all variables hi other than hj, and Z is a normalization constant obtained by summing over the numerator for all values of hj.
Early work on variational methods for graphical models is well represented in Jordan, Ghahramani, Jaakkola, and Saul (1999). If distributions are placed over parameters as well as hidden variables, variational Bayesian methods and variational Bayesian EM can be used to perform more fully Bayesian learning (Ghahramani and Beal, 2001). Winn and Bishop (2005) gives a good comparison of belief propagation and variational inference methods when viewed as message passing algorithms. Bishop’s textbook (Bishop, 2006), as well as Koller and Friedman (2009)’s, provide further detail and more advanced machine learning techniques based on the variational perspective.