
Robot Trajectory Generation in Joint Space
Abstract
In order to generate desired robot trajectory, this chapter proposes a different method from the previous works like inverse kinematics and dynamic time warping. The classic hidden Markov model (HMM) is modified such that it is more feasible to generate trajectory in joint space. We introduce a new auxiliary output in HMM to help the training process. The Lloyd's algorithm is modified for HMM, such that it can solve the problems in joint space learning. The proposed method is validated with a two-link planar robot and a four degree-of-freedom (4-DoF) exoskeleton robot.
Keywords
Joint space; Tarjectory generation; Hidden Markov model
10.1 Codebook and key-points generation
The dynamics of a n-link robot in joint space can be written as
M(q)⋅⋅q+c(q,⋅q)⋅q+g(q)+F(⋅q)=τ
where q∈ℜn![]() denotes the links angles, ⋅q∈ℜn
denotes the links angles, ⋅q∈ℜn![]() denotes the links velocity, M(q)∈ℜn×n
denotes the links velocity, M(q)∈ℜn×n![]() is the inertia matrix, c(q,⋅q)∈ℜn×n
is the inertia matrix, c(q,⋅q)∈ℜn×n![]() is the centripetal and Coriolis matrix, g(q)∈ℜn
is the centripetal and Coriolis matrix, g(q)∈ℜn![]() is the gravity vector, F∈ℜn
is the gravity vector, F∈ℜn![]() is the frictional terms, and τ∈ℜn
is the frictional terms, and τ∈ℜn![]() is the input control vector.
is the input control vector.
The object is to generate the desired trajectory q⁎![]() from the demonstrations in the joint space Q=[Q1⋯Qn]T
from the demonstrations in the joint space Q=[Q1⋯Qn]T![]() , Qi=[X1i⋯Xmi]T
, Qi=[X1i⋯Xmi]T![]() . Here, the trajectory Xri
. Here, the trajectory Xri![]() defines ith joint and rth trajectory; it is defined as Xri={qi(l)}
defines ith joint and rth trajectory; it is defined as Xri={qi(l)}![]() , l=1⋯Tri
, l=1⋯Tri![]() , Tri
, Tri![]() is the total sample number of the joint angles. There are m trajectories for each joint. The trajectory number m is not necessary large, because a human cannot repeat the same motion only so many times and this may cause a repeat calculation in HMM. The data length Tri
is the total sample number of the joint angles. There are m trajectories for each joint. The trajectory number m is not necessary large, because a human cannot repeat the same motion only so many times and this may cause a repeat calculation in HMM. The data length Tri![]() is different from one demonstration to another, because of a different speed, and a starting/ending time.
is different from one demonstration to another, because of a different speed, and a starting/ending time.
Each joint for each demonstration has its own codebook defined as Ci![]() , i=1⋯n
, i=1⋯n![]() . A codebook can be regarded as a Ni
. A codebook can be regarded as a Ni![]() dimension vector, i.e., Ci=[ci1⋯ciNi]T
dimension vector, i.e., Ci=[ci1⋯ciNi]T![]() . The codebook dimension Ni
. The codebook dimension Ni![]() is selected by prior knowledge of the trajectory's geometry.
is selected by prior knowledge of the trajectory's geometry.
We use Lloyd's algorithm to train the codebook Ci(t)![]() . Here, t is noted as the training time. The initial codebook is defined as Ci(1)
. Here, t is noted as the training time. The initial codebook is defined as Ci(1)![]() . A bad initial condition may reach local minima. A heuristics method [160] is used to find a better Ci(1)
. A bad initial condition may reach local minima. A heuristics method [160] is used to find a better Ci(1)![]() . Since the heuristics method needs a lot time, Ci(1)
. Since the heuristics method needs a lot time, Ci(1)![]() can also be selected randomly from Xri
can also be selected randomly from Xri![]() .
.
The objective of using Lloyd's algorithm to create the codebook is to minimize a quantization error with certain data distribution. We need nearest-neighbor and centroid conditions, which are commonly used in Lloyd's algorithm. For one point qi(l1)![]() in the trajectory, we want to find the nearest codebook element by calculating
in the trajectory, we want to find the nearest codebook element by calculating
min1⩽j⩽N|qi(l1)−cij|,l1=1⋯T,i=1⋯n
If the nearest codebook element is cik![]() , the region Rij
, the region Rij![]() (i=1⋯n
(i=1⋯n![]() , j=1⋯Ni
, j=1⋯Ni![]() ) is defined as
) is defined as
Rik={qi(l1)}=[rik1⋯rikpik],k=1⋯sri
where pik![]() is the length of the region Rik
is the length of the region Rik![]() , sri
, sri![]() is the region number of the joint i and the demonstration r.
is the region number of the joint i and the demonstration r.
Obversely, the center of the region Rij![]() should be cij
should be cij![]() . The new center of Rij
. The new center of Rij![]() can be calculated as
can be calculated as
cij=1pijpij∑l=1rijl

It is the centroid condition. The normal Lloyd's algorithm uses selected points to construct the centers [42]. We calculate the mean value of all points in the region Rij![]() . The advantage is that it can be updated online.
. The advantage is that it can be updated online.
With (10.3) and (10.4), we can calculate cij(t)![]() recursively. We use the following quantization error to design a stop criterion. The average quantization error for Xij={qi(l)}
recursively. We use the following quantization error to design a stop criterion. The average quantization error for Xij={qi(l)}![]() , l=1⋯T
, l=1⋯T![]() , is defined as
, is defined as
εij(t)=1TT∑l=1|qi(l)−cij(t)|

where t is the recursive calculation times. We define a relative quantization error as
Δεij(t)=|εij(t+1)−εij(t)εij(t+1)|
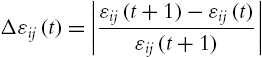
The codebook calculation is stopped when the relative error (10.6) is small enough as
Δεij(t)⩽ˉε
where ˉε![]() is a prior defined upper bound.
is a prior defined upper bound.
Remark 10.1
We use Lloyd's algorithm to quantize the robot joint trajectories and obtain the codebook. Since we use the minimum distance as in (10.2), the codebook obtained from the above recursive method is optimal; see [42]. This means each joint angle qi(l)![]() has a minimal distance to its codebook element. The quantization is in Y-axis (joint angle axis). We do not consider time-axis. So the similarity of the trajectories with different time or speed can be measured directly. The advantage of this method is that we do not need dynamic time warping (DTW) as [140].
has a minimal distance to its codebook element. The quantization is in Y-axis (joint angle axis). We do not consider time-axis. So the similarity of the trajectories with different time or speed can be measured directly. The advantage of this method is that we do not need dynamic time warping (DTW) as [140].
In order to train the hidden Markov model, we need key-points and observation symbols. These will be generated from the above codebook. The key-points are the start point, the end point o, and the center point in the time-axis of the codebook. If the time index of cij![]() in (10.4) is defined as tij
in (10.4) is defined as tij![]() (i=1⋯n
(i=1⋯n![]() , j=1⋯Ni
, j=1⋯Ni![]() ), then the key-points are calculated as
), then the key-points are calculated as
kij=tij+ti(j+1)−tij2
For each demonstration the key-points set are Kri=[ki1⋯ki,vri]T![]() (i=1⋯n
(i=1⋯n![]() , r=1⋯m
, r=1⋯m![]() ), vri
), vri![]() is the key point number in Kri
is the key point number in Kri![]() . Since the key-point is in the center of the Rij
. Since the key-point is in the center of the Rij![]() and the starting and ending points of the trajectory are also key-points, vri=sri+2
and the starting and ending points of the trajectory are also key-points, vri=sri+2![]() .
.
The observation symbols are the joint angles at the time of key-points. When they are less than the codebook, we use the codebook values. Ori=[oi1⋯oiNi]T![]() (i=1⋯n
(i=1⋯n![]() , r=1⋯m
, r=1⋯m![]() ):
):
{oij(,q)=ci,j+1if cij⩽qri(k)⩽ci,j+1oij(s,)=j+1otherwise,j=1⋯Ni,k=1⋯vri

where s is the symbol of the observation, q is the value of the codebook.
Lloyd's algorithm allows us to set the dimensions of the key-points and the observation symbols are the same as that of the codebook. We avoid the manual tuning process as in [42,140,152].
We use the following example to explain how to use Lloyd's algorithm to generate the codebook, key-points, and observation symbols.
Example 10.1
A robot draws a circle. The angle of Joint-1 is shown in Fig. 10.1. We first show how the codebook number N will affect the results. The two square waves corresponds to N=3![]() and N=4
and N=4![]() . When N=3
. When N=3![]() , there are 3 quantizations in the Y-axis. They generate 5 regions in the trajectory, s11=5
, there are 3 quantizations in the Y-axis. They generate 5 regions in the trajectory, s11=5![]() , R11⋯R15
, R11⋯R15![]() . The key-points are in the center of each segment of the square waves. With the starting point and ending point, the key-point number of K11
. The key-points are in the center of each segment of the square waves. With the starting point and ending point, the key-point number of K11![]() is 7, v11=s11+2=7
is 7, v11=s11+2=7![]() . When N=4
. When N=4![]() , the region number in (10.3) is s11=7
, the region number in (10.3) is s11=7![]() , and the key-point number is v11=9
, and the key-point number is v11=9![]() . If there are 3 demonstrations, then r=1,2,3
. If there are 3 demonstrations, then r=1,2,3![]() ; see Fig. 10.2. The velocities are different; usually the dynamic time warping is needed to put them together in the time-axis. Here, we use Lloyd's algorithm; the key-point number of these three demonstrations are the same, N=3
; see Fig. 10.2. The velocities are different; usually the dynamic time warping is needed to put them together in the time-axis. Here, we use Lloyd's algorithm; the key-point number of these three demonstrations are the same, N=3![]() , s11=s21=s31=5
, s11=s21=s31=5![]() . Although the key-points in the time-axis are different, the observation symbols in the Y-axis are similar.
. Although the key-points in the time-axis are different, the observation symbols in the Y-axis are similar.


The following algorithm explains the calculation process of the codebook Ci![]() , key-points Kri
, key-points Kri![]() , and the observation symbols Ori
, and the observation symbols Ori![]() .
.
Algorithm 1
Algorithm 10.1
Calculation of codebook, key-points, and observation symbols.
Obtain demonstrations Q=[Q1⋯Qn]T![]() , Qi=[X1i⋯Xmi]T
, Qi=[X1i⋯Xmi]T![]()
Set the codebook size N
For i=1![]() to n
to n
For r=1![]() to m
to m
t=1
![]()
While Δεij(t)⩽ˉε![]()
For j=1![]() to Ni
to Ni![]()
Calculate the region Rij(t)![]() with (10.3)
with (10.3)
Calculate center cij(t)![]() with (10.4)
with (10.4)
Calculate the relative quantization error with (10.6)
End for j
t=t+1
![]()
End while
calculate key-points Kri![]() with (10.8)
with (10.8)
calculate of the observation symbols Ori![]() with (10.9)
with (10.9)
End for r
End for i
10.2 Joint space trajectory generation with a modified hidden Markov model
After the codebook, key-points, and the observation symbols are generated by Lloyd's algorithm, they are used for training a discrete Hidden Markov Model (HMM). This model can generate a desired trajectory in the joint space as we want; see Fig. 10.3.

A HMM can be understood as a finite state machine where at any instant N, the different states are defined as S={S1,S2,S3...SN}![]() . At regular intervals, the HMM may change its states. The time associated with the changes are denoted by t=1,2,...
. At regular intervals, the HMM may change its states. The time associated with the changes are denoted by t=1,2,...![]() . The changed states are denoted by ht
. The changed states are denoted by ht![]() . In the case of process modeling, the change (transition) probabilities only depend on the current state tk
. In the case of process modeling, the change (transition) probabilities only depend on the current state tk![]() and its previous states tk−1
and its previous states tk−1![]() , tk−2,⋯
, tk−2,⋯![]()
P(ht=Sj|ht−1=Sk,ht−2=Sk,...)=P(ht=Sj|ht−k=Sk)
where t=1,2,...![]() , k=t−1,t−2,...
, k=t−1,t−2,...![]() .
.
Since the right-hand side of the above equality is independent of t, each transition probability defined aij![]() as
as
aij=P(ht=Sj|ht−1=Si),1⩽i,j⩽N
Now we define the transition probability distribution matrix as A={aij}![]() . If each state can lead to any other state in a single transition, aij>0
. If each state can lead to any other state in a single transition, aij>0![]() .
.
The number of distinct observation is defined as M. The symbols corresponding to the observable output of the system is defined as
V={v1,v2,...,vM}
The distribution of observing the symbol is defined as B={bj(k)}![]() . This probability distribution of the symbol k in state j is
. This probability distribution of the symbol k in state j is
bj(k)=P[vk|ht=Sj],1<j<N,1<k<M
A graphical representation of a HMM is Fig. 10.4. This is a graphical representation of the HMM of Fig. 10.2. Here, the codebook number N1=4![]() , the hidden state number v1=7
, the hidden state number v1=7![]() . The configuration of this HMM is the well-known left–right topology.
. The configuration of this HMM is the well-known left–right topology.

The probability distribution of the initial state is defined as π={πi}![]() :
:
πi=P[h1=Si],1<i<N
Given suitable for N, M, A, B, and π, a HMM generates a sequence of observations as O=[O1,O2,...OT]![]() according to the following algorithm. Each observation Oi
according to the following algorithm. Each observation Oi![]() is a symbol of the set V in (10.12):
is a symbol of the set V in (10.12):
- 1. Select an initial state h1=Si
 according to the initial distribution πi
according to the initial distribution πi . Set time t=1
. Set time t=1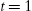 .
. - 2. Select Ot=vk
 according to the observation probability distribution of the symbols Si
according to the observation probability distribution of the symbols Si , i.e., bi(k)
, i.e., bi(k) .
. - 3. Make a transition to the new state ht+l=Sj
 according to the probability distribution of Si, i.e., aij
according to the probability distribution of Si, i.e., aij .
. - 4. Set the time interval t=t+1
 , go to Step 2, until t=T
, go to Step 2, until t=T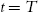 .
.
With the above procedure, a HMM can be represented as
λ=(A,B,π)
For pth joint, the HMM λi![]() can be considered a generalization of the following mixture model [116]:
can be considered a generalization of the following mixture model [116]:
λp=(Ap,Bp,πp)
Since the difference in joint space is much bigger than task space with respect to motion speed and starting point, and the demonstrations cannot be many. The HMM model (10.16) cannot generate a desired trajectory with good accuracy in the joint space. We modify the HMM (10.16) into the following form:
λp=(Ap,Bp,πp,ˆqp)
where ˆqp=[ˆqp1⋯ˆqpNp]T![]() is the output of the HMM (scaled joint angle), which is defined in (10.1).
is the output of the HMM (scaled joint angle), which is defined in (10.1).
The output of HMM ˆqp![]() is also regarded as one demonstration, and is sent to HMM again for its training.
is also regarded as one demonstration, and is sent to HMM again for its training.
The number of states Ap![]() relates to the number of key-points. Although the states in HMM are hidden, and the algorithm of the codebook and key-points generation represents the physical significance of the trajectory. The state of pth joint is defined as Sp=[sp1,...spvp]T
relates to the number of key-points. Although the states in HMM are hidden, and the algorithm of the codebook and key-points generation represents the physical significance of the trajectory. The state of pth joint is defined as Sp=[sp1,...spvp]T![]() . The hidden state number vp
. The hidden state number vp![]() is the maximum of the key-point number:
is the maximum of the key-point number:
vp=max1⩽r⩽m{vrp}
where m is the demonstration number, vp![]() is the hidden state number, and Np
is the hidden state number, and Np![]() is the codebook number.
is the codebook number.
We use the key-point number vrp![]() as the number of states of HMM. Since vrp
as the number of states of HMM. Since vrp![]() depends on the codebook Cp
depends on the codebook Cp![]() , the m trajectories have the same key-point number, which is defined as vp
, the m trajectories have the same key-point number, which is defined as vp![]() . The missing points are assigned with the correspond values of the other demonstration. The observation symbols are Op=[op1,⋯opNp]T
. The missing points are assigned with the correspond values of the other demonstration. The observation symbols are Op=[op1,⋯opNp]T![]() (p=1⋯n
(p=1⋯n![]() ).
).
In order to train the model (10.17) with the data generated the Lloyd's algorithm in the last section, we use the following four steps:
1) Given a sequence of observations O=O1O2...OT![]() and the model λp=(Ap,Bp,πp,qp)
and the model λp=(Ap,Bp,πp,qp)![]() , calculate the probability of the sequence of observations P(O|λp)
, calculate the probability of the sequence of observations P(O|λp)![]() .
.
The direct way to calculate the probability of O1O2...OT![]() with respect to λp
with respect to λp![]() is enumerating every possible state sequence of length T (the number of observations). Considering a sequence of fixed states H=h1h2...hT
is enumerating every possible state sequence of length T (the number of observations). Considering a sequence of fixed states H=h1h2...hT![]() , the probability of the observation sequence O=O1O2...OT
, the probability of the observation sequence O=O1O2...OT![]() for this sequence is
for this sequence is
P(O|H,λp)=T∏t=1P(Ot|ht,λp)

Under the independence assumption for the observations, the joint probability of O and H is
P(O|H,λp)=bh1(O1)bh2(O2)⋯bhT(OT)
The probability of O is calculated by adding this joint probability over all possible state sequences hi![]() :
:
P(O|λp)=πah1h2ah2h3⋅⋅⋅ahT−1hT=∑h1h2...hTπibh1(O1)ah1h2ah2h3⋅⋅⋅ahT−1hTbhT(OT)

We use the following feedforward–feedback process to calculate (10.21).
We define αt(i)![]() as
as
αt(i)=P(O1,O2,...Ot,(ht=Si|λp))βt(i)=P(Ot+1,Ot+2,...OT,(ht=Si|λp))

where αt(i)![]() is the probability of the sequence of partial observation (up to time t<T
is the probability of the sequence of partial observation (up to time t<T![]() ) and the state Si
) and the state Si![]() . βt(i)
. βt(i)![]() is the probability of the partial observation sequence from t+1
is the probability of the partial observation sequence from t+1![]() .
.
The feedforward process is as follows: a) start from α1(i)=πibi(O1)![]() ; then
; then
at+1=[N∑i=1αt(i)ai,j]bj(O1)

finally, P(O|λp)≈N∑i=1αt![]() .
.
The feedback process is as follows: b) start from βT(i)=1![]() ; then
; then
βt(i)=∑j=1aijbj(Ot+1)βt+1(j)
finally, P(O|λp)≈∑j=1βt+1(j)πibi(O1)![]() .
.
2) Find a sequence Si=[si1,...sivi]T![]() such that the probability of occurrence of the sequence O=O1,O2,...,OT
such that the probability of occurrence of the sequence O=O1,O2,...,OT![]() is an optimal sequence in the sense of
is an optimal sequence in the sense of
δT(i)=maxh1,h2,...,hT−1P(h1h2...hT=i,O1O2...OT|λp)
We need the highest probability through a single path. Considering the first t observation:
δt+1(j)=[maxδt(i)aij]bj(Ot+1)
In order to maximize the equation at each t,j![]() , we use the following recursive procedure: a) start from δt(i)=πibi(O1)
, we use the following recursive procedure: a) start from δt(i)=πibi(O1)![]() ; b) then δt(j)=max[δt−1(i)aij]bj(Ot)
; b) then δt(j)=max[δt−1(i)aij]bj(Ot)![]() ; c) finally,
; c) finally,
S⁎T=argmax1⩽i⩽N[δT(i)]
This is to find maxim possible state in the codes book, i.e., we want to find
max1⩽l⩽vi{bilj},j=1⋯Ni
The index of the maximum bilj![]() is scj
is scj![]() . Then we obtain the symbol set {sc1⋯scNi}
. Then we obtain the symbol set {sc1⋯scNi}![]() .
.
3) Use P(O|λp)![]() in Step 1 and the optimal sequence in Step 2 to train the HMM. This means training the λp
in Step 1 and the optimal sequence in Step 2 to train the HMM. This means training the λp![]() with Sp
with Sp![]() to maximize P[Op|λp]
to maximize P[Op|λp]![]() .
.
The value of the state in the instant t is defined as r(t)![]() . The state transition matrix Ap={aplj}
. The state transition matrix Ap={aplj}![]() :
:
aplj=P[r(t+1)=spj|r(t)=spl],1⩽l,j⩽vp
(10.25) represents the probability of being in the state spj![]() at time t+1
at time t+1![]() given the state sil
given the state sil![]() at time t. The initial elements ailj
at time t. The initial elements ailj![]() of the state transition matrix Ai(1)
of the state transition matrix Ai(1)![]() is selected as uniform distribution as
is selected as uniform distribution as
{∑jailj=1l<jailj=0otherwisei=1⋯n

The observation probability matrix Bp={bplj}![]() is
is
bplj=P[opl at t|r(t)=spj],1⩽l⩽Np,1⩽j⩽vp
This means the states cannot go back, and will jump when the key-points miss from the observed sequences. The initial condition for bilj![]() is
is
{bilj=0oil is the symbol of the demonstration lbilj=P[oil() at t|r(1)=sij]=1otherwise

The initial states distribution πp(1)=[πp1⋯πpNp]=[1,0⋯0]![]() ,
,
πpj(1)=P[r(1)=spj],1<j<Np
We define
ξt(i,j)=αt(i)aijbj(Ot+1)βt+1(j)P(O|λ)αt(i)aijbj(Ot+1)βt+1(j)N∑i=1N∑j=1αt(i)aijbj(Ot+1)βt+1(j)γt(i)=N∑j=1ξt(i,j)

Here, ξt(i,j)![]() gives the characteristic of a probability measure, and γt(i)
gives the characteristic of a probability measure, and γt(i)![]() is the probability of being S⁎T
is the probability of being S⁎T![]() given the sequence of observations O.
given the sequence of observations O.
By the Baum–Welch algorithm [9], the probabilities P[r(t+1)=sij|r(t)=sil]![]() and the emission distribution P[oil at t|r(t)=sij]
and the emission distribution P[oil at t|r(t)=sij]![]() are
are
aij=T−1∑t=1ξt(i,j)/T−1∑t=1γt(i)bj(k)=∑s.tOt=vkγt(i)/T−1∑t=1γt(i)
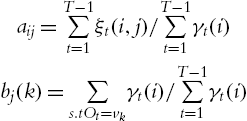
4) Decode these symbols into values qp![]() .
.
The output ˆqp![]() can be regarded as the decoded values of the observation symbols from the codebook:
can be regarded as the decoded values of the observation symbols from the codebook:
ˆqp=[ˆqi1⋯ˆqiNi]=[oi,sc1(.,h)⋯oi,scNi(.,h)]
The output of the HMM ˆq![]() is a discrete state. In order to generate a smooth trajectory, we use spline interpolation. We use the following third-order (cubic) spline:
is a discrete state. In order to generate a smooth trajectory, we use spline interpolation. We use the following third-order (cubic) spline:
st(x)=at(x−ˆqt)3+bt(x−ˆqt)2+ct(x−ˆqt)+dt
where t=1,2⋯Ti![]() , is the number of the piecewise functions. Since the time index of the output is the key-points Kri
, is the number of the piecewise functions. Since the time index of the output is the key-points Kri![]() in (10.8), the total time of the trajectory ˆq
in (10.8), the total time of the trajectory ˆq![]() is
is
Ti=1vivi∑j=1kij,i=1⋯n

When the discrete point xt![]() is the output of the HMM xij
is the output of the HMM xij![]() , the spline function gives a smooth trajectory ˆq⁎(t)
, the spline function gives a smooth trajectory ˆq⁎(t)![]() . After time scale, the desired trajectory is
. After time scale, the desired trajectory is
ˆq⁎(αt)
where α is time scale factor in joint space. Finally, we give the complete scheme of our algorithm; see Fig. 10.5.

10.3 Experiments of learning trajectory
We evaluate the effectiveness of the proposed method with two examples: a two-link revolute joint arm (planar elbow manipulator) and our 4-DoF exoskeleton robot (CINVESRobot-1). The experiments are implemented in Matlab without code optimization. The computer is a PC with Intel Core i3 3.30 GHz processor. We use Kevin Murphy's HMM Toolbox [98] (Baum–Welch algorithm [9]) to train the HMM.
We compare our method (LHMM) with the other two approaches: HMM in task space with the inverse kinematics calculation (THMM), and HMM in joint space with the dynamic time warping (JHMM).
10.3.1 Two-link planar elbow manipulator
We use this example to show our method can learn space and time differences in the demonstrations, and to show how the time difference affects the training results. There are about 8%![]() (0.1 second) differences.
(0.1 second) differences.
The definitions of the two-link robot are shown in Fig. 10.6. By direct calculation, the forward kinematic and the inverse kinematics are
x=l1cosq1+l2cos(q1+q2),y=l1sinq1+l2sin(q1+q2)
q2=tan−1±√1−D2D,D=x2+y2−l21−l222l1l2q1=tan−1(yx)−tan−1(l2sinq2l1+l2cosq2)


1) We first show how our algorithm works with time difference. We draw three similar broken lines in task space with different velocities; see Fig. 10.7. These lines are almost the same in task space. However, in joint space they are different; see Fig. 10.8.


We use N1=N2=100![]() as the codebook numbers for the two joints. These values are chosen heuristically to balance computation complexity and the modeling accuracy. The key-point numbers of the joints are obtained from Lloyd's algorithm, for Joint-1, v11=62
as the codebook numbers for the two joints. These values are chosen heuristically to balance computation complexity and the modeling accuracy. The key-point numbers of the joints are obtained from Lloyd's algorithm, for Joint-1, v11=62![]() , v21=63
, v21=63![]() , v31=61
, v31=61![]() ; for Joint-2, v12=76
; for Joint-2, v12=76![]() , v22=77
, v22=77![]() , v32=75
, v32=75![]() . By (10.18), the state numbers of HMM for each joint are v1=63
. By (10.18), the state numbers of HMM for each joint are v1=63![]() , v2=77
, v2=77![]() . After the HMM is trained, it generates desired trajectories q⁎1
. After the HMM is trained, it generates desired trajectories q⁎1![]() and q⁎2
and q⁎2![]() with different velocity (10.29). If we select α=1
with different velocity (10.29). If we select α=1![]() , the solid lines Fig. 10.8 are the desired joint angles. We hope that the robot moves two times faster than its demonstrations. We select α=0.5
, the solid lines Fig. 10.8 are the desired joint angles. We hope that the robot moves two times faster than its demonstrations. We select α=0.5![]() , and is shown by the solid lines in Fig. 10.9. It is interesting to see that the corresponding task space trajectory does not change, which is the solid line in Fig. 10.8.
, and is shown by the solid lines in Fig. 10.9. It is interesting to see that the corresponding task space trajectory does not change, which is the solid line in Fig. 10.8.

2) The second test is to show how our algorithm works for the space difference. The codebook numbers are also N1=N2=100![]() . The key-point numbers are v11=60
. The key-point numbers are v11=60![]() , v21=51
, v21=51![]() , v31=55
, v31=55![]() , v12=64
, v12=64![]() ,
, ![]() ,
, ![]() . The generated trajectory in the task space is the solid line in Fig. 10.10. Their trajectories in joint space are shown in Fig. 10.11.
. The generated trajectory in the task space is the solid line in Fig. 10.10. Their trajectories in joint space are shown in Fig. 10.11.


3) THMM works very well for the speed difference (Fig. 10.8), because the demonstrations in task space are similar, and the inverse kinematics (10.31) are known. However, it does not work well for the space difference (Fig. 10.10), because HMM cannot work well with less demonstrations in task space. On the other hand, our method works in joint space with Lloyd's algorithm. It is not affected by these demonstrations; see Fig. 10.12.

JHMM can work for both speed and space differences. Fig. 10.13 shows the results of the speed difference. The accuracy of JHMM is less than our LHMM; see Fig. 10.10 and Fig. 10.11. The error comes from the dynamic time warping.

The modified HMM (10.17) uses the output, and it can learn the joint space trajectories with small number of demonstrations (three training samples), while the original HMM (10.16) cannot generate the joint space trajectories with three demonstrations.
10.3.2 4-DoF upper limb exoskeleton
The computer control platform for our upper limb exoskeleton is CINVESRobot-1. We first draw a 3-D “O” in the task space three times; see Fig. 10.14. At the same time, the joint angles are saved in the computer as the training trajectories; see Fig. 10.15. Then we use our modified HMM to train a model. Since the drawing speeds are different, the data size of the three demonstration are 629, 576, and 615. We select the codebook numbers ![]() . The key-point numbers are
. The key-point numbers are ![]() ,
, ![]() ,
, ![]() . (See also Fig. 10.16.) After the HMM is trained, we used it to generate desired trajectories in the joint space; see the solid lines in Fig. 10.17. These trajectories are sent to the lower level controller. The three motors use PID control to follow the trajectories. As a result, the robot draws another “O” in the task space; see the solid line in Fig. 10.18.
. (See also Fig. 10.16.) After the HMM is trained, we used it to generate desired trajectories in the joint space; see the solid lines in Fig. 10.17. These trajectories are sent to the lower level controller. The three motors use PID control to follow the trajectories. As a result, the robot draws another “O” in the task space; see the solid line in Fig. 10.18.





An advantage of our joint space method is the time scale of the desired trajectory can be changed such that the “O” in the task space is faster than the demonstrations. The superhuman performance can be realized easily by our modified HMM. Fig. 10.19 shows the trajectory generated by our method is twice as fast as the training demonstrations; here, ![]() in (10.29).
in (10.29).

For this example, we do not compare our method LHMM with THMM, because the task space method THMM does not work with three demonstrations. JHMM can work in joint space for different speeds. Fig. 10.19 shows the result in task space. It is almost “O,” but the accuracy is much less than our LHMM, because the high dimension (3D) approximation of DTW is not good.
10.4 Conclusions
The advantage of programming robot by demonstration in joint space is to avoid the inverse kinematics. The disadvantage is that the demonstrations in joint space are strong time-dependent. Wer uses Lloyd's algorithm and modifies HMM to solve the problems in joint space.
We use Lloyd's algorithm to encode and quantize the input vectors. This approach improves accuracy compared with the dynamic time warping method. The traditional HMM is modified such that it can generate trajectories in joint space. Simulation and experimental results are also proposed. The results show that the proposed method is more effective to generate robot trajectory. Although there are few works in joint space, we believe this direct method can be applied in more robots in the future.