
Chapter 6. Active Record Migrations
Baby step to four o’clock. Baby step to four o’clock.
—Bob Wiley, in the movie What About Bob (Touchstone Pictures, 1991)
It’s a fact of life that the database schema of your application will evolve over the course of development. Tables are added, names of columns are changed, things are dropped—you get the picture. Without strict conventions and process discipline for the application developers to follow, keeping the database schema in proper lock-step with application code is traditionally a very troublesome job.
Migrations are the Rails way of helping you to evolve the database schema of your application (also known as its DDL) without having to drop and re-create the database each time you make a change. And not having to drop and recreate the database each time a change happens means that you don’t lose your development data. That may or may not be that important, but is usually very convenient. The only changes made when you execute a migration are those necessary to move the schema from one version to another, whether that move is forward or backward in time.
Of course, being able to evolve your schema without having to recreate your databases and the loading/reloading of data is an order of magnitude more important once you’re in production.
6.1 Creating Migrations
Rails provides a generator for creating migrations.
$ rails generate migration
Usage:
rails generate migration NAME [field:type field:type] [options]
At minimum, you need to supply descriptive name for the migration in CamelCase (or underscored_text, both work,) and the generator does the rest. Other generators, such as the model and scaffolding generators, also create migration scripts for you, unless you specify the --skip-migration option.
The descriptive part of the migration name is up to you, but most Rails developers that I know try to make it match the schema operation (in simple cases) or at least allude to what’s going on inside (in more complex cases).
Note that if you change the classname of your migration to something that doesn’t match its filename, you will get an uninitialized constant error when that migration gets executed.
6.1.1 Sequencing Migrations
Prior to Rails 2.1, the migrations were sequenced via a simple numbering scheme baked into the name of the migration file, and automatically handled by the migration generator. Each migration received a sequential number. There were many inconveniences inherent in that approach, especially in team environments where two developers could check in a migration with the same sequence number. Thankfully those issues have been eliminated by using timestamps to sequence migrations.
Migrations that have already been run are listed in a special database table that Rails maintains. It is named schema_migrations and only has one column:

When you pull down new migrations from source control, rake db:migrate will check the schema_migrations table and execute all migrations that have not yet run (even if they have earlier timestamps than migrations that you’ve added yourself in the interim).
6.1.2 Irreversible Migrations
Some transformations are destructive in a manner that cannot be reversed. Migrations of that kind should raise an ActiveRecord::IrreversibleMigration exception in their down method. For example, what if someone on your team made a silly mistake and defined the telephone column of your clients table as an integer? You can change the column to a string and the data will migrate cleanly, but going from a string to an integer? Not so much.

Getting back to the Migration API itself, here is the 20090124223305_create_clients.rb file again, from earlier in the chapter, after adding a couple of column definitions for the clients table:

As you can see in the example, migration directives happen within two class method definitions, self.up and self.down. If we go to the command line in our project folder and type rake db:migrate, the clients table will be created. Rails gives us informative output during the migration process so that we see what is going on:

Normally, only the code in the up method is run, but if you ever need to rollback to an earlier version of the schema, the down method specifies how to undo what happened in up.
To execute a rollback, use the migrate task, but pass it a version number to rollback to, as in rake db:migrate VERSION=20090124223305.
6.1.3 create_table(name, options, & block)
The create_table method needs at minimum a name for the table and a block containing column definitions. Why do we specify identifiers with symbols instead of strings? Both will work, but symbols require one less keystroke.
The create_table method makes a huge, but usually true assumption that we want an autoincrementing, integer-typed, primary key. That is why you don’t see it declared in the list of columns. If that assumption happens to be wrong, it’s time to pass create_table some options in a hash.
For example, how would you define a simple join table consisting of two foreign key columns and not needing its own primary key? Just pass the create_table method an :id option set to false, as a boolean, not a symbol! It will stop the migration from autogenerating a primary key altogether:

If all you want to do is change the name of the primary key column from its default of ‘id’, pass the :id option a symbol instead. For example, let’s say your corporation mandates that primary keys follow the pattern tablename id. Then the earlier example would look as follows:

The :force => true option tells the migration to go ahead and drop the table being defined if it exists. Be careful with this one, since it will produce (possibly unwanted) data loss when run in production. As far as I know, the :force option is mostly useful for making sure that the migration puts the database in a known state, but isn’t all that useful on a daily basis.
The :options option allows you to append custom instructions to the SQL CREATE statement and is useful for adding database-specific commands to your migration. Depending on the database you’re using, you might be able to specify things such as character set, collation, comments, min/max sizes, and many other properties using this option.
The :temporary => true option specifies creation of a temporary table that will only exist during the current connection to the database. In other words, it only exists during the migration. In advanced scenarios, this option might be useful for migrating big sets of data from one table to another, but is not commonly used.
Sebastian says ...
A little known fact is that you can remove old migration files (while still keeping newer ones) to keep the db/migrate folder to a manageable size. You can move the older migrations to a db/archived_migrations folder or something like that. Once you do trim the size of your migrations folder, use the rake db:reset task to (re)create your database from db/schema.rb and load the seeds into your current environment.
6.1.4 change_table(table_name, & block)
This basically works just like create_table and accepts the same kinds of column definitions.
6.1.5 API Reference
The following table details the methods that are available in the context of create_table and change_table methods within a migration class.
change(column_name, type, options = {})
Changes the column’s definition according to the new options. The options hash optionally contains a hash with arguments that correspond to the options used when adding columns.
t.change(:name, :string, :limit => 80)
t.change(:description, :text)
change_default(column_name, default)
Sets a new default value for a column.
t.change_default(:qualification, 'new')
t.change_default(:authorized, 1)
column(column_name, type, options = {})
Adds a new column to the named table. Uses the same kind of options detailed in Section 6.1.6.
t.column(:name, :string)
Note that you can also use the short-hand version by calling it by type. This adds a column (or columns) of the specified type (string, text, integer, float, decimal, datetime, timestamp, time, date, binary, boolean).
t.string(:goat)
t.string(:goat, :sheep)
t.integer(:age, :quantity)
index(column_name, options = {})
Adds a new index to the table. The column_name parameter can be one symbol or an array of symbols referring to columns to be indexed. The name parameter lets you override the default name that would otherwise be generated.

belongs_to(*args) and references(*args)
These two methods are aliases to each other. They add a foreign key column to another model, using Active Record naming conventions. Optionally adds a _type column if the :polymorphic option is set to true.
create_table :accounts do
t.belongs_to(:person)
end
create_table :comments do
t.references(:commentable, :polymorphic => true)
end
remove(*column_names)
Removes the column(s) specified from the table definition.
t.remove(:qualification)
t.remove(:qualification, :experience)
remove_index(options = {})
Removes the given index from the table.
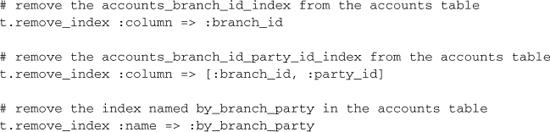
remove_references(*args) and remove_belongs_to
Removes a reference. Optionally removes a type column.
t.remove_belongs_to(:person)
t.remove_references(:commentable, :polymorphic => true)
remove_timestamps
Here’s a method that you will never use, unless you forgot to add timestamps in the create_table block and do it in a later migration. It removes the timestamp columns. (created_at and updated_at) from the table.
rename(column_name, new_column_name)
Renames a column. The old name comes first, a fact that I usually can’t remember.
t.rename(:description, :name)
timestamps
Adds Active Record-maintained timestamp (created_at and updated_at) columns to the table.
t.timestamps
6.1.6 Defining Columns
Columns can be added to a table using either the column method, inside the block of a create_table statement, or with the add_column method. Other than taking the name of the table to add the column to as its first argument, the methods work identically.
create_table :clients do |t|
t.column :name, :string
end
add_column :clients, :code, :string
add_column :clients, :created_at, :datetime
The first (or second) parameter obviously specifies the name of the column, and the second (or third) obviously specifies its type. The SQL92 standard defines fundamental data types, but each database implementation has its own variation on the standards.
If you’re familiar with database column types, when you examine the preceding example it might strike you as a little weird that there is a database column declared as type string, since databases don’t have string columns—they have char or varchars types.
Column Type Mappings
The reason for declaring a database column as type string is that Rails migrations are meant to be database-agnostic. That’s why you could (as I’ve done on occasion) develop using Postgres as your database and deploy in production to Oracle.
A complete discussion of how to go about choosing the right data type for your application needs is outside the scope of this book. However, it is useful to have a reference of how migration’s generic types map to database-specific types. The mappings for the databases most commonly used with Rails are in Table 6.1.
Table 6.1. Column Mappings for the Databases Most Commonly Used with Rails
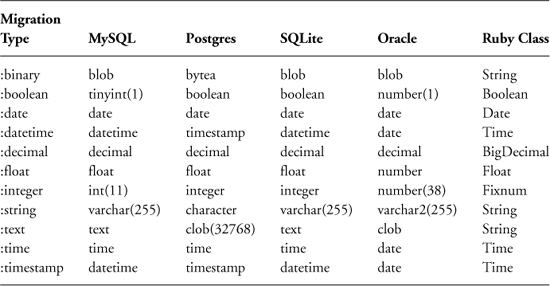
Each connection adapter class has a native_database_types hash which establishes the mapping described in Table 6.1. If you need to look up the mappings for a database not listed in Table 6.1, you can pop open the adapter Ruby code and find the native_database_types hash, like the following one inside the PostgreSQLAdapter class within postgresql_adapter.rb:

Column Options
For many column types, just specifying type is not enough information. All column declarations accept the following options:
:default => value
Sets a default to be used as the initial value of the column for new rows. You don’t ever need to explicitly set the default value to null. Just leave off this option to get a null default value. It’s worth noting that MySQL 5.x ignores default values for binary and text columns.
:limit => size
Adds a size parameter to string, text, binary, or integer columns. Its meaning varies depending on the column type that it is applied to. Generally speaking, limits for string types refers to number of characters, whereas for other types it specifies the number of bytes used to store the value in the database.
:null => false
Makes the column required at the database level by adding a not null constraint.
Decimal Precision
Columns declared as type :decimal accept the following options:
:precision => number
Precision is the total number of digits in a number.
:scale => number
Scale is the number of digits to the right of the decimal point. For example, the number 123.45 has a precision of 5 and a scale of 2. Logically, the scale cannot be larger than the precision.
Note
Decimal types pose a serious opportunity for data loss during migrations of production data between different kinds of databases. For example, the default precisions between Oracle and SQL Server can cause the migration process to truncate and change the value of your numeric data. It’s always a good idea to specify precision details for your data.
Column Type Gotchas
The choice of column type is not necessarily a simple choice and depends on both the database you’re using and the requirements of your application.
:binaryDepending on your particular usage scenario, storing binary data in the database can cause big performance problems. Active Record doesn’t generally exclude any columns when it loads objects from the database, and putting large binary attributes on commonly used models will increase the load on your database server significantly. If you must put binary content in a commonly-used class, take advantage of the select method to only bring back the columns you need.
:booleanThe way that boolean values are stored varies from database to database. Some use 1 and 0 integer values to represent true and false, respectively. Others use characters such as T and F. Rails handles the mapping between Ruby’s true and false very well, so you don’t need to worry about the underlying scheme yourself. Setting attributes directly to database values such as 1 or F may work correctly, but is considered an anti-pattern.
:datetime and :timestampThe Ruby class that Rails maps to datetime and timestamp columns is Time. In 32-bit environments, Time doesn’t work for dates before 1902. Ruby’s DateTime class does work with year values prior to 1902, and Rails falls back to using it if necessary. It doesn’t use DateTime to begin for performance reasons. Under the covers, Time is implemented in C and is very fast, whereas DateTime is written in pure Ruby and is comparatively slow.
:timeIt’s very, very rare that you want to use a :time datatype; perhaps if you’re modeling an alarm clock. Rails will read the contents of the database as hour, minute, and second values, into a Time object with dummy values for the year, month, and day.
:decimalOlder versions of Rails (prior to 1.2) did not support the fixed-precision :decimal type and as a result many old Rails applications incorrectly used :float datatypes. Floating-point numbers are by nature imprecise, so it is important to choose :decimal instead of :float for most business-related applications.
Tim says ...
If you’re using a float to store values which need to be precise, such as money, you’re a jackass. Floating point calculations are done in binary rather than decimal, so rounding errors abound in places you wouldn’t expect.
>> 0.1+0.2 == 0.3=> false>> BigDecimal('0.1') + BigDecimal('0.2') == BigDecimal('0.3')=> true
:floatDon’t use floats to store currency values, or more accurately, any type of data that needs fixed precision. Since floating-point numbers are pretty much approximations, any single representation of a number as a float is probably okay. However, once you start doing mathematical operations or comparisons with float values, it is ridiculously easy to introduce difficult to diagnose bugs into your application.
:integer and :stringThere aren’t many gotchas that I can think of when it comes to integers and strings. They are the basic data building blocks of your application, and many Rails developers leave off the size specification, which results in the default maximum sizes of 11 digits and 255 characters, respectively. You should keep in mind that you won’t get an error if you try to store values that exceed the maximum size defined for the database column, which again, is 255 characters by default. Your string will simply get truncated. Use validations to make sure that user-entered data does not exceed the maximum size allowed.
:textThere have been reports of text fields slowing down query performance on some databases, enough to be a consideration for applications that need to scale to high loads. If you must use a text column in a performance-critical application, put it in a separate table.
Custom Data Types
If use of database-specific datatypes (such as :double, for higher precision than :float) is critical to your project, use the config.active_record.schema_format = :sql setting in config/application.rb to make Rails dump schema information in native SQL DDL format rather than its own cross-platform compatible Ruby code, via the db/schema.rb file.
‘‘Magic’’ Timestamp Columns
Rails does magic with datetime columns, if they’re named a certain way. Active Record will automatically timestamp create operations if the table has columns named created_at or created_on. The same applies to updates when there are columns named updated_at or updated_on.
Note that created_at and updated_at should be defined as datetime, but if you use t.timestamps then you don’t have to worry about what type of columns they are.
Automatic timestamping can be turned off globally, by setting the following variable in an initializer.
ActiveRecord::Base.record_timestamps = false
The preceding code turns off timestamps for all models, but record_timestamps is class-inheritable, so you can also do it on a case-by-case basis by setting self.record_timestamps to false at the top of specific model classes.
6.1.7 Command-line Column Declarations
You can supply name/type pairs on the command line when you invoke the migration generator and it will automatically insert the corresponding add_column and remove_column methods.
$ rails generate migration AddTitleBodyToPosts
title:string body:text published:boolean
This will create the AddTitleBodyToPosts in db/migrate/20080514090912_add_title_body_to_posts.rb with this in the up migration:
add_column :posts, :title, :string
add_column :posts, :body, :text
add_column :posts, :published, :boolean
And this in the down migration:
remove_column :posts, :published
remove_column :posts, :body
remove_column :posts, :title
6.2 Data Migration
So far we’ve only discussed using migration files to modify the schema of your database. Inevitably, you will run into situations where you also need to perform data migrations, whether in conjunction with a schema change or not.
6.2.1 Using SQL
In most cases, you should craft your data migration in raw SQL using the execute command that is available inside a migration class.
For example, say you had a phones table, which kept phone numbers in their component parts and later wanted to simplify your model by just having a number column instead. You’d write a migration similar to this one (only the up method is shown, for brevity):

The naive alternative to using SQL in the example above would be more lines of code and much, much slower.
Phone.find_each do |p|
p.number = p.area_code + p.prefix + p.suffix
p.save
end
In this particular case, you could use Active Record’s update_all method to still do the data migration in one line.
Phone.update_all("set number = concat(area_code, prefix, suffix)")
However you might hit problems down the road as your schema evolves; as described in the next section, you’d want to declare an independent Phone model in the migration file itself. That’s why I advise sticking to raw SQL whenever possible.
6.2.2 Migration Models
If you declare an Active Record model inside of a migration script, it’ll be namespaced to that migration class.
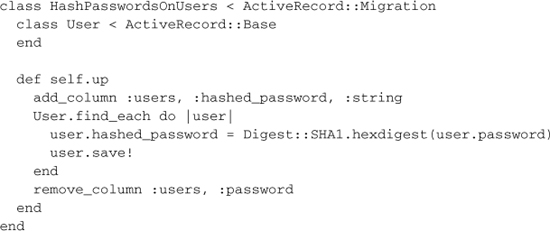
Why not use just your application model classes in the migration scripts directly? As your schema evolves, older migrations that use model classes directly can and will break down and become unusable. Properly namespacing migration models prevent you from having to worry about name clashes with your application’s model classes or ones that are defined in other migrations.
Durran says ...
Note that Active Record caches column information on the first request to the database, so if you want to perform a data migration immediately after a migration you may run into a situation where the new columns have not yet been loaded. This is a case where using reset_column_information can come in handy. Simply call this class method on your model and everything will be reloaded on the next request.
6.3 schema.rb
The file db/schema.rb is generated every time you migrate and reflects the latest status of your database schema. You should never edit db/schema.rb by hand since this file is auto-generated from the current state of the database. Instead of editing this file, please use the migrations feature of Active Record to incrementally modify your database, and then regenerate this schema definition.
Note that this schema.rb definition is the authoritative source for your database schema. If you need to create the application database on another system, you should be using db:schema:load, not running all the migrations from scratch. The latter is a flawed and unsustainable approach (the more migrations you’ll amass, the slower it’ll run and the greater likelihood for issues).
It’s strongly recommended to check this file into your version control system. First of all, it helps to have one definitive schema definition around for reference. Secondly, you can run rake db:schema:load to create your database schema from scratch without having to run all migrations. That’s especially important considering that as your project evolves, it’s likely that it will become impossible to run migrations all the way through from the start, due to code incompatibilities, such as renaming of classes named explicitly.
6.4 Database Seeding
The automatically created file db/seeds.rb is a default location for creating seed data for your database. It was introduced in order to stop the practice of inserting seed data in individual migration files, if you accept the premise that migrations should never be used for seeding example or base data required by your application. It is executed with the rake db:seed task (or created alongside the database when you run rake db:setup).
At its simplest, the contents of seed.rb is simply a series of create! statements that generate baseline data for your application, whether it’s default or related to configuration. For example, let’s add an admin user and some billing codes to our time and expenses app:
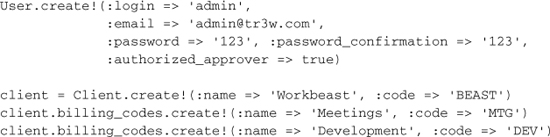
Why use the bang version of the create methods? Because otherwise you won’t find out if you had errors in your seed file. An alternative would be to use find_or_create_by methods to make seeding idempotent.
![]()
Another common seeding practice worth mentioning is calling delete_all prior to creating new records, so that seeding does not generate duplicate records. This practice avoids the need for idempotent seeding routines and lets you be very secure about exactly what your database will look like after seeding.

6.5 Database-Related Rake Tasks
The following rake tasks are included by default in boilerplate Rails projects.
db:create and db:create:all
Create the database defined in config/database.yml for the current Rails.env (Or create all of the local databases defined in config/database.yml in the case of db:create:all.)
db:drop and db:drop:all
Drops the database for the current RAILS_ENV. (Or drops all of the local databases defined in config/database.yml in the case of db:drop:all.)
db:forward and db:rollback
The db:rollback task moves your database schema back one version. Similarly, the db:forward task moves your database schema forward one version and is typically used after rolling back.
db:migrate
Applies all pending migrations. If a VERSION environment variable is provided, then db:migrate will apply pending migrations through the migration specified, but no further. The VERSION is specified as the timestamp portion of the migration file name.
If the VERSION provided is older than the current version of the schema, then this task will actually rollback the newer migrations.
db:migrate:down
Invoked without a VERSION, this task will migrate all the way down the version list to an empty database, assuming that all your migrations are working correctly.
With a VERSION, this task will invoke the down method of the specified migration only. The VERSION is specified as the timestamp portion of the migration file name.

db:migrate:up
Invoked without a VERSION, this task will migrate up the version list, behaving the same as db:migrate.
With a VERSION, this task will invoke the up method of the specified migration only. The VERSION is specified as the timestamp portion of the migration file name.

Tim says ...
The db:migrate:up and db:migrate:down tasks make for useful keybindings in migrations files. In Vim with rails.vim, for example, invoke :.Rake in a self.up or self.down method definition to invoke said task with the correct VERSION argument, or invoke it outside of both to invoke db:migrate:redo.
db:migrate:redo
Executes the down method of the latest migration file, immediately followed by its up method. This task is typically used right after correcting a mistake in the up method or to test that a migration is working correctly.
db:migrate:reset
Resets your database for the current environment using your migrations (as opposed to using schema.rb).
db:reset and db:setup
The db:setup creates the database for the current environment, loads the schema from db/schema.rb, then loads the seed data. It’s used when you’re setting up an existing project for the first time on a development workstation. The similar db:reset task does the same thing except that it drops and recreates the database first.
db:schema:dump
Create a db/schema.rb file that can be portably used against any DB supported by Active Record. Note that creation (or updating) of schema.rb happens automatically any time you migrate.
db:schema:load
Loads schema.rb file into the database for the current environment.
db:seed
Load the seed data from db/seeds.rb as described in this chapter’s section Database Seeding.
db:structure:dump
Dump the database structure to a SQL file containing raw DDL code in a format corresponding to the database driver specified in database.yml for your current environment.

I’ve rarely needed to use this task. It’s possible that some Rails teams working in conjunction with DBAs that exercise strict control over their application’s database schemas will need this task on a regular basis.
db:test:prepare
Check for pending migrations and load the test schema by doing a db:schema:dump followed by a db:schema:load.
This task gets used very often during active development whenever you’re running specs or tests without using Rake. (Standard spec-related Rake tasks run db:test:prepare automatically for you.)
db:version
Returns the timestamp of the latest migration file that has been run. Works even if your database has been created from db/schema.rb, since it contains the latest version timestamp in it:
ActiveRecord::Schema.define(:version => 20100122011531)
6.6 Conclusion
This chapter covered the fundamentals of Active Record migrations. In the following chapter, we continue our coverage of Active Record by learning about how model objects are related to each other and interact via associations.