
Chapter 14. Iteration Planning
“It is a capital mistake to theorize before one has data.”
—Sherlock Holmes, Scandal in Bohemia
A release plan is an excellent high-level view of how a team intends to deliver the most valuable product they can. However, a release plan provides only the high-level view of the product being built. It does not provide the short-term, more detailed view that teams use to drive the work that occurs within an iteration. With an iteration plan, a team takes a more focused, detailed look at what will be necessary to implement completely only those user stories selected for the new iteration.
An iteration plan is created in an iteration planning meeting. This meeting should be attended by the product owner, analysts, programmers, testers, database engineers, user interaction designers, and so on. Anyone involved in taking a raw idea and turning it into a functioning product should be present.
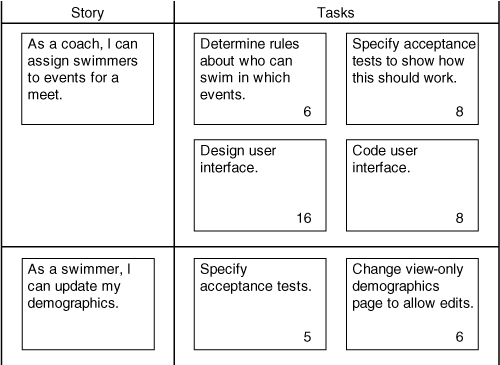
Tangibly, an iteration plan can be as simple as a spreadsheet or a set of note cards with one task handwritten on each card. In either case, tasks and stories should be organized so that it’s possible to tell which tasks go with which stories. For example, see Table 14.1, which shows an iteration plan in a spreadsheet. Tasks are shown one per row and are indented beneath the story to which they apply.
Table 14.1. An Iteration Plan Shown as a Simple Spreadsheet

As an alternative to a spreadsheet, see Figure 14.1, which illustrates using note cards for iteration planning. The cards can be arranged as in that figure on a table or floor, or by taping or pinning them to a wall. For collocated teams, my preference is to do iteration planning with note cards. The team may walk out of an iteration planning meeting and immediately type the cards into a software system, if they desire, but there are very real benefits to using cards during the meeting.
Figure 14.1. Iteration planning can be done with note cards on a table or wall.
One of the most significant advantages to using note cards during iteration planning is that it allows everyone to participate in the process. If tasks are being typed into a system during the iteration planning meeting, someone has his or her fingers on a keyboard. There is tremendous power to having control over the keyboard. All conversations had better involve the typist, or nothing will get entered into the release plan. Worse, whoever has the keyboard can change what gets entered into the release plan.
Two examples attest to this power. In the first case, the team discussed a particular item and decided it should be estimated at twelve hours. The keyboard was in the control of a combination project manager/technical lead. He entered an estimate of eight into the system because “there’s no way it will take that long,” even though he was extremely unlikely to be the one who would do the task.
In the second case, the team I was coaching discussed how a new feature would be implemented—would it be server-side Java code or a stored procedure in the database? Everyone but the team lead, who had the keyboard, agreed it would be implemented through stored procedures. He was asked to create a task of “add stored procedures” on their spreadsheet. Instead, he typed “Write data storage code.” His message was clear: This issue has not been resolved.
Compare these two situations to an iteration planning meeting in which anyone can grab a card and write a task at any time. Using cards is a much more democratic and collaborative approach and is likely to lead to better results throughout the iteration and the project, not just during that meeting.
Tasks Are Not Allocated During Iteration Planning
Before looking at the things that are done during iteration planning, it’s important to clarify one thing that is not done. While planning an iteration, tasks are not allocated to specific individuals. At the start of the iteration, it may appear obvious who will work on a specific task; however, based on the progress of the whole team against the entire set of tasks, what is obvious at the start may not be what happens during the iteration. For example, when planning an iteration we may assume that our database administrator will complete the “tune the advanced search query” task because she has the best SQL skills on the team. However, if she’s unable to get to this task, someone else may step forward and do it.
Individuals do not sign up for tasks until the iteration begins and generally sign up for only one or two related tasks at a time. New tasks are not begun until previously selected ones are completed.
There’s nothing to gain and quite a bit to lose by assigning individuals to specific tasks during iteration planning. Projects do best when they foster a “we’re all in this together” attitude—when team members pick up slack for each other knowing that the favor will be returned. When individuals sign up for specific tasks at the beginning of the iteration, it works against fostering a unified commitment to achieving the goals of the iteration.
How Iteration and Release Planning Differ
The release plan looks forward through the release of the product, usually three to six months out at the start of a new project. In contrast, the iteration plan looks ahead only the length of one iteration, usually two to four weeks. The user stories of the release plan are decomposed into tasks on the iteration plan. Where the user stories of a release plan are estimated in story points or ideal days, the tasks on the iteration plan are estimated in ideal hours.
Why are the tasks of an iteration plan estimated in hours but the stories of a release plan are estimated in story points or ideal days? Primarily because it is possible to do so. The work of an iteration is no more than a few weeks off, and the team should have a reasonable level of insight into the work, especially after discussing during the iteration planning meeting. This allows them to credibly estimate the tasks of an iteration in hours. The user stories that comprise a release each represent multiple tasks, are more vague, and less understood so they must be estimated in more abstract units such as story points or ideal days.
These primary differences between a release plan and an iteration plan are summarized in Table 14.2.
Table 14.2. The Primary Differences between a Release and an Iteration Plan

The primary purpose of iteration planning is to refine suppositions made in the more coarse-grained release plan. The release plan is usually intentionally vague about the specific order in which user stories will be worked on. Additionally, at the time of iteration planning the team knows more than when the release plan was last updated. Planning the iteration as it begins allows the team to make use of their recently acquired knowledge. In this way, agile planning becomes a two-stage process. The first stage is the release plan, with its rough edges and general uncertainties. The second stage is the iteration plan. An iteration plan still has some rough edges and continues to be uncertain. However, because it is created concurrent with the start of a new iteration, an iteration plan is more detailed than a release plan.
Creating the iteration plan leads a team into discussions about both product design and software design. Product design discussions, for example, may be around topics such as the best combination of stories for optimizing value, interpretation of feedback from showing working software to customers, or the extent to which a desired feature should be implemented (that is, will 20% of the feature and effort deliver 80% of the value?). Software design discussions may, for example, involve the appropriate architectural tier in which to implement a new feature, which technologies should be used, whether existing code can be reused, and so on. As a result of these discussions the team comes to a better understanding of what should and will be built, and they also create a list of the tasks needed to achieve their goal for the iteration.
Velocity-Driven Iteration Planning
At a broad level, there are two ways of planning an iteration, which I refer to as velocity-driven and commitment-driven. Different teams use different approaches, and each can be successful. Additionally, the two general approaches can be combined to varying degrees. In this section, we’ll consider velocity-driven iteration planning; in the next, we’ll focus on commitment-driven iteration planning.
The steps involved in velocity-driven iteration planning are shown in Figure 14.2. First, the team collaboratively adjusts priorities. They may have learned something in the preceding iteration that alters their priorities. Next, they identify the target velocity for the coming iteration. The team then selects an iteration goal, which is a general description of what they wish to accomplish during the coming iteration. After selecting an iteration goal, the team selects the top-priority user stories that support that goal. As many stories are selected as necessary for the sum of their ideal-day or story-point estimates to equal the target velocity. Finally, each selected story is split into tasks, and each task is estimated. These steps are described in more detail throughout the rest of this chapter.
Figure 14.2. The sequence of steps in velocity-driven iteration planning.

Adjust Priorities
Imagine all of the user stories either physically stacked up or sorted within a spreadsheet such that the most valuable story is at the top and the least valuable is at the bottom. The project could progress by always taking stories from the top of this prioritized list to start each iteration. However, business and project conditions change quickly, so it is always worth a quick reconsideration of priorities.
One source of changes to priorities is the iteration review meeting, which is held after an iteration is finished. During the iteration review, the new functionality and capabilities that were added during the iteration are demonstrated to stakeholders, the extended project community, and anyone else who is interested. Valuable feedback is often received during these iteration reviews. The product owner herself should generally not come up with new ideas or changes during the iteration review, because she’s been involved daily throughout the iteration. However, many others (including potential customers and users) may be seeing the results of the iteration for the first time. They will often have good new ideas that could preempt previously high-priority items.
As described in Chapter 9, “Prioritizing Themes,” user stories and themes are prioritized based on their financial value to the product, their cost, the amount and significance of what the team will learn, and the amount of risk reduced. Ideally, a team should wait until after the iteration review meeting before discussing priorities for the coming iteration. After all, what they hear during the iteration review may influence them, and it’s hard to prioritize next iteration’s work if you are not entirely sure of what will be completed in this iteration. However, in many organizations I’ve found it useful to hold a prioritization meeting a few days before the start of a new iteration. I do this to fit the iteration review and the iteration planning meetings into the same day more easily.
An iteration review will typically take thirty to sixty minutes. For a large product with multiple teams, it’s quite feasible that the product owner and other key stakeholders necessary for prioritization discussions could spend half a day in iteration reviews. Add another four hours to plan an iteration, and there may not be time to discuss priorities on the same day.
I usually schedule the prioritization meeting for two days before the end of the iteration. By that time, it’s normally clear if there will be unfinished work from the current iteration. This allows the product owner to decide whether finishing that work will be a priority for the coming iteration. The product owner conducts the prioritization meeting and involves anyone she thinks can contribute to a discussion of the project’s priorities. After having this meeting, the product owner can usually quickly and on the fly adjust priorities based on anything that happens during the iteration review.
Determine Target Velocity
The next step in velocity-driven iteration planning is to determine the team’s target velocity. The default assumption by most teams is that their velocity in the next iteration will equal the velocity of the most recent iteration. Beck and Fowler (2000) call this yesterday’s weather, because our best guess of today’s weather is that it will be like yesterday’s weather. Other teams prefer to use a moving average over perhaps the last three iterations.
If a team has not worked together before or is new to their agile process, they will have to forecast velocity. Techniques for doing so are described in Chapter 16, “Estimating Velocity.”
Identify an Iteration Goal
With their priorities and target velocity in mind, the team identifies a goal they would like to achieve during the iteration. The goal succinctly describes what they would like to accomplish during that period. As an example, the SwimStats team may select “All demographics features are finished” as an iteration goal. Other example iteration goals for SwimStats could include the following:
• Finish all event time reports.
• Get security working.
The iteration goal is a unifying statement about what will be accomplished during the iteration. It does not have to be very specific. For example, “Make progress on reports” is a good iteration goal. It does not have to be made more specific, as in “Finish 15 reports” or “Do the meet results reports.” If “Make progress on reports” is the best description of what will be worked on in the coming iteration, it is a good statement of that goal.
Select User Stories
Next, the product owner and team select stories that combine to meet the iteration goal. If the SwimStats team selected an iteration goal of “All demographics features are finished,” they would work on any demographics-related stories that were not yet finished. This might include
• As a swimmer, I can update my demographics.
• As a coach, I can enter demographic data on each of my swimmers.
• As a coach, I can import a file of all demographic data.
• As a coach, I can export a file of all demographic data.
In selecting the stories to work on, the product owner and team consider the priority of each story. For example, if exporting a file of demographic data is near the bottom of the prioritized requirements list for the product, it may not be included in the iteration. In that case, the iteration goal could have been better stated as “The most important demographics features are finished.”
Split User Stories into Tasks
Once the appropriate set of user stories has been selected, each is decomposed into the set of tasks necessary to deliver the new functionality. Suppose the highest-priority user story is “As a coach, I can assign swimmers to events for an upcoming meet.” This user story will be turned into a list of tasks, such as:
• Determine rules that affect who can be assigned to which events.
• Write acceptance test cases that show how this should work.
• Design the user interface.
• Get user interface feedback from coaches.
• Code the user interface.
• Code the middle tier.
• Add new tables to database.
• Automate the acceptance tests.
A common question around iteration planning is what should be included. All tasks necessary to go from a user story to a functioning, finished product should be identified. If there are analysis, design, user interaction design, or other tasks necessary, they need to be identified and estimated. Because the goal of each iteration is to produce a potentially shippable product, take care to include tasks for testing and documenting the product. Including test tasks is important because the team needs to think right at the start of the iteration about how a user story will be tested. This helps engage testers right from the start of the iteration, which improves the cross-functional behavior of the team.
Include Only Work That Adds Value to This Project
The iteration plan should identify only those tasks that add immediate value to the current project. Obviously, that includes tasks that may be considered analysis, design, coding, testing, user interface design, and so on. Don’t include the hour in the morning when you answer email. Yes, some of those email messages are project-related, but tasks like “answer email, 1 hour” should not be included in an iteration plan.
Similarly, suppose you need to meet with the company’s director of personnel about a new annual review process. That should not be included in the iteration plan. Even though project team members will be reviewed using the new process, the meeting to discuss it (and any follow-on work you need to do) is not directly related to developing the product. So no tasks associated with it become part of the iteration plan.
Be Specific Until It’s a Habit
New agile teams are often not familiar with or skilled at writing automated unit tests. However, this is a skill they work to cultivate during the first few iterations. During that period, I encourage programmers to identify and estimate unit testing tasks explicitly. A programmer may, for example, identify that coding a new feature will take eight hours and that writing its unit tests will take five hours. Later, once unit testing has become a habit for the programmers, the programmer would write only one card saying to code the new feature and would give it an estimate that included time to automate the unit tests. Once something like unit testing becomes a habit, it can be included within another task. Until then, however, making it explicit helps keep awareness of the task high.
Meetings Count (A Lot)
You should identify, estimate, and include tasks for meetings related to the project. When estimating the meeting, be sure to include the time for all participants, as well as any time spent preparing for the meeting. Suppose the team schedules a meeting to discuss feedback from users. All seven team members plan to attend the one-hour meeting, and the analyst plans to spend two hours preparing for the meeting. The estimate for this task is nine hours. I usually enter this into the iteration plan as a single nine-hour task, rather than as a separate task for each team member.
Bugs
An agile team has the goal of fixing all bugs in the iteration in which they are discovered. They become able to achieve this as they become more proficient in working in short iterations, especially through relying on automated testing. When a programmer gives an estimate for coding something, that estimate includes time for fixing any bugs found in the implementation, or a separate task (“Correct bugs”) is identified and estimated. My preference is for identifying a single task but not considering it complete until all of its tests pass.
A defect found later (or not fixed during the iteration in which it was discovered) is treated the same way as a user story. Fixing the defect will need to be prioritized into a subsequent iteration in the same way that any other user story would be. Outside an iteration, the whole idea of a defect starts to go away. Fixing a bug and adding a feature become two ways of describing the same thing.
Handling Dependencies
Often, developing one user story will depend upon the previous implementation of another. In most cases, these dependencies are not a significant issue. There is usually what I consider a natural order to implementing user stories—that is, there is a sequence that makes sense to both developers and the product owner.
It is not a problem when there are dependencies among stories that lead to developing them in their natural order. The natural order is usually the order the team assumed when they estimated the stories. For example, the SwimStats team would probably assume that swimmers can be added to the system before they can be deleted. When stories are worked on in a sequence other than what was assumed when estimating, during iteration planning the team will often have to include additional tasks that make it possible to work on stories in the new order.
As an example, the natural order for the SwimStats website would be to complete the features that let a user add new swimmers to the system and then the features that let a user view an individual swimmer’s fastest times in each event. It’s a little unusual to think about seeing a swimmer’s fastest times before having the screens through which swimmers are added to the system. However, it could be done if the product owner and team wanted to develop the features in that order. To do so, they would, of course, need to design enough of the database to hold swimmers and their times. They would also have to put at least one swimmer and her times into the database. Because this is part of the feature they don’t want to do first, they would add the swimmer (and her times) to the database directly rather than through any user interface and software they developed.
For the SwimStats team to do this, during iteration planning they will need to identify a few tasks that would not have been identified if these two stories had been worked on in their natural order. For example, if the ability to add swimmers existed already, the team would not need to include a task of “Design database tables for information about individual swimmers.” However, because the stories are being worked on out of their natural order, they will need to include this task.
Does that mean that working out of the natural order will cause the project to take longer? Two answers: Probably not, and it doesn’t matter.
First, the project will probably not take longer; all we’ve done is shift some tasks from one user story to another. Designing the swimmer tables in this example would have happened sooner or later. When the time comes to work on the story about adding new swimmers to the system, that story will be done more quickly because part of its work is already complete.
You may be worried about the impact this task shifting has on the estimates given to the two stories. We may, for example, have shifted a point or an ideal day of work from one story to the other. In most cases, this isn’t a big deal, and the differences will wash out over the course of the project. If anything, I’ve observed this to be a pessimistic shift, in that a five-point story becomes a six-point story. But because the team gives itself credit for only five points when they’re finished, they slightly understate their velocity. Because the impact is small with a slightly pessimistic bias, I usually don’t worry about it. However, if you’re concerned about these impacts or if the task shifting is much more significant, re-estimate the stories involved as soon as you decide to work on them in other than the natural order.
Second, even if working on the stories in this order does cause the project to take longer, it doesn’t matter, because there presumably was some good reason for working on them out of their natural order. The team may want to work on stories in a particular order so that they can address a technical risk earlier. Or a product owner may want earlier user feedback on a story that would more naturally have been developed later. By developing the stories out of their natural order, the team is able to get early feedback and potentially save a month or two of rework near the end of the project (when the schedule is least likely to be able to accommodate such a change).
Work That Is Difficult to Split
Some features are especially difficult to split into tasks. For example, I was recently in a planning meeting discussing a small change to a legacy feature. No one was comfortable in his or her ability to think through all of the possible impacts of the change. We were certain that some sections of the code would be affected but were not sure whether other sections would be. The changes were small in the sections we were sure about; we estimated them at a total of four hours. If the other sections were affected, we thought the estimate could go much higher, possibly as high as twenty hours. We couldn’t be sure without looking at the code, and we didn’t want to stop a planning meeting for that. Instead, we wrote these two tasks:
• Determine what’s affected—two hours.
• Make the changes—ten hours.
This first task is called a spike. A spike is a task included in an iteration plan that is being undertaken specifically to gain knowledge or answer a question. In this case, the team did not have a good guess at something, so they created two tasks: one a spike and one a placeholder with a guess at the duration. The spike would help the team learn how they’d approach the other task, which would allow them to estimate it.
Estimate Tasks
The next step in velocity-driven iteration planning is to estimate each task. Some teams prefer to estimate tasks after all have been identified; other teams prefer to estimate tasks as each is identified. Task estimates are expressed in ideal time. So if I think that a task will take me six hours of working time, I give it an estimate of six hours. I do this even if six hours of time on the task will take me an entire eight-hour day.
Although I agree with accepted advice that the best estimates come from those who will do the work (Lederer and Prasad 1992), I believe that task estimating on an agile project should be a group endeavor. There are four reasons for this.
First, because tasks are not allocated to specific individuals during iteration planning, it is impossible to ask the specific person who will do the work.
Second, even though we expect a specific individual will be the one to do a task, and even though he may know the most about that task, it does not mean that others have nothing to contribute. Suppose during an iteration planning meeting, James says, “It will take me about two hours to program that—it’s trivial!” However, you remember that just last month James worked on a similar task and made a similar comment, and that it took him closer to sixteen hours. This time, when James says that a similar task is going to take only two hours, you might add, “But James, the last time you worked on a similar task, you thought it would be two hours, and it took you sixteen.” Most likely, James will respond with a legitimate reason why this case truly is different, or he’ll agree that there is some difficulty or extra work in this type of task that he has been systematically forgetting.
Third, hearing how long something is expected to take often helps teams identify misunderstandings about a user story or task. Upon hearing an unexpectedly high estimate, a product owner or analyst may discover that the team is heading toward a more detailed solution than necessary. Because the estimate is discussed among the team, this can be corrected before any unneeded effort is expended.
Finally, when the person who will do the work provides the estimate, the person’s pride and ego may make him reluctant to admit later that an estimate was incorrect. When an estimate is made collaboratively, this reluctance to admit an estimate is wrong goes away.
Some Design Is OK
Naturally, it’s necessary for there to be some amount of design discussion while creating this list of tasks and estimates. We can’t create a list of tasks if we don’t have some idea of how we’re going to do the work. Fortunately, though, when planning an iteration, it isn’t necessary to go very far into the design of a feature.
The product owner, analysts, and user interface designers may discuss product design, how much of a feature should be implemented, and how it will appear to users. The developers may discuss options of how they will implement what is needed. Both types of design discussion are needed and appropriate. However, I’ve never been in an iteration planning meeting where it’s become necessary to draw a class diagram or similar model. A desire to do so is probably the best warning sign of taking the design too far during iteration planning. Save those discussions for outside iteration planning
It’s not necessary to go so far as drawing a design, because all that’s necessary at this point are guesses about the work that will be needed to complete the features. If you get into the iteration and discover the tasks are wrong, get rid of the initial tasks and create new ones. If an estimate is wrong, cross it out and write a new value. Writing tasks and estimates on note cards is a great approach because each card carries with it a subtle reminder of impermanence.
The Right Size for a Task
The tasks you create should be of an approximate size so that each developer is able to finish an average of one per day. This size works well for allowing work to flow smoothly through your agile development process. Larger tasks tend to get bottled up with a developer or two, and the rest of the team can be left waiting for them to complete the task. Additionally, if the team is holding short daily meetings (Schwaber and Beedle 2002; Rising 2002), having tasks of this size allows each developer to report the completion of at least one task on most days.
Naturally, there will often be tasks that are larger than this. But larger tasks should be generally understood to be placeholders for one or more additional tasks that will be added as soon as they are understood. If you need to create a sixteen-hour task during iteration planning, do so. However, once the task is more adequately understood, augment or replace it. This may mean replacing the initial card with more or less than the initially estimated sixteen hours.
Commitment-Driven Iteration Planning
A commitment-driven approach is an alternative way to plan an iteration. Commitment-driven iteration planning involves many of the same steps as velocity-driven iteration planning. However, rather than creating an iteration plan that uses the yesterday’s weather idea to determine how many story points or ideal days should be planned into the current iteration, the team is asked to add stories to the iteration one by one until they can commit to completing no more. The overall commitment-driven approach is shown in Figure 14.3.
Figure 14.3. The activities of commitment-driven iteration planning.
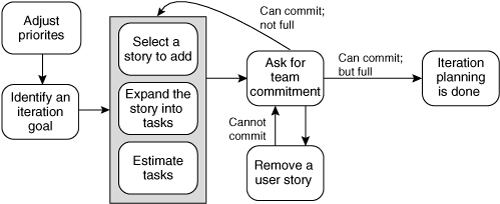
The first steps—adjusting priorities and identifying an iteration goal—are the same as in the velocity-driven approach. The next step, selecting a story to add to the iteration, is different. The product owner and team still select the highest-priority story that supports the iteration goal. However, in commitment-driven iteration planning, stories are selected and decomposed into tasks, and the tasks estimated one story at a time. This is different from the velocity-driven approach, in which a set of stories whose estimates equaled the estimated velocity were selected.
Stories are selected one at a time because after each story is split into tasks and the tasks estimated, the team decides whether or not they can commit to delivering that story during the iteration.
Ask for a Team Commitment
In their study of what makes teams successful, Larson and LaFasto (1989) determined that a unified commitment made by all team members is one of the key factors contributing to team success. During an iteration planning meeting, I ask the team, “Can you commit to delivering the features we’ve discussed?” Notice that the question I ask is not “Can you commit to delivering the tasks we’ve identified?” That is a very different question and a far weaker commitment, because it is a commitment to complete a set of tasks rather than a commitment to deliver new functionality.
If new tasks are discovered during the iteration (and they almost certainly will be), a team that is committed to delivering the functionality described by a user story will try to complete the new tasks as well. A team that committed to only an identified list of tasks may not. In either case, it is possible that the newly discovered tasks will take long enough that they cannot be completed during the iteration. In that case, the team will need to discuss the situation with the product owner and see if there is still a way to meet the iteration goal; they may need to reduce the functionality of a story or drop one entirely.
I ask a team if they can commit after each user story is split into tasks and the tasks are estimated. For the first user story, the question often seems silly. There may be seven people on the team, planning to work a two-week iteration. Perhaps they’ve identified only thirty-four hours of work so far, and I ask if they can commit to it. Their answer (either verbal or through the confused looks on their faces) is “Of course we can commit to this. There are seven of us for two weeks, and this is only thirty-four hours of work.” However, as the meeting progresses and as more user stories are brought into the iteration, the answer to my question, “Can you commit?” begins to require some thought. Eventually, we reach a point where the team cannot commit any further. If they cannot, they may choose to drop a story and replace it with a smaller one before finishing.
Summing the Estimates
The best way I’ve found for a team to determine whether they can commit to a set of user stories is to sum up the estimates given to the tasks and see if the sum represents a reasonable amount of work. There may very well be a large amount of uncertainty on some tasks, because the work hasn’t been designed and requirements are vague. However, summing the estimates still gives some indication of the overall size of the work.
Suppose a team of seven is working in two-week iterations. They have 560 hours available each iteration (7 people × 10 days × 8 hours per day). We know that some amount of time will be spent on activities that are not shown on task cards—answering email, participating in meetings, and so on. Similarly, we know the estimates are wrong; they are, after all, estimates, not guarantees. For these reasons, we cannot expect this team to sign up for 560 hours of tasks. In fact, most teams are successful when their planned work (the sum of their task cards) represents between four and six hours per day. For our team of seven people, working two-week iterations means they can probably plan between 280 and 420 hours. Where a given team will end up within this range is influenced by how well they identify the tasks for a given user story, how accurately those tasks are estimated, the amount of outside commitments by team members, and the amount of general corporate overhead for the team. After as few as a couple of iterations, most teams begin to get a feel for approximately how many hours they should plan for an iteration.
Before committing to the work of an iteration, the team needs to look at the tasks and get a feel for whether they represent an appropriate distribution of work based on the various skills within the team. Is the Java programmer likely to be overloaded, while the HTML programmer has nothing to do this iteration? Are the selected user stories easy to program but time-consuming or difficult to test, thereby overloading the tester? Do the stories selected each need analysis and user interaction design before coding can begin?
A team in a situation like this should first try to find ways to better share work. Can the HTML programmer in this example help the tester? Can someone other than the user interaction designer do that work? If not, can we leave out of this iteration some stories that need user interaction design, and can we bring in some other stories that do not? The key is that everyone on the team is accountable for contributing whatever is within their capabilities, regardless of whether it is their specialty.
When assessing the ability to commit to completing a set of new functionality, some teams prefer to allocate each task to a specific person and then assess whether each individual is able to commit to that amount of work. This approach works well, and I’ve recommended it in the past (Cohn 2004). However, I’ve found that by not allocating tasks while planning the iteration and not doing the personal math needed to make individual commitments, the team benefits from the creation of a “we’re all in this together” mindset.
If you do find a need to allocate tasks to individuals while planning an iteration, the allocations should be considered temporary and subject to change once the iteration is under way.
Maintenance and the Commitment
In addition to making progress on a project, many teams are responsible for support and maintenance of another system. It may be a prior version of the product they are working on, or it may be an unrelated system. When a team makes a commitment to complete a set of stories during an iteration, they need to do so with their maintenance and support load in mind. I am not referring to general bug fixes that can be prioritized in advance. Those should go through the regular iteration planning prioritization process. By maintenance and support activities, I mean those unpredictable but required parts of many teams’ lives—supporting a production website or database, taking support calls from key customers or first-tier technical support, and so on.
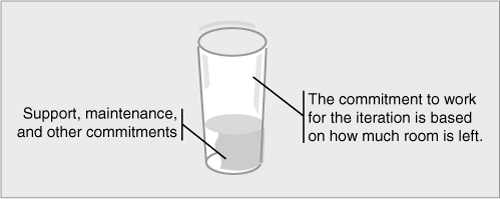
I think of an iteration as an empty glass. The first things poured into the glass are the team’s unchangeable commitments, such as support and maintenance of other products. Whatever room remains in the glass is available for the team when they commit to the work of an iteration. This is shown in Figure 14.4. Clearly, a team whose glass is 10% full with support work will have time to commit to more other work than will a team whose glass starts 90% full.
Figure 14.4. Other commitments determine how much a team can commit to during an iteration.
In most situations, the team will not be able to predict their upcoming support load very accurately. They should know a long-term average, but averaging twenty hours of support per week is not the same as having twenty hours every week. If the support and maintenance load exceeds expectations during an iteration, they may not be able to meet their commitment. They need to counter this by trying to exceed their commitment when the support and maintenance load is less than expected in some iterations. This variability is inescapable on teams with significant support and maintenance obligations.
My Recommendation
Both velocity-driven and commitment-driven iteration planning are viable approaches; however, my preference is for the commitment-driven approach. Although velocity plays a critical role in release planning, I do not think it should play an equivalent role in iteration planning. There are two reasons for this.
First, because velocity is a measure of coarse-grained estimates (story points or ideal days), it is not accurate enough for planning the work of short iterations. We can use these coarse-grained estimates for estimating the overall amount of work a team will complete during an iteration. We cannot, however, use them in the same way for planning the shorter-term work of a single iteration.
Second, a team would need to complete twenty to thirty user stories per iteration for errors in the story-point or ideal-day estimates to average out. Very few teams complete this many stories in an iteration.
To see the result of these problems, suppose a team has had a velocity of thirty in each of the past five iterations. That’s about as consistent as it gets, and it’s likely they’ll complete thirty points again in the coming iteration. However, we know that not all five-point stories are the same. If we were to sort through a large collection of five-point stories, we know we could identify six five-point stories that all looked slightly easier than five points. We might be wrong on some, but if this was the first time we tried this, we’d probably succeed. We might increase our velocity from thirty to forty. On the other hand, we could instead select only the five-point stories that seem slightly harder. We still think they should be estimated at five points, but they are slightly harder than the other five-point stories.
On a project, we’re not going to dig through our collection of user stories and try to find the “easy fives” or the “hard fives.” However, most teams plan between three and a dozen stories into each iteration. When pulling that few stories into an iteration, a team will certainly get lucky and select all slightly easy ones or unlucky and select all slightly harder ones occasionally.
Because too few stories are completed in a single iteration for these to average out, I prefer not to use velocity when planning an iteration. However, because these differences do average out over the course of a release, velocity works extremely well for release planning.
Relating Task Estimates to Story Points
I’m often asked to explain the relationship between task estimates used during iteration planning and the story points or ideal days used for longer-range release planning. I see teams go astray when they start to believe there is a strong relationship between a story point and an exact number of hours. For example, I helped a team recently that had tracked their actual number of productive hours per iteration and their velocity per iteration. From this, they calculated that each story point took approximately twelve hours of work. Their view became the mistaken certainty that each story point always equaled twelve hours of work. However, the real case was something closer to that shown in Figure 14.5.
Figure 14.5. Distribution of the time needed to complete a one-point user story.
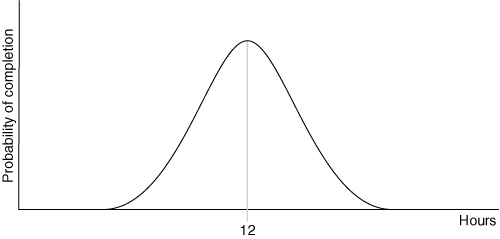
Figure 14.5 shows that on average, it will take twelve hours to complete a one-point user story. However, it also shows that some one-point stories will take less, and some will take more. Until the team estimates a story’s underlying tasks, it is hard to know where a particular story lies on a curve such as this.
Although Figure 14.5 shows the distribution of hours for a one-point user story, Figure 14.6 shows the hypothetical distributions for one-, two-, and three-point stories. In this figure, each story point is still equivalent to twelve hours on average. However, it is possible that some one-point stories will take longer than some two-point stories.
Figure 14.6. Distribution of times to complete one-, two-, and three-point stories.
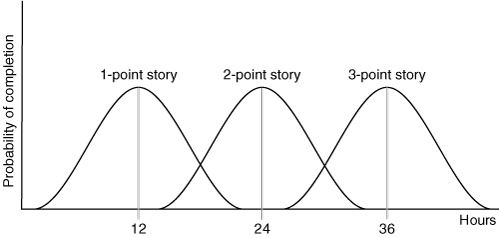
That some two-point stories will take less time to develop than some one-point stories is entirely reasonable and to be expected. It is not a problem as long as there are sufficient stories in the release for these outliers to average out, and as long as everyone on the project remembers that some stories will take longer than others, even though their initial, high-level estimates were the same.
When I started managing agile projects, my teams routinely started their iterations on a Monday and ended them on a Friday. We’d do this whether the specific team was using two-, three-, or four-week iterations. Mondays seemed like a natural day to begin an iteration, and Fridays were an obvious day to end on. I changed my mind about this after I began coaching a team that was developing a website that was busy during the week and barely used on the weekend.
The most logical night for this team to deploy new web updates was Friday evening. If something went wrong, they could fix it over the weekend, and the impact would be minimal because the site was very lightly used during that time. To accommodate this, this team decided to run two-week iterations that would start on a Friday and end on a Thursday. This worked wonderfully. Fridays were spent doing an iteration review and in planning the next iteration. This took until midafternoon most Fridays, after which the team would either get started on the work of the new iteration or occasionally head out for drinks or bowling. The iteration would start in earnest the following Monday. This was great because there was no dread of a Monday filled with meetings, as there was when Monday was review and planning day.
The team also benefited by occasionally using Friday morning to wrap up any last-minute work they’d been unable to finish on Thursday. They didn’t make a habit of this, and it happened only a few times; however, spending a few hours on a Friday morning wrapping things up was preferable to coming in over the weekend (as they would have done with a Monday iteration start).
Summary
Unlike a release plan, an iteration plan looks in more detail at the specific work of a single iteration. Rather than the three-to-nine month horizon of a typical release plan, the iteration plan looks out no further than a single iteration. The fairly large user stories of a release plan are decomposed into tasks on the iteration plan. Each task is estimated in terms of the number of ideal hours the task will take to complete.
There are two general approaches to planning an iteration: velocity-driven and commitment-driven. The two approaches share many steps and often result in the creation of the same iteration plan.
Discussion Questions
1. Which approach to iteration planning do you prefer: velocity-driven or commitment-driven? Why?
2. What do you think of not having team members sign up for specific tasks during iteration planning?