
They come from a much older version of the matrix, but like so many back then, they caused more problems than they solved. | ||
| --Persephone, Matrix Reloaded | ||
In Chapter 5, we examined how concurrency in a C++ program can be accomplished by decomposing your program into either multiple processes or multiple threads. We discussed a process, which is a unit of work created by the operating system. We explained the POSIX API for process management and the several system calls that can be used to create processes: fork(), fork-exec(), system(), and posix_spawn(). We showed you how to build C++ interface components, interface classes, and declarative interfaces that can be used to simplify part of the POSIX API for process management. In the chapter we cover:
What is a thread?
The pthread API for thread management
Thread scheduling and priorities
Thread contention scope
Extending the
thread_objectto encapsulate thread attribute functionality
A thread is a sequence or stream of executable code within a process that is scheduled for execution by the operating system on a processor or core. All processes have a primary thread. The primary thread is a process's flow of control or thread of execution. A process with multiple threads has as many flows of controls as there are threads. Each thread executes independently and concurrently with its own sequence of instructions. A process with multiple threads is multithreaded. There are user-level threads and kernel-level threads. Kernel-level threads are a lighter burden to create, maintain, and manage on the operating system as compared to a process because very little information is associated with a thread. A kernel thread is called a lightweight process because it has less overhead than a process.
Threads execute independent concurrent tasks of a program. Threads can be used to simplify the program structure of an application with inherent concurrency in the same way that functions and procedures make an application's structure simpler by encapsulating functionality. Threads can encapsulate concurrent functionality. Threads use minimal resources shared in the address space of a single process as compared to an application, which uses multiple processes. This contributes to an overall simpler program structure being seen by the operating system. Threads can improve the throughput and performance of the application if used correctly, by utilizing multicore processors concurrently. Each thread is assigned a subtask for which it is responsible, and the thread independently manages the execution of the subtask. Each thread can be assigned a priority reflecting the importance of the subtask it is executing.
There are three implementation models for threads:
User- or application-level threads
Kernel-level threads
Hybrid of user- and kernel-level threads
Figure 6-1 shows a diagram of the three thread implementation models. Figure 6-1(a) shows user-level threads, Figure 6-1 (b) shows kernel-level threads, and Figure 6-1 (c) shows the hybrid of user and kernel threads.
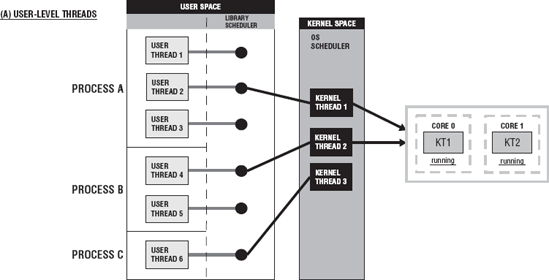
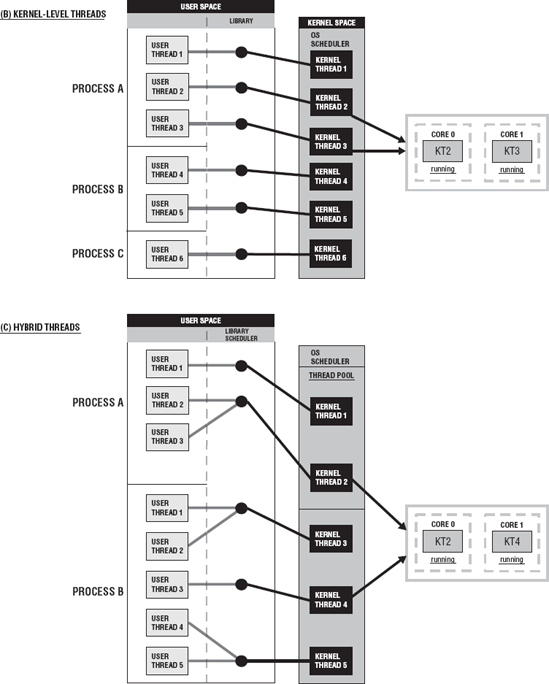
One of the big differences between these implementations is the mode they exist in and the ability of the threads to be assigned to a processor. These threads run in user or kernel space or mode.
In user mode, a process or thread is executing instructions in the program or linked library. They are not making any calls to the operating system kernel.
In kernel mode, the process or thread is making system calls such as accessing resources or throwing exceptions. Also, in kernel mode, the process or thread can access objects that are defined in kernel space.
User-level threads reside in user space or mode. The runtime library, also in user space, manages these threads. They are not visible to the operating system and, therefore, cannot be scheduled to a processor core. Each thread does not have its own thread context. So, as far as simultaneous execution of threads, there is only one thread per process that will be running at any given time and only a single processor core allocated to that process. There may be thousands or tens of thousands user-level threads for a single process, but they have no impact on the system resources. The runtime library schedules and dispatches these threads. As you can see in Figure 6-1 (a), the library scheduler chooses a thread from the multiple threads of a process, and that thread is associated with the one kernel thread allowed for that process. That kernel thread will be assigned to a processor core by the operating system scheduler. User-level threads are considered a "many-to-one" thread mapping.
Kernel-level threads reside in kernel space and are kernel objects. With kernel threads, each user thread is mapped to or bound to a kernel thread. The user thread is bound to that kernel thread for the life of the user thread. Once the user thread terminates, both threads leave the system. This is called a "one-to-one" thread mapping and is depicted in Figure 6-1 (b). The operating system scheduler manages, schedules, and dispatches these threads. The runtime library requests a kernel-level thread for each of the user-level threads. The operating system's memory management and scheduling subsystem must be considered for very large numbers of user-level threads. You have to know what the allowable number of threads per process is. The operating system creates a context for each thread. The context for a thread is discussed in the next section of this chapter. Each of the threads from a process can be assigned to a processor core as the resources become available.
A hybrid thread implementation is a cross between user and kernel threads and allows both the library and the operating system to manage the threads. User threads are managed by the runtime library scheduler, and the kernel threads are managed by the operating system scheduler. With this implementation, a process has its own pool of kernel threads. The user threads that are runnable are dispatched by the runtime library and are marked as available threads ready for execution. The operating system selects a user thread and maps it to one of the available kernel threads in the pool. More than one user thread may be assigned to the same kernel thread. In Figure 6-1 (c) process A has two kernel threads in its pool, whereas process B has three. Process A's user threads 2 and 3 are mapped to kernel thread 2. Process B has five threads; user threads 1 and 2 are mapped to a single kernel thread (3), and user threads 4 and 5 are mapped to a single kernel thread (5). When a new user thread is created, it is simply mapped to one of the existing kernel threads in the pool. This implementation uses a "many-to-many" thread mapping. A many-to-one mapping is suggested by some for this approach. Many user threads would be mapped to one kernel thread, as you saw in the preceding example. So, the requests for kernel threads would be less than the number of user threads.
The pool of kernel threads is not destroyed and re-created. These threads are always in the system. They are allocated to different user-level threads when necessary as opposed to creating a new kernel thread whenever a new user-level thread is created, as it is with pure kernel-level threads. A context is created only for each of the threads in the pool. With the kernel and hybrid threads, the operating system allocates a group of processor cores that the process's threads are allowed to run on. The threads can execute only on those processor cores assigned to their process.
User- and kernel-level threads also become important when determining a thread's scheduling model and contention scope. Contention scope determines which threads a given thread contends with for processor usage, and it also becomes very important in relation to the operating system's memory management for large numbers of threads.
The operating system manages the execution of many processes. Some of the processes are single processes that come from various programs, systems, and application programs, and some of the processes come from a single application or program that has been decomposed into many processes. When one process is removed from a core and another process becomes active, a context switch takes place between those processes. The operating system must keep track of all the information that is needed to restart that process and start the new process in order for it to become active. This information is called the context and describes the present state of the process. When the process becomes active, it can continue execution right where it was preempted. The information or context of the process includes:
Process id
Pointer to executable
The stack
Memory for static and dynamically allocated variables
Processor registers
Most of the information for the context of a process has to do with describing the address space. The context of a process uses many system resources, and it takes some time to switch from the context of one process to that of another. Threads also have a context. Table 6-1 contrasts the process context, as discussed in Chapter 5, with the thread context. When a thread is preempted, a context switch between threads takes place. If the threads belong to the same process, they share the same address space because the threads are contained in the address of the process to which they belong. So, most of the information needed to reinstate a process is not needed for a thread. Although the process shares much with its threads, most importantly its address space and resources, some information is local or unique to the thread, while other aspects of the thread are contained within the various segments of the process.
Table 6.1. Table 6-1
Process | Thread | |
|---|---|---|
Pointer to executable | x | |
Stack | x | x |
Memory (data segment and heap) | x | |
State | x | x |
Priority | x | x |
Status of program I/O | x | |
Granted privileges | x | |
Scheduling information | x | |
Accounting information | x | |
Information pertaining to resources | x | |
Information pertaining to events and signals | x | |
Register set
| x | x |
The information unique or local to a thread comprises the thread id, processor registers (what the state of registers is when the thread is executing, including the program counter and stack pointer), the state and priority of the thread, and thread-specific data (TSD). The thread id is assigned to the thread when it is created. Threads have access to the data segment of their process; therefore, threads can read or write to the globally declared data of their process. Any modification by one thread in the process is accessible by all threads in that process as well as by the main thread. In most cases, this requires some type of synchronization in order to prevent inadvertent updates. A thread's locally declared variables should not be accessed by any of its peer threads. They are placed in the stack of the thread, and when the thread has completed, they are removed from the stack.
Synchronization between threads is discussed in Chapter 7.
The TSD is a structure that contains data and information private to a thread. TSD can contain private copies of a process's global data. It can also contain signal masks for a thread. Signal masks are used to identify signals of a specific type that will not be received by the thread when sent to its process. Otherwise, if a process is sent a signal by the operating system, all threads in its address space also receive that signal. The thread receives all signal types that are not masked.
A thread shares text and stack segment with its process. Its instruction pointer points to some location within the process's text segment to the next executable thread instruction, and the stack pointer points to the location in the process stack where the top of the thread's stack begins. Threads can also access any environment variables. All of the resources of the process, such as file descriptors, are shared with its threads.
Threads can be implemented in hardware as well as software. Chip manufacturers implement cores that have multiple hardware threads that serve as logical cores. Cores with multiple hardware threads are called simultaneous multithreaded (SMT) cores. SMT brings to hardware the concept of multithreading, in similar way to software threads. SMT-enabled processors execute many software threads or processes simultaneously within the processor cores. Having software threads executing simultaneously within a single processor core increases a core's efficiency because wait time from elements such as I/O latencies is minimized. The logical cores are treated as unique processor cores by the operating system. They require some duplicate hardware that stores information for the context of the thread such as instruction counters and register sets. Other hardware or structures are duplicated or are shared among the threads' contexts, depending on the processor core.
Sun's UltraSparc T1, IBM's Cell Broadband Engine CBE, and various Intel multicore processors utilize SMT or chip-level multithreading (CMT), implementing from two to eight threads per core. Hyperthreading is Intel's implementation of SMT in which its primary purpose is to improve support for multithreaded code. Hyperthreading or SMT technology provides an efficient use of CPU resources under certain workloads by executing threads in parallel on a single processor core.
Threads share most of their resources with other threads of the same process. Threads own resources that define their context. Threads must share other resources such as processors, memory, and file descriptors. File descriptors are allocated to each process separately, and threads of the same process compete for access to these descriptors. A thread can allocate additional resources such as files or mutexes, but they are accessible to all the threads of the process.
There are limits on the resources that can be consumed by a single process. Therefore, all the resources of peer threads in combination must not exceed the resource limit of the process. If a thread attempts to consume more resources than the soft resource limit defines, it is sent a signal that the process's resource limit has been reached.
When threads are utilizing their resources, they must be careful not to leave them in an unstable state when they are canceled. A terminated thread that has left a file open may cause damage to the file or cause data loss once the application has terminated. Before it terminates, a thread should perform some cleanup, preventing these unwanted situations from occurring.
Both threads and processes can provide concurrent program execution. The use of system resources needed for context switching, throughput, communication between entities, and program simplification is an issue that you need to consider when deciding whether to use multiple processes or threads.
When you are creating a process, the main thread may be the only thread needed to carry out the function of the process. In a process with many concurrent subtasks, multiple threads can provide asynchronous execution of the subtasks with less overhead for context switching. With low processor availability or a single core, however, concurrently executing processes involve heavy overhead because of the context switching required. Under the same condition using threads, a process context switch would occur only when a thread from a different process was the next thread to be assigned the processor. Less overhead means fewer system resources used and less time taken for context switching. Of course, if there are enough processors to go around, then context switching is not an issue.
The throughput of an application can increase with multiple threads. With one thread, an I/O request would halt the entire process. With multiple threads, as one thread waits for an I/O request, the application continues to execute. As one thread is blocked, another can execute. The entire application does not wait for each I/O request to be filled; other tasks can be performed that do not depend on the blocked thread.
Threads also do not require special mechanisms for communication with other threads of the process called peer threads. Threads can directly pass and receive data from other peer threads. This saves system resources that would have to be used in the setup and maintenance of special communication mechanisms if multiple processes were used. Threads communicate by using the memory shared within the address space of the process. For example, if a queue is globally declared by a process, Thread A of the process can store the name of a file that peer thread Thread B is to process. Thread B can read the name from the queue and process the data.
Processes can also communicate by shared memory, but processes have separate address spaces and, therefore, the shared memory exists outside the address space of both processes. If you have a process that also wants to communicate the names of files it has processed to other processes, you can use a message queue. It is set up outside the address space of the processes involved and generally requires a lot of setup to work properly. This increases the time and space used to maintain and access the shared memory.
Threads can easily corrupt the data of a process. Without synchronization, threads' write access to the same piece of data can cause data race. This is not so with processes. Each process has its own data, and other processes don't have access unless special communication is set up. The separate address spaces of processes protect the data from possible inadvertent corruption by other processes. The fact that threads share the same address space exposes the data to corruption if synchronization is not used. For example, assume that a process has three threads: Thread A, Thread B, and Thread C. Threads A and B update a counter, and Thread C is to read each update and then use that value in a calculation. Thread A and B both attempt to write to the memory location concurrently. Thread B overwrites the data written by Thread A before Thread C reads it. Synchronization should have been used to ensure that the counter is not updated until Thread C has read the data.
The issues of synchronization between threads and processes will be discussed in Chapter 7.
If a thread causes a fatal access violation, this may result in the termination of the entire process. The access violation is not isolated to the thread because it occurs in the address space of the process. Errors caused by a thread are more costly than errors caused by processes. Threads can create data errors that affect the entire memory space of all the threads. Threads are not isolated, whereas processes are isolated. A process can have an access violation that causes the process to terminate, but all of the other processes continue executing if the violation isn't too bad. Data errors can be restricted to a single process. Processes can protect resources from indiscriminate access by other processes. Threads share resources with all the other threads in the process. A thread that damages a resource affects the whole process or program.
Threads are dependent and cannot be separated from their process. Processes are more independent than threads. An application can divide tasks among many processes, and those processes can be packaged as modules that can be used in other applications. Threads cannot exist outside the process that created them and, therefore, are not reusable.
There are many similarities and significant differences between threads and processes. Threads and processes have an id, a set of registers, a state, and a priority, and both adhere to a scheduling policy. Like a process, threads have an environment that describes the entity to the operating system — the process or thread context. This context is used to reconstruct the preempted process or thread. Although the information needed for the process is much more than that needed for the thread, they serve the same purpose.
Threads and child processes share the resources of their parent process without requiring additional initialization or preparation. The resources opened by the process are immediately accessible to the threads or child processes of the parent process. As kernel entities, threads and child processes compete for processor usage. The parent process has some control over the child process or thread. The parent process can:
Cancel
Suspend
Resume
Change the priority
of the child process or thread. A thread or process can alter its attributes and create new resources, but it cannot access the resources belonging to other processes.
As we have indicated, the most significant difference between threads and processes is that each process has its own address space, and threads are contained in the address space of their process. This is why threads share resources so easily, and Interthread Communication is so simple. Child processes have their own address space and a copy of the data segment of its parent, so when a child modifies its data, it does not affect the data of its parent. A shared memory area has to be created in order for parent and child processes to share data. Shared memory is a type of Interprocess Communication (IPC) mechanism, which includes such things as pipes and First-In, First-Out (FIFO) scheduling policies. They are used to communicate or pass data between processes.
Interprocess Communication is discussed in Chapter 7.
Whereas processes can exercise control over other processes with which they have a parent-child relationship, peer threads are on an equal level regardless of who created them. Any thread that has access to the thread id of another peer thread can cancel, suspend, resume, or change the priority of that thread. In fact, any thread within a process can kill the process by canceling the primary thread, terminating all the threads of the process. Any changes to the main thread may affect all the threads of the process. If the priority of the main thread is changed, all the threads within the process that inherited that priority are also altered.
Table 6-2 summarizes the key similarities and differences between threads and processes.
Table 6.2. Table 6-2
Differences between Threads and Processes | |
|---|---|
Both have an id, set of registers, state, priority, and scheduling policy. | Threads share the address space of the process that created it; processes have their own address. |
Both have attributes that describe the entity to the OS. | Threads have direct access to the data segment of their process; processes have their own copy of the data segment of the parent process. |
Both have an information block. | Threads can directly communicate with other threads of their process; processes must use Interprocess Communication to communicate with sibling processes. |
Both share resources with the parent process. | Threads have almost no overhead; processes have considerable overhead. |
Both function as independent entities from the parent process. | New threads are easily created; new processes require duplication of the parent process. |
The creator can exercise some control over the thread or process. | Threads can exercise considerable control over threads of the same process; processes can exercise control only over child processes. |
Both can change their attributes. | Changes to the main thread (cancellation, priority change, and so on) may affect the behavior of the other threads of the process; changes to the parent process do not affect child processes. |
Both can create new resources. | |
Neither can access the resources of another process. |
There is information about the thread used to determine the context of the thread. This information is used to reconstruct the thread's environment. What makes peer threads unique from one another is the id, the set of registers that defines the state of the thread, its priority, and its stack. These attributes are what give each thread its identity.
The POSIX thread library defines a thread attribute object that encapsulates a subset of the properties of the thread. These attributes are accessible and modifiable by the creator of the thread. These are the thread attributes that are modifiable:
A thread attribute object can be associated with one or multiple threads. An attribute object is a profile that defines the behavior of a thread or group of threads. Once the object is created and initialized, it can be referenced repeatedly in calls to the thread creation function. If used repeatedly, a group of threads with the same attributes are created. All the threads that use the attribute object inherit all the property values. Once a thread has been created using a thread attribute object, most attributes cannot be changed while the thread is in use.
The scope attribute describes which threads a particular thread competes with for resources. Threads contend for resources within two contention scopes:
Threads compete with other threads for processor usage according to the contention scope and the allocation domains (the set of processors to which it is assigned). Threads with process scope compete with threads within the same process, while threads with systemwide contention scope compete for resources with threads of other processes allocated across the system. A thread that has system scope is prioritized and scheduled with respect to all of the systemwide threads.
The thread's stack size and location are set when the thread is created. If the size and location of the thread's stack are not specified during creation, a default stack size and location are assigned by the system. The default size is system dependent and is determined by the maximum number of threads allowed for a process, the allotted size of a process's address space, and the space used by system resources. The thread's stack size must be large enough for any function calls; for any code external to the process, such as library code, called by the thread; and for local variable storage. A process with multiple threads should have a stack segment large enough for all of its thread's stacks. The address space allocated to the process limits the stack size, thus limiting the size of each of the thread's stacks. The thread's stack address may be of some importance to an application that accesses memory areas that have diverse properties. The important things to remember when you specify the location of a stack is how much space the thread requires and to ensure that the location does not overlap other peer threads' stacks.
Detached threads are threads that have become detached from their creator. They are not synchronized with other peer threads or the primary thread when it terminates or exits. They still share the address space with their process, but because they are detached, the process or thread that created them relinquishes any control over them. When a thread terminates, the id and the status of the terminated thread are saved by the system. By default, once the thread is terminated, the creator is notified. The thread id and the status are returned to the creator. If the thread is detached, once the thread is terminated, no resources are used to save the status or thread id. These resources are immediately available for reuse by the system. If it is not necessary for the creator of the thread to wait until a thread terminates before continuing processing or if a thread does not require any type of synchronization with other peer threads once terminated, that thread may be a detached thread.
The threads inherit scheduling attributes from the process. Threads have a priority, and the thread with the highest priority is executed before threads with lower priority. By prioritizing threads, tasks that require immediate execution or response from the system are allotted the processor for a time slice. Executing threads are preempted if a thread of higher priority is available. A thread's priority can be lowered or raised. The scheduling policy also determines when a thread is assigned the processor. FIFO, round robin (RR), and other scheduling policies are available. In general, it is not necessary to change the scheduling attributes of the thread during process execution. It may be necessary to make changes to scheduling if changes in the process environment occur that change the time constraints, causing you to need to improve the process's performance. But take into consideration that changing the scheduling attributes of specific processes within an application can have a negative impact on the overall performance of the application.
We have discussed the process and the thread's relationship with its process. Figure 6-2 shows the architecture of a process that contains multiple threads. Both have context and attributes that make a process unique from other processes in the system and attributes that makes a thread unique from its peer threads. A process has a text (code), data, and stack segment. The threads share their text and stack segment with the process. A process's stack normally starts in high memory and works its way down. The thread's stack is bounded by the start of the next thread's stack. As you can see, the thread's stack contains its local variables. The process's global variables are located in the data segment. The context for Threads A and B has thread ids, state, priority, the processor registers, and so on. The program counter (PC) points to the next executable instruction in function task1 and task2 in the code segment. The stack pointer (SP) points to the top of their respective stacks. The thread attribute object is associated with a thread or group of threads. In this case, both threads use the same thread attribute.
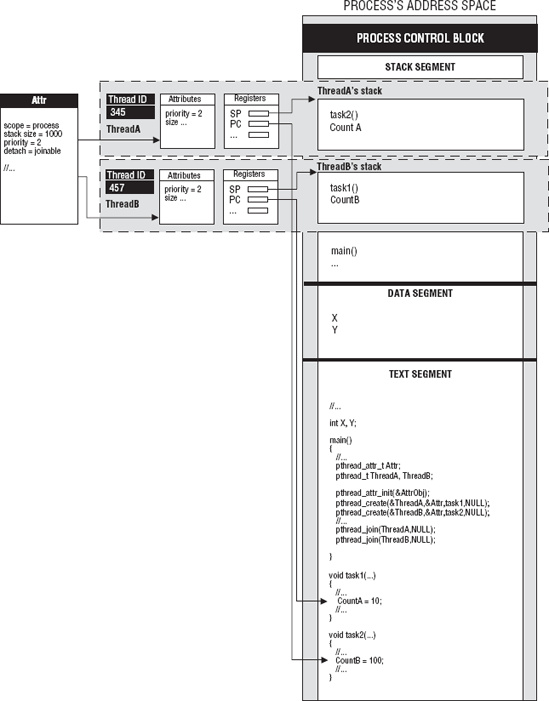
The thread is the unit of execution when a process is scheduled to be executed. If the process has only one thread, it is the primary thread that is assigned to a processor core. If a process has multiple threads and there are multiple processors available to the process, all of the threads are assigned to processors.
When a thread is scheduled to execute on a processor core, it changes its state. A thread state is the mode or condition that a thread is in at any given time. Threads have the same states and transitions mentioned in Chapter 5 for processes. There are four commonly implemented states:
Runnable
Running (active)
Stopped
Sleeping (blocked)
There are several transitions:
Preempt
Signaled
Dispatch
Timer runout
The primary thread can determine the state of an entire process. The state of the primary thread is that same as the state of the process, if it's the only thread. If the primary thread is sleeping, the process is sleeping. If the primary thread is running, the process is running. For a process that has multiple threads, all threads of the process have to be in a sleeping or stopped state in order for the whole process to be considered sleeping or stopped. On the other hand, if one thread is active (runnable or running), then the process is considered active.
There are two types of contention scopes for threads:
Threads with process contention scope contend with threads of the same process. These are hybrid threads (user- and kernel-level threads), whereby the system creates a pool of kernel-level threads, and user-level threads are mapped to them. These kernel-level threads are unbound and can be mapped to one thread or mapped to many threads. The kernel then schedules the kernel threads onto processors according to their scheduling attributes.
Threads with system contention scope contend with threads of processes systemwide. This model consists of one user-level thread per kernel-level thread. The user thread is bound to a kernel-level thread throughout the lifetime of the thread. The kernel threads are solely responsible for scheduling thread execution on one or more processors. This model schedules all threads against all other threads in the system, using the scheduling attributes of the thread. The default contention scope of a thread is implementation defined. For example, for Solaris 10, the default contention scope is process, but for SuSe Linux 2.6.13, the default is system scope. As a matter of fact for SuSe Linux 2.6.13, process contention scope is not supported at all.
Figure 6-3 shows the differences between process and system thread contention scopes. There are two processes in a multicore environment of eight cores. Process A has four threads, and process B has two threads. Process A has three threads that have process scope and one thread with system scope. Process B has two threads, one with process scope and one thread with system scope. Process A's threads with process scope compete for core 0 and core 1, and process B's thread with process scope will utilize core 2. Process A and B's threads with system scope compete for cores 4 and 5. The threads with process scope are mapped to a pool of threads. Process A has a pool of three kernel-level threads and process B has a pool of two kernel-level threads.
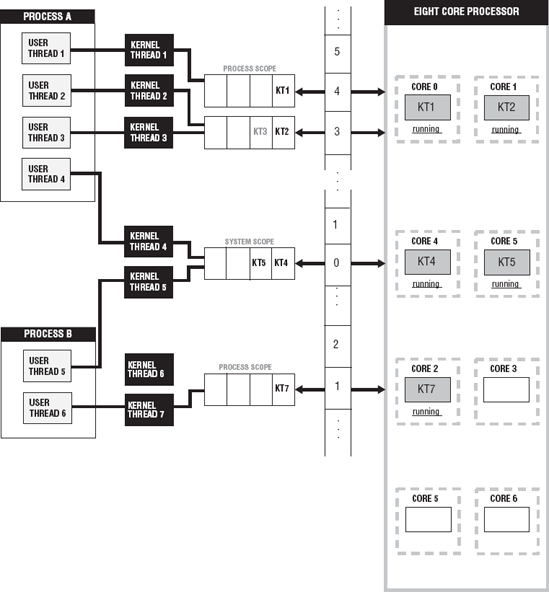
Contention scope can potentially impact on the performance of your application. The process scheduling model potentially provides lower overhead for making scheduling decisions, since there are only threads of a single process that need to be scheduled.
The scheduling policy and priority of the process belong to the primary thread. Each thread can have its own scheduling policy and priority separate from the primary thread. The priority value is an integer that has a maximum and minimum value. When threads are prioritized, tasks that require immediate execution or response from the system are favored. In a preemptive operating system, executing threads are preempted if a thread of higher priority (the lower the number, the higher the priority) and the same contention scope is available.
For example, in Figure 6-3, process A has two threads (2, 3) with priority 3 and one thread (1) with priority 4. They are assigned to processor cores 0 and 1. The threads with priority 4 and 3 are runnable, and each is assigned to a processor. Once thread 3 with priority 3 becomes active, thread 1 is preempted and thread 3 is assigned the processor. In process B, there is one thread with process scope, and it has a priority 1. There is only one available processor for process B. The threads with system scope are not preempted by any of the threads of process A or B with process scope. They compete for processor usage only with other threads that have system scope.
The ready queues are organized as sorted lists in which each element is a priority level. This was discussed in Chapter 5 as well. In Chapter 5, Figure 5-6 shows ready queues. Each priority level in the list is a queue of threads with the same priority level. All threads of the same priority level are assigned to the processor using a scheduling policy: FIFO, RR, or another.
A round-robin scheduling policy considers all threads to be of equal priority, and each thread is given the processor for only a time slice. Task executions are interweaved. For example, a program that filters characters from a text file is divided into three threads. Thread 1, the primary thread, reads in each line from the file and writes each to a vector as a string. Then the primary thread creates three more threads and waits for the threads to return. Each thread has its own set of characters that it is to remove from the strings. Each thread utilizes two queues, and one queue contains the strings that have been previously filtered by another thread. Once the thread has filtered a string, it is written to the second queue. The queues are global data. The primary thread is in a ready queue running preemptively until it creates the other threads; then it sleeps until all its threads return. The other threads have equal priority using a round-robin scheduling policy. A thread cannot filter a string that has not been written to a queue, so synchronized access to the source queue is required. The thread tests the mutex. If the mutex is locked, then there are no strings available, or the source queue is in use. The thread has to wait until the mutex is unlocked. If the mutex is available, then there are strings in the source queue, and the source queue is not in use. A string is read from the queue; the thread filters the string and then writes it to the output queue. The output queue serves as the source queue for another thread. At some point, Thread 2 is assigned the processor. Its source is the vector that contains all the strings to be filtered. The thread has to filter the string and then write the filtered string to its output queue so that thread 2 has something to process, then thread 3, and so on. The RR scheduling affects the execution of the threads with two processor cores. This scheduling policy inhibits the proper execution of this program. We discuss using the correct concurrency models later in this chapter.
With FIFO scheduling and a high priority, there is no interweaving of the execution of these tasks. A thread assigned to a processor dominates the processor until it completes execution. This scheduling policy can be used for applications where a set of threads needs to complete as soon as possible.
The "other" scheduling policy can be a customization of a scheduling policy. For example, a FIFO scheduling policy can be customized to allow random unblocking of threads, or you can use a policy with the appropriate scheduling that advances thread execution.
The FIFO and RR scheduling policies take on different characteristics on a multiple processors. The scheduling allocation domain determines the set of processors on which the threads of a process or application may run. Scheduling policies can be affected by the number of processor cores and the number of threads in a process. As with the example of threads filtering characters from a string, if there are the same number of cores as threads, using an RR scheduling policy may result in better throughput. But it is not always possible to have same number of threads as cores. There may be more threads than cores. In general, relying on the number of cores to significantly impact the performance of your application is not the best approach.
Here is an example of a simple threaded program. This simple multithreaded program has a main thread and the functions that the threads will execute. The concurrency model determines the manner in which the threads are created and managed. We will discuss concurrency models in the next chapter. Threads can be created all at once or under certain conditions. In Example 6-1 the delegation model is used to show the simple multithreaded program.
Example 6.1. Example 6-1
// Example 6-1 Using the delegation model in a simple threaded program.
using namspace std;
#include <iostream>
#include <pthread.h>
void *task1(void *X) //define task to be executed by ThreadA
{
cout << "Thread A complete" << endl;
return (NULL);
}
void *task2(void *X) //define task to be executed by ThreadB
{
cout << "Thread B complete" << endl;
return (NULL);
}
int main(int argc, char *argv[]){
pthread_t ThreadA,ThreadB; // declare threads
pthread_create(&ThreadA,NULL,task1,NULL); // create threads
pthread_create(&ThreadB,NULL,task2,NULL);
// additional processing
pthread_join(ThreadA,NULL); // wait for threads
pthread_join(ThreadB,NULL);
return (0);
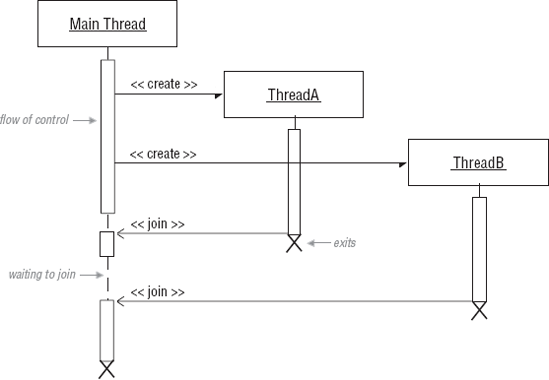
}In Example 6-1, the primary thread is the boss thread. The boss thread declares two threads, ThreadA and ThreadB. pthread_create() creates the threads and associates them with the tasks they are to execute. The two tasks, task1 and task2, each send a message to the standard out. pthread_create() causes the threads to immediately execute their assigned tasks. The pthread_join function works the same way as wait() does for processes. The primary thread waits until both threads return. Figure 6-4 contains the sequence diagram showing the flow of control for Example 6-1. In Figure 6-4, pthread_create() causes a fork in the flow of control in the primary thread. Two additional flows of control, ThreadA and ThreadB, execute concurrently. pthread_create() returns immediately after the threads are created because it is an asynchronous function. As each thread executes its set of instructions, pthread_join() causes the primary thread to wait until the thread terminates and rejoins the main flow of control.
All multithreaded programs using the POSIX thread library must include this header:
<pthread.h>
In order to compile and link multithreaded applications in the Unix or Linux environments using the g++ or gcc command line compilers, be sure to link the pthread library to your application using the -l compiler switch. This switch is immediately followed by the name of the library:
-lpthread
This causes your application to link to the library that is compliant with the multithreading interface defined by POSIX 1003.1c standard. The pthread library, libpthread.so, should be located in the directory where the system stores its standard library, usually /usr/lib. If it is located in that standard directory, then your compile line would look like this:
g++ -o a.out test_thread.cpp -lpthread
If it is not located in a standard location, use the -L option to make the compiler look in a particular directory before searching the standard locations:
g++ -o a.out -L /src/local/lib test_thread.cpp -lpthreadThis tells the compiler to look in the /src/local/lib directory for the pthread library before searching in the standard locations.
As you will see later in this chapter, the complete programs in this book are accompanied by a program profile. The program profile contains implementation specifics such as headers and libraries required and compile and link instructions. The profile also includes a note section that contains any special considerations that need to be followed when executing the program. There are no program profiles for examples.
The pthreads library can be used to create, maintain, and manage the threads of multithreaded programs and applications. When you are creating a multithreaded program, threads can be created any time during the execution of a process because they are dynamic. pthread_create() creates a new thread in the address space of a process.
Synopsis
#include <pthread.h>
int pthread_create(pthread_t *restrict thread, const pthread_attr_t *restrict attr,
void *(*start_routine)(void*), void *restrict arg);The thread parameter points to a thread handle or thread id of the thread to be created. The new thread has the attributes specified by the attribute object attr. The thread parameter immediately executes the instructions in start_routine with the arguments specified by arg. If the function successfully creates the thread, it returns the thread id and stores the value in thread. The restrict keyword is added for alignment with a previous IEEE standard. Here is the call to pthread_create() from Example 6-1:
pthread_create(&ThreadA,NULL,task1,NULL);
Here, attr is NULL; the default thread attributes will be used by the new thread ThreadA. There are no specified arguments. For new attributes for the thread, a pthread_attr_t object is created and initialized and then passed to the pthread_create(). The new thread then takes on the attributes of attr when it is created. If attr is changed after the thread has been created, it does not affect any of the thread's attributes. If start_routine returns, the thread returns as if pthread_exit() was called using the return value of start_routine as its exit status.
If successful, the function returns 0. If the function is not successful, no new thread is created, and the function returns an error number. If the system does not have the resources to create the thread or if the thread limit for the process has been reached, the function fails. The function also fails if the thread attribute is invalid or if the caller thread does not have permission to set the necessary thread attributes.
Listing 6-1 shows a primary thread passing an argument from the command line to the functions executed by the threads. The command-line argument is also used to determine the number of threads to be created.
Example 6.1. Listing 6-1
//Listing 6-1 Passing arguments to a thread from the command line.
1 using namespace std;
2
3 #include <iostream>
4 #include <pthread.h>
5
6
7 void *task1(void *X)
8 {
9 int *Temp;
10 Temp = static_cast<int *>(X);
11
12 for(int Count = 0;Count < *Temp;Count++)
13 {
14 cout << "work from thread: " << Count << endl;
15 }
16 cout << "Thread complete" << endl;
17 return (NULL);
18 }
19
20
21
22 int main(int argc, char *argv[])23 {
24 int N;
25
26 pthread_t MyThreads[10];
27
28 if(argc != 2){
29 cout << "error" << endl;
30 exit (1);
31 }
32
33 N = atoi(argv[1]);
34
35 if(N > 10){
36 N = 10;
37 }
38
39 for(int Count = 0;Count < N;Count++)
40 {
41 pthread_create(&MyThreads[Count],NULL,task1,&N);
42
43 }
44
45
46 for(int Count = 0;Count < N;Count++)
47 {
48 pthread_join(MyThreads[Count],NULL);
49
50 }
51 return(0);
52
53
54 }
55
56At Line 27, an array of 10 pthread_t MyThread types is declared. N holds the command-line argument. At Line 43, N MyThreads types are created. Each thread is passed N as an argument as a void *. In the function task1, the argument is cast from a void * to an int *, as follows:
10 Temp = static_cast<int *>(X);
The function executes a loop that is iterated the number of times indicated by the value passed to the function. The function sends its message to standard out. Each thread created executes this function. The instructions for compiling and executing Listing 6-1 are contained in Program Profile 6-1, which follows shortly.
This is an example of passing a command-line argument to the thread function and using the command-line argument to determine the number of threads to create. If it is necessary to pass multiple arguments to the thread function, you can create a struct or container with all the required arguments and pass a pointer to that structure to the thread function. But we show an easier way to achieve this by creating a thread object later in this chapter.
Accepts an integer from the command line and passes the value to the thread function. The thread function executes a loop that then sends a message to standard out. The argument is used as the stopping case for the loop invariant. The argument also determines the number of threads to be created. Each thread executes the same function.
pthread_join() is used to join or rejoin flows of control in a process. pthread_join() causes the calling thread to suspend its execution until the target thread has terminated. It is similar to the wait() function used by processes. This function is called by the creator of a thread who waits for the new thread to terminate and return, thus rejoining the calling thread's flow of control. The pthread_join() can also be called by peer threads if the thread handle is global. This allows any thread to join flows of control with any other thread in the process. If the calling thread is canceled before the target thread returns, this causes the target thread to become zombied. Detached threads are discussed later in the chapter. Behavior is undefined if different peer threads simultaneously call the pthread_join() function on the same thread.
#include <pthread.h> int pthread_join(pthread_t thread, void **value_ptr);
The thread parameter is the target thread the calling thread is waiting on. If the target thread returns successfully, its exit status is stored in value_ptr. The function fails if the target thread is not a joinable thread or, in other words, if it is created as a detached thread. The function also fails if the specified thread thread does not exist.
There should be a pthread_join() function called for all joinable threads. Once the thread is joined, this allows the operating system to reclaim storage used by the thread. If a joinable thread is not joined to any thread or if the thread that calls the join function is canceled, then the target thread continues to utilize storage. This is a state similar to that of a zombied process when the parent process has not accepted the exit status of a child process. The child process continues to occupy an entry in the process table.
As mentioned earlier in this chapter, the process shares its resources with the threads in its address space. Threads have very few of their own resources, but the thread id is one of the resources unique to a thread. The pthread_self() function returns the thread id of the calling thread.
Synopsis
#include <pthread.h> pthread_t pthread_self(void);
When a thread is created, the thread id is returned to the calling thread. Once the thread has its own id, it can be passed to other threads in the process. This function returns the thread id with no errors defined.
Here is an example of calling this function:
pthread_t ThreadId; ThreadId = pthread_self();
A thread calls this function, and the function returns the thread id assigned to the variable ThreadId of type pthread_t.
The thread id is also returned to the calling thread of pthread_create(). If the thread is successfully created, the thread id is stored in pthread_t.
You can treat thread ids as opaque types. Thread ids can be compared but not by using the normal comparison operators. You can determine whether two thread ids are equivalent by calling pthread_equal():
#include <pthread.h> int pthread_equal(pthread_t tid1, pthread_t tid2);
pthread_equal() returns a nonzero value if the two thread ids reference the same thread. If they reference different threads, it returns zero.
Threads have a set of attributes that can be specified at the time that the thread is created. The set of attributes is encapsulated in an object, and the object can be used to set the attributes of a thread or group of threads. The thread attribute object is of type pthread_attr_t. This structure can be used to set these thread attributes:
Size of the thread's stack
Location of the thread's stack
Scheduling inheritance, policy, and parameters
Whether the thread is detached or joinable
Scope of the thread
The pthread_attr_t has several methods to set and retrieve these attributes. Table 6-3 lists the methods used to set the attributes.
Table 6.3. Table 6-3
Types of Attribute Functions | pthread Attribute Functions |
|---|---|
pthread_attr_init() pthread_attr_destroy() | |
pthread_attr_setstacksize() pthread_attr_getstacksize() pthread_attr_setguardsize() pthread_attr_getguardsize() pthread_attr_setstack() pthread_attr_getstack() pthread_attr_setstackaddr() pthread_attr_getstackaddr() | |
pthread_attr_setdetachstate() pthread_attr_getdetachstate() | |
pthread_attr_setscope() pthread_attr_getscope() | |
Scheduling inheritance |
pthread_attr_setinheritsched() pthread_attr_getinheritsched() |
Scheduling policy |
pthread_attr_setschedpolicy() pthread_attr_getschedpolicy() |
Scheduling parameters |
pthread_attr_setschedparam() pthread_attr_getschedparam() |
The pthread_attr_init() and pthread_attr_destroy() functions are used to initialize and destroy thread attribute objects.
Synopsis
#include <pthread.h> int pthread_attr_init(pthread_attr_t *attr); int pthread_attr_destroy(pthread_attr_t *attr);
pthread_attr_init() initializes a thread attribute object with the default values for all the attributes. attr is a pointer to a pthread_attr_t object. Once attr has been initialized, its attribute values can be changed by using the pthread_attr_set functions listed in Table 6-3. Once the attributes have been appropriately modified, attr can be used as a parameter in any call to the pthread_create() function. If this is successful, the function returns 0. If it is not successful, the function returns an error number. The pthread_attr_init() function fails if there is not enough memory to create the object.
The pthread_attr_destroy() function can be used to destroy a pthread_attr_t object specified by attr. A call to this function deletes any hidden storage associated with the thread attribute object. If it is successful, the function returns 0. If it is not successful, the function returns an error number.
The attribute object is first initialized with the default values for all of the individual attributes used by a given implementation. Some implementations do not support the possible values for an attribute. Upon successful completion, pthread_attr_init() returns a value of 0. If an error number is returned, this may indicate that the value is not supported. For example, for the contention scope, PTHREAD_SCOPE_PROCESS is not supported by the Linux environment. Calling:
int pthread_attr_setscope(pthread_attr_t *attr, int contentionscope);
returns an error code. Table 6-4 lists the default values for Linux and Solaris environment.
Table 6.4. Table 6-4
SuSE Linux 2.6.13 Default Values | Solaris 10 Default Values | |
|---|---|---|
pthread_attr_setdetachstate() |
PTHREAD_CREATE_JOINABLE |
PTHREAD_CREATE_JOINABLE |
pthread_attr_setscope() |
PTHREAD_SCOPE_SYSTEM (PTHREAD_SCOPE_PROCESS is not supported) |
PTHREAD_SCOPE_PROCESS |
pthread_attr_setinheritsched() |
PTHREAD_EXPLICIT_SCHED |
PTHREAD_EXPLICIT_SCHED |
pthread_attr_setschedpolicy() |
SCHED_OTHER |
SCHED_OTHER |
pthread_attr_setschedparam() |
sched_priority = 0 |
sched_priority = 0 |
pthread_attr_setstacksize() | not specified |
NULL allocated by system |
pthread_attr_setstackaddr() | not specified |
NULL 1-2 MB |
pthread_attr_setguardsize() | not specified |
PAGESIZE |
By default, when a thread exits, the thread system stores the thread's completion status and thread id when the thread is joined with another thread. If an exiting thread is not joined with another thread, the exiting thread is said to be detached. The completion status and thread id are not stored in this case. A pthread_join() cannot be used on a detached thread. If it is used, pthread_join() returns an error.
Synopsis
#include <pthread.h>
int pthread_attr_setdetachstate(pthread_attr_t *attr,
int *detachstate);
int pthread_attr_getdetachstate(const pthread_attr_t *attr,
int *detachstate);The pthread_attr_setdetachstate() function can be used to set the detachstate attribute of the attribute object. The detachstate parameter describes the thread as detached or joinable. The detachstate can have one of these values:
PTHREAD_CREATE_DETACHEDPTHREAD_CREATE_JOINABLE
The PTHREAD_CREATE_DETACHED value causes all the threads that use this attribute object to be created as detached threads. The PTHREAD_CREATE_JOINABLE value causes all the threads that use this attribute object to be joinable. The default value of detachstate is PTHREAD_CREATE_JOINABLE. If it is successful, the function returns 0. If it is not successful, the function returns an error number. The pthread_attr_setdetachstate() function fails if the value of detachstate is not valid.
The pthread_attr_getdetachstate() function returns the detachstate of the attribute object. If it is successful, the function returns the value of detachstate to the detachstate parameter and 0 as the return value. If it is not successful, the function returns an error number.
Threads that are already running can become detached. For example, a thread may no longer be interested in the results of the target thread. The thread may detach to allow its resources to be reclaimed once the thread exits.
Synopsis
int pthread_detach(pthread_t tid);
In Example 6-2, the ThreadA is created as a detached thread using an attribute object. ThreadB is detached after it has been created.
Example 6.3. Example 6-2
// Example 6-2 Using an attribute object to create a detached thread and changing
// a joinable thread to a detached thread.
//...
int main(int argc, char *argv[])
{
pthread_t ThreadA,ThreadB;
pthread_attr_t DetachedAttr;
pthread_attr_init(&DetachedAttr);
pthread_attr_setdetachstate(&DetachedAttr,PTHREAD_CREATE_DETACHED);
pthread_create(&ThreadA,&DetachedAttr,task1,NULL);
pthread_create(&ThreadB,NULL,task2,NULL);
//...
pthread_detach(pthread_t ThreadB);
//pthread_join(ThreadB,NULL); cannot call once detached
return (0);
}Example 6-2 declares an attribute object DetachedAttr. The pthread_attr_init() function is used to initialize the attribute object. ThreadA is created with the DetachedAttr attribute object. This attribute object has set detachstate to PTHREAD_CREATE_DETACHED. ThreadB is created with the default value for detachstate, PTHREAD_CREATE_JOINABLE. Once it is created, pthread_detach() is called. Now that ThreadB is detached, pthread_join() cannot be called for this thread.
So far we have talked about creating threads, using thread attribute objects, creating joinable and detached threads, and returning thread ids. Now we discuss managing the threads. When you create applications with multiple threads, there are several ways to control how threads behave and how they use and compete for resources. Part of managing threads is setting the scheduling policy, the priority of the threads, and so on. This contributes to the performance of the threads and, therefore, to the performance of the application. Thread performance is also determined by how the threads compete for resources, either on a process or system scope. The scheduling, priority, and scope of the thread can be set by using a thread attribute object. Because threads share resources, access to resources has to be synchronized. Thread synchronization also includes when and how threads are terminated and canceled.
A thread terminates when it comes to the end of the instructions of its routine. When the thread terminates, the pthread library reclaims the system resources the thread was using and stores its exit status. A thread can also be terminated by another peer thread prematurely before it has executed all its instructions. The thread may have corrupted some process data and may have to be terminated.
A thread's execution can be discontinued by several means:
A thread can self-terminate by calling pthread_exit().
Synopsis
#include <pthread.h> int pthread_exit(void *value_ptr);
When a joinable thread function has completed executing, it returns to the thread calling pthread_join() for which it was the target thread. When the terminating thread calls pthread_exit(), it is passed the exit status in value_ptr. The exit status is returned to pthread_join(). Cancellation cleanup handler tasks that have not executed execute along with the destructors for any thread-specific data.
When this function is called, no resources used by the thread are released. No application visible process resources, including mutexes and file descriptors, are released. No process-level cleanup actions are performed. When the last thread of a process exits, the process has terminated with an exit status of 0. This function cannot return to the calling thread, and there are no errors defined for it.
It may be necessary for one thread to terminate a peer thread. pthread_cancel() is used to terminate peer threads. The thread parameter is the thread to be canceled. The function returns 0 if successful and an error if not successful. The pthread_cancel() function fails if the thread parameter does not correspond to an existing thread.
Synopsis
#include <pthread.h> int pthread_cancel(pthread_t thread);
An application may have a thread that monitors the work of other threads. If a thread performs poorly or is no longer needed, in order to save system resources it may be necessary to terminate that thread. A user may desire to cancel an executing operation. Multiple threads may be used to solve a problem, but once the solution is obtained by a thread, all of the other threads can be canceled by the monitor or the thread that obtained the solution.
A call to pthread_cancel() is a request to cancel a peer thread. The request can be granted immediately, granted at a later time, or even ignored. The target thread may terminate immediately or defer termination until a logical point in its execution. The thread may have to perform some cleanup tasks before it terminates. The thread also has the option to refuse termination.
There is a cancellation process that occurs asynchronously to the returning of the pthread_cancel() when a request to cancel a peer thread is granted. The cancel type and cancel state of the target thread determines when cancellation actually takes place. The cancelability state describes the cancel condition of a thread as being cancelable or uncancelable. A thread's cancelability type determines the thread's ability to continue after a cancel request. The cancelability state and type are dynamically set by the thread itself.
pthread_setcancelstate() and pthread_setcanceltype() are used to set the cancelability state and type of the calling thread. pthread_setcancelstate() sets the calling thread to the cancelability state specified by state and returns the previous state in oldstate. pthread_setcanceltype() sets the calling thread to the cancelability type specified by type and returns the previous state in oldtype.
Synopsis
#include <pthread.h> int pthread_setcancelstate(int state, int *oldstate); int pthread_setcanceltype(int type, int *oldtype);
The values for state and oldstate for setting the cancel state of a thread are:
PTHREAD_CANCEL_DISABLEPTHREAD_CANCEL_ENABLE
PTHREAD_CANCEL_DISABLE causes the thread to ignore a cancel request. PTHREAD_CANCEL_ENABLE causes the thread to concede to a cancel request. This is the default state of any newly created thread. If successful, the function returns 0. If not successful, the function returns an error number. The pthread_setcancelstate() may fail if not passed a valid state value.
pthread_setcanceltype() sets the calling thread to the cancelability type specified by type and returns the previous state in oldtype. The values for type and oldtype are:
PTHREAD_CANCEL_DEFFERED causes the thread to put off termination until it reaches its cancellation point. This is the default cancelability type for any newly created threads. PTHREAD_CANCEL_ASYNCHRONOUS causes the thread to terminate immediately. If successful, the function returns 0. If not successful, the function returns an error number. The pthread_setcanceltype() may fail if not passed a valid type value.
The pthread_setcancelstate() and pthread_setcanceltype() are used together to establish the cancelability of a thread. Table 6-5 list combinations of state and type and a description of what occurs for each combination.
Table 6.5. Table 6-5
Take a look at the Example 6-3.
Example 6.3. Example 6-3
// Example 6-3 task3 thread sets its cancelability state to allow thread
// to be canceled immediately.
void *task3(void *X)
{
int OldState,OldType;
// enable immediate cancelability
pthread_setcancelstate(PTHREAD_CANCEL_ENABLE,&OldState);
pthread_setcanceltype(PTHREAD_CANCEL_ASYNCHRONOUS,&OldType);
ofstream Outfile("out3.txt");
for(int Count = 1;Count < 100;Count++)
{
Outfile << "thread C is working: " << Count << endl;
}
Outfile.close();
return (NULL);
}In Example 6-3, cancellation is set to take place immediately. This means that a request to cancel the thread can take place at any point of execution in the thread's function. So, the thread can open the file and be canceled while it is writing to the file.
Cancellation of a peer thread should not be taken lightly. Some threads are of such a sensitive nature that they may require safeguards against untimely cancellation. Installing safeguards in a thread's function may prevent undesirable situations. For example, consider threads that share data. Depending on the thread model used, one thread may be processing data that is to be passed to another thread for processing. While the thread is processing data, it has sole possession of the data by locking a mutex. If a thread is canceled before the mutex is released, this will cause deadlock. The data may be required to be in some state before it can be used again. If a thread is canceled before this is done, an undesirable condition may occur. Depending on the type of processing that a thread is performing, thread cancellation should be performed only when it is safe.
A vital thread may prevent cancellation entirely. Therefore, thread cancellation should be restricted to threads that are not vital, points of execution that do not have locks on resources or are in the process of executing vital code. Set the cancelability of the thread to the appropriate state and type. Cancellations should be postponed until all vital cleanups have taken place, such as releasing mutexes, closing files, and so on. If the thread has cancellation cleanup handler tasks, they are performed before cancellation. When the last handler returns, the destructors for thread-specific data, if any, are called, and the thread is terminated.
When a cancel request is deferred, the termination of the thread is postponed until later in the execution of the thread's function. When it occurs, it should be safe to cancel the thread because it is not in the middle of locking a mutex, executing critical code, or leaving data in some unusable state. These safe locations in the code's execution are good locations for cancellation points. A cancellation point is a checkpoint where a thread checks if there are any cancellation requests pending and, if so, concedes to termination.
Cancellation points are marked by a call to pthread_testcancel(). This function checks for any pending cancellation request. If a request is pending, it causes the cancellation process to occur at the location this function is called. If there are no cancellations pending, then the function continues to execute with no repercussions. This function call should be placed at any location in the code where it is considered safe to terminate the thread.
Synopsis
#include <pthread.h> void pthread_testcancel(void);
In Example 6-3, the cancelability of the thread was set for immediate cancelability. Example 6-4 uses a deferred cancelability, the default setting. A call to pthread_testcancel() marks where it is safe for the thread to be canceled, before the file is opened or after the thread has closed the file.
Example 6.4. Example 6-4
// Example 6-4 task1 thread sets its cancelability state to be deferred.
void *task1(void *X)
{
int OldState,OldType;
//not needed default settings for cancelability
pthread_setcancelstate(PTHREAD_CANCEL_ENABLE,&OldState);
pthread_setcanceltype(PTHREAD_CANCEL_DEFERRED,&OldType);
pthread_testcancel();
ofstream Outfile("out1.txt");
for(int Count = 1;Count < 1000;Count++)
{
Outfile << "thread 1 is working: " << Count << endl;
}
Outfile.close();
pthread_testcancel();return (NULL);
}In Example 6-5, two threads are created and then canceled.
Example 6.5. Example 6-5
//Example 6-5 shows two threads being canceled.
//...
int main(int argc, char *argv[])
{
pthread_t Threads[2];
void *Status;
pthread_create(&(Threads[0]),NULL,task1,NULL);
pthread_create(&(Threads[1]),NULL,task3,NULL);
// ...
pthread_cancel(Threads[0]);
pthread_cancel(Threads[1]);
for(int Count = 0;Count < 2;Count++)
{
pthread_join(Threads[Count],&Status);
if(Status == PTHREAD_CANCELED){
cout << "thread" << Count << " has been canceled" << endl;
}
else{
cout << "thread" << Count << " has survived" << endl;
}
}
return (0);
}In Example 6-5, the primary thread creates two threads. Then it issues a cancellation request for each thread. The main thread calls the pthread_join() function for each thread. The pthread_join() function does not fail if it attempts to join with a thread that has already been terminated. The join function just retrieves the exit status of the terminated thread. This is good because the thread that issues the cancellation request may be a different thread than the thread that calls pthread_join(). Monitoring the work of all the worker threads may be the sole task of a single thread that also cancels threads. Another thread may examine the exit status of threads by calling the pthread_join() function. This type of information can be used to statistically evaluate which threads have the best performance. In this example, the main thread joins and examines each thread's exit status in a loop. A canceled thread may return an exit status PTHREAD_CANCELED.
In these examples, cancellation points marked by a call to pthread_testcancel() are placed in user-defined functions. When you are calling library functions from the thread function that uses asynchronous cancellation, is it safe for the thread to be canceled?
The pthread library defines functions that can serve as cancellation points and are considered asynchronous cancellation-safe functions. These functions block the calling thread, and while the calling thread is blocked, it is safe to cancel the thread. These are the pthread library functions that act as cancellation points:
pthread_testcanel()pthread_cond_wait()pthread_timedwaitpthread_join()
If a thread with a deferred cancelability state has a cancellation request pending when making a call to one of these pthread library functions, the cancellation process is initiated.
Table 6-6 lists some of the POSIX system calls that are required to be cancellation points. These pthread and POSIX functions are safe to be used as deferred cancellation points, but they may not be safe for asynchronous cancellation. A library call that is not asynchronously safe that is canceled during execution can cause library data to be left in an incompatible state. The library may have allocated memory on the behalf of the thread and, when the thread is canceled, may still have a hold on that memory. In this case, before making such library calls from a thread that has asynchronous cancelability, it may be necessary to change the cancelability state before the call and then change it back after the function returns.
Table 6.6. Table 6-6
POSIX System Calls (Cancellation Points) | ||
|---|---|---|
|
|
|
|
| |
|
|
|
|
| |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| |
|
| |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| |
For other library and systems functions that are not cancellation safe (asynchronously or deferred), it may be necessary to write code preventing a thread from terminating by disabling cancellation or deferring cancellation until after the function call has returned.
Example 6-6 is a wrapper for the library or system call. The wrapper changes the cancelability to deferred, makes the function or system call, and then resets cancelability to previous type. Now it would be safe to call pthread_testcancel().
We mentioned earlier that a thread may need to perform some final processing before it is terminated, such as closing files, resetting shared resources to a consistent state, releasing locks, or deallocating resources. The pthread library defines a mechanism for each thread to perform last minute tasks before terminating. A cleanup stack is associated with every thread. The cleanup stack contains pointers to routines that are to be executed during the cancellation process. The pthread_cleanup_push() function pushes a pointer to the routine to the cleanup stack.
Synopsis
#include <pthread.h> void pthread_cleanup_push(void (*routine)(void *), void *arg); void pthread_cleanup_pop(int execute);
The routine parameter is a pointer to the function to be pushed to the stack. The arg parameter is passed to the function. The function routine is called with the arg parameter when the thread exits under these circumstances:
The function does not return.
The pthread_cleanup_pop() removes routine's pointer from the top of the calling thread's cleanup stack. The execute parameter can have a value of 1 or 0. If 1, the thread executes routine even if it is not being terminated. The thread continues execution from the point after the call to this function. If the value is 0, the pointer is removed from the top of the stack without executing.
For each push, there needs to be a pop within the same lexical scope. For example, task4() requires a cleanup handler to be executed when the function exits or canceled.
In Example 6-7, task4() pushes the cleanup handler cleanup_task4() to the cleanup stack by calling the pthread_cleanup_push() function. The pthread_cleanup_pop() function is required for each call to the pthread_cleanup_push() function. The pop function is passed 0, which means the handler is removed from the cleanup stack but is not executed at this point. The handler is executed if the thread that executes task4() is canceled.
Example 6.7. Example 6-7
//Example 6-7 task4 () pushes cleanup handler cleanup_task4 () onto cleanup stack.
void *task4(void *X)
{
int *Tid;
Tid = new int;
// do some work
//...
pthread_cleanup_push(cleanup_task4,Tid);
// do some more work
//...
pthread_cleanup_pop(0);
}In Example 6-8, task5() pushes cleanup handler cleanup_task5() onto the cleanup stack. The difference in this case is pthread_cleanup_pop() is passed 1, which means that the handler is removed from the cleanup stack but executes at this point. The handler is executed regardless of whether the thread that executes task5() is canceled or not. The cleanup handlers, cleanup_task4() and cleanup_task5() are regular functions that can be used to close files, release resources, unlock mutexes, and so forth.
Managing the thread's stack includes setting the size of the stack and determining its location. The thread's stack is usually automatically managed by the system. But you should be aware of the system-specific limitations that are imposed by the default stack management system. They might be too restrictive, and that's when it may be necessary to do some stack management. If your application has a large number of threads, you may have to increase the upper limit of the stack established by the default stack size. If an application utilizes recursion or calls to several functions, many stack frames are required. Some applications require exact control over the address space. For example, an application that has garbage collection must keep track of allocation of memory.
The address space of a process is divided into the text and static data segments, free store, and the stack segment. The location and size of the thread's stacks are carved out of the stack segment of its process. A thread's stack stores a stack frame for each routine it has called but that has not exited. The stack frame contains temporary variables, local variables, return addresses, and any other additional information the thread needs to finds its way back to previously executing routines. Once the routine has exited, the stack frame for that routine is removed from the stack. Figure 6-5 shows how stack frames are generated and placed onto a stack.
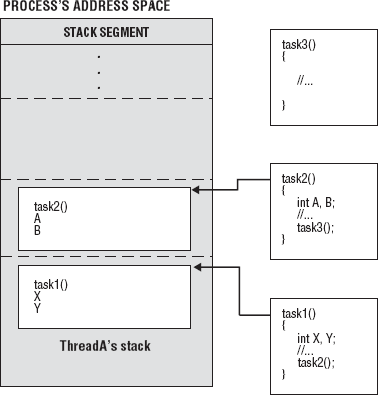
In Figure 6-5, ThreadA executes task1. task1 creates some local variables, does some processing, and then calls task2. A stack frame is created for task1 and placed on the stack. task2 creates local variables, and then calls task3. A stack frame for task2 is placed on the stack. After task3() has been completed, flow of control returns to task2(), which is popped from the stack. After task2() has executed, flow of control is returned to task1(), which is popped from the stack. Each stack must be large enough to accommodate the execution of all peer threads' functions along with the chain of routines that will be called. The size and location of a thread's stack can be set or examined by several methods defined by the attribute object.
There are two attribute methods concerned with the size of the thread's stack.
Synopsis
#include <pthread.h>
int pthread_attr_getstacksize(const pthread_attr_t *restrict attr,
size_t *restrict stacksize);
int pthread_attr_setstacksize(pthread_attr_t *attr, size_t *stacksize);The pthread_attr_getstacksize() returns the default stack size minimum. The attr is the thread attribute object from which the default stack size is extracted. When the function returns, the default stack size in bytes is stored in stacksize and the return value is 0. If not successful, the function returns an error number.
The pthread_attr_setstacksize() sets the stack size minimum. The attr is the thread attribute object for which the stack size is set. The stacksize is the minimum size of the stack in bytes. If the function is successful, the return value is 0. If not successful, the function returns an error number. The function fails if stacksize is less than PTHREAD_MIN_STACK or exceeds the system minimum. The PTHREAD_STACK_MIN will probably be a lower minimum than the default stack minimum returned by pthread_attr_getstacksize(). Consider the value returned by the pthread_attr_getstacksize() before raising the minimum size of a thread's stack.
In Example 6-9, the stack size of a thread is changed by using a thread attribute object. It retrieves the default size from the attribute object and then determines whether the default size is less than the minimum stack size desired. If so, the offset is added to the default stack size. This becomes the new minimum stack size for this thread.
Example 6.9. Example 6-9
// Example 6-9 Changing the stack size of a thread using an offset.
#include <limits.h>
//...
pthread_attr_getstacksize(&SchedAttr,&DefaultSize);
if(DefaultSize < PTHREAD_STACK_MIN){
SizeOffset = PTHREAD_STACK_MIN — DefaultSize;
NewSize = DefaultSize + SizeOffset;
pthread_attr_setstacksize(&Attr1,(size_t)NewSize);
}There is a tradeoff in setting the size. The stack size is fixed. A large stack means there is less of a probability there will be stack overflow. But on the other hand a large stack means more expense in terms of swap space and real memory for the stack.
Setting the stack size and stack location may make your program unportable. The stack size and location you set for your program on one platform may not match the stack size and location of another platform.
Once you decide to manage the thread's stack, you can retrieve and then set the location of the stack by using these attribute object methods:
Synopsis
#include <pthread.h>
int pthread_attr_setstackaddr(pthread_attr_t *attr, void *stackaddr);
int pthread_attr_getstackaddr(const pthread_attr_t *restrict attr,
void **restrict stackaddr);The pthread_attr_setstackaddr() sets the base location of the stack to the address specified by stackattr for the thread created with the thread attribute object attr. This address addr should be within the virtual address space of the process. The size of the stack will be at least equal to the minimum stack size specified by PTHREAD_STACK_MIN. If successful, the function returns 0. If not successful, the function returns an error number.
pthread_attr_getstackaddr() retrieves the base location of the stack address for the thread created with the thread attribute object specified by the attr. The address is returned and stored in the stackaddr. If it is successful, the function returns 0. If not successful, the function returns an error number.
The stack attributes (size and location) can be set by using a single function.
Synopsis
#include <pthread.h>
int pthread_attr_setstack(pthread_attr_t *attr, void *stackaddr,
size_t stacksize);
int pthread_attr_getstack(const pthread_attr_t *restrict attr,
void **restrict stackaddr, size_t *restrict stacksize);pthread_attr_setstack() sets both the stack size and location of a thread created using the specified attribute object attr. The base location of the stack is set to the stackaddr, and the size of the stack is set to the stacksize. pthread_attr_getstack() retrieves the stack size and location of a thread created using the specified attribute object attr. If this is successful, the stack location is stored in stackaddr, and the stack size is stored in stacksize. If successful, these functions return 0. If not successful, an error number is returned. The pthread_setstack() fails if the stacksize is less than PTHREAD_STACK_MIN or exceeds some implementation-defined limit.
Threads execute independently. They are assigned to a processor core and execute the task they have been given. Each thread is given a scheduling policy and priority that dictates how and when it is assigned to a processor. The scheduling policy of a thread or group of threads can be set by an attribute object using these functions:
Synopsis
#include <pthread.h>
#include <sched.h>
int pthread_attr_setinheritsched(pthread_attr_t *attr, int inheritsched);
void pthread_attr_setschedpolicy(pthread_attr_t *attr, int policy);
int pthread_attr_setschedparam(pthread_attr_t *restrict attr,
const struct sched_param *restrict param);pthread_attr_setinheritsched() is used to determine how the thread's scheduling attributes are set, by inheriting the scheduling attributes either from the creator thread or from an attribute object. inheritsched can have one of these values:
PTHREAD_INHERIT_SCHED:Thread scheduling attributes are inherited from the creator thread, and any scheduling attributes of the attr are ignored.PTHREAD_EXPLICIT_SCHED:Thread scheduling attributes are set to the scheduling attributes of the attribute objectattr.
If inheritsched value is PTHREAD_EXPLICIT_SCHED, then pthread_attr_setschedpolicy() is used to set the scheduling policy and pthread_attr_setschedparam() is used to set the priority.
The pthread_attr_setschedpolicy() sets the scheduling policy of the thread attribute object attr. policy values can be one of the following defined in the <sched.h> header:
SCHED_FIFO:First-In, First-Out scheduling policy whereby the executing thread runs to completion.SCHED_RR:Round robin scheduling policy whereby each thread is assigned to processor only for a time slice.SCHED_OTHER:Another scheduling policy (implementation-defined). By default, this is the scheduling policy of any newly created thread.
Use pthread_attr_setschedparam() to set the scheduling parameters of the attribute object attr used by the scheduling policy. param is a structure that contains the parameters. The sched_param structure has at least this data member defined:
struct sched_param {
int sched_priority;
//...
};It may also have additional data members, along with several functions that return and set the priority minimum, maximum, scheduler, parameters, and so on. If the scheduling policy is either SCHED_FIFO or SCHED_RR, then the only member required to have a value is sched_priority.
Use sched_get_priority_max() and sched_get_priority_max(), as follows, to obtain the maximum and minimum priority values.
Synopsis
#include <sched.h> int sched_get_priority_max(int policy); int sched_get_priority_min(int policy);
Both functions are passed the scheduling policy policy for which the priority values are requested, and both return either the maximum or minimum priority values for the scheduling policy.
Example 6-10 shows how to set the scheduling policy and priority of a thread by using the thread attribute object.
Example 6.11. Example 6-10
// Example 6-10 Using the thread attribute object to set scheduling
// policy and priority of a thread.
#include <pthread.h>
#include <sched.h>
//...
pthread_t ThreadA;
pthread_attr_t SchedAttr;
sched_param SchedParam;
int MidPriority,MaxPriority,MinPriority;
int main(int argc, char *argv[])
{
//...
// Step 1: initialize attribute object
pthread_attr_init(&SchedAttr);
// Step 2: retrieve min and max priority values for scheduling policy
MinPriority = sched_get_priority_max(SCHED_RR);
MaxPriority = sched_get_priority_min(SCHED_RR);
// Step 3: calculate priority value
MidPriority = (MaxPriority + MinPriority)/2;
// Step 4: assign priority value to sched_param structure
SchedParam.sched_priority = MidPriority;
// Step 5: set attribute object with scheduling parameter
pthread_attr_setschedparam(&SchedAttr,&SchedParam);
// Step 6: set scheduling attributes to be determined by attribute object
pthread_attr_setinheritsched(&SchedAttr,PTHREAD_EXPLICIT_SCHED);
// Step 7: set scheduling policy
pthread_attr_setschedpolicy(&SchedAttr,SCHED_RR);
// Step 8: create thread with scheduling attribute object
pthread_create(&ThreadA,&SchedAttr,task1,NULL);
//...
}In Example 6-10, the scheduling policy and priority of ThreadA is set using the thread attribute object SchedAttr. This is done in eight steps:
Initialize attribute object.
Retrieve min and max priority values for scheduling policy.
Calculate priority value.
Assign priority value to the
sched_paramstructure.Set the attribute object with a scheduling parameter.
Set scheduling attributes to be determined by attribute object.
Set the scheduling policy.
Create a thread with the scheduling attribute object.
In Example 6-10, we set the priority to be an average value. But the priority can be set to be any value between the maximum and minimum priority values allowed by the scheduling policy for the thread. With these methods, the scheduling policy and priority are set in the thread attribute object before the thread is created or running. To dynamically change the scheduling policy and priority, use pthread_setschedparam() and pthread_setschedprio().
Synopsis
#include <pthread.h>
int pthread_setschedparam(pthread_t thread, int policy,
const struct sched_param *param);
int pthread_getschedparam(pthread_t thread, int *restrict policy,
struct sched_param *restrict param);
int pthread_setschedprio(pthread_t thread, int prio);pthread_setschedparam() sets both the scheduling policy and priority of a thread directly without the use of an attribute object. thread is the id of the thread, policy is the new scheduling policy, and param contains the scheduling priority. The pthread_getschedparam() returns the scheduling policy and scheduling parameters and stores their values in policy and param parameters, respectively, if successful. If successful, both functions return 0. If not successful, both functions return an error number. Table 6-7 lists the conditions in which these functions may fail.
The pthread_setschedprio() is used to set the scheduling priority of an executing thread whose thread id is specified by the thread. prio specifies the new scheduling priority of the thread. If the function fails, the priority of the thread is not changed, and an error number is returned. If it is successful, the function returns 0. The conditions under which this function fails are listed in Table 6-7.
Table 6.7. Table 6-7
Failure Conditions | |
|---|---|
int pthread_getschedparam
(pthread_t thread,
int *restrict policy,
struct sched_param
*restrict param);
| The |
int pthread_setschedparam
(pthread_t thread,
int *policy,
const struct
sched_param *param);
| The The The calling thread does not have the appropriate permission to set the scheduling parameters or policy of the specified thread. The The implementation does not allow the application to change one of the parameters to the specified value. |
int pthread_setschedprio (pthread_t thread, int prio); | The The The calling thread does not have the appropriate permission to set the scheduling priority of the specified thread. The The implementation does not allow the application to change the priority to the specified value. |
Remember to carefully consider why it is necessary to change the scheduling policy or priority of a running thread. This may diversely affect the overall performance of your application. Threads with higher priority preempt running threads with lower priority. This may lead to starvation, a thread constantly being preempted and, therefore, not able to complete execution.
The contention scope of the thread determines which set of threads a thread competes with for processor usage. The contention scope of a thread is set by the thread attribute object.
#include <pthread.h>
int pthread_attr_setscope(pthread_attr_t *attr, int contentionscope);
int pthread_attr_getscope(const pthread_attr_t *restrict attr,
int *restrict contentionscope);The pthread_attr_setscope() sets the contention scope property of the thread attribute object specified by attr. The contention scope of the thread attribute object will be set to the value stored in the contentionscope. contentionscope can have these values:
PTHREAD_SCOPE_SYSTEM:System scheduling contention scopePTHREAD_SCOPE_PROCESS:Process scheduling contention scope
System contention scope means the thread contends with others threads of other processes systemwide. pthread_attr_getscope() returns the contention scope attribute from the thread attribute object specified by the attr. If it is successful, the contention scope of the thread attribute object is returned and stored in the contentionscope. Both functions return 0 if successful and an error number otherwise.
Knowing the thread resource limits of your system is a key to having your application appropriately manage them. Examples of utilizing the system resources have been discussed in previous section. When setting the stack size of a thread, PTHREAD_MIN_STACK is the lower minimum. The stack size should not be below the value of the default stack minimum returned by pthread_attr_getstacksize(). The maximum number of threads per process places an upper bound on the number of worker threads that can be created for a process. sysconf() is used to return the current value of configurable system limits or options. Your system defines several variables and constant counterparts concerned with threads, processes, and semaphores. In Table 6-8, we list some of them to give you an idea to what is available.
Table 6.8. Table 6-8
Variable | Name Value | Description |
|---|---|---|
_SC_THREADS |
_POSIX_THREADS | Supports threads |
_SC_THREAD_ATTR_STACKADDR |
_POSIX_THREAD_ATTR_STACKADDR | Supports thread stack address attribute |
_SC_THREAD_ATTR_STACKSIZE |
_POSIX_THREAD_ATTR_STACKSIZE | Supports thread stack size attribute |
_SC_THREAD_STACK_MIN |
PTHREAD_STACK_MIN | Minimum size of thread stack storage in bytes |
_SC_THREAD_THREADS_MAX |
PTHREAD_THREADS_MAX | Maximum number of threads per process |
_SC_THREAD_KEYS_MAX |
PTHREAD_KEYS_MAX | Maximum number of keys per process |
_SC_THREAD_PRIO_INHERIT |
_POSIX_THREAD_PRIO_INHERIT | Supports priority inheritance option |
_SC_THREAD_PRIO |
_POSIX_THREAD_PRIO_ | Supports thread priority option |
_SC_THREAD_PRIORITY_SCHEDULING |
_POSIX_THREAD_PRIORITY_SCHEDULING | Supports thread priority scheduling option |
_SC_THREAD_PROCESS_SHARED |
_POSIX_THREAD_PROCESS_SHARED | Supports process-shared synchronization |
_SC_THREAD_SAFE_FUNCTIONS |
_POSIX_THREAD_SAFE_FUNCTIONS | Supports thread safe functions |
_SC_THREAD_DESTRUCTOR_ITERATIONS |
_PTHREAD_THREAD_DESTRUCTOR_ITERATIONS | Determines the number of attempts made to destroy thread-specific data on thread exit |
_SC_CHILD_MAX |
CHILD_MAX | Maximum number of processes allowed to a UID |
_SC_PRIORITY_SCHEDULING |
_POSIX_PRIORITY_SCHEDULING | Supports process scheduling |
_SC_REALTIME_SIGNALS |
_POSIX_REALTIME_SIGNALS | Supports real-time signals |
_SC_XOPEN_REALTIME_THREADS |
_XOPEN_REALTIME_THREADS | Supports X/Open POSIX real-time threads feature group |
_SC_STREAM_MAX |
STREAM_MAX | Determines the number of streams one process can have open at a time |
_SC_SEMAPHORES |
_POSIX_SEMAPHORES | Supports semaphores |
_SC_SEM_NSEMS_MAX |
SEM_NSEMS_MAX | Determines the maximum number of semaphores a process may have |
_SC_SEM_VALUE_MAX |
SEM_VALUE_MAX | Determines the maximum value a semaphore may have |
_SC_SHARED_MEMORY_OBJECTS |
_POSIX_SHARED_MEMORY_OBJECTS | Supports shared memory objects |
Here is an example of a call to sysconf():
if(PTHREAD_STACK_MIN == (sysconf(_SC_THREAD_STACK_MIN))){
//...
}The constant value of PTHREAD_STACK_MIN is compared to the _SC_THREAD_STACK_MIN value returned by the sysconf().
A library is thread safe or reentrant when its functions may be called by more than one thread at a time without requiring any other action on the caller's part. When designing a multithread application, you must be careful to ensure that concurrently executing functions are thread safe. We have already discussed making user-defined functions thread safe, but an application often calls functions defined by the system or a third-party supplied library. We have discussed system functions that are safe as cancellation points, but some of these functions and/or libraries are thread safe, while others are not. If the functions are not thread safe, then this means the functions:
Contain static variables
Access global data
Are not reentrant
If the function contains static variables, then those variables maintain their values between invocations of the function. The function requires the value of the static variable in order to operate correctly. When concurrent multiple threads invoke this function, a race condition occurs.
If the function modifies a global variable, then multiple threads invoking that function may each attempt to modify that global variable. If concurrent multiple accesses to the global variable are not synchronized, then a race condition can occur here as well. Consider concurrent multiple threads executing functions that set errno. With some of the threads, the function fails, and errno is set to an error message. Meanwhile, other threads execute successfully. Depending on the compiler implementation, errno is thread safe, but if it's not, when a thread checks the state of errno, which message does it report?
Reentrant code is a block of code that cannot be changed while it is in use. Reentrant code avoids race conditions by removing references to global variables and modifiable static data. The code can be shared by multiple concurrent threads or processes without a race condition occurring. The POSIX standard defines several functions as reentrant. They are easily identified by a _r attached to the function name of the nonreentrant counterpart. Some are:
If the function accesses unprotected global variables, contains static modifiable variables, or is not reentrant, then the function is considered thread unsafe.
System- and third-party-supplied libraries may have two different versions of their standard libraries, one version for single-threaded applications and the other version for multithreaded applications. Whenever a multithreaded environment is anticipated, link to the multithreaded versions of the library. Other environments do not require multithreaded applications to be linked to the multithreaded version of the library but only require macros to be defined for reentrant versions of functions to be declared. The application can then be compiled as thread safe.
It is not always possible to use multithreaded versions of functions. In some instances, multithreaded versions of particular functions are not available for a given compiler or environment. Some functions' interfaces cannot be made thread safe simply. In addition, you may be faced with adding threads to an environment that uses functions that were only meant to be used in a single-threaded environment. Under these conditions, mutexes can be used to wrap all such functions within the program.
For example, a program has three concurrently executing threads. Two of the threads, ThreadA and ThreadB, both concurrently execute task1(), which is not thread safe. The third thread, ThreadC, executes task2(). To solve the problem of task1(), the solution may be to simply wrap access to task1() by ThreadA and ThreadB with a mutex:
ThreadA
{
lock()
task1()
unlock()
}
ThreadB
{
lock()
task1()
unlock()
}
ThreadC
{
task2()
}If this is done, then only one thread accesses task1() at a time. But what if task1() and task2() both modify the same global or static variable? Although ThreadA and ThreadB are using mutexes with task1(), ThreadC executes task2() concurrently with either of these threads. In this situation, a race condition occurs. Avoiding race conditions requires synchronized access to the global data. We discuss this topic in Chapter 7.
To illustrate another type of race condition when dealing with iostream library, say that you have two threads, Thread A and Thread B, sending output to the standard output stream, cout. cout is an object of type ostream. Using inserters (>>) and extractors (<<) invokes the methods of the cout object. Are these methods thread safe? If ThreadA is sending the message:
Global warming is a real problem.
to stdout and Thread B is sending the message:
Global warming is not a real problem.
will the output be interleaved and produce the following message?
Global warming is a Global warming is not a real problem real problem.
In some cases, thread-safe functions are implemented as atomic functions. Atomic functions are functions that cannot be interrupted once they begin to execute. In the case of cout, if the inserter operation is implemented as atomic, then this interweaving cannot take place. When you have multiple calls to the inserter operation, they are executed as if they were in serial order. ThreadA's message will be displayed, then ThreadB's, or vice versa. This is an example of serializing a function or operation in order to make it thread safe.
This may not be the only way to make a function thread safe. A function may interweave operations if it has no adverse effect. For example, if a method adds or removes elements to or from a structure that is not sorted and two different threads invoke that method, interweaving their operations will not have an adverse effect.
If it is not known which functions from a library are thread safe and which are not, you have three choices:
Restrict use of all thread-unsafe functions to a single thread
Do not use any of the thread unsafe functions
Wrap all potential thread unsafe functions within a single set of synchronization mechanisms
To extend the last option, you can create interface classes for all thread unsafe functions that will be used in a multithreaded application. The idea of a wrapper was illustrated when making a cancellation point for system calls earlier in this chapter. The unsafe functions are encapsulated within an interface class. That class can be combined with the appropriate synchronization objects and can be used by the host class through inheritance or composition. This approach reduces the possibility of race conditions and is discussed in Chapter 7. However, first we want to discuss the thread_object interface class introduced in Chapter 4 and extend it to encapsulate the thread attribute object.
A thread interface class was introduced in Chapter 4. The interface class acts as a wrapper that allows something to appear differently than it does normally. The new interface provided by an interface class is designed to make the class easier to use, more functional, safer, or more semantically correct. In this chapter, we have introduced a number of pthread functions used to manage a thread, including the creation and usage of the thread attribute object. The thread_object class was a simple skeleton class. Its purpose was to encapsulate the pthread thread interface and to supply object-oriented semantics and components so that you can implement the models you produce in the SDLC more easily. Now it's time to expand the thread_object class to encapsulate some of the functionality of the thread attribute object. Listing 6-2 shows the declaration of the new thread_object and user_thread classes.
Example 6.2. Listing 6-2
//Listing 6-2 Declaration of the new thread_object and user_thread.
1 #ifndef __THREAD_OBJECT_H
2 #define __THREAD_OBJECT_H
3
4 using namespace std;
5 #include <iostream>
6 #include <pthread.h>
7 #include <string>
8
9 class thread_object{
10 pthread_t Tid;
11
12 protected:
13 virtual void do_something(void) = 0;
14 pthread_attr_t SchedAttr;
15 struct sched_param SchedParam;
16 string Name;
17 int NewPolicy;
18 int NewState;
19 int NewScope;
20 public:
21 thread_object(void);
22 ~thread_object(void);
23 void setPriority(int Priority);
24 void setSchedPolicy(int Policy);
25 void setContentionScope(int Scope);
26 void setDetached(void);
27 void setJoinable(void);
28
29 void name(string X);
30 void run(void);
31 void join(void);
32 friend void *thread(void *X);
33 };
34
35
36 class filter_thread: public thread_object{37 protected: 38 void do_something(void); 39 public: 40 filter_thread(void); 41 ~filter_thread(void); 42 }; 43 44 #endif 45 46
For the thread_object we have included methods that set:
scheduling policies
priority
state
contention scope
of the thread_object. Instead of a user_thread, we are defining a filter_thread that defines the do_something() method. This class is used in the next chapter on synchronization.
Listing 6-3 is the class definition of the new thread_object class.
Example 6.3. Listing 6-3
//Listing 6-3 A definition of the new thread_object class.
1 #include "thread_object.h"
2
3 thread_object::thread_object(void)
4 {
5 pthread_attr_init(&SchedAttr);
6 pthread_attr_setinheritsched(&SchedAttr,PTHREAD_EXPLICIT_SCHED);
7 NewState = PTHREAD_CREATE_JOINABLE;
8 NewScope = PTHREAD_SCOPE_PROCESS;
9 NewPolicy = SCHED_OTHER;
10 }
11
12 thread_object::~thread_object(void)
13 {
14
15 }
16
17 void thread_object::join(void)
18 {
19 if(NewState == PTHREAD_CREATE_JOINABLE){
20 pthread_join(Tid,NULL);
21 }
22 }23
24 void thread_object::setPriority(int Priority)
25 {
26 int Policy;
27 struct sched_param Param;
28
29 Param.sched_priority = Priority;
30 pthread_attr_setschedparam(&SchedAttr,&Param);
31 }
32
33
34 void thread_object::setSchedPolicy(int Policy)
35 {
36 if(Policy == 1){
37 pthread_attr_setschedpolicy(&SchedAttr,SCHED_RR);
38 pthread_attr_getschedpolicy(&SchedAttr,&NewPolicy);
39 }
40
41 if(Policy == 2){
42 pthread_attr_setschedpolicy(&SchedAttr,SCHED_FIFO);
43 pthread_attr_getschedpolicy(&SchedAttr,&NewPolicy);
44 }
45 }
46
47
48 void thread_object::setContentionScope(int Scope)
49 {
50 if(Scope == 1){
51 pthread_attr_setscope(&SchedAttr,PTHREAD_SCOPE_SYSTEM);
52 pthread_attr_getscope(&SchedAttr,&NewScope);
53 }
54
55 if(Scope == 2){
56 pthread_attr_setscope(&SchedAttr,PTHREAD_SCOPE_PROCESS);
57 pthread_attr_getscope(&SchedAttr,&NewScope);
58 }
59 }
60
61
62 void thread_object::setDetached(void)
63 {
64 pthread_attr_setdetachstate(&SchedAttr,PTHREAD_CREATE_DETACHED);
65 pthread_attr_getdetachstate(&SchedAttr,&NewState);
66
67 }
68
69 void thread_object::setJoinable(void)
70 {
71 pthread_attr_setdetachstate(&SchedAttr,PTHREAD_CREATE_JOINABLE);
72 pthread_attr_getdetachstate(&SchedAttr,&NewState);
73 }
74
7576 void thread_object::run(void)
77 {
78 pthread_create(&Tid,&SchedAttr,thread,this);
79 }
80
81
82 void thread_object::name(string X)
83 {
84 Name = X;
85 }
86
87
88 void * thread (void * X)
89 {
90 thread_object *Thread;
91 Thread = static_cast<thread_object *>(X);
92 Thread->do_something();
93 return(NULL);
94 }In Listing 6-3, the constructor defined at Lines 3-10 initializes a thread attribute object for this class SchedAttr. It sets the inheritsched attribute to PTHREAD_EXPLICIT_SCHED so that the thread that is created uses the attribute's object to define its scheduling and priorities instead of inheriting them from its creator thread. By default, the thread's state is JOINABLE. The other methods are self-explanatory:
setPriority(int Priority) setSchedPolicy(int Policy) setContentionscope(int Scope) setDetached() setJoinable()
The join() checks to see if the thread is joinable before it calls pthread_join() in Line 20. Now when the thread is created in Line 78, the pthread_create() uses the SchedAttr object:
pthread_create(&Tid,&SchedAttr,thread,this);
Listing 6-4 shows the definition for the filter_thread.
Example 6.4. Listing 6-4
//Listing 6-4 A definition of the filter_thread class.
1 #include "thread_object.h"
2
3
4 filter_thread::filter_thread(void)
5 {
6 pthread_attr_init(&SchedAttr);
7
8
9 }
1011
12 filter_thread::~filter_thread(void)
13 {
14
15 }
16
17 void filter_thread::do_something(void)
18 {
19 struct sched_param Param;
20 int Policy;
21 pthread_t thread_id = pthread_self();
22 string Schedule;
23 string State;
24 string Scope;
25
26 pthread_getschedparam(thread_id,&Policy,&Param);
27 if(NewPolicy == SCHED_RR){Schedule.assign("RR");}
28 if(NewPolicy == SCHED_FIFO){Schedule.assign("FIFO");}
29 if(NewPolicy == SCHED_OTHER){Schedule.assign("OTHER");}
30 if(NewState == PTHREAD_CREATE_DETACHED){State.assign("DETACHED");}
31 if(NewState == PTHREAD_CREATE_JOINABLE){State.assign("JOINABLE");}
32 if(NewScope == PTHREAD_SCOPE_PROCESS){Scope.assign("PROCESS");}
33 if(NewScope == PTHREAD_SCOPE_SYSTEM){Scope.assign("SYSTEM");}
34 cout << Name << ":" << thread_id << endl
35 << "----------------------" << endl
36 << " priority: "<< Param.sched_priority << endl
37 << " policy: "<< Schedule << endl
38 << " state: "<< State << endl
39 << " scope: "<< Scope << endl << endl;
40
41 }
42In Listing 6-4, the filter_thread constructor in Lines 4-9 initializes with the thread attribute object SchedAttr. The do_something() method is defined. In filter_thread, this method simply sends to cout thread information:
Name of the thread
Thread id
Priority
Scheduling policy
State
Scope
Some values may not be initialized because they were not set in the attribute object. This method will be redefined in the next chapter.
Now, multiple filter_thread objects can be created, and each can set the attributes of the thread. Listing 6-5 shows how multiple filter_thread objects are created.
Example 6.5. Listing 6-5
//Listing 6-5 is main line to create multiple filter_thread objects.
1 #include "thread_object.h"
2 #include <unistd.h>
3
4
5 int main(int argc,char *argv[])
6 {
7 filter_thread MyThread[4];
8
9 MyThread[0].name("Proteus");
10 MyThread[0].setSchedPolicy(2);
11 MyThread[0].setPriority(7);
12 MyThread[0].setDetached();
13
14 MyThread[1].name("Stand Alone Complex");
15 MyThread[1].setContentionScope(1);
16 MyThread[1].setPriority(5);
17 MyThread[1].setSchedPolicy(2);
18
19 MyThread[2].name("Krell Space");
20 MyThread[2].setPriority(3);
21
22 MyThread[3].name("Cylon Space");
23 MyThread[3].setPriority(2);
24 MyThread[3].setSchedPolicy(2);
25
26 for(int N = 0;N < 4;N++)
27 {
28 MyThread[N].run();
29 MyThread[N].join();
30 }
31 return (0);
32 }In Listing 6-5, four filter_threads were created. This is the output for Listing 6-5:
Proteus:Stand Alone Complex:32 ---------------------- priority: 7 ---------------------- policy: FIFO priority:5 state: policy: DETACHEDFIFO scope: state: PROCESSJOINABLE scope: SYSTEM
Krell Space:4 ---------------------- priority: 3 policy: OTHER state: JOINABLE scope: PROCESS Cylon Space:5 ---------------------- priority: 2 policy: FIFO state: JOINABLE scope: PROCESS
The main thread does not wait for a detached thread (Proteus), and the output is a little messed up. Proteus starts its output, and then it is interrupted with output from Stand Alone Complex. As mentioned earlier, standard cout is not thread safe. If all the threads are joinable, then the output would be as you would expect:
Proteus:2 ---------------------- priority: 7 policy: FIFO state: JOINABLE scope: PROCESS Stand Alone Complex:3 ---------------------- priority: 5 policy: FIFO state: JOINABLE scope: SYSTEM Krell Space:4 ---------------------- priority: 3 policy: OTHER state: JOINABLE scope: PROCESS Cylon Space:5 ---------------------- priority: 2 policy: FIFO state: JOINABLE scope: PROCESS
Demonstrates the use of filter_thread class. Four threads are created; each is assigned a name. Each invokes the methods that modify some of the attributes of the thread that will be created.
c++ -o program6-2 program6-2.cc thread_object.cc filter_thread.cc -lpthread
./program6-2
The thread_object class encapsulates some of the functionality of the thread attribute object. The filter_thread is the user thread. It inherits the thread_object and defines the do_something(), the function that is executed by the thread. The functionality of this class will be extended again to form the assertion class that is used as part of a pipeline model executed in Chapter 7.
A thread is a sequence or stream of executable code within a process that is scheduled for execution by the operating system on a processor or core. This chapter has been all about dealing with multithreading. The key things you can take away from this discussion of multithreading are as follows:
All processes have a primary thread that is the process's flow of control. A process with multiple threads has as many flows of controls in which each executes independently and concurrently. A process with multiple threads is multithreaded.
Kernel-level threads or lightweight processes are a lighter burden on the operating system as compared to a process to create, maintain, and manage because very little information is associated with a thread. Kernel threads are executed on the processor. They are created and managed by the system. User-level threads are created and managed by a runtime library.
Threads can be used to simplify the program's structure, model the inherent concurrency using minimal resources, or execute independent concurrent tasks of a program. Threads can improve the throughput and performance of the application.
Threads and processes both have an id, a set of registers, a state, and a priority, and both adhere to a scheduling policy. Both have a context used to reconstruct the preempted process or thread. Threads and child processes share the resources of their parent process and compete for processor usage. The parent process has some control over the child process or thread. A thread or process can alter its attributes and create new resources, but cannot access the resources belonging to other processes. The most significant difference between threads and processes is each process has its own address space and threads are contained in the address space of its process.
The POSIX thread library defines a thread attribute object that encapsulates a subset of the properties of the thread. These attributes are accessible and modifiable. The thread attribute is of type
pthread_attr_t. pthread_attr_init()initializes a thread attribute object with the default values. Once the attributes have been appropriately modified, the attribute object can be used as a parameter in any call to thepthread_create()function.The
thread_objectinterface class acts as a wrapper that allows something to appear differently than it does normally. The new interface is designed to make the class easier to use, more functional, safer, or more semantically correct. Thethread_objectcan be extended to encapsulate the attribute object.
In Chapter 7, we will discuss communication and synchronization between processes and threads. Concurrent tasks may be required to communicate between them to synchronize work or access to shared global data.