
Chapter 3. Practice 0: Source Code Management and Scripted Builds

Practices required for any development team larger than zero.
About Zero Practices
You’re probably wondering, “What’s the deal with these zero-level practices? Why not just start with one?” This is a book about Lean practices and, specifically, which practices give you the most bang for your buck.
However, there are some practices that you should be using whether you are trying to adopt Lean practices or not. These are not really Lean practices, but they are necessary prerequisites. That’s why we refer to them as zero-level practices.
If you’re not already using these practices, forget about everything else (for now), stop what you’re doing, and get with the program. Seriously, these are fundamental practices that you need to be following before you try any additional improvements.
The two zero-level practices we’re talking about here are source code management (SCM) and scripted builds.
Many books and articles talk about the tools you use to implement these practices but fail to address the common model of use behind them. In this chapter we give an overview of these important topics, along with a short synopsis of the functional side of each practice. In Appendix A you will find links to more in-depth material to help you implement these practices with the tool of your choice.
Source Code Management
SCM, also known as revision control or version control, basically means keeping all of your source code and other project artifacts in a central repository that maintains a complete version history of every single file.
There are both centralized and distributed flavors of version control systems. We introduce the basic concepts using a centralized system because they are more widely used. Later in the chapter we discuss the minor differences between the two flavors and why one may suit your team better than the other.
Though each SCM system has its own nomenclature, especially for the more advanced set of commands, there are several basic operations common to all systems. Whenever you want to get the current code from an existing project, you can check out a version of that repository. You can then add, modify, and remove files by checking in changes, and you can also update, which downloads the changes that the rest of your team has made to the repository since your checkout or last update.
Benefits
Versioning is the most basic and important capability an SCM system provides. The SCM system stores a complete revision history of every change made to every file. Each modification is assigned a revision number, and you can access prior versions in a multitude of convenient ways. If you check in a change and then discover some unintended consequences, it is easy to revert to the previous working version.
If you discover a bug, you can temporarily go back to a version before the bug was introduced, and then do a diff between that and the current version to see exactly what was changed. It’s easy to diff between the current and past versions of a single file or even the entire repository!
In most SCM systems, you can also use tags to mark a specific version of the code. This is really useful if you want to mark a release of your software. You can roll back to a tagged version just as you can to a date or a revision number. The ability to easily access prior versions is not just a convenience; it provides a safety net that allows your team to fearlessly make changes to your software.
Your SCM system also makes it easier to effectively collaborate and communicate in a team environment. Whenever a developer checks in a change, the system stores metadata about who made the revision and when it occurred. This data is searchable and can help in a number of situations. For example, if a new member of the team is getting up to speed on a section of code, he can look through the history to find out who created the file and who has been modifying it over time. He can use this data to determine the best person to ask for a peer review or to team with for a design decision or a tricky bug.
SCM provides a shared workspace that helps the team document and share designs and ideas. Documentation is most useful when it is kept up-to-date and when it is close to the code. If your team stores documentation and design artifacts alongside the code in your repository, it is much more likely to be used and kept up-to-date. It will also have the same revision history as the code. This means that if you extract a copy of the codebase for a particular date or tag, you will get the proper versions of both the code and the corresponding documentation.
Centralized SCM
Most mainstream SCM systems such as Concurrent Version System (CVS), Subversion, and ClearCase are centralized, meaning that they use a single centralized repository to store your files. Teams usually host this repository on a server that everyone has access to, and everyone is provided full permissions so that they can both check in (to contribute) and update (to pull the latest code that the rest of the team has checked into the repository). Figure 3-1 shows this type of system.
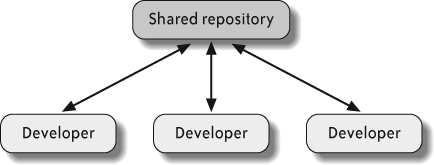
Centralized SCM systems have been around since the early 1970s. Since SCM is a core system that the entire team relies on, these systems tend to hang around for a long time. Of the major systems still in use today, CVS is the oldest, having gained popularity in the late 1980s. ClearCase was introduced in 1990 to meet the needs of larger corporations, and Subversion is the most modern, introduced in 2000 to improve on CVS. Today, Subversion is by far the most popular choice for new projects.
In centralized systems, when you check out a copy of the repository, you download a local working copy of every file in the repository. When you make a change, the system can tell that you modified your working copy, but the copy in the central repository remains untouched. This means that you can make as many modifications as you’d like to your working copy without affecting anyone else on your team. When you are ready to share your changes with the team, you must check them in, which pushes your working copy of the files up to the centralized repository. Finally, when your team updates (downloads the latest version of the files from the repository), they will get the changes from your check-in.
As in any team environment, it is important to communicate effectively to avoid getting in each other’s way. When using a centralized SCM system, there are some common idioms that most teams adopt to keep everything running smoothly:
- Update before checking in changes
Before checking in, you want to test your change against the current codebase, so always update before checking in changes. That will ensure that you aren’t testing against outdated code. If your team is checking in often (as they should be), it is normal for several changes to be made to the repository in the time it takes you to make your change. The SCM system will alert you that your copy of a file is stale if you try to check in a file that someone has updated since your last update. That said, the system only looks at individual files and not at your code’s dependencies. For instance, the SCM system will let you check in a .cpp file even if someone has modified a .h file that it relies on. Once you ingrain this idiom into your process, you will never be burned by testing against old code.
- Don’t break the build
Since everyone on the team updates from the same codebase, developers are usually encouraged to wait until their features are tested and working before checking them in. If you check in buggy code, no one on your team will be able to build and run the software until you fix the problem. So the quality of your code and testing directly affects your team’s productivity.
- Check in changes frequently
If you are going to follow the idiom of not breaking the build, you must break your implementation down into small changes to avoid working for long periods of time without the safety net of version control. Check in after each one of those small changes. If you do happen to break the build, the small scope of the change will make it easier to locate and fix the source of the problem.
Your SCM system will automatically merge for you every time you check in a change—if it can. The system can usually merge a file automatically as long as there aren’t two changes in the same spot. If that happens, as it does in the following example scenario, the system kicks that responsibility back to you.
Two developers on your project each need to add a new constant to a constants file. Each checks out the file and makes his change on the last line. The first developer checks in his working copy of the file without incident. When the second developer attempts to check in, he is alerted that his working copy of the file is out-of-date and that he must update before checking in. Upon updating, the system is unable to automatically merge the repository’s copy into his working copy, so he must perform the merge manually by inspecting the file and adding his content in the correct place. After he merges, he is able to check in his version of the file without incident.
On occasion, you may get stuck performing a manual merge, but in most cases it can easily be avoided with disciplined team communication and coordination.
Command line versus GUI tool
Most SCM systems offer both a command-line interface and a graphical user interface (GUI). The command-line interface provides all of the basic capabilities, but using a GUI gives you a much more intuitive interface for most operations. For example, Figure 3-2 shows which files are modified in both the command-line and visual interfaces in a folder under version control with Subversion.

On the left, you can see that using the command svn status provides you with the name of
the modified file, denoting it with an M in the status column. On the right, you
can see the familiar Windows Explorer interface and TortoiseSVN’s
icon overlays. The overlays are used to place checkmarks on the
files that are unmodified and exclamation points on the file that
has been changed. TortoiseSVN is one of the most commonly used
Subversion GUI tools in the Windows environment.
Diffing, or looking at the differences (Figure 3-3), allows you to more deeply examine exactly which lines have been changed within a file.

As you can see on the left, the command-line interface does allow you to see which changes have been made, but even in this trivially simple example, the visual interface on the right provides a more intuitive way of looking at the differences.
Distributed SCM
Distributed SCM systems, such as git and Mercurial, are much newer than their centralized counterparts. They were created to satisfy the requirements of large open source projects, which have large codebases and distributed teams of developers. The innovative solutions they implement address some of the problems that teams of all sizes run into when using centralized SCM. That said, their relative immaturity makes it difficult to recommend their use for teams new to the concept of SCM.
The biggest difference between centralized and distributed systems is that in a distributed system you don’t check out or download a working copy of the files; instead, you clone or download a copy of the entire functioning repository. This includes the entire revision history, and it gives you the ability to perform virtually all SCM operations locally, without connecting to a central server. In other words, a distributed system allows you to check in to your local copy of the repository (Figure 3-4).

In practice, changes are often not implemented and checked in one line at a time. Developers often end up making changes in several places within a file or in multiple files to implement a single change. In a centralized system, all of these subchanges go totally unversioned because the developer does not check them in until she checks the entire change into the central repository. In a distributed system, since you have a full working copy of the repository, you can check in to your local copy as often as you’d like without affecting anyone else on the team. You can check in your subchanges to version your progress within a single change. This allows you to take full advantage of the SCM safety net, even if you get stuck making a large change before checking in to the central repository. When you have completed your change, you push from your local repository up to the central repository to share it with your team.
A distributed SCM system also has other advantages and disadvantages that we will only briefly mention. You will learn more about them if you choose a distributed tool for your team’s SCM. The speed of common SCM operations is extremely fast because they operate on your local copy of the repository and do not require any network access. Distributed systems can also scale to larger and more ad hoc teams by supporting workflows that do not rely on a single shared central repository. On the downside, each developer in a distributed system has his own working copy of the entire repository, so he needs to understand some advanced commands that only the SCM administrator needs to know in a centralized system.
If You Don’t Know Where to Start
If you have no idea which SCM system to go with and your company doesn’t have any restrictions over which software to use, we recommend using Subversion and the TortoiseSVN GUI (if you are using Windows). Subversion is far and away the most popular SCM system in use today, so it has a plethora of resources to turn to both in book and online form. It is also relatively easy to set up and get existing projects under revision control. TortoiseSVN is one of the most mature and easiest visual interfaces for Windows. Subversion also has excellent support on Linux platforms, with both a command-line interface and several popular visual tools available, such as RapidSVN.
Scripted Builds
The goal of scripted builds is to automate the entire process of building your system. As a result, your system is built the same way every time. This eliminates hidden errors and makes it easier to bring new developers into your team. It also makes it easier to test and release your software.
Many tools are available for creating scripted builds. Most development environments include a build tool, which is what teams generally use. For example, C and C++ projects normally use make, whereas Java projects normally use Ant. No matter which system your team uses, the goal is to have a single command or script that you can run to build all of your software. That build script should be under SCM so that you can check out your project on any machine and successfully build your system.
The most common problem that teams run into when creating a scripted build system is leaving out key components. Your build script should set all necessary environment variables, and you should include all data files and correct versions of all dependent libraries in your SCM system. It may seem like overkill to include dependent libraries, but it will make your builds more robust by guaranteeing that you are linking against tested versions of libraries instead of relying on older or newer libraries that may be installed on a target system.
You must also be vigilant in maintaining your scripted build system. It is easy to allow manual procedures to creep back into your build process, so test regularly by building on a clean system or virtual machine before it becomes a problem.
Discipline in an Integrated Environment
Using a shared codebase under SCM and a scripted build system creates an integrated environment and promotes an increased level of team interaction. If your team is disciplined about sharing and coordinating, you can maximize the benefit of your new tools.
Share
Commit as often as possible, preferably after each chunk of progress is complete. If everyone builds against your latest code, your team will discover integration problems such as bugs and design flaws very quickly, before they become more time-consuming and expensive to fix. Committing often can also improve your team morale. When each member of the team regularly updates, it makes progress more tangible and increases the sense of a shared goal, which will boost the whole team’s productivity.
Coordinate
Avoid stepping on each other’s toes by coordinating development and design tasks. Don’t feel like you have to put this coordination off until your team meetings. You should pull together the necessary team members and address design issues as soon as they present themselves. This will both eliminate unnecessary rework and help you design code that is easy to integrate.
Summary
Once you have checked all necessary resources into a source code management system, created a fully scripted build system, and worked on your team’s discipline, you are well prepared to begin your Lean journey. In the next five chapters, you will build on top of these basic practices while increasing both quality and productivity.