
Chapter 6. Task Refactoring
No, it isn’t strange, after changes upon changes, we are more or less the same.
After changes we are more or less the same..
—Paul Simon (b. 1941)
The Boxer
REWRITING QUERIES IS OFTEN CONSIDERED TO BE THE ULTIMATE WAY TO IMPROVE A PROGRAM THAT accesses a database. Even so, it is neither the most interesting nor the most efficient way to refactor a program. You will certainly encounter from time to time a query that severe editing will speed up beyond recognition. But increasingly, as optimizers become more sophisticated and as statistics collection becomes more automated and more accurate, query tuning grows into the kind of skill you exhibit on social occasions to show that you have other qualities besides being a handsome, witty, and cultivated individual.
In real life, the tuning of single SQL statements is no longer as vital as it used to be. What is increasingly important isn’t to master the SQL skills that allow you to improve existing statements, but rather to master those that allow you to perform in very few data accesses what somebody less enlightened could write in only a convoluted procedural fashion. Indeed, both skill sets are very close in spirit; as you saw in Chapter 5, efficiently rewriting a statement is about hitting the tables fewer times, and so is efficiently designing an SQL application. But you must take a high-level view and consider not only what you feed into a query and what it returns, but also where the filtering criteria are coming from and what you are ultimately going to do with the data you’ve just retrieved. Once you have all of this clear in your mind, perhaps you’ll be able to perform a complicated process in much fewer steps, simplifying your program and taking full advantage of the power of the DBMS. Almost anyone can design a succession of relatively efficient (and untunable) unitary SQL statements. It’s (re)thinking the whole task that is difficult and thrilling—something that the optimizer will never do for you.
At this point, it is probably worth mentioning that I regularly meet advocates of “ease of maintenance” who, although admitting that some SQL code could bear improvement, claim that it is worth trading better code for simpler code that will be easier to maintain. Somehow, I have always felt that the argument was spoiled by the obvious interest of my interlocutors (project managers with the IT company that wrote the application) in defending the work done so far and in assigning less expensive beginners to maintenance (you can always blame poor performance on the DBMS, the administrators, and the hardware).
I’m probably biased, but I am unconvinced that a lot of calls, nested loops, and branching all over the place are a real improvement over a sophisticated SQL query in the middle of an otherwise rather plain program (it isn’t forbidden to add comments to the query), especially when I see the difference in performance. The learning curve is probably much steeper with SQL than with a procedural language, which young developers have usually practiced more at university labs, but I cannot believe that lowering programming standards generates good returns in the long term. I just want to demonstrate you what you can do, show what benefits you can expect, compare procedural complexity to SQL complexity, and let you decide what to do.
The SQL Mindset
Every SQL specialist will tell you that whenever you write SQL statements, you mustn’t think the same way you think when you write a procedural or object-oriented program. You don’t operate against variables: you operate against rows, millions of them sometimes. If, like many people do, you envision an SQL table as a kind of array of records or a sublimated file, chances are that you will want to process it like you would process an array or a file in a procedural program. Referring to an SQL “statement” is, in fact, misleading when you are a programmer experienced in another language. SQL statements are statements to the extent that they state what data you want to be returned or modified, but they are not statements in the same sense as procedural statements, which are simple steps in a program. In fact, an SQL statement is a program of its own that generates many low-level operations, as I hope Chapter 5 amply demonstrated. The difficulty that besets us is that SQL statements (and in particular, select statements) don’t interface too well with procedural languages: you have to loop on a result set to retrieve the data, and therefore, cursors and loops are a natural feature of the vast majority of SQL applications.
Using SQL Where SQL Works Better
If loops in SQL programs are probably unavoidable at some point, I usually find in programs many flow constructs that are unnecessary. Tons of them. Seeing at the beginning of a procedure the declaration of dozens of variables to hold results returned from a database is often a bad omen. The question is, when you loop on a result set, what do you do with what you return from the database? If you display the data to the user, or write it to a file, or send it over a network, there is nothing to say against the loop and you are beyond criticism. But if the data that is retrieved is just fed into a series of cascading statements, or if it is further processed in the application to get results that the DBMS could have returned directly, chances are that SQL is poorly used.
Here is another way to ask the same question: how much value does your code add to the processing of data? I once encountered a case that fortunately is not too typical but exemplifies SQL misuse extremely well. The pseudocode looked something like this:
open a cursor associated to a query
loop
fetch data from the cursor
exit loop if no data is found
if (some data returned by the query equals a constant) then
...
do things
...
end if
end loopThere was no else to the if construct. If we want to process only a subset of what the cursor returns, why return it? It would have been much simpler to add the condition to the where clause of the query. The if construct adds no value; fetching more rows than necessary means more data transiting across the network and fetch operations for naught.
In a similar vein, I once was called to the rescue on a program written about 8,000 miles away from the previous example, not so much because it was executing slowly, but rather because it was regularly crashing after having exhausted all available memory. What I found is a loop on the result of a query (as usual), fetching data into a structure called accrFacNotPaid_Struct, and inside that loop the following piece of code: [43]
// check to see if entry based upon cycle rid and expense code exists
TripleKey tripleKey = new TripleKey(accrFacNotPaid_Struct.pid_deal,
accrFacNotPaid_Struct.cycle_rid,
accrFacNotPaid_Struct.expense_code);
if (tripleKeyValues.containsKey(tripleKey)) {
MapFacIntAccrNotPaidCache.FacIntStr
existFacNotPaid_Struct =
(MapFacIntAccrNotPaidCache.FacIntStr)tripleKeyValues.get(tripleKey);
existFacNotPaid_Struct.accrual_amount += accrFacNotPaid_Struct.accrual_amount;
}
else
{
tripleKeyValues.put(tripleKey, accrFacNotPaid_Struct);
mapFacIntAccrNotPaidCache.addAccrNotPaid(accrFacNotPaid_Struct);
mapFacIntAccrNotPaidCache.addOutstdngAccrNotPaid(accrFacNotPaid_Struct);
}To me, duplicating the data returned from database tables into dynamically allocated structures didn’t seem like the brightest of ideas. The final blow, though, was the understanding that with just the following bit of code, I could have accomplished what the developer was trying to achieve:
select pid_deal, cycle_rid, expense_code, sum(accrual_amount) from ... group by pid_deal, cycle_rid, expense_code
So much for the virtuoso use of Java collections.
If SQL can do it easily, there is no need to do it in the code. SQL will process data faster. That’s what it was designed to do.
Assuming Success
Another cultural gap between the procedural and the SQL mindsets is the handling of errors and exceptional cases. When you write a procedural program, good practice dictates that you check, before doing anything, that the variables to be handled make sense in the context in which they’re being used. Whenever you encounter a procedural program that does the same thing when it interacts with a database, you can be sure that it can be greatly improved.
Many developers assume that the only costly interactions with the database are those that result in physical input/output (I/O) operations on the database server. In fact, any interaction with the database is costly: the fastest of SQL statements executes many, many machine instructions, and I am not even considering communications between the program and database server.
If paranoia is almost a virtue in C++, for instance, it becomes a vice if every single check is implemented by an SQL query. When you are programming in SQL, you mustn’t think “control,” you must think “data integrity” or, if you like it better, “safe operation.” An SQL statement must do only what it is supposed to do and nothing more; but, instead of protecting the execution of your statement by roadblocks, moats, and barbed wire, you must build safeguards into the statement.
Let’s take an example. Suppose your project specs read as follows:
We have a number of member accounts that have been locked because members have failed to pay their membership fee. The procedure must take an account identifier and check that the sum of payments received for this account in the past week results in a positive balance. If this is the case and if the account was locked, then it must be unlocked.
A specific error message must be issued if the account doesn’t exist, if the payments received during the past week are insufficient, or if the account isn’t locked.
Most of the time, the logic of the code will look like this:
// Check that the account exists select count(*) from accounts where accountid = :idif count = 0 =>"Account doesn't exist" // Check that payments are sufficient //(group bybecause there may be several transactions) select count(x.*) from (select a.accountid from accounts a, payment b where b.payment_date >=<today minus seven days>and a.accountid = b.accountid group by a.accountid having sum(b.amount) + a.balance >= 0) as xif count = 0 =>"Insufficient payment" // Check whether account is locked select count(*) from accounts where accountid = :id and locked = 'Y'if count = 0 =>"Account isn't locked" // Unlock account update accounts set locked = 'N' where accountid = :id
This is a straight implementation of specs, and a poor one in an SQL context. In such a case, the correct course to take is to ensure that the update shall do nothing if we aren’t in the specified conditions. We are unlikely to wreck much if the account doesn’t exist. The only things we really need to care about are whether the member’s account is in the black and whether it is currently locked.
Therefore, we can write a safe update statement as follows:
update accounts a
set a.locked = 'N'
where a.accountid = :id
and a.locked = 'Y'
and exists (select null
from payments p
where p.accountid = a.accountid
and p.paymentdate >= <today minus seven days>
group by p.accountid
having sum(p.amount) >= a.balance)This statement will do no more harm to the database than the super-protected statement. Of course, in the process of rewriting the statement, we have lost any way to check error conditions. Or have we? All database interfaces provide either a function or an environment variable that tells us how many rows were updated by the last statement. So, let’s say we’re talking about the $$PROCESSED variable. We can replace preemptive screening with forensic analysis:
if ($$PROCESSED = 0) then /* Oops, not what was expected */ select locked from accounts where a.accountid = :id if no data found => account doesn't exist else if locked = 'N' then account wasn't locked else insufficient payment
Those two algorithms were coded as Visual Basic functions (the full code is downloadable from the book site and described in Appendix A). The unlocked_1 function implements the inefficient algorithm within the application, which checks conditions first and does the update when it gets the “all clear” signal; the unlocked_2 function implements a correct SQL algorithm that executes first and then checks whether the execution didn’t work as expected. Figure 6-1 shows the result when both procedures were run on about 40,000 accounts, with a variable percentage of rows ending in error.
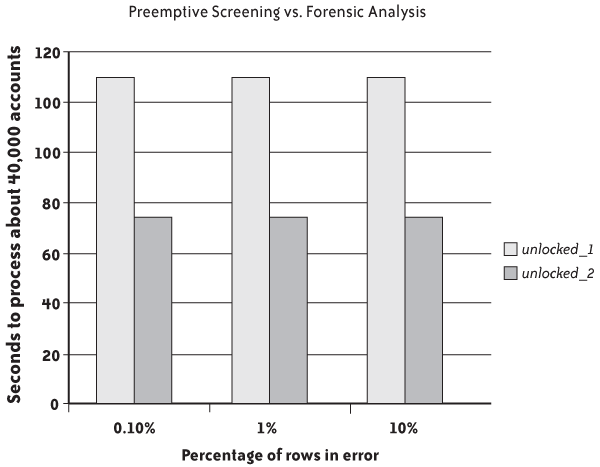
It’s clear which method is most efficient: we could expect convergence if processing were to fail in most cases, but with a reasonable percentage of errors the “optimistic” version implemented by unlocked_2 outperforms the “pessimistic” version of unlocked_1 by a factor of two.
Every test that accesses the database and precedes the statement that really matters has a heavy cost compared to the rest of the code. If you check first, then do, you penalize everyone. If you do first, then check (if necessary) the overhead will be applied only to operations that failed in the first place. Even if a check runs very fast, taking, say, 0.001 second of CPU time, if you repeat it two million times it consumes 33 minutes of CPU time, which can hurt badly at peak hours when the CPU becomes a critical resource.
Restructuring the Code
You saw in Chapter 5 that one of the guiding principles of statement refactoring is to try to reduce the number of “visits” to each table, and in particular, to each row. To refactor tasks, you must apply the same principles: if the same table is touched by two successive statements, you must question whether what you do in the program between the two statements truly justifies the return trip to the database server. It is relatively easy to decide whether statements that follow each other sequentially can be combined into a single foray in the database. Programs in which the logical path is winding can be much harder to beat into a handful of efficient statements. But SQL allows much logic to be grafted upon data access, as you will see next.
Combining Statements
Very often, one finds in programs successions of statements that are not really justified as “standalone” statements. For instance, I have seen several cases of scripts in which a number of successive updates were applied to the same table when several of them could have easily been performed as a single statement, or data that was inserted by one statement to be updated by the next statement, when the final result could have been inserted at once. This slicing up of operations seems pretty common in scripts that build a decision support system or that migrate data before an upgrade; the process is thought of as a sequence of successive operations, which is good, but is coded in the same way, which is bad. An or in the where clause and a clever use of case is often all that is needed to divide runtimes by two, three, or more depending on the number of statements you can combine.
Pushing Control Structures into SQL
A number of successive queries applied to the same table should attract your attention, even when they are embedded in if … then … else constructs. Look at the following example, which contains three queries, but where only two tables are referenced (identifiers starting with p_ denote parameters that are passed to the queries):
select count(*)
into nAny
from t1
where chaid = p_chaid
and tneid = p_tneid
and levelname = 'LEVEL1';
if nAny > 0 then
[ assignments 1 ]
else
select count(*)
into nAny
from t1
where chaid = p_chaid
and tneid = p_tneid
and levelname = 'LEVEL2';
if nAny > 0 then
[ assignments 2 ]
else
[ assignment 3 ]
if p_taccode = 'SOME VALUE' then
select count (*)
into nAny
from t2
where taccode = p_taccode
and tpicode = p_tpicode
and tneid = p_tneid
and ttelevelname = 'LEVEL2';
if nAny > 0
[ assignment 4 ]
else
[ assignment 5 ]
end if;
else
[ assignment 6 ]
end if;
end if;
end if; The first two queries are hitting the same table; worse, they are applying the same conditions except for the value of one constant. Indeed, we might have histograms, an index on column levelname, and very different distributions of values LEVEL1 and LEVEL2; these are possibilities that should be checked before stating that there is a huge performance gain waiting to be achieved. The fact that two columns out of three in the where clause are suffixed by id causes me to think that they belong to a composite primary key. If my hypothesis is true, the speed of execution of the two queries will be about the same, and if we manage to combine them, the resultant query should run significantly faster.
Using aggregates
Aggregates are often convenient for simplifying if … then … else constructs. Instead of checking various conditions successively, they allow you to collect in a single pass a number of results that can be tested later, without any further access to the database. The previous example would be a good ground for this technique. If I replace the first two statements with the following:
select sum(case levelname
when 'LEVEL1' then 1
else 0
end) as count1,
sum(case levelname
when 'LEVEL2' then 1
else 0
end) as count2
into nAny1, nAny2
from t1
where chaid = p_chaid
and tneid = p_tneid
and levelname in ('LEVEL1', 'LEVEL2'),I probably won’t make the first query measurably longer, and I’ll no longer have to run the second one: I’ll just need to successively test the values of nAny1 and nAny2. My improvement factor will naturally depend on the number of times I get 0 in nAny1 and in nAny2. A query or two should help us get a quick estimate.
Using coalesce() instead of if … is null
Some tests may call for certain replacements. The following snippet is shorter than the previous example, but is actually more challenging. Its purpose is to determine the value to assign to variable s_phacode:
select max(dphorder)
into n_dphorder
from filphase
where filid = p_filid
and phacode || stepcode != 'RTERROR'
and phacode || substr(stepcode,1,3) != 'RTSUS'
and dphdteffect <= p_date;
if n_dphorder is null then
s_phacode := 'N/A'
else
select max(phacode)
into s_phacode
from filphase
where filid = p_filid
and dphorder = n_dphorder;
end if;In the first query, I cannot say that the comparison of concatenated columns to constants enraptures me, but the fact that conditions are inequalities means that indexes, which prefer affirmation, are unlikely to be much help here. I would have preferred seeing this:
where (phacode != 'RT'
or (stepcode != 'ERROR' and stepcode not like 'SUS%'))But we are talking detail here, and this shouldn’t impair performance because negative conditions are unlikely to be selective.
Since the only purpose of the n_dphorder variable is to fetch a value that is to be re-injected, the first step consists of replacing the variable with the first query in the second query:
select coalesce(max(phacode), 'N/A') into s_phacode from filphase where filid = p_filid and dphorder = (select max(dphorder) from filphase where filid = p_filid and phacode || stepcode != 'RTERROR' and phacode || substr(stepcode,1,3) != 'RTSUS' and dphdteffect <= p_date);
If the subquery returns null, the main query will return null too, because there may not be any case where the condition on dphorder is satisfied. I use coalesce() rather than a test in the calling code so that whatever happens, I get what I want in a single query.
I still have two references to the filphase table, but they are inside a single query. Because I expect the first original query to return a defined value in most cases, I’ll execute only one round trip to the SQL engine where I would otherwise have generally executed two. More importantly, the SQL engine gets a query that gives the optimizer more opportunities for improvement than two separate queries. Of course, we can also try to rewrite the query further and ease the work of the optimizer, as we saw in the previous chapter. As the query is written here, we would have to check a number of things. If (filid, dphorder) happens to be the primary key, as it may well be, limiting the following query to the first row returned offers some possibilities, if you are ready to deal with the case when no data is found:
select phacode
from filphase
where filid = p_filid
and dphdteffect <= p_date
and (phacode != 'RT'
or (stepcode != 'ERROR' and stepcode not like 'SUS%'))
order by dphorder desc, phacode descUsing exceptions
Sometimes statements cannot be efficiently combined or rewritten, but digging a little will usually reveal many procedural processes that can be written better, particularly in stored functions and procedures. "Utility” functions, which are usually called over and over, are an excellent ground for refactoring. When you monitor statements that are issued against a database and you search the origin of relatively short statements that are executed so often that they load the server heavily, they usually come from utility functions: lookup functions, transcoding functions, and so forth.
Whenever you can get rid of a user-defined function that executes calls to the database and replace this function (if you really need it) with a view, you should not hesitate to do so. And you should not be impressed by the apparent complexity of the function—very often, complexity is merely the product of poor SQL handling.
Here is another real example. In an Oracle application, there are a number of distinct series of codes. All code series are identified by their name and are listed in a table named codes. To each series is associated a number of codes, and since this is an internationalized application, a message is associated to each (code, supported language) combination. Translated messages are stored in the code_values table. Here is the code for the function:
/* Function getCodeValue
Desc : Returns, in the language specified, the value of a code provided
in a code series provided.
Parameters : 1. p_code_series - Name of the code series
2. p_code - Code to be searched for
3. p_language - Language to be used for searching
4. p_ret_desc (boolean) - True, if function should return
the decoded text
False, if function should return
the no. of records returned from
the code_values table
(mostly this helps to verify, if
it returns 1 or 0 rows)
*/
function getCodeValue( p_code_series in codes.code_series%type
, p_code in code_values.code%type
, p_language in code_values.language%type
, p_ret_desc in boolean :=true
-- true = Description , false=count
) return varchar2 is
cursor c_GetCodeText ( v_code_series in codes.code_series%type
, v_code in code_values.code%type
, v_language in code_values.language%type
) is
select cv.text
from code_values cv,
codes c
where c.code_series = cv.code_series
and c.code_series = v_code_series
and cv.code = v_code
and cv.language = v_language;
v_retvalue code_values.code_value_text%type;
v_temp number;
begin
select count(1)
into v_temp
from code_values cv,
codes c
where c.code_series = cv.code_series
and c.code_series = p_code_series
and cv.code = p_code
and cv.language = p_language;
if p_ret_desc then -- return the Decoded text
/* check if it returns multiple values */
if coalesce(v_temp,0) = 0 then
/* no value returned */
v_RetValue :='';
elsif coalesce(v_temp,0) = 1 then
/* if it returns one record, then find the decoded text and
return */
open c_GetCodeText(p_code_series, p_code, p_language);
fetch c_GetCodeText into v_retvalue;
close c_GetCodeText;
else
/* if it returns multiple values, then also return only first
value. We can modify the code here to return NULL or process
it differently if needed.
*/
open c_GetCodeText(p_code_series, p_code, p_language);
fetch c_GetCodeText into v_retvalue;
close c_GetCodeText;
end if;
else -- return only the count for the code
v_retvalue := v_temp;
end if;
return v_retvalue;
end getCodeValue;All right. Here we have two queries that are basically the same, one that checks whether there is a match and one (the cursor query) that actually does the job. Let’s take a closer look at the query:
select cv.text
from code_values cv,
codes c
where c.code_series = cv.code_series
and c.code_series = v_code_series
and cv.code = v_code
and cv.language = v_language;The v_code_series parameter is used to specify the “code family,” and the code_series value that matches the parameter is used in turn to access the proper row in code_values. As you saw in the preceding chapter, the only justification for doing this would be the need to check that we really have a matching row in code. Developer, my friend, do the words foreign key ring a bell? Oracle is perfectly able to ensure that there will be no inconsistency between codes and code_values. A useless access to codes using its primary key will certainly not add much to the cost of the query; but, as I would expect the triplet (code_series, code, language) to be the primary key of code_values, if I execute two primary key accesses where one is enough, I am doubling the cost. There may be times when this function is intensely used, and when it will matter.
Now, let’s look at the function. The same mistake is made twice, in the query that counts and in the query that really returns the value. But why count when we really want the data? Let’s analyze what is done after the number of matching values is counted:
First,
coalesce(v_temp, 0)is checked. There is no need to be paranoid. When you count, you get either0or a value greater than0. Gettingnullis impossible. It could have been worse, and we have at least avoidedcoalesce(abs(v_temp), 0). Of course, it’s a really minor mistake, with no real performance implication. But seeing this type of construct sends bad signals, and it should incite you to look for more serious mistakes in the code. As David Noor, one of the early reviewers of this book, pleasantly put it: dumb, insignificant errors are often found near dumb, highly significant errors.Second, we check whether we find one, zero, or more than one code. Dealing with zero or one code doesn’t require any prior count: all you have to do is fetch the value and check for the error condition that is generated when there is nothing to fetch (in PL/SQL, it will be implemented by an exception block that will catch the predefined
no_data_foundexception). For the other error condition, what do we do when we find several codes? Well, there is another predefined exception,too_many_rows. But I just said that I would expect (code_series, code, language) to be the primary key ofcode_values. If primary keys are correctly defined, and I don’t think that is asking much, it simply cannot happen any more often thancount(*)returningnull. The lengthy comment about how to properly handle that case would lead us to believe that the developer carefully thought about it. Actually, he simply didn’t think in SQL terms.
The way the code is written, with the use of if … elsif … else … end if instead of multiple if … end if blocks, and the ratio of comment to code prove that we have a developer with some experience and probably a decent mastery of procedural languages. But he gave several signs that his understanding of SQL and relational databases is rather hazy.
The core of this function should be:
begin
select text
into v_text
from code_values
where code_series = p_code_series
and code = p_code
and language = p_language;
if p_ret_desc then
return v_text;
else
return 1;
end if;
exception
when no_data_found then
if p_ret_desc then
return '';
else
return 0;
end if;
end;All the other tests in the code are made useless by:
alter table codes add constraint codes_pk primary key(code_series); alter table code_values add constraint code_values_pk primary key(code_series, code, language); alter table code_values add constraint code_values_fk foreign key (code_series) references codes(code_series);
If I want to assess how much my work has improved the original function, I can estimate that getting rid of a useless join in a query that was executed twice improved performance by a factor of two. Realizing that the query had to be executed only once in all cases improves by another factor of two when I actually want the text associated with the code. I can only hope that it is by far the most common case.
For hairsplitters, we could argue that we could make the function as I rewrote it earlier slightly more efficient when we just want to check for the existence of a message. If I ask for the text to be returned, the SQL engine will search the primary key index, and will find there the address of the matching row (unless my index is a clustering index, but we are in an Oracle context, so it shouldn’t be). Getting the row itself will require one extra access to another block in memory, which is useless if I just want to check the existence of an index entry. Therefore, if checking for the existence of a message is something critical (which is unlikely), we could improve the function by executing select 1 when the text is not wanted. But the necessity of the option that only counts isn’t very clear to me; testing what is returned is more than enough.
The lesson to learn from such an example is that if you really want an efficient program, one of the keys is to find the divide between what belongs to the database side and what belongs to the “wrapping language” side. Nearly all developers tilt the scale to the side they master best, which is natural; doing too much on the procedural side is by far the most common approach, but I have also seen the opposite case of people wanting to perform all the processes from inside the database, which is often just as absurd. If you want to be efficient, your only tool mustn’t be a hammer.
Naturally, when a function becomes something that simple, its raison d'être becomes questionable. If it is called from within an SQL statement, an outer join (to cater to the case of the missing message) with code_values would be far more efficient.
Fetching all you need at once
As a general rule, whenever you need something from the database, it is much more efficient to write the query so that it always returns what you ultimately want without requiring a subsequent query. This rule is even more important when there are high odds that several queries will be issued. For example, consider the handling of messages in various languages that are stored in a database. Very often, when you want to return some text in a given language, you are not sure whether all the strings have been translated. But there is usually at least one language in which all the messages are up-to-date, and this language is defined as the default language: if a message cannot be found in the user’s favorite language, it is returned in the default language (if the user cannot make sense of it, at least the technical support team will be able to).
For our purposes, let’s say the default language is Volapück (code vo).
You can code something like this:
select message_string from text_table where msgnum = ? and lang = ?
And if the query returns no rows, you can issue this to get the Volapück message:
select message_string from text_table where msgnum = ? and lang = 'vo'
Alternatively, you can issue a single query:
select message_string
from (select message_string,
case lang
when 'vo' then 2
else 1
end k
from text_table
where msgnum = ?
and lang in (?, 'vo')
union all
select '???' message_string,
3 k
from dual
order by 2) as msgand limit the output to the first row returned using the syntax of your SQL dialect (top 1, limit 1, or where rownum = 1). The ordering clause ensures that this first row will be the message in the preferred language, if available. This query is slightly more complicated than the basic query, particularly if you are right out of “SQL 101” (fresh, enthusiastic, and eager to learn). But the calling program will be much simpler, because it no longer has to worry about the query returning no rows. Will it be faster? It depends. If you have an energetic team of translators that misses a message only once in a while, performance will probably be a tad slower with the more complex query (the difference will probably be hardly noticeable). However, if some translations are not up-to-date, my guess is that the single query will pay dividends before long.
But as in the example with code_values, the real prize isn’t always having one query instead of sometimes having one and occasionally having two: the real prize is that now that we have one statement, we can turn this statement into a subquery and directly graft it into another query. This, in turn, may allow us to get rid of loops, and have straight SQL processes.
Shifting the logic
To conclude our discussion of variations on the injection of control logic flow inside SQL statements, there are also cases when, even if you cannot have a single statement, a little remodeling can bring significant improvements.
Suppose you have the following:
select from A where ...
test on result of the query
if some condition
update table B
else
update table CIf the second case—that is, the update of table C—is by far the most common occurrence, something such as the following is likely to be faster on average, if executing the update that includes the first query is faster than executing the query and then the update:
update table C where (includes condition on A)
if nothing is updated then
update table BGetting Rid of count()
In the previous examples you saw some samples of useless calls to count(). Developers who abuse count() are almost … countless. Needless to say, when you need to publish an inventory report that tells how many items are in stock, a count() is blameless. Generally speaking, a count() associated to a group by clause has a good business-related reason to be issued. The occurrences of count() I have an issue with are those that are plain tallies. In most cases, they are issued, as in one of the previous examples, as tests of existence.
Again, we are in the situation of paranoid programming that procedural developers with little exposure to SQL are so fond of. There is no need to check beforehand whether data exists. If you want to fetch data, just do it, and handle the case when nothing is found. If you want to update or delete data, just do it, and check afterward whether the number of rows that were affected is what you expected; if it isn’t, it is time for emergency measures. But for the 99% of cases that will work smoothly, there is no need to execute two queries when only one is needed. If you execute two queries for each transaction, you will be able to execute on the same hardware only half the number of transactions you could with only one query.
So far, I have encountered only one case for which a prior count has the appearance of solid justification: the requirement to display the total number of rows found in searches that can return pages and pages of results. If the number of rows is too high, the user may want to refine his search—or the program may cancel the search. This legitimate requirement is usually implemented in the worst possible way: a count(*) is substituted with the list of columns that follows the select in the real query, without paying attention to the core query. But even a tightly tailored initial count is, in most cases, one query too many.
I mentioned in Chapter 5 the case of a count() that could run 10 times faster if we simply removed two external joins that were useless for restricting the result set; I also mentioned that the query was pointless in the first place. Here is the whole story: the problem was that from time to time, a user was issuing a (slow) query that was returning around 200,000 rows, causing the application server to time out and all sorts of unpleasant consequences to ensue. The early tally of the number of rows was introduced to be able to prevent queries from executing if the result set contained more than 5,000 rows. In that case, the user had to refine the search criteria to get a more manageable result.
My recommendation was to limit, in all cases, the result set to 5,001 rows. The only difficulty was in getting the number of rows at the same time as the rows were retrieved, without issuing any additional query. MySQL, Oracle, and SQL Server all allow it, in one way or another.
With MySQL, for instance, the solution would have been to issue this:
select ... limit 5001;
followed by this:
select found_rows();
Both Oracle and SQL Server allow us to return the total number of rows in the result set on each row, thanks to the count(*) over () construct, which gets the data and the tally in one operation. You might think that, apart from reducing the number of round trips to the database, the benefit is light and a regular count distinct from a regular fetch takes place on the server. Actually, very often the SQL engine needn’t execute an additional count: when the data that you return is sorted, which is rather common, you mustn’t forget that before returning to you the very first row in the result set, the SQL engine has to compare it to every other row in the result set. The full result set, and therefore its number of rows, is known when you get the first row of a sorted result set.
With that said, in the case of MySQL, found_rows() cannot be called before you fetch the data from the result set you want to evaluate, which can seem of little value. After all, you can fetch the result set, count the lines along the way, and know the result without having to call found_rows() afterward. Using the transactions table introduced in Chapter 1 and a limit set to 500 rows, I attempted to cheat. I executed a select statement, then called found_rows() before fetching the result from my query in sample_bad.php that follows:
<?php
require('config.php'),
/* Use prepared statements */
$mycnt = 0;
$stmt = $db->stmt_init();
$stmt2 = $db->stmt_init();
if ($stmt-<prepare("select accountid, txdate, amount"
. " from (select accountid, txdate, amount"
. " from transactions"
. " where curr = 'GBP'"
. " limit 501) x"
. " order by accountid, txdate")
&& $stmt2->prepare("select found_rows()")) {
$stmt->execute();
$stmt->bind_result($accountid, $txdate, $amount);
$stmt2->execute();
$stmt2->bind_result($cnt);
if ($stmt2->fetch()) {
printf("cnt : %d
", $cnt);
} else {
printf("cnt not found
");
}
while ($stmt->fetch()) {
$mycnt++;
}
$stmt->close();
$stmt2->close();
} else {
echo $stmt->error;
}
$db->close();
?>It didn’t work, and when I ran it I got the following result:
$ php sample_bad.php cnt not found
You really have to fetch the data (even with the SQL_CALC_FOUND_ROWS modifier) to have found_rows() return something. If you want to know how many rows you get when you put an immutable cap over the number of rows retrieved before you have fetched everything, you must cheat a little harder. This is what I did in sample_ok.php:
<?php
require('config.php'),
/* create a prepared statement */
$stmt = $db->stmt_init();
if ($stmt->prepare("select counter, accountid, txdate, amount"
. " from ((select 1 k, counter, accountid, txdate, amount"
. " from (select 502 counter,"
. " accountid,"
. " txdate,"
. " amount "
. " from (select accountid, txdate, amount"
. " from transactions"
. " where curr = 'GBP'"
. " limit 501) a"
. " order by accountid, txdate) c"
. " union all"
. " (select 2 k, found_rows(), null, null, null)"
. " order by k) x)"
. " order by counter, accountid, txdate")) {
$stmt->execute();
$stmt->bind_result($counter, $accountid, $txdate, $amount);
// Fetch the first row to see how many rows are in the result set
if ($stmt->fetch()) {
if ($counter == 501) {
printf("Query returns more than 500 rows.
");
} else {
while ($stmt->fetch()) {
printf("%6d %15s %10.2f
", $accountid, $txdate, $amount);
}
}
} else {
echo $stmt->error;
}
$stmt->close();
} else {
echo $stmt->error;
}
$db->close();
?>Through a union all, I concatenated the call to found_rows() to the execution of the query of which I wanted to count the rows; then I added the first order by to ensure that the result of found_rows() was displayed after the data, to ascertain that it would indeed count the number of rows in my result set. Then I sorted the result in reverse order, having written my query so that the number of rows would always be returned first and the remainder sorted according to my will.
Naturally, the full result set was fetched on the server; as my maximum number of rows was rather small, the double sort was not an issue. The big advantage was that I knew immediately, after having fetched only one row, whether it was worthwhile to fetch the rest of the data. It simplified my program enormously on the client side.
I’d like to call your attention to an optimization. When displaying the result of a search, it is customary to have an order by clause. For example, if you write:
select ... order by ... limit 501
at most 501 rows will be returned, but the full result set of the query (as it would be returned without the limiting clause) has to be walked for the sort. If you write:
select *
from (select ...
limit 501) as x
order by ...you will get the first 501 rows returned by the query, and then you will sort them, which may be considerably faster. If the limitation clause fires—that is, if the query returns more than 501 rows—both queries will return a different result, and the second one will be pretty meaningless. But if your goal is to discard any result set that contains more than 500 rows, it matters very little whether the 501 rows that are returned are the first ones or not. If the result set contains 500 rows or less, both writings will be equivalent in terms of result set and speed.
I gladly admit that the MySQL query errs on the wild side. The task is much easier with SQL Server or Oracle, for which you can use count() with the over () clause and return the total number of rows in the result set on each line. With SQL Server, the query will read as follows:
select accountid, txdate, amount, count(*) over () counter
from (select top 501
accountid, txdate, amount
from transactions
where curr = 'GBP') as tx
order by accountid, txdateIf this query finds, say, 432 rows, it will repeat 432 in the last column of every row it returns.
Note once again that I am careful to limit the number of rows returned, and then to sort. Because I know I will discard the result when I get 501 rows, I don’t mind getting a meaningless result in that case.
The question, though, is whether replacing something as simple as a count(*) with a single expression as complicated as the MySQL one is worthwhile. Most people are persuaded that simple SQL is faster. The answer, as always, must be qualified.
To explain this point, I wrote three simple PHP programs derived from the previous MySQL example. I looped on all 170 currencies in my currencies table. For each one, I fetched the transactions if there were fewer than 500 of them; otherwise, I just displayed a message that read “more than 500 transactions”. To ensure optimal test conditions, I indexed the transactions table on the curr column that contains the currency code.
In the first program that follows, I have two statements—$stmt and $stmt2, which respectively count the number of transactions and actually fetch the data when there are fewer than 500 transactions for the currency in my two-million-row table:
<?php
require('config.php'),
/* create two prepared statements */
$stmt = $db->stmt_init();
$stmt2 = $db->stmt_init();
if ($stmt->prepare("select count(*) from transactions where curr = ?")
&& $stmt2->prepare("select accountid, txdate, amount"
. " from transactions"
. " where curr = ?"
. " order by accountid, txdate")) {
if ($result = $db->query("select iso from currencies")) {
while ($row = $result->fetch_row()) {
/* Bind to the count statement */
$curr = $row[0];
$counter = 0;
$stmt->bind_param('s', $curr);
$stmt->execute();
$stmt->bind_result($counter);
while ($stmt->fetch()) {
}
if ($counter > 500) {
printf("%s : more than 500 rows
", $curr);
} else {
if ($counter > 0) {
/* Fetch */
$stmt2->bind_param('s', $curr);
$stmt2->execute();
$stmt2->bind_result($accountid, $txdate, $amount);
/* We could display - we just count */
$counter2 = 0;
while ($stmt2->fetch()) {
$counter2++;
}
printf("%s : %d rows
", $curr, $counter2);
} else {
printf("%s : no transaction
", $curr);
}
}
}
$result->close();
}
}
$stmt->close();
$stmt2->close();
$db->close();
?>In the second program, I made just one improvement: I want to count whether I have less than or more than 500 transactions. From the standpoint of my program, having 501 transactions is exactly the same as having 1,345,789 transactions. However, in its innocence, the SQL engine doesn’t know this. You tell it to count, and it counts—down to the very last transaction. My improvement, therefore, was to replace this:
select count(*) from transactions where curr = ?
with this:
select count(*)
from (select 1
from transactions
where curr = ?
limit 501) xIn the third program, I have only the following “complicated” statement:
<?php
require('config.php'),
require('sqlerror.php'),
$stmt = $db->stmt_init();
if ($stmt->prepare("select counter, accountid, txdate, amount"
. " from ((select 1 k, counter, accountid, txdate, amount"
. " from (select 502 counter,"
. " accountid,"
. " txdate,"
. " amount "
. " from (select accountid, txdate, amount"
. " from transactions"
. " where curr = ?"
. " limit 501) a"
. " order by accountid, txdate) c"
. " union all"
. " (select 2 k, found_rows(), null, null, null)"
. " order by k) x)"
. " order by counter, accountid, txdate")) {
if ($result = $db->query("select iso from currencies")) {
while ($row = $result->fetch_row()) {
/* Bind to the count statement */
$curr = $row[0];
$counter = 0;
$stmt->bind_param('s', $curr);
$stmt->execute();
$stmt->bind_result($counter, $accountid, $txdate, $amount);
if ($stmt->fetch()) {
if ($counter > 500) {
printf("%s : more than 500 rows
", $curr);
$stmt->reset();
} else {
$counter2 = 0;
while ($stmt->fetch()) {
$counter2++;
}
printf("%s : %d rows
", $curr, $counter2);
}
} else {
printf("%s : no transaction
", $curr);
}
}
$result->close();
}
}
$stmt->close();
$db->close();
?>I ran and timed each program several times in succession. The result is shown in Figure 6-2. On my machine, the average time to process my 170 currencies with the first program and a full count was 7.38 seconds. When I limited my count to what I really needed, it took 6.09 seconds. And with the single query, it took 6.28 seconds.
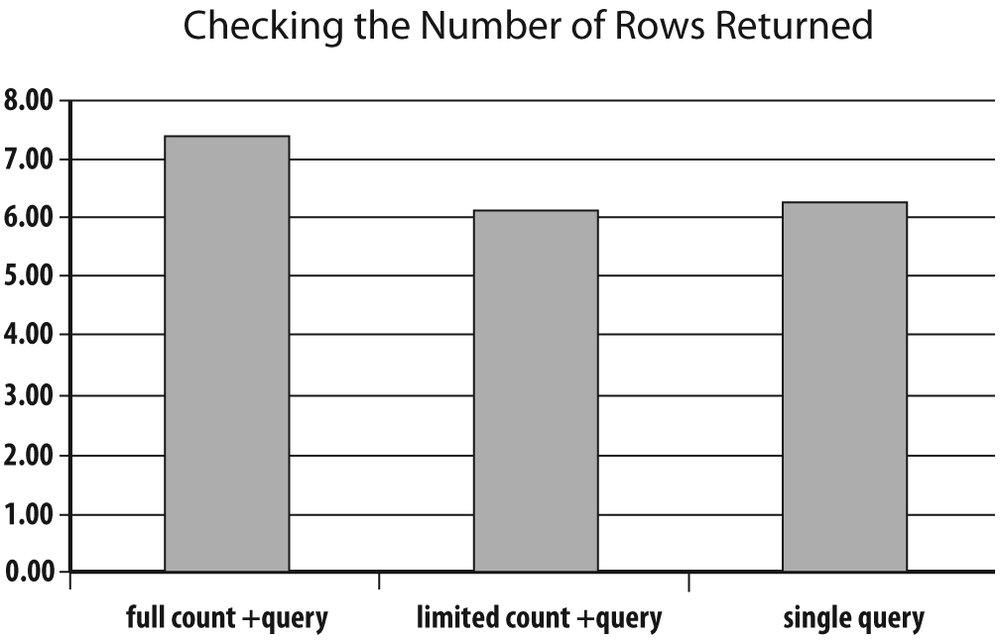
A difference of one fat second in processing only 170 entries is a gain I find impressive. You can imagine what kind of difference you would see if you had to repeat these operations tens of thousands of times—and think about the price of a machine 15% faster than what you currently have. Although the SQL expression in the third program is complicated, sorts twice, and does all kinds of ugly things, it behaves rather honorably, even if it’s not as fast as the second program.
In this case, identification of the result set was pretty fast. To check what happens when it takes longer to get the result set, I ran tests with Oracle this time, using the analytical version of count() [44] to return the total number of rows in the result set on each row. I ran the query with an index on currencies which gave me a “fast where clause,” and without an index on currencies which gave me a “slow where clause.” As you can imagine, the difference in processing time was not on the same order of magnitude. To ease comparison, I have assigned time 100 to the basic version of the program (full count, then query) and expressed the other results relative to this one. The full picture is shown in Figure 6-3. With the fast where clause, the result mirrors what I obtained with MySQL: basically, the query is so fast that the overhead induced by the analytical function offsets the advantage of having a single round trip to the database. But with the slow where clause the balance is shifted. Because it now takes time to identify the rows, finding them and counting them in a single operation brings a very significant benefit.
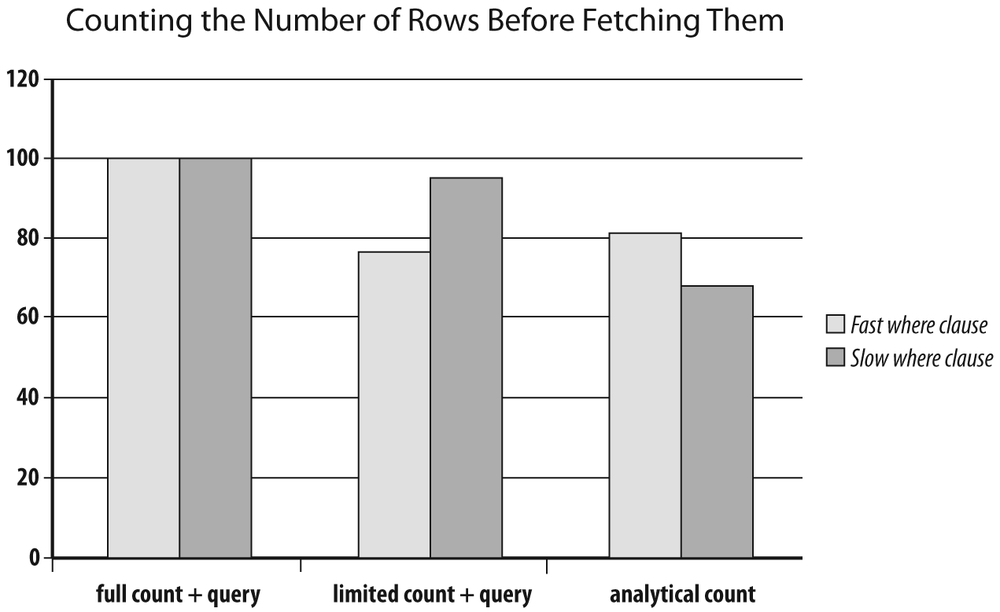
The lesson to learn from this is that removing a prior count by re-injecting the tally into the query that actually returns data, whether it is with the relatively elegant use of count() over () or with something slightly more clunky, brings more benefits, as the identification of the result set is slow and painful. Therefore, it is a technique that can bring a very significant improvement when used properly.
The case when we are not ready to discard search results that return a very large number of rows is not very different, except that you cannot use the optimization methods that consist of reducing the result set before sorting. In that case, you cannot afford a meaningless sort. But otherwise, even if you operate by batches, using the common technique of returning successive “pages” of data, the basic ideas are very similar.
Avoiding Excesses
I insisted in the preceding paragraphs on the importance of reducing the number of SQL statements and trying to get as much as possible in a single statement. An important point to keep in mind is that the goal isn’t to have a single, monstrous, singing and dancing SQL statement; the goal is to have as few statements as possible along one execution path, which isn’t exactly the same thing. I sometimes encounter statements with conditions such as the following:
where 1 = ? and ...
There is no point in sending the statement to the SQL engine, having it analyzed, and letting the DBMS decide, upon the value of the parameter, whether it should execute the statement or not. The decision of executing or not executing a statement belongs to the calling program. The more interesting cases are those where branching depends on the result of queries, constructs that are similar to the following one:
select c1, ... into var1, ... from T where ... if (var1 = ...) then New operations against the database [else] end if;
In such a case, depending on the nature of the conditions, you can use the different techniques I described earlier.
Getting Rid of Loops
Getting rid of some statements by letting SQL deal with conditions will improve a number of cases, but the real El Dorado of refactoring lies in the removal of loops that contain SQL statements. In the majority of cases, these are themselves loops on the result set of a query (cursor loops). The removal of loops not only improves performance, but also improves code readability, which is a desirable software engineering objective for maintenance.
When you execute statements in a loop, you send in quick succession identical statements (except for a few parameters that may vary) to the DBMS. You multiply context switches between your wrapping program and the SQL engine, you give the optimizer very small morsels to work on, and you end up with programs that are often slower than what they ought to be—orders of magnitude slower.
Here is a very simple example: I used emp and dept, the sample tables describing employees and departments traditionally used by Oracle, to return the names of employees and the names of the departments where they work. First I used a loop on emp, using the returned department number to fetch the name of the department. Then I used a straight join. I used the regular 14-row and 4-row sample tables; my only improvement was to respectively declare that empno is the primary key of emp and deptno is the primary key of dept, and gathering statistics on both tables. To magnify the differences, I ran my test 20,000 times, and this is the last result of two successive runs:
ORACLE-SQL> declare 2 v_ename emp.ename%type; 3 v_dname dept.dname%type; 4 n_deptno dept.deptno%type; 5 cursor c is select ename, deptno 6 from emp; 7 begin 8 for i in 1 .. 20000 9 loop 10 open c; 11 loop 12 fetch c into v_ename, n_deptno; 13 exit when c%notfound; 14 select dname 15 into v_dname 16 from dept 17 where deptno = n_deptno; 18 end loop; 19 close c; 20 end loop; 21 end; 22 / PL/SQL procedure successfully completed. Elapsed: 00:00:27.46 ORACLE-SQL> declare 2 v_ename emp.ename%type; 3 v_dname dept.dname%type; 4 cursor c is select e.ename, d.dname 5 from emp e 6 inner join dept d 7 on d.deptno = e.deptno; 8 begin 9 for i in 1 .. 20000 10 loop 11 open c; 12 loop 13 fetch c into v_ename, v_dname; 14 exit when c%notfound; 15 end loop; 16 close c; 17 end loop; 18 end; 19 / PL/SQL procedure successfully completed. Elapsed: 00:00:09.01
Without the cursor loop, my code runs three times faster. Yet, I am in the most favorable of cases: primary key search, everything in memory, running a procedure that isn’t stored but behaves as though it were (a single PL/SQL block is passed to the DBMS). It doesn’t seem far-fetched to imagine that in cases where tables are slightly more voluminous and operations are slightly less straightforward, this “modest” 3:1 ratio erupts into something considerably more impressive.
Many times, trying to think without a loop causes you to completely rethink the process and gain several orders of magnitude in performance. Consider, for instance, the following pattern, which is rather common when you are interested in the most recent event (in the widest acceptance of the word) linked to an item:
loop
select ...
where date_col = (select max(date_col)
from ...
where <condition on something returned by the loop>
and ....)The subquery hits the same “history table” as the outer query and depends on what is returned by the loop. Very often, this subquery is also correlated and depends on the outer query as well. As a result, the number of times when it will be executed is likely to be enormous. If you replace the whole loop with something such as the following:
select ..
from t1
inner join (select c1, max(date_col) date_col
from ...
where ...
group by c1) x
on x.c1 = t1....
and x.date_col = t1.date_col
where ...you compute once and for all the dates of interest, de-correlate everything, and end up with a much more efficient query that your friend, the optimizer, will process at lightning speed now that it can see the full picture.
There is only one snag with the removal of loops: sometimes cursor loops are justified. Before refactoring a program, you must therefore understand why the original developers used a loop in the first place. Very often, it is because they didn’t know better; but there are cases where loops were the chosen technical answer to a legitimate concern.
Reasons behind loops
People execute statements in loops for one of several reasons:
If … then … elselogicAs you just saw, it is often possible to push
if … then … elselogic inside queries. Having a single query inside a loop removes the need for the loop, and the whole block can generally be replaced with a join that glues together the query in the cursor and the query inside the block. Actually, here lies the real benefit of replacing proceduralif … then … elselogic with an SQL query.- To change operations that affect several tables in sequence
Sometimes some data is collected—for instance, it’s read from a staging table loaded from an XML stream—and then it is inserted into several tables in the process of storing the hierarchical XML structure into a clean relational structure.
- To make changes that the developer wants to be committed on a regular basis, inside the loop, to satisfy one or several goals
- Releasing locks
Depending on the coarseness of locking, updates may severely impair concurrency. If any uncommitted change blocks either people who want to read the data being changed, or people who want to change some other data in the same table, locks should be released as quickly as possible. The only way to release locks is to end a transaction, either by committing or by rolling back the changes. If you execute a single, long-running update, there is no way to commit before it’s over. By processing data in small batches inside a loop, you get better control of your locks.
- Not generating too much “undo”
You are probably familiar with the fact that if you are operating in transactional mode, each time you change some data the DBMS will save the original value. This is how you can cancel your changes at any time and roll back to a state where you know the data is consistent. In practice, it means you need some storage for temporarily recording the “undo history” until you commit your changes and make them final. Depending on the product, undo information will go to the transaction log or to a dedicated storage area. In a massive update, storage requirements can run high: some long-running transactions have been known to fail for lack of undo space. Even worse, when a long-running transaction fails, the undoing takes roughly the same amount of time as the doing, making a bad situation worse. And after a system crash, it can also lengthen the period of unavailability, because when a database restarts after a crash, it must roll back all pending transactions before users can work normally. This is another case that provides a motive to operate on smaller slices that are regularly committed.
- Error handling
If you massively update data (e.g., if you update data from temporary tables in a staging area), one wrong piece of data, such as data that violates an integrity constraint, is enough to make the whole update fail. In such a situation, you need to first identify the faulty piece of data, which is sometimes difficult, and then relaunch the full process after having fixed the data. Many developers choose to process by small chunks: what was successfully updated can be committed as soon as you are sure the data is correctly loaded, and incorrect data can be identified whenever it is found.
While we’re on the topic of transactions, I must state that commit statements weigh more heavily on performance than many developers realize. When you return from a call that executes a commit, you implicitly get a guarantee that your changes have been recorded and will remain, regardless of what happens. For instance, if the system crashes, when the DBMS hands back control to your program after a successful commit, it solemnly pledges that your changes will still be there after the restart, even if the system crashes in the next 0.00001 second. There is not an infinite number of ways to ensure the persistence of updates: you must write them to disk. Commit statements bring to the flow of activity a sudden change of pace. Just imagine some hectic in-memory activity, with programs scanning pages, jumping from an index page to the corresponding table pages, changing data here and there, waiting sometimes for a page brought into memory to be scanned or modified. At the same time, some changed pages are asynchronously written to the database files in the background. Suddenly, your program commits. I/O operations become synchronous. For your program, everything freezes (not too long, fortunately, but allow me some poetic license) until everything is duly recorded into the journal file that guarantees the integrity of your database. Then the call returns, and your program breaks loose again.
In this scenario, you must walk a very fine line: if you commit too often, your program will just spend a lot of its elapsed time in an I/O wait state. If you don’t commit often enough, your program may block several concurrent transactions (or end up being blocked by an equally selfish program in the fatal embrace of a deadlock). You must keep these points in mind when analyzing the contents of a loop.
Analysis of loops
Whenever you encounter SQL processing within a loop, you should ask yourself the following questions immediately, because you’ll often find loops where none are necessary:
- Do we have only
selectstatements in the loop, or do we also haveinsert, update, ordeletestatements? If you have only
selectstatements, you have much less to worry about in terms of the more serious locking and transaction issues unless the program is running with a high isolation level [45] (I talk about isolation levels in the next chapter). If many different tables are referenced inside the loop within a mishmash ofif … then … elselogic, it will probably be difficult to get rid of the loop; sometimes the database design falls into the “interesting” category and writing clean SQL is mission impossible. But if you can reduce the innards of the loop to a single statement, you can get rid of the loop.- If we have inserts, do we insert data into temporary tables or into final tables?
Some developers have a love for temporary tables that I rarely find justified, even if they sometimes have their use. Many developers seem to ignore
insert … select …. I have regularly encountered cases where a complicated process with intermediate filling of temporary tables could be solved by writing more adult SQL and inserting the result of a query directly. In these cases, the gain in speed is always very impressive.- If the database content is changed within the loop, are the changes committed inside or outside the loop?
Checking where changes are committed should be the first thing you do when reviewing code, because transaction management is the soundest of all justifications for executing SQL statements within loops. If there is no
commitwithin the loop, the argument crumbles: instead of improving concurrency, you make contention worse because chances are your loop will be slower than a single statement, and therefore, your transactions will hold locks longer.If you have no
commitstatement inside the loop, you can decide on two opposite courses: committing inside the loop or trying to get rid of the loop. If you encounter serious locking issues, you should probably commit inside the loop. Otherwise, you should try to get rid of the loop.
Challenging loops
As you saw in this chapter, in many cases you can simplify complicated procedural logic and graft it into SQL statements. When you have reached the stage where inside the cursor loop you have nothing but variable assignment and one query, you usually have won: replacing the whole loop with a single query is often just a small step away. But even when operations that change the contents of the database are involved, you can sometimes break the loop curse:
- Successive change operations
The case of multiple change operations applied to several tables in sequence (e.g., inserting the data returned by a cursor loop into two different tables of data coming from a single data source) is more difficult. First, too few people seem to be aware that multitable operations are sometimes possible (Oracle introduced multitable
insertin version 9). But even without them, you should explore whether you can replace the loop with successive statements—for instance, whether you can replace this:loop on select from table A insert data into table B; insert data into table C;
with this:
insert into table B select data from table A; insert into table C select data from table A;
Even if you have referential integrity constraints between tables
BandC, in general this will work perfectly well (you can run into difficulties if referential constraints are exceedingly complex, as sometimes happens). Naturally, performance will depend on the speed of the query (or queries, because the queries need not be exactly identical) that returns data from tableA. If it’s hopelessly slow, the loop may be faster, all things considered. However, if you got any benefit from reading Chapter 5 and you managed to speed up the query, the two successiveinsertstatements will probably be faster, and all the more so if the result set on which we loop contains many rows.You no doubt have noticed that I am happily trampling on one of my core principles, which is to not access the same data repeatedly. However, I am trampling on it with another principle as moral warrant, which is that doing in my program what can be done within the SQL engine is pointless, even when my program is a stored procedure that runs on the server.
- Undo generation
The case of undo generation is another legitimate concern, which is often answered a little lightly. I have rarely seen the rate at which changes are committed being decided after some kind of study about how much undo was generated, how long it took to roll back a transaction that failed just before the commit, or simply a comparison of the different rates. Too often, the number of operations between commits seems to be a random number between 100 and 5,000.
Actually, it’s what you are doing that decides whether undo generation will be critical. When you insert data, the DBMS doesn’t need to record petabytes of information to undo what you are doing in case of failure (even if you are inserting a lot of data). I have seen a DBMS swallow every day eight million rows injected by a single
insert … select …without any hiccups, even though the statement was running for one hour (which was considerably faster than the alternative loop). How fast you will be able to undo in case of failure depends on whether you are inserting the data at the end of a table (in which case it will be easy to truncate everything that your process has added), or whether, in the process, the DBMS is using your data to fill up “holes” left over from prior deletions.When you delete data, it’s a different matter; you will probably have a lot of data to save as you delete, and undoing in case of failure will, in practice, mean inserting everything back. But if you really have to delete massive amounts of data,
truncateis probably the command you want; if it isn’t possible to truncate a full table or partition, you should consider saving what you want to keep to a temporary table (for once), truncating, and then re-injecting, which in some cases may make processes run much faster.Updates sit somewhere in the middle. But in any case, don’t take for granted that you absolutely need to commit on a regular basis. Try different commit rates. Ask the database administrators to monitor how much undo your transactions are generating. You may discover that finally no real technical constraint is forcing you to commit often, and that some loops may go away.
- Transactions
The stronger arguments against some types of rewriting, such as using multiple
insert … select …statements, are the handling of transactions and error management. In the previous loop example:loop on select from table A insert data into table B; insert data into table C;
I can commit my changes after having inserted data into tables
BandC, either after each iteration or after any arbitrary number of iterations. With the doubleinsert … select …approach it is likely that the only time I can commit changes is when bothinsertstatements have completed.I have no clear and easy answer to those arguments, which are important ones. [46] Opposite answers are defensible, and what is acceptable often depends on ancillary circumstances.
When batch processes are initiated by receipt of a file, for instance, my choice is usually to favor speed, remove all the loops I can remove, and commit changes as little as I can. If something breaks, we still have the original file and (assuming that we don’t have multiple data sources) fixing and rerunning will mean nothing more than a delay. Because very often a loopless program will run far more quickly than a procedural program, the run/failure/fix/run sequence will take much less time than a program that loops and commits often. Taking a little risk on execution is acceptable if there is no risk on data.
When the data source is a network flow, everything depends on whether we are working in a cancel-and-replace mode or whether everything must be tracked. If everything must be tracked, very regular
commitstatements are a necessity. As always, it’s a question of what you are ready to pay for in terms of time and infrastructure for what level of risk. The answers are operational and financial, not technical.I am not convinced that the question of locks should be given prominence when choosing between a procedural and a more relational approach. Releasing locks on a regular basis isn’t a very sound strategy when massive updates are involved. When you execute a
commitstatement in a loop, all you do is release locks to grab other locks in the next iteration. You can find yourself in one of two situations:Your program is supposed to run alone, in which case locking is a nonissue and you should aim to maximize throughput. There is no better way to maximize throughput than to remove as many procedural elements as possible.
Your program runs concurrently with another program that tries to acquire the same lock. If your program briefly holds a lock and releases it, you have nothing to gain, but you allow the concurrent process to get the lock in the very small interval when you don’t own it, and it can block you in turn. The concurrent process may not play as fair as you do, and it may keep the lock for a long time. The whole concept of concurrency is based on the idea that programs don’t need the same resources at the same time. If your program is blocked while another program is running, you are better off locking the resources you need once and for all, doing what you can to minimize the global time when you hold the resources, and then, when you’re done, handing it over to another program. Sometimes sequential execution is much faster than parallel execution.
The case of row locking is a little more compelling, and its success depends on how the various programs access the rows. But here we are touching on issues that relate to the flow of operations, which is the topic of the next chapter.