
9.1 Response Time Requirement Pattern 195
9.2 Throughput Requirement Pattern 204
9.3 Dynamic Capacity Requirement Pattern 212
9.4 Static Capacity Requirement Pattern 215
9.5 Availability Requirement Pattern 217
By "performance" we mean the same as in the Olympic Games: how fast, how long, how big, how much. But there are no medals for success, only boos from the crowd for failure. Performance deals with factors that can be measured, though that doesn't mean performance requirements always specify goals using absolute numbers. In fact, it's best to avoid numbers if you can (for reasons discussed soon). It also helps to avoid stating performance requirements in terms that are hard to measure—in particular, in terms that would take an unreasonable length of time to test, such as mean time between failure. As with the rest of this book, we're talking here about typical commercial software systems, not anything life-critical such as aircraft or medical instruments.
This chapter contains requirement patterns for five types of performance encountered often in commercial systems, as shown in Figure 9-1. (Note that the dynamic and static capacity requirement patterns are separate because their characteristics are distinctly different.) You might come across others. When specifying a requirement for another performance factor, consider the issues that apply to all (or most) types of performance, which are discussed in the Common Performance Issues subsection that comes next.
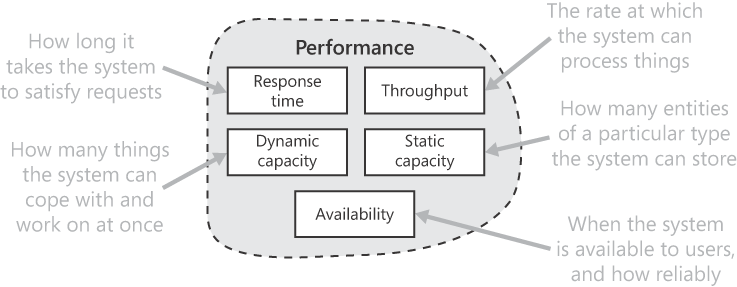
Unfortunately, there are no agreed definitions for the main terms used in this chapter, especially performance, capacity, and quality. I base the usage here upon the meanings we'd expect in a brochure for a new car: performance figures for top speed, acceleration, engine power, passenger capacity, load capacity, and so on. Its quality refers to intangibles: how well-built it is, how comfortable, what a pleasure to drive—which don't lend themselves to being quantified, the attributes the car company must convey with extravagant adjectives and flowery language. This chapter doesn't deal with quality requirements.
If an aspect of performance is worth specifying, it's worth specifying well, which demands thought and care. If it's not worth that effort, leave it out (or express it informally, not as requirements) because it will just waste everyone's time. Performance requirements are important because they can have a profound effect upon the architecture of the whole system; it's not always a matter of throwing in more hardware until it works well enough. We're faced with a dilemma of either specifying requirements in a way that's easy to write but a nightmare to build to and test, or having to formulate requirements that might look twisted and convoluted to a nontechnical audience. There are genuine difficulties to overcome; it's up to you whether you tackle them in the requirements or whether you brush them under the carpet, for the poor developers and testers to sort out.
This section describes a number of issues that recur in the performance requirement patterns in this chapter. Some are likely to apply to all types of performance (not just those covered here), the rest just to most of them. These issues are important and can have a profound impact on how performance should be specified and whether a performance requirement you write is meaningful at all. They are presented in rough order of impact (highest impact first).
Issue 1: Easy to write equals hard to implement. Most kinds of performance can be expressed very neatly—but when they are, they tend to be unhelpful. "The system shall be available 24×7, give users a one-second response time, handle 1,000 simultaneous users, process 200 orders per minute, and store 1,000,000 customers." A piece of cake to write! But for each performance target you set, ask yourself: what do you expect developers to do with it? Numerical performance targets like these are often so remote from the job of the software that it's reasonable to ask how developers are supposed to react to them: what should they do differently (assuming they code professionally as a matter of course)? If there are no obvious steps they can take, they can hardly be held responsible if the system fails to reach the target. Also, it's usually not possible to test whether a system achieves numerical performance targets until after it's been built (sometimes not until it's installed and running live), by which time it will take much fuss and rework to fix. Nevertheless, you should always get an early feel for the order of magnitude of each prospective performance target. For example, are we talking about hundreds of customers or millions?
Instead, if you can, specify requirements for steps to be taken to contribute to good performance in the area in question. All the performance requirement patterns in this chapter are "divertive" patterns—see Chapter 3—that try to steer you away from the obvious. (But be aware that this is the opposite of what other authors advise. They like the precision and apparent certainty of numeric performance targets. I will present my arguments and leave it to you to decide.)
The situation might appear a little different when you intend to purchase a solution: any off-the-shelf product either satisfies quantitative performance requirements or it doesn't. But if a third party is building a solution just for you, it's just as unfair to present them with purely quantitative targets as it would be to your own developers. And are you prepared to take their word their solution performs as promised? Finally, it's untidy for the requirements to make assumptions about the nature of the solution.
Issue 2: Are we specifying a complete, running system or just the software? To go anywhere, software needs hardware to drive it, and the performance of the whole system (hardware plus software) depends on the power of the hardware. Software is to hardware as a trailer is to a tractor. Setting performance targets for software in isolation is meaningless and silly, yet it happens (and is worth a quiet chuckle when you see it). If any component that affects a performance target is outside your control, you can't promise to achieve it, so don't make it a requirement. But you can state it informally in the requirements specification, if you like. One way out is to define an indicative hardware set-up and define performance requirements for it. (See the "Step 3: Choose Indicative Hardware Set-up" section in the throughput requirement pattern later in this chapter for further details.)
System performance can also depend on how third-party software products behave. If a particular call to such a product turns out to be slow, you could be unable to meet performance targets. If there is any third-party software, is it under your control or not? If it is, reassure yourself that it performs well enough. If it's not under your control—that is, it's outside the scope of the system as specified—don't hold your performance goals hostage to how well it performs.
Issue 3: Which part of the system does this performance target apply to? For most kinds of performance, a performance requirement can apply to a single function, a group of functions, a single interface, and so on, or it can apply to everything (all functions). Always make clear what the requirement applies to. Also, don't make it apply to more than it needs to, because it could be difficult (that is, expensive) or impossible for some things, things we might not be bothered about anyway. For example, demanding user response time of a second for everything might be impossible to achieve for some processing-intensive functions and as soon as they're treated as exceptions, respect is lost for the whole requirement. (Developers also lose respect for anyone who writes unachievable requirements.)
Issue 4: Avoid arbitrary performance targets. If someone gives you a performance goal, ask them where it came from and ask them to justify it. "Plucked out of thin air" isn't a good enough reason. Performance targets can result from a mixture of assumptions, reasoning, and calculations. If so, make all this background information available to your readers, either by including it in the requirements specification or by telling them where it can be found (for example, in a sizing model). Too many performance requirements are arbitrary. If there isn't a good enough reason for them, leave them out.
Issue 5: How critical is this performance factor to the business? The severity of the damage done if an aspect of a system performs inadequately varies enormously: from disastrous to mildly irritating (or perhaps not even noticed). If the system runs out of free storage capacity (disk space), it could fail completely; if response times grow a little, it might not matter. So ask yourself how critical this performance factor is. What's the worst that could happen? If we risk serious damage, place extra stress on measuring and monitoring actual performance (which is the subject of the next issue). At the other end of the scale, if the potential damage is negligible, why bother to specify it at all?
If you have difficulty ascertaining from your customer how important this performance level is to them, ask how much extra they're prepared to pay to achieve it: an extra 10 percent of the total system cost? Fifty percent? One hundred percent? (These are the sorts of figures we could be talking about.) The answer doesn't translate directly into a priority or justify particular steps, but it does give a good idea of how seriously to treat it.
Issue 6: How can we measure actual performance? Setting a target isn't much use unless you can tell how well you're doing against it. Who'd buy a car without a speedometer? Measuring actual performance is often left as a testing activity, with external tools wheeled in like the machines that monitor patients in a hospital. But it's much more convenient to have this ability built into the system itself. Then it can be used in a production system, and by developers. Some types of performance cannot be determined by the system itself (for example, the response time perceived by a remote user); other types of performance cannot easily be perceived externally (for example, how long an internal system process takes). Monitoring functions are a common subject of extra requirements in the performance requirement patterns in this chapter. Note that for some kinds of performance (such as response time), the act of measuring and recording performance could itself take time and effort and so affect the result a little—though we can be reassured that performance can only get better if such measuring is removed (or switched off).
Monitoring functions are always useful in letting a system administrator see how well a system is running, but they're not usually seen as contributing to the system's business goals, so they're usually given a low priority or dropped altogether (and perhaps built quietly by developers for their own use). Arguing that they play a key part in meeting performance targets provides the solid justification they need in order to earn their rightful place in the requirements.
Issue 7: By when does this performance target need to be met? Some performance targets reflect planned business volumes that will take time (perhaps years) to achieve. Always state the timeframe in such cases. This allows optimizations to be made at the best time for the business and the development team. In particular it can save unwarranted effort being devoted to performance during the initial implementation phase, which is usually the busiest.
Issue 8: Put only one performance target in each requirement. Don't lump several targets together. Separating them gives each target the prominence and respect it deserves, lets you give each one its own priority, and makes it easier (for testers in particular) to track each one.
Issue 9: What can be done if this performance target is not met? Pondering this question can give you a useful insight into how seriously to treat this aspect of performance—that is, how much care it deserves and how big a mess we risk if we don't. Can it be improved by beefing up the hardware? Is tweaking the software likely to help? If the problem lies with a third-party product, are we stuck with it? If this aspect of performance isn't good enough, where does the responsibility lie: hardware, software, a bit of both—or will it be impossible to tell? Don't treat this issue as a way to assign blame (because blame comes into play only after a mess occurs and doesn't help prevent it) but as a way to understand the performance needs better so that there won't be a mess in the first place.
Related patterns: | None |
Anticipated frequency: | Between zero and three requirements, rarely more |
Pattern classifications: | Pervasive: Maybe |
Use the response time requirement pattern to specify how much time the system may take to respond to a request. It is typically used where the time an operation takes is of interest to a person (normally a user) or another system.
Do not use the response time requirement pattern just for the sake of it. If a particular response time isn't vital, don't worry about it.
Response time is the length of time between a request being submitted at a particular place to a system and a response being perceived at the same place. It is most popularly applied to user response time, which is the length of time between a user submitting a request (hitting the button) and the response being displayed on their screen. But this pattern can be used for other operations, for instance physical processes (such as the time to manufacture or physically deliver something) and processes involving multiple people (for example, if a step must be approved by a supervisor). Note, though, that it's especially hard to pin time targets to the system itself in such cases. It's especially important that, instead, you break it down into its parts and identify ways to make each part efficient.
Four distinct ways exist for stating a response time goal:
- Approach 1: Define a quantitative requirement.
This is the commonest way and the one usually suggested. The content of this type of requirement is described in the "Strategy 1" section that follows. This is an easy option—you can simply invent a figure if you like—but it's problematic to implement and test (as argued in "Issue 1: Easy to write equals hard to implement" earlier in this chapter). A requirement of this type is of most use when deciding what hardware configuration is needed, once the system has already been built.
- Approach 2: State it informally.
Explain it for the edification of developers about what we're after, but not as a requirement. State the same information as if you were writing a requirement according to Approach 1, but write it as casual guidance for developers. Since it's informal, it needn't be as rigorous as if you were writing a requirement—but still give some thought to each of the items of information mentioned.
- Approach 3: Define requirements for steps to take to contribute to good response times.
Rather than state a quantitative performance target, it's much more fruitful to dig deeper to identify and specify steps that can be taken to give the system the best possible response time. These steps are regarded as extra requirements in this requirement pattern and are discussed in the Extra Requirements subsection coming up. This is the hard option but the most helpful to developers.
- Approach 4: Say nothing.
Having thought about response times for some aspect of a system, a perfectly valid option is to decide not to mention it in the requirements specification. At several points, this requirement pattern suggests saying nothing. Positive inaction!
In addition to simply choosing one of these ways, they can be combined into richer strategies. Two suggest themselves:
Strategy 1: Break down end-to-end quantitative target. The only response times for which we have a natural feel are those experienced by users, so this is a sensible starting point—but it's not helpful if part is outside the scope of the system. This strategy turns an end-to-end response time into one just for those parts within our control. Perform the following steps:
Decide on a maximum acceptable response time to users (called end-to-end because it includes everything): for example, two seconds.
Identify the constituent pieces involved in delivering the response. This need be done only at a very high level, for the purpose of allocating time to each piece. For example, everything between a Web user's PC and our back-end application could be regarded as one piece. Or you could treat the Internet as one piece and your router, firewall, Web server, and internal network as another piece. Any external system that must be called would be another piece. Some pieces might be outside the system's scope. Assume an indicative hardware set-up as necessary.
Allocate a fraction of the end-to-end response time to each component (or group of components—for example, all those out of scope). This will involve some guesswork, but you probably won't go far wrong. In our example, we might allocate to our application system half a second of the overall two seconds.
Specify a response time requirement for that portion that is within the scope of the system, using the amount of response time allocated to it. Alternatively, you can specify a separate requirement for each logical component within scope.
This strategy is especially important when dealing with processes that involve human intervention (such as manual approval by a supervisor), or other kinds of nonsystem delays.
Strategy 2: Quantitative target and contributing steps. The aim is to get the benefit of both. Start by defining a quantitative performance target (Approach 1), and then study it and identify steps that help achieve it (Approach 3). Once you've identified these steps, you can demote the original performance target to an informal description (Approach 2).
If requirements are being specified at two levels—that is, business requirements first and detailed requirements afterwards—Approach 1 suits the business requirements and Approach 3 the detailed requirements.
These two strategies aren't mutually exclusive: you can use the first and then the second. All these ways and strategies have their place. Which one is best depends on how important the performance target is, the scope of the system being specified (is it the software only?), the nature of your development environment (how much do you trust your developers to do a good job?), and personal preference.
The following list describes what a quantitative response time requirement (as per Approach 1) should contain. It's so lengthy because it explains how thinking about a particular item of information can steer you to framing the requirement in a different way.
Type of operation What does this requirement apply to? Is it for a specific function, a collection of functions, all functions for a class of users, or something else? Don't impose a demand on all user functions; apply it only to those that genuinely need it. Limit its scope as much as possible. Exclude rarely used functions. Use a requirement of this type to inform developers of those areas whose performance they should worry about.
Exceptional cases Is the response time target likely to be unachievable in some cases? For example, functions that involve intensive processing will be slower, so it's unfair to judge them against the same goal. However, it's difficult to know at requirements time which functions have lots of work to do—and yet we don't want to let developers get away with inefficiency by using intensive processing as an excuse. You must find the right balance.
Timing boundaries What exactly are we measuring? That is, what causes the stopwatch to start and what causes it to stop? Be precise, because differences in interpretation could profoundly affect how well the system satisfies the requirement. For example, if you're requesting a Web page (say, containing many images), are you measuring to when the page begins to display, when its main structure is displayed, or when the whole page is fully displayed (with all the images)?
Pick boundaries such that everything from start to finish is within the scope of the system being specified. Exclude anything over which you've got no control (such as a potentially slow public network). In fact, set the boundaries so that they span as few variable factors as possible. If you can't do this, identify indicative hardware or assumed performance (such as Internet connection speed) for the parts that are outside the system's scope—though they are in themselves hard to specify and won't behave uniformly even then. If you end up setting a target for the system's internal response time, it won't be directly observable by a user, so you need a way for the software to measure and record it (which is described in the "Response Time Monitoring" subsection of the Extra Requirements section later in this pattern).
Tolerable length of time This is the maximum acceptable response time itself. Ordinarily, this should be an absolute quantity (two seconds, or half an hour, say), because values such as fast, quick, and imperceptible are subjective and can't be verified definitively. (I say "ordinarily" because on a rare occasion it's preferable to use a subjective measure. I have in mind the situation where we merely want to prevent unusually slow response times, rather than insist on very good ones. In this case, it's advantageous to avoid defining "unusually slow" in case anything faster is regarded as fine even if it's still slow.) It is always possible to replace a subjective value by picking an absolute quantity to represent it. For example, fast might be defined as less than one second in this context, and imperceptible as less than a twentieth of a second—in rough accordance with the frames-per-second rate of human sight: the blink of an eye.
If we're pressured to include factors outside the system's scope, an alternative strategy is to define a unit of measurement to use as a datum and then to express a performance target in terms of this unit. For example, if we define one boing to be the time it takes to show a simple (reference) Web page, from request to completed display, then we could set the acceptable response time for some other function at four boings, or two boings plus half a second. This strategy has the advantage of taking into account the actual speed of variables outside our control. The value of a boing isn't fixed; it varies according to the environment. For a PC on a local network, a boing might be half a second; with a slow Internet connection, a boing might be five seconds. It's possible to phrase a requirement to avoid having to name your artificial unit of time. You can use the same unit in more than one requirement (in which case it's difficult to avoid naming it).
Justification of length of time Where did the tolerable length of time figure come from? This could include a calculation and/or argument, or it could refer to an external source where the justification is given (such as a sizing model). If the figure is arbitrary, or you can't find a good reason for it, maybe it's not important.
Indicative hardware set-up Try using this if your timing boundaries go beyond the scope of the system—especially if you're specifying software only. This must include every component that affects the response time: server machine, external services that are called, Web server, firewall, router, communications networks, client machine, and so on. Treat the unpleasantness of doing this as an incentive to push the timing boundaries as close to the system's scope as possible.
Alternatively, you can refer to a description of indicative hardware given elsewhere.
High load caveat When any system's very busy, response times are liable to degrade. You can't ignore this factor. It makes sense for a response time target to apply only up to a certain load. Don't attempt to predict at what load level it will start to degrade noticeably, but you could define a level of business activity (in terms of throughput or simultaneous users) that the system must be able to handle while still meeting response time targets.
Something else to insist on is graceful degrading of performance under load: to not tolerate instant gridlock as soon as some threshold load is reached. It's unrealistic to specify this in precise terms, so the best approach is to ask that response times must degrade only incrementally (gradually) as load increases and that a sudden jump in response times must never occur.
Motivation Why are you specifying this performance goal? Why do you need good response time? It could be so the user can get more work done (an employee), or it could be that if they're bored they'll go somewhere else (a casual Web visitor). The answer to this question might hint that a quantitative performance requirement is not the best approach: perhaps you should reformulate the requirement to tackle the motivation. For example, the motivation for a fast download of software by a Web visitor might be so that they don't give up impatiently halfway through. Since it's unreasonable to demand that a download of unknown size be done in a specified time, you could replace it by a requirement that the visitor be given an indication of progress or be sufficiently entertained while the download takes place. Displaying a progress bar might be enough. (This topic is revisited in the "Response Time Masking and Explaining" subsection.) You don't always need to state the motivation explicitly in the requirement itself, but always ask yourself what it is.
Here are a few example response time requirements with quantitative targets:
Summary | Definition |
|---|---|
Inquiry response time | Any inquiry shall complete the display of its results, from the time the user submits the request, in no longer than 4 seconds plus the display time of a simple reference page from the same location. This figure is based on anecdotal tests indicating that users begin to lose patience soon after this time. This requirement does not apply to inquiries across large volumes of data where arbitrary selection criteria are allowed. |
The average time for the transaction switch to route a customer request to a service shall be less than 300 milliseconds. (This figure has been calculated as one twentieth of the time that a reasonable customer would consider acceptable to wait for a typical transaction. An acceptable wait for a typical transaction is taken as 6 seconds—based on timed figures for the processing of credit card transactions.) | |
Each Web page produced by the system shall be fully displayed in no longer than 10 seconds from the time the user requested it, when using a 56k bits per second modem connection. This requirement does not apply to pages containing one or more large images. This requirement does not apply when the number of users currently using the system exceeds 90% of the simultaneous user capacity (as stated in «User capacity requirement ID»). Above this level, it is acceptable for the display time to increase in rough proportion to the number of simultaneous users. | |
Any error in the format of data entered by a user shall be pointed out to the user with a suitable error message no more than 1 second after they submit the information to the system. Note that this requirement need not rely upon network communications being fast enough: local validation on the user's machine would also satisfy it (although validation must in all cases be performed on the server side too, because not to do so would represent a security weakness). |
Here are some example response time requirements that do not mention quantitative targets:
Summary | Definition |
|---|---|
No user function shall have an average response time in normal system operation that a reasonable user would consider excessive for that type of function. | |
It shall be possible to issue an employee identity card on request sufficiently fast for "while-you-wait" delivery. Ten minutes is regarded as an acceptable wait time for the purposes of this requirement, though this should not be treated as a clear boundary between "good" and "bad." A quicker time would deliver increased user satisfaction with the system, and a longer time increased irritation. | |
Fast display of personal happiness calculator | A happiness club member shall get fast response when displaying the personal happiness calculator for the first time after entering the club's Web site. (This requirement makes no judgment on how the happiness calculator is implemented. It can be taken to mean that a long delay while waiting for an applet or other software to load is unacceptable. At the same time, it cannot be read as ruling out use of such software.) This requirement is not specified in terms of an absolute length of time, partly because display time is affected by factors outside the company's control (most notably the member's connection speed). To put it another way, to specify a time we would also need to specify the PC and communications to which it applies. It is recognized that this requirement is stated in subjective terms—but so is deciding whether response time is too slow. Thus, the person verifying the system is granted a degree of freedom in deciding whether it feels acceptable in practice. It was decided that this was preferable to setting arbitrary targets in advance. |
They're diverse and deserve thought. That's the first thing to say about extra requirements that might be written about response time, either in addition to or instead of a quantitative response time requirement. Three categories of extra requirements are discussed here, each one in its own section that follows:
Steps that contribute to good response times Things to be done to help the system perform well.
Response time monitoring Functions for measuring response times and letting administrators see them.
Response time masking and explaining Ways to lessen the chance of a user becoming impatient or confused while waiting for a response.
Steps that Contribute to Good Response Times There are innumerable ways to improve response times. They depend upon the nature of your system and your environment, and this section doesn't attempt to identify them. It's up to you to find any major logical steps that suit your situation, where "logical" means it addresses what we need but not how. The development team is in a position to identify other ways to deliver the best possible response times. Here are a few token examples of requirements that contribute to good response times:
Observe that the first requirement here is likely to have a major impact on the architecture of the system: two databases, which involves significant additional functionality to maintain and update, functionality for which you might or might not choose to define requirements. Also observe that the intent paragraph in each of the first two examples is expressed in terms of its effect on an expected solution but that the requirements themselves do not mandate this solution.
Response Time Monitoring Measuring response time sounds straightforward, but it seems that however you try to do it, little practical difficulties crop up. There are three main ways to measure response times:
Using the system itself This is limited to the scope of the system itself, which means a server system can measure only internal response times—which is fine if this is how your response time targets are expressed. There are two difficulties with a response time measured by the system: first, what to do with the measurement—because storing it would take machine time and effort (it can't be done within any existing database update, since the response time clock is still ticking then)—and second, the act of measuring could add a little extra work and make the response time marginally longer, so you might want to be able to switch measuring on and off.
If the scope of your system includes software on each user's machine, that software could record response times. But you then also need means to gather that information centrally (that is, to send it back to base) and for the central system to be able to receive and store it.
Using an external measurement tool There are products that do this, both commercial and free, to let you measure response times at any point in a network or on a user device. In a normal business environment, it's not sensible to consider building your own. To measure user response time, software must be installed on the user's machine, which can be restrictive. (You can't get response times for an arbitrary external visitor to your Web site, for example.)
By hand Use a stopwatch to record how long something takes. This is tedious and subject to human error. The results must be recorded by hand, too. If the results are to take into account the circumstances, they must be recorded as well (date and time, network connection speed, and such like), which adds to the work. Then you have to collate the recorded results.
Often, response times are measured and checked only when testing the system, but being able to do so when the system is running live is valuable.
Once you have response time measurements, what do you want to do with them? The two main uses are to
Produce and present statistics. They can show response times in a variety of ways, depending on the richness of the response time data that has been gathered: per function, per class of user, or according to the system load. But gathering enough data for statistics of this sort is a major commitment.
Raise an alarm if response times are inadequate or grow slower.
Response Time Masking and Explaining There are limits to how much we can reduce response times. Some types of operations are bound to take a relatively long time, such as downloading software. We have to live with it, and we must turn our attention to how we can make the user's experience as painless as possible. Even if it leads to a longer overall wait, it's probably worth it. Options include
Warning the user before any possible wait This is common courtesy and should be universal, but plenty of Web sites don't do this. Also tell the user beforehand how big any download will be.
Letting the user know what's happening This could be a simple message: "Download in progress." Better is a progress bar of some kind, although how hard this is to implement (or whether it's feasible at all) depends on the technology used, which you might not know at requirements time.
Masking the delay So that the user doesn't perceive it or perceives it less. Perform the slow operation in the background while letting the user do something else—or keep them occupied in some other way. There are various tricks. Give the user something to read while they wait. Chop up the delay into more than one piece. Don't force a user to download parts of your software they might never use. They all involve extra work, so only insist on them if it's worth it. It might be worthwhile going to trouble for a visitor to your Web site (a potential customer) but not for a humble employee.
Some of these options might sound like solutions—that is, rightfully the preserve of the development team. If you want to leave them free to pick the best option, frame the requirement in terms of what you want to achieve (the motivation), though you can mention a suggested solution informally, too.
Here are a couple of representative example requirements:
Summary | Definition |
|---|---|
Slow operation prewarning | At any point from which the user can initiate an operation that would take longer than 20 seconds (when using a 1-Mbps Internet connection), a warning to this effect shall be displayed. |
A progress bar shall be displayed to the user while the happiness calculator software is being downloaded to the user's PC, to show what percentage of the download has been done. |
Consider what a developer is expected to do with each response time requirement.
If no requirements are present for features that contribute to good response time, consider what features might be appropriate.
Consider whether a suitable hardware set-up will be available against which to test response time requirements.
If any high-load caveats are specified, consider how to simulate a suitably heavy load in a test environment.
How are you going to measure response times accurately? Does the system itself contain any ability to measure response times? If not, and that's the only way, insist on this capability being added.
Related patterns: | Scalability, response time, inter-system interface |
Anticipated frequency: | One requirement in a straightforward case, up to three or more per system and per inter-system interface (for one or more interfaces) |
Pattern classifications: | None |
Use the throughput requirement pattern to specify a rate at which the system—or a particular inter-system interface—must be able to perform some type of input or output processing.
How fast can we throw things at our system? This is the type of question most commonly answered by throughput requirements. Less frequently: how fast must our system churn things out? This sounds easy enough to specify: just say how many whatsits per whenever. But unfortunately it's not as simple as all that—and it can be downright difficult to write satisfactory throughput requirements, for several reasons. First, how do we work out what rate we need? It involves predicting the future, which is never spot-on at the best of times but might be little more than guesswork if this is a new business venture or if we're building a product for other businesses to use. Second, if critical pieces—particularly the main hardware and, for an interface, the communication lines—are outside the scope of the system, how can we set meaningful throughput targets for the software alone?
Before agonizing about how to work out a throughput target, ask yourself: what's it for? Can we do without it? Don't specify throughput just for the sake of it. For most systems, being scalable is more important than achieving a fixed throughput figure. If we specify strict scalability requirements, we can often either avoid specifying throughput at all or we can specify a relatively modest throughput target, confident that if we need more, we can scale up (normally by adding more hardware). If you don't have a sound basis for determining target throughput, it's often better not to try, rather than putting forward impressive-looking figures that are meaningless and perhaps dangerously misleading.
These days, throughput is mainly an issue for a commercial system only if there are a large number of users, which means either it's open to the world (typically via the Internet) or it's used by a large organization. This requirement pattern assumes we're dealing with a high throughput system—because with available technology, anything else can be handled comfortably simply by buying more hardware and using better underlying products (such as a database). There's nothing to be gained by writing a requirement that the system must cope with at least two orders per day.
You can't specify throughput just by asking people or by thinking about it, scratching your head a bit, and then writing it down. There are several things to figure out, and you're probably going to have to do some calculations. Here's a suggested approach, which chops the problem into several more manageable pieces:
Step 1: Decide what to measure. Pick something that's fundamental to the system. For a retail system, it could be new orders (how many we must be able to receive in a given time, that is). One system could have several throughput requirements for different measures, but don't worry about secondary activities whose volumes depend largely on something you've already chosen; they're taken care of in Step 2.
Step 2: Work out other relative volumes (if necessary). Devise formulae for working out the relative volume of secondary activities of interest based on the thing whose throughput we're measuring (for example, how many order inquiries per order). In effect, this is a little model of relative volumes, which can form part of an overall sizing model.
Step 3: Choose indicative hardware set-up (if necessary). If hardware is outside the scope of the system, define a rough hardware set-up for which to specify a throughput target.
Step 4: Determine average throughput. Organizations think of projected business in terms of relatively long timeframes: per month, per week, or perhaps per day (relatively long, that is, from the point of view of a computer rated in billions of cycles per second). Begin throughput calculations by thinking in the same way as the business, which gives us an average throughput over a relatively long period of time.
Step 5: Determine peak throughput. The load on the system won't stay constant: a conveniently average throughput won't be delivered every minute or every second. How much will it vary? What's the busiest it will get? It's the answer to the last question that gives us our target throughput—because the system must cope with the peak load.
Each of these steps is described in more detail in its own section that follows. Steps 4 and 5 need to be performed for each distinct measure identified in Step 1.
Step 1: Decide What To Measure For the main throughput target, pick the thing most important to the organization. For a business this means the one that makes the money, which isn't necessarily the one with the highest volume. In most systems it's the business transactions. (That's why for a retail system, we'd pick orders rather than inquiries.) If you have several common things, pick the one that happens most frequently. It's best to pick only one thing for which to set an overall throughput target. Step 2 takes the system's secondary throughputs into account.
There could be several different types of the thing on which you've decided to base throughput—several different types of business transactions, for example. In this case, either pick one (the most important or the most numerous one) and treat the others as secondary (and deal with them in Step 2) or estimate what percentage of the total each type represents. The final results are the same.
In addition to the system's main throughput target you can set a separate throughput target for each inter-system interface for which this factor is important. This makes sense only if there's no direct relationship between the system throughput and that of the interface in question; if every transaction is sent down the interface, it doesn't need its own target.
Distinguish between incoming and outgoing throughput. Usually, it's the incoming throughput that constitutes the load on the system; the system can send things out with much less effort (invoices, emails—no matter what they are). The exception is systems whose main purpose is producing something. One incoming transaction could generate one or more outgoing transaction. The net effect, in terms of communications bandwidth, could be more than the consideration of just the incoming transactions would indicate. Communication pipes, however, aren't the same as physical pipes: a heavy flow one way doesn't necessarily mean there's no room for anything to go the other way, and the capacity one way might differ from the capacity the other way.
Step 2: Work Out Other Relative Volumes In Step 1 we identified what requests to base our throughput measuring on. But handling them isn't the only work the system has to do. Step 2 aims to get an idea of the load imposed by everything else. However, the results of this step don't feed into the throughput requirement itself. It serves two purposes: first, to gain a better understanding of the overall load on the system, and second, to supply useful information to whoever will decide what size hardware is needed. (It's not possible to size the hardware at requirements time.)
Draw up a list of the other everyday activities of the system (or, for an inter-system interface, the other things the interface handles): important inquiries, registration of customers, and so on. Then estimate how many of each of these there will be on average for each one of the things the throughput measures. For a Web retail site, we might estimate that product inquiries outnumber orders fifty to one, the number of new customers registering is a third of the number of orders, and there are two order inquiries for each order.
A spreadsheet is the most convenient tool to use; it lets us easily change the primary volume and recalculate all the others. If you've already created an overall sizing model, add these factors to it.
One extra factor that's often useful to add is the origin of the things we're measuring. Where do they come from? What owns or produces them? For example, the origin of business transactions might be customers. Estimating the rate at which a single origin entity creates such transactions can then form the basis for our throughput calculations, in a way that people find more natural. Asking how many orders an average customer will place per month is easier to picture than an absolute total number of orders in isolation (though wherever you start, you ought to reach the same results).
There is a slight danger that the developers will take trouble to make sure the primary transaction type is handled lightning fast, to satisfy the throughput requirement. This might leave everything else disproportionately—and perhaps unacceptably—slow. It's hard for the requirements to protect against this: you can hardly ban or complain about the efficient execution of anything.
Step 3: Choose Indicative Hardware Set-Up If we're building a system for a particular organization, we have only its projected business volume to worry about, so we can specify target throughput independently of hardware. The hardware can be chosen later, when we've built the software and know how well it performs. In this case, bypass Step 3.
On the other hand, if we're specifying only the software for a system without knowing the power of the machines it will run on, we can't just throw up our hands and announce that it's impossible to specify throughput requirements. That would render even the most inefficient software acceptable (as far as the requirements are concerned). This dilemma is particularly important when building a product because different customers might have enormous variations in their business volumes. One answer is to devise an indicative hardware set-up (such-and-such machine with a so-and-so processor running this operating system and that database, and so on) and to state the throughput it must achieve.
A slightly different approach is to focus on one aspect of hardware performance—the machine's CPU cycle rate is the obvious one—and specify target throughput against it. For example, we could demand one business transaction for every 10 million CPU cycles (so a 2 GHz machine would handle 200 business transactions per second). This is a rather simplistic alternative. It doesn't take into account any of the other factors that affect throughput, and it forces you to deal in unfamiliar quantities. (Can you feel the CPU cycles go by?)
It's distasteful for the requirements process to address hardware at all, but we have no alternative if we must address performance in the absence of a concrete underlying environment. A car maker couldn't tell you the top speed of a planned new car if its engine size isn't known yet.
Step 4: Determine Average Throughput Now it's time to approach the gurus who can foretell the future of the business. This is the domain of sales and marketing and senior management; no one else possesses such powers. Arrange a session with them to discuss and set down business volume projections. The goal of Step 4 is to determine the volume of business in terms of the time period the business feels most comfortable with (per year, quarter, month, week, or day)—and thus average throughput.
Give your business gurus free reign to express their estimates of business volumes however they wish, but intervene if they start talking in terms that aren't measurable. Doing Steps 1 and 2 beforehand—or at least preparing a first version of your sizing model—lets you demonstrate and tinker with it during the session. It's usually most natural to start by discussing volumes in terms of whatever comes most naturally—often numbers of customers rather than transactions, and then how many transactions each customer will make in a given time period. That is, take a step back from the thing you'll actually base the throughput target on.
For an established business (if we're replacing an existing system, say), target throughput can usually be set with a reasonable degree of reliability. For a new venture it's largely guesswork. Be alert to the eternal optimism of sales predictions. ("In five years' time, 50 percent of the world's population will be buying their whatever-they-are online, and we intend to have 90 percent of that market.") If that happens, bring the discussion down to earth by asking what volumes will be in the shorter term. It's far better to cater for smaller initial volumes and require the system to be scalable than gear up for starry-eyed exaggerations. This demonstrates that it's important to always associate a timeframe with every throughput target—indeed, every performance target of any kind. If possible, do so relative to when the system goes live, rather than an absolute date. It's perfectly acceptable to specify two targets for the same thing, covering different timeframes—either putting both in the same requirement or writing two separate requirements. The latter allows the targets to be assigned different priorities.
Other factors you might want to take into account include budget (how much high-power hardware can the organization afford?) and the potential damage to the business if it cannot cope with demand. Also, if the business is subject to seasonal variation, base the target throughput on the busiest season (or time of year) or special busy dates. For example, a system for a florist can expect to be most busy on Valentine's Day.
Step 5: Determine Peak Throughput Assuming we have an average throughput (from Step 4), how do we turn that into a real, immediate, here-and-now throughput? What's the greatest load we must be ready for? In a sense, our system must be a marathoner, a middle-distance runner, and a sprinter all in one—and the peak throughput says how fast it must be able to sprint. The aim of Step 5 is to determine a short-term peak throughput based on the long-term average.
The rest of this section applies to incoming throughput. Outgoing throughput is easier to determine because we typically have a lot more control over when it happens (for example, producing invoices or sending emails). Outgoing throughput also tends to be less important, because it usually imposes less of a processing load.
What's the ideal unit time period for which to set peak throughput? A day and an hour are too long because they provide plenty of time to satisfy the target while still having long periods with little (or even no) throughput. A second is too short because it implies that the target throughput must be achieved every second, which leaves little room for even fleeting hiccups. What's the point of such a tight requirement if it's not possible for any user to notice if it wasn't achieved? Indeed, no one would probably notice if the system did nothing at all for a second. Let's not split hairs and debate funny time periods like five minutes or thirty seconds. Keeping to nice round numbers, the most convenient time period is therefore a minute. The rest of this section assumes we're calculating throughput for the peak minute. If you have sound business reasons for a different time period, then use it.
The extent to which peak throughput varies from the average depends on numerous factors according to the nature of the system. Common factors are
- Factor 1: The system's availability window
This means its normal hours of operation. For a company's internal system running from 9 to 5, a day's average throughput is crammed into eight hours. For an always-open Web system, it's spread over 24 hours.
- Factor 2: Naturally popular times
At what times of day is a typical user most likely to use the system (according to their local time zone)? If you're offering a service to businesses, it's likely to be busiest during working hours. If it's recreational, it'll probably be in the evening and at weekends.
- Factor 3: Geographic distribution
How widely spread are your users? Across different time zones? If your system is available worldwide, do you have a dominant region from which most of your business comes (such as North America)? This factor can lead to complex patterns of load through the day.
- Factor 4: High activity triggers
Do you have any situations that are unusually busy? Is there anything that could cause peak throughput to be much higher than the average? For example, if you're selling concert tickets online, you can expect to be deluged the moment tickets for a popular artist become available.
Build a model as sophisticated as you like or as simple as you can get away with to calculate the peak throughput. In addition to these factors there will also always be natural variations from minute to minute. A statistician would be able to work this out properly, but in the absence of one, resort to guessing. If you have no meaningful data at all, you must assume the peak throughput will be appreciably higher than the average, but not massively so. A factor of double might be a reasonable assumption of last resort.
Once we've figured out a throughput target, a requirement for it needs to contain the following:
Throughput object type. State the sort of thing whose throughput is to be measured (such as new orders).
Target throughput quantity and unit time period (for example, 10 per second).
A statement about contingency (if you wish). In some circumstances, it's worth adding a contingency factor on top of the estimated throughput. (That factor is usually a semi-arbitrary percentage—say, 10 percent or 20 percent.) If you decide to do so, state the amount of contingency that's included in the target. Ordinarily you'd increase the contingency in line with your uncertainty, but that could prove expensive here (in extra hardware cost). If you include a contingency without saying so, the development team might add their own contingency as well, and no one will know what's going on: you could end up with an over-engineered system without realizing. If you don't include a contingency, say so, if there's a risk of anyone wondering.
Part of system (if relevant). A throughput requirement applies either to the system as a whole or just to a part (usually an inter-system interface). If this requirement is for a part, say which.
Justification. Where did the target figure come from? How was it calculated? What figures were used as the basis for the calculation? In only the simplest cases is a self-contained justification concise enough to fit within the requirement; otherwise, refer to a justification that resides elsewhere. Either include it as informal material in the specification or keep it externally. Referring to a sizing model is fine.
The justification might contain sensitive information that you don't want all readers of the requirements specification to see. If so, omit it from the specification. Consider omitting reference to it altogether if you don't want some readers feeling like second-class citizens.
Target achievement timeframe. How far into the system's life does the target need to be achieved? It might be immediately after it's installed, after a year, or at some distant time in the future ("eventually").
Indicative hardware description (if relevant), from Step 3 of the preceding approach.
Summary | Definition |
|---|---|
«Throughput type» rate | «Part of system» shall be able to handle «Throughput object type» transactions at a rate of at least «Throughput quantity» per «Unit time period» [when using «Indicative hardware set-up»]. [«Target achievement timeframe statement».] [«Contingency statement».] [«Justification statement».] |
Summary | Definition |
|---|---|
Order entry rate | The initial system shall be able to handle the entry of orders by customers at a rate of at least 10 per second. No contingency has been added; this rate represents the actual demand expected. See the system sizing model for details of how this figure has been arrived at. It is located at «Sizing model location». |
Verifying whether the system achieves a throughput requirement can be difficult and tedious if the system itself doesn't help, so features for measuring throughput are the first candidates for extra requirements. Then we can think about steps to maximize throughput and how we want the system to react when it reaches its throughput limits. Here are some topics to consider writing extra requirements for:
Monitoring throughput Monitoring can be divided into immediate and reflective: immediate tells us the throughput level right now; reflective provides statistics on throughput levels over an extended period, to highlight busy periods and throughput trends.
Limiting throughput We can't stop incoming traffic directly (or, at least, it's usually too drastic to), but we can consider restricting the causes of traffic—such as limiting the number of active users, perhaps by preventing users logging in if the number already logged in has reached the limit. This could be refined to let in some users but not others—registered customers but not casual visitors, for example. Another step could be to disable resource-intensive secondary functions at times of high load.
Maximizing throughput What steps can we take to squeeze the most through the system? One way is to "clear the decks" during times of peak throughput: arrange for some other processing to be done at other times. That depends on how much load is imposed by other processing. If it's not much, it's not worth bothering. Also consider insisting upon separate machines for background processing.
High throughput characteristics Computer systems, like all complex and temperamental creatures, can behave differently when pushed to their limits. The response time requirement pattern recommends putting caveats on that aspect of performance when the system is experiencing high load, but there might be others that you want to apply only when the throughput is within its stated limit.
Implementation sizing model It's sometimes useful to have a good sizing model to help determine the hardware needed to achieve a given throughput level, particularly if you're building a product. You can make this a requirement. State who will use this model: your customers or only representatives of your organization. A requirement of this kind effectively asks the development or testing team to extend any sizing model produced during the requirements process to take into account the software's actual performance.
Design to maximize the efficiency of high-volume transactions. For example, don't send information more than once. And keep interactions as simple as possible—don't use two request-response pairs when one would suffice.
Even if there is no requirement for throughput monitoring, it's useful to incorporate at least a rudimentary way of showing current throughput. Find out whether an automated throughput tester is going to be purchased or built for the testing team. If so, make sure it's available to the development team for their use, too.
Attempting to manually make suitably large numbers of requests to a system is, in most cases, logistically impossible. To test throughput, you need an automated way to generate a high volume of requests. You might find a product to do this job, or you might have to build your own software for the purpose (in which case treat it as a serious development effort). Whichever way you go, a good automated throughput testing tool should let you do these things:
Define the requests to submit to the system (and the expected response to each one). The two basic ways are either to pregenerate large quantities of test data or to define rules by which test data can be generated on the fly.
Start submitting requests (and stop, when you've done enough).
Dynamically change the rate at which requests are submitted. This allows you simulate low, average, and heavy demand levels.
Monitor the response time of each request. This provides an external picture of how the system behaves.
Validate each response. This doesn't tell you about throughput per se, but being able to automatically check that large numbers of responses are as you expect is a valuable bonus.
Simulate the load on the system likely to be imposed by other activities, because it's not realistic to assume the system will be able to devote its full attention to one kind of request.
Generate reports on the system's performance. The accumulated response time data can be used to calculate throughput figures. It can also provide response time statistics: the shortest, average, and longest response times, and how response times vary with throughput.
The throughput that a system can handle doesn't vary proportionately with the power of its hardware, so it's hard to figure out just what testing using a hardware set-up different from that of the production environment tells you: extrapolations are likely to be difficult and unreliable. There are also many hardware factors that determine its overall power: the number and speed of CPUs, memory, disk drives, network bandwidth, and more. A sizing model helps, but it's still only a model and will have limited accuracy. Modify the sizing model based on observations from the real system.
Related patterns: | None |
Anticipated frequency: | Up to two requirements |
Pattern classifications: | None |
Use the dynamic capacity requirement pattern to specify the quantity of a particular type of entity for which the system must be able to perform processing at the same time. It is intended primarily for the number of simultaneous users a system must be capable of handling. It also suggests what do to when too many users come along at once.
Specifying dynamic capacity is difficult, unless you have an existing system from which you can obtain figures. It doesn't help developers, except as a rough idea of scale. It comes into its own only when sizing hardware, after the system has been built. Demanding that a system be scalable is much more valuable and can be done instead of demanding a particular capacity level—see the scalability requirement pattern in Chapter 10 . Nevertheless, the topics discussed in the Extra Requirements subsection are well worth thinking about. Those requirements are often more useful than a dynamic capacity requirement itself—in particular, being able to exert control on the load imposed on your system. A Web site is open for the whole world to come and visit, but if even a small country turned up all at once, you'd be trampled underfoot unless you took precautions.
You can calculate an expected number of simultaneous users using a sizing model, but producing a decent estimate is tricky and takes a lot of care. You need to work out how an average user behaves: when they visit, how long they stay, which functions they use (and how many times). If your users are distributed across multiple time zones, take into account what percentage of users reside in each time zone—and adjust their visit times to the system's local time zone.
A dynamic capacity requirement should contain these items:
Type of entity What sort of thing are we stating capacity for? In the case of simultaneous user capacity, this is either all users or just one or more class of users (for example, customer). If two different user classes behave in very different ways (that is, place very different levels of demand on the system), treat them separately—or else we're adding apples and oranges. For a system driving a Web site, two fundamental classes of users exist: external (customers and casual visitors) and internal (employees, and perhaps employees of partner companies). An internal user might impose a smaller load on the system (per minute) than an external user to whom we might, say, display fancy graphics. And we might have fewer internal users logged in at any one time, although it is important for employee productivity that the system has adequate dynamic capacity for them.
Note that a dynamic capacity requirement doesn't concern itself with the duration of user sessions.
Number of entities How many must the system be able to handle at once?
Entity condition In what state must an entity be in order to count? What must they be doing to be regarded as dynamically using the system? For example, we typically count users who are logged in, actively using the system, or both. Define this carefully and explain it precisely, or else users who aren't dynamically using the system are likely to be included. In particular, users might leave the system without telling us (logging out); this is the norm for visitors to Web sites. Write an entity condition clause to exclude departed visitors from the count of dynamic users. The subject of what to do about users who don't log out (what we might call "stale" user sessions) is dealt with in the Extra Requirements and Considerations for Development subsections of this pattern.
Duration of peak, if relevant Some systems have peaks of activity that last only a relatively short time. If so, describe the nature of such peaks—what causes them, when, and for how long—because it might be possible to take steps to squeeze the best possible performance from the system while peaks last (by "clearing the decks" so that the system has as little other work as possible during these times). If this item is omitted, the system must be able to maintain this capacity level all the time it is running.
Concessions during peak period If we're specifying dynamic capacity for a peak period (that is, short continuous duration), what concessions in other areas (in functionality and/or performance) can be made to help boost dynamic capacity?
Achievement timeframe By when must the system be able to cater for this capacity level? If this isn't stated, it's reasonable to assume the system will cater for this capacity level from the moment it is installed and for ever thereafter.
Summary | Definition |
|---|---|
Simultaneous «Entity type» capacity | The system shall be able satisfy «Entity count» simultaneous «Entity type»s «Entity condition statement» [«Duration of peak statement»]. [«Achievement timeframe statement».] [«Peak period concession statement»]. |
Summary | Definition |
|---|---|
The system shall accommodate 100 customers logged in and active simultaneously. A user is deemed to be active if they have submitted a request to the system in the past five minutes. | |
The system shall accommodate 200 customers logged in and active simultaneously when tickets for a popular concert go on sale—from half an hour before the published sale time until two hours afterwards. The definition of active customer is as given in the previous requirement. During a popular concert initial sale peak, it is acceptable for secondary services offered by the Web site (including any involving large downloads or the streaming of audio or video) to be shut down. It is also acceptable to prevent internal users from accessing any functions that involve intensive processing. |
A dynamic capacity requirement could have the following kinds of extra requirements—though they are all useful in their own right, and they can be specified even if you decide not to specify a dynamic capacity requirement at all:
Limit the number of users allowed in at once. This is usually achieved by preventing someone logging in if there are already at least a certain number of users logged in. This scheme can be refined to treat classes of users (or specific users) in different ways. For example, when the system is busy, we could let in only high-priority users.
Consider ways to reduce the load on the system imposed by internal users at times when it's exceptionally busy. Perhaps we could arrange for intensive work to be done at times of low external load. You could require the ability to temporarily disable functions that cause intensive processing.
A monitoring function to show the number of users currently active is always useful. This could show how many users are being handled by each server machine, and how many users of each type. It could let you dig down and view information on a selected individual session (start time, time since last request, user type, functions accessed). But be careful what you ask for, because it could be costly in development effort and its potential impact on performance. System monitoring is discussed further, with an example requirement, in the "Attack Direction 6: Duration of Failures" section of the availability requirement pattern later in this chapter.
Add one or more inquiry or report to show the number of active users over time, and perhaps also according to time of day (in order to identify peaks).
To help achieve a dynamic capacity requirement, developers might free up valuable system resources used by users who appear to have gone away. This, of course, is an implementation matter that doesn't concern the requirements. But it could have consequences the user might notice if they do return. They might be forced to log in again, or details of what they had done in the session might be lost, or their first response might be a little slower than normal (while the system fetches the details of their session and allocates any resources the session needs). If these sorts of consequences are unacceptable, write requirements to prevent them. But bear in mind that by doing so, extra hardware (or other steps) might be needed to achieve the dynamic capacity goals.
Demand a function to forcibly eject (log out) a selected user. This could be accompanied by a related function to bar a selected user, to stop them coming back. Neither of these functions directly affect dynamic capacity, but they can help if a particular user's actions are imposing a significant load on the system (either by accident or maliciously).
Raise an alarm if the number of simultaneous users exceeds a set number. You could ask for the ability for several different thresholds, each with its own alarm severity.
A sophisticated system could let a system administrator tinker with rules for allocating user sessions to machines, to give certain users (or types of users) better performance. This can also allow the load on a machine to be reduced, preparatory to shutting it down (for example for maintenance or upgrading). However, features such as this stray close to prescribing solutions: they are hard to specify without making assumptions about the nature of the solution.
Most of these are features for observing how well the system is performing, and for controlling it in order to squeeze maximum performance from it. The scalability requirement pattern (in Chapter 10) discusses further measures that contribute to achieving high dynamic capacity, such as the ability to add resources (server machines, for example) dynamically.
Consider how to deal with "stale" user sessions (again, where the user has departed without logging out). If a user session takes up precious resources, there are two approaches to making the most of them. First, they can be freed up by forcibly ending the session, which could inconvenience the user if they attempt to return shortly after. Second, we could store the session details elsewhere (such as in the database) so that the session can be revived if the user does come back.
Make provision for processing load to be spread across multiple server machines so that the system's dynamic capacity isn't held hostage by the performance of a single machine and whether that one machine can satisfy a given dynamic capacity target. Again, this says that scalability is usually more valuable than being able to achieve a particular performance goal. What would happen, for instance, if the volume of business turned out to be larger than anticipated? It's better to be able to react positively than to throw up your hands and plead that the system performs as asked for.
Any dynamic capacity target (such as the number of users logged in simultaneously) is likely to be so high that imposing this load manually will be difficult. After all, if the target is small, there's little point in the requirement being there. A test team (even if it conscripted extra volunteers) has better things to do than trying to manually replicate the activity of a collection of users twice its number. The only option is to use software to simulate this many users. There are products for this purpose, and it's easier to buy one of these than to embark on developing software in house to do the job.
Related patterns: | Data longevity, data archiving, scalability |
Anticipated frequency: | Between zero and two requirements, rarely more |
Pattern classifications: | Affects database: Yes |
Use the static capacity requirement pattern to specify the quantity of a particular type of entity that the system must be able to store permanently (typically in a database).
Do not use the static capacity requirement pattern to specify for how long information must be retained; use the data longevity requirement pattern for that. Also do not use it to specify how much disk space the system needs.
With storage being so cheap and databases able to handle vast quantities of data, static capacity itself isn't a critical issue per se: we're unlikely to have trouble finding enough disk space for whatever we need to store. The importance of a static capacity requirement is indirect: that all aspects of the system be designed and built so as to be practical and work well when the target number of entities are present. For example, an inquiry or report that shows every individual entity is impractical if we have more than a few hundred.
Most business systems have one type of entity that determines the quantity of most or all other high volume entities—one that drives everything else of note. Customer is typically the best type of entity to use. It determines the number of derivative entities—its extended family—such as (customer-initiated) transactions, a history of customer details changes, customer preferences, and so on. A system could have more than one type of driving entity that are independent of one another volumewise; if so, write (or consider writing) a static capacity requirement for each one.
A sizing model can be used to roughly estimate the disk space needed for a system's database, based on a target number of driving entities and the logical structure of this type of entity (see the data structure requirement pattern in Chapter 6) and its derivative entities, such as transactions. Add a large contingency (50 percent?) for extra overhead and columns added during the database design stage, plus a fixed chunk for configuration data (say, 20 Mb?) and space for chronicle data (which could itself be very large). Also add space for any multimedia resources (such as a picture of each customer, if you have them). But regard any such estimate as indicative only.
A static capacity requirement should contain
Type of entity What sort of thing are we guaranteeing enough room for (for example, customer)?
Number of entities What's the minimum number the system must be able to store, and still work well?
Entity inclusion criteria Which entities count for capacity purposes? If this item is omitted, all entities of the stated type are included. The purpose of this is to permit excluded entities to be removed (or moved somewhere else, where they have less impact on performance). For example, if we include only active customers—and we need to state precisely what that means—we are at liberty to take out all inactive ones, if that will help keep the system running smoothly. That's not to say excluded entities must be removed; if the system runs fine with them present, there's no performance reason why they can't stay. However, there must be a requirement for a function to remove the excluded entities (see the data longevity and data archiving requirement patterns in Chapter 6). This item has the effect of granting the development team a degree of leeway.
Achievement timeframe By when must the system be ready for this capacity level? If omitted, the system must always support this capacity.
Summary | Definition |
|---|---|
Total «Entity type» capacity | The system shall be able to handle a minimum of «Entity count» «Entity type»s. «Entity inclusion criteria». [«Achievement timeframe statement».] |
Summary | Definition |
|---|---|
The system shall be able to handle a minimum of 50,000 customers upon initial installation. | |
Eventual customer capacity | The system shall eventually be able to handle a minimum of 1,000,000 customers. This figure covers only those customers who have accessed the Web site in the past three months or placed an order within the past twelve months. It is not expected that this level of business will be reached earlier than two years after initial implementation. |
A static capacity requirement can prompt extra requirements for the following kind of functions:
Remove inactive information, to stop the system getting clogged up with data. (See the data longevity and data archiving requirement patterns.)
Statistical inquiries or reports to show changes in the number of entities over time. This reporting could be linked to changes in other performance measures over time (for example, how growth in business volume has affected average response times).
Raise an alarm if the number of entities reaches beyond a set number (or within a set limit of an actual capacity estimated by the system itself, perhaps based on available disk space).
Check that every specified function that accesses any type of entity whose volume is affected by a static capacity requirement will be practical to use and can be implemented with acceptable response time.
A way is needed to generate a sufficient quantity of data. This involves either invoking the system's software or writing something to emulate what it does.
You can't simply extrapolate performance at one capacity level to deduce performance at a higher capacity. Or, rather, the greater the difference (ratio) between the two levels, the greater the risk the extrapolation will be wrong (due to performance degrading). A factor of two or maybe four isn't a risk; a factor of ten is just about tolerable; twenty or more isn't good enough. To test that a system caters for a stated capacity, you need to generate that many (or a number smaller by a factor whose risk you consider acceptable). And you need to generate a representative quantity of every other type of dependent entity: transactions, chronicle entries, and so on. To do this, you need software to manufacture artificial data.
Use the availability requirement pattern to define when the system is available to users: the system's "normal opening times" (which could be "open all hours") plus how dependably the system (or a part of the system) is available when it should be. This requirement pattern is written to fit systems that appear to have a life of their own, such as server type systems that sit waiting with a range of services for users to call upon whenever they wish. It is not meaningful to specify availability in the same way for desktop-type applications (such as a diagram editor) that you start up when you want.
This requirement pattern has not been written to satisfy the demands of life-critical systems. It is for normal business systems, where the most disastrous outcome is commercial (financial).
It's easy to say "the system shall be available 24×7," but even the most bullet-proof, fail-safe, over-engineered system won't roll on for ever. Anyone who's aware of that should have qualms about such a blanket requirement. In any case, "24×7" has become cliché: it's often not intended to be taken literally when used in speech, so you can't rely on it being taken seriously when stated as a requirement. Fortunately, there's an easy answer to that too: add a percentage to it. "The system shall be available to users for 24 hours a day, every day, 99 percent of the time." That's better. But where has this figure of 99 percent come from? It sounds suspiciously arbitrary. And if I'm a software developer, what am I to do when I encounter such a requirement? What should I do differently if it said 99.9 percent? If I'm the project manager, how much will it cost to achieve this 99 percent? If I'm a tester, how can I test that the system satisfies this requirement? If I run it for a week nonstop without incident, is that good enough? No, requirements like this are unhelpful to everyone. It's time to go back to the drawing board.
Let's start by recognizing that our revised easy requirement is conveying two things. First, what I'll call the availability window, which is the times during which we want the system to be available (for example, 24 hours every day, or stated business hours). And second, how dependably it should be available during those times (the hard part!). The availability window is easy to specify and says a lot about the nature of the system, so begin by writing a requirement for it. It can be 24×7 if necessary, but making it less reduces the pressure on developers. The converse unavailability window (scheduled downtime) gives time for the various housekeeping and other extracurricular activities every system must perform—for which 24×7 allows no dedicated time at all. Doing these things during the unavailability window makes it easier to provide high availability the rest of the time. Define the bounds of the availability window according to what you require, not what sounds attractive.
The remainder of this section discusses an overall approach to specifying availability. For clarity, it leaves out the details of how to carry out each step and how to specify the resulting requirements; they are covered in the Extra Requirements subsection.
Before going any further, we must recognize that our availability goals cover only components within the scope of our system. We cannot be held responsible for the availability of anything that's outside our control. It's essential to state this clearly and prominently in the requirements specification—or everyone will naturally attribute to the system any downtime due to external causes. If the discussion and setting of availability goals must include external factors, separate the goals for the system from external goals. For example, if the customers of a Web-based service are to perceive less than one hour's downtime per month, we could allocate ten minutes of that to Internet communication unavailability (outside our control, but for which figures can be obtained), five minutes to Web server unavailability (assuming it to be outside scope) and forty-five minutes to unavailability of our system. The latter could then be sub-allocated into five minutes for hardware and operating system and forty minutes for our own application software. These allocations can be adjusted. For example, by choosing high-quality, replicated hardware and high-quality third-party products, we can reduce their allocations, leaving as much as possible for our own software. But this takes us into the technical realm that the requirements stage should eschew as far as possible.
Separate downtime allocations can be given to different parts of the system. If so, statistics should be gathered once the system goes live to see how well each part is going against its target. To do this, the duration of each failure must be correctly assigned to the correct cause—system or external—which isn't always easy to do. It's also liable to be contentious if different managers are responsible for different parts of the system. It's questionable whether a system can dependably work out when it's been available, but if you want it to, define requirements for what you want it to record. Otherwise, gathering these statistics is a manual process.
Our availability conundrum can be summed up as
We don't know what we'd get if we ignored availability.
We can't work out how much we need, or how much we're prepared to pay for it.
We don't know how much we could improve it by if we tried, nor how much it would cost.
To produce requirements for those features that our system needs in order to achieve the business' availability goals, we must satisfactorily unravel all three parts of the conundrum. That's a tall order; in fact, it is literally impossible, and the following paragraphs point out why. But that doesn't mean we should give up; we just have to set our sights a bit lower.
Taking (a) first, every system has what we can call a natural availability level, which is what you get if your developers build the system without paying any special attention to availability. (Notice that I say your developers, because if they're highly skilled your system will have a higher natural availability level than if they were mediocre.) The trouble with our system's natural availability level is that we can't possibly know what it is until well after it's been built. We might have a gut feel, but any attempt to quantify it would be just a wild guess. Nevertheless, it's a useful concept for discussion purposes: it helps us tell when we're on shaky ground.
For (b), the news is better: we can paint a reasonably clear picture of how important availability of this system is to the business—by quizzing key stakeholders about the damage the business would suffer in various situations, and asking them how much they'd be prepared to invest to reduce the chances of it happening. The results are still not strictly systematic—because of our inability to determine the chances of such failures happening, nor how much it would actually cost to do better—but they give the project team a sense of how far to go to improve availability. They also give stakeholders a good understanding of the issues.
Moving on to (c), achieving anything higher than the natural availability level is going to cost money. You'll also quickly reach a point of rapidly diminishing returns, where each incremental increase in availability costs noticeably more. The following graph demonstrates the cost of increasing availability—though I stress it is indicative only and not based on real figures. Cost 1 is that of the natural availability system, which—we discover eventually—has 95 percent availability. Building a system with 99.5 percent availability would cost roughly twice as much—double the whole system budget, that is. This demonstrates how vital it is to get availability requirements right: few other aspects of a system can have such a large impact on its cost.
Figure 9-2 shows the whole y-axis down to zero to point out that 95 percent availability is actually quite a high figure. Also, being prepared to accept reduced availability in an effort to reduce cost is usually a waste of time.
We run into further trouble when we try to specify ways to improve our system's availability: we can't know how much effect each possible precaution will have. If a system already exists, we can at least spot the most common failings and focus on them; but we can't do that for a system that's yet to be built. Hints can be found by looking at experiences with the organization's other systems, or systems previously built by the same development team, or similar systems.
The best way to achieve our availability goals is to specify requirements for a wide range of features that contribute. These requirements can be identified by investigating the three main causes of downtime (regular housekeeping, periodic upgrades and unexpected failure) and working out ways to reduce them. Each of these requirements can contain an estimate of its availability benefit. Give each one a low priority by default—though you can give a higher priority to any you feel deserves it (because many of these features will be worthwhile in their own right). Post-requirements planning can estimate the cost—in development effort and/or the financial cost of purchasing extra hardware or third-party products—of implementing each requirement. These benefit and cost estimates then let you make more informed choices of which of these requirements to implement: some requirements will emerge as more cost-effective than others.
The resulting requirements might not give stakeholders assurances in the terms they seek (or are used to seeing), but to do so would be misleading, because you couldn't guarantee the system will achieve them.
The steps to take are as follows (and the subsections referred to are within the Extra Requirements section later in this pattern):
- Step 1:
Write a requirement for the availability window, as per the template and example in this pattern. If different chunks of the system can have different availability windows, write a requirement for each one.
- Step 2:
Work out the seriousness of the impact on the business of downtime—as described in the section titled "The Business Impact of Downtime."
- Step 3:
Specify what is to happen when the system is unavailable or not working properly, as described in the "Partial Availability" section.
- Step 4:
Give a thought to surreptitious unavailability—which means bursts of poor response time when background work is being done by the system—if the unavailability window is small or nonexistent, as described in the "Surreptitious Unavailability" section.
- Step 5:
Specify requirements for features to improve availability—by investigating the causes of downtime and working out ways to reduce them, as described in the "Requirements for Reducing Downtime" section.
All the preceding steps are undertaken as part of the requirements specification process. Further steps, which follow, can be done later, after cost estimates have been made for implementing the system—including specific estimates for all the requirements that contribute to increasing availability:
- Step 6:
Estimate the cost of implementing each requirement for improving availability. This should be done as part of the project's main estimation process.
- Step 7:
Calculate the cost effectiveness of each requirement for improving availability, based on its estimated cost and its estimated effectiveness. A spreadsheet is perhaps the most convenient vehicle for doing this. Use these cost effectiveness values to decide whether to implement any of these requirements immediately; adjust the priority of each requirement accordingly.
A requirement to specify the availability window needs to contain the following:
Normal availability extent The times during which the system is planned to be available. This could be "always" (24×7), or a start and end time each day—and perhaps which days of the week, too.
Meaning of available A definition of what is meant by available in the context of this requirement. This must not be stated in terms that depend on how the system is implemented (for example, the availability of an individual server machine). For a typical system, available means that users are able to log in and perform whatever functions they have access to. Assuming a system is either available or not is something of an over-simplification; see the "Partial Availability" subsection later in this pattern for a discussion of the possibilities in between.
Tolerated downtime qualifier (optional) A caveat recognizing that perfect availability can't be guaranteed, and describing where more details are to be found about the amount of downtime that would be considered tolerable.
This template is for a requirement that defines the availability window of a system, with an optional clause for a tolerable level of unavailability (which needn't itself be in quantitative terms).
Summary | Definition |
|---|---|
«Extent» availability | The system shall normally be available to users «Availability extent description» [, except in exceptional circumstances of a frequency and duration not to exceed «Tolerated downtime qualifier»]. "Normally available" shall be taken to mean «Availability meaning». |
As for the template, these examples define the availability window. All other requirements related to availability are covered in the Extra Requirements section.
The proper specifying of availability can involve numerous extra requirements of diverse kinds; they might include many features that developers find desirable but which do not normally appear justified to the business. Typing them directly to the availability goals of the business provides that justification.
This section is divided into four in accordance with the approach described in the preceding Discussion section: the business impact of downtime, partial availability, surreptitious unavailability, and requirements for reducing downtime. The last of these is where the serious action is, and it is itself broken down into six separate areas, each covered in its own subsection.
The Business Impact of Downtime The first questions to ask are: Just how vital is high availability? Why's it needed? What's it for? Does survival of the business depend on it—in which case you've got to go to enormous trouble and expense? Or is it just nice to have, like a company intranet outside office hours, where if it's down you'll try again later? Answers to these sorts of questions are your best guide to the most suitable way to frame availability goals.
You can work out the seriousness of the impact on the business of downtime (during the availability window) by presenting key stakeholders with a few scenarios. One might be: the system fails altogether at 9 a.m. on Monday morning. How much damage has the business suffered after half an hour of the system being down? After two hours? Six hours? Three days? Pick the point at which serious pain starts, and then ask: How much extra is the business prepared to invest to reduce the chances of suffering this much damage? (Recognize that there's a kind of backward connection here: longer failures do more damage but are easier to shorten, so it's necessary to find shortest downtime period that hurts.)
Write up the results of these exercises as informal narrative in the requirements specification. Don't simply record every remark that was made: distill the salient conclusions into a few punchy points. Where possible, identify the source of the statement (if it's a senior executive, say) to give it added weight. The aim is to guide anyone involved in planning or developing the system—to give them a feel for the lengths they should go to. Here are a couple of examples:
"An outage of more than twenty-four hours would lead to a permanent loss of 25 percent of customers. (Source: marketing manager)."
"We're prepared to pay an extra «Amount of money» if it means we can be up and running again two hours after a major incident. (Source: CEO)."
These are targets only: it's impossible to guarantee they'll be achieved, because nothing's going to force the gremlins in the machine to abide by them. So stating them as requirements—things the system is required to satisfy—is problematical and actually reduces their credibility. Statements like these carry more weight when they're not requirements.
If you still feel the urge to state an availability percentage (or, equivalently, a tolerable amount of downtime per given time period), go ahead. If so, it's preferable for this to be an informal statement too—because it can't be guaranteed either.
Partial Availability What should happen when the system isn't fully or properly available to users but is still alive enough to do something? See if there's some fallback position that lets you deliver a reduced service to users or at least inform them that something's wrong. When one part of a system fails, most of the time the rest keeps on running. So treating all failures as all-or-nothing gives an exaggerated picture of their effect on availability. Still, because availability is already too complicated to calculate, you can, if you wish, ignore the subtleties of partial availability when confronting quantitative availability levels.
It can be worthwhile to divide a system into two or three chunks for the purpose of availability goals. These chunks could be according to their importance or the technology we know each uses. For example, if we're building a Web site and the system behind it, it would make sense to state higher availability goals for the static parts of the Web site than for the interactive parts (placing orders, say).
When the system is partially available, the working part might be able to adapt accordingly. For example, if the software behind our Web site fails (or is down for maintenance), we'd like to let our users know that certain functions are temporarily unavailable—perhaps by having fallback static Web pages to display in this situation. Here's an example requirement:
Summary | Definition |
|---|---|
When the system is unavailable to users, any attempt by a user to access the system shall result in the display of a page informing them that it is unavailable. This response is not expected if those parts of the system needed to provide such a display are themselves not running—though all practical steps shall be taken to make to the user that something is wrong. |
The requirements can't state the reaction to every type of failure (and mustn't attempt to), but they may address a small number of salient ones. It's also possible to specify requirements for steps that are to be taken when appropriate to improve error handling; these can act as guidelines for developers.
Surreptitious Unavailability If we don't give our system spare time to do its housekeeping (that is, no unavailability window), it is forced to do it while users are active. This can manifest itself as intermittent slow response time or possibly a disconcerting delay (say, 30 seconds or a minute) if it stops certain types of processing for users altogether. We can call this surreptitious unavailability, because the system is unavailable for this time but in such a way that the unavailability is difficult to notice.
If degraded performance is tolerable for a short while, adjust your performance requirements to allow it—and to say how much is acceptable—though at requirements time it's impossible to know how much time might be needed. You could also stipulate quiet times of day (or days of the week) to which such tasks are restricted. If degraded performance is unacceptable, make this clear, either in the relevant performance requirements themselves or in an additional requirement. Otherwise, developers are likely to argue that response time during housekeeping is a special case. Either way, bring this issue out into the open early.
Demanding both constant availability and consistently good response times is liable to create a squeeze that puts pressure on developers—and costs extra to deal with. (That this appears to happen rarely is perhaps due to surreptitious unavailability being ignored.) Relax this squeeze if you can: don't write onerous requirements unless there's a genuine need. If the goal is for the effect of background housekeeping not to be noticeable—which is usually perfectly acceptable—it's a good idea to permit a degrading of user response times small enough to fit the bill (say, by 10 percent).
Here are a few example requirements for alternative ways to prevent surreptitious unavailability getting out of hand (though they can be used in combination if need be):
Requirements for Reducing Downtime We can increase a system's availability by examining the three main causes of downtime—maintenance, periodic upgrades, and unexpected failure—and working out ways to reduce them. Some of these ways will be more cost-effective than others. Decisions on which ones to implement (and when) can be taken later in the project: it usually makes business sense to defer some in order to deliver the system faster. The role of the requirements here is to provide the information on which these decisions can be based: to demonstrate what precautions can be taken, what effect each is likely to have, and some idea of their complexity.
Requirements specifying features introduced to help achieve availability targets can be diverse and numerous (so there is a lot to work through in this section!). They span the duplication of hardware and software components and features needed by the products you use (such as the database). They also cover functions for monitoring, startup and shutdown, error diagnosis, software installation, security, and potentially other things that don't have an obvious connection to availability. Lots of these functions the system needs anyway, but improving availability might demand that they be better: more powerful, faster, easier to use—in general, built with more care and attention.
In lots of systems, many of these behind-the-scenes functions are often cobbled together as an afterthought, with little time allocated to developing them. Part of the reason is that most requirements specifications omit them altogether—because their connection to the system's business goals appears tenuous and normal users don't use them. Connecting functions directly with availability goals that are in turn attached to business goals gives us solid justification for including those functions and for treating them with the same seriousness as the rest of the system. This is an important point: well worth highlighting.
To identify extra requirements for functions that help us achieve our availability goals, we need to look at the reasons systems are unavailable. Anything that reduces any of these causes will increase our expected availability. Let's introduce a few straightforward formulae. The first one breaks the problem down into three constituent factors:
Formula 1: Total downtime = Maintenance + Upgrades + Failures
where | Total downtime is the amount of time during any given period for which the system is unavailable to users during the planned availability window. Maintenance is regular housekeeping that needs to be performed to keep the system operating smoothly—such as database backups—or business processing that cannot be done while users are accessing the system and which must be performed during the availability window. The stopping-and-restarting of any component counts as maintenance if it must be done periodically. Upgrades are the installing of new software or hardware, and all related tasks. Failures are anything that goes wrong that renders the system unavailable. |
Assign every cause of downtime to one of these three factors. The dividing lines between them aren't always clear-cut. For example, if new software has to be rushed into production to forestall a looming failure known in advance, should that count as a normal upgrade or a failure? You could introduce an extra category for "preemptive corrections" and perhaps more for other boundary regions. They could be useful for management purposes, but they would only cloud the following discussion so they're omitted here.
A second formula can be applied either to all outages collectively or to one of the three factors at a time:
Formula 2: Downtime = Frequency of outages × Average outage duration
(We talk about average duration here because we're making estimates for the future, not dealing with actual outages in the past.)
Maximizing availability is equivalent to minimizing frequency and duration for each of the three factors. Frequency needs to be treated separately from duration because reducing one involves different steps to reducing the other. Let's consider each of the three factors in turn and suggest ways to minimize their frequency and duration—giving us six directions from which to attack the problem and which are discussed in the following six subsections in the order indicated in this table:
Frequency | Duration | |
|---|---|---|
Maintenance | 1 | 2 |
Upgrades | 3 | 4 |
Failures | 5 | 6 |
But first observe that downtime for maintenance and upgrades will be zero if they can be undertaken wholly outside the availability window. Every serious system has various sorts of housekeeping tasks it must undertake. Many of these tasks are usually easier to do if nothing else is happening at the same time—especially real work by pesky users.
All of these six attack directions must be considered for everything that is within the scope of the system. This includes hardware—if that's in scope. It also includes all third-party products you need—if they're in scope. The implication is that the project team is free to choose all the products the system needs—in particular, to choose products that enable us to satisfy the availability requirements. A complication arises if product choices are forced on the project. If possible, treat these products as outside the system's scope and, accordingly, separate their availability goals from the availability goals of the system in scope. This isn't always possible, however, and you might have to accept responsibility for the availability of a product that's somewhat outside your control. There can also be cloudy areas. For example, if the choice of database has already been made, you might still be able to reconfigure it or purchase add-ons so as to increase its availability.
For each of the six attack directions, it's necessary to work through each of the types of constituent technical pieces in turn. The main ones are
Hardware. Consider the following:
The computer(s) on which the system will run.
Computers running other software: database, Web server, firewall, and so on.
Users' desktop machines (conceivably!).
Communications hardware, including internal networking devices, cabling and phone lines, and hardware.
Power supplies, both the normal and emergency uninterruptible supplies.
Third-party software products, such as database, Web server, and middleware.
Our own software.
Draw up a list of all those pieces relevant to your environment that have a bearing on the availability of your system. For each of the six attack directions, consider each item on your list and specify requirements for it as appropriate (as described in the following six attack direction subsections).
Again, worry about only those pieces that are within the scope of your system, as defined in the requirements specification. If the list you draw up includes things you believe shouldn't be the project's concern, you might have set the system's scope too broadly and need to reduce it. Nevertheless, it's useful to put in the requirements specification a list of all the pieces outside scope whose failure can affect the availability of your system—because your stakeholders might want to check their dependability and perhaps improve some of them.
Each requirement created to improve any of these attack directions should include a statement estimating the extent to which it contributes. Occasionally, it's possible to state the extent categorically (not as a mere estimate). This statement can be omitted if the requirement's definition already makes the effect obvious. A suggested template for such statements is
"It is estimated that this requirement reduces «Factor» by/to «Extent».
where | «Factor» is one of the six attack directions |
and | «Extent» is the average amount by which it improves the factor." |
An average is usually worked out by estimating in what percentage of failures this requirement will help, and by how much it helps on average then. For example, something that helps in five percent of failures but typically saves then 20 minutes will save an average of one minute per failure. Here are some examples:
"It is estimated that this requirement reduces average duration of daily housekeeping by five minutes."
"This requirement reduces frequency of upgrades by three per year."
"It is estimated that this requirement reduces duration of each application software failure by 15 minutes on average."
Always stress when anything is just an estimate. At requirements time, we don't know how much the system is going to cost or what its "natural" availability will be. So we have little idea how much extra it'll cost to achieve stated availability goals. Even metrics determined from previous projects (if you have any) wouldn't tell us much. Too much depends on technology choices that (usually) have yet to be made. It is therefore impossible for the requirements to make concrete judgments on what features our software needs in order to deliver acceptable availability. And this is even before we begin to think about how much it would cost.
There is a risk that the total of the downtime savings indicated in these requirements might add up to more downtime than we anticipate—by overselling the benefit of some of the preventive steps. To prevent this happening, you could extract all these figures and, say, put them in a spreadsheet.
If availability demands aren't onerous or if you have confidence that the system's natural availability level will be good enough, you can leave out of the initial implementation all the requirements for increasing availability. They can be introduced selectively later once we see how good the system's actual availability is and the causes of any failures that do occur. It is, however, a good idea for developers to bear in mind all the availability-related requirements—to make provision for them so that it's straightforward to add them later. Also. choose third-party products that satisfy these requirements as far as possible: it would be disappointing to have to replace a third-party product later just because it's not reliable enough.
Now for the six attack directions themselves. Note that they're all written to cover hardware and third-party products as well as our own software.
Attack Direction 1: Frequency of Maintenance Commercial systems historically do their regular maintenance once a day: the old end-of-day run. This is a convenient and natural cycle. There might be sound business or technical reasons for doing system maintenance several times a day—or less than once a day. These reasons should take precedence over the desire to reduce frequency of maintenance as part of our efforts to improve availability. But this section would be failing in its duty if it didn't point out that doing maintenance less often improves availability (if user access must be curtailed to perform maintenance). On the other hand, there might be a trade-off between maintenance frequency and maintenance duration: when doing it less often means it takes longer each time.
A system can have more than one type of maintenance—for example, daily and monthly. Moving some processing from a frequently run type to a one less frequently run would then reduce the total maintenance time—and improve availability. But it's rare that the requirements can effect changes like this; they are more a design matter.
Here's an example requirement for the record—but it does look rather old-fashioned:
Attack Direction 2: Duration of Maintenance Duration of maintenance can be brought down to zero for most types of system through the use of suitable products (especially the database); it might take some extra development effort, too. Here are some sample requirements for a few things that contribute to reducing (or eliminating) maintenance time:
Summary | Definition |
|---|---|
Database backups while system active | A database product shall be selected that permits backing up of the database while other database activities are going on. It is estimated that this requirement reduces duration for which the system would be unavailable to users for maintenance by fifteen minutes each day. |
Each product used (both software and hardware) shall be chosen on the basis that it can be depended upon to run for an extended duration without needing to be restarted. It is estimated that this requirement reduces duration for which the system would be unavailable to users for maintenance by thirty minutes each week. | |
Housekeeping while system active | All system housekeeping tasks that can be performed while the system is available to users (such as purging old data) shall be. It is estimated that this requirement reduces duration for which the system would be unavailable to users for maintenance by ten minutes each day. |
Note that these requirements contribute to reducing both maintenance duration and frequency, so the estimates of their impact must reflect both.
Attack Direction 3: Frequency of Upgrades The frequency with which the various components of the system are upgraded is determined primarily by the forces that motivate the upgrade: to introduce new features or other software improvements, fix defects, add faster hardware, and so on. Those forces will usually strike a sensible balance with the forces that don't want the system interrupted. Nevertheless, if it's important for availability reasons to limit the frequency of system shutdowns for upgrades, the requirements are the place to say so. Each type of component in the system (hardware, third-party products, our own software, and so on) has its own upgrade considerations, and therefore need to be treated separately in these requirements.
It's worth observing, though, that stable systems need upgrading less frequently—and because high-quality systems are stable, this implies that quality reduces frequency of upgrades. There's also a trend towards more iterative development methodologies (shorter development cycles with more frequent deliveries, that is), but it's not necessary to install every iteration live. Iterative approaches don't force us into more frequent upgrades.
Requirements that address upgrade frequency are more technical than requirements should be. But if you want to go further—to take steps to perform upgrades without interrupting user access—you'll have to get more technical still. It is possible to design systems in such a way that you can upgrade software components while the system is running, but it's very hard to do. Don't expect an average development team to be capable of tackling it. And expect it to be expensive, for both development and testing.
Here are a couple of example requirements:
Attack Direction 4: Duration of Upgrades A typical system upgrade in many organizations is poorly planned and is of a duration that cannot be predicted in advance. It can drag on to be a thirty-six hour marathon of frequent coffee breaks and late night pizzas. The people involved might be lauded for their stamina and dedication, but their heroics shouldn't be necessary and involve risks.
The duration of an upgrade can be reduced by preparation, which costs time and money. The shorter the duration, the more preparation must be done (to cram all the work into the smallest possible window). As you make the window smaller, the preparation effort grows exponentially. Possible steps:
Rehearse what needs to be done. This can include trying out the upgrade on a test system (or more than one).
Automate as much as possible. Write scripts, or more substantial software. Often these aren't regarded as "real software," but they are, and they should be treated just as seriously as any other software. After all, if they do something wrong, they can do just as much damage.
Prepare instructions for the work that needs to be done. Arrange for as many tasks to be performed in parallel as possible.
Do as much as possible beforehand. Spend your precious downtime on only those tasks that must be done while the system is down.
Bring in as many people as necessary. If minimizing the time it takes is the top priority, bring in as many people as it takes.
Some organizations omit some or even all of these steps—often out of sheer ignorance. While requirements cannot involve themselves in the conduct of a particular upgrade, they can indicate the lengths that should be taken to reduce the duration of each one. They're useful if they merely alert people responsible for upgrades to the fact that it's possible to make preparations.
If you have multiple instances of the system to upgrade, preparation becomes more cost-effective because it's shared across all those instances. Software for automating upgrades is particularly important if you're specifying a product. In this case, you definitely need to specify proper requirements for the upgrade software.
Avoid setting a time limit for upgrades unless there is a genuine business reason. Even for one system, upgrade durations will vary. We just want each one to take as little time as possible. If we set a limit of three hours, we'd still want a two-hours-by-hand upgrade to be done more quickly if possible.
Here are a couple of example requirements:
Summary | Definition |
|---|---|
Minimize software upgrade duration | All reasonable steps shall be taken to minimize the length of time for which the system must be shut down when upgrading its software. "Reasonable steps" shall be taken to mean up to two person days of effort for each hour of downtime saved. It is estimated that this requirement reduces average software upgrade duration by two hours. |
Upgrade instructions | Instructions shall be written for each system upgrade, to describe all the steps that must be taken to install it successfully. |
Attack Direction 5: Frequency of Failures What we're talking about here is reliability, in the sense of rarely going wrong. There are two types of failures: accidental (such as software defects, hardware breakages) and deliberate (primarily malicious attacks by someone either outside or inside the organization). We need to take steps to prevent both. Minimizing accidental failures is achieved by quality. For hardware and purchased software, this means buying reliable, high-quality products. For our own software, it means building with quality: primarily sound development to keep software defects to a minimum and good testing to find them. Hardware reliability can also be enhanced by replication: having more than one of everything (or some things).
Protecting against deliberate attempts to cause failures is a matter of security. It includes firewalls and antivirus software, as well as access control to prevent valid users doing things they shouldn't.
There's only one requirement here, because we don't have room to cover the other topics that contribute most to stopping failures: good development and testing practices, and security.
Attack Direction 6: Duration of Failures A system that fails only once a year would appear to be of high quality. But that counts for nothing if it takes three weeks to recover from that one failure. Stopping failures from happening in the first place is usually given much higher priority than keeping the duration of each shutdown to a minimum. But according to our Formula 2 for total downtime, reducing their duration is just as important.
When a failure occurs, its duration is determined by the following formula:
Formula 3: Outage time = Time to detect + Time to react + Time to fix
where | Outage time is the length of time from the moment the system became unavailable to users until it becomes available again. Time to detect is the length of time it takes to detect the failure and to raise the alarm. It includes the time it takes to notify people. Time to react is the length of time between people being notified until the first person can begin to work on the problem. Time to fix is the length of time it takes to investigate and rectify the problem and make the system available to users. |
Imagine your average system crashing at 2 a.m. The time to detect is the half-hour it took a dozing operator to spot the usual messages are missing from the screen; the time to react is the hour and a half it took to phone, wake, and drag into the office the on-call programmer; the time to fix is the three hours the programmer looked for subtle clues among paltry evidence before finding the cause (the thirty seconds spent rectifying the silly fault hardly registers), plus the half hour it took to restart everything. Minimizing outage time involves minimizing all three factors: it's little use having lightning-fast system monitoring detect a problem in a millisecond if it still takes hours to fix. It also means paying for a taxi to get the programmer to the office ten minutes faster is just as valuable as fixing it ten minutes quicker, which is something for expenses-conscious managers to bear in mind.
It's analogous to a house fire. The duration of the fire is how long it burns before someone raises the alarm, the time it takes for the fire brigade to arrive and put out the fire—oh, plus the time before you can repair the damage and move in again. The last point is worth noting: what we're interested in is how long it takes before everything's back to normal.
The preceding formula assumes human intervention is necessary, but it is possible for a system to deal with some types of problems automatically. For example, if a system monitor detects an expected process is not running, it could start it up. In such cases outage time equals time to detect plus time for automated reaction. It must be stressed, however, that it's hard to develop automated responses that properly rectify an identified problem, and such responses are possible for only a few kinds of fault. The system monitor in this example doesn't do that: it doesn't prevent the problem recurring, which it would do repeatedly if an error in the relevant process's software caused it to crash each time it starts up.
The remainder of this section deals with each of the three factors in Formula 3 in turn. It addresses only features that can be built into a system, although operational factors have an equally large (or larger) part to play. Requirements are not the place to deal with the details of operational matters.
Time to detect Minimizing the time it takes to detect a failure involves spotting any problem as fast as possible and then notifying whoever should be notified, also as rapidly as can be.
In an office full of people, if one person suddenly collapses, others would notice and come to their assistance. In contrast, if one machine in a network (or one process in a machine) collapses, the natural reaction of its colleague machines is to do nothing or at most to complain that it's not doing its job. If we want machines to feign a little concern, we have to tell them how. For this, requirements should be specified, covering three aspects:
Any piece of software that detects a serious error must raise an alarm.
Special system monitoring facilities are needed to check that all machines and processes that should be running are running and to raise an alarm if they're not. They need to run on more than one machine, if they are to detect the failure of a machine on which they run.
A notification mechanism is needed—something to raise an alarm on request—to tell nominated human beings there's a problem that someone needs to fix. This might provide some way for the people to acknowledge being notified. And if no one acknowledges the notification, the mechanism might notify more people.
The first two are types of problem detection, and the third covers what to do when a problem is detected. All involve investigating the specific needs of your system and its environment: one-size-fits-all requirements won't work here. Here are some questions to ask—and when answering them keep in mind that the primary concern is reducing response time:
What constitutes a serious error? Don't attempt to identify them individually, but define criteria by which any type of error can be judged whether it counts as serious.
Which people need to be notified when a serious error is detected? Does it depend on what kind of error? Does it change according to the time of day (especially outside normal office hours)?
By what means should we notify people? A message on a screen, email, pager, SMS, instant message, ring a loud bell, tell some other system? Do we need to notify one person by multiple means? Should we use different means for different people or at different times of the day? Should the means to use vary depending on how serious the error is?
Do we need acknowledgment that someone is taking responsibility for the problem? What if no one acknowledges doing so?
It's not necessary to ask what machines and processes need to be monitored, because that's too technical. It's possible to specify a requirement for this in general, technology-independent terms (as the second example requirement that follows does).
The detecting of an error or the raising of an alarm could take other actions too, if we want—say, for exceptionally serious errors. For example, if an attack by hackers was detected, we might want to shut down the system completely. This is within the scope of the subject of availability only insofar as it prevents further damage, but it demonstrates that the features being discussed here can be beneficial in ways beyond just reducing the duration of failures.
Software that checks a system's availability can also be a basis for statistics on its availability. Up to a point, that is, because the checker could itself fail and can tell us nothing when it's not running. It also needs to be built to cater for deliberate system downtime and, ideally, to have a way of distinguishing the three types of downtime, which means system shutdown lets the operator express why the system is being shut down.
Here are some requirements covering the three aspects listed:
In practice, notification mechanisms deserve to be specified in more detail than in the second requirement here. You could even treat it as an infrastructure in its own right. Examples of various notification-related example requirements are given in the extendability requirement pattern in Chapter 10.
Time to react Getting investigators working on a failure is largely an operational matter, which doesn't concern the requirements. Steps might include making provision for emergency access to the live system by people (mainly developers) who normally don't have it. It might be, though, that special features can be added to the system to enable quicker access by whoever is to investigate a failure. These could include
Remote access facilities, if the system doesn't otherwise need them. The intent here is to allow someone to dial in from home, especially after hours, to work on the problem.
Access control extensions, to allow an investigator to do more in an emergency situation than they would normally be allowed to.
Bear in mind, though, that some types of failures could also affect the working of these features too, if hardware on which they depend has failed. Insisting on replication of components used in combating a failure is worthwhile. Even if rarely needed, it is precisely at times of crisis that they will be called upon.
Observe, too, that these features give an investigator exceptional ability to do deliberate damage and they thereby constitute a risk (however small) of facilitating a worse incident. Lest you consider such a coincidence unlikely, a malicious developer could contrive a failure precisely to provide this opportunity.
Here are a couple of example requirements:
Time to fix Minimizing the time it takes to fix a failure involves providing investigators with as much information about the problem as possible and giving them the best tools for probing the state of the system. This is a subject that's often completely ignored when specifying and developing systems (beyond chronicling errors), but at the very least you should reflect on whether it deserves serious consideration. Another important way to getting a system up and running quickly is making provision for disaster recovery; this topic is discussed at the end of this section.
The information to help diagnose a failure needs to be gathered as a matter of course while the system is running normally—like an aircraft's black box flight recorder. Steps that can be taken to gather this information include:
Record everything that happens in the system that might be of interest, especially errors (even those not serious enough to constitute a system failure).
Insist that all error messages be clear, correct, and detailed. Considerable time can be wasted if a problem produced an error message that was uninformative or, worse, misleading. An investigator could be sent off on a wild goose chase.
Here's an example requirement for each of these two steps:
As for diagnostic tools to investigate a problem, steps to consider include:
Identify a range of tools likely to be useful for investigation, and install them on the system.
If it is unacceptable to have the investigative tools permanently installed (for valid security reasons because they do constitute a security risk), have them readily at hand. There might be several ways to do this: having software ready to install, or having a separate machine containing the tools ready to connect to the live network.
Document error messages—not necessarily all, but those about which something extra can usefully be said. These explanations can tell an investigator what an error really means, what causes it, and how to respond to it. The set of error message explanations must be made available to investigators. While this step might appear to relate to the gathering of information, the set of error messages actually constitutes a diagnostic tool.
Develop special software to examine the integrity of the system, especially its data. Programmers sometimes create such software for their own use in testing, which then usually languishes unknown and unappreciated, which is a waste. Regarding such utilities as part of the mainstream system can make it available to help when a problem occurs.
Here's an example requirement for the second step:
Another way to get a system up and running again quickly is to invest in a disaster recovery system: a duplicate hardware and software environment, preferably in a different physical location. As its name suggests, such a set-up lets you get up and running again when anything up to and including a disaster befalls the main site. But it doesn't help if the reason for the failure was a major software fault that affects the second system, too. Disaster recovery involves a lot more than setting up a second environment, and it must be investigated—and later tested—thoroughly. Bear in mind that any upgrades performed on the production system must also be performed on the disaster recovery system. Here are some simple example requirements that suggest a few aspects to worry about but that in practice deserve to be specified in much more detail:
If you're faced with an unfriendly availability requirement, question it: "What am I supposed to do with that?" Should that get you nowhere, work your way through the suggestions in the Extra Requirements subsection in this pattern to come up with a swag of concrete steps to take. You can even formulate them as requirements if you like. Then implement them.
Too many kinds of extra requirements related to availability exist to discuss them here. But pay particular attention to the availability window specified for the system, because this affects whether housekeeping tasks must be performed while users are accessing the system.
Throughout the development process, document any problem you detect that could affect system availability and explain how to deal with it and recover when it occurs. Check with the testing team to see if they have discovered this problem already, as they might have valuable additional information and insights.
A classic availability requirement (of the "24×7 availability 99.9 percent of the time" kind) is so hard to test that it's not even worth trying for a normal commercial system, which is the root of the argument against such requirements in the first place. The kind of starting-point availability requirement advocated by this pattern (that defines the availability window) is more practical to test: you need to simulate a small number of days' running (you might even consider that one day suffices) and check that there's nothing that prevents you running the system constantly during the specified hours. Whenever you encounter a primary availability requirement, first ask yourself how easy it is to test. Also be alert for the two nastiest kinds: those that are impossible to test, and those that are feasible but impractical to test.
No matter what form availability requirements take, testing should include running the system continuously for an extended period, which means for as long as you can but certainly for several days. Running for a month or more continuously is excellent. Keep a wary eye open for memory leaks: observe how much memory each process takes up, and check that it doesn't grow steadily the longer the process has been running. Any software that's expected to run for an extended period will surely lead to unhappiness if it has a memory leak. Pass it back to the development team smartly, but also let it keep on running to see what happens.
Requirements whose aim is to deliver availability (those covered in the Extra Requirements section earlier in this pattern) are too diverse to enumerate here. Treat each one individually on its own merits. If extra requirements of these kinds have not been formally specified, but developers have devised their own steps to achieve availability goals, you could find out what those steps are and test them as if they were requirements. It's impractical to prove that all the steps demanded to increase availability actually deliver a stated availability level. The best you can do is review any reasoning or calculations performed by the analyst or developers and ask yourself if their assumptions look reasonable.
Test for surreptitious unavailability. Find out if any housekeeping-type tasks are performed while users are active. If so, perform a range of user functions while this housekeeping is underway, and test its effect on response time.
Nearly all systems are installed containing known defects. Document well each known defect that has the potential to affect the availability of the system. Explain what causes it, how to diagnose whether it was the cause of a system failure, and how to respond when it happens. Make these explanations as easy to find as possible in the event of a failure. These steps can reduce the length of a system outage significantly.