
In this chapter:
7.1 Living Entity Requirement Pattern 129
7.2 Transaction Requirement Pattern 133
7.3 Configuration Requirement Pattern 138
7.4 Chronicle Requirement Pattern 144
7.5 Information Storage Infrastructure 154
Builders of systems tend to take a cavalier and ad hoc attitude to information: we lack rules for when data can be deleted; we're relaxed about losing data; we permit data to be modified without retaining a record of what it was before; we don't know who did what; we can't tell how amounts were calculated. It's hardly surprising that so many systems handle data in a sloppy and messy manner. This chapter aims to impose some order and consistency, by introducing a scheme for dividing all data entities into fixed categories that share many important characteristics. It then presents a requirement patterns for the most important categories of data entity, namely living entity, transaction, configuration, and chronicle, and suggests demands to make on all entities in each category. These categories are shown in Figure 7-1.
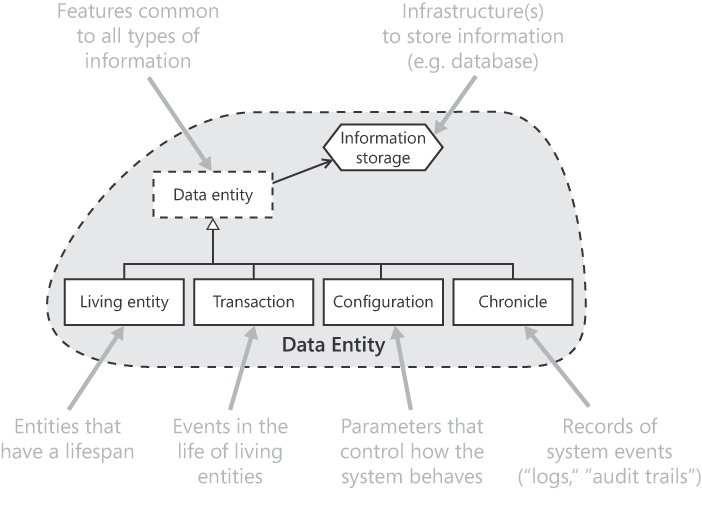
To satisfy information-related requirements, a system needs a supporting infrastructure for information storage, to store information persistently (most commonly in a database); sometimes it needs more than one. The requirement patterns in this chapter are organized and written with a view to using a database as the main storage mechanism, which is true for almost all business systems. These patterns do, however, work perfectly well for data stored in flat files and more specialized repositories (for example, electronic directories for finding addresses, such as those adhering to LDAP, the Lightweight Directory Access Protocol). A database provides all the operations we need to store and retrieve our data. But these operations are at too low a level to relate meaningfully to requirements. We need a stepping-stone to help bridge the gap. This chapter divides a typical business system's data into seven key categories—according to the ways in which that data should be handled. We can then define, for each category, rules that apply to all data in that category (via pervasive extra requirements), to save having to worry about such matters for each individual type of data. In a typical business system, we find the following categories of data:
Each type of information is placed in one (and only one) of these categories, each of which has been chosen to recognize the special characteristics the information has. We can then define requirements to enforce rules for the sound handling of each category. Potential requirements are discussed in the requirement patterns in this chapter. Don't worry if one or two of the category names look rather abstract: you needn't expose readers of requirements specifications to them.
In the preceding table, the In requirements column indicates whether requirements are needed for that category of data. Not all data in a database is visible or of direct use to users; some is intermediate "massaged" data, is there to improve performance, or helps in other ways to keep the system running smoothly. Structures for this sort of data are created during the design of the database and don't appear at the requirements stage. Only data of direct interest to users is reflected in requirements (indicated by a Yes in the table), and only those categories of data have had requirement patterns written for them. Data entities for which Usually not is shown don't result directly from requirements, but there could be a requirement or two that refers obliquely to or implies the presence of such data. Also "Usually not" is preferred to "No" because it would be rash to say that there will never be requirements for these categories of data.
Each entity, regardless of its category, needs a name. Make it concise, unique, and descriptive—describing the kind of thing it stores. A useful convention is to express each one in the singular (so "customer," not "customers"). Avoid vague collective terms, such as "inventory," that don't tell you what that entity contains.
Requirements for specific sorts of information define both the data needed to operate the business and any associated functionality. But there are several areas, common to all types of information, for which extra requirements are sometimes appropriate or for which it is worthwhile to specify supporting functionality once rather than each time. Some areas to consider are:
Information integrity, including database back-ups and restore/recovery It can be dangerous to assume that all your information will magically always be there for you, intact, pristine, and available. Some judicious extra requirements can proclaim a few things that we should be able to rely on—partly for insurance and partly to remind the developers of pitfalls to avoid.
Multi-part information entry Any function that involves entry of information in multiple parts (that is, split over multiple screens) needs to be able to handle failure partway through. The simplest way is to record nothing (or act as if nothing has been recorded) until everything has been entered—but expect users to find this frustrating, because they then have to rekey the first information if the user exits partway through. However, if information is stored after each screen is entered, the system should provide a way for the user to pick up where they left off—which can be complicated and cumbersome to implement (so it costs more).
Co-ordination of multiple data stores If your system interacts with another system, and both store data, trouble could result when one of them fails: their data could be inconsistent. This is a technical matter, but point it out so it won't be forgotten, and think through possible problems (which might be significant) and how to deal with them—such as special corrective software, for which we'd need requirements.
Timed and co-ordinated changes Sometimes, changes to information in a system need to be made at a precise moment in time (such as a change in a tax rate at midnight on a specific date, mandated in legislation). Sometimes a collection of changes needs to be made at the same time (such as a revamping of a shop's pricing and discounting). Special provision must be made if you want these sorts of changes to be made while the system is available to users, with minimal risk of human error.
Approval of actions A user of a computer system usually goes ahead and does what they want, but a business sometimes wants some actions approved by a second person before those actions take effect. See the approval requirement pattern in Chapter 11.
Areas 4 and 5 have aspects in common, especially if your system ends up having a general mechanism for storing changes before applying them (which is discussed in the Considerations for Development section of the approval requirement pattern).
Inquiries When you're specifying a particular type of information (or a function for entering it) is a good time to ask yourself who will want to look at this information and why. For each function for entering information, there should be at least one function to view it—at the very least to let the user see whether what they entered was actually recorded, in the event of a system failure.
The subsections that follow deal with each of these areas in turn—except Areas 5 and 6, which are covered in the approval requirement pattern in Chapter 11 and the inquiry requirement pattern in Chapter 8. Areas 1 and 6 are likely to be relevant in all commercial systems; ask yourself whether the other areas apply to your system.
Information Integrity, Including Database Back-Ups and Restore/Recovery First of all, what do we mean by "information integrity"? It can be summed up by the ACID properties possessed by any reliable database, which are: atomic—any change is made either completely or not at all; consistent—whichever way you look at the data, you get the same picture; isolated—no change is affected by any other change that's in progress but not yet completed; and durable—any completed change stays there. Backing up the information can be regarded as providing durability even when a storage disk is lost. Restoring is the act of copying from a back-up when the main data is lost, and then recovery is the act of bringing the restored data up to date using an update log of changes made since the back-up was taken.
Strictly speaking, if we want information integrity at all, we should define requirements for it. But if we're storing our data in a proper database, it's reasonable to assume that it will take good care of our data and guarantee its integrity. (If you're not happy with that, then by all means specify requirements you expect your database product to satisfy.) This isn't true for other places where information is stored: flat files provide no protection against data loss, for example. Developers like using flat files for such things as configuration parameters and imported/exported data, and they often forget about the integrity of this data—so it's a good idea to add a requirement to demand the integrity of all data, and emphasize that this includes flat files. Such a requirement can also demand (implicitly or explicitly) that any online directory (such as LDAP) or similar product that you use must store its data in a proper database.
You could draw up a list of all the types of information in your system (taking a broad interpretation of "information" for this purpose), including:
Web pages, including page templates (such as JSP or ASP pages), style sheets, and help pages.
All flat files referenced by the system, especially configuration files. Don't forget files that belong to third party products (since they are indirectly part of your system). Including files used by the operating system is perhaps going too far.
Emails and any other types of electronic messages sent and received, including attachments.
Document templates (such as for letters generated using a mail merge facility).
Then go through the list asking what would happen if you lost the disk on which those files live. Bear in mind that even if you have back-up copies of these files, you will lose all changes made since the last back-up copy. If some of the possibilities scare you, take steps to protect against them—for which you need to define some requirements. The more of this information you can store in a database, the better.
Here are some suggested pervasive requirements for this area. The first one is uncompromising, and is impractical for some systems and over-the-top for others. The second one is a gentler alternative—but its laxness still means that a disk failure could leave an unpleasant mess (though you will at least know how big a mess). It's possible to specify a compromise in between these two.
Multi-Part Information Entry Have you ever bought anything from a Web site that involved a longer succession of Web pages than you expected, and just when you thought you'd entered everything, they hit you with yet another page? Then you quit because one little piece of information isn't at hand, and when you returned later, you had to start from the beginning again? Or you couldn't tell whether your order was in there somewhere, and if so, what state it was in? Systems abound that give an unpleasant experience through lack of consideration for their users—for example, by not accommodating users who deviate from the expected path. The main reason is neglect that can be avoided by specifying suitable requirements. (One could argue that use cases that emphasize the primary path can be partly to blame. Also, having to write a second use case to cover the completion of a half-finished process is somewhat tedious, and hard to in an easy-to-follow way without repetition.)
Things that can be done to improve multi-part information entry include:
Allow the user to recommence entering information later on, from the point they had reached previously.
If the system assigns a transaction number (for example, an order number), tell the user what it is as soon as it's allocated. This lets them know that the system has registered at least some of the information that they've taken the trouble to enter. (You could go further and inform them of incomplete transactions—say, the next time they log in, or via email.)
Inform the user where they are in the process: first, the status of the transaction (for example, has an order been placed yet?), and second, how many more screens are yet to come. If this isn't possible (because the number of steps depends on what values the user enters), then at a minimum, tell them there's at least one more screen to come. A help page that explains the steps in the transaction (perhaps as some kind of flow chart) is also useful.
Let the user go back to the previous screen. This might sound obvious, but unless you state it as a requirement, the system has no obligation to provide it.
If you want the system to do any of these things, write requirements for them. Here are a few sample extra requirements that apply to all multi-stage data entry functions:
You could write a version of any or all of these requirements to cover a specific function instead of all of them.
Co-ordination of Multiple Data Stores This means co-ordinating your system with one or more other systems, when each system stores data for itself. Imagine you're specifying a system for a Web-based retail site (a Web shop). You subcontract some products to a supplier, by passing a suborder to them. What happens if either your system or the supplier's system fails while in the middle of processing an order? Systems can be built to deal with situations like this—but if all the possible failures aren't recognized and handled, you could be in trouble when one that you don't accommodate occurs.
Requirements shouldn't worry about how to co-ordinate the updating of data in multiple systems. But they should identify what each system involved must be able to do to play its part, especially in the area of resilience. This is particularly important for each system to which we're interfacing, for various reasons. First, any external system is outside our control. Second, it might already exist. Third, it might require modification, even if it otherwise has all the functionality we need of it—it might already handle a "here is an order" message, but not "did you get this order?" or "delete this order" messages. Fourth, it might not be modified quickly enough. Fifth, it might be expensive to modify. Sixth, it might not be within our power to have it modified at all. In short, the implications could be significant, and they need to be brought to light as early as possible.
For each type of action that involves two or more systems, nominate one system—usually the first one in which data storage occurs—as being in charge. This system is responsible for three things in addition to its own processing:
Keep track that other systems have fulfilled their responsibilities. This involves recording each step in the processing, including when requests are sent to other systems and when acknowledgements are received.
Detect when another system hasn't done its job.
Complete the processing once the system that failed is back. This can be initiated either manually or automatically.
If the system we're specifying is the one in charge, specify requirements to cover these three things to our satisfaction. If our system isn't in charge, write requirements to cover what the system in charge expects of us. (But don't be surprised if it expects nothing, because systems poorly built in this respect are abundant.) Usually, one system is in charge for all types of actions, but it is possible for one system to be in charge for some actions and another system to be in charge for others.
Let's reiterate that the steps described in the previous paragraph must be performed for each type of action that involves two or more systems—although in practice, the number of types of action is usually very small—perhaps only one. While completing incomplete actions must be done in action-specific ways, the initiation of them can be grouped together. So, when we know that an external system that failed is now back, we could have a single function that initiates completion of all types of incomplete actions involving that system.
One way to provide integrity for transactions that span multiple databases—and one that avoids having to figure out all this messy co-ordination for ourselves—is to use a transaction processing monitor product (usually called a TP Monitor), but this can be impractical for technical, performance, cost, or business reasons.
A couple of further subjects you might want to consider are:
Would it be beneficial for the system to modify the way it behaves once it has detected that a particular external system is not responding? For example, we could stop accepting orders for that supplier's products, or we could send subsidiary orders to an alternative supplier instead.
What if a failed external system never comes back? This is an extreme situation, but it is worthwhile devising a fallback plan in case a company you deal with disappears.
Here are a couple of sample extra requirements for a Web shop customer order transaction:
Summary | Definition |
|---|---|
Customer order recovery from failure | The system shall be able to recover cleanly from failure during the processing of an order received from a customer, whether the failure occurs in the system itself or in a supplier's system with which an order is placed. This shall include a user function to initiate upon request the completion of incomplete orders involving a selected supplier. |
Incomplete order inquiry | There shall be an inquiry that shows a summary of orders received from customers for which processing is incomplete. For each supplier to which at least one subsidiary order has been sent without acknowledgment, this inquiry shall show the following information:
This inquiry does not show a list of individual orders because such a list might be too large to view. |
Timed and Co-ordinated Changes A timed changeis a change to information that needs to occur at a precise, predetermined moment in time. For example, switching to or from summer time might need to happen at precisely 2 a.m. on a designated Sunday morning. And moving the Ruthenian Dinar across to the Euro might need to be done at midnight on a published date.
Co-ordinated changesare a collection of related changes to information that all need to be applied at exactly the same time. When a retailer changes its pricing schedule—raising some prices, lower others, modifying discount rates, introducing a range of special offers—it won't want them to be done in dribs and drabs; it'll want them all to happen at once.
Timed changes and co-ordinated changes have much in common with each other (including the possibility that a set of co-ordinated changes could happen at a specified time), which is why they're dealt with together in this section. Both also have much in common with the approval of actions (the subject of the approval requirement pattern)—first, because all involve the need to store the details of actions before acting on them, and second, because we might want to approvetimed or co-ordinated changes before accepting them.
Innumerable systems have managed to get away without proper provision for timed and co-ordinated changes. After all, making changes manually at the right time, and a set of individual changes one after the other offers only a tiny window during which the system doesn't behave exactly as it should. The hope is that no one will notice. In the main, that's true—and if something should go askew, it might not be tracked to its actual cause. Also, if your system doesn't need 24-hour-a-day availability, you can make these changes when nothing else is happening. But if you need to make such changes while users are active, and you don't want to risk something like this going wrong, take the trouble to see that these changes are made properly. While there is a tendency for more systems to be available at all times, the mentality of system builders has lagged behind: nearly all seem unaware of all the implications—and the extra functionality that such systems need.
A further reason for allowing timed changes and co-ordinated changes to be entered beforehand is so they can be reviewed and checked, and any mistakes can be corrected—that is, to reduce human error. (This is also a reason for having them approved, too.) In any case, changes made in the wee small hours by whoever's working that shift, based on scribbled notes left by someone else, sound more at risk of human error than most.
Even if you manually make a timed change at the right time, you're still likely to need to know what the previous value was and when it was changed. For example, if a sales tax rate is changed at midnight on a certain date, we still should be able to calculate sales tax amounts on orders placed before this date. Again, systems have managed to survive without being able to do this—by performing calculations immediately—but it's untidy: it's hard to justify (say, for audit purposes) what the system did, and if any mistake was made, it's difficult to rectify. (You'll probably have to go, cap in hand, to the developers whose omission led to the problem in the first place.)
Timed and co-ordinated changes most commonly apply to changes in configuration, but they can happen to other types of information. Indeed, they could conceivably apply to any type of function. But worry about that eventuality only if and when you encounter it.
Timed and co-ordinated changes are another area in which lurk all sorts of easily forgotten things, including:
Don't allow backdated timed changes. If you were to enter a time in the past, in all likelihood the change wouldn't be made at all—but you can't be sure what the software would do.
What do you want to happen if a user is in the middle of entering a timed change (particularly a half-finished set of co-ordinated changes) when its time is reached? For instance, a user is halfway through entering some price changes to be applied at midnight when the silicon clock strikes twelve. Should we do nothing, or should we apply the changes that have been entered? Is Cinderella better off wearing just one glass slipper, or neither?
What happens to a timed change that needs approval but hasn't been approved by the time it's due? Should we warn someone when this situation looms?
Provide at least one inquiry that lists pending changes. Let users see both timed changes and unapproved changes (regardless of whether they are timed); they can be shown in a single inquiry or separately in two. Decide which sorts of changes each user can see.
Allow timed changes to be modified and removed before they have been applied. This includes the ability to modify the time at which a change is to be made.
Prevent entry of two separate changes to the same thing at the same time. When a user's entering a timed change, it would also be helpful to warn them of any other pending change to the same thing.
Once you've discovered one thing for which approval, a timed change, or a co-ordinated change is needed, your eyes are open to spotting more. As soon as you have more than one of these things (or if you see prospects for introducing more in the future), it can become worthwhile to introduce a general mechanism for storing actions that aren't ready to happen. Such a mechanism can be used as the basis for approvals, timed changes, and co-ordinated changes, as well as combinations of them. This involves creating a place where you can store any kind of pending action you wish and a range of functions for updating and viewing it—for which you need to specify requirements. But ask for a general mechanism of this kind only if it's worthwhile, because it's a big and complicated undertaking.
Here are a few requirements for timed and co-ordinated changes:
Summary | Definition |
|---|---|
When making a change to a sales tax rate, it shall be possible to nominate a date and time at which the change is to take effect. Every proposed change to a sales tax rate must be approved by a member of the finance department. | |
It shall be possible to enter a set of pricing changes and to have none applied until all have been entered. | |
Pricing changes timed | It shall be possible to have a set of pricing changes automatically applied at a predetermined date and time. |
Use the living entity requirement pattern to define a type of entity for which information is stored and which has a lifespan (that is, is created, can be modified any number of times, and eventually terminated).
Do not use the living entity requirement pattern for any entity that is part of the system's configuration; use the configuration requirement pattern instead.
A requirement for a living entity is primarily to define the information that needs to be stored for it (field by field), as well as related details such as how each entity can be uniquely identified (using IDs or other keys). Secondarily, a requirement for a living entity can also cover functions for editing (adding, modifying, and removing) and viewing an entity; these can be achieved either explicitly, or implicitly by the use of pervasive requirements that mandate such functions for all living entities. However, if there's anything particular to be said about any one of these functions, write a separate requirement for that function.
A requirement for a living entity must define at least:
Entity name Make it clear, unique, and concise.
An explanation of the entity This is to make it clear what it is, what it's for, (and, if appropriate, also what it's not for).
The information the entity contains Present this in the form of a data structure. Usually the requirement itself defines the data structure, but it can alternatively refer to another requirement that defines it. In both cases, the data structure is as described in the data structure requirement pattern. These map roughly to the columns of a database table.
The definition of each item of information can also contain relevant details about the entry, validation, display of its value (including whether it is to be displayed at all), and/or such things as whether it can be amended after the entity has been added. Such information can be included in a requirement defining the data type in question if it applies to all occurrences of it (as per the data type requirement pattern in Chapter 6).
The way(s) in which an entity is uniquely identified State its ID (or IDs) plus any other ways of uniquely identifying it. (These later turn into indexes of a database table.)
Parent entity details (If any.) An entity of one type can sometimes only be created if some other entity already exists. A banking system might insist that a bank account can only be created if the customer it belongs to already exists. Describe the relationship with the parent or parents (because there could be more than one, and they could be different types of entity), including whether it is essential or optional.
Summary | Definition |
|---|---|
«Entity name» | The system shall store the following information about a «Entity name»:
A «Entity name» is «Entity explanation». Each «Entity name» is uniquely identified by «Entity identifier(s)». [«Parent entity details».] |
Summary | Definition |
|---|---|
The system shall store the following information about a customer:
Each customer is uniquely identified by its customer ID. |
See also the Extra Requirements section in the introduction to this chapter.
There are several kinds of pervasive requirements that can be written to apply to all living entities, to avoid having to specify them repeatedly for each type of entity. These are:
Editing functions We need to be able to add, modify, and remove an entity. Each function to modify an entity needs to identify which information can be modified (or, if it's more convenient, which cannot). If your system allows people to modify information about themselves, distinguish what they are allowed to change from what other users are allowed to change. For example, a Web shop customer might be able to change their personal details and preferences; an employee of the shop might be unable to change these things. Refer to the user authorization requirement patterns in Chapter 11 for how to specify in more detail who is allowed to do what.
Inquiry functions Specify one to list all the living entities of a certain type (or, if there are too many to list, some sort of selection or search mechanism), and one to display the details of a selected entity.
Change history This is typically a record of every modification to an entity (including adding and removing). It could either record every changed value (so as to have a complete picture of every change) or merely the fact that something changed. Knowing every changed value is attractive—but it's also a lot more development effort (and raises other matters—such as restricting access to sensitive information in change histories), so ask for it only for those entities for which it's justified. If in doubt, leave it out.
Common data These are items of information to be present in every type of living entity. They are typically used for information such as who last changed an entity and when.
If an adequate change history is maintained for each entity, common data identifying who made changes and when is not strictly necessary, because it can be derived from the change history.
Logical remove only When we ask for a living entity to be removed, we don't want all trace of it to disappear (because that might cause difficulties); we merely want it to behave as if it's no longer active. All respectable databases will prevent something from being removed if it is being referred to (that's called referential integrity), but we don't want it to be removed even if nothing refers to it.
Here are sample pervasive requirements for some of these things:
Follow-on requirements (for a specific living entity) can also be written for any of the first three kinds of pervasive requirement, regardless of whether a pervasive requirement has been written on the same subject. A requirement can override any of the pervasive requirements by stating which of them does not apply to a particular living entity or class of living entities. Similarly, for any of these standard functions, a requirement can be written to describe features needed by a particular type of living entity (or class of living entities). This requirement would then override the standard function as specified in the pervasive requirement. If you do this, check that it's clear that only one function of each type is needed for each type of entity: you wouldn't want developers to build one to satisfy the pervasive requirement and another for the specific requirement.
Even if no pervasive requirements have been specified for the topics discussed in the previous Extra Requirements section, you might regard some of them worth acting upon—simply as good practice.
Use the transaction requirement pattern to define a type of event in the life of a living entity, and/or a function for entering such a transaction.
Transactions are the lifeblood of any commercial system: they're usually where the money comes from. So handling them well is critical to a system's success. A system might have only a small number of types of transaction, and it might take surprisingly few requirements to specify them; even so, it's important to get these few right. Examples of transactions: a purchase from a Web retail site, renewing a magazine subscription, making a successful bid at an auction.
A transaction is a representation of something that happens at a point in time. For most kinds of transactions, this is clear and straightforward. A bank customer requests a cash withdrawal, which is deemed to take place the moment the cash is handed over. The transaction's details are fixed at the moment it is deemed to happen. This is an important rule: systems that break it are asking for trouble sooner or later. After the bank customer has walked off with their cash, the bank can't play around with the amount withdrawn or pretend it was paid from someone else's account: changing any of the transaction's details would be incorrect. If a genuine mistake was made (such as the wrong customer's account being debited), the only way to fix it is by means of one or more further transactions. Who'd trust a bank that did otherwise? (The purpose of the first pervasive requirement in the Extra Requirements section is to enforce this rule.)
A simple after-the-fact record that some event occurred (for example, an entry in a log or in a change history of a living entity) is not a transaction for the purposes of this requirement pattern; it is categorized as chronicle information (as defined in the introduction to this chapter).
Now for another subtlety to worry about! If a transaction doesn't happen immediately, and its processing uses one or more configuration values, consider what to do if one of those values changes after the transaction was entered but before it happened. For example, if our Web shop's mailing charges change after receiving an order but before shipping it, should we levy the old charge (which is what we told the customer) or the new one (which is what it'll actually cost us—if we're merely passing this on)? Neither way is ideal. We could do better if the mailing charge changes were entered in advance, but even then we probably won't know beforehand whether shipping will occur before or after the change. A simple solution usually suffices once a situation like this has been spotted, but it's still worth recognizing it in the requirement. A picky, intricate answer is rarely necessary and is a sign that your solution is too complicated—which means potentially fragile and unsatisfactory software.
A requirement for a transaction needs to define at least the following:
Transaction name State what it's called.
An explanation of the transaction Describe what it is and what it's for.
The information the transaction contains Give this in the form of a data structure. This can include details about how particular values are entered, validated, and displayed. (See this part of the living entity requirement pattern, earlier in this chapter, for a little further explanation.)
How a transaction is uniquely identified This enables us to distinguish two transactions whose details might otherwise be identical (or at least hard to tell apart). Computer systems are sufficiently fast that to differentiate on the basis of time, you need to get down to very small gradations of time—certainly much less than a second, and possibly finer than the accuracy of the machine's clock). The safest way is to allocate a transaction ID to each transaction—even if people rarely need to refer to them.
Owner living entity details This identifies the entity on whose behalf the transaction is being performed: the customer making a purchase, the bank account from which cash is being debited. (Assume every type of transaction belongs to a living entity, because you're unlikely to encounter one that doesn't.) A type of transaction could conceivably have more than one owner—but they're rare.
When the transaction is deemed to happen State this in terms of steps in the life of the transaction. It could be when the transaction's entered, when it's accepted (in a sense meaningful to the system—such as when a shop has checked that it has in stock all the products in an order), or when it's approved (say, manually by a person). This is the moment from which no changes are allowed. If the "happen time" isn't stated in the requirement, the transaction can be assumed to happen immediately when it is entered. Even if a transaction has separate steps for acceptance, approval, or other actions, its entry time could still be regarded as the time it happened.
Transaction longevity (Optional.) How long should transactions of this sort hang around? That is, after how long does it become eligible for deletion? This effectively incorporates the intent of a longevity requirement (as per the data longevity requirement pattern in Chapter 6), which is good practice to consider for each type of transaction, even if you decide not to state it in the requirement explicitly.
Summary | Definition |
|---|---|
«Transaction name» | There shall be a function to create a «Transaction name» transaction for a «Owner living entity name». Each «Transaction name» shall contain the following information:
A «Transaction name» is «Transaction explanation». Each «Transaction name» is uniquely identified by «Transaction identifier(s)». A «Transaction name» is deemed to have happened «Transaction happen time description». [«Transaction longevity statement».] |
Account adjustment | It shall be possible to post an adjustment (debit or credit) to the account of a selected customer. An adjustment shall contain the following information:
A unique ID shall automatically be allocated to each account adjustment. It is expected that authority to use this will be restricted to very few employees. |
See also the Extra Requirements in the introduction to this chapter.
If you're going to specify performance requirements for anything in your system, it's most likely to be for the processing of transactions—because they're usually the highest volume, most visible, most financially significant part of a commercial system. It's illuminating to try calculating daily or monthly volumes for each type of transaction—even if only in a cursory manner, and even if it only serves to point out that you have little idea how busy your system's likely to be. Refer to all the requirement patterns in Chapter 9 for types of performance for which you could consider specifying requirements.
Here's a pervasive requirement to enforce the rule stated previously:
Always adhere to the rule of never modifying any transaction after the fact. And take care processing transactions, because they're important.
Testing that transactions are handled well is perhaps the most important testing of all, because the functions to process transactions tend to be the most heavily used and are highly visible. So testers should prepare a large number of test cases that cover all eventualities. Identify all the relevant permutations that a complex transaction can have, including states, transitions between states, and error conditions. Then build test cases for them all.
Pay special attention to the statement in a transaction requirement about when a transaction is deemed to happen. Test that a transaction cannot be changed after this point. When testing a complex transaction, ask yourself at each stage whether it's clear where you stand: is it obvious whether the transaction has been accepted? Can you tell what you're allowed to change? Are the financial implications spelled out? For example, is it clear to a customer how much they must pay? And are the actual computed consequences what you expected?
Use the configuration requirement pattern to define parameter values that control how the system behaves.
Configuration values are either systemwide or they are associated with configuration entities that behave very much like living entities—but the emphasis is on the values rather than the entities, and configuration requirements tend to reflect this. A systemwide configuration value is one for which there is only one instance: the same value is used everywhere in the system; other configuration values have multiple instances, each one used in a different circumstance. A bank might set a different cash withdrawal limit for each currency; in this case the currency is the configuration entity, and each instance of a currency has its own withdrawal limit configuration value.
A configuration value can exist at one of several degrees of flexibility, which run as follows (from least to most flexible):
Hard-coded Values defined in the software itself are to be avoided. It's bad practice. Every configuration value must be modifiable so it can be set without involving developers. Do this even if you can't envisage it ever changing. Even if you're building a system just for your own company's use, the company might want to sell it if it's really nice; this has happened to systems in the past—only to run into severe trouble and embarrassment when hard-coded company-specific values come to light.
A hard-coded value can occasionally slip in without anyone (even the developer) realizing. Pay special attention to calculation formulae. For example, bank interest calculations vary from one currency to another. (See the calculation formula requirement pattern in Chapter 6 for the gory details.) You need to be on your toes, especially if you're new to the industry you're working in.
Systemwide For each systemwide value you identify, ask yourself whether it's genuinely a single value. Sometimes shortsightedness leads to parameters being made systemwide when they should actually vary—by country, by language, by currency, by customer type, by account type, by company, in some other way, or in a combination of more than one thing.
In several configuration entities (And perhaps systemwide, too.) This includes successive defaulting if the value isn't explicitly present at a particular level.
A couple of other recurring subjects have special considerations when applied to configuration:
Access control Examine the access control needs for each configuration value. Don't simply assume that one important person will look after all the configuration, because it's risky to put control over everything into one person's hands. Give proper thought to organizing your configuration values, so that values with a related purpose are grouped together; it's not necessarily the same as the physical organization of the data. Separate the editing of sensitive, rarely-changed values from others, so they're harder to change by mistake. This is best worked out after all the configuration requirements have been determined, for obvious reasons. Grouping values according to when they can be changed is a good starting point. (See the user authorization requirement patterns in Chapter 11 for more.)
Integrity Configuration, like all data, is best stored in a database. Recall the discussion about data integrity in the introduction to this chapter (Area 1). Storing configuration values in a flat file might be convenient for developers (especially if new types of values keep being added), but it's dangerous. Consider first what happens if you lose the disk that the file's stored on: what changes were made since it was last backed up? And second, when do changes take effect? If a configuration file is read into memory when the system starts up, will a change be read into memory straight away? If not, how do we cause it to? The whole situation is messy, and the best answer is to avoid the risk altogether: mandate that all configuration data is to be stored in a database. If developers really want the flexibility that they use flat files for, they can choose to store a whole configuration "file" as a blob in a database—but that doesn't by itself solve all these complications.
There are two ways of structuring a configuration requirement:
Define a configuration value, and then describe the level (or levels) at which it lives.
This way is preferable purely because it focuses its attention onto a single aspect of configuration, which makes it hard to escape describing it properly. It also saves duplication if you want to configure a value at multiple levels. One drawback of this way is that it doesn't let you see together all the configurable values defined for a particular entity, which also means developers and database designers have to pull all the values together for themselves.
Define a configuration entity, the whole of which forms part of the configuration.
This way is more convenient if you have several items of information to specify at the same level, but it discourages saying much about each one.
A requirement for a configuration value needs to contain:
Name and purpose It's important to make clear the intended use of each configuration value, especially where there are multiple values with similar meanings. If developers inadvertently use the wrong value, the resulting errors could be subtle and hard to detect; much damage could be done before it's sorted out.
Representative value For a systemwide value, this is either the expected value (if this is known) or a sensible suggested value. It gives readers an idea of what we have in mind. It can sometimes stimulate useful discussion: someone remarking that it's not a realistic value might be a sign we've misunderstood something. These representative values can also be used when initially setting up the developed system, both for testing and for live use.
Data type Either specify this in-line as described in the data type requirement pattern in Chapter 6, or refer to a separate requirement that defines a data type.
Level(s) This is either "systemwide" or the name of the configuration entity to which the value belongs (per currency, per account type, and so on). A value may exist at more than one level; if so, explain how precedence (and perhaps defaulting, too) is to be handled. For example, if an approval limit is set for a person, use that; otherwise if a limit is set for a role, use that; as a last resort, use a systemwide default limit.
When the value can be changed. See the preceding section Don't Mess with a Running Production Line. Note the rules for what value to assume if the requirement doesn't say explicitly.
A requirement for a configuration entity contains:
Entity name
The purpose of the entity What is it, and what is it for?
The entity's contents Write it in the form of a data structure. When each value can be changed can be stated explicitly as necessary. An example can be given for each value.
How an entity is uniquely identified State its ID (or IDs).
When the entity can be changed This applies to all the entity's values, except those for which it is explicitly overridden. If omitted, a default is assumed, as described in the preceding section Don't Mess with a Running Production Line.
Every value in a configurable entity is regarded as a configurable value (we don't count its ID and supporting information such as last-changed-date as "values" in this sense), and configurable values live only in configurable entities. So none of the values in any living entity (say, a customer) constitutes part of the system's configuration.
The first template here is for specifying a single configuration value; the second is for a whole configuration entity.
See also the Extra Requirements in the introduction to this chapter.
Here is a pervasive requirement to enforce a "no hard-coding" rule:
Here are a few basic requirements to facilitate preventing configuration values from being edited at the wrong time:
These requirements do not pretend to be adequate for proper system management.
Consider the effect of changing each configuration value while the system is running. If this might cause problems, take steps to prevent damaging changes from being made. Also publicize the potential danger, so everyone who ought to know does know and so that it is properly documented.
Introduce extra configuration values if you need to; it's perfectly natural for extra ways to control the system to arise during development. Don't hard-code values. Again, publicize any new value and have it properly documented.
The testing of the basics of configuration—adding, modifying, removing, and viewing values—is essentially the same as for living entities. But once that's been done, test the effect of changes of configuration upon the functions that use it. As has been noted previously, changing certain configuration values can have profound effects—possibly very negative effects. Many of these sensitive things are systemwide variables, so take a look through all the systemwide variables for ones that look dangerous to modify.
Bear in mind that extra configuration values, over and above those specified in the requirements, might have been introduced during design and development.
Related patterns: | Transaction |
Anticipated frequency: | Between one and twenty requirements |
Pattern classifications: | None |
Use the chronicle requirement pattern to specify that a certain type or range of types of event (occurrence) in the life of the system must be recorded.
Do not use the chronicle requirement pattern to record anything that has a financial role of any kind; use the transaction requirement pattern for them.
One dictionary defines a chronicle as "a record or register of events in chronological order." As a verb, it means "to record in or as if in a chronicle." These match perfectly this requirement pattern's uses of the word: a chronicle is a place where events are permanently stored. You can avoid using the word "chronicle" in requirements, though, so you don't have to explain it to your readers. The aim of chronicling is to build up a picture of anything that happens in the day-to-day life of the system and might be of future interest: like built-in closed-circuit television cameras. Its primary use is to assist investigation when something goes wrong—whether it be a software problem, employee fraud, attack by hackers, or hardware or other kind of failure. Chronicles can also yield a wide range of statistics, based on the volumes of different types of events.
This requirement pattern uses the terms event and occurrence interchangeably to mean anything that occurs within the system while it's running and which the system is aware of and is able to act upon. We can chronicle any event (occurrence)—which means pretty much whatever we choose to; it's not restricted to events that trigger some kind of system action. Events can include database updates, errors detected by the system, user actions, milestones in system processes (such as starting up and shutting down), and passing preset thresholds (such as when free disk space goes below a certain level). We also use the verbs to record and to store when talking about what we do with an event; it means the permanent storage of information about the event, which is to remain unmodified and unmodifiable (a faithful snapshot of the event).
Anything that's recorded in a transaction (in the sense used by the transaction requirement pattern) needn't be recorded in a chronicle as well. Conversely, a chronicle requirement merely states that an event must be recorded, not how—so it's quite acceptable to record it in the form of a transaction (provided it is never subsequently modified).
The key features of a chronicle are that it must be:
Chronological It records event in the order in which they happened.
Faithful It records exactly what happened. Record the details correctly, and don't let them be tampered with afterwards.
Complete It records all events of any type being chronicled, because to record some but not others would be misleading. Also, don't allow events to be deleted.
Reliable It is not susceptible to system failure. Among other things, this prevents a wrongdoer from covering their tracks by causing the system to crash.
This requirement pattern makes no judgment about how many distinct chronicles a system has: it might put everything in one, or it might use different chronicles for different things (or separate them for other reasons, such as per company in a multi-company system); that's an implementation matter. Chronicle requirements should do likewise. Nor do we stipulate in what form chronicles are to be stored (such database tables or flat files), though the Extra Requirements section suggests demands that may render some forms unacceptable. That's one reason why we don't use the terms "log" or "logging" here, because it might lead your readers (especially developers) to make inappropriate assumptions—both about what does and doesn't belong in a log and about the implied use of a logging product (which might in fact not satisfy our requirements). Use the words "log" and "logging" in requirements if you choose, but bear in mind that this could influence the implementation by implying a particular kind of solution. For similar reasons, we don't talk about "audit trails," because readers might interpret that in different ways.
It's useful to recognize the difference between occurrences that are related to a living entity and those that aren't, because of their relative volumes. (We'll have a lot more of the former.) Think about how many occurrences of each type are likely to occur.
It's possible (and often convenient) to incorporate the need to record each use of a function in the requirement for that function, but strictly speaking, they are separate requirements (as demonstrated by the fact that verifying the resulting records is a separate testing step). Writing a separate requirement also prompts you to give proper thought to what information should be recorded. You can also write a chronicle requirement that applies to a set of functions. (This, too, sounds like lumping separate requirements together, but they are all of the same nature. It's better to add several apples together than an apple and an orange.) Make a conscious decision at the start of the requirements specification process about which approach you wish to take. Being consistent throughout has the benefit of reducing the chances of some kinds of chronicle entries being neglected.
Individual chronicle requirements concern what events are recorded and what information is recorded about each one. (Functions that enable us to make use of this information are covered in the Extra Requirements section later in this pattern.)
A chronicle requirement should contain:
The type(s) of occurrence to record A chronicle requirement can specify the recording of a specific type of event or the recording of a range of types of events—in ways that can be defined quite broadly. It's attractive to be specific, but in doing so, we risk both missing certain things and also causing an explosion in the number of requirements. The best answer is to specify classes of events (defining their scope in terms of criteria that let someone test whether something fits or not), and if necessary, write another chronicle requirement for each specific type of event that we definitely want recorded.
A system cannot record things that it cannot perceive, so don't ask it to. Recording all break-ins and unauthorized access, for example, is impossible: a system can only record those it detects.
The information to record about each occurrence Every occurrence pertaining to a user action must include the ID of the user. Every one reflecting a change in data should enable both before and after values to be determined (which doesn't necessarily mean storing both in the change itself, so long as both can be obtained from somewhere—such as obtaining the before value from the previous change). Every one pertaining to an organization must identify that organization. Every one pertaining to a server machine must identify that machine.
Severity (Optionally.) If the occurrence indicates a problem, the severity tells how serious it is. Either identify a severity value defined in a separate severity scheme requirement (as explained in the Extra Requirements section later in this pattern), or describe it in general terms (to allow it to be mapped to a formal severity level when they are defined later). If you say nothing about severity, it means you're happy for it to be decided later, either by the development team or by whoever configures the system before it goes into production. If the occurrence is clearly not an error, don't mention its severity.
In some cases, it's appropriate for the severity to depend not just on the type of event but also on one or more other values. For example, the severity of a low disk space event might become more serious as the free space dwindles.
Summary | Definition |
|---|---|
Record«Occurrence type(s) summary» | Every«Occurrence type(s) description» shall automatically be recorded. For each, the following shall be recorded:
[Each such event shall be treated as having a severity of «Severity description».] |
A relatively extensive list of example requirements is given here to identify a number of types of events that a typical commercial system might want to chronicle and to demonstrate a few variations in approach. As a result, there is a degree of overlap and consequently repetition in these requirements.
There are various types of extra requirements that can be specified for chronicling. They are all easier to apply across the board to all chronicling in the system (or selected parts of it), rather than following on from an individual chronicle requirement. These types of extra requirements are:
Access control Who's allowed to see what in chronicles? This topic appears at the top of this list because the others need to take it into account—and access control requirements can have a significant bearing on what kinds of solutions are acceptable.
Common chronicle features What characteristics do we want our chronicles to demonstrate? The most important are the key features described in the Discussion section earlier in this pattern: to be chronological, faithful, complete, and reliable.
Chronicle view functions There's no point in creating chronicles if there's no way to see what's in them. See the "Chronicle View Functions" section that follows.
Severity levels For chronicles to work properly, the severity levels used in all events must be consistent: it's unacceptable for minor events to look as though they're severe. We can write requirements to define severity levels and others to assign levels to different types of events.
Purging chronicles For how long should chronicle data be kept? It's possible to retain different types of events for different lengths of time—particularly if they are stored in different chronicles—but this makes it harder to interpret what happened during those periods of time affected. To make sense of them, we certainly need to keep track of the date from which each type of event is present, so it's possible to tell whether omission of data could be due to it having been removed (which is covered in the third example requirement in the "Common Chronicle Features" section that follows).
Archiving chronicles If chronicles are archived and loaded into another database for study (let's say a "reporting system" database), care must be taken if actions on the secondary database are chronicled—because these events could pollute the chronicles. The answer is to have two distinct sets of chronicles that are strictly kept apart. If you're doing anything along these lines, carefully think through what might transpire, and specify suitable requirements to prevent trouble.
Triggering other actions It's useful to be able to notify people when a severe event occurs. The best way to do this is to build it into the chronicle mechanism itself, so it works for any type of event. This could be extended to allow other kinds of actions to be triggered by events. Work out what you want, and write requirements for it.
Turning chronicling on and off Recording events in chronicles can affect the system's performance, especially when recording a high volume of events. It can be useful to turn the chronicling of certain types of events on and off. Allow this only for non-error events. Being able to switch off low-volume events serves no purpose.
Switching chronicling on and switching it off are themselves events that must be recorded, because they affect what we can expect to see in chronicles. Without doing so, we could never tell whether the absence of an event was due to an event not occurring or because chronicling was off at the time. (This point is dealt with by the third example requirement in the "Common Chronicle Features" section that follows.)
The first four of these topics are covered in more detail in the following subsections.
Chronicle Access Control If we control which information each user can access, the same restrictions should apply when that information finds its way into chronicles. After all, we're wasting our time if a user can bypass access control restrictions by examining events recorded in chronicles. (This is in addition to control over who can access the chronicle view functions themselves.) Strangely, this loophole is common in systems, though rarely recognized as such (often because systems administrators keep chronicles to themselves, and chronicles commonly lack detailed information). Here's a requirement for plugging the gap:
Summary | Definition |
|---|---|
Any information recorded about an event shall be subject to access control rules at least as strong as those that apply to the original information. This requirement applies regardless of the form in which event information is stored (including flat files and "logs"). For example, if a user is not allowed to access a particular customer's details, they shall not be able to view details of an event that records changes to that customer's details (though it is acceptable for them to be made aware of the presence of the event). |
The explicit reference to "logs" is just so there can be no misunderstandings on this point. This requirement might look innocuous, but it's likely to have a major impact on the implementation of chronicling: it makes it appreciably more complex and rules out many off-the-shelf products. So don't ask for "proper" access control of this sort unless you really need it—because it won't endear you to whoever has to implement it.
Common Chronicle Features We can only expect chronicles to be chronological, faithful, complete, and reliable if we ask for these things in requirements, as these examples do:
Chronicle View Functions Chronicles that store a wide variety of events are a rich resource that can tell you much about what the system—and consequently the business—has been doing. Functions for viewing chronicles can be divided into the detailed—which show individual events (and can be used for investigative purposes)—and the statistical, which summarize them into totals (for various purposes—including management, marketing, and system load analysis).
The number of chronicles a system has, and what events are recorded in which one, is an implementation matter that doesn't concern the requirements. Consequently, requirements for chronicle view functions cannot distinguish separate chronicles; they must limit themselves to the types of events that are to be shown. However, it is possible for chronicle view functions to include chronological-based information—especially transactions—from elsewhere in the database to give a more complete picture of what was going at the time. The case for doing this is strong if it's a close call whether to regard something as a transaction or a chronicle event.
Summary | Definition |
|---|---|
There shall be an inquiry that lists recorded events that match given selection criteria. The selection criteria shall include (but need not be limited to): The user shall be able to supply or omit whichever criteria they wish. Any item of information to which the user does not have access shall not be displayed. The user shall be warned if particular types of events requested are unavailable for some or all of the time period being shown (due to their having been archived). |
Severity Levels Should a requirements specification define event severity levels? Defining a complete set constrains the implementation, but defining none makes it hard to describe the severity of a type of event in the requirements. A middle course is best: define a few fundamental severity levels, but allow the implementation to have more. The bare minimum severity levels are "normal" and "severe." Normal is for something that can be expected to happen during the normal running of the system, which is not an error. Severe is for a problem that warrants attention by a person. But you should include at least one level in between these two. Choose different names for the levels if you wish. When devising severity levels, consider differentiating between errors that affect just a single entity (such as one customer) and those that affect the system as a whole—and have separate severity levels for the two types. (The example requirement that follows doesn't do this.) Write a requirement that identifies the severity levels you want. Every definition of a severity level must include a readable description of its meaning.
Take care when assigning the severity level of a type of event. Don't let severe events be neglected, but don't "cry wolf," either. The volume of severe events must be kept small, or their impact will be lost.
Chronicle requirements can specify the severity of particular types of events, but their severities can be defined in other ways—in particular, by making them configurable. This adds a degree of flexibility, but changing severity levels once the system is in production is potentially dangerous and can lead to confusion.
Summary | Definition |
|---|---|
Event severity levels | The system shall support at least the following event severity levels (or their equivalents):
|
Event type severity | Each type of event that can be recorded shall have a severity defined for it. |
Performance is a major consideration. It's straightforward enough to develop chronicle capabilities but much harder without having an appreciable impact on the processing time of the occurrence being recorded. If possible, use chronicle software already written for this purpose—provided you can find such software that satisfies all the requirements laid down.
Estimate the likely volume of each class of events. Base it on the sizing model, if there is one (and perhaps extend the model). Consider keeping high-volume and low-volume chronicles separate from each other.
Record all occurrences using a timestamp generated by the system itself—because if it came from elsewhere, we shouldn't trust it.
Having as many as possible of a system's activities recorded is of great assistance during testing, because these records provide invaluable information about what happened in the system. So, when reviewing requirements, testers should press for as many types of events as possible to be recorded.
You should cause all the types of events for which chronicle requirements are specified. This can be difficult, especially for obscure error conditions. Insisting that every conceivable condition must be tested is rather picky in typical commercial systems; if you insist upon it, one option is to ask developers to modify the software to allow it to simulate them.
Separate broad-scope chronicle requirements (those that ask for a range of occurrences to be chronicled—according to specified criteria) from specific chronicle requirements; it's clear what to test for the latter. But the former are open-ended; to test such a requirement properly, identify within the delivered system all the functions and occurrences that satisfy the criteria, and then test each one in turn. Both the identifying and the testing could be very onerous.
An information storage infrastructure lets us store information persistently—that is, it's still there when we switch the machine off—and retrieve it later. Information infrastructures vary significantly in their characteristics, and for this reason, a system might use more than one of them, and sometimes more than one of the same type (such as a heavyweight server database plus a lightweight database on client PCs).
The most prevalent kind of storage mechanism for commercial systems is a database. Other kinds are a file system for reading and writing flat files (though there's usually—but not always—little point in saying anything about this as an infrastructure, because it's built in to every operating system and programming language, so it's there anyway); a transaction monitor (if we need to co-ordinate changes made to more than one database); and a document management system (if our system accesses the contents of "documents"). You can also regard information retrieval mechanisms as information infrastructures that make use of information stored elsewhere; these include a directory service (such as one adhering to LDAP) and a search engine (to provide powerful means of finding things). This is a very diverse range of types of products, and we can expect requirements for them to vary accordingly.
What will a calling system expect to be able to ask this information infrastructure to do for it? What kinds of requests will it make? If we're asking for a database, a system will invoke it using standard database operations (of which the most important are the so-called CRUD ones: create, read, update and delete). It's reasonable to assume that any database product will supply these operations, so there's little to be gained by spelling them out. Similarly, we can expect any file system to let us read and write the raw content of any flat file and to read the file system to see what files are present.
We might want the ability to easily replace one product with another. In this case, it might be helpful to go into a bit more detail about how we talk to it—perhaps by mentioning a standard (such as SQL or ODBC, for a database), which will, in theory, let us use any product that adheres to that standard.
One way to look at implementation requirements is to see them as specifying the criteria by which to choose the most suitable information storage (or retrieval) product.
Some behind-the-scenes capabilities that we might want an information storage infrastructure to have are the ability to create back-ups of data and to recover data in the event of a failure (such as losing a disk drive). We might also want to ask for all changes to be atomic (all or nothing), to maintain data in a consistent state, and for each change to be isolated from other changes being made at the same time. (These are three of the ACID properties: atomic, consistent, isolated, and durable—the last of which is implicit in an information storage infrastructure.) Other considerations that might be important include capacity (especially if you need to be able to store huge quantities of data) and security features (such as being able to encrypt data, and access control).
Requirements for any kind of storage infrastructure other than databases must take into account its special characteristics.