
The advantage of a bad memory is that one enjoys several times the same good things for the first time.
Any software of any reasonable complexity is best designed if organized in layers. Each layer represents a logical section of the system. A layer is hosted on a physical tier (for example, a server machine). Multiple layers can be hosted on the same tier, and each layer can optionally be moved to a separate tier at any time and possibly with limited work.
Most of the time, you arrange a three-tiered architecture with some flavors of service orientation just to make each layer ready for a possible move to a different physical tier. There are various reasons to move a layer onto its own tier: a quest for increased scalability, the need for stricter security measure, and also increased reliability because the layers become decoupled in case of machine failure.
In a three-tiered scenario, you typically have a presentation layer where you first take care of processing any user input and then arranging responses, a business logic layer (BLL) that includes all the functional algorithms and calculations that make the system work and interact with other layers, and the data access layer (DAL) where you find all the logic required to read and write from a storage.
When it comes to layers, the principle of separation of concerns (SoC) that I introduced in Chapter 13, is more important than ever. A golden rule of any layered system states that no communication should be allowed between non-interfacing layers. In other words, you should never directly access the DAL from within the presentation layer. In terms of Web Forms development, this point is blissfully ignored when you use a SqlDataSource component right from the button click event handler of a Web page!
In this chapter, I’ll describe the intended role and content of business and data access layers and touch on a few technologies that help you write them. I’ll do that from a Web Forms and ASP.NET perspective, but be aware that a large part of the content has a general validity that goes beyond the Web world. I’ll cover presentation layers and related patterns in the next chapter.
Everybody agrees that a multitiered system has a number of benefits in terms of maintainability, ease of implementation, extensibility, and testability. Implementation of a multitiered system, however, is not free of issues and, perhaps more importantly, it’s not cheap.
Can you afford the costs? Do you really need it?
A three-tiered architecture is not mandatory for every Web application or for software applications in general. Effective design and, subsequently, layers are a strict requirement for systems with a considerable lifespan—typically, line-of-business systems you build for a customer and that are vital to the activity of that given customer. When it comes to Web sites, however, a lot of them are expected to stay live for only a short time or are fairly simple online windows for some shops or business. Think, for example, of sites arranged to promote a community meeting or a sports event. These sites are plain content management systems where the most important aspect is providing timely information via a back-office module. Honestly, it’s not really key here to design them carefully with service orientation, layers, and cross-database persistence. Themes like scalability, robustness, and security don’t apply to just any site or application. However, the longer the lifespan is, the more likely it is that you will also need to address carefully these concerns.
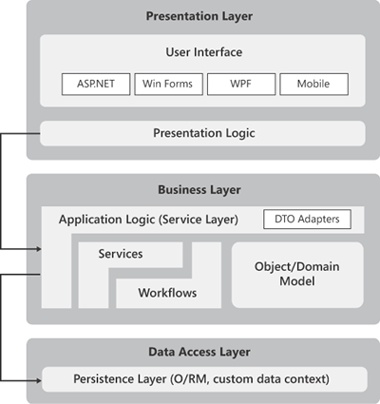
Figure 14-1 provides a glimpse of a three-tiered system with all the modules that we are going to consider in this chapter and the next one.
As I see things, it’s essential that you, as an architect or developer, be very aware of this model. However, awareness means that you know it, and because you know it, you also know when it’s worthwhile for you to opt for such a complex and sophisticated design. Some of the blocks shown in Figure 14-1 can be merged if there’s really no reason for them to have their own life. The general view might not faithfully represent the particular view of your application. In architecture, it always depends on the context. And adapting the general view to the particular context is the essence of the architect’s job.
Note
In my training classes, I always use a specific example to illustrate the previous point. As a parent, you must tell your kids that they use the crosswalk whenever they need to go across the street. When you do it yourself, in some situations, you adapt the general rule to a specific shortcut, and if no cars are coming you just cross wherever you are. That’s because you’re an adult and because, having evaluated pros and cons, you actually made a good decision. If the nearest crosswalk is half a mile away and no car is in sight, why walk that extra distance?
In my classes, I always take the example a bit farther and tell nice stories about how Italians apply the pattern to parking. But if you’re interested in hearing about that, well, it’s best if you attend the next class!
Where do you start designing the layers of a real-world system? Ouch! That’s a really tough point. It depends. Trying to go to the root of it, I’d say it depends on the methodology you use to process requirements. Which methodology you apply also depends on something. It usually depends on your skills, your attitude, and your preference, as well as what seems to be best in the specific business scenario and context.
Any system has its own set of requirements that originate use-cases. The ultimate goal of the application is implementing all use-cases effectively.
A classic approach entails that you figure out what data and behaviors are required by all use-cases (or just one use-case) and build a good representation of the data involved and the related actions. So you start from the business layer, and in particular from modeling the entities in play and their relationships.
I start my building from the business layer, and my main reason for that is to have as soon as possible a well-defined set of entities and relationships to persist and build a user interface around. To get my entities and relationships, however, I need to take a deep look at UI expectations and storage constraints, if any.
The business logic layer is the heart of the system and the place where the behavior of the system is implemented. The behavior is just one aspect of the design of a system; another key aspect is data.
Data is collected and displayed in the presentation layer, and it’s persisted and retrieved in the data access layer. Living in the middle, the business layer is where the data is processed according to some hard-coded behavior. (Note that in some very dynamic systems, the behavior can also be dynamically defined.)
Generally speaking, the BLL is made of a few parts: the application’s logic, the domain logic, a representation for domain data, plus optional components such as local services and workflows. Invoked from the presentation layer, the application logic orchestrates services and DAL to produce a response for any client requests.
The domain logic is any logic that can be associated with entities (if any) that populate the problem’s domain. The domain logic represents the back end of the application and can be shared by multiple applications that target the same back end. For example, an online banking application, a trading application, and a back-office application will likely share a common piece of logic to deal with accounts and money transfers. On top of that, each application might invoke the common logic through different algorithms.
Application and domain logic work side by side and exchange data represented in some way. Finally, domain and application logic might need to invoke the services of special components that provide business-specific workflows or calculations.
Business logic is a collection of assemblies to host. In a typical Web scenario, the BLL goes in-process with ASP.NET on the Web server tier. It goes in a separate server process mostly for scalability reasons. In a smart-client scenario, the location of the BLL might vary a bit. For example, the BLL can live entirely on the client, can be split across the client and server, or live entirely on the server. When the BLL is deployed remotely, you need services (for example, WCF services) to communicate with it.
The list of components that form the BLL can be implemented using a number of design patterns.
Design patterns for the BLL belong to two major groups: procedural and object-oriented patterns. For many years, we’ve been using procedural patterns such as Transaction Script (TS) and Table Module (TM). More recently, a significant increase in complexity and flexibility demand had us shifting toward object-oriented patterns such as Active Record and Domain Model.
In the .NET space, the Table Module pattern has been popularized by special Microsoft Visual Studio technologies such as typed DataSets and table adapters. LINQ-to-SQL and Entity Framework move toward a Domain Model pattern. A number of open-source frameworks, on the other hand, provide an effective implementation of the Active Record pattern. Among the others, we have Subsonic and Castle Active Record. Let’s review the basics of the various design patterns and how concrete technologies are related to each.
The Transaction Script (TS) pattern envisions the business logic as a series of logical transactions triggered by the presentation. Subsequently, modeling the business logic means mapping transactions onto the methods of one or more business components. Each business component then talks to the data access layer either directly or through relatively dumb data objects.
When you partition transaction scripts into business components, you often group methods by entity. You create one method per each logical transaction, and the selection of methods is heavily inspired by use-cases. For example, you create an OrderAPI business component to house all transaction scripts related to the “order” entity. Likewise, you create a CustomerAPI component to expose all methods related to action the system needs to perform on customers. In relatively simple scenarios, you come up with one business component per significant database table. Each UI action ends up mapped to a method on a TS object. The TS pattern encompasses all steps, including validation, processing, and data access. Figure 14-2 shows a graphical representation of the BLL according to the Transaction Script pattern.
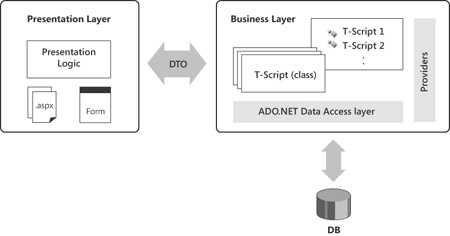
Note that in the context of TS, a transaction indicates a monolithic logical operation; it has no relationships to database management systems (DBMS) transactions.
The TS pattern is good for simple scenarios. The logic is implemented in large chunks of code, which can be difficult to understand, maintain, and reuse. In addition, TS favors code duplication and requires a lot of attention and refactoring to keep this side effect under control.
According to the Table Module pattern, each object represents a database table and its entire content. The table module class has nearly no properties and exposes a method for each operation on the table, whether it’s a query or an update. Methods are a mix of application logic, domain logic, and data access code. This is the pattern behind typed DataSets and table adapters that you find in Visual Studio 2005 and later.
The overall design of the BLL is clearly database-centric with a table-level granularity. Compared to TS, the Table Module pattern gives you a bit more guidance on how to do things. The success of this pattern is largely attributable to the support offered by Visual Studio and the availability in .NET of handy recordset data structures such as DataSets. Figure 14-3 shows the design of a system architected with the Table Module pattern.

In procedural patterns, BLL and DAL are too often merged together. Most of the time, the DAL is where you package your ADO.NET code for physical data access.
The Table Module pattern is based on objects, but it’s not an object-based pattern for modeling the business logic. Why? Because it doesn’t care much about the business; it focuses, instead, on the tables. Table Module does have objects, but they are objects representing tables, not objects representing the domain of the problem.
The real shift toward an object-oriented design starts when you envision the application as a set of interrelated objects—which is a different thing than using objects to perform data access and calculations. An object-based model has two main levels of complexity—simple and not-so-simple. A good measure of this complexity is the gap between the domain’s object model and the relational data model you intend to create to store your data.
A simple model is when your entities map closely to tables in the data model. A not-so-simple model is when some mapping is required to load and save domain objects to a relational database. The Active Record pattern is your choice when you want an object-oriented design and when your domain logic is simple overall.
In Active Record, each class essentially represents a record in a database table: the classes usually have instance methods that act on the represented record and perform common operations such as save and delete. In addition, a class might have some static methods to load an object from a database record and it might perform some rich queries involving all records. Classes in an Active Record model have methods, but these methods are mostly doing Create, Read, Update, Delete (CRUD) operations. There’s nearly no domain logic in the classes of an Active Record model, even though nothing prevents you from adding that.
An aspect that makes Active Record so attractive to developers is its extreme simplicity and elegance and, just as significantly, the fact that in spite of its simplicity it works surprisingly well for a many Web applications—even fairly large Web applications. I wouldn’t be exaggerating to say that the Active Record model is especially popular among Web developers and less so among Windows developers.
Beyond the simplicity and elegance of the model, available tools contribute significantly to make Active Record such a popular choice. Which tool should you use to implement an Active Record model?
LINQ-to-SQL is definitely an option. Fully integrated in Visual Studio 2008 and later, LINQ-to-SQL allows you to connect to a database and infer a model from there. As a developer, your classes become available in a matter of seconds at the end of a simple wizard. In addition, your classes can be recreated at any time as you make changes, if any, to the database. In terms of persistence, LINQ-to-SQL is not really a canonical Active Record model because it moves persistence to its internal DAL—the data context. LINQ-to-SQL incorporates a persistence engine that makes it look like a simple but effective Object/Relational Mapper (O/RM) tool with full support for advanced persistence patterns such as Identity Map and, especially, Unit of Work.
Castle Active Record is another framework that has been around for a few years and that offers a canonical implementation of the Active Record pattern. Finally, an emerging framework for Active Record modeling is SubSonic. (See http://www.subsonicproject.com.)
Unlike Castle Active Record, SubSonic can generate classes for you but does so in a way that is more flexible than in LINQ-to-SQL: it uses T4 templates. A T4 template is a .tt text file that Visual Studio 2008 and later can process and expand to a class. If you add a T4 template to a Visual Studio project, it soon turns it into a working class. This mechanism offers you an unprecedented level of flexibility because you can modify the structure of the class from the inside and not just extend it with partial classes as in LINQ-to-SQL, and it also removes the burden of writing that yourself as you must do with Castle Active Record.
In the Domain Model pattern, objects are aimed at providing a conceptual view of the problem’s domain. Objects have no relationships with the database and focus on the data owned and behavior to offer. Objects have both properties and methods and are not responsible for their own persistence. Objects are uniquely responsible for actions related to their role and domain logic.
Note
Two similar terms are often used interchangeably: object model and domain model. An object model is a plain graph of objects, and no constraints exist on how the model is designed. A domain model is a special object model in which classes are expected not to have any knowledge of the persistence layer and no dependencies on other classes outside the model.
A domain model is characterized by entities, value objects, factories, and aggregates. Entities are plain .NET objects that incorporate data and expose behavior. Entities don’t care about persistence and are technology agnostic.
In a domain model, everything should be represented as an object, including scalar values. Value objects are simple and immutable containers of values. You typically use value objects to replace primitives such as integers. An integer might indicate an amount of money, a temperature, or perhaps a quantity. In terms of modeling, by using integers instead of more specific types you might lose some information.
In a domain model, using a factory is the preferred way of creating new instances. Compared to the new operator, a factory offers more abstraction and increases the readability of code. With a factory, it’s easier to understand why you are creating a given instance.
Finally, an aggregate is an entity that controls one or more child entities. The association between an aggregate root and its child objects is stronger than a standard relationship. Callers, in fact, talk to the aggregate root and will never use child objects directly. Subsequently, controlled entities are processed and persisted only through the root aggregate. Aggregates are generally treated as a single unit in terms of data exchange. The major benefit of aggregates is grouping together strongly related objects so that they can be handled as a single unit while being expressed as individual classes.
Figure 14-4 is a representation of a system that uses the Domain Model pattern.
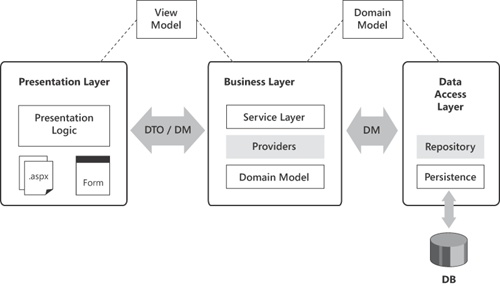
There are two ways of going with a Domain Model pattern. The simplest way is to design your entities and relationships with Entity Framework. After you have designed the layout of your entities and scalar objects, you generate the code using, preferably, the POCO code generator. What you get in the first place is an anemic domain model, where anemic indicates that classes are plain data containers and offer no behavior. However, Entity Framework lets you add methods to entities through the mechanism of partial classes. This also allows you to create factories quite easily.
The second way is to create your own set of classes and then use an O/RM tool (for example, Entity Framework or NHibernate), or a handmade ADO.NET layer, to persist it. This approach offers greater expressivity because it allows you to introduce aggregates. Note that value objects, factories, and aggregates are concepts related to Domain Model that are introduced by a specific design methodology—Domain-Driven Design, or DDD. Although DDD is a proven methodology to deal with real-world complexity, it doesn’t mean that you can’t have an effective model without following literally all DDD recommendations.
Entity Framework doesn’t help you much when it comes to DDD, but it doesn’t prevent you from using it as well. In Entity Framework, you have no native API to create aggregates.
However, your data access layer can be designed to expose aggregate roots and let you work with them in a way that is consistent with DDD practices.
Note
When you organize the business layer around a web of interconnected objects—a domain model—you neatly separate entities that the application logic (and sometimes the presentation logic) works with from any layer of code that is responsible for persistence. In this context, the DAL gains its own valuable role with full separation of concerns and responsibilities—the DAL just gets an object model and persists it to a store.
The application logic is the part of the BLL that contains endpoints, as required by use-cases. The application logic is the layer that you invoke directly from the presentation layer. The layer coordinates calls to the domain model, workflows, services, and the DAL to orchestrate just the behavior required by the various use-cases.
You can’t just believe that all this logic belongs to the presentation layer. (As you’ll see better in the next chapter, in ASP.NET Web Forms the presentation layer is mostly the code-behind class!)
To better understand the role and importance of the application logic, consider the following example. You are working on a use-case that describes the submission of a new order. Therefore, you need an endpoint in the application logic that orchestrates the various steps of this operation. These might be any of the following: validating customer and order information, checking the availability of ordered goods, checking the credit status of the customer, finding a shipper that agrees to deliver the goods within the specified time, synching up with the shipper system, registering the order, and finally triggering any automatic refill procedures if the order reduces goods in stock below a safe threshold.
The Service Layer pattern defines an additional layer that sits in between two interfacing layers—typically, the presentation layer and BLL. In practical terms, implementing a service layer requires you to create a collection of classes that include all the methods you need to call from the presentation layer. In other words, the classes that form the “service layer” shield the presentation layer from the details of the BLL and DAL. These classes are also the sole part of the application to modify if use-cases happen to change.
The word “service” here isn’t necessarily meant to suggest some specific technology to build services (for example, WCF). The service layer is just a layer of classes that provides services to the presentation. However, service-orientation and specific service technologies make the whole solution even worthier of your consideration and more successful.
In a typical Web Forms scenario, the application logic lives side by side with the ASP.NET pages on the Web server machine. This means that any calls from the code-behind to classes in the service layer are in-process calls. Likewise, classes in the service layer are plain CLR classes and don’t require service contracts and configuration.
In a desktop scenario, or if you implement a multitiered Web architecture, the service layer is likely living in a different process space. In this case, the service layer is implemented as a real layer of Windows Communication Foundation (WCF) or REST services.
I recommend you start coding plain classes and upgrade to services just when you need to. In WCF, at least, a service is a class with something around it, and that “something” is essentially the service contract and configuration. If you design your service layer classes to be highly decoupled, based on an interface, and to expose data contracts, it will take you just a few moments to add attributes and binding information and switch to WCF services for, say, queued or transactional calls.
A service layer is almost always beneficial to nearly all applications of some complexity that use a layered architecture. A possible exception is when you find out that your service layer is just a pass-through layer and is limited to forward calls to a specific component in the BLL or DAL. If you need some orchestration before you accomplish an operation, you do need a service layer. Take a look at Figure 14-5.

If the orchestration logic (represented by the gears) lives on the presentation tier, you end up placing several cross-tier calls in the context of a single user request. With a remotable service layer, though, you go through just one roundtrip per request. This is just what SOA papers refer to as the Chatty anti-pattern.
In Figure 14-5, you also see different blocks referring to services. The service layer is made of a collection of methods with a coarse-grained interface that I refer to in the figure as macro services. These services implement use-cases and do not contain any domain logic. Micro services, conversely, are domain-logic services you control or just autonomous services that your BLL needs to consume.
In a service layer, you should have only methods with a direct match to actions in a use-case. For example, you should have a FindAllOrders method only if you have a use-case that requires you to display all orders through the user interface. However, you should not have such a method if the use-case requires the user to click a button to escalate all unprocessed orders to another department. In this case, there’s no need to display to the user interface (and subsequently to roundtrip from the service layer) the entire list of orders. Here’s a sample class in a service layer:
public interface IOrderService
{
void Create(Order o);
IList<Order> FindAll();
Order FindByID(Int32 orderID);
}
public class OrderService : IOrderService
{
...
}A fundamental point in a service layer is the types used in the signatures. What about the Order type in the previous code snippet? Is it the same Order entity you might have in the domain model? Is it something else?
In general, if you can afford to expose domain model objects in the service contract, by all means do that. Your design is probably not as pure as it should be, but you save yourself a lot of time and effort. You must be aware that by using the same entity types in the presentation layer and BLL, you get additional coupling between the presentation and business layers. This is more than acceptable if the presentation and business layers are within the same layer. Otherwise, sharing the domain model forces you to have the same (or compatible) runtime platform on both sides of the network.
If you’re looking for the greatest flexibility and loose coupling, you should consider using ad hoc data transfer objects (DTO). A data transfer object is a plain container shaped by the needs of the view. A data transfer object contains just data and no behavior.
When you use data transfer objects, you likely need an extra layer of adapters. An adapter is a class that builds a data transfer object from a graph of domain entities. An adapter is bidirectional in the sense that it also needs a method to take a data transfer object coming from the presentation and break up its content into pieces to be mapped on entities.
The additional workload required by using data transfer objects is significant in moderately complex projects also. In fact, you need two adapters (or translators) for each data transfer object and likely two data transfer objects for each service layer method (one for input and one for output.)
It’s not a matter of being lazy developers; it’s just that a full data transfer object implementation requires a lot of work.
Note
Effective tools are a great way to make a full DTO implementation affordable and, to some extent, sustainable. A common tool that really saves you a ton of work is AutoMapper. (See http://automapper.codeplex.com.) AutoMapper is an object-to-object mapper that employs a convention-based algorithm. All it does is copy values from one object (for example, a domain entity) to another (for example, a DTO) using a configurable algorithm to resolve mapping between members. At this point, AutoMapper can be easily considered a best practice in modern development.
No matter how many abstraction layers you build in your system, at some point you need to open a connection to some database. That’s where and when the data access layer (DAL) fits in. The DAL is a library of code that provides access to data stored in a persistent container, such as a database. In a layered system, you delegate this layer any task that relates to reading from, and writing to, the persistent storage of choice.
Until recently, the DAL was just fused to the BLL and limited to a superset of the ADO.NET library created for the purpose of making writing data access code easier. In other words, for many years of the .NET era, the DAL has been simply a layer of helper methods to write data access quickly.
The shift toward a more conceptual view of the problem’s domain, and subsequently the advent of the Domain Model pattern, brought new interest in the role of the DAL. Now that you have a domain model exposed as the real database in the application’s eyes, you really need a distinct and well-defined layer that bridges the gap between the domain model and storage.
Although the role of the DAL is still the same as it was 20 years ago, the technologies are different, as is the approach to it taken by architects and developers. It’s interesting to briefly review the inner nature of the DAL in light of the pattern used for the BLL.
Having a BLL organized in table module classes leads you to having a database-centric vision of the system. Every operation you orchestrate in the application logic is immediately resolved in terms of database operations. It’s natural, at this point, to create an in-memory representation of data that closely reflects the structure of the underlying tables.
With the Table Module pattern, you have table classes and methods to indicate query or update operations. Any data being exchanged is expressed through ADO.NET container types such as DataSet and DataTable. Any data access logic is implemented through ADO.NET commands or batch updates.
The DAL still has the role of persisting data to databases, but data is stored in database-like structures (for example, DataSet), and a system framework (for example, ADO.NET) offers great support for working with DataSet types. As a result, BLL and DAL are merged together and are rather indistinguishable. The DAL, when physically distinct from BLL and living in its own assembly, is nothing more than a library of helper methods.
An Active Record BLL makes domain data available in the form of objects with a close resemblance to records of database tables. You no longer deal with super-array types such as DataSet, but instead have an object model to map to table records.
The DAL, therefore, has a clearer role here. It exists to bridge the gap between entities in the object model and database tables. The mapping work required from the DAL is relatively simple because there’s not much abstraction to cope with. Mapping between object properties and table columns is neat and well defined; the storage is a relational database.
The benefit of using Active Record instead of Table Module is mostly in the fact that an Active Record object model can be created to be a real strongly typed counterpart of a table. In this regard, it fits better than a generic container such as DataSets and can be extended at will. The drawback is in the extra work required to create the model, but fortunately many tools exist to infer the model directly from tables.
According to the Domain Model pattern, you create from the ground up an entity model with any appropriate relationships. More importantly, you do so while being completely ignorant about persistence. First, you create the object model that best represents the business domain; second, you think of how to persist it. As odd as it might sound, in a Domain Model scenario the database is purely part of the infrastructure. (See Figure 14-6.)
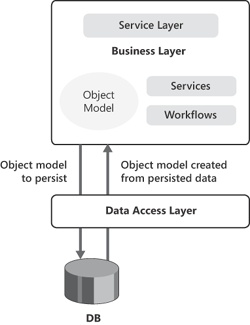
A DAL has four main responsibilities toward its consumers. In the first place, a DAL persists data to the physical storage and supplies CRUD services to the outside world. Second, the DAL is responsible for servicing any queries for data it receives. Finally, a DAL must be able to provide transactional semantics and handle concurrency properly. Conceptually, the DAL is a sort of black box exposing four contracted services, as shown in Figure 14-7.
Who does really write the DAL? Is it you? And why should you write a DAL yourself? Is it perhaps that you have a strict nonfunctional requirement that explicitly prohibits the use of an ad hoc tool such as an O/RM? Or is it rather that you think you would craft your DAL better than any commercial O/RM tools?
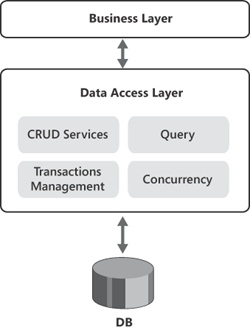
In a domain-based world, a well-built DAL is nearly the same as a well-built O/RM tool. So unless you have strict nonfunctional requirements that prohibit it, you should use an O/RM. Entity Framework is the official O/RM tool you find in the Microsoft stack of technologies. NHibernate is an even more popular tool that has been around for quite a few years now and that is close to its maturity.
In some simple scenarios, it might be acceptable for the DAL to be invoked from the presentation layer. This happens when you actually have only two tiers: the presentation layer and the storage. Beyond this, the DAL is a constituent part of the back end and is invoked from the application logic.
The next issues to resolve are the following: Should you allow any service layer classes to know the nitty-gritty details of the DAL implementation? Should you wrap the DAL implementation in an interfacing module that provides a fixed interface regardless of the underlying details? As usual, it depends.
In the past, every architect would have answered the previous questions with a sounding yes. Today, it is likely the same answer, but for different reasons. For years, the primary reason for wrapping the DAL in the outermost container has been to achieve database independence.
Wrapping the DAL in a pluggable component greatly simplifies the task of installing the same application in different servers or using it for customers with a different database system.
Today, the advent of O/RM tools has dwarfed this specific aspect of the DAL. It’s the O/RM itself that provides database independence today. At the same time, other compelling reasons show up that make interfacing the DAL still a great idea.
A common way to hide the implementation details and dependencies of the DAL is using the Repository pattern. There are a couple of general ways you can implement the pattern. One consists of defining a CRUD-like generic interface with a bunch of Add, Delete, Update, and Get methods. Here’s an example:
public interface IRepository<T> : ICollection<T>, IQueryable<T>
{
public void Add(T item)
{ ... }
public bool Contains(T item)
{ ... }
public bool Remove(T item)
{ ... }
public void Update(T item)
{ ... }
public IQueryable<T> Include(Expression<Func<T, object>> subSelector)
{ ... }
}The type T indicates the type of entity, such as Customer, Order, or Product. Next, you create an entity-specific repository object where you add ad hoc query methods that are suited for the entity. Here’s an example:
public interface IProductRepository : IRepository<Product>
{
IQueryable<Product> GetProductsOnSale();
}Classes in the service layer deal with repositories and ignore everything that’s hidden in their implementation. Figure 14-8 shows the summarizing graphic.
Another approach to building a repository consists of simply creating entity-specific repository classes and giving each one the interface you like best.
Today, testability is an excellent reason to interface the DAL. As shown in Figure 14-8, it allows you to plug in a fake DAL just for the purpose of testing service layer classes. Another scenario, however, is gaining ground on popularity: upgrading the existing DAL based on an on-premises database for the cloud.
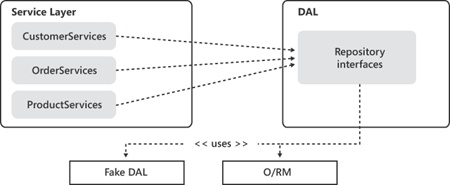
So it seems that a common practice for implementing a DAL is using an O/RM. Using an O/RM is not trivial, but tools and designers in the Microsoft and Visual Studio world make it considerably simpler. More to the point, with Entity Framework or LINQ-to-SQL you can hardly do it wrong. (Even though you can sometimes do it in a suboptimal way.)
Which O/RM should you use? In this brief gallery, I present two of the most popular choices (Entity Framework and NHibernate) and one for which there’s considerable debate about whether it belongs to the group (LINQ-to-SQL). I’m skipping over a review of all commercial O/RMs.
I like LINQ-to-SQL, period. When Microsoft released Entity Framework 1 in the fall of 2008, it promptly signaled the end of LINQ-to-SQL development—at least, active development, which involved adding new features. In the .NET Framework 4, LINQ-to-SQL is fully supported and it has even been slightly improved by the fixing of a few bugs and less-than-optimal features. Still, LINQ-to-SQL is a sort of dead-end; however, if it works for you today, it’ll likely work for you in the future.
I like to call LINQ-to-SQL “the poor man’s O/RM.” It’s a lightweight, extensible, data access option with some known limitations; however, it’s a well-defined and well-balanced set of features. LINQ-to-SQL pushes the “It’s easy, it’s fast, and it works” standard that is just what many developers are looking for.
LINQ-to-SQL works by inferring the entity model from a given database, and it supports only Microsoft SQL Server. LINQ-to-SQL doesn’t let you add much abstraction (for example, scalar types), but it does offer a POCO model that you can extend with partial classes and customize with partial methods.
Technically, LINQ-to-SQL implements many of the design patterns that characterize a true O/RM, such as Unit of Work (transactionality), Query object (query), and Identity Map. If you refer to the responsibilities of the DAL shown in Figure 14-7, you find nothing that LINQ-to-SQL can’t do. That’s why I’m listing it here. It’s the simplest of the O/RMs, but it’s not simplistic.
If you know LINQ-to-SQL, then Entity Framework might look like its big brother. Entity Framework is more expressive, comes with a richer designer for model and mappings, and supports multiple databases. If you get to Entity Framework from another O/RM tool, you might find it a bit different.
The only purpose of an O/RM tool is to persist an object model to some database. Entity Framework certainly does this, but it also helps you in the creation of the model. Most O/RM tools out there can persist any object model you can map to a database. Entity Framework builds on the Entity Relationship Model to let you create an abstract model of entities and relationships that it can then transform into plain C# partial classes.
When Entity Framework generates the source files for a model, it creates distinct files for each entity plus a class for the data context. From a design perspective, it’s key that these files go in distinct assemblies. Logically speaking, in fact, entities form the domain model whereas the data context object belongs to the DAL. It’s perhaps a little difference, but it’s immensely important from a design perspective.
Entity Framework can generate source files in three different ways. The default approach entails you getting entity classes with a dependency on the framework. All entity classes inherit from a built-in class defined in Entity Framework and incorporate some default behavior related to persistence. Another approach gets you plain old CLR classes with no dependencies on anything. This approach is POCO. Finally, Entity Framework can also generate entity classes that have the additional capability of tracking their changes.
Finally, Entity Framework supports Code-Only mode, which basically consists of the behavior that most of the other O/RM tools offer—you create your domain model as a plain library and then instruct Entity Framework on how to persist it. Code-Only is just the fluent API you use to define mappings to a database.
Note
As long as you intend to remain within the Microsoft stack, which O/RM should you use? LINQ-to-SQL or Entity Framework? The simple answer is Entity Framework because Entity Framework is the flagship product that will receive care and attention in the foreseeable future. What if you feel comfortable with LINQ-to-SQL and find it kind of costly to upgrade to Entity Framework?
In general, if your application has enough life ahead of it (no less than two years), after which a full redesign is acceptable, you can go with LINQ-to-SQL today and plan to upgrade later. However, keep in mind LINQ-to-SQL is not the light edition of Entity Framework; it has a slightly different programming API, and no migration path exists yet.
NHibernate is perhaps the most popular O/RM available today. It’s open-source software with a strong and active community to back it up. NHibernate requires you to provide a library of classes and a bunch of mapping XML files. Based on that, it offers a rich API to write your logic for persistence.
With the release of Entity Framework 4, the technical gap is shrinking more and more and mostly has been reduced to fine-tuning the framework’s behavior. The two main differences are the LINQ provider for expressing queries on entities, which is definitely superior in Entity Framework, and the absence in Entity Framework of second-level caching.
In addition, NHibernate looks like a more mature framework, closer to perfection in a way. Put another way, with the exception of adding a LINQ provider to it, I don’t really see how NHibernate can be significantly improved. As it is, NHibernate offers a number of extensibility points (lacking in Entity Framework) and more expressivity when it comes to dealing with paged collections and batch reads and writes. Companion tools (for example, profilers, caches, and sharding) are numerous for NHibernate and (currently) hard to write for Entity Framework because of the aforementioned lack of extensibility points.
Note
Sharding is a database design technique that consists of horizontal partitioning. In essence, the row set of a logical table is physically stored in multiple tables. Each partition is known as a shard and may be located on a distinct database server. The goal of sharding is gaining scalability by reducing table and index size and making search faster.
Note
So here’s a point-blank question: Entity Framework or NHibernate? Skipping the usual (and reasonable) point that it depends on the context, skills, and requirements, I’d say that with Entity Framework you don’t get the same programming power of NHibernate. However, if you don’t need that power, over all, you can work nicely and safer with Entity Framework, in the sense that you hardly ever screw things up.
An O/RM tools persists entities by generating and executing SQL commands. Is the SQL code generated by O/RMs reliable? In general, trusting an O/RM is not a bad idea, but constantly verifying the quality of the job they do is an even better idea. With any O/RM, a savvy developer will usually define the fetch plan and use the SQL profiler tool of choice to see what is coming out. Obviously, if the SQL code is patently bad, you intervene and in some way (changing the fetch plan or inserting stored procedures) you fix it.
In general, using stored procedures should be considered a last resort, but there might be cases in which they come to the rescue. An example is when quite complex queries can’t be expressed efficiently through classic cursor-based syntax and requires, instead, a SET-based approach to boost the performance. In this case, a stored procedure can be the best option.
A plausible scenario that could lead you to unplugging your DAL is that you replace the current storage with something else, from yet another relational DBMS system. If you simply switch from SQL Server to, say, Oracle, most of the O/RM tools can absorb the change quite nicely. At worst, you pay some money to a third-party company to get a driver. A more delicate situation, though, is when you replace the storage layer of the application with something different, such as a cloud database or, say, a model managed by Microsoft Dynamics CRM, or perhaps a NoSQL solution such as MongoDB, RavenDB, or CouchDB.
As far as cloud databases are concerned, you can use a variety of solutions. For example, you can move to SQL Azure, which offers a transparent API and can be easily plugged into your system via Entity Framework.
Alternatively, you can choose a cloud solution such as Amazon SimpleDB, Amazon RDS, or perhaps S3. In all these cases, your access to data happens through Web services. And Web services require you to rewrite your DAL to invoke the proper Web service instead of opening an O/RM session.
More in general, perhaps with the sole (current) exception of SQL Azure and Entity Framework, going to the cloud requires you to unplug the current DAL and roll a new one. It’s definitely a compelling reason to keep the DAL loosely coupled to the rest of the system.
A layered system doesn’t necessarily have to rely on a classic relational storage whose physical model is the topic of endless discussion and whose optimization is left to external gurus. In some business scenarios, Microsoft Dynamics CRM represents an even better option for building line-of-business applications that fall under the umbrella of a Customer Relationship Management (CRM) system.
Within Dynamics CRM 2011, you express the data model using a mix of built-in and custom entities. You can think of a CRM entity as a database record where attributes of an entity map roughly to columns on a database table. Dynamics CRM 2011 exposes data to developers using a bunch of WCF and REST endpoints. This makes it possible for developers of Web applications to capture data, process that as necessary, and arrange a custom user interface.
In other words, the Dynamics CRM model might become the BLL and DAL that the service layer talks to. It’s yet another scenario that makes loosely coupling of back-end layers exactly the way to go when building layered solutions.
A storage option that is gaining momentum is schema-less storage that is often summarized as a NoSQL solution. A classic relational database is a collection of relations where a relation is defined as a set of tuples sharing the same attributes—the schema. NoSQL stores just refuse relations.
NoSQL stores still refer to a form of structured storage in which each stored document may have its own schema, which is not necessarily shared with other documents in the same store. A document is exposed as a collection of name/value pairs; it is stored in some way (for example, as individual files) and accessed through a REST interface.
A NoSQL database is characterized by the lack of a schema, the lack of a structured query language, and an often distributed and redundant architecture. NoSQL databases belong to three main families: document stores, key/value stores, and object databases.
A document store saves documents as JSON objects and defines views/indexes. Objects can be arbitrarily complex and have a deep structure. To this category belong popular tools such as CouchDB, Raven, and MongoDB.
A key/value store saves tuples of data in a main table. Each row has a set of named columns, and values can be arbitrarily complex. Google’s BigTable, Cassandra, and Memcached are examples of key/value NoSQL stores.
Finally, an object database stores serialized objects instead of primitive data and offers query capabilities. A popular choice is Db4O.
Most applications today are articulated in layers. Every time you add a layer to an application, you add a bit more code and, subsequently, extra CPU cycles. And you worsen the overall performance of the application. Is this all true?
Technically speaking, it couldn’t be truer. However, a few extra CPU cycles are not necessarily what really matters. Software architecture, more than programming, is a matter of tradeoffs. Layers add benefits to any software of some complexity. Layers add separation of concerns and favor code injection and the right level of coupling.
In this chapter, I went through two of the three layers you find in a classic multitiered system: the business layer and the data access layer. The next chapter is reserved for the presentation layer and for the most appropriate pattern for Web Forms applications—the Model-View-Presenter pattern.