
24. Internet Data Handling and Encoding
This chapter describes modules related to processing common Internet data formats and encodings such as base 64, HTML, XML, and JSON.
base64
The base64 module is used to encode and decode binary data into text using base 64, base 32, or base 16 encoding. Base 64 is commonly used to embed binary data in mail attachments and with parts of the HTTP protocol. Official details can be found in RFC-3548 and RFC-1421.
Base 64 encoding works by grouping the data to be encoded into groups of 24 bits (3 bytes). Each 24-bit group is then subdivided into four 6-bit components. Each 6-bit value is then represented by a printable ASCII character from the following alphabet:

If the number of bytes in the input stream is not a multiple of 3 (24 bits), the data is padded to form a complete 24-bit group. The extra padding is then indicated by special '=' characters that appear at the end of the encoding. For example, if you encode a 16-byte character sequence, there are five 3-byte groups with 1 byte left over. The remaining byte is padded to form a 3-byte group. This group then produces two characters from the base 64 alphabet (the first 12 bits, which include 8 bits of real data), followed by the sequence '==', representing the bits of extra padding. A valid base 64 encoding will only have zero, one (=), or two (==) padding characters at the end of the encoding.
Base 32 encoding works by grouping binary data into groups of 40 bits (5 bytes). Each 40-bit group is subdivided into eight 5-bit components. Each 5-bit value is then encoded using the following alphabet:
![]()
As with base 64, if the end of the input stream does not form a 40-bit group, it is padded to 40 bits and the '=' character is used to represent the extra padding in the output. At most, there will be six padding characters ('======'), which occurs if the final group only includes 1 byte of data.
Base 16 encoding is the standard hexadecimal encoding of data. Each 4-bit group is represented by the digits '0'–'9' and the letters 'A'–'F'. There is no extra padding or pad characters for base 16 encoding.
b64encode(s [, altchars])
Encodes a byte string s using base 64 encoding. altchars, if given, is a two-character string that specifies alternative characters to use for '+' and '/' characters that normally appear in base 64 output. This is useful if base 64 encoding is being used with filenames or URLs.
b64decode(s [, altchars])
Decodes string s, which is encoded as base 64 and returns a byte string with the decoded data. altchars, if given, is a two-character string that specifies the alternative characters for '+' and '/' that normally appear in base 64–encoded data. TypeError is raised if the input s contains extraneous characters or is incorrectly padded.
standard_b64encode(s)
Encodes a byte string s using the standard base 64 encoding.
standard_b64decode(s)
Decodes string s using standard base 64 encoding.
urlsafe_b64encode(s)
Encodes a byte string s using base 64 but uses the characters '-' and '_' instead of '+' and '/', respectively. The same as b64encode(s, '-_').
urlsafe_b64decode(s)
Decodes string s encoded with a URL-safe base 64 encoding.
b32encode(s)
Encodes a byte string s using base 32 encoding.
b32decode(s [, casefold [, map01]])
Decodes string s using base 32 encoding. If casefold is True, both uppercase and lowercase letters are accepted. Otherwise, only uppercase letters may appear (the default). map01, if present, specifies which letter the digit 1 maps to (for example, the letter 'I' or the letter 'L'). If this argument is given, the digit '0' is also mapped to the letter 'O'. A TypeError is raised if the input string contains extraneous characters or is incorrectly padded.
b16encode(s)
Encodes a byte string s using base 16 (hex) encoding.
b16decode(s [,casefold])
Decodes string s using base 16 (hex) encoding. If casefold is True, letters may be uppercase or lowercase. Otherwise, hexadecimal letters 'A'–'F' must be uppercase (the default). Raises TypeError if the input string contains extraneous characters or is malformed in any way.
The following functions are part of an older base 64 module interface that you may see used in existing Python code:
decode(input, output)
Decodes base 64–encoded data. input is a filename or a file object open for reading. output is a filename or a file object open for writing in binary mode.
decodestring(s)
Decodes a base 64–encoded string, s. Returns a string containing the decoded binary data.
encode(input, output)
Encodes data using base 64. input is a filename or a file object open for reading in binary mode. output is a filename or a file object open for writing.
encodestring(s)
Encodes a byte string, s, using base 64.
binascii
The binascii module contains low-level functions for converting data between binary and a variety of ASCII encodings, such as base 64, BinHex, and UUencoding.
a2b_uu(s)
Converts a line of uuencoded text s to binary and returns a byte string. Lines normally contain 45 (binary) bytes, except for the last line that may be less. Line data may be followed by whitespace.
b2a_uu(data)
Converts a string of binary data to a line of uuencoded ASCII characters. The length of data should not be more than 45 bytes. Otherwise, the Error exception is raised.
a2b_base64(string)
Converts a string of base 64–encoded text to binary and returns a byte string.
b2a_base64(data)
Converts a string of binary data to a line of base 64–encoded ASCII characters. The length of data should not be more than 57 bytes if the resulting output is to be transmitted through email (otherwise it might get truncated).
Converts a string of hexadecimal digits to binary data. This function is also called as unhexlify(string).
b2a_hex(data)
Converts a string of binary data to a hexadecimal encoding. This function is also called as hexlify(data).
a2b_hqx(string)
Converts a string of BinHex 4–encoded data to binary without performing RLE (Run-Length Encoding) decompression.
rledecode_hqx(data)
Performs an RLE decompression of the binary data in data. Returns the decompressed data unless the data input is incomplete, in which case the Incomplete exception is raised.
rlecode_hqx(data)
Performs a BinHex 4 RLE compression of data.
b2a_hqx(data)
Converts the binary data to a string of BinHex 4–encoded ASCII characters. data should already be RLE-coded. Also, unless data is the last data fragment, the length of data should be divisible by 3.
crc_hqx(data, crc)
Computes the BinHex 4 CRC checksum of the byte string data. crc is a starting value of the checksum.
crc32(data [, crc])
Computes the CRC-32 checksum of the byte string data. crc is an optional initial CRC value. If omitted, crc defaults to 0.
csv
The csv module is used to read and write files consisting of comma-separated values (CSV). A CSV file consists of rows of text, each row consisting of values separated by a delimiter character, typically a comma (,) or a tab. Here’s an example:
![]()
Variants of this format commonly occur when working with databases and spreadsheets. For instance, a database might export tables in CSV format, allowing the tables to be read by other programs. Subtle complexities arise when fields contain the delimiter character. For instance, in the preceding example, one of the fields contains a comma and must be placed in quotes. This is why using basic string operations such as split(',') are often not enough to work with such files.
reader(csvfile [, dialect [, **fmtparams])
Returns a reader object that produces the values for each line of input of the input file csvfile. csvfile is any iterable object that produces a complete line of text on each iteration. The returned reader object is an iterator that produces a list of strings on each iteration. The dialect parameter is either a string containing the name of a dialect or a Dialect object. The purpose of the dialect parameter is to account for differences between different CSV encodings. The only built-in dialects supported by this module are 'excel' (which is the default value) and 'excel-tab', but others can be defined by the user as described later in this section. fmtparams is a set of keyword arguments that customize various aspects of the dialect. The following keyword arguments can be given:

writer(csvfile [, dialect [, **fmtparam]])
Returns a writer object that can be used to create a CSV file. csvfile is any file-like object that supports a write() method. dialect has the same meaning as for reader() and is used to handle differences between various CSV encodings. fmtparams has the same meaning as for readers. However, one additional keyword argument is available:

A writer instance, w, supports the following methods:
w.writerow(row)
Writes a single row of data to the file. row must be a sequence of strings or numbers.
Writes multiple rows of data. rows must be a sequence of rows as passed to the writerow() method.
![]()
Returns a reader object that operates like the ordinary reader but returns dictionary objects instead of lists of strings when reading the file. fieldnames provides a list of field names used as keys in the returned dictionary. If omitted, the dictionary key names are taken from the first row of the input file. restkey provides the name of a dictionary key that’s used to store excess data—for instance, if a row has more data fields than field names. restval is a default value that’s used as the value for fields that are missing from the input—for instance, if a row does not have enough fields. The default value of restkey and restval is None. dialect and fmtparams have the same meaning as for reader().
![]()
Returns a writer object that operates like the ordinary writer but writes dictionaries into output rows. fieldnames specifies the order and names of attributes that will be written to the file. restval is the value that’s written if the dictionary being written is missing one of the field names in fieldnames. extrasaction is a string that specifies what to do if a dictionary being written has keys not listed in fieldnames. The default value of extrasaction is 'raise', which raises a ValueError exception. A value of 'ignore' may be used, in which case extra values in the dictionary are ignored. dialect and fmtparams have the same meaning as with writer().
A DictWriter instance, w, supports the following methods:
w.writerow(row)
Writes a single row of data to the file. row must be a dictionary that maps field names to values.
w.writerows(rows)
Writes multiple rows of data. rows must be a sequence of rows as passed to the writerow() method.
Sniffer()
Creates a Sniffer object that is used to try and automatically detect the format of a CSV file.
A Sniffer instance, s, has the following methods:
s.sniff(sample [, delimiters])
Looks at data in sample and returns an appropriate Dialect object representing the data format. sample is a portion of a CSV file containing at least one row of data. delimiters, if supplied, is a string containing possible field delimiter characters.
s.has_header(sample)
Looks at the CSV data in sample and returns True if the first row looks like a collection of column headers.
Dialects
Many of the functions and methods in the csv module involve a special dialect parameter. The purpose of this parameter is to accommodate different formatting conventions of CSV files (for which there is no official “standard” format)—for example, differences between comma-separated values and tab-delimited values, quoting conventions, and so forth.
Dialects are defined by inheriting from the class Dialect and defining the same set of attributes as the formatting parameters given to the reader() and writer() functions (delimiter, doublequote, escapechar, lineterminator, quotechar, quoting, skipinitialspace).
The following utility functions are used to manage dialects:
register_dialect(name, dialect)
Registers a new Dialect object, dialect, under the name name.
unregister_dislect(name)
Removes the Dialect object with name name.
get_dialect(name)
Returns the Dialect object with name name.
list_dialects()
Returns a list of all registered dialect names. Currently, there are only two built-in dialects: 'excel' and 'excel-tab'.
Example

email Package
The email package provides a wide variety of functions and objects for representing, parsing and manipulating email messages encoded according to the MIME standard.
Covering every detail of the email package is not practical here, nor would it be of interest to most readers. Thus, the rest of this section focuses on two common practical problems—parsing email messages in order to extract useful information and creating email messages so that they can be sent using the smtplib module.
Parsing Email
At the top level, the email module provides two functions for parsing messages:
message_from_file(f)
Parses an email message read from the file-like object f which must be opened in text mode. The input message should be a complete MIME-encoded email message including all headers, text, and attachments. Returns a Message instance.
message_from_string(str)
Parses an email message by reading an email message from the text string str. Returns a Message instance.
A Message instance m returned by the previous functions emulates a dictionary and supports the following operations for looking up message data:

In addition to these operators, m has the following methods that can be used to extract information:
m.get_all(name [, default])
Returns a list of all values for a header with name name. Returns default if no such header exists.
m.get_boundary([default])
Returns the boundary parameter found within the 'Content-type' header of a message. Typically the boundary is a string such as '===============0995017162==' that’s used to separate the different subparts of a message. Returns default if no boundary parameter could be found.
Returns the character set associated with the message payload (for instance, 'iso-8859-1').
m.get_charsets([default])
Returns a list of all character sets that appear in the message. For multipart messages, the list will represent the character set of each subpart. The character set of each part is taken from 'Content-type' headers that appear in the message. If no character set is specified or the content-type header is missing, the character set for that part is set to the value of default (which is None by default).
m.get_content_charset([default])
Returns the character set from the first 'Content-type' header in the message. If the header is not found or no character set is specified, default is returned.
m.get_content_maintype()
Returns the main content type (for example, 'text' or 'multipart').
m.get_content_subtype()
Returns the subcontent type (for example, 'plain' or 'mixed').
m.get_content_type()
Returns a string containing the message content type (for example, 'multipart/mixed' or 'text/plain').
m.get_default_type()
Returns the default content type (for example, 'text/plain' for simple messages).
m.get_filename([default])
Returns the filename parameter from a 'Content-Disposition' header, if any. Returns default if the header is missing or does not have a filename parameter.
m.get_param(param [, default [, header [, unquote]]])
Email headers often have parameters attached to them such as the 'charset' and 'format' parts of the header 'Content-Type: text/plain; charset="utf-8"; format=flowed'. This method returns the value of a specific header parameter. param is a parameter name, default is a default value to return if the parameter is not found, header is the name of the header, and unquote specifies whether or not to unquote the parameter. If no value is given for header, parameters are taken from the 'Content-type' header. The default value of unquote is True. The return value is either a string or a 3-tuple (charset, language, value) in the event the parameter was encoded according to RFC-2231 conventions. In this case, charset is a string such as 'iso-8859-1', language is a string containing a language code such as 'en', and value is the parameter value.
m.get_params([default [, header [, unquote]]])
Returns all parameters for header as a list. default specifies the value to return if the header isn’t found. If header is omitted, the 'Content-type' header is used. unquote is a flag that specifies whether or not to unquote values (True by default). The contents of the returned list are tuples (name, value) where name is the parameter name and value is the value as returned by the get_param() method.
m.get_payload([i [, decode]])
Returns the payload of a message. If the message is a simple message, a byte string containing the message body is returned. If the message is a multipart message, a list containing all the subparts is returned. For multipart messages, i specifies an optional index in this list. If supplied, only that message component will be returned. If decode is True, the payload is decoded according to the setting of any 'Content-Transfer-Encoding' header that might be present (for example, 'quoted-printable', 'base64', and so on). To decode the payload of a simple non-multipart message, set i to None and decode to True or specify decode using a keyword argument. It should be emphasized that the payload is returned as a byte string containing the raw content. If the payload represents text encoded in UTF-8 or some other encoding, you will need to use the decode() method on the result to convert it.
m.get_unixfrom()
Returns the UNIX-style 'From ...' line, if any.
m.is_multipart()
Returns True if m is a multipart message.
m.walk()
Creates a generator that iterates over all the subparts of a message, each of which is also represented by a Message instance. The iteration is a depth-first traversal of the message. Typically, this function could be used to process all the components of a multipart message.
Finally, Message instances have a few attributes that are related to low-level parsing process.
m.preamble
Any text that appears in a multipart message between the blank line that signals the end of the headers and the first occurrence of the multipart boundary string that marks the first subpart of the message.
m.epilogue
Any text in the message that appears after the last multipart boundary string and the end of the message.
m.defects
A list of all message defects found when parsing the message. Consult the online documentation for the email.errors module for further details.
The following example illustrates how the Message class is used while parsing an email message. The following code reads an email message, prints a short summary of useful headers, prints the plain text portions of the message, and saves any attachments.
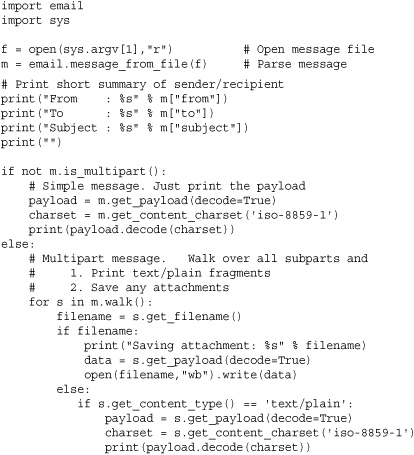
In this example, it is important to emphasize that operations that extract the payload of a message always return byte strings. If the payload represents text, you also need to decode it according to some character set. The m.get_content_charset() and payload.decode() operations in the example are carrying out this conversion.
Composing Email
To compose an email message, you can either create an empty instance of a Message object, which is defined in the email.message module, or you can use a Message object that was created by parsing an email message (see the previous section).
Message()
Creates a new message that is initially empty.
An instance m of Message supports the following methods for populating a message with content, headers, and other information.
m.add_header(name, value, **params)
Adds a new message header. name is the name of the header, value is the value of the header, and params is a set of keyword arguments that supply additional optional parameters. For example, add_header('Foo','Bar',spam='major') adds the header line 'Foo: Bar; spam="major"' to the message.
m.as_string([unixfrom])
Converts the entire message to a string. unixfrom is a Boolean flag. If this is set to True, a UNIX-style 'From ...’ line appears as the first line. By default, unixfrom is False.
Adds an attachment to a multipart message. payload must be another Message object (for example, email.mime.text.MIMEText). Internally, payload is appended to a list that keeps track of the different parts of the message. If the message is not a multipart message, use set_payload() to set the body of a message to a simple string.
m.del_param(param [, header [, requote]])
Deletes the parameter param from header header. For example, if a message has the header 'Foo: Bar; spam="major"', del_param('spam','Foo') would delete the 'spam="major"' portion of the header. If requote is True (the default), all remaining values are quoted when the header is rewritten. If header is omitted, the operation is applied to the 'Content-type' header.
m.replace_header(name, value)
Replaces the value of the first occurrence of the header name with value value. Raises KeyError if the header is not found.
m.set_boundary(boundary)
Sets the boundary parameter of a message to the string boundary. This string gets added as the boundary parameter to the 'Content-type' header in the message. Raises HeaderParseError if the message has no content-type header.
m.set_charset(charset)
Sets the default character set used by a message. charset may be a string such as 'iso-8859-1' or 'euc-jp'. Setting a character set normally adds a parameter to the 'Content-type' header of a message (for example, 'Content-type: text/html; charset="iso-8859-1"').
m.set_default_type(ctype)
Sets the default message content type to ctype. ctype is a string containing a MIME type such as 'text/plain’ or 'message/rfc822'. This type is not stored in the 'Content-type' header of the message.
![]()
Sets the value of a header parameter. param is the parameter name, and value is the parameter value. header specifies the name of the header and defaults to 'Content-type'. requote specifies whether or not to requote all the values in the header after adding the parameter. By default, this is True. charset and language specify optional character set and language information. If these are supplied, the parameter is encoded according to RFC-2231. This produces parameter text such as param*="'iso-8859-1'en-us'some%20value".
m.set_payload(payload [, charset])
Sets the entire message payload to payload. For simple messages, payload can be a byte string containing the message body. For multipart messages, payload is a list of Message objects. charset optionally specifies the character set that was used to encode the text (see set_charset).
m.set_type(type [, header [, requote]])
Sets the type used in the 'Content-type' header. type is a string specifying the type, such as 'text/plain' or 'multipart/mixed'. header specifies an alternative header other than the default 'Content-type' header. requote quotes the value of any parameters already attached to the header. By default, this is True.
m.set_unixfrom(unixfrom)
Sets the text of the UNIX-style 'From ...' line. unixfrom is a string containing the complete text including the 'From' text. This text is only output if the unixfrom parameter of m.as_string() is set to True.
Rather than creating raw Message objects and building them up from scratch each time, there are a collection of prebuilt message objects corresponding to different types of content. These message objects are especially useful for creating multipart MIME messages. For instance, you would create a new message and attach different parts using the attach() method of Message. Each of these objects is defined in a different submodule, which is noted in each description.
![]()
Defined in email.mime.application. Creates a message containing application data. data is a byte string containing the raw data. subtype specifies the data subtype and is 'octet-stream' by default. encoder is an optional encoding function from the email.encoders subpackage. By default, data is encoded as base 64. params represents optional keyword arguments and values that will be added to the 'Content-type' header of the message.
MIMEAudio(data [, subtype [, encoder [, **params]]])
Defined in email.mime.audio. Creates a message containing audio data. data is a byte string containing the raw binary audio data. subtype specifies the type of the data and is a string such as 'mpeg' or 'wav'. If no subtype is provided, the audio type will be guessed by looking at the data using the sndhdr module. encoder and params have the same meaning as for MIMEApplication.
MIMEImage(data [, subtype [, encoder [, **params]]])
Defined in email.mime.image. Creates a message containing image data. data is a byte string containing the raw image data. subtype specifies the image type and is a string such as 'jpg' or 'png'. If no subtype is provided, the type will be guessed using a function in the imghdr module. encoder and params have the same meaning as for MIMEApplication.
MIMEMessage(msg [, subtype])
Defined in email.mime.message. Creates a new non-multipart MIME message. msg is a message object containing the initial payload of the message. subtype is the type of the message and defaults to 'rfc822'.
![]()
Defined in email.mime.multipart. Creates a new MIME multipart message. subtype specifies the optional subtype to be added to the ‘Content-type: multipart/subtype' header. By default, subtype is 'mixed'. boundary is a string that specifies the boundary separator used to make each message subpart. If set to None or omitted, a suitable boundary is determined automatically. subparts is a sequence of Message objects that make up the contents of the message. params represents optional keyword arguments and values that are added to the 'Content-type' header of the message. Once a multipart message has been created, additional subparts can be added using the Message.attach() method.
MIMEText(data [, subtype [, charset]])
Defined in email.mime.text. Creates a message containing textual data. data is a string containing the message payload. subtype specifies the text type and is a string such as 'plain' (the default) or 'html'. charset is the character set, which defaults to 'us-ascii'. The message may be encoded depending on the contents of the message.
The following example shows how to compose and send an email message using the classes in this section:
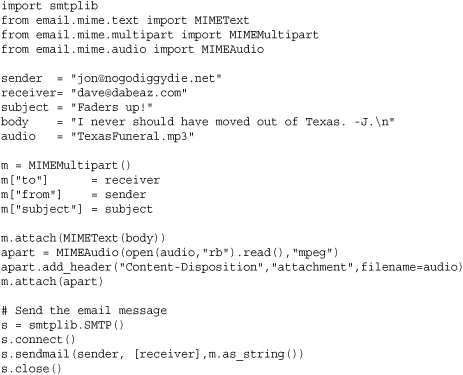
Notes
• A number of advanced customization and configuration options have not been discussed. Readers should consult the online documentation for advanced uses of this module.
• The email package has gone through at least four different versions, where the underlying programming interface has been changed (i.e., submodules renamed, classes moved to different locations, etc.). This section has documented version 4.0 of the interface that is used in both Python 2.6 and Python 3.0. If you are working with legacy code, the basic concepts still apply, but you may have to adjust the locations of classes and submodules.
hashlib
The hashlib module implements a variety of secure hash and message digest algorithms such as MD5 and SHA1. To compute a hash value, you start by calling one of the following functions, the name of which is the same as represented algorithm:

An instance d of the digest object returned by any of these functions has the following interface:

An alternative construction interface is also provided by the module:
new(hashname)
Creates a new digest object. hashname is a string such as 'md5' or 'sha256' specifying the name of the hashing algorithm to use. The name of the hash can minimally be any of the previous hashing algorithms or a hashing algorithm exposed by the OpenSSL library (which depends on the installation).
hmac
The hmac module provides support for HMAC (Keyed-Hashing for Message Authentication), which is described in RFC-2104. HMAC is a mechanism used for message authentication that is built upon cryptographic hashing functions such as MD5 and SHA-1.
new(key [, msg [, digest]])
Creates a new HMAC object. Here, key is a byte string containing the starting key for the hash, msg contains initial data to process, and digest is the digest constructor that should be used for cryptographic hashing. By default, digest is hashlib.md5. Normally, the initial key value is determined at random using a cryptographically strong random number generator.
An HMAC object, h, has the following methods:
h.update(msg)
Adds the string msg to the HMAC object.
h.digest()
Returns the digest of all data processed so far and returns a byte string containing the digest value. The length of the string depends on the underlying hashing function. For MD5, it is 16 characters; for SHA-1, it is 20 characters.
h.hexdigest()
Returns the digest as a string of hexadecimal digits.
h.copy()
Makes a copy of the HMAC object.
Example
The primary use of the hmac module is in applications that need to authenticate the sender of a message. To do this, the key parameter to new() is a byte string representing a secret key known by both the sender and receiver of a message. When sending a message, the sender will create a new HMAC object with the given key, update the object with message data to be sent, and then send the message data along with the resulting HMAC digest value to the receiver. The receiver can verify the message by computing its own HMAC digest value (using the same key and message data) and comparing the result to the digest value received. Here is an example:

HTMLParser
In Python 3, this module is called html.parser. The HTMLParser module defines a class HTMLParser that can be used to parse HTML and XHTML documents. To use this module, you define your own class that inherits from HTMLParser and redefines methods as appropriate.
HTMLParser()
This is a base class that is used to create HTML parsers. It is initialized without any arguments.
An instance h of HTMLParser has the following methods:
h.close()
Closes the parser and forces the processing of any remaining unparsed data. This method is called after all HTML data has been fed to the parser.
h.feed(data)
Supplies new data to the parser. This data will be immediately parsed. However, if the data is incomplete (for example, it ends with an incomplete HTML element), the incomplete portion will be buffered and parsed the next time feed() is called with more data.
h.getpos()
Returns the current line number and character offset into that line as a tuple (line, offset).
h.get_starttag_text()
Returns the text corresponding to the most recently opened start tag.
h.handle_charref(name)
This handler method is called whenever a character reference such as '&#ref;' is encountered. name is a string containing the name of the reference. For example, when parsing 'å', name will be set to '229'.
h.handle_comment(data)
This handler method is called whenever a comment is encountered. data is a string containing the text of the comment. For example, when parsing the comment '<!--comment-->', data will contain the text 'comment'.
h.handle_data(data)
This handler is called to process data that appears between tags. data is a string containing text.
h.handle_decl(decl)
This handler is called to process declarations such as '<!DOCTYPE HTML ...>'. decl is a string containing the text of the declaration not including the leading '<!' and trailing '>'.
This handler is called whenever end tags are encountered. tag is the name of the tag converted to lowercase. For example, if the end tag is '</BODY>', tag is the string 'body'.
h.handle_entityref(name)
This handler is called to handle entity references such as '&name;'. name is a string containing the name of the reference. For example, if parsing '<', name will be set to 'lt'.
h.handle_pi(data)
This handler is called to handle processing instructions such as '<?processing instruction>'. data is a string containing the text of the processing instruction not including the leading '<?' or trailing '>'. When called on XHTML-style instructions of the form '<?...?>', the last '?' will be included in data.
h.handle_startendtag(tag, attrs)
This handler processes XHTML-style empty tags such as '<tag name="value"... />'. tag is a string containing the name of the tag. attrs contains attribute information and is a list of tuples of the form (name, value) where name is the attribute name converted to lowercase and value is the attribute value. When extracting values, quotes and character entities are replaced. For example, if parsing '<a href="http://www.foo.com"/>', tag is 'a' and attrs is [('href','http://www.foo.com')]. If not defined in derived classes, the default implementation of this method simply calls handle_starttag() and handle_endtag().
h.handle_starttag(tag, attrs)
This handler processes start tags such as '<tag name="value" ...>'. tag and attrs have the same meaning as described for handle_startendtag().
h.reset()
Resets the parser, discarding any unprocessed data.
The following exception is provided:
HTMLParserError
Exception raised as a result of parsing errors. The exception has three attributes. The msg attribute contains a message describing the error, the lineno attribute is the line number where the parsing error occurred, and the offset attribute is the character offset into the line.
Example
The following example fetches an HTML document using the urllib package and prints all links that have been specified with '<a href="...">' declarations:
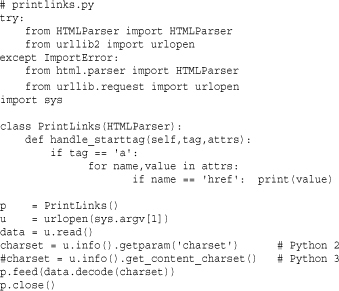
In the example, it must be noted that any HTML fetched using urllib is returned as a byte string. To properly parse it, it must be decoded into text according to the document character set encoding. The example shows how to obtain this in Python 2 and Python 3.
Note
The parsing capabilities of HTMLParser tend to be rather limited. In fact, with very complicated and/or malformed HTML, the parser can break. Users also find this module to be lower-level than is useful. If you are writing programs that must scrape data from HTML pages, consider the Beautiful Soup package (http://pypi.python.org/pypi/BeautifulSoup).
json
The json module is used to serialize and unserialize objects represented using JavaScript Object Notation (JSON). More information about JSON is available at http://json.org, but the format is really just a subset of JavaScript syntax. Incidentally, it’s almost the same as Python syntax for representing lists and dictionaries. For example, a JSON array is written as [value1, value2, ... ], and a JSON object is written as {name:value, name:value, .... }.
The following list shows how JSON values and Python values are mapped. The Python types listed in parentheses are accepted when encoding but are not returned when decoding (instead, the first listed type is returned).

For string data, you should assume the use of Unicode. If byte strings are encountered during encoding, they will be decoded into a Unicode string using 'utf-8' by default (although this can be controlled). JSON strings are always returned as Unicode when decoding.
The following functions are used to encode/decode JSON documents:
dump(obj, f, **opts)
Serializes obj to a file-like object f. opts represents a collection of keyword arguments that can be specified to control the serialization process:

dumps(obj, **opts)
The same as dump() except that a string containing the result is returned.
Deserializes a JSON object on the file-like object f and returns it. opts represents a set of keyword arguments that can be specified to control the decoding process and are described next. Be aware that this function calls f.read() to consume the entire contents of f. Because of this, it should not be used on any kind of streaming file such as a socket where JSON data might be received as part of a larger or ongoing data stream.

loads(s, **opts)
The same as load() except that an object is deserialized from the string s.
Although these functions share the same names as functions from the pickle and marshal modules and they serialize data, they are not used in the same way. Specifically, you should not use dump() to write more than one JSON-encoded object to the same file. Similarly, load() cannot be used to read more than one JSON-encoded object from the same file (if the input file has more than one object in it, you’ll get an error). JSON-encoded objects should be treated in the same manner as HTML or XML. For example, you usually don’t take two completely separate XML documents and just concatenate them together in the same file.
If you want to customize the encoding or decoding process, inherit from these base classes:
JSONDecoder(**opts)
A class that decodes JSON data. opts represents a set of keyword arguments that are identical to those used by the load() function. An instance d of JSONDecoder has the following two methods:
d.decode(s)
Returns the Python representation of the JSON object in s. s is a string.
Returns a tuple (pyobj, index) where pyobj is the Python representation of a JSON object in s and index is the position in s where the JSON object ended. This can be used if you are trying to parse an object out of an input stream where there is extra data at the end.
JSONEncoder(**opts)
A class that encodes a Python object into JSON. opts represents a set of keyword arguments that are identical to those used by the dump() function. An instance e of JSONEncoder has the following methods:
e.default(obj)
Method called when a Python object obj can’t be encoded according to any of the normal encoding rules. The method should return a result which is one of the types that can be encoded (for example, a string, list, or dictionary).
e.encode(obj)
Method that’s called to create a JSON representation of Python object obj.
e.iterencode(obj)
Creates an iterator that produces the strings making up the JSON representation of Python object obj as they are computed. The process of creating a JSON string is highly recursive in nature. For instance, it involves iterating over the keys of a dictionary and traversing down into other dictionaries and lists found along the way. If you use this method, you can process the output in a piecemeal manner as opposed to having everything collected into a huge in-memory string.
If you define subclasses that inherit from JSONDecoder or JSONEncoder, you need to exercise caution if your class also defines _ _init_ _(). To deal with all of the keyword arguments, here is how you should define it:

mimetypes
The mimetypes module is used to guess the MIME type associated with a file, based on its filename extension. It also converts MIME types to their standard filename extensions. MIME types consist of a type/subtype pair—for example 'text/html', 'image/png', or 'audio/mpeg'.
guess_type(filename [, strict])
Guesses the MIME type of a file based on its filename or URL. Returns a tuple (type, encoding) in which type is a string of the form "type/subtype" and encoding is the program used to encode the data for transfer (for example, compress or gzip). Returns (None, None) if the type cannot be guessed. If strict is True (the default), then only official MIME types registered with IANA are recognized (see http://www.iana.org/assignments/media-types). Otherwise, some common, but unofficial MIME types are also recognized.
guess_extension(type [, strict])
Guesses the standard file extension for a file based on its MIME type. Returns a string with the filename extension including the leading dot (.). Returns None for unknown types. If strict is True (the default), then only official MIME types are recognized.
guess_all_extensions(type [, strict])
The same as guess_extension() but returns a list of all possible filename extensions.
init([files])
Initializes the module. files is a sequence of filenames that are read to extract type information. These files contain lines that map a MIME type to a list of acceptable file suffixes such as the following:
![]()
read_mime_types(filename)
Loads type mapping from a given filename. Returns a dictionary mapping filename extensions to MIME type strings. Returns None if filename doesn’t exist or cannot be read.
add_type(type, ext [, strict])
Adds a new MIME type to the mapping. type is a MIME type such as 'text/plain', ext is a filename extension such as '.txt', and strict is a Boolean indicating whether the type is an officially registered MIME type. By default, strict is True.
quopri
The quopri module performs quoted-printable transport encoding and decoding of byte strings. This format is used primarily to encode 8-bit text files that are mostly readable as ASCII but which may contain a small number of non-printing or special characters (for example, control characters or non-ASCII characters in the range 128-255). The following rules describe how the quoted-printable encoding works:
• Any printable non-whitespace ASCII character, with the exception of '=', is represented as is.
• The '=' character is used as an escape character. When followed by two hexadecimal digits, it represents a character with that value (for example, '=0C'). The equals sign is represented by '=3D'. If '=' appears at the end of a line, it denotes a soft line break. This only occurs if a long line of input text must be split into multiple output lines.
• Spaces and tabs are left as is but may not appear at the end of line.
It is fairly common to see this format used when documents make use of special characters in the extended ASCII character set. For example, if a document contained the text “Copyright © 2009”, this might be represented by the Python byte string b'Copyright xa9 2009'. The quoted-printed version of the string is b'Copyright =A9 2009' where the special character 'xa9' has been replaced by the escape sequence '=A9'.
decode(input, output [, header])
Decodes bytes into quopri format. input and output are file objects opened in binary mode. If header is True, then the underscore (_) will be interpreted as a space. Otherwise, it is left alone. This is used when decoding MIME headers that have been encoded. By default, header is False.
decodestring(s [, header])
Decodes a string s. s may be a Unicode or byte string, but the result is always a byte string. header has the same meaning as with decode().
encode(input, output, quotetabs [, header])
Encodes bytes into quopri format. input and output are file objects opened in binary mode. quotetabs, if set to True, forces tab characters to be quoted in addition to the normal quoting rules. Otherwise, tabs are left as is. By default, quotetabs is False. header has the same meaning as for decode().
encodestring(s [, quotetabs [, header]])
Encodes byte string s. The result is also a byte string. quotetabs and header have the same meaning as with encode().
Notes
The quoted-printable data encoding predates Unicode and is only applicable to 8-bit data. Even though it is most commonly applied to text, it really only applies to ASCII and extended ASCII characters represented as single bytes. When you use this module, make sure all files are in binary mode and that you are working with byte strings.
xml Package
Python includes a variety of modules for processing XML data. The topic of XML processing is large, and covering every detail is beyond the scope of this book. This section assumes the reader is already familiar with some basic XML concepts. A book such as Inside XML by Steve Holzner (New Riders) or XML in a Nutshell by Elliotte Harold and W. Scott Means (O’Reilly and Associates) will be useful in explaining basic XML concepts. Several books discuss XML processing with Python including Python & XML by Christopher Jones (O’Reilly and Associates) and XML Processing with Python by Sean McGrath (Prentice Hall).
Python provides two kinds of XML support. First, there is basic support for two industry-standard approaches to XML parsing—SAX and DOM. SAX (Simple API for XML) is based on event handling where an XML document is read sequentially and as XML elements are encountered, handler functions get triggered to perform processing. DOM (Document Object Model) builds a tree structure representing an entire XML document. Once the tree has been built, DOM provides an interface for traversing the tree and extracting data. Neither the SAX nor DOM APIs originate with Python. Instead, Python simply copies the standard programming interface that was developed for Java and JavaScript.
Although you can certainly process XML using the SAX and DOM interfaces, the most convenient programming interface in the standard library is the ElementTree interface. This is a Python-specific approach to XML parsing that takes full advantage of Python language features and which most users find to be significantly easier and faster than SAX or DOM. The rest of this section covers all three XML parsing approaches, but the ElementTree approach is given the most detail.
Readers are advised that the coverage here is really only focused on basic parsing of XML data. Python also includes XML modules related to implementing new kinds of parsers, building XML documents from scratch, and so forth. In addition, a variety of third-party extensions extend Python’s capabilities with additional XML features such as support for XSLT and XPATH. Links to further information can be found at http://wiki.python.org/moin/PythonXml.
XML Example Document
The following example illustrates a typical XML document, in this case a description of a recipe.
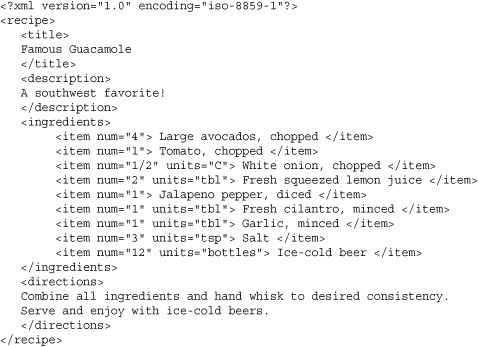
The document consists of elements that start and end with tags such as <title>...</title>. Elements are typically nested and organized into a hierarchy—for example, the <item> elements that appear under <ingredients>. Within each document, a single element is the document root. In the example, this is the <receipe> element. Elements optionally have attributes as shown for the item elements <item num="4">Large avocados, chopped</item>.
Working with XML documents typically involves all of these basic features. For example, you may want to extract text and attributes from specific element types. To locate elements, you have to navigate through the document hierarchy starting at the root element.
xml.dom.minidom
The xml.dom.minicom module provides basic support for parsing an XML document and storing it in memory as a tree structure according to the conventions of DOM. There are two parsing functions:
parse(file [, parser])
Parses the contents of file and returns a node representing the top of the document tree. ile is a filename or an already-open file object. parser is an optional SAX2-compatible parser object that will be used to construct the tree. If omitted, a default parser will be used.
parseString(string [, parser])
The same as parse(), except that the input data is supplied in a string instead of a file.
Nodes
The document tree returned by the parsing functions consists of a collection of nodes linked together. Each node n has the following attributes which can be used to extract information and navigate through the tree structure:

In addition to these attributes, all nodes have the following methods. Typically, these are used to manipulate the tree structure.
n.appendChild(child)
Adds a new child node, child, to n. The new child is added at the end of any other children.
n.cloneNode(deep)
Makes a copy of the node n. If deep is True, all child nodes are also cloned.
n.hasAttributes()
Returns True if the node has any attributes.
n.hasChildNodes()
Returns True if the node has any children.
n.insertBefore(newchild, ichild)
Inserts a new child, newchild, before another child, ichild. ichild must already be a child of n.
n.isSameNode(other)
Returns True if the node other refers to the same DOM node as n.
n.normalize()
Joins adjacent text nodes into a single text node.
n.removeChild(child)
Removes child child from n.
n.replaceChild(newchild,oldchild)
Replaces the child oldchild with newchild. oldchild must already be a child of n.
Although there are many different types of nodes that might appear in a tree, it is most common to work with Document, Element, and Text nodes. Each is briefly described next.
Document Nodes
A Document node d appears at the top of the entire document tree and represents the entire document as a whole. It has the following methods and attributes:
d.documentElement
Contains the root element of the entire document.
d.getElementsByTagName(tagname)
Searches all child nodes and returns a list of elements with a given tag name tagname.
d.getElementsByTagNameNS(namespaceuri, localname)
Searches all child nodes and returns a list of elements with a given namespace URI and local name. The returned list is an object of type NodeList.
Element Nodes
An Element node e represents a single XML element such as '<foo>...</foo>'. To get the text from an element, you need to look for Text nodes as children. The following attributes and methods are defined to get other information:
e.tagName
The tag name of the element. For example, if the element is defined by '<foo ...>', the tag name is 'foo'.
e.getElementsByTagName(tagname)
Returns a list of all children with a given tag name.
e.getElementsByTagNameNS(namespaceuri, localname)
Returns a list of all children with a given tag name in a namespace. namespaceuri and localname are strings that specify the namespace and tag name. If a namespace has been declared using a declaration such as '<foo xmlns:foo="http://www.spam.com/foo">', namespaceuri is set to 'http://www.spam.com/foo'. If searching for a subsequent element '<foo:bar>', localname is set to 'bar'. The returned object is of type NodeList.
e.hasAttribute(name)
Returns True if an element has an attribute with name name.
e.hasAttributeNS(namespaceuri, localname)
Returns True if an element has an attribute named by namespaceuri and localname. The arguments have the same meaning as described for getElementsByTagNameNS().
e.getAttribute(name)
Returns the value of attribute name. The return value is a string. If the attribute doesn’t exist, an empty string is returned.
e.getAttributeNS(namespaceuri, localname)
Returns the value of the attributed named by namespaceuri and localname. The return value is a string. An empty string is returned if the attribute does not exist. The arguments are the same as described for getElementsByTagNameNS().
Text Nodes
Text nodes are used to represent text data. Text data is stored in the t.data attribute of a Text object t. The text associated with a given document element is always stored in Text nodes that are children of the element.
Utility Functions
The following utility methods are defined on nodes. These are not part of the DOM standard, but are provided by Python for general convenience and for debugging.
n.toprettyxml([indent [, newl]])
Creates a nicely formatted string containing the XML represented by node n and its children. indent specifies an indentation string and defaults to a tab (' '). newl specifies the newline character and defaults to '
'.
Creates a string containing the XML represented by node n and its children. encoding specifies the encoding (for example, 'utf-8'). If no encoding is given, none is specified in the output text.
n.writexml(writer [, indent [, addindent [, newl]]])
Writes XML to writer. writer can be any object that provides a write() method that is compatible with the file interface. indent specifies the indentation of n. It is a string that is prepended to the start of node n in the output. addindent is a string that specifies the incremental indentation to apply to child nodes of n. newl specifies the newline character.
DOM Example
The following example shows how to use the xml.dom.minidom module to parse and extract information from an XML file:

Note
The xml.dom.minidom module has many more features for changing the parse tree and working with different kinds of XML node types. More information can be found in the online documentation.
xml.etree.ElementTree
The xml.etree.ElementTree module defines a flexible container object ElementTree for storing and manipulating hierarchical data. Although this object is commonly used in conjunction with XML processing, it is actually quite general-purpose—serving a role that’s a cross between a list and dictionary.
ElementTree objects
The following class is used to define a new ElementTree object and represents the top level of a hierarchy.
ElementTree([element [, file]])
Creates a new ElementTree object. element is an instance representing the root node of the tree. This instance supports the element interface described next. file is either a filename or a file-like object from which XML data will be read to populate the tree.
An instance tree of ElementTree has the following methods:
tree._setroot(element)
Sets the root element to element.
tree.find(path)
Finds and returns the first top-level element in the tree whose type matches the given path. path is a string that describes the element type and its location relative to other elements. The following list describes the path syntax:

If you are working with a document involving XML namespaces, the tag strings in a path should have the form '{uri}tag' where uri is a string such as 'http://www.w3.org/TR/html4/'.
tree.findall(path)
Finds all top-level elements in the tree that match the given path and returns them in document order as a list or an iterator.
tree.findtext(path [, default])
Returns the element text for the first top-level element in the tree matching the given path. default is a string to return if no matching element can be found.
tree.getiterator([tag])
Creates an iterator that produces all elements in the tree, in section order, whose tag matches tag. If tag is omitted, then every element in the tree is returned in order.
tree.getroot()
Returns the root element for the tree.
tree.parse(source [, parser])
Parses external XML data and replaces the root element with the result. source is either a filename or file-like object representing XML data. parser is an optional instance of TreeBuilder, which is described later.
Writes the entire contents of the tree to a file. file is either a filename or a file-like object opened for writing. encoding is the output encoding to use and defaults to the interpreter default encoding if not specified ('utf-8' or 'ascii' in most cases).
Creating Elements
The types of elements held in an ElementTree are represented by instances of varying types that are either created internally by parsing a file or with the following construction functions:
Comment([text])
Creates a new comment element. text is a string or byte string containing the element text. This element is mapped to XML comments when parsing or writing output.
Element(tag [, attrib [, **extra]])
Creates a new element. tag is the name of the element name. For example, if you were creating an element '<foo>....</foo>', tag would be 'foo'. attrib is a dictionary of element attributes specified as strings or byte strings. Any extra keyword arguments supplied in extra are also used to set element attributes.
fromstring(text)
Creates an element from a fragment of XML text in text—the same as XML() described next.
ProcessingInstruction(target [, text])
Creates a new element corresponding to a processing instruction. target and text are both strings or byte strings. When mapped to XML, this element corresponds to '<?target text?>'.
SubElement(parent, tag [, attrib [, **extra]])
The same as Element(), but it automatically adds the new element as a child of the element in parent.
XML(text)
Creates an element by parsing a fragment of XML code in text. For example, if you set text to '<foo>....</foo>', this will create a standard element with a tag of 'foo'.
XMLID(text)
The same as XML(text) except that 'id' attributes are collected and used to build a dictionary mapping ID values to elements. Returns a tuple (elem, idmap) where elem is the new element and idmap is the ID mapping dictionary. For example, XMLID('<foo id="123"><bar id="456">Hello</bar></foo>') returns (<Element foo>, {'123': <Element foo>, '456': <Element bar>}).
The Element Interface
Although the elements stored in an ElementTree may have varying types, they all support a common interface. If elem is any element, then the following Python operators are defined:

All elements have the following basic data attributes:

Elements support the following methods, some of which emulate methods on dictionaries:
elem.append(subelement)
Appends the element subelement to the list of children.
elem.clear()
Clears all of the data in an element including attributes, text, and children.
elem.find(path)
Finds the first subelement whose type matches path.
elem.findall(path)
Finds all subelements whose type matches path. Returns a list or an iterable with the matching elements in document order.
elem.findtext(path [, default])
Finds the text for the first element whose type patches path. default is a string giving the value to return if there is no match.
elem.get(key [, default])
Gets the value of attribute key. default is a default value to return if the attribute doesn’t exist. If XML namespaces are involved, then key will be a string of the form '{uri}key}' where uri is a string such as 'http://www.w3.org/TR/html4/'.
Returns all subelements in document order.
elem.getiterator([tag])
Returns an iterator that produces all subelements whose type matches tag.
elem.insert(index, subelement)
Inserts a subelement at position index in the list of children.
elem.items()
Returns all element attributes as a list of (name, value) pairs.
elem.keys()
Returns a list of all of the attribute names.
elem.remove(subelement)
Removes element subelement from the list of children.
elem.set(key, value)
Sets attribute key to value value.
Tree Building
An ElementTree object is easy to create from other tree-like structures. The following object is used for this purpose.
TreeBuilder([element_factory])
A class that builds an ElementTree structure using a series of start(), end(), and data() calls as would be triggered while parsing a file or traversing another tree structure. element_factory is an operation function that is called to create new element instances.
An instance t of TreeBuilder has these methods:
t.close()
Closes the tree builder and returns the top-level ElementTree object that has been created.
t.data(data)
Adds text data to the current element being processed.
t.end(tag)
Closes the current element being processed and returns the final element object.
t.start(tag, attrs)
Creates a new element. tag is the element name, and attrs is a dictionary with the attribute values.
Utility Functions
The following utility functions are defined:
dump(elem)
Dumps the element structure of elem to sys.stdout for debugging. The output is usually XML.
iselement(elem)
Checks if elem is a valid element object.
iterparse(source [, events])
Incrementally parses XML from source. source is a filename or a file-like object referring to XML data. events is a list of event types to produce. Possible event types are 'start', 'end', 'start-ns', and 'end-ns'. If omitted, only 'end' events are produced. The value returned by this function is an iterator that produces tuples (event, elem) where event is a string such as 'start' or 'end' and elem is the element being processed. For 'start' events, the element is newly created and initially empty except for attributes. For 'end' events, the element is fully populated and includes all subelements.
parse(source)
Fully parses an XML source into an ElementTree object. source is a filename or file-like object with XML data.
tostring(elem)
Creates an XML string representing elem and all of its subelements.
XML Examples
Here is an example of using ElementTree to parse the sample recipe file and print an ingredient list. It is similar to the example shown for DOM.

The path syntax of ElementTree makes it easier to simplify certain tasks and to take shortcuts as necessary. For example, here is a different version of the previous code that uses the path syntax to simply extract all <item>...</item> elements.

Consider an XML file 'recipens.xml' that makes use of namespaces:

To work with the namespaces, it is usually easiest to use a dictionary that maps the namespace prefix to the associated namespace URI. You then use string formatting operators to fill in the URI as shown here:

For small XML files, it is fine to use the ElementTree module to quickly load them into memory so that you can work with them. However, suppose you are working with a huge XML file with a structure such as this:

Reading a large XML file into memory tends to consume vast amounts of memory. For example, reading a 10MB XML file may result in an in-memory data structure of more than 100MB. If you’re trying to extract information from such files, the easiest way to do it is to use the ElementTree.iterparse() function. Here is an example of iteratively processing <album> nodes in the previous file:

The key to using iterparse() effectively is to get rid of data that you’re no longer using. The last statement musicNode.remove(album) is throwing away each <album> element after we are done processing it (by removing it from its parent). If you monitor the memory footprint of the previous program, you will find that it stays low even if the input file is massive.
Notes
• The ElementTree module is by far the easiest and most flexible way of handling simple XML documents in Python. However, it does not provide a lot of bells and whistles. For example, there is no support for validation, nor does it provide any apparent way to handle complex aspects of XML documents such as DTDs. For these things, you’ll need to install third-party packages. One such package, lxml.etree (at http://codespeak.net/lxml/), provides an ElementTree API to the popular libxml2 and libxslt libraries and provides full support for XPATH, XSLT, and other features.
• The ElementTree module itself is a third-party package maintained by Fredrik Lundh at http://effbot.org/zone/element-index.htm. At this site you can find versions that are more modern than what is included in the standard library and which offer additional features.
xml.sax
The xml.sax module provides support for parsing XML documents using the SAX2 API.
parse(file, handler [, error_handler])
Parses an XML document, file. file is either the name of a file or an open file object. handler is a content handler object. error_handler is an optional SAX errorhandler object that is described further in the online documentation.
parseString(string, handler [, error_handler])
The same as parse() but parses XML data contained in a string instead.
Handler Objects
To perform any processing, you have to supply a content handler object to the parse() or parseString() functions. To define a handler, you define a class that inherits from ContentHandler. An instance c of ContentHandler has the following methods, all of which can be overridden in your handler class as needed:
c.characters(content)
Called by the parser to supply raw character data. content is a string containing the characters.
c.endDocument()
Called by the parser when the end of the document is reached.
c.endElement(name)
Called when the end of element name is reached. For example, if '</foo>’ is parsed, this method is called with name set to 'foo'.
c.endElementNS(name, qname)
Called when the end of an element involving an XML namespace is reached. name is a tuple of strings (uri, localname) and qname is the fully qualified name. Usually qname is None unless the SAX namespace-prefixes feature has been enabled. For example, if the element is defined as '<foo:bar xmlns:foo="http://spam.com">', then the name tuple is (u'http://spam.com', u'bar').
c.endPrefixMapping(prefix)
Called when the end of an XML namespace is reached. prefix is the name of the namespace.
c.ignorableWhitespace(whitespace)
Called when ignorable whitespace is encountered in a document. whitespace is a string containing the whitespace.
c.processingInstruction(target, data)
Called when an XML processing instruction enclosed in <? ... ?> is encountered. target is the type of instruction, and data is the instruction data. For example, if the instruction is '<?xml-stylesheet href="mystyle.css" type="text/css"?>, target is set to 'xml-stylesheet' and data is the remainder of the instruction text 'href="mystyle.css" type="text/css"'.
c.setDocumentLocator(locator)
Called by the parser to supply a locator object that can be used for tracking line numbers, columns, and other information. The primary purpose of this method is simply to store the locator someplace so that you can use it later—for instance, if you needed to print an error message. The locator object supplied in locator provides four methods—getColumnNumber(), getLineNumber(), getPublicId(), and getSystemId()—that can be used to get location information.
c.skippedEntity(name)
Called whenever the parser skips an entity. name is the name of the entity that was skipped.
Called at the start of a document.
c.startElement(name, attrs)
Called whenever a new XML element is encountered. name is the name of the element, and attrs is an object containing attribute information. For example, if the XML element is '<foo bar="whatever" spam="yes">', name is set to 'foo' and attrs contains information about the bar and spam attributes. The attrs object provides a number of methods for obtaining attribute information:

c.startElementNS(name, qname, attrs)
Called when a new XML element is encountered and XML namespaces are being used. name is a tuple (uri, localname) and qname is a fully qualified element name (normally set to None unless the SAX2 namespace-prefixes feature has been enabled). attrs is an object containing attribute information. For example, if the XML element is '<foo:bar xmlns:foo="http://spam.com" blah="whatever">', then name is (u'http://spam.com', u'bar'), qname is None, and attrs contains information about the attribute blah. The attrs object has the same methods as used in when accessing attributes in the startElement() method shown earlier. In addition, the following additional methods are added to deal with namespaces:

c.startPrefixMapping(prefix, uri)
Called at the start of an XML namespace declaration. For example, if an element is defined as '<foo:bar xmlns:foo="http://spam.com">', then prefix is set to 'foo' and uri is set to 'http://spam.com'.
Example
The following example illustrates a SAX-based parser, by printing out the ingredient list from the recipe file shown earlier. This should be compared with the example in the xml.dom.minidom section.

Notes
The xml.sax module has many more features for working with different kinds of XML data and creating custom parsers. For example, there are handler objects that can be defined to parse DTD data and other parts of the document. More information can be found in the online documentation.
xml.sax.saxutils
The xml.sax.saxutils module defines some utility functions and objects that are often used with SAX parsers, but are often generally useful elsewhere.
escape(data [, entities])
Given a string, data, this function replaces certain characters with escape sequences. For example, '<' gets replaced by '<'. entities is an optional dictionary that maps characters to the escape sequences. For example, setting entities to { u'xf1' : 'ñ' } would replace occurences of ñ with 'ñ'.
unescape(data [, entities])
Unescapes special escape sequences that appear in data. For instance, '<' is replaced by '<'. entities is an optional dictionary mapping entities to unescaped character values. entities is the inverse of the dictionary used with escape()—for example, { 'ñ' : u'xf1' }.
quoteattr(data [, entities])
Escapes the string data, but performs additional processing that allows the result value to be used as an XML attribute value. The return value can be printed directly as an attribute value—for example, print "<element attr=%s>" % quoteattr(somevalue). entities is a dictionary compatible for use with the escape() function.
XMLGenerator([out [, encoding]])
A ContentHandler object that merely echoes parsed XML data back to the output stream as an XML document. This re-creates the original XML document. out is the output document and defaults to sys.stdout. encoding is the character encoding to use and defaults to 'iso-8859-1'. This can be useful if you’re trying to debug your parsing code and use a handler that is known to work.