
16. String and Text Handling
This chapter describes the most commonly used Python modules related to basic string and text processing. The focus of this chapter is on the most common string operations such as processing text, regular expression pattern matching, and text formatting.
codecs
The codecs module is used to handle different character encodings used with Unicode text I/O. The module is used both to define new character encodings and to process character data using a wide range of existing encodings such as UTF-8, UTF-16, etc. It is far more common for programmers to simply use one of the existing encodings, so that is what is discussed here. If you want to create new encodings, consult the online documentation for further details.
Low-Level codecs Interface
Each character encoding is assigned a common name such as 'utf-8' or 'big5'. The following function is used to perform a lookup.
lookup(encoding)
Looks up a codec in the codec registry. encoding is a string such as 'utf-8'. If nothing is known about the requested encoding, LookupError is raised. Otherwise, an instance c of CodecInfo is returned.
A CodecInfo instance c has the following methods:
c.encode(s [, errors])
A stateless encoding function that encodes the Unicode string s and returns a tuple (bytes, length_consumed). bytes is an 8-bit string or byte-array containing the encoded data. length_consumed is the number of characters in s that were encoded. errors is the error handling policy and is set to 'strict' by default.
c.decode(bytes [, errors])
A stateless encoding function that decodes a byte string bytes and returns a tuple (s, length_consumed). s is a Unicode string, and length_consumed is the number of bytes in bytes that were consumed during decoding. errors is the error-handling policy and is set to 'strict’ by default.
c.streamreader(bytestream [, errors])
Returns a StreamReader instance that is used to read encoded data. bytestream is a file-like object that has been opened in binary mode. errors is the error-handling policy and is 'strict' by default. An instance r of StreamReader supports the following low-level I/O operations:

c.streamwriter(bytestream [, errors])
Returns a StreamWriter instance that is used to write encoded data. bytestream is a file-like object that has been opened in byte-mode. errors is the error handling policy and is 'strict' by default. An instance w of StreamWriter supports the following low-level I/O operations:

c.incrementalencoder([errors])
Returns an IncrementalEncoder instance that can be used to encode strings in multiple steps. errors is 'strict' by default. An instance e of IncrementalEncoder has these methods:

c.incrementaldecoder([errors])
Returns an IncrementalDecoder instance that can be used to decode byte strings in multiple steps. errors is 'strict' by default. An instance d of IncrementalDecoder has these methods:

I/O-Related Functions
The codecs module provides a collection of high-level functions that are used to simplify I/O involving encoded text. Most programmers will use one of these functions instead of the low-level codecs interface described in the first section.
open(filename, mode[, encoding[, errors[, buffering]]])
Opens filename in the given mode and provides transparent data encoding/decoding according to the encoding specified in encoding. errors is one of 'strict', 'ignore', 'replace', 'backslashreplace', or 'xmlcharrefreplace'. The default is 'strict'. buffering has the same meaning as for the built-in open() function. Regardless of the mode specified in mode, the underlying file is always opened in binary mode. In Python 3, you can use the built-in open() function instead of codecs.open().
EncodedFile(file, inputenc[, outputenc [, errors]])
A class that provides an encoding wrapper around an existing file object, file. Data written to the file is first interpreted according to the input encoding inputenc and then written to the file using the output encoding outputenc. Data read from the file is decoded according to inputenc. If outputenc is omitted, it defaults to inputenc. errors has the same meaning as for open() and defaults to 'strict'.
iterencode(iterable, encoding [, errors])
A generator function that incrementally encodes all of the strings in iterable to the specified encoding. errors is 'strict' by default.
iterdecode(iterable, encoding [, errors])
A generator function that incrementally decodes all of the byte strings in iterable according to the specified encoding. errors is 'strict' by default.
Useful Constants
codecs defines the following byte-order marker constants that can be used to help interpret files when you don’t know anything about the underlying encoding. These byte-order markers are sometimes written at the beginning of a file to indicate its character encoding and can be used to pick an appropriate codec to use.

Standard Encodings
The following is a list of some of the most commonly used character encodings. The encoding name is what you would pass to functions such as open() or lookup() when specifying an encoding. A full list of encodings can be found by consulting the online documentation for the codecs module (http://docs.python.org/library/codecs).

Notes
• Further use of the codecs module is described in Chapter 9, “Input and Output.”
• Consult the online documentation for information on how to create new kinds of character encodings.
• Great care needs to be taken with the inputs to encode() and decode() operations. All encode() operations should be given Unicode strings, and all decode() operations should be given byte strings. Python 2 is not entirely consistent in this regard, whereas Python 3 strictly enforces the distinction between strings. For example, Python 2 has some codecs that map byte-strings to byte-strings (e.g., the “bz2” codec). These are unavailable in Python 3 and should not be used if you care about compatibility.
re
The re module is used to perform regular-expression pattern matching and replacement in strings. Both unicode and byte-strings are supported. Regular-expression patterns are specified as strings containing a mix of text and special-character sequences. Because patterns often make extensive use of special characters and the backslash, they’re usually written as “raw” strings, such as r'(?P<int>d+).(d*)'. For the remainder of this section, all regular-expression patterns are denoted using the raw string syntax.
Pattern Syntax
The following special-character sequences are recognized in regular expression patterns:


Standard character escape sequences such as '
' and ' ' are recognized as standard characters in a regular expression (for example, r'
+' would match one or more newline characters). In addition, literal symbols that normally have special meaning in a regular expression can be specified by preceding them with a backslash. For example, r'*' matches the character *. In addition, a number of backslash sequences correspond to special sets of characters:

The d, D, s, S, w, and W special characters are interpreted differently if matching Unicode strings. In this case, they match all Unicode characters that match the described property. For example, d matches any Unicode character that is classified as a digit such as European, Arabic, and Indic digits which each occupy a different range of Unicode characters.
Functions
The following functions are used to perform pattern matching and replacement:
compile(str [, flags])
Compiles a regular-expression pattern string into a regular-expression object. This object can be passed as the pattern argument to all the functions that follow. The object also provides a number of methods that are described shortly. flags is the bitwise OR of the following:

escape(string)
Returns a string with all nonalphanumerics backslashed.
findall(pattern, string [,flags])
Returns a list of all nonoverlapping matches of pattern in string, including empty matches. If the pattern has groups, a list of the text matched by the groups is returned.
If more than one group is used, each item in the list is a tuple containing the text for each group. flags has the same meaning as for compile().
finditer(pattern, string, [, flags])
The same as findall(), but returns an iterator object instead. The iterator returns items of type MatchObject.
match(pattern, string [, flags])
Checks whether zero or more characters at the beginning of string match pattern. Returns a MatchObject on success or None otherwise. flags has the same meaning as for compile().
search(pattern, string [, flags])
Searches string for the first match of pattern. flags has the same meaning as for compile(). Returns a MatchObject on success or None if no match was found.
split(pattern, string [, maxsplit = 0])
Splits string by the occurrences of pattern. Returns a list of strings including the text matched by any groups in the pattern. maxsplit is the maximum number of splits to perform. By default, all possible splits are performed.
sub(pattern, repl, string [, count = 0])
Replaces the leftmost nonoverlapping occurrences of pattern in string by using the replacement repl. repl can be a string or a function. If it’s a function, it’s called with a MatchObject and should return the replacement string. If repl is a string, back-references such as '6' are used to refer to groups in the pattern. The sequence 'g<name>' is used to refer to a named group. count is the maximum number of substitutions to perform. By default, all occurrences are replaced. Although these functions don’t accept a flags parameter like compile(), the same effect can be achieved by using the (?iLmsux) notation described earlier in this section.
subn(pattern, repl, string [, count = 0])
Same as sub(), but returns a tuple containing the new string and the number of substitutions.
Regular Expression Objects
A compiled regular-expression object, r, created by the compile() function has the following methods and attributes:
r.flags
The flags argument used when the regular expression object was compiled, or 0 if no flags were specified.
r.groupindex
A dictionary mapping symbolic group names defined by r'(?P<id>)' to group numbers.
r.pattern
The pattern string from which the regular expression object was compiled.
r.findall(string [, pos [, endpos]])
Identical to the findall() function. pos and endpos specify the starting and ending positions for the search.
r.finditer(string [, pos [, endpos]])
Identical to the finditer() function. pos and endpos specify the starting and ending positions for the search.
r.match(string [, pos] [, endpos])
Checks whether zero or more characters at the beginning of string match. pos and endpos specify the range of string to be searched. Returns a MatchObject for a match and returns None otherwise.
r.search(string [, pos] [, endpos])
Searches string for a match. pos and endpos specify the starting and ending positions for the search. Returns a MatchObject for a match and returns None otherwise.
r.split(string [, maxsplit = 0])
Identical to the split() function.
r.sub(repl, string [, count = 0])
Identical to the sub() function.
r.subn(repl, string [, count = 0])
Identical to the subn() function.
Match Objects
The MatchObject instances returned by search() and match() contain information about the contents of groups as well as positional data about where matches occurred. A MatchObject instance, m, has the following methods and attributes:
m.expand(template)
Returns a string that would be obtained by doing regular-expression backslash substitution on the string template. Numeric back-references such as "1" and "2" and named references such as "g<n>" and "g<name>" are replaced by the contents of the corresponding group. Note that these sequences should be specified using raw strings or with a literal backslash character such as r'1' or '\1'.
m.group([group1, group2, ...])
Returns one or more subgroups of the match. The arguments specify group numbers or group names. If no group name is given, the entire match is returned. If only one group is given, a string containing the text matched by the group is returned. Otherwise, a tuple containing the text matched by each of the requested groups is returned. An IndexError is raised if an invalid group number or name is given.
m.groups([default])
Returns a tuple containing the text matched by all groups in a pattern. default is the value returned for groups that didn’t participate in the match (the default is None).
Returns a dictionary containing all the named subgroups of the match. default is the value returned for groups that didn’t participate in the match (the default is None).
m.start([group])
m.end([group])
These two methods return the indices of the start and end of the substring matched by a group. If group is omitted, the entire matched substring is used. Returns None if the group exists but didn’t participate in the match.
m.span([group])
Returns a 2-tuple (m.start(group), m.end(group)). If group didn’t contribute to the match, this returns (None, None). If group is omitted, the entire matched substring is used.
m.pos
The value of pos passed to the search() or match() function.
m.endpos
The value of endpos passed to the search() or match() function.
m.lastindex
The numerical index of the last group that was matched. It’s None if no groups were matched.
m.lastgroup
The name of the last named group that was matched. It’s None if no named groups were matched or present in the pattern.
m.re
The regular-expression object whose match() or search() method produced this MatchObject instance.
m.string
The string passed to match() or search().
Example
The following example shows how to use the re module to search for, extract data from, and replace a text pattern in a string.
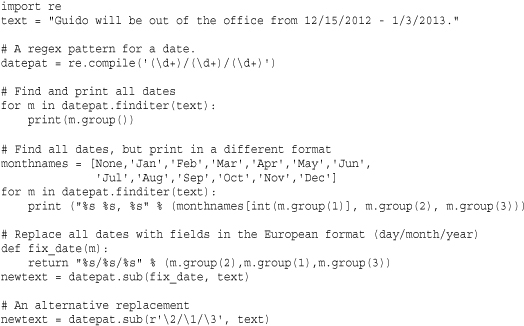
Notes
• Detailed information about the theory and implementation of regular expressions can be found in textbooks on compiler construction. The book Mastering Regular Expressions by Jeffrey Friedl (O’Reilly & Associates, 1997) may also be useful.
• The most difficult part of using the re module is writing the regular expression patterns. For writing patterns, consider using a tool such as Kodos (http://kodos.sourceforget.net).
string
The string module contains a number of useful constants and functions for manipulating strings. It also contains classes for implementing new string formatters.
Constants
The following constants define various sets of characters that may be useful in various string processing operations.

Note that some of these constants (for example, letters and uppercase) will vary depending on the locale settings of the system.
Formatter Objects
The str.format() method of strings is used to perform advanced string formatting operations. As seen in Chapter 3, “Types and Objects,” and Chapter 4, “Operators and Expressions,” this method can access items of sequences or mappings, attributes of objects, and other kinds of related operations. The string module defines a class Formatter that can be used to implement your own customized formatting operation. This class exposes the pieces that implement the string formatting operation and allow you to customize them.
Formatter()
Creates a new Formatter instance. An instance f of Formatter supports the following operations.
f.format(format_string, *args, **kwargs)
Formats the string format_string. By default, the output is the same as calling format_string.format(*args, **kwargs). For example, f.format("{name} is {0:d} years old", 39,name="Dave") creates the string "Dave is 39 years old".
f.vformat(format_string, args, kwargs)
A method that actually carries out the work of f.format(). args is a tuple of positional arguments, and kwargs is a dictionary of keyword arguments. This is a faster method to use if you have already captured argument information in a tuple and dictionary.
f.parse(format_string)
A function that creates an iterator for parsing the contents of the format string format_string. The iterator sweeps over the format string and produces tuples of the format (literal_text, field_name, format_spec, conversion). literal_text is any literal text that precedes the next format specifier enclosed in braces { ... }. It may be an empty string if there is no leading text. field_name is a string that specifies the field name in the format specifier. For example, if the specifier is '{0:d}', then the field name is '0'. format_spec is the format specifier that appears after the colon—for example, 'd' in the previous example. It will be an empty string if it wasn’t specified. conversion is a string containing the conversion specifier (if any). In the previous example, it is None, but if the specifier was '{0!s:d}', it would be set to 's'. field_name, format_spec, and conversion will all be None for the last fragment of the format string.
f.get_field(fieldname, args, kwargs)
Extracts the value associated with a given fieldname from args and kwargs. fieldname is a string such as "0" or "name" as returned by the parse() method shown previously. Returns a tuple (value, key) where value is the field value and key is used to locate the value in args or kwargs. If key is an integer, it is an index in args. If it is a string, it is the key used in kwargs. The fieldname may include additional indexing and attribute lookup such as '0.name’ or '0[name]'. In this case, the method carries out the extra lookup and returns the appropriate value. However, the value of key in the returned tuple is just set to '0'.
f.get_value(key, args, kwargs)
Extracts the object from args or kwargs corresponding to key. If key is an integer, the object is taken from args. If it is a string, it is taken from kwargs.
f.check_unused_args(used_args, args, kwargs)
Checks for unused arguments in the format() operation. used_args is a set of all of the used argument keys (see get_field()) that were found in the format string. args and kwargs are the positional and keyword arguments passed to format(). The default behavior is to raise a TypeError for unused arguments.
f.format_value(value, format_spec)
Formats a single value according to the given format specification. By default, this simply executes the built-in function format(value, format_spec).
f.convert_field(value, conversion)
Converts a value returned by get_field() according to the specified conversion code. If conversion is None, value is returned unmodified. If conversion is 's' or 'r', value is converted to a string using str() or repr(), respectively.
If you want to create your own customized string formatting, you can create a Formatter object and simply use the default methods to carry out the formatting as you wish. It is also possible to define a new class that inherits from Formatter and reimplements any of the methods shown earlier.
For details on the syntax of format specifiers and advanced string formatting, refer to Chapter 3 and Chapter 4.
Template Strings
The string module defines a new string type, Template, that simplifies certain string substitutions. An example can be found in Chapter 9.
The following creates a new template string object:
Template(s)
Here, s is a string and Template is defined as a class.
A Template object, t, supports the following methods:
t.substitute(m [, **kwargs])
This method takes a mapping object, m (for example, a dictionary), or a list of keyword arguments and performs a keyword substitution on the string t. This substitution replaces the string '$$' with a single '$' and the strings '$key' or '${key}' with m['key’] or kwargs['key'] if keyword arguments were supplied. key must spell a valid Python identifier. If the final string contains any unresolved '$key' patterns, a KeyError exception is raised.
t.safe_substitute(m [, **kwargs])
The same as substitute() except that no exceptions or errors will be generated. Instead, unresolved $key references will be left in the string unmodified.
Contains the original strings passed to Template().
The behavior of the Template class can be modified by subclassing it and redefining the attributes delimiter and idpattern. For example, this code changes the escape character $ to @ and restricts key names to letters only:
![]()
Utility Functions
The string module also defines a couple of functions for manipulating strings that aren’t defined as a method on string objects.
capwords(s)
Capitalizes the first letter of each word in s, replaces repeated whitespace characters with a single space, and removes leading and trailing whitespace.
maketrans(from, to)
Creates a translation table that maps each character in from to the character in the same position in to. from and to must be the same length. This function is used to create arguments suitable for use with the translate() method of strings.
struct
The struct module is used to convert data between Python and binary data structures (represented as Python byte strings). These data structures are often used when interacting with functions written in C, binary file formats, network protocols, or binary communication over serial ports.
Packing and Unpacking Functions
The following module-level functions are used to pack and unpack data in byte strings. If your program is repeatedly performing these operations, consider the use of a Struct object described in the next section.
pack(fmt, v1, v2, ...)
Packs the values v1, v2, and so on into a byte string according to the format string in fmt.
pack_into(fmt, buffer, offset, v1, v2 ...)
Packs the values v1, v2, and so forth into a writable buffer object buffer starting at byte offset offset. This only works with objects that support the buffer interface. Examples include array.array and bytearray objects.
unpack(fmt, string)
Unpacks the contents of a byte string according to the format string in fmt. Returns a tuple of the unpacked values. The length of string must exactly match the size of the format as determined by the calcsize() function.
unpack_from(fmt, buffer, offset)
Unpacks the contents of a buffer object according to the format string in fmt starting at offset offset. Returns a tuple of the unpacked values.
calcsize(fmt)
Calculates the size in bytes of the structure corresponding to a format string fmt.
Struct Objects
The struct module defines a class Struct that provides an alternative interface for packing and unpacking. Using this class is more efficient because the format string is only interpreted once.
Struct(fmt)
Creates a Struct instance representing data packed according to the given format code. An instance s of Struct has the following methods that work exactly the same as their functional counterparts described in the previous section:

Format Codes
The format strings used in the struct module are a sequence of characters with the following interpretations:
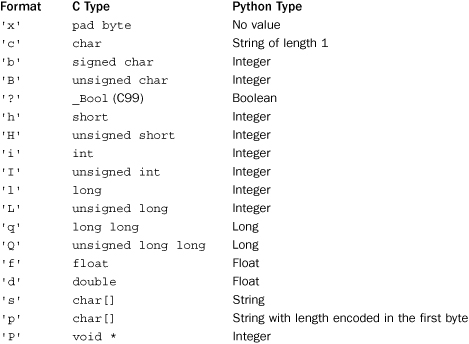
Each format character can be preceded by an integer to indicate a repeat count (for example, '4i' is the same as 'iiii'). For the 's' format, the count represents the maximum length of the string, so '10s' represents a 10-byte string. A format of '0s' indicates a string of zero length. The 'p' format is used to encode a string in which the length appears in the first byte, followed by the string data. This is useful when dealing with Pascal code, as is sometimes necessary on the Macintosh. Note that the length of the string in this case is limited to 255 characters.
When the 'I' and 'L' formats are used to unpack a value, the return value is a Python long integer. In addition, the 'P' format may return an integer or long integer, depending on the word size of the machine.
The first character of each format string can also specify a byte ordering and alignment of the packed data, as shown here:

Native byte ordering may be little-endian or big-endian, depending on the machine architecture. The native sizes and alignment correspond to the values used by the C compiler and are implementation-specific. The standard alignment assumes that no alignment is needed for any type. The standard size assumes that short is 2 bytes, int is 4 bytes, long is 4 bytes, float is 32 bits, and double is 64 bits. The 'P' format can only use native byte ordering.
Notes
• Sometimes it’s necessary to align the end of a structure to the alignment requirements of a particular type. To do this, end the structure-format string with the code for that type with a repeat count of zero. For example, the format 'llh0l' specifies a structure that ends on a 4-byte boundary (assuming that longs are aligned on 4-byte boundaries). In this case, two pad bytes would be inserted after the short value specified by the 'h' code. This only works when native size and alignment are being used—standard size and alignment don’t enforce alignment rules.
• The 'q’ and 'Q' formats are only available in “native” mode if the C compiler used to build Python supports the long long data type.
unicodedata
The unicodedata module provides access to the Unicode character database, which contains character properties for all Unicode characters.
bidirectional(unichr)
Returns the bidirectional category assigned to unichr as a string or an empty string if no such value is defined. Returns one of the following:
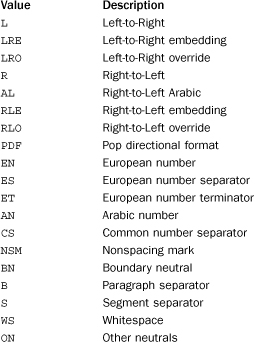
category(unichr)
Returns a string describing the general category of unichr. The returned string is one of the following values:
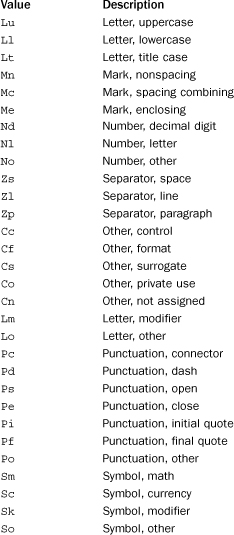
Returns an integer describing the combining class for unichr or 0 if no combining class is defined. One of the following values is returned:

Returns the decimal integer value assigned to the character unichr. If unichr is not a decimal digit, default is returned or ValueError is raised.
decomposition(unichr)
Returns a string containing the decomposition mapping of unichr or the empty string if no such mapping is defined. Typically, characters containing accent marks can be decomposed into multicharacter sequences. For example, decomposition(u"u00fc") ("ü") returns the string "0075 0308" corresponding to the letter u and the umlaut (¨) accent mark. The string returned by this function may also include the following strings:

digit(unichr[, default])
Returns the integer digit value assigned to the character unichr. If unichr is not a digit, default is returned or ValueError is raised. This function differs from decimal() in that it works with characters that may represent digits but that are not decimal digits.
east_asian_width(unichr)
Returns the east Asian width assigned to unichr.
lookup(name)
Looks up a character by name. For example, lookup('COPYRIGHT SIGN') returns the corresponding Unicode character. Common names can be found at http://www.unicode.org/charts.
mirrored(unichr)
Returns 1 if unichr is a “mirrored” character in bidirectional text and returns 0 otherwise. A mirrored character is one whose appearance might be changed to appear properly if text is rendered in reverse order. For example, the character '(' is mirrored because it might make sense to flip it to ')' in cases where text is printed from right to left.
name(unichr [, default])
Returns the name of a Unicode character, unichr. Raises ValueError if no name is defined or returns default if provided. For example, name(u'xfc') returns 'LATIN SMALL LETTER U WITH DIAERESIS'.
normalize(form, unistr)
Normalizes the Unicode string unistr according to normal form form. form is one of 'NFC', 'NFKC', 'NFD', or 'NFKD'. The normalization of a string partly pertains to the composition and decomposition of certain characters. For example, the Unicode string for the word “resumé” could be represented as u'resumu00e9' or as the string u'resumeu0301'. In the first string, the accented character é is represented as a single character. In the second string, the accented character is represented by the letter e followed by a combining accent mark (`). 'NFC' normalization converts the string unistr so that all of the characters are fully composed (for example, é is a single character). 'NFD' normalization converts unistr so that characters are decomposed (for example, é is the letter e followed by an accent). 'NFKC' and 'NFKD' perform the same function as 'NFC' and 'NFD' except that they additionally transform certain characters that may be represented by more than one Unicode character value into a single standard value. For example, Roman numerals have their own Unicode character values but are also just represented by the Latin letters I, V, M, and so on. 'NFKC' and 'NFKD' would convert the special Roman numeral characters into their Latin equivalents.
numeric(unichr[, default])
Returns the value assigned to the Unicode character unichr as a floating-point number. If no numeric value is defined, default is returned or ValueError is raised. For example, the numeric value of U+2155 (the character for the fraction "1/5") is 0.2.
unidata_version
A string containing the Unicode database version used (for example, '5.1.0').
Note
For further details about the Unicode character database, see http://www.unicode.org.