
26. Extending and Embedding Python
One of the most powerful features of Python is its ability to interface with software written in C. There are two common strategies for integrating Python with foreign code. First, foreign functions can be packaged into a Python library module for use with the import statement. Such modules are known as extension modules because they extend the interpreter with additional functionality not written in Python. This is, by far, the most common form of Python-C integration because it gives Python applications access to high-performance programming libraries. The other form of Python-C integration is embedding. This is a process by which Python programs and the interpreter are accessed as a library from C. This latter approach is sometimes used by programmers who want to embed the Python interpreter into an existing C application framework for some reason—usually as some kind of scripting engine.
This chapter covers the absolute basics of the Python-C programming interface. First, the essential parts of the C API used to build extension modules and embed the Python interpreter are covered. This section is not intended to be a tutorial, so readers new to this topic should consult the “Embedding and Extending the Python Interpreter” document available at http://docs.python.org/extending, as well as the “Python/C API Reference Manual” available at http://docs.python.org/c-api. Next, the ctypes library module is covered. This is an extremely useful module that allows you to access functions in C libraries without writing any additional C code or using a C compiler.
It should be noted that for advanced extension and embedding applications, most programmers tend to turn to advanced code generators and programming libraries. For example, the SWIG project (http://www.swig.org) is a compiler that creates Python extension modules by parsing the contents of C header files. References to this and other extension building tools can be found at http://wiki.python.org/moin/IntegratingPythonWithOtherLanguages.
Extension Modules
This section outlines the basic process of creating a handwritten C extension module for Python. When you create an extension module, you are building an interface between Python and existing functionality written in C. For C libraries, you usually start from a header file such as the following:

These function prototypes have some kind of implementation in a separate file. For example:

Here is a C main() program that illustrates the use of these functions:

Here is the output of the previous program:

An Extension Module Prototype
Extension modules are built by writing a separate C source file that contains a set of wrapper functions which provide the glue between the Python interpreter and the underlying C code. Here is an example of a basic extension module called _example:



Extension modules always need to include "Python.h". For each C function to be accessed, a wrapper function is written. These wrapper functions accept either two arguments (self and args, both of type PyObject *) or three arguments (self, args, and kwargs, all of type PyObject *). The self parameter is used when the wrapper function is implementing a built-in method to be applied to an instance of some object. In this case, the instance is placed in the self parameter. Otherwise, self is set to NULL.args is a tuple containing the function arguments passed by the interpreter. kwargs is a dictionary containing keyword arguments.
Arguments are converted from Python to C using the PyArg_ParseTuple() or PyArg_ParseTupleAndKeywords() function. Similarly, the Py_BuildValue() function is used to construct an acceptable return value. These functions are described in later sections.
Documentation strings for extension functions should be placed in separate string variables such as py_gcd_doc and py_replace_doc as shown. These variables are referenced during module initialization (described shortly).
Wrapper functions should never, under penalty of certain flaming death, mutate data received by reference from the interpreter. This is why the py_replace() wrapper is making a copy of the received string before passing it to the C function (which modifies it in place). If this step is omitted, the wrapper function may violate Python’s string immutability.
If you want to raise an exception, you use the PyExc_SetString() function as shown in the py_distance() wrapper. NULL is returned to signal that an error has occurred.
The method table _examplemethods is used to associate Python names with the C wrapper functions. These are the names used to call the function from the interpreter. The METH_VARARGS flag indicates the calling conventions for a wrapper. In this case, only positional arguments in the form of a tuple are accepted. It can also be set to METH_VARARGS | METH_KEYWORDS to indicate a wrapper function accepting keyword arguments. The method table additionally sets the documentation strings for each wrapper function.
The final part of an extension module performs an initialization procedure that varies between Python 2 and Python 3. In Python 2, the module initialization function init_example is used to initialize the contents of the module. In this case, the Py_InitModule("_example",_examplemethods) function creates a module, _example, and populates it with built-in function objects corresponding to the functions listed in the method table. For Python 3, you have to create an PyModuleDef object _examplemodule that describes the module. You then write a function PyInit_ _example() that initializes the module as shown. The module initialization function is also the place where you install constants and other parts of a module, if necessary. For example, the PyModule_AddIntMacro() is adding the value of a preprocessor to the module.
It is important to note that naming is critically important for module initialization. If you are creating a module called modname, the module initialization function must be called initmodname() in Python 2 and PyInit_modname() in Python 3. If you don’t do this, the interpreter won’t be able to correctly load your module.
Naming Extension Modules
It is standard practice to name C extension modules with a leading underscore such as '_example'. This convention is followed by the Python standard library itself. For instance, there are modules named _socket, _thread, _sre, and _fileio corresponding to the C programming components of the socket, threading, re, and io modules. Generally, you do not use these C extension modules directly. Instead, you create a high-level Python module such as the following:

The purpose of this Python wrapper is to supply additional support code for your module or to provide a higher-level interface. In many cases, it is easier to implement parts of an extension module in Python instead of C. This design makes it easy to do this. If you look at many standard library modules, you will find that they have been implemented as a mix of C and Python in this manner.
Compiling and Packaging Extensions
The preferred mechanism for compiling and packaging an extension module is to use distutils. To do this, you create a setup.py file that looks like this:

In this file, you need to include the high-level Python file (example.py) and the source files making up the extension module (pyexample.c, example.c). To build the module for testing, type the following:
% python setup.py build_ext --inplace
This will compile the extension code into a shared library and leave it in the current working directory. The name of this library will be _examplemodule.so, _examplemodule.pyd, or some similar variant.
If the compilation was successful, using your module is straightforward. For example:

More complicated extension modules may need to supply additional build information, such as include directories, libraries, and preprocessor macros. They can also be included in setup.py, as follows:

If you want to install an extension module for general use, you simply type python setup.py install. Further details about this are found in Chapter 8, “Modules, Packages, and Distribution.”
In some situations, you may want to build an extension module manually. This almost always requires advanced knowledge of various compiler and linker options. The following is an example on Linux:
![]()
Type Conversion from Python to C
The following functions are used by extension modules to convert arguments passed from Python to C. Their prototypes are defined by including the Python.h header file.
int PyArg_ParseTuple(PyObject *args, char *format, ...);
Parses a tuple of positional arguments in args into a series of C variables. format is a format string containing zero or more of the specifier strings from Tables 26.1–26.3, which describe the expected contents of args. All the remaining arguments contain the addresses of C variables into which the results will be placed. The order and types of these arguments must match the specifiers used in format. Zero is returned if the arguments could not be parsed.
![]()
Table 26.1 Numeric Conversions and Associated C Data Types for PyArg_Parse*
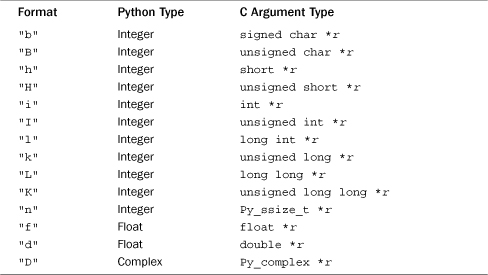
Table 26.2 String Conversions and Associated C Data Types for PyArg_Parse*
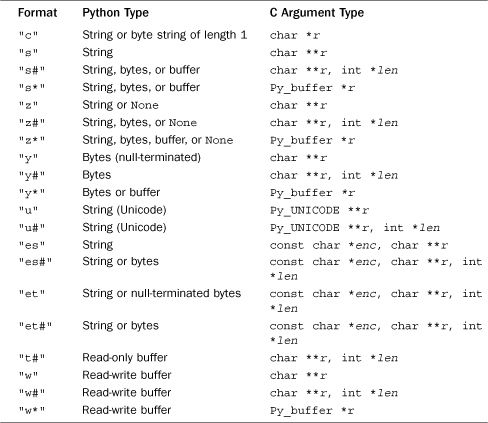
Table 26.3 Python Object Conversions and Associated C Data Types for PyArg_Parse*
Parses both a tuple of positional arguments and a dictionary of keyword arguments contained in kwargs. format has the same meaning as for PyArg_ParseTuple(). The only difference is that kwlist is a null-terminated list of strings containing the names of all the arguments. Returns 1 on success, 0 on error.
Table 26.1 lists the format codes that are placed in the format argument to convert numbers. The C argument type column lists the C data type that should be passed to the PyArg_Parse*() functions. For numbers, it is always a pointer to a location where the result should be stored.
When signed integer values are converted, an OverflowError exception is raised if the Python integer is too large to fit into the requested C data type. However, conversions that accept unsigned values (e.g., 'I', 'H', 'K', and so on) do not check for overflow and will silently truncate the value if it exceeds the supported range. For floating-point conversions, a Python int or float may be supplied as input. In this case, integers will be promoted to a float. User-defined classes are accepted as numbers as long as they provide appropriate conversion methods such as _ _int_ _() or _ _float_ _(). For example, a user-defined class that implements _ _int_ _() will be accepted as input for any of the previously shown integer conversions (and _ _int_ _() invoked automatically to do the conversion).
Table 26.2 shows the conversions that apply to strings and bytes. Many of the string conversions return both a pointer and length as a result.
String handling presents a special problem for C extensions because the char * datatype is used for many different purposes. For instance, it might refer to text, a single character, or a buffer of raw binary data. There is also the issue of what to do with embedded NULL characters ('x00') that C uses to signal the end of text strings.
In Table 26.2, the conversion codes of "s", "z", "u", "es", and "et" should be used if you are passing text. For these codes, Python assumes that the input text does not contain any embedded NULLs—if so, a TypeError exception is raised. However, the resulting string in C can be safely assumed to be NULL-terminated. In Python 2, both 8-bit and Unicode strings can be passed, but in Python 3, all conversions except for "et" require the Python str type and do not work with bytes. When Unicode strings are passed to C, they are always encoded using the default Unicode encoding used by the interpreter (usually UTF-8). The one exception is the "u" conversion code that returns a string using Python’s internal Unicode representation. This is an array of Py_UNICODE values where Unicode characters are typically represented by the wchar_t type in C.
The "es" and "et" codes allow you to specify an alternative encoding for the text. For these, you supply an encoding name such as 'utf-8' or 'iso-8859-1', and the text will be encoded into a buffer and returned in that format. The "et" code differs from "es" in that if a Python byte-string is given, it is assumed to have already been encoded and is passed through unmodified. One caution with "es" and "et" conversions is that they dynamically allocate memory for the result and require the user to explicitly release it using PyMem_Free(). Thus, code that uses these conversions should look similar to this:

For handling text or binary data, use the "s#", "z#", "u#", "es#", or "et#" codes. These conversions work exactly the same as before except that they additionally return a length. Because of this, the restriction on embedded NULL characters is lifted. In addition, these conversions add support for byte strings and any other objects that support something known as the buffer interface. The buffer interface is a means by which a Python object can expose a raw binary buffer representing its contents. Typically, you find it on strings, bytes, and arrays (e.g., the arrays created in the array module support it). In this case, if an object provides a readable buffer interface, a pointer to the buffer and its size is returned. Finally, if a non-NULL pointer and length are given to the "es#" and "et#" conversions, it is assumed that these represent a pre-allocated buffer into which the result of the encoding can be placed. In this case, the interpreter does not allocate new memory for the result and you don’t have to call PyMem_Free().
The conversion codes of "s*" and "z*" are similar to "s#" and "z#" except that they populate a Py_buffer structure with information about the received data. More information about this can be found in PEP-3118, but this structure minimally has attributes char *buf, int len, and int itemsize that point to the buffer, the buffer length (in bytes), and the size of items held in the buffer. In addition, the interpreter places a lock on the buffer that prevents it from being changed by other threads as long as it is held by extension code. This allows the extension to work with the buffer contents independently, possibly in a different thread than the interpreter. It is up to the user to call PyBuffer_Release() on the buffer after all processing is complete.
The conversion codes of "t#", "w", "w#", and "w*" are just like the "s" family of codes except that they only accept objects implementing the buffer interface. "t#" requires the buffer to be readable. The "w" code requires the buffer to be both readable and writable. A Python object supporting a writable buffer is assumed to be mutable. Thus, it is legal for a C extension to overwrite or modify the buffer contents.
The conversion codes of "y", "y#", and "y*" are just like the "s" family of codes except that they only accept byte strings. Use these to write functions that must only take bytes, not Unicode strings. The "y" code only accepts byte strings that do not contain embedded NULL characters.
Table 26.3 lists conversion codes that are used to accept arbitrary Python objects as input and to leave the result as type PyObject *. These are sometimes used for C extensions that need to work with Python objects that are more complicated than simple numbers or strings—for example, if you needed a C extension function to accept an instance of a Python class or dictionary.
The "O", "S", and "U" specifiers return raw Python objects of type PyObject *. "S" and "U" restrict this object to be a string or Unicode string, respectively.
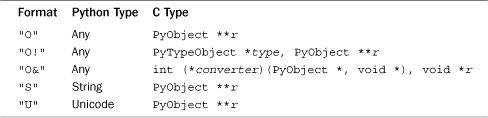
The "O!" conversion requires two C arguments: a pointer to a Python type object and a pointer to a PyObject * into which a pointer to the object is placed. A TypeError is raised if the type of the object doesn’t match the type object. For example:
![]()
The following list shows the C type names corresponding to some Python container types that might be commonly used with this conversion.

The "O&" conversion takes two arguments (converter, addr) and uses a function to convert a PyObject * to a C data type. converter is a pointer to a function with the prototype int converter(PyObject *obj, void *addr), where obj is the passed Python object and addr is the address supplied as the second argument in PyArg_ParseTuple(). converter() should return 1 on success, 0 on failure. On error, the converter should also raise an exception. This kind of conversion can be used to map Python objects such as lists or tuples into C data structures. For example, here is a possible implementation of the distance() wrapper from our earlier code:

Finally, argument format strings can contain a few additional modifiers related to tuple unpacking, documentation, error messages, and default arguments. The following is a list of these modifiers:

The "(items)" unpacks values from a Python tuple. This can be a useful way to map tuples into simple C structures. For example, here is another possible implementation of the py_distance() wrapper function:

The modifier "|" specifies that all remaining arguments are optional. This can appear only once in a format specifier and cannot be nested. The modifier ":" indicates the end of the arguments. Any text that follows is used as the function name in any error messages. The modifier ";" signals the end of the arguments. Any following text is used as the error message. Note that only one of : and ; should be used. Here are some examples:

Type Conversion from C to Python
The following C function is used to convert the values contained in C variables to a Python object:
PyObject *Py_BuildValue(char *format, ...)
This constructs a Python object from a series of C variables. format is a string describing the desired conversion. The remaining arguments are the values of C variables to be converted.
The format specifier is similar to that used with the PyArg_ParseTuple* functions, as shown in Table 26.4.
Table 26.4 Format Specifiers for Py_BuildValue()
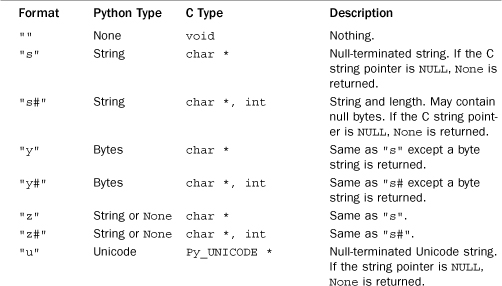


Here are some examples of building different kinds of values:

For Unicode string conversions involving char *, it is assumed that the data consists of a series of bytes encoded using the default Unicode encoding (usually UTF-8). The data will be automatically decoded into a Unicode string when passed to Python. The only exceptions are the "y" and "y#" conversions that return a raw byte string.
Adding Values to a Module
In the module initialization function of an extension module, it is common to add constants and other support values. The following functions can be used to do this:
int PyModule_AddObject(PyObject *module, const char *name, PyObject *value)
Adds a new value to a module. name is the name of the value, and value is a Python object containing the value. You can build this value using Py_BuildValue().
int PyModule_AddIntConstant(PyObject *module, const char *name, long value)
Adds an integer value to a module.
![]()
Adds a string value to a module. value must be a null-terminated string.
void PyModule_AddIntMacro(PyObject *module, macro)
Adds a macro value to a module as an integer. macro must be the name of preprocessor macro.
void PyModule_AddStringMacro(PyObject *module, macro)
Adds a macro value to a module as a string.
Error Handling
Extension modules indicate errors by returning NULL to the interpreter. Prior to returning NULL, an exception should be set using one of the following functions:
void PyErr_NoMemory()
Raises a MemoryError exception.
void PyErr_SetFromErrno(PyObject *exc)
Raises an exception. exc is an exception object. The value of the exception is taken from the errno variable in the C library.
void PyErr_SetFromErrnoWithFilename(PyObject *exc, char *filename)
Like PyErr_SetFromErrno(), but includes the file name in the exception value as well.
void PyErr_SetObject(PyObject *exc, PyObject *val)
Raises an exception. exc is an exception object, and val is an object containing the value of the exception.
void PyErr_SetString(PyObject *exc, char *msg)
Raises an exception. exc is an exception object, and msg is a message describing what went wrong.
The exc argument in these functions can be set to one of the following:
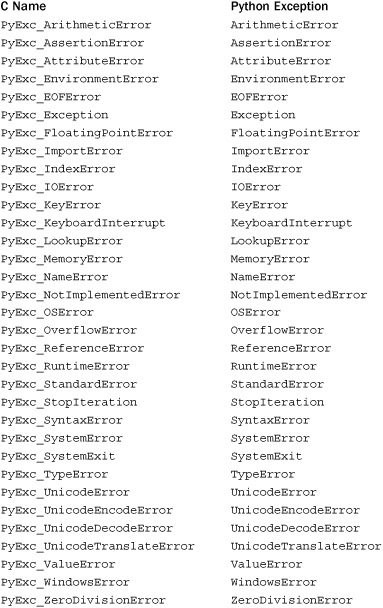
The following functions are used to query or clear the exception status of the interpreter:
void PyErr_Clear()
Clears any previously raised exceptions.
PyObject *PyErr_Occurred()
Checks to see whether or not an exception has been raised. If so, the current exception value is returned. Otherwise, NULL is returned.
int PyErr_ExceptionMatches(PyObject *exc)
Checks to see if the current exception matches the exception exc. Returns 1 if true, 0 otherwise. This function follows the same exception matching rules as in Python code. Therefore, exc could be a superclass of the current exception or a tuple of exception classes.
The following prototype shows how to implement a try-except block in C:

Reference Counting
Unlike programs written in Python, C extensions may have to manipulate the reference count of Python objects. This is done using the following macros, all of which are applied to objects of type PyObject *.

Manipulating the reference count of Python objects in C is a delicate topic, and readers are strongly advised to consult the “Extending and Embedding the Python Interpreter” document available at http://docs.python.org/extending before proceeding any further. As a general rule, it is not necessary to worry about reference counting in C extension functions except in the following cases:
• If you save a reference to a Python object for later use or in a C structure, you must increase the reference count.
• Similarly, to dispose of an object that was previously saved, decrease its reference count.
• If you are manipulating Python containers (lists, dicts, and so on) from C, you may have to manually manipulate reference counts of the individual items. For example, high-level operations that get or set items in a container typically increase the reference count.
You will know that you have a reference counting problem if your extension code crashes the interpreter (you forgot to increase the reference count) or the interpreter leaks memory as your extension functions are used (you forgot to decrease a reference count).
Threads
A global interpreter lock is used to prevent more than one thread from executing in the interpreter at once. If a function written in an extension module executes for a long time, it will block the execution of other threads until it completes. This is because the lock is held whenever an extension function is invoked. If the extension module is thread-safe, the following macros can be used to release and reacquire the global interpreter lock:
Py_BEGIN_ALLOW_THREADS
Releases the global interpreter lock and allows other threads to run in the interpreter. The C extension must not invoke any functions in the Python C API while the lock is released.
Py_END_ALLOW_THREADS
Reacquires the global interpreter lock. The extension will block until the lock can be acquired successfully in this case.
The following example illustrates the use of these macros:

Embedding the Python Interpreter
The Python interpreter can also be embedded into C applications. With embedding, the Python interpreter operates as a programming library where C programs can initialize the interpreter, have the interpreter run scripts and code fragments, load library modules, and manipulate functions and objects implemented in Python.
An Embedding Template
With embedding, your C program is in charge of the interpreter. Here is a simple C program that illustrates the most minimal embedding possible:

In this example, the interpreter is initialized, a short script is executed as a string, and the interpreter is shut down. Before proceeding any further, it is usually a good idea to get the prior example working first.
Compilation and Linking
To compile an embedded interpreter on UNIX, your code must include the "Python.h" header file and link against the interpreter library such as libpython2.6.a. The header file is typically found in /usr/local/include/python2.6, and the library is typically found in /usr/local/lib/python2.6/config. For Windows, you will need to locate these files in the Python installation directory. Be aware that the interpreter may depend on other libraries you need to include when linking. Unfortunately, this tends to be platform-specific and related to how Python was configured on your machine—you may have to fiddle around for a bit.
Basic Interpreter Operation and Setup
The following functions are used to set up the interpreter and to run scripts:
int PyRun_AnyFile(FILE *fp, char *filename)
If fp is an interactive device such as tty in UNIX, this function calls PyRun_InteractiveLoop(). Otherwise, PyRun_SimpleFile() is called. filename is a string that gives a name for the input stream. This name will appear when the interpreter reports errors. If filename is NULL, a default string of "???" is used as the file name.
int PyRun_SimpleFile(FILE *fp, char *filename)
Similar to PyRun_SimpleString(), except that the program is read from the file fp.
int PyRun_SimpleString(char *command)
Executes command in the _ _main_ _ module of the interpreter. Returns 0 on success, -1 if an exception occurred.
int PyRun_InteractiveOne(FILE *fp, char *filename)
Executes a single interactive command.
int PyRun_InterativeLoop(FILE *fp, char *filename)
Runs the interpreter in interactive mode.
void Py_Initialize()
Initializes the Python interpreter. This function should be called before using any other functions in the C API, with the exception of Py_SetProgramName(), PyEval_InitThreads(), PyEval_ReleaseLock(), and PyEval_AcquireLock().
int Py_IsInitialized()
Returns 1 if the interpreter has been initialized, 0 if not.
void Py_Finalize()
Cleans up the interpreter by destroying all the sub-interpreters and objects that were created since calling Py_Initialize(). Normally, this function frees all the memory allocated by the interpreter. However, circular references and extension modules may introduce memory leaks that cannot be recovered by this function.
void Py_SetProgramName(char *name)
Sets the program name that’s normally found in the argv[0] argument of the sys module. This function should only be called before Py_Initialize().
char *Py_GetPrefix()
Returns the prefix for installed platform-independent files. This is the same value as found in sys.prefix.
char *Py_GetExecPrefix()
Returns the exec-prefix for installed platform-dependent files. This is the same value as found in sys.exec_prefix.
char *Py_GetProgramFullPath()
Returns the full path name of the Python executable.
char *Py_GetPath()
Returns the default module search path. The path is returned as a string consisting of directory names separated by a platform-dependent delimiters (: on UNIX, ; on DOS/Windows).
int PySys_SetArgv(int argc, char **argv)
Sets command-line options used to populate the value of sys.argv. This should only be called before Py_Initialize().
Accessing Python from C
Although there are many ways that the interpreter can be accessed from C, four essential tasks are the most common with embedding:
• Importing Python library modules (emulating the import statement)
• Getting references to objects defined in modules
• Calling Python functions, classes, and methods
• Accessing the attributes of objects (data, methods, and so on)
All of these operations can be carried out using these basic operations defined in the Python C API:
PyObject *PyImport_ImportModule(const char *modname)
Imports a module modname and returns a reference to the associated module object.
PyObject *PyObject_GetAttrString(PyObject *obj, const char *name)
Gets an attribute from an object. This is the same as obj.name.
int PyObject_SetAttrString(PyObject *obj, const char *name, PyObject *value)
Sets an attribute on an object. This is the same as obj.name = value.
PyObject *PyEval_CallObject(PyObject *func, PyObject *args)
Calls func with arguments args. func is a Python callable object (function, method, class, and so on). args is a tuple of arguments.
![]()
Calls func with positional arguments args and keyword arguments kwargs. func is a callable object, args is a tuple, and kwargs is a dictionary.
The following example illustrates the use of these functions by calling and using various parts of the re module from C. This program prints out all of the lines read from stdin that contain a Python regular expression supplied by the user.

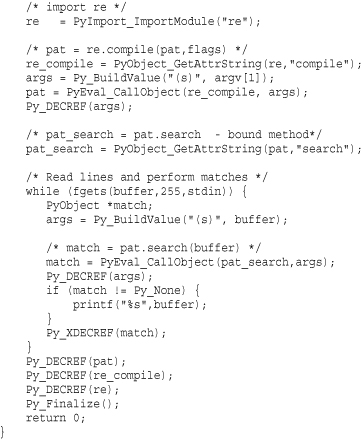
In any embedding code, it is critically important to properly manage reference counts. In particular, you will need to decrease the reference count on any objects created from C or returned to C as a result of evaluating functions.
Converting Python Objects to C
A major problem with embedded use of the interpreter is converting the result of a Python function or method call into a suitable C representation. As a general rule, you need to know in advance exactly what kind of data an operation is going to return. Sadly, there is no high-level convenience function like PyArg_ParseTuple() for converting a single object value. However, the following lists some low-level conversion functions that will convert a few primitive Python data types into an appropriate C representation as long as you know exactly what kind of Python object you are working with:

For any types more complicated than this, you will need to consult the C API documentation (http://docs.python.org/c-api).
ctypes
The ctypes module provides Python with access to C functions defined in DLLs and shared libraries. Although you need to know some details about the underlying C library (names, calling arguments, types, and so on), you can use ctypes to access C code without having to write C extension wrapper code or compile anything with a C compiler. ctypes is a sizable library module with a lot of advanced functionality. Here, we cover the essential parts of it that are needed to get going.
Loading Shared Libraries
The following classes are used to load a C shared library and return an instance representing its contents:
CDLL(name [, mode [, handle [, use_errno [, use_last_error]]]])
A class representing a standard C shared library. name is the name of the library such as 'libc.so.6' or 'msvcrt.dll'.mode provides flags that determine how the library is loaded and are passed to the underlying dlopen() function on UNIX. It can be set to the bitwise-or of RTLD_LOCAL, RTLD_GLOBAL, or RTLD_DEFAULT (the default). On Windows, mode is ignored. handle specifies a handle to an already loaded library (if available). By default, it is None.use_errno is a Boolean flag that adds an extra layer of safety around the handling of the C errno variable in the loaded library. This layer saves a thread-local copy of errno prior to calling any foreign function and restores the value afterwards. By default, use_errno is False.use_last_error is a Boolean flag that enables a pair of functions get_last_error() and set_last_error() that can be used to manipulate the system error code. These are more commonly used on Windows. By default, use_last_error is False.
WinDLL(name [, mode [, handle [, use_errno [, use_last_error]]]])
The same as CDLL() except that the functions in the library are assumed to follow the Windows stdcall calling conventions (Windows).
The following utility function can be used to locate shared libraries on the system and construct a name suitable for use as the name parameter in the previous classes. It is defined in the ctypes.util submodule:
find_library(name)
Defined in ctypes.util. Returns a path name corresponding to the library name.name is a library name without any file suffix such as 'libc', 'libm', and so on The string returned by the function is a full path name such as '/usr/lib/libc.so.6'. The behavior of this function is highly system-dependent and depends on the underlying configuration of shared libraries and environment (for example, the setting of LD_LIBRARY_PATH and other parameters). Returns None if the library can’t be located.
Foreign Functions
The shared library instances created by the CDLL() class operates as a proxy to the underlying C library. To access library contents, you just use attribute lookup (the operator). For example:

In this example, operations such as libc.rand() and libc.atoi() are directly calling functions in the loaded C library.
ctypes assumes that all functions accept parameters of type int or char * and return results of type int. Thus, even though the previous function calls “worked,” calls to other C library functions do not work as expected. For example:
![]()
To address this problem, the type signature and handling of any foreign function func can be set by changing the following attributes:
func.argtypes
A tuple of ctypes datatypes (described here) describing the input arguments to func.
func.restype
A ctypes datatype describing the return value of func.None is used for functions returning void.
func.errcheck
A Python callable object taking three parameters (result, func, args) where result is the value returned by a foreign function, func is a reference to the foreign function itself, and args is a tuple of the input arguments. This function is called after a foreign function call and can be used to perform error checking and other actions.
Here is an example of fixing the atof() function interface, as shown in the previous example:

The ctypes.d_double is a reference to a predefined datatype. The next section describes these datatypes.
Datatypes
Table 26.5 shows the ctypes datatypes that can be used in the argtypes and restype attributes of foreign functions. The “Python Value” column describes the type of Python data that is accepted for the given data type.

To create a type representing a C pointer, apply the following function to one of the other types:
POINTER(type)
Defines a type that is a pointer to type type. For example, POINTER(c_int) represents the C type int *.
To define a type representing a fixed-size C array, multiply an existing type by the number of array dimensions. For example, c_int*4 represents the C datatype int[4].
To define a type representing a C structure or union, you inherit from one of the base classes Structure or Union. Within each derived class, you define a class variable _fields_ that describes the contents. _fields_ is a list of 2 or 3 tuples of the form (name, ctype) or (name, ctype, width), where name is an identifier for the structure field, ctype is a ctype class describing the type, and width is an integer bit-field width. For example, consider the following C structure:
![]()
The ctypes description of this structure is
![]()
Calling Foreign Functions
To call functions in a library, you simply call the appropriate function with a set of arguments that are compatible with its type signature. For simple datatypes such as c_int, c_double, and so forth, you can just pass compatible Python types as input (integers, floats, and so on). It is also possible to pass instances of c_int, c_double and similar types as input. For arrays, you can just pass a Python sequence of compatible types.
To pass a pointer to a foreign function, you must first create a ctypes instance that represents the value that will be pointed at and then create a pointer object using one of the following functions:
byref(cvalue [, offset])
Represents a lightweight pointer to cvalue. cvalue must be an instance of a ctypes datatype. offset is a byte offset to add to the pointer value. The value returned by the function can only be used in function calls.
pointer(cvalue)
Creates a pointer instance pointing to cvalue. cvalue must be an instance of a ctypes datatype. This creates an instance of the POINTER type described earlier.
Here is an example showing how you would pass a parameter of type double * into a C function:

It should be noted that you cannot create pointers to built-in types such as int or float. Passing pointers to such types would violate mutability if the underlying C function changed the value.
The cobj.value attribute of a ctypes instance cobj contains the internal data. For example, the reference to dval.value in the previous code returns the floating-point value stored inside the ctypes c_double instance dval.
To pass a structure to a C function, you must create an instance of the structure or union. To do this, you call a previous defined structure or union type StructureType as follows:
StructureType(*args, **kwargs)
Creates an instance of StructureType where StructureType is a class derived from Structure or Union. Positional arguments in *args are used to initialize the structure members in the same order as they are listed in _fields_. Keyword arguments in **kwargs initialize just the named structure members.
Alternative Type Construction Methods
All instances of ctypes types such as c_int, POINTER, and so forth have some class methods that are used to create instances of ctypes types from memory locations and other objects.
ty.from_buffer(source [,offset])
Creates an instance of ctypes type ty that shares the same memory buffer as source.source must be any other object that supports the writable buffer interface (e.g., bytearray, array objects in the array module, mmap, and so on). offset is the number of bytes from the start of the buffer to use.
ty.from_buffer_copy(source [, offset])
The same as ty.from_buffer() except that a copy of the memory is made and that source can be read-only.
ty.from_address(address)
Creates an instance of ctypes type ty from a raw memory address address specified as an integer.
ty.from_param(obj)
Creates an instance of ctypes type ty from a Python object obj. This only works if the passed object obj can be adapted into the appropriate type. For example, a Python integer can be adapted into a c_int instance.
ty.in_dll(library, name)
Creates an instance of ctypes type ty from a symbol in a shared library. library is an instance of the loaded library such as the object created by the CDLL class. name is the name of a symbol. This method can be used to put a ctypes wrapper around global variables defined in a library.
The following example shows how you might create a reference to a global variable int status defined in a library libexample.so.
![]()
Utility Functions
The following utility functions are defined by ctypes:
addressof(cobj)
Returns the memory address of cobj as an integer. cobj must be an instance of a ctypes type.
alignment(ctype_or_obj)
Returns the integer alignment requirements of a ctypes type or object. ctype_or_obj must be a ctypes type or an instance of a type.
cast(cobj, ctype)
Casts a ctypes object cobj to a new type given in ctype. This only works for pointers, so cobj must be a pointer or array and ctype must be a pointer type.
create_string_buffer(init [, size])
Creates a mutable character buffer as a ctypes array of type c_char. init is either an integer size or a string representing the initial contents. size is an optional parameter that specifies the size to use if init is a string. By default, the size is set to be one greater than the number of characters in init. Unicode strings are encoded into bytes using the default encoding.
create_unicode_buffer(init [, size])
The same as create_string_buffer(), except that a ctypes array of type c_wchar is created.
get_errno()
Returns the current value of the ctypes private copy of errno.
get_last_error()
Returns the current value of the ctypes private copy of LastError on Windows.
memmove(dst, src, count)
Copies count bytes from src to dst.src and dst are either integers representing memory addresses or instances of ctypes types that can be converted to pointers. The same as the C memmove() library function.
memset(dst, c, count)
Sets count bytes of memory starting at dst to the byte value c. dst is either an integer or a ctypes instance. c is an integer representing a byte in the range 0-255.
resize(cobj, size)
Resizes the internal memory used to represent ctypes object cobj. size is the new size in bytes.
set_conversion_mode(encoding, errors)
Sets the Unicode encoding used when converting from Unicode strings to 8-bit strings. encoding is the encoding name such as 'utf-8', and errors is the error-handling policy such as 'strict' or 'ignore'. Returns a tuple (encoding, errors) with the previous setting.
Sets the ctypes-private copy of the system errno variable. Returns the previous value.
set_last_error(value)
Sets the Windows LastError variable and returns the previous value.
sizeof(type_or_cobj)
Returns the size of a ctypes type or object in bytes.
string_at(address [, size])
Returns a byte string representing size bytes of memory starting at address address. If size is omitted, it is assumed that the byte string is NULL-terminated.
wstring_at(address [, size])
Returns a Unicode string representing size wide characters starting at address address. If size is omitted, the character string is assumed to be NULL-terminated.
Example
The following example illustrates the use of the ctypes module by building an interface to the set of C functions used in the very first part of this chapter that covered the details of creating Python extension modules by hand.

As a general note, usage of ctypes is always going to involve a Python wrapper layer of varying complexity. For example, it may be the case that you can call a C function directly. However, you may also have to implement a small wrapping layer to account for certain aspects of the underlying C code. In this example, the replace() function is taking extra steps to account for the fact that the C library mutates the input buffer. The distance() function is performing extra steps to create Point instances from tuples and to pass pointers.
Note
The ctypes module has a large number of advanced features not covered here. For example, the library can access many different kinds of libraries on Windows, and there is support for callback functions, incomplete types, and other details. The online documentation is filled with many examples so that should be a starting point for further use.
Advanced Extending and Embedding
Creating handwritten extension modules or using ctypes is usually straightforward if you are extending Python with simple C code. However, for anything more complex, it can quickly become tedious. For this, you will want to look for a suitable extension building tool. These tools either automate much of the extension building process or provide a programming interface that operates at a much higher level. Links to a variety of such tools can be found at http://wiki.python.org/moin/IntegratingPythonWithOtherLanguages. However, a short example with SWIG (http://www.swig.org) will be shown just to illustrate. In the interest of full disclosure, it should be noted that SWIG was originally created by the author.
With automated tools, you usually just describe the contents of an extension module at a high level. For example, with SWIG, you write a short interface specification that looks like this:

Using this specification, SWIG automatically generates everything needed to make a Python extension module. To run SWIG, you just invoke it like a compiler:
![]()
As output, it generates a set of .c and .py files. However, you often don’t have to worry much about this. If you are using distutils and include a .i file in the setup specification, it will run SWIG automatically for you when building an extension. For example, this setup.py file automatically runs SWIG on the listed example.i file.

It turns out that this example.i file and the setup.py file are all that are needed to have a working extension module in this example. If you type python setup.py build_ext --inplace, you will find that you have a fully working extension in your directory.
Jython and IronPython
Extending and embedding is not restricted to C programs. If you are working with Java, consider the use of Jython (http://www.jython.org), a complete reimplementation of the Python interpreter in Java. With jython, you can simply import Java libraries using the import statement. For example:
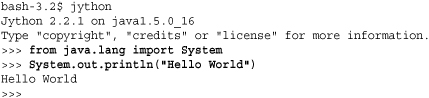
If you are working with the .NET framework on Windows, consider the use of IronPython (http://www.codeplex.com/Wiki/View.aspx?ProjectName=IronPython), a complete reimplementation of the Python interpreter in C#. With IronPython, you can easily access all of the .NET libraries from Python in a similar manner. For example:

Covering jython and IronPython in more detail is beyond the scope of this book. However, just keep in mind that they’re both Python—the most major differences are in their libraries.