
14
Introducing the Domain Modeling Building Blocks
WHAT’S IN THIS CHAPTER?
- The role of tactical patterns in creating an effective object-oriented domain model
- Introducing value objects, entities, domain services, and modules to model your domain and behaviors
- An overview of the lifecycle patterns: aggregate, factory, and repository
- The emerging patterns of event sourcing and domain events
Wrox.com Code Downloads for this Chapter
The wrox.com code downloads for this chapter are found at www.wrox.com/go/domaindrivendesign on the Download Code tab. The code is in the Chapter 14 download and individually named according to the names throughout the chapter.
Mapping the implementation model back to the analysis model and ensuring they are bound to one another is hard. To guide developers and clarify designs, Evans has built upon the domain model pattern that was first catalogued in Martin Fowler’s book Patterns of Enterprise Application Architecture. He introduces a pattern language containing a number of building block patterns to enable the creation of effective domain models. The patterns, built around best-practice, object-oriented techniques, are sometimes referred to as the tactical patterns of Domain-Driven Design (DDD). Many of the patterns themselves are not new, but Evans was the first to group them in this manner as an aid for developers to create effective domain models. This chapter gives a high-level introduction to the tactical building block patterns of Domain-Driven Design. Each pattern has its own chapter in this part of the book where it is covered in more detail.
Although this chapter and the rest of this part detail techniques for creating domain models, the implementation tactics for building domain models should remain flexible and open to innovation. Evans’s original text favored an object-oriented approach, but don’t overlook the different modeling paradigms, as discussed in Chapter 5, “Domain Model Implementation Patterns.” The domain events pattern, which you will read about later in this chapter, was not included in the original building blocks, something that Evans recently said he regretted. In addition, functional programming and event sourcing (covered in Chapter 18, “Domain Events”) are becoming popular ways to express domain models.
The patterns used to create domain models and tie implementation to analysis have continually evolved since Evans’s original text. The semantics of how you create domain models can and will change, what is important is to represent concepts in code using the language of the domain—the Ubiquitous Language.
Tactical Patterns
The role of the tactical patterns in DDD is to manage complexity and ensure clarity of behavior within the domain model. You use the patterns to capture and convey meaning, relationships, and logic within the domain. The patterns are built around solid object-oriented principles, and many are catalogued in widely regarded design books, namely Patterns of Enterprise Application Architecture, by Martin Fowler, and Design Patterns: Elements of Reusable Object-Oriented Software, by Ralph Johnson, John Vlissides, Richard Helm, and Erich Gamma.
Each building block pattern is designed to have a single responsibility; it could be to represent a concept in the domain like an entity or a value object, or it could be to ensure that the concepts of the domain are kept uncluttered from lifecycle concerns like the factory or repository objects. In a way, you can view the building blocks as a ubiquitous language (UL) for developers to use as a framework for constructing rich and useful domain models.
You can use numerous building block patterns, shown in Figure 14.1, in the creation of a domain model. Note that the application services pattern is a client of the domain model and is therefore not covered in this part of the book. Application services are covered in Chapter 25, “Commands: Application Service Patterns for Processing Business Use Cases.”

FIGURE 14.1 Tactical patterns—domain model building blocks.
Patterns to Model Your Domain
The following patterns represent the policies and logic within the problem domain. They express relationships between objects, model rules, and bind the detail of the analysis model to the code implementation model. These are the patterns that express the elements of your model in code.
Entities
An entity represents a concept in your domain that is defined by its identity rather than its attributes. Although an entity’s identity remains fixed throughout its lifecycle, its attributes may change. An entity is responsible for defining what it means to be the same; in code this is often achieved by overriding the equality operations of a class.
An example of an entity is a product; its unique identity won’t change once it is set but its description, price, etc., can be altered many times. Entities are mutable as the attributes can change.
Figure 14.2 shows the main concepts of an entity.

FIGURE 14.2 An entity.
In Listing 14-1, you see a product modeled as an entity.
Listing 14-1 shows that the identifier of a product is set on construction and there are no methods to change it. The Product entity delegates all work to the Money and Option value objects—the attributes/characteristics of the Order. The product entity encapsulates data and exposes behavior; the data of the class is hidden.
You will also have noticed that the entity has a generic base class that takes the type used for identification. Within the base class are the overridden equality methods, similar to what you saw in the Money value object. However, this time when comparing objects, you compare the type and the ID.
For completeness, Listing 14-2 shows the implementation of the Entity base class.
Listing 14-2 shows that by inheriting from this base class, you keep the logic that determines equality between entities within the entity itself. The abstract base class keeps all the noise of identity and equality checking out of the implementation class so that it can focus on business logic.
Value Objects
Value objects represent the elements or concepts of your domain that are known only by their characteristics; they are used as descriptors for elements in your model; they do not require a unique identity. Because value objects have no conceptual identity within the model, they are defined by their attributes; their attributes determine their identity. Value objects don’t need identity because they are always associated with another object and are therefore understood within a particular context. For instance, you may have an order entity that uses value objects to represent the order shipping address, items, courier information, and so on. Not one of these characteristics needs identity itself because it only has meaning within the context of being attached to an order. An order address that is not attached to an order does not have meaning. Value objects are comparable based on their attributes, and like entities are responsible for any equality checks.
Because they are defined by their attributes, value objects are treated as immutable; that is, once constructed, they can never alter their state. A good example of a value object is money. It doesn’t matter that you can’t distinguish between the same five one pound coins or one dollar bills in your pocket. You don’t care about the currency’s identity—only about its value and what it represents. If somebody swapped a five dollar bill for one you have in your wallet, it would not change the fact that you still have five dollars. Of course, in real life, money can have a unique identifier in the form of a serial number, but the domain model does not reflect real life. Instead, it is an abstraction of it built to fulfill the needs of use cases within the problem domain. Figure 14.3 shows the main concepts of a value object.

FIGURE 14.3 A value object.
Listing 14-3 shows money modeled as a value object.
As you can see from Listing 14-3 the equality methods have been overridden, meaning that the Money object is compared only by its attributes; in this instance, the attributes are the value and the currency. The money class is immutable. Once it has been created, it cannot change state. The add method returns a new instance of a Money object. This is known as closure of operations because you are not altering the state of the original money object. Another value object is used to capture the concept of currency. You delegate to the currency object when comparing equality. Again, the equality methods have been overridden.
Domain Services
Domain services encapsulate domain logic and concepts that are not naturally modeled as value objects or entities in your model. Domain services have no identity or state; their responsibility is to orchestrate business logic using entities and value objects. A good example of a domain service is a shipping cost calculator as shown in Listing 14-4. This service is a business function that, given a set of consignments (value objects) and a collection of weight bandings, can calculate the cost of shipping. This functionality does not sit comfortably on a domain object, so it is better represented as a domain service.
The ShippingCostCalculator encapsulates the domain logic that calculates the shipping cost of consignment based on the weight of a collection of consignments, along with the weight of a box. By organizing this logic under a specific domain service and naming it, you can explicitly talk to domain experts about a particular piece of domain logic such as a policy or a process in a concise manner. The ShippingCostCalculator may have been an implicit concept held by the business, but by naming it, you have ensured it is now explicit and should be added to the UL and the analysis model.
Modules
Modules in C# are implemented as namespaces or projects. You use them to organize and encapsulate related concepts (entities and value objects) so you can simplify your understanding of larger domain models. Modules are used to decompose the domain model. Don’t confuse them with subdomains that decompose the domain and bounded contexts that delimit the applicability of a domain model. As shown in Figure 14.4, module names are lifted straight from the UL and enable distinct parts of the domain model to be understood in isolation. Modules enable developers to quickly read and understand a domain model in code before digging deep into class files. They also act as a responsibility boundary, clearly defining parts of the domain model and ensuring that relationships between domain objects are kept to a minimum. Apply modules to promote low coupling and high cohesion within your domain model. Try limiting the contents of a module to a cohesive set.

FIGURE 14.4 Modules used to organize domain concepts within a domain model.
LifeCycle Patterns
The following patterns deal with the creation and persistence of the objects that represent the structure of the domain.
Aggregates
Entities and value objects collaborate to form complex relationships that meet invariants within the domain model. When dealing with large interconnected associations of objects, it is often difficult to ensure consistency and concurrency when performing actions against domain objects. Figure 14.5 shows a large object graph. Trying to treat this collection of objects as one conceptual whole is difficult and could result in performance problems for an application. For example we would not want to block a customer updating an address on her account just because an earlier order’s status is being changed at the same time. These two things are unrelated and need not share a consistency or concurrency boundary.

FIGURE 14.5 A large object graph.
Domain-Driven Design has the Aggregate pattern to ensure consistency and to define transactional concurrency boundaries for object graphs. Large models are split by invariants and grouped into aggregates of entities and value objects that are treated as a conceptual whole. As shown in Figure 14.6, you can distill the model into aggregates.
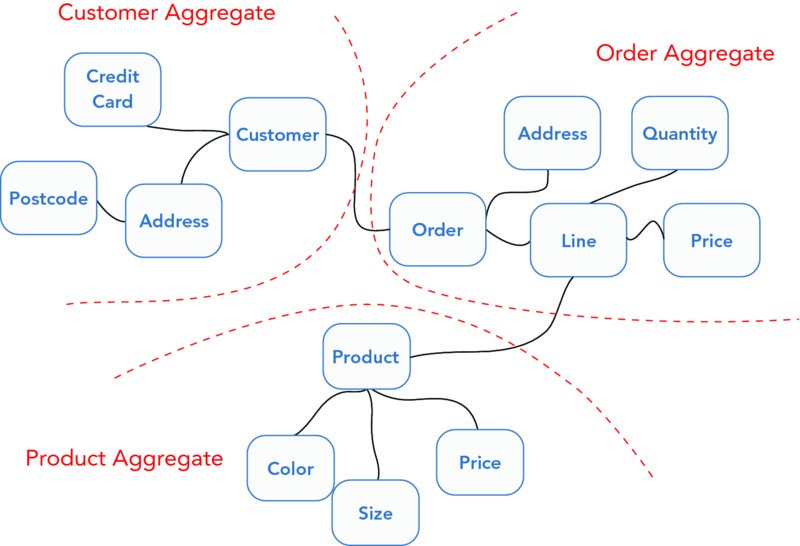
FIGURE 14.6 A large object graph split into aggregates.
Relationships between aggregate roots should be implemented by keeping a reference to the ID of another aggregate root and not a reference to the object itself, as shown in Figure 14.7. This principle helps to keep a boundary between aggregates and avoids the need to load large object graphs that are not required.

FIGURE 14.7 An aggregate root acts as the entry point to the aggregate.
The aggregate groupings in Figure 14.6 and 14-7 at first glance look like a reasonable way to split the object graph; however, defining aggregate groups based purely on related concepts only goes some way to improve consistency and concurrency challenges. Take the customer aggregate, if an address is amended at the same time that some personal details of a customer are changed we could introduce blocking issues. These two concepts although related to a customer do not require an invariant. Therefore, we can split these into two separate aggregates and use this same logic for a credit card, then group them all under a customer module, as can be seen in Figure 14.8.

FIGURE 14.8 Aggregates should be based around invariants.
An aggregate root, shown in Figure 14.9, acts as the entry point into the aggregate. No other entity or value object outside of the aggregate can hold a reference to an object within the aggregate. Objects outside the aggregate can only reference the aggregate root of another aggregate. Any changes to objects in the aggregate need to come through the root. The root encapsulates the data of the aggregate and only exposes behaviors to change it.

FIGURE 14.9 An aggregate root acts as the entry point to the aggregate.
Factories
If the creation of an entity or a value object is sufficiently complex, you should delegate the construction to a factory. A factory ensures that all invariants are met before the domain object is created. If a domain object is simple and has no special rules for valid construction, favor a constructor method over a factory object. You can also use factories when re-creating domain objects from persistent storage.
In Listing 14-5, you see that a Customer entity has a factory method to enable an address to be created with a valid customer ID.
Repositories
A domain model needs a method for persisting and hydrating an aggregate. Because an aggregate is treated as an atomic unit, you should not be able to persist changes to an aggregate without persisting the entire aggregate. A repository, as shown in Figure 14.11, is a pattern that abstracts the underlying persistence store from the model allowing you to create a model without thinking about infrastructure concerns. The repository is the mechanism that you should use to retrieve and persist aggregates. For view rendering, a repository is not required, and querying against a data store is the most efficient method for reporting needs. A repository is an infrastructure concern, so it is not always necessary to abstract away the underlying framework doing all the hard work. It can be more worthwhile to lean on ORM (Object Relational Mapper) frameworks to act as a repository; examples include NHibernate, RavenDB, and Entity Framework. Many developers get hung up on this pattern. Think of it simply as a method of persistence and rehydration. Treat it like infrastructure, and don’t get hung up on abstracting it away.

FIGURE 14.10 A factory.

FIGURE 14.11 A repository.
Emerging Patterns
Since Eric Evans’ original text, two patterns have emerged that are useful for creating domain models. Namely the domain events pattern, covered in Chapter 18, and the event sourcing pattern, covered in Chapter 22 (“Event Sourcing”).
Domain Events
Domain events signify something that has happened in the problem domain that the business cares about. You can use events to record changes to a model in an audit fashion, or you can use them as a form of communication across aggregates. Often an operation on a single aggregate root can result in side effects that are outside the aggregate root boundary. Other aggregates within the model can listen for events and act accordingly.
For example, consider the basket within an e-commerce site, as shown in Figure 14.12. Every time a customer places an item in a basket, it’s important to update the recommended products that are displayed on the site. In this scenario, after a domain event is raised with details of the basket, a customer’s recommendations are modified. The event is subscribed to by the recommendation’s bounded context. Without using a domain event, you need to explicitly couple the basket bounded context to the recommendation context. Domain events give a more natural flow of communication and focus on the when.

FIGURE 14.12 A domain event.
In Listing 14-6, you see a domain event being published from a basket.
In Listing 14-7, you see a recommendation service handling the event raised by the basket.
Don’t worry too much about the syntax of the code at this stage; it is covered in Chapter 18. Domain events play a crucial role in the code.
Event Sourcing
A popular alternative to traditional snapshot-only persistence is event sourcing. Instead of storing the state of an entity in a database, you store the series of events that lead up to the state. Storing all of the events increases the analytical capabilities of a business. Instead of just asking what the current state of an entity is, a business can ask what the state was at any time in the past, as shown in Figure 14.13.

FIGURE 14.13 Storing events, not snapshots
Being able to query the state of your domain model at any time in the past provides a competitive business advantage because you can correlate events that have occurred in the real world with changes to the state of your domain model. Online travel agents may want to investigate why the number of bookings had a massive dip in a certain month. With event sourcing, they can rebuild the state of their catalog and re-run the searches that their users made to understand why those users did not find a vacation they wanted.
As a DDD practitioner, not only is your responsibility to suggest the possibility of using event sourcing to the business, but you also have to learn new ways of modeling your domain to support event sourcing. In particular, you need to move away from dumping an entity’s state into a database using an ORM. Instead, you need to find a way of modeling, capturing, and persisting domain events. You may even need to add event store functionality to an existing database. All of these concerns are covered in detail in Chapter 22.
The Salient Points
- The tactical patterns of DDD are Evans’s building blocks based on Martin Fowler’s patterns for use when creating an Object-Oriented Domain model.
- The building blocks are guides to creating effective domain models, but they are only guides. The way you implement domain models can vary greatly, so don’t get too hung up on the building block patterns.
- Entities
- Are defined by their identity.
- Identity remains constant throughout its lifetime.
- Are responsible for equality checks.
- Value Objects
- Describe the properties and characteristics within the problem domain.
- Have no identity.
- Are immutable, meaning that they cannot be changed. Instead properties modeled as value objects must be replaced.
- Domain Services
- Contain domain logic that can’t naturally be placed in an entity or value object, whereas application services orchestrate the execution of domain logic but don’t actually implement it.
- Have no internal state, so you can call it repeatedly with the same input, and it always gives the same output.
- Modules
- Are used to decompose, organize, and increase the readability of the domain model.
- Namespaces, an implementation of modules, can be applied to reduce coupling and increase cohesion within the domain model.
- Enable readers to quickly understand the design of a model.
- Help to define clear boundaries between domain objects.
- Encapsulate concepts that can be understood independently of each other. They operate on a higher level of abstraction than aggregates and entities.
- Aggregates
- Decompose large object graphs into small clusters of domain objects to reduce the complexity of the technical implementation of the domain model.
- Represent domain concepts, not just generic collections of domain objects.
- Are based around domain invariants.
- Are a consistency boundary to ensure the domain model is kept in a reliable state.
- Ensure transactional concurrency boundaries are set at the right level of granularity to ensure a usable application by avoiding blocking at the database level.
- Factories
- Separate use from construction.
- Encapsulate complex entity and value object construction.
- Repositories
- Expose the interface of an in-memory collection of aggregate roots.
- Should not be used for reporting.
- Provide the retrieval and persistence needs of aggregate roots.
- Decouple the domain layer from database strategies and infrastructure code.
- Domain Events
- Are significant occurrences in the real-world problem domain that business users care about; they are part of the ubiquitous language (UL).
- Are an emerging design pattern that makes domain events more explicit in code.
- Are akin to publish-subscribe, where events are raised and event handlers handle them.
- Event Sourcing
- Replaces traditional snapshot-only storage with a full history of events that produce the current state.
- Allows powerful querying capabilities that revolve around time, known as temporal queries.