
11
Introduction to Bounded Context Integration
WHAT’S IN THIS CHAPTER?
- How to integrate bounded contexts that form a distributed system
- Fundamental challenges inherent to building distributed systems
- Understanding how the principles of Service Oriented Architecture (SOA) can help to build loosely coupled bounded contexts and independent teams
- Addressing nonfunctional requirements while keeping an explicit event-driven domain model using reactive DDD
Wrox.com Code Downloads for This Chapter
The wrox.com code downloads for this chapter are found at www.wrox.com/go/domaindrivendesign on the Download Code tab. The code is in the Chapter 11 download and individually named according to the names throughout the chapter.
After identifying the bounded contexts in your system (as discussed in Chapter 6, “Maintaining the Integrity of Domain Models with Bounded Contexts,” and Chapter 7, “Context Mapping”), the next step is to decide how you will integrate them to carry out full business use cases. One of the big challenges you face in this process is successfully designing a robust distributed system. For example, each step of placing an order, billing the customer, and arranging shipping may belong to a different bounded context running as a separate piece of software on a separate physical machine or cloud instance. In this chapter, you learn about fundamental concepts in distributed computing that allow you to retain explicit domain concepts while gracefully dealing with nonfunctional requirements, such as scalability and reliability, that are inherent to distributed systems.
Technical challenges are only one part of integrating bounded contexts and building distributed systems; social challenges are the other. Distributed systems are often too large for a single team to maintain responsibility of, requiring a number of teams to take ownership of one or more bounded contexts. This chapter introduces you to teamwork and communication patterns that successful teams use to build highly scalable systems using Domain-Driven Design (DDD). One common pattern is the adoption of Service Oriented Architecture (SOA).
SOA is an architectural style for building business-oriented, loosely coupled software services. This chapter shows you that, by conceptualizing bounded contexts as SOA services, you can use the principles of SOA to create loosely coupled, bounded contexts that help solve the technical and social challenges of bounded context integration. You also learn about the benefits event-driven reactive programming provides and how it synergizes with DDD by modeling communication between bounded contexts as events that occur in the domain.
Event-driven systems also bring challenges. Most notably they require developers to think differently about how they design their systems, and also give rise to eventual consistency. So this chapter also discusses the drawbacks and options for dealing with them. In addition this chapter also touches on operational concerns like monitoring service level agreements (SLAs) and errors.
After reading this chapter that lays the foundation of bounded context integration, the next chapters provide concrete coding examples of building systems that integrate bounded contexts by applying these concepts. After completing this and the next two chapters, you will be ready to start applying these concepts and your new technical skills to build event-driven distributed systems synergistically with DDD.
How to Integrate Bounded Contexts
Software services need to have relationships with each other to provide advanced behaviors. It is your responsibility to choose these relationships and the methods of communication. This massive responsibility can have significant impacts on the speed of delivery, the efficiency, and the success of a project. You may need to integrate with an external payment provider, or you may need to communicate with a system written by another team in your company. In fact, you probably have a number of internal and external relationships like this on most projects.
When you choose relationships between services that reflect your domain, you get the familiar benefits of DDD, such as an explicit model that facilitates conversations with domain experts, allowing new concepts to be incorporated smoothly. Many organizations find that judicious choice of boundaries and communication protocols allows each team to work independently without hindering others.
The choice of communication method alone can be the difference between having an application that scales up to ten million users during periods of heavy viral growth, and a system that collapses in the same scenario taking the whole business down with it. Choosing the communication method is often easier once you’ve identified the relationship. A good place to start identifying relationships is by identifying your bounded contexts.
Bounded Contexts Are Autonomous
As systems grow, dependencies become more significant in a negative way. You should strive to avoid most forms of coupling unless you have a very good reason. A coupling on code means that one team can break another team’s code or cause bottlenecks that slow down the delivery of new features. A runtime coupling between subsystems means that one system cannot function without the other.
If you design loosely coupled bounded contexts that limit dependencies, each bounded context can be developed in isolation. Its codebase can be evolved without fear of breaking behavior in another bounded context, and its developers do not have to wait for developers in other bounded contexts to carry out some work or approve a change.
Ultimately, when bounded contexts are loosely coupled there are likely to be fewer bottlenecks and a higher probability that business value will get created faster and more efficiently.
The Challenges of Integrating Bounded Contexts at the Code Level
You learned in Chapter 6 that bounded contexts represent discrete business capabilities, like sales or shipping. Just as you might walk through the corridors of the company you work for and see signs identifying each part of the business, it is good practice to partition your software systems in line with these business capabilities.
When you’re looking at the shipping code, you’re focused on the shipping part of the business. It’s not that helpful if you have concepts from the Sales Department getting in the way of adding a new feature that integrates a new shipping provider. In fact, making changes to the shipping code might break sales features. If you’ve heard of the Single Responsibility Principle (SRP), this will make perfect sense to you. In DDD, you can use the SRP to isolate separate business capabilities into separate bounded contexts. It is sometimes acceptable for your bounded contexts to live as separate modules/projects inside the same solution, though.
Multiple Bounded Contexts Exist within a Solution
Once you have identified bounded contexts, it’s useful to remind everyone building the system that there is a bigger picture. By putting all of the bounded contexts inside a single code repository or solution it can help developers to see that there is a world outside of their bounded context. Understanding the bigger picture is important because bounded contexts combine to carry out full business use cases.
It is not strictly necessary for each bounded context to live inside the same source code repository or solution (e.g., a Visual Studio solution), though. In some cases, it is not possible because bounded contexts are written in different programming languages that do not even run on the same operating system.
There is no single correct answer that determines where the code for your bounded contexts should live. You need to assess the trade-offs and decide which approach is best for you.
Namespaces or Projects to Keep Bounded Contexts Separate
If you do choose to locate all of your bounded contexts inside a single solution, there is an increased risk of creating dependencies between them. If two bounded contexts use code from another project inside the same solution, there is a dangerous risk of one bounded context breaking the other. Imagine that you have a User class in a shared project called Eccommerce.Common or similar:
public class User
{
public String Name {get; set;}
public String Id {get; set;}
public void UpdateAddress(Address newAddress)
{
...
}
}If the Shipping bounded context decides to change the implementation of UpdateAddress(), it might break the Sales bounded context, which relied on the old address being persisted in a certain location or format. Also, the teams that rely on the shared code might need to have meetings to decide how it can be changed and when they will be able to update their code to accommodate the change. This kind of dependency between teams can slow down a project and introduce undesirable political scenarios. Figure 11.1 visualizes a single solution that contains multiple independent bounded contexts.
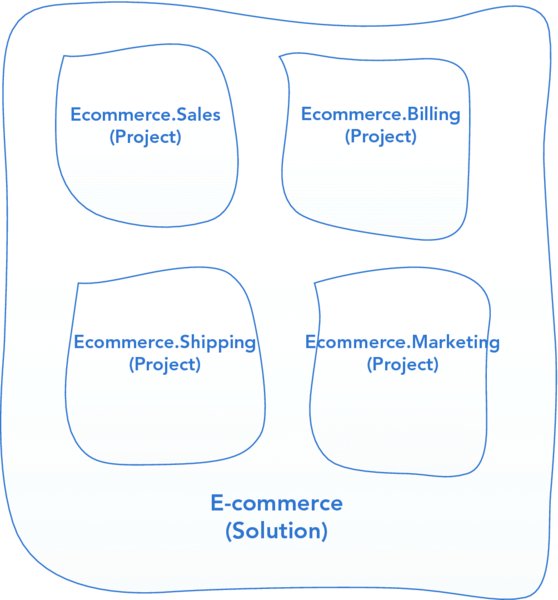
FIGURE 11.1 Multiple bounded contexts inside a single solution.
Integrating via the Database
Another common dependency that slows down teams is the database. For example, the Sales bounded context’s team wants to update the User schema, but no one is sure if this will break code in the Shipping bounded context or the Billing bounded context. It’s likely that several teams will be distracted from working on business priorities to support the Sales bounded context’s schema change. A dependency between teams is undesirable because the rate of delivering new features is reduced while the teams synchronize.
If you’ve used database integration in the past you may also be familiar with another common problem, where each model that integrates through the database has similar but distinct domain concepts. This strategy becomes painful when multiple models use the same shared schema. For example, in the domain of furniture, suppliers may sell mass-produced furniture and custom-made furniture. These two parts of the business are likely to have many differences and are likely to be separate bounded contexts. But if they reside in the same codebase, there is the likelihood that the similarities of each model will result in the use of a shared schema for all types of furniture, as shown in Figure 11.2.

FIGURE 11.2 Multiple bounded contexts using a shared schema.
Initially, the two models of the custom-made and mass-produced bounded contexts may easily map onto the shared schema—but they are likely to diverge in the future. When differences between the models start to appear, the shared schema may have columns relevant to one model but not the other. For example, the custom-made furniture model may require a new manufacturing _ priority column that has no relevance to the mass-produced context. Yet the shared schema will need to include the new field. In some scenarios columns may even be used for different purposes by each model. Creating reports from a shared schema that is used by multiple bounded contexts can be error-prone, ambiguous, or misleading to the business.
Fundamentally, sharing a schema between models with different semantics can be an expensive violation of the SRP. When the codebase is small the consequences are less severe. But as the system grows, the pain is likely to increase exponentially as each bounded context pulls in different directions.
Multiple Teams Working in a Single Codebase
If you split your domain into multiple bounded contexts that each has its own codebase you will preclude a whole category of organizational problems. When all of your developers are working on a single large codebase you will have more work in progress (WIP) on a single codebase than if you had a greater number of smaller codebases (each with a small amount of WIP). Excess WIP is a prolific, and usually unnoticed, source of inefficiency in the software industry.
WIP is a problem when you want to release new features. How can you release one completed feature if other features are still in progress? Many teams turn to feature branches; when a piece of work is complete, it is then merged into the master branch and released. But this means that you have long-lived branches. If you try to merge a branch after working on it for two weeks, you may be so far behind that the merge may not even be possible. Essentially you lose all the benefits of continuous integration. And you can spend as much time fighting merges and releasing code as you spend on writing it.
In a large domain you can easily have 10 or more developers all working on separate features. They will make great progress in adding the new features, but as-mentioned, trying to merge and release the code can be excruciatingly painful. Consequently deploys are likely to be more risky, needing more QA and manual regression testing. In the worst case, deploys can take a whole day of the company’s time where no new value is created.
When many companies are now using continuous delivery and deploying value to their customers multiple times per day, it makes it painfully clear that a single codebase shared by multiple teams can result in heavy costs to the business. A single monolithic codebase is also the kind that is no fun to work on.
Models Blur
If you have a complex domain that effectively has multiple bounded contexts, but you have only one codebase, it is inevitable that boundaries of each model will not remain intact. Code from one bounded context will become coupled to code in another, leading to tight dependencies. As previously mentioned, once you introduce dependencies between bounded contexts you introduce friction that stops them evolving independently and each team working optimally.
Alternatively, if you have separate projects or modules for each bounded context, you remove the possibility of coupling. You might have code in two bounded contexts that look very similar, and you may feel you are violating the Don’t Repeat Yourself (DRY) principle, but a lot of the time that is not a problem. Very often you will find that even though the code looks the same to begin with, it changes in each bounded context for different reasons as new concepts and insights emerge. By not coupling the bounded concepts, there is no friction when you try to incorporate the new concepts and insights.
Even if the code is the same and it never changes, usually the duplication causes no problem. Duplication is a problem because you may update code in one place, and forget to update it in another. However, this is rarely a problem when you have loosely coupled, bounded contexts that are intended to run in isolation. There are very few reasons that the same concept in two bounded contexts should be changed at the same time. So don’t worry about duplicating similar code, and instead focus on isolating your bounded context and maintaining their boundaries.
Use Physical Boundaries to Enforce Clean Models
To retain the integrity of your bounded contexts and ensure they are autonomous, the most widely used approach is to use a shared-nothing architecture, where each bounded context has its own codebases, datastores, and team of developers. When done correctly, this approach results in a system composed of verticals, as demonstrated in Figure 11.3.

FIGURE 11.3 Autonomous bounded contexts with a shared-nothing architecture.
When each bounded context is physically isolated, no longer can developers in one bounded context call methods on another, or store data in a shared schema. Since there is a distinct physical separation, they have to go out of their way to introduce coupling. More than likely, they will be put off by the extra effort or brought up to speed by another team member before they can create an unnecessary dependency.
Once bounded contexts are clearly isolated and the potential for coupling is significantly reduced, other external factors are unlikely to influence the model. For example, if a concept is added or refined in one bounded context it will not affect concepts that look similar in other bounded contexts, which could easily get caught up in the changes had there been a single codebase. Fundamentally, the clear physical separation allows each bounded context to evolve only for internal reasons, resulting in an uncompromised domain model and more efficient delivery of business value in the short and long term.
Integrating with Legacy Systems
When you are faced with the constraints of integrating bounded contexts that are comprised of legacy code, there are a number of patterns you can use to limit the impact of the legacy on other parts of the system. These patterns help you manage the complexity and save you from having to reduce the explicitness of your new code in order to integrate the legacy components.
Bubble Context
Teams that are unfamiliar with DDD but want to begin applying it to a legacy system are advised to consider using a bubble context. Because bubble contexts are isolated from existing codebases, they provide a clean slate for creating and evolving a domain model. Remember, DDD works best when you have full control over the domain model and are free to frequently iterate on it as you gain new domain insights. A bubble context facilitates frequent iteration even when legacy code is involved.
For bubble contexts to be effective, a translation layer is necessary between the bubble and the legacy model(s). The DDD concept of an anti-corruption layer (ACL) is ideal for this need, as shown in Figure 11.4.

FIGURE 11.4 A bubble context.
Design and implementation of the ACL is a key activity when building a bubble context. It needs to keep details of the legacy system completely isolated from the bubble while at the same time accurately translating queries and commands from the bubble into queries and commands in the legacy model. It then has to map the response from the legacy into the format demanded by the bubble. Accordingly, the ACL itself can be a complex component that requires a lot of continued investment.
Autonomous Bubble Context
If you want to integrate with legacy code, but do not want to create a bubble context that is so dependent on the legacy code, you can instead use an autonomous bubble. Whereas a bubble context gets all its data from the legacy system, an autonomous bubble is more independent—having its own datastore(s) and being able to run in isolation of the legacy code or other bounded contexts, as shown in Figure 11.5.

FIGURE 11.5 An autonomous bubble context.
Sometimes crucial to the autonomous bubble context’s independence is asynchronous communication with other new and legacy contexts. Consequently, the ACL—a synchronizing ACL—often takes on the role of carrying out the asynchronous communication, as also illustrated in Figure 11.5.
Since the autonomous bubble context has its own datastore it does not require updating legacy codebases or schemas. Any new data can be stored in the autonomous bubble’s datastore. This is an important characteristic to keep in mind when deciding between the bubble and the autonomous bubble. However, the costs and complexity of asynchronous synchronization can be significantly higher.
Exposing Legacy Systems as Services
When a legacy system needs to be consumed by multiple new contexts the cost of creating a dedicated ACL for each context can be excessive. Instead, you can expose the legacy context as a service that requires less translation by the new contexts. A common, and often simple approach, is to expose an HTTP API that returns JSON, as shown in Figure 11.6. This is formally known as the Open Host pattern.
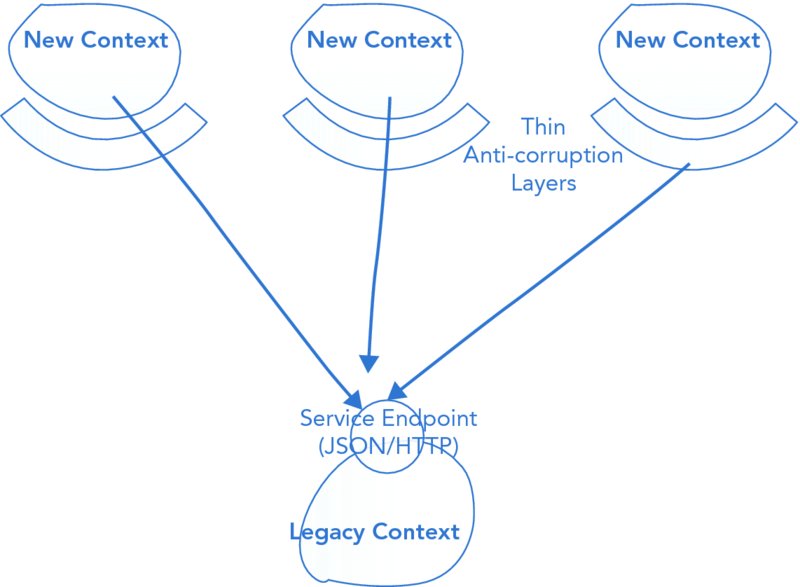
FIGURE 11.6 Exposing a legacy context as a JSON web service.
Each consuming context must still translate the response from the legacy context into its own internal model. However, the translation complexity in this scenario should be mitigated by the simplicity of the API provided by the open host.
While exposing legacy contexts as services can be more efficient when there are multiple consumers, both of the bubble approaches should still be considered. Two of the main drawbacks in exposing legacy contexts as services are that, first, modifications are required to the legacy context that may not be necessary with a bubble. Second, exposing a format that is easily consumable by multiple consumers may be challenging.
Admittedly, choosing a legacy integration strategy can be confusing. However, with three approaches to choose from, you can see that harnessing the benefits of DDD on legacy systems is definitely possible.
Integrating Distributed Bounded Contexts
The phenomenal growth in the number of people using the Internet means that many applications today need to be able to support huge levels of web traffic. If the number of users cannot be supported, a business will not maximize its revenue potential. Primarily, the problem is a hardware one: A single affordable server is usually not powerful enough to support all the users that a popular website may have. Instead, the load needs to be spread across multiple machines. And it’s not just websites, it’s all of the back end of services that make up a system.
Spreading load across multiple machines is such a common problem that it has given rise to the cloud boom. Businesses are using cloud-hosted solutions to rapidly scale their system’s price efficiently. If you design your systems so that they can be spread across multiple machines, you can take advantage of cloud hosting to efficiently scale your systems.
Another key reason that modern systems are distributed is fault tolerance. If one server fails or develops a problem, other servers must be able to take on the increased load to avoid end users suffering.
Having to distribute a system introduces the need to break it up into smaller deployable components. This poses a challenge to maintaining the explicitness that DDD strives for.
Integration Strategies for Distributed Bounded Contexts
Distributed systems, although helping to solve the problems of high scalability, come with their own set of problems. Luckily, you do have some choice about which set of problems you need to face, because there are a number of different integration strategies. Remote procedure call (RPC) and asynchronous messaging are prevalent options and encompass most of this chapter. However, sometimes sharing files or databases can be a good enough alternative.
Distributed systems bring nonfunctional requirements to the table: scalability, availability, reliability. Scalability is the ability to be able to support increasing loads, such as more concurrent users. Availability is concerned with how often the application is online, running, and supporting its users. Another consideration is reliability, which is concerned with how well a system copes with errors. You’ll see shortly that these requirements are often traded off with the amount of coupling in a system and the level of complexity.
When integrating your bounded contexts, it’s important to get an idea from the business what its nonfunctional requirements are so that you can choose an integration strategy that lets you meet them with the least amount of effort. Some options, such as messaging, take more effort to implement, but they provide a solid foundation for achieving high scalability and reliability. On the other hand, if you don’t have such strong scalability requirements, you can integrate bounded contexts with a small initial effort using database integration. You can then get on with shipping other important features sooner.
Unfortunately, you can’t just ask the business how scalable a system needs to be or how reliable it should be. Try to give them scenarios and explain the costs of each scenario. For example, you could tell them that you can guarantee 99.9999% reliability, but it will cost triple the amount of guaranteeing 99.99%.
Database Integration
An accessible approach to integrating bounded contexts is letting one application write to a specific database location that another application reads from. It’s likely that you would want to employ this approach in first-iteration Minimum Viable Products (MVPs) or nonperformance critical parts of the system.
As an example, when you place an order, the Sales bounded context could add it to the Sales table in a SQL database. Later on, the Billing bounded context would come along and verify whether any new records had been added to the table. If it found any, it would then process the payment for each of them.
Implementing this solution has a few possibilities. The most likely example involves the Billing bounded context polling the table at a certain frequency, such as every 5 minutes, and keeping track of which orders it has processed by updating a column in the same row—paymentProcessed perhaps. You can see a visual representation of this in Figure 11.7.

FIGURE 11.7 Database integration.
Database integration also has some loose coupling benefits. Because both systems communicate through writing and reading to a database, the implementation of each system is free to change providing it maintains compatibility with the existing schema. However, the systems are coupled to the same database, so this style of solution can really start to hurt you as the system grows. Database locks are just one painful problem you might come up against. As increasingly more orders are added to the table by one part of the system and then updated by another, the two systems will be competing for database resources. The database will likely be a single point of failure (SPOF), meaning that if it grinds to a halt, both applications will suffer. Some databases, like SQL Server, are hard to cluster, so you have to keep buying bigger, more expensive hardware to scale.
Another drawback is that database integration doesn’t guide you into a good solution for handling faults. What if the Sales bounded context crashes before saving an order? Is the order lost? What if the database goes down? Does that mean the company cannot take orders? These are big problems that you are left on your own to devise solutions for when using database integration.
Flat File Integration
If you aren’t using a database in your project, setting one up just to integrate two components can be unnecessary overhead. This is one example in which flat file integration may be good enough. One component puts files on a server somewhere, while another application picks them up later, in a similar way to database integration. Flat file integration is a more flexible approach than database integration, but you have to be more creative, which can in turn mean more effort and slower lead times on important business functionality. In Figure 11.8, you can see one possible implementation of a flat file integration alternative to the database integration solution in Figure 11.8.

FIGURE 11.8 Flat file integration.
Flat file integration retains the loose coupling features of database integration without suffering from the database locking problem. Unfortunately, you have to work harder to compensate for this. One area of compensation involves the file format. Because there is no schema or standard query language, you are responsible for creating your own file format and ensuring that all applications understand it and use it correctly. Because this is more manual work, it does increase the possibility for error, although a lot depends on your circumstances.
Because flat file integration is a do-it-yourself solution, there are no scalability or reliability guidelines. It’s completely dependent on the choice of technologies you use and how you implement them. If you do need an approach that scales, going to all that effort can be a massive waste and a massive risk. RPC, discussed next, is a common alternative that is a relatively well known quantity in terms of scalability and reliability characteristics.
RPC
Imagine if you could keep your monolithic almost identical but get the scalability benefits of a distributed system. This is the motivating force behind the use of RPC. When using RPC, any method invocation could call another service across the network; it’s not possible to tell unless you look at the implementation. Can you tell how many network calls would occur if you ran the following code snippet?
var order = salesBoundedContext.CreateOrder(orderRequest);
var paymentStatus = billingBoundedContext.ProcessPaymentFor(order);
if (paymentStatus.IsSuccessful)
{
shippingBoundedContext.ArrangeShippingFor(order);
}It’s impossible to tell how many network calls occur in the previous code snippet because you don’t know what happens inside any of the methods that are called. There could be in-memory logic, or there could be network calls to other applications that carry out the logic. Proponents of RPC see this trait as a huge benefit because it is a minimally invasive solution. In some situations, RPC can be the best choice.
When choosing RPC, you have a lot of freedom, because RPC itself is a concept that you can implement in a variety of ways. If you were to talk to enough companies using RPC, you would find examples using most kinds of web service—Simple Object Access Protocol (SOAP), REpresentational State Transfer (REST), eXtensible Markup Language (XML)—using a variety of different technologies, such as Windows Communication Foundation (WCF). RPC tends to be easier than flat file integration because most programming communities have frameworks that deal with a lot of the infrastructure for you.
Many distributed systems novices are tempted to use RPC because most of their existing code can be reused. This is a compelling case for choosing RPC, but it is also a drawback. In a later section (“The Challenges of DDD with Distributed Systems”), you learn in some detail why RPC’s appeal has some deep flaws for achieving scalability and reliability. That is why there is a need for asynchronous, reactive messaging solutions.
Messaging
Quite simply, networks are unreliable. Even the biggest companies like Netflix and Amazon suffer from network problems that result in system outages (http://www.thewhir.com/web-hosting-news/netflix-outage-caused-by-ec2-downtime-reports). Reactive solutions try to embrace failure by increasing reliability using asynchronous messaging patterns for communication. This means that when a message fails, there is a way for the system to detect this and try it again later (such as storing it in a queue) or take a different course of action.
Unfortunately, using messaging usually means that, unlike RPC, your code looks drastically different. When you look at RPC code, there’s no hint of the network; when you look at many messaging solutions, it’s clear that code is asynchronous, and there’s probably a network involved. Not only that, but the entire design and architecture of messaging systems are significantly different, and teams are challenged with an intimidating learning curve. Fortunately, you will learn about messaging in this chapter and the next because, along with RPC, it is the other common option used for building distributed DDD systems. In particular, you will learn that the asynchronous nature of messaging also provides the platform for improved scalability.
REST
If you want the scalability and reliability benefits of messaging solutions, but you want to use Hypertext Transport Protocol (HTTP) instead of messaging frameworks, try REST. REST involves modeling your endpoints as hypermedia-rich resources and using many of the benefits of HTTP, such as its verbs and headers. You can then build event-driven systems on top of HTTP with REST to get many of the benefits of a messaging system, and sometimes fewer of the problems.
REST is also a useful tool for exposing your system as an application programming interface (API) for other applications to integrate with. After learning about distributed systems concepts in this chapter, you will learn more about integrating with REST in Chapter 13, “Integrating via HTTP with RPC and REST.”
The Challenges of DDD with Distributed Systems
When your bounded contexts are separate services that communicate with each other over the network, you have a distributed system. In these systems, choosing the wrong integration strategy might cause slow or unreliable systems that lead to negative business impacts. Development teams need to understand approaches to building distributed systems that can reduce the potential and severity of these problems and allow a business to scale as demand grows.
Accepting that failures happen, and preparing for them, is a critical aspect of building distributed systems, but one that is not inherent to RPC.
The Problem with RPC
When the time comes to scale your application from a single codebase to a number of smaller subsystems, you might be tempted to replace the implementation of a class with an HTTP call. The old logic then moves to a new subsystem, which is the target of this HTTP call. It’s tempting because you can spread the load across two machines without having to change much code. In fact, the code looks the same, as the previous code snippet (repeated below) demonstrates:
var order = salesBoundedContext.CreateOrder(orderRequest);
var paymentStatus = billingBoundedContext.ProcessPaymentFor(order);
if (paymentStatus.IsSuccessful)
{
shippingBoundedContext.ArrangeShippingFor(order);
}Each method call can be processed entirely in memory or can make an HTTP call to another service that carries out the logic. Remember that this is the goal of RPC: to make network communication transparent. Have a look at Figure 11.9 to see an example of an e-commerce system using RPC to place an order.

FIGURE 11.9 E-commerce system using synchronous RPC.
Although RPC feels like good use of object-oriented programming and encapsulation, it has some significant flaws that the distributed systems community has known for years. These flaws can easily negate the determined effort you spent frequently collaborating with domain experts and finely crafting your domain models. To save you suffering from the pain caused by RPC, you will now learn its inherent problems before being shown alternative approaches that attempt to address its drawbacks. You will then be able to decide for yourself if RPC or messaging is the best choice for the projects you work on.
RPC Is Harder to Make Resilient
Because RPC makes network communication transparent, it encourages you to forget the network is there. Unfortunately, network errors do happen, meaning that systems using RPC are more likely to be unreliable. Network errors have been such a major source of problems in distributed systems that they feature prominently in the Fallacies of Distributed Computing (http://blog.newrelic.com/2011/01/06/the-fallacies-of-distributed-computing-reborn-the-cloud-era/). Essentially, time and again, it has been proven that networks are neither reliable nor free from bandwidth and latency costs that RPC implementations often take for granted.
In an online order processing scenario in which the Billing bounded context makes an HTTP call to a third-party payment provider, if the network is down or the payment provider goes offline, the order cannot be completed. At this point, the potential customer will be unhappy that she can’t purchase products, and the business will be even less happy considering it missed out on revenue. Consider the case of a busy Christmas period or a major sporting occasion; a large part of the business model for many companies is maximizing opportunity at these key events. If the system is down, there could be severe consequences for the business. You will see later in this chapter how to avoid these problems, even when major failures happen.
RPC Costs More to Scale
Using the same e-commerce scenario, the scalability limitations of systems that use RPC can be demonstrated. Consider the case in which a business stakeholder sends you an e-mail expressing concern at the number of complaints received from users. You are being told that hundreds of users are reporting a very slow website, while others are reporting that sometimes they completely fail to reach the home page at all because of timeout errors. The problem is a scaling issue because the current system cannot support the current number of concurrent users.
To improve user satisfaction and reduce the number of complaints, the website would need to be faster and able to support more concurrent users. Unfortunately, the Sales, Billing, and Shipping bounded contexts all have to do some processing before the user gets a response, as illustrated in Figure 11.9. That means all of them need increased resources in order to give the business a faster website. If just the website gets faster servers, the user will still be waiting the same amount of time for each of the bounded contexts to do their work. This is undesirable because it is not easy to just make the website faster.
As before, alternative techniques exist that allow the business to scale just the website, or indeed any other bounded context, in isolation on an efficient, as-needed basis. You will read about them later in this chapter.
RPC Involves Tight Coupling
Systems that use RPC have tightly coupled software components that can lead to couplings between teams as well as technical problems like those you just read about. When a system makes an RPC call to another system, there are actually multiple forms of tight coupling that you really need to be aware of. First, there is a logical coupling, because the logic in the service making the call is coupled to the service receiving the call. Second, there is a temporal coupling, because the service making the call expects a response straight away.
Logical Coupling
Removing dependencies on shared code can still result in coupling. If a service makes a call to another service, the called service has to exist and has to behave in a way that the calling service understands. Therefore, the calling service is logically coupled to the receiving service. The kinds of pain caused by a logical coupling can be similar to a shared-code dependency—changes in one place break functionality in another. Logical couplings can also cause pain when the service being called goes down due to failure, because in those cases neither service is functioning. This hurts reliability.
Temporal Coupling
Performance is a feature. The more performant a website is, the more research indicates that users will be converted into paying customers. If part of your system needs a speed increase to improve some aspect of user experience, it can be difficult if that component relies on another component to do some part of the processing and respond immediately. This is known as temporal coupling, and it is inherent to RPC. Figure 11.9 highlights temporal coupling, showing the user waiting for a response while each bounded context takes its turn to perform some processing. This leads to a component not being able to scale independently.
Distributed Transactions Hurt Scalability and Reliability
Transactions are a best practice for maintaining data consistency. Unfortunately, when building distributed systems, transactions carry a high cost because of the involvement of network communication. As a result, scalability and reliability can be negatively impacted for reasons such as excessive long-held database locks or partial failures. Therefore, you should carefully consider distributed transactions, as well as RPC, when building distributed systems.
A typical example of a distributed transaction is booking a holiday that consists of a hotel and a flight, where your system stores hotels but flights are handled by an external system. When you place an order, a lock is put on the hotel room in your database. The lock is then held for a while until the flight is booked. Because it takes on average a few seconds to make the HTTP call over the Internet to the flight company, the number of database locks and connections grows. Once you reach a tipping point with databases, they tend to fall over and reject new connections or worse. As your system starts to scale up, the severity of this issue only increases, meaning that opportunities for revenue loss increase.
Another concern when using distributed transactions is partial availability. What if you lock a hotel database record and find the flight provider is offline? In a distributed transaction, you have a failure, meaning the transaction aborts or rolls back. If there’s no specific business requirement for hotels and flights to be booked at the same time, this is again a loss of revenue due to avoidable technical errors.
Bounded Contexts Don’t Have to Be Consistent with Each Other
So what do you do instead of using database locks to prevent undesirable scenarios occurring, like booking a hotel room when there is no flight available? A common approach is to just roll forward into a new state that corrects the problem. In the holiday booking scenario, that would mean cancelling the hotel reservation when the flight booking fails. But this would not happen inside a single transaction. What this does mean is that your bounded contexts will have inconsistent views of the world. An order might exist in one of them, but not in another. In other parts of the system, a user might have updated his address, but the update hasn’t reached other bounded contexts yet. This often isn’t ideal, but you have to remember that the more you want to scale, the more you may have to make these kinds of trade-offs.
By avoiding distributed transactions, you can handle partial failures without incurring revenue loss. Once the hotel is booked, for example, it doesn’t matter if the flight provider is offline or in some failure mode. You can book the flight when the provider comes back online or is working properly. You’ll see examples of this later in this chapter and the next.
Allowing temporary inconsistencies in your system is not a radical approach. It’s quite a common concept in distributed systems and goes by the name of eventual consistency.
Eventual Consistency
Although your system may be in inconsistent states, the aim is always to reach consistency at some point for each piece of data. (The system overall will probably never be in a fully consistent state). In the previous example, perceived consistency was achieved by arranging the flight when the provider came back online. Essentially, this is eventual consistency, but it applies to a much wider range of scenarios.
One important acronym that goes along with eventual consistency is BASE, which stands for Basically Available, Soft state, Eventual consistency. This is in contrast to ACID (Atomicity, Consistency, Isolation, Durability), which you are probably familiar with from relational databases. These acronyms highlight the fundamental differences in consistency semantics between the two approaches.
In the next chapter you see examples of how to build messaging systems that cater to eventual consistency in a way that tries not to hurt user experience. However, sacrificing user experience can be one of the big drawbacks to using eventual consistency. It’s common for websites to allow you to place an order or add some other piece of information yet not have immediate confirmation. This upsets some users, and rightly so in a lot of cases. But there are also many success stories, from large companies like Amazon (http://cacm.acm.org/magazines/2009/1/15666-eventually-consistent/fulltext) to much smaller companies. If you do your homework and plan diligently, you give yourself a great chance of getting the scalability benefits of eventual consistency while still providing a great user experience.
Aside from the example in the next chapter, you are encouraged to spend a bit of time learning more about eventual consistency before you build a real system that uses it. Pat Helland’s influential paper “Life Beyond Distributed Transactions: An Apostate’s Opinion” is recommended reading (http://cs.brown.edu/courses/cs227/archives/2012/papers/weaker/cidr07p15.pdf). Martin Fowler also has a good piece on not being afraid of living without transactions (http://martinfowler.com/bliki/Transactionless.html).
Event-Driven Reactive DDD
For more than 20 years, distributed systems experts have known about the limitations of synchronous RPC and instead preferred asynchronous, event-driven messaging solutions in many situations (http://armstrongonsoftware.blogspot.co.uk/2008/05/road-we-didnt-go-down.html). Before delving into the fundamentals of why this approach can be more beneficial, you will see how to use it to remedy the resilience and scalability issues of the previous RPC example.
In this section, you learn how choosing a good integration strategy can have massive scalability and reliability benefits that make a positive business impact. What you are about to see is an alternative solution using the principles of reactive programming (http://www.reactivemanifesto.org/)—a philosophy that replaces RPC with asynchronous messages. Figure 11.10 shows the design of a reactive messaging alternative to the RPC implementation shown in Figure 11.9.

FIGURE 11.10 Replacing RPC with reactive.
Demonstrating the Resilience and Scalability of Reactive Solutions
In Figure 11.10, you can see that when a user places an order with the website, a message is asynchronously sent to the Billing bounded context indicating that an order has been placed. In turn, the Billing bounded context emits an asynchronous PaymentAccepted event after communicating with the payment provider. The Shipping bounded context subscribes to the PaymentAccepted event, arranging shipping for an order when one is received. Meanwhile, the user interacting with the website gets an immediate response as soon as his intent to place an order is captured. He then gets an e-mail later once everything is confirmed. There’s no wait for the asynchronous messages to flow through the bounded contexts. The performance problem is solved by processing the order asynchronously, but what about the resiliency problems?
To solve the resiliency problems, each message is put in a queue until the recipient(s) has successfully processed it. Now reconsider the problems that can occur during the processing of someone’s intent to place an order. If the payment provider is experiencing problems, the message is stored in a queue and retried when the payment provider is available. If one of the bounded contexts has a hardware failure or contains a programming bug, the message again sits in a queue waiting for the bounded context to come back online. As you can now see, reactive solutions provide the platform for exceptional levels of resilience, particularly compared to RPC alternatives.
To further understand how the reactive solution increases scalability, think back to the case in which users are reporting that the website is unusably slow. You can easily achieve the optimal solution of scaling out by adding more instances of the web application to a load balancer without changes to the hardware used for the bounded contexts. Whenever bottlenecks occur in the system, you have more granular choices to make about where to add new hardware. Ultimately, this means the business makes more cost-effective use of hardware or cloud resources. In the old example, it might not even be possible to scale out each of the bounded contexts because of the way they have been programmed. This means they would have to be scaled up, which can be relatively more expensive.
Challenges and Trade-Offs of Asynchronous Messaging
Be careful about forming the impression that reactive programming solves all your problems and makes life easy, because a lot of effort on your part is still required. As with many decisions you need to make in software development, taking the reactive approach has positive and negative consequences that you need to trade off against the constraints you are currently working to. Here are some of the challenges you are likely to face when building reactive applications: increased difficulty in debugging your asynchronous solution, more indirection in your code when others try to understand how it works, and eventual consistency. You also have the added complexity of more infrastructure components that deliver and retry messages.
Don’t worry too much about having to learn new techniques, though. Instead, be excited. You will see concrete examples in the next chapter of how infrastructure technologies assist you in debugging asynchronous systems. You will even see that, by having sensible naming and code structure conventions, working out what asynchronous code is doing doesn’t have to be such a huge problem. A conceptual framework will also be outlined that puts you well on your way to coming to grips with eventual consistency.
Is RPC Still Relevant?
You should consider RPC as a tool that might be the best choice for certain situations. It poses scalability and reliability problems, but sometimes they might not be the most important constraints. Chapter 13 shows you how to build HTTP-based services for DDD systems that use RPC so that you can apply them in the situations described next.
Time-to-Market Advantages
Sometimes you just need to get a new feature or product out on the Internet for customers to evaluate. The business may want to beat a competitor, or it may just want to evaluate user reaction to the product. In these scenarios, scalability and reliability are not a problem. So if you feel that building an RPC-based solution meets these requirements, you should look for a good reason not to use it. One reason that it may give you a time-to-market advantage is that more developers are familiar with HTTP than they are with messaging frameworks and concepts. Therefore, you can hire people quicker, and they can build the system quicker.
Easier to Hire and Train Developers
It’s hard to think of a developer who doesn’t know HTTP, whereas those building distributed systems with messaging platforms are a little harder to come by. So when you’re hiring people or building a team, you have a bigger pool to choose from if you’re building an RPC-based system. If you go down the messaging route, you may need to train people to not only use messaging frameworks, but use the fundamental concepts you’ve learned about in this chapter so they can design and build messaging systems properly.
Platform Decoupled
A big drawback to using many messaging frameworks is they don’t really provide tight integration across different development run times and operating systems. You’ll see in the next chapter how NServiceBus is great for integrating. NET applications, but as soon as you introduce another type of message bus, even one that is designed for .NET, life becomes a bit trickier (although certainly not impossible). Some messaging frameworks do claim to handle cross-platform scenarios, though. So they may be worth investigation if you have bounded contexts running on different platforms.
External Integration
You saw in the e-commerce example that you have to communicate with external services like payment providers. This kind of communication across the Internet doesn’t use messaging for many reasons. Instead, it uses HTTP. You may want other websites and applications to integrate with your system, perhaps showing your products and services on their website. To do this, you will nearly always provide REST or RPC APIs over HTTP. This ensures that everybody is able to integrate with your APIs because everyone knows and is capable of working with HTTP.
SOA and Reactive DDD
In the previous section, you saw the need to go reactive in scenarios that require scalable, fault-tolerant distributed systems. In this section, you learn how to work down to a structured reactive solution from your bounded contexts using the principles of SOA. In the process, you discover how SOA guides you into having independent teams that can develop their solutions in parallel while still achieving smooth runtime integration.
Underlying SOA is the need to isolate different pieces of software that represent different capabilities of the business, such as billing customers or arranging shipping. In the true SOA sense, services need to be loosely coupled to other services and highly autonomous—able to carry out their specific functionality without help from other services. Loosely coupled services provide a number of technical and business benefits. For a start, the development teams responsible for them can work in parallel with minimal cross-team disruption. You see later in this section how to achieve this but first, you see how loosely coupled services are the ideal stepping stone to go from bounded contexts to integrated distributed systems based on reactive principles.
View Your Bounded Contexts as SOA Services
If reactive programming is a set of low-level technical guidelines that lead to loosely coupled software components, and SOA is a high-level concept that facilitates loosely coupled business capabilities, then the combination appears perfect for creating business-oriented, scalable, resilient distributed systems. The missing link so far is how to combine these benefits with DDD. One answer is to view your bounded contexts as SOA services so that you can map high-level bounded contexts onto low-level, event-driven software components. Now you have the potential for the business alignment benefits of SOA and scalability/resiliency benefits of reactive programming. Full examples of implementing the concepts introduced in this section are provided in the next chapter.
Decompose Bounded Contexts into Business Components
Inside a bounded context you may have a number of responsibilities. In a Shipping bounded context, for example, there may be logic to deal with priority orders and standard orders. By isolating each major responsibility as a component, you’ll find yourself having clearer conversations with the business and all the other benefits of DDD that you’ve already seen arise from making the implicit explicit. Additionally, you’ll have increased clarity in your codebase by having two separate modules, each with a single responsibility. These types of components are called business components. You can see examples in Figure 11.11 of the different business components that might exist inside a Shipping bounded context.

FIGURE 11.11 Decomposing the shipping bounded context into business components.
Don’t try too hard to identify business components up front. Instead, tease them apart over time. Often you will notice patterns in communication with domain experts, or patterns in code that repeatedly check for the same condition. These are your triggers to dig deeper and restructure your model(s).
One important rule is that SOA services are just logical containers; once you’ve decomposed a bounded context in business components, the service itself has no remaining artifacts or behavior. Just as services need to be decoupled and share no dependencies, the same rule applies to business components—no shared dependencies, even with other business components inside the same bounded context. However, business components themselves are also just logical containers that are composed of components.
Decompose Business Components into Components
Business components may be responsible for handling multiple events, so you should break them down for further benefits. For example, in the Shipping bounded context, the Priority Shipping business component may handle OrderPlaced and OrderCancelled messages. By having these messages processed by different software components, it’s easier to better align hardware resources with the needs of the business. The business may want a rapid response to the OrderPlaced event so that shipping is arranged as soon as possible. However, it’s not so important for them to respond as quickly to OrderCancelled messages because there are so few of them. Therefore, if the Priority Shipping business component is broken down into the Arrange Shipping component and the Cancel Shipping component, the business can put the Arrange Shipping component on blazing-fast, bare-metal servers while allowing the Cancel Shipping component to slowly grind away on a small virtualized server. Figure 11.12 shows an example of how the business components inside a Shipping bounded context could be broken down into components.

FIGURE 11.12 Shipping bounded context broken down into business components and components.
Ultimately, the benefit of components is that the business can spend money intelligently on the specific parts of the system that are likely to result in increased revenue. Hardware economics is just one of the benefits, though. Another is the possibility of locating components on different networks in line with business priority and performance needs. So, some bounded contexts that need high performance can have blazing-fast servers and dedicated high-bandwidth networks. In general, by having granular components you have more flexibility to align with the needs of the business.
As you may have gathered, components are the unit of deployment. Figure 11.13 visualizes this by showing how you can deploy different components in an e-commerce application on different machines or cloud instances with varying resource levels (CPU, RAM, SSDs, and so on).

FIGURE 11.13 Possible deployment view of components in the Shipping bounded context.
Whereas bounded contexts and business components are distinct enough that having RPC calls between them or a shared database can lead to resilience or scalability problems, the same is not true for components. Components often work together very closely; therefore, having shared dependencies like a database increases cohesion without necessarily causing problems. You are still free to use messaging between components if you feel it gives the best trade off in a given situation, though.
You can use Figure 11.14 to help you remember that shared dependencies may exist only inside a business component, not between them.

FIGURE 11.14 Sharing dependencies is only allowed between components inside the same business component.
The term component, like many others in software development, is vague and ambiguous. In this chapter, you can see that there are business components and components (without a prefix). Unfortunately, the community hasn’t really come up with a standard name for what this chapter refers to as just components. Udi Dahan refers to them as autonomous components (http://www.drdobbs.com/web-development/business-and-autonomous-components-in-so/192200219). Others refer to them as components (as in this chapter) based on the component-based development definition (http://en.wikipedia.org/wiki/Component-based _ software _ engineering). Yet others are now starting to refer to them as micro services, as shown in the next section.
Going Even Further with Micro Service Architecture
Netflix uses a fine-grained approach to SOA that other companies are now starting to apply under the name Micro Service Architecture (MSA). Some of the biggest reported benefits of MSA are its time-to-market and experimentation advantages. So if you find yourself working for a business that likes to make lots of changes to its system and measure the impact of every change to drive the evolution of new and existing features, you should consider MSA.
Following the guidance in this chapter so far will get you close to an MSA, where each component is akin to a micro service. However, MSA has some distinct differences. Each micro service must be completely autonomous so that the business feature can be added, removed, or modified without impacting any other micro service. Therefore, each micro service should have its down database and, almost certainly, communicate using events via publish/subscribe because commands and RPC introduce coupling. At least, this is the style of MSA described by Fred George, one of the first people to start talking about MSA, in his Oredev 2012 talk (https://www.youtube.com/watch?v=q3q6ZsjZ_f0). Another feature of micro services that many people agree on, although it is certainly contentious, is that they should be less than a thousand lines of code.
For more information on MSA, Martin Fowler’s introductory blog series is a useful place to begin (http://martinfowler.com/articles/microservices.html).
The Salient Points
- These days, the majority of applications you are likely to build are distributed systems because large web traffic arises from everyone having access to the Internet, and from many devices.
- Applying DDD to distributed systems still provides lots of benefits, but there are new challenges when integrating bounded contexts.
- Some of the challenges are technical, such as scalability and reliability, whereas others are social, such as integrating teams and developing at a high velocity.
- A number of techniques exist for building distributed systems that trade off simplicity, maintainability, and scalability. Database integration, for instance, can be quick to set up, but isn’t recommended for use in high-scalability environments.
- RPC and messaging are the most common forms of distributed systems integration and the ones you are most likely to use. They are significantly different in nature, so it’s essential you understand what benefits and complications they will add to your system.
- You can use the loosely coupled, business-oriented philosophy of SOA to help design your bounded context integration strategy by thinking of bounded contexts as SOA services.
- Combining SOA and reactive programming provides the platform to align your infrastructure with business priorities, deal with scalability and reliability challenges, and organize your teams by aligning them with bounded contexts to reduce communication overhead.