
21
Repositories
WHAT’S IN THIS CHAPTER?
- The role and responsibilities of the repository pattern
- The misunderstandings of the repository pattern
- The difference between a domain model and a persistence model
- Strategies for persisting your domain model based on the capabilities of your persistence framework
Wrox.com Code Downloads for This Chapter
The wrox.com code downloads for this chapter are found at www.wrox.com/go/domaindrivendesign on the Download Code tab. The code is in the Chapter 21 download and individually named according to the names throughout the chapter.
How do you create, persist, and retrieve domain objects while maintaining a domain model that is not distracted by technical concerns? For domain objects that need to live beyond in- memory use and be retrieved later, a mapping to a persistence store is required. In order to avoid blurring the lines of responsibility between domain logic and infrastructure code, repositories can be employed. Repositories ensure that persistence ignorance is retained by storing domain aggregates behind a collection façade disguising the true underlying infrastructural mechanism. Repositories ensure technical complexities are kept out of the domain model.
Repositories
A repository is used to manage aggregate persistence and retrieval while ensuring that there is a separation between the domain model and the data model. It mediates between these two models by using a collection façade that hides the complexities of the underlying storage platform and any persistence framework. The repository provides similar functionality to a .NET collection for storing and removing aggregates, but it can also include more explicit querying functionality and offer summary information on the aggregate collection.
Repositories differ from traditional data access strategies in three ways:
- They restrict access to domain objects by only allowing the retrieval and persistence of aggregate roots, ensuring all changes and invariants are handled by aggregates.
- They keep up the persistence-ignorant façade by hiding the underlying technology used to persist and retrieve aggregates.
- Most importantly, they define a boundary between the domain model and the data model.
So what does a repository look like? Listing 21-1 shows an interface for a repository that manages the persistence and retrieval of customer aggregates. The interface is kept within the domain model namespace because it is part of the domain model, with the implementation residing in the technical infrastructure namespace.
A typical client of a repository is the application service layer. A repository defines all the data-access methods that an application service requires to carry out a business task. The implementation comes under the infrastructure namespace and is usually backed by a persistence framework to do the heavy lifting. Listing 21-2 shows an implementation of the ICustomerRepository using the NHibernate framework.
The implementation of the repository in this case simply delegates to NHibernate’s ISession interface, which acts as a gateway to the data model. The actual mapping of domain objects to the data model is handled via XML, fluent code, or attribute mapping. Because NHibernate provides POCO persistence (persistence without requiring the domain model objects to inherit or implement any classes), it can map the domain model directly to the data model. Don’t worry if you have no experience with NHibernate or Object Relational Mappers (ORMs); some implementation exercises at the end of this chapter explain how to use RavenDB, Entity Framework, and NHibernate to implement a repository.
The salient point to take away is that repositories hide technical complexity from your domain model, enabling domain objects to focus solely on business concepts and logic.
A Misunderstood Pattern
There is much misunderstanding and confusion around the repository pattern, with many regarding it as unnecessary ceremony and needless abstraction. When it’s not used in conjunction with a rich domain model, the repository pattern is overly complex and can be avoided for a simpler data access object or better by using a persistence framework directly. However, when modeling a solution for a complex domain, the repository is an extension of the model. It reveals the intent behind aggregate retrieval and can be written in a manner that is meaningful to the domain rather than a technical framework.
Is the Repository an Antipattern?
Many developers have negatively blogged that a repository is an antipattern because it hides the capabilities of an underlying persistence framework. This is actually the point of the repository. Instead of offering an open interface into the data model that supports any query or modification, the repository makes retrieval explicit by using named query methods and limiting access to the aggregate level. By making retrieval explicit, it becomes easy to tune queries, and more importantly express the intent of the query in terms a domain expert can understand rather than in SQL. Besides queries, the repository exposes meaningful persistence methods instead of blindly allowing all the create, read, update, and delete (CRUD) methods, regardless of how appropriate each may be.
The point of the repository pattern is not to make it easier to test your code or to make it easy to swap out underlying persistence storage options. It’s to keep your domain model and technical persistence framework separate so your model can evolve without being affected by the underlying technology. Without a repository layer, your persistence infrastructure will likely leak into your domain model and weaken its integrity and ultimately usefulness.
The backlash against the repository pattern seems to stem from a lack of understanding about where and why it should be used. It is a pattern that is useful in certain circumstances but not all. Just like a domain model pattern or any design pattern, blindly applying it to all problems results in more complexity, not less.
The Difference between a Domain Model and a Persistence Model
If your persistence store is a relational database and you are using an ORM—which is designed to remove the need to manually map objects to rows and properties to columns, and write raw SQL—you might be wondering why to bother implementing the repository pattern because you already have a framework that abstracts away the persistence technology. The issue, however, is that an ORM only abstracts the relational data model. It merely represents the data model in an object-oriented manner, enabling you to manipulate data easily in code.
The persistence model that your ORM maps to is different from your domain model, as shown in Figure 21.1. The persistence model is the one within your relational database; it’s made up of tables and columns, not entities and value objects. For some domain models, the data model may appear similar, or even the same, but conceptually they are very different. Your domain model is an abstraction of your problem domain, rich in behavior and language. The data model is simply a storage structure to contain the state of your domain model at a given time. ORMs map to the data model and make using it easier. They have little to do with domain models. The role of the repository is to keep the two models separate and not to let them blur into one. An ORM is not a repository, but a repository can use it to persist the state of domain objects.

FIGURE 21.1 An ORM maps between the domain and persistence model.
If your domain model is similar to your data model, a sophisticated ORM like NHibernate may be able to map your domain objects directly to the datastore. However, if not, you may be best served having a completely separate data model instead of compromising your domain model. This chapter examines some of the options to achieve this a little later. For document stores, this problem doesn’t exist, and the domain model can be serialized without compromise.
The benefit to separating the data model from the domain model is that it allows you to evolve the domain model without having to constantly think of the data storage and how it will be persisted. Of course, it will ultimately need to be persisted, and you may need to take a pragmatic view and make compromises, but these compromises should be made only when absolutely required, and after the modeling effort is complete rather than up front with the creation of a model.
The Generic Repository
Developers love to reuse code. They generalize a concept to create a common class that can be used for all variations, even though separate explicit solutions would convey the intent of each concept far better. Often you see a form of generic repository contract defined within the domain model. Listing 21-3 shows such an interface with all the operations you would need, including an open-to- extension query method.
A repository contract defined in the domain layer would inherit this interface and would resemble Listing 21-4.
The problem with a contract like this is that it assumes that all your aggregates support the same behavior and have the same needs. Some aggregates may be read only, and some may not support the remove method. When an aggregate does not support a concept, you will often find the repository implementation throwing an exception, as in Listing 21-5.
Another problem with the interface is the leaky abstraction of the FindAllMatching methods. By providing a method open to extension, you are making it impossible to control queries and optimize fetching strategies. This support of ad hoc queries can quickly lead to severe performance problems in relational databases.
Trying to apply a generalizing strategy to all repositories is a bad idea. It says nothing about the intent behind the retrieval of aggregates. Like all problems, it is better to be explicit. Define your repositories based on their individual needs, and be explicit when naming query methods, as shown in Listing 21-6.
When it comes to implementation, there is a place for the generic repository. Behind the concrete implementation, a generic repository can be used to avoid code duplication. As shown in Listing 21-7, this couples an explicit contract with the benefit of code reuse.
If you are using a persistence framework, there is no need to abstract it; you can use this directly within the concrete implementation of a repository. An example using the RavenDB framework is shown in Listing 21-8.
Here you don’t abstract away from the underlying framework because there is no value in doing so. Remember that you are only keeping technical concerns out of the domain model. All other parts of the application need not abstract and hide the implementation details, because this misdirection only proves to confuse readers of the code.
Aggregate Persistence Strategies
Your design strategy, the shape of your aggregates, and whether you are working in a greenfield or a brownfield environment will affect the options for the way you persist your domain objects. The thing that should be at the front of your mind, however, is that you should create your domain objects without thinking about persistence requirements; that is the job of the repository. Your domain objects should be free from any infrastructural code and be as POCO (Plain Old C# Objects) as possible. Compromises should be made only as a last resort.
Using a Persistence Framework That Can Map the Domain Model to the Data Model without Compromise
If you are mapping to a relational database in a greenfield environment and you are using an ORM that supports persistent ignorant domain objects, you will be able to map your domain model directly to the data model, as shown in Figure 21.2.

FIGURE 21.2 An ORM maps between the domain and the persistence model.
An ORM usually uses reflection to persist your domain objects and supports the persistence of a fully encapsulated domain model with private getters and setters. Some ORMs require small additions to your domain objects, such as a parameterless constructor in the case of NHibernate, but this is a small price to pay for a seamless map from the domain to the data model.
If you are using a document store where the framework can serialize your aggregate, as shown in Figure 21.3, you will be able to map the aggregate directly without needing an additional mapping to a data model.

FIGURE 21.3 An aggregate can be serialized and stored.
A framework that allows your domain model to be free of infrastructural concerns can enable you to evolve your model without compromise and can have a big impact on how you approach modeling.
Using a Persistence Framework That Cannot Map the Domain Model Directly without Compromise
If you are using a persistence framework that does not allow your domain model to be persistence ignorant, you need to take a different approach to the way you persist and retrieve your domain objects so they remain free of infrastructural concerns. There are a number of ways that you can achieve this, but all affect the domain model and the shape of your aggregates. This is, of course, the compromise you need to make your application work.
Public Getters and Setters
A simple method to enable the persistence of domain objects is to ensure that all properties have public getters and setters. The problem is that this leaves your domain objects open to being left in an invalid state because clients can bypass your state-altering methods. You can avoid this through code reviews and governance. However, exposing your properties does make it easy to persist your domain model because your repository has easy access to the domain object’s state.
In Listing 21-9, you can see that the Basket domain object has public properties for both its collection of items and its delivery cost. If a client bypasses the Add method and instead directly adds an item to the collection, the delivery cost is not updated.
On the plus side, however, a repository implementation can keep the data model separate from the domain model. Listing 21-10 shows an example of what this might look like.
In Listing 21-10, you can see that the data model is retrieved and then mapped to a new instance of the basket domain object. This enables the domain model to be completely unaware of any persistence store, but this is at the cost of exposing the properties of your domain model.
Using the Memento Pattern
If you don’t want to expose your domain model’s properties and want them to be totally encapsulated, you can utilize the memento pattern. The Gang of Four pattern lets you restore an object to a previous state. The previous state in this instance can be stored in a database. The way in which it works is that an aggregate produces a snapshot of itself that can be persisted. The aggregate would know how to hydrate itself from the same snapshot. It’s important to understand that the snapshot is not the data model; it’s merely the state of the aggregates, which again is free from any persistence framework. The repository would still have to map the snapshot to the data model. Figure 21.4 shows a graphical representation of this pattern.

FIGURE 21.4 The memento pattern enables you to map a snapshot of the domain model to the persistence model.
Listing 21-11 shows an implementation of the memento pattern on the Basket aggregate.
The repository implementation would look like Listing 21-12.
Another option is to map the snapshot directly to your data model if you are using a persistence framework that allows this but may not allow mapping a full domain object.
Event Streams
Another way to persist your domain model is to use an event stream. Event streams are similar to the memento pattern, but instead of taking a snapshot in time of your aggregate, your repository persists all the events that have occurred to the aggregate in the form of domain events. Listen for events from the domain, and map them to a data model. Again, you need a factory method to reconstruct and replay these events to rebuild the aggregate. Figure 21.5 shows a graphical representation. Event streams are coved in Chapter 22

FIGURE 21.5 Save the events that have occurred to an aggregate.
Be Pragmatic
In all the strategies of domain-model persistence, it pays to be pragmatic. A pure domain model should be persistence ignorant in that it should be immune to changes required by the needs of any underlying persistence framework. Purity is good in theory, but in practice it can be difficult to achieve, and sometimes you must choose a pragmatic approach.
If you have a corporate policy on datastores or frameworks, you may need to make compromises when it comes to physically persisting your domain objects. Ensure that you choose a strategy that befits the framework and data storage options available. Don’t fight your framework, and recognize that you may need to change your domain model based on performance and scalability. However don’t think about these things; start pure, then be pragamatic when you need to. Don’t let technical framework drive your design; think in aggregates and explicit retrieval of data rather than ad hoc querying.
A Repository Is an Explicit Contract
The contract of a repository is more than just a CRUD interface. It is an extension of the domain model and is written in terms that the domain expert understands. Your repository should be built from the needs of the application use cases rather than from a CRUD-like data access standpoint. The application layer is the client that pulls aggregates from the repository and delegates work to them. Your domain model houses the contracts but rarely uses them except for a specific use case represented in a domain service.
The repository is not an object. It is a procedural boundary and an explicit contract that requires just as much effort when naming methods upon it as the objects in your domain model do. Your repository contract should be specific and intention revealing and mean something to your domain experts.
Consider the repository interface in Listing 21-13. It enables the client to query for domain objects by any means. The contract is flexible and open to extension, but it tells you nothing of the needs or the intent of the retrieving strategies at play in the domain model to obtain collections of aggregates. To truly understand how these methods are used, a developer needs to trawl through all the code to understand the intent and need of queries, let alone how to optimize them. Because the contract is so wide and unspecific, it becomes useless as a boundary and as an interface.
Take a look at a different style of repository contract in Listing 21-14. The contract is explicit and tells you a lot about how aggregates are used. Gone are the open-to-extension methods, replaced by two explicit querying methods named in a manner that reveals intent and that is aligned to the language of the domain experts. You are applying the Tell, Don’t Ask principle, making the repository do all the hard work by abstracting the query method. It is now clear how you can optimize these queries in the infrastructure implementation.
The repository is the contract between the domain model and the persistence store. It should be written only in terms of the domain and without a thought to the underlying persistence framework. Define intent and make it explicit; do not treat the repository contract like object-oriented (OO) code.
Transaction Management and Units of Work
Transaction management is chiefly the concern of the application service layer. However, because the repository and transaction management are tightly aligned, it’s pertinent to mention them here. (A more detailed examination of transaction management can be found in the following chapter.) A repository is only concerned with the management of a single collection of aggregate roots, whereas a business case could result in updates to multiple types of aggregates.
Transaction management is handled by a unit of work. The role of the unit-of-work pattern is to keep track of all changes to aggregates during a business task. Once all changes have taken place, the unit of work then coordinates the updating of the persistence store within a transaction. To ensure that data integrity is not compromised if an issue arises partway through committing changes to the datastore, all changes are rolled back to ensure that the data remains in a valid state.
In NHibernate, the unit of work pattern is implemented by the session object. In Listing 21-15, an application service is dependent on two repositories to coordinate the task of applying loyalty points. To manage the transaction, a unit of work in the form of NHibernate’s session object is required. No changes are persisted to the database until the transaction started by the unit of work is committed.
You don’t need to abstract the underlying persistence framework at the application service level because there is no value to it. Here you are being explicit and using the NHibernate framework directly. It is only at the domain model that you need to keep persistence ignorance. At the application service layer, you don’t abstract the framework because it orchestrates both infrastructure and domain logic.
To make things a little clearer, Figure 21.6 shows how the repositories interact with the session object (NHibernate’s implementation of the unit-of-work pattern).

FIGURE 21.6 The unit-of-work pattern.
To ensure changes are made within the same transaction, the repositories must use the session instance, which the application service layer is using. This is achieved via employment of a factory or inversion of control container to create the application service, which is discussed in detail in the next chapter. The repository instance gets the session injected via its constructor, as shown in Listing 21-16.
Alternatively, you can use setter-based injection to ensure the repositories have access to the same session instance as the application service. This makes it even more explicit as to what is going on. Listing 21-17 shows how the application service would be updated to leverage setter-based injection on the repository.
Because the unit-of-work pattern has nothing to do with the domain and is purely a technical concern, it doesn’t make sense to include the EnlistIn method directly on the repository interface contract. You can instead use a separate interface for this to hide the enlist method and ensure you check for the existence of a session in the repository before carrying out any work (see Listing 21-18).
To Save or Not To Save
A repository should represent a collection of aggregates and behave just like a .NET collection, completely hiding the underlying persistence mechanism. A .NET collection holds references to objects, so any changes made to an object doesn’t require them to be explicitly updated within the collection. This means that you won’t find a save or update method on a collection; ideally, your repository would behave in the same manner. However, mimicking a collection-like façade is largely down to the capabilities of your persistence framework of choice. A persistence framework that does not support change tracking needs to expose a save method, and the application service that coordinates domain activity needs to ensure that it explicitly persists retrieved aggregates after changes are made to them. If you are choosing not to leverage some kind of persistence framework, you need to do a lot of work. It’s best to take a look at some of the options that can help you take the chore out of manual persistence.
Persistence Frameworks That Track Domain Object Changes
ORM frameworks such as NHibernate can track changes in objects that are retrieved by them. Because changes are tracked implicitly, the client of the repository, which is generally the application service, doesn’t need to explicitly save these objects. This means there is no requirement for a Save method on the repository contract because changes made are pushed to the persistence store when the unit of work is marked as complete. Consider Listing 21-19, showing both the repository contract and a sample application service. It uses an abstraction on the unit-of-work pattern, which can be implemented by a persistence framework or manually.
To track changes to domain objects, a persistence framework either takes a snapshot of the retrieved aggregates at read time and compares when persisting the unit of work to determine what to persist, or it returns a proxy of the aggregate and tracks changes as they happen. Once the call to the commit on the unit of work is made, the framework determines if any change has occurred and then generates the SQL required to persist that change in the data model.
Having to Explicitly Save Changes to Aggregates
If you are using a framework to map a data model that does not support change tracking, such as a micro ORM, or you are using raw ADO.NET, you need to support a save method on the repository contract and ensure that the application service calls with the changed domain object. Listing 21-20 shows a repository interface with the Save method and how the application service would use it. You can still call the unit of work to ensure that all changes occur within a transaction.
The Repository as an Anticorruption Layer
When you’re working in a brownfield environment with an existing persistence store, a repository can help keep the domain model pure by acting as an anticorruption layer, enabling you to create a model without its shape being affected by any underlying infrastructure complexities.
As you have read, a data model and a domain model can be very different. A data model may be spread over several tables or even databases. Also, multiple forms of persistence store can be used, such as flat files, web services, and relational or NoSQL stores. Whatever persistence store you find yourself using, it should not shape the domain model. Repositories map to aggregates, not tables; for example, more than one entity can occupy a single table, as was covered in Chapter 16, where it was shown how to use explicit implementations for different states. Repositories can also store a model over more than a single data store, as shown in Figure 21.7.

FIGURE 21.7 The repository acts as an anticorruption layer.
Other Responsibilities of a Repository
Besides the persistence and retrieval of aggregates, the repository pattern can expose other facts about its collection of domain objects. For instance, a repository can expose the number of aggregates in its collection, as shown in Listing 21-21.
Entity ID Generation
If your database or another infrastructural service controls the seeding of IDs, you can abstract this behind the repository and expose it to the application service. It can provide identity explicitly via a method on the interface, as shown in listing 21-22.
A repository can also assign an ID during persistence. Usually this is accomplished by having the datastore as the seed for an entity’s ID. Listing 21-23 shows part of the XML mapping document for NHibernate. The nested generator tag class attribute defines what generates the ID of the entity. In this case, it is native, and the underlying database automatically generates IDs for the entity via the database identity-seed data type. Later you will see other options for generating the identifier of the entity. The unsaved value attribute is used by NHibernate to compare with the business entity’s identifier to help determine if an object has been persisted or is transient (unsaved).
Don’t worry if you are not familiar with NHibernate because you will be working through some exercises at the end of this chapter to show you how to implement these patterns in practice.
Collection Summaries
Besides counting the number of aggregates you have in a collection, you may want some other summary information on what the collection contains without having to pull back each aggregate and summarize manually. In Listing 21-24, the summary value object can give counts on specific types of customers. For intensive queries and calculations that are best run closer to the raw data, a summary view can be extremely powerful.
Concurrency
When multiple users are concurrently changing the state of a domain object, it is important that users are working against the latest version of an aggregate and that their changes don’t overwrite other changes that they are not aware of. There are two forms of concurrency control: optimistic and pessimistic. The optimistic concurrency option assumes that there are no issues with multiple users making changes simultaneously to the state of business objects, also known as last change wins. For some systems, this is perfectly reasonable behavior; however, when the state of your business objects needs to be consistent with the state when retrieved from the database, pessimistic concurrency is required.
Pessimistic concurrency can come in many flavors, from locking the data table when a record is retrieved to keeping a copy of the original contents of a business object and comparing that to the version in the datastore before an update is made to ensure there have been no changes to a record during a transaction. Many persistence frameworks use a version number to check whether a business entity has been amended since being retrieved from the database. Upon an update, the version number of the business entity is compared to the version number residing in the database before committing a change. This ensures that the business entity has not been modified since being retrieved.
As an example, NHibernate supports optimistic concurrency in several ways. One method that it employs is to use a version tag in the XML mapping file, as shown in Listing 21-25.
The Version property is set when the Product entity is retrieved from the datastore. If you feel uncomfortable with the Version property being on the Product entity because in the domain that you are modeling, a version isn’t an attribute of a product, you could use an Entity Layer Supertype class, as shown in Listing 21-26 (see also Chapter 16) or return a proxy version of the Product entity and include the version ID within.
In Listing 21-27 from an application service class, you can see that when a Product entity is being saved to the database, the version of the changed entity is included in the where clause. NHibernate compares the values and throws a StaleObjectStateException because the Person object has been modified since you made your second change. The program should then alert the user that the Product entity has changed or been deleted since the original retrieval and the update have failed.
In Listing 21-27, an exception is thrown if the product was modified in the small amount of time between retrieving it from the persistence store to commit the changes on it. What is more likely is that a product changes while the user is viewing it on her desktop/browser. In this situation, the product can be updated while the user is reviewing the data, and the user can then overwrite changes unbeknownst to her. To prevent this from happening, the version flag should be sent to the UI with the view model, and the same version should be sent back with the UpdatedProductPriceInformation command. The updated code in Listing 21-28 checks to see if the version that the user was using is the same as the one retrieved from the repository. If it’s not, an exception is thrown, and the user can request the fresh updated data and review it again before submitting a price update.
Audit Trails
If your data model requires metadata that does not make sense in your domain, you can utilize your repository to meet the requirements. Often changes to objects need to be marked with a last change date, which has no meaning to the domain. You can apply this metadata via the repository implementation.
Audit trails and logging can also be supplied via the repository. If you are deleting an aggregate, the repository can log the event for auditing and perhaps take a snapshot of the aggregate or a summary of it.
Repository Antipatterns
As with any pattern there are a number of recommended practices that should be avoided. These are known as antipatterns.
Antipatterns: Don’t Support Ad Hoc Queries
A repository is an explicit contract between the domain model and the persistence mechanism. By exposing a generic catch-all method for querying in an ad hoc manner, you are weakening this layer of abstraction. Consider the contract in Listing 21-29.
The FindBy method takes some form of customer query, perhaps in the form of a specification. The challenge here is that the client can write any type of query, meaning all fetch paths need to be optimized. A method like this weakens the repository’s contract and completely removes the intent and meaning of querying the repository. The repository should not be open to extension; it is a boundary and procedural in nature. Instead, favor named methods so that you can write specific code that can be performance tuned and tailored to the underling persistence framework. New methods that are added can then be tuned, and the most appropriate fetching strategy can be created.
Exposing IQueryable on a repository is another flavor of supporting ad hoc query methods. The IQueryable interface is an extremely flexible pattern for data access; however, it can enable your data model to leak into your domain model. There is nothing wrong with using the IQueryable interface behind the boundary of your repository or directly accessing the data model for reporting needs, as shown in Listing 21-30.
Antipatterns: Lazy Loading Is Design Smell
Aggregates should be built around invariants and contain all the properties necessary to enforce those invariants. Therefore, when loading an aggregate, you need to load all of it or none of it. If you have a relational database and are using an ORM for your data model, you may be able to lazy load some domain object properties. This enables you to defer loading parts of an aggregate you don’t need. However, the problem with this is that if you can get away with only partially loading an aggregate, you probably have your aggregate boundaries wrong. Also, if data-fetching patterns are affecting your aggregates, you may have built aggregates around views and not business rules.
Antipatterns: Don’t Use Repositories for Reporting Needs
The needs of your user-interface screens and the needs of business logic are very different. There will often be a mismatch between information required for a screen and the data contained within a single aggregate root. If only one or two properties are required for display purposes, an entire aggregate needs to be hydrated. Worse still, your domain objects may need extra information to support views that may make little sense to the domain objects they are attached to.
Further still, if you’re creating a view model for a screen that spans multiple aggregate roots, you need to pull them all back and pick out the information you require.
Running reports using a transaction model can be slow and compromise the integrity of your model because of the additional properties for UI screens. It is better to use a framework to directly query a read store; this could be the same datastore you use for the transactional work, or it could be a denormalized store.
Don’t abstract the persistence framework when querying your data model for reporting purposes. You’ll read more about this in the next chapter.
Repository Implementations
In this section, you will work through some repository implementations based on popular .NET persistence frameworks, namely:
- NHibernate
- RavenDB
- Entity Framework
- Dapper Micro ORM
For the examples, you will use a small domain model based on the bidding logic of eBay. Figure 21.8 shows the domain model you will be using. You will not be following a test-first development methodology, because this is an exercise to show you an implementation of a repository rather than how to drive the design of your domain model. With this in mind, you will build up the solutions in a manner where you can follow along and create them yourself.
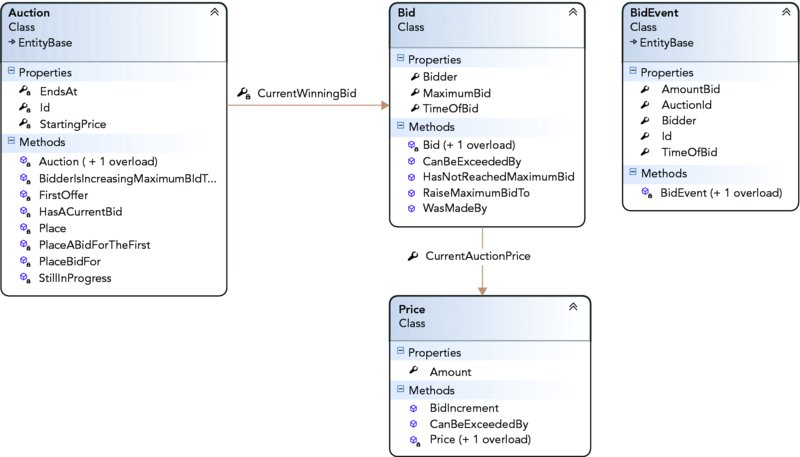
FIGURE 21.8 Solution object model.
The model represents the logic that handles eBay’s automatic bidding mechanism:
- When a bidder makes a bid, he enters the maximum amount that he is willing to pay for the item. However, his actual bid is the minimum amount required to beat the previous bid or starting price.
- When a second bidder places a bid, an automatic bidder bids on behalf of the previous bidder up to his maximum amount or enough to beat the second bidder.
- If the second bidder exceeds the previous bidder’s maximum bid, the previous bidder is notified that he has been outbid.
- If the second bidder matches the previous bidder’s maximum bid, the previous bidder is still the winner of the auction because he was first to bid.
Each of the persistence frameworks that you will use will have a small impact on your domain model. The examples will demonstrate that no matter what persistence framework you are using, you can still support a domain model that is persistent ignorant.
Persistence Framework Can Map Domain Model to Data Model without Compromise
The first two examples of repository implementation use NHibernate and RavenDB. Both of these frameworks allow direct mapping of a domain model to a data model with little or no compromise.
NHibernate Example
NHibernate is a port of the popular open source Hibernate framework for Java. It’s a framework that has been around for years, and it’s a proven and robust piece of software. NHibernate is an ORM. One of the best features of NHibernate is the support for persistence ignorance; this means that your business objects don’t have to inherit from base classes or implement framework interfaces. NHibernate uses an instance of an ISession, which is an implementation of the unit of work pattern. ISession is also the object you use to query your database with. It acts as your persistence manager and gateway into the database, allowing you to query against it, as well as saving, deleting, and adding entities. There are a number of ways to map business objects to database tables in NHibernate. One of the most popular is via an XML configuration file, but attributes and a fluent code mapping option are also available. This example uses the older XML mapping style.
The domain model in this example has no public properties and is totally encapsulated. You use NHibernate’s ability to persist encapsulated models.
Solution Setup
Create a new blank Visual Studio solution named DDDPPP.Chap21.NHibernateExample and add to this a class library named DDDPPP.Chap21.NHibernateExample.Application and a console application named DDDPPP.Chap21.NHibernateExample.Presentation. Within the Presentation project, add a reference to the application. Next, create the following folders in the DDDPPP.Chap21.NHibernateExample.Application project:
- Application
- Infrastructure
- Model
You can delete Class1.cs that is automatically created because you won’t be needing it. Your solution should now match Figure 21.9.
FIGURE 21.9 Visual Solution project structure
Before you build out the application, you need to reference the NHibernate assemblies. Open the NuGet package manager and install NHibernate, as shown in Figure 21.10.
FIGURE 21.10 NuGet Package Manager
Creating the Model
The first thing you are going to do is to create the model. You will be utilizing domain events, so you need to create the infrastructure to support raising and handling events. You will use the framework that you built in Chapter 18, “Domain Events.” Add a new class to the Infrastructure folder of the Application class library project called DomainEvents with Listing 21-31. You can find details about how this class works in Chapter 18.
You will also be using the value object base class that was covered in Chapter 15, “Value Objects.” Create the ValueObject class, as defined in Listing 21-32, in the Infrastructure folder.
The last piece of infrastructure is to create a base class for the entities within the model, as shown in Listing 21-33.
With the infrastructure sorted, you can build out the domain model. From within the Model folder of the DDDPPP.Chap21.NHibernateExample.Application project, create the following two folders that will contain the two aggregates that make up the domain model.
- Auction
- BidHistory
The first aggregate that you will build is the Auction aggregate. The Auction aggregate contains all the domain rules around placing bids. You need a value object to represent the money concept in the model. Using Listing 21-34, create a value object named Money in the Auction folder.
As you read in Chapter 15, a value object is immutable; you cannot alter its state. This is why the add method returns a new Money object rather than changing the state of the object itself.
In the constructor, there is a small piece of logic that ensures you have a nonnegative money amount. If not, one of the following two exceptions in Listing 21-35 is thrown. Add these two classes to the Auctions folder.
The next concept that you have in your auction domain is that of an offer. An offer is how much a bidder is willing to pay for an item in the auction. The reason you have the concept of an offer is that only offers that exceed the bid increment are turned into bids. The Offer class is also a value object. Create the Offer class within the Auction folder with the code shown in Listing 21-36.
The auction price represents the current price of the winning bid; the price has a method that calculates the bid increment. This is again a value object. Add the Price class to the Model folder with Listing 21-37. In the real eBay bidding system, there are far more bid increment levels. Here there are only three to keep the exercise simple.
The WinningBid, yet another value object, represents a bidder’s accepted offer. Create the WinningBid class within the Model folder with Listing 21-38.
The domain service AutomaticBidder bids on a member’s behalf up to his maximum bid if he is outbid. It bids only as much as needed to remain the highest bidder, up to the bidder’s maximum amount. Create the AutomaticBidder class in the Model folder with Listing 21-39.
BidPlaced is a domain event signifying that a bid was placed. Add the class to the Model folder using Listing 21-40.
The OutBid class is another domain event. It is raised if a bidder is outbid, as shown in Listing 21-41.
The Auction shown in Listing 21-42 is an entity and the aggregate root. The Auction class has no public properties and only exposes a single method to enable bids to be placed. The results of bids placed are raised as domain events.
Notice that the AutomaticBidder class is instantiated directly within the Auction class as opposed to being injected as a dependency. The dependency injection pattern is useful when there is a selection of multiple implementations of a given dependency interface, but because there’s only one implementation of the AutomaticBidder and there is no need to mock or stub the domain service, you can safely instantiate it directly.
The repository contract for the Auction aggregate has only two methods: one to find an auction by ID and one to add an auction. NHibernate can track changes, so the repositories can act like collection interfaces; there is no need to add an explicit save method to the repository. Add the contract definition in Listing 21-43 to the Auction folder. This is implemented within the infrastructure folder.
The second and final aggregate is really only a collection of value objects that represent the bidding history of an auction. Using Listing 21-44, create a new value object named Bid within the BidHistory folder.
The only other item for this aggregate is the repository contract, as shown in listing 21-45. The repository exposes a method to return the number of bids placed against an auction and has a method to persist new bids.
The domain model of the application is now complete. Your solution should look like Figure 21.11.

FIGURE 21.11 The Visual Studio solution structure
Application Service
With the model complete, you will now build the application service layer, which is the client of the domain model. Within the Application folder, add two folders:
- BusinessUseCases
- Queries
The BusinessUseCases folder contains all the features and use cases of the application, whereas the Queries folder contains all the queries required to report on the state of the domain model.
Creating an auction requires a starting price and an end date. Clients of the application service use a data transfer object (DTO) to carry the information to create an auction. Using Listing 21-46, create the DTO within the BusinessUseCases folder.
The application service that handles the request is detailed in Listing 21-47. The CreateAuction application service simply creates a new auction and adds it to the repository. The only thing of note is that you are wrapping the action within an NHibernate transaction. The application service is able to obtain NHibernate’s unit of work pattern, the ISession variable, via the constructor. As you will see later, the ISession that is passed through the constructor is the same as what’s used in the repository implementation this is the relationship between the unit of work and the repository within the application service. This ensures that the application service layer controls when changes are committed to domain objects.
The ISession is the main interface that persists and retrieves business entities and can be thought of as NHibernate’s gateway to the database. The NHibernate site defines ISession as the “persistence manager.” The ISession is NHibernate’s unit of work implementation. Because the ISession interface implements the unit of work pattern discussed earlier in this chapter, no changes occur until a transaction is committed. Another pattern built into NHibernate is identity map, which maintains a single instance of a business entity in the ISession no matter how many times you retrieve it.
Time is an important concept in the auction domain, and bids should only be able to be placed while the auction is still active. As always, you never want to tie your domain objects to the system clock because it makes testing difficult. So with this in mind, you will abstract the concept of a clock by defining an interface named IClock within the Infrastructure folder, as shown in Listing 21-48.
For the application, you will use the system clock. Create an implementation of the IClock interface, again within the Infrastructure folder, using Listing 21-49.
The second business use case that you will create an application service for is the task of bidding on an auction. Using Listing 21-50, create a class named BidOnAuction.
Again, you wrap the method call in an NHibernate transaction. This is important because a successful bid raises a domain event, which results in a bid being added to the BidHistoryRepository. The call to place a bid is also wrapped in a try catch with the StaleObjectStateException, resulting in the bid being placed again. The StaleObjectStateException is thrown if the auction is updated by another member between it being retrieved from the repository and the unit of work committing. In this exercise, you try again to place the bid with the refreshed auction to work against the latest version.
NHibernate Repository Implementation
With the model and application service layers complete, you can focus on the NHibernate repository implementation. The first thing you need to do is map the aggregates. Using Listing 21-51, add a new XML file to the Infrastructure folder named Auction.hbm.xml.
This chapter doesn’t go into detail about the syntax of these files because this is not a book on using NHibernate, but it should be easy to work out how NHibernate maps columns and tables to business entities and properties. For a deeper insight into the world of NHibernate, check out the many online resources or the book NHibernate in Action.
For NHibernate to pick up the mapping file, ensure that you change the Build Action property of the field to Embedded Resource, as shown in Figure 21.12.
FIGURE 21.12 The build action property of the XML Mapping file
To map a bid, add a second XML file to the Infrastructure folder named Bid.hbm.xml with Listing 21-52, again selecting Embedded Resource for the Build Action property of the file.
The repository implementations live under the infrastructure namespace. The first is the auction repository implementation, as defined in Listing 21-53.
As you can see, the ISession variable does all the work, which is why it’s vital that the instance that is injected via the constructor is the same that is injected into the constructors of the application services. Otherwise, the application service can’t control the unit of work.
The implementation for the BidHistory repository, shown in listing 21-54, is equally simple, with the only difference being the addition of a simple query to provide summary information on the number of bids for an auction.
There are a few constraints to using NHibernate. One is that all objects being persisted need to have a parameterless constructor. Luckily, the constructor can be private, so this will have no effect on your model. This is a small price to pay for a persistence framework that allows your domain model to be POCO.
Update the Auction class and add a private constructor, as shown in Listing 21-55.
Update the WinningBid class and add a private constructor, as shown in Listing 21-56.
Update the Price class and add a private constructor, as shown in Listing 21-57.
You may have noticed in the mapping that you mapped an ID property for the Bid class. NHibernate needs to have an ID present for each object that it maps. Update the Bid class and add a private constructor and a new property to hold an ID that will be set by NHibernate, as shown in Listing 21-58.
You may have also noticed that the mapping for the Auction entity had a version property. This property ensures that the data is not stale (it hasn’t changed since pulling it from the database). When NHibernate persists the entity, it checks to ensure that the version is the same; if it’s not, it throws a StaleObjectStateException. This exception is handled by the application service and in your auction domain; if this happens, try to apply the offer again.
Add a version property to the Entity class, as shown in Listing 21-59.
Database Schema
For the database you can use the free MS SQL Express (http://www.microsoft.com/web/platform/database.aspx). You can probably work out the schema from the mapping; in fact, NHibernate can actually build the database from the mapping. However, here is the full database schema. Create a database named AuctionExample and run Listing 21-60 to set it up.
Your table schema will resemble Figure 21.13.

FIGURE 21.13 The database schema
Querying
You will turn your attention to the query side of the application service. The query services report on the state of the auctions. The first view of the auction is a summary of its status. Instead of returning the domain object, you will use a simple view model. Using Listing 21-61, create the AuctionStatus class within the Queries folder.
The auction status query requires native SQL to be used because you have no public getters to transform the aggregate into an AuctionStatus DTO. However, this cleanly separates the domain model from the application’s reporting needs and prevents the repository from having to deal with reporting concerns.
The other report that the application needs to give access to is the history of bids against the auction. Again, you don’t want to expose your domain objects, so you will create a specific DTO, shown in Listing 21-63. Even though it closely resembles the real Bid domain object, the BidInformation class represents a completely different concern and will not be affected if the Bid value object evolves.
Again, the query service, Listing 21-64, that pulls back information on the bids placed against an auction needs to go directly to the database to pull back a view because of the encapsulated domain model.
Configuration
NHibernate needs a small piece of configuration to work. Update the app.config of the Presentation project so that it matches Listing 21-65. Then change the connection string depending on your database instance name.
To tie all the dependencies together, you will utilize an inversion-of-control container. The container of choice will be StructureMap. Install StructureMap using the NuGet package manager just as you did with the NHibernate package, but this time ensure that StructureMap is referenced in both projects. Add a class named Bootstrapper, Listing 21-66, that wires the application service layer dependencies.
The ISessionFactory is typically created as a singleton object because of the relatively expensive operation of creating it. One of the jobs of the ISessionFactory is to provide ISession instances. You use StructureMap to ensure that the same version of the ISession variable is used for all repositories and all application services during a process, meaning that the application service can control the unit of work.
Presentation
Finally, to show the application in action, you will simulate users bidding on an auction. Add Listing 21-67 to the Program file of the Presentation project.
Figure 21.14 shows the program running.

FIGURE 21.14 The running program
RavenDB Example
RavenDB is a schemaless document database that stores domain objects as JSON (JavaScript Object Notation) documents. Therefore, there is no mismatch between the data and the domain model. In this example, you change the domain model so that the properties are public, but you keep the setters private.
Solution Setup
Before you start with the Visual Studio solution, you need to install RavenDB. The easiest way to install RavenDB is to download the latest installer from RavenDB’s website at http://ravendb.net/download. Every RavenDB server instance is manageable via a remotely accessible Silverlight application: the RavenDB Management Studio. After installing it, you can navigate to http://localhost:8080/ to view the RavenDB Management Studio.
After installing RavenDB, create a new blank Visual Studio solution named DDDPPP.Chap21.RavenDBExample and add to this a class library named DDDPPP.Chap21.RavenDBExample.Application and a console application named DDDPPP.Chap21.RavenDBExample.Presentation. Within the Presentation project, add a reference to the application. Next, create the following folders in the DDDPPP.Chap21.RavenDBExample.Application project:
- Application
- Infrastructure
- Model
You can delete the Class1.cs that is automatically created because you won’t be needing it. Use NuGet to install the RavenDB client libraries, as shown in Figure 21.15.

FIGURE 21.15 Install RavenDB client libraries via NuGet.
Build out the application in the same manner as you did for the NHibernate example, or simply copy the class files into this new solution, ensuring you update the namespaces. Remove the following classes that were specific to the NHibernate example:
- BusinessUseCasesBidOnAuction.cs
- BusinessUseCasesCreateAuction.cs
- QueriesAuctionStatusQuery.cs
- QueriesBidHistoryQuery.cs
- InfrastructureAuction.hbm.xml
- InfrastructureBid.hbm.xml
- InfrastructureAuctionRepository.cs
- InfrastructureBidHistoryRepository.cs
- Bootstrapper.cs
You are left with a solution that resembles Figure 21.16.
FIGURE 21.16 Solution explorer with an application based on the NHibernate sample.
The classes you removed are replaced with RavenDB’s repository implementation.
Altering the Model
The model is nearly identical to the model that was built in the NHibernate example. It still requires a parameterless constructor in each of the domain objects. As you are modeling with public getters, you need to change the properties of the Auction class to match Listing 21-68.
There is also a public method on the Auction class named HasBeenBidOn that will be used within the application service query method to report on the state of the auction. The only other change is to make the getter Value property of the Money class public so you can report on it, as shown in Listing 21-69.
An additional class that is required for the RavenDB example is the inclusion of the BidHistory domain object. This object contains all the bids placed against an auction in the order they were placed. Add this class to the BidHistory folder of the domain model with Listing 21-70.
To retrieve the BidHistory object, you need to add a new method to the IBidHistoryRepository contract, as shown in Listing 21-71.
Application Service
The application service only differs from the NHibernate solution because it uses RavenDB’s IDocumentSession type as opposed to NHibernate’s ISession. There is also a different exception that is thrown if concurrency is broken. RavenDB supports implicit transactions, which means they are built in to the IDocumentSession. You don't need to explicitly wrap the call in a transaction, as shown in Listing 21-72.
You don’t use the Version property on the Entity base class with RavenDB because it already has a version tag built in by default. When loading a document from RavenDB, it caches the Etag that relates to it. The Etag is basically the version stamp. When the call to commit the session is made, RavenDB checks to see if the Etag has been updated since retrieving the document. If it has, the ConcurrencyException is thrown.
The CreateAuction application service is simple, and it’s similar to the NHibernate implementation, as displayed in Listing 21-73.
Querying
Because you now have public properties on the Auction entity, you can transform them into the DTOs that the query services return. First create the AuctionStatusQuery with Listing 21-74.
The query to return the bids for a given auction uses the BidHistory object to ensure the ordering of the bids is correct because this is domain logic. Add the BidHistoryQuery class to the solution with Listing 21-75.
RavenDB Repository Implementation
As you will remember, the IBidHistoryRepository contract exposes a count of the number of bids against an auction. To support this, you create an index to improve querying for this data. Add the index class BidHistory_NumberOfBids with Listing 21-76 to the Infrastructure folder.
The BidHistoryRepository implementation, Listing 21-77, is similar to the NHibernate implementation apart from the use of the index created earlier to return the number of bids placed against an auction. Notice that in the query, you are calling the customization WaitForNonStaleResultsAsOfNow because RavenDB is eventually consistent and you are blocking the thread to ensure the index is up to date.
The implementation of the IAuctionRepository is straightforward and is shown in Listing 21-78.
Configuration
You will use StructureMap to wire up the dependencies of your application service. Install the StructureMap libraries, as you did for the NHibernate example, using NuGet. Then add the following Bootstrappper class, Listing 21-79, to the route of the application class library project.
Lastly, there is a small configuration that is required in the app.config file of the Presentation console project, as shown in Listing 21-80.
The Program class file within the Presentation console project is the same as the NHibernate version. Once you run the sample program, you can launch RavenDB’s management studio and inspect the auction document, as shown in Figure 21.17.

FIGURE 21.17 Inspecting the document inside RavenDB Management Studio.
Persistence Framework Cannot Map Domain Model Directly without Compromise
For the persistence frameworks that are unable to map a domain model directly to the data model, you need to take a different approach to persistence. It is still important to ensure that your data model does not affect the structure of your domain model and that your domain model can evolve cleanly. You will run through two exercises: one using Entity Framework and the other raw ADO.NET with some help from Dapper, a micro ORM.
Entity Framework Example
The Entity Framework is Microsoft’s enterprise-level ORM. It has similar capabilities to NHibernate, but it’s fair to say that the NHibernate framework is a more mature project with more features for mapping a domain model directly. In this example, you use Entity Framework to map only the data model and utilize the memento pattern to provide a snapshot of the state of the domain model for storage.
Solution Setup
Create a new blank Visual Studio solution named DDDPPP.Chap21.EFExample and add to this a class library named DDDPPP.Chap21.EFExample.Application and a console application named DDDPPP.Chap21.EFExample.Presentation. Within the Presentation project, add a reference to the application. You can delete the Class1.cs that is automatically created because you won’t be needing it. Use NuGet to install the Entity Framework client libraries, as shown in Figure 21.18.

FIGURE 21.18 Install Entity Framework client libraries via NuGet.
Build out the application in the same manner as you did for the NHibernate example, or simply copy the class files into this new solution, ensuring that you update the namespaces. Remove the following classes that were specific to the NHibernate example:
- BusinessUseCasesBidOnAuction.cs
- BusinessUseCasesCreateAuction.cs
- QueriesAuctionStatusQuery.cs
- QueriesBidHistoryQuery.cs
- InfrastructureAuction.hbm.xml
- InfrastructureBid.hbm.xml
- InfrastructureAuctionRepository.cs
- InfrastructureBidHistoryRepository.cs
- Bootstrapper.cs
You are left with a solution that resembles Figure 21.19.

FIGURE 21.19 Solution explorer with an application based on the NHibernate sample.
Also, create the database tables using the same schema you used for the NHibernate example, if you haven’t already created the database.
Altering the Model
Because you are going to implement the memento pattern, you need the aggregate to produce a snapshot of itself so you can map it to a data model. The first snapshot you will create is of the WinningBid value object. Using Listing 21-81, add a new class to the Auction folder within the Model folder named WinningBidSnapshot.
Next, create a snapshot for the auction itself, as shown in Listing 21-82. This holds the WinningBidSnapshot and provides a full snapshot of the Auction aggregate.
Finally, create a snapshot for the state of the money value object, as shown in Listing 21-83.
Because you need access to setters and getters of the Version and Id properties, update the accessibility levels so that they have protected setters and public getters, as shown in Listing 21-84.
To extract the state of the domain objects within the auction aggregate, you need to add a new public method that returns a snapshot. The first object to add this method to is the Money value object. Update the Money class to include the new GetSnapshot method, as shown in Listing 21-85.
Do the same for the WinningBid object, but for this more complex type, add a new static factory method that enables a WinningBid to be created from a snapshot, as shown in Listing 21-86.
Finally, update the Auction class by adding the static factory class to hydrate an auction from a snapshot and the method to obtain a snapshot, as shown in Listing 21-87.
You also need to add the BidHistory object, as you did in the RavenDB example. Listing 21-88 shows an example.
To retrieve the BidHistory object, you need to amend the IBidHistoryRepository, as shown in Listing 21-89.
Because you can’t track changes implicitly with your domain objects, you need to explicitly save them, which means you must add a save method to the IAuctionRepository, as shown in Listing 21-90.
Entity Framework Repository Implementation
Create a new folder within the Infrastructure folder named DataModel. Here you stall the data model objects that map to your database tables and rows. The first object to create represents a row within the Auction table, as shown in Listing 21-91.
The second data object, Listing 21-92, represents a row within the BidHistory table.
You will use Entity Framework’s code-first mapping to map the data model to the database. Add a new folder to the Infrastructure folder named Mapping. The AuctionMap class, Listing 21-93, maps the AuctionDTO to the Auctions database table.
Similarly, the BidMap, Listing 21-94, maps the BidDTO to the BidHistory table.
To talk to the database, you need a context, as shown in Listing 21-95. The Entity Framework DbContext is similar to NHibernate’s ISession and RavenDB’s IDocumentSession. It is effectively Entity Framework’s implementation of the unit-of-work pattern.
The implementation of the repository is different from what you have seen in the NHibernate and RavenDB examples. Because you are unable to map the domain model directly to the data model, the repository needs to extract the snapshot and map that instead. The AuctionRepository implementation is shown in Listing 21-96.
The BidHistoryRepository works along the same lines as what’s shown in Listing 21-97.
Application Service
There isn’t much difference in either of the application services from what you have seen up to now except for using the DbContext, which is Entity Framework’s unit of work implementation. The only thing of note is to say that Entity Framework implicitly wraps the call to SaveChanges in a transaction so you don’t need to. You can see these changes in Listing 21-98.
In the BidOnAuction application service, Listing 21-99, you need to explicitly call the Save method on the repository. The only other difference is that the exception type that is thrown when there is a concurrency issue is different from both the NHibernate and RavenDB examples.
Querying
To implement the queries, you can utilize the snapshots to populate the view models, as shown in Listing 21-100 and Listing 21-101 for the AuctionStatusQuery and the BidHistoryQuery.
Configuration
Again, you will be using StructureMap to wire up your dependencies, so install it as before from NuGet and create a bootstrapper class with Listing 21-102.
Lastly, add the XML snippet in Listing 21-103 to the app.config within the Presentation console application.
If you run the console application, you will see the same results as in the previous NHibernate and RavenDB examples.
Micro ORM Example
Dapper is a micro ORM, meaning that it helps you map database rows to objects but (by design) does little else. In this example, you need to build your own unit of work implementation and concurrency checks.
Solution Setup
To get started, create a new blank Visual Studio solution named DDDPPP.Chap21.MicroORM and add to this a class library named DDDPPP.Chap21.MicroORM.Application and a console application named DDDPPP.Chap21.MicroORM.Presentation. Within the Presentation project, add a reference to the application. You can delete the Class1.cs that is automatically created because you won't be needing it. Use NuGet to install the Dapper client libraries, as shown in Figure 21.20.

FIGURE 21.20 Install Dapper client libraries via NuGet.
The model is the same as the model you created for the Entity Framework example. It also has the database schema that you used in both the NHibernate and Entity Framework examples. Build out the application in the same manner as you did for the Entity Framework, but exclude the following files:
- BusinessUseCases/BidOnAuction.cs
- BusinessUseCases/CreateAuction.cs
- Infrastructure/Mapping
- Infrastructure/AuctionDatabaseContext.cs
- Infrastructure/AuctionRepository.cs
- Infrastructure/BidHistoryRepository.cs
- Bootstrapper.cs
You should now be left with a solution that resembles Figure 21.21.

FIGURE 21.21 Skeleton solution based on the Entity Framework solution.
Infrastructure
In this example we’re using a micro ORM. Micro orms tend to focus on simplicity and performance, as such they have less features than their fully automated cousins Entity Framework and NHibernate. Consequently we will need to implement the unit of work pattern ourselves. The unit of work structure in this example is based on the framework that Tim McCarthy uses in his book .NET Domain-Driven Design with C#: Problem-Design-Solution.
The IAggregateDataModel interface, Listing 21-104, is actually a pattern in itself called the marker interface pattern. The interface acts as metadata for a class, and methods that interact with instances of that class test for the existence of the interface before carrying out their work. You will see this pattern used later in this chapter when you build a repository layer that only persists business objects that implement the IAggregateDataModel interface.
The unit of work implementation uses the IAggregateDataModel interface to reference any business entity that is partaking in an atomic transaction. Add another interface to the Infrastructure project named IUnitOfWorkRepository, Listing 21-105, with the contract listing that follows.
The IUnitOfWorkRepository is a second interface that all repositories are required to implement if they intend to be used in a unit of work. You could have added this contract definition to the model Repository interface that you will add later, but the interfaces are addressing two different types of concerns. This is the definition of the Interface Segregation Principle. You are not going to be deleting anything in your application, so there is no need to add that method.
Finally, add a third interface to the Infrastructure project named IUnitOfWork, the definition of which you can find in Listing 21-106.
The IUnitOfWork interface requires the IUnitOfWorkRepository when registering an amend/ addition/deletion so that, on commitment, the unit of work can delegate the work of the actual persistence method to the appropriate concrete implementation. The logic behind the IUnitOfWork methods will become a lot clearer when you look at a default implementation of the IUnitOfWork interface and create the repositories.
The last class to create is the ConcurrencyException, Listing 21-107, which is thrown if the auction is updated between retrieving it, placing a bid, and persisting it.
Application Service
Both of the application services should be familiar to you by now. Listing 21-108 and Listing 21-109 change because of your implementation of the unit of work and because of your concurrency exception type.
ADO.NET Repository Implementation
You need to make the AuctionDTO, Listing 21-110, and BidDTO, Listing 21-111, implement the IAggregateDataModel interface because these two classes are persisted using the unit of work implementation.
Both AuctionRepository and BidHistoryRepository, shown in Listing 21-112 and Listing 21-113, implement the domain model repository contracts IAuctionRepository and IBidHistoryRepository, as well as the IUnitOfWorkRepository interface. The implementations of both repository methods simply delegate work to the unit of work, passing the entity to be persisted along with a reference to the repository, which of course implements the IUnitOfWorkRepository. As seen previously when the unit of work’s Commit method is called, the unit of work refers to the repository’s implementation of the IUnitOfWorkRepository contract to perform the real persistence requirements. This is the same behavior as you saw in the enterprise-level frameworks. Because the repositories need to obtain a connection string from the app.config file, you need to add a reference to the Systems.Configuration assembly, as shown in Figure 21.22.
FIGURE 21.22 Add a reference to System.Configuration.
To complete the repository implementation, you need to implement the unit-of-work interface. Add a new class to the Infrastructure folder named UnitOfWork, and use Listing 21-113 to update the newly created class.
You are required to add a reference to System.Transactions so you can use the TransactionScope class, as shown in Figure 21.23, which ensures the persistence will commit in an atomic transaction.

FIGURE 21.23 Add a reference to System.Transactions.
The UnitOfWork class uses three dictionaries to track pending changes to business entities. The first dictionary corresponds to entities to be added to the datastore. The second dictionary tracks entities to be updated, and the third deals with entity removal. A matching IUnitOfWorkRepository is stored against the entity key in the dictionary and is used in the Commit method to call the repository, which contains the code to actually persist an entity. The Commit method loops through each dictionary and calls the appropriate IUnitOfWorkRepository method, passing a reference to the entity. The work in the Commit method is wrapped in a TransactionScope using a block; this ensures that no work is done until the TransactionScope Complete method is called. If an exception occurs while you are performing work within the IUnitOfWorkRepository, all work is rolled back, and the datastore is left in its original state.
Configuration
Again, you will wire up the dependencies of the application services using StructureMap, which you can install via NuGet just as you did with NHibernate and RavenDB. The code is shown in Listing 21-115.
To set the connection string to the database, update the App.Config within the presentation project to match the XML markup in Listing 21-116.
You can now run the program and see the same results, as in all the examples.
The Salient Points
- The repository mediates between the domain model and the data model; it maps the domain model to a persistence store.
- The repository pattern is a procedural boundary, keeping the domain model free of infrastructural concerns.
- The repository is a contract, not a data access layer. It explicitly states what operations are available for each aggregate—that is, which you can modify and which you can remove.
- The repository is for transactional behavior, not for ad hoc reporting. Using explicit query names provides more information.
- A repository hides the mechanisms for querying the data model and supports the Tell, Don’t Ask principle.
- An ORM framework is not a repository. The repository is an architectural pattern, whereas an ORM is a means to represent the data model as an object model. A repository can use an ORM to assist in mediating between the domain model and the data model
- Your persistence framework affects the way your domain model is constructed. Be pragmatic, and don’t fight your framework in the quest for needless purity.
- The repository is best used for bounded contexts with a rich domain model. For simpler bounded contexts without complex business logic, use the persistence framework directly.
- When managing transactions, use a unit of work. The unit of work tracks which objects have been removed, added, or updated. The repository is responsible for the actual persistence, performed within a transaction coordinated by the unit of work.
- A repository should be scoped to updating a single aggregate; it should not control a transaction. This should be the responsibility of a unit of work.