
22
Event Sourcing
WHAT’S IN THIS CHAPTER?
- An introduction to event sourcing and the problems it solves
- Guidance and examples for building event-sourced domain models
- How to build an Event Store
- Examples of building Event Stores on top of RavenDB and SQL Server
- Examples of using Greg Young’s Event Store
- A discussion of how CQRS synergizes with event sourcing
- A list of trade-offs to help you understand when event sourcing is a good choice and when you should avoid it
Wrox.com Code Downloads for This Chapter
The wrox.com code downloads for this chapter are found at www.wrox.com/go/domaindrivendesign on the Download Code tab. The code is in the Chapter 22 download and individually named according to the names throughout the chapter.
Bringing a competitive business advantage and exciting technical challenges, it’s clear why a storage mechanism called event sourcing has gained a lot of popularity in recent years. Because a full history of activity is stored, event sourcing allows businesses to deeply understand many aspects of their data, including detailed behavior of their customers. With this historical information, new and novel queries can be asked that inform product development, marketing strategies, and other business decisions. Using event sourcing, you can determine what the state of the system looked like at any given point in time and how it reached any of those states. For many domains, this is a game-changing capability.
Many systems today store only the current state of the domain model, thereby precluding the opportunity to analyze historical behavior. So, fundamental to event sourcing are new ways of storing data and new ways of building domain models with inherent challenges and advantages. This chapter takes you through concrete step-by-step examples of many such scenarios. You will even see how to build an Event Store and be introduced to a purpose-built Event Store.
Domain-Driven Design (DDD) practitioners often like to combine event sourcing with CQRS as the basis for enhanced scalability and performance. CQRS is fundamentally about denormalization, but such is the synergy with event sourcing that a whole community has formed around the combination. This makes understanding and disambiguating the concepts highly important. It’s also important to be realistic in light of all the hype generated by the community. So this chapter helps you understand when event sourcing might not be an efficient choice.
In preparation for the technical examples, this chapter begins by accentuating the importance of event sourcing using comparisons with traditional current-state-only storage. This, and all the other examples in the chapter, are based on a pay-as-you-go service offered by a cell phone network operator. With this service, customers add credit to their account by topping-up their balance with vouchers or Top-Up cards. Credit allows them to make phone calls.
The Limitations of Storing State as a Snapshot
If you only store the current state of your domain model, you don’t have a way of understanding how the system reached that state. Consequently, you cannot analyze past behavior to uncover new insights or to work out what has gone wrong. This can be demonstrated by examining a support case presented to the customer service department of a cell phone network operator. A customer reported her dissatisfaction at having an empty balance after she recently topped up and then made only a few short phone calls. She is convinced that she should still have remaining credit. By looking at the database, the customer service assistant pulls up the customer’s account information that is shown in Table 22.1.
TABLE 22.1 Customer’s Pay-as-You-Go Account Activity
| Customer ID | Allowance (Minutes) |
| 123456789 | 0 |
Looking at the customer’s account in Table 22.1, all the customer service assistant can do is agree that the account balance is empty. It’s not possible to work out how the account reached this state by viewing recent call and top-up details. Using the logs from her phone and receipts for her top-ups, the customer supports her argument by providing the history of her account, as shown in Table 22.2.
TABLE 22.2 Customer’s Actual Account Activity
| Previous Allowance (Minutes) | Action | Current Allowance (Minutes) |
| 0 | Top up $10 | 20 |
| 20 | 10-minute call | 10 |
| 15 | 5-minute call | 0 |
If you observe Table 22.2, it follows that $10 buys 20 minutes of phone calls. Incorrectly, though, the balance is 0 after only a 10-minute and a 5-minute phone call. There is a bug in the system, but the business cannot easily prove it just by looking at its data because it only shows the current state. It does not keep a history of the customer’s activity.
By storing state as a snapshot, the cell phone operator also lacks the ability to use the rich history of customer behavior to improve its services. It is unable to correlate user behavior with marketing promotions, and it is unable to look for patterns in user activity that can be capitalized on as new or enhanced streams of revenue.
In this scenario, there is a clear business case for the cell phone network operator to at least consider using event sourcing as a way to record account history. It might be able to gain a competitive advantage and a reduction in customer service complaints just by storing the state of its domain model as a stream of events.
Gaining Competitive Advantage by Storing State as a Stream of Events
You can acquire the ability to analyze full historical data by storing each event of significance in chronological order with its timestamp. You then derive current state by replaying events. Significantly, though, you can do more than just work out the current state; you can replay any subsequence of events to work out the state, and activity that caused it, for any point in history. This is known as a temporal query—a game-changing capability inherent to event sourcing.
Temporal Queries
Temporal queries are like the ability to travel back in time, because essentially, you can rewind the state of your domain model to a previous point in history. Using a temporal query, the Customer Service department could accurately assess its customer’s complaints about an incorrect balance. It could repeatedly check the state at previous points in time until it found the event that incorrectly deducted double the amount from the allowance. Figure 22.1 illustrates how temporal queries could be applied to the event stream representing the customer’s pay-as-you-go account activity detailed previously in Table 22.1.
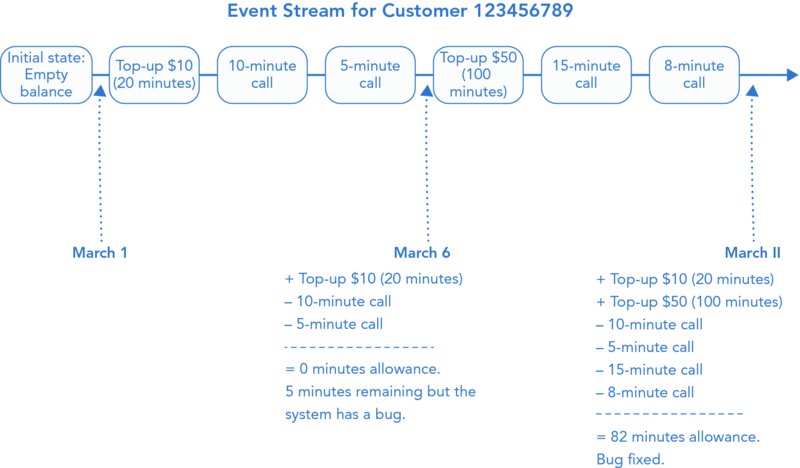
FIGURE 22.1 Calculating the state for any point in history by replaying events.
Replaying events is the mechanism that underlies temporal queries. Figure 22.1 illustrates how subsequences of events are used to calculate the state of the customer’s account at two different points in history. Throughout your life and career as a developer, you have been exposed to temporal queries similar to these. Examples include bank accounts or version control systems (VCSs) like Git or Subversion. With each of these concepts, you can rewind state to any point in history by replaying all the events that occurred prior to it. Later in this chapter, you will see examples of performing temporal queries against a real Event Store.
By taking advantage of the event stream in Figure 22.1, the cell phone operator can now ask any question about the history of the account. But, even more interestingly, the operator can also combine information from many customers’ accounts to work out behaviors of specific demographics. Such information can be used to make quantitative marketing and product development decisions or guide experimentation. Projections are the underlying feature that enables combining events from multiple streams to carry out these kinds of complex temporal queries.
Projections
A limitation of some event stores is a difficulty in carrying out ad hoc queries against multiple event streams, which in a SQL database would be achievable with straightforward joins. To get around this problem, event stores use a concept called projections, which are queries that map a set of input event streams onto one or more new output streams. For example, a cell phone operator can project the event streams for many of its customers to answer questions like these: “What was the total number of minutes used on a specific day by a specific demographic around the time of a certain sporting event” and “Did the total usage increase or decrease among a certain demographic when there was a special offer?” Figure 22.2 illustrates how arbitrary questions like these can be asked by combining events from multiple streams using projections.

FIGURE 22.2 Creating projections from multiple event streams.
In Figure 22.2, each event stream that represents the account of a single customer is fed into the projection function. A projection function can do a number of things, including keeping state or emitting new events. The projection function in Figure 22.2 is going to emit all events that occurred between March 1 and March 5, and where the account holder is between 16 and 24 years of age, into a new event stream. This new stream is the projection. With all the required events in a single stream, it is then easy and efficient to query all of them to find out totals, averages, or any other piece of information that needs to be extracted.
You can project a set of input streams onto more than one output. As you’ll see later in this chapter, with Greg Young’s Event Store, you have a lot of power and flexibility. You can use the rich capabilities of JavaScript in projection functions.
Snapshots
A consequence of storing state as events is that event streams can grow very large, meaning that the time to replay events can continue to increase significantly. To avoid this performance hit, event stores use snapshots. As Figure 22.3 illustrates, snapshots are intermediate steps in an event stream that represent the state after replaying all previous events.

FIGURE 22.3 Efficiently restoring state by using snapshots.
When an application wants to load the current state of an aggregate from an event stream, all it has to do is find the latest snapshot. Using that snapshot as the initial state, it need then only replay all the subsequent events in the stream.
Event-Sourced Aggregates
For compatibility with event sourcing, aggregates need to be event oriented. Importantly, they need to be able to calculate their state by applying a series of events. DDD practitioners find that a nice side effect of this is that their aggregates are more behavior oriented, providing heightened levels of domain event expressiveness. Another satisfying benefit is that persistence tends to be loosely coupled and less problematic.
Structuring
There are a few key details involved when creating aggregates for event-sourced domain models. Of these details, the most important is for an aggregate to be able to apply a domain event and update its state according to the appropriate business rule(s). Second, a list of uncommitted events needs to be maintained so that they can be persisted to an Event Store. Third, an aggregate needs to maintain a record of its version and provide the ability to create snapshots and restore from them.
Adding Event-Sourcing Capabilities
It’s often useful to create a base class, as per Listing 22-1, which all your aggregates inherit from to encapsulate commonality.
Changes is the collection of uncommitted events, and obviously Version keeps track of the aggregate’s version, which will be explained in more detail shortly. Apply() takes a DomainEvent that aggregates must handle by applying business rules and updating state.
LISTING 22-2 shows a concrete (partial) aggregate implementation that represents a customer’s pay-as-you-go account. This illustrates the expressiveness that can be layered on top of Apply().
The implementation of Apply() in Listing 22-2 uses a tiny amount of dynamic magic that allows highly expressive event-handling methods. In Listing 22-2, these handlers are the When() methods. Each overload of When() is intended to read almost declaratively, expressing what business rules should apply and how the state should change when each type of event occurs. Apply() also updates the Version field each time an event is applied. This is helpful when working out whether an aggregate has changed before an operation is carried out on it. An aggregate’s version is the sequence number, relative to the start of the aggregate’s event stream, of the last event that has been passed into its Apply().
Exposing Expressive Domain-Focused APIs
Apply() is mostly an implementation detail that won’t be called outside the aggregate. The reason it is public is to enable the aggregate to be rehydrated (explained shortly). Outside of an aggregate, services still communicate through expressive APIs, being unaware of event-related features. This is exemplified by TopUp() in the updated PayAsYouGoAccount aggregate shown in Listing 22-3.
LISTING 22-3 shows the view of an aggregate that external domain and application services would see. They would not know that the aggregate used event sourcing; they would only see expressive high-level APIs like TopUp() that clearly express domain concepts. From this perspective, the similarity to non-event-sourced aggregates is similar.
To clarify that events are mostly an implementation detail and that interaction with an aggregate from the service layer will be similar, Listing 22-4 presents the TopUpCredit application service. Try to focus on how there is no trace of event sourcing and how this would look almost identical to interaction with a non-event-sourced aggregate.
When TopUp() is invoked, either the CreditSatisfiedFreeCallAllowanceOffer or the CreditAdded domain event will occur based on the InclusiveMinutesOfferBusiness policy. Importantly, the outcome of these actions will result in a new event being raised. This new event will need to cause an update of the aggregate’s state, after being passed into Apply(). But the event will also need to be persisted so that it can be replayed anytime the aggregate is loaded from its event stream. Causes() takes care of these concerns by adding the event to Changes—the collection of uncommitted events—and then feeding the event into Apply().
Adding Snapshot Support
One remaining aggregate detail that needs to be addressed before persistence can be tackled is the ability to create snapshots. The aggregates themselves need to create the snapshots, because they contain the domain logic that builds state by replaying all previous events. Accordingly, it’s convenient to add a method onto aggregates that builds a snapshot and one that restores the aggregate. An example of each is shown in Listing 22-5.
In Listing 22-5, the constructor overload that takes a PayAsYouGoSnapshot restores the state of the aggregate to match the state of the PayAsYouGoAccountSnapshot. As previously discussed, this is a performance-improving shortcut that is equivalent to applying all the events that occurred before the snapshot was created. For this to work, though, snapshots need to accurately represent an aggregate’s state. You can see in Listing 22-5 that GetPayAsYouGoAccountSnapshot() ensures this happens by creating a snapshot and using the correct values to populate it. The PayAsYouGoAccountSnapshot is shown in Listing 22-6.
Persisting and Rehydrating
Persisting event-sourced aggregates is just a case of storing the uncommitted changes in an event store. Similarly, loading the aggregate, also known as rehydrating, requires you to load and replay all previously stored events, with the option to use snapshots as a shortcut. You saw in the previous examples that Changes and Apply() are used for these purposes, respectively.
Creating an Event-Sourcing Repository
LISTING 22-7 contains an example repository implementation that handles loading and saving PayAsYouGoAccount aggregates (initially ignoring snapshots).
In Listing 22-7, the three major operations that repositories need to support are shown: creating streams, appending to streams, and loading streams. Creating an event stream involves creating a new stream with an initial set of events, as Add() shows. In a similar fashion, Save() appends the uncommitted events of a PayAsYouGoAccount aggregate to an existing stream. Lastly, FindBy() loads a PayAsYouGoAccount given its ID.
Loading aggregates is a little more complex than creating or updating because you have to decide which events should be loaded from the stream by specifying the highest and lowest version number (useful for reloading an aggregate to a previous state). Once all the events are pulled back from the Event Store, they are passed into the aggregate’s Apply() so that the aggregate’s state will be built. This is the only time when an external service should call Apply().
A detail that’s important to discern from Listing 22-7 is the name of the event stream that has the format {AggregateType}-{AggregateId}, and for good reason. Having a stream per aggregate means you only have to replay events for a single aggregate when loading it—not events for every aggregate of that type. This has significant performance advantages and provides the platform for better scalability. It can also make life easier when snapshots are involved.
Adding Snapshot Persistence and Reloading
Snapshots are a performance enhancement to avoid loading the entire history of events in a stream, as previously mentioned. Snapshots are usually created by a background process such as a Windows service. A basic example of a background job that creates snapshots for the PayAsYouGoAccount aggregate, using a RavenDB-based event store, is shown in Listing 22-8.
Essentially, the background job in Listing 22-8 is going to loop through the IDs of all aggregates and create a snapshot for each of them every 12 hours. In a production-quality version, you may want to iterate through smaller sets of IDs, you may want to add logging, and you will likely want to adjust the 12-hour period to something more optimal for your environment. It’s also likely that you may want to create snapshots based on some condition, such as the number of events that have occurred since the last snapshot.
Once you are generating and storing snapshots, you can optimize your loading strategy by using the latest snapshot as the initial state. Listing 22-9 shows an updated PayAsYouGoRepository.FindBy() implementation that takes advantage of snapshots.
You can see in Listing 22-9 that FindBy() has been updated with a call to _ eventStore.GetLatestSnapshot(). If this method returns a snapshot, the fromEventNumber is bumped up to the version after the snapshot. This ensures that subsequent calls to _ eventStore.GetStream() will only retrieve events that occurred after that snapshot. You can also see the other change; if a snapshot is found, the PayAsYouGoAccount aggregate is created with the snapshot as the initial state.
Handling Concurrency
Sometimes you want the operation of adding an event to a stream to fail. This is often the case when multiple users are updating the state of an aggregate at the same time, and you want to avoid a change being committed if the aggregate has updated after the new change was requested but not committed. You might already be familiar with this concept: optimist concurrency (http://technet.microsoft.com/en-us/library/aa213031(v=sql.80).aspx).
In an event-sourced application, you can implement optimistic concurrency with two additional steps. First, when an aggregate is loaded, it keeps a record of the version number it had at the start of the transaction. Second, just before any new events are appended to the stream, a check is carried out to ensure that the last persisted version number matches the version number the aggregate had at the start of the transaction. Listing 22-10 and Listing 22-11 illustrate this process.
LISTING 22-10 contains an updated PayAsYouGoAccount aggregate with an InitialVersion property, representing the version of the last event that was persisted prior to the aggregate being loaded. This value is then passed into the Event Store’s AppendEventsToStream(), as shown in Listing 22-11, where the Event Store implementation can then check to ensure this version is still the most up to date. Later in the chapter, you will see an event store implementation that shows how to fully implement this feature.
Testing
Unit testing event-sourced aggregates involves asserting that events have occurred. This is done by checking the collection of uncommitted events belonging to the aggregate. An example demonstrating this for PayAsYouGoAccount.TopUp() is shown in Listing 22-12.
After a PayAsYouGoAccount has an inclusive minutes offer applied to it, if the customer tops up by the inclusive minute offer’s threshold, the customer is given free credits in addition to her top-up amount. The test in Listing 22-12 verifies that when a top up does not meet the criteria, no free minutes are applied. It does this by asserting that only a single CreditAdded event exists within the aggregate’s uncommitted events, and the state of the aggregate has been increased only by the amount of the top up. You can see this with the calls to Assert.Equal() at the bottom of Listing 22-12.
LISTING 22-12 is a common case when testing event-sourced aggregates; you will interact with them through expressive high-level application programming interfaces (APIs), like TopUp(). You will then assert that events were added to the uncommitted list, and state changed accordingly. This will often apply to both high-level integration tests and low-level unit tests. The major difference is whether you mock collaborators and external services or pass in real implementations.
Building an Event Store
To build applications that use event sourcing, you can use a purpose-built event store or create one of your own. Creating one of your own really just means using an existing tool in a novel way. So in this section, you will see how you can use RavenDB and SQL Server as the basis for event stores. Creating your own event store is also a hands-on way to increase your understanding of the core concepts.
You saw the IEventStore interface being used previously by the PayAsYouGoAccoutRepository in Listing 22-11. This is the interface that the Event Store being created in this section will implement. IEventStore is shown in its entirety in Listing 22-13.
Designing a Storage Format
Designing or choosing a storage format is one of the big challenges when building event store functionality. Using your chosen technology, at a minimum you need to provide the ability to create event streams, append events to them, and pull those events back out again in the same order. It’s also likely that you will want to support snapshotting.
In this example, the storage format is based on three document types: EventStream, EventWrapper, and SnapshotWrapper. EventStream represents an event stream but only contains meta data such as its Id and Version. EventWrapper wraps and represents an individual domain event, containing all the event’s data plus meta data about the stream it belongs to. SnapshotWrapper represents a single snapshot. An alternative strategy would have been to have a single document that contained the meta data, events, and snapshots for each aggregate. You are free to design and refine your own format as you see fit.
RavenDB is a document database in which each document is a JavaScript Object Notation (JSON) object. Handily, Raven’s C# client library automatically converts Plain Old C# Object (POCO) classes into the required JSON for you. This means that the three document types to be used as the basis for event store functionality need only be declared in code. EventStream, EventWrapper, and SnapshotWrapper are shown in Listings 22-14 through 22-16, respectively.
Creating Event Streams
Now that you’ve chosen a document type to represent an event stream, creating an instance of an event stream involves creating a document of that type. This is demonstrated with the initial implementation of an event store that supports the creation of streams, as shown in Listing 22-17.
RavenDB is the underlying storage technology represented by its IDocumentSession interface. You can see the implementation of CreateNewStream() in Listing 22-17 is using an IDocumentSession to store an EventStream object. As mentioned, RavenDB converts this EventStream object to JSON and creates a new document for it. Conceptually, at the point RavenDB creates the EventStream document, the new event stream has been created. However, it doesn’t contain any events.
Appending to Event Streams
Once event streams have been created, the next challenge is to provide the ability to append events to them. In this example, an event is represented by an EventWrapper, a class that wraps a domain event with meta data so that when it is persisted, it can be associated with the correct event stream. An updated implementation of EventStore that supports appending EventWrappers is shown in Listing 22-18.
AppendEventsToStream() stores each EventWrapper as a unique document. But this is an implementation detail; all callers of AppendEventsToStream() know is that the event was appended to the appropriate stream. However, because each event is a unique document, there needs to be some way of retrieving all events for a given stream. EventWrapper contains the meta data that enables this: the ID of the stream and an event version number. These values are populated by EventStream.RegisterEvent(), as shown previously in Listing 22-14. As you’ll see in the next example, querying for events in a stream is then mainly a case of searching for events whose EventStreamId matches the name of the stream whose events are being queried.
Querying Event Streams
When building event store functionality, as a minimum you need to include the ability to query for all the events in a stream. You will also need to provide the ability to query by the version or ID of an event to support snapshot loading. An updated implementation of EventStore that provides these capabilities is shown in Listing 22-19.
As previously discussed, the convention for representing event streams in this example is to store each event as a unique EventWrapper document containing the ID of the stream it belongs to. You can see in Listing 22-19 that the where clause adheres to this convention by specifying that only EventWrappers with the passed-in stream name should be selected.
In addition to loading all events for a stream, the fromVersion and toVersion parameters are used as part of the query. They specify the earliest and latest event that should be pulled back from the stream, respectively. As you will see in the next example, this is an important capability when snapshots are involved.
Adding Snapshot Support
To enable snapshots, you must provide the facility to store them. In this example, SnapshotWrapper is used to wrap snapshots with additional meta data—the name of the stream it belongs to and the date it was added. Listing 22-20 demonstrates an updated version of EventStore with the ability to save snapshots.
AddSnapshot<T>() allows consumers to store a snapshot for a given stream by wrapping the snapshot with a SnapshotWrapper that contains the name of the stream it belongs to and the time it was saved. As Listing 22-21 shows, these two pieces of meta data allow consumers of EventStore to get the latest snapshot for any stream simply by passing in the name of the stream.
Hopefully, you can see the benefits of using SnapshotWrapper by observing the code in Listing 22-21. Its StreamName and Created fields are used to build a query that finds the latest saved snapshot for the name of the passed-in stream. In combination with AddSnapshot<T>(), this is a clean API for storing a snapshot of any type and pulling it out later. But this is just one possible solution; you may find alternative solutions that fit your needs better. Creative thinking is encouraged.
Managing Concurrency
Many modern applications are multiuser, meaning that different users view and update the same piece of data at the same time. If one user attempts to update some data but another has changed it without the other user realizing, it’s sometimes essential that the update fails. As mentioned, this is optimistic concurrency. A generic way of handling optimistic concurrency in event stores is to verify that the version number of the last stored event matches the version number that the new update is based on.
Keeping track of the expected version at the application level was shown previously in Listing 22-11, where the InitialVersion property was added to the aggregate and then passed into the event store each time new events were appended to the stream. Listing 22-22 shows how an updated version of EventStore.AppendEventsToStream() uses this version number to abort saving any events if the expected version number does not match the version number of the last stored event—meaning a new event(s) has been added since this transaction began, and thus the user was probably not aware of it.
If an expected version number is passed into AppendEventsToStream, the EventStore ensures that before appending new events, the passed-in version number matches the version number of the last stored event. This is shown in Listing 22-22. In particular, the private CheckForConcurrencyError() carries out the comparison logic and throws an OptimisticConcurrencyException if the version numbers aren’t the same.
Unfortunately, the solution in Listing 22-22 is not robust enough when used with RavenDB because of the possibility of a race condition. If you look carefully, you’ll notice there will be a short period between the completion of CheckForConcurrencyError() and _ documentSession.Store(). What would happen if a new event was appended to the stream in this period? Both events would be appended to the stream, even though CheckForConcurrenyError() aims to prevent this. Fortunately, you can configure RavenDB for optimistic concurrency, so it does not store an event if the stream has been updated since the event occurred.
Whichever technologies you use to build an event store, race conditions will likely be a factor you need to deal with if you’re supporting optimistic concurrency. Locking the stream and checking the ID of the last committed event is likely to be the process you will rely on for this. To lock an event stream stored in RavenDB, the first step is to enable optimistic concurrency, as shown in Listing 22-23.
RavenDB provides support for optimistic concurrency. Listing 22-23 shows how it is enabled by setting session.Advanced.UseOptimisticConcurreny to true. As Listing 22-23 also shows, this can be configured in the service layer (explained more in Chapter 25: “Commands: Application Service Patterns for Processing Business Use Cases”), where the lifecycle of objects is managed, often with a container. (ObjectFactory is the IoC container in Listing 22-23.) Essentially, the code in Listing 22-23 ensures that each new web request, or each thread, gets its own document session with optimistic concurrency enabled. It’s important for each thread or web request to get its own session because all changes made in a session can be rolled back together.
Once enabled, RavenDB enforces optimistic concurrency by aborting transactions and throwing ConcurrencyExceptions when an event being stored has been modified in another IDocumentSession since the current IDocumentSession was created. Listing 22-24 illustrates how this applies to EventStore by showing a full business use case that is carried out by the TopUpCredit application service.
An instance of IDocumentSession is created at the start of a web request and passed into the TopUpCredit application service shown in Listing 22-24. TopUpCredit then finds the relevant account using a repository and tops up its credit, causing domain events to be added to the aggregate’s list of uncommitted events. These uncommitted events are queued up for storage in RavenDB when Save() is called on the repository. Finally, when SaveChanges() is called on the IDocumentSession ( _ unitOfWork), RavenDB commits the changes and persists them to disk. However, if RavenDB notices that the event stream these events are being appended to has been modified by another IDocumentSession since the IDocumentSession passed into TopUpCredit was started, it does not commit the changes. Instead, it throws the ConcurrencyException you can see being handled in Listing 22-24.
A SQL Server-Based Event Store
SQL Server is another common storage option for building event stores. There are several open source projects that provide guidance and reference implementations to help you along. Ncqrs (https://github.com/ncqrs/ncqrs/blob/master/Framework/src/Ncqrs/Eventing/Storage/SQL/MsSqlServerEventStore.cs) and NEventStore (https://github.com/NEventStore/NEventStore/blob/master/src/NEventStore/Persistence/Sql/SqlPersistenceEngine.cs) are among the most popular. Ncqrs is used as a case study in the following short section.
Choosing a Schema
When you’re choosing to use SQL to store events and streams, an important consideration is schema. Those who have built event stores on top of SQL suggest being minimalistic with schema while storing event data as blobs of XML or JSON. The recommendation is a generic, domain-agnostic schema like the one shown in Listing 22-25.
One difference to the RavenDB event store you previously saw is that this schema uses [uniqueidentifiers], also known as GUIDs, as the ID for an event stream (referred to in Listing 22-25 as an event source). In your application, you can get away with whichever type you prefer. Apart from that difference, you can see a similarity to the RavenDB-based approach, where each event is a unique record, and the concept of a stream is a logical one that relies on associating events by the ID of the stream they belong to.
Creating a Stream
Most of the implementation of the Ncqrs event store is obviated by the schema. For example, creating a new stream is simply a case of adding a new record to the EventSources table. This is exemplified in Listing 22-26. Do note that Ncqrs uses the term event source, which is what has been referred to as an event stream elsewhere in the chapter.
Saving Events
The schema also obviates saving events. Listing 22-27 demonstrates this by showing how each event is added as a new row in the Events table, with a reference to the event stream it belongs to.
Loading Events from a Stream
Listing 22-28 uses a sample from Ncqrs that reads events from a stream. This is akin to IEventStore.GetStream() shown earlier in the chapter, and with similar logic. All events that reference the passed-in stream name (id) are returned if they fall within the range of the supplied minVersion and maxVersion.
You can see the full implementation of ReadEventFromDbReader() referenced in Listing 22-28 on GitHub (https://github.com/ncqrs/ncqrs/blob/master/Framework/src/Ncqrs/Eventing/Storage/SQL/MsSqlServerEventStore.cs).
Snapshots
A dedicated table is used to store snapshots in Ncqrs. Using the ID of event stream (also known as an event source), Listing 22-29 shows how snapshots are saved, and Listing 22-30 shows how they are loaded.
Is Building Your Own Event Store a Good Idea?
During the early days of event sourcing, there were no commercial tools. Instead, developers had to build event-sourcing capabilities on top of existing technologies like SQL databases or document databases, as shown in this section. This means that it’s definitely achievable. But if you move on to more advanced scenarios like projections, complex temporal queries, and enhancing scalability, you may find you are spending a lot of time away from adding business value. This is why you may want to consider a purpose-built technology like Greg Young’s Event Store (also known as the Event Store) that provides many advanced features out of the box.
Using the Purpose-Built Event Store
Choosing to use an existing event store reduces the amount of work you have to do up front to get started with event sourcing. Also, by choosing an event store like Greg Young’s Event Store, you get many additional features out of the box, including advanced projections and multinode clustering for highly scalable environments. To demonstrate using event store, the examples in this section remain oriented around the pay-as-you-go service offered by a fictitious cell phone network operator. You see how to build an alternative IEventStore implementation using the Event Store C# client library, as well as running queries and projections in the admin web UI. To work through these examples, you need Event Store installed on your machine.
Installing Greg Young’s Event Store
To run projections, Event Store version 3.0.0 rc2 is required (http://download.geteventstore.com/binaries/eventstore-net-v3.0.0rc2.zip). Once you’ve downloaded the zip file, you need to extract it to a folder of your choice. From within the directory you extract to, you can start Event Store with the following PowerShell command. You need to start PowerShell with Administrator privileges.
.EventStore.SingleNode.exe ––db .ESData ––run-projections=allA few tweaks are necessary to enable projections. By navigating to the admin web UI (http://localhost:2113/projections), you can enable projections by accessing the Projections tab and starting the following projections: $by _ category and $stream _ by _ category. (Click on the link and then click the Start button.)
Using the C# Client Library
You can take advantage of Event Store in your applications by writing a persistence layer that uses the official Event Store C# client library. Alternatively, Event Store has a Hypertext Transport Protocol (HTTP) API that you will see in Chapter 26: “Queries: Domain Reporting.” In this example, you see a new implementation of IEventStore that can be switched with the RavenDB version you created earlier in the chapter. This implementation relies on the following NuGet packages:
Install-Package EventStore.Client -version 2.0.2.0
Install-Package Newtonsoft.Json -version 6.0.3EventStore.Client is the official client library, created by the Event Store team. It uses TCP to communicate with Event Store. Newtonsoft.Json is necessary because events are stored as JSON; therefore, they need to be serialized to and from C# classes. Listing 22-31 shows the GetEventStore implementation of IEventStore that provides concrete examples of these details.
It’s worth spending a few moments looking at Listing 22-31. Notice how using a purpose-built event store requires less work than the RavenDB or SQL Server-based approaches shown earlier in the chapter. Two noticeable examples of this are querying for events and optimistic concurrency support. When querying for events in GetEventStream(), you simply pass in the name of the stream with a starting version and number of events to retrieve. In the RavenDB solution, there was a moderately complex query with a number of clauses. This is because Event Store natively supports the concept of a stream, rather than logically simulating one.
Native stream support is also the reason optimistic concurrency is less work to implement. As you can see with Event Store’s IEventStoreConnection.AppendToStream(), you only have to pass in the expected version number of the last stored event; Event Store takes care of all the optimistic concurrency checking and management for you.
One advantage that RavenDB does have is that it deals with the serialization to JSON and back. In Listing 22-31, you can see that the type of the event—the name of the C# class—is stored as a header in MapToEventStoreStorageFormat(). This header is then used on the way back out when events are reconstructed from JSON, as shown in RebuildEvent(). In both cases, there is a need to coordinate the serialization and deserialization logic yourself.
Snapshot support is implemented by creating a new event stream for each aggregate’s snapshots. Using a purpose-built Event Store shines for this use case as well. You can see in GetLatestSnapshot() that you can make a single query to retrieve the latest snapshot by really leaning on IEventStore.ReadStreamEventsBackwards(), passing in 1 as the number of events to return.
One important detail that isn’t shown is creating the initial connection to Event Store. Listing 22-32 shows how you can use the client library’s EventStoreConnection.Create() to do this.
LISTING 22-32 shows how to create a TCP connection to an Event Store instance running locally on the default port of 1113. However, you should change the port and address to those that you configured Event Store to run on.
Running Temporal Queries
Greg Young and the Event Store team have decided that JavaScript is the best tool for making queries and creating projections. Shortly, you will see examples of creating temporal queries in Event Store’s user-friendly web UI. First, though, you need to import some data into your locally running version of Event Store. This chapter’s sample code contains a class called ImportTestData in the EventStoreDemo project. This has a TestMethod that you can run from within Visual Studio, and it populates Event Store with a number of events for a collection of PayAsYouGoAccount aggregates. Once you have run the test, you can see the newly created streams and their events by navigating to the Stream tab in the web UI (http://localhost:2113/web/streams.htm). You should see activity similar to Figure 22.4, indicating that the streams were created.

FIGURE 22.4 Event Store’s stream tab indicating the test data was successfully inserted.
Querying a Single Stream
Despite sounding a bit fancy, temporal queries don’t have to be big and complicated. A short query that might be useful is showing a customer how many minutes he used on a given day. It could be the current day, or it could be a date in the past. This helps customers understand if they are using their phone too much. Listing 22-33 shows the JavaScript needed for this query.
Queries in Event Store begin when you specify which events you want to query. In Listing 22-33, fromStream() is specifying that the query should apply to all events in a single stream representing a single PayAsYouGoAccount. You can get the ID of an event stream from the Streams tab in the web UI. Each event in the stream, starting with the oldest, is then passed into when(). Inside when() is a pattern match that determines which events are handled and how. In Listing 22-33, you can see that only events of type PhoneCallCharged are handled.
The result of an Event Store query is a JavaScript object known as the state of the query. This object is passed into when() with each event and is updated repeatedly as per your query logic. You can see that the state in Listing 22-33 is initialized inside the $init handler as a JavaScript object with a single property called minutes. It’s up to you to decide the structure of this state in each of your queries. It just has to be valid JavaScript. Listing 22-33 uses the state by augmenting its minutes property each time a PhoneCallCharged event, which represents a phone call on June 4, is handled.
After running the query in Listing 22-33 on the Query tab of Event Store’s web UI (http://localhost:2113/web/query.htm), you will see output similar to Figure 22.5.

FIGURE 22.5 Result of running a query in the Event Store web UI.
Figure 22.5 shows how Event Store displays the results of a query as its final state in the right State pane. As mentioned, you determine the structure of the state yourself and can have whatever properties are necessary. For example, you might want to enhance the query in Listing 22-33 to keep a total for the number of minutes used on multiple dates, where each date is a separate property on the state. This query is shown in Listing 22-34.
In Listing 22-34, the state contains three properties, corresponding to each date. Each of these properties is increased by the number of minutes used up during phone calls on the relevant date.
Querying Multiple Streams
Event Store is not limited to querying a single stream. For many use cases, it’s important to combine data from multiple streams, akin to joins in SQL. Listing 22-35 shows how the combined total minutes used on each date can be calculated for all pay-as-you-go accounts.
Event Store’s fromCategory() works by combining all streams whose name begins with the passed-in name, suffixed with a hyphen. For example, the query in Listing 22-35 matches all events in all streams whose name begins with PayAsYouGoAccount-. However, a small gotcha is that Event Store looks for the last hyphen. This is the reason for the private StreamName() method in the GetEventStore class shown in Listing 22-35, which removes all but the first hyphen.
Creating Projections
Instead of just calculating state, sometimes you want the ability to take subsets of events and create an entirely new stream from them. This can be crucial in a large system with millions or billions of events. Take the cell phone network operator, for example; if there a millions of customers each with lots of account activity, there could easily be billions of events. It would be inefficient to run queries across all of them. Projections solve this problem by letting you select only events that you are interested in by putting them in a new stream and then running your query against the newly created stream. Listing 22-36 shows a projection that groups all the top ups made by all customers into a new stream called AllTopUps.
Running the projection in Listing 22-36 causes all CreditAdded events that exist in any PayAsYouGoAccount stream to be added to a new stream called AllTopUps. This means it is possible to run queries against all the CreditAdded events without having to load all the other events in the streams like PhoneCallCharged. Event Store’s key tool for providing this behavior is linkTo(), which adds a link in the stream whose name matches the first argument (AllTopUps in this example) to the passed-in event. Projections are run by navigating to the Projections tab, choosing New Projection, and filling out the form, as per Figure 22.6.

FIGURE 22.6 Creating a projection in the web UI.
Figure 22.6 shows a one-time projection being created. However, the Select Mode field can instead be set to Continuous. This is useful when you want the projection to be applied to new events as they are stored in near-real time. CQRS is a common example of where you might want to do this, as you will see shortly.
You can learn a lot more about the projection capabilities of Event Store on the official blog (http://geteventstore.com/blog/). There is a multipart series devoted to projections (http://geteventstore.com/blog/20130309/projections-8-internal-indexing/index.html).
CQRS with Event Sourcing
As a way to improve performance and scalability, you may want to create materialized views of your events. Doing so prevents the need for many queries to continually be run against a single event stream. Instead, precomputed values will be available for each specific need. A scenario that demonstrates this problem occurs when a number of web pages all run different queries against a single event stream, as shown in Figure 22.7.
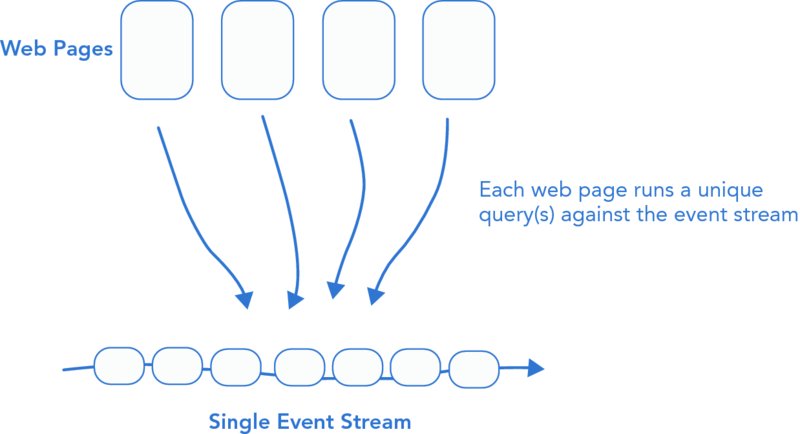
FIGURE 22.7 One event stream used to support many different queries and use cases.
As load increases on any of the web pages, the single event stream is put under increasing amounts of stress. This means that less important pages may substantially degrade the performance of important pages. A solution to this problem is to create a new materialized view of the data to support each page, as shown in Figure 22.8.

FIGURE 22.8 Creating materialized/denormalized views of the event stream to support each use case.
The solution in Figure 22.8 is CQRS; where commands (writes) go via the domain model to the event stream, and queries (reads) are run against the materialized views (also known as view caches). You can see that the problem of certain use cases impeding others is heavily mitigated because each has its own view cache for querying. As a direct benefit, you can see contention on the single event stream has been lessened; now fewer (if any) taxing ad hoc queries are run against it.
This section is just a quick glimpse of CQRS and how it synergizes with event sourcing. In Chapter 24: “CQRS: An Architecture of a Bounded Context,” you will see a more in-depth discussion of CQRS, including how you can apply it to a variety of scenarios that don’t involve event sourcing.
Using Projections to Create View Caches
To implement CQRS with event sourcing, you need some way to create denormalized views from your event streams. The answer is to use projections that were previously introduced. The materialized views in Figure 22.8 are examples of where projections can be used for CQRS.
As you’ve seen previously in this chapter, if you’re using a purpose-built tool like Event Store, you already have the functionality to use projections and implement CQRS. However, when building an event store of your own, you need to create the functionality yourself, which might not be a trivial task. Fortunately, RavenDB provides the capability to create projections (http://ayende.com/blog/4530/raven-event-sourcing).
CQRS and Event Sourcing Synergy
Although CQRS and event sourcing are standalone concepts that you can use independently of the other, a strong following of developers find a significant advantage from combining them. Figure 22.6 illustrated the ease at which you can create view caches as projections from event streams. But there are other synergistic benefits, too.
Event Streams as Queues
One of the examples in Chapter 13: “Integrating via HTTP with RPC and REST,” showed how Event Store exposes event streams as a hypermedia Atom feed. This was an alternative to using a message bus. Again, the benefit of this is that your event store saves your having to use a queue; likewise, it saves your having to use another technology for view caches and another for the denormalization process.
No Two-Phase Commits
Because an Event Store is your main source of data, the tool you use for projections, and your queueing technology, there are no two-phase commits (or distributed transactions) to worry about. Once an event is in a stream, it is successfully in the queue and has successfully been saved. In contrast, if you were storing events in a database, publishing them with a message bus, and updating a view cache in another database all inside the same transaction, you may have to carefully plan how a failure in either of these actions would be handled, such as rolling back the others. Greg Young further details this on his blog (http://codebetter.com/gregyoung/2010/02/13/cqrs-and-event-sourcing/).
Recapping the Benefits of Event Sourcing
If this is your first encounter with event sourcing, you may still be processing some of the details and building a mental model. That’s completely understandable and something that everyone goes through. This section recaps some of the benefits that event sourcing can bring to your projects. Hopefully, at least if you don’t remember all the details, you will still have an understanding of when you might want to consider using event sourcing.
Competitive Business Advantage
This chapter began by discussing the fundamental rationale for using event sourcing: allowing the business to gain a competitive advantage by being able to analyze not just its data, but the entire history of behavior that produced the current state of its data. If two companies are competing in a market and one is able to lean on event sourcing to perform powerful analysis, it may be able to use the knowledge to expedite development of its products or services.
Expressive Behavior-Focused Aggregates
Communicating with domain experts is a significant aspect of applying DDD and realizing its benefits. To support this, it’s important to have a domain model that expresses the conceptual model using the ubiquitous language (UL). As you saw earlier in this chapter, event-sourced aggregates are almost declarative, with each overload of When() reading like a sentence:
When {Domain Event} {Apply Business Rules}This makes the domain model even more useful in knowledge-crunching sessions. Even in general, it can speak much more clearly to other developers who might be new to the domain or codebase.
Simplified Persistence
Persisting aggregates with Object Relational Mappers (ORMs) has traditionally been a topic of controversy and a source of pain for many software teams due to the impedance mismatch. As you saw in this chapter, persisting and rehydrating events from an event stream do not suffer from this problem because there is no impedance mismatch. This means that the ORM technology does not constrain the database model or require complex mappings. In fact, with event sourcing, there is a real possibility that you can change the persistence technology with polymorphism. You saw in this chapter that multiple implementations of IEventStore can be switched as necessary.
It’s worth noting that the IEventStore abstraction does have small leaks, so there’s no guarantee you can easily switch out an event storage provider with another. One example is the stream names; Event Store’s fromCategory() is based on the last hyphen in the name. You did see, though, that there was an easy workaround for this in GetEventStore.
Superior Debugging
Earlier in the chapter you saw how event sourcing can make systems easier to debug. If you think about it, you have the entire history of behavior stored in your event store. So you can easily rerun any sequence of events to work out which event caused an incorrect state change or some other type of bug. You don’t have to guess about the sequence of events that may have led to a problem occurring.
Weighing the Costs of Event Sourcing
It’s important to be realistic about the negative aspects of event sourcing, too. Even event store vendors are advising people to think carefully about where to use it. You need to invest additional time, and the payback may not always be worth it—especially because there are a number of different considerations that may be demanding of your time.
Versioning
As you learn more about the domain and you continue to enhance the product(s) you are building, new concepts and information need to be added to the domain model. As a result, you may need to rename events, move data between events, or perform some other change that alters the format of your events. This presents a big problem, because you will already have an event stream containing events in the old format(s). There are solutions to this problem, and they don’t always require much effort. However, versioning can definitely be a problem if you don’t pay it enough respect.
New Concepts to Learn and Skills to Hone
Projections, temporal queries, snapshots—many concepts may be new to a team that is choosing to use event sourcing for the first time. As with many things, you need to combine theory with practical experimenting before you become proficient, so you should be prepared for your team’s rate of development to be slower in the short term. You may also consider allocating time for learning and experimentation. These costs may apply to some extent anytime someone new joins the team who is unfamiliar with event sourcing.
New Technologies to Learn and Master
You can reuse existing database technologies like SQL Server for event sourcing, but it’s likely that many will choose to use a purpose-built event store. The cost of this is the extra time it takes to learn the technology—not just using it, but running it on live servers and monitoring its behavior and resource usage. It’s hard to quantify just how much, but putting an event store into production for the first time almost certainly requires an investment in people hours.
Greater Data Storage Requirements
It’s obvious that storing the entire history of activity that led to the state requires more information to be stored on disk than just storing state. Fortunately, storage is incredibly cheap nowadays, and this is unlikely to be a concern for many. However, it is something that you should keep in mind and monitor accordingly.
Additional Learning Resources
- Event Store provides a technology-agnostic discussion of event sourcing—http://docs.geteventstore.com/.
- Martin Fowler has an article on event sourcing—http://martinfowler.com/eaaDev/EventSourcing.html.
- Jérémie Chassaing has a number of event sourcing articles on his blog—http://thinkbeforecoding.com/tag/Event%20Sourcing.
- Lev Gorodinski shows how to apply DDD and event sourcing with F#—http://gorodinski.com/blog/2013/02/17/domain-driven-design-with-fsharp-and-eventstore/.
- Event sourcing with Akka (Scala or Java)—http://doc.akka.io/docs/akka/snapshot/scala/persistence.html.
- The DDD/CQRS Google group—https://groups.google.com/forum/#!forum/dddcqrs.
The Salient Points
- Event sourcing replaces traditional snapshot-only storage with a full history of events that produce the current state.
- You can rewind the state to any previous point in history with event sourcing.
- Storing history allows powerful querying capabilities that revolve around time—temporal queries.
- Temporal queries can be a game-changing business capability, allowing greater analytical insights.
- Domain models need to contain event-oriented aggregates when using event sourcing.
- Event-sourced aggregates allow for the declarative expression of business rules and looser coupling to the persistence technology.
- You can implement an event store using existing storage options like document databases and SQL Server.
- Event Store is a purpose-built event store that natively supports the concept of streams and provides advanced functionality, like projections.
- CQRS and event sourcing are a synergistic combination that uses projections to create view caches.
- Event sourcing can often be a lot of effort without a worthwhile return on investment, so don’t use it without careful consideration