
19
Aggregates
WHAT’S IN THIS CHAPTER?
- How to deal with complex entity and value object relationships
- Why the aggregate is the most powerful tactical pattern
- How to size and structure aggregates
- The role of the aggregate root
- Understanding aggregate consistency guidelines
Wrox.com Code Downloads for this Chapter
The wrox.com code downloads for this chapter are found at www.wrox.com/go/domaindrivendesign on the Download Code tab. The code is in the Chapter 19 download and individually named according to the names throughout the chapter.
A domain model’s structure is composed of entities and value objects that represent concepts in the problem domain. It is, however, the number and type of relationships between domain objects that can cause complexity and confusion when implementing a domain model in code. Associations that do not support behavior and exist only to better reflect reality add unnecessary complexity to a domain model. Associations that can be traversed in more than one direction also increase complexity. This is why designing relationships between domain objects is equally as important as designing the domain objects themselves.
Even when all associations in a model are justified, a large model still has technical challenges, making it difficult to choose transactional and consistency boundaries that both reflect the problem domain and perform well.
This chapter covers best practices for keeping the relationships between domain objects simple and aligned with domain invariants. It also introduces the Domain-Driven Design (DDD) concept of an aggregate—a consistency boundary that decomposes large models into smaller clusters of domain objects that are technically easier to manage. Both of these topics focus on helping you manage complexity within your domain models.
Aggregates are an extremely important pattern at your disposal when designing a domain model. They help you manage technical complexity, and they add a higher level of abstraction that can simplify talking and reasoning about the domain model.
Managing Complex Object Graphs
During the early stages of designing a model, novice DDD practitioners tend to focus on the entities and value objects of the domain, paying little attention to the relationships between the domain objects. They often default to associations that mirror real life or, even worse, the underlying data model. The result of not justifying each association and ensuring it matches a domain invariant is a domain model that hides important concepts, confuses both domain experts and developers, and is technically challenging to implement.
Dependencies can become overwhelming, especially when you have many-to-many relationships. It’s important to remind yourself that the domain model is not the same as the data model. And, perhaps just as important, the purpose of the domain model is to support invariants and uses cases rather than user interfaces.
Avoiding complex object graphs doesn’t have to be difficult. You can easily reduce the number of associations between entities and value objects by only allowing relationships in a single direction. To decrease the number of relationships, you can justify their inclusion. If the relationship is not required (does not work to fulfill an invariant), don’t implement it. Basically, don’t model real life. The relationship may exist in the problem domain, but it may not provide a benefit by existing in your code.
To summarize, modeling domain object associations based on the needs of use cases and not real life can ensure a simpler domain model and a more performant system. Associations between domain objects are there to support invariants, not user interface concerns. Simplify associations in object graphs. Model relationships from the point of view of a single traversal direction. Simplify the model, and you will make it easier to implement and maintain in code.
Favoring a Single Traversal Direction
A model that is built to reflect reality will contain many bidirectional object relationships. This means that two objects contain a reference to each other. Take the example of a procurement system, as shown in Figure 19.1. You can traverse between Supplier and PurchaseOrders in both directions. Similarly, you can traverse from a Supplier to all the Products that they can supply and back from a Product to the collection of Suppliers that it is available from. You also can traverse from a PurchaseOrder to the list of Products that it contains and from a Product to the list of purchase orders that have been raised against it. ORMs have made it too easy to create these types of bidirectional relationships in code, which can lead to deep object graphs and degraded runtime performance.

FIGURE 19.1 Complexity-causing bidirectional relationships.
Is it really necessary to load all the Products a Supplier has when you only want to make a change to its contact details? Does it matter if a Product does not have a navigable list of Suppliers? As you can see, a bidirectional relationship adds technical complexity and obscures domain concepts. An especially important domain concept that it hides is the owner of the relationship. To simplify the relationship, you can constrain it to a single traversal direction, as shown in Figure 19.2.
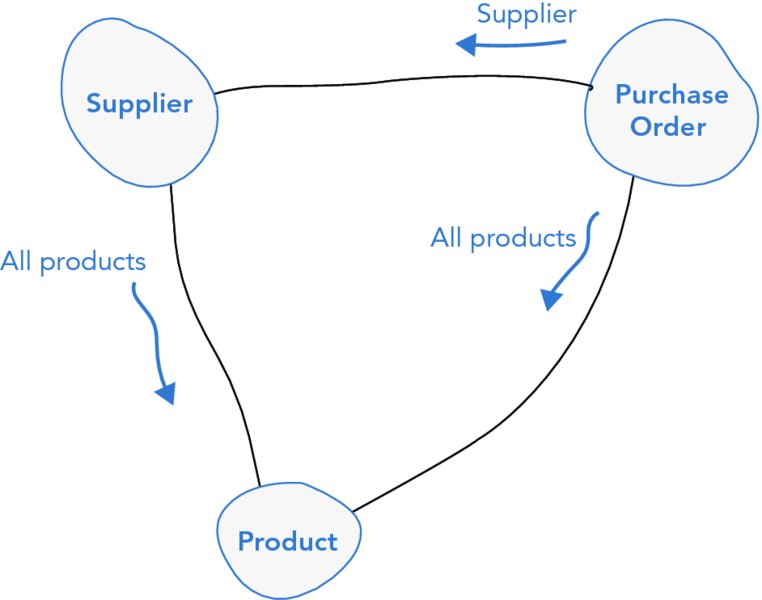
FIGURE 19.2 Constraining a bidirectional association.
By selecting a uni-directional relationship between the entities the domain model has been simplified. Essentially, a bidirectional relationship has been converted into a unidirectional relationship. This is a fundamental pattern for reducing complexity that you can be liberal with.
When defining object relationships, it is good practice to ensure that you explicitly ask: What is the behavior that an association is fulfilling, and who needs the relationship to function? This will help you avoid creating unnecessary bidirectional relationships. The procurement scenario is a simple example, but in a larger domain model with many bidirectional associations, things can quickly become extremely complicated, especially when it comes to persistence and retrieval.
Qualifying Associations
If you are implementing associations as object references to support domain invariants and those associations are one- or many-to-many, you should qualify the associations to reduce the number of objects that need to be hydrated. Consider Figure 19.3. The domain object Contract represents a mobile phone contract, and Calls represents all calls made on that contract. Calls is required to understand how many free minutes are available for the current period so that a customer can be billed correctly. Customers on the twenty-third month of a 24-month contract will have many hundreds of call data. Loading all these Calls reduces the performance. However, this is inefficient and unnecessary if all the invariant requires is the calls for the current period to compute any remaining free minutes.

FIGURE 19.3 Qualifying associations.
To qualify the association, only the calls for the current period can be retrieved, as highlighted in Figure 19.4.

FIGURE 19.4 Qualifying associations with filter criteria from the Ubiquitous Language (UL).
To optimize performance, you can apply this qualification at the data access/database level using the following code snippet.
In general, the greater the number of items in an associated collection—the cardinality—the more complex the technical implementation will become. Therefore, aim for lower cardinality by adding constraints to collections. It’s best to be explicit when it comes to collections; don’t fall into the trap of simply re-creating the data model in code.
Preferring IDs Over Object References
As repeated throughout this book, the primary purpose of your domain model is to model the invariants of your system to support business use cases. Therefore, relationships between domain objects should exist only for behavioral needs. Relationships that do not support behaviors can increase complexity in the implementation of the domain model. Object references are the classic example of adding unnecessary, complexity-increasing relationships to a domain model.
Understandably, many developers find the natural way to model a relationship in code as an object reference. For example, in real life a customer has many orders, but in the solution space of the application, there may be no invariant that requires a Customer object to hold a collection of all Orders belonging to that customer. Modeling this relationship using object references, as shown in Figure 19.5, adds unnecessary complexity.

FIGURE 19.5 Modeling relationships with object references increases complexity.
Because every association is implemented as an object reference, to place an order, you could use the following code to traverse the object graph.
This code could be slow because a large object graph (the Customer and all its existing Orders) needs to be loaded for the basic use case of placing an order. All that really needs to happen is for the retrieved customer to have an order added to its collection with the default delivery address of the customer set as the order dispatch address. But many of the objects loaded are not involved in the use case. These problems arise because the relationship is modeled as an object reference, requiring all objects in the object graph to be loaded from persistence collectively. You might argue that lazy loading makes the problems go away, but lazy loading can further complicate the model; also, it communicates little of how the domain objects are used to fulfill business cases.
The alternative method to implement associations is storing the ID of the object and using a repository within an application service to fetch domain objects that are required for a use case. By using the repository, you can reduce the object references in the model and therefore the complexity. Figure 19.6 shows the clearer object model without the unnecessary object references.

FIGURE 19.6 Simplified relationships using IDs instead of object references.
By preferring IDs and repositories, you need to carry out the coordination in an application service, as shown in Listing 19-4. In this case, the call to _addressBookRepository.FindBy() is the alternative to having an object reference on the Customer object itself.
You can ascertain if an object reference is necessary by asking the question: Is the association supporting a domain invariant for a specific use case? In the example of customers and orders, a Customer has Orders, but an Order only needs a Customer’s ID to meet invariants; it doesn’t require a navigable reference. Try not to carelessly model real life or add a traversal object reference to match the data model; add object references only when they are necessary to meet the requirements of an invariant. In all other cases, favor IDs and repositories to reduce the coupling in your domain model.
Figure 19.7 visualizes the common structure of a domain model that needlessly models real life and contains a proliferation of object references. Alternatively, Figure 19.8 shows a partitioned model with fewer associations between objects, favoring IDs instead of object references. If you follow the advice in this section, Figure 19.8 is what you should be aiming for if you want an explicit domain model with reduced technical complexity. In the remainder of this chapter, you will see how DDD aggregates help you achieve it.

FIGURE 19.7 Complex domain model with an abundance of unnecessary associations.

FIGURE 19.8 Clearer domain model based only on essential associations.
Aggregates
Reducing and constraining relationships between domain objects simplifies the technical implementation and reflects a deeper insight into the domain. This is highly desirable for making the code easier to manage and concepts easier to communicate, but there is still a need to judiciously group objects that are used together so that a system performs well and is reliable. Aggregates help you achieve all these goals by guiding you into cohesively grouping objects around domain invariants while also acting as a consistency and concurrency boundary.
Aggregates are the most powerful of all tactical patterns, but they are one of the most difficult to get right. There are many guidelines and principles you can lean on to help with the construction of effective aggregates, but often developers focus only on the implementation of these rules and miss the true purpose and use of an aggregate, which is to act as a consistency boundary.
Design Around Domain Invariants
Domain invariants are statements or rules that must always be adhered to. If domain invariants are ever broken, you have failed to accurately model your domain. A basic example of an invariant is that winning auction bids must always be placed before the auction ends. If a winning bid is placed after an auction ends, the domain is in an invalid state because an invariant has been broken and the domain model has failed to correctly apply domain rules.
Using invariants as a design heuristic for aggregates makes sense because invariants often involve multiple domain objects. When all domain objects involved in an invariant reside within the same aggregate, it is easier to compare and coordinate them to ensure that their collective states do not violate a domain invariant.
In the winning bid scenario, both the auction and the winning bid would be modeled as different objects. If both of them resided within a different aggregate, no single aggregate would have a reference to both objects and thus be able to ensure that at no point was the invariant broken, even temporarily. This is bad because invariants should never be broken.
Higher Level of Domain Abstraction
By grouping related domain objects, you can refer to them collectively as a single concept—a desirable characteristic that lets you communicate and reason more efficiently. Aggregates afford these benefits of abstraction to your domain model by allowing you to refer to a collection of domain objects as a single concept. Instead of an order and order lines, you can refer to them collectively as an order, for example.
Consistency Boundaries
To ensure a system is usable and reliable, there is a strong need to make good choices about which data should be consistent and where transactional boundaries should lie. When applying DDD, these choices arise from grouping objects that are involved in the same business use case(s). These cohesive groups of domain objects are aggregates.
Transactional Consistency Internally
One option for consistency is to have a single aggregate by wrapping the entire domain model in a single transactional boundary. The problem with this is that in a collaborative domain when many changes are being performed there is the potential for a conflict for changes that are completely unrelated. The problem would likely manifest as blocking issues at the database level or failed updates (due to pessimistic concurrency).
Figure 19.9 demonstrates problems that can arise through choosing suboptimal transactional boundaries that span too many objects. User A wants to add an address to a customer record, whereas user B wants to change the state of the same customer’s order. There are no invariants that state while an order is being updated the personal details of a customer cannot change, but in this scenario if both updates are made at the same time, one of the user’s changes will be blocked or rejected.

FIGURE 19.9 Locking caused by large transactional boundary.
You might be tempted to assume that having no transactional boundaries would solve all the problems. That would be dangerous, though, because then consistency problems can arise that cause domain-invariant violations. Figure 19.10 shows how two different users are updating the same order; one is applying a discount code to the order, while another is modifying an order line. Because there is no concurrency check and the change is not transactional, both changes will be made, resulting in a broken invariant. In this case, the order could have a massive discount applied that is no longer applicable.

FIGURE 19.10 Inconsistent data arising from lack of transactional boundaries.
To correctly apply consistency and transactional boundaries, DDD practitioners rely on the aggregate pattern. As alluded to, an aggregate is an explicit grouping of domain objects designed to support the behaviors and invariants of a domain model while acting as a consistency and transactional boundary. An aggregate treats the cluster of domain objects as a conceptual whole in that there are no order lines—only an order. The order lines do not exist or make sense outside the concept of an order. The aggregate defines the boundary of the cluster of domain objects and separates it in terms of consistency and transactional mechanism from all other domain objects outside it.
Figure 19.11 shows the result of applying invariant-driven aggregate design to the order example. You can see the customer and order are treated as two independent aggregates because there are no invariants in the domain that involve both of them.
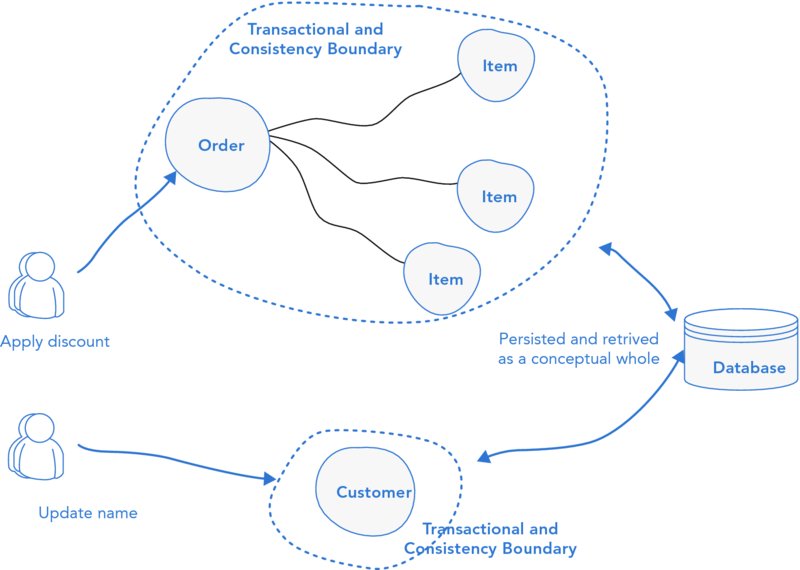
FIGURE 19.11 Aligning transactional boundaries with domain invariants.
To enforce consistency in the cluster of domain objects, all interaction needs to go through a single entity known as the aggregate root (explained in more detail later in the chapter), as highlighted in Figure 19.12. Objects outside of the aggregates can have no access to any of the internal objects of the aggregate; this ensures control of the domain objects and ensures consistency within the aggregate.

FIGURE 19.12 Enforcing consistency with help from aggregate roots.
Domain objects are not retrieved or persisted individually. The aggregate as a whole is pulled from and committed to the datastore via a repository. Aggregates are the only things that can be persisted and retrieved from the database. No parts of the aggregates can be separately pulled from the data store unless it is purely for reporting. This leads to eventual consistency between aggregates.
Eventual Consistency Externally
Because aggregates are persisted and retrieved atomically, as a conceptual whole, a rule that spans two or more aggregates will not be immediately consistent (if only one aggregate is modified per transaction). Instead, the rule will be eventually consistent. This is because the aggregate being updated only ensures transactional consistency internally. It is not responsible for updating anything outside its consistency boundary. Therefore, aggregates sometimes have a stale piece of information they retrieved from another aggregate, as shown in Figure 19.13.

FIGURE 19.13 Aggregates are eventually consistent externally.
To demonstrate an eventually consistent rule spanning multiple aggregates, consider a loyalty policy: If a customer has spent more than $100 in the past year, she gets 10% off all further purchases. In the domain model, there are separate order and loyalty aggregates. When an order is placed, the Order aggregate is updated inside a transaction exclusively. At that point, the Loyalty aggregate does not have a consistent view of the customer’s purchase history because it was not updated in the same transaction. However, the Order aggregate can publish an event signalling the order was created, which the Loyalty aggregate can subscribe to. In time the loyalty object will be able to update the customer’s loyalty when it handles the event, as Figure 19.14 shows.

FIGURE 19.14 Eventually consistent Loyalty aggregate.
Importantly, there is a period in which a customer’s loyalty does not accurately reflect how much she has spent. This is an undesirable characteristic in isolation, but as a trade-off it prevents you from having to save lots of objects within a single transaction.
It is vital that you get business buy-in when designing eventually consistent aggregates due to user experience drawbacks and edge cases that may occur due to out-of-sync aggregates.
Special Cases
Sometimes it is actually good practice to modify multiple aggregates within a transaction. But it’s important to understand why the guidelines exist in the first place so that you can be aware of the consequences of ignoring them.
When the cost of eventual consistency is too high, it’s acceptable to consider modifying two objects in the same transaction. Exceptional circumstances will usually be when the business tells you that the customer experience will be too unsatisfactory. You shouldn’t just accept the business’s decision, though; it never wants to accept eventual consistency. You should elaborate on the scalability, performance, and other costs involved when not using eventual consistency so that the business can make an informed, customer-focused decision.
Another time it’s acceptable to avoid eventual consistency is when the complexity is too great. You will see later in this chapter that robust eventually consistent implementations often utilize asynchronous, out-of-process workflows that add more complexity and dependencies.
To summarize, saving one aggregate per transaction is the default approach. But you should collaborate with the business, assess the technical complexity of each use case, and consciously ignore the guideline if there is a worthwhile advantage, such as a better user experience.
Favor Smaller Aggregates
In general, smaller aggregates make a system faster and more reliable, because less data is being transferred and fewer opportunities for concurrency conflicts arise. Accordingly, you should have a bias for small aggregates during design. Try starting small and justifying the addition of each new concept to the aggregate. However, it is still crucial to faithfully model the domain so the size of an aggregate is not the only criteria of good design.
Some consequences of large aggregate design will now be discussed so that you can consciously design aggregates rather than just aimlessly try to make them small. Sometimes you will benefit by having larger aggregates, so understanding when the guidelines don’t apply is useful.
Large Aggregates Can Degrade Performance
Each member of an aggregate increases the amount of data that needs to be loaded from and saved to a database, directly affecting performance. Performance can really be harmed, though, when an aggregate spans many tables or documents in a database. Each table requires an additional query or join, which can definitely hurt the local performance of the query and potentially the overall stress on database servers.
Admittedly, the overhead of big aggregates could be inconsequential in many cases. But at the other extreme, the performance degradation may be severe enough to have a damaging business impact. By aiming for smaller aggregates, you reduce the risk of performance problems. If you do ever need to make performance optimizations, a smaller aggregate means compromises to your domain model can be confined to a smaller area.
Large Aggregates Are More Susceptible to Concurrency Conflicts
A large aggregate is likely to have more than one responsibility, meaning it is involved in multiple business use cases. Subsequently, there is greater opportunity for multiple users to be making changes to a single aggregate. As a further consequence, the likelihood of a concurrency conflict increases, reducing the usability and user satisfaction of your application.
You can use this knowledge when you design your aggregates. You can quantify the number of business use cases an aggregate is involved in. The higher the number, the more you should question your aggregate boundaries and experiment with alternative designs. Again, though, domain alignment is important. Sometimes a single use case might be the optimal number, whereas some aggregates might genuinely be necessary in multiple business use cases.
Large Aggregates May Not Scale Well
Aggregate design is also influenced by scalability concerns. Larger aggregates may span many database tables or documents. This is a form of coupling at the database level, which may prevent you from relocating or repartitioning subsets of the data that have a negative impact on scalability.
With domain-focused aggregates, there are fewer dependencies between your data. This enables you to refactor or relocate data on a more granular basis. For example, if you were working on an e-commerce system and wanted to move just the order data into a different database, there would be less friction than if you had to repartition your aggregates so that order data was not unnecessarily coupled to other kinds of data, such as customer addresses or loyalty.
You can find many stories online of companies relocating parts of their data into different databases. In fact, this trend has been coined polyglot persistence. One high-profile example is British broadcasting giant Sky, which decided to move storage of its online checkout data from MySQL to Cassandra (http://www.computerworlduk.com/in-depth/applications/3474411/sky-swaps-oracle-for-cassandra-to-reduce-online-shopping-errors/) to combat severe performance degradations as it rapidly acquired new online customers.
In many cases, each bounded context having its own datastore (see Chapter 11, “Introduction to Bounded Context Integration”) makes for a solid foundation for scalability. But in some cases, you may have hotspots within a bounded context; favoring smaller aggregate design may put you in good shape to deal with them.
Defining Aggregate Boundaries
An aggregate’s boundary determines which objects will be consistent with each other and which domain invariants will be easy to enforce. It is arguably the most important aspect of designing an aggregate. This section contains a number of principles that can help you decide which objects should be grouped as an aggregate.
eBidder: The Online Auction Case Study
To provide a realistic example of defining aggregates, in this section you follow a fictitious application that is based on the domain of an online auction site, somewhat like eBay, called eBidder. Figure 19.15 shows the bounded contexts that have been defined for the solution space.

FIGURE 19.15 eBidder bounded contexts.

FIGURE 19.16 Listing bounded context aggregates.
The Listing bounded context deals with the items for sale and the format that they are being sold in, whether that is an auction or a fixed price. The Disputes bounded context covers any disputes raised between a seller and member over a listing. The Membership bounded context covers membership to the eBidder site. Finally, the Selling Account bounded context looks after fees and selling activities. In this section, just the Listing bounded context is used to demonstrate aggregate design principles.
Figure 19.16 shows the domain model for the Listing bounded context. The full source code for this application is available as part of this chapter’s sample code.
An instance of the Listing entity represents an item being sold by a seller. Once sold, it can be dispatched via a number of shipping methods, can be listed in categories, and can accept many forms of payment method. A listing can also have questions raised about it from members; these questions can have answers from the seller. A listing has a selling format such as an auction, and an auction can have many members bid on it. At any time, an auction will always have a winning bid after the first bid has been placed. Finally, a member can watch different listings without bidding.
Aligning with Invariants
The most fundamental rule for creating an aggregate is that the cluster of domain objects must be based on domain invariants. This was touched on earlier in the chapter and will be demonstrated in further detail here.
When defining aggregates, you need to identify objects that work together and must be consistent with each other to fulfill business use cases. Here are some of the domain rules that can form the basis of deciding which clusters of objects should be aggregates in the Listing bounded context:
- Each listing must be in at least one category and offer at least one payment type and one shipping method.
- A listing is sold via an auction. An auction has a start and end date and keeps track of the winning bid.
- When a member places a bid, he can enter the maximum amount that he would be happy to pay for the item. However, only the amount required to become the winning bidder is bid. If a second member bids, the auction automatically bids up to the maximum amount. Each automatic bid is logged as a bid.
- A member can ask questions about a listing. A seller can then provide an answer that closes the question.
- An auction can generate many bids, but the current price is defined by the winning bid.
- Members can watch items.
Questions can be asked of a listing; however, there are no invariants that requires data from both questions and listings apart from a reference that can be implemented via an ID property. A listing as a concept can exist without a question, and a question does not depend on any other domain objects apart from an answer. Therefore, an aggregate boundary can be defined around questions and answers, as shown in Figure 19.17.

FIGURE 19.17 Question aggregate boundary definition.
An auction represents the format of the listing. It holds data on the start and end dates along with the current winning bid, including the maximum amount that the member would bid up to. For bidding to occur, the auction has to be active, and the value of the winning bid must be less than the intended bid. The auction does not depend on the details of the listing to perform its role. With this information, an aggregate boundary can be defined around the auction and winning bid domain objects, as highlighted in Figure 19.18.

FIGURE 19.18 Auction aggregate boundary definition.
A listing contains all information on the item being sold, including what category it is in, what payment methods can be used to pay for the item, and which shipping methods are available for the item. An invariant requires a listing to have a shipping method, category, and payment method. Accordingly, the listing aggregate can be defined as shown in Figure 19.19.

FIGURE 19.19 Listing aggregate boundary definition.
A bid is a historical event; therefore, it can exist as its own aggregate because it is not involved in any invariants. The member and seller only have their identifiers shared so they, too, can become their own aggregates. A member can watch an auction but doesn’t have any invariants and is just a container with the listing ID and member ID; it, too, can be its own aggregate, as illustrated in Figure 19.20.
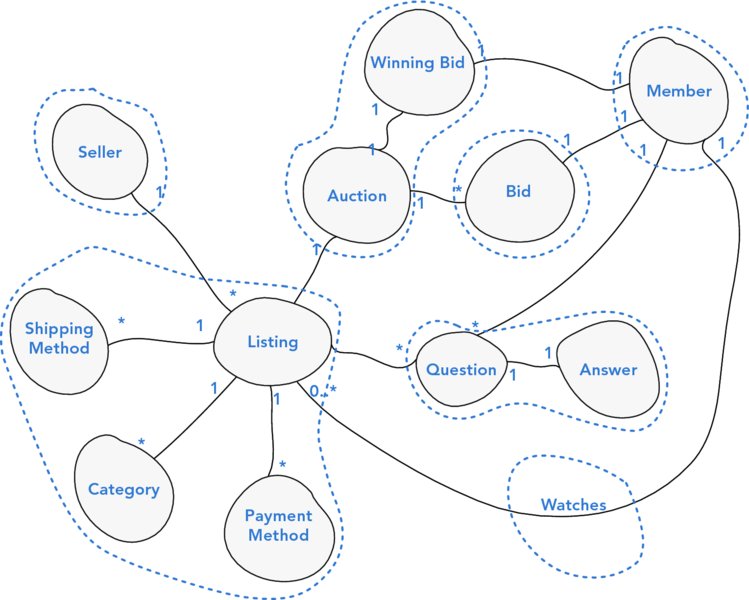
FIGURE 19.20 All aggregate boundary definitions.
Aligning with Transactions and Consistency
You should try to align your aggregate boundaries with transactions, because the higher the number of aggregates being modified in a single transaction, the greater the chance of a concurrency failure. Therefore, strive to modify a single aggregate per use case to keep the system performant. Figure 19.21 shows how the auction and listing boundaries are aligned with transactions; each aggregate is modified inside a separate transaction.

FIGURE 19.21 Aligning aggregates with transactional boundaries.
If you find that you are modifying more than one aggregate in a transaction, it may be a sign that your aggregate boundaries can be better aligned with the problem domain. You should try to find new insights by discussing the use case with domain experts or experimenting with your model. With the latter approach, see if you can resolve the issue by making your aggregates eventually consistent so that only one needs to be updated inside the transaction. It is advisable to get a business perspective on what parts of a system may acceptably be eventually consistent and include them in your aggregate design. In the eBidder application, it’s not acceptable for the Auction and WinningBid to be eventually consistent. This is why they are members of the same aggregate.
Ignoring User Interface Influences
Aggregates should not be designed around UIs. On a listing’s page, you would find details of the seller, the current auction price, and the item’s details. If the aggregate boundaries were to be defined based on UI needs, the size of the aggregate would become large and would cause locking if a seller wanted to amend a description at the same time as a member wanted to place a bid.
Instead of creating large aggregates to satisfy UIs, it’s common practice to map from multiple aggregates onto a single view model that contains all the data a page needs. This will usually be in the form of an application service making multiple repository calls to load aggregates, and then mapping information from the aggregates onto the view model.
In spite of the guidelines to populate a view model from multiple aggregates, there are still drawbacks to this approach that should make you consider alternatives in some cases. One clear sign that you may need to try a different solution is when you are querying three or more repositories to populate a single page. Three database calls can lead to poor performance and excessive load on your servers. In such a scenario, you may want to consider CQRS, which is covered in Chapter 24, “CQRS: An Architecture of a Bounded Context ”
Avoiding Dumb Collections and Containers
A common aggregate misconception is that they are merely collections or containers for other objects. This can be a dangerous misconception that results in a lack of clarity in your domain model. Whenever you see a collection or a container-like concept, you shouldn’t blindly assume that it is an aggregate.
In the eBidder application, you could look at the auction entity and be tempted to bring its collection of bids into the aggregate. This is logical because, conceptually, an auction has a collection of bids. As you saw in the previous section, though, bids don’t belong to an aggregate because there is no domain invariant that applies to both concepts. This type of thinking can lead to complex object graphs, bloated aggregates, and none of the advantages that aggregates bring.
Don’t Focus on HAS-A Relationships
Your aggregates should not be influenced by your data model. Associations between domain objects are not the same as database table relationships. Data models need to represent each HAS-A relationship to support referential integrity and build reports for business intelligence and user interface screens. A listing HAS questions, and a listing HAS AN auction, but this does not need to be modeled as a single aggregate. Remember, an aggregate represents a concept in your domain and is not a container for items. A listing does not need a question or a collection of questions to exist, nor does it need to hold this collection to meet any domain invariants. Why would you need to load all the questions to add another?
Auctions and listings are slightly different because there is a one-to-one relationship here. However, from the perspective of use cases and the invariants of the domain, all behaviors on listings need not be consistent with the auction aggregate because there are no invariants that span across them.
When including domain objects in an aggregate, don’t simply focus on the HAS-A relationship; justify each grouping and ensure that each object is required to define the behavior of the aggregate instead of just being related to the aggregate.
Refactoring to Aggregates
Defining aggregate boundaries is a reversible and continual activity. There’s no need to put yourself under pressure to get your design perfect at the initial attempt. Instead, you should continually be looking for improvements as you learn more about the domain. One scenario that can be particularly enlightening is the addition of a new business use case to your model. A new use case may involve existing entities and uncover new relationships. Consequently, new domain invariants may arise that don’t fit well with your existing aggregate designs.
Technical insights can also affect your aggregates—especially performance. If you find that saving—or more likely loading—an aggregate is outside the acceptable performance range, it might be a sign that your aggregate is too large. Undoubtedly, a major performance problem is an acceptable reason to redefine your aggregate boundaries even if conceptually there is an acceptable fit. However, it’s also possible that the performance problem is a symptom of a suboptimal conceptual design, so you may want to engage with domain experts or experiment with alternative designs first.
Satisfying Business Use Cases—Not Real Life
Focus on modeling aggregates from the perspective of your business use cases. Ask what invariants must be met to fulfill a use case. By taking this approach, you are less likely to fall into the trap of modeling real life. Instead, you will have small behavior-focused aggregates.
Listen 19-5 shows the use case of placing a bid. You will notice that it doesn’t require information on the listing, its category, or description to place a bid. This is why the listing and auction aggregates were modeled separately.
Aggregates represent concepts in the solution space; they don’t reflect real life. They are merely abstractions used to solve problems in the most effective way while reducing technical complexity. With that in mind, define the boundaries of your aggregates from the point of view of your business use cases—outside in and with a focus on the domain invariants.
Implementing Aggregates
Aggregate design is a continuous process that is influenced by feedback from your implementation. Persistence, consistency, and concurrency are all important implementation details that can be tricky to get right and may cause you to rethink your aggregate boundaries. Understanding what references are allowed between aggregates is particularly tricky to remember and is likely to feed back into your design process. This is where the concept of an aggregate root can guide you.
Selecting an Aggregate Root
For an aggregate to remain consistent, its constituent parts should not be shared throughout the domain model or made accessible to the service layer. Following this guideline prevents other parts of an application from putting an aggregate into an inconsistent state. But an aggregate still needs to provide behavior somehow. The answer is to choose an entity for each aggregate to be its aggregate root. All communication with an aggregate should then occur only via its root.
An aggregate root is an entity that has been chosen as the gateway into the aggregate. Figure 19.22 illustrates how the Auction entity is the root of the auction aggregate.

FIGURE 19.22 Aggregate roots are the gateway into an aggregate.
An aggregate root coordinates all changes to the aggregate, ensuring that clients cannot put the aggregate into an inconsistent state. It upholds all invariants of the aggregate by delegating to other entities and value objects in the aggregate cluster.
Domain objects only exist as part of an aggregate, as part of a conceptual whole. As previously mentioned, without the root, clients would have access to the internal structure of an aggregate, be able to bypass the behavior, and interact with member entities directly, as can be seen in the following code snippet:
basket.Items.Find(x => x.ProductId == productId).Quantity = newQuantity;The invariant being broken in this example is that an order may have a maximum quantity of ten for each item. By moving the behavior to the root, as shown in the following code snippet, the aggregate’s internal members can be encapsulated to protect the invariants of the aggregate.
basket.ChangeQuantityOf(productId, newQuantity);Within the body of ChangeQuantity() is logic that prohibits a Customer, or any other client of the aggregate, from increasing the quantity of any item to greater than ten. In doing so, the root is carrying out its duty of enforcing the invariant.
Exposing Behavioral Interfaces
As with entities and other domain objects, it’s highly desirable to expose an aggregate’s behavior so that your model explicitly communicates domain concepts. For an aggregate, this means exposing expressive methods on the root for other aggregates to interact with. An aggregate root mediates between other members of an aggregate and is thus the entry point for all external communication. These characteristics are demonstrated by the skeleton of the auction aggregate shown in the following snippet.
ReduceTheStartingPrice(), CanPlaceBid(), and PlaceBidFor() are the behaviors exposed by the aggregate root, and therefore the aggregate. These methods express domain concepts and operate on other members of the aggregate but do not expose them. As discussed previously, this enables the Auction aggregate root to ensure that the entire aggregate is always consistent. In this example, the other members of the aggregate are the encapsulated references to the StartingPrice value object and the WinningBid value object.
Not all members of an aggregate are directly accessible from the root. It’s acceptable, and sometimes good design, for them to be a level or two down the object graph. Examples of this in the auction aggregate are the MaximumBid and CurrentAuctionPrice value objects that belong to the WinningBid and not the Auction aggregate root, as shown by the WinningBid skeleton in Listing 19-7.
Protecting Internal State
You learned in previous chapters that encapsulating domain structure is important because it enhances the ability to refactor the domain model as your knowledge of the domain improves. Those suggestions, like being wary of getters and setters, are also highly applicable to aggregates. If you follow the advice in the previous section to expose behavioral interfaces, you are already taking a big step toward protecting the internal structure of an aggregate.
If you look back to Listing 19-6 showing the Auction skeleton, you see a behavior-focused aggregate root. The public interfaces consist only of behavior. All references to internal members of the objects are encapsulated as private member variables. If an aggregate exposes getters and setters, the internals of the aggregate may be exposed. Other domain objects or application services might then become coupled to them, damaging your ability to refactor the domain model as you gain new insights. Further, external clients of the aggregate may then be able to put it into an inconsistent state.
Allowing Only Roots to Have Global Identity
You may hear DDD practitioners referring to local and global identity. That’s just a concise way of expressing that an aggregate root has a global identity because it can be accessed from outside the aggregate, whereas other members of an aggregate have a local identity because they are internal to the aggregate. Figure 19.23 visualizes this.

FIGURE 19.23 Aggregate roots have global identity.
Referencing Other Aggregates
Almost always, aggregate roots should keep a reference to the ID of another aggregate root and not a reference to the object itself. This is an important guideline, especially when using ORMs, because loading one aggregate from the database may load all the others that it holds a reference to. Such an occurrence can cause critical performance degradation and hard-to-debug lazy loading issues.
In the Listing bounded context of the eBidder application, the auction aggregate contains a reference to the ID of the Listing being auctioned, as the following snippet shows. This is because the Listing is not part of the Auction aggregate, and an object reference can cause the previously discussed persistence problems.
public class Auction : Entity<Guid>
{
...
private Guid ItemId { get; set; }
...
}As you saw in the first part of this chapter, referencing other aggregate roots by ID incurs the small cost of relying on repositories to carry out an on-demand lookup of the referenced aggregate in the service layer, similar to the following snippet:
var auction = auctionRepository.FindById(auctionId);
var listing = listingRepository.FindById(auction.ItemId);
// carry out business use-caseEach additional repository call is likely to be an additional round-trip to the database. You might think this is suboptimal compared to a single query that fetches all the required data in a single round-trip. Admittedly, in isolation this is not ideal, but by applying the aggregate pattern across your domain model, you should see benefits to the system as a whole by an overall more efficient data-access strategy.
There might still be cases in which you are making three of four repository calls. If performance is any kind of concern, you should feel free to reevaluate trade-offs. Maybe it would be better to have one large aggregate to optimize the use case. If the rest of your aggregates are in good shape, it’s unlikely to be a problem. However, you might instead want to consider using CQRS or event sourcing.
Admittedly, there are a few subtleties regarding which types of references between aggregates are and aren’t allowed. The remainder of this section shows examples that clarify them.
Nothing Outside An Aggregate’s Boundary May Hold a Reference to Anything Inside
An easy rule to remember, and one that has been repeated throughout this chapter, is that nothing outside an aggregate should hold a reference to its inner members, as Figure 19.24 illustrates. As discussed, this is important because it protects the inner structure of the aggregate and prevents the aggregate from being put into an inconsistent state.

FIGURE 19.24 Consumers of an aggregate may not hold a reference to the aggregate’s internal members.
Consumers of the aggregate may only hold a reference to the aggregate root—except for the special case discussed next.
The Aggregate Root Can Hand Out Transient References to the Internal Domain Objects
Even though an aggregate cannot contain a reference to an internal member of another aggregate, it is acceptable to hold a transient reference—one that is used, ideally, inside a single method.

FIGURE 19.25 Sharing information between aggregates by using copies of internal objects.
If you think about it, a transient reference to the inner member of an aggregate that is held in a temporary variable is not likely to cause persistence issues. It is not part of the aggregate’s object graph, so it is not loaded when the aggregate that requires a transient reference is loaded. However, although in theory this is safe, in practice you should be careful about handing out object references due to the potential for abuse and coupling. Instead, it’s advisable to prefer sharing copies or views of an object rather than a reference as shown in Figure 19-25.
Objects within the Aggregate Can Hold References to Other Aggregate Roots
Paradoxically, it is okay for nonaggregate roots to hold a reference to aggregate roots from other aggregates, as shown in Figure 19.26 where the WinningBid from inside the auction aggregate is holding a reference to the root of another aggregate. (This is a unidirectional relationship.)

FIGURE 19.26 Non aggregate roots can hold a reference to roots from other aggregates.
In this scenario, holding a reference specifically means storing the ID rather than the object reference or pointer, as Listing 19-8 shows. The WinningBid is holding a reference to the Member that placed the bid by storing its ID.
As previously discussed, entire aggregates are loaded from persistence. So if an object stores a direct reference to another object, both aggregates need to be loaded from persistence. This is covered in more detail in the next section.
Implementing Persistence
Only aggregate roots can be obtained directly with database queries. The domain objects that are inner components of the aggregate can be accessed only via the aggregate root. Each aggregate has a matching repository that abstracts the underlying database and that will only allow aggregates to be persisted and hydrated. This is crucial in ensuring that invariants are met and aggregates are kept consistent. You are susceptible to these problems if child objects of an aggregate can be accessed by directly connecting to the database.
Figure 19.27 shows how aggregates should and should not be loaded from a database if you want to ensure that invariants are not broken and aggregates are fully consistent.

FIGURE 19.27 Aggregates should be loaded from a database entirely to protect their integrity.
Persisting at the granularity of aggregates can be easier to reason about and maintain knowing that you only need to have a one-to-one mapping between aggregates and repositories. It also means that you can think in terms of aggregates. Whenever you need information or behavior, you just need to know which aggregate to load and which repository to use. This is exemplified by Listing 19-9 that shows the trivial implementation of the AnswerAQuestionService application service that only has to care about one repository and loading a single aggregate with it.
You can see the interface for the IQuestionRepository in the next snippet. Notice how it only saves and loads the entire aggregate:
public interface IQuestionRepository
{
Question FindBy(Guid id);
void Add(Question question);
}Your repositories aren’t limited to aggregate ID lookups. In fact, there are few rules outside the fact that methods should save and load entire aggregates. For instance, you may want to load all questions for a certain member, as the following snippet shows:
public interface IQuestionRepository
{
Question FindBy(Guid id);
void Add(Question question);
IEnumerable<Question> FindByMemberId(Guid memberId);
}Implementations of your repositories will vary according to your chosen data access and data storage technologies. With an ORM like NHibernate, you can often just pass the aggregate root into the session and the entire aggregate is persisted. On the other hand, with raw SQL, you need to manually store each member of the aggregate.
You may be concerned that there are cases in which loading an entire aggregate is inefficient or unnecessary, when instead you just want to load a single domain object. However, after some experience of applying DDD, you may come to realize that these scenarios are rare. Take an order line, for example. Would you ever want to load a single order line without the rest of the order aggregate? What could you possibly do with it? Scenarios requiring single domain objects are the exception to the rule. More often, they indicate dubious aggregate boundaries.
Access to Domain Objects for Reading Can Be at the Database Level
When handling business use cases, an aggregate is all that you should pull from the database. For reporting on the state of the domain, however, you need not worry about aggregates. Reporting or querying can be performed directly at the database level without the need to hydrate domain objects. Instead, thin view models can be populated by viewing specific queries. As shown in Figure 19.28, an aggregate should be the only domain concept pulled from the database when fulfilling a use case, but for reporting, a simple query against the database is fine.

FIGURE 19.28 Loading aggregates versus going directly to the database.
A Delete Operation Must Remove Everything within the Aggregate Boundary at Once
When you delete an aggregate root, you must remove all the child domain objects as well within the same transaction. Components of an aggregate root cannot live on after the root is removed because they have no context and no meaning without the root. For example, an order line has no meaning if the order is removed.
Avoiding Lazy Loading
Many ORMs allow you to load data from a database only when it is accessed in code. Although the intention is to improve performance, the unpredictability of this feature, known as lazy loading, can actually lead to severe performance and reliability penalties. It is highly recommended that you seriously consider avoiding lazy loading unless you have an extremely good reason. If you keep your aggregates small, you are unlikely to need lazy loading.
One of the many ways lazy loading can hurt the performance of your application is by causing the dreaded select n+1. Essentially, this problem involves each item in a collection being retrieved individually from the database, rather than collectively in a single query. Each additional query requires an extra database connection and network transportation overhead, leading to inefficient and slow data access. Consider Listing 19-10, for example.
This code is from a special events domain model, where groups of people can book adventure days to celebrate birthdays or corporate events. If this code were using lazy loading, each iteration of the foreach loop might cause an additional query to the database to get the details for a single guest. Imagine a Christmas celebration booking for an office of 50 colleagues. That could be an astonishing 51 database queries (one for the booking, and one for each guest). That’s not a problem if you can afford to give away performance, but in many systems the poor performance of queries like this destroys user experience.
Implementing Transactional Consistency
As you’ve learned, an aggregate must be fully persisted or fully rolled back within a transaction to retain consistency. It doesn’t matter if an aggregate is stored in one table or many; when an aggregate is persisted, it needs to commit in a single transaction to ensure that, in the event of failure, the aggregate isn’t stored in an inconsistent state.
Figure 19.29 shows how the boundary for the auction aggregate is its consistency boundary. All members of the auction aggregate must be updated or rolled back atomically.

FIGURE 19.29 Aggregate boundaries are consistency boundaries.
Being consistent means that each member of an aggregate has access to the latest state of other members of the aggregate. In the auction aggregate, this means that whenever WinningBid is updated, the Auction entity must immediately know about it. This rule is easy to apply within an aggregate because objects within an aggregate can contain direct object references to each other. The following snippet highlights that the Auction aggregate root is implemented with transactional consistency:
public class Auction : Entity<Guid>
{
...
private WinningBid WinningBid { get; set; }
...
}Whenever an Auction’s WinningBid is updated, the Auction immediately has access to the updated value. This is because the Auction has a reference to the WinningBid object. So it always gets the latest value from the source of truth.
Outside of an aggregate, and subsequently outside the consistency boundary, the rules are the opposite; consistency does not have to be strict. This is because references to the innards of an aggregate are not allowed. In the Auction example, a reference to WinningBid may not be held by other aggregates. Therefore, when the WinningBid is updated, it is not easy for other aggregates or services that use this value to be notified. Instead, they must be eventually consistent—having to deal with stale data, as you saw earlier in the chapter.
Implementing transactional consistency largely depends on your persistence technology and choice of client library. ORMs like Hibernate and NHibernate offer explicit transactions that commit or roll back everything that happens inside it. Some databases, like RavenDB, provide a similar interface.
Implementing Eventual Consistency
Fundamentally, eventual consistency is implemented by aggregates handing out copies of their data to other aggregates, and consequently, aggregates being able to deal with the fact that the information they have received may be stale. This is because, when one aggregate is updated, other aggregates that received a partial copy of its state are not updated immediately with a copy of the new value. As you learned earlier in the chapter, this is why an aggregate’s boundary is also a consistency boundary.
There are strategies for implementing eventual consistency. At a basic level, you can simply run transactions synchronously. A benefit of this approach is that the period when aggregates are inconsistent is minimal. This solution is not recommended because it can be risky and difficult to implement well. The common strategy for implementing eventual consistency is the asynchronous approach, using an out-of-process technology like NServiceBus that was introduced in Chapter 12, “Integrating via Messaging.” Aggregates stay inconsistent for longer periods of time with the asynchronous approach, but the implementation is more reliable.
Rules That Span Multiple Aggregates
As you learned earlier in the chapter, eventual consistency usually arises when domain rules span multiple aggregates. In this example, you will see how to implement eventual consistency for an e-commerce loyalty program; customers who spend more than $1,000 in one year get a 10% reduction on all future purchases. Initially, you might be tempted to update the order and loyalty aggregate inside the same transaction. As you’ve learned, though, this increases the chances of a concurrency conflict and reduces scalability options.
Loyalty is often a scenario that does not need immediate consistency. As a customer, it’s nice to have the 10% discount applied immediately, but you’re probably content to wait until the next working day for the discount to come into effect. Remember, before implementing eventual consistency, you should have a business agreement. Assuming that stakeholders agreed this rule could have a next-working-day service level agreement (SLA), the following example demonstrates implementing it using eventual consistency and asynchronous domain events.
Asynchronous Eventual Consistency
Asynchronous eventual consistency leads to more reliable systems because operations can usually be retried when failure occurs. However, the drawback is that you need to introduce new technologies and services to carry out and manage the asynchronous behavior. If you’re already using a messaging technology like Kafka, Akka, or NServiceBus for sending messages between bounded contexts, the costs of implementing asynchronous eventual consistency for aggregates will not be as high.
Eventually, consistent aggregates can be implemented in the same style that Chapters 11 through 13 implemented eventual consistency between bounded contexts—by using asynchronous domain events. This was illustrated previously in Figure 19.14 where, within a single transaction, an aggregate is updated and an event is published. And then in a subsequent transaction, the event is handled and acted upon.
One pattern that works well with eventually consistent aggregates is using the domain event patterns and its DomainEvents class to trigger the process. Inside an event handler, you publish the event with a messaging framework. Listing 19-11 shows the updated OrderApplicationService using NServiceBus’s IBus interface to publish an event indicating the order has been placed.
At some point in the future, probably on a different thread or even a different server, the messaging framework invokes a handler that runs the second transaction to update the loyalty. Again, using NServiceBus, the handler appears similar to Listing 19-12.
Using a messaging framework isn’t the only type of asynchronous solution. Another option that you learned about in Chapter 11, “Introduction to Bounded Context Integration,” is database integration. In this example, instead of a message being fired, a flag could be set in the database. Later, a scheduled job could run periodically that scans all new orders, and updates the loyalty of each customer, as shown in Figure 19.30.
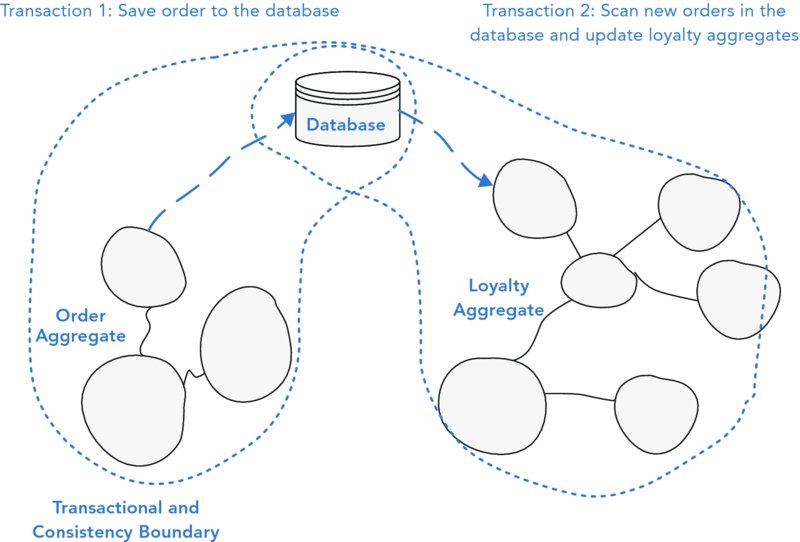
FIGURE 19.30 Eventual consistency using database integration.
As you may be thinking, asynchronous eventual consistency has inherently more complexity, including messaging technologies, asynchronous workflows, and operational monitoring. It’s recommended that you decide on a case-by-case basis whether you want to update multiple aggregates in a single transaction or use one of the approaches to eventual consistency.
Implementing Concurrency
An aggregate root can protect invariants by mediating access to internal components. However, it cannot prevent an aggregate from becoming inconsistent due to multiple users modifying it. In collaborative environments, when multiple users change the state of a business object and try to concurrently persist it to the database, a mechanism needs to be in place to ensure that one user’s modification does not negatively affect the state of the transaction for other concurrent users.
There are two forms of concurrency control: optimistic and pessimistic. The optimistic concurrency option assumes that there are no issues with multiple users making changes simultaneously to the state of business objects, also known as last change wins. For some systems, this is perfectly reasonable behavior; however, when the state of your business objects needs to be consistent with the state when retrieved from the database, pessimistic concurrency is required.
Pessimistic concurrency can come in many flavors, from locking the data table when a record is retrieved to keeping a copy of the original contents of a business object and comparing that to the version in the data store before an update is made. This ensures that no changes from other parties are made during a transaction. Concurrency can be implemented by having a version/timestamp on aggregates. In this section, you use a version number to check whether a business entity has been amended since being retrieved from the database. Upon an update, the version number of the business entity is compared to the version number residing in the database before committing a change. If the version numbers don’t match an exception is raised. This ensures that the business entity has not been modified since being retrieved.
A common three-step approach to implementing concurrency support in an aggregate is to add a version number to the root:
public class Loyalty : Entity<Guid>
{
...
public int Version { get; private set; }
...
}Then increment the version number before the transaction is committed. But before that, check the version number against the latest version number.
Admittedly, this generic approach to concurrency will sometimes only be a risk mitigation strategy. Depending on features provided by your data-access library, there could still be a tiny period of time between checking for the latest version number and successfully committing the transaction. Unfortunately, it is possible for the aggregate to be saved inside another transaction inside this period of time. This is why it is desirable to enable datastore or persistence-library level concurrency checking. Many persistence libraries, like NHibernate, Entity Framework, and the RavenDB client, can be configured to manage concurrency for you.
The Salient Points
- Reduce bidirectional relationships in the domain to communicate more about relationships between domain objects, decrease the implementation complexity, and show traversal direction bias, which helps with where to place domain logic.
- Qualify associations by adding constraints to reduce technical complexity.
- Only add object references when you need to traverse an association to fulfill an invariant; otherwise, simply a reference via an identifier.
- Include associations that support domain invariants; don’t simply model real life or replicate the data model in code.
- Aggregates decompose large object graphs into small clusters of domain objects to reduce the complexity of the technical implementation of the domain model.
- Aggregates represent domain concepts, not just generic collections of domain objects.
- Align aggregate boundaries with domain invariants to help enforce them.
- Aggregates are a consistency boundary to ensure the domain model is kept in a reliable state.
- Aggregates ensure transactional boundaries are set at the right level of granularity to ensure a usable application by avoiding blocking at the database level.
- Aim for smaller aggregates to reduce transactional locking and reduce consistency complexities.
- An aggregate root is an entity of the aggregate that is chosen as the gateway into the aggregate. The aggregate root ensures the aggregate is always consistent and invariants are enforced.
- An aggregate root has global identity; the domain objects within the aggregate only have identity within the context of the aggregate root.
- Domain objects outside the aggregate can only hold a reference to the aggregate root.
- When an aggregate is deleted all the domain objects within it must be removed as well.
- No domain objects outside the boundary of the aggregate can hold a reference to internal objects.
- An aggregate root can return copies or references of internal domain objects for use in domain operations, but any changes to these objects must be via the aggregate root.
- Aggregates, not individual domain objects, are persisted and hydrated from the database via the repository.
- An aggregate’s internal domain objects can hold references to other aggregate roots.
- Transactions should, ideally, not cross aggregate boundaries.
- There can be inconsistencies between aggregates; use domain events to update aggregates in a separate transaction.