
5
Analysis of Variance (ANOVA) – Fixed Effects Models
5.1 Introduction
In the analysis of variance, we assume that parameters of random variables depend on non‐random variables, called factors. The values a factor can take we call factor levels or in short levels. We discuss cases where one, two or three factors have an influence on the observations.
An experimenter often has to find out in an experiment whether different values of several variables or of several factors have different results on the experimental material. If the effects of several factors have to be examined, the conventional method means to vary only one of these factors at once and to keep all other factors constant. To investigate the effect of p factors this way, p experiments have to be conducted. It can be that the results at the levels of a factor investigated depend on the constant levels of other factors, which means that interactions between the factors exist. The British statistician R. A. Fisher recommended experimental designs by varying the levels of all factors at the same time. For the statistical analysis of the experimental results of such designs (they are called factorial experiments), Fisher developed a statistical procedure: the analysis of variance. The first publication about this topic stemmed from Fisher and Mackenzie (1923), a paper about the analysis of field trials in Fisher's workplace at Rothamsted Experimental Station in Harpenden, UK. A good overview is given in Scheffé (1959) and in Rasch and Schott (2018).
The analysis of variance is based on the decomposition of the sum of squared deviations of the observations from the total mean of the experiment into components. Each of the components is assigned to a specific factor or to interactions of factors or to the experimental error. Further, a corresponding decomposition of the degrees of freedom belonging to sums of squared deviations is done. The analysis of variance is mainly used to estimate the effects of factor levels or to test statistical hypotheses (model I in this chapter), or to estimate components of variance that can be assigned to the different factors (model II – see Chapter 6).
The analysis of variance can be applied to several problems based on mathematical models called model I, model II and the mixed model, respectively. The problem leading to model I is as follows: all factor levels have been particularly selected and involved in the experiment because just these levels are of practical interest. The objective of the experiment is to find out whether the effects of the different levels (or factor level combinations) differ significantly or randomly from each other. The experimental question can be answered by a statistical test if particular assumptions are fulfilled. The statistical conclusion refers to (finite) factor levels specifically selected.
In this chapter, problems in a model I are discussed and these are the estimation of the effects and the interaction effects of the several factors and testing the significance of these effects.
We also show how to determine the optimal size of an experiment. For all these cases we assume that we have to plan an experiment with a type I risk α = 0.05 and a power 1 − ß = 0.95.
5.1.1 Remarks about Program Packages
For the analysis, we can use the program package R as we have downloaded it. Those who like to analyse data by IBM‐SPSS Statistics find programs in Rasch and Schott (2018) and who prefer SAS can find corresponding programs in Rasch et al. (2008). For experimental designs, we use in R the command
> install.packages("OPDOE")and> library(OPDOE)
OPDOE stands for ‘optimal design of experiments’ and was used in Chapter 3. The R syntax for calculating the sample size for analysis of variance (or for short ANOVA) can be found by >size.anova; a description of how to use OPDOE is found by
> help(size.anova)
Detailed instructions and examples are given in chapter 3 of Rasch et al. (2011).
5.2 Planning the Size of an Experiment
For planning the size of a balanced experiment, this means equal sample sizes for the effects, precision requirements are needed, as in Chapter 3. The following approach is valid for all sections of this chapter. Besides the precision requirement of the two risks α and β (or the power of the F‐test 1 − β) the non‐centrality parameter λ of the non‐central F‐distribution with f1 and f2 degrees of freedom has to be given in advance. With the (1 − α)‐ and the β‐quantile of the non‐central F‐distribution with f1 and f2 degrees of freedom and the non‐centrality parameter λ we have to solve the equation
This equation plays an important role in all sections of this chapter. In addition to f1, f2, α, and β the difference δ between the largest and the smallest effect (main effect or in the following sections also interaction effect), to be tested against null, belongs to the precision requirement. We denote the solution λ in 5.1 by
Let Emin, Emax be the minimum and the maximum of q effects E1, E2, … , Eq of a fixed factor E or an interaction, respectively. Usually we standardise the precision requirement by the relative precision requirement ![]() .
.
If Emax − Emin ≥ δ then for the non‐centrality parameter of the F‐distribution (for even q) with ![]() holds
holds
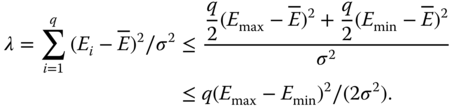
From this it follows
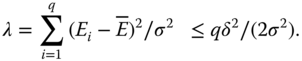
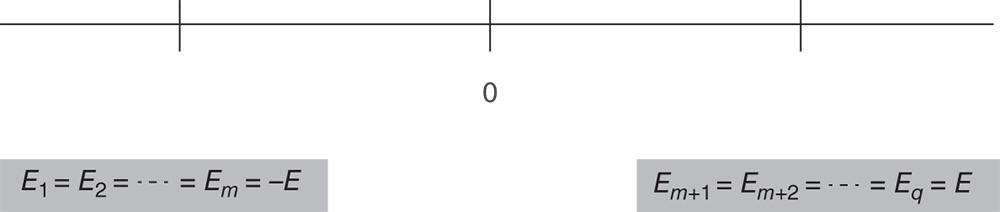
The minimal size of the experiment needed depends on λ accordingly to the exact position of all q effects. However, this is unknown when the experiment starts. We consider two extreme cases, the most favourable (resulting in the smallest minimal size nmin) and the least favourable (resulting in the largest minimal size nmax). The least favourable case leads to the smallest non‐centrality parameter λmin and by this to the so‐called maximin size nmax. This occurs if the q − 2 non‐extreme effects equal ![]() . For
. For ![]() this is shown in the following scheme.
this is shown in the following scheme.

The most favourable case leads to the largest non‐centrality parameter λmax and by this to the so‐called minimin size nmin. If q = 2m (even) this is the case, if m of the Ei equal Emin and the m other Ei equal Emax. If q = 2m + 1 (odd) again m of the Ei should equal Emin and m other Ei should equal Emax, and the remaining effect should be equal to one of the two extremes Emin or Emax. For ![]() this is shown in the following scheme for even q.
this is shown in the following scheme for even q.
When we plan an experiment, we always obtain equal sub‐class numbers. Therefore, we use models and ANOVA tables mainly for the equal subclass number case because we then have simpler formulae for the expected mean squares. In the analysis programs, unequal sub‐class numbers are also possible.
In Section 5.3 we give a theoretical ANOVA – table (for random variables) with expected mean squares E(MS). To find a proper F‐statistic for testing a null hypothesis corresponding to a fixed row in the table we proceed as follows. If the null hypothesis is correct the numerator and denominator of F have the same expectation. In general it is a ratio of two MS of a particular null hypothesis with the corresponding degrees of freedom. This ratio is centrally F‐distributed if the numerator and the denominator in the case that the hypothesis is valid have the same expectation. This equality is, however, not sufficient if unequal subclass numbers occur, for instance it is not sufficient if the MS are not independent of each other. In this case, we obtain only a test statistic that is approximately F‐distributed. Such cases occur in Chapter 6. We write τ = δ/σ.
5.3 One‐Way Analysis of Variance
In this section, we investigate the effects of one factor.
From a populations or universes, G1, … , Ga random samples Y1, … , Ya of size n1, … , na, respectively are drawn independently of each other. We write ![]() . The yi are assumed to be distributed in the populations Gi as
. The yi are assumed to be distributed in the populations Gi as ![]() with {μi} = (μi, ⋯, μi)T. Further we write μi = μ + ai (i = 1, … , a). Then we have one factor A with the factor levels Ai; i = 1,…, a and write
with {μi} = (μi, ⋯, μi)T. Further we write μi = μ + ai (i = 1, … , a). Then we have one factor A with the factor levels Ai; i = 1,…, a and write
We call μ the total mean and ai the effect of the ith level of factor A. The total size of the experiment is ![]() .
.
In Table 5.1, we find the scheme of the observations of an experiment with a levels A1, ⋯, Aa of factor A and ni observations for the ith level Ai of A. We use Equation 5.3 with the side conditions
Table 5.1 Observations yij of an experiment with a levels of a factor A.
| 1 | 2 | … | a | |
|
yij |
y11 y12 ⋮ |
y21 y22 ⋮ |
⋯ ⋯ ⋮ ⋯ |
ya1 ya2 ⋮ |
|
ni Yi. |
n1 Y1. |
n2 Y2. |
… … |
na Ya. |
For testing the hypothesis, eij and by this also yij is assumed to be normally distributed.
For testing hypotheses about μ + ai further assumptions are not needed but to test hypotheses about ai we need a so‐called reparametrisation condition like ![]() or
or ![]() ; both are equivalent if all ni = n and this we call the balanced case.
; both are equivalent if all ni = n and this we call the balanced case.
In this chapter, we use the point convention for writing sums. In the one‐way case discussed in this section we have
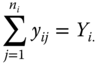
and
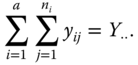
The arithmetic means are ![]() and
and ![]()
Estimators ![]() for
for ![]() for μ in the model 5.3 are given by
for μ in the model 5.3 are given by
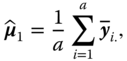
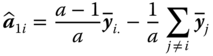
if we assume ![]() and by
and by
if we assume ![]() . For estimable functions, we drop the left subscripts and write the symbols as in 5.3.
. For estimable functions, we drop the left subscripts and write the symbols as in 5.3.
The ni are called sub‐class numbers. Both estimators are identical in the balanced case if ni = n (i = 1, … , a).
The reader may ask which reparametrisation condition he should use. There is no general answer. Besides the two forms above, many others are possible. However, fortunately many of the results derived below are independent of the side condition chosen. Often estimates of the ai are less interesting than those for estimable functions of the parameters such as μ + ai and ai − aj and these estimable functions give the same answer for all side conditions.
The variance σ2 in both cases is unbiasedly estimated by
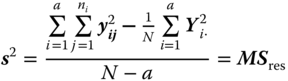
Table 5.2 gives the ANOVA table for model 5.3. In this table SS means sum of squares, MS means mean squares and df means degrees of freedom. We call this table a theoretical ANOVA table because we write the entries as random variables that are functions of the underlying random samples Y1, … , Ya. If we have observed data as realisations of the random samples then the column E(MS) is dropped and nothing in the table is in bold print.
Table 5.2 Theoretical ANOVA table: one‐way classification, model I.
| Source of variation | SS | df | MS | E(MS) for ni = n |
| Main effect A |
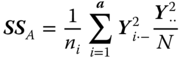 |
a−1 | ||
| Residual |
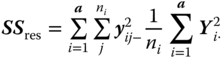 |
N−a | σ2 |
Table 5.3 is the empirical ANOVA table corresponding to Table 5.2.
Table 5.3 Empirical ANOVA table: one‐way classification, model I.
| Source of variation | SS | df | MS |
| Main effect A |
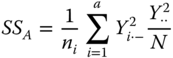 |
a − 1 | |
| Residual |
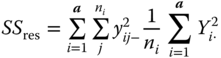 |
N − a | |
| Total |
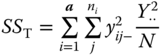 |
N − 1 |
5.3.1 Analysing Observations
Estimable functions of the model parameters are for instance μ + ai(i = 1, … , a) or ai − aj(i, j = 1, … , a; i ≠ j) with the estimators (using (5.4)–5.7)
and
respectively. They are independent of the special choice of the reparametrisation condition.
Besides point estimation, an objective of an experiment (model I) is to test the null hypothesis H0 : ai = aj for all i ≠ j against the alternative that at least two of the effects ai differ from each other. This null hypothesis corresponds to the assumption that the effects of the factor considered for all a levels are equal. The basis of the corresponding tests is the fact that the sum of squared deviations SS of yij from the total mean of the experiment ![]() can be broken down into independent components.
can be broken down into independent components.
The total sum of squared deviations of the observations from the total mean of the experiment is
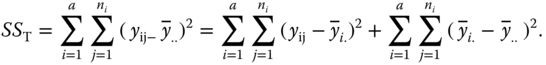
The left‐hand side is called SS total or for short SST, the first component of the right‐hand side is called SS within the treatments or levels of factor A (for short SS within SSres) and the last component of the right hand side SS between the treatments or levels of factor A (SSA), respectively.
We generally write
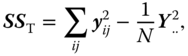
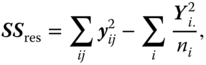
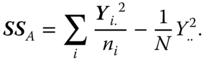
It is known from Rasch and Schott (2018, theorem 5.4) that
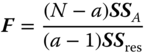
is distributed as F(a − 1, N − a, λ) with the non‐centrality parameter
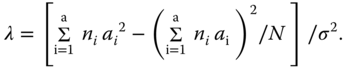
If H0 : a1 = … = aa is valid then we have λ = 0, and thus, F is F(a − 1, N − a) distributed. Therefore, the hypothesis H0: a1 = … = aa is tested by an F‐test. The ratios ![]() and
and ![]() are called mean squares between treatments and within treatments or residual mean squares, respectively.
are called mean squares between treatments and within treatments or residual mean squares, respectively.
5.3.2 Determination of the Size of an Experiment
In the case of the one‐way classification we determine the required experimental size for the most favourable as well as for the least favourable case, i.e. we are looking for the smallest n (for instance n = 2q) so that for λmax = λ and for λmin = − λ, respectively, 5.2 is fulfilled.
The experimenter must select a size n in the interval nmin ≤ n ≤ nmax but if he wants to be on the safe side, he must choose n = nmax. The package OPDOE of R allows the determination of the minimal size for the most favourable and the least favourable case in dependence on α, β, δ, σ and the number a of the levels of the factor A. The corresponding algorithm stems from Lenth (1986) and Rasch et al. (1997). In any case one can show that the minimal experimental size is smallest for the balanced case if n1 = n2 = … = na = n, which can be reached by planning the experiment.
5.4 Two‐Way Analysis of Variance
The two‐way ANOVA is a procedure for experiments to investigate the effects of two factors. Let us investigate a varieties of wheat and b fertilisers in their effect on the yield (kilogram per hectare). The a varieties as well as the b fertilisers are assumed to be fixed (selected consciously), as always in this chapter with fixed effects. One of the factors is factor variety (factor A), and the other factor is fertiliser (factor B). In this and the next chapter the number of levels of a factor X is denoted by the same (small) letter x as the factor (a capital letter) itself. So, factor A has a, and factor B has b levels in the experiment. In experiments with two factors, the experimental material is classified in two directions. For this, we list the different possibilities:
- (a)
Observations occur in each level of factor A combined with each level of factor B. There are a · b combinations (classes) of factor levels. We say factor A is completely crossed with factor B or that we have a complete cross‐classification.
- (a1) For each combination (class) of factor levels there exists one observation [(nij = 1 with nij being the number of observations in class (Ai. Bj).].
- (a2)
For each combination (class) (i, j) the level i of factor A with the level j of factor B we have
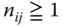 observations, with at least one nij > 1. If all nij = n, we have a cross‐classification with equal class numbers, called a balanced experimental design.
observations, with at least one nij > 1. If all nij = n, we have a cross‐classification with equal class numbers, called a balanced experimental design.
- (b) At least one level of factor A occurs together with at least two levels of the factor B, and at least one level of factor B occurs together with at least two levels of the factor A, but we have no complete cross‐classification. Then we say factor A is partially crossed with factor B, or we have an incomplete cross‐classification.
- (c) Each level of factor B occurs together with exactly one level of factor A. This is a nested classification of factor B within factor A. We also say that factor B is nested within factor A and write B ≺ A.
Summarising the types of two‐way classification we have:
- (a) nij = 1 for all (i, j) → complete cross‐classification with one observation per class
- (b) nij ≥ 1 for all (i,j) → complete cross‐classification
- (c) nij = n ≥ 1 for all (i, j) → complete cross‐classification with equal sub‐class numbers
- (d) At least one nij = 0 → incomplete cross‐classification.
If nkj ≠ 0, then nij = 0 for i ≠ k (at least one nij > 1 and at least two nij ≠ 0) → nested classification.
5.4.1 Cross‐Classification (A × B)
The observations yijk of a complete cross‐classification are real numbers. In class (i,j) occur the observations yijk, k = 1, … , nij. In block designs, we often have nij = 1 with single subclass numbers. If all nij = n are equal, we have the case of equal subclass numbers, which we discuss now.
Without loss of generality, we represent the levels of factor A as the rows and the levels of factor B as the columns in the tables. When empty classes occur, i.e. some nij equal zero, we have an incomplete cross‐classification; such a case occurs for incomplete block designs.
Let the random variables yijk in the class (i, j) be a random sample of a population associated with this class. The mean and variance of the population of such a class are called true mean and variance, respectively. The true mean of the class (i, j) is denoted by ηij. Again we consider the case that the levels of the factors A and B are chosen consciously (model I).
We call
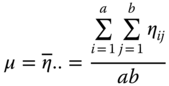
the overall expectation of the experiment.
The difference ![]() is called the main effect of the ith level of factor A, the difference
is called the main effect of the ith level of factor A, the difference ![]() is called the main effect of the j‐th level of factor B. The difference
is called the main effect of the j‐th level of factor B. The difference ![]() is called the effect of the ith level of factor A under the condition that factor B occurs in the jth level. Analogously,
is called the effect of the ith level of factor A under the condition that factor B occurs in the jth level. Analogously, ![]() is called the effect of the jth level of factor B under the condition that factor A occurs in the ith level.
is called the effect of the jth level of factor B under the condition that factor A occurs in the ith level.
The distinction between the main effect and ‘conditional effect’ is important if the effects of the levels of one factor depend on the effect of the level of the other factor. In the analysis of variance, we then say that an interaction between the two factors exists. We define the effects of these interactions (and use them in place of the conditional results).
The interaction (a, b)ij between the ith level of factor A and the jth level of factor B in a two‐way cross‐classification is the difference between the conditional effect of the level Ai of factor A for a given level Bj of the factors B and the main effect of the level Ai of A.
Under the assumption above the random variable yij of the cross‐classification varies randomly around the class mean in the form
We assume that the so‐called error variables eijk are independent of each other N(0, σ2) distributed and write for a balanced design the model I equation:
with (a, b)ij = 0 if n = 0. We assume the following side conditions:
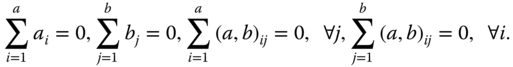
If in 5.14 all (a, b)ij = 0 we call
a model without interactions or an additive model, respectively.
5.4.1.1 Parameter Estimation
We can estimate the parameters in any model of ANOVA by the least squares method. We minimise in the case of model (5.16)
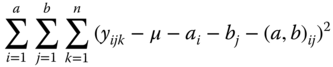
under the side conditions 5.17 and receive (using the dot convention analogue to Section 5.3)
5 Models with Interactions
We consider the model 5.15. Because E(Y) is estimable we have
estimable. The BLUE of ηij is
From 5.6 it follows
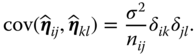
It is now easy to show that differences between ai or between bj are not estimable. All estimable functions of the components of 5.15 without further side conditions contain interaction effects (a, b)ij. It follows from theorem 5.7 in Rasch and Schott (2018) that
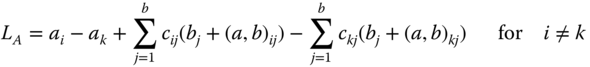
or analogously
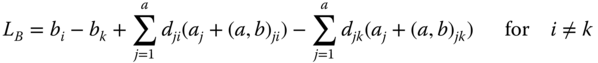
is estimable if crs = 0 for nrs = 0 and drs = 0 for nrs = 0 as well as
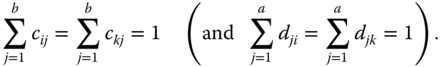
The BLUE of an estimable function of the form 5.21 is given by
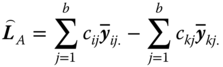
with variance
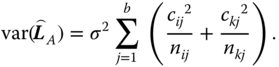
We consider the following example.
5 Connected Incomplete Cross‐Classifications
In an incomplete cross‐classification we have (a, b)ij = 0 if nij = 0. Further we choose the factors A and B so that a ≥ b.
An (incomplete) cross‐classification is called connected if
is non‐singular. If |W| = 0, then the cross‐classification is disconnected.
5.4.1.2 Testing Hypotheses
In this section, testable hypotheses and tests of such hypotheses are considered.
5 Models without Interactions
We start with model 5.18 and assume a connected cross‐classification (W above non‐singular).
If, as in 5.18, nij = n (equal sub‐class numbers), simplifications for the tests of hypotheses about the main effects result. We have the possibility further to construct an analysis of variance table, in which SSA, SSB, SSres = SSR add to SStotal = SST.
If in model 5.18 n ≥ 1 for all i and j, then the sum of squared deviations of the yijk from the total mean ![]() of the experiment
of the experiment

can be written as
with
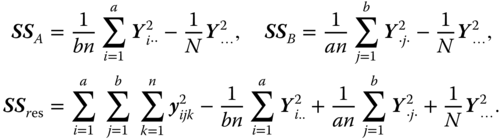
SSA + SSB and SSres are independently distributed, and for normally distributed yijk we have ![]() distributed as CS(a − 1, λa),
distributed as CS(a − 1, λa), ![]() as CS(b − 1, λb) and
as CS(b − 1, λb) and ![]() as CS(N − a − b + 1) with non‐centrality parameters
as CS(N − a − b + 1) with non‐centrality parameters
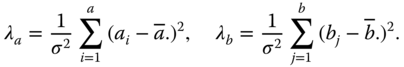
Therefore, ![]() is non‐centrally F‐distributed with a − 1 and N − a − b + 1 degrees of freedom and non‐centrality parameter
is non‐centrally F‐distributed with a − 1 and N − a − b + 1 degrees of freedom and non‐centrality parameter ![]() and
and ![]() is non‐centrally F‐distributed with b − 1 and N − a − b + 1 degrees of freedom and non‐centrality parameter
is non‐centrally F‐distributed with b − 1 and N − a − b + 1 degrees of freedom and non‐centrality parameter ![]() .
.
The realisations of these formulas are summarised in Table 5.7.
Table 5.7 Empirical ANOVA table of a two‐way cross‐classification with equal subclass numbers (nij = n).
| Source of Variation | SS | df | MS | F |
| Between the levels of A | 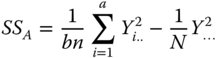 |
a − 1 | 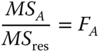 |
|
| Between the levels of B | 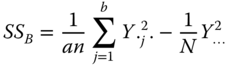 |
b − 1 | 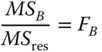 |
|
| Residual | SSres = SST − SSA − SSB | N − a − b + 1 | 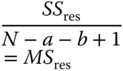 |
When the null hypothesis HA0 : a1 = a2 = ⋯ = aa = 0 is correct, then λa = 0. This null hypothesis can therefore be tested by ![]() . If FA > F(a − 1, N − a − b + 1, 1 − α) the null hypothesis is rejected with a first kind risk α. When the null hypothesis HB0 : b1 = b2 = ⋯ = bb = 0 is correct, then λb = 0. This null hypothesis can therefore be tested by
. If FA > F(a − 1, N − a − b + 1, 1 − α) the null hypothesis is rejected with a first kind risk α. When the null hypothesis HB0 : b1 = b2 = ⋯ = bb = 0 is correct, then λb = 0. This null hypothesis can therefore be tested by ![]() . If FB > F(b − 1, N − a − b + 1, 1 − α) the null hypothesis is rejected with a first kind risk α.
. If FB > F(b − 1, N − a − b + 1, 1 − α) the null hypothesis is rejected with a first kind risk α.
Table 5.9 ANOVA Table of Example 5.9.
| Source of variation | SS | df | MS | F |
| Between the storages | 43.2261 | 3 | 14.4087 | 186.7 |
| Between the forage crops | 0.8978 | 1 | 0.8978 | 11.63 |
| Residual | 0.2315 | 3 | 0.0772 | |
| Total | 44.3554 | 7 |
5 Models with Interactions
We consider now model 5.16 and assume a connected cross‐classification.
The ANOVA table for this case is Table 5.10.
Table 5.10 Analysis of variance table of a two‐way cross‐classification with equal sub‐class numbers for model I with interactions under Condition 5.17.
| Source of variation | SS | df | MS | E(MS) | F |
| Between rows (A) | 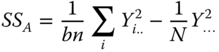 |
a − 1 | 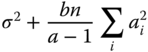 |
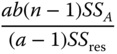 |
|
| Between columns (B) | 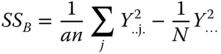 |
b − 1 | 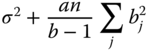 |
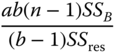 |
|
| Interactions | 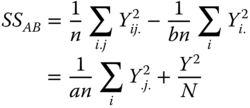 |
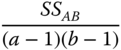 |
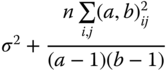 |
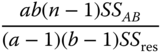 |
|
| Within classes (residual) | 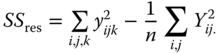 |
ab(n − 1) | 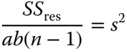 |
σ2 |
In the case of equal subclass numbers, we use the side conditions 5.17 and test the hypotheses
with the F‐statistics
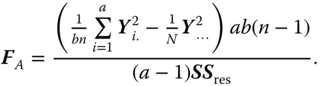
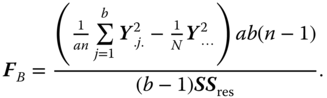
and
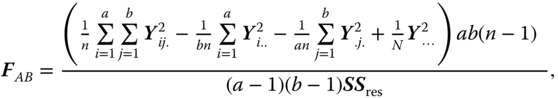
SSA, SSB, SSAB and SSres are independently distributed, and for normally distributed yijk it is ![]() as CS(a − 1, λa),
as CS(a − 1, λa), ![]() as CS(b − 1, λb),
as CS(b − 1, λb), ![]() as CS((a−1)(b − 1), λab) and
as CS((a−1)(b − 1), λab) and ![]() as CS(N − a − b + 1) distributed with non‐centrality parameters
as CS(N − a − b + 1) distributed with non‐centrality parameters ![]() and
and ![]() , respectively.
, respectively.
Therefore ![]() is non‐centrally F‐distributed with a − 1 and N − a − b + 1 degrees of freedom and non‐centrality parameter
is non‐centrally F‐distributed with a − 1 and N − a − b + 1 degrees of freedom and non‐centrality parameter ![]() ,
, ![]() is non‐centrally F‐distributed with b − 1 and N − a − b + 1 degrees of freedom and non‐centrality parameter
is non‐centrally F‐distributed with b − 1 and N − a − b + 1 degrees of freedom and non‐centrality parameter ![]() and
and ![]() is non‐centrally F‐distributed with (a − 1)(b − 1) and N − a − b + 1 degrees of freedom and non‐centrality parameter
is non‐centrally F‐distributed with (a − 1)(b − 1) and N − a − b + 1 degrees of freedom and non‐centrality parameter
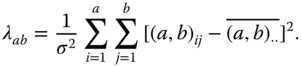
When the null hypotheses above are correct, then the corresponding non‐centrality parameter is zero. The corresponding null hypothesis can therefore be tested by ![]() ,
, ![]() and
and ![]() , respectively. If FA > F(a − 1, N − a − b + 1, 1 − α) the null hypothesis
, respectively. If FA > F(a − 1, N − a − b + 1, 1 − α) the null hypothesis ![]() is rejected with a first kind risk α. If FB > F(b − 1, N − a − b + 1, 1 − α) the null hypothesis
is rejected with a first kind risk α. If FB > F(b − 1, N − a − b + 1, 1 − α) the null hypothesis ![]() is rejected with a first kind risk α. Finally, if FAB > F((a − 1)(b − 1), N − a − b + 1, 1 − α) the null hypothesis HA × B0 is rejected with a first kind risk α.
is rejected with a first kind risk α. Finally, if FAB > F((a − 1)(b − 1), N − a − b + 1, 1 − α) the null hypothesis HA × B0 is rejected with a first kind risk α.
Table 5.11 Observations of the carotene storage experiment of Example 5.12.
| Forage crop | |||
| Green rye | Lucerne | ||
| Kind of storage | Glass |
8.39 7.68 9.46 8.12 |
9.44 10.12 8.79 8.89 |
| Sack |
5.42 6.21 4.98 6.04 |
5.56 4.78 6.18 5.91 |
|
Table 5.12 ANOVA table for the carotene storage experiment of Example 5.12.
| Source of variation | SS | df | MS | F |
| Between the kind of storage | 41.6347 | 1 | 41.6347 | 101.70 |
| Between the forage crops | 0.7098 | 1 | 0.7098 | 1.73 |
| Interactions | 0.9073 | 1 | 0.9073 | 2.22 |
| Within classes (residual) | 4.9128 | 12 | 0.4094 | |
| Total | 48.1646 | 15 |
5.4.2 Nested Classification (A≻B)
A nested classification is a classification with super‐ and sub‐ordinated factors, where the levels of a sub‐ordinated or nested factor are considered as further subdivision of the levels of the super‐ordinated factor. Each level of the nested factor occurs in just one level of the super‐ordinated factor. An example is the subdivision of the United States into states (super‐ordinated factor A) and counties (nested factor B).
As for the cross‐classification we assume that the random variables yijk vary randomly from the expectations ηij, i.e.
and that eijk are, independently of each other, N(0, σ2)‐distributed. With
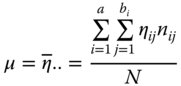
the total mean of the experiment is defined.
In nested classification, interactions cannot occur.
The difference ![]() is called the effect of the ith level of factor A, the difference bij = ηij − ηi. is the effect of the jth level of B within the ith level of A.
is called the effect of the ith level of factor A, the difference bij = ηij − ηi. is the effect of the jth level of B within the ith level of A.
The model equation for yijk in the balanced case then reads
(interactions do not exist).
Usual side conditions are
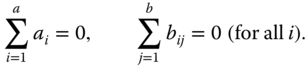
or
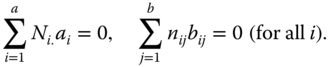
Minimising
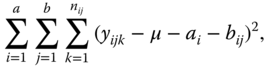
under the side conditions 5.28, we obtain the BLUE
The total sum of squares is again split into components
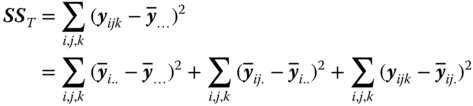
or
where SSA is the SS between the A levels, SSB in A is the SS between the B levels within the A levels and SSres is the SS within the classes (B levels).
The SS are written in the form
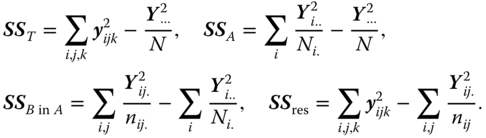
Here and in the sequel, we assume the side conditions 5.28.
The expectations of the MS are given in Table 5.13.
Table 5.13 Theoretical ANOVA table of the two‐way nested classification for model I.
| Source of variation | SS | df | MS | E(MS) |
| Between A levels | 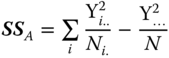 |
a − 1 | 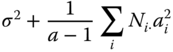 |
|
| Between B levels within A levels | 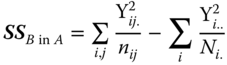 |
B. − a | 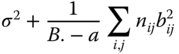 |
|
| Within B levels (residual) | 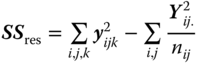 |
N − B. | σ2 |
MSA, MSB in A and MSres in Table 5.13 are independently of each other distributed as CS(a − 1, λa), CS(B. − a, λb in a) and CS(N − B.), respectively, where
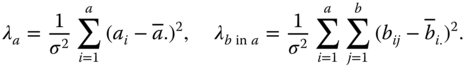
Therefore

and

Using this the null hypothesis HA0: a1 = … = aa, can be tested by ![]() , which, under HA0 is distributed as F(a − 1, N − B.).
, which, under HA0 is distributed as F(a − 1, N − B.).
The null hypothesis HB0: b11 = … = bab, can be tested by ![]() , which, under HB0, is distributed as F(B. − a, N − B.).
, which, under HB0, is distributed as F(B. − a, N − B.).
5.5 Three‐Way Classification
The principle underlying the two‐way ANOVA (two‐way classification) is also useful if more than two factors occur in an experiment. In this section, we only give a short overview of the cases with three factors without proving all statements because the principles of proof are similar to those in the case with two factors.
We consider the case with three factors because it often occurs in applications, which can be handled with a justifiable number of pages, and because besides the cross‐classification and the nested classification a mixed classification occurs. At this point, we make some remarks about the numerical analysis of experiments using ANOVA. Certainly, a general computer program for arbitrary classifications and numbers of factors with unequal class numbers can be elaborated. However, such a program, even with modern computers, is not easy to apply because the data matrices easily obtain several tens of thousands of rows. Therefore, we give for some special cases of the three‐way analysis of variance numerical solutions for which easy‐to‐use programs are written using R.
Problems with more than three factors are described in Hartung et al. (1997) and in Rasch et al. (2008).
5.5.1 Complete Cross‐Classification (A×B × C)
We assume that the observations of an experiment are influenced by three factors A, B, and C with a, b, and c levels A1, … , Aa, B1, … , Bb, and C1, … , Cc, respectively. For each possible combination (Ai, Bj, Ck) let n ≥ 1 observations yijkl (l = 1, ⋯, n) be present. If the subclass numbers nijkl are not all equal or if some of them are zero but the classification is connected, we must use in R different models in >lm(). For the testing of interaction A × B, in the formula A × B must be placed before A × B × C; for the testing of interaction A × C, in the formula A × C must be placed before A × B × C; for the testing of interaction B × C in the formula B × C must be placed before A × B × C. An example of the analysis of an unbalanced three‐way cross‐classification with R is described at the end of this section.
Each combination (Ai, Bj, Ck) (i = 1, ⋯, a; j = 1, ⋯, b; k = 1, ⋯, c) of factor levels is called a class and is characterised by (i, j, k). The expectation in the population associated with the class (i, j, k) is ηijk.
We define


and

The overall expectation is
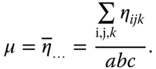
The main effects of the factors A, B, and C we define by
Assuming that the experiment is performed at a particular level Ck of the factor C we have a two‐way classification with the factors A and B, and the conditional interactions between the levels of the factors A and B for fixed k are given by
The interactions (a, b)ij between the ith A level and the jth B level are the means over all C levels, i.e. (a, b)ij is defined as
The interactions between A levels and C levels (a, c)ik and between B levels and C levels (b, c)jk are defined by
and
respectively.
The difference between the conditional interactions between the levels of two of the three factors for the given level of the third factor and the (unconditional) interaction of these two factors depends only on the indices of the levels of the factors, and not on the factor for which the interaction of two factors is calculated. We call it the second order interaction (a, b, c)ijk (between the levels of three factors). Without loss of generality we write
The interactions between the levels of two factors are called first‐order interactions. From the definition of the main effect and the interactions we write for ηijk
Under the definitions above, the side conditions for all values of the indices not occurring in the summation at any time are
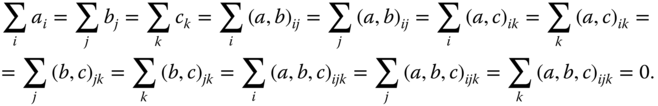
The n observations yijkl in each class are assumed to be independent of each other and N(0, σ2)‐distributed. The variable (called error term) eijkl is the difference between yijkl and the expectation ηijk of the class, i.e. we have
or
By the least squares method we obtain the following estimators:
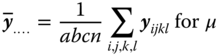
as well as
If any of the interaction effects in 5.30 are zero the corresponding estimator above is dropped the others remain unchanged. The following model equations lead to different SSres, as shown in Table 5.15.
Table 5.15 ANOVA table of a three‐way cross‐classification with equal subclass numbers (model I).
| Source of variation | SS | df |
| Between A levels | 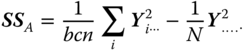 |
a − 1 |
| Between B levels | 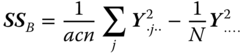 |
b − 1 |
| Between C levels | 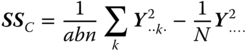 |
c − 1 |
| Interaction A × B | 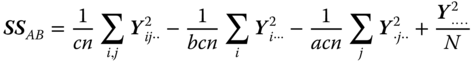 |
(a − 1)(b − 1) |
| Interaction A × C | 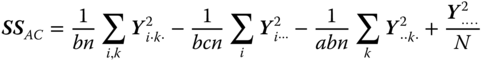 |
(a − 1)(c − 1) |
| Interaction B × C | 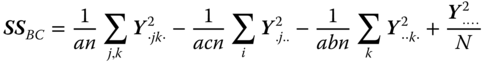 |
(b − 1)(c − 1) |
| Interaction A × B × C | (a − 1)(b − 1)(c − 1) | |
|
Within the classes (residual), (5.30) |
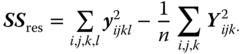 |
abc(n − 1) |
|
Within the classes (residual), (5.31) |
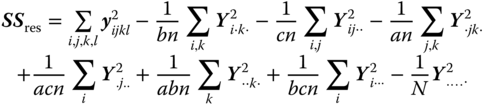 |
(a − 1)(b − 1) (c − 1) + abc(n − 1) |
| MS in (5.30) | E(MS) in (5.30) | F in (5.30) |
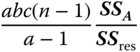 |
||
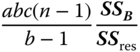 |
||
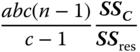 |
||
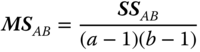 |
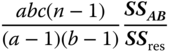 |
|
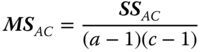 | 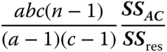 |
|
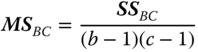 |
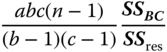 |
|
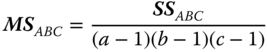 |
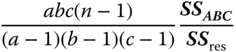 |
|
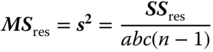 |
σ2 |
We may split the overall sum of squares ![]() into eight components: three corresponding with the main effects, three with the first order interactions, one with the second order interaction, and one with the error term or the residual. The corresponding SS are shown in the ANOVA table (Table 5.15). In this table N is, again, the total number of observations, N = abcn.
into eight components: three corresponding with the main effects, three with the first order interactions, one with the second order interaction, and one with the error term or the residual. The corresponding SS are shown in the ANOVA table (Table 5.15). In this table N is, again, the total number of observations, N = abcn.
The following hypotheses can be tested (H0x is one of the hypotheses H0A, … , H0ABC; SSx is the corresponding SS).
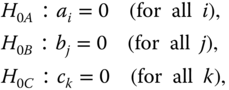
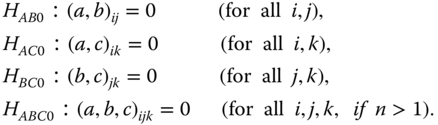
Under the hypothesis ![]() are independent of each other, with the df given in the ANOVA table, centrally χ2‐distributed. Therefore, the test statistics given in column F of the ANOVA table are, with the corresponding degrees of freedom, centrally F‐distributed. For n = 1 all hypotheses except HABC0 can be tested under the assumption (a, b, c)ijk = 0 for all i, j, k because then
are independent of each other, with the df given in the ANOVA table, centrally χ2‐distributed. Therefore, the test statistics given in column F of the ANOVA table are, with the corresponding degrees of freedom, centrally F‐distributed. For n = 1 all hypotheses except HABC0 can be tested under the assumption (a, b, c)ijk = 0 for all i, j, k because then ![]() and
and ![]() , under Hx0(x = A, B, C, etc.), are independent of each other centrally χ2_‐distributed. The test statistic Fx is given by
, under Hx0(x = A, B, C, etc.), are independent of each other centrally χ2_‐distributed. The test statistic Fx is given by

If the null hypotheses are not true, we have non‐central distributions with non‐centrality parameters analogous to those in Section 5.4.
If the subclass numbers nijkl are not all equal or if some of them are zero but the classification is connected, we must change the formula for testing the two‐factor interactions. In the following example, we give an unbalanced three‐way cross‐classification.
5.5.2 Nested Classification (C ≺ B ≺ A)
We speak about a three‐way nested classification if factor C is sub‐ordinated to factor B and factor B is sub‐ordinated to factor A, i.e. if C ≺ B ≺ A. We assume that the random variable yijkl varies randomly with expected value ηijk(i = 1, … , a; j = 1, … , bi; k = 1, … , cij), i.e. we assume
where eijkl, independent of each other, are N(0, σ2)‐distributed. Using
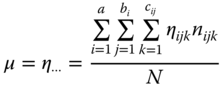
we define the total mean of the experiment as 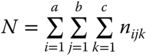 .
.
The difference ![]() is called the effect of the ith level of A, the difference
is called the effect of the ith level of A, the difference ![]() is called the effect of the jth level of B within the ith level of A and the difference
is called the effect of the jth level of B within the ith level of A and the difference ![]() is called the effect of the kth level of C within the jth level of B and the ith level of A.
is called the effect of the kth level of C within the jth level of B and the ith level of A.
Then we model the observations using
There exist no interactions. We consider 5.32 with ![]() under the side conditions
under the side conditions
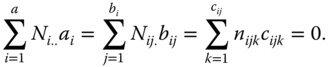
Minimising

under the side conditions above, leads to the BLUE of the parameters as follows
![]()
![]()
In a three‐way nested classification we have
with 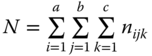 ,
, ![]() and
and
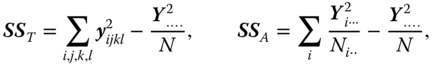
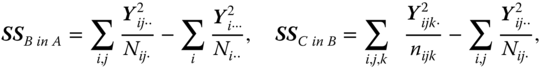
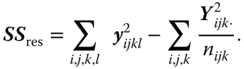
The variables ![]() up to
up to ![]() are, with
are, with ![]() , pairwise independently CS(a − 1, λa), CS(B. − a, λb), CS(C.. − B., λc), respectively, and
, pairwise independently CS(a − 1, λa), CS(B. − a, λb), CS(C.. − B., λc), respectively, and ![]() is CS(N − C..)‐distributed. The non‐centrality parameters λa, λb and λc vanish under the null hypotheses HA0 : ai = 0 (i = 1, . … a), HB0 : bij = 0 (i = 1, . … a; j = 1, … , bi), HC0 : cijk = 0 (i = 1, . … a; j = 1, … , bi; k = 1, … , cij), so that the usual F statistics can be used. Table 5.19 shows the SS and MS for calculating the F‐statistics. If HA0 is valid FA is F(a − 1, N − C..)‐distributed. If HB0 is valid then FB is F(B − a, N − C..)‐distributed, and if HC0 is valid then Fc is F(C.. − B., N − C..)‐distributed.
is CS(N − C..)‐distributed. The non‐centrality parameters λa, λb and λc vanish under the null hypotheses HA0 : ai = 0 (i = 1, . … a), HB0 : bij = 0 (i = 1, . … a; j = 1, … , bi), HC0 : cijk = 0 (i = 1, . … a; j = 1, … , bi; k = 1, … , cij), so that the usual F statistics can be used. Table 5.19 shows the SS and MS for calculating the F‐statistics. If HA0 is valid FA is F(a − 1, N − C..)‐distributed. If HB0 is valid then FB is F(B − a, N − C..)‐distributed, and if HC0 is valid then Fc is F(C.. − B., N − C..)‐distributed.
Table 5.19 ANOVA table of a three‐way nested classification for model I.
| Source of Variation | SS | df | MS | E(MS) | F |
| Between A | 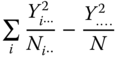 |
a − 1 | 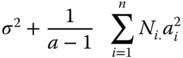 |
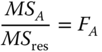 |
|
| Between B in A | 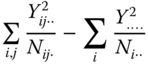 |
B. − a | 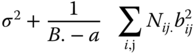 |
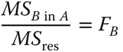 |
|
| Between C in B and A | 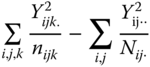 |
C.. − B. | 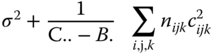 |
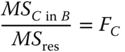 |
|
| Residual | 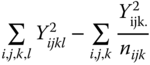 |
N − C.. | σ2 | ||
| Total | 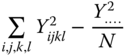 |
N − 1 |
5.5.3 Mixed Classifications
In experiments with three or more factors besides a cross‐classification or a nested classification, we often find a further type of classification, the so‐called mixed (partially nested) classifications. In the three‐way ANOVA, two mixed classifications occur (Rasch 1971). We consider the case that the birth weight of piglets is observed in a three‐way classification with factors boar, sow within boar and gender of the piglet. The latter is cross‐classified with the nested factors boar and sow.
5.5.3.1 Cross‐Classification between Two Factors where One of Them Is Sub‐Ordinated to a Third Factor ((B ≺ A)xC)
If in a balanced experiment a factor B is sub‐ordinated to a factor A and both are cross‐classified with a factor C then the corresponding model equation is given by
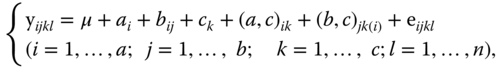
In 5.34 μ is the general experimental mean, ai is the effect of the ith level of factor A; bij is the effect of the jth level of factor B within the ith level of factor A; ck is the effect of the kth level of factor C. Further (a, c)ik and (b, c)jk(i) are the corresponding interaction effects and eijkl are the random error terms.
As usual, the error terms eijkl are independently distributed with expectation zero and the same variance σ2; for testing and confidence estimation normality is assumed in addition.
Model 5.34 is considered under the side conditions for all indices not occurring in the summation
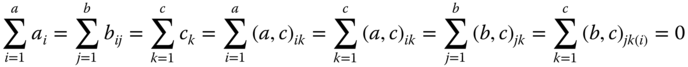
and
(for all i,j, k, l).
The observations
are allocated as shown in Table 5.21 (we restrict ourselves to the so‐called balanced case where the number of B levels is equal for all A levels and the subclass numbers are equal).
Table 5.21 Observations of a mixed classification type (A≻B) × C with a = 2, b = 3, c = 2, n = 2.
| A1 | A2 | |||||
| B11 | B12 | B13 | B21 | B22 | B23 | |
| C1 |
288 295 |
355 369 |
329 343 |
310 282 |
303 321 |
299 328 |
| C2 |
278 272 |
336 342 |
320 315 |
288 287 |
302 297 |
289 284 |
5.5.3.2 Cross‐Classification of Two Factors, in which a Third Factor is Nested (C ≺ (A × B))
If two cross‐classified factors (A × B) are super‐ordered to a third factor (C) we have another mixed classification. The model equation for the random observations in a balanced design is given by
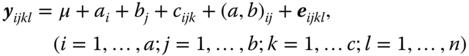
This is again the situation of model I; the error terms eijkl again fulfil condition 5.36.
We assume that for all values of the indices not occurring in the summation, we have the side conditions
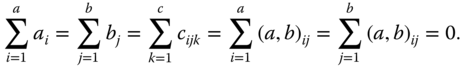
The total sum of squared deviations can be split into components
with
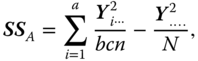
the SS between the A levels,
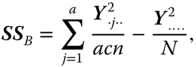
the SS between the B levels,
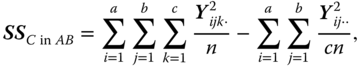
the SS between the C levels within the A × B combinations,
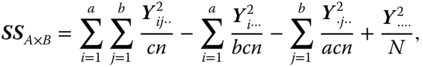
the SS for the interactions between factor A and factor B, and
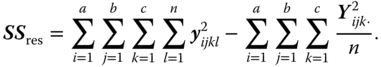
The expectations of the MS in this model are shown in Table 5.23 and the hypotheses
Table 5.23 ANOVA table and expectations of the MS for model I of a balanced three‐way ANOVA A with B cross‐classified, C nested in the A x B combinations.
| Source of variation | SS | |
| Between A levels | 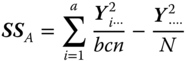 |
|
| Between B levels | 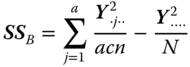 |
|
|
Between C levels in A × B combinations |
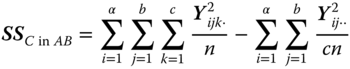 |
|
| Interaction A × B | 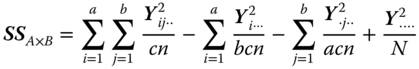 |
|
| Residual | 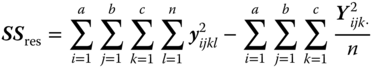 |
|
| df | MS | E(MS) under (5.38) |
| a − 1 | 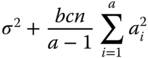 |
|
| b − 1 | 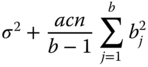 |
|
| ab(c − 1) | 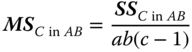 |
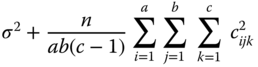 |
| (a − 1)(b − 1) | 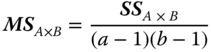 |
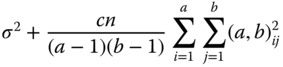 |
| N − abc | σ2 |
HA0 : ai = 0, HB0 : bj = 0, HC0 : cijk = 0, HAB0 : (a, b)ij = 0,
where the zero values are assumed to hold for all indices used in the hypotheses, can be tested by using the corresponding F‐statistic as the ratios of MSA, MSB, MSC, and MSA × B, respectively, (as numerator) and MSres (as denominator).
References
- Fisher, R.A. and Mackenzie, W.A. (1923). Studies in crop variation. II. The manurial response of different potato varieties. Journal of Agricultural Sciences 13: 311–320.
- Hartung, J., Elpelt, B., and Voet, B. (1997). Modellkatalog Varianzanalyse. München: Oldenburg Verlag.
- Kuehl, R.O. (1994). Statistical Principles of Research Design and Analysis. Belmont, California: Duxbury Press.
- Lenth, R.V. (1986). Computing non‐central Beta probabilities. Appl. Statistics 36: 241–243.
- Rasch, D. (1971). Mixed classification the three‐way analysis of variance. Biom. Z. 13: 1–20.
- Rasch, D. and Schott, D. (2018). Mathematical Statistics. Oxford: Wiley.
- Rasch, D., Wang, M., and Herrendörfer, G. (1997). Determination of the size of an experiment for the F‐test in the analysis of variance. Model I. In: Advances in Statistical Software 6. The 9th Conference on the Scientific Use of Statistical Software. Heidelberg: Springer.
- Rasch, D., Herrendörfer, G., Bock, J., Victor, N., and Guiard, V. Hrsg. (2008). Verfahrensbibliothek Versuchsplanung und ‐ auswertung, 2. verbesserte Auflage in einem Band mit CD. R. Oldenbourg Verlag München Wien.
- Rasch, D., Pilz, J., Verdooren, R., and Gebhardt, A. (2011). Optimal Experimental Design with R. Boca Raton: Chapman and Hall.
- Scheffé, H. (1959). The Analysis of Variance. New York, Hoboken: Wiley.