
4
Confidence Estimations – One‐ and Two‐Sample Problems
4.1 Introduction
In confidence estimation, we construct random regions in the parameter space so that this region covers the unknown parameter with a given probability, the confidence coefficient. In this book we consider special regions, namely intervals called confidence intervals. We then speak about interval estimation. We will see that there are analogies to the test theory concerning the optimality of confidence intervals, which we exploit to simplify many considerations.
A confidence interval is a function of the random sample; that is to say, it is also random in the sense of depending on chance, hence we speak of a random interval. However, once calculated based on observations, the interval has, of course, non‐random bounds. Sometimes only one of the bounds is of interest; the other is then fixed – this concerns the estimator as well as the estimate itself. At least one boundary of a confidence interval must be random; if both boundaries are random, the interval is two‐sided, and if only one boundary is random, it is one‐sided.
We make no difference between a random interval and its realisation with real boundaries but speak always about confidence intervals. What we mean in special cases will be easy to understand. When we speak about the expected length of a confidence interval, we of course mean a random interval.
4.2 The One‐Sample Case
We start with normal distributions and confidence intervals for the expectation.
4.2.1 A Confidence Interval for the Expectation of a Normal Distribution
4.2.2 A Confidence Interval for the Variance of a Normal Distribution
We again assume that the components of the random sample Y = (y1, … , yn)T are N(μ, σ2) distributed with μ and σ2 unknown. To construct a two‐sided (1 − α) confidence interval for σ2 we use its unbiased estimator s2 and use as in Chapter 3 the test statistic ![]() which is centrally χ2 ‐distributed with n − 1 degrees of freedom. Therefore
which is centrally χ2 ‐distributed with n − 1 degrees of freedom. Therefore
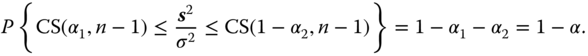
However, contrary to the tests about expectations it is not optimal to split α into equal parts as reasonable for the corresponding uniformly most powerful unbiased (UMPU) test. However, the unequal case does not always give a shorter expected length and therefore we use the split of α into equal parts. From (4.11) with α1 = α2 = α we obtain a (1 − α) confidence interval for σ2 as

The half‐expected length of this interval is 
4.2.3 A Confidence Interval for a Probability
Let us presume n independent trials in each of which a certain event A occurs with the same probability p. A (1 − α) confidence interval for p can be calculated from the number of occurrences y of the event A under the n observations as [l(n,y,α); u(n,y,α)], with the lower bound l(n,y,α) and the upper bound, u(n,y,α), respectively given by:
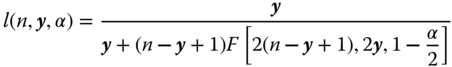

F(f1, f2, P) is the P‐quantile of an F‐distribution with f1 and f2 degrees of freedom.
For other interval estimators of a binomial proportion see Pires and Amado (2008).
To determine the minimum sample size approximately, it seems better to use the half‐expected width of a normal approximated confidence interval for p. Such an interval is given by

This interval has an approximate half‐expected width ![]() . The requirement that this is smaller than δ leads to the sample size
. The requirement that this is smaller than δ leads to the sample size

If nothing is known about p, we must take into account the least favourable case p = 0.5, which gives the maximum of the minimal sample size, the maximum size.
4.3 The Two‐Sample Case
We discuss here only differences between location parameters of two populations; for variances we had to consider ratios but the reader can derive the corresponding intervals using the approach described for differences. We assume that the character of interest in each population is modelled by a normally distributed random variable. That is to say, we draw independent random samples of size n1 and n2, respectively, from populations 1 and 2. The observations of the random variables y11, y12, … , ![]() on the one hand and y21, y22, … ,
on the one hand and y21, y22, … , ![]() on the other hand will be y11, y12, … ,
on the other hand will be y11, y12, … , ![]() and y21, y22, … ,
and y21, y22, … , ![]() . We call the underlying parameters μ1 and μ2, respectively, and further
. We call the underlying parameters μ1 and μ2, respectively, and further ![]() and
and ![]() , respectively. The unbiased estimators are then for the expectations
, respectively. The unbiased estimators are then for the expectations ![]() and
and ![]() , respectively, and for the variances
, respectively, and for the variances ![]() and
and ![]() , respectively (according to Section 3.2).
, respectively (according to Section 3.2).
4.3.1 A Confidence Interval for the Difference of Two Expectations – Equal Variances
If in the two‐sample case the two variances are equal, usually from the two samples y11, y12, … , ![]() and y21, y22, … ,
and y21, y22, … , ![]() a pooled estimator
a pooled estimator ![]() of the common variance σ2 is calculated.
of the common variance σ2 is calculated.
The two‐sided confidence interval is

The lower (1 − α) confidence interval is given by

and the upper one by

4.3.2 A Confidence Interval for the Difference of Two Expectations – Unequal Variances
If in the two‐sample case, the two variances ![]() and
and ![]() are unequal, sample variances
are unequal, sample variances ![]() and
and ![]() from the two independent samples y11, y12, … ,
from the two independent samples y11, y12, … , ![]() and y21, y22, … ,
and y21, y22, … , ![]() are used.
are used.
The confidence interval

is an approximate (1 − α) confidence interval (Welch 1947) with  degrees of freedom.
degrees of freedom.
4.3.3 A Confidence Interval for the Difference of Two Probabilities
Let us say that we are interested in a certain characteristic A from the elements of a population of size N. The number of elements in this population with characteristic A is N(A). The population fraction with characteristic A is π = N(A)/N. We take a random sample of size n with replacement from this population and then the random variable k of elements with this characteristic A has a binomial distribution B(n, π) with the parameters π and n.
The sample fraction p = k/n is an unbiased estimator of π with expectation E(p) = π and variance var(p) = π(1 − π)/n. If neither k nor n − k is less than 5 and if the sample size n is large then the distribution of k can be approximated by a normal distribution with the mean μ = p, the sample fraction, and variance σ2 = p(1 − p)/n.
In practice the researcher is very often interested in the difference between the population fractions with characteristic A in the two populations I and II, namely π1 and π2. Suppose we have a random sample of size n1 from population I and another independent sample of size n2 from population II. Then the unbiased estimator of π1 − π2 is the difference of the sample fractions p1 − p2. If neither k1 nor n1 − k1 and k2 nor n2 − k2 is less than 5 and if the sample sizes n1 and n2 are large then the distribution of k can be approximated by a normal distribution with mean μ = p1 − p2 and variance σ2 = p1(1 − p1)/n1 + p2(1 − p2)/n2.
A confidence interval with confidence coefficient 1 − α for π1 − π2 is then approximated with
References
- Altman, D.G., Machin, D., Bryant, T.N., and Gardner, M.J. (2002). Statistics with Confidence; Confidence Intervals and Statistical Guidelines, 2e. Bristol: British Medical Journal Books.
- Best, E.W.R., Walker, C.B., Baker, P.M. et al. (1967). Summary of a Canadian Study on Smoking and Health. Can. Med. Assoc. J. 96 (15): 1104–1108.
- Goodfield, M.J.D., Andrew, L., and Evans, E.G.V. (1992). Short‐term treatment of dermatophyte onchomyotis with terbinafine. BMJ 304: 1151–1154.
- Newcombe, R.G. (1998). Interval estimation for the difference between independent proportions: comparison of eleven methods. Stat. Med. 17: 873–890.
- Pires, A.M. and Amado, C. (2008). Interval estimators for a binomial proportion: comparison of twenty methods. RevStat Stat. J. 6 (2): 165–197.
- Rasch, D. and Schott, D. (2018). Mathematical Statistics. Oxford: Wiley.
- Rasch, D. and Tiku, M.L. (eds. 1985) Robustness of statistical methods and nonparametric statistics. Proc. Conf. on Robustness of Statistical Methods and Nonparametric Statistics, Schwerin (DDR), May 29 June 2, 1983. Reidel Publ. Co. Dordrecht.
- Welch, B.L. (1947). The generalization of students problem when several different population variances are involved. Biometrika 34: 28–35.