
5
Data Leakage and Data Wrangling in Machine Learning for Medical Treatment
P.T. Jamuna Devi1* and B.R. Kavitha2
1J.K.K. Nataraja College of Arts and Science, Komarapalayam, Tamilnadu, India
2Vivekanandha College of Arts and Science, Elayampalayam, Tamilnadu, India
Abstract
Currently, healthcare and life sciences overall have produced huge amounts of real-time data by ERP (enterprise resource planning). This huge amount of data is a tough task to manage, and intimidation of data leakage by inside workers increases, the companies are wiping far-out for security like digital rights management (DRM) and data loss prevention (DLP) to avert data leakage. Consequently, data leakage system also becomes diverse and challenging to prevent data leakage. Machine learning methods are utilized for processing important data by developing algorithms and a set of rules to offer the prerequisite outcomes to the employees. Deep learning has an automated feature extraction that holds the vital features required for problem solving. It decreases the problem of the employees to choose items explicitly to resolve the problems for unsupervised, semisupervised, and supervised healthcare data. Finding data leakage in advance and rectifying for it is an essential part of enhancing the definition of a machine learning problem. Various methods of leakage are sophisticated and are best identified by attempting to extract features and train modern algorithms on the problem. Data wrangling and data leakage are being handled to identify and avoid additional processes in healthcare in the immediate future.
Keywords: Data loss prevention, data wrangling, digital rights management, enterprise resource planning, data leakage
5.1 Introduction
Currently, in enterprise resource planning (ERP) machine learning and deep learning perform an important role. In the practice of developing the analytical model with machine learning or deep learning the data set is gathered as of several sources like a sensor, database, file, and so on [1]. The received data could not be utilized openly to perform the analytical process. To resolve this dilemma two techniques such as data wrangling and data preprocessing are used to perform Data Preparation [2]. An essential part of data science is data preparation. It is made up of two concepts like feature engineering and data cleaning. These two are inevitable to obtain greater accuracy and efficiency in deep learning and machine learning tasks [3]. Raw information is transformed into a clean data set by using a procedure is called data preprocessing. Also, each time data is gathered from various sources in raw form which is not sustainable for the analysis [4]. Hence, particular stages are carried out to translate data into a tiny clean dataset. This method is implemented in the previous implementation of Iterative Analysis. The sequence of steps is termed data preprocessing. It encompasses data cleaning, data integration, data transformation, and data reduction.
At the moment of creating an interactive model, the Data Wrangling method is performed. In other terms, for data utilization, it is utilized to translate raw information into a suitable format. This method is also termed Data Munging. This technique also complies with specific steps like subsequently mining the data from various sources, the specific algorithm is performed to sort the data, break down the data into a dispersed structured form, and then finally the data is stored into a different database [5]. To attain improved outcomes from the applied model in deep learning and machine learning tasks the data structure has to be in an appropriate way. Some specific deep learning and machine learning type require data in a certain form, for instance, null values are not supported by the Random Forest algorithm, and thus to carry out the random forest algorithm null values must be handled from the initial raw data set [6]. An additional characteristic is that the dataset needs to be formatted in such a manner that there are more than single deep learning and machine learning algorithm is performed in the single dataset and the most out of them has been selected. Data wrangling is an essential consideration to implement the model. Consequently, data is transformed to the appropriate possible format prior to utilizing any model intro it [7]. By executing, grouping, filtering, and choosing the correct data for the precision and implementation of the model might be improved. An additional idea is that once time series data must be managed each algorithm is performed with various characteristics. Thus, the time series data is transformed into the necessary structure of the applied model by utilizing Data Wrangling [8]. Consequently, the complicated data is turned into a useful structure for carrying out an evaluation.
5.2 Data Wrangling and Data Leakage
Data wrangling is the procedure of cleansing and combining complex and messy data sets for simple access and evaluation. With the amount of data and data sources fast-growing and developing, it is becoming more and more important for huge amounts of available data to be organized for analysis. Such a process usually comprises manually transforming and mapping data from a single raw form into a different format to let for more practical use and data organization. Deep learning and machine learning perform an essential role in the modern-day enterprise resource planning (ERP). In the practice of constructing the analytical model with machine learning or deep learning the data set is gathered as of a variety of sources like a database, file, sensors, and much more. The information received could not be utilized openly to perform the evaluation process. To resolve this issue, data preparation is carried by utilizing the two methods like data wrangling and data preprocessing. Data wrangling enables the analysts to examine more complicated data more rapidly, to accomplish more precise results, and due to these, improved decisions could be made. Several companies have shifted to data wrangling due to the achievement that it has made.
Data leakage describes a mistake they are being made by the originator of a machine learning model where they mistakenly share information among the test and training datasets. Usually, when dividing a data set into testing and training sets, the aim is to make sure that no data is shared among the two. Data leakage often leads to idealistically high levels of performance on the test set, since the model is being run on data that it had previously seen—in a certain capacity—in the training set.
Data wrangling is also known as data munging, data remediation, or data cleaning, which signifies various processes planned to be converted raw information into a more easily utilized form. The particular techniques vary from project to project based on the leveraging data and the objective trying to attain.
Some illustrations of data wrangling comprise:
- Combining several data sources into one dataset for investigation
- Finding mistakes in the information (for instance, blank cells in a spreadsheet) and either deleting or filling them
- Removing data that is either irrelevant or unnecessary to the project that one is functioning with
- Detecting excessive outliers in data and either explain the inconsistencies or deleting them so that analysis can occur
Data wrangling be able to be an automatic or manual method. Scenarios in which datasets are extremely big, automatic data cleaning is becoming a must. In businesses that hire a complete data group, a data researcher or additional group representative is usually liable for data wrangling. In small businesses, nondata experts are frequently liable for cleaning their data prior to leveraging it.
5.3 Data Wrangling Stages
- Individual data project demands a distinctive method to make sure their final dataset is credible and easily comprehensible ie different procedures usually notify the proposed methodology. These are often called data wrangling steps or actions shown in Figure 5.1.
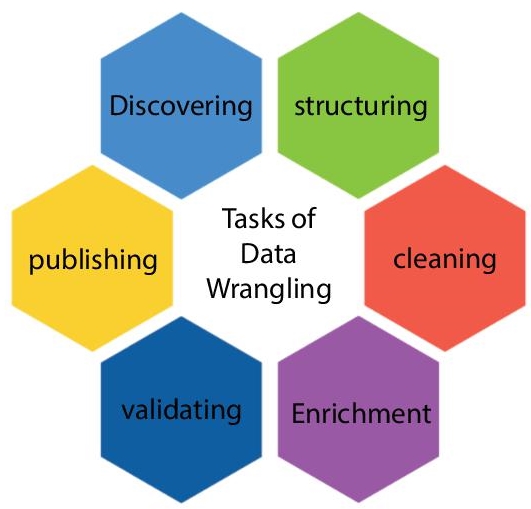
Figure 5.1 Task of data wrangling.
5.3.1 Discovery
Discovery means the method of getting acquainted with the data so one can hypothesize in what way one might utilize it. One can compare it to watching in the fridge before preparing meals to view what things are available.
During finding, one may find patterns or trends in the data, together with apparent problems, like lost or inadequate values to be resolved. This is a major phase, as it notifies each task that arises later.
5.3.2 Structuring
Raw information is usually impractical in its raw form since it is either misformatted or incomplete for its proposed application. Data structuring is the method of accepting raw data and translating it to be much more easily leveraged. The method data takes would be dependent on the analytical model that we utilize to interpret them.
5.3.3 Cleaning
Data cleaning is the method of eliminating fundamental inaccuracies in the data that can alter the review or make them less important. Cleaning is able to take place in various types, comprising the removal of empty rows or cells, regulating inputs, and eliminating outliers. The purpose of data cleaning is to make sure that there are no inaccuracies (or minimal) that might affect your last analysis.
5.3.4 Improving
When one realizes the current data and have turned it into a more useful state, one must define out if one has all of the necessary data projects at hand. If that is not the case, one might decide to enhance or strengthen the data by integrating values from additional datasets. Therefore, it is essential to realize what other information is accessible for usage.
If one determines that fortification is required, one must repeat these steps for new data.
5.3.5 Validating
Data validation is the method of checking that data is simultaneously coherent and of sufficiently high quality. Throughout the validation process, one might find problems that they want to fix or deduce that the data is ready to be examined. Generally, validation is attained by different automatic processes, and it needs to be programmed.
5.3.6 Publishing
When data is verified, one can post it. This includes creating it accessible to other people inside the organization for additional analysis. The structure one uses to distribute the data like an electronic file or written report will be based on data and organizational objectives.
5.4 Significance of Data Wrangling
Any assessments a company carries out would eventually be restricted by data notifying them. If data is inaccurate, inadequate, or incorrect, then the analysis is going to be reducing the value of any perceptions assembled.
Data wrangling aims to eliminate that possibility by making sure that the data is in a trusted state prior to it is examined and leveraged. This creates an important portion of the analytic process.
It is essential to notice that the data wrangling can be time-consuming and burdensome resources, especially once it is made physically. Therefore, several organizations establish strategies and good practices that support workers to simplify the process of data cleaning—for instance, demanding that data contain specific data or be in a certain structure formerly it has been uploaded to the database.
Therefore, it is important to realize the different phases of the data wrangling method and the adverse effects that are related to inaccurate or erroneous data.
5.5 Data Wrangling Examples
While usually performed by data researchers & technical assistants, the results of data wrangling are felt by all of us. For this part, we are concentrating on the powerful opportunities of data wrangling with Python.
For instance, data researchers will utilize data wrangling to web scraping and examine performance advertising data from a social network. This data could even be coupled with network analysis to come forward with an all-embracing matrix explaining and detecting marketing efficiency and budget costs, hence informing future pay-out distribution[14].
5.6 Data Wrangling Tools for Python
Data wrangling is the most time-consuming part of managing data and analysis for data researchers. There are multiple tools on the market to sustain the data wrangling endeavors and simplifying the process without endangering the functionality or integrity of data.
Pandas
Pandas is one of the most widely used data wrangling tools for Python. Since 2009, the open-source data analysis and manipulation tool has evolved and aims of being the “most robust and resilient open-source data analysis/manipulation tool available in every language.”
Pandas’ stripped-back attitude is aimed towards those with an already current level of data wrangling knowledge, as its power lies in the manual features that may not be perfect for beginners. If someone is willing to learn how to use it and to exploit its power, Pandas is the perfect solution shown in Figure 5.2.

Figure 5.2 Pandas (is a software library that was written for Python programming language for data handling and analysing).
NetworkX
NetworkX is a graph data-analysis tool and is primarily utilized by data researchers. The Python package for the “setting-up, exploitation, and exploration of the structure, dynamics, and functionality of the complicated networks” can support the simplest and most complex instances and has the power to collaborate with big nonstandard datasets shown in Figure 5.3.

Figure 5.3 NetworkX.
Geopandas
Geopandas is a data analysis and processing tool designed specifically to simplify the process of working together with geographical data in Python. It is an expansion of Pandas datatypes, which allows for spatial operations on geometric kinds. Geopandas lets to easily perform transactions in Python that would otherwise need a spatial database shown in Figure 5.4.
Figure 5.4 Geopandas.
Extruct
One more expert tool, Extruct is a library to extract built-in metadata from HTML markup by offering a command-line tool that allows the user to retrieve a page and extract the metadata in a quick and easy way.
5.7 Data Wrangling Tools and Methods
Multiple tools and methods can help specialists in their attempts to wrangle data so that others can utilize it to reveal insights. Some of these tools can make it easier for data processing, and others can help to make data more structured and understandable, but everyone is convenient to experts as they wrangle data to avail their organizations.
Processing and Organizing Data
A particular tool an expert uses to handle and organize information can be subject to the data type and the goal or purpose for the data. For instance, spreadsheet software or platform, like Google Sheets or Microsoft Excel, may be fit for specific data wrangling and organizing projects.
Solutions Review observes that big data processing and storage tools, like Amazon Web Services and Google BigQuery, aid in sorting and storing data. For example, Microsoft Excel can be employed to catalog data, like the number of transactions a business logged during a particular week. Though, Google BigQuery can contribute to data storage (the transactions) and can be utilized for data analysis to specify how many transactions were beyond a specific amount, periods with a specific frequency of transactions, etc.
Unsupervised and supervised machine learning algorithms can contribute to the process and examine the stored and systematized data. “In a supervised learning model, the algorithm realizes on a tagged data set, offering an answer key that the algorithm can be used to assess their accuracy on training data”. “Conversely, an unsupervised model offers unlabeled data that the algorithm attempts to make any sense of by mining patterns and features on its own.”
For example, an unsupervised learning algorithm could be provided 10,000 images of pizza, changing slightly in size, crust, toppings, and other factors, and attempt to make sense of those images without any existing labels or qualifiers. A supervised learning algorithm that was intended to recognize the difference between data sets of pictures of either pizza or donuts could ideally categorize through a huge data set of images of both. Both learning algorithms would permit the data to be better organized than what was incorporated in the original set.
Cleaning and Consolidating Data
Excel permits individuals to store information. The organization Digital Vidya offers tips for cleaning data in Excel, such as removing extra spaces, converting numbers from text into numerals, and eliminating formatting. For instance, after data has been moved into an Excel spreadsheet, removing extra spaces in separate cells can help to offer more precise analytics services later on. Allowing text-written numbers to have existed (e.g., nine rather than 9) may hamper other analytical procedures.
Data wrangling best practices may vary by individual or organization who will access the data later, and the purpose or goal for the data’s use. The small bakery may not have to buy a huge database server, but it might need to use a digital service or tool that is the most intuitive and inclusive than a folder on a desktop computer. Particular kinds of database systems and tools contain those offered by Oracle and MySQL.
Extracting Insights from Data
Professionals leverage various tools for extracting data insights, which take place after the wrangling process.
Descriptive, predictive, diagnostic, and prescriptive analytics can be applied to a data set that was wrangled to reveal insights. For example, descriptive analytics could reveal the small bakery how much profit is produced in a year. Descriptive analytics could explain why it generated that amount of profit. Predictive analytics could reveal that the bakery may also see a 10% decrease in profit over the coming year. Prescriptive analytics could emphasize potential solutions that may help the bakery alleviate the potential drop.
Datamation also notes various kinds of data tools that can be beneficial to organizations. For example, Tableau allows users to access visualizations of their data, and IBM Cognos Analytics offers services that can help in different stages of an analytics process.
5.8 Use of Data Preprocessing
Data preprocessing is needed due to the existence of unformatted real-world data. Predominantly real-world data is made up of
Missing data (Inaccurate data) —There are several causes for missing data like data is not continually gathered, an error in data entry, specialized issues with biometric information, and so on.
The existence of noisy data (outliers and incorrect data)—The causes for the presence of noisy data might be a technical challenge of tools that collect data, a human error when entering data, and more.
Data Inconsistency—The presence of data inconsistency is because of the presence of replication within data, dataentry, that contains errors in names or codes i.e., violation of data restrictions, and so on. In order to process raw data, data preprocessing is carried out shown in Figure 5.5.
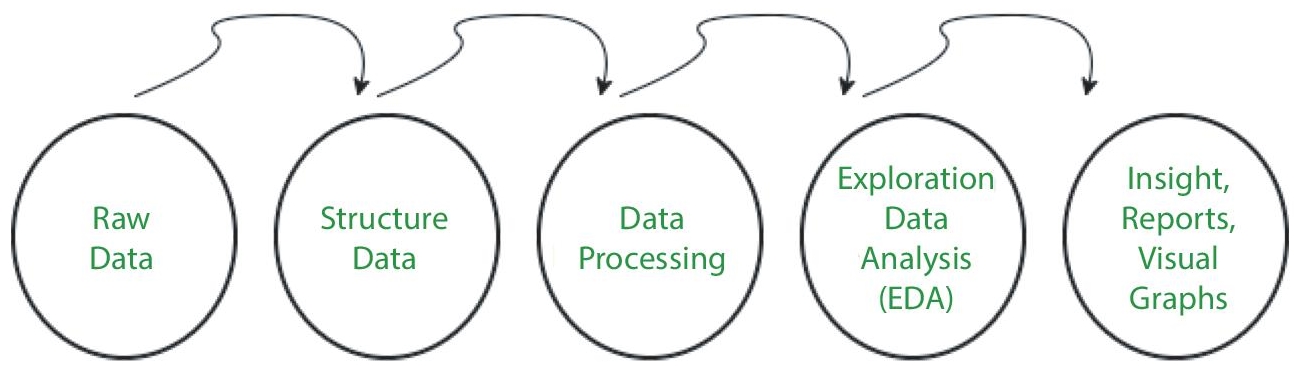
Figure 5.5 Data processing in Python.
5.9 Use of Data Wrangling
While implementing deep learning and machine learning, data wrangling is utilized to manipulate the problem of data leakage.
Data leakage in deep learning/machine learning
Because of the overoptimization of the applied model, data leakage leads to an invalid deep learning/machine learning model. Data leakage is a term utilized once the data from the exterior, i.e., not portion of the training dataset is utilized for the learning method of the model. This extra learning of data by the applied model will negate the calculated estimated efficiency of the model [9].
For instance, once we need to utilize the specific feature to perform Predictive Analysis, but that particular aspect does not exist at the moment of training dataset then data leakage would be created within the model. Leakage of data could be shown in several methods that are listed below:
- Data Leakage for the training dataset from the test dataset.
- Leakage of the calculated right calculation to the training dataset.
- Leakage of upcoming data into the historical data.
- Utilization of data besides the extent of the applied algorithm.
The data leakage has been noted from the two major causes of deep learning/machine learning algorithms like training datasets and feature attributes (variables) [10].
Leakage of data is noted at the moment of the utilization of complex datasets. They are discussed later:
- The dataset is a difficult problem while splitting the time series dataset into test and training.
- Enactment of sampling in a graphic issue is a complicated task.
- Analog observations storage is in the type of images and audios in different files that have a specified timestamp and size.
Performance of data preprocessing
Data pretreatment is performed to delete the reason of raw real-world data and lost data to handle [11]. Following three distinct steps can be performed,
- Ignores the Inaccurate record—It is the most simple and effective technique to manage inaccurate data. But this technique must not be carried out once the number of inaccurate data is massive or if the pattern of data is associated with an unidentified fundamental root of the cause of the statement problem.
- Filling the lost value by hand—It is one of the most excellent-selected techniques. But there is one constraint that once there is a big dataset and inaccurate values are big after that, this methodology is effective as it will be a time-consuming task.
- Filling utilizing a calculated value—The inaccurate values can be filled out by calculating the median, mean, or mode of the noted certain values. The different methods might be the analytical values that are calculated by utilizing any algorithm of deep learning or machine learning. But one disadvantage of this methodology is that it is able to produce systematic errors within the data as computed values are inaccurate regarding the noted values.
Process of handling the noisy data.
A method that can be followed are specified below:
- Machine learning—This can be performed on the data smoothing. For instance, a regression algorithm is able to be utilized to smooth data utilizing a particular linear function.
- Clustering method—In this method, the outliers can be identified by categorizing the related information in a similar class, i.e., in a similar cluster.
- Binning method—In this technique, data sorting is achieved regarding the desired values of the vicinity. This technique is also called local smoothing.
- Removing manually—The noisy data can be taken off by hand by humans, but it is a time-consuming method so largely this approach is not granted precedence.
- The contradictory data is managed to utilize the external links and knowledge design tools such as the knowledge engineering process.
Data Leakage in Machine Learning
The leakage of data can make to generate overly enthusiastic if not entirely invalid prediction models. The leakage of data is as soon as information obtained externally from the training dataset is utilized to build the model [12]. This extra information may permit the model to know or learn anything that it otherwise would not know and in turn, invalidating the assessed efficiency of the model which is being built.
This is a major issue for at least three purposes:
- It is a challenge if one runs a machine learning contest. The leaky data is applied in the best models instead of being a fine generic model of the basic issue.
- It is an issue while one is a company that provides your data. Changing an obfuscation and anonymization can lead to a privacy breach that you never expected.
- It is an issue when one develops their own forecasting model. One might be making overly enthusiastic models, which are sensibly worthless and may not be utilized in manufacturing.
To defeat there are two fine methods that you can utilize to reduce data leakage while evolving predictive models are as follows:
- Carry out preparation of data within the cross-validation folds.
- Withhold a validation dataset for final sanity checks of established models.
Performing Data Preparation Within Cross-Validation Folds
While data preparation of data, leakage of information in machine learning may also take place. The impact is overfitting the training data, and which has an overly enthusiastic assessment of the model’s efficiency on undetected data. To standardize or normalize the whole dataset, one could sin leakage of data then cross-validation has been utilized to assess the efficiency of the model.
The method of rescaling data that one carried out had an understanding of the entire distribution of data in the training dataset while computing the scaling parameters (such as mean and standard deviation or max and min). This knowledge was postmarked rescaled values and operated by all algorithms in a cross-validation test harness [13].
In this case, a nonleaking assessment of machine learning algorithms would compute the factors for data rescaling within every folding of the cross-validation and utilize these factors to formulate the data on every cycle on the held-out test fold. To recompute or reprepare any necessary data preparation within cross-validation folds comprising tasks such as removal or outlier, encoding, selection of feature, scaling feature and projection techniques for dimensional reduction, and so on.
Hold Back a Validation Dataset
An easier way is to divide the dataset of training into train and authenticate the sets and keep away the validation dataset. After the completion of modeling processes and actually made-up final model, assess it on the validation dataset. This might provide a sanity check to find out if the estimation of performance is too enthusiastic and was disclosed.
5.10 Data Wrangling in Machine Learning
The establishment of automatic solutions for data wrangling deals with one most important hurdle: the cleaning of data needs intelligence and not a simple reiteration of work. Data wrangling is meant by having a grasp of exactly what does the user seeks to solve the differences between data sources or say, the transformation of units.
A standard wrangling operation includes these steps: mining of the raw information from sources, the usage of an algorithm to explain the raw data into predefined data structures, and transferring the findings into a data mart for storing and upcoming use.
At present, one of the greatest challenges in machine learning remains in computerizing data wrangling. One of the most important obstacles is data leakage, i.e., throughout the training of the predictive model utilizing ML, it utilizes data outside of the training data set, which is not verified and unmarked.
The few data-wrangling automation software currently available utilize peer-to-peer ML pipelines. But those are far away and a few in-between. The market definitely needs additional automated data wrangling programs.
These are various types of machine learning algorithms:
- Supervised ML: utilized to standardize and consolidate separate data sources.
- Classification: utilized in order to detect familiar patterns.
- Normalization: utilized to reorganize data into the appropriate manner.
- Unsupervised ML: utilized for research of unmarked data

Figure 5.6 Various types of machine learning algorithms.
As it is, a large majority of businesses are still in the initial phases of the implementation of AI for data analytics. They are faced with multiple obstacles: expenses, tackling data in silos, and the fact that it really is not simple for business analysts—those who do not need an engineering or data science experience—to better understand machine learning shown in Figure 5.6.
5.11 Enhancement of Express Analytics Using Data Wrangling Process
Our many years of experience in dealing with data demonstrated that the data wrangling process is the most significant initial step in data analytics. Our data wrangling process involves all the six tasks like data discovery, (listed above), etc, in order to formulate the enterprise data for the analysis. The data wrangling process will help to discover intelligence within the most different data sources. We will correct human mistakes in collecting and tagging data and also authenticate every data source.
5.12 Conclusion
Finding data leakage in advance and revising for it is a vital part of an improvement in the definition of a machine learning issue. Multiple types of leakage are delicate and are best perceived by attempting to extract features and train modern algorithms on the problem. Data wrangling and data leakage are being handled to identify and avoid the additional process in health services in the foreseeable future.
References
- 1. Basheer, S. et al., Machine learning based classification of cervical cancer using K-nearest neighbour, random forest and multilayer perceptron algorithms. J. Comput. Theor. Nanosci., 16, 5-6, 2523–2527, 2019.
- 2. Deekshaa, K., Use of artificial intelligence in healthcare and medicine, Int. J. Innov. Eng. Res. Technol., 5, 12, 1–4. 2021.
- 3. Terrizzano, I.G. et al., Data wrangling: The challenging journey from the wild to the lake. CIDR, 2015.
- 4. Joseph, M. Hellerstein, T. R., Heer, J., Kandel, S., Carreras, C., Principles of data wrangling, Publisher(s): O’Reilly Media, Inc. ISBN: 9781491938928 July 2017.
- 5. Quinto, B., Big data visualization and data wrangling, in: Next-Generation Big Data, pp. 407–476, Apress, Berkeley, CA, 2018.
- 6. McKinney, W., Python for data analysis, Publisher(s): O’Reilly Media, Inc. ISBN: 9781491957660 October 2017.
- 7. Koehler, M. et al., Data context informed data wrangling. 2017 IEEE International Conference on Big Data (Big Data), IEEE, 2017.
- 8. Kazil, J. and Jarmul, K., Data wrangling with Python Publisher(s): O’Reilly Media, Inc. ISBN: 9781491948774 February 2016
- 9. Sampaio, S. et al., A conceptual approach for supporting traffic data wrangling tasks. Comput. J., 62, 3, 461–480, 2019.
- 10. Jiang, S. and Kahn, J., Data wrangling practices and collaborative interactions with aggregated data. Int. J. Comput.-Support. Collab. Learn., 15, 3, 257–281, 2020.
- 11. Azeroual, O., Data wrangling in database systems: Purging of dirty data. Data, 5, 2, 50, 2020.
- 12. Patil, M.M. and Hiremath, B.N., A systematic study of data wrangling. Int. J. Inf. Technol. Comput. Sci., 1, 32–39, 2018.
- 13. Konstantinou, N. et al., The VADA architecture for cost-effective data wrangling. Proceedings of the 2017 ACM International Conference on Management of Data, 2017.
- 14. Swetha, K.R., Niranjanamurthy, M., Amulya, M.P., Manu, Y.M., Prediction of pneumonia using big data, deep learning and machine learning techniques. 2021 6th International Conference on Communication and Electronics Systems (ICCES), pp. 1697–1700, 2021, doi: 10.1109/ICCES51350.2021.9489188.
Note
- *Corresponding author: [email protected]