
6
Importance of Data Wrangling in Industry 4.0
Rachna Jain1, Geetika Dhand2 , Kavita Sheoran2 and Nisha Aggarwal2*
1JSS Academy of Technical Education, Noida, India
2Maharaja Surajmal Institute of Technology, New Delhi, India
Abstract
There is tremendous growth in data in this industry 4.0 because of vast amount of information. This messy data need to be cleaned in order to provide meaningful information. Data wrangling is a method of converting this messy data into some useful form. The main aim of this process is to make stronger intelligence after collecting input from many sources. It helps in providing accurate data analysis, which leads to correct decisions in developing businesses. It even reduces time spent, which is wasted in analysis of haphazard data. Better decision skills are driven from management due to organized data. Key steps in data wrangling are collection or acquisition of data, combining data for further use and data cleaning which involves removal of wrong data. Spreadsheets are powerful method but not making today’s requirements. Data wrangling helps in obtaining, manipulating and analyzing data. R language helps in data management using different packages dplyr, httr, tidyr, and readr. Python includes different data handling libraries such as numpy, Pandas, Matplotlib, Plotly, and Theano. Important tasks to be performed by various data wrangling techniques are cleaning and structuring of data, enrichment, discovering, validating data, and finally publishing of data.
Data wrangling includes many requirements like basic size encoding format of the data, quality of data, linking and merging of data to provide meaningful information. Major data analysis techniques include data mining, which extracts information using key words and patterns, statistical techniques include computation of mean, median, etc. to provide an insight into the data. Diagnostic analysis involves pattern recognition techniques to answer meaningful questions, whereas predictive analysis includes forecasting the situations so that answers help in yielding meaningful strategies for an organization. Different data wrangling tools include excel query/spreadsheet, open refine having feature procurement, Google data prep for exploration of data, tabula for all kind of data applications and CSVkit for converting data. Thus, data analysis provides crucial decisions for an organization or industry. It has its applications in vast range of industries including health-care and retail industries. In this chapter, we will summarize major data wrangling techniques along with its applications in different areas across the domains.
Keywords: Data wrangling, data analysis, industry 4.0, data applications, Google Sheets, industry
6.1 Introduction
Data Deluge is the term used for explosion of data. Meaningful information can be extracted from raw data by conceptualizing and analyzing data properly. Data Lake is the meaningful centralized repository made from raw data to do analytical activities [1]. In today’s world, every device that is connected to the internet generates enormous amount of data. A connected plane generates 5 Tera Byte of data per day, connected car generates 4 TB of data per day. A connected factory generates 5 Penta Byte of data per day. This data has to be organized properly to retrieve meaningful information from it. Data management refers to data modeling and management of metadata.
Data wrangling is the act of cleaning, organizing, and enriching raw data so that it can be utilized for decision making rapidly. Raw data refers to information in a repository that has not yet been processed or incorporated into a system. It can take the shape of text, graphics, or database records, among other things. The most time-consuming part of data processing is data wrangling, often known as data munging. According to data analysts, it can take up to 75% of their time to complete. It is time-consuming since accuracy is critical because this data is gathered from a variety of sources and then used by automation tools for machine learning.
6.1.1 Data Wrangling Entails
- Bringing data from several sources together in one place
- Putting the data together
- Cleaning the data to account for missing components or errors
Data wrangling refers to iterative exploration of data, which further refers to analysis [2]. Integration and cleaning of data has been the issue in research community from long time [3]. Basic features of any dataset are that while approaching dataset for the first-time size and encoding has to be explored. Data Quality is the central aspect of data projects. Data quality has to be maintained while documenting the data. Merging & Linking of data is another important tasks in data management. Documentation & Reproducibility of data is also equally important in the industry [4].
Data wrangling is essential in the most fundamental sense since it is the only method to convert raw data into useful information. In a practical business environment, customer or financial information typically comes in pieces from different departments. This data is sometimes kept on many computers, in multiple spreadsheets, and on various systems, including legacy systems, resulting in data duplication, erroneous data, or data that cannot be found to be utilized. It is preferable to have all data in one place so that you can get a full picture of what is going on in your organization [5].
6.2 Steps in Data Wrangling
While data wrangling is the most critical initial stage in data analysis, it is also the most tiresome, it is frequently stated that it is the most overlooked. There are six main procedures to follow when preparing data for analysis as part of data munging [6].
- Data Discovery: This is a broad word that refers to figuring out what your data is all about. You familiarize yourself with your data in this initial stage.
- Data Organization: When you first collect raw data, it comes in all shapes and sizes, with no discernible pattern. This data must be reformatted to fit the analytical model that your company intends to use [7].
- Data Cleaning: Raw data contains inaccuracies that must be corrected before moving on to the next stage. Cleaning entails addressing outliers, making changes, or altogether erasing bad data [8].
- Data Enrichment: At this point, you have probably gotten to know the data you are working with. Now is the moment to consider whether or not you need to embellish the basic data [9].
- Data Validation: This activity identifies data quality problems, which must be resolved with the appropriate transformations [10]. Validation rules necessitate repetitive programming procedures to ensure the integrity and quality of your data.
- Data Publishing: After completing all of the preceding processes, the final product of your data wrangling efforts is pushed downstream for your analytics requirements.
Data wrangling is an iterative process that generates the cleanest, most valuable data before you begin your analysis [11]. Figure 6.1 displays that how messy data can be converted into useful information.
This is an iterative procedure that should result in a clean and useful data set that can then be analyzed [12]. This is a time-consuming yet beneficial technique since it helps analysts to extract information from a big quantity of data that would otherwise be unreadable. Figure 6.2 shows the organized data using data wrangling.

Figure 6.1 Turning messy data into useful statistics.
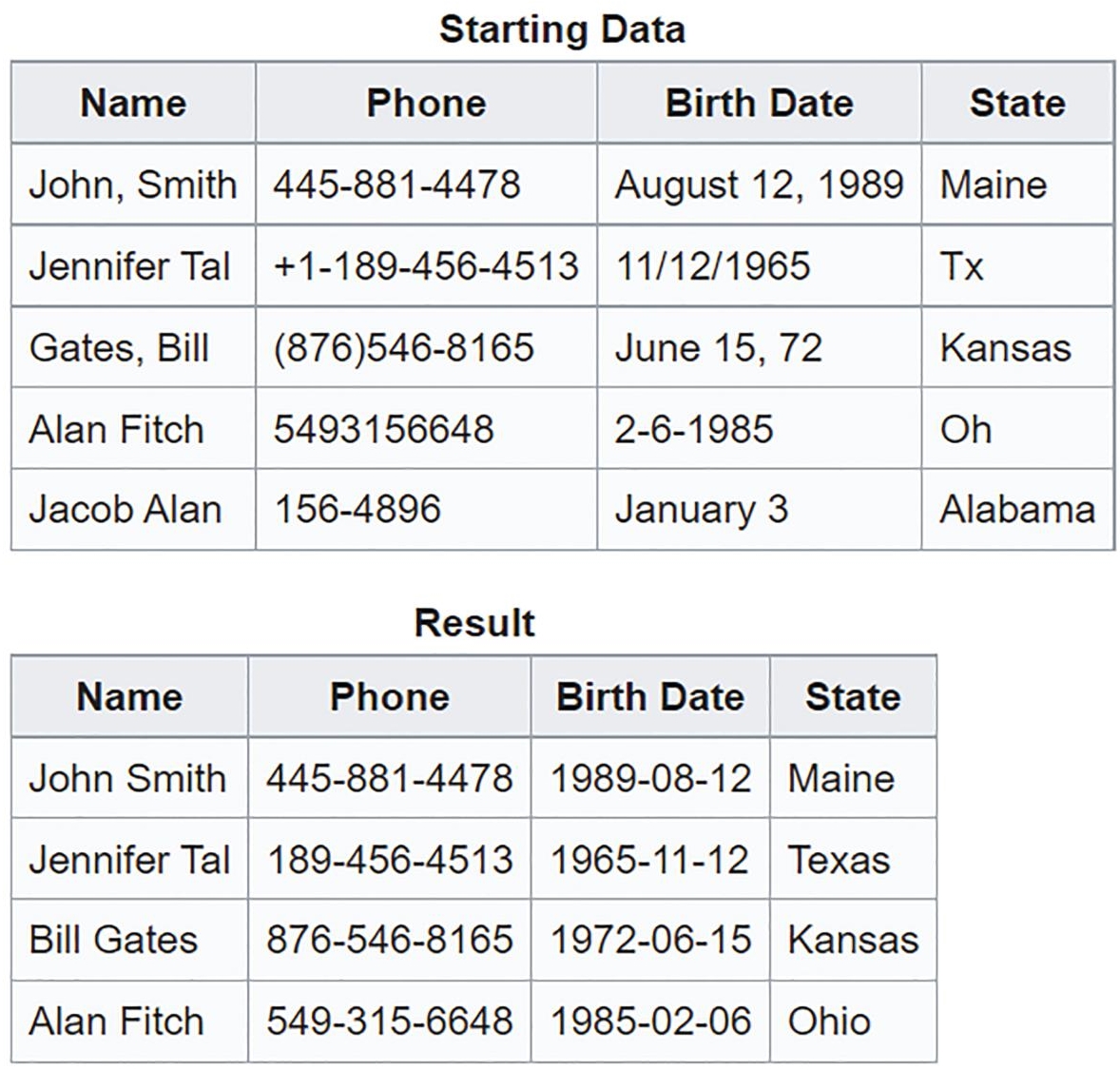
Figure 6.2 Organized data using data wrangling.
6.2.1 Obstacles Surrounding Data Wrangling
In contrast to data analytics, about 80% of effort is lost in gaining value from big data through data wrangling [13]. As a result, efficiency must improve. Until now, the challenges of big data with data wrangling have been solved on a phased basis, such as data extraction and integration. Continuing to disseminate knowledge in the areas with the greatest potential to improve the data wrangling process. These challenges can only be met on an individual basis.
- Any data scientist or data analyst can benefit from having direct access to the data they need. Otherwise, we must provide brief orders in order to obtain “scrubbed” data, with the goal of granting the request and ensuring appropriate execution [14]. It is difficult and time-consuming to navigate through the policy maze.
- Machine Learning suffers from data leaking, which is a huge problem to solve. As Machine Learning algorithms are used in data processing, the risks increase gradually. Data accuracy is a crucial component of prediction [15].
- Recognizing the requirement to scale queries that can be accessed with correct indexing poses a problem. Before constructing a model, it is critical to thoroughly examine the correlation. Before assessing the relationship to the final outcome, redundant and superfluous data must be deleted [16]. Avoiding this would be fatal in the long run. Frequently, in huge data sets of files, a cluster of closely related columns appears, indicating that the data is redundant and making model selection more difficult. Despite the fact that these repeatednesses will offer a significant correlation coefficient, it will not always do so [17].
- There are a few main difficulties that must be addressed. For example, different quality evaluations are not limited, and even simple searches used in mappings would necessitate huge updates to standard expectations in the case of a large dataset [18]. A dataset is frequently devoid of values, has errors, and contains noise. Some of the causes include soapy eye, inadvertent mislabeling, and technical flaws. It has a well-known impact on the class of data processing tasks, resulting in subpar outputs and, ultimately, poorly managed business activity [19]. In ML algorithms, messy, unrealistic data is like rubbing salt in the wounds. It is possible that a trained dataset algorithm will be unsuitable for its purposes.
- Reproducibility and documentation are critical components of any study, but they are frequently overlooked [20]. Data processing and procedures across time, as well as the regeneration of previously acquired conclusions, are mutual requirements that are challenging to meet, particularly in mutually interacting connectivity [21].
- Selection bias is not given the attention it deserves until a model fails. It is very important in data science. It is critical to make sure the training data model is representative of the operating model [22]. In bootstrapped design, ensuring adequate weights necessitates building a design specifically for this use.
- Data combining and data integration are frequently required to construct the image. As a result, merging, linking divergent designs, coding procedures, rules, and modeling data are critical as we prepare data for later use [23].
6.3 Data Wrangling Goals
- Reduce Time: Data analysts spend a large portion of their time wrangling data, as previously indicated. It consumes much of the time of some people. Consider putting together data from several sources and manually filling in the gaps [24]. Alternatively, even if code is used, stringing it together accurately takes a long time. Solvexia, for example, can automate 10× productivity.
- Data analysts can focus on analysis: Once a data analyst has freed up all of the time they would have spent wrangling data, they can use the data to focus on why they were employed in the first place—to perform analysis [25]. Data analytics and reporting may be produced in a matter of seconds using automation techniques.
- Decision making that is more accurate and takes less time: Information must be available quickly to make business decisions [26]. You can quickly make the best decision possible by utilizing automated technologies for data wrangling and analytics.
- More in-depth intelligence: Data is used in every facet of business, and it will have an impact on every department, from sales to marketing to finance [27]. You will be able to better comprehend the present state of your organization by utilizing data and data wrangling, and you will be able to concentrate your efforts on the areas where problems exist.
- Data that is accurate and actionable: You will have ease of mind knowing that your data is accurate, and you will be able to rely on it to take action, thanks to proper data wrangling [28].
6.4 Tools and Techniques of Data Wrangling
It has been discovered that roughly 80% of data analysts spend the majority of their time wrangling data rather than doing actual analysis. Data wranglers are frequently employed if they possess one or more of the following abilities: Knowledge of a statistical language, such as R or Python, as well as SQL, PHP, Scala, and other programming languages.
6.4.1 Basic Data Munging Tools
- Excel Power Query/Spreadsheets — the most basic structuring tool for manual wrangling.
- OpenRefine — more sophisticated solutions, requires programming skills
- Google DatePrep — for exploration, cleaning, and preparation.
- Tabula — swiss army knife solutions — suitable for all types of data
- DataWrangler — for data cleaning and transformation.
- CSVKit — for data converting
6.4.2 Data Wrangling in Python
- Numpy (aka Numerical Python) — The most basic package is Numpy (also known as Numerical Python). Python has a lot of capabilities for working with n-arrays and matrices. On the NumPy array type, the library enables vectorization of mathematical operations, which increases efficiency and speeds up execution.
- Pandas — intended for quick and simple data analysis. This is particularly useful for data structures with labelled axes. Explicit data alignment eliminates typical mistakes caused by mismatched data from many sources.
- Matplotlib — Matplotlib is a visualisation package for Python. Line graphs, pie charts, histograms, and other professional-grade figures benefit from this.
- Plotly — for interactive graphs of publishing quality. Line plots, scatter plots, area charts, bar charts, error bars, box plots, histograms, heatmaps, subplots, multiple-axis, polar graphs, and bubble charts are all examples of useful graphics.
- Theano —Theano is a numerical computing library comparable to Numpy. This library is intended for quickly defining, optimising, and evaluating multi-dimensional array mathematical expressions.
6.4.3 Data Wrangling in R
- Dplyr — a must-have R tool for data munging. The best tool for data framing. This is very handy when working with data in categories.
- Purrr — useful for error-checking and list function operations.
- Splitstackshape — a tried-and-true classic. It is useful for simplifying the display of complicated data sets.
- JSOnline — a user-friendly parsing tool.
- Magrittr — useful for managing disjointed sets and putting them together in a more logical manner.
6.5 Ways for Effective Data Wrangling
Data integration, based on current ideas and a transitional data cleansing technique, has the ability to improve wrapped inductive value.
Manually wrangling data or data munging allows us to manually open, inspect, cleanse, manipulate, test, and distribute data. It would first provide a lot of quick and unreliable data [29]. However, because of its inefficiency, this practice is not recommended. In single-case current analysis instances, this technique is critical. Long-term continuation of this procedure takes a lot of time and is prone to error owing to human participation. This method always has the risk of overlooking a critical phase, resulting in inaccurate data for the consumers [30].
To make matter better, we now have program-based devices that have the ability to improve data wrangling. SQL is an excellent example of a semiautomated method [31]. When opposed to a spreadsheet, one must extract data from the source into a table, which puts one in a better position for data profiling, evaluating inclinations, altering data, and executing data and presenting summary from queries within it [32]. Also, if you have a repeating command with a limited number of data origins, you can use SQL to design a process for evaluating your data wrangling [33]. Further advancement, ETL tools are a step forward in comparison to stored procedures [34]. ETLs extract data from a source form, alter it to match the consequent format, and then load it into the resultant area. Extraction-transformation-load possesses a diverse set of tools. Only a few of them are free. When compared to Standard Query Language stored queries, these tools provide an upgrade because the data handling is more efficient and simply superior. In composite transformations and lookups, ETLs are more efficient. They also offer stronger memory management capabilities, which are critical in large datasets [35].
When there is a need for duplicate and compound data wrangling, constructing a company warehouse of data with the help of completely automated workflows should be seriously considered. The technique that follows combines data wrangling with a reusable and automated mentality. This method then executes in an automated plan for current data load from a current data source in an appropriate format. Despite the fact that this method involves more thorough analysis, framework, and adjustments, as well as current data maintenance and governance, it offers the benefits of reusing extraction-transformation-load logic, and we may rework the adapted data in a number of business scenarios [36].
Data manipulation is critical in any firm research and should not be overlooked. Building timetable automated based chores to get the most out of data wrangling, adapting various data parts in a similar format saving the analysts time to deliver enhanced data combined commands is an ideal scenario for managing ones disruptive data.
6.5.1 Ways to Enhance Data Wrangling Pace
- These solutions are promising, but we must concentrate on accelerating the critical data wrangling process. It cannot be afforded to lose speed in data manipulation, so necessary measures must be taken to improve performance.
- It is difficult to emphasize the needs to the important concerns to be handled at any given time. It would also be necessary to get quick results. The best way to cope with these problems will be described later. Each problem must be isolated in order to discover the best answer. There is a need to create some high-value factors and treat them with greater urgency. We must keep track of duties and solutions in order to speed up the process of developing a solid strategy.
- Assimilation of data specialists from industries other than the IT sector exemplifies a trend that today’s businesses are not encouraging, which has resulted in a trend that modern-day firms have abandoned, resulting in the issues that have arisen. Even while data thrives for analysis, it is reliant on the function of an expert by modelling our data, which is different from data about data.
- There must be an incentive to be part of a connected society and to examine diverse case studies in your sector. Analyzing the performance of your coworkers is an excellent example of how to improve.
- Joining communities that care about each other could help you learn faster. We gain a lot of familiarity with a community of people that are determined to advance their careers in data science by constantly learning and developing on a daily basis. With the passage of time, we have gained more knowledge through evaluating many examples. They have the potential to be extremely important.
- Every crew in a corporation has its own goals and objectives. However, they all have the same purpose in mind. Collaboration with other teams, whether engineering, data science, or various divisions within a team, can be undervalued but crucial. It brings with it a new way of thinking. We are often stuck in a rut, and all we need is a slight shift in viewpoint. For example, the demand to comprehend user difficulties may belong in the gadget development team, rather than in the thoughts of the operations team, because it might reduce the amount of time spent on logistics. As a result, collaboration could speed up the process of locating the perfect dataset.
- Data errors are a well-known cause of delays, and they are caused by data mapping, which is extremely challenging in the case of data wrangling. Data manipulation is one answer to this problem. It does not appear to be a realistic solution, but it does lessen the amount of time we spend mapping our data. Data laboratories are critical in situations when an analyst has the opportunity to use potential data streams, as well as variables to determine whether they are projecting or essential in evaluating or modeling the data.
- When data wrangling is used to gather user perceptions with the help of Face book, Twitter, or any other social media, polls, and comment sections, it enhances knowledge of how to use data appropriately, such as user retention. However, the complexity increases when the data wrangle usage is not identified. The final outcome obtained through data wrangling would be unsatisfactory. As a result, it is critical to extract the final goal via data wrangling while also speeding up the process.
- Intelligent awareness has the ability to extract information and propose solutions to data wrangling issues. We must determine whether scalability and granularity are maintained and respond appropriately. Try to come up with a solution for combining similar datasets throughout different time periods. Find the right gadgets or tools to help you save time when it comes to data wrangling. We need to know if we can put in the right structure with the least amount of adjustments. To improve data wrangling, we must examine findings.
- The ability to locate key data in order to make critical decisions at the correct time is critical in every industry. Randomness or complacency has no place in a successful firm, and absolute data conciseness is required.
6.6 Future Directions
Quality of data, merging of different sources is the first phase of data handling. Heterogeneity of data is the problem faced by different departments in an organization. Data might be collected from outside sources. Analyzing data collected from different sources could be a difficult task. Quality of data has to be managed properly since different organization yield content rich in information but quality of data becomes poor. This research paper gave a brief idea about toolbox from the perspective of a data scientist that will help in retrieving meaningful information. Brief overview of tools related to data wrangling has been covered in the paper. Practical applications of R language, RStudio, Github, Python, and basic data handling tools have been thoroughly analyzed. User can implement statistical computing by reading data either in CSV kit or in python library and can analyze data using different functions. Exploratory data analysis techniques are also important in visualizing data graphics. This chapter provides a brief overview of different toolset available with a data scientist. Further, it can be extended for data wrangling using artificial intelligence methods.
References
- 1. Terrizzano, I.G., Schwarz, P.M., Roth, M., Colino, J.E., Data wrangling: The challenging yourney from the wild to the lake, in: CIDR, January 2015.
- 2. Furche, T., Gottlob, G., Libkin, L., Orsi, G., Paton, N.W., Data wrangling for big data: Challenges and opportunities, in: EDBT, pp. 473–478, March 2016.
- 3. Kandel, S., Heer, J., Plaisant, C., Kennedy, J., Van Ham, F., Riche, N.H., Weaver, C., Lee, B., Brodbeck, D., Buono, P., Research directions in data wrangling: Visualizations and transformations for usable and credible data. Inf. Vis., 10, 4, 271–288, 2011.
- 4. Endel, F. and Piringer, H., Data wrangling: Making data useful again. IFAC-PapersOnLine, 48, 1, 111–112, 2015.
- 5. Dasu, T. and Johnson, T., Exploratory Data Mining and Data Cleaning, vol. 479, John Wiley & Sons, 2003.
- 6. https://www.bernardmarr.com/default.asp?contentID=1442 [Date: 11/11/2021]
- 7. Freeland, S.L. and Handy, B.N., Data analysis with the solarsoft system. Sol. Phys., 182, 2, 497–500, 1998.
- 8. Brandt, S. and Brandt, S., Data Analysis, Springer-Verlag, 1998.
- 9. Berthold, M. and Hand, D.J., Intelligent Data Analysis, vol. 2, Springer, Berlin, 2003.
- 10. Tukey, J.W., The future of data analysis. Ann. Math. Stat, 33, 1, 1–67, 1962.
- 11. Rice, J.A., Mathematical Statistics and Data Analysis, Cengage Learning, 2006.
- 12. Fruscione, A., McDowell, J.C., Allen, G.E., Brickhouse, N.S., Burke, D.J., Davis, J.E., Wise, M., CIAO: Chandra’s data analysis system, in: Observatory Operations: Strategies, Processes, and Systems, vol. 6270p, International Society for Optics and Photonics, June 2006.
- 13. Heeringa, S.G., West, B.T., Berglund, P.A., Applied Survey Data Analysis, Chapman and Hall/CRC, New York, 2017.
- 14. Carpineto, C. and Romano, G., Concept Data Analysis: Theory and Applications, John Wiley & Sons, 2004.
- 15. Swan, A.R. and Sandilands, M., Introduction to geological data analysis. Int. J. Rock Mech. Min. Sci. Geomech. Abstr., 8, 32, 387A, 1995.
- 16. Cowan, G., Statistical Data Analysis, Oxford University Press, 1998.
- 17. Bryman, A. and Hardy, M.A. (eds.), Handbook of Data Analysis, Sage, 2004.
- 18. Bendat, J.S. and Piersol, A.G., Random Data: Analysis and Measurement Procedures, vol. 729, John Wiley & Sons, 2011.
- 19. Ott, R.L. and Longnecker, M.T., An Introduction to Statistical Methods and Data Analysis, Cengage Learning, 2015.
- 20. Nelson, W.B., Applied Life Data Analysis, vol. 521, John Wiley & Sons, 2003.
- 21. Hair, J.F. et al., Multivariate Data Analysis: A global perspective, 7th ed., Upper Saddle River, Prentice Hall, 2009.
- 22. Gelman, A., Carlin, J.B., Stern, H.S., Rubin, D.B., Bayesian Data Analysis, Chapman and Hall/CRC, New York, 1995.
- 23. Rabiee, F., Focus-group interview and data analysis. Proc. Nutr. Soc., 63, 4, 655–660, 2004.
- 24. Agresti, A., Categorical data analysis, vol. 482, John Wiley & Sons, 2003.
- 25. Davis, J.C. and Sampson, R.J., Statistics and Data Analysis in Geology, vol. 646, Wiley, New York, 1986.
- 26. Van de Vijver, F. and Leung, K., Methods and data analysis of comparative research, Allyn & Bacon, 1997.
- 27. Daley, R., Atmospheric Data Analysis, Cambridge University Press, 1993.
- 28. Bolger, N., Kenny, D.A., Kashy, D., Data analysis in social psychology, in: Handbook of Social Psychology, vol. 1, pp. 233–65, 1998.
- 29. Bailey, T.C. and Gatrell, A.C., Interactive Spatial Data Analysis, vol. 413, Longman Scientific & Technical, Essex, 1995.
- 30. Pavlo, A., Paulson, E., Rasin, A., Abadi, D.J., DeWitt, D.J., Madden, S., Stonebraker, M., A comparison of approaches to large-scale data analysis, in: Proceedings of the 2009 ACM SIGMOD International Conference on Management of Data, pp. 165–178, June 2009.
- 31. Eriksson, L., Byrne, T., Johansson, E., Trygg, J., Vikström, C., Multi-and Megavariate Data Analysis Basic Principles and Applications, vol. 1, Umetrics Academy, 2013.
- 32. Eriksson, L., Byrne, T., Johansson, E., Trygg, J., Vikström, C., Multi-and Megavariate Data Analysis Basic Principles and Applications, vol. 1, Umetrics Academy, 2013.
- 33. Hedeker, D. and Gibbons, R.D., Longitudinal data analysis, Wiley-Interscience, 2006.
- 34. Ilijason, R., ETL and advanced data wrangling, in: Beginning Apache Spark Using Azure Databricks, pp. 139–175, Apress, Berkeley, CA, 2020.
- 35. Rattenbury, T., Hellerstein, J.M., Heer, J., Kandel, S., Carreras, C., Principles of Data Wrangling: Practical Techniques for Data Preparation, O’Reilly Media, Inc, 2017.
- 36. Koehler, M., Abel, E., Bogatu, A., Civili, C., Mazilu, L., Konstantinou, N., ... Paton, N.W., Incorporating data context to cost-effectively automate end-to-end data wrangling. IEEE Trans. Big Data, 7, 1, 169–186, 2019.
Note
- *Corresponding author: [email protected]