
CHAPTER 18
Managing Risk
The CompTIA Network+ certification exam expects you to know how to
• 1.4 Given a scenario, configure the appropriate IP addressing components
• 3.1 Given a scenario, use appropriate documentation and diagrams to manage the network
• 3.2 Compare and contrast business continuity and disaster recovery concepts
• 3.3 Explain common scanning, monitoring and patching processes and summarize their expected outputs
• 3.5 Identify policies and best practices
• 4.6 Explain common mitigation techniques and their purposes
• 5.2 Given a scenario, use the appropriate tool
To achieve these goals, you must be able to
• Describe the industry standards for risk management
• Discuss contingency planning
• Examine safety standards and actions
Companies need to manage risk, to minimize the dangers posed by internal and external threats. They need policies in place for expected dangers and also procedures established for things that will happen eventually. This is contingency planning. Finally, every company needs proper safety policies. Let’s look at all three facets of managing risk.
Test Specific
Risk Management
IT risk management is the process of how organizations deal with the bad things (let’s call them attacks) that take place on their networks. The entire field of IT security is based on the premise that somewhere, at some time, something will attack some part of your network. The attack may take as many forms as your paranoia allows: intentional, unintentional, earthquake, accident, war, meteor impact … whatever.
What do we do about all these attacks? You can’t afford to build up a defense for every possible attack—nor should you need to, for a number of reasons. First, different attacks have different probabilities of taking place. The probability of a meteor taking out your server room is very low. There is, however, a pretty good chance that some clueless user will eventually load malware on their company-issued laptop. Second, different attacks/potential problems have different impacts. If a meteor hits your server room, you’re going to have a big, expensive problem. If a user forgets his password, it’s not a big deal and is easily dealt with.
The CompTIA Network+ certification covers a number of issues that roughly fit under the idea of risk management. Let’s run through each of these individually.

NOTE One of the scariest attacks is a data breach. A data breach is any form of attack where secured data is taken or destroyed. The many corporate database hacks we’ve seen over the last few years—databases containing information about user passwords, credit card information, and other personal identification—are infamous examples of data breaches.
Security Policies
A security policy is a written document that defines how an organization will protect its IT infrastructure. There are hundreds of different security policies, but for the scope of the CompTIA Network+ certification exam we only need to identify just a few of the most common ones. These policies include internal and external ones that affect just about every organization.
NOTE The CompTIA Network+ exam, is in my opinion, way too light in its coverage of security policies. The CompTIA Security+ exam does a much better job, but even it is a bit slim. Check out the Wikipedia entry for “security policy” to discover the many types of security policies in use today.
Acceptable Use Policy
The acceptable use policy (AUP) defines what is and what is not acceptable to do on an organization’s computers. It’s arguably the most famous of all security policies as this is one document that pretty much everyone who works for any organization is required to read, and in many cases sign, before they can start work. The following are some provisions contained in a typical acceptable use policy:
• Ownership Equipment and any proprietary information stored on the organization’s computers are the property of the organization.
• Network Access Users will access only information they are authorized to access.
• Privacy/Consent to Monitoring Anything users do on the organization’s computers is not private. The organization will monitor what is being done on computers at any time.
• Illegal Use No one may use an organization’s computers for anything that breaks a law. (This is usually broken down into many subheadings, such as introducing malware, hacking, scanning, spamming, and so forth.)
NOTE Many organizations require employees to sign an acceptable use policy, especially if it includes a consent to monitoring clause.
Network Access Policies
Companies need a policy that defines who can do what on the company’s network. The network access policy defines who may access the network, how they may access the network, and what they can access. Network access policies may be embedded into policies such as VPN policy, password policy, encryption policy, and many others, but they need to be in place. Let’s look at a couple specifically called out on the CompTIA Network+ exam objectives.
• Privileged user agreement policy A privileged user has access to resources just short of those available to administrators. Anyone granted one of those accounts should know the policies on what he or she can access without escalating a permission request. (This sort of policy also reflects on standard employee management of role separation, where users might have privileged access, but only to content that fits in their role in the company.)
• Password policy Password policies revolve around strength of password and rotation frequency (how often users have to change their passwords, password reuse, and so on.) See “Training” later in this chapter for details.
• Data loss prevention policy Data loss prevention (DLP) can mean a lot of things, from redundant hardware and backups, to access levels to data. A DLP policy takes into consideration many of these factors and helps minimize the risk of loss or theft of essential company data.
• Remote access policy A remote access policy (like the VPN policy mentioned a moment ago) enforces rules on how and when and from what device users can access company resources from remote locations. A typical restriction might be no access from an open wireless portal, for example.
Policies reinforce an organization’s IT security. Policies help define what equipment is used, how data is organized, and what actions people take to ensure the security of an organization. Policies tell an organization how to handle almost any situation that might arise (such as disaster recovery, covered later in this chapter).
Externally Imposed Policies
Government laws and regulations impose policies on organizations. There are rules restricting what a company employee can bring with him or her to a conference in another country, for example. There are security policies that provide international export controls that restrict what technology—including hardware and software—can be exported.
The licensing restrictions on most commercial software allow users to travel with that software to other countries. Microsoft sells worldwide, for example, so visiting Beijing in the spring with the Microsoft Office 365 suite installed on your laptop is no big deal. Commercial encryption software, on the other hand, generally falls into the forbidden-for-foreign-travel list.
Data affected by laws, such as health information spelled out in the Health Insurance Portability and Accountability Act of 1996 (HIPAA), should not be stored on devices traveling to other countries. Often such data requires special export licenses.
Most organizations devote resources to comply with externally imposed policies. Just about every research university in the United States, for example, has export control officers who review all actions that risk crossing federal laws and regulations. It’s a really huge subject that the CompTIA Network+ only lightly touches.
Adherence to Policies
Given the importance of policies, it’s also imperative for an organization to adhere to its policies strictly. This can often be a challenge. As technologies change, organizations must review and update policies to reflect those changes.
Change Management
An IT infrastructure is an ever-changing thing. Applications are updated, operating systems change, server configurations adjust; change is a tricky part of managing an infrastructure. Change needs to happen, but not at the cost of losing security. The process of creating change in your infrastructure in an organized, controlled, safe way is called change management.
Change management usually begins with a change management team. This team, consisting of people from all over your organization, is tasked with the job of investigating, testing, and authorizing all but the simplest changes to your network.
Changes tend to be initiated at two levels: strategic-level changes, typically initiated by management and major in scope (for example, we’re going to switch all the servers from Windows to Linux); and infrastructure-level changes, typically initiated by a department by making a request to the change management team. The CompTIA Network+ exam stresses the latter type of change, where you are the person who will go before the change management team. Let’s go over what to expect when dealing with change management.
Initiating the Change
The first part of many change processes is a request from a part of the organization. Let’s say you’re in charge of IT network support for a massive art department. There are over 150 graphic artists, each manning a powerful macOS workstation. The artists have discovered a new graphics program that they claim will dramatically improve their ability to do what they do. After a quick read of the program’s features on its Web site, you’re also convinced that this a good idea. It’s now your job to make this happen.
Create a change request. Depending on the organization, this can be a highly official document or, for a smaller organization, nothing more than a detailed e-mail message. Whatever the case, you need to document the reason for this change. A good change request will include the following:
• Type of change Software and hardware changes are obviously part of this category, but this could also encompass issues like backup methods, work hours, network access, workflow changes, and so forth.
• Configuration procedures What is it going to take to make this happen? Who will help? How long will it take?
• Rollback process If this change in some way makes such a negative impact that going back to how things were before the change is needed, what will it take to roll back to the previous configuration?
• Potential impact How will this change impact the organization? Will it save time? Save money? Increase efficiency? Will it affect the perception of the organization?
• Notification What steps will be taken to notify the organization about this change?
Dealing with the Change Management Team
With your change request in hand, it’s time to get the change approved. In most organizations, change management teams meet at fixed intervals, so there’s usually a deadline for you to be ready at a certain time. From here, most organizations will rely heavily on a well-written change request form to get the details. The approval process usually consists of considering the issues listed in the change request, but also management approval and funding.
Making the Change Happen
Once your change is approved, the real work starts. Equipment, software, tools, and so forth must be purchased. Configuration teams need to be trained. The change committee must provide an adequate maintenance window: the time it will take to implement and thoroughly test the coming changes. As part of that process, the committee must authorize downtime for systems, departments, and so on. Your job is to provide notification of the change to those people who will be affected, if possible providing alternative workplaces or equipment.
Documenting the Change
The ongoing and last step of the change is change management documentation. All changes must be clearly documented, including but not limited to:
• Network configurations, such as server settings, router configurations, and so on
• Additions to the network, such as additional servers, switches, and so on
• Physical location changes, such as moved workstations, relocated switches, and so on
Patching and Updates
It’s often argued whether applying patches and updates to existing systems fits under change management or regular maintenance. In general, all but the most major patches and updates are really more of a maintenance issue than a change management issue. But, given the similarity of patching to change management, it seems that here is as good a place as any to discuss patching.

EXAM TIP CompTIA calls regularly updating operating systems and applications to avoid security threats patch management.
When we talk about patching and updates, we aren’t just talking about the handy tools provided to us by Microsoft Windows or Ubuntu Linux. Almost every piece of software and firmware on almost every type of equipment you own is subject to patching and updating: printers, routers, wireless access points, desktops, programmable logic controllers (PLCs) … everything needs a patch or update now and then.
What Do We Update?
In general, specific types of updates routinely take place. Let’s cover each of these individually, starting with the easiest and most famous, operating system (OS) updates.
OS updates are easily the most common type of update. Individuals install automatic updates on their OSs with impunity, but when you’re updating a large number of systems, especially critical nodes like servers, it’s never a good idea to apply all OS updates without a little bit of due diligence beforehand. Most operating systems provide some method of network server-based patching, giving administrators the opportunity to test first and then distribute patches when they desire.
All systems use device drivers, and they are another part of the system we often need to patch. In general, we only apply driver updates to fix an incompatibility, incorporate new features, or repair a bug. Since device drivers are only present in systems with full-blown operating systems, all OS-updating tools will include device drivers in their updates. Many patches will include feature changes and updates, as well as security vulnerability patches.
Feature changes/updates are just what they sound like: adding new functionality to the system. Remember back in the old days when a touchscreen phone only understood a single touch? Then some phone operating system came out to provide multi-touch. Competitors responded with patches to their own phone OSs that added the multi-touch feature.
All software of any complexity has flaws. Hardware changes, exposing flaws in the software that supports that hardware; newer applications create unexpected interactions; security standards change over time. All of these factors mean that responsible companies patch their products after they release them. How they approach the patching depends on scope: major vs. minor updates require different actions.
When a major vulnerability to an OS or other system is discovered, vendors tend to respond quickly by creating a fix in the form of a vulnerability patch. If the vulnerability is significant, that patch is usually made available as soon as it is complete. Sometimes, these high-priority security patches are even pushed to the end user right away.
Less significant vulnerabilities get patched as part of a regular patch cycle. You may have noticed that on the second Wednesday of each month, Microsoft-based computers reboot. Since October of 2003, Microsoft has sent out patches that have been in development and are ready for deployment on the second Tuesday of the month. This has become known as Patch Tuesday. These patches are released for a wide variety of Microsoft products, including operating systems, productivity applications, utilities, and more.
Firmware updates are far less common than software updates and usually aren’t as automated (although a few motherboard makers might challenge this statement). In general, firmware patching is a manual process and is done in response to a known problem or issue. Keep in mind that firmware updates are inherently risky, because in many cases it’s difficult to recover from a bad patch.
How to Patch
In a network environment, patching is a routine but critical process. Here are a few important steps that take place in almost every scenario of a network patch environment:
• Research As a critical patch is announced, it’s important to do some research to verify that the patch is going to do what you need it to do and that people who have already installed the patch aren’t having problems.
• Test It’s always a good idea to test a patch on a test system when possible.
• Configuration backups Backing up configurations is critical, especially when backing up firmware. The process of backing up a configuration varies from platform to platform, but almost all PCs can back up their system setups, and switches and routers have well-known “backup-config” style commands.
A single system may have many patches over time. When necessary, you might find yourself having to perform a downgrade or rollback of the patch, returning to a patch that is one or two versions old. This is usually pretty easy on PCs because OSs track each update. With firmware, the best way to handle this is to track each upgrade and keep a separate copy for each patch in case a downgrade/rollback is needed.
NOTE Patches, whether major or minor, require thorough testing before techs or administrators apply them to clients throughout the network. Sometimes, though, a hot fix might slip through to patch a security hole that then breaks other things inadvertently. In those cases, by following good patch management procedures, you can roll back—the Windows terminology—or downgrade by removing the patch. You can then push an upgrade when a better patch is made available.
Training
End users are probably the primary source of security problems for any organization. We must increase end user awareness and training so they know what to look for and how to act to avoid or reduce attacks. Training users is a critical piece of managing risk. While a formal course is preferred, it’s up to the IT department to do what it can to make sure users have an understanding of the following:
• Security policies Users need to read, understand, and, when necessary, sign all pertinent security policies.
• Passwords Make sure users understand basic password skills, such as sufficient length and complexity, refreshing passwords regularly, and password control. Traditional best practices for complexity, for example, use a minimum length of 8 characters—longer is better—with a combination of upper- and lowercase letters, numbers, and nonalphanumeric symbols, like !, $, &, and so on. Management should insist on new passwords every month, plus not allow users to reuse a password for a period of a year or more
EXAM TIP The best-password practices listed here are what you’re going to see on the CompTIA Network+ N10-007 exam. Don’t miss those questions. Nevertheless…
In 2017, the National Institute of Standards and Technologies released revised password guidelines that flip the traditional best practices on their head. Gone is the need for multiple types of characters—they’re too easy to crack. Gone is the regular rotation requirement (and thus reuse restrictions). What they’ve added is that you check a suggested password against the very long lists of passwords already in the cracking software. See Chapter 19 for more on password cracking techniques.
• System and workplace security Make sure users understand how to keep their workstations secure through screen locking and not storing written passwords in plain sight.
• Social engineering Users need to recognize typical social-engineering tactics and know how to counter them.
• Malware Teach users to recognize malware attacks and train them to deal with them.
Points of Failure
System failures happen; that’s not something we can completely prevent. The secret to dealing with failures is to avoid a single point of failure: one system that, if it fails, will bring down an entire process, workflow, or, worse yet, an entire organization.
It’s easy to say, “Oh, we will just make two of everything!” (This would create redundancy where needed.) But you can’t simply make two of everything. That would create far too much unnecessary hardware and administration. Sure, redundancy is fairly easy to do, but the trick is to determine where the redundancy is needed to avoid single points of failure without too much complexity, cost, or administration. We do this process by identifying two things: critical assets and critical nodes.
Critical Assets
Every organization has assets that are critical to the operation of the organization. A bakery may have one PLC-controlled oven, a sales group might have a single database, or a Web server rack might only be connected to the Internet through one ISP. The process of determining critical assets is tricky and is usually a senior management process.
Critical Nodes
Unlike critical assets, critical nodes are very much unique to IT equipment: servers, routers, workstations, printers, and so forth. Identifying critical nodes is usually much clearer than identifying critical assets because of the IT nature of critical nodes and the fact that the IT department is always going to be painfully aware of what nodes are critical. Here are a few examples of critical nodes:
• A file server that contains critical project files
• A single Web server
• A single printer (assuming printed output is critical to the organization)
• An edge router
High Availability
Once you have identified the critical nodes in your network, it’s important to ensure they keep working without interruption or downtime; in other words, to make sure critical systems have high availability (HA). Core to building high availability into a network is failover, the ability for backup systems to detect when a master has failed and then to take over.
How does all the network traffic know to use the backup system? That’s where the idea of a virtual IP comes in. A virtual IP is a single IP address shared by multiple systems. If that sounds a lot like what Network Address Translation (NAT) does, well, you’re right. The public IP address on NATed networks is a common implementation of a virtual IP, but virtual IPs are not limited to NAT. The way servers can fail over without dropping off the network is for all the servers in the cluster to accept traffic from a single, common IP—this common address is considered a virtual IP.
Building with high availability in mind extends to more than just servers; default gateway routers are another critical node that can be protected by adding redundant backups. The two protocols used to provide this redundancy are the open standard Virtual Router Redundancy Protocol (VRRP) and the Cisco proprietary Hot Standby Router Protocol (HSRP). The nice thing about VRRP and HSRP is that, conceptually, they both perform the same function. They take multiple routers and gang them together into a single virtual router with a single virtual IP address that clients use as a default gateway.
NOTE VRRP and HSRP do not provide load balancing, where multiple machines work together to share operational work. With these protocols, only one router is active at a time. You definitely get fault tolerance though.
Redundancy
Redundancy is an important factor in maintaining the organization’s ability to continue operations after a disaster. This means the organization must maintain redundant systems, equipment, data, and even personnel. It also may mean the organization maintains redundant facilities, such as alternate processing sites (see “Business Continuity” later in the chapter for more details). Redundant processes are also important, since critical data or equipment (or even public infrastructure, such as power) may be unavailable, forcing the business to come up with alternative business practices for conducting its mission.
An organization can achieve redundancy in systems and data in several different ways, or usually in a combination of several ways at once. Redundancy is strongly related to the concept of fault tolerance, which is the ability of the system to continue to operate in the event of a failure of one of its components. Redundant systems, as well as the components they comprise, contribute to fault tolerance. Two ways to provide for both redundancy and fault tolerance include clustering and load balancing, terms that are usually associated with servers, data storage, and networking equipment (such as clustered firewalls or proxy servers), but that could be applied to a variety of assets and services. Data redundancy can also be provided by backups, which can be restored in the event of an emergency.
Clustering, in the traditional sense, means to have multiple pieces of equipment, such as servers, connected, which appear to the user and the network as one logical device, providing data and services to the organization. Clusters usually share high-speed networking connections as well as data stores and applications and are configured to provide redundancy if a single member of the cluster fails.
NOTE The term virtual as used in this section means something slightly different than it did in Chapter 15, “Virtualization and Cloud Computing,” where it was used to describe software-only servers and networking devices. Here, virtual is about multiple routers being addressed—by the virtual IP—as a single logical router.
Standard Business Documents
Dealing with third-party vendors is an ongoing part of any organization. When you are dealing with third parties, you must have some form of agreement that defines the relationship between you and the third party. The CompTIA Network+ exam expects you to know about five specific business documents: a service level agreement, a memorandum of understanding, a multi-source agreement, a statement of work, and a nondisclosure agreement. Let’s review each of these documents.
Service Level Agreement
A service level agreement (SLA) is a document between a customer and a service provider that defines the scope, quality, and terms of the service to be provided. In CompTIA terminology, SLA requirements are a common part of business continuity and disaster recovery (both covered a little later in this chapter).
SLAs are common in IT, given the large number of services provided. Some of the more common SLAs in IT are provided by ISPs to customers. A typical SLA from an ISP contains the following:
• Definition of the service provided Defines the minimum and/or maximum bandwidth and describes any recompense for degraded services or downtime.
• Equipment Defines what equipment, if any, the ISP provides. It also specifies the type of connections to be provided.
• Technical support Defines the level of technical support that will be given, such as phone support, Web support, and in-person support. This also defines costs for that support.
Memorandum of Understanding
A memorandum of understanding (MOU) is a document that defines an agreement between two parties in situations where a legal contract wouldn’t be appropriate. An MOU defines the duties the parties commit to perform for each other and a time frame for the MOU. An MOU is common between companies that have only occasional business relations with each other. For example, all of the hospitals in a city might generate an MOU to take on each other’s patients in case of a disaster such as a fire or tornado. This MOU would define costs, contacts, logistics, and so forth.
Multi-source Agreement
Manufacturers of various network hardware agree to a multi-source agreement (MSA), a document that details the interoperability of their components. For example, two companies might agree that their gigabit interface converters (GBICs) will work in Cisco and Juniper switches.
Statement of Work
A statement of work (SOW) is in essence a legal contract between a vendor and a customer. An SOW defines the services and products the vendor agrees to supply and the time frames in which to supply them. A typical SOW might be between an IT security company and a customer. An SOW tends to be a detailed document, clearly explaining what the vendor needs to do. Time frames must also be very detailed, with milestones through the completion of the work.
Nondisclosure Agreement
Any company with substantial intellectual property will require new employees—and occasionally even potential candidates—to sign a nondisclosure agreement (NDA). An NDA is a legal document that prohibits the signer from disclosing any company secrets learned as part of his or her job.
Security Preparedness
Preparing for incidents is the cornerstone of managing risk. If you decide to take the next logical CompTIA certification, the CompTIA Security+, you’ll find an incredibly detailed discussion of how the IT security industry spends inordinate amounts of time and energy creating a secure IT environment. But for the CompTIA Network+ certification, there are two issues that come up: vulnerability scanning and penetration testing.
Vulnerability Scanning
Given the huge number of vulnerabilities out there, it’s impossible for even the most highly skilled technician to find them by manually inspecting your infrastructure. The best way to know your infrastructure’s vulnerabilities is to run some form of program—a vulnerability scanner—that will inspect a huge number of potential vulnerabilities and create a report for you to then act upon.
There is no single vulnerability scanner that works for every aspect of your infrastructure. Instead, a good network tech will have a number of utilities that work for their type of network infrastructure. Here are a few of the more popular vulnerability scanners and where they are used.
Microsoft Baseline Security Analyzer (MBSA) is designed to test individual systems. It’s getting a little old, but still does a great job of testing one Microsoft Windows system for vulnerabilities.
Nmap is a port scanner, a software tool for testing a network for vulnerabilities. Port scanning queries individual nodes, looking for open or vulnerable ports and creating a report. Actually, it might be unfair to say that Nmap is only a port scanner, as it adds other useful tools. Written by Gordon Lyon, Nmap is very popular, free, and well maintained. Figure 18-1 shows sample output from Nmap, Zenmap GUI version.
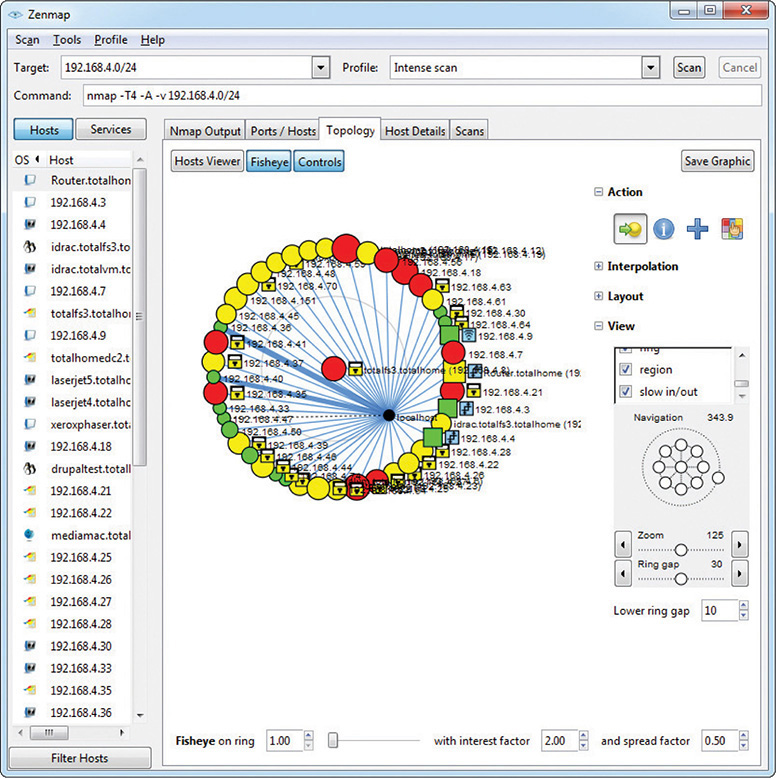
Figure 18-1 Nmap output
When you need to perform more serious vulnerability testing, it’s common to turn to more aggressive and powerful comprehensive testers. There are plenty out there, but two dominate the field: Nessus and OpenVAS. Nessus (Figure 18-2), from Tenable Network Security, is arguably the first truly comprehensive vulnerability testing tool and has been around for almost two decades. Nessus is an excellent, well-known tool. Once free to everyone, Nessus is still free for home users, but commercial users must purchase a subscription.
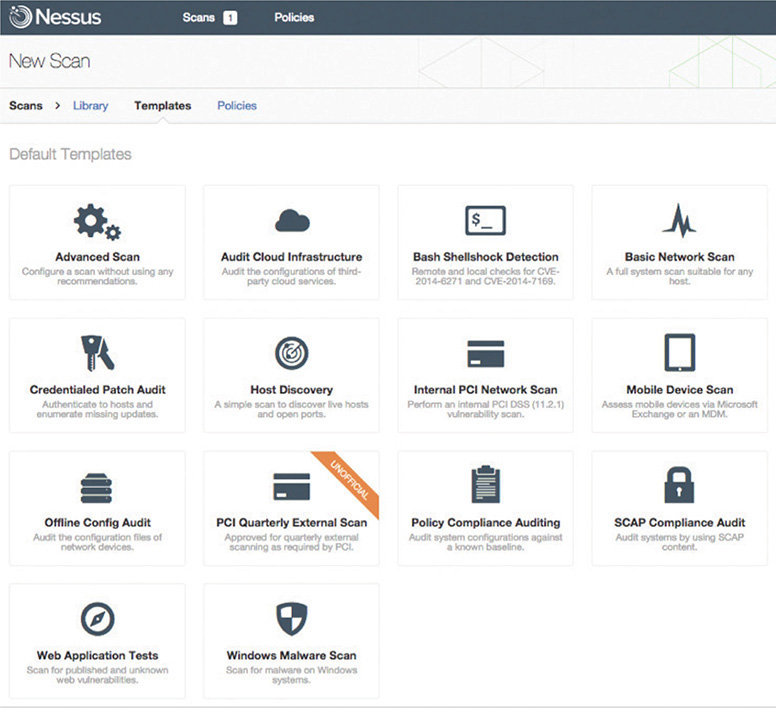
Figure 18-2 Nessus output
OpenVAS is an open source fork of Nessus that is also extremely popular and, in the opinion of many security types, superior to Nessus.
You need to be careful not to use the term vulnerability scanning to mean “just running some program to find weaknesses.” Vulnerability scanning is only a small part of a more strategic program called vulnerability management, an ongoing process of identifying vulnerabilities and dealing with them. The tools we use are a small but important part of the overall process.
Penetration Testing
Once you’ve run your vulnerability tools and hardened your infrastructure, it’s time to see if your network can stand up to an actual attack. The problem with this is that you don’t want real bad guys making these attacks. You want to be attacked by a “white hat” hacker, who will find the existing vulnerabilities and exploit them to get access. Instead of hurting your infrastructure or stealing your secrets, this hacker reports findings so that you can further harden your network. This is called penetration testing (pentesting).
NOTE A legal pentest requires lots of careful documentation that defines what the pentester is to test, the level of testing, time frames, and documentation.
Unlike vulnerability testing, a good pentest requires a skilled operator who understands the target and knows potential vulnerabilities. To that end, there are a number of tools that make this job easier. Two examples are Aircrack-ng and Metasploit.
Aircrack-ng is an open source tool for pentesting pretty much every aspect of wireless networks. It’s powerful, relatively easy to use (assuming you understand 802.11 wireless networks in great detail), and completely free.
Metasploit is a unique, open source tool that enables the pentester to use a massive library of attacks as well as tweak those attacks for unique penetrations. Metasploit is the go-to tool for vulnerability testing. You simply won’t find a professional in this arena who does not use Metasploit. Metasploit isn’t pretty, so many people use the popular Armitage GUI front end to make it a bit easier (Figure 18-3).
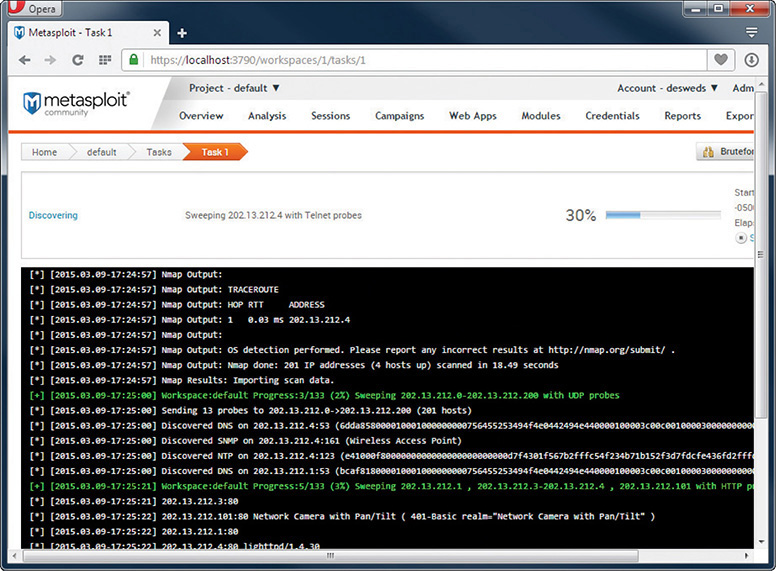
Figure 18-3 Metasploit output
There are also a number of highly customized Linux-based tools that incorporate many tools into a single bootable drive. One of the most famous packages is Kali Linux. It’s hard to find a good security person who doesn’t have a bootable Kali Linux USB drive.
Contingency Planning
Despite the best efforts of competent techs, there will be times when the integrity of an infrastructure is compromised—an incident. Incidents can and will vary in size and scope, from something as simple as an attack that was caught and stopped to something serious such as a data breach or a hurricane wiping out a data center. Whatever the case, organizations should develop a set of contingency plans—documents about how to limit damage and recover quickly—to respond to these incidents.
The CompTIA Network+ exam covers several aspects of contingency planning that we can divide into three groups based on the severity and location of the incident: incident response, disaster recovery, and business continuity. Incidents that take place within the organization that can be stopped, contained, and remediated without outside resources are handled by incident response planning. If an incident can no longer be contained, causing significant damage or danger to the immediate infrastructure, it is covered under disaster recovery. Last, if the disaster requires actions offsite from the primary infrastructure, it is under the jurisdiction of business continuity.
While related but not directly connected to contingency planning, we have forensics. Let’s hit all these, but keep in mind that this is only the lightest touch on these very complex aspects of contingency planning. The goal of the CompTIA Network+ certification is only to introduce you to these concepts so that you progress to the next level (hopefully CompTIA Security+).
Incident Response
The cornerstone of incident response is the incident response team—usually one or more trained, preassigned first responders with policies in place for what to do. Depending on the type of event, the team may be responsible for things like: deciding whether it qualifies as an incident the team should address, ignore, or escalate; evaluating the scope and cause of the issue; preventing further disruption; resolving the cause; restoring order to affected systems; and identifying ways to prevent a recurrence. Most incidents are handled at this level. Organizations will have detailed incident response policies that will guide the actions of the team in various incident scenarios. However, if an incident is so vast that the incident response team cannot stop, contain, or remediate it, disaster recovery comes into play.
Disaster Recovery
Disaster recovery is a critical part of contingency planning that deals directly with recovering your primary infrastructure from a disaster. A disaster is an event that disables or destroys substantial amounts of infrastructure, such as a hurricane or flood.
Disaster recovery starts with an organization developing a disaster recovery plan. An organization considers likely disasters and creates plans for how to deal with them. The actual plans vary by the type of disaster, but there are a few concepts you’ll find in just about every situation.
First there is a disaster recovery team, whose goal is to get the IT infrastructure up and running at the primary business location(s). One of the big jobs here is creating data backups and making sure those backups are available quickly in the face of any negative event. Any company prepared for a disaster has one or more backup copies—or snapshots—of essential data. The backed-up files comprise an archive of important data that the disaster recovery team can retrieve in case of some disaster.
In the early days of computing, such a backup was done via specific backup software onto some form of magnetic tape. Tape was cheap compared to hard drive space and was easy to move from one location to another. Backups followed fairly specific rotations, so that most of the essential data was always up to date in multiple locations.
Tape is slow and old these days, but hard drives and Internet connections are cheap and fast. Backups roll to removable hard drives and/or directly up into the cloud.
NOTE I don’t mean to make it sound as though tape backups are no longer used. They are. Many tape solutions still fully support the traditional backups as well, which are discussed next.
Traditional Data Backup Techniques
The goal of backing up data is to ensure that when a system dies, there will be an available, recent copy you can use to restore the system. You could simply back up the complete system at the end of each day—or whatever interval you feel is prudent to keep the backups fresh—but complete backups can be a tremendous waste of time and materials. Instead of backing up the entire system, take advantage of the fact that not all of the files will be changed in any given period; much of the time you only need to back up what’s changed since your last backup.
Traditional backups use a file attribute called the archive bit to perform backups. The following backup types are most often supported: full, incremental, and differential.
• In a full backup, every file selected is backed up, and the archive bit is turned off for every file backed up. This is the standard “back it all up” option.
• An incremental backup includes only files with the archive bit turned on. In other words, it copies only the files that have been changed since the last full or incremental backup. This backup turns off the archive bits.
• A differential backup copies all the files that have been changed since the last full backup. It doesn’t turn off the archive bits.
EXAM TIP Be sure you know the types of backups, including which ones change the archive bits and which ones do not.
Most companies do a big weekly full backup, followed by incremental or differential backups at the end of every business day.
Notice that a differential backup is a cumulative backup. Because the archive bits are not set, it keeps backing up all changes since the last full backup. This means the backup files will get progressively larger throughout the week (assuming a standard weekly normal backup). The incremental backup, by contrast, only backs up files changed since the last full or incremental backup. Each incremental backup file will be relatively small and also totally different from the previous backup file.
The bottom line on incremental vs. differential is this. Incremental requires less storage space, but restoring from backup takes longer than differential. Differential requires more storage space but requires only two steps to restore from backup: restore the full backup, then restore the differential for that week.
Backup Plan Assessments
A proper assessment of a backup plan records how much data might by lost and how long it would take to restore. A recovery point objective (RPO) is the state of the backup when the data is recovered—in essence, how much data will be lost if a backup is used. Most restored systems have some amount of lost data based on when the last backup took place. Real-time backups, which are really just redundant servers, are the exception. The recovery time objective (RTO) is the amount of time needed to restore full functionality from when the organization ceases to function.
The CompTIA Network+ objectives directly refer to two hardware-specific disaster recovery items, MTBF and MTTR. I’ll throw MTTF into the middle just for fun. Here’s the scoop on these concepts.
The mean time between failures (MTBF) factor, which typically applies to hardware components, represents the manufacturer’s best guess (based on historical data) regarding how much time will pass between major failures of that component. This assumes that more than one failure will occur, which means that the component will be repaired rather than replaced. Organizations take this risk factor into account because it may affect likelihood and impact of the risks associated with critical systems.
The mean time to failure (MTTF) factor indicates the length of time a device is expected to last in operation. In MTTF, only a single, definitive failure will occur and will require that the device be replaced rather than repaired.
Lastly, the mean time to recovery (MTTR) is the amount of time it takes for a hardware component to recover from failure.
Disaster recovery handles everything from restoring hardware to backups, but only at the primary business location. Anything that requires moving part of the organization’s business offsite until recovery is complete is a part of business continuity.
Business Continuity
When the disaster disables, wipes out, floods, or in some other way prevents the primary infrastructure from operating, the organization should have a plan of action to keep the business going at remote sites. The planning and processes necessary to make this happen are known as business continuity (BC). Organizations plan for this with business continuity planning (BCP). Good BCP will deal with many issues, but one of the more important ones—and one that must be planned well in advance of a major disaster—is the concept of backup sites.
Every business continuity plan includes setting up some form of secondary location that enables an organization to continue to operate should its primary site no longer function. We tend to break these secondary sites into three different types: cold, warm, and hot.
• A cold site is a location that consists of a building, facilities, desks, toilets, parking—everything that a business needs … except computers. A cold site will generally take more than a few days to bring online.
• A warm site is the same as a cold site, but adds computers loaded with software and functioning servers—a complete hardware infrastructure. A warm site lacks current data and may not have functioning Internet/network links. Bringing this site up to speed may start with activating your network links, and it most certainly requires loading data from recent backups. A warm site should only take a day or two to bring online.
• A hot site has everything a warm site does, but also includes very recent backups. It might need just a little data restored from a backup to be current, but in many cases a hot site is a complete duplicate of the primary site. A proper hot site should only take a few hours to bring online.
Business continuity isn’t just about backup sites, but this aspect is what the CompTIA Network+ exam focuses on. Another term related to continuity planning is succession planning: identifying people who can take over certain positions (usually on a temporary basis) in case the people holding those critical positions are incapacitated or lost in an incident.
Forensics
Computer forensics is the science of gathering, preserving, and presenting evidence stored on a computer or any form of digital media that is presentable in a court of law. Computer forensics is a highly specialized science, filled with a number of highly specialized skills and certifications. Three of the top computer forensic certifications are the Certified Forensic Computer Examiner (CFCE), offered by the International Association of Computer Investigative Specialists (IACIS); the Certified Computer Examiner (CCE) certification, from the International Society of Forensic Computer Examiners (ISFCE); and the GIAC Certified Forensic Analyst (GCFA), offered by the Global Information Assurance Certification (GIAC) organization. Achieving one of these challenging certifications gets you well on your way to a great career in forensics.
The CompTIA Network+ exam doesn’t expect you to know all there is to know about computer forensics, but instead wants you, as the typical technician, to understand enough of forensics that you know what to do in the rare situation where you find yourself as the first line of defense.
In general, CompTIA sees you as either the first responder or the technician responsible for supporting the first responder. The first responder in a forensic situation is the person or robot whose job is to react to the notification of a computer crime by determining the severity of the situation, collecting information, documenting findings and actions, and providing the information to the proper authorities. In a perfect world, a first responder has a toolbox of utilities that enables him or her to capture the state of the system without disturbing it. At the very least they need to secure the state of the media (mainly hard drives) as well as any volatile memory (RAM) in a way that removes all doubt of tampering either intentionally or unintentionally.
NOTE One of the first mistakes any first responder can make is to turn off or reboot a computer. There’s a very hot debate in the forensics community about what to do when you have to seize devices. Most experts say to pull the plug.
Like so many aspects of computer security, there isn’t a single school of thought on how exactly you should do computer forensics. There are, however, a number of basic attitudes and practices that every school of thought share, especially at the very basic level covered by the CompTIA Network+ exam.
In general, when you are in a situation where you are the first responder, you need to
• Secure the area
• Document the scene
• Collect evidence
• Interface with authorities
Secure the Area
The first step for a first responder is to secure the area. In most cases someone in authority has determined the person or persons who are allegedly responsible and calls you in to react to the incident. As a first responder, your job is to secure the systems involved as well as secure the immediate work areas.
The main way you secure the area is by your presence at the scene. If possible, you should block the scene from prying eyes or potential disturbance. If it’s an office, lock the door, define the area of the scene, and mark it off in some way if possible.
Keep in mind that an incident is rarely anything as exciting (or scary) as catching a user committing a felony! In most cases an incident involves something as simple as trying to determine if a user introduced malware into a system or if a user was playing World of Warcraft during work hours. In these cases it’s often easy to do your job. Simply observe the system and, if you identify an issue, provide that information in house. The rules for forensics still apply. If, however, you’re responding to one of the more scary scenarios, it’s important for you as a first responder to understand when you need to escalate an issue. Given that you were called in to react to a particular incident, most escalation situations involve you discovering something more serious than you expected.
Document the Scene
Once you have secured the area, it’s time to document the scene. You need to preserve the state of the equipment and look for anything that you might need to inspect forensically.
NOTE It’s always a good idea to use a camera to document the state of the incident scene, including taking pictures of the operating state of computers and switches and the location of media and other devices.
While it’s obvious you’ll want to locate computers, switches, WAPs, and routers, be sure to take copious notes, paying particular attention to electronic media. Here are a few items you will want to document:
• Smartphones
• Optical media
• External hard drives
• Thumb drives
• Cameras
• VoIP phones
Collect Evidence
With the scene secured and documented, it’s time to start the evidence/data collection. The moment you take something away from an incident scene or start to handle or use any devices within the incident scene, there is a chance that your actions could corrupt the evidence you are collecting. You must handle and document all evidence in a very specific manner. Chain of custody, as the name implies, is the paper trail of who has accessed or controlled a given piece of evidence from the time it is initially brought into custody until the incident is resolved. From the standpoint of a first responder, the most important item to keep in mind about chain of custody is that you need to document what you took under control, when you did it, what you did to it, and when you passed it to the next person in line.
From a strict legal standpoint, the actual process of how you obtain evidence and collect data is a complex business usually left to certified forensic examiners. In general it boils down to using specialized utilities and tools, many of which are unique for the type of data you are retrieving. The tools used also differ depending on different OSs, platforms, and the personal tastes of the examiners. Every forensic examiner has a number of these tools in his or her unique forensic toolkit.
If you need to transport any form of evidence, make sure to document for chain of custody as well as inventory. In other words, make a list of who has what equipment/evidence at any one time. Pack everything carefully. You don’t want a dropped case to destroy data! If you are transporting evidence, don’t leave the evidence at any time. Delay your lunch break until after you hand the evidence over to the next person! Follow the proper procedures for data transport to avoid any problems with the evidence.
The end result of your forensics is a forensics report. In general, this is where you report your findings, if any. A good forensics report will include the following:
• Examiner’s name and title
• Examiner’s qualifications
• Objective for the forensics
• Any case or incident numbers
• Tools used
• Where the examination took place
• Files found
• Log file output
• Screen snapshots
There are two places where the forensic reports (and forensic evidence) might be used: legal holds and electronic discovery. A legal hold is the process of an organization preserving and organizing data in anticipation of or in reaction to a pending legal issue. For example, a company might discover that your forensic report includes findings of criminal activity that requires reporting to the authorities. In that case the data and the reports must be preserved in such a way that, should a legal authority want access to that data, they can reasonably access it. Electronic discovery (or e-discovery) is the process of actually requesting that data and providing it in a legal way.
Safety
Managing risk to employee physical health falls into three broad categories: electrical safety, physical/installation safety, and emergency procedures. Most companies of any size implement clear safety procedures and policies to keep employees intact and functioning. Let’s wrap up this chapter with a discussion of these topics.
Electrical Safety
Electrical safety in a networking environment covers several topics: the inherent danger of electricity, grounding, and static.
As you’ll recall from Science 101, electricity can shock you badly, damage you, or even kill you. Keep the networking closet or room clear of clutter. Never use frayed cords. Use the same skills you use to avoid getting cooked by electricity in everyday life.
It is very important with networking to use properly grounded circuits. This is more a data safety issue than a personal safety issue. Poorly grounded circuits can create a ground loop—where a voltage differential exists between two parts of your network. This can cause data to become unreadable. Improper grounding also exposes equipment to more risk from power surges.
Electrostatic discharge (ESD)—the passage of a static electrical charge from one item to another—can damage or destroy computing equipment. It’s important to wear a properly connected anti-ESD wrist strap when replacing a NIC or doing anything inside a workstation (Figure 18-4).

Figure 18-4 Anti-ESD wrist strap
The risks from ESD get a lot smaller when you stop opening up computing machines. Routers, switches, and other networking boxes are enclosed and thus protected from technician ESD. Even when you insert a module in a router or switch, the rack is metal and protected and the box should be attached to the rack and thus grounded too.
Physical/Installation Safety
IT techs live in a dangerous world. We’re in constant danger of tripping, hurting our backs, and getting burned by hot components. You also need to keep in mind what you wear (in a safety sense). Let’s take a moment to discuss these physical safety issues and what to do about them.
If you don’t keep organized, hardware technology will take over your life. Figure 18-5 shows a corner of my office, a painful example of a cable “kludge.”

Figure 18-5 Mike’s cable kludge
Cable messes such as these are dangerous tripping hazards. While I may allow a mess like this in my home office, all cables in a business environment are carefully tucked away behind computer cases, run into walls, or placed under cable runners. If you see a cable that is an obvious tripping hazard, contact the person in charge of the building to take care of it immediately. The results of ignoring such hazards can be catastrophic (see Figure 18-6).

Figure 18-6 What a long, strange trip it’s been.
Another physical safety issue is lifting equipment. Computers, printers, routers—everything we use—all seem to come to us in heavy boxes. Remember never to lift with your back; lift with your legs, and always use a hand truck if available. You are never paid enough to risk your own well-being. Lifting is an important consideration in an important part of a network tech’s life: working with racks.
Rack Installation and Maintenance
Installing components into a rack isn’t too challenging of a process. Standard 19-inch equipment racks are designed to accept a tremendous amount of abuse, making it sometimes far too easy for people to use them in ways where failure is almost a guarantee. In general, you need to keep in mind three big areas when using rack-mounted equipment: power, mounting, and environment.
Power
Rack-mounted equipment has a number of special power needs. At an absolute minimum, start with a proper power source. A single small rack can get away with a properly grounded, 20-amp dedicated circuit. Larger installations will require larger, sometimes dedicated power transformers supplied by the local power grid.
NOTE Different rack manufacturers have specific rules and standards for rack electrical grounding. Refer to the installation instructions and consider hiring professional installers when placing your racks.
When you get down to individual racks, it’s always a good idea to provide each rack with its own rack-mounted UPS. You then connect every device to that UPS. If you’re using power converters, always use a single power converter per rack.
Mounting
Installing gear into a safe, electrically sound, stable rack is a well-established process. For components that connect directly to a rack, such as switches, routers, and patch panels, hold them in place and secure them with four screws (Figure 18-7). The chassis are designed to support the weight of the devices.

Figure 18-7 Directly connected device in rack
Racks come in a number of styles, including enclosed, open frame, and “goal post.” Best practices call for the rack to be secured to the surrounding facility structure to prevent movement or an off-balance situation from becoming a network disaster.
Bigger devices connect to the rack via a rail system. The standard procedure here is to install the rail system in the rack using locking brackets (Figure 18-8). Then install the device into the rail or tray.

Figure 18-8 Securing the rail system
Follow standard safety practices when installing gear, especially if you use power tools. Tool safety means, for example: use the properly sized screwdriver head; wear safety goggles when cutting wires; don’t use a band saw to miter joints. The usual practices will both get you through any exam question and keep you safe in the workplace.
Environment
Racks with servers, switches, routers, and such go into closets or server rooms and they dump heat. The environment within this space must be monitored and controlled for both temperature and humidity. Network components work better when cool rather than hot.
The placement of a rack should optimize the airflow in a server area. All racks should be placed so that components draw air in from a shared cool row and then exhaust the hot air into a hot row.
The heating, ventilation, and air conditioning (HVAC) system should be optimized to recirculate and purify the hot air into cool air in a continuous flow. What’s the proper temperature and humidity level? The ideal for the room, regardless of size, is an average temperature of 68 degrees Fahrenheit and ~50% humidity. A proper fire suppression system—one that can do things like detect fire, cut power to protect sensitive equipment, displace oxygen with fire-suppressing gasses, alert relevant staff, and activate sprinklers in a pinch—is an absolute must for any server closet or room. You need to get any electrical spark out quickly to minimize server or data loss.
Finally, follow the guidelines in the material safety data sheet (MSDS) for the racks and network components to determine best practices for recycling and so forth. An MSDS, as you’ll recall from both your CompTIA A+ studies and from previous chapters, details how you should deal with just about any component, including information on replacement parts, recycling, and more.
Emergency Procedures
A final step in managing risk in any company is to have proper emergency procedures in place before the emergencies happen. Here are five essential aspects that should be covered:
• Building layout
• Fire escape plan
• Safety/emergency exits
• Fail open/fail close
• Emergency alert system
Exit plans need to cover building layout, fire escape plans, and the locations of emergency exits. Exit signs should be posted strategically so people can quickly exit in a real emergency.
Secured spaces, such as server rooms, need some kind of default safety mechanism in case of an emergency. Locked doors need to fail open—doors default to open in case of emergency—or fail closed—doors lock in case of emergency.
Finally, nothing beats a properly loud emergency alert system blaring away to get people moving quickly. Don’t forget to have annual fire drills and emergency alert mixers to make certain all employees know what they need to know.
Chapter Review
Questions
1. Which item should be found in a security policy?
A. Acceptable use policy
B. Emergency exit plan
C. Service level agreement
D. Instruction on how to fill out a change request form
2. Through what mechanism is a change to the IT structure initiated?
A. Users make a change to their environment, then report the result to the change management team.
B. A user requests funding for a change to upper management, then submits a requisition to the change management team to source and purchase new equipment.
C. Users submit a change request to the change management team.
D. The change management team issues a proposed change to users in the organization, then evaluates the responses.
3. Users need training from the IT department to understand which of the following?
A. How to troubleshoot lost network connections
B. How to secure workstations with screen-locking and password-security techniques
C. How to send e-mail to the change management team
D. How to check their network connection
4. When is a memorandum of understanding used?
A. As part of a legal contract
B. As part of a statement of work (SOW)
C. When a service level agreement (SLA) expires
D. When a legal contract is not appropriate
5. The best way to know the vulnerabilities of an IT infrastructure is to run what?
A. A system-wide antivirus scanner
B. Cable certifier
C. Critical asset scanner
D. Vulnerability scanner
6. What is succession planning?
A. Identifying personnel who can take over certain positions in response to an incident
B. The career path by which employees of an organization can grow through the ranks
C. The selection of failover servers in the event of a catastrophic server failure
D. The selection of failover routers in the event of a catastrophic router failure
7. During and after a change to the IT infrastructure, what must be done?
A. Downtime must be scheduled.
B. New equipment must be installed.
C. Operating systems must be patched.
D. The changes must be documented.
8. What is the job of a first responder?
A. Investigate data on a computer suspected to contain crime evidence.
B. React to the notification of a computer crime.
C. Power off computers suspected of being used in criminal activity.
D. Wipe the drives of computers suspected of being used in criminal activity.
9. When working inside equipment, what should Jane do?
A. Ensure that the equipment is secured to the rack with four screws.
B. Wear a properly connected anti-ESD wrist strap.
C. Have a fire extinguisher nearby and review its proper use.
D. Wear safety goggles and fire retardant gloves.
10. The placement of a rack should optimize what?
A. Airflow
B. HVAC
C. MSDS
D. Emergency procedures
Answers
1. A. An acceptable use policy is a typical item found in a security policy.
2. C. Users submit a change request to the change management team to effect a change to an IT structure.
3. B. Typical user training includes how to secure workstations with screen-locking and password-security techniques.
4. D. A memorandum of understanding is used when a legal contract is not appropriate.
5. D. Run a vulnerability scanner to find weaknesses in an IT infrastructure.
6. A. Identifying personnel who can take over certain positions in response to an incident is essential in succession planning.
7. D. When changing an IT infrastructure, always document the changes.
8. B. A first responder reacts to the notification of a computer crime.
9. B. Jane should almost always wear a properly connected anti-ESD wrist strap when working inside equipment.
10. A. Figure out the proper airflow when placing a rack.