
CHAPTER 19
Protecting Your Network
The CompTIA Network+ certification exam expects you to know how to
• 1.3 Explain the concepts and characteristics of routing and switching
• 2.2 Given a scenario, determine the appropriate placement of networking devices on a network and install/configure them
• 2.3 Explain the purposes and use cases for advanced networking devices
• 4.1 Summarize the purposes of physical security devices
• 4.2 Explain authentication and access controls
• 4.4 Summarize common networking attacks
• 4.5 Given a scenario, implement network device hardening
• 4.6 Explain common mitigation techniques and their purposes
• 5.5 Given a scenario, troubleshoot common network service issues
To achieve these goals, you must be able to
• Discuss common security threats in network computing
• Discuss common vulnerabilities inherent in networking
• Describe methods for hardening a network against attacks
• Explain how firewalls protect a network from threats
The very nature of networking makes networks vulnerable. A network must allow multiple users to access serving systems. At the same time, the network must be protected from harm. Doing so is a big business and part of the whole risk management issue touched on in Chapter 18, “Managing Risk.” This chapter concentrates on threats, vulnerabilities, network hardening, and firewalls.
Test Specific
Network Threats
A network threat is any form of potential attack against your network. Don’t think only about Internet attacks here. Sure, hacker-style threats are real, but there are so many others. A threat can be a person sneaking into your offices and stealing passwords, or an ignorant employee deleting files they should not have access to in the first place. Natural disasters, like earthquakes, fires, floods, and crazed squirrels, are also threats.
Just by reading the word “potential” you should know that this list could go on for pages. This section includes a list of common network threats. CompTIA does not include all of these in the Network+ N10-007 objectives (because they’re covered in CompTIA A+ or Security+), but I’ve included them here to give a real-world sense of scope:
• Spoofing
• Packet/protocol abuse
• Zero-day attack
• ARP cache poisoning
• Denial of service (with a lot of variations on a theme)
• Man-in-the-middle
• Session hijacking
• Brute force
• Compromised system
• Insider threat/malicious employee
• VLAN hopping
• Administrative access control
• Malware
• Social engineering
• And more!
It’s quite a list, so let’s get started.
Spoofing
Spoofing is the process of pretending to be someone or something you are not by placing false information into your packets. Any data sent on a network can be spoofed. Here are a few quick examples of commonly spoofed data:
• Source MAC address and IP address, to make you think a packet came from somewhere else
• E-mail address, to make you think an e-mail came from somewhere else
• Web address, to make you think you are on a Web page you are not on
• User name, to make you think a certain user is contacting you when in reality it’s someone completely different
Generally, spoofing isn’t so much a threat as it is a tool to make threats. If you spoof my e-mail address, for example, that by itself isn’t a threat. If you use my e-mail address to pretend to be me, however, and to ask my employees to send to you their user names and passwords for network login? That’s clearly a threat. (And also a waste of time; my employees would never trust me with their user names and passwords.)
One of the more aggressive spoofing attacks targets DNS servers, the backbone of network naming on all of our networks today. In DNS cache poisoning, an attacker targets a DNS server to query an evil DNS server instead of the correct one. The server can in turn tell the target DNS server spoofed DNS information. The DNS server will cache that spoofed information, spreading it to hosts and possibly other servers.

EXAM TIP The CompTIA Network+ exam objectives refer to DNS cache poisoning as simply DNS poisoning. Expect to see the shortened term on the exam.
To prevent DNS cache poisoning, the typical use case scenario is to add Domain Name System Security Extensions (DNSSEC) for domain name resolution.
All the DNS root and top-level domains (plus hundreds of thousands of other DNS servers) use DNSSEC.
Packet/Protocol Abuse
No matter how hard the Internet’s designers try, it seems there is always a way to take advantage of a protocol by using it in ways it was never meant to be used. Anytime you do things with a protocol that it wasn’t meant to do and that abuse ends up creating a threat, this is protocol abuse. A classic example involves the Network Time Protocol (NTP).
The Internet keeps time by using NTP servers. Without NTP providing accurate time for everything that happens on the Internet, anything that’s time sensitive would be in big trouble.
Here’s what happened. No computer’s clock is perfect, so NTP is designed for each NTP server to have a number of peers. Peers are other NTP servers that one NTP server can compare its own time against to make sure its clock is accurate. Occasionally a person running an NTP server might want to query the server to determine what peers it uses. The command used on just about every NTP server to submit queries is called ntpdc. The ntpdc command puts the NTP server into interactive mode so that you can then make queries to the NTP server. One of these queries is called monlist. The monlist query asks the NTP server about the traffic going on between itself and peers. If you query a public NTP server with monlist, it generates a lot of output:
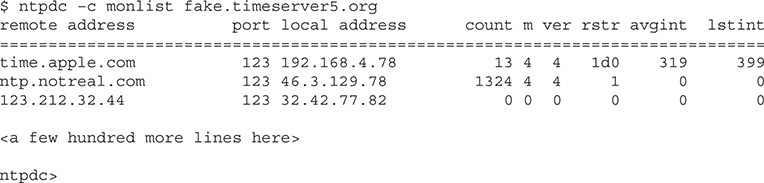
A bad guy can hit multiple NTP servers with the same little command—with a spoofed source IP address—and generate a ton of responses from the NTP server to that source IP. Enough of these requests will bring the spoofed source computer—now called the target or victim—to its knees. We call this a DoS attack (covered a bit later), and it’s a form of protocol abuse.
If that’s not sinister enough, hackers can also use evil programs that inject unwanted information into packets in an attempt to break another system. We call these malformed packets. Programs such as Scapy give you the capability to custom-form (or should we say malform?) packets and send them to anyone. You can use this to exploit a server that isn’t designed to handle such attacks. What will happen if you send a DHCP request packet into which you have placed totally incorrect information in the Options field? What, you didn’t know DHCP request packets have options? That’s OK, most techs don’t know that, but the guy doing this to your DHCP server is hoping that when your DHCP reads the request it will break the server somehow: giving root access, shutting down the DHCP server, whatever. This is an exploit created by packet abuse.
Zero-Day Attacks
The way (software or methods) an exploit takes advantage of a vulnerability is called an attack surface. The timeframe in which a bad guy can exploit a vulnerability in an attack surface before patches are applied to prevent the exploit is called an attack window. New attacks using vulnerabilities that haven’t yet been identified (and fixed) are called zero-day attacks.
ARP Cache Poisoning
ARP cache poisoning attacks target the ARP caches on hosts and switches. As we saw back in Chapter 6, “TCP/IP Basics,” the process and protocol used in resolving an IP address to an Ethernet MAC address is called Address Resolution Protocol (ARP).
Every node on a TCP/IP network has an ARP cache that stores a list of known IP addresses and their associated MAC addresses. On a Windows system you can see the ARP cache using the arp –a command. Here’s part of the result of typing arp –a on my system:

If a device wants to send an IP packet to another device, it must encapsulate the IP packet into an Ethernet frame on wired LANs. If the sending device doesn’t know the destination device’s MAC address, it sends a special broadcast called an ARP request. In turn, the device with that IP address responds with a unicast packet to the requesting device. Figure 19-1 shows a Wireshark capture of an ARP request and response.
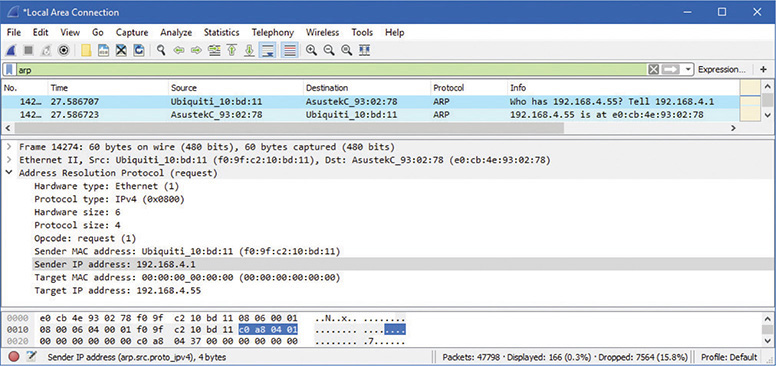
Figure 19-1 ARP request and response
The problem with ARP is that there is no security. Any device that can get on a LAN can wreak havoc with ARP requests and responses. For example, ARP enables any device at any time to announce its MAC address without first getting a request. Additionally, ARP has a number of very detailed but relatively unused specifications. A device can just declare itself to be a “router.” How that information is used is up to the writer of the software used by the device that hears this announcement. More than a decade ago, ARP poisoning caused a tremendous amount of trouble.
Poisoning in Action
Here’s how an ARP cache poison attack works. Figure 19-2 shows a typical tiny network with a gateway, a switch, a DHCP server, and two clients. Assuming nothing has recently changed with the computers’ IP addresses, each system’s ARP cache should look something like Figure 19-3. (ARP caches don’t store computer names, but I’ve added them for clarity.)
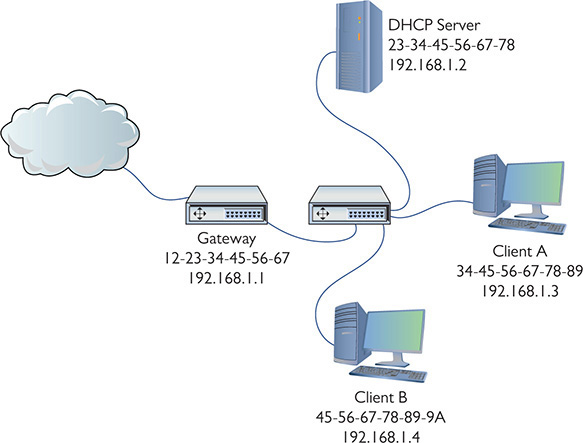
Figure 19-2 Our happy network
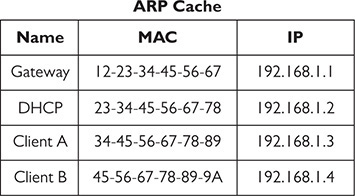
Figure 19-3 Each computer’s ARP cache should look about the same.
If a bad actor can get inside the network (like plugging into an unused Ethernet port), using the proper tools, he can send false ARP frames that each computer reads, placing evil data into their ARP caches (which is why this is called ARP cache poisoning). See Figure 19-4.
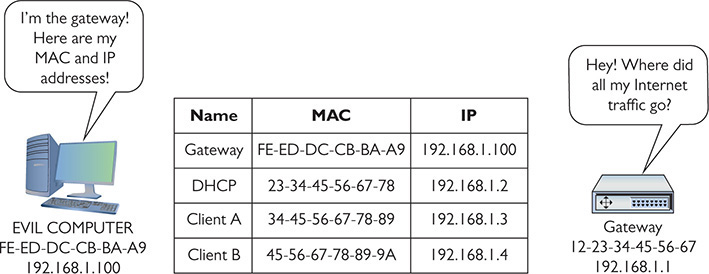
Figure 19-4 Every system’s ARP cache is now poisoned.
Once the poisoning starts, the evil computer can perform a man-in-the-middle attack, reading every packet going through it, as shown in Figure 19-5 (which shows the evil computer with its own ISP connection, although it could also use the gateway’s connection as well).
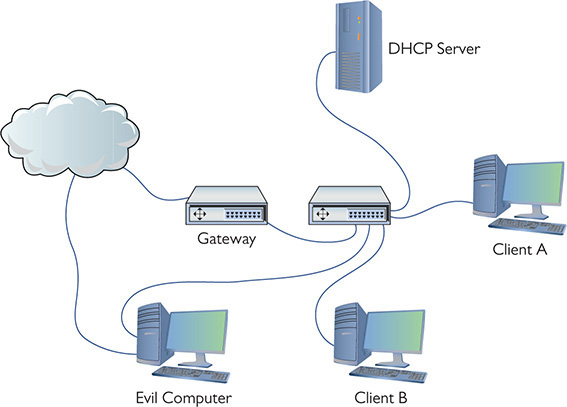
Figure 19-5 ARP cache poisoning enables a man-in-the-middle attack.
Dynamic ARP Inspection and DHCP Snooping
Clearly, we’d like to avoid this type of attack. Cisco’s Dynamic ARP Inspection (DAI) technology in switches keeps track of ARP information, compiling a list of known good, identifiable IP and MAC addresses (Figure 19-6).
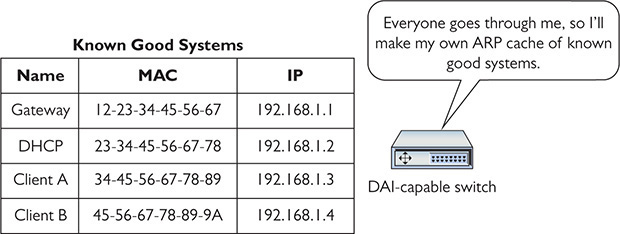
Figure 19-6 DAI database
Now if an ARP poisoner suddenly decides to attack this network, the DAI-capable switch notices the unknown ARP commands and blocks them (Figure 19-7).
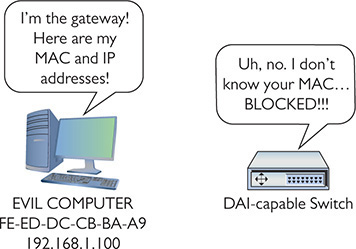
Figure 19-7 DAI in action
DHCP snooping is like DAI—in fact, they share the same database—in that it creates a list of MAC addresses for all of a network’s known DHCP servers and clients. If an unknown MAC address starts sending DHCP server messages, the DHCP snoop–capable switch will block that device, stopping all unauthorized DHCP traffic and sending some form of alarm to the appropriate person.
EXAM TIP Implementing Dynamic ARP Inspection (DAI) and DHCP snooping enhances switch port protection, a key network hardening technique. On a terminology side note, CompTIA uses switch port (two words), but many techs and some documentation use switchport (one word). It’s the same thing.
Denial of Service
Hundreds of millions of servers on the Internet provide a multitude of different services. Given the amount of security now built in at so many different levels, it’s more difficult than ever for a bad guy to cripple any one particular service by exploiting a weakness in the servers themselves. So what’s a bad guy (or gal, group, or government) to do to shut down a service he doesn’t like, even if he is unaware of any exploits on the target servers? Why, denial of service, of course!
A denial of service (DoS) attack is a targeted attack on a server (or servers) that provides some form of service on the Internet (such as a Web site), with the goal of making that site unable to process any incoming server requests. DoS attacks come in many different forms. The simplest example is a physical attack, where a person physically attacks the servers. Bad guys could go to where the servers are located and shut them down or disconnect their Internet connections, in some cases permanently. Physical DoS attacks are good to know for the exam, but they aren’t very common unless the service is very small and served in only a single location.
The most common form of DoS is when a bad guy uses his computer to flood a targeted server with so many requests that the service is overwhelmed and ceases functioning. These attacks are most commonly performed on Web and e-mail servers, but any Internet service’s servers can be attacked via some DoS method.
The secret to a successful DoS attack is to send as many packets as quickly as possible to the victim. Not only do bad guys want to send a lot of packets, they want the packets to contain some kind of request that the target server must process as long as possible. The aspect of a DoS attack that makes a server do a lot of processing and responding is called amplification, thus the term for this attack is an amplified DoS attack. A simple monlist command to an NTP server, like we discussed earlier, generates a big response from the server.
Internet-service servers are robust devices, designed to handle a massive number of requests per second. These robust servers make it tricky for a single bad guy at a single computer to send enough requests to slow them down. Far more menacing, and far more common than a simple DoS attack, are distributed denial of service (DDoS) attacks. A DDoS uses hundreds, thousands, or even millions of computers under the control of a single operator to launch a coordinated attack. DDoS operators don’t own these computers, but instead use malware (discussed later) to take control of computers. A single computer under the control of an operator is called a zombie or bot. A group of computers under the control of one operator is called a botnet.

NOTE Zombified computers aren’t always immediately obvious. DDoS operators often wait weeks or months after a computer’s been infected to take control of it.
To take control of your network’s computers, someone has to install malware on the computer. Again, anti-malware, training, and procedures will keep your computers safe from zombification (as long as they aren’t bitten by an already zombified computer).
The goal of a botnet operator conducting a DDoS attack is to send as many amplified requests as possible, but botnets are only one way to do this. Another tactic used in DDoS attacks is to send requests with the target server’s IP address as the source IP address to otherwise normally operating servers, such as DNS or NTP servers. This is called reflection or a reflective DDoS attack. These servers then send massive numbers of amplified responses to the target. Such a huge increase in the number of packets—a traffic spike—will bring the target down.
Deauthentication Attack
A deauthentication (deauth) attack—a form of DoS attack—targets 802.11 Wi-Fi networks specifically by sending out a frame that kicks a wireless client off its current WAP connection. A rogue WAP nearby presents a great and often automatic alternative option for connection. The rogue WAP connects the client to the Internet and then proceeds to collect data from that client.
The deauth attack targets a specific Wi-Fi frame called a deauthentication frame, normally used by a WAP to kick an unauthorized WAP off its network. The attacker flips this narrative on its head, using the good disconnect frame for evil purposes. (And here you thought only wired networks got all the love from DoS attacks.) Refer to Chapter 14, “Wireless Networking,” to refresh your memory on Wi-Fi security.
NOTE A friendly or unintentional DoS attack is just as it’s named: a system is brought down unintentionally. The most common form of friendly DoS occurs on a super-busy server: an organization’s infrastructure isn’t strong enough to keep up with legitimate demand. This is very common on the Web when a popular site makes a reference to a small site or someone mentions the small site on a radio or TV program, resulting in a massive increase in traffic to the small site. This unintentional DoS attack goes by many names, such as slashdotting or the Reddit hug of death.
Man-in-the-Middle
In a man-in-the-middle attack, an attacker taps into communications between two systems, covertly intercepting traffic thought to be only between those systems, reading or in some cases even changing the data and then sending the data on. A classic man-in-the-middle attack would be a person using special software on a wireless network to make all the clients think his laptop is a WAP. He could then listen in on that wireless network, gathering up all the conversations and gaining access to passwords, shared keys, or other sensitive information. Man-in-the-middle attacks are commonly perpetrated using ARP poisoning.
Session Hijacking
Somewhat similarly to man-in-the-middle attacks, session hijacking tries to intercept a valid computer session to get authentication information. Unlike man-in-the-middle attacks, session hijacking only tries to grab authentication information, not necessarily listening in like a man-in-the-middle attack.
Brute Force
Brute force is an attack where a threat agent guesses every permutation of some part of data. Most of the time the term “brute force” refers to an attempt to crack a password, but the term applies to other attacks. You can brute force a search for open ports, network IDs, user names, and so on. Pretty much any attempt to guess the contents of some kind of data field that isn’t obvious (or is hidden) is considered a brute force attack.
Physical/Local Access
Not all threats to your network originate from faraway bad guys. There are many threats that lurk right in your LAN, inside your network. This is a particularly dangerous place as these threats don’t need to worry about getting past your network edge defenses such as firewalls or WAPs. You need to watch out for problems with hardware, software, and, worst of all, the people who are on your LAN.
Compromised System
Like any technology, computers can and will fail—usually when you can least afford for it to happen. Hard drives crash, servers lock up, the power fails—it’s all part of the joy of working in the networking business. Because of this, you need to create redundancy in areas prone to failure (like installing backup power in case of electrical failure) and perform those all-important data backups. Beyond that, the idea is to deploy redundant hardware to provide fault tolerance. Take advantage of technologies like redundant array of inexpensive disks (RAID) to spread data across multiple drives. Buy a server case with multiple power supplies, or add a second NIC.
Insider Threats
The greatest hackers in the world will all agree that being inside an organization, either physically or by access permissions, makes evildoing much easier. Malicious employees are a huge threat because of their ability to directly destroy data, inject malware, and initiate attacks. These are collectively called insider threats.
Trusted and Untrusted Users A worst-case scenario from the perspective of security is unsecured access to private resources. A couple of terms come into play here. There are trusted users and untrusted users. A trusted user is an account that has been granted specific authority to perform certain or all administrative tasks. An untrusted user is just the opposite; an account that has been granted no administrative powers.
Trusted users with poor password protection or other security leakages can be compromised. Untrusted users can be upgraded “temporarily” to accomplish a particular task and then forgotten. Consider this situation: A user accidentally copied a bunch of files to several shared network repositories. The administrator does not have time to search for and delete all of the files. The user is granted deletion capability and told to remove the unneeded files. Do you feel a disaster coming? The newly created trusted user could easily remove the wrong files. Careful management of trusted users is the simple solution to these types of threats.
Every configurable device, like a multilayer switch, has a default password and default settings, all of which can create an inadvertent insider threat if not addressed. People sometimes can’t help but be curious. A user might note the IP address of a switch on his network, for example, and run Telnet or SSH “just to see.” Because it’s so easy to get the default passwords/settings for devices with a simple Google search, that information is available to the user. One change on that switch might mean a whole lot of pain for the network tech or administrator who has to fix things.
Dealing with such authentication issues is pretty straightforward. Before bringing any system online, change any default accounts and passwords. This is particularly true for administrative accounts. Also, disable or delete any “guest” accounts (make sure you have another account created first!).
Malicious Users Much more worrisome than accidental accesses to unauthorized resources are malicious users who consciously attempt to access, steal, or damage resources. Malicious users or actors may represent an external or internal threat.
What does a malicious user want to do? If they are intent on stealing data or gaining further access, they may try packet sniffing. This is difficult to detect, but as you know from previous chapters, encryption is a strong defense against sniffing. One of the first techniques that malicious users try is to probe hosts to identify any open ports. There are many tools available to poll all stations on a network for their up/down status and for a list of any open ports (and, by inference, all closed ports too). Angry IP Scanner and nmap are great tools for troubleshooting hosts, but can be used for these types of malevolent activities.
Having found an open port, another way for a malicious user to gain information and additional access is to probe a host’s open ports to learn details about running services. This is known as banner grabbing. For instance, a host may have a running Web server installed. Using a utility like nmap or Netcat, a malicious user can send an invalid request to port 80 of the server. The server may respond with an error message indicating the type and version of Web server software that is running. With that information, the malicious actor can then learn about vulnerabilities of that product and continue their pursuit. The obvious solution to port scanning and banner grabbing is to not run unnecessary services (resulting in an open port) on a host and to make sure that running processes have current security patches installed.
In the same vein, a malicious user may attempt to exploit known vulnerabilities of certain devices attached to the network. MAC addresses of Ethernet NICs have their first 24 bits assigned by the IEEE. This is a unique number assigned to a specific manufacturer and is known as the organizationally unique identifier (OUI), sometimes called the vendor ID. By issuing certain messages such as broadcasted ARP frames, a malicious user can collect all of the OUI numbers of the wired and wireless nodes attached to a network or subnetwork. Using common lookup tools, the malicious user can identify devices by OUI numbers assigned to particular manufacturers. The past few years have seen numerous DDoS attacks using zombified Internet of Things (IoT) devices, such as security cameras.
VLAN Hopping
An older form of attack that still comes up from time to time is called VLAN hopping. The idea behind VLAN hopping is to take a system that’s connected to one VLAN and, by abusing VLAN commands to the switch, convince the switch to change your switchport connection to a trunk link.
Administrative Access Control
All operating systems and many switches and routers come with some form of access control list (ACL) that defines what users can do with a device’s shared resources. An access control might be a file server giving a user read-only privileges to a particular folder, or a firewall only allowing certain internal IP addresses to access the Internet. ACLs are everywhere in a network. In fact, you’ll see more of them from the standpoint of a firewall later in this chapter.
Every operating system—and many Internet applications—are packed with administrative tools and functionality. You need these tools to get all kinds of work done, but by the same token, you need to work hard to keep these capabilities out of the reach of those who don’t need them.
NOTE The CompTIA Network+ exam does not test you on the details of file system access controls. In other words, don’t bother memorizing details like NTFS permissions, but do appreciate that you have fine-grained controls available.
Make sure you know the administrative accounts native to Windows (administrator), Linux (root), and macOS (root). You must carefully control these accounts. Clearly, giving regular users administrator/root access is a bad idea, but far more subtle problems can arise. I once gave a user the Manage Documents permission for a busy laser printer in a Windows network. She quickly realized she could pause other users’ print jobs and send her print jobs to the beginning of the print queue—nice for her but not so nice for her co-workers. Protecting administrative programs and functions from access and abuse by users is a real challenge and one that requires an extensive knowledge of the operating system and of users’ motivations.
NOTE Administering your super accounts is only part of what’s called user account control. See “Controlling User Accounts” later in this chapter for more details.
Malware
The term malware defines any program or code (macro, script, and so on) that’s designed to do something on a system or network that you don’t want to have happen. Malware comes in many forms, such as viruses, worms, macros, Trojan horses, rootkits, adware, and spyware. We’ll examine all these malware flavors in this section. Stopping malware, by far the number one security problem for just about everyone, is so important that we’ll address that topic in its own section later in this chapter, “Anti-malware Programs.”
Crypto-malware/Ransomware
Crypto-malware uses some form of encryption to lock a user out of a system. Once the crypto-malware encrypts the computer, usually encrypting the boot drive, in most cases the malware then forces the user to pay money to get the system decrypted. When any form of malware makes you pay to get the malware to go away, we call that malware ransomware. If a crypto-malware uses a ransom, we commonly call it crypto-ransomware.
Crypto-ransomware is one of the most troublesome malwares today, first appearing around 2012 and still going strong. Zero-day variations of crypto-malware, with names such as CryptoWall or WannaCry, are often impossible to clean.
NOTE Most crypto-malware propagates via a Trojan horse. See the upcoming “Trojan Horse” section for more information.
Virus
A virus is a program that has two jobs: to replicate and to activate. Replication means it makes copies of itself, often as code stored in boot sectors or as extra code added to the end of executable programs. A virus is not a stand-alone program, but rather something attached to a host file, kind of like a human virus. Activation is when a virus does something like erase the boot sector of a drive. A virus only replicates to other applications on a drive or to other drives, such as flash drives or optical media. It does not replicate across networks. Plus, a virus needs human action to spread.
Worm
A worm functions similarly to a virus, though it replicates exclusively through networks. A worm, unlike a virus, doesn’t have to wait for someone to use a removable drive to replicate. If the infected computer is on a network, a worm will immediately start sending copies of itself to any other computers it can locate on the network. Worms can exploit inherent vulnerabilities in program code, attacking programs, operating systems, protocols, and more. Worms, unlike viruses, do not need host files to infect.
Macro
A macro is any type of virus that exploits application macros to replicate and activate. A macro is also programming within an application that enables you to control aspects of the application. Macros exist in any application that has a built-in macro language, such as Microsoft Excel, that users can program to handle repetitive tasks (among other things).
Logic Bomb
A logic bomb is code written to execute when certain conditions are met, usually with malicious intent. A logic bomb could be added to a company database, for example, to start deleting files if the database author loses her job. Or, the programming could be added to another program, such as a Trojan horse.
Trojan Horse
A Trojan horse is a piece of malware that looks or pretends to do one thing while, at the same time, doing something evil. A Trojan horse may be a game, like poker, or a free screensaver. The sky is the limit. The more “popular” Trojan horses turn an infected computer into a server and then open TCP or UDP ports so a remote user can control the infected computer. They can be used to capture keystrokes, passwords, files, credit card information, and more. Trojan horses do not replicate.
Rootkit
For a virus or Trojan horse to succeed, it needs to come up with some method to hide itself. As awareness of malware has grown, anti-malware programs make it harder to find new locations on a computer to hide. A rootkit takes advantage of very low-level operating system functions to hide itself from all but the most aggressive of anti-malware tools. Worse, a rootkit, by definition, gains privileged access to the computer. Rootkits can strike operating systems, hypervisors, and even firmware.
Adware/Spyware
There are two types of programs that are similar to malware in that they try to hide themselves to an extent. Adware is a program that monitors the types of Web sites you frequent and uses that information to generate targeted advertisements, usually pop-up windows. Many of these programs use Adobe Flash. Adware isn’t, by definition, evil, but many adware makers use sneaky methods to get you to use adware, such as using deceptive-looking Web pages (“Your computer is infected with a virus—click here to scan NOW!”). As a result, adware is often considered malware. Some of the computer-infected ads actually install a virus when you click them, so avoid these things like the plague.
Spyware is a function of any program that sends information about your system or your actions over the Internet. The type of information sent depends on the program. A spyware program will include your browsing history. A more aggressive form of spyware may send keystrokes or all of the contacts in your e-mail. Some spyware makers bundle their product with ads to make them look innocuous. Adware, therefore, can contain spyware.
Social Engineering
A considerable percentage of attacks against your network fall under the heading of social engineering—the process of using or manipulating people inside the networking environment to gain access to that network from the outside. The term “social engineering” covers the many ways humans can use other humans to gain unauthorized information. This unauthorized information may be a network login, a credit card number, company customer data—almost anything you might imagine that one person or organization may not want a person outside of that organization to access.
Social engineering attacks aren’t considered hacking—at least in the classic sense of the word—although the goals are the same. Social engineering is where people attack an organization through the people in the organization or physically access the organization to get the information they need.
The most classic form of social engineering is the telephone scam in which someone calls a person and tries to get him or her to reveal his or her user name/password combination. In the same vein, someone may physically enter your building under the guise of having a legitimate reason for being there, such as a cleaning person, repair technician, or messenger. The attacker then snoops around desks, looking for whatever he or she has come to find (one of many good reasons not to put passwords on your desk or monitor). The attacker might talk with people inside the organization, gathering names, office numbers, or department names—little things in and of themselves, but powerful tools when combined later with other social engineering attacks.
These old-school social engineering tactics are taking a backseat to a far more nefarious form of social engineering: phishing.

CAUTION All these attacks are commonly used together, so if you discover one of them being used against your organization, it’s a good idea to look for others.
Phishing
In a phishing attack, the attacker poses as some sort of trusted site, like an online version of your bank or credit card company, and solicits you to update your financial information, such as a credit card number. You might get an e-mail message, for example, that purports to be from PayPal telling you that your account needs to be updated and provides a link that looks like it goes to http://www.paypal.com. Upon clicking the link, however, you end up at a site that resembles the PayPal login but is actually http://100.16.49.21/2s82ds.php, a phishing site.
Physical Intrusion
You can’t consider a network secure unless you provide some physical protection to your network. I separate physical protection into two different areas: protection of servers and protection of clients.
Server protection is easy. Lock up your servers to prevent physical access by any unauthorized person. Large organizations have special server rooms, complete with card-key locks and tracking of anyone who enters or exits. Smaller organizations should at least have a locked closet. While you’re locking up your servers, don’t forget about any network switches! Hackers can access networks by plugging into a switch, so don’t leave any switches available to them.
Physical server protection doesn’t stop with a locked door. One of the most common mistakes made by techs is to walk away from a server while still logged in. Always log off from your server when you’re not actively managing the server. As a backup, add a password-protected screensaver (Figure 19-8).
Figure 19-8 Applying a password-protected screensaver to a server
Locking up all of your client systems is difficult, but your users should be required to perform some physical security. First, all users should lock their computers when they step away from their desks. Instruct them to press the WINDOWS KEY-L combination to perform the lock. Hackers take advantage of unattended systems to get access to networks.
Second, make users aware of the potential for dumpster diving and make paper shredders available. Last, tell users to mind their work areas. It’s amazing how many users leave passwords readily available. I can go into any office, open a few desk drawers, and invariably find little yellow sticky notes with user names and passwords. If users must write down passwords, tell them to put them in locked drawers!
NOTE A Windows PC should be locked down when it’s not actively being used. The simplest thing to teach your users to do is to press the WINDOWS KEY-L combination when they get up from their desks. The effects from the key combination vary according to both the version of Windows and whether a system is a member of a workgroup or domain, but all will require the user to log in to access his or her account (assuming the account is password protected in the first place, of course!).
Common Vulnerabilities
If a threat is an action that threat agents do to try to compromise our networks, then a vulnerability is a potential weakness in our infrastructure that a threat might exploit. Note that I didn’t say that a threat will take advantage of the vulnerability: only that the vulnerability is a weak place that needs to be addressed.
EXAM TIP Look for comparison questions on zero-day attacks and other exploits vs. vulnerabilities.
Some vulnerabilities are obvious, such as connecting to the Internet without an edge firewall or not using any form of account control for user files. Other vulnerabilities are unknown or missed, and that makes the study of vulnerabilities very important for a network tech. This section explores a few common vulnerabilities.
NOTE If you want to get an idea as to the depth of vulnerabilities, check out the Common Vulnerabilities and Exposures (CVE) database hosted by MITRE Corporation here: https://cve.mitre.org/.
Unnecessary Running Services
A typical system running any OS is going to have a large number of important programs running in the background, called services. Services do the behind-the-scenes grunt work that users don’t need to see, such as wireless network clients and DHCP clients. There are client services and server services.
As a Windows user, I’ve gotten used to seeing zillions of services running on my system, and in most cases I can recognize only about 50 percent of them—and I’m good at this! In a typical system, not all these services are necessary, so you should disable unneeded network services.
From a security standpoint, there are two reasons it’s important not to run any unnecessary services. First, most OSs use services to listen on open TCP or UDP ports, potentially leaving systems open to attack. Second, bad guys often use services as a tool for the use and propagation of malware.
The problem with trying not to run unnecessary services is the fact that there are just so many of them. It’s up to you to research services running on a particular machine to determine if they’re needed or not. It’s a rite of passage for any tech to review the services running on a system, going through them one at a time. Over time you will become familiar with many of the built-in services and get an eye for spotting the ones that just don’t look right. There are tools available to do the job for you, but this is one place where you need skill and practice.
Closing unnecessary services closes TCP/UDP ports. Every operating system has some tool for you to see exactly what ports are open. Figure 19-9 shows an example of the netstat command in macOS.
Figure 19-9 netstat in action
EXAM TIP Closing ports can lead to a common network service issue, that of blocked TCP/UDP ports. A typical scenario you might need to troubleshoot at a client level is a newly installed Internet-aware application (like a game) that can’t access the Internet. Blocked ports—by an overly zealous tech or user—can block network access.
A similar scenario on the server side can occur when one tech blocks ports and doesn’t properly document his or her actions. Another tech wouldn’t necessarily know the ports are blocked and could look to other issues when confronted with an application that can’t access the network.
Unpatched/Legacy Systems
Unpatched systems—including operating systems and firmware—and legacy systems present a glaring security threat. You need to deal with such problems on live systems on your network. When it comes to unpatched OSs, well, patch or isolate them! There’s a number of areas in the book that touch on proper patching, so we won’t go into more detail here.
Unpatched firmware presents a little more of a challenge. Most firmware never needs to be or gets patched, but once in a while you’ll run into devices that have a discovered flaw or security hole. These you’ll need to patch.
EXAM TIP Look for questions on hardening network systems that discuss disabling unnecessary systems, patching and upgrades for software, and upgrading firmware.
The process of patching device firmware varies from device to device, so you’ll need to do some research on each. In general, you’ll download a patch from the manufacturer and run it on the device. Make sure you have good power before you start the patch. If something goes wrong in the update, you’ll brick whatever device you’re trying to patch. There’s no undo or patch rollback with firmware, so patch only when necessary.
Legacy systems are a different issue altogether. By legacy we mean systems that are no longer supported by the OS maker and are no longer patched. In that case you need to consider the function of the system, update if possible, and if not possible, you need to isolate the legacy systems behind some type of firewall that will give them the support they need. Equally, you need to be extremely careful about adding any software or hardware to the systems as doing so might create even more vulnerabilities.
Most companies and institutions have policies and best practices in place for dealing with legacy systems. Every computing device has a system life cycle, from shiny and new, to patched and secure, to “you’re still using that old junk?”
System life cycle policies address asset disposal with the concept of reuse, repurpose, recycle. You shouldn’t just throw old gear in the trash. Your old switches and routers might be perfect for a hungry non-profit’s network. Donate and take a tax write-off. Repurpose older WAPs as simple bridges for devices that don’t need high speed, for example, like printers and multifunction devices. Deal with anything that stored data by putting it through a shredder and tossing the remains in metal recycling.
Unencrypted Channels
The open nature of the Internet has made it fairly common for us to use secure protocols or channels such as VPNs, SSL/TLS, and SSH. It never ceases to amaze me, however, how often people use unencrypted channels—especially in the most unlikely places. It was only a few years ago I stumbled upon a tech using Telnet to do remote logins into a very critical router for an ISP.
In general, look for the following insecure protocols and unencrypted channels:
• Using Telnet instead of SSH for remote terminal connections.
• Using HTTP instead of HTTPS on Web sites.
• Using insecure remote desktops like VNC.
• Using any insecure protocol in the clear. Run them through a VPN!
Cleartext Credentials
Older protocols offer a modicum of security—you often need a valid user name and password, for example, when connecting to a File Transfer Protocol (FTP) server. The problem with such protocols (FTP, Telnet, POP3) is that user names and passwords are sent from the user to the server in cleartext. Credentials can be captured and, because they’re not encrypted, cleartext credentials can be readily discovered.
There are many other places where cleartext turns up, such as in third-party applications and improperly configured applications that would normally have encrypted credentials.
The problem with third-party applications using cleartext credentials is that there’s no way for you to know if they do so or not. Luckily, we live in a world filled with people who run packet sniffers on just about everything. These vulnerabilities are often discovered fairly quickly and reported. Most likely, you’ll get an automatic patch.
The last place where cleartext credentials can still come through is poor configuration of applications that would otherwise be well protected. Almost any remote control program has some form of “no security” level setting. This might be as obvious as a “turn off security” option or it could be a setting such as Password Authentication Protocol (PAP) (which, if you recall, means cleartext passwords). The answer here is understanding your applications and knowing ahead of time how to configure the application to ensure good encryption of credentials.
RF Emanation
Radio waves can penetrate walls, to a certain extent, and accidental spill, called RF emanation, can lead to a security vulnerability. Avoid this by placing some form of filtering between your systems and the place where the bad guys are going to be using their super high-tech Bourne Identity spy tools to pick up on the emanations.
To combat these emanations, the U.S. National Security Agency (NSA) developed a series of standards called TEMPEST. TEMPEST defines how to shield systems and manifests in a number of different products, such as coverings for individual systems, wall coverings, and special window coatings. Unless you work for a U.S. government agency, the chance of you seeing TEMPEST technologies is pretty small.
Hardening Your Network
Once you’ve recognized threats and vulnerabilities, it’s time to start applying security hardware, software, and processes to your network to prevent bad things from happening. This is called hardening your network. Let’s look at three aspects of network hardening: physical security, network security, and host security.
Physical Security
There’s an old saying: “The finest swordsman in all of France has nothing to fear from the second finest swordsman in all of France.” It means that they do the same things and know the same techniques. The only difference between the two is that one is a little better than the other. There’s a more modern extension of the old saying that says: “On the other hand, the finest swordsman in all of France can be defeated by a kid with a rocket launcher!” Which is to say that the inexperienced, when properly equipped, can and will often do something totally unexpected.
Proper security must address threats from the second finest swordsman as well as the kid. We can leave no stone unturned when it comes to hardening the network, and this begins with physical security. Physical threats manifest themselves in many forms, including property theft, data loss due to natural damage such as fire or natural disaster, data loss due to physical access, and property destruction resulting from accident or sabotage.
Let’s look at physical security as a two-step process. First, prevent and control access to IT resources to appropriate personnel. Second, track the actions of those authorized (and sometimes unauthorized) personnel.
Prevention and Control
The first thing we have to do when it comes to protecting the network is to make the network resources accessible only to personnel who have a legitimate need to fiddle with them. Start with the simplest approach: a lock. Locking the door to the network closet or equipment room that holds servers, switches, routers, and other network gear goes a long way in protecting the network. Key control is critical here and includes assigning keys to appropriate staff, tracking key assignments, and collecting the keys when they are no longer needed by individuals who move on. This type of access must be guarded against circumvention by ensuring policies are followed regarding who may have or use the keys. The administrator who assigns keys should never give one to an unauthorized person without completing the appropriate procedures and paperwork.
Locking down servers within the server room with unique keys adds another layer of physical security to essential devices. Additionally, all modern server chassis come with tamper detection features that will log in the motherboard’s nonvolatile RAM (NVRAM) if the chassis has been opened. The log will show chassis intrusion with a date and time. And it’s not just the server room (and resources with it) that we need to lock up. How about the front door? There are a zillion stories of thieves and saboteurs coming in through the front (or sometimes back) door and making their way straight to the corporate treasure chest. A locked front door can be opened by an authorized person, and an unauthorized person can attempt to enter through that already opened door, what’s called tailgating. While it is possible to prevent tailgating with policies, it is only human nature to “hold the door” for that person coming in behind you. Tailgating is especially easy to do when dealing with large organizations in which people don’t know everyone else. If the tailgater dresses like everyone else and maybe has a badge that looks right, he or she probably won’t be challenged. Add an armload of gear, and who could blame you for helping that person by holding the door?
There are a couple of techniques available to foil a tailgater. The first is a security guard. Guards are great. They get to know everyone’s faces. They are there to protect assets and can lend a helping hand to the overloaded, but authorized, person who needs in. They are multipurpose in that they can secure building access, secure individual room and office access, and perform facility patrols. The guard station can serve as central control of security systems such as video surveillance and key control. Like all humans, security guards are subject to attacks such as social engineering, but for flexibility, common sense, and a way to take the edge off of high security, you can’t beat a professional security guard or two.
For areas where an entry guard is not practical, there is another way to prevent tailgating called a mantrap. A mantrap is an entryway with two successive locked doors and a small space between them providing one-way entry or exit. After entering the first door, the second door cannot be unlocked until the first door is closed and secured. Access to the second door may be a simple key or may require approval by someone else who watches the trap space on video. Unauthorized persons remain trapped until they are approved for entry, let out the first door, or held for the appropriate authorities.
Brass keys aren’t the only way to unlock a door. This is the 21st century, after all. Twenty-five years ago, I worked in a campus facility with a lot of interconnected buildings. Initial access to buildings was through a security guard and then we traveled between the buildings with connecting tunnels. Each end of the tunnels had a set of sliding glass doors that kind of worked like the doors on the starship Enterprise. We were assigned badges with built-in radio frequency ID (RFID) chips. As we neared a door, the RFID chip was queried by circuitry in the door frame called a proximity reader, checked against a database for authorization, and then the door slid open electromechanically.
It was so cool and so fast that people would jog the hallways during lunch hours and not even slow down for any of the doors. A quarter century later, the technology has only gotten better. The badges in the old days were a little larger than a credit card and about three times as thick. Today, the RFID chip can be implanted in a small, unobtrusive key fob, like the kind you use to unlock your car.
EXAM TIP Smart cards today use microprocessor circuitry to enable authentication, among other things. They can certainly be used to gain access, but also to make transactions and more.
If there is a single drawback to all of the physical door access controls mentioned so far, it is that access is generally governed by something that is in the possession of someone who has authorization to enter a locked place. That something may be a key, a badge, a key fob with a chip, or some other physical token. The problem here, of course, is that these items can be given or taken away. If not reported in a timely fashion, a huge security gap exists.
To move from the physical possession problem of entry access, physical security can be governed by something that is known only to authorized persons. A code or password that is assigned to a specific individual for a particular asset can be entered on an alphanumeric keypad that controls an electric or electromechanical door lock. There is a similar door lock mechanism called a cipher lock. A cipher lock is a door unlocking system that uses a door handle, a latch, and a sequence of mechanical push buttons. When the buttons are pressed in the correct order, the door unlocks and the door handle works. Turning the handle opens the latch or, if you pressed the wrong order of buttons, clears the unlocking mechanism so you can try again. Care must be taken by staff who are assigned a code to protect that code.
This knowledge-based approach to access control may be a little better than a possession-based system because information is more difficult to steal than a physical token. However, poor management of information can leave an asset vulnerable. Poor management includes writing codes down and leaving the notes easily accessible. Good password/code control means memorizing information where possible or securing written notes about codes and passwords.
Well-controlled information is difficult to steal, but it’s not perfect because sharing information is so easy. Someone can loan out his or her password to a seemingly trustworthy friend or co-worker. While most times this is probably not a real security risk, there is always a chance that there could be disastrous results. Social engineering or over-trusting can cause someone to share a private code or password. Systems should be established to reassign codes and passwords regularly to deal with the natural leakage that can occur with this type of security.
EXAM TIP All this talk about intangible asset control, like passwords, doesn’t mean you should ignore tangible asset control. Many companies employ RFID and other electronic devices as asset tracking tags for inventory control purposes. Plus they’ll use low-tech physical security tools like special stickers or zip ties for tamper detection in its most basic use of the term.
The best way to prevent loss of access control is to build physical security around a key that cannot be shared or lost. Biometric access calls for using a unique physical characteristic of a person to permit access to a controlled IT resource. Doorways can be triggered to unlock using fingerprint readers, facial recognition cameras, voice analyzers, retinal blood vessel scanners, or other, more exotic characteristics. While not perfect, biometrics represent a giant leap in secure access. For even more effective access control, multifactor authentication can be used, where access is granted based on more than one access technique. For instance, in order to gain access to a secure server room, a user might have to pass a fingerprint scan and have an approved security fob.
Let me point out something related to all of this door locking and unlocking technology. Physical asset security is important, but generally not as important as the safety of people. Designers of these door-locking systems must take into account safety features such as what happens to the state of a lock in an emergency like a power failure or fire. Doors with electromechanical locking controls can respond to an emergency condition and lock or unlock automatically, respectively called fail close or fail open. Users and occupants of facilities should be informed about what to expect in these types of events.
Monitoring
Okay, the physical assets of the network have been secured. It took guards, locks, passwords, eyeballs, and a pile of technology. Now, the only people who have access to IT resources are those who have been carefully selected, screened, trained, and authorized. The network is safe, right? Maybe not. You see, here comes the old problem again: people are human. Humans make mistakes, humans can become disgruntled, and humans can be tempted. The only real solution is heavily armored robots with artificial intelligence and bad attitudes. But until that becomes practical, maybe what we need to do next is to ensure that those authorized people can be held accountable for what they do with the physical resources of the network.
Enter video surveillance. With video surveillance of facilities and assets, authorized staff can be monitored for mistakes or something more nefarious. Better still, our kid with a rocket launcher (remember him?) can be tracked and caught after he sneaks into the building.
Let’s look at two video surveillance concepts. Video monitoring entails using remotely monitored visual systems and covers everything from identifying a delivery person knocking on the door at the loading dock, to looking over the shoulder of someone working on the keyboard of a server. IP cameras and closed-circuit televisions (CCTVs) are specific implementations of video monitoring. CCTV is a self-contained, closed system in which video cameras feed their signal to specific, dedicated monitors and storage devices. CCTV cameras can be monitored in real time by security staff, but the monitoring location is limited to wherever the video monitors are placed. If real-time monitoring is not required or viewing is delayed, stored video can be reviewed later as needed.
EXAM TIP Many small office/home office (SOHO) video surveillance systems rely on motion detection systems that start and stop recordings based on actions caught by the camera(s). This has the advantage of saving a lot of storage space, hopefully only catching the bad guys on film when they’re breaking into your house or stealing your lawn gnomes.
IP cameras have the benefit of being a more open system than CCTV. IP video streams can be monitored by anyone who is authorized to do so and can access the network on which the cameras are installed. The stream can be saved to a hard drive or network storage device. Multiple workstations can simultaneously monitor video streams and multiple cameras with ease.
Network Security
Protecting network assets is more than a physical exercise. Physically speaking, we can harden a network by preventing and controlling access to tangible network resources through things like locking doors and video monitoring. Next we will want to protect our network from malicious, suspicious, or potential threats that might connect to or access the network. This is called access control and it encompasses both physical security and network security. In this section we look at some technologies and techniques to implement network access control, including user account control, edge devices, posture assessment, persistent and non-persistent agents, guest networks, and quarantine networks.
Controlling User Accounts
A user account is just information: nothing more than a combination of a user name and password. Like any important information, it’s critical to control who has a user account and to track what these accounts can do. Access to user accounts should be restricted to the assigned individuals (no sharing, no stealing), and those accounts should have permission to access only the resources they need, no more. This control over what a legitimate account can do is called the principle of least privilege approach to network security and is, by far, the most common approach used in networks.
Tight control of user accounts helps prevent unauthorized access or improper access. Unauthorized access means a person does something beyond his or her authority to do. Improper access occurs when a user who shouldn’t have access gains access through some means. Often the improper access happens when a network tech or administrator makes a mistake.
Disabling unused accounts is an important first step in addressing these problems, but good user account control goes far deeper than that. One of your best tools for user account control is to implement groups. Instead of giving permissions to individual user accounts, give them to groups; this makes keeping track of the permissions assigned to individual user accounts much easier.
Figure 19-10 shows an example of giving permissions to a group for a folder in Windows Server. Once a group is created and its permissions are set, you can then add user accounts to that group as needed. Any user account that becomes a member of a group automatically gets the permissions assigned to that group.
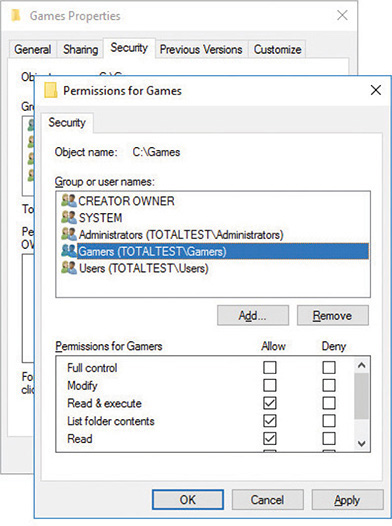
Figure 19-10 Giving a group permissions for a folder in Windows
Figure 19-11 shows an example of adding a user to a newly created group in the same Windows Server system.
Figure 19-11 Adding a user to a newly created group
You should always put user accounts into groups to enhance network security. This applies to simple networks, which get local groups, and to domain-based networks, which get domain groups. Do not underestimate the importance of properly configuring both local groups and domain groups.
Groups are a great way to get increased complexity without increasing the administrative burden on network administrators because all network operating systems combine permissions. When a user is a member of more than one group, which permissions does he or she have with respect to any particular resource?
In all network operating systems, the permissions of the groups are combined; this results in the effective permissions the user has to access a given resource. Let’s use an example from Windows Server. If Timmy is a member of the Sales group, which has List Folder Contents permission to a folder, and he is also a member of the Managers group, which has Read and Execute permissions to the same folder, Timmy will have List Folder Contents and Read and Execute permissions to that folder.
Combined permissions can also lead to conflicting permissions, where a user does not get access to a needed resource because one of his groups has Deny permission to that resource. Deny always trumps any other permission.
Watch out for default user accounts and groups—they can grant improper access or secret backdoor access to your network! All network operating systems have a default Everyone group, and it can easily be used to sneak into shared resources. This Everyone group, as its name implies, literally includes anyone who connects to that resource. Some versions of Windows give full control to the Everyone group by default. All of the default groups—Everyone, Guest, Users—define broad groups of users. Never use them unless you intend to permit all those folks to access a resource. If you use one of the default groups, remember to configure it with the proper permissions to prevent users from doing things you don’t want them to do with a shared resource!
All of these groups only do one thing for you: they enable you to keep track of your user accounts. That way you know resources are only available for users who need those resources, and users only access the resources you want them to use.
Before I move on, let me add one more tool to your kit: diligence. Managing user accounts is a thankless and difficult task, but one that you must stay on top of if you want to keep your network secure. Most organizations integrate the creating, disabling/enabling, and deleting of user accounts with the work of their human resources folks. Whenever a person joins, quits, or moves, the network admin is always one of the first to know!
The administration of permissions can become incredibly complex—even with judicious use of groups. You now know what happens when a user account has multiple sets of permissions to the same resource, but what happens if the user has one set of permissions to a folder and a different set of permissions to one of its subfolders? This brings up a phenomenon called inheritance. I won’t get into the many ways different network operating systems handle inherited permissions. Luckily for you, the CompTIA Network+ exam doesn’t test you on all the nuances of combined or inherited permissions—just be aware they exist. Those who go on to get more advanced certifications, on the other hand, must become extremely familiar with the many complex permutations of permissions.
Edge
Access control can be broadly defined as exactly what it sounds like: one or more methods to govern or limit entry to a particular environment. Historically, this was accomplished and enforced with simply communicated rules and policies and human oversight. As systems grew in size and sophistication, it became possible to enforce the governing rules using automated technology, relieving managers to focus on other tasks. These control technologies began their developmental life as a central control system with peripheral actuators.
Let me show you what I mean. Take the example of the Star Trek–like security door system I talked about in the “Physical Security” section a little while ago. That system worked by having a computer with a database of doors, staff, and a decision matrix. Because it controlled many doors, it was centrally located and had wires running to and from it to every controlled door on the campus. Each door had two peripherals installed: a proximity reader with a status indicator, and a door open/close actuator. The proximity reader would read the data from the RFID chip carried by someone and send the data over a sometimes very long data cable to the control computer.
The computer would take the data and the door identifier and check to see it the data was valid, current, and authorized to pass through the door. If it did not meet authorization criteria, a data signal was sent back down the data line to cause a red LED to blink on the proximity reader. Of course, the door would not open. If all of the criteria were met for authorization, a good signal was sent down the data line to make a green LED glow, and power was sent down the line to operate the door actuator.
We’ve talked about the benefits of this system, so let’s look at a few drawbacks. First, the system was proprietary. As systems like these were introduced, competition stymied any effort to create industry standards. Central control meant that large, powerful boxes had to be developed as central controllers. Expandability became an issue as controllers maxed out the number of security doors they could support. Finally, the biggest problem was the large amount of cabling needed to support large numbers of doors and potentially great distances from the central controller. The problem was made worse when facilities had to retrofit non-secure doors for secure ones.
A lot of time and technology has passed since those days. Today’s automated secure entry systems take advantage of newer technologies by leveraging existing network wiring. By using IP traffic and Power over Ethernet (PoE), the entire system can usually run over the existing wiring. Applications and protocols have been standardized so they can run on existing server hardware.
Also contributing to the simplification and standardization of these security systems are edge devices. An edge device is a piece of hardware that has been optimized to perform a task. Edge devices work in coordination with other edge devices and controllers.
The primary defining characteristic of an edge device is that it is installed closer to a client device, such as a workstation or a security door, than to the core or backbone of a network. In this instance, a control program that tracks entries, distributes and synchronizes copies of databases, and tracks door status can be run on a central server. In turn, it communicates with edge devices. The edge devices keep a local copy of the database and make their own decisions about whether or not a door should be opened.
Posture Assessment
Network access control (NAC) is a standardized approach to verify that a node meets certain criteria before it is allowed to connect to a network. Many product vendors implement NAC in different ways. Network Admission Control (also known as NAC) is Cisco’s version of network access control.
Cisco’s NAC can dictate that specific criteria must be met before allowing a node to connect to a secure network. Devices that do not meet the required criteria can be shunted with no connection or made to connect to another network. The types of criteria that can be checked are broad ranging and can be tested for in a number of ways. For the purposes of this text, we are mostly concerned about verifying that a device attempting to connect is not a threat to network security.
Cisco uses posture assessment as one of the tools to implement NAC. Posture assessment is a feature of certain advanced Cisco network appliances. A switch or router that has posture assessment enabled and configured will query network devices to confirm that they meet minimum security standards before being permitted to connect to the production network.
Posture assessment includes checking things like type and version of anti-malware, level of QoS, and type/version of operating system. Posture assessment can perform different checks at succeeding stages of connection. Certain tests can be applied at the initial physical connection. After that, more checks can be conducted prior to logging in. Prelogin assessment may look at the type and version of operating system, detect whether keystroke loggers are present, and check whether the station is real or a virtual machine. The host may be queried for digital certificates, anti-malware version and currency, whether the machine is real or virtual, and a large list of other checks.
If everything checks out, the host will be granted a connection to the production network. If posture assessment finds a deficiency or potential threat, the host can be denied a connection or connected to a non-production network until it has been sufficiently upgraded.
Persistent and Non-persistent Agents
How does a host respond to a posture assessment query? Like a lot of things, the answer depends on the environment. Let’s focus on a workstation to answer this question. A workstation requires something called an agent to answer a posture assessment query. An agent is a process or program running within the computer that scans the computer to create an inventory of configuration information, resources, and assets. When the workstation attempts to connect to the network through a posture assessment–enabled device, it is the agent that answers the security query.
Agents come in two flavors. The first is a small scanning program that, once installed on the computer, stays installed and runs every time the computer boots up. These agents are composed of modules that perform a thorough inventory of each security-oriented element in the computer. This type of agent is known as a persistent agent. If there is no agent to respond to a posture assessment query, the node is not permitted to connect to the production network.
Sometimes a computer needs to connect to a secure network via a Web site portal. Some portals provide VPN access to a corporate network, while others provide a less-robust connection. In either case, it is important that these kinds of stations meet the appropriate security standards before they are granted access to the network, just as a dedicated, onsite machine must. To that end, a posture assessment is installed at the endpoint. The endpoint in this instance is the device that actually creates a secure attachment to the production network. At the workstation, a small agent that scans only for the queried conditions is downloaded and run. If the query is satisfied that the station needing access is acceptable, connection is granted and the node can access the production network. When the node disconnects from the network and leaves the portal site, the agent is released from memory. This type of agent is known as a non-persistent agent.
It is worthwhile to note a couple of things here that, while not necessarily critical to the CompTIA Network+ exam, can be useful to know in the real world. First, the Cisco network admission control process does not consist solely of the posture assessment module in an edge device and the node agent. There is also the Cisco Access Control Server (ACS). It is within this program/process/server that the actual decision to admit or deny a node is made. From there, the ACS directs the edge access device to allow a connection or to implement a denial or redirect. There are additional components and configurations required to create a complete network access control system.
Also useful to know is that Cisco is not the only player in town (although they are decidedly the biggest in this arena) and using an agent is not the only way to check a node for security compliance. To paraphrase Shakespeare: “There are more things in heaven and earth, Horatio … and they aren’t all workstations.” There are tablets, smartphones, other bring-your-own devices (BYOD), switches, printers, and plenty of other things that can connect to a network. For this reason, there needs to be a flexible, cross-platform method of checking for node security before granting access to a secure network. For these platforms, an 802.1X supplicant, in the form of either an agent or a client, can be installed in the device. You’ll remember 802.1X from Chapter 10, “Securing TCP/IP.”
Further, a number of vendors have implemented agent-less posture assessment capability. Using a variety of techniques, hosts can be checked for things like a device fingerprint (set of characteristics that uniquely identifies a particular device), a CVE ID, or other agent-less responses. These techniques are easily implemented on a large variety of platforms and they work in a wide array of network environments.
Whether a station responds to a posture assessment query with or without an agent, the result is still one of three options: clearance into the network, connection denied, or redirect to a non-production network. Let’s talk about those non-production networks.
Guest Networks and Quarantine Networks
It may be desirable for an organization to provide a connection to the Internet as a service to visitors and clients. Envision a coffee shop that welcomes its patrons to check e-mail on their portable devices while enjoying an iced latte with two pumps of white cacao mocha. As you turn on your laptop to scan for Wi-Fi networks, two SSIDs appear. One SSID is labeled CustomerNet and the other is called CorpNet. Some might try to hack into CorpNet, but clearly the intent is for consumers to attach to CustomerNet and gain access to the Internet through that connection. The CustomerNet network is an example of a guest network.
A guest network can contain or allow access to any resource that management deems acceptable to be used by non-secure hosts that attach to the guest network. Those resources might include an Internet connection, a local Web server with a company directory or catalog, and similar assets that are nonessential to the function of the organization.
In the preceding example, access to the guest network results from a user selecting the correct SSID. More in line with the goals of this book would be a scenario where a station attempts to connect to a network but is refused access because it does not conform to an acceptable level of security. In this case, the station might be assigned an IP address that only enables it to connect to the guest network. If the station needs access to the production network, the station could be updated to meet the appropriate security requirements. If it only requires the resources afforded by the guest network, then it’s good to go.
Whenever a node is denied a connection to the production network, it is considered to be quarantined. It is common practice for suspicious nodes or nodes with active threats detected to be denied a connection or sent to a quarantine network.
So let’s put it all together. An organization may have a multitude of production networks, a guest network, and a quarantine network. Who gets to go where? Stations that pass a profile query performed by an edge device with posture assessment features can connect to a production network. From there, access to the various networks and resources is determined by privileges granted to the login credentials.
If a station does not pass the posture query but does not appear to pose a threat, it will likely be connected to the guest network. Stations with active malware or that display a configuration that is conducive to hacking will be quarantined with no connection or connected to a quarantine network.
Device Hardening
Proper network hardening requires implementing device hardening. Many of the hardening techniques and best practices discussed for network access and server security apply to switches, routers, and network appliances. Let’s look at five topics.
Network devices come with default credentials, the username and password that enables you to log into the device for configuration. Changing default credentials should be the first step in hardening a new device. As with any other system, avoiding common passwords adds security.
Keep network devices up to date. That means upgrading firmware, patching and updating as necessary to close any security gaps exposed over time.
Services on network devices like routers include common things, like Telnet and HTTP access; and also things you don’t normally see, like TCP and UDP small services, debugging and testing tools that primarily use ports 20 and lower. If enabled, these services can be used to launch DoS and other attacks. All modern Cisco devices have these disabled; Cisco’s hardening rules insist on disabling unnecessary services.
Using secure protocols hardens network devices. Don’t use Telnet to access a managed switch or router, for example, but use SSH so that the communication is encrypted.
Disabling unused ports on network devices enhances port security for access control. This includes standard IP ports and device ports, both physical and virtual for the latter.
EXAM TIP Attackers can use traffic floods—excessive or malformed packets—to conduct DoS attacks on networks and hosts, targeting vulnerable switches through their switch ports. Better switches today employ flood guards to detect and block excessive traffic. This enhances switch port protection.
Host Security
The first and last bastion of defense for an entire infrastructure’s security is at the individual hosts. It’s the first bastion for preventing dangerous things that users do from propagating to the rest of the network. It’s the last bastion in that anything evil coming from the outside world must be stopped here.
We’ve talked about local security issues several times in this book and even in this chapter. User accounts and strong passwords, for example, obviously provide a first line of defense at the host level. So let’s look at another aspect of host security: malware prevention and recovery.
Malware Prevention and Recovery
The only way to protect your PC permanently from getting malware is to disconnect it from the Internet and never permit any potentially infected software to touch your precious computer. Because neither scenario is likely these days, you need to use specialized anti-malware programs to help stave off the inevitable assaults. Even with the best anti-malware tools, there are times when malware still manages to strike your computer. When you discover infected systems, you need to know how to stop the spread of the malware to other computers, how to fix infected computers, and how to remediate (restore) the system as close to its original state as possible.
Malware Prevention If your PC has been infected by malware, you’ll bump into some strange things before you can even run an anti-malware scan. Like a medical condition, malware causes unusual symptoms that should stand out from your everyday computer use. You need to become a PC physician and understand what each of these symptoms means.
Malware’s biggest strength is its flexibility: it can look like anything. In fact, a lot of malware attacks can feel like normal PC “wonkiness”—momentary slowdowns, random one-time crashes, and so on. Knowing when a weird application crash is actually a malware attack is half the battle.
A slow PC can mean you’re running too many applications at once or you’ve been hit with malware. How do you tell the difference? In this case, it’s the frequency. If it’s happening a lot, even when all of your applications are closed, you’ve got a problem. This goes for frequent lockups, too. If Windows starts misbehaving (more than usual), run your anti-malware application right away.
Malware, however, doesn’t always jump out at you with big system crashes. Some malware tries to rename system files, change file permissions, or hide files completely. Most of these issues are easily caught by a regular anti-malware scan, so as long as you remain vigilant, you’ll be okay.
NOTE While it’s not necessarily a malware attack, watch out for hijacked e-mail accounts, too, belonging either to you or to someone you know. Hackers can hit both e-mail clients and Webmail users. If you start receiving some fishy (or phishy) e-mail messages, change your Web-based e-mail password or scan your PC for malware.
Some malware even fights back, defending itself from your many attempts to remove it. If your Windows Update feature stops working, preventing you from patching your PC, you’ve most likely got malware. If other tools and utilities throw up an “Access Denied” road block, you’ve got malware. If you lose all Internet connectivity, either the malware is stopping you or removing the malware broke your connection. In this case, you might need to reconfigure your Internet connection: reinstall your NIC and its drivers, reboot your router, and so on.
Even your browser and anti-malware applications can turn against you. If you type in one Web address and end up at a different site than you anticipated, a malware infection might have overwritten your hosts file and thus automatically changed the DNS resolver cache. Most browser redirections point you to phishing scams or Web sites full of free downloads (that are, of course, covered in malware). In fact, some free anti-malware applications are actually malware—what techs call a rogue anti-malware program. You can avoid these rogue applications by sticking to the recommended lists of anti-malware software found online.
Watch for security alerts in Windows, either from Windows’ built-in security tools or from your third-party anti-malware program. Windows 10 includes a tool called Security and Maintenance (see Figure 19-12). (Windows 7 calls this Action Center.) You don’t actually configure much using these applets; they just tell you whether or not you are protected. These tools place an icon and pop up a notification in the notification area whenever Windows detects a problem.
Figure 19-12 Windows 10 Security and Maintenance
Symptoms of a Compromised System A system hit by malware will eventually show the effects, although in any number of ways. The most common symptoms of malware on a compromised system are general sluggishness and random crashes. In some cases, Web browsers might default to unpleasant or unwanted Web sites. Frequently, compromised systems increase network outflow a lot.
If you get enough compromised systems in your network, especially if those systems form part of a botnet or DDoS attack force, your network will suffer. The amount of traffic specifically doing the bidding of the malware on the systems can hog network bandwidth, making the network sluggish.
Watch for top talkers—systems with very high network output—and a network that doesn’t seem nearly as fast as the specs say it should be. Monitor employee complaints about sluggish machines or poor network performance carefully and act as soon as you think you might have infected systems. You need to deal with malware—hopefully catching it before it strikes, but dealing with it swiftly when it does. Let’s go there next.
Dealing with Malware You can deal with malware in several ways: anti-malware programs, training and awareness, patch management, and remediation.
At the very least, every computer should run an anti-malware program. If possible, add an appliance that runs anti-malware programs against incoming data from your network. Also remember that an anti-malware program is only as good as its updates—keep everyone’s definition file (explained a bit later) up to date with, literally, nightly updates! Users must be trained to look for suspicious ads, programs, and pop-ups, and understand that they must not click these things. The more you teach users about malware, the more aware they’ll be of potential threats. Your organization should have policies and procedures in place so everyone knows what to do if they encounter malware. Finally, a good tech maintains proper incident response records to see if any pattern to attacks emerges. He or she can then adjust policies and procedures to mitigate these attacks.
EXAM TIP One of the most important malware mitigation procedures is to keep systems under your control patched and up to date through proper patch management. Microsoft does a very good job of putting out bug fixes and patches as soon as problems occur. Microsoft isn’t perfect, and sometimes new exploits are found in the patches they release. Still, at the end of the day, a patched system will likely be more secure than an unpatched one. If your systems aren’t set up to update automatically, then perform manual updates regularly.
Anti-malware Programs An anti-malware program such as a classic antivirus program protects your PC in two ways. It can be both sword and shield, working in an active seek-and-destroy mode and in a passive sentry mode. When ordered to seek and destroy, the program scans the computer’s boot sector and files for viruses and, if it finds any, presents you with the available options for removing or disabling them. Anti-malware programs can also operate as virus shields that passively monitor a computer’s activity, checking for viruses only when certain events occur, such as a program executing or a file being downloaded.
NOTE The term antivirus is becoming obsolete (as are anti-spyware and similar terms). Viruses are only a small component of the many types of malware. Many people continue to use the term as a synonym for anti-malware.
Anti-malware programs use different techniques to combat different types of malware. They detect boot sector viruses simply by comparing the drive’s boot sector to a standard boot sector. This works because most boot sectors are basically the same. Some anti-malware programs make a backup copy of the boot sector. If they detect a virus, the programs use that backup copy to replace the infected boot sector. Executable viruses are a little more difficult to find because they can be on any file in the drive. To detect executable viruses, the anti-malware program uses a library of signatures. A signature is the code pattern of a known virus. The anti-malware program compares an executable file to its library of signatures. There have been instances where a perfectly clean program coincidentally held a virus signature. Usually, the anti-malware program’s creator provides a patch to prevent further alarms.
Anti-malware software comes in multiple forms today. First is the classic host-based anti-malware that is installed on individual systems. Host-based anti-malware works beautifully, but is hard to administer when you have a number of systems. An alternative used in larger networks is network-based anti-malware. In this case a single anti-malware server runs on a number of systems (in some cases each host has a small client). These network-based programs are much easier to update and administer.
Last is cloud/server-based anti-malware. These servers store the software on a remote location (in the cloud or on a local server), but it’s up to each host to access the software and run it. This has the advantage of storing nothing on the host system and making updating easier, but suffers from lack of administration as it’s still up to the user on each host to run the anti-malware program.
EXAM TIP Expect a question on the CompTIA Network+ exam that addresses the security implications/considerations of malware and cloud resources. Who is responsible for security, the provider or the customer? Framed this way, a typical correct answer puts cloud resource security on the provider, not the customer. The customer is responsible for host security.
Firewalls
Firewalls are devices or software that protect an internal network from unauthorized access by acting as a filter. That’s right; all a firewall does is filter traffic that flows through its ports. Firewalls are essential tools in the fight against malicious programs on the Internet.
The most basic job of the firewall is to look at each packet and decide based on a set of rules whether to block or allow the traffic. This traffic can be either inbound traffic, packets coming from outside the network, or outbound traffic, packets leaving the network.
Types of Firewalls
Firewalls come in many different forms. The types covered in this section are the common ones CompTIA wants you to be familiar with.
Software vs. Hardware Firewalls
The network-based firewall is often implemented in some sort of hardware appliance or is built into the router that is installed between the LAN and the wilds of the Internet. Most network techs’ first encounter with a network-based firewall is the SOHO firewall built in to most consumer-grade routers. These firewalls form the first line of defense, providing protection for the whole network. While they do a great job of protecting whole networks, they can’t provide any help if the malicious traffic is originating from inside the network itself. That is why we have host-based firewalls.
A host-based firewall is a software firewall installed on a “host” that provides firewall services for just that machine. A great example of this type of firewall is the Windows Firewall/Windows Defender Firewall (Figure 19-13) that has shipped with every version of Windows since XP. This makes the host-based firewall probably one of the most common types of firewalls you will encounter in your career as a network tech.
Figure 19-13 Windows Defender Firewall in Windows 10
Advanced Firewall Techniques and Features
Knowing that a firewall can live in the network or on a host is all well and good, but firewalls are very sophisticated these days and you should be familiar with the features that separate a modern firewall from a dumb packet filter. One of the first modern techniques added to firewalls is stateful inspection, or the capability to tell if a packet is part of an existing connection. In other words, the firewall is aware of the packet’s state, as it relates to other packets. This is an upgrade to the older stateless inspection model where the firewall looked at each packet fresh, with no regard to the state of the packet’s relation to any other packet.
Building on the stateful firewall, firewalls that are application/context aware operate at Layer 7 of the OSI model and filter based on the application or service that originated the traffic. This makes context-aware firewalls invaluable in stopping port-hopping applications such as BitTorrent from overloading your network.
Next-Generation Firewalls A next-generation firewall (NGFW) functions at multiple layers of the OSI model to tackle traffic no traditional firewall can filter alone. A Layer 3 firewall can filter packets based on IP addresses, for example. A Layer 5 firewall can filter based on port numbers. Layer 7 firewalls understand different application protocols and can filter on the contents of the application data. An NGFW handles all of this and more.
Unified Threat Management Finally, modern, dedicated security appliances implement unified threat management (UTM), marrying traditional firewalls with other security services, such as network-based IPS, load balancing, and more. (CompTIA uses the term UTM appliance to describe appliances that implement UTM.) UTM mitigates aggressive attacks such as advanced persistent threats (APTs)—organized, ongoing attacks on a specific entity. (A good example of an APT is a terrorist organization trying to hack into government security agency computers.)
Implementing and Configuring Firewalls
Now that you have a solid understanding of what a firewall is and how it works, let’s delve into the details of installing and configuring a hardware firewall on a network. We’ll start with the now familiar Bayland Widgets network and their gateway (Figure 19-14).
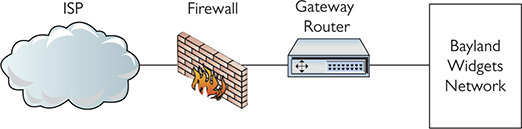
Figure 19-14 Bayland Widgets network gateway
The location of the firewall in the Bayland Widgets network is one of the most common locations for a firewall. By placing the firewall between the trusted internal network and the Internet, it can see all the traffic flowing between the two networks. This also means that the firewall’s performance is critical for our connection speed. If the firewall becomes overloaded, it can easily bring a 1-Gbps Internet connection down to 100 Mbps or slower speeds—yikes! In this case, Bayland Widgets has chosen a powerful Cisco ASA security appliance to provide the firewall.
Physically installing a firewall is just like installing other networking equipment such as routers and switches. The entry-level or SOHO models usually have a fixed number of ports, often with a fixed-purpose function (like dedicated ports for WAN traffic). Enterprise-grade hardware (typically supporting 200+ users) often is built around the idea of a flexible function that supports having cards added for different interface types and that can be reconfigured as the network changes. Once the hardware is plugged in, it’s time to start configuring your firewall’s settings.
Restricting Access via ACLs
Modern firewalls come with a massive number of features, and configuring them can be a daunting task for any network tech. But at its core, configuring a firewall is about defining which traffic can flow and which traffic shall not pass. This rule often takes the form of an access control list (ACL), a rule applied to an interface that allows or denies traffic based on things like source or destination IP addresses. ACLs can restrict access to network resources.
NOTE A basic ACL can be thought of as a stateless firewall. In fact, many of the early firewalls were just ACLs on routers.
Now that we know what an ACL is, let’s take a look at one that you might find on a Cisco router or firewall:
![]()
That looks rather cryptic at first glance, but what it’s doing is very simple. The beginning of the first line, access-list 10, tells IOS that we want to create an ACL and its number is 10 (back in the day, IOS ACLs only had numbers, not names). The end of the first line, deny 10.11.12.0 0.0.0.255, is the actual rule we want the firewall to apply. In this case, it means deny all traffic from the 10.11.12.0/24 subnet.
That’s all well and good; any traffic coming from the 10.11.12.0/24 subnet will be dropped like a bad habit. But what’s up with that second line, access-list 10 permit any? Well, that’s there because of a very important detail about ACLs: they have an implicit deny any, or automatically deny any packets that don’t match a rule. So in this case, if we stopped after the first line, no traffic would get through because we don’t have a rule that explicitly permits it! So to make our ACL be a firewall instead of a brick wall, the last rule in this list will permit through any traffic that wasn’t dropped by the first rule.
Once the ACL has been created, it must be assigned to an interface to be of any use. One interesting feature of ACLs is that they don’t just get plugged in to an interface. You must specify the rules that apply to each direction the traffic flows. Traffic flowing through an interface can be thought of as either inbound, traffic entering from the network, or outbound, traffic flowing from the firewall out to the network. This is an important detail because you can and often want to have different rules for traffic entering and leaving through an interface.

SIM Check out the excellent Chapter 19 “Implicit Deny” Show! over at http://totalsem.com/007. It’s a good tool for reviewing filtering techniques.
ACLs are but one method for configuring a firewall. While they may seem primitive, we’ve only scratched the surface of what they can do. More advanced ACLs provide the interface to many of the advanced stateful features of a modern firewall. But don’t discount the simple ones we’ve looked at here. They are still very important in modern network security, providing the critical filtering to keep traffic flowing where it should and, maybe more importantly, from flowing where it shouldn’t.
EXAM TIP Firewalls and other advanced networking devices offer all sorts of filtering. Web filtering, for example, enables networks to block specific Web site access. In contrast, content filtering enables administrators to filter traffic based on specific signatures or keywords (such as profane language). IP filtering blocks specific IP address traffic; port filtering blocks traffic on specific ports. All of these filtering options are fairly standard network hardening techniques.
The CompTIA Network+ objectives use adjectives applied to devices to describe these filtering options. They’re pretty straightforward. A content filter is an advanced networking device that implements content filtering.
DMZ and Firewall Placement
The use of a single firewall between the network and the ISP in the example shown in Figure 19-14 is just one approach to firewall placement. That configuration works well in simple networks or when you want strong isolation between all clients on the inside of the firewall. But what happens when we have servers, like a Web server, that need less restricted access to the Internet? That’s where the concepts of the DMZ and internal/external firewalls come in.
A demilitarized zone (DMZ) is a network segment carved out by normally two routers—with firewalls—to provide a special place (a zone) on the network for any servers that need to be publicly accessible from the Internet. By definition, a DMZ uses network segmentation as a mitigation technique against attacks on the network.
NOTE A bastion host is simply a machine that is fully exposed to the Internet. It sits outside any firewalls, or in a DMZ that is configured to provide no filtering of Internet traffic. Because a designation of bastion host is based on placement within the network, any unprotected machine can be considered a bastion host. In fact, you can think of the firewall as a bastion host!
The most common DMZ design is to create a DMZ by using two routers with firewalls to create a perimeter network. With a perimeter network (Figure 19-15), the two firewalls carve out areas with different levels of trust. The firewall that sits between the perimeter network and the Internet is known as an external firewall. It protects the public servers from known Internet attacks, but still allows plenty of traffic through to the public-facing servers.
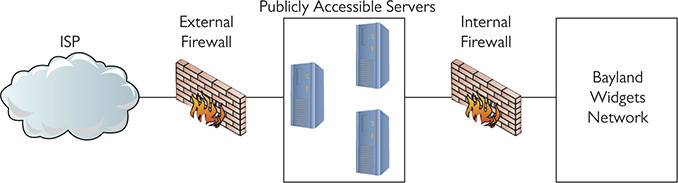
Figure 19-15 Tasty firewall sandwich
These servers are still publicly accessible, though, and are still more vulnerable to attack and takeover. That’s acceptable for the public-facing servers, but the light protection afforded by the external firewall is unacceptable for internal systems. That’s where the internal firewall comes in; it sits between the perimeter network and the trusted network that houses all the organization’s private servers and workstations. The internal firewall provides extremely strong ACLs to protect internal servers and workstations.
Honeypots and Honeynets
As described, firewalls are bidirectional “filter” systems that can prevent access into a network or out of a network. It’s a good system, but nothing is foolproof. Any high-value network resource provides sufficient motivation for a nefarious actor to work through the hoops to get at your goodies. Remember that malicious hackers have three primary weapons to gain access to computer assets: expertise, time, and money (to pay others with more expertise and to buy time).
To protect our network from expert hackers with too much time on their hands, we layer roadblocks to exhaust their time. We upgrade those roadblocks, and add more where practical, to defeat a hacker’s expertise. We can also use something from our own arsenal that works in conjunction with our roadblocks: a detour.
Have you ever seen one of those sports-type movies where a ragtag team of misfits is playing a pro team? In the beginning of the game the pros are beating the brains out of the misfits. Then, when the misfits have had enough of a drubbing, the captain calls a play to “Let ’em through.” The bad guy comes through and gets a pasting or two of his own. The network security equivalents to “Let ’em through” are honeypots and honeynets.
Now, “letting them through” is about choices. A network administrator may elect to make access to honeypots and honeynets an easy thing. Or, the network administrator may lay them out as a reward to a hacker after breaking through the normal protection barriers. This is a choice that depends on a lot of variables. In either case, a honeypot is a computer that presents itself as a sweet, tempting target to a hacker but, in reality, is a decoy. Honeypots can be as simple as a “real” network machine with decoy files in it. A text file called PASSWORDS.TXT with fake contents makes for an enticing objective.
Of course, there are much more sophisticated products that can run on a computer as a program or within a virtual machine. These products can mimic all of the features of a real computer asset, including firewalls and other roadblocks to keeping a hacker occupied and wasting time on a resource that will yield no value in the end.
Scale up a honeypot to present a complete network as a decoy and you have a honeynet. A honeynet, like a honeypot, could be built by constructing an actual network, but that wouldn’t be very cost effective. Honeynets can run on a single computer or within a virtual machine and can look like a simple network or a vast installation.
Honeypots and honeynets are useful tools not just in their diversionary value, but in that they can also monitor and report the characteristics of attacks that target them.
When deploying honeypots and honeynets, it is critical that they be segmented from any live or production networks. Pure isolation is the ideal goal. Network segmentation can be achieved by creating a disconnected network or assigning them to an isolated VLAN.
Troubleshooting Firewalls
The firewalls used in modern networks are essential and flexible tools that are critical for securing our networks. Yet, this flexibility means a misconfigured firewall becomes more likely, and with it the threat of a security breach. You should be familiar with a couple of issues that can crop up, incorrect ACL settings and misconfigured applications.
When troubleshooting firewalls, a common place for misconfigurations to pop up is in the ACLs. Because of implicit deny, all nonmatching traffic is blocked by default. So if a newly installed firewall refuses to pass any traffic, check to see if it’s missing the permit any ACL rule.
The other source of firewall misconfigurations you should know about concerns applications. With firewalls, “application” means two different things depending on whether you are configuring a network-based firewall or a host-based firewall.
With a network-based firewall, “application,” in most situations, can be read as “protocol.” Because ACLs on modern firewalls can use protocols as well as addresses and ports, a careless entry blocking an application/protocol can drop access to an entire class of applications on the network.
With a host-based firewall, “application” has its traditional meaning. A host-based firewall is aware of the actual applications running on the machine it’s protecting, not just the traffic’s protocol. With this knowledge, the firewall can be configured to grant or deny traffic to individual applications, not just protocols, ports, or addresses. When dealing with incorrect host-based firewall settings here, symptoms are most likely to pop up when an application has been accidentally added to the deny list. When this happens, the application will no longer be able to communicate with the network. Fortunately, on a single system the fix is easy: open the firewall settings, look for the application’s name or executable, and change the deny to allow.
Chapter Review
Questions
1. A hacker who sends an e-mail but replaces his return e-mail address with a fake one is _______________ the e-mail address.
A. hardening
B. malware
C. spoofing
D. emulating
2. Which of the following is a tool to prevent ARP cache poisoning?
A. DHCP
B. DAI
C. Edge firewall
D. DNS snooping
3. A computer compromised with malware to support a botnet is called a _______________.
A. zombie
B. reflection
C. DDoS
D. locked node
4. The goal of this aspect of a DoS attack is to make the attacked system process each request for as long as possible.
A. reflection
B. rotation
C. destruction
D. amplification
5. A user’s machine is locked to a screen telling her she must call a number to unlock her system. What kind of attack is this?
A. DDoS
B. Logic bomb
C. Ransomware
D. Worm
6. An attack where someone tries to hack a password using every possible password permutation is called what?
A. Man-in-the-middle
B. Spoofing
C. Rainbow table
D. Brute force
7. Which Windows utility displays open ports on a host?
A. netstat
B. ping
C. ipconfig
D. nbtstat
8. Which of the following protocols are notorious for cleartext passwords? (Select two.)
A. SSH
B. Telnet
C. HTTPS
D. POP3
9. The NSA’s TEMPEST security standards are used to combat which risk?
A. RF emanation
B. Spoofing
C. DDoS
D. Malware
10. Bob is told by his administrator to go to www.runthisantimalware.com and click the “Run the program” button on that site to check for malware. What form of anti-malware delivery is this called?
A. Host-based
B. Network-based
C. Cloud-based
D. FTP-based
Answers
1. C. This is a classic example of spoofing.
2. B. Cisco Dynamic ARP Inspection (DAI) is designed to help prevent ARP cache poisoning.
3. A. All of the compromised systems on a botnet are called zombies.
4. D. The goal of amplification is to keep the targeted server as busy as possible.
5. C. Ransomware attacks can be brutal, demanding money to unlock your content.
6. D. Brute force uses every possible permutation and is often used in password cracking.
7. A. Only netstat shows all open ports on a Windows system.
8. B and D. Both Telnet and POP3 use cleartext passwords.
9. A. TEMPEST is designed to reduce RF emanation using enclosures, shielding, and even paint.
10. C. The fact that he is going to a Web site shows this is cloud-based.