
2
BASIC PREMISES
Designing human error out of systems was one of the earliest activities of human factors (e.g., Fitts and Jones, 1947). Error counts have been used as a measure of performance in laboratory studies since the beginning of experimental psychology. In fact an episode involving a “human error” was the stimulus for one of the earliest developments in experimental psychology. While error has a long history in human factors and experimental psychology, the decade of the 1980s marked the beginning of an especially energetic period for researchers exploring issues surrounding the label “human error.” This international and cross-disciplinary debate on the nature of erroneous actions and assessments has led to a new paradigm about what is error, how to study error, and what kinds of countermeasures will enhance safety. This chapter is an overview of these results. It also serves as an introduction to the later chapters by presenting basic concepts that recur frequently throughout the book.
FIFTEEN PREMISES
The starting point for going behind the label human error is that:
“Human error” is an attribution after the fact.
Attributing an outcome as the result of error is a judgment about human performance. Such a judgment is rarely applied except when an accident or series of events have occurred that ended with a bad outcome or nearly did so. Thus, these judgments are made ex post facto, with the benefit of hindsight about the outcome or close call. This factor makes it difficult to attribute specific incidents and outcomes to “human error” in a consistent way. Traditionally, error has been seen as a thing in itself – a kind of cause of incidents, a meaningful category that can be used to aggregate specific instances. As a thing, different instances of error can be lumped together and counted as in laboratory studies of human performance or as in risk analyses. Different kinds of errors could be ignored safely and error treated as a homogenous category. In the experimental psychology laboratory, for example, errors are counted as a basic unit of measurement for comparing performance across various factors. This use of error, however, assumes that all types of errors can be combined in a homogenous category, that all specific errors can be treated as equivalent occurrences. This may be true when one has reduced a task to a minimum of content and context as is traditional in laboratory tasks. But real-world, complex tasks carried out by domain practitioners embedded in a larger temporal and organizational context are diverse. The activities and the psychological and behavioral concepts that are involved in these tasks and activities are correspondingly diverse. Hence, the resulting observable erroneous actions and assessments are diverse. In other words, in real fields of practice (where real hazards exist):
Erroneous assessments and actions are heterogeneous.
One case may involve diagnosis; another may involve perceptual motor skills. One may involve system X and another system Y. One may occur during maintenance, another during operations. One may occur when there are many people interacting; another may occur when only one or a few people are present.
Noting the heterogeneity of errors was one of the fundamental contributions made by John Senders to begin the new and intensive look at human error in 1980. An understanding of erroneous actions and assessments in the real world means that we cannot toss them into a neat causal category labeled “human error.” It is fundamental to see that:
Erroneous assessments and actions should be taken as the starting point for an investigation, not an ending.
This premise is the cornerstone of the paradigm shift for understanding error (Rasmussen, 1986), and much of the material in this book should help to indicate why this premise is so fundamental.
It is common practice for investigators to see errors simply as a specific and flawed piece of human behavior within some particular task. Consider a simple example. Let us assume that practitioners repeatedly confuse two switches, A and B, and inadvertently actuate the wrong one in some circumstances. Then it seems obvious to describe the behavior as a human error where a specific person confused these two switches. This type of interpretation of errors is stuck in describing the episode in terms of the external mode of appearance or the surface manifestation (these two switches were confused), rather than also searching for descriptions in terms of deeper and more general categorizations and underlying mechanisms. For example, this confusion may be an example of a more abstract category such as a slip of action (see Norman, 1981 or Reason and Mycielska, 1982) or a mode error (see Sarter and Woods, 1995, or Part IV).
Hollnagel (1991a, 1993) calls this the difference between the phenotype (the surface appearance) and the genotype of errors (also see the taxonomy of error taxonomies in Rasmussen et al., 1987). Typically, the explicit or implicit typologies of erroneous actions and assessments, such as those used in formal reporting systems categorize errors only on the basis of phenotypes. They do not go beyond the surface characteristics and local context of the particular episode.
As early as Fitts and Jones (1947), researchers were trying to find deeper patterns that cut across the particular. The work of the 1980s has expanded greatly on the repertoire of genotypes that are related to erroneous actions and assessments. In other words, the research has been searching to expand the conceptual and theoretical basis that explains data on system breakdowns involving people. We will lay out several of these in later chapters: ones that are related to cognitive system factors that influence the formation of intentions to act, and ones that are influenced by skillful or clumsy use of computer technology. If we can learn about or discover these underlying patterns, we gain leverage on how to change human-machine systems and about how to anticipate problems prior to a disaster in particular settings.
Thus, in a great deal of the recent work on error, erroneous actions and assessments are treated as the starting point for an investigation, rather than a conclusion to an investigation. The label “error” should be the starting point for investigation of the dynamic interplay of larger system and contextual factors that shaped the evolution of the incident (and other contrasting incidents). The attribution of “human error” is no longer adequate as an explanation for a poor outcome; the label “human error” is not an adequate stopping rule. It is the investigation of factors that influence the cognition and behavior of groups of people, not the attribution of error in itself, that helps us find useful ways to change systems in order to reduce the potential for disaster and to develop higher reliability human-machine systems. In other words, it is more useful from a system design point of view to see that:
Erroneous actions and assessments are a symptom, not a cause.
There is a great diversity of notions about what “human error” means. The term is problematic, in part, because it is often used in a way that suggests that a meaningful cause has been identified, namely the human. To shed this causal connotation, Hollnagel (1993, p. 29) has proposed the term “erroneous action,” which means “an action that fails to produce the expected result or which produces an unwanted consequence.” We prefer this term for the same reason.
Another contributor to the diversity of interpretations about human error is confusion between outcome and process. To talk to each other about error we must be very clear about whether we are referring to bad outcomes or a defect in a process for carrying out some activity. We will emphasize the difference between outcome (or performance) failures and defects in the problem-solving process.
Outcome (or performance) failures are defined in terms of a categorical shift in consequences on some performance dimension. They are defined in terms of some potentially observable standard and in terms of the language of the particular field of activity. If we consider military aviation, some examples of outcome failures might include an unfulfilled mission goal, a failure to prevent or mitigate the consequences of some system failure on the aircraft, or a failure to survive the mission. Typically, an outcome failure (or a near miss) provides the impetus for an accident investigation.
Process defects are departures from some standard about how problems should be solved. Generally, the process defect, instantaneously or over time, leads to or increases the risk of some type of outcome failure. Process defects can be defined in terms of a particular field of activity (e.g., failing to verify that all safety systems came on as demanded following a reactor trip in a nuclear power plant) or cognitively in terms of deficiencies in some cognitive or information processing function (e.g., as slips of action, Norman, 1981; fixations or cognitive lockup, De Keyser and Woods, 1990; or vagabonding, Dorner, 1983).
The distinction between outcome and process is important because the relationship between them is not fixed. In other words:
There is a loose coupling between process and outcome.
This premise is implicit in Abraham Lincoln’s vivid statement about process and outcome:
If the end brings me out all right what is said against me won’t amount to anything. If the end brings me out wrong, ten angels swearing I was right would make no difference.
Today’s students of decision making echo Lincoln: “Do not judge the quality of a decision by how it turns out. These decisions are inevitably gambles. No one can think of all contingencies or predict consequences with certainty. Good decisions may be followed by bad outcomes” (Fischhoff, 1982, p. 587; cf. also Edwards, 1984). For example, in critical care medicine it is possible that the physician’s assessments, plans, and therapeutic responses are “correct” for a trauma victim, and yet the patient outcome may be less than desirable; the patient’s injuries may have been too severe or extensive.
Similarly, not all process defects are associated with bad outcomes. Less than expert performance may be insufficient to create a bad outcome by itself; the operation of other factors may be required as well. This is in part the result of successful engineering such as defenses in depth and because opportunities for detection and recovery occur as the incident evolves.
The loose coupling of process and outcome occurs because incidents evolve along a course that is not preset. Further along there may be opportunities to direct the evolution towards successful outcomes, or other events or actions may occur that direct the incident towards negative consequences.
Consider a pilot who makes a mode error which, if nothing is done about it, would lead to disaster within some minutes. It may happen that the pilot notices certain unexpected indications and responds to the situation, which will divert the incident evolution back onto a benign course. The fact that process defects do not always or even frequently lead to bad outcomes makes it very difficult for people or organizations to understand the nature of error, its detection and recovery.
As a result of the loose coupling between process and outcome, we are left with a nagging problem. Defining human error as a form of process defect implies that there exists some criterion or standard against which the performance has been measured and deemed inadequate. However, what standard should be used? Despite many attempts, no one has succeeded in developing a single and simple answer to this question. However, if we are ambiguous about the particular standard adopted to define “error” in particular studies or incidents, then we greatly retard our ability to engage in a constructive and empirically grounded debate about error. All claims about when an action or assessment is erroneous in a process sense must be accompanied by an explicit statement of the standard used for defining departures from good process.
One kind of standard that can be invoked is a normative model of task performance. For many fields of activity where bad outcomes can mean dire consequences, there are no normative models or there are great questions surrounding how to transfer normative models developed for much simpler situations to a more complex field of activity. For example, laboratory-based normative models may ignore the role of time or may assume that cognitive processing is resource-unlimited.
Another possible kind of standard is standard operating practices (e.g., written policies and procedures). However, work analysis has shown that formal practices and policies often depart substantially from the dilemmas, constraints, and tradeoffs present in the actual workplace (e.g., Hirschhorn, 1993). For realistically complex problems there is often no one best method; rather, there is an envelope containing multiple paths each of which can lead to a satisfactory outcome. This suggests the possibility of a third approach for a standard of comparison. One could use an empirical standard that asks: “What would other similar practitioners have thought or done in this situation?” De Keyser and Woods (1990) called these empirically based comparisons neutral practitioner criteria. A simple example occurred in regard to the Strasbourg aircraft crash (Monnier, 1992). Mode error in pilot interaction with cockpit automation seems to have been a contributor to this accident. Following the accident, several people in the aviation industry noted a few precursor incidents or “dress rehearsals” for the crash where similar mode errors had occurred, although the incidents did not evolve as far towards negative consequences. (At least one of these mode errors resulted in an unexpected rapid descent, and the ground proximity warning system alarm alerted the crew who executed a go-around).
Whatever kind of standard is adopted for a particular study:
Knowledge of outcome (hindsight) biases judgments about process.
People have a tendency to judge the quality of a process by its outcome. The information about outcome biases their evaluation of the process that was followed (Baron and Hershey, 1988). The loose coupling between process and outcome makes it problematic to use outcome information as an indicator for error in a process. (Part V explains the outcome bias and related hindsight bias and discusses their implications for the study of error.)
Studies of disasters have revealed an important common characteristic:
Incidents evolve through the conjunction of several failures/factors.
Actual accidents develop or evolve through a conjunction of several small failures, both machine and human (Pew et al., 1981; Perrow, 1984; Wagenaar and Groeneweg, 1987; Reason, 1990). This pattern is seen in virtually all of the significant nuclear power plant incidents, including Three Mile Island, Chernobyl, the Brown’s Ferry fire, the incidents examined in Pew et al. (1981), the steam generator tube rupture at the Ginna station (Woods, 1982), and others. In the near miss at the Davis-Besse nuclear station (US. N.R.C., NUREG-1154, 1985), there were about 10 machine failures and several erroneous actions that initiated the loss-of-feedwater accident and determined how it evolved.
In the evolution of an incident, there are a series of interactions between the human-machine system and the hazardous process. One acts and the other responds, which, in turn, generates a response from the first, and so forth. Incident evolution points out that there is some initiating event in some human and technical system context, but there is no single clearly identifiable cause of the accident (Rasmussen, 1986; Senders and Moray, 1991). However, several points during the accident evolution can be identified where the evolution can be stopped or redirected away from undesirable outcomes.
Gaba, Maxwell and DeAnda (1987) applied this idea to critical incidents in anesthesia, and Cook, Woods and McDonald (1991a), also working in anesthesia, identified several different patterns of incident evolution. For example, “acute” incidents present themselves all at once, while in “going sour” incidents, there is a slow degradation of the monitored process (see Woods and Sarter, 2000, for going sour patterns in aviation incidents).
One kind of “going sour” incident, which is called decompensation incidents, occurs when an automatic system’s responses mask the diagnostic signature produced by a fault (see Woods and Cook, 2006 and Woods and Branlat, in press). As the abnormal influences produced by a fault persist or grow over time, the capacity of automatic systems to counterbalance or compensate becomes exhausted. At some point they fail to counteract and the system collapses or decompensates. The result is a two-phase signature. In phase 1 there is a gradual falling off from desired states over a period of time. Eventually, if the practitioner does not intervene in appropriate and timely ways, phase 2 occurs – a relatively rapid collapse when the capacity of the automatic systems is exceeded or exhausted. During the first phase of a decompensation incident, the gradual nature of the symptoms can make it difficult to distinguish a major challenge, partially compensated for, from a minor disturbance (see National Transportation Safety Board, 1986a). This can lead to a great surprise when the second phase occurs (e.g., some practitioners who miss the signs associated with the first phase may think that the event began with the collapse; Cook, Woods and McDonald, 1991a). The critical difference between a major challenge and a minor disruption is not the symptoms, per se, but rather the force with which they must be resisted. This case illustrates how incidents evolve as a function of the interaction between the nature of the trouble itself and the responses taken to compensate for that trouble.
Some of the contributing factors to incidents are always in the system.
Some of the factors that combine to produce a disaster are latent in the sense that they were present before the incident began. Turner (1978) discusses the incubation of factors prior to the incident itself, and Reason (1990) refers to potential destructive forces that build up in a system in an explicit analogy to resident pathogens in the body. Thus, latent failures refer to problems in a system that produce a negative effect but whose consequences are not revealed or activated until some other enabling condition is met. Examples include failures that make safety systems unable to function properly if called on, such as the error during maintenance that resulted in the emergency feedwater system being unavailable during the Three Mile Island incident (Kemeny Commission, 1979). Latent failures require a trigger, that is, an initiating or enabling event, that activates its effects or consequences. For example, in the Space Shuttle Challenger disaster, the decision to launch in cold weather was the initiating event that activated the consequences of the latent failure – a highly vulnerable booster-rocket seal design. This generalization means that assessment of the potential for disaster should include a search for evidence about latent failures hidden in the system (Reason, 1990).
When error is seen as the starting point for study, when the heterogeneity of errors (their external mode of appearance) is appreciated, and the difference between outcome and process is kept in mind, then it becomes clear that one cannot separate the study of error from the study of normal human behavior and system function. We quickly find that we are not studying error, but rather, human behavior itself, embedded in meaningful contexts. As Rasmussen (1985) states:
It … [is] important to realize that the scientific basis for human reliability considerations will not be the study of human error as a separate topic, but the study of normal human behavior in real work situations and the mechanisms involved in adaptation and learning. (p. 1194)
The point is that:
The same factors govern the expression of expertise and of error.
Jens Rasmussen frequently quotes Ernst Mach (1905, p. 84) to reinforce this point:
Knowledge and error flow from the same mental sources, only success can tell one from the other.
Furthermore, to study error in real-world situations necessitates studying groups of individuals embedded in a larger system that provides resources and constraints, rather than simply studying private, individual cognition. To study error is to study the function of the system in which practitioners are embedded. Part III covers a variety of cognitive system factors that govern the expression of error and expertise. It also explores some of the demand factors in complex domains and the organizational constraints that both play an important role in the expression of error and expertise.
Underlying all of the previous premises there is a deeper point:
Lawful factors govern the types of erroneous actions or assessments to be expected.
Errors are not some mysterious product of the fallibility or unpredictability of people; rather errors are regular and predictable consequences of a variety of factors. In some cases we understand a great deal about the factors involved, while in others we currently know less, or it takes more work to find out. This premise is not only useful in improving a particular system, but also assists in defining general patterns that cut across particular circumstances. Finding these regularities requires examination of the contextual factors surrounding the specific behavior that is judged faulty or erroneous. In other words:
Erroneous actions and assessments are context-conditioned.
Many kinds of contextual factors are important to human cognition and behavior (see Figures 1.1, 1.2, and 1.3). The demands imposed by the kinds of problems that can occur are one such factor. The constraints and resources imposed by organizational factors are another. The temporal context defined by how an incident evolves is yet another (e.g., from a practitioner’s perspective, a small leak that gradually grows into a break is very different from an incident where the break occurs quite quickly). Part III discusses these and many other cognitive system factors that affect the expression of expertise and error.
Variability in behavior and performance turns out to be crucial for learning and adaptation. In some domains, such as control theory, an error signal, as a difference from a target, is informative because it provides feedback about goal achievement and indicates when adjustments should be made. Error, as part of a continuing feedback and improvement process, is information to shape future behavior. However, in certain contexts this variability can have negative consequences. As Rasmussen (1986) puts it, in “unkind work environments” variability becomes an “unsuccessful experiment with unacceptable consequences.” This view emphasizes the following important notion:
Enhancing error tolerance, error detection, and error recovery together produce safety.
Again, according to Rasmussen (1985):
The ultimate error frequency largely depends upon the features of the work interface which support immediate error recovery, which in turn depends on the observability and reversibility of the emerging unacceptable effects. The feature of reversibility largely depends upon the dynamics and linearity of the system properties, whereas observability depends on the properties of the task interface which will be dramatically influenced by the modern information technology.
Figure 2.1 illustrates the relationship between recovery from error and the negative consequences of error (outcome failures) when an erroneous action or assessment occurs in some hypothetical system. The erroneous action or assessment is followed by a recovery interval, that is, a period of time during which actions can be taken to reverse the effects of the erroneous action or during which no consequences result from the erroneous assessment. If error detection occurs, the assessment is updated or the previous actions are corrected or compensated far before any negative consequences accrue. If not, then an outcome failure has occurred. There may be further recovery intervals during which other outcome consequences (of a more severe nature) may be avoided if detection and recovery actions occur. Note that this schematic – seeing the build up to an accident as a series of opportunities to detect and revise that went astray – provides one frame for avoiding hindsight bias in analyzing cognitive processes leading up to a failure (e.g., the analyses of foam debris risk prior to the Columbia space shuttle launch; Columbia Accident Investigation Board, 2003; Woods, 2005).
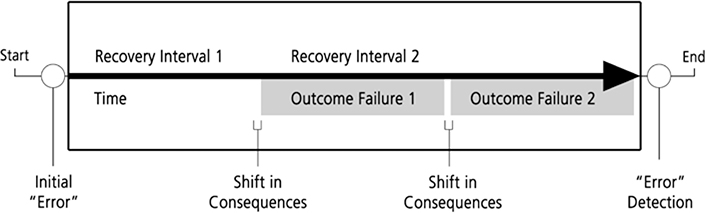
A field of activity is tolerant of erroneous actions and assessments to the degree that such errors do not immediately or irreversibly lead to negative consequences. An error-tolerant system has a relatively long recovery interval, that is, there are extensive opportunities for reversibility of actions. Error recovery depends on the observability of the monitored process which is in large part a property of the human-computer interface for computerized systems. For example, is it easy to see if there is a mismatch between expected state and the actual state of the system? Several studies show that many human-computer interfaces provide limited observability, that is, they do not provide effective visualization of events, change and anomalies in the monitored process (e.g., Moll van Charante, Cook, Woods, Yue, and Howie, 1993, for automated operating room devices; Woods, Potter, Johannesen, and Holloway, 1991, for intelligent systems for fault management of space vehicle systems; Sarter and Woods, 1993, for cockpit automation). The opaque nature of the interfaces associated with new technology is particularly troubling because it degrades error recovery. Moll van Charante et al. (1993) and Cook, Woods, and Howie (1992) contain data directly linking low observability through the computer interface to critical incidents in the case of one automated operating room device, and Sarter and Woods (1997) link low observability through the interface to problems in mode awareness for cockpit automation (cf. also the Therac-25 accidents, in which a radiation therapy machine delivered massive doses of radiation, for another example where low observability through the computer interface to an automatic system blocked error or failure detection and recovery; Leveson and Turner, 1992).
While design to minimize or prevent erroneous actions is good practice, one cannot eliminate the possibility for error. It seems that the path to high reliability systems critically depends on design to enhance error recovery prior to negative consequences (Lewis and Norman, 1986; Rasmussen, 1986; Reason, 1990). Rasmussen (1985) points out that reported frequencies of “human error” in incident reports are actually counts of errors that were not detected and recovered from, prior to some negative consequence or some criterion for cataloging incidents. Opportunities for the detection and correction of error, and hence tools that support people in doing so are critical influences on how incidents will evolve (see Seifert and Hutchins, 1992, for just one example).
Enhancing error tolerance and error recovery is a common prescription for designing systems (e.g., Norman, 1988). Some methods include:
a. design to prevent an erroneous action, for example, forcing functions which constrain a sequence of user actions along particular paths;
b. design to increase the tolerance of the underlying process to erroneous actions; and
c. design to enhance recovery from errors and failures through effective feedback and visualizations of system function – enhanced observability of the monitored process.
Let us pause and summarize a few important points: failures involve multiple contributing factors. The label error is often used in a way that simply restates the fact that the outcome was undesirable. Error is a symptom indicating the need to investigate the larger operational system and the organizational context in which it functions. In other words:
Systems fail.
If we examine actual accidents, we will typically find that several groups of people were involved. For example, in the Dallas windshear aircraft crash (National Transportation Safety Board, 1986b), the incident evolution involved the crew of the aircraft in question, what other planes were doing, air traffic controllers, the weather service, company dispatch, company and industry pressures about schedule delays.
Failures involve multiple groups, computers, and people, even at the sharp end.
One also finds in complex domains that error detection and recovery are inherently distributed over multiple people and groups and over human and machine agents. This is the case in aircraft-carrier flight operations (Rochlin, La Porte, and Roberts, 1987), maritime navigation (Hutchins, 1990), power plant startup (Roth and Woods, 1988) and medication administration (Patterson, Cook, Woods and Render, 2004). Woods et al. (1987) synthesized results across several studies of simulated and actual nuclear power plant emergencies and found that detection and correction of erroneous state assessments came primarily from other crew members who brought a fresh point of view into the situation. Miscommunications between air traffic control and commercial airline flight decks occur frequently, but the air transport system has evolved robust cross-people mechanisms to detect and recover from communication breakdowns, for example, crew cross-checks and read-backs, although miscommunications still can play a role in accidents (National Transportation Safety Board, 1991). Systems for cross-checking occur in pilots’ coordination with cockpit automation. For example, pilots develop and are taught cross-check strategies to detect and correct errors that might occur in giving instructions to the flight computers and automation. There is evidence, though, that the current systems are only partially successful and that there is great need to improve the coordination between people and automated agents in error or failure detection (e.g., Sarter and Woods, 1997; Branlat, Anders, Woods and Patterson, 2008).
Systems are always made up of people in various roles and relationships. The systems exist for human purposes. So when systems fail, of course human failure can be found in the rubble. But progress towards safety can be made by understanding the system of people and the resources that they have evolved and their adaptations to the demands of the environment. Thus, when we start at “human error” and begin to investigate the factors that lead to behavior that is so labeled, we quickly progress to studying systems of people embedded in a larger organizational context. In this book we will tend to focus on the sharp-end system, that is, the set of practitioners operating near the process and hazards, the demands they confront, and the resources and constraints imposed by organizational factors.
The perception that there is a “human error problem” is one force that leads to computerization and increased automation in operational systems. As new information and automation technology is introduced into a field of practice what happens to “human error”? The way in which technological possibilities are used in a field of practice affects the potential for different kinds of erroneous actions and assessments. It can reduce the chances for some kinds of erroneous actions or assessments, but it may create or increase the potential for others. In other words:
The design of artifacts affects the potential for erroneous actions and paths towards disaster.
Artifacts are simply human-made objects. In this context we are interested particularly in computer-based artifacts from individual microprocessor-based devices such as infusion pumps for use in medicine to the suite of automated systems and associated human-computer interfaces present in advanced cockpits on commercial jets. One goal for this book is to focus on the role of design of computer-based artifacts in safety.
Properties of specific computer-based devices or aspects of more general “vectors” of technology change influence the cognition and activities of those people who use them. As a result, technology change can have profound repercussions on system operation, particularly in terms of the types of “errors” that occur and the potential for failure. It is important to understand how technology change shapes human cognition and action in order to see how design can create latent failures which may contribute, given the presence of other factors, to disaster. For example, a particular technology change may increase the coupling in a system (Perrow, 1984). Increased coupling increases the cognitive demands on practitioners. If the computer-based artifacts used by practitioners exhibit “classic” flaws such as weak feedback about system state (what we will term low observability), the combination can function as a latent failure awaiting the right circumstances and triggering events to lead the system close to disaster (see Moll van Charante et al., 1993, for one example of just this sequence of events).
One particular type of technology change, namely increased automation, is assumed by many to be the prescription of choice to cure an organization’s “human error problem.” One recent example of this attitude comes from a commentary about cockpit developments envisioned for a new military aircraft in Europe:
The sensing, processing and presentation of such unprecedented quantities of data to inform and protect one man requires new levels of.. system integration. When proved in military service, these automation advances will read directly across to civil aerospace safety. They will also assist the industrial and transport communities’ efforts to eliminate ‘man-machine interface’ disasters like King’s Cross, Herald of Free Enterprise, Clapham Junction and Chernobyl. (Aerospace, November, 1992, p. 10)
If incidents are the result of “human error,” then it seems justified to respond by retreating further into the philosophy that “just a little more technology will be enough” (Woods, 1990b; Billings, 1991). Such a technology-centered approach is more likely to increase the machine’s role in the cognitive system in ways that will squeeze the human’s role (creating a vicious cycle as evidence of system problems will pop up as more human error). As S. S. Stevens noted (1946):
The faster the engineers and the inventors served up their ‘automatic’ gadgets to eliminate the human factor the tighter the squeeze became on the powers of the operator.
And as Norbert Wiener noted some years later (1964, p. 63):
The gadget-minded people often have the illusion that a highly automatized world will make smaller claims on human ingenuity than does the present one. … This is palpably false.
Failures to understand the reverberations of technological change on the operational system hinder the understanding of important issues such as what makes problems difficult, how breakdowns occur, and why experts perform well.
Our strategy is to focus on how technology change can increase or decrease the potential for different types of erroneous actions and assessments. Later in the book, we will lay out a broad framework that establishes three inter-related linkages: the effect of technology on the cognitive activities of practitioners; how this, in turn, is linked to the potential for erroneous actions and assessments; and how these can contribute to the potential for disaster.
The concept that the design of the human-machine system, defined very broadly, affects or “modulates” the potential for erroneous actions and assessments, was present at the origins of Human Factors when the presence of repeated “human errors” was treated as a signal pointing to context-specific flaws in the design of human-machine systems (e.g., cockpit control layout). This idea has been reinforced more recently when researchers have identified kinds of design problems in computer-based systems that cut across specific contexts. In general, “clumsy” use of technological powers can create additional mental burdens or other constraints on human cognition and behavior that create opportunities for erroneous actions and assessments by people, especially in high criticality, high workload, high tempo operations (Wiener, 1989; Sarter and Woods, 1997; Woods and Hollnagel, 2006).
Computer-based devices, as typically designed, tend to exhibit classic human-computer cooperation flaws such as lack of feedback on device state and behavior (e.g., Norman, 1990b; Woods, 1995a). Furthermore, these human-computer interactions (HCI) flaws increase the potential for erroneous actions and for erroneous assessments of device state and behavior. The low observability supported by these interfaces and the associated potential for erroneous state assessment is especially troublesome because it impairs the user’s ability to detect and recover from failures, repair communication breakdowns, and detect erroneous actions.
These data, along with critical incident studies, directly implicate the increased potential for erroneous actions and the decreased ability to detect errors and failures as one kind of important contributor to actual incidents. The increased potential for error that emanates from poor human-computer cooperation is one type of problem that can be activated and progress towards disaster when in the presence of other potential factors.
Our goals are to expose various design “errors” in human-computer systems that create latent failures, show how devices with these characteristics shape practitioner cognition and behavior, and how these characteristics can create new possibilities for error and new paths to disaster. In addition, we will examine data on how practitioners cope with the complexities introduced by the clumsy use of technological possibilities and how this adaptation process can obscure the role of design and cognitive system factors in incident evolution. This information should help developers detect, anticipate, and recover from designer errors in the development of computerized devices.
HOW COMPLEX SYSTEMS FAIL
Our understanding of how accidents happen has undergone significant changes over the last century (Hollnagel, 2004). Beginning with ideas on industrial safety improvements and the need to contain the risk of uncontrolled energy releases, accidents were initially viewed as the conclusion of a sequence of events (which involved “human errors” as causes or contributors). This has now been replaced by a systemic view in which accidents emerge from the coupling and interdependence of modern systems. The key theme is how system change and evolution produce complexities which challenge people’s ability to understand and manage risk in interdependent processes. Inspired in part by new sciences that study complex co-adaptive processes (results on emergent properties, fundamental tradeoffs, non-linear feedback loops, distributed control architectures, and multi-agent simulations), research on safety has shifted from linear cause-effect analyses and reductive models that focus on component level interventions.
Today, safety research focuses more on the ability of systems to recognize, adapt to and absorb disruptions and disturbances, even those that fall beyond the capabilities that the system was trained or designed for. The latest intellectual turn, made by what is called Resilience Engineering, sees how practitioners and organizations, as adaptive, living systems, continually assess and revise their approaches to work in an attempt to balance tradeoffs across multiple goals while remaining sensitive to the possibility of failure. The research studies how safety is created, how organizations learn prior to accidents, how organizations monitor boundaries of safe operation while under pressure to be faster, better and cheaper (Hollnagel, Woods and Leveson, 2006).
COGNITIVE SYSTEMS
The demands that large, complex systems operations place on human performance are mostly cognitive. The third part of the book focuses on cognitive system factors related to the expression of expertise and error. The difference between expert and inexpert human performance is shaped, in part, by three classes of cognitive factors: knowledge factors – how knowledge is brought to bear in specific situations, attentional dynamics – how mindset is formed, focuses and shifts focus as situations evolve and new events occur, and strategic factors – how conflicts between goals are expressed in situations and how these conflicts are resolved. However, these cognitive factors do not apply just to an individual but also to teams of practitioners. In addition, the larger organization context – the blunt end of the system – places constraints and provides resources that shape how practitioners can meet the demands of a specific field of practice.
One of the basic themes that have emerged in more recent work on expertise and error is the need to model team and organizational factors (Hutchins, 1995a). Part III integrates individual, team, and organizational perspectives by viewing operational systems as distributed and joint human-machine cognitive systems. It also lays out the cognitive processes carried out across a distributed system that govern the expression of expertise as well as error in real systems. It explores some of the ways that these processes go off track or break down and increase the vulnerability to erroneous actions.
COMPUTERS
The fourth part of the book addresses the clumsy use of new technological possibilities in the design of computer-based devices and shows how these “design errors” can create the potential for erroneous actions and assessments. Some of the questions addressed in this part include:
![]() What are these classic design “errors” in human-computer systems, computer-based advisors, and automated systems?
What are these classic design “errors” in human-computer systems, computer-based advisors, and automated systems?
![]() Why do we see them so frequently in so many settings?
Why do we see them so frequently in so many settings?
![]() How do devices with these characteristics shape practitioner cognition and behavior?
How do devices with these characteristics shape practitioner cognition and behavior?
![]() How do practitioners cope with the complexities introduced by clumsy use of technological possibilities?
How do practitioners cope with the complexities introduced by clumsy use of technological possibilities?
![]() What do these factors imply about the human contribution to risk and to safety?
What do these factors imply about the human contribution to risk and to safety?
We will refer frequently to mode error as an exemplar of the issues surrounding the impact of computer technology and error. We use this topic as an example extensively because it is an error form that exists only at the intersection of people and technology. Mode error requires a device where the same action or indication means different things in different contexts (i.e., modes) and a person who loses track of the current context. However there is a second and perhaps more important reason that we have chosen this error form as a central exemplar. If we as a community of researchers cannot get design and development organizations to acknowledge, deal with, reduce, and better cope with the proliferation of complex modes, then it will prove difficult to shift design resources and priorities to include a user-centered point of view.
HINDSIGHT
The fourth part of the book examines how the hindsight bias affects the ability to learn from accidents and to learn about risks before accidents occur. It shows how attributions of error are a social and psychological judgment process that occurs as stakeholders struggle to come to grips with the consequences of failures. Many factors contribute to incidents and disasters. Processes of casual attribution influence which of these many factors we focus on and identify as causal. Causal attribution depends on who we are communicating to, on the assumed contrast cases or causal background for that exchange, on the purposes of the inquiry, and on knowledge of the outcome (Tasca, 1990).
Hindsight bias, as indicated above, is the tendency for people to “consistently exaggerate what could have been anticipated in foresight” (Fischhoff, 1975). Studies have consistently shown that people have a tendency to judge the quality of a process by its outcome. The information about outcome biases their evaluation of the process that was followed. Decisions and actions followed by a negative outcome will be judged more harshly than if the same decisions had resulted in a neutral or positive outcome. Indeed this effect is present even when those making the judgments have been warned about the phenomenon and been advised to guard against it (Fischhoff, 1975, 1982).
The hindsight bias leads us to construct “a map that shows only those forks in the road that we decided to take,” where we see “the view from one side of a fork in the road, looking back” (Lubar, 1993, p. 1168). Given knowledge of outcome, reviewers will tend to simplify the problem-solving situation that was actually faced by the practitioner. The dilemmas, the uncertainties, the tradeoffs, the attentional demands, and double binds faced by practitioners may be missed or under-emphasized when an incident is viewed in hindsight. Typically, the hindsight bias makes it seem that participants failed to account for information or conditions that “should have been obvious” or behaved in ways that were inconsistent with the (now known to be) significant information. Possessing knowledge of the outcome, because of the hindsight bias, trivializes the situation confronting the practitioner and makes the “correct” choice seem crystal clear.
The hindsight bias has strong implications for studying erroneous actions and assessments and for learning from system failures. If we recognize the role of hindsight and psychological processes of causal judgment in attributing error after-the-fact, then we can begin to devise new ways to study and learn from erroneous actions and assessments and from system failure.
In many ways, the topics addressed in each chapter interact and depend on the concepts introduced in the discussion of other topics from other chapters. For example, the chapter on the clumsy use of computer technology in some ways depends on knowledge of cognitive system factors, but in other ways it helps to motivate the cognitive system framework. There is no requirement to move linearly from one chapter to another. Jump around as your interests and goals suggest.
CAVEATS
There are several topics the book does not address. First, we will not consider research results on how human action sequences can break down including slips of action such as substitution or capture errors. Good reviews are available (Norman, 1981; Reason and Mycielska, 1982; and see Byrne and Bovair, 1997). Second, we do not address the role of fatigue in human performance. Research on fatigue has become important in health care and patient safety (for recent results see Gaba and Howard, 2002). Third, we will not be concerned with work that goes under the heading of Human Reliability Analysis (HRA), because (a) HRA has been dominated by the assumptions made for risk analysis of purely technological systems, assumptions that do not apply to people and human-machine systems very well, and (b) excellent re-examinations of human reliability from the perspective of the new look behind error are available (cf., Hollnagel, 1993, 2004).