
You would ideally like your database application to scale linearly with the number of database users and the volume of data. However, it is common to find that performance degrades as the number of users increases and as the volume of data grows. One cause for degradation is blocking. In fact, database blocking is usually the biggest enemy of scalability for database applications.
In this chapter, I cover the following topics:
The fundamentals of blocking in SQL Server
The ACID properties of a transactional database
Database lock granularity, escalation, modes, and compatibility
ANSI isolation levels
The effect of indexes on locking
The information necessary to analyze blocking
A SQL script to collect blocking information
Resolutions and recommendations to avoid blocking
Techniques to automate the blocking detection and information collection processes
In an ideal world, every SQL query would be able to execute concurrently, without any blocking by other queries. However, in the real world, queries do block each other, similar to the way a car crossing through a green traffic signal at an intersection blocks other cars waiting to cross the intersection. In SQL Server, this traffic management takes the form of the lock manager, which controls concurrent access to a database resource to maintain data consistency. The concurrent access to a database resource is controlled across multiple database connections.
I want to make sure things are clear before moving on. Three terms are used within databases that sound the same and are interrelated but have different meanings. These are frequently confused, and people often use the terms incorrectly. These terms are locking, blocking, and deadlocking. Locking is an integral part of the process of SQL Server managing multiple connections. When a connection needs access to a piece of data, a lock of some type is placed on it. This is different from blocking, which is when one connection needs access to a piece of data and has to wait for another connection's lock to clear. Finally, deadlocking is when two connections form what is sometimes referred to as a deadly embrace. They are each waiting on the other for a lock to clear. Deadlocking could also be referred to as a permanent blocking situation. Deadlocking will be covered in more detail in Chapter 13. Please understand the differences between these terms and use them correctly. It will help in your understanding of the system, your ability to troubleshoot, and your ability to communicate with other database administrators and developers.
In SQL Server, a database connection is identified by a session ID (SPID). Connections may be from one or many applications and one or many users on those applications; as far as SQL Server is concerned, every connection is treated as a separate session. Blocking between two sessions accessing the same piece of data at the same time is a natural phenomenon in SQL Server. Whenever two sessions try to access a common database resource in conflicting ways, the lock manager ensures that the second session waits until the first session completes its work. For example, a session might be modifying a table record while another session tries to delete the record. Since these two data access requests are incompatible, the second session will be blocked until the first session completes its task.
On the other hand, if the two sessions try to read a table concurrently, both sessions are allowed to execute without blocking, since these data accesses are compatible with each other.
Usually, the effect of blocking on a session is quite small and doesn't affect its performance noticeably. At times, however, because of poor query and/or transaction design (or maybe bad luck), blocking can affect query performance significantly. In a database application, every effort should be made to minimize blocking and thereby increase the number of concurrent users that can use the database.
In SQL Server, a database query can execute as a logical unit of work in itself, or it can participate in a bigger logical unit of work. A bigger logical unit of work can be defined using the BEGIN TRANSACTION statement along with COMMIT and/or ROLLBACK statements. Every logical unit of work must conform to a set of four properties called ACID properties:
Atomicity
Consistency
Isolation
Durability
I cover these properties in the sections that follow, because understanding how transactions work is fundamental to understanding blocking.
A logical unit of work must be atomic. That is, either all the actions of the logical unit of work are completed or no effect is retained. To understand the atomicity of a logical unit of work, consider the following example (atomicity.sql in the download):
--Create a test table
IF (SELECT OBJECT_ID('dbo.t1')
) IS NOT NULL
DROP TABLE dbo.t1
GO
CREATE TABLE dbo.t1
(
c1 INT CONSTRAINT chk_c1 CHECK (c1 = 1)
)
GO
--All ProductIDs are added into t1 as a logical unit of work
INSERT INTO dbo.t1
SELECT p.ProductID
FROM Production.Product AS p
GO
SELECT *
FROM dbo.t1 --Returns 0 rowsSQL Server treats the preceding INSERT statement as a logical unit of work. The CHECK constraint on column c1 of table dbo.t1 allows only the value 1. Although the ProductID column in the Production.Product table starts with the value 1, it also contains other values. For this reason, the INSERT statement won't add any records at all to the table dbo.t1, and an error is raised because of the CHECK constraint. This atomicity is automatically ensured by SQL Server.
So far, so good. But in the case of a bigger logical unit of work, you should be aware of an interesting behavior of SQL Server. Imagine that the previous insert task consists of multiple INSERT statements. These can be combined to form a bigger logical unit of work as follows (logical.sql in the download):
BEGIN TRAN --Start: Logical unit of work
--First:
INSERT INTO dbo.t1
SELECT p.ProductID FROM Production.Product AS p
--Second:
INSERT INTO dbo.t1 VALUES(1)
COMMIT --End: Logical unit of work
GOWith table dbo.t1 already created in atomicity.sql, the BEGIN TRAN and COMMIT pair of statements defines a logical unit of work, suggesting that all the statements within the transaction should be atomic in nature. However, the default behavior of SQL Server doesn't ensure that the failure of one of the statements within a user-defined transaction scope will undo the effect of the prior statement(s). In the preceding transaction, the first INSERT statement will fail as explained earlier, whereas the second INSERT is perfectly fine. The default behavior of SQL Server allows the second INSERT statement to execute, even though the first INSERT statement fails. A SELECT statement, as shown in the following code, will return the row inserted by the second INSERT statement:
SELECT * FROM dbo.t1 --Returns a row with t1.c1 = 1
The atomicity of a user-defined transaction can be ensured in the following two ways:
Let's look at these quickly.
SET XACT_ABORT ON
You can modify the atomicity of the INSERT task in the preceding section using the SET XACT_ABORT ON statement:
SET XACT_ABORT ONGOBEGIN TRAN --Start: Logical unit of work --First: INSERT INTO dbo.t1 SELECT p.ProductID FROM Production.Product AS p --Second: INSERT INTO dbo.t1 VALUES(1) COMMIT --End: Logical unit of work GOSET XACT_ABORT OFFGO
The SET XACT_ABORT statement specifies whether SQL Server should automatically roll back and abort an entire transaction when a statement within the transaction fails. The failure of the first INSERT statement will automatically suspend the entire transaction, and thus the second INSERT statement will not be executed. The effect of SET XACT_ABORT is at the connection level, and it remains applicable until it is reconfigured or the connection is closed. By default, SET XACT_ABORT is OFF.
Explicit Rollback
You can also manage the atomicity of a user-defined transaction by using the TRY/CATCH error-trapping mechanism within SQL Server. If a statement within the TRY block of code generates an error, then the CATCH block of code will handle the error. If an error occurs and the CATCH block is activated, then the entire work of a user-defined transaction can be rolled back, and further statements can be prevented from execution, as follows (rollback.sql in the download):
BEGIN TRY
BEGIN TRAN --Start: Logical unit of work
--First:
INSERT INTO dbo.t1
SELECT p.ProductID
FROM Production.Product AS p--Second:
INSERT INTO dbo.t1
VALUES (1)
COMMIT --End: Logical unit of work
END TRY
BEGIN CATCH
ROLLBACK
PRINT 'An error occurred'
RETURN
END CATCHThe ROLLBACK statement rolls back all the actions performed in the transaction until that point. For a detailed description of how to implement error handling in SQL Server–based applications, please refer to the MSDN Library article titled "Using TRY...CATCH in Transact SQL" (http://msdn.microsoft.com/en-us/library/ms179296.aspx) or to the introductory article "SQL Server Error Handling Workbench" (http://www.simple-talk.com/sql/t-sql-programming/sql-server-error-handling-workbench/).
Since the atomicity property requires that either all the actions of a logical unit of work are completed or no effects are retained, SQL Server isolates the work of a transaction from that of others by granting it exclusive rights on the affected resources so that the transaction can safely roll back the effect of all its actions, if required. The exclusive rights granted to a transaction on the affected resources block all other transactions (or database requests) trying to access those resources during that time period. Therefore, although atomicity is required to maintain the integrity of data, it introduces the undesirable side effect of blocking.
A logical unit of work should cause the state of the database to travel from one consistent state to another. At the end of a transaction, the state of the database should be fully consistent. SQL Server always ensures that the internal state of the databases is correct and valid by automatically applying all the constraints of the affected database resources as part of the transaction. SQL Server ensures that the state of internal structures, such as data and index layout, are correct after the transaction. For instance, when the data of a table is modified, SQL Server automatically identifies all the indexes, constraints, and other dependent objects on the table and applies the necessary modifications to all the dependent database objects as part of the transaction.
The logical consistency of the data required by the business rules should be ensured by a database developer. A business rule may require changes to be applied on multiple tables. The database developer should accordingly define a logical unit of work to ensure that all the criteria of the business rules are taken care of. SQL Server provides different transaction management features that the database developer can use to ensure the logical consistency of the data.
As just explained, maintaining a consistent logical state requires the use of transactions to define the logical unit of work as per the business rules. Also, to maintain a consistent physical state, SQL Server identifies and works on the dependent database objects as part of the logical unit of work. The atomicity characteristic of the logical unit of work blocks all other transactions (or database requests) trying to access the affected object(s) during that time period. Therefore, even though consistency is required to maintain a valid logical and physical state of the database, it also introduces the undesirable side effect of blocking.
In a multiuser environment, more than one transaction can be executed simultaneously. These concurrent transactions should be isolated from one another so that the intermediate changes made by one transaction don't affect the data consistency of other transactions. The degree of isolation required by a transaction can vary. SQL Server provides different transaction isolation features to implement the degree of isolation required by a transaction.
Note
Transaction isolation levels are explained later in the chapter in the "Isolation Levels" section.
The isolation requirements of a transaction operating on a database resource can block other transactions trying to access the resource. In a multiuser database environment, multiple transactions are usually executed simultaneously. It is imperative that the data modifications made by an ongoing transaction be protected from the modifications made by other transactions. For instance, suppose a transaction is in the middle of modifying a few rows in a table. During that period, to maintain database consistency, you must ensure that other transactions do not modify or delete the same rows. SQL Server logically isolates the activities of a transaction from that of others by blocking them appropriately, which allows multiple transactions to execute simultaneously without corrupting one another's work.
Excessive blocking caused by isolation can adversely affect the scalability of a database application. A transaction may inadvertently block other transactions for a long period of time, thereby hurting database concurrency. Since SQL Server manages isolation using locks, it is important to understand the locking architecture of SQL Server. This helps you analyze a blocking scenario and implement resolutions.
Note
The fundamentals of database locks are explained later in the chapter in the "Capturing Blocking Information" section.
Once a transaction is completed, the changes made by the transaction should be durable. Even if the electrical power to the machine is tripped off immediately after the transaction is completed, the effect of all actions within the transaction should be retained. SQL Server ensures durability by keeping track of all pre- and post-images of the data under modification in a transaction log as the changes are made. Immediately after the completion of a transaction, even if SQL Server, the operating system, or the hardware fails (excluding the log disk), SQL Server ensures that all the changes made by the transaction are retained. During restart, SQL Server runs its database recovery feature, which identifies the pending changes from the transaction log for completed transactions and applies them on the database resources. This database feature is called roll forward.
The recovery interval period depends on the number of pending changes that need to be applied to the database resources during restart. To reduce the recovery interval period, SQL Server intermittently applies the intermediate changes made by the running transactions as configured by the recovery interval option. The recovery interval option can be configured using the sp_configure statement. The process of intermittently applying the intermediate changes is referred to as the checkpoint process. During restart, the recovery process identifies all uncommitted changes and removes them from the database resources by using the pre-images of the data from the transaction log.
The durability property isn't a direct cause of blocking since it doesn't require the actions of a transaction to be isolated from those of others. But in an indirect way, it increases the duration of the blocking. Since the durability property requires saving the pre- and post-images of the data under modification to the transaction log on disk, it increases the duration of the transaction and blocking.
When a session executes a query, SQL Server determines the database resources that need to be accessed, and if required, the lock manager grants database locks to the session. The query is blocked if another session has already been granted the locks; however, to provide both transaction isolation and concurrency, SQL Server uses different lock granularities and modes, as explained in the sections that follow.
SQL Server databases are maintained as files on the physical disk. In the case of a nondatabase file such as an Excel file, the file may be written to by only one user at a time. Any attempt to write to the file by other users fails. However, unlike the limited concurrency on a nondatabase file, SQL Server allows multiple users to modify (or access) contents simultaneously, as long as they don't affect one another's data consistency. This decreases blocking and improves concurrency among the transactions.
To improve concurrency, SQL Server implements lock granularities at the following resource levels:
Row (
RID)Key (
KEY)Page (
PAG)Extent (
EXT)Heap or B-tree (HoBT)
Table (
TAB)Database (
DB)
Let's take a look at these lock levels in more detail.
Row-Level Lock
This lock is maintained on a single row within a table and is the lowest level of lock on a database table. When a query modifies a row in a table, an RID lock is granted to the query on the row. For example, consider the transaction on the following test table (rowlock.sql):
--Create a test table
IF(SELECT OBJECT_ID('dbo.t1')) IS NOT NULL
DROP TABLE dbo.t1
GO
CREATE TABLE dbo.t1 (c1 INT)
INSERT INTO dbo.t1 VALUES(1)
GO
BEGIN TRAN
DELETE dbo.t1 WHERE c1 = 1
SELECT tl.request_session_id
,tl.resource_database_id
,tl.resource_associated_entity_id
,tl.resource_type
,tl.resource_description
,tl.request_mode
,tl.request_status
FROM sys.dm_tran_locks tl
ROLLBACKThe dynamic management view sys.dm_tran_locks can be used to display the lock status. The query against sys.dm_tran_locks in Figure 12-1 shows that the DELETE statement acquired an RID lock on the row to be deleted.

Note
I explain lock modes later in the chapter in the "Lock Modes" section.
Granting an RID lock to the DELETE statement prevents other transactions from accessing the row.
The resource locked by the RID lock can be represented in the following format from the resource_description column:
DatabaseID:FileID:PageID:Slot(row)
In the output from the query against sys.dm_tran_locks in Figure 12-1, the DatabaseID is displayed separately under the resource_database_id column. The resource_description column value for the RID type represents the remaining part of the RID resource as 1:984:0. In this case, a FileID of 1 is the primary data file, a PageID of 984 is a page belonging to table dbo.t1 identified by the ObjId column, and a slot (row) of 0 represents the row position within the page. You can obtain the table name and the database name by executing the following SQL statements:
SELECT OBJECT_NAME(72057594061127680) SELECT DB_NAME(14)
The row-level lock provides a very high concurrency, since blocking is restricted to the row under effect.
Key-Level Lock
This is a row lock within an index, and it is identified as a KEY lock. As you know, for a table with a clustered index, the data pages of the table and the leaf pages of the clustered index are the same. Since both the rows are the same for a table with a clustered index, only a KEY lock is acquired on the clustered index row, or limited range of rows, while accessing the row(s) from the table (or the clustered index). For example, consider having a clustered index on the table t1 (keylock.sql):
CREATE CLUSTERED INDEX i1 ON dbo.t1(c1)
If you now rerun the following:
BEGIN TRAN
DELETE dbo.t1 WHERE c1 = 1
SELECT tl.request_session_id
,tl.resource_database_id
,tl.resource_associated_entity_id
,tl.resource_type
,tl.resource_description
,tl.request_mode
,tl.request_status
FROM sys.dm_tran_locks tl
ROLLBACKthe corresponding output from sys.dm_tran_locks shows a KEY lock instead of the RID lock, as you can see in Figure 12-2.

When you are querying sys.dm_tran_locks, you will be able to retrieve the database identifier, resource_database_id, and the object, resource_associated_entity_id, but to get to the particular resource (in this case, the page on the key), you have to go to the resource_description column for the value, which is (0200c411ba73). In this case, the IndId of 1 is the clustered index on table dbo.t1.
Note
Different values for the IndId column and how to determine the corresponding index name are explained later in the "Effect of Indexes on Locking" section.
Like the row-level lock, the key-level lock provides a very high concurrency.
Page-Level Lock
This is maintained on a single page within a table or an index and is identified as a PAG lock. When a query requests multiple rows within a page, the consistency of all the requested rows can be maintained by acquiring either RID/KEY locks on the individual rows or a PAG lock on the entire page. From the query plan, the lock manager determines the resource pressure of acquiring multiple RID/KEY locks, and if the pressure is found to be high, the lock manager requests a PAG lock instead.
The resource locked by the PAG lock may be represented in the following format in the resource_description column of sys.dm_tran_locks:
DatabaseID:FileID:PageID
The page-level lock increases the performance of an individual query by reducing its locking overhead, but it hurts the concurrency of the database by blocking access to all the rows in the page.
Extent-Level Lock
This is maintained on an extent (a group of eight contiguous data or index pages) and is identified as an EXT lock. This lock is used, for example, when an ALTER INDEX REBUILD command is executed on a table and the pages of the table may be moved from an existing extent to a new extent. During this period, the integrity of the extents is protected using EXT locks.
Heap or B-tree Lock
A heap or B-tree lock is used to describe when a lock to either object could be made. This means a lock on an unordered heap table, a table without a clustered index, or a lock on a B-tree object, usually referring to partitions. A setting within the ALTER TABLE function, new to SQL Server 2008, allows you to exercise a level of control over how locking escalation (covered in the "Lock Escalation" section) is affected with the partitions. Because partitions are stored across multiple filegroups, each one has to have its own data allocation definition. This is where the HoBT comes into play. It acts like a table-level lock but on a partition instead of on the table itself.
Table-Level Lock
This is the highest level of lock on a table, and it is identified as a TAB lock. A table-level lock on a table reserves access to the complete table and all its indexes.
When a query is executed, the lock manager automatically determines the locking overhead of acquiring multiple locks at the lower levels. If the resource pressure of acquiring locks at the row level or the page level is determined to be high, then the lock manager directly acquires a table-level lock for the query.
The resource locked by the TAB lock will be represented in resource_description in the following format:
DatabaseID:ObjectID
A table-level lock requires the least overhead compared to the other locks and thus improves the performance of the individual query. On the other hand, since the table-level lock blocks all write requests on the entire table (including indexes), it can significantly hurt database concurrency.
Sometimes an application feature may benefit from using a specific lock level for a table referred to in a query. For instance, if an administrative query is executed during nonpeak hours, then a table-level lock may not affect concurrency much, but it can reduce the locking overhead of the query and thereby improve its performance. In such cases, a query developer may override the lock manager's lock level selection for a table referred to in the query using locking hints:
SELECT * FROM <TableName> WITH(TABLOCK)
Database-Level Lock
This is maintained on a database and is identified as a DB lock. When an application makes a database connection, the lock manager assigns a database-level shared lock to the corresponding SPID. This prevents a user from accidentally dropping or restoring the database while other users are connected to it.
SQL Server ensures that the locks requested at one level respect the locks granted at other levels. For instance, while a user acquires a row-level lock on a table row, another user can't acquire a lock at any other level that may affect the integrity of the row. The second user may acquire a row-level lock on other rows or a page-level lock on other pages, but an incompatible page- or table-level lock containing the row won't be granted to other users.
The level at which locks should be applied need not be specified by a user or database administrator; the lock manager determines that automatically. It generally prefers row-level and key-level locks while accessing a small number of rows to aid concurrency. However, if the locking overhead of multiple low-level locks turns out to be very high, the lock manager automatically selects an appropriate higher-level lock.
When a query is executed, SQL Server determines the required lock level for the database objects referred to in the query and starts executing the query after acquiring the required locks. During the query execution, the lock manager keeps track of the number of locks requested by the query to determine the need to escalate the lock level from the current level to a higher level.
The lock escalation threshold is dynamically determined by SQL Server during the course of a transaction. Row locks and page locks are automatically escalated to a table lock when a transaction exceeds its threshold. After the lock level is escalated to a table-level lock, all the lower-level locks on the table are automatically released. This dynamic lock escalation feature of the lock manager optimizes the locking overhead of a query.
It is possible to establish a level of control over the locking mechanisms on a given table. This is the T-SQL syntax to change this:
ALTER TABLE schema.table SET (LOCK_ESCALATION = DISABLE)
This syntax will disable lock escalation on the table entirely (except for a few special circumstances). You can also set it to TABLE, which will cause the escalation to go to a table lock every single time. You can also set lock escalation on the table to AUTO, which will allow SQL Server to make the determination for the locking schema and any escalation necessary.
The degree of isolation required by different transactions may vary. For instance, consistency of data is not affected if two transactions read the data simultaneously, but the consistency is affected if two transactions are allowed to modify the data simultaneously. Depending on the type of access requested, SQL Server uses different lock modes while locking resources:
Shared (
S)Update (
U)Exclusive (
X)Intent:
Intent Shared (
IS)Intent Exclusive (
IX)Shared with Intent Exclusive (SIX)
Schema:
Schema Modification (
Sch-M)Schema Stability (
Sch-S)
Bulk Update (BU)
Key-Range
Shared (S) Mode
Shared mode is used for read-only queries, such as a SELECT statement. It doesn't prevent other read-only queries from accessing the data simultaneously, since the integrity of the data isn't compromised by the concurrent reads. But the concurrent data modification queries on the data are prevented to maintain data integrity. The (S) lock is held on the data until the data is read. By default, the (S) lock acquired by a SELECT statement is released immediately after the data is read. For example, consider the following transaction:
BEGIN TRAN SELECT * FROM Production.Product AS p WHERE p.ProductID = 1 --Other queries COMMIT
The (S) lock acquired by the SELECT statement is not held until the end of the transaction. The (S) lock is released immediately after the data is read by the SELECT statement under read_committed, the default isolation level. This behavior of the (S) lock can be altered using a higher isolation level or a lock hint.
Update (U) Mode
Update mode may be considered similar to the (S) lock but with an objective to modify the data as part of the same query. Unlike the (S) lock, the (U) lock indicates that the data is read for modification. Since the data is read with an objective to modify it, more than one (U) lock is not allowed on the data simultaneously in order to maintain data integrity, but concurrent (S) locks on the data are allowed. The (U) lock is associated with an UPDATE statement.
The action of an UPDATE statement actually involves two intermediate steps:
Read the data to be modified.
Modify the data.
Different lock modes are used in the two intermediate steps to maximize concurrency. Instead of acquiring an exclusive right while reading the data, the first step acquires a (U) lock on the data. In the second step, the (U) lock is converted to an exclusive lock for modification. If no modification is required, then the (U) lock is released; in other words, it's not held until the end of the transaction. Consider the following example, which demonstrates the locking behavior of the UPDATE statement (create_t1.sql in the download):
--Create a test table
IF (SELECT OBJECT_ID('dbo.t1')
) IS NOT NULL
DROP TABLE dbo.t1;
GO
CREATE TABLE dbo.t1 (c1 INT, c2 DATETIME);
INSERT INTO dbo.t1
VALUES (1, GETDATE());
GOConsider the following UPDATE statement (update1.sql in the download):
BEGIN TRANSACTION Tx1
UPDATE dbo.t1
SET c2 = GETDATE()
WHERE c1 = 1;
COMMITTo understand the locking behavior of the intermediate steps of the UPDATE statement, you need to obtain data from sys.dm_tran_locks at the end of each step. You can obtain the lock status after each step of the UPDATE statement by following the steps outlined next. You're going have three connections open that I'll refer to as Connection 1, Connection 2, and Connection 3. This means three different query windows in Management Studio. You'll run the queries in the connections I list in the order that I specify to arrive at a blocking situation and be able to observe those blocks as they occur. The initial query listed previously is in Connection 1.
Block the second step of the
UPDATEstatement by first executing a transaction from a second connection (update2.sqlin the download), Connection 2:--Execute from second connection BEGIN TRANSACTION Tx2 --Retain an (S) lock on the resource SELECT * FROM t1 WITH (REPEATABLEREAD) WHERE c1 = 1; --Allow sp_lock to be executed before second step of -- UPDATE statement is executed by transaction Tx1 WAITFOR DELAY '00:00:10'; COMMITThe
REPEATABLEREADlocking hint, running in Connection 2, allows theSELECTstatement to retain the (S) lock on the resource.While the transaction
Tx2is executing, execute theUPDATEtransaction (update1.sql) from the first connection (repeated here for clarity), Connection 1:BEGIN TRANSACTION Tx1 UPDATE dbo.t1 SET c2 = GETDATE() WHERE c1 = 1; COMMITWhile the
UPDATEstatement is blocked, query thesys.dm_tran_locksDMV from a third connection, Connection 3, as follows:SELECT tl.request_session_id ,tl.resource_database_id ,tl.resource_associated_entity_id ,tl.resource_type ,tl.resource_description ,tl.request_mode ,tl.request_status FROM sys.dm_tran_locks tl;The output from
sys.dm_tran_locks, in Connection 3, will provide the lock status after the first step of theUPDATEstatement since the lock conversion to an exclusive (X) lock by theUPDATEstatement is blocked by theSELECTstatement.The lock status after the second step of the
UPDATEstatement will be provided by the query againstsys.dm_tran_locksin theUPDATEtransaction in Connection 3.
The lock status provided from sys.dm_tran_locks after the individual steps of the UPDATE statement is as follows:
Figure 12-3 shows the lock status after step 1 of the
UPDATEstatement (obtained from the output fromsys.dm_tran_locksexecuted on the third connection, Connection 3, as explained previously).Note
The order of these rows is not that important.
Figure 12-4 shows the lock status after step 2 of the
UPDATEstatement.
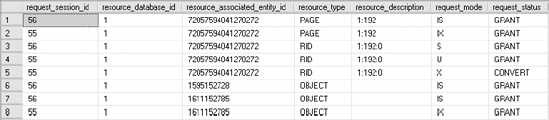

From the sys.dm_tran_locks output after the first step of the UPDATE statement, you can note the following:
A (
U) lock is granted to the SPID on the data row.A conversion to an (
X) lock on the data row is requested.
From the output of sys.dm_tran_locks after the second step of the UPDATE statement, you can see that the UPDATE statement holds only an (X) lock on the data row. Essentially, the (U) lock on the data row is converted to an (X) lock.
By not acquiring an exclusive lock at the first step, an UPDATE statement allows other transactions to read the data using the SELECT statement during that period, since (U) and (S) locks are compatible with each other. This increases database concurrency.
Note
I discuss lock compatibility among different lock modes later in this chapter.
You may be curious to learn why a (U) lock is used instead of an (S) lock in the first step of the UPDATE statement. To understand the drawback of using an (S) lock instead of a (U) lock in the first step of the UPDATE statement, let's break the UPDATE statement into the following two steps:
Read the data to be modified using an (
S) lock instead of a (U) lock.Modify the data by acquiring an (
X) lock.
Consider the following code (split_update.sql in the download):
BEGIN TRAN
--1. Read data to be modified using (S)lock instead of (U)lock.
-- Retain the (S)lock using REPEATABLEREAD locking hint,
-- since the original (U)lock is retained until the conversion
-- to (X)lock.
SELECT *
FROM t1 WITH (REPEATABLEREAD)
WHERE c1 = 1;
--Allow another equivalent update action to start concurrently
WAITFOR DELAY '00:00:10';
--2. Modify the data by acquiring (X)lock
UPDATE t1 WITH (XLOCK)
SET c2 = GETDATE()
WHERE c1 = 1;
COMMITIf this transaction is executed from two connections simultaneously, then it causes a deadlock as follows:
Msg 1205, Level 13, State 45, Line 14 Transaction (Process ID 57) was deadlocked on lock resources with another process and has been chosen as the deadlock victim. Rerun the transaction.
Both transactions read the data to be modified using an (S) lock and then request an (X) lock for modification. When the first transaction attempts the conversion to the (X) lock, it is blocked by the (S) lock held by the second transaction. Similarly, when the second transaction attempts the conversion from (S) to (X), lock, it is blocked by the (S) lock held by the first transaction, which in turn is blocked by the second transaction. This causes a circular block and therefore a deadlock.
To avoid this typical deadlock, the UPDATE statement uses a (U) lock instead of an (S) lock at its first intermediate step. Unlike an (S) lock, a (U) lock doesn't allow another (U) lock on the same resource simultaneously. This forces the second concurrent UPDATE statement to wait until the first UPDATE statement completes.
Exclusive (X) Mode
Exclusive lock mode provides an exclusive right on a database resource for modification by data manipulation queries such as INSERT, UPDATE, and DELETE. It prevents other concurrent transactions from accessing the resource under modification. Both the INSERT and DELETE statements acquire (X) locks at the very beginning of their execution. As explained earlier, the UPDATE statement converts to the (X) lock after the data to be modified is read. The (X) locks granted in a transaction are held until the end of the transaction.
The (X) lock serves two purposes:
It prevents other transactions from accessing the resource under modification so that they see a value either before or after the modification, not a value undergoing modification.
It allows the transaction modifying the resource to safely roll back to the original value before modification, if needed, since no other transaction is allowed to modify the resource simultaneously.
Intent Shared (IS), Intent Exclusive (IX), and Shared with Intent Exclusive (SIX) Modes
Intent Shared, Intent Exclusive, and Shared with Intent Exclusive intent locks indicate that the query intends to grab a corresponding (S) or (X) lock at a lower lock level. For example, consider the following transaction on the test table (isix.sql in the download):
IF (SELECT OBJECT_ID('t1')
) IS NOT NULL
DROP TABLE t1
GO
CREATE TABLE t1 (c1 INT)
INSERT INTO t1
VALUES (1)
GOBEGIN TRAN
DELETE t1
WHERE c1 = 1
--Delete a row
SELECT tl.request_session_id
,tl.resource_database_id
,tl.resource_associated_entity_id
,tl.resource_type
,tl.resource_description
,tl.request_mode
,tl.request_status
FROM sys.dm_tran_locks tl ;
ROLLBACKFigure 12-5 shows the output from sys.dm_tran_locks.

The (IX) lock at the table level (TAB) indicates that the DELETE statement intends to acquire an (X) lock at a page level, row level, or key level. Similarly, the (IX) lock at the page level (PAG) indicates that the query intends to acquire an (X) lock on a row in the page. The (IX) locks at the higher levels prevent another transaction from acquiring an incompatible lock on the table or on the page containing the row.
Flagging the intent lock—(IS) or (IX)—at a corresponding higher level by a transaction, while holding the lock at a lower level, prevents other transactions from acquiring an incompatible lock at the higher level. If the intent locks were not used, then a transaction trying to acquire a lock at a higher level would have to scan through the lower levels to detect the presence of lower-level locks. While the intent lock at the higher levels indicates the presence of a lower-level lock, the locking overhead of acquiring a lock at a higher level is optimized. The intent locks granted to a transaction are held until the end of the transaction.
Only a single (SIX) can be placed on a given resource at once. This prevents updates made by other transactions. Other transactions can place (IS) locks on the lower-level resources while the (SIX) lock is in place.
Furthermore, there can be combination of locks requested (or acquired) at a certain level and the intention of having lock(s) at a lower level. There can be (SIU) and (UIX) lock combinations indicating that an (S) or a (U) lock is acquired at the corresponding level and (U) or (X) lock(s) are intended at a lower level.
Schema Modification (Sch-M) and Schema Stability (Sch-S) Modes
Schema Modification and Schema Stability locks are acquired on a table by SQL statements that depend on the schema of the table. A DDL statement, working on the schema of a table, acquires an (Sch-M) lock on the table and prevents other transactions from accessing the table. An (Sch-S) lock is acquired for database activities that depend on the table schema but do not modify the schema, such as a query compilation. It prevents an (Sch-M) lock on the table, but it allows other locks to be granted on the table.
Since, on a production database, schema modifications are infrequent, (Sch-M) locks don't usually become a blocking issue. And because (Sch-S) locks don't block other locks except (Sch-M) locks, concurrency is generally not affected by (Sch-S) locks either.
Bulk Update (BU) Mode
The Bulk Update lock mode is unique to bulk load operations. These operations are the older-style bcp (bulk copy), the BULK INSERT statement, and inserts from the OPENROWSET using the BULK option. As a mechanism for speeding up these processes, you can provide a TABLOCK hint or set the option on the table for it to lock on bulk load. The key to (BU) locking mode is that it will allow multiple bulk operations against the table being locked but prevent other operations while the bulk process is running.
Key-Range Mode
The Key-Range mode is applicable only while the isolation level is set to Serializable (more on transaction isolation levels in the later "Isolation Levels" section). The Key-Range locks are applied to a series, or range, of key values that will be used repeatedly while the transaction is open. Locking a range during a serializable transaction ensures that other rows are not inserted within the range, possibly changing result sets within the transaction. The range can be locked using the other lock modes, making this more like a combined locking mode rather than a distinctively separate locking mode. For the Key-Range lock mode to work, an index must be used to define the values within the range.
SQL Server provides isolation to a transaction by preventing other transactions from accessing the same resource in an incompatible way. However, if a transaction attempts a compatible task on the same resource, then, to increase concurrency, it won't be blocked by the first transaction. SQL Server ensures this kind of selective blocking by preventing a transaction from acquiring an incompatible lock on a resource held by another transaction. For example, an (S) lock acquired on a resource by a transaction allows other transactions to acquire an (S) lock on the same resource. However, an (Sch-M) lock on a resource by a transaction prevents other transactions from acquiring any lock on that resource.
The lock modes explained in the previous section help a transaction protect its data consistency from other concurrent transactions. The degree of data protection or isolation a transaction gets depends not only on the lock modes but also on the isolation level of the transaction. This level influences the behavior of the lock modes. For example, by default, an (S) lock is released immediately after the data is read; it isn't held until the end of the transaction. This behavior may not be suitable for some application functionality. In such cases, you can configure the isolation level of the transaction to achieve the desired degree of isolation.
SQL Server implements six isolation levels, four of them as defined by ISO:
Two other isolation levels provide row versioning, which is a mechanism whereby a version of the row is created as part of data manipulation queries. This extra version of the row allows read queries to access the data without acquiring locks against it. The extra two isolation levels are as follows:
Read Committed Snapshot (actually part of the Read Committed isolation)
Snapshot
The four ISO isolation levels are listed in increasing order of degree of isolation. You can configure them at either the connection or query level by using the SET TRANSACTION ISOLATION LEVEL statement or the locking hints, respectively. The isolation level configuration at the connection level remains effective until the isolation level is reconfigured using the SET statement or until the connection is closed. All the isolation levels are explained in the sections that follow.
Read Uncommitted is the lowest of the four isolation levels, and it allows SELECT statements to read data without requesting an (S) lock. Since an (S) lock is not requested by a SELECT statement, it neither blocks nor is blocked by the (X) lock. It allows a SELECT statement to read data while the data is under modification. This kind of data read is called a dirty read. For an application in which the amount of data modification is minimal and makes a negligible impact on the accuracy of the data read by the SELECT statement, you can use this isolation level to avoid blocking the SELECT statement by a data modification activity.
You can use the following SET statement to configure the isolation level of a database connection to the Read Uncommitted isolation level:
SET TRANSACTION ISOLATION LEVEL READ UNCOMMITTED
You can also achieve this degree of isolation on a query basis using the NOLOCK locking hint:
SELECT * FROM Production.Products WITH(NOLOCK);
The effect of the locking hint remains applicable for the query and doesn't change the isolation level of the connection.
The Read Uncommitted isolation level avoids the blocking caused by a SELECT statement, but you should not use it if the transaction depends on the accuracy of the data read by the SELECT statement or if the transaction cannot withstand a concurrent change of data by another transaction.
It's very important to understand what is meant by a dirty read. Lots of people think this means that while a field is being updated from Tusa to Tulsa, a query can still read the previous value. Although that is true, much more egregious data problems could occur. Since no locks are placed while reading the data, indexes may be split. This can result in extra or missing rows of data returned to the query. To be very clear, using Read Uncommitted in any environment where data manipulation is occurring as well as data reads can result in unanticipated behaviors. The intention of this isolation level is for systems primarily focused on reporting and business intelligence, not online transaction processing.
The Read Committed isolation level prevents the dirty read caused by the Read Uncommitted isolation level. This means that (S) locks are requested by the SELECT statements at this isolation level. This is the default isolation level of SQL Server. If needed, you can change the isolation level of a connection to Read Committed by using the following SET statement:
SET TRANSACTION ISOLATION LEVEL READ COMMITTED
The Read Committed isolation level is good for most cases, but since the (S) lock acquired by the SELECT statement isn't held until the end of the transaction, it can cause nonrepeatable read or phantom read issues, as explained in the sections that follow.
The behavior of the Read Committed isolation level can be changed by the database option READ_COMMITTED_SNAPSHOT. When this is set to ON, row versioning is used by data manipulation transactions. This places an extra load on tempdb because previous versions of the rows being changed are stored there while the transaction is uncommitted. This allows other transactions to access data for reads without having to place locks on the data, which can improve the speed and efficiency of all the queries in the system.
To see the row versioning in practice, first you need to create a test database for use with this one sample. Because the AdventureWorks2008 database comes with filestream objects enabled, this prevents row versioning from functioning.
CREATE DATABASE VersionTest;
Modify the VersionTest database so that READ_COMMITTED_SNAPSHOT is turned on:
ALTER DATABASE VersionTest
SET READ_COMMITTED_SNAPSHOT ON;Load one table into the new VersionTest database for the purposes of testing:
USE VersionTest; GO SELECT * INTO dbo.Product FROM AdventureWorks2008.Production.Product;
Now imagine a business situation. The first connection and transaction will be pulling data from the Production.Product table, acquiring the color of a particular item (read_commited.sql):
BEGIN TRANSACTION; SELECT p.Color FROM dbo.Product AS p WHERE p.ProductID = 711;
A second connection is made with a new transaction that will be modifying the color of the same item (change_color.sql).
BEGIN TRANSACTION; UPDATE dbo.Product SET Color = 'Coyote' WHERE ProductID = 711; SELECT p.Color FROM dbo.Product AS p WHERE p.ProductID = 711;
Running the SELECT statement after updating the color, you can see that the color was updated. But if you switch back to the first connection and rerun the original SELECT statement, you'll still see the color as Blue. Switch back to the second connection, and finish the transaction:
COMMIT TRANSACTION
Switching again to the first transaction, commit that transaction, and then rerun the original SELECT statement. You'll see the new color updated for the item, Coyote. You can delete the database created before continuing:
DROP DATABASE VersionTest;
Note
If the tempdb is filled, data modification using row versioning will continue to succeed, but reads may fail since the versioned row will not be available. If you enable any type of row versioning isolation within your database, you must take extra care to maintain free space within tempdb.
The Repeatable Read isolation level allows a SELECT statement to retain its (S) lock until the end of the transaction, thereby preventing other transactions from modifying the data during that time. Database functionality may implement a logical decision inside a transaction based on the data read by a SELECT statement within the transaction. If the outcome of the decision is dependent on the data read by the SELECT statement, then you should consider preventing modification of the data by other concurrent transactions. For example, consider the following two transactions:
Normalize the price for
ProductID = 1: ForProductID = 1, ifPrice > 10, decrease the price by 10.Apply a discount: For
ProductswithPrice > 10, apply a discount of 40 percent.
Considering the following test table (repeatable.sql in the download):
IF (SELECT OBJECT_ID('dbo.MyProduct')
) IS NOT NULL
DROP TABLE dbo.MyProduct;
GO
CREATE TABLE dbo.MyProduct
(ProductID INT
,Price MONEY);
INSERT INTO dbo.MyProduct
VALUES (1, 15.0);you can write the two transactions like this (repeatable_trans.sql):
--Transaction 1 from Connection 1
DECLARE @Price INT ;
BEGIN TRAN NormailizePrice
SELECT @Price = Price
FROM dbo.MyProduct AS mp
WHERE mp.ProductID = 1 ;
/*Allow transaction 2 to execute*/
WAITFOR DELAY '00:00:10'
IF @Price > 10
UPDATE dbo.MyProduct
SET Price = Price - 10
WHERE ProductID = 1 ;
COMMIT
GO
--Transaction 2 from Connection 2
BEGIN TRAN ApplyDiscount
UPDATE dbo.MyProduct
SET Price = Price * 0.6 --Discount = 40%
WHERE Price > 10 ;
COMMITOn the surface, the preceding transactions may look good, and yes, they do work in a single-user environment. But in a multiuser environment where multiple transactions can be executed concurrently, you have a problem here!
To figure out the problem, let's execute the two transactions from different connections in the following order:
Start transaction 1 first.
Start transaction 2 within 10 seconds of the start of transaction 1.
As you may have guessed, at the end of the transactions, the new price of the product (with ProductID = 1) will be −1.0. Ouch—it appears that you're ready to go out of business!
The problem occurs because transaction 2 is allowed to modify the data while transaction 1 has finished reading the data and is about to make a decision on it. Transaction 1 requires a higher degree of isolation than that provided by the default isolation level (Read Committed). As a solution, you want to prevent transaction 2 from modifying the data while transaction 1 is working on it. In other words, provide transaction 1 with the ability to read the data again later in the transaction without being modified by others. This feature is called repeatable read. Considering the context, the implementation of the solution is probably obvious. After re-creating the table, you can write this:
SET TRANSACTION ISOLATION LEVEL REPEATABLE READGO--Transaction 1 from Connection 1 DECLARE @Price INT ; BEGIN TRAN NormailizePrice SELECT @Price = Price FROM dbo.MyProduct AS mp WHERE mp.ProductID = 1 ; /*Allow transaction 2 to execute*/ WAITFOR DELAY '00:00:10' IF @Price > 10 UPDATE dbo.MyProduct SET Price = Price - 10 WHERE ProductID = 1 ; COMMIT GOSET TRANSACTION ISOLATION LEVEL READ COMMITTED --Back to defaultGO
Increasing the isolation level of transaction 1 to Repeatable Read will prevent transaction 2 from modifying the data during the execution of transaction 1. Consequently, you won't have an inconsistency in the price of the product. Since the intention isn't to release the (S) lock acquired by the SELECT statement until the end of the transaction, the effect of setting the isolation level to Repeatable Read can also be implemented at the query level using the lock hint:
--Transaction 1 from Connection 1
DECLARE @Price INT ;
BEGIN TRAN NormailizePrice
SELECT @Price = Price
FROM dbo.MyProduct AS mp WITH(REPEATABLEREAD)
WHERE mp.ProductID = 1 ;
/*Allow transaction 2 to execute*/
WAITFOR DELAY '00:00:10'
IF @Price > 10
UPDATE dbo.MyProduct
SET Price = Price - 10
WHERE ProductID = 1 ;
COMMIT
GOThis solution prevents the data inconsistency of MyProduct.Price, but it introduces another problem to this scenario. On observing the result of transaction 2, you realize that it could cause a deadlock. Therefore, although the preceding solution prevented the data inconsistency, it is not a complete solution. Looking closely at the effect of the Repeatable Read isolation level on the transactions, you see that it introduced the typical deadlock issue avoided by the internal implementation of an UPDATE statement, as explained previously. The SELECT statement acquired and retained an (S) lock instead of a (U) lock, even though it intended to modify the data later within the transaction. The (S) lock allowed transaction 2 to acquire a (U) lock, but it blocked the (U) lock's conversion to an (X) lock. The attempt of transaction 1 to acquire a (U) lock on the data at a later stage caused a circular blocking, resulting in a deadlock.
To prevent the deadlock and still avoid data corruption, you can use an equivalent strategy as adopted by the internal implementation of the UPDATE statement. Thus, instead of requesting an (S) lock, transaction 1 can request a (U) lock using an UPDLOCK locking hint when executing the SELECT statement:
--Transaction 1 from Connection 1
DECLARE @Price INT ;
BEGIN TRAN NormailizePrice
SELECT @Price = Price
FROM dbo.MyProduct AS mp WITH(UPDLOCK)
WHERE mp.ProductID = 1 ;
/*Allow transaction 2 to execute*/
WAITFOR DELAY '00:00:10'
IF @Price > 10
UPDATE dbo.MyProduct
SET Price = Price - 10
WHERE ProductID = 1 ;
COMMIT
GOThis solution prevents both data inconsistency and the possibility of the deadlock. If the increase of the isolation level to Repeatable Read had not introduced the typical deadlock, then it would have done the job. Since there is a chance of a deadlock occurring because of the retention of an (S) lock until the end of a transaction, it is usually preferable to grab a (U) lock instead of holding the (S) lock, as just illustrated.
Serializable is the highest of the six isolation levels. Instead of acquiring a lock only on the row to be accessed, the Serializable isolation level acquires a range lock on the row and the next row in the order of the data set requested. For instance, a SELECT statement executed at the Serializable isolation level acquires a (RangeS-S) lock on the row to be accessed and the next row in the order. This prevents the addition of rows by other transactions in the data set operated on by the first transaction, and it protects the first transaction from finding new rows in its data set within its transaction scope. Finding new rows in a data set within a transaction is also called a phantom read.
To understand the need for a Serializable isolation level, let's consider an example. Suppose a group (with GroupID = 10) in a company has a fund of $100 to be distributed among the employees in the group as a bonus. The fund balance after the bonus payment should be $0. Consider the following test table (serializable.sql in the download):
IF (SELECT OBJECT_ID('dbo.MyEmployees')
) IS NOT NULL
DROP TABLE dbo.MyEmployees;
GO
CREATE TABLE dbo.MyEmployees
(EmployeeID INT
,GroupID INT
,Salary MONEY);
CREATE CLUSTERED INDEX i1 ON dbo.MyEmployees (GroupID);
INSERT INTO dbo.MyEmployees
VALUES (1, 10, 1000);
--Employee 1 in group 10
INSERT INTO dbo.MyEmployees
VALUES (2, 10, 1000);
--Employee 2 in group 10
--Employees 3 & 4 in different groups
INSERT INTO dbo.MyEmployees
VALUES (3, 20, 1000);
INSERT INTO dbo.MyEmployees
VALUES (4, 9, 1000);The preceding business functionality may be implemented as follows (bonus.sql in the download):
DECLARE @Fund MONEY = 100
,@Bonus MONEY
,@NumberOfEmployees INT
BEGIN TRAN PayBonus
SELECT @NumberOfEmployees = COUNT(*)
FROM dbo.MyEmployees
WHERE GroupID = 10
/*Allow transaction 2 to execute*/
WAITFOR DELAY '00:00:10'
IF @NumberOfEmployees > 0
BEGIN
SET @Bonus = @Fund / @NumberOfEmployees
UPDATE dbo.MyEmployees
SET Salary = Salary + @Bonus
WHERE GroupID = 10
PRINT 'Fund balance =
' + CAST((@Fund - (@@ROWCOUNT * @Bonus)) AS VARCHAR(6)) + ' $'
END
COMMIT
GOThe PayBonus transaction works well in a single-user environment. However, in a multiuser environment, there is a problem.
Consider another transaction that adds a new employee to GroupID = 10 as follows (new_employee.sql in the download) and is executed concurrently (immediately after the start of the PayBonus transaction) from a second connection:
--Transaction 2 from Connection 2 BEGIN TRAN NewEmployee INSERT INTO MyEmployees VALUES(5, 10, 1000) COMMIT
The fund balance after the PayBonus transaction will be –$50! Although the new employee may like it, the group fund will be in the red. This causes an inconsistency in the logical state of the data.
To prevent this data inconsistency, the addition of the new employee to the group (or data set) under operation should be blocked. Of the five isolation levels discussed, only Snapshot isolation can provide a similar functionality, since the transaction has to be protected not only on the existing data but also from the entry of new data in the data set. The Serializable isolation level can provide this kind of isolation by acquiring a range lock on the affected row and the next row in the order determined by the i1 index on the GroupID column. Thus, the data inconsistency of the PayBonus transaction can be prevented by setting the transaction isolation level to Serializable.
Remember to re-create the table first:
SET TRANSACTION ISOLATION LEVEL SERIALIZABLEGODECLARE @Fund MONEY = 100 ,@Bonus MONEY ,@NumberOfEmployees INT BEGIN TRAN PayBonus SELECT @NumberOfEmployees = COUNT(*) FROM dbo.MyEmployees WHERE GroupID = 10 /*Allow transaction 2 to execute*/ WAITFOR DELAY '00:00:10' IF @NumberOfEmployees > 0 BEGIN SET @Bonus = @Fund / @NumberOfEmployees UPDATE dbo.MyEmployees SET Salary = Salary + @Bonus WHERE GroupID = 10 PRINT 'Fund balance = ' + CAST((@Fund - (@@ROWCOUNT * @Bonus)) AS VARCHAR(6)) + ' $' END COMMIT GOSET TRANSACTION ISOLATION LEVEL READ COMMITTED --Back to defaultGO
The effect of the Serializable isolation level can also be achieved at the query level by using the HOLDLOCK locking hint on the SELECT statement, as shown here:
DECLARE @Fund MONEY = 100
,@Bonus MONEY
,@NumberOfEmployees INT
BEGIN TRAN PayBonus
SELECT @NumberOfEmployees = COUNT(*)
FROM dbo.MyEmployees WITH(HOLDLOCK)
WHERE GroupID = 10
/*Allow transaction 2 to execute*/
WAITFOR DELAY '00:00:10'
IF @NumberOfEmployees > 0
BEGIN
SET @Bonus = @Fund / @NumberOfEmployees
UPDATE dbo.MyEmployees
SET Salary = Salary + @Bonus
WHERE GroupID = 10
PRINT 'Fund balance =
' + CAST((@Fund - (@@ROWCOUNT * @Bonus)) AS VARCHAR(6)) + ' $'
END
COMMIT
GOYou can observe the range locks acquired by the PayBonus transaction by querying sys.dm_tran_locks from another connection while the PayBonus transaction is executing, as shown in Figure 12-6.
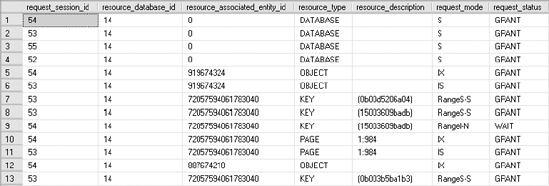
The output of sys.dm_tran_locks shows that shared-range (RangeS-S) locks are acquired on three index rows: the first employee in GroupID = 10, the second employee in GroupID = 10, and the third employee in GroupID = 20. These range locks prevent the entry of any new employee in GroupID = 10.
The range locks just shown introduce a few interesting side effects:
No new employee with a
GroupIDbetween 10 and 20 can be added during this period. For instance, an attempt to add a new employee with aGroupIDof 15 will be blocked by thePayBonustransaction:--Transaction 2 from Connection 2 BEGIN TRAN NewEmployee
INSERT INTO dbo.MyEmployees VALUES(6, 15, 1000)COMMITIf the data set of the
PayBonustransaction turns out to be the last set in the existing data ordered by the index, then the range lock required on the row, after the last one in the data set, is acquired on the last possible data value in the table.
To understand this behavior, let's delete the employees with a GroupID > 10 to make the GroupID = 10 data set the last data set in the clustered index (or table):
DELETE dbo.MyEmployees WHERE GroupID > 10
Run the updated bonus.sql and new_employee.sql again. Figure 12-7 shows the resultant output of sys.dm_tran_locks for the PayBonus transaction.
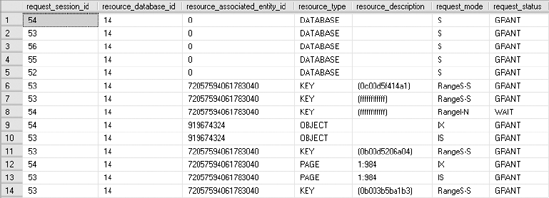
Figure 12.7. sys.dm_tran_locks output showing extended range locks granted to the serializable transaction
The range lock on the last possible row (KEY = ffffffffffff) in the clustered index, as shown in Figure 12-7, will block the addition of employees with all GroupIDs greater than or equal to 10. You know that the lock is on the last row, not because it's displayed in a visible fashion in the output of sys.dm_tran_locks but because you cleaned out everything up to that row previously. For example, an attempt to add a new employee with GroupID = 999 will be blocked by the PayBonus transaction:
--Transaction 2 from Connection 2
BEGIN TRAN NewEmployee
INSERT INTO dbo.MyEmployees VALUES(7, 999, 1000)
COMMITGuess what will happen if the table doesn't have an index on the GroupID column (in other words, the column in the WHERE clause)? While you're thinking, I'll re-create the table with the clustered index on a different column:
IF (SELECT OBJECT_ID('dbo.MyEmployees')
) IS NOT NULL
DROP TABLE dbo.MyEmployees
GO
CREATE TABLE dbo.MyEmployees
(EmployeeID INT
,GroupID INT
,Salary MONEY)
CREATE CLUSTERED INDEX i1 ON dbo.MyEmployees (EmployeeID)
INSERT INTO dbo.MyEmployees
VALUES (1, 10, 1000)
--Employee 1 in group 10
INSERT INTO dbo.MyEmployees
VALUES (2, 10, 1000)
--Employee 2 in group 10
--Employees 3 & 4 in different groups
INSERT INTO dbo.MyEmployees
VALUES (3, 20, 1000)
INSERT INTO dbo.MyEmployees
VALUES (4, 9, 1000)
GORerun the updated bonus.sql and new_employee.sql. Figure 12-8 shows the resultant output of sys.dm_tran_locks for the PayBonus transaction.
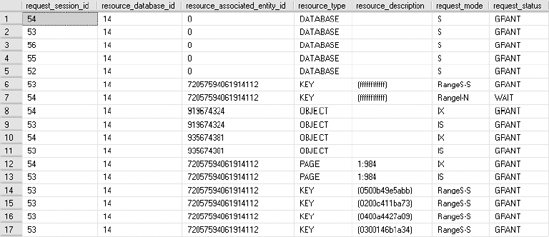
Figure 12.8. sys.dm_tran_locks output showing range locks granted to the serializable transaction with no index on the WHERE clause column
Once again, the range lock on the last possible row (KEY = ffffffffffff) in the new clustered index, as shown in Figure 12-8, will block the addition of any new row to the table. I will discuss the reason behind this extensive locking later in the chapter in the "Effect of Indexes on the Serializable Isolation Level" section.
As you've seen, the Serializable isolation level not only holds the share locks until the end of the transaction like the Repeatable Read isolation level but also prevents any new row in the data set (or more) by holding range locks. Because this increased blocking can hurt database concurrency, you should avoid the Serializable isolation level.
Snapshot isolation is the second of the row-versioning isolation levels available in SQL Server 2008. Unlike Read Committed Snapshot isolation, Snapshot isolation requires an explicit call to SET TRANSACTION ISOLATION LEVEL at the start of the transaction in addition to setting the isolation level on the database. Snapshot isolation is meant as a more stringent isolation level than the Read Committed Snapshot isolation. Snapshot isolation will attempt to put an exclusive lock on the data it intends to modify. If that data already has a lock on it, the snapshot transaction will fail. It provides transaction-level read consistency, which makes it more applicable to financial-type systems than Read Committed Snapshot.
Indexes affect the locking behavior on a table. On a table with no indexes, the lock granularities are RID, PAG (on the page containing the RID), and TAB. Adding indexes to the table affects the resources to be locked. For example, consider the following test table with no indexes (create_t1_2.sql in the download):
IF (SELECT OBJECT_ID('dbo.t1')
) IS NOT NULL
DROP TABLE dbo.t1
GO
CREATE TABLE dbo.t1 (c1 INT, c2 DATETIME)
INSERT INTO dbo.t1
VALUES (1, GETDATE())Observe the locking behavior on the table for the transaction (indexlock.sql in the download):
BEGIN TRAN LockBehavior UPDATE dbo.t1 WITH (REPEATABLEREAD) --Hold all acquired locks SET c2 = GETDATE() WHERE c1 = 1 --Observe lock behavior using sp_lock from another connection WAITFOR DELAY '00:00:10' COMMIT
Figure 12-9 shows the output of sys.dm_tran_locks applicable to the test table.

The following locks are acquired by the transaction:
An (
IX) lock on the tableAn (
IX) lock on the page containing the data rowAn (
X) lock on the data row within the table
When the resource_type is an object, the resource_associated_entity_id column value in sys.dm_tran_locks indicates the object_id of the object on which the lock is placed. You can obtain the specific object name on which the lock is acquired from the sys.object system table as follows:
SELECT OBJECT_NAME(<object_id>)
The effect of the index on the locking behavior of the table varies with the type of index on the WHERE clause column. The difference arises from the fact that the leaf pages of the nonclustered and clustered indexes have a different relationship with the data pages of the table. Let's look into the effect of these indexes on the locking behavior of the table.
Because the leaf pages of the nonclustered index are separate from the data pages of the table, the resources associated with the nonclustered index are also protected from corruption. SQL Server automatically ensures this. To see this in action, create a nonclustered index on the test table:
CREATE NONCLUSTERED INDEX i1 ON dbo.t1(c1)
On running the LockBehavior transaction (indexlock.sql) again, and querying sys.dm_tran_locks from a separate connection, you get the result shown in Figure 12-10.
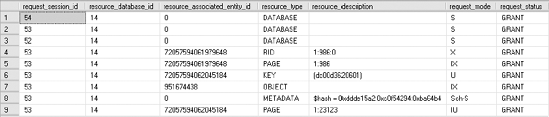
Figure 12.10. sys.dm_tran_locks output showing the effect of a nonclustered index on locking behavior
The following locks are acquired by the transaction:
An (
IU) lock on the page containing the nonclustered index row, (IndId = 2)A (
U) lock on the nonclustered index row within the index page, (IndId = 2)An (
IX) lock on the table, (IndId = 0)An (
IX) lock on the page containing the data row, (IndId = 0)An (
X) lock on the data row within the data page, (IndId = 0)
Note that only the row-level and page-level locks are directly associated with the nonclustered index. The next higher level of lock granularity for the nonclustered index is the table-level lock on the corresponding table.
Thus, nonclustered indexes introduce an additional locking overhead on the table. You can avoid the locking overhead on the index by using the ALLOW_ROW_LOCKS and ALLOW_PAGE_LOCKS options in ALTER INDEX (indexoption.sql in the download):
--Avoid KEY lock on the index rowsALTER INDEX i1 ON dbo.t1SET (ALLOW_ROW_LOCKS = OFF,ALLOW_PAGE_LOCKS= OFF);BEGIN TRAN LockBehavior UPDATE dbo.t1 WITH (REPEATABLEREAD) --Hold all acquired locks SET c2 = GETDATE() WHERE c1 = 1; --Observe lock behavior using sp_lock from another connection WAITFOR DELAY '00:00:10'; COMMITALTER INDEX i1 ON dbo.t1SET (ALLOW_ROW_LOCKS = ON,ALLOW_PAGE_LOCKS= ON);
You can use these options when working with an index to enable/disable the KEY locks and PAG locks on the index. Disabling just the KEY lock causes the lowest lock granularity on the index to be the PAG lock. Configuring lock granularity on the index remains effective until it is reconfigured. Modifying locks like this should be a last resort after many other options have been tried. This could cause significant locking overhead that would seriously impact performance of the system.
Figure 12-11 displays the output of sys.dm_tran_locks executed from a separate connection.

The only lock acquired by the transaction on the test table is an (X) lock on the table (IndId = 0).
You can see from the new locking behavior that disabling both the KEY lock and the PAG lock on the index using the sp_indexoption procedure escalates lock granularity to the table level. This will block every concurrent access to the table or to the indexes on the table, and consequently it can hurt the database concurrency seriously. However, if a nonclustered index becomes a point of contention in a blocking scenario, then it may be beneficial to disable the PAG locks on the index, thereby allowing only KEY locks on the index.
Note
Using this option can have serious side effects. You should use it only as a last resort.
Since for a clustered index the leaf pages of the index and the data pages of the table are the same, the clustered index can be used to avoid the overhead of locking additional pages (leaf pages) and rows introduced by a nonclustered index. To understand the locking overhead associated with a clustered index, convert the preceding nonclustered index to a clustered index:
CREATE CLUSTERED INDEX i1 ON t1(c1) WITH DROP_EXISTING
If you run indexlock.sql again and query sys.dm_tran_locks in a different connection, you should see the resultant output for the LockBehavior transaction on t1 in Figure 12-12.

The following locks are acquired by the transaction:
An (
IX) lock on the table, (IndId = 0)An (
IX) lock on the page containing the clustered index row (IndId = 1)An (
X) lock on the clustered index row within the table (or clustered index) (IndId = 1)
The locks on the clustered index row and the leaf page are actually the locks on the data row and data page too, since the data pages and the leaf pages are the same. Thus, the clustered index reduced the locking overhead on the table compared to the nonclustered index.
Reduced locking overhead of a clustered index is another benefit of using a clustered index over a nonclustered index.
Indexes play a significant role in determining the amount of blocking caused by the Serializable isolation level. The availability of an index on the WHERE clause column (that causes the data set to be locked) allows SQL Server to determine the order of the rows to be locked. For instance, consider the example used in the section on the Serializable isolation level. The SELECT statement uses a GroupID filter column to form its data set, like so:
... SELECT @NumberOfEmployees = COUNT(*) FROM dbo.MyEmployees WITH(HOLDLOCK) WHERE GroupID = 10 ...
A clustered index is available on the GroupID column, allowing SQL Server to acquire a (RangeS-S) lock on the row to be accessed and the next row in the correct order.
If the index on the GroupID column is removed, then SQL Server cannot determine the rows on which the range locks should be acquired, since the order of the rows is no longer guaranteed. Consequently, the SELECT statement acquires an (IS) lock at the table level instead of acquiring lower-granularity locks at the row level, as shown in Figure 12-13.
Figure 12.13. sys.dm_tran_locks output showing the locks granted to a SELECT statement with no index on the WHERE clause column
By failing to have an index on the filter column, you significantly increase the degree of blocking caused by the Serializable isolation level. This is another good reason to have an index on the WHERE clause columns.
Although blocking is necessary to isolate a transaction from other concurrent transactions, sometimes it may rise to excessive levels, adversely affecting database concurrency. In the simplest blocking scenario, the lock acquired by an SPID on a resource blocks another SPID requesting an incompatible lock on the resource. To improve concurrency, it is important to analyze the cause of blocking and apply the appropriate resolution.
In a blocking scenario, you need the following information to have a clear understanding of the cause of the blocking:
The connection information of the blocking and blocked SPIDs: You can obtain this information from the
sys.dm_os_waiting_tasksdynamic management view or thesp_who2system stored procedure.The lock information of the blocking and blocked SPIDs: You can obtain this information from the
sys.dm_tran_locksDMV.The SQL statements last executed by the blocking and blocked SPIDs: You can use the
sys.dm_exec_requestsDMV combined withsys.dm_exec_sql_textandsys.dm_exec_query_planor SQL Profiler to obtain this information.
You can also obtain the following information from the SQL Server Management Studio by running the Activity Monitor. The Processes page provides connection information of all SPIDs. This shows blocked SPIDS, the process blocking them, and the head of any blocking chain with details on how long the process has been running, its SPID, and other information. It is possible to put Profiler to work using the blocking report to gather a lot of the same information. You can find more on this in the "Profiler Trace and the Blocked Process Report Event" section.
To provide more power and flexibility to the process of collecting blocking information, a SQL Server administrator can use SQL scripts to provide the relevant information listed here.
To arrive at enough information about blocked and blocking processes, you can bring several dynamic management views into play. This query will show information necessary to identify blocked processes based on those that are waiting. You can easily add filtering to only access processes blocked for a certain period of time or only within certain databases, and so on (blocker.sql):
SELECT tl.request_session_id AS WaitingSessionID
,wt.blocking_session_id AS BlockingSessionID
,wt.resource_description
,wt.wait_type
,wt.wait_duration_ms
,DB_NAME(tl.resource_database_id) AS DatabaseName
,tl.resource_associated_entity_id AS WaitingAssociatedEntity
,tl.resource_type AS WaitingResourceType
,tl.request_type AS WaitingRequestType
,wrt.[text] AS WaitingTSql
,btl.request_type BlockingRequestType
,brt.[text] AS BlockingTsql
FROM sys.dm_tran_locks tl
JOIN sys.dm_os_waiting_tasks wt
ON tl.lock_owner_address = wt.resource_address
JOIN sys.dm_exec_requests wr
ON wr.session_id = tl.request_session_id
CROSS APPLY sys.dm_exec_sql_text(wr.sql_handle) AS wrt
LEFT JOIN sys.dm_exec_requests br
ON br.session_id = wt.blocking_session_id
OUTER APPLY sys.dm_exec_sql_text(br.sql_handle) AS brt
LEFT JOIN sys.dm_tran_locks AS btl
ON br.session_id = btl.request_session_id;To understand how to analyze a blocking scenario and the relevant information provided by the blocker script, consider the following example (block_it.sql in the download). First, create a test table:
IF (SELECT OBJECT_ID('dbo.t1')
) IS NOT NULL
DROP TABLE dbo.t1;
GO
CREATE TABLE dbo.t1
(c1 INT
,c2 INT
,c3 DATETIME);
INSERT INTO dbo.t1
VALUES (11, 12, GETDATE());
INSERT INTO dbo.t1
VALUES (21, 22, GETDATE());Now, open three connections, and run the following two queries concurrently. Once they're run, use the blocker.sql script in the third connection. Execute the code in Listing 12-1 first.
Execute Listing 12-2 while the User1 transaction is executing.
This creates a simple blocking scenario where the User1 transaction blocks the User2 transaction.
The output of the blocker script provides information immediately useful to begin resolving blocking issues. First, you can identify the specific session information including the session ID of both the blocking and waiting sessions. You get an immediate resource description from the waiting resource, the wait type, and the length of time, in milliseconds, that the process has been waiting. It's that value that allows you to provide a filter to eliminate short-term blocks, which are part of normal processing.
The database name is supplied because blocking can occur anywhere in the system, not just in AdventureWorks2008. You'll want to identify it where it occurs. The resources and types from the basic locking information are retrieved for the waiting process.
The blocking request type is displayed, and both the waiting T-SQL and blocking T-SQL, if available, are displayed. Once you have the object where the block is occurring, having the T-SQL so that you can understand exactly where and how the process is either blocking or being blocked is a vital part of the process of eliminating or reducing the amount of blocking. All this information is available from one simple query. Figure 12-14 shows the sample output from the earlier blocked process.
Be sure to go back to Connection 1 and commit or roll back the transaction.
The Profiler provides an event called "Errors and Warning: Blocked Process Report." This event works off the blocked process threshold that you need to provide to the system configuration. This script sets the threshold to five seconds:
EXEC sp_configure 'blocked process threshold', 5 ; RECONFIGURE;
That would normally be a very low value in most systems. A general rule would be to start with a setting at 30 seconds and adjust up or down as seems appropriate for your databases, servers, and their workloads. If you have an established performance service-level agreement (SLA), you could use that as the threshold. Once the value is set, you can configure alerts so that emails or pages are sent if any process is blocked longer than the value you set. It also acts as a trigger for the Profiler event.
To set up a trace that captures the Blocked Process report, first open Profiler. (Although you should use scripts to set up this event and trace in a production environment, I'll show how to use the GUI.) Select a Blank template, navigate to the Events Selection page, and expand Errors and Warnings in order to select Blocked Process Report. You should have something similar to Figure 12-15.
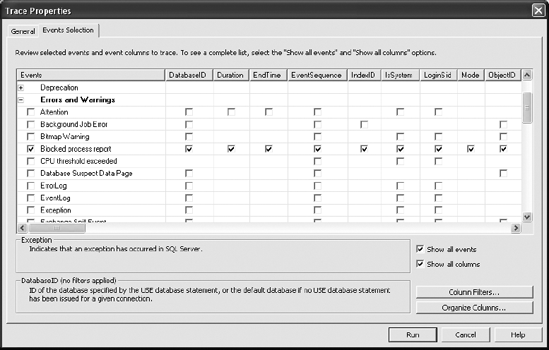
You need to be sure that the TextData column is also selected. If you still have the queries running from the previous section that created the block, all you need to do now is click the Run button to capture the event. Otherwise, go back to Listings 12-1 and 12-2 and run them in two different connections. After the blocked process threshold is passed, you'll see the event fire. And fire. Every five seconds it will fire if that's how you've configured it and you're leaving the connections running from Listings 12-1 and 12-2. What's generated is a rather hard to read XML file:
<blocked-process-report>
<blocked-process>
<process id="process50801c0" taskpriority="0" logused="0"
waitresource="RID: 14:1:1279:0" waittime="5212" ownerId="9616"
transactionname="User2" lasttranstarted="2008-12-19T10:02:29.617" XDES="0x730bbe0"
lockMode="S" schedulerid="2" kpid="2468" status="suspended" spid="53" sbid="0"
ecid="0" priority="0" trancount="1" lastbatchstarted="2008-12-19T10:02:29.617"
lastbatchcompleted="2008-12-19T10:01:42.990" clientapp="Microsoft SQL Server
Management Studio - Query" hostname="FRITCHEYGXP" hostpid="5748"
loginname="CORPfritcheyg" isolationlevel="read committed (2)"
xactid="9616" currentdb="14"
lockTimeout="4294967295" clientoption1="671098976" clientoption2="390200">
<executionStack>
<frame line="2" stmtstart="24"
sqlhandle="0x020000001be0f42a9b3a6fd8eae5b4ae648e87cc70b1f6ba"/>
<frame line="2" stmtstart="40" stmtend="114"
sqlhandle="0x020000003c6c8b1b2150baa2bc7c06d7557a87169ea51e5a"/>
</executionStack>
<inputbuf>
BEGIN TRAN User2
SELECT c2 FROM dbo.t1 WHERE c1 = 11;
COMMIT
</inputbuf>
</process>
</blocked-process>
<blocking-process>
<process status="sleeping" spid="54" sbid="0" ecid="0" priority="0" trancount="1"
lastbatchstarted="2008-12-19T10:02:27.163"
lastbatchcompleted="2008-12-19T10:02:27.163"
clientapp="Microsoft SQL Server Management Studio - Query"
hostname="FRITCHEYGXP" hostpid="5748" loginname="CORPfritcheyg"
isolationlevel="read committed (2)" xactid="9615" currentdb="14"
lockTimeout="4294967295" clientoption1="671098976" clientoption2="390200">
<executionStack/>
<inputbuf>
BEGIN TRAN User1
UPDATE dbo.t1
SET c3 = GETDATE();
--rollback
</inputbuf>
</process>
</blocking-process>
</blocked-process-report>But if you look through it, the elements are clear. <blocked-process> shows information about the process that was blocked including familiar information such as the SPID, the database ID, and so on. It doesn't include some of the other information that you can easily get from T-SQL queries such as the query string of the blocked and waiting process. But with the SPID available, you can get them from the cache, if available, or you can combine the Blocked Process report with other trace events such as RPC:Starting to show the query information. However, that will add to the overhead of using this long term within your database. If you know you have a blocking problem, this can be part of a short-term monitoring project to capture the necessary blocking information.
Once you've analyzed the cause of a block, the next step is to determine any possible resolutions. A few techniques you can use to do this are as follows:
Optimize the queries executed by blocking and blocked SPIDs.
Decrease the isolation level.
Partition the contended data.
Use a covering index on the contended data.
Note
A detailed list of recommendations to avoid blocking appears later in the chapter in the section "Recommendations to Reduce Blocking."
To understand these resolution techniques, let's apply them in turn to the preceding blocking scenario.
Optimizing the queries executed by the blocking and blocked SPIDs helps reduce the blocking duration. In the blocking scenario, the queries executed by the SPIDs participating in the blocking are as follows:
Blocking SPID:
BEGIN TRAN User1 UPDATE dbo.t1 SET c3 = GETDATE()
Blocked SPID:
BEGIN TRAN User2 SELECT c2 FROM dbo.t1 WHERE c1 = 11 COMMIT
Let's analyze the individual SQL statements executed by the blocking and blocked SPIDs to optimize their performance:
The
UPDATEstatement of the blocking SPID accesses the data without aWHEREclause. This makes the query inherently costly on a large table. If possible, break the action of theUPDATEstatement into multiple batches using appropriateWHEREclauses. If the individualUPDATEstatements of the batch are executed in separate transactions, then fewer locks will be held on the resource within one transaction, and for shorter time periods.The
SELECTstatement executed by the blocked SPID has aWHEREclause on columnc1. From the index structure on the test table, you can see that there is no index on this column. To optimize theSELECTstatement, you should create a clustered index on columnc1:CREATE CLUSTERED INDEX i1 ON t1(c1)
Note
Since the table fits within one page, adding the clustered index won't make much difference to the query performance. However, as the number of rows in the table increases, the beneficial effect of the index will become more pronounced.
Optimizing the queries reduces the duration for which the locks are held by the SPIDs. The query optimization reduces the impact of blocking; it doesn't prevent the blocking completely. However, as long as the optimized queries execute within acceptable performance limits, a small amount of blocking may be neglected.
Another approach to resolve blocking can be to use a lower isolation level, if possible. The SELECT statement of the User2 transaction gets blocked while requesting an (S) lock on the data row. The isolation level of this transaction can be decreased to Read Uncommitted so that the (S) lock is not requested by the SELECT statement. The Read Uncommitted isolation level can be configured for the connection using the SET statement:
SET TRANSACTION ISOLATION LEVEL READ UNCOMMITTEDGOBEGIN TRAN User2 SELECT c2 FROM dbo.t1 WHERE c1 = 11; COMMIT GOSET TRANSACTION ISOLATION LEVEL READ COMMITTED --Back to defaultGO
The Read Uncommitted isolation level can also be configured for the SELECT statement at a query level by using the NOLOCK locking hint:
BEGIN TRAN User2 SELECT c2 FROM dbo.t1 WITH(NOLOCK) WHERE c1 = 11; COMMIT
The Read Uncommitted isolation level avoids the blocking faced by the User2 transaction.
This example shows the utility of reducing the isolation level. However, as a production solution, this has severe problems. Not only can you get dirty reads, which means that the data returned by the select statement is changing or changed, but you can get inconsistent reads. It's possible while reading uncommitted data to get extra rows or fewer rows as pages are split and rearranged by the actions of other queries. Reading uncommitted data is a very popular way to reduce contention and increase performance on the database, but it comes at a very high cost in terms of data accuracy. Be very aware of these costs prior to attempting to use this as an active solution within your database.
When dealing with very large data sets or data that can be very discretely stored, it is possible to apply table partitioning to the data. Partitioned data is split horizontally, meaning by certain values (for example, splitting sales data up by month). This allows the transactions to execute concurrently on the individual partitions, without blocking each other. These separate partitions are treated as a single unit for querying, updating, and inserting; only the storage and access are separated out by SQL Server. It should be noted that partitioning is available only in the Developer Edition and Enterprise Edition of SQL Server.
In the preceding blocking scenario, the data could be separated by date. This would entail setting up multiple filegroups and splitting the data per a defined rule. Once the UPDATE statement gets a WHERE clause, then it and the original SELECT statement will be able to execute concurrently on two separate partitions.
Partitioning the table does add some overhead to maintain integrity between the parts of the table. However, if done properly, it can improve both performance and concurrency on very large data sets.
In a blocking scenario, you should analyze whether the query of the blocking or the blocked SPID can be fully satisfied using a covering index. If the query of one of the SPIDs can be satisfied using a covering index, then it will prevent the SPID from requesting locks on the contended resource. Also, if the other SPID doesn't need a lock on the covering index (to maintain data integrity), then both SPIDs will be able to execute concurrently without blocking each other.
For instance, in the preceding blocking scenario, the SELECT statement by the blocked SPID can be fully satisfied by a covering index on columns c1 and c2:
CREATE NONCLUSTERED INDEX iAvoidBlocking ON dbo.t1(c1, c2)
The transaction of the blocking SPID need not acquire a lock on the covering index since it accesses only column c3 of the table. The covering index will allow the SELECT statement to get the values for columns c1 and c2 without accessing the base table. Thus, the SELECT statement of the blocked SPID can acquire an (S) lock on the covering-index row without being blocked by the (X) lock on the data row acquired by the blocking SPID. This allows both transactions to execute concurrently without any blocking.
Consider a covering index as a mechanism to "duplicate" part of the table data whose consistency is automatically maintained by SQL Server. This covering index, if mostly read-only, can allow some transactions to be served from the "duplicate" data while the base table (and other indexes) can continue to serve other transactions.
Single-user performance and the ability to scale with multiple users are both important for a database application. In a multiuser environment, it is important to ensure that the database operations don't hold database resources for a long time. This allows the database to support a large number of operations (or database users) concurrently without serious performance degradation. The following is a list of tips to reduce/avoid database blocking:
Keep transactions short.
Perform the minimum steps/logic within a transaction.
Do not perform costly external activity within a transaction, such as sending acknowledgment email or performing activities driven by the end user.
Optimize queries using indexes.
Create indexes as required to ensure optimal performance of the queries within the system.
Avoid a clustered index on frequently updated columns. Updates to clustered index key columns require locks on the clustered index and all nonclustered indexes (since their row locator contains the clustered index key).
Consider using a covering index to serve the blocked
SELECTstatements.
Consider partitioning a contended table.
Use query timeouts to control runaway queries.
Avoid losing control over the scope of the transactions because of poor error-handling routines or application logic.
Use
SET XACT_ABORT ONto avoid a transaction being left open on an error condition within the transaction.Execute the following SQL statement from a client error handler (
TRY/CATCH) after executing a SQL batch or stored procedure containing a transaction:IF @@TRANCOUNT > 0 ROLLBACK
Use the lowest isolation level required.
Use the default isolation level (Read Committed).
Consider using row versioning to help reduce contention.
You can automate the process of detecting a blocking condition and collecting the relevant information using SQL Server Agent. SQL Server provides the Performance Monitor counters shown in Table 12-1 to track the amount of wait time.
Table 12.1. Performance Monitor Counters
Object | Counter | Instance | Description |
|---|---|---|---|
|
|
| The average amount of wait time for each lock that resulted in a wait |
|
| Total wait time for locks in the last second |
You can create a combination of the SQL Server alerts and jobs to automate the following process:
Determine when the average amount of wait time exceeds an acceptable amount of blocking using the
Average Wait Time (ms)counter. Based on your preferences, you can use theLock Wait Time (ms)counter instead.Once you've established the minimum wait, set Blocked Process Threshold. When the average wait time exceeds the limit, notify the SQL Server DBA of the blocking situation through email and/or a pager.
Automatically collect the blocking information using the blocker script or a trace using the Blocked Process report for a certain period of time.
To set up the Blocked Process report to run automatically, first create the SQL Server job, called Blocking Analysis, so that it can be used by the SQL Server alert created later. You can create this SQL Server job from SQL Server Management Studio to collect blocking information by following these steps:
Generate a trace script (as detailed in Chapter 3) using the "
Errors And Warnings: Blocked process reportevent. Set a stop time to ten minutes greater than the current time. Using thesp_trace_createprocedure in the generated script, set the parameter@stoptime = SELECT DATEADD(mi,10,GETDATE()).In Management Studio, expand the server by selecting <ServerName>

On the General page of the New Job dialog box, enter the job name and other details, as shown in Figure 12-16.
On the Steps page, click New, and enter the command to run the trace script from a Windows command prompt (or you could run it from PowerShell or create the script as a procedure), as shown in Figure 12-17.
You can use the following command:
sqlcmd -E -S<servername> -iC: racescript.sql
The output of the blocker script is determined as part of the trace that you created.
Return to the New Job dialog box by clicking OK.
Click OK to create the SQL Server job. The SQL Server job will be created with an enabled and runnable state to collect blocking information for ten minutes using the trace script.

You can create a SQL Server alert to automate the following tasks:
Inform the DBA via email, SMS text, or pager.
Execute the Blocking Analysis job to collect blocking information for ten minutes.
You can create the SQL Server alert from SQL Server Enterprise Manager by following these steps:
In Management Studio, while still in the SQL Agent area of the Object Explorer, right-click Alerts, and select New Alert.
On the General page of the new alert's Properties dialog box, enter the alert name and other details, as shown in Figure 12-18. The specific object you need to capture information from for your instance is Locks (MSSQL$GF2008:Locks in Figure 12-18).
On the Response page, click New Operator, and enter the operator details, as shown in Figure 12-19.
Return to the new alert's Properties dialog box by clicking OK.
On the Response page, enter the remaining information shown in Figure 12-20.
The Blocking Analysis job is selected to automatically collect the blocking information.
Once you've finished entering all the information, click OK to create the SQL Server alert. The SQL Server alert will be created in the enabled state to perform the intended tasks.
Ensure that the SQL Server Agent is running.
The SQL Server alert and the job together will automate the blocking detection and the information collection process. This automatic collection of the blocking information will ensure that a good amount of the blocking information will be available whenever the system gets into a massive blocking state.
Even though blocking is inevitable and is in fact essential to maintain isolation among transactions, it can sometimes adversely affect database concurrency. In a multiuser database application, you must minimize blocking among concurrent transactions.
SQL Server provides different techniques to avoid/reduce blocking, and a database application should take advantage of these techniques to scale linearly as the number of database users increases. When an application faces a high degree of blocking, you can collect the relevant blocking information using a blocker script to understand the root cause of the blocking and accordingly use an appropriate technique to either avoid or reduce blocking.
Blocking can not only hurt concurrency but can also cause an abrupt termination of a database request in the case of circular blocking. We will cover circular blocking, or deadlocks, in the next chapter.