
R E P R I N T 1
![]()
packetC Language for High Performance Packet Processing
by Ralph Duncan and Peder Jungck
Abstract
Increasingly, applications that process network packets, especially those that inspect packet payload content, need to run at speeds in the range of 1-40 Gigabits per second. These requirements encourage exploiting specialized hardware. Thus, typical approaches involve programming a specific network processor in assembly language or a C dialect that exposes machine-specific particulars so developers can closely control task switching and machine-specific resources. This paper describes CloudShield Technology's alternative approach, which combines a parallel model, the packetC language and heterogeneous multiprocessor implementations. The parallel packet processing model uses coarse-grain, SPMD parallelism to free users from thread management and it requires the host system to locate protocol headers in the packet before a parallel copy of the program executes. The packetC language abstracts and encapsulates familiar packet processing data sets and operations into new aggregate data types and operators, e.g., for packets, databases and searchsets. These language constructs can be implemented by ordinary arrays, strings, instructions, etc. However, they are especially amenable to being implemented with specialized hardware without requiring any specific hardware. Our current implementation combines FPGAs, microcoded NPUs (Network Processing Units), content addressable memories and other specialized chips.
Categories and Subject Descriptors D.3.3 [Programming Languages]: Language Constructs and Features – data types and structures
General Terms Languages.
Keywords high performance, deep packet inspection, network processing; programming languages, parallel processing
1. Introduction
Designers of systems that process network packets are pushed to provide ever higher performance by several factors. First, the sheer amount of data to be moved continues to increase, as audio and video data continues its march from dedicated appliance to personal computer to hand-held device. Second, the transmission mediums offer ever faster transmission speeds (e.g., those specified by SONET/SDH[1,2] and 10GbE) [3].
The need for faster packet processing is especially evident in applications that perform deep packet inspection (DPI), e.g., those that recognize viruses or perform legal intercepts for law enforcement agencies [4]. These applications not only find and analyze protocol headers in the packet (such as those for TCP or IPv4); they also examine the packet's contents or payload, For example, deep packet inspection may consist of searching the payload for the presence of a particular computer virus or other items of interest. The proliferation of malicious software artifacts heightens the demand for secure services that execute DPI actions at a time when the sheer volume of data to be checked and the speed at which the checking must be done is also increasing.
Our reaction to these pressures is to harness both parallel computing and specialized processors to do the needed packet processing. However, it is desirable to free network application developers from the mechanics of managing parallel processes as much as possible. Similarly, abstracting the details of specialized devices from the software development process will streamline the application software lifecycle, as well as increase the resulting applications' portability. With these goals in mind, CloudShield developed a general model of parallel packet processing, defined a high-level packetC language to express the model and produced a heterogeneous multiprocessor to implement it (Figure 1).
2. A Parallel Packet Processing Model
The model's overriding goal is to present an intuitive view of parallel packet processing to the developer, one in which task management mechanics are largely hidden, memory is partitioned in a straightforward way and predictable protocol analysis is performed by the system as part of setting up an individual program copy for execution.
The main structural components of the model are listed below and shown in Figure 2:
- Parallel tasks are expressed at the level of a small program processing a single packet (SPMD, Single Program Multiple Data parallelism).
- There is a ‘global ’memory shared by all packet programs and private memories for each program copy.
- Data stores in the shared memory capture application domain information, such as session, protocol and search term data.

Figure 1. Relationships: among the parallel processing model, packetC language, hardware platform
- The host system manages program copies and pre-calculates layer offsets (protocol header locations) that are present in the packet.
With this model developers design a program to process a single packet, instead of designing a central program and a set of discrete tasks. Application developers rely on the host system to replicate the program, provide each program copy with packets to process and steer processed packets to the next stage of the encompassing system (or to the oblivion of being dropped).
Application developers are not involved with synchronizing individual tasks. However, some developer awareness of parallelism is required when dealing with shared data. There are three basic kinds of shared data. First, packet and session information that is of interest to multiple program copies should be shared, e.g., to recognize denial of service attacks originating from a particular origin. Second, program copies may have common search terms, e.g. a character sequence that characterizes a particular computer virus. In addition, users may want to manage global counters, buffers and so forth.
A key aspect of the model is its requirement that the host system prepare two things for each packet program copy before it is triggered:
- Access to the packet, itself, in the form of an array of unsigned bytes (in big endian order).
- A collection of flags and integers that indicate whether a standard protocol layer is present in the packet and, if it is, the offset from the packet array's start where that protocol information (header) is found (Figure 3).
System calculation of protocol offsets before a program copy is triggered is significant because detecting the presence of various standard network protocols (equivalent to naturally aligned C-style structures) involves non-trivial processing. Thus, the model frees application developers to concentrate on what is distinctive in their packet application, not what is common.
Using this model to develop high performance applications requires a programming language that provides parallelism at a coarse level of granularity and that can be mapped to specialized hardware that satisfies the requirements for layer offset precalculation. The next section describes our attempt to define such a language.
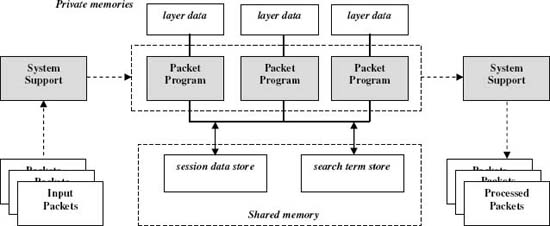
Figure 2. Parallel packet processing model. Copyright CloudShield Technologies, 2008.

Figure 3. System-provided data for each packet program copy. Copyright CloudShield Technologies, Inc., 2008.
3. packetC Language
The packetC language [5] was developed from the following imperatives:
- Use the C99 variant of the C language [6] for operators (arithmetic, logical and bitwise), conditional statements and overall syntax.
- Avoid runtime crashes by removing pointers, address operators and dynamic memory allocation (and by using unsigned integer arithmetic that wraps, rather than overflows or underflows).
- Increase result reliability by stronger typing rules and by avoiding implicit type conversions or promotions; require explicit, readily traced conversions.
- Support the model's SPMD parallelism and its shared memory aggregates for session and search term data.
A short paper cannot exhaustively present language features, though a forthcoming Specification will do that [5]. Instead, we sketch features most involved with parallelism and optimized application performance. Those constructs and the corresponding parallel model features are show below and in Figure 4.
- Packet program copies are expressed with a packet main program.
- Shared and private memories are specified through a simple scheme for locating their declarations in the source code text.
- The pre-calculated layer offset information is available to each packet main in a system-provided structure, the packet information block (PIB).
- Shared session and protocol information is kept in database aggregates and individual records.
- Shared search items in string and regular expression form are represented by the searchset aggregate type.
These constructs are present because they address fundamental application domain needs. However, their specific form is also intended to facilitate optimizations and implementation by specialized hardware. A more detailed discussion of key constructs follows.
3.1 Program Structure overview: packet main, shared and private memories
In this short discussion we are interested in the packetC packet module. A simplified description of the module's structure is given below.
<module header>
<global decls> // types, fns, vars
<packet main>
<optional function declarations>
This structure is similar to C/C99 programs but has some key differences. The components are shown in example code below, then discussed.
packet module malwareDetector;
// global section
int trojansFound = 0; //sharedCounter
void someUtilityFn(int i) {…}
// type, database & searchset decls
// function declarations
void main ( $PACKET currPack ) {
// type, alias, variable decls
…
// body of program to be replicated
}
// optional forward decl'd functions
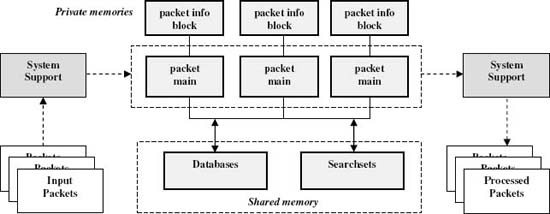
Figure 4. Mapping the packet processing model to packetC language constructs. Copyright CloudShield Technologies, 2008.
The module header declaration identifies whether this is a packet module to be replicated (parallelized) or one of the other module types.
Global declarations are visible from the point of their appearance to the bottom of the module text. Thus, placing type, alias or constant declarations here is a matter of arranging desired visibility. The extended aggregate types, databases and searchsets, are always declared here and shared by all program mains. Functions can be declared or included here.
The packet main is similar in appearance to a C main but it is not a true function and has the following characteristics:
- The packet main is the unit of parallelization. The host system effectively produces as many copies as feasible, though it has wide latitude in choosing how to accomplish this.
- Packet mains do not return values.
- Nested function declarations may appear immediately after main's arguments but before any executable statements or other kinds of declarations.
The packet main is the essential unit of parallel execution, but much of the domain-specific capability resides in the data structures and operations on them described below.
3.2 Shared Memory and Semaphores
Although most parallel processing mechanics are hidden from the user, packetC does provide an explicit means to coordinate parallel processes' access to shared variables. Mutual exclusion is provided by the lock and unlock constructs, which offer a mutex or binary semaphore capability [7]. The constructs act as binary operators; each takes a global variable as an argument. Lock returns the true value if the variable was unlocked and the packet main (process) executing the lock attempt has just locked the variable. Similarly, unlock returns true if the variable is unlocked, whether it already was unlocked or was locked by the process executing unlock and has now become unlocked. A simple spin-lock example follows.
int myInt; // in shared space
…
while ( ! lock(myInt) ) {}; //spin lock
…// while myint is locked take actions
unlock( myInt );
3.3 Packet Information Block and Descriptors
The PIB holds the results of pre-scanning the packet for Layer 2, 3 and 4 locations. (Layer terminology refers to the seven network layers defined by the OSI model [8]). This data is determined afresh for each packet, i.e., for each copy of the packetC program. Thus, the location of a particular kind of protocol header may vary from one packet to another. The key kinds of PIB data are whether a given kind of protocol header is present, its location (if it is) and additional ‘type ’information about the sort of transmission that the packet represents. PIB definitions are shown below with omissions for readability.
typedef int $PACKETINFO$;
typedef int $PACKETFLAG$;
// define actions upon egress
enum int $PACKET_ACTION {
DROP_PACKET,
FORWARD_PACKET
};
// define types for OSI layers 2-4
enum $PACKETINFO$ L2TYPE {
L2TYPE_OTHER = 0,
L2TYPE_SONET_PPP = 1,
…
L2TYPE_802_3_802_1Q = 36;
};
enum $PACKETINFO$ L3TYPE {…};
enum $PACKETINFO$ L4TYPE {
L4TYPE_OTHER = 0,
L4TYPE_TCP = 1,
L4TYPE_UDP = 2,
…
L4TYPE_SCTP = 8;
};
struct $PIB {
$PACKET_ACTION action;
$PACKETINFO$ length;
bits $PACKETFLAG$ {
replica : 1;
L3_chkSum_valid : 1;
L3_chkSum_recalc : 1;
L4_chkSum_valid : 1;
L4_chkSum_recalc : 1;
IPV6_fragment : 1;
…
pad : 22;
} flags; // end of container
L2TYPE L2_type;
L3TYPE L3_type;
L4TYPE L4_type;
$PACKETINFO$ L2_offset;
$PACKETINFO$ MPLS_offset;
$PACKETINFO$ L3_offset;
$PACKETINFO$ L4_offset;
$PACKETINFO$ payload_offset;
$PACKETINFO$ P_destAddr_offset;
}; // end of struct
This information is most effectively exploited by the packetC descriptor construct. A descriptor is a C-style structure with a starting address that is an offset into the packet (byte array). The descriptor is essentially superimposed on the packet array. In practice, a descriptor starting address (defined by an atclause) usually includes one or more PIB offset values. This lets the descriptor, which commonly defines a protocol header, vary with each execution of a packet main. With this practice, the descriptor will always capture the requisite information, as it moves to the packet location where the PIB indicates that a given protocol begins. The example below shows a descriptor.
descriptor TCPstruct {
short sourcePort;
short destPort;
int sequenceNum;
int ackNum;
_
} cs_TCP_protocol at pib.L4_Offset;
3.4 Databases: Types, Masking and Operations
Packet processing applications often store data from one packet (e.g., IP source and destination addresses, protocols, etc.) and consult that data while processing a subsequent packet. To handle such data collections, packetC provides a database type, which is treated in source code as a 1-dimensional array of user-defined, C-style structures (Figure 5). packetC implementations can implement databases with arrays, content-addressable memory, database chips and so forth. A sample declaration of a database and its base type structure is shown below.
struct stype { short dest; short src;};
database stype myDB[50];
Applications often match data in the current packet against a subset of each database record, e.g., find a database record which matches an IP source address. Associating a mask with database records facilitates matching only the data subset of interest. Thus, packetC databases and records (individual database elements) are implicitly masked. Given a database or record base type s, a packetC compiler creates a structure composed of data and mask fields, each of structure type s. Thus, the type for each database element in the sample code above is effectively:
struct newtype { stype data; stype mask;};
Defining masks in terms of structure fields is more intuitive and reliable than defining them in terms of long hexadecimal literals. Although the user does not have to explicitly declare the mask portion of databases or records, they must take masks into account with initialization and assignment or have all mask bits default to a value of 1.
record stype aRec = {{0,16},{0,0xffff}};
The only portions of a database element's data portion that is used in matches are those which have bits in the corresponding mask part set to 1 (see Figure 5).
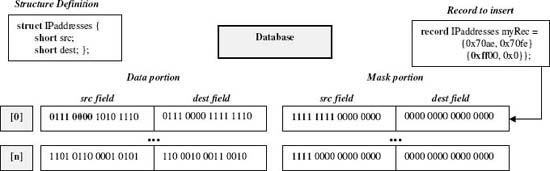
Figure 5. Inserting a record with mask bits set for part of an IP address packet field. Copyright CloudShield Technologies, 2008.
Masked database operations – creating, modifying and matching records -- create multiple optimization opportunities:
- Streamlining representations and operations when all of a database's mask bits are set or all records use the same mask.
- Managing constant mask values and mask values known at compile-time.
- Tracking the flow of mask value changes.
- Using specialized hardware for database operations.
We use C++-style method syntax for database-specific operations. Other operations (e.g., assignment, arithmetic) use familiar C operators and, when appropriate, array syntax to indicate individual database elements.
row = myDB.insert( aRec );// return row
myDB[3].delete();
myDB[4].data = myStruct;
// ret matching DB element idx, offset
resultStruct = myDB.match( myStruct );
3.5 Searchsets: Types and Operations
packetC supports examining packet content (the payload or portion other than protocols) with a searchset aggregate. Sear-chsets are syntactically similar to 2-dimensional byte arrays of strings and support matching:
- Ordinary strings.
- Regular expressions.
A searchset declaration's leftmost dimension specifies the number of strings, while the rightmost one specifies the maximum string length. Null terminators are explicitly expressed.
searchset ss[2][4] = {“cat”,”dogx00”};
regex searchset rSS[2][7] =
{“.*?mail”, “.*?from” };
Searchset operators, match and find, also use a method-like syntax to specify that an argument, typically the packet, another array or an array slice, will be searched in an effort to match the searchset's strings or regular expressions. For a searchset element of n bytes, match tries to match against the argument's first n bytes (with intuitive rules to handle mismatched size scenarios). Find seeks to locate the searchset contents to any contiguous bytes within the argument.
ans = ss.match( packet[32:35] );
ans = rSS.find( entirePacket );
As is the case with database operations, these operations are amenable to optimizations, especially by using firmware, FPGAs and specialized chips. The next section sketches how CloudShield maps language constructs to specialized hardware to optimize packetC performance.
4. Mapping packetC to a Heterogeneous Multiprocessor
CloudShield Technologies produces a family of heterogeneous multiprocessors for high-performance network packet processing, for example, the CS-2000 [9]. The hardware particulars are the object of both granted and ongoing patent activities; not all architectural details are made public. Thus, the intent of this section is to maintain trade secrets while imparting enough information to give the reader a sense of how packetC constructs can be implemented to deliver high performance. The general hardware mapping is indicated by Figure 6. Implementation highlights are as follows:
- FPGAs and microcode running on a dedicated subset of NPU (Network Processing Unit) cores control the packet pipeline, analyze the packet and pre-locate protocol headers.
- An ensemble of NPU cores, each running multiple contexts, executes the program copies and dedicated system programs (see below). Although past products have dedicated as many as 288 contexts to running user programs, the current, faster NPUs employ 88 user program contexts. Forthcoming products will employ more than a thousand.
- Commodity memories provide the processing ensemble with memory for variables and aggregates local to a packet main program.
- A custom FPGA and DRAM provide the shared memory for scalars and C-style aggregates.
- packetC databases are mapped to commercial T-CAM (Ternary Content Addressable Memory) chips with NPU microcode implementing complex database instructions.
- Searchsets are implemented in several ways, e.g., by using specialized regular expression processor chips and dedicated NPU cores to implement search instructions.
Allocating packetC functionality to specialized processors and memories plays an essential role in achieving high performance. Orchestrating this diverse ensemble is also critical. However, what distinguishes packetC from similar packet processing languages is not that specialized devices are involved in fielded applications but how the machine specifics are hidden in the language. With that in mind, the next section reviews other approaches to programming languages for high performance network applications.
5. Related Work
Recent research and commercial efforts include a variety of efforts to develop programming languages that support high performance network packet processing applications.
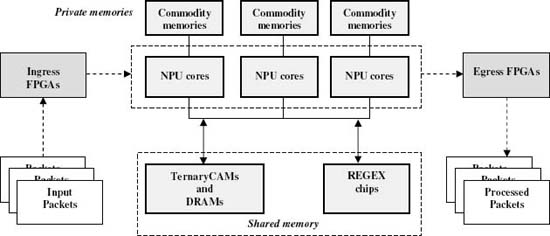
Figure 6. Mapping packetC language constructs to physical components. Copyright CloudShield Technologies, 2009.
In [10] L. George and M. Blume present the NOVA language and compiler for the IXP network processor. NOVA features include aggregates in the form of records and tuples, familiar control-flow constructs, functions and exceptions. NOVA and packetC share an aversion to run-time memory allocation: both omit C-style malloc functionality or recursive functions. The language does allow mutual dependencies “but all recursive calls are restricted to be in tail-call position” [10]. However, like most network programming systems, NOVA does not presume that the host system finds network protocol headers before a program runs. Instead, it provides a layout construct to provide bitfield capabilities useful for finding and manipulating headers in the packet.
Intel Corporation's Microengine C is targeted to the IXP1200 chip [11]. This is a C dialect with domain-driven omissions (floating-point type, function pointers or runtime stack) and many extensions. The IXP architecture features a general-purpose processor and six microengines, RISC processors optimized for packet processing. The processing model is a threading model; programs are broken into multiple threads that are partitioned across multiple microengines. The user manages communications among threads and processes and typically swaps out a task that reads from or writes to memory. Microengine C reflects machine-specific memory classes, FIFOs and register classes. The language provides an extensive battery of intrinsics and support for inlining that facilitates exploiting the architecture.
NetPDL (Network Protocol Description Language) [12, 13] is an XML-based language aimed at developing a database of standard network protocols, i.e., header descriptions for standard protocols. The designers seem primarily interested in providing a reusable repository of protocol definitions, rather than in defining an application language, although the language does include provisions for expressions and application development.
J. Wagner and R. Leupers discuss a C dialect and its compiler for the Infineon network processor [14]. The key language extensions provide the capability to manipulate protocol headers by mapping parts of the packet to special registers and accessing arbitrary bit-width operands without the usual alignment restrictions. The compiler maps C arrays with the register qualifier to a special register file. By using an Infineon bit-field pointer and bit-width arguments, the programmer can specify operands within the register file that have arbitrary sizes and alignments, including those that span more than one register. Compiler intrinsics (compiler-known functions) are the key language extension that grants users access to these capabilities at a high language level.
CUDA is a parallel processing architecture for programming NVIDIA graphics processing units (GPUs) [15]. Although it is targeted to computer game processing (e.g., image texture rendering), it has been used for other kinds of application as well. CU-DA is designed for executing a large number of program threads in a fine-grained parallel fashion. Threads are organized into independent thread blocks, which share memory and synchronization barriers. Because of the overhead of transferring data into the GPUs, this approach encourages executing as many instructions as possible for each memory access. The language reflects the NVIDIA GPU hardware, organized as a set of SIMD multiprocessors with shared memory.
None of these languages share packetC's requirement for system-furnished protocol location, although NOVA and the Infineon C dialect facilitate user protocol location. Whereas packetC uses coarse-grain, SPMD parallelism, other languages use very fine-grain parallelism, e.g., Microengine C and CUDA. Other approaches often expose a specific machine's registers or memory organization, where packetC defines functional entities, such as databases and searchsets, which are amenable to specialized hardware implementation without requiring any specific one.
6. Status and Future Research
We have developed a cross-compiler for packetC that runs under both Windows and Linux and targets several CloudShield products. The compiler implements all the major extensions to C but has some gaps. Testing and use status is as follow:
- The prototype compiler passes more than 1800 custom language validation tests.
- The compiler passes a collection of domain-specific tests, handling access control lists and recognizing a large number of standard protocol headers.
- Selected users are experimenting with a beta-release.
Since the compiler is immature, we plan substantial enhancements for both classic and domain-specific optimizations. The two major data type extensions, databases and searchsets, offer significant possibilities for further optimization. Database masking can be optimized by managing predictable kinds of masks (e.g., with all bits set, with one or two statically-defined user masks), as well as by tracking how dynamic mask values are assembled. Searchset operations are also a rich source of potential optimization, such as using alternative implementation strategies based on the characteristics of the searchset or of searchset arguments (such as array slices) that are determined at run-time. Our efforts will be geared to both classic flow analysis and on the possibilities offered by a heterogeneous multiprocessing platform.
7. Summary
At the level of individual language constructs, databases and searchsets are natural extensions for packet processing in general and deep packet inspection in particular. However, the most promising language construct may be the descriptor feature, which effectively lets protocol headers automatically move to the relevant location in each packet. Rather than search a large byte array or buffer for the headers, the user defines structures that ‘float’ to the correct location without user intervention. Moreover, by linking successive descriptor at-clause addresses, the user can readily build a protocol header stack.
Ultimately, packetC's contributions to the packet processing language spectrum revolve around how it treats machine specifics. Instead of being geared to a single specialized processor (e.g., by offering language extensions that reveal a network processor's register groups, FIFOs, etc.), the model and language view the system as a collection of specialized components. Thus, the language hides specific processor characteristics not as a conceptual nicety but because the model and language view the system as:
- A collection of many different specialized components. Thus, no one component receives privileged treatment to expose its specifics for programmer manipulation.
- An ensemble of changeable components. Implicit in this world-view is the notion that any particular component (i.e., a chip currently providing database or string-matching services) is apt to be changed.
Thus, packetC and its parent model embody a dynamic perspective of packet processing systems: one where systems are composed of highly specialized devices that may be replaced at any time. A major benefit of this approach is the opportunity to develop high performance, real-time packet applications that do not require sweeping recoding when different hardware components are introduced.
Acknowledgments
This research was supported by US Air Force contract FA 7037-04-C-0011. Peder Jungck, Dwight Mulcahy and Ralph Duncan are the co-authors of the packetC language. Gary Oblock and Matt White contributed to language and compiler development. Andy Norton, Kenneth Ross, Kai Chang, Mary Pham, Alfredo Chorro-Rivas and Minh Nguyen provided valuable help. Professors Rajiv Gupta and Rainer Leupers contributed citations and papers. Detailed referee comments were especially helpful.
References
[1] ANSI T1.105: SONET - Basic Description including Multiplex Structure, Rates and Formats.
[2] ANSI T1.119/ATIS PP 0900119.01.2006: SONET - Operations, Administration, Maintenance, and Provisioning (OAM&P) - Communications.
[3] IEEE Std 802.3ae-2002. To be superseded by more recent but not finalized IEEE Std 802.3-2008.
[4] N. Anderson, Deep packet inspection meets 'Net neutrality, CALEA. July 25, 2007, retrieved on January 16, 2009 from http://arstechnica.com/articles/culture/Deep-packet-inspection-meets-net-neutrality.ars.
[5] CloudShield Technologies. “packetC Programming Language Specification. Rev. 1.128, October 10, 2008.
[6] ISO/IEC 9899:1999. Standard for the C programming language. May 2005 version. (‘C99’).
[7] M. Raynal, A simple taxonomy for distributed mutual exclusion algorithms. ACM SIGOPS Operating Systems Review, 25(2), 47-50, 1991.
[8] International Organization for Standardization (ISO) 7498. Open Systems Interconnections (OSI) reference model, 1983.
[9] CloudShield Technologies. CS-2000 Technical Specifications. Product datasheet available from CloudShield Technologies, 212 Gibraltar Dr., Sunnyvale, CA, USA 94089, 2006.
[10] L. George and M. Blume. Taming the IXP network processor. In Proceedings of the ACM SIGPLAN ‘03 Conference on Programming Language Design and Implementation, San Diego, California, USA, ACM, pp. 26-37, June 2003.
[11] Intel Microengine C Compiler Language Support: Reference Manual. Intel Corporation, order number 278426-004, August 10, 2001.
[12] NetPDL Core Specification, NetBee. Retrieved from www.nbee.org/doku.php?id=netpdl:core_specs on 01/07/2009.
[13] F. Risso and M. Baldi. NetPDL: an extensible XML-based language for packet header description. In Computer Networks. The International Journal of Computer and Telecommunications Networking, 50(5), 2006.
[14] J. Wagner and R. Leupers: C compiler design for a network processor. IEEE Trans. On CAD, 20(11): 1-7, 2001.
[15] NVIDIA Corporation. NVIDIA CUDA Compute Unified Device Architecture: Programming Guide. Version 1.0, June 23, 2007.
R. Duncan and P. Jungck. “packetC language for high performance packet processing.” In Proceedings of the 11th IEEE Intl. Conf. High Performance Computing and Communications, (Seoul, South Korea), pp. 450–457, June 25–27, 2009. Reprinted with permission from Springer Science+Business Media.