
R E P R I N T 3
![]()
Dynamically Accessing Packet Header Fields at High-speed
by Ralph Duncan, Peder Jungck and Kenneth Ross
Abstract
A significant part of packet processing consists of detecting whether certain standard protocol headers are present, where they are located and whether they include optional information. Packet processing programs are on tight time budgets, especially to handle speeds in the gigabits per second (gbps) range. Thus, high-speed mechanisms for finding and accessing headers are critical. Our approach lets users define headers as C-style structures in a high-level language, packetC [1], and specify header locations in terms of offsets from the start of the current packet, which is treated as an array of unsigned bytes. These offsets can be expressed in terms of network layer offsets, constant values, runtime-calculated variables and combinations of all of these. This paper focuses on the principal forms these offset expressions can take and on how our FPGAs (Field Programmable Gate Arrays), compiler and interpreter collectively handle them at runtime. For simple and complex header offset scenarios we provide users with intuitive, high-level ways to describe offsets and provide effective runtime mechanisms to access header fields.
Categories and Subject Descriptors D.3.3 [Programming Languages]: Language Constructs and Features – data types and structures
General Terms Languages.
Keywords parallel processing, packetC, network processing, network protocols
1. Introduction
A major part of packet processing consists of detecting whether specific protocol headers are present in the packet, where they are located and whether they include optional fields. Since packet processing programs are on tight time budgets, especially when handling speeds of 10-40 gigabits per second (gbps) or greater, high-speed mechanisms for finding and accessing headers are critical.
The CloudShield approach lets users define protocol headers as C-style structures in a high-level language, packetC [1] and specify header location in terms of offsets from the start of the current packet, which is treated as an unsigned byte array.
These offsets can be expressed in terms of
- Network layer offsets (for layers two, three and four)
- Fixed values (unsigned integer literals)
- Runtime-calculated variable values
- Combinations of all three
A previous paper described our high-level approach to protocol processing, focusing on system data structures and the packet descriptor data type [2]. This paper emphasizes
- The several forms that offset expressions can take
- How FPGA preprocessing, the compiler and the interpreter contribute to handling the several forms
- Providing users a fast way to access protocol fields for each of the different offset scenarios.
The paper is organized in the followed way. First, we sketch other programming languages' treatment of headers. Second, we summarize CloudShield's overall approach to parallelism and to packet-oriented programming. We then describe the three basic forms of protocol offset calculation and how our implementation handles them. A performance section illustrates each form with an application example and presents performance data. Concluding remarks summarize the forms, their application and their performance.
Intel Corporation's Microengine C is a C dialect for programming its IXP1200 network processor family[3]. The IXP multi-core architecture features a general-purpose Reduced Instruction Set (RISC) processor core and multiple microengine cores optimized for packet processing. A library of macros, functions and data types accompanies Mi-croengine C [4] and provides structure types for standard protocols, such as IPv4. The structures are not automatically associated with packet locations. Users employ library functions to read, verify or write specified protocol fields [4] (for examples, see p. 3-107).
J. Wagner and R. Leupers discuss a C dialect for the Infineon network processor [5]. The language supports processing header fields by allowing portions of the packet to be mapped to special registers and by providing compiler intrinsics (functions known to the compiler) that manipulate those registers. The intrinsics allow users to flexibly manipulate register operands as having arbitrary bit-widths, lacking typical alignment restrictions and having the ability to span multiple registers. The system is not geared to automatically locating protocols but rather to aiding the application program in finding and accessing headers.
NetPDL (Network Protocol Description Language) [6] is an XML-based language for recognizing, describing and displaying standard network protocols. A primary motivation for NetPDL development appears to be developing XML protocol descriptions that can be reused in a variety of software tools. The NetPDL Core Specification [7] provides expressions and logic for recognizing protocols and optional fields.
L. George and M. Blume describe the NOVA language geared to the IXP network processor in [8]. NOVA does not automate locating protocol headers but supports describing and manipulating headers through a layout data type, which has packed and unpacked forms. As the code examples below show, the packed form is similar to a C-style bitfield description of the entire structure, whereas the unpacked form describes the structure a word at a time.
Layout ipv6header = { // packed form;
version : 4,
priority : 4,
flow_label :24,
… } type unpacked (ipv6header) = [
version : word,
priority : word,
flow_label : word,
]
An overlay construct lets users specify alternative layout internal organizations. In response the NOVA compiler apparently generates instructions to store appropriate values into the various alternatives.
Although our data type for representing protocol headers has similarities to the structure-based types described above, it differs significantly in its capacity for expressing a runtime offset where the header will be located. Calculating information related to that offset is, in turn, tied to our model for parallel packet processing.
3. Parallel Processing Model
Our model is geared to presenting application developers with an intuitive view of parallel packet processing and with a machine-independent approach to programming such applications. Thus, significant model features are:
- Using coarse-grained parallelism at the packet level
- Hiding machine specifics with a high-level programming language, packetC [1]
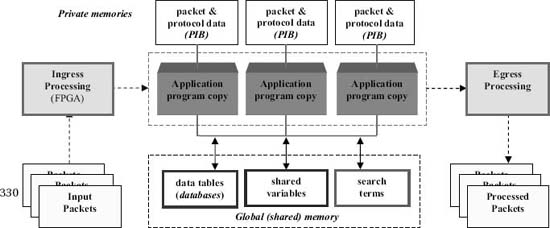
Figure 1. Parallel packet processing model. Copyright CloudShield Technologies, 2011.
- Providing application domain capabilities via data type extensions
- Hiding machine specifics behind a virtual machine.
In packetC developers express parallelism at a coarsegrained level with a small program (a packet main) that completely processes one packet at a time. Concurrently executing copies of such a program constitute single program multiple data (SPMD) parallelism. This kind of coarse-grain parallelism frees the developer from fine-grain mechanics, like synchronizing low-level tasks.
This parallel packet processing model is shown in Fig. 1. When packets enter the system an ingress processor searches the packet for protocol headers, prepares a packet information block (PIB) that characterizes the current packet, and writes the packet as an array of unsigned bytes. The system allocates each packet to a context (an application program copy) which processes it from start to finish.
As the figure shows, each application copy has a private memory for variables. In addition, each program copy may access data structures in a global or shared memory.
Upon a program copy's completion, its current packet can be dropped, forwarded or re-queued. When a packet is forwarded it is sent to an egress processor for postprocessing and routing.
The model can be implemented in a variety of ways. Our current implementation combines using a heterogeneous set of processors and using the packetC programming language, described in the next section.
4. Programming Language Approach
The packetC language [1] is designed to express parallel network applications in terms of
- A short, cohesive program, not a set of lower-level tasks
- Extended data types and operators that resemble familiar high-level language constructs
In line with these objectives, packetC uses the C99 variant of C for operators, conditional statements and overall syntax. Because of the high security and reliability requirements in many packet-processing environments, C constructs for address operators, pointers and dynamic allocation are not available. packetC's most distinctive features are the following data type extensions (and their operators):
- Databases: symmetrical structures organized into data and mask halves with the same user-specified structure base type [9].
- Searchsets: aggregates composed of strings or regular expressions to match against packet contents [10].
- References: a classic, computer science reference capability for abstracting database and searchset operations.
- Descriptors: structs that automatically move to a packet location to overlay a protocol header.
The descriptor type – and the effective implementation of expressions specifying its runtime location – is the primary subject of this discussion. The next section describes this data type in detail.
5. Descriptors and At-Clause Expressions
The packetC descriptor construct has been discussed in detail elsewhere as a data type [2]. As the example below shows, it is a C-style structure with differences in bitfield syntax and semantics to reduce implementation variation.
descriptor ipv4Descr {
bits byte {
version : 4;
headerLength: 4;
}
byte typeOfService;
short totalLength;
short ipv4_identification;
short ipv4_fragmentOffset;
byte ipv4_ttl;
byte ipv4_protocol;
short ipv4_checksum;
int ipv4_sourceAddress;
int ipv4_destaddress;
int ipv4_payload;
} ipv4Header at pib.L3_offset;
The primary difference between structures and descriptors is that the latter has an at-clause to describe where it will be at runtime in terms of being superimposed onto the current packet, described as an array of unsigned bytes. An at-clause may either specify a static location (offset from the packet's start) where the descriptor will be found for any packet or specify an offset that must be dynamically calculated and can vary in value from packet to packet.
The canonical form of an at-clause expression is
layerOffset + literalValue + userVariable
where the terms are defined as follows:
- layerOffset: one of the several standard offsets that the model dictates should be pre-calculated (in our case it is done by an FPGA; see ingress processing in Fig. 1): L2, L3, L4, MPLS and payload offsets
- literalOffset: a user-provided integer literal, which may be subject to implementation-specified limitations
- userVariable: a user-specified variable; its presence in the expression forces a dynamic, runtime calculation of the expression's value.
Although no one of the three terms must be present in a legal at-clause expression, at least one of them must be. Each of the three terms involves different runtime mechanisms with different performance implications. The section that follows describes and illustrates those mechanisms.
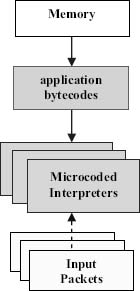
Figure 2. Interpreters applying a program to input packets. Copyright CloudShield Technologies, 2011.
6. Packets in Virtual Machine and Bytecodes
Our current implementation compiles packetC source code into bytecodes that are processed by microcoded interpreters. These interpreters implement the virtual machine described by the bytecodes. Although some by-tecode details are proprietary, the bytecodes let the program's current packet be indexed in two ways:
- Via ordinary indexing: the user explicitly specifies index terms with positive integer values
- Via packet access constants: the compiler creates integer values that encode an invariant packet offset in terms of one of the precalculated offsets (see section 5), plus an optional constant displacement.
At any given time, dozens of copies of the interpreter (more than 90) are concurrently interpreting an application's bytecode representation, each of them applying the program to a different packet (Fig. 2).
7. Protocol Access Scenarios and Mechanisms
An example application, albeit simplified, illustrates the three basic forms that a descriptor at-clause can take and the kind of protocol header scenarios that they describe. Different runtime mechanisms can be used to calculate where the descriptor's fields are located for these scenarios. The application examines a DNS response to a query for the IP address of www.cloudshield.com and extracts contents of specific fields.
7.1 Simple Layer Offset
The example involves the three headers shown in Fig. 3 (the layer two, three and four headers are not shown). The first protocol of interest is a DNS response protocol.
Its offset from the beginning of the packet is defined by the start of the packet payload, which is pre-calculated by the ingress processor FPGA, as shown in Fig. 1.
Thus, we know at compile-time that the payload offset value will be present in the PIB field, payloadOffset, at runtime. For each descriptor field the compiler generates a packet access constant (PAC) that encodes a designator for the payload offset and the field's offset from the descriptor's start. The descriptor is shown below.
descriptor DNSResponseStruct {
short transactionID;
bits short
{
Response : 1;
opcode : 4;
authoritative : 1;
truncated : 1;
recursion : 1;
recAvail : 1;
z : 1;
answerAuth : 1;
nonAuth : 1;
replyCode : 4;
} flags;
short questions;
short answerRRs;
short authorityRRS;
short additionalRRs;
} DNS_response at pib.payloadOffset;
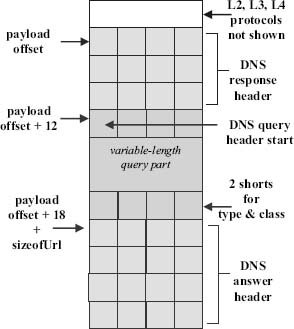
Figure 3. DNS query response headers. Copyright CloudShield Technologies, 2011.
7.2 Layer Offset Plus Constant
A DNS query header reiterates the original question and follows the DNS response header, which has a fixed size of twelve bytes (see Fig. 3). Thus, the query header's runtime location will always start at twelve bytes past the payload offset, as shown in the descriptor specification below. Our compiler generates a value that indicates which pre-calculated offset is needed and the 12 byte displacement.
descriptor DNSQueryStruct {
byte prefixLength; // always present
byte prefixByte1;
…
byte prefixByteN;
byte nameLength; // always present
byte nameByte1;
…
byte nameByteN;
short type; // always present
short class; // always present
} DNS_response at pib.payloadOffset + 12;
This header has variable-length fields for the answer prefix (e.g., “www”) and the name. Thus, we cannot know at compile-time precisely where headers that follow this one will start. Instead, such headers' at-clauses must describe an offset that will be calculated at run-time: as the next section shows.
7.3 LayerOffset Plus Constant + User Dynamic Value
The DNS answer header immediately follows the DNS query header, which always starts twelve bytes past the payload offset. The query header's size will be the invariant part (the four fields marked as “always present” in the code above), plus whatever the variable portion is for a given query. Thus, the DNS answer header's offset will be
- The DNS query header offset ( payload offset + 12 bytes), plus
- The length of the DNS header's invariant part ( six bytes total for the four fields always present), plus
- The length of the DNS header's variable portion, calculated by the user-supplied function sizeOfUrl.
The resulting descriptor is shown below.
descriptor DNSAnswerStruct {
short name; // an alias for the URL
short type; // type of the alias
short class; // class of response data
short ttl1; // time to live (1st half)
short ttl2; // time to live (2nd half)
short data; // length of the data
int addr; // IP address of the URL
} DNS_answer at
pib.payloadOffset + 18 + sizeOfUrl();
For this case the compiler generates code to calculate a variable value that combines the PIB's payloadOffset field, the literal 18 and the result of a call to the user-specified function, sizeOfUrl. The next section compares the performance differences that result from these scenarios.
8. Experiments
This section shows the performance range for accessing headers with the three basic kinds of descriptor at-clause:
- Pre-calculated layer offset only
- Pre-calculated layer offset + constant
- Pre-calculated layer offset + constant + runtime-calculated value.
In each case a 32-bit integer field in a header is accessed and assigned to a variable (shown below). On our machine the first two operations can be realized with a single byte-code via packet access constants (Sec. 6). The DNS answer case not only requires calculating an offset value at run-time (which is rare), it involves a function call. Thus, it shows the worst-case performance we are likely to see with realistic standard header scenarios.
//Test1 at pib.payLoadOffset
numAnswers = (int)DNS_response.answerRRs;
//Test2 at pib.payLoadOffset + 12
urlPrefixlength = (int)DNS_query.prefixLength;
//Test3 at pib.payLoadOffset + 18 + sizeOfUrl()
ipAddress = DNS_answer.addr; // an int result
Because our platform's scheduling algorithm sometimes penalizes programs with only a few on-chip instructions, we added one time-consuming, off-chip instruction to each test -- a packetC match operation on a Ternary Content Addressable Memory (TCAM) chip [9]. Thus, the tests show comparative speed for the three scenarios, rather than the raw performance for accessing header fields alone.
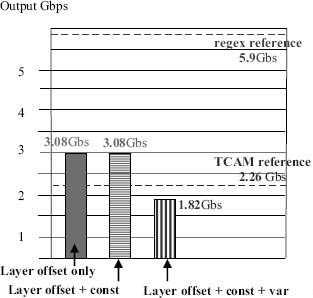
Figure 4. Throughput for DNS header field access applications. Copyright CloudShield Technologies, 2011.
We ran the tests on a CloudShield Deep Packet Processing Module (DPPM) blade made for IBM as a PN41 [11]. An IXIA Optixia®X16 traffic generator [12] with an LSM10G Ethernet processing blade produced 100-byte DNS response packets. The results depicted in Fig. 4 also show packetC performance on TCAM-based flow [9] and regex applications [10] as reference points.
9. Performance Analysis
In an earlier paper we reported results that showed packetC programs comprised solely of 4-12 descriptor field accesses ran somewhere between 9 and 10 Gbps [2]. When we first ran Test-1 and Test-2 (each with only a single descriptor field access), they completed more quickly than a system thread could forward a processed packet out of the system. That atypical behavior filled up queues and inverted results, making the simple tests appear to run more slowly than Test-3 with its off-chip access of a regex chip.
Since realistic packet applications do not consist of several instructions, we penalized each of our tests with the same ‘handicap, ’the off-chip associative memory match mentioned earlier, which produced intuitive results:
- Tests 1 and 2 (each with one match operation and one header field read operation that uses a packet access constant) executed at a bit over 3 Gbps, faster than a simple associative memory application, which executes at 2.26 Gbps [9].
- Test 3 (with one match operation and a run-time calculated field offset that involves an off-chip trip to the regex chip) ran at 1.82 Gbps. This is slightly slower than the associative memory application (at 2.26 Gps), which is expected, since the test has off-chip accesses of both a regex chip and associative memory.
The tests for header field access, with the added TCAM match, run roughly within the 2-9+Gbps usually seen on this platform with simple programs.
10. Summary
The packet language provides an intuitive, high-level way to express protocol headers as C-style structures. Its at-clause construct is flexible enough to support a full spectrum of real-world offset scenarios, including those that require runtime-calculated components.
Effective means for high-speed access to header fields defined by compile-time offsets are provided by using:
- An FPGA to pre-calculate standard offsets
- The compiler to encode standard offset identity and additional displacement constants in a scalar form
- A microcoded interpreter to exploit the encoded offset information to effect fast packet access
When header locations must be dynamically calculated at runtime packetC can express a broad range of dynamic scenarios. The performance of dynamically calculated offsets varies widely with the complexity and nature of the offset calculation.
The performance described in this paper and an earlier one [2] are consonant with our implementation being a fielded, commercial platform that runs many applications in the 2-9 Gbps range.
We are currently investigating enhancements to packetC header capabilities, including new security features and at-clause enhancements.
Acknowledgments
Peder Jungck, Dwight Mulcahy and Ralph Duncan are the co-authors of the packetC language. Jim Frandeen contributed timely technical information.
References
[1] R. Duncan and P. Jungck. packetC language for high performance packet processing. In Proceedings of the 11th IEEE Intl. Conf. High Performance Computing and Communications, (Seoul, South Korea), pp. 450-457, June 25-27, 2009.
[2] R. Duncan, P. Jungck and K. Ross. A paradigm for processing network protocols in parallel. In Proceedings of the 10th Intl. Conf. on Algorithms and Architectures for Parallel Processing, (Busan, South Korea), pp. 52-67, May 21-23, 2010.
[3] Intel Microengine C Compiler Language Support: Reference Manual. Intel Corporation, order number 278426-004, August 10, 2001.
[4] Intel Microengine C Networking Library for the IXP1200 Network Processor: Reference Guide. Intel Corporation, December, 2001.
[5] J. Wagner and R. Leupers: C compiler design for a network processor. IEEE Trans. On CAD, 20(11): 1-7, 2001.
[6] F. Risso and M. Baldi: NetPDL: an extensible XML-based language for packet header description. In Computer Networks. The International Journal of Computer and Telecommunications Networking, 50(5), 2006.
[7] Computer Networks Group (NetGroup) at Politecnico di Torino, NetPDL Core Specification, NetBee. Retrieved on 4/28/2011 from www.nbee.org/doku.php?id=netpdl:core_specs.
[8] L. George and M. Blume. Taming the IXP network processor. In Proceedings of the ACM SIGPLAN ‘03 Conference on Programming Language Design and Implementation, San Diego, California, USA, ACM, pp. 26-37, June 2003.
[9] R. Duncan, P. Jungck and K. Ross. packetC language and parallel processing of masked databases. Proceedings of the 39th Intl. Conf. on Parallel Processing, (San Diego), pp. 472-481, September 13-16, 2010.
[10] R. Duncan, P. Jungck, K. Ross and S. Tillman. Packet Content matching with packetC Searchsets. Proceedings of the 16th Intl. Conf. on Parallel and Distributed Systems, (Shanghai, China), pp. 180-188, December 8-10, 2010.
[11] International Business Machine Corporation. IBM BladeCenter PN41. Product datasheet available from IBM Systems and Technology Group, Route 100, Somers, New York, USA 10589, 2008.
[12] IXIA. Optixia®X16. Retrieved on 9/16/2010 from http://www.ixiacom.com/products/display?skey=ch_optixia_x16.
Intel is a trademark of Intel Corporation in the United States and/or other countries. IBM is a trademark of International Business Machines Corporation in the United Sta.tes and/or other countries. Optixia is a trademark of Ixia in the United States and/or other countries.
R. Duncan, P. Jungck, and K. Ross. “Dynamically accessing packet header fields at high-speed.” Proceedings of the 12th International Conference on Parallel and Distributed Computing, Applications and Technologies (Gwangju, South Korea), Oct. 20-22, 2011, pp. 6-11. Reprinted with permission from the IEEE.