
R E P R I N T 6
![]()
References for Run-time Aggregate Selection with Strong Typing
by Ralph Duncan, Peder Jungck, Kenneth Ross and Dwight Mulcahy
Abstract
Network packet processing often involves having the results of a d atabase match or packet content search select the next program operation. Our packetC[1] language provides specialized aggregate data types, databases[2] for masked matching and searchsets[3] for packet payload search terms. It is common to chain operations on these types, so that the result of one operation selects the specific aggregate to use for the next operation. packetC offers a reference data type to support this kind of chaining. A packetC reference provides an abstract way to refer to one of the extended data type aggregates in source code. At runtime the reference construct's value will indicate a particular aggregate of the relevant type. Thus, this construct is a classic reference in the computer science sense of a mechanism for indirect variable access. Unlike a C++ reference our construct must be assignable to support chaining that is driven by runtime results. Unlike a C-style pointer our reference must have strong typing, since runtime recovery from an illegal reference value (indicating a nonexistent or inappropriate aggregate) is not practical in this unforgiving, high-speed domain. The paper illustrates practical applications and shows that compressed code from using references does not cause performance penalties.
Categ ories and Subject Descriptors D.3.3 [Programming Languages]: Language Constructs and Features – data ty pes and structures
General Terms Languages.
Keywords programming languages; parallel processing, packetC, references, network processing
1. Introduction
Network applications often use the results of matching packet characteristics against a database or of finding strings in the packet payload to select the next table on which to operate. For example, when a packet fragment match es an element in an array of virus signatures, the array index can drive whether to match the packet?s origins agains t a database of government-sponsored hackers, versus one containing freelance hackers. packetC[1], a C dialect for packet processing, provides reference types for two specialized data types. A reference variable provides a way to determine at run-time which particular aggregate to use.
Users can employ arrays of reference variables to conditionally chain aggregate operations. When a construct containing a reference variable is executed, the effect is as if the selected aggregate had been hard-coded at that location.
The reference construct involves reference variables, as well as ref and deref operators. A reference variable:
- Indicates a packetC database or searchset without being synonymous with that aggregate.
- Has an implementation-specific value that cannot be directly manipulated by a user.
- Is restricted to a specific base type at declaration.
- Is only assigned a value by a ref operator applied to an aggregate of the right type as its operand.
- Behaves as if it had been replaced in the source code by the aggregate value produced by applying the deref operator to the reference.
// Example database decls & reference variable
struct stype { short dest; short src;};
database stype malwareFlows[500];
database stype virusFlows[500];
// declare a reference var limited to
// databases with ‘stype’ base type
reference db : stype refDB = ref(virusFlows);
A deref operator?s result can appear anywhere that the name of the dereferenced aggregate could appear (see example below). By dereferencing such a variable, developers can make an aggregate operation contingent on a result without producing code that enumerates all the possible dereferenced values. The following example uses types and variables from the code example above.
// deref entire DB element or individual fields
stype structVar;
structVar = deref( refDB ) [0] ;
structVar.dest = deref( refDB )[1].dest;
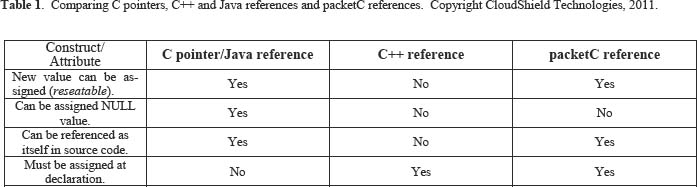
The paper is organized as follows. First, we compare packetC references to C pointers, C++ references and relational database foreign keys. We sketch our parallel programming model and packetC language. Next we describe reference declarations and operators. Experiments then show that using references does not harm performance.
2. Related Language Constructs
Significant attributes of reference constructs include:
- Reseatability (value changeable after declaration)
- Strong typing protects against illegal values
- Values hidden to protect against illegal values.
- Nullability (reference can take a null value).
To show where packetC references fit into the spectrum of similar constructs, we compare them to their nearest analogs: C pointers, Java references, C++ references (Table 1) and to the database concept of a foreign key.
A C pointer holds a memory address in the form of a numeric value. Despite some implementation variability, users can depend on a pointer holding the value of an address (or null value) and being amenable to pointer arithmetic operations [4]. Java references share reseatability and nullability attributes but their values are generally not directly accessible to users (e.g., for arithmetic).
A packetC reference is not constrained to be an address; it simply designates one of a finite set of aggregates, all of which share a common type signature and are visible from the reference variable?s scope. The user cannot assume particular memory characteristics for a reference variable in a given implementation (e.g., size or layout).
A C++ reference [5] is a more restricted construct than a C pointer or a packetC reference. It must be declared with a non-null value that cannot be changed afterward. Subsequently, source code cannot refer to the reference identifier as an entity in itself, since any occurrence of the identifier indicates the referenced object, instead.
In relational databases a foreign key specifies a connection – and associated constraints – between two tables [6]. The key identifies columns in the referencing table that refer to columns in the referenced (i.e., the foreign) table (Fig. 1). The referencing columns must be primary or candidate keys of the referenced table (i.e., they must be non-null key values that uniquely select a single row in a table). In addition, the value(s) in one row of the referencing columns must occur in just one row of the referenced table. Thus, a row of the referencing table maps unambiguously to a single row of the referenced table.
packetC references can also be used to link certain kinds of aggregates together or, more precisely, link operations on them. This requires organizing reference values in an array, as shown in Fig. 1. For example, match operations
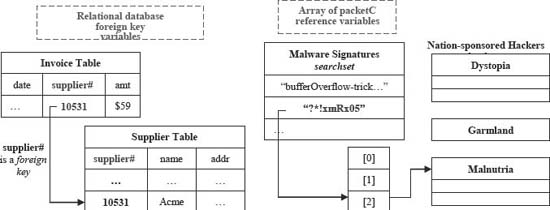
Figure 1. Table linkage with a relational database foreign key and via packetC references. Copyright CloudShield Technologies, 2011.
on packetC databases or searchsets return the index of the matching element if a match is found. By arranging the array of references and the elements (rows) of a database or searchset appropriately, a user can make the match result select which aggregate to use in a subsequent operation (Fig. 1 and see section 7). These operations unfold as part of a broader scheme for processing network packets in parallel, a scheme that the next section sketches.
3. Parallel Processing Model
packetC reflects a parallel packet processing model (Fig. 2) with the following key attributes:
- Coarse-grained parallelism
- Machine characteristic hiding
- Host system executive responsibilities
- Shared and private memory division
The developer expresses parallelism at a coarse-grained level with a small program (a packetC packet main) that processes one packet at a time in end-to-end fashion. Thus, the model uses single program multiple data (SPMD) parallelism. This frees the developer from fine-grain mechanics, like synchronizing tasks.
Machine characteristics are hidden when possible, not only to facilitate customers porting their code but so that we can replace subsystems with different chips or replace hardware with software implementations without rendering existing programs obsolete. Hence, packetC does not reflect register classes, caches, memory banks, etc.
The model requires that the host system manage execution of program copies, handle packet ingress and egress, and pre-calculate layer offsets of protocol headers present in the packet. Those offsets are stored in a system provided packet information block (PIB), described in [7].
The model partitions memory into:
- Global memory with scalars and aggregates shared by all packet programs.
- A private memory for each program copy for variables that are not visible to other program copies.
4. packetC Language Overview
Another paper gives an overview of packetC as a language [1], so this section provides only a short sketch. We designed the language to meet these goals:
- Use the C99 variant of C for familiar operators, conditional statements and overall syntax.
- Reduce runtime exceptions and performance uncertainties by removing pointers, address operators and dynamic memory allocation -- and by using unsigned integer arithmetic to avoid overflows and underflows.
- Increase reliability by stronger typing rules and by disallowing implicit type conversions or promotions.
- Support our processing model?s SPMD parallelism.
Distinctive packetC data type extensions appear below:
- Descriptors: structs that ‘float’ to a packet location to overlay a packet protocol header [7].
- Databases: structure aggregates divided into ‘data’ and ‘mask’ halves for wildcarded matching against packet contents [2].
- Searchsets: aggregates of strings or regular expressions to match against packet contents [3].
- References: provide a classic reference capability for databases and searchsets. Unlike C pointers or C++ references, these references must be assignable (to chain on the basis of runtime results) and be protected by strong typing, since trying to access a nonexistent aggregate creates an exception that cannot be handled in this time intensive application domain.
The next section describes reference constructs in detail.
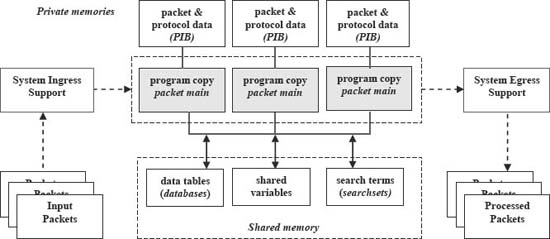
Figure 2. Parallel packet processing model and language features (in italics). Copyright CloudShield Technologies, 2011.
5. packetC References and Rationales
5.1 Motivation for Reseatability (Assignability)
Our motivation for a reference construct springs from network applications' need to selectively perform matching operations on the basis of a preliminary march or search's results. Thus, a reseatable reference construct is required, so that the reference's value may be set at runtime in response to another operation's results, rather than be set only at declaration time, like C++ references.
5.2 Motivation for Strong Typing
packetC emphasizes reliability, since real-time network applications cannot tolerate high-overhead error-handling. No matter how the identity of a database or searchset is represented in a reference variable value, some form of strong typing is required in assigning values to a reference variable because an illegal value would cause unpredictable behavior at runtime and packet processing applications lack the time budget for elaborate exception handling. Thus, reference variables are restricted to accessing databases (by structure base type) and searchsets (by the two possible searchset types). The next section describes these semantics in detail.
6. packetC References as Language Construct
6.1 Reference Variable Declarations
packetC databases[2] resemble arrays of structures; each array element is a structure, subdivided into nested data and mask structures of a common type. Database elements often contain selected packet attributes that characterize flows, related packets that constitute a network dialogue. Databases allow matching a current packet to a flow in the database by using mask parts to select which data parts (which packet attributes) are used in the match.
Because databases have a structure base type, packetC reference variables to databases are also declared in terms of a base type and can only reference a database with that base type. To ensure that a reference always has a legal value at run-time, the declaration must set the reference variable to a legal, non-null value. (Note: a typedef is not needed to establish a packetC type name).
struct stype { short dest; short src;};
database stype malwareFlows[500];
database stype virusFlows [300];
// declare reference var of ‘stype’ base type
reference db : stype refDB = ref(virusFlows);
// ‘reseat’ reference to DB of ‘stype’
refDB = ref(malwareFlows); // legal
// ERROR: try to reseat to DB of another type
database tuple5Type currentFlows[4000];
refDB = ref(currentFlows); // ERROR
packetC searchsets[3] contain either an ordered set of strings or of regular expressions for specifying patterns to be found in a packet's contents. Because these two forms have different restrictions on what methods can be applied to them, a searchset's elements cannot mix strings and regular expressions. Thus, reference variables for searchsets are declared in terms of indicating searchsets for strings or for regular expressions. The code example below shows the two declaration forms.
searchset sSet[3][3] = {“dog”,”cat”,”bat”};
reference set: string refStr = ref(sSet);
//
searchset regSet[2][7] ={“.*?from”,”.*?mai l”};
reference set: regex refReg = ref(regSet);
6.2 The ref and deref Operators
The ref operator has already been shown in declaration examples. It takes a single operator, which must be either
- The name of a database with the same structure base type as the reference variable?s base type.
- The name of a searchset with a string or regular expression type that matches the string or regex keyword in the reference variable declaration.
The deref operator takes a reference variable operand and produces the referent at that point in the source code. It is not as if all the aggregate?s values were present at that code location but, rather, it is as if the referent?s current name had been hard-coded there.
// (types from 6.1) deref a database; same as
// structVar.dest = virusFlows[2].dest
structVar.dest = deref( refDB )[2].dest;
// reference a string searchset for match
// method with array slice operand; same as
// result = sSet.match(pkt[64:66]);
result = deref(refStr).match(pkt[64:66]);
// reference a regex searchset for find method
// with packet array slice as operand, same as
// result = regSet.find(pkt[0:end]);
result = deref(regSet).find(pkt[0:end]);
A packetC dereference produces an lvalue that indicates an aggregate object. Thus, it acts as a substitute for the lvalue at that source code location. This property can lead to unusual code forms (much as pointer dereferencing does in C); however, it provides capabilities for compact, generic programming, as experiments show below.
7. Current packetC Implementation
7.1 Hardware Implementation Overview
CloudShield Technologies? products [8] use multi-core network processing units (NPUs), field-programmable gate arrays (FPGAs) and other specialized processors. Our overall approach has the following characteristics.
- Microcode executing on a dedicated subset of NPU cores works with FPGAs to control the packet pipeline, analyze packets and locate protocol headers.
- A n ensemble of NPUs, each running multiple contexts, executes SPMD copies of packetC programs.
- A custom FPGA manages shared memory for scalars and arrays, and manages access to ternary content-addressable memory (TCAM).
- TCAM chips and regular expression processors implement operations on packetC?s database and sear-chset types.
7.2 Software Implementation – Interpreting
Our packetC compilation tool-chain generates proprietary bytecodes that combine RISC-style arithmetic with high-level instructions. These include complex instructions for database and searchset operations, such as the one below.
// if a record matches a database
// element, return row that matched
rownum = myDB.match( myRecord );
// The corresponding bytecode
Database_match(maskKind,
myRecord.data, myRecord.mask, returnInfoDirective)
Dozens of copies of a micro-coded interpreter run on the NPUs and interpret user programs translated into the bytecode form. When necessary, these interpreters push data to specialized processors. This is the case for operations on both data types used with references, databases and searchsets. To provide insight in these mechanics before presenting the experiments, we sketch the hardware implementation for these operations below.
7.3 Implementation of Database Operations
CloudShield's CS 2000 [8] uses Netlogic NSE 5512 TCAM chips to implement packetC database operations. Communications to effect those operations flow between
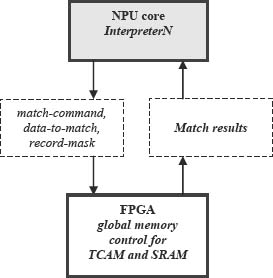
Figure 3. Communications for a database match between an interpreter and the FPGA managing global memory and TCAMs. . Copyright CloudShield Technologies, 2011.
Figure 4. Using PAX port 2500 for searchset find operations. . Copyright CloudShield Technologies, 2011.
the interpreters and TCAM chips, mediated by a ‘Silicon Database’ module, implemented with a custom Xilinx Virtex-II Pro” FPGA (Fig. 3).
7.4 Implementation of Searchset FIND Operations
We currently implement find operations for searchsets by downloading compiled rules that describe them to an IDT PAX.port 2500 content inspection engine [9]. String searchsets are first preprocessed into simple regular expressions by custom tools without packetC user intervention and invoke the IDT PAX compiler to create the pattern memory contents that will be downloaded into PAX SRAM.
At runtime find arguments are sent to the PAX subsystem, which holds its compiled regular expression rules in a specialized IDT zero bus turnaround (ZBT) SRAM as pattern memory (Fig. 4). The provisions for dynamically updating the pattern memory are beyond the scope of this paper and are not shown in the figure.
8. Reference Performance: Chained Operations
This section examines the reference construct's impact on source code size and performance. The experiment consists of coding a representative chained operation scenario with and without using packet references. The experiment used a CloudShield PN41 [10] 10 Gigabit Ethernet blade hosting the packetC application. The DPPM blade contains an Intel Corporation® IXP 2800 NPU and custom Xilinx, Inc.® Virtex® 5 FPGAs. Netlogic, Inc.® NSE 5512 TCAM chips implement the databases. We used an IXIA® XM12 traffic generator [11] to generate network traffic at a maximum of 10 gigabits per second (Gbps) and approximately 14 million packets per second (pps).
Network packet flows are a related sequence of packets that form a coherent communication from a source to a destination across a network. The experimental application defines a packetC database, with each of the four database rows geared to matching one of the following kinds of network traffic: HTTP, VoIP, email, DNS. Based on which of the four database cases a packet matches, the program searches the packet payload for matches with strings in one of four possible searchsets.
The database declaration and flow matching is conducted in terms of a structure with packet protocol information, as shown below.
struct ipv4Tuple {
int scrAddr;
int destAddr;
short srcPort;
short destPort;
byte protocol;
};
database ipv4Tuple flowTable[4] = {…};
try { matchRow = flowTable.match( flow ); }
catch ( ERR_DB_NOMATCH ) {…exit; }
The searchset declarations for each kind of network traffic we are handling follow.
searchset httpVerbs[2][4] = {"GET", "POST"};
searchset sipVerbs[2][6] = {"INVITE","BYE"};
searchset badGuys[5][20] = {"acapone",
“jdillinger”, “pbfloyd”,
“bonnie”, “clyde” };
searchset sites[4][20] = {“yahoo.com”,
“google.com”, “purepeople.com”,
“cnn.com”}; // DNS
8.1 Version 1: Without references
The version without references must explicitly code each possible searchset operation that could occur, using the relevant identifier for each one. Since only one of the sear-chsets could be used after a given database match, the code for the possible searchset operations must be structured conditionally, e.g., by using a switch statement as we did to implement this version.
try { matchedRow = flowTable.match(flow); }
catch ( ERR_DB_NOMATCH ) {…}
try { // do the desired chained operation
switch (matchedRow) {
case 0:
result=httpVerbs.find(pkt[0:end]);
break;
case 1:
result = sipVerbs.find(pkt[0:end]);
break;
case 2:
result = badGuys.find(pkt[0:end]);
break;
case 3:
result = sites.find(pkt[0:end]);
break;
default:
exit;
}
catch ( ERR_SET_NOTFOUND ) {…}
8.2 Version 2: Using references
To exploit the reference construct in this situation, we need an array of references in which the:
- Index values correspond to the database rows (records) to be matched during the initial operation.
- Array element values correspond to the searchsets to be used for the next operation.
The relevant array declaration is shown below.
reference set:string refSet[4] =
{ref(httpVerbs),
ref (sipVerbs), ref(badGuys), ref(sites)};
We can now replace coding find operations for each of the possible database match results (i.e., for each possible searchset name) with a single searchset find, abstracting out the individual searchset names and replacing them with a solitary variable holding the reference array's index values. Using the deref operator on an element of that reference array at runtime effectively delivers the referenced aggregate as the searchset upon which the find method will operate (shown below).
try {
matchedRow = flowTable.match(flow);
result = deref(refSet[matchedRow]).find
(pkt[0:end]);
catch (…) {…}
8.3 Results: Source Code Reduction and Performance
As expected, for a chained operation where the target operation involves n alternatives (i.e., subsequent operations on alternative databases or searchsets), using a reference construct can shrink the code from n constructs that reflect the alternatives (e.g., try/catch pairs, switch cases, etc.) to a single construct.
Our experiments suggest that, for this application domain and hardware, using reference constructs does not cause meaningful performance differences. Fig 5 shows that, when measuring throughput in gigabits per second (gbps), the application?s throughput for packet sizes 300 and 1000 bytes do not vary for hundredths of a gbps. Only at a packet size of 2000 bytes is there a discernable difference, with the using-references version achieving 6.15 gbps and the without-references version running at 6.14 gbps. This small variation could be an artifact of experiment mechanics.
We were concerned that the overhead of moving packet data to the regex chip for the searchset find operation was dwarfing all other effects. To check this, we coded a version of the application in which the second operation was another database match operation, one that involved four alternative databases. The results in Fig. 5.c. show no meaningful performance difference caused by references being used or not.
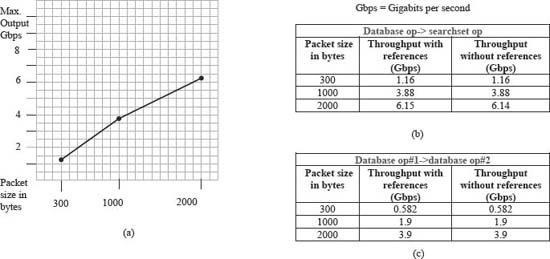
Figure 5. Performance with and without references. (a) Throughput sensitivity to packet size (database result drives searchset operation). (b) Comparison for database result drives searchset operation. (c) Comparison for database result drives a second database operation. Copyright CloudShield Technologies, 2011.
In these tested applications the version without references will require a comparison and jumps to execute the switch statement control flow. Even though we are currently treating the details of how we encode reference values as proprietary, we can state that a dereferencing operation typically involves 2-3 instructions to shift or mask off irrelevant parts of the encoded data. Any differences in application versions’ execution time that are due to differences in which set of several ‘ordinary’ instructions are executed will be dwarfed by the time spent to move data to either the TCAM or regex subsystems. Thus, for the planned use of packetC reference constructs with databases and searchsets, there does not appear to be performance penalties.
9. Summary
In much the same way that a single variable can abstract many individual literal values from source code, a single, reseatable reference construct – in the broad, computer science sense of ‘reference’ – can abstract many individual variables from source code, replacing the appearance of many identifiers with a single construct.
Our practical context for this kind of abstracting specific variables out of the source code is to compress the coding for operations on specialized aggregates as part of highspeed network packet processing. In this context the benefits of the packetC reference construct are:
- To remove redundant code patterns that differ only by specific aggregate names (see switch statement in 8.1)
- To facilitate chaining operations on these aggregates in cases where the result of one operation selects the specific aggregate to use in the next operation. This use also involves organizing references values in arrays (see Sections 2 and 8.2).
- To prevent a reference variable or array element from hold an illegal value at run-time in an environment where graceful recovery from exceptions is rare.
We believe the experiments show it is possible to get these benefits without a discernable performance penalty. As long as the reference encoding and decoding schemes are straightforward, this seems to be a likely outcome. Such encoding schemes can be as simple as using integer or string values to uniquely identify a particular aggregate.
In our case, the bytecodes for performing database and searchset operations make it relatively easy to store, decode and use such a designator. Specific bytecodes are not shown in the text above because CloudShield continues to treat the bytecodes as proprietary details for business reasons unrelated to the packetC reference construct.
In conclusion, a reseatable, type-safe reference construct is useful in a high-speed, packet-processing environment, especially for chaining operations common to the application domain. It is possible to implement such a construct in ways with no discernable performance penalty, at least for this specific environment.
Acknowledgments
Peder Jungck, Dwight Mulcahy and Ralph Duncan are the co-authors of the packetC language. Andy Norton, Greg Triplett, Kai Chang, Mary Pham, Alfredo Chorro-Rivas and Minh Nguyen provided valuable help in many areas.
References
[1] R. Duncan and P. Jungck. packetC language for high performance packet processing. In Proceedings of the 11th EEE Intl. Conf. High Performance Computing and Communications, (Seoul, South Korea), pp. 450-457, June 25-27, 2009.
[2] R. Duncan, P. Jungck and K. Ross. packetC language and parallel processing of masked databases. Proceedings of the 39th Intl. Conf. on Parallel Processing, (San Diego), pp. 472-481, September 13-16, 2010.
[3] R. Duncan, P. Jungck, K. Ross and S. Tillman. Packet Content matching with packetC Searchsets. Proceedings of the 16th Intl. Conf. on Parallel and Distributed Systems, (Shanghai, China), pp. 180-188, December 8-10, 2010.
[4] ISO/IEC 9899:1999. Standard for the C programming language. May 2005 version. (‘C99’), especially section 6.3.2.3.
[5] ISO/IEC ISO/IEC 14882:2003. (corrected version of the 1998 C++ standard).
[6] Wikipedia. Article on “Foreign key,” Retrieved on January 22, 2011 from http://en.wikipedia.org/wiki/Foreign_key.
[7] R. Duncan, P. Jungck and K. Ross. A paradigm for processing network protocols in parallel. In Proceedings of the 10th Intl. Conf. on Algorithms and Architectures for Parallel Processing, (Busan, South Korea), pp. 52-67, May 21-23, 2010.
[8] CloudShield Technologies. CS-2000 Technical Specifications. Product datasheet available from CloudShield Technologies, 212 Gibraltar Dr., Sunnyvale, CA, USA 94089, 2006.
[9] H.J. Chao and B. Liu. “High Performance Switches and Routers.” John Wiley and Sons, Hoboken, New Jersey, 2007, pp. 562-564.
[10] International Business Machines Corporation. IBM Blade Center PN41. Product datasheet available from IBM Systems and Technology Group, Route 100, Somers, New York, USA 10589, 2008.
[11] IXIA. XM12 High Performance Chassis. Retrieved from http://www.ixia.com.com/products/chassis/display?skey=ch_optixia_xm12 on January 24, 2011.
Ixia is a trademark of Ixia in the United States and/or other countries. NETL7 is a trademark of NetLogic Microsystems, Inc. in the United States and/or other countries. Xilinx Virtex-II Pro is a trademark of Xilinx Inc. in the United States and/or other countries.
R. Duncan, P. Jungck, K. Ross, and D. Mulcahy. “References for run-time aggregate selection with strong typing.” 2011. Printed by permission.