
![]()
Analyzing Your Information Life Cycle
“Think simple” as my old master used to say—meaning reduce the whole of its parts into the simplest terms.
—Frank Lloyd Wright
Understanding how information flows and progresses within your organization will reveal and steer you toward an elegant enterprise content management solution. In this chapter, I provide guidance on how to analyze information life cycles within an organization by applying the content life cycle model I introduced in Chapter 1. I also share techniques for how you can build an inventory of your organization’s content and how you can analyze business processes relating to your content. Finally, I discuss how you can identify your content’s security requirements.
After reading this chapter, you will know how to
- Apply the content life cycle model to your content.
- Build an inventory of your organization’s content.
- Analyze and diagram your content-related business processes.
- Identify your information security needs.
- Document your content life cycle requirements.
Applying the Content Life Cycle Model
Models make complex information easier to understand and easier to communicate. They reveal patterns and dependencies that otherwise might not be noticeable, helping to elaborate or clarify requirements, highlighting any exceptions or outliers to consider, all to help analyze a problem and to support designing a solution. Applying the content life cycle model to your organization’s content will guide your analysis by helping to reduce the complexity and scale of enterprise content into a comprehensible model.
You might recall the content life cycle model I introduced in Chapter 1. As I mentioned then, I expanded the details for my content life cycle model from the AIIM information life cycle model, a model focusing on five life cycle phases: capture, store, manage, deliver, and preserve. I did this to make the model more concrete for analyzing content and its life cycle within a SharePoint environment. With a few extra details, I maintained most of the simplicity of the model so that it is easy to follow and can fit a variety of scenarios, but I added some hooks or anchor points where you can apply it to an actual content instance.
Figure 3-1 illustrates the content life cycle model, included again here for your convenience. This model provides several entry points into the life cycle, including the beginning with a user creating or receiving a piece of content and capturing it in SharePoint. The model also includes a convenient entry point where SharePoint manages the content, if you would rather take a more system-oriented functional view. Alternatively, you can start with how users discover content and then interact with it, if you prefer to analyze your existing content. Wherever you start, eventually you will apply and work your way through the entire content life cycle.
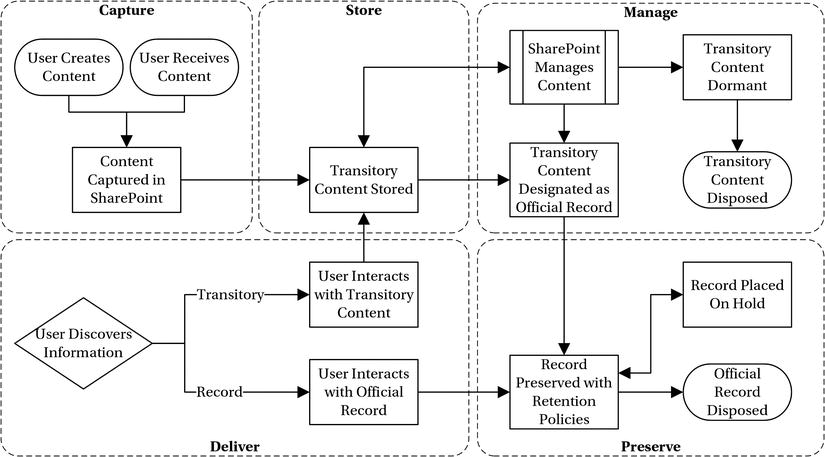
Figure 3-1. The content life cycle model
Before I jump into applying the model to your content, I want to offer a word of caution if you choose to start with analyzing how SharePoint manages the content, that is, the functional view. This can be a tempting entry point, because the functionality in SharePoint is already architected and documented, leaving you to make configuration decisions for each aspect. Its functions gives you a known list of things to configure and decisions to make, which can feel comforting at first; however, without the information about the actual content and its uses, those configuration decisions will not be as obvious or as comfortable as they might first seem.
I find this comes up when well-intentioned business analysts want to make progress and work with the information they have, which initially is product guides and other materials documenting SharePoint features. It could stem from some of the marketing language around the product and its capabilities, but an effective ECM program goes beyond working one’s way through a list of product features, deciding what to enable and how to configure it. This always seems to constrain a design where a team ends up trying to pigeonhole a use case into some functional constraint the team decided on too early in the process. Forcing something to fit with a contrived constraint only builds up complexity and complications through your ECM solution design and implementation, and ultimately it has a negative effect on user adoption.
Another danger I see occurs with project teams that are replacing one system with SharePoint as part of the project delivery, and in their approach, they heavily document the existing system and all of its features, a document that then serves as a requirements list for the SharePoint implementation. As far as I can tell, this seems to stem from a desire to avoid upsetting users with the system change, and so someone announces that the change will not lose any functionality—in essence making a promise to users that anything they can do in the old system, they will also be able to do in the new system. I see this run into trouble when the project team takes that promise too literally as they document every function in the old legacy system, only looking at the new system from the perspective of how it can replicate the old system.
![]() Tip There is generally no point to replace old systems, only to reproduce the old system on a new platform.
Tip There is generally no point to replace old systems, only to reproduce the old system on a new platform.
Instead, I recommend you start with one of the other entry points and follow the content, from either creation or discovery, tracing it through the life cycle, using the content to drive design decisions. When you understand the content and its use cases throughout the life cycle, you are then in a good position to make solution design decisions by looking at how SharePoint can implement and manage the content while supporting its use cases. You might even find that SharePoint alone cannot support one of your use cases, indicating that you might need to integrate with another system, procure a third-party extension for SharePoint, or include custom development as part of your ECM solution.
![]() Important Start with the content and let the content and its use cases drive your enterprise content management design.
Important Start with the content and let the content and its use cases drive your enterprise content management design.
Following my advice, let’s start with where the content starts: when a user or automated process captures content into the system. For my purposes here, I will refer to the system as SharePoint, since this is a book about ECM in SharePoint. Often during the analysis phase, I prefer to remain more abstract and general in documenting the process to avoid having technology drive a solution, such as capturing content into the system. Although in this case, I know the system is SharePoint, but I still avoid getting too specific on the functionality or the technical details at this point. I do not say, for example, capture the content in a team site’s document library, because at this point, I want a higher-level view of the life cycle.
If you pick a piece of content and look at its capture process into SharePoint, you might notice that you can move backward from the capture point to identify stages in the content creation not captured in the content life cycle model. This can include a stage where a user creates and interacts with the content outside SharePoint. For example, a user might create a funding proposal document on their desktop and work with it for a period, even e-mailing it around to different users who provide input on the document, before eventually uploading it to a SharePoint site. Figure 3-2 illustrates the activities in the creation process for a document prior to its capture in SharePoint.

Figure 3-2. A content creation process for a document prior to its capture in SharePoint
This proposal document is a perfect example for how you can refine requirements and solution designs by applying the content life cycle model to your organization’s content. The most notable thing the model does is highlight an exception to the model: the content goes through a fragment of a life cycle before it enters the SharePoint ECM model. This may or may not be how you want the process to flow in the future, but for now, the model helps you to uncover where the exceptions exist. Perhaps this exception is one you can resolve by guiding the users to collaborate on the content entirely within SharePoint, either in a team site or a My Site library.
You might find a similar exception for a piece of content that a user receives and eventually captures in SharePoint. For example, a vendor might e-mail an invoice to a user in the organization, and then it sits in the user’s inbox for a time before he or she forwards it to someone else, who then captures it in SharePoint. Again, there is a fragment of life cycle not captured prior to the content life cycle model for SharePoint. Figure 3-3 illustrates the phases in this receiving process for an e-mailed invoice.
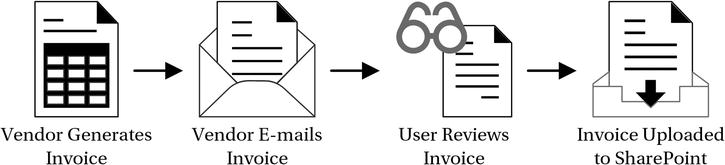
Figure 3-3. A content receiving process for an external user’s report
This e-mailed invoice process reveals another exception to the content life cycle model: the content lives in the organization for a time outside the boundaries of the model. Now, this is not to say the exception is bad and that you should alter the process; it merely highlights that an exception exists, allowing you to analyze it further to make those types of process design decisions. If you did want to resolve this exception, you could alter the process by e-mail-enabling a document library or discussion board to capture the content directly into SharePoint and into the model.
How users discover content provides another area for you to analyze and uncover exceptions. In the content life cycle model, I included discovery from the system’s point of view—meaning that the model begins with users discovering content from within the system. You might come across exceptions to this discovery entry-point, with the most popular being a process similar to e-mailing a colleague and asking if they can recommend any content. This would be a fragment of life cycle not captured in the discovery process, because the user is going outside SharePoint to discover relevant content. Figure 3-4 illustrates this process where a user discovers content by using the SharePoint search portal.

Figure 3-4. A content discovery process involving direct user interaction
Bypassing the search portal and directly asking colleagues for references to content may not be a negative process, particularly if you want to encourage users to interact with each other to leverage one another’s expertise and to cultivate teamwork. However, it does highlight an exception to the model where users rely on other users rather than on the system to discover certain kinds of content. With any exception, this gives you an opportunity to investigate and analyze deeper, where a closer look might reveal that the search engine does not provide results with enough relevance to locate this content efficiently, or it might reveal that the content’s metadata does not align with the recommendations on a user’s My Site. Whatever the underlying drivers behind an exception, the model will help you identify and analyze them, and through this process, you have the opportunity to optimize processes where appropriate.
![]() Note This exception of users asking for content rather than searching for it themselves reminds me of a web site (www.lmgtfy.com) that pokes fun at people in a passive-aggressive way, letting them know that they could have searched for an answer on their own by saying “let me Google that for you.”
Note This exception of users asking for content rather than searching for it themselves reminds me of a web site (www.lmgtfy.com) that pokes fun at people in a passive-aggressive way, letting them know that they could have searched for an answer on their own by saying “let me Google that for you.”
The process is similar to those for analyzing how SharePoint manages content, particularly for any exceptions to the model where another system or a manual process manages content. Another system might extend the capabilities in SharePoint, such as when you use a separate system for your records repository, whether because your organization wishes to maintain its investment in the system or because the system provides richer features and capabilities than does SharePoint. Remember, the point is to recognize and analyze the exceptions to the model, not to force everything to fit the model by forcing everything into SharePoint.
![]() Note Please see Chapter 16, where I discuss integrating SharePoint with external systems and other records repositories.
Note Please see Chapter 16, where I discuss integrating SharePoint with external systems and other records repositories.
So far, I looked at the entry points in the content life cycle model and at how you can apply those to your organization to identify and further analyze any exceptions. Similarly, you can look at the endpoints, where SharePoint disposes of the content. The most prominent question to analyze here is whether the endpoint exists—does your organization dispose of content? You might notice an exception to the model here as well, and it will certainly stand out if you do not have a process for disposing transitory content or official records once they reach the end of their life cycle and no longer offer any value to your organization.
You might also find an exception to the model in manual processes to dispose of content in place of automated system-managed processes. For example, you might host team sites for marketing campaigns, all with a manual process where the site owners are supposed to archive any content they feel will be useful historical references in the future, while disposing the rest. Manual processes are easy to forget as other more urgent tasks vie for a user’s attention, but at the same time, your users might not like the idea of the system automatically destroying their content after a set duration, which might be the underlying driver for the process being manual in the first place. To resolve this exception, you might design a workflow with steps for approval or another type of branching logic requiring user input, thus offering you a compromise between manual and automated disposal processes, while still having SharePoint manage the disposal process.
Within the model itself, you can trace the flow of content to identify any gaps. For example, if you have content that persists as transitory content rather than an official record—a likely scenario motivating many readers of this book, I suspect—then this highlights a gap in your organization’s content life cycle. Not every piece of content has to go on to become a record, but it either should become a record or be disposed of, as the model indicates. Transitory content should not live on in perpetuity in a transitory state.
You can apply the content life cycle model to validate content processes, identify exceptions and gaps to analyze, or simply to understand a type of content in context. As I started the section saying, it is simply a tool to make the complexity and scale of your enterprise content easier to understand and analyze. This is not a fixed process that you must conform to, nor one you must enforce on every piece of content. You can have many valid reasons to include exceptions to the model, and the model will help you identify and analyze them.
Analyzing the life cycle of your organization’s content is a lengthy process, but its outcome produces valuable insights and information for your enterprise content management solution. However, you cannot reasonably scale to analyze every piece of content; instead, you should focus on your main classes of content. I may have gotten ahead of myself here by looking at how to analyze the content before I clarified what content to focus on, but the analysis stays the same whether you analyze individual pieces of content or general classes of content. Let’s shift now to look at ways to identify classes of content in your organization that you can apply to the content life cycle model and analyze.
Building an Inventory of Your Organization’s Content
Building an inventory of content in any environment except the smallest and simplest may sound like a monumental task, and perhaps it is, especially if you attempt to do this manually. I am not suggesting you create an Excel spreadsheet and begin on the journey of itemizing each piece of content wherever it might be within your organization. I imagine there is probably just too much content, and chances are it changes too quickly for you to have any hope of keeping up. Besides, that kind of detailed raw data does not have any practical use.
Nonetheless, understanding what content you have is useful and you can use this information to design the rest of your enterprise content management solution. You do not need to know each individual file, but knowing an aggregation of the type and number of files will prove to be invaluable. As such, I am really talking about building an inventory of the kinds of content within your organization—everything from the file formats to the broad categories of content types users create and work with.
There are a few ways you can approach building such an inventory. For example, from more elegant and prepackaged to cruder and improvised, you can
- Procure a tool specializing in analyzing directory contents and file structures.
- Use an enterprise search engine to crawl content, and then analyze its reports or run custom search queries.
- Write a script to enumerate the contents of storage drives and aggregate the results.
- Eyeball the contents of storage drives and estimate the most common kinds of content.
I like automating the task myself, whether with a specialized tool or another option. Computers are great at parsing mass amounts of information, and collecting and aggregating data about it, the output of which enables you to analyze your inventory of different kinds of content. Some tools work better than others do, but even the most rudimentary custom PowerShell script can get you started. Your challenge will be to segregate the content into kinds of content, not simply by file extension or directory.
Identifying kinds of content is the primary objective for an inventory, but you might also find other metadata information interesting and useful. For this reason, a tool that offers a comprehensive report with different attributes for the content might be more valuable for you. You will find the tool especially useful if you can use these attributes to filter or group the content in a custom view, allowing you to answer other questions, such as how many Word documents your organization has that are over 5MB, or even better, what is the monthly growth in number of documents or corpus size.
As you gather data about your content, you should also make note of where your organization stores content. What is stored on shared drives and what is stored in SharePoint or another repository? You should also look at the content’s freshness and the ongoing value it provides, if any. How active are users with the content? Knowing this type of information will help give you a better sense about how your organization produces and consumes information.
Knowing the different kinds of content your organization uses will make your later analysis easier. You can reference your content inventory in the next chapter as you build your information architecture. And even better than that, in Chapter 6 I discuss how to design and implement SharePoint content types, making the task quite straightforward when you already have a list of the main types of content in your organization. All of the work you put in early with this analysis to create an inventory of content will continue to make your job easier later, such as in Chapter 9 when I discuss enterprise search, or again in Chapter 15 when I discuss content retention and disposition.
![]() Tip You can use some of the content’s attribute information to aid a content cleanup initiative, such as by highlighting potential content to dispose, or for mapping content migration rules.
Tip You can use some of the content’s attribute information to aid a content cleanup initiative, such as by highlighting potential content to dispose, or for mapping content migration rules.
Capturing information about multiple attributes will help you answer a variety of questions—both those you know about and want to answer today, and those that will come up throughout your ECM program. Once I organize a content inventory into broad classes listing the types of content, I like to add descriptions to each class describing the type of content it includes. I also like to capture other information as well, such as where the class of content fits in the content life cycle and whether it transforms into another content class as it progresses through the life cycle.
Of course, content includes more than just document files; it includes other units of information, such as web pages, list items, and e-mail messages. Be sure to capture information about these other types of content as you conduct your content inventory.
If your organization is new to SharePoint, then some of these other types of content might not be as prevalent as organizations with SharePoint deployments. Alternatively, you might have another system that is similar to SharePoint or an aspect of SharePoint, such as a wiki. Wiki pages capture blobs of text that users produce while they are collaborating and capturing knowledge. In your content inventory, you might capture details on the different types of wiki pages and the kinds of content they entail.
Articles and web pages published on your intranet and public web sites represent a unit of information you need to consider, whether your portal content managers publish the pages through a content management system similar to SharePoint, or they publish the pages manually by copying and pasting the files onto the server’s directory. At this stage, you are taking an inventory about what content you have, so you do not have to get overly detailed here; instead, you can focus on what types of web content your organization uses and where.
![]() Note Please see Chapter 7 for more information on web publishing and web content management.
Note Please see Chapter 7 for more information on web publishing and web content management.
E-mail messages represent your hardest challenge to describe and class together. People use e-mail for almost anything content-related within an organization, everything from sending a traditional letter or memo to a colleague, to sharing and collaborating on a document as users send around different versions. E-mail is generic and multipurpose, making it difficult to generalize and categorize, but at its core, it is an electronic message, a communication transmitting a unit of information between two or more people.
Finally, your organization has physical, nonelectronic content. This is a good stage to start considering that content too. You can include it in your content inventory and begin to look what kind of physical documents your organization produces and consumes in its operations. You do not have to worry so much yet about whether or how you could replace any of these physical documents with electronic content and processes. For now, just take an inventory about what is there.
![]() Note Please see Chapter 16, where I discuss physical documents more from the perspective of managing physical records.
Note Please see Chapter 16, where I discuss physical documents more from the perspective of managing physical records.
As you read this book, you will expand and build on this list of useful information to capture in a content inventory. I do not want to get ahead of myself just yet, so I will stick with these basics for now. This captures information about the content in your organization, valuable details about what content exists, its characteristics, and how it is used, all serving as your core analysis—it is, after all, enterprise content management. All of your other analysis will build around this core, starting with your business processes within a class of content.
COLLECTING DATA TO DRIVE YOUR ECM PROGRAM
Enterprise content management can feel daunting and intimidating at first glance, and it does involve some complexity with a lot of moving pieces to analyze, but I think most of the unfriendly feelings stem from a lack of information—a black hole of information to guide decisions and implementation designs. You cannot jump in and start building content types without knowing the underlying content, at least not effectively. The same is true with the other aspects of enterprise content management, which can all leave the process feeling unapproachable and intimidating.
You can build confidence and momentum on an enterprise content management implementation by filling those information gaps with raw data, such as a content inventory. ECM projects involve a lot of analysis work, as almost anyone who has done one will probably tell you, but the order of when you perform the analysis tasks can make all the difference. Taking inventories to gather data about your organization’s existing state will give you a solid base to analyze and design an effective enterprise content management solution, no matter how complex it is in your environment.
Analyzing Your Content-Related Business Processes
Content does not live in isolation. It usually relates to a business process in some way. With an inventory of content and an understanding for how it fits within the content life cycle model, you can begin to understand what drives the content, process wise, and how the content relates to business processes within your organization. Some of the more valuable aspects of an enterprise content management program relate to identifying and formalizing these business processes that you can associate with different classes of content.
Applying the content life cycle model can help to identify some business processes, particularly those processes that relate to the content’s progression through the model. For example, content disposition requires a process to determine when transitory content has reached the end of its life cycle or when a record’s retention period has lapsed. Designating a piece of content as an official record also requires a process. These are two obvious content-related business processes visible in the content life cycle model, but a typical organization will also have many more processes underlying the model, some formal and some informal, and they may change depending on the class of content.
To start, take your content inventory and pick a class of content to analyze closer. Look at how the content changes or passes through different phases of the content life cycle model and identify any business processes that you notice. Also, pay attention to where content changes hands to see if there are any processes related to the content transitioning from person to person. I also try to answer the following questions as I analyze content for related business processes:
- Does the content have any obvious or existing processes?
- Are there metadata fields related to tracking the content’s status or state?
- Is there an approver for a piece of content or for the phases the content progresses through?
- Do users perform any informal processes with the content inside or outside the system?
Essentially, the trick is to take a close look at the content and consider it from every angle. Through a close analysis, you will get a good sense of the content’s related processes, such as how users use it and how SharePoint needs to manage it.
Some of your content-related business processes exist ahead of the content’s creation and some trailing from the content’s creation—by this I mean that some processes lead into the creation of a piece of content while other processes use the output of a piece of content in the process itself. By thinking about where a process falls in relation to a piece of content, you can uncover those processes that might otherwise be unapparent. You can do this by considering what occurs before a user creates the content, or even more specifically, what triggers a user to create the content.
The processes that come after or from the content are easy for you to identify and capture because you only have to follow what users do with the content. Does the content contain information about a request that other users then reference as they decide whether to approve the request? Does the content become a record of a decision a team made or a team’s progress or status at a particular time? What happens to the content afterward?
Not every piece of content has an elaborate business process attached to it. Some processes might be formal, such as an approval process for employee vacation requests. Some processes are more informal, such as a team member updating a wiki page to add new information to their documentation. Generally, I focus most on capturing business process details for anywhere the process matters, and usually these are the more formal ones. If your day is anything like mine, you simply do not have the time to analyze every single process with the same degree of rigor, and so concentrating on the most important processes will help you maximize your time.
Identifying the content-related business processes will help you to analyze and better understand the content and its requirements. Nevertheless, this information continues to be useful after your initial content analysis, particularly when it comes time to design any system-managed workflows you want to associate with the content. For starters, you will have a list of all the workflows you need to design and implement. On top of that, you will have a lot of the workflow analysis and high-level design done already, leaving you to focus on filling in the details and designing the actual implementation.
For example, if you are analyzing the process relating to an electronic form, you will identify the major activities and decisions involved in that process during this stage. Later, when you reach the point where you are ready to design and implement the actual e-form and its related workflow, you already have a good sense of the steps involved and what the process will ultimately accomplish.
![]() Note Please see Chapter 8, for more details on designing an e-form approval workflow.
Note Please see Chapter 8, for more details on designing an e-form approval workflow.
While I write a sentence to describe a piece of content and its purpose, I adopt a different format to communicate any of its related business processes. Describing a business process in one or two paragraphs can be difficult to follow. For those more complex process, it may take you several paragraphs to describe, making it that much more difficult for the reader to follow or grasp quickly. If I do want to use text to describe a process, then I format the text as a use case by creating a numbered list of simple statements describing each of the steps in the process. Alternatively, and more often, I diagram the process.
Diagramming Your Business Processes Using Microsoft Visio
You can use any diagramming tool you prefer to diagram your business processes. Microsoft Visio is one of the primary tools I use as I analyze an organization’s content and content life cycle because it can summarize and simplify a lot of complex information, all with the arrangement of shapes in the diagram used to present and communicate the information effectively to many different audiences. Visio has several different diagram templates available for diagramming a process or a state, some of which you will see me use for my diagrams throughout this book.
![]() Note To learn more about Visio, please see the Microsoft Office site at http://office.microsoft.com/visio.
Note To learn more about Visio, please see the Microsoft Office site at http://office.microsoft.com/visio.
There are a few Visio templates that I use most often to diagram details about an organization’s content and processes. Each diagrams and presents information in a different way, depending on the purpose of the template. These templates include the following:
- Process diagram: A basic flowchart consisting mainly of activity boxes and decision diamonds to diagram the activities and decisions involved in a process.
- Swim-lane process diagram: A diagram that builds on the process diagram, with swim-lane rows used to identify the role responsible for the activities or decisions contained within a swim-lane.
- Workflow diagram: A diagram that contains icons that visually represent the task in the workflow.
- Entity-relationship (ER) diagram: A data design that models the different entities and the relationships between them, often used to model database tables (entities) and the foreign-key relationship constraints between tables.
Visio also includes other templates for other types of diagrams, such as data flow diagrams, UML diagrams, sitemap diagrams, and network diagrams. You choose the appropriate template depending on your communication goal for the diagram. For communicating content-related processes, I find that one of the four diagrams I listed earlier serves my purpose the most often.
One of the challenges with diagramming complex information is deciding what to include in the diagram. If you include too much detail, your diagram will become complex and difficult to follow, resulting in less effective communication. How much information to include or not is more an art than a formula, and it depends on your audience and the purpose of the diagram. A functional specification for a software product requires more detail because developers will code software based on the diagram. Diagrams for content-related processes do not need that much detail, at least not yet. For now, I usually just focus on the main activities and decisions, and I filter out the rest of the details.
I find color helpful as a way to include extra information without complicating the diagram, as I describe in the following sidebar. You may have noticed in my content life cycle diagram that I included dashed boxes to identify the AIIM information life cycle phases, subtly adding this extra information without complicating my diagram. You can experiment with other organizing techniques that communicate extra information, such as boxes or diagram annotations.
FORMATTING YOUR DIAGRAMS
One thing I like to do with my diagrams is to incorporate color whenever possible. I had to omit color for my diagrams in this book because it is printed in black-and-white, but normally I will include a variety of colors in my diagrams. I do this to make them more vivid and more visually appealing, as well as to organize and highlight information within the diagram.
For example, I may highlight important activities and decisions in one color, or I may use different colors to represent different phases or different responsibilities. I adjust the colors, fill, and line format for individual shapes to add emphasis and appeal. Visio 2013 also has some great themes for shapes and it has interesting effects that you can apply to individual shapes within your diagram.
I find the autolayout features in Visio never produce a result I like, at least not yet, so I usually layout my shapes manually and I use the shape alignment and distribution tools in the product to format a professional and polished look.
Identifying Your Information Security Needs
Sometimes security requirements for a piece of content are less rigid, with those security requirements not entailing high-maintenance or requiring too much rigor. Indeed, much of your content may fall into this variety—content that users may or may not restrict and limit access to, being content without sensitive or confidential information, making it acceptable to share with a wider audience within the organization. This type of content still has security requirements, and I discuss how to identify and manage them later in this section. First, let’s look at the other end of the scale, content with strict and thorough security requirements.
Certain types of content are so sensitive and critical to an organization that they require detailed and limited security. You manage the access control for this type of content on a need-to-know basis, typically with people who are involved with the content’s information, either as the producers of the content or as decision makers relying on the content. More secure content also has a more limited audience.
There are many kinds of content at the more secure end of the scale, including the following (in no particular order):
- Intellectual property (IP): From scientific patients to video game algorithms, an organization’s intellectual property helps them compete for research funding or sales prospects by differentiating them from other firms.
- Research and development: From mining companies conducting feasibility studies to pharmaceutical labs testing new drug treatments, firms want to protect their data and prevent other firms from stealing their ideas.
- Personally identifiable information: From government agencies with private citizen data to credit card payment gateways with transaction information, organizations require extra diligence in protecting personal information.
- Tactical and strategic plans: From militaries to corporations, their plans of attack or plans for competitive advantage benefit the organization the most when the plans remain a secret from outside adversaries.
These are just a few examples to get you thinking. A firm will have all kinds of content that they want to keep out of the public domain, and they will probably want to keep it contained within a limited group of people within the firm. You can contrast this with an article posted on a firm’s public blog—obviously the security requirements for a public blog post will not require any of the confidentially restrictions since it is publicly disclosed, although it will still have some security requirements, such as who can edit the post.
To complicate matters, a unit of information can transition through different levels of security as well. For example, a press release announcing a public company’s earnings for the previous quarter will have a specific date and time when the company will make the information public. Before that time, the financial information must remain secure and secret; otherwise, disclosures would give an investor an unfair advantage and thus would be subject to an inside trader investigation by the securities commission. However, eventually the press release will become public knowledge and its security requirements will change.
Knowing your content will help you plan and identify your security requirements along with any information architecture and business processes. If you built an inventory of your content as I discussed earlier, now you can go through and think about the range of security each type of content requires. Think about whether the security requirements change for a unit of information of a particular kind of content. What triggers the change and have you captured the trigger in the business processes that relate to the content?
Just as managing permissions for each individual user will not scale or manage well, managing security levels for individual pieces of content equally will not scale well. If you become overly granular in your security management, you risk applying missing or inconsistent permission settings to content, resulting in possible security holes. Security works most effectively when you generalize settings into groups, and then apply the group to individual items, such as applying permissions to security groups for several items to share, and then adding users to the group to grant those permissions. Incidentally, security also works more efficiently when you manage it through security groups, because groups will simplify and centralize the administration of security.
Similar to groups, you can use categories to design your security solution and establish consistency across your organization. Broad content classification categories allow you to generalize content into one of a few sensitivity levels. This eases the burden for training users because users will only need to know a few different information classification levels, the ways to decide between them to classify content, and an understanding for how users should treat content classified at each level. A well-understood and communicated classification level in turn reinforces security by ensuring users are aware of how to treat a piece of content and who they can share it with, ultimately reducing the occurrence of accidental disclosure of private information.
For example, when working in the federal public sector in my country, the Government of Canada will first conduct a security screening and then assign a security clearance level to an individual—both for outside consultants and for government employees. An individual then has clearance to access information classified with a clearance level that matches his or her own, with a caveat that they also need to have a valid business reason to access the information. Users must classify all information within the Government according to its security or sensitivity level; otherwise, the information is public. The following lists the Government of Canada’s information classification levels:
- Protected: Designated information that applies to sensitive personal, private, and business information.
- Confidential: Classified information that when compromised could cause limited injury to the national interest.
- Secret: Classified information that when compromised could cause serious injury to the national interest.
- Top Secret: Classified information that when compromised could cause exceptionally grave injury to the national interest.
![]() Note For more information on the Government of Canada’s Information Management policies, please see their web site at www.tbs-sct.gc.ca/pol/doc-eng.aspx?id=16557.
Note For more information on the Government of Canada’s Information Management policies, please see their web site at www.tbs-sct.gc.ca/pol/doc-eng.aspx?id=16557.
I have seen organizations adopt the Government’s information classification levels and I have seen others design their own or adapt some hybrid. For example, the following lists some other self-descriptive information classification levels, each of which can come with a set of restrictions:
- Employee Personally Identifiable Information (PII)
- Protected Health Information (PHI)
- Customer Identifiable Information
- Confidential—Full Time Employee Only
- Confidential—Internal Only (Employees and Contractors)
- Confidential—Internal and Partners
Of course, you do not have to fit all your content classification needs into this one category. I discuss this more in the next chapter, but at this stage, you might begin to consider other ways you can classify content in common groups. The following lists a few examples:
- Sensitivity Level
- Business Impact
- Regulatory Association
Just as with any other metadata, utilizing multiple categories will leave your information design with multiple ways to classify content, making it that much more self-descriptive for users; plus, multiple categories offer additional dimensions to organize and filter lists of content. Having multiple categories to classify your content facilitates advanced information management scenarios as well, such as enabling sophisticated workflow logic and e-discovery queries.
You can implement these content classifications in SharePoint as part of the metadata you associate with a piece of content. You will continue to identify different classification categories in the next chapter as you design your enterprise taxonomy, and in Chapter 6, I discuss how to configure metadata for content classification. For now, start to consider some of the categories you can use to classify your content.
![]() Tip The more content classification you can automate for your users, the more effective your information management strategy will be. You can also increase its effectiveness by making content classifications more prominent and noticeable for users, such as adding information to a Word document’s notification bar or changing the display color of a SharePoint list item to reflect its classification.
Tip The more content classification you can automate for your users, the more effective your information management strategy will be. You can also increase its effectiveness by making content classifications more prominent and noticeable for users, such as adding information to a Word document’s notification bar or changing the display color of a SharePoint list item to reflect its classification.
As you work through your inventory of content and you start to identify general classifications to group different kinds of content, you will begin to get a sense of how complex your information security requirements are. If you generalize your security requirements enough for each similar kind of content, as I mentioned, you will simplify your security requirement into a few broad and manageable categories. From there, you can begin to look at these categories to consider the appropriate scopes of security, and you can use these scopes to identify how you will implement the different kinds of content and security in SharePoint.
![]() Note Please see Chapter 12, where I discuss different options to secure content in SharePoint.
Note Please see Chapter 12, where I discuss different options to secure content in SharePoint.
In short, look for ways to group and generalize your security requirements to cover similar kinds of content. This strategy will allow you to scale and it will ease the burden on users to implement and follow the security policies. You achieve this when you avoid getting overly caught up in the particulars of each individual piece of content, and instead focus on major categories to group content within. Focus on the forest, not the trees.
Documenting Your Content Life Cycle Requirements
Documenting these requirements is not the same as creating a functional specification. A functional specification describes the system and its functions. Conversely, a requirements document describes the interaction with content, the content life cycle phases, and the business rules or events (those rules and events outside the system) that trigger a change or progression through the life cycle.
I stress this because too often I see people jump straight into a functional specification, attempting to describe the process from the perspective of the system; but this is premature at this stage because you have to understand the business and the business problems before you can determine the most effective solution and implementation details. Let the business analysis and the use cases you identify guide you toward the solution, not a list of product configuration options.
I confess that I slip and look at functional specifications prematurely sometimes myself. With prepackaged products, it is easy to accidently skip the business analysis and jump right into the solution—the functional implementation details. It happens sometimes on software development teams too when a team is building an entirely new system. I find it is particularly easy with a packaged software product like SharePoint because the system exists; you are not inventing it, all you are doing is configuring it.
Hence, it can be tempting to jump right into those implementation details by skipping to the function specification. I notice that I am especially prone to this if the project feels like a routine one (or at least routine to me—the outside consultant who repeats many projects with different clients, but there is probably nothing routine about it for the client). I try to stay conscious of this behavior to avoid skipping the business requirements and use cases, and I focus on staying disciplined to understand the business needs first. I encourage you to do the same: understand the problem thoroughly from the business’s perspective first before you start deciding on implementation details and functional specifications.
Jumping right into a functional specification does not automatically lead to a project failure, although it may and frequently does, but it usually at least challenges a project. The main challenge it causes is it introduces design constraints much too early. These constraints come from making system decisions early before you understand all the use cases and before you have thoroughly analyzed the problem space. These constraints also often come from people other than the solution architect, people who are not qualified to make design decisions.
I see constraints come up related to all sorts of SharePoint functionality early in a project, such as deciding to do any of the following before conducting any analysis:
- Lock down the user interface
- Implement a specific number of templates
- Decide on universal workflows
- Limit privileges and functionality
These all tend to come up as an overreaction to overly limited and narrow or even nonexistent or misunderstood requirements, and in most cases someone inexperienced with ECM solutions drives these requirements forward. Avoid slipping into this danger zone yourself, and do not let stakeholders or teammates drive premature implementation designs based on faulty perceptions, inaccurate requirements, and missing business analysis.
![]() Note Simply calling a premature system implementation constraint a “business requirement” does not make it a business requirement. The business users and the project manager are not the SharePoint experts, nor are they the solution architect. Keep them focused on articulating business processes and business problems, not on designing solutions that introduce implementation constraints.
Note Simply calling a premature system implementation constraint a “business requirement” does not make it a business requirement. The business users and the project manager are not the SharePoint experts, nor are they the solution architect. Keep them focused on articulating business processes and business problems, not on designing solutions that introduce implementation constraints.
I refer to this process as introducing implementation constraints because it steers a project and the project team off track toward a direction, one that the team has to then work around, and it may cause them to compromise an aspect or add complexity into the solution design, usually without reconsidering a premature constraint. These constraints lead a team down a more challenging path, or worse, the wrong path, a path stemming from making the wrong decision too early in the process before you analyzed the requirements and understood the problem space. This is the danger I want you to avoid, and I want you to avoid it by focusing on your content requirements from the perspective of the business and the business user’s purpose.
I have already set you up with many of the tools you need to document your content requirements effectively, particularly with the content inventory, the content process diagrams, and the content security needs. At this stage, you can put these things together and describe the main classes of content in your organization. You do not have to focus on the hierarchy details for the content at this point, but if you notice any candidates as a more specialized class of content, you can note the potential relationship. However, you should avoid getting caught up on this analysis just yet, because your main goal is to understand and describe the content.
![]() Note Please see Chapter 4, where I look at when and how to identify relationships between classes of content.
Note Please see Chapter 4, where I look at when and how to identify relationships between classes of content.
Next, I find it useful to give a brief sentence that describes the general purpose of a class of content. I write this from the perspective of the business, and to help write this sentence, I ask different types of questions about it, such as the following:
- What purpose does it serve?
- How does it benefit the organization?
- What contribution does it add?
- Where does it fit with the business strategy?
- What are its objectives?
- Why is it useful to users?
After describing its purpose, I then describe the content’s security details as I described in the previous section. I like to indicate the sensitivity and privacy for a class of content, including classifications, such as whether it is confidential or whether it contains personal information. Along with these attributes, I indicate the intended audiences for the content as well as any security restrictions I identified during the content analysis phase. If security aspects relate to a state change at some point in the content’s life cycle, I like to capture that here as well, along with the details about what triggers a change. For example, as when the security restrictions change after a small group finishes collaborating on a piece of content and publishes it into the public domain.
The next thing I include in a content requirements document is any policies associated with the content that I identified during the analysis, particularly for any retention or disposition policies. These policies can relate to approvals required in the content creation process or to other types of workflows or restrictions that relate to a particular class of content. If you have the details about any process involved with a policy, you can capture that here as well; otherwise, I discuss workflow and other policy aspects later in this book.
![]() Note Please see Chapter 6 for more on creating document management workflows.
Note Please see Chapter 6 for more on creating document management workflows.
Finally, I like to include the content process diagram I mentioned previously with the requirements document so people can see where the content fits within the content life cycle model, and what phases apply to it. If I were documenting the content requirements in a Word document, then I would include an image of the process diagram in line with the requirement details of a content class. If instead I am documenting the requirements using a tabular format such as an Excel spreadsheet, then I usually just include a hyperlink reference to the diagram, typically linking to the item in a SharePoint site. The process diagram shows the content in context, and it helps to summarize a lot of additional information that will be useful to you and your project team as you design an enterprise content management solution.
With all of this information, you can work toward understanding your enterprise content, an understanding that will serve as a key component in designing your ECM solution. This approach designs and builds your solution starting from the content and working outward, which helps you to better understand how your organization uses enterprise content, leading you to solve the right problems with an elegant solution.
This requirements document will serve as your knowledge of the problem and it will provide input into the rest of your solution design activities. Content and information about content is core to any enterprise content management initiative, returning your investment in this phase to benefit you again and again throughout your ECM program. If you find yourself stuck or struggling with an aspect of an enterprise content management solution, return to your requirements and process documentation that you produce in this phase to determine whether you were thorough enough with the content analysis. Often revisiting and extending this analysis will resolve issues and remove blockers stalling an enterprise content management initiative.
SAMPLE CONTENT REQUIREMENTS DOCUMENT FRAGMENT
Content Class: Expense Reimbursement Report
File Type: InfoPath Web Form
Description: A form containing employee information and tabular data about business-related expenses the employee is submitting for reimbursement.
Privacy Categorization: Personal
Content Classification: Confidential
Retention Policy: 3 Years
Other Attributes: Project reference, cost center, attachments of scanned receipts
Related Business Process: The following illustration provides an example of the related business process, specifically, an expense reimbursement approval process.
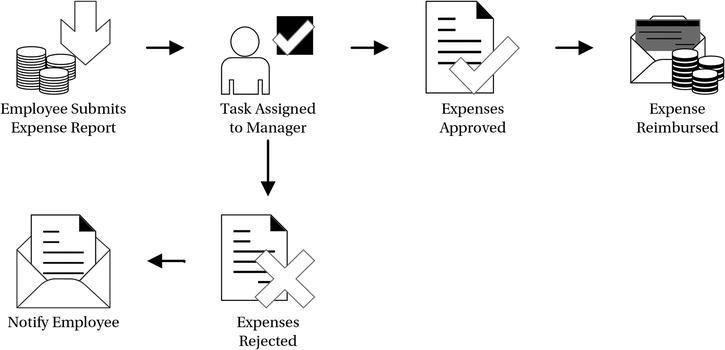
Other Details: For billable expenses to clients, the system transforms a copy of the approved expense report into a PDF file to e-mail to the client.
Wrapping Up
Your organization probably has mass amounts of content, each piece of which serves its own purpose. Identifying and understanding general classes of this content and its related business processes is the first major step toward designing an effective enterprise content management solution, and this is done through analyzing the content itself, seeing how users use it, and recognizing its purpose. In this chapter, I provided an approach to identifying and understanding your content by applying the content life cycle model to your different kinds of content. By looking at your content within the context of the model, you can uncover and analyze any gaps or exceptions from the model for a particular kind of content. I then provided guidance on how to take an inventory of the content in your organization and analyze the business processes related to different kinds of content. Finally, I described how to identify your information security needs and how you can document your content life cycle requirements.
Knowing your content, its processes, and any other of its requirements, all form a foundation for your enterprise content management initiative, because the rest of your ECM program will utilize and build upon whatever information you capture. With an understanding of your organization’s content and some preliminary ways to classify it, you can begin to organize and structure additional ways to categorize content and the relationships between different kinds of content. In the next chapter, I build on your analysis of the content itself and provide you with tools you can use to design hierarchies and patterns for categorizing and organizing your content, ultimately leading you to produce your information architecture.