
![]()
Efficient JavaScript Data Structures
Efficient use of system resources is essential to most game applications, to ensure that the game runs correctly and as smoothly as possible across a range of devices and browsers. Here, the term “resources” can refer to available memory, CPU execution time, or other processing or storage units in the system. Although JavaScript can be considered a rather high-level language, the data structures employed by JavaScript application code can significantly impact upon resource usage.
Much of the information here is taken from the significant amount of research and engineering manpower that the Turbulenz team has invested in high performance HTML5. As an open-source, proven engine that boasts a portfolio including several fully playable 2D and 3D games, the Turbulenz engine (turbulenz.com) represents a valuable resource for developers seeking to learn more about HTML5 and understand what is possible with modern web technology.
For many experienced HTML5 engineers the material presented may need little or no explanation. However, the authors hope this chapter will serve as an introduction for newcomers, and as a reference and explanation of some fundamental optimization concepts.
As with all optimization, it is important to measure the effect of code and data changes on memory and execution time. This is something of a universal mantra when writing and maintaining high-performance code, and it is even more important in the case of JavaScript and the browsers. Execution performance and memory usage characteristics can vary wildly across JavaScript engines and HTML5 implementations, and all of the major browsers are changing rapidly as their developers continue to aggressively address the bottlenecks experienced by high performance interactive applications.
For this reason, it is highly recommended that developers measure performance over a range of target browser and versions, and keep track of how new browser releases affect their code. As another consequence of the variety and changing nature of browser performance characteristics, this article intentionally avoids mentioning specific JavaScript engines or browsers, and concentrates on general strategies for efficiently handling application data in HTML5 applications.
The Importance of Data Structures
Almost all variables stored in the JavaScript engine require more memory than the equivalent native data structure. The JavaScript engines implement numbers as either 32-bit signed integers (where frequently only 31-bits are used for the integer value) or 64-bit floating-point numbers. JavaScript Objects must behave like dynamic key-value dictionaries, with all of the (non-trivial) memory and execution overhead required to support this system.
All Object properties are referenced by string name. Modern JavaScript engines use a variety of techniques to reduce the cost of retrieving and storing data by name, and in many cases these can be highly effective. Particularly in the case where the engine can correctly predict the “type” of object being dereferenced, the cost of storing and retrieving data can be comparable to native code. Here “type” may refer to a set of known properties that make up an Object “template” or a specific underlying native implementation of the Object. However, in the general case, the engine may need to hash strings, perform hash-table lookups, and traverse prototype hierarchies and scopes in order to find a given piece of stored data.
Garbage collection has traditionally been a source of “long” (up to several hundred milliseconds) pauses that can be noticeable in interactive JavaScript applications. This situation is now all but resolved as all “major” JavaScript engines have addressed this issue rather effectively, using strategies such as “generations” to avoid freezing execution and traversing all active objects on the heap. The evolution of solutions to this problem provides a good example of the varied and changing nature of the HTML5 implementations. The different JavaScript engines introduced solutions at different times in their development history, but as of today garbage collection is much less of an issue in modern browsers.
However, make sure that it has minimal impact on older browsers and browsers running to on low-end platforms, it is generally advisable to keep total Object count as low as possible and to minimize the number of temporary Objects being dynamically created at runtime.
As you shall see, Object count has a pronounced effect on memory usage and as a general rule, structures that use fewer Objects to store the same amount of data are likely to result in more efficient code execution. This principle, along with an understanding of how data is stored and accessed for some common object types, is fundamental to designing data structures that support optimal execution across various HTML5 implementations.
Object Hierarchies
The process of flattening data structures can be a very effective way of reducing object count, and thereby memory overhead and the cost of looking up data. “Flattening” here involves replacing hierarchies or subhierarchies of objects with single Objects or Arrays. For example, consider the object structure in Listing 4-1.
Listing 4-1. A Naïve Particle Structure
Particle
{
position:
{
x: <number>
y: <number>
z: <number>
}
velocity:
{
x: <number>
y: <number>
z: <number>
}
}
An immediate gain in memory efficiency (and runtime performance) can be achieved by flattening this structure, as shown in Listing 4-2.
Listing 4-2. A Flat Particle Structure
Particle
{
position_x: <number>
position_y: <number>
position_z: <number>
velocity_x: <number>
velocity_y: <number>
velocity_z: <number>
}
The code in Listing 4-2 is clearly very simplified, but illustrates an effective way of reducing the object count (and thereby memory usage) and the number of property lookups required to access various properties (improving performance).
A simple particle simulation based on these structures (particles accelerating under gravity) shows that flattening the structure in this way yields a memory saving of between 25% and 35%, and execution of a trivial particle simulation (updating position based on velocity, and velocity based on a fixed acceleration vector) showed a speed increase of roughly 25% on all browsers, with one browser showing roughly a 30% reduction in execution cost.
We can explain the memory savings by noting that each particle is now represented as a single Object with a list of six properties, rather than three Objects: particle, position, and velocity with a combined property count of eight and, more significantly, all of the extra properties and infrastructure required by the JavaScript runtime. Execution cost savings likely result because fewer property lookup and dereferencing operations are required to reach a given piece of data.
As a storage mechanism, JavaScript Arrays can often be more efficient than Objects in several scenarios. Most JavaScript engines have optimized implementations of Arrays, with very low overhead for access to indexed properties, efficient storage of sparse data, and flags to inform that garbage collector when the Array does not need to be traversed (e.g. if it only contains primitive data such as numbers).
The process of looking up indexed properties on Arrays is generally cheaper than accessing named properties on generic Objects. This is particularly true when the indices or keys are fully dynamic (and thereby the JIT compiler cannot predict them at compile time), as well as for code that iterates through all items in a structure.
Structures such as those discussed in the simple particle example in Listing 4-1 are very commonly stored in Arrays (a so-called “array of structures”). In this case, a very effective way to save memory is to completely flatten an array of Particle structures into a “structure of arrays,” as shown in Listing 4-3.
Listing 4-3. A List of Particles as a Structure of Arrays
// Each particle consists of 6 numbers
var particles_posx = new Array(numParticles);
var particles_posy = new Array(numParticles);
var particles_posz = new Array(numParticles);
var particles_velx = new Array(numParticles);
var particles_vely = new Array(numParticles);
var particles_velz = new Array(numParticles);
In this way, code accesses and uses the data as shown in Listing 4-4.
Listing 4-4. Simulation Code Using a Structure of Arrays
var velocity_x;
var velocity_y;
var velocity_z;
for (var i = 0 ; i < numParticles; ++i)
{
velocity_x = particles_velx[i];
velocity_y = particles_vely[i];
velocity_z = particles_velz[i];
particles_posx[i] += deltaTime * velocity_x;
particles_posy[i] += deltaTime * velocity_y;
particles_posz[i] += deltaTime * velocity_z;
// continue simulation ...
}
In Listing 4-4, all data is stored in just six Objects. Compared to the Array of flattened Objects, some simple experiments showed this to yield a memory savings of between 35% and 45%. That is a 40% to 60% savings compared to the original hierarchical version. This memory savings is a result of drastically reducing the number of Objects required to maintain the data, and allowing the JavaScript engine to store it as a few large contiguous lists of values rather than a large list of references to structures, each with some named properties.
Note that although the way the data is referenced has changed, the impact on the maintainability of the code is small. The effort required to add or remove properties from individual particles is roughly the same as it would be for the original data structure.
You can reduce object count even further if you are willing to sacrifice some readability (see Listing 4-5).
Listing 4-5. A Single Interleaved Array
// Each particle consists of 6 numbers
// Single Array containing the all particle attributes.
// [ posx, posy, posz, velz, vely, velz, // particle 0
// posx, posy, posz, velz, vely, velz, // particle 1
// posx, posy, posz, velz, vely, velz, // particle 2
// . . .
// ]
var particles = new Array(6 * numParticles);
The code in Listing 4-5 maintains a single Array containing all properties of all objects. Individual properties of a given particle must be addressed by their relative indices, as shown in Listing 4-6.
Listing 4-6. Simulation Code Using a Single Interleaved Array
var velocity_x;
var velocity_y;
var velocity_z;
var endIdx = 6 * numParticles;
for (var i = 0 ; i < endIdx ; i = i + 6)
{
velocity_x = particles[i+3];
velocity_y = particles[i+4];
velocity_z = particles[i+5];
particles[i+0] += deltaTime * velocity_x;
particles[i+1] += deltaTime * velocity_y;
particles[i+2] += deltaTime * velocity_z;
// continue simulation ...
}
The set of all particles now requires only one object, instead of six. In this case, the memory savings will be trivial compared to using an Array per property, although in more complex cases involving a large number of independent systems, changes of this kind can have an impact.
In our experiments, switching to a single flat Array did indeed show no significant memory difference, but gave between a 10% and 25% speed increase depending on the browser. One explanation for both the speed increase and the discrepancy across browsers is that using a single object in this way presents the JIT compiler with several opportunities for optimization (which, of course, it may or may not take advantage of).
Some JIT compilers can take a “guess” at the type of certain variables and emit fast code to directly access object properties. In this case, the generated native code must check that incoming objects are indeed of the correct type before enabling their fast-path. Where the data is spread across several Arrays, the type-check must be made for each object. Furthermore, a single Array allows the code to maintain only a single index and address all data elements as fixed offsets from that single register. Note also that memory access for our particular example will very likely be cache-coherent.
This completely flattened structure has been commonly used by Turbulenz to optimize engine and game code for more demanding 3D games and games that must run efficiently on mobile platforms. Unfortunately, this approach does sometimes involve sacrificing maintainability, since changes to the original Particle structure require extremely error-prone changes across a disproportionately large amount of code. Naturally, it is important to be sure that this extra maintenance cost is justified.
Of course, there are a variety of compromises that can be reached to balance performance with readability, depending on how critical a given bit of code is determined to be. For example, in the Particles case in Listing 4-6, one obvious middle ground would be to use an Array for each of position and velocity, as shown in Listing 4-7.
Listing 4-7. Splitting Data into Logical Groups
// One Array for position x,y, and z of all particles.
// particles_pos = [
// posx, posy, posz, // particle 0
// posx, posy, posz, // particle 1
// . . .
// ]
//
// Array for velocity x,y, and z of all particles.
// particles_vel = [
// velz, vely, velz, // particle 0
// velz, vely, velz, // particle 1
// . . .
// ]
var particles_pos = new Array(3 * numParticles);
var particles_vel = new Array(3 * numParticles);
In Listing 4-7, only two Arrays are required, but changes to the data structure (such as adding new Particle properties) can be made without unnecessarily large code changes.
The data for memory usage and performance given above should be interpreted with caution. Apart from the rapidly changing HTML5 implementations, which can render any performance data out-of-date, it can be rather difficult to get an accurate measurement of true execution cost and memory usage. Memory usage in particular can be difficult to measure. Some browsers provide tools to take a snapshot of the JavaScript heap, whereas others do not expose this information.
However, for completeness, the results of our approximate measurements during the preparation of this content are given in Figures 4-1 and 4-2 for a simulation involving 1,000,000 particles. We intentionally omit browser names and versions, and further details of the experiment to underline the fact that this data is purely for illustrative purposes.
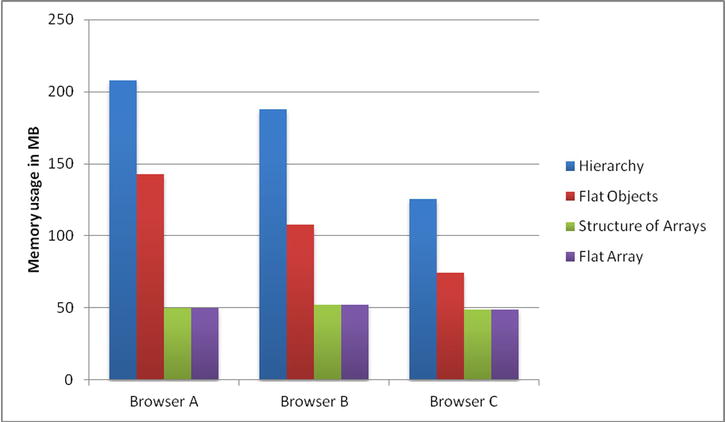
Figure 4-1. Approximate memory usage of the various data structures
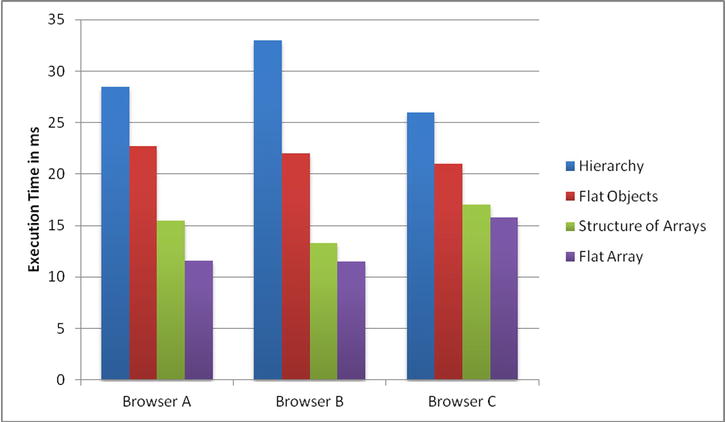
Figure 4-2. Approximate execution time of simulation for various data structures
Some noteworthy patterns appear. Firstly, memory usage follows roughly the trend one would expect. The solutions involving flat arrays introduce very little overhead, occupying almost as little memory as the equivalent native representation, which we would expect to be 48,000,000 bytes == 6 * 8 * 1,000,000 (== properties per particle * size of property * number of particles). Particularly in the case of memory usage, the more optimal solutions appear to have more consistent and predictable costs across browsers.
Although the effectiveness of each optimization can be seen to vary across the browsers, all the techniques introduced so far have a measurable positive effect on both memory and execution time over all the browsers tested. The technique we will discuss next had a measurable, but less uniform, impact on the measurements.
ArrayBuffers and ArrayBufferViews
The TypedArray standard describes an interface that allows JavaScript code to access raw memory buffers by reading and writing native types (at the level of signed or unsigned bytes, shorts, ints, as well as float and double values). Intended in part for manipulating graphics data (such as vertex, index, or texture buffers) in a format that can be directly consumed by graphics hardware, ArrayBuffers and ArrayBufferViews also introduce many opportunities for optimization in the JavaScript engine.
Broadly, an ArrayBuffer represents a contiguous memory buffer with no type information, and an ArrayBufferView (such as Int8Array or Float32Array) represents a “window” onto some subregion of that buffer, exposing the memory as an array of specific native types. Multiple ArrayBufferViews of different types can point to regions of the same ArrayBuffer, and can overlap with each other. A slightly more complex particle structure that uses floating point and lower precision integer data is illustrated by Listing 4-8.
Listing 4-8. Combining Different Native Data Types into a Single Memory Buffer
// Implementation of this native structure:
//
// struct Particle
// {
// float position_x, position_y, position_z;
// float velocity_x, velocity_y, velocity_z;
// uint16_t timeToLive, flags;
// };
//
// Particle stride in bytes: 6*4 + 2*2 = 28
// Particle stride in words: 7
// Particle stride in half words: 14
// The underlying memory buffer
var particlesBuffer = new ArrayBuffer(numParticles * 28);
// Access the buffer as float32 data
var particlesF32 = new Float32Array(particlesBuffer);
// Access the buffer as uint16_t data, offset to start at
// ‘timeToLive’ for the first particle.
var particlesU16 = new Uint16Array(particlesBuffer, 6*4);
// ‘position’ and ‘velocity’ for the i-th particle can be accessed:
// particlesF32[(7*i) + 0] ... particlesF32[(7*i) + 5]
// ‘timeToLive’ and ‘flags’ for the i-th particle is accessed as:
// particlesU16[(14*i) + 0] and particlesU16[(14*i) + 1]
Care must be taken to specify offsets and strides correctly, but it should be clear that a small number of objects can be used to finely control the type and layout of data in memory. See the TypedArray specification at http://www.khronos.org/registry/typedarray/specs/latest for full details.
The first obvious advantage of TypedArrays over regular Arrays is the potential memory saving. Much game code only requires 32-bit floating-point numbers, rather than the 64-bit values that JavaScript uses by default. In the particle example of the previous section, replacing Arrays with Float32Arrays does indeed reduce memory usage of the data structure by roughly 50%. Further memory savings can be made where lower precision integers can be used in place of generic JavaScript numbers.
The major JavaScript engines all have an internal concept of ArrayBuffer and ArrayBufferView that allows them to make important code optimizations. When the engine can correctly predict that an Object is a specific ArrayBufferView, it can dereference the data directly from memory, bypassing the usual property lookup process. Furthermore, because the retrieved data is of a known type, in some special cases it may not need to be converted to the usual 64-bit floating-point representation before operations can be performed.
For example, replacing Array with Float32Array in the code in Listing 4-8 and ensuring that all constants are stored in Float32Arrays means that most of the simulation can (in the ideal case) be translated by the JIT compiler into simple memory reads and writes, and primitive operations on 32-bit floating-point numbers. In general, this will be much faster than the equivalent operations on values of which the compiler cannot predict the type. However, it can be very difficult to predict how many of these optimizations a given engine will perform. Optimizations at this level naturally require several conditions to be met, for example the destination of the operation must be known to be of the correct type to ensure that calculation results are not affected.
The Math.fround function, included in the sixth edition of the ECMAScript specification, provides a way to explicitly tell the JavaScript engine that a given operation can use 32-bit precision. It is not yet widely supported at the time this article is published, but is an example of how the programmer can provide optimization hints to the JavaScript engine.
It should be made clear at this stage that TypedArrays do have some drawbacks. At the time of writing, they can be much more expensive than Arrays to create, and the JIT compilers still do not take advantage of all possible optimizations. In some cases, Arrays can actually result in faster execution, particularly where temporary Objects are created and destroyed frequently (although in general it is advisable to minimize the number of transient objects required by a given algorithm).
In our simple particle system in Listing 4-tk, we saw a speed increase of about 10% on some browsers when all variables use Float32Arrays; however, we saw a slight speed decrease on other browsers compared to the flat JavaScript Array.
Complex Structures as Single ArrayBufferViews
In the Turbulenz engine, we have written and tested several implementations of a Math library to operate on Matrix, Vector, and Quaternion Objects, including a set of native implemented functions. At the time of writing, we have settled on a solution where all objects (Vector3, Vector4, Matrix33, Matrix34, ....) are single Float32Array objects of the appropriate size.
To avoid creation of temporary objects, all math operations optionally take a destination argument, which allows temporary or scratch variables to be reused to avoid too much Object creation and destruction.
In some cases, such as our 3D animation library, or 2D and 3D physics engine, structures, or arrays containing several math primitives are implemented as single Float32Arrays containing, say, a sequence of Quaternion objects representing animation bones.
In other situations, Float32Arrays can be used to represent structures that include non-float data, so properties such as flags or indices, which might otherwise be stored as integers, are also kept in a single Float32Array along with numerical data. It is important to be aware of the trade-off that has been made with code clarity here, but for key areas that can very easily become an execution bottleneck, we are giving the JavaScript engines the best possible opportunity to save memory and optimize JIT-generated code.
Custom tools represent an opportunity to improve code maintainability while using flat structures in this way. For example, in the case of flattening an array of structures into a single Array or Float32Array, a simple code transformation could generate the code in Listing 4-4 from source code of the form, as shown in Listing 4-9.
Listing 4-9. Maintainable Source Code That Could Be Used to Generate Listing 4-4
for (var i = 0 ; i < endIdx ; i = i + PARTICLES_STRIDE)
{
var velocity_x = particles[i+PARTICLES_VEL_X];
var velocity_y = particles[i+PARTICLES_VEL_Y];
var velocity_z = particles[i+PARTICLES_VEL_Z];
...
This allows properties to be added and removed with relative ease. More complex tool-based solutions are conceivable that could generate the same output from even higher level code, particularly where more accurate type information is available at compile time (as is often the case for languages such as TypeScript, which the Turbulenz engine has adopted throughout the core engine). Tooling of this kind may also represent a trade-off if it introduces a build step where one was previously not necessary.
Late Unpacking
Data cannot always easily be flattened, and sometimes the runtime representation is necessarily a memory-hungry hierarchy of objects. In these cases, it is sometimes possible and preferable to encode data into custom byte-code or strings, and decode the data on the fly, as required.
There is an obvious trade-off made with CPU resources here. The encoded data must be unpacked into its equivalent object hierarchy, and potentially this process must be repeated each time the hierarchy is destroyed. However, since the TypedArray interfaces give full access to raw memory buffers, it is possible to decode (and encode) even binary compression formats to save memory effectively.
Best Practices
The concepts discussed above are relatively simple, and imply some straightforward best practices. Here we describe a few of these, as well as some recommendations based on the experience of our engineers developing engine technology and porting and creating high-performance 3D HTML5 games.
The importance of measurement has already been mentioned above, but this cannot be understated. The behavior of JavaScript and HTML5 implementations is not just varied, but rapidly changing. The true effectiveness of a given optimization on execution speed and memory consumption is very rarely quantifiable in terms of a single number. In the worst case, diversity of HTML5 implementations may mean that developers are required to maintain several code paths and determine which to enable based on browser version.
The browsers themselves often provide useful tools, including memory and code profilers as well as convenient debugging environments. In general, these may have some limitations (for example, JavaScript heap profilers may not take into account raw memory used by ArrayBuffers, or graphics resources such as textures or vertex buffers), but they form a useful part of the toolbox for measuring code behavior. Keep in mind that different profiling tools may have different side effects, so it is usually most effective to compare the results from several of them (ideally from two or three major browsers) before drawing conclusions.
At the code level, we have found that it is important to maintain clear relationships between data structures, including keeping the responsibility for creation and destruction well defined. As well as making code easier to understand and maintain, clear ownership policies allow applications to accurately and consistently “null-out” references to unused objects. This helps to avoid memory leaks, which in JavaScript refers to unnecessary objects on the heap, wasting both memory and CPU resources, but kept alive by dangling references.
Conclusion
An impressive level of performance and efficiency can already be achieved using HTML5, and the pace of improvements of modern browsers is high. The gap between native code and optimized JavaScript is closing, and indications are that further improvements are still possible. The comments and examples given here cover some simple cases, and hopefully illustrate some easy ways to ensure a good level of efficiency when developing performance-sensitive applications with JavaScript.
The research efforts, experience, and talents of several people from the Turbulenz engineering team were leveraged in the creation of this chapter. In particular, Michael Braithwaite and David Galeano deserve special thanks for sharing their extensive knowledge of the technology and their real-world experience creating fully featured high quality HTML5 games.