
Chapter 6. Content Management Systems
In this chapter, we’ll look at how you can use MongoDB as a data storage engine for a content management system (CMS). In particular, we’ll examine two main areas of CMS development. Our first use case, Metadata and Asset Management, deals with how we can model our metadata (pages, blog posts, photos, videos) using MongoDB.
Our next use case, Storing Comments, explores several different approaches to storing user comments in a CMS, along with the trade-offs for each approach.
Metadata and Asset Management
In any kind of a content management system, you need to decide on the basic objects that the CMS will be managing. For this section, we’ve chosen to model our CMS on the popular Drupal CMS. (Drupal does have a MongoDB plug-in, but we’ve chosen a simpler implementation for the purposes of illustration in this section.) Here, we explore how MongoDB can be used as a natural data model backend for such a CMS, focusing on the storage of the major types of content in a CMS.
Solution Overview
To build this system, we’ll use MongoDB’s flexible schema to store all
content “nodes” in a single collection nodes regardless of type. This guide
provides prototype schemas and describes common operations for the
following primary node types:
- Basic page
- Basic pages are useful for displaying infrequently changing text such as an About page. With a basic page, the salient information is the title and the content.
- Blog post
- Blog posts are part of a “stream” of posts from users on the CMS, and store title, author, content, and date as relevant information.
- Photo
- Photos participate in photo galleries, and store title, description, author, and date along with the actual photo binary data.
Note that each type of node may participate in groups of nodes. In particular, a basic page would be part of a folder on the site, a blog post would be part of a blog, and a photo would be part of a gallery. This section won’t go into details about how we might group these nodes together, nor will it address navigational structure.
Schema Design
Although documents in the nodes collection contain
content of different types, all documents have a similar structure and a
set of common fields. Consider the following prototype document for a
“basic page” node type:
{_id:ObjectId(...)),metadata:{nonce:ObjectId(...),type:'basic-page'parent_id:ObjectId(...),slug:'about',title:'About Us',created:ISODate(...),author:{_id:ObjectId(…),name:'Rick'},tags:[...],detail:{text:'# About Us ...'}}}
Most fields are descriptively titled. The parent_id field identifies
groupings of items, as in a photo gallery, or a particular blog. The
slug field holds a URL-friendly unique representation of the node,
usually that is unique within its section for generating URLs.
All documents also have a detail field that varies with the document
type. For the basic page, the detail field might hold the text of
the page. For a blog entry, the detail field might hold a
subdocument. Consider the following prototype for a blog entry:
{...metadata:{...type:'blog-entry',parent_id:ObjectId(...),slug:'2012-03-noticed-the-news',...,detail:{publish_on:ISODate(…),text:'I noticed the news from Washington today…'}}}
Photos require a different approach. Because photos can be potentially large, it’s important to separate the binary photo storage from the node’s metadata. GridFS provides the ability to store larger files in MongoDB.
GridFS
GridFS is actually a convention, implemented in the client, for storing large blobs of binary data in MongoDB. MongoDB documents are limited in size to (currently) 16 MB. This means that if your blob of data is larger than 16 MB, or might be larger than 16 MB, you need to split the data over multiple documents.
This is just what GridFS does. In GridFS, each blob is represented by:
- One document that contains metadata about the blob (filename, md5 checksum, MIME type, etc.), and
- One or more documents containing the actual contents of the blob, broken into 256 kB “chunks.”
While GridFS is not optimized in the same way as a traditional distributed filesystem, it is often more convenient to use. In particular, it’s convenient to use GridFS:
- For storing large binary objects directly in the database, as in the photo album example, or
- For storing file-like data where you need something like a distributed filesystem but you don’t want to actually set up a distributed filesystem.
As always, it’s best to test with your own data to see if GridFS is a good fit for you.
GridFS stores data in two collections—in this case, cms.assets.files,
which stores metadata, and cms.assets.chunks, which stores the data
itself. Consider the following prototype document from the
cms.assets.files collection:
{_id:ObjectId(…),length:123...,chunkSize:262144,uploadDate:ISODate(…),contentType:'image/jpeg',md5:'ba49a...',metadata:{nonce:ObjectId(…),slug:'2012-03-invisible-bicycle',type:'photo',locked:ISODate(...),parent_id:ObjectId(...),title:'Kitteh',created:ISODate(…),author:{_id:ObjectId(…),name:'Jared'},tags:[…],detail:{filename:'kitteh_invisible_bike.jpg',resolution:[1600,1600],…}}}
Note that in this example, most of our document looks exactly the same as a
basic page document. This helps to facilitate querying nodes, allowing us to use
the same code for either a photo or a basic page. This is facilitated by the fact
that GridFS reserves the metadata field for user-defined data.
Operations
This section outlines a number of common operations for building and interacting with the metadata and asset layer of the CMS for all node types. All examples in this document use the Python programming language, but of course you can implement this system using any language you choose.
Create and edit content nodes
The most common operations inside of a CMS center on creating and
editing content. Consider the following insert operation:
db.cms.nodes.insert({'metadata':{'nonce':ObjectId(),'parent_id':ObjectId(...),'slug':'2012-03-noticed-the-news','type':'blog-entry','title':'Noticed in the News','created':datetime.utcnow(),'author':{'id':user_id,'name':'Rick'},'tags':['news','musings'],'detail':{'publish_on':datetime.utcnow(),'text':'I noticed the news from Washington today…'}}})
One field that we’ve used but not yet explained is the nonce field.
A nonce is a value that is designed to be only used once. In our CMS, we’ve
used a nonce to mark each node when it is inserted or updated. This helps us to
detect problems where two users might be modifying the same node
simultaneously. Suppose, for example, that Alice and Bob both decide to update
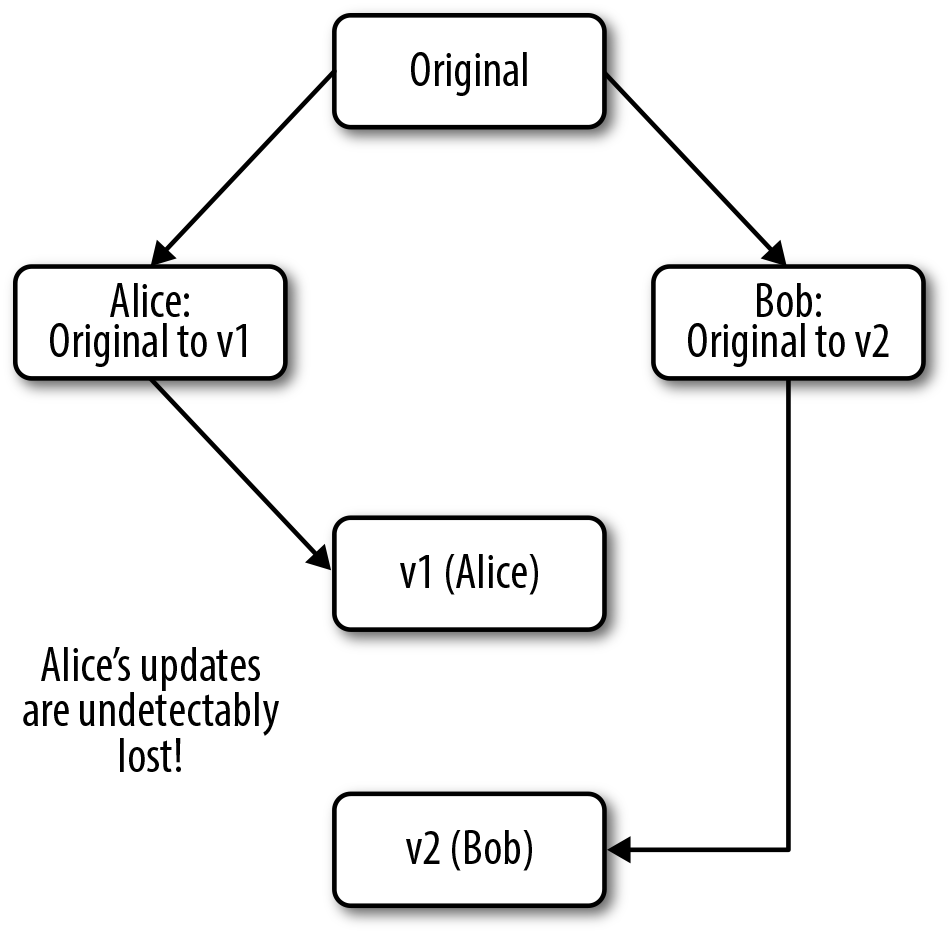
the About page for their CMS, and the sequence goes something like this (Figure 6-1):
- Alice saves her changes. The page refreshes, and she sees her new version.
- Bob then saves his changes. The page refreshes, and he sees his new version.
- Alice and Bob both refresh the page. Both of them see Bob’s version. Alice’s version has been lost, and Bob didn’t even know he was overwriting it!
A nonce can fix this problem by ensuring that updates to a node only succeed when you’re updating the same version of the document that you’re editing, as shown in Figure 6-2.
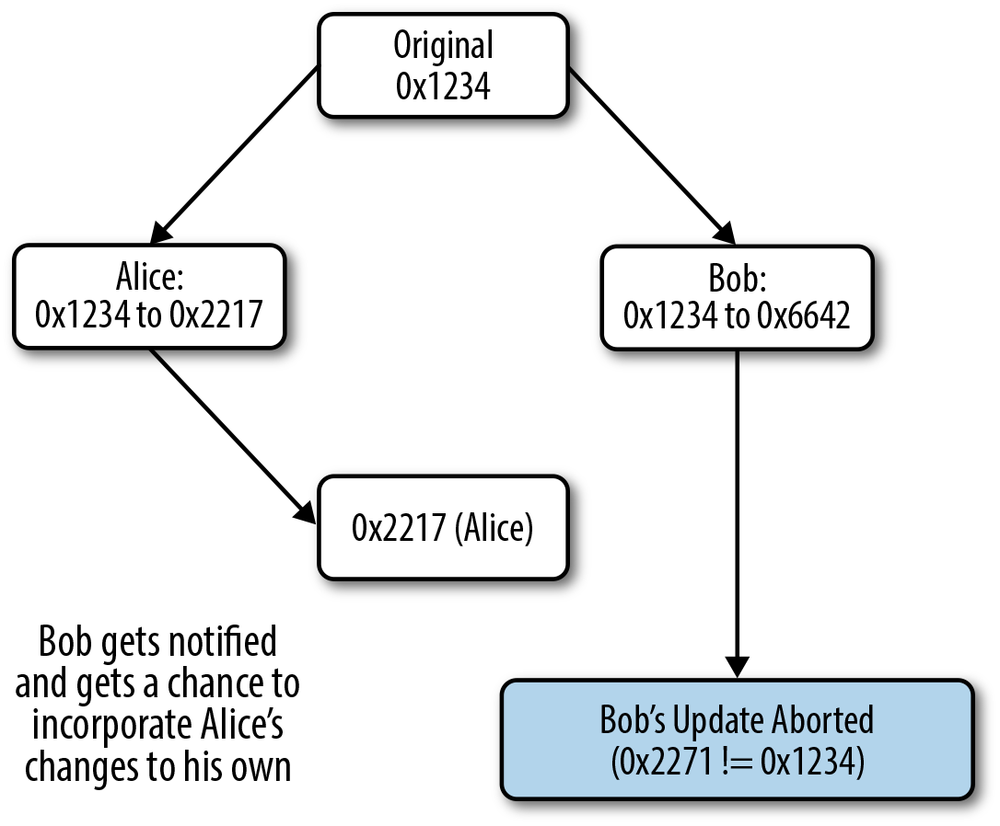
By using our nonce field, we can detect editing collisions and give the user
the opportunity to resolve them. Our update operation for a content node, then,
looks something like the following:
defupdate_text(parent_id,slug,nonce,text):result=db.cms.nodes.update({'metadata.parent_id':parent_id,'metadata.slug':slug,'metadata.nonce':nonce},{'$set':{'metadata.detail.text':text,'metadata.nonce':ObjectId()}},safe=True)
ifnotresult['updatedExisting']:raiseConflictError()
-
Here, we use
safemode to let MongoDB tell us whether it found a document to update or not. By including thenoncein the query, we ensure that the document will only be updated if it has not been modified since we loaded thenonce(which may have been a different web request).
Here, we simply raise an exception. More advanced approaches might keep a history of the document and show differences, allowing the user to resolve them manually.
We might also want to perform metadata edits to the item such as adding tags:
db.cms.nodes.update({'metadata.parent_id':parent_id,'metadata.slug':slug},{'$addToSet':{'tags':{'$each':['interesting','funny']}}})
In this example, the $addToSet operator will only add values
to the tags field if they do not already exist in the tags array;
there’s no need to supply or update the nonce.
To support updates and queries on the metadata.parent_id and
metadata.slug fields and to ensure that two editors don’t create
two documents with the same parent or slug, we can create a unique index on
these two fields:
>>>db.cms.nodes.ensure_index([...('metadata.parent_id',1),('metadata.slug',1)],unique=True)
Upload a photo
Uploading photos to our CMS requires some extra attention, as the amount of data
to be transferred can be substantially higher than for a “normal” content
node. This led to our decision to use GridFS for the storage of
photos. Furthermore, we would rather not load the entire photo’s data into
memory at once, so the following code “streams” data through to MongoDB, one chunk
at a time:
defupload_new_photo(input_file,parent_id,slug,title,author,tags,details):fs=GridFS(db,'cms.assets')now=datetime.utcnow()withfs.new_file(content_type='image/jpeg',metadata=dict(nonce=bson.ObjectId(),type='photo',locked=now,parent_id=parent_id,slug=slug,title=title,created=now,author=author,tags=tags,detail=detail))asupload_file:whileTrue:chunk=input_file.read(upload_file.chunk_size)
ifnotchunk:breakupload_file.write(chunk)# unlock the filedb.assets.files.update(
{'_id':upload_file._id},{'$set':{'locked':None}})
-
Though most of our photo information goes into the
metadatafield, the MIME content type is one of the supported fields at the “top level” of GridFS files.-
When creating a photo, we set a
lockedvalue to indicate when the upload started. This helps us detect stalled uploads and conflicting updates later.-
Since we’re storing files in GridFS in chunks of
chunk_size, we read them from the client using the same buffer size.-
Finally, we unlock the record, signifying that the upload is completed.
Because uploading the photo spans multiple documents and is a nonatomic
operation, we “lock” the file during upload by writing the current datetime in
the record. The following code shows how the locked field is used to manage updates
to the photo content:
defupdate_photo_content(input_file,parent_id,slug):fs=GridFS(db,'cms.assets')# Delete the old version if it's unlocked or was locked more than 5# minutes agofile_obj=db.cms.assets.find_one({'metadata.parent_id':parent_id,'metadata.slug':slug,'metadata.locked':None})iffile_objisNone:threshold=datetime.utcnow()-timedelta(seconds=300)file_obj=db.cms.assets.find_one({'metadata.parent_id':parent_id,'metadata.slug':slug,'metadata.locked':{'$lt':threshold}})iffile_objisNone:raiseFileDoesNotExist()fs.delete(file_obj['_id'])# update content, keep metadata unchangedfile_obj['locked']=datetime.utcnow()withfs.new_file(**file_obj):whileTrue:chunk=input_file.read(upload_file.chunk_size)ifnotchunk:breakupload_file.write(chunk)# unlock the filedb.assets.files.update({'_id':upload_file._id},{'$set':{'locked':None}})
As with the basic operations, editing tags is almost trivial:
db.cms.assets.files.update({'metadata.parent_id':parent_id,'metadata.slug':slug},{'$addToSet':{'metadata.tags':{'$each':['interesting','funny']}}})
Since our queries tend to use both metadata.parent_id and metadata.slug, a
unique index on this combination is sufficient to get good performance:
>>>db.cms.assets.files.ensure_index([...('metadata.parent_id',1),('metadata.slug',1)],unique=True)
Locate and render a node
To locate a “normal” node based on the value of metadata.parent_id and
metadata.slug, we can use the find_one operation rather than find:
node=db.nodes.find_one({'metadata.parent_id':parent_id,'metadata.slug':slug})
To locate an image based on the value of metadata.parent_id and
metadata.slug, we use the GridFS method get_version:
code,sourceCode,pythonfs=GridFS(db,'cms.assets')withfs.get_version({'metadata.parent_id':parent_id,'metadata.slug':slug})asimg_fpo:# do something with the image file
Search for nodes by tag
To retrieve a list of “normal” nodes based on their tags, the query is straightforward:
nodes=db.nodes.find({'metadata.tags':tag})
To retrieve a list of images based on their tags, we’ll perform a search on
cms.assets.files directly:
image_file_objects=db.cms.assets.files.find({'metadata.tags':tag})fs=GridFS(db,'cms.assets')forimage_file_objectindb.cms.assets.files.find({'metadata.tags':tag}):image_file=fs.get(image_file_object['_id'])# do something with the image file
In order to make these queries perform well, of course, we need an index on metadata.tags:
>>>db.cms.nodes.ensure_index('metadata.tags')>>>db.cms.assets.files.ensure_index('metadata.tags')
Generate a feed of recently published blog articles
One common operation in a blog is to find the most recently published blog post, sorted in descending order by date, for use on the index page of the site, or in an RSS or ATOM feed:
articles=db.nodes.find({'metadata.parent_id':'my-blog''metadata.published':{'$lt':datetime.utcnow()}})articles=articles.sort({'metadata.published':-1})
Since we’re now searching on parent_id and published, we need an index on these
fields:
>>>db.cms.nodes.ensure_index(...[('metadata.parent_id',1),('metadata.published',-1)])
Sharding Concerns
In a CMS, read performance is more critical than write performance. To
achieve the best read performance in a shard cluster, we need to ensure that
mongos can route queries to their particular shards.
Warning
Keep in mind that MongoDB cannot enforce unique indexes across shards. There
is, however, one exception to this rule. If the unique index is the shard key
itself, MongoDB can continue to enforce uniqueness in the index. Since
we’ve been using the compound key (metadata.parent_id, metadata.slug) as a
unique index, and we have relied on this index for correctness, we need
to be sure to use it as our shard key.
To shard our node collections, we can use the following commands:
>>>db.command('shardcollection','dbname.cms.nodes',{...key:{'metadata.parent_id':1,'metadata.slug':1}}){ "collectionsharded": "dbname.cms.nodes", "ok": 1}>>>db.command('shardcollection','dbname.cms.assets.files',{...key:{'metadata.parent_id':1,'metadata.slug':1}}){ "collectionsharded": "dbname.cms.assets.files", "ok": 1}
To shard the cms.assets.chunks collection, we need to use the files_id
field as the shard key. The following operation will shard the
collection (note that we have appended the _id field to guard against an
enormous photo being unsplittable across chunks):
>>>db.command('shardcollection','dbname.cms.assets.chunks',{...key:{'files_id':1,'_id':1}}){ "collectionsharded": "dbname.cms.assets.chunks", "ok": 1}
Note that sharding on the _id field ensures routable queries because
all reads from GridFS must first look up the document in
cms.assets.files and then look up the chunks separately by files_id.
Storing Comments
Most content management systems include the ability to store and display user-submitted comments along with any of the normal content nodes. This section outlines the basic patterns for storing user-submitted comments in such a CMS.
Solution Overview
MongoDB provides a number of different approaches for storing data like user comments on content from a CMS. There is no one correct implementation, but rather a number of common approaches and known considerations for each approach. This section explores the implementation details and trade-offs of each option. The three basic patterns are:
- Store each comment in its own document
- This approach provides the greatest flexibility at the expense of some additional application-level complexity. For instance, in a comment-per-document approach, it is possible to display comments in either chronological or threaded order. Furthermore, it is not necessary in this approach to place any arbitrary limit on the number of comments that can be attached to a particular object.
- Embed all comments in the “parent” document
- This approach provides the greatest possible performance for displaying comments at the expense of flexibility: the structure of the comments in the document controls the display format. (You can, of course, re-sort the comments on the client side, but this requires extra work on the application side.) The number of comments, however, is strictly limited by MongoDB’s document size limit.
- Store comments separately from the “parent,” but grouped together with each other
- This hybrid design provides more flexibility than the pure embedding approach, but provides almost the same performance.
Also consider that comments can be threaded, where comments are always replies to a “parent” item or to another comment, which carries certain architectural requirements discussed next.
Approach: One Document per Comment
If we wish to store each comment in its own document, the documents in our
comments collection would have the following structure:
{_id:ObjectId(...),node_id:ObjectId(...),slug:'34db',posted:ISODateTime(...),author:{id:ObjectId(...),name:'Rick'},text:'This is so bogus ... '}
This form is only suitable for displaying comments in chronological order. Comments store the following:
-
The
node_idfield that references the node parent -
A URL-compatible
slugidentifier -
A
postedtimestamp -
An
authorsubdocument that contains a reference to a user’s profile in theidfield and their name in thenamefield -
The full
textof the comment
In order to support threaded comments, we need to use a slightly different structure:
{_id:ObjectId(...),node_id:ObjectId(...),parent_id:ObjectId(...),slug:'34db/8bda'full_slug:'2012.02.08.12.21.08:34db/2012.02.09.22.19.16:8bda',posted:ISODateTime(...),author:{id:ObjectId(...),name:'Rick'},text:'This is so bogus ... '}
This structure:
-
Adds a
parent_idfield that stores the contents of the_idfield of the parent comment -
Modifies the
slugfield to hold a path composed of the parent or parent’s slug and this comment’s unique slug -
Adds a
full_slugfield that combines the slugs and time information to make it easier to sort documents in a threaded discussion by date
Operation: Post a new comment
To post a new comment in a chronologically ordered (i.e., without discussion
threading) system, we just need to use a regular insert():
slug=generate_pseudorandom_slug()db.comments.insert({'node_id':node_id,'slug':slug,'posted':datetime.utcnow(),'author':author_info,'text':comment_text})
To insert a comment for a system with threaded comments, we first need to
generate the appropriate slug and full_slug values based on the parent comment:
posted=datetime.utcnow()# generate the unique portions of the slug and full_slugslug_part=generate_pseudorandom_slug()full_slug_part=posted.strftime('%Y.%m.%d.%H.%M.%S')+':'+slug_part# load the parent comment (if any)ifparent_slug:parent=db.comments.find_one({'node_id':node_id,'slug':parent_slug})slug=parent['slug']+'/'+slug_partfull_slug=parent['full_slug']+'/'+full_slug_partelse:slug=slug_partfull_slug=full_slug_part# actually insert the commentdb.comments.insert({'node_id':node_id,'slug':slug,'full_slug':full_slug,'posted':posted,'author':author_info,'text':comment_text})
Operation: View paginated comments
To view comments that are not threaded, we just need to select all comments
participating in a discussion and sort by the posted field. For
example:
cursor=db.comments.find({'node_id':node_id})cursor=cursor.sort('posted')cursor=cursor.skip(page_num*page_size)cursor=cursor.limit(page_size)
Since the full_slug field contains both hierarchical information
(via the path) and chronological information, we can use a simple sort
on the full_slug field to retrieve a threaded view:
cursor=db.comments.find({'node_id':node_id})cursor=cursor.sort('full_slug')cursor=cursor.skip(page_num*page_size)cursor=cursor.limit(page_size)
To support these queries efficiently, maintain two compound indexes
on node_id, posted and node_id, full_slug:
>>>db.comments.ensure_index([...('node_id',1),('posted',1)])>>>db.comments.ensure_index([...('node_id',1),('full_slug',1)])
Operation: Retrieve comments via direct links
To directly retrieve a comment, without needing to page through all
comments, we can select by the slug field:
comment=db.comments.find_one({'node_id':node_id,'slug':comment_slug})
We can also retrieve a “subdiscussion,” or a comment and all of its
descendants recursively, by performing a regular expression prefix query
on the full_slug field:
importresubdiscussion=db.comments.find_one({'node_id':node_id,'full_slug':re.compile('^'+re.escape(parent_full_slug))})subdiscussion=subdiscussion.sort('full_slug')
Since we’ve already created indexes on { node_id: 1, full_slug: 1 } to
support retrieving subdiscussions, we don’t need to add any other indexes here
to achieve good performance.
Approach: Embedding All Comments
This design embeds the entire discussion of a comment thread inside of
its parent node document.
Consider the following prototype topic document:
{_id:ObjectId(...),...,metadata:{...comments:[{posted:ISODateTime(...),author:{id:ObjectId(...),name:'Rick'},text:'This is so bogus ... '},...],}}
This structure is only suitable for a chronological display of all
comments because it embeds comments in chronological order. Each
document in the array in the comments contains the comment’s date,
author, and text.
To support threading using this design, we would need to embed comments within comments, using a structure more like the following:
{_id:ObjectId(...),...lotsoftopicdata...metadata:{...,replies:[{posted:ISODateTime(...),author:{id:ObjectId(...),name:'Rick'},text:'This is so bogus ... ',replies:[{author:{...},...},...]}...]}}
Here, the replies field in each comment holds the subcomments, which
can in turn hold subcomments.
Operation: Post a new comment
To post a new comment in a chronologically ordered (i.e., unthreaded)
system, we need the following update:
db.cms.nodes.update({...nodespecification...},{'$push':{'metadata.comments':{'posted':datetime.utcnow(),'author':author_info,'text':comment_text}}})
The $push operator inserts comments into the comments
array in correct chronological order. For threaded discussions, the
update operation is more complex. To reply to a comment, the following code
assumes that it can retrieve the path as a list of positions, for the
parent comment:
ifpath!=[]:str_path='.'.join('replies.%d'%partforpartinpath)str_path+='.replies'else:str_path='replies'db.cms.nodes.update({...nodespecification...},{'$push':{'metadata.'+str_path:{'posted':datetime.utcnow(),'author':author_info,'text':comment_text}}})
This constructs a field name of the form metadata.replies.0.replies.2... as
str_path and then uses this value with the $push operator to insert the new
comment into the replies array.
Operation: View paginated comments
To view the comments in a nonthreaded design, we need to use the $slice operator:
node=db.cms.nodes.find_one({...nodespecification...},{...somefieldsrelevanttoyourpagefromtherootdiscussion...,'metadata.comments':{'$slice':[page_num*page_size,page_size]}})
To return paginated comments for the threaded design, we must retrieve the whole document and paginate the comments within the application:
node=db.cms.nodes.find_one(...nodespecification...)defiter_comments(obj):forreplyinobj['replies']:yieldreplyforsubreplyiniter_comments(reply):yieldsubreplypaginated_comments=itertools.slice(iter_comments(node),page_size*page_num,page_size*(page_num+1))
Operation: Retrieve a comment via direct links
Instead of retrieving comments via slugs as in Approach: One Document per Comment,
the following example retrieves comments using their position in the comment list
or tree. For chronological (i.e., nonthreaded) comments, we’ll just use the
$slice operator to extract a single comment, as follows:
node=db.cms.nodes.find_one({'node_id':node_id},{'comments':{'$slice':[position,position]}})comment=node['comments'][0]
For threaded comments, we must know the correct path through the tree in our application, as follows:
node=db.cms.nodes.find_one(...nodespecification...)current=node.metadataforpartinpath:current=current.replies[part]comment=current
Approach: Hybrid Schema Design
In the “hybrid approach,” we store comments in “buckets” that hold about 100 comments. Consider the following example document:
{_id:ObjectId(...),node_id:ObjectId(...),page:1,count:42,comments:[{slug:'34db',posted:ISODateTime(...),author:{id:ObjectId(...),name:'Rick'},text:'This is so bogus ... '},...]}
Each document maintains page and count data that contains metadata
regarding the page number and the comment count in this page, in addition
to the comments array that holds the comments themselves.
Operation: Post a new comment
In order to post a new comment, we need to $push the comment
onto the last page and $inc that page’s comment
count. Consider the following example that adds a comment onto the last page of
comments for some node:
defpost_comment(node,comment):result=db.comment_pages.update({'node_id':node['_id'],'page':node['num_comment_pages'],'count':{'$lt':100}},{'$inc':{'count':1},'$push':{'comments':comment}},upsert=True)ifnotresult['updatedExisting']:db.cms.nodes.update({'_id':node['_id'],'num_comment_pages':node['num_comment_pages']},{'$inc':{'num_comment_pages':1}})db.comment_pages.update({'node_id':node['_id'],'page':node['num_comment_pages']+1},{'$inc':{'count':1},'$push':{'comments':comment}},upsert=True)
There are a few things to note about this code:
-
The first update will only
$pusha comment if the page is not yet full.-
If the last comment page is full, we need to increment the
num_comment_pagesproperty in the node (so long as some other process has not already incremented that property).-
We also need to re-run the update to
$pushthe comment onto the newly created comment page. Here, we’ve dropped thecountconstraint to make sure the$pushgoes through. (While it’s technically possible that 100 other concurrent writers were adding comments and the new page is already full, it’s highly unlikely, and the application works just fine if there happen to be 101 comments on a page.)
To support the update operations, we need to
maintain a compound index on node_id, page in the comment_pages collection:
>>>db.comment_pages.ensure_index([...('node_id',1),('page',1)])
Operation: View paginated comments
The following function defines how to paginate comments where the number of comments on a page is not known precisely (i.e., with roughly 100 comments, as in this case):
deffind_comments(discussion_id,skip,limit):query=db.comment_pages.find({'node_id':node_id})query=query.sort('page')forpageinquery:new_skip=skip-page['count']ifnew_skip>=0:skip=new_skipcontinueelifskip>0:comments=page['comments'][skip:]else:comments=page['comments']skip=new_skipforcommentincomments:iflimit==0:breaklimit-=1yieldcommentiflimit==0:break
Here, we iterate through the pages until our skip requirement is satisfied,
then yield comments until our limit requirement is satisfied. For example, if
we have three pages of comments with 100, 102, 101, and 22 comments on each page, and
we wish to retrieve comments where skip=300 and limit=50, we’d use the
following algorithm:
Skip | Limit | Discussion |
300 | 50 | Page 0 has 100 comments, so |
200 | 50 | Page 1 has 102 comments, so |
98 | 50 | Page 2 has 101 comments, so set |
0 | 47 | Page 3 has 22 comments, so return them all and set |
0 | 25 | There are no more pages; terminate loop. |
Operation: Retrieve a comment via direct links
To retrieve a comment directly without paging through all preceding pages of commentary, we’ll use the slug to find the correct page, and then use application logic to find the correct comment:
page=db.comment_pages.find_one({'node_id':node_id,'comments.slug':comment_slug},{'comments':1})forcommentinpage['comments']:ifcomment['slug']=comment_slug:break
To perform this query efficiently, we’ll need a new index on node_id,
comments.slug (this is assuming that slugs are only guaranteed unique within
a node):
>>>db.comment_pages.ensure_index([...('node_id',1),('comments.slug',1)])
Sharding Concerns
For all of the architectures just discussed, we will want the node_id field to
participate in any shard key we pick.
For applications that use the “one document per comment” approach,
we’ll use the slug (or full_slug, in the case of threaded comments)
fields in the shard key to allow the mongos instances to route requests by
slug:
>>>db.command('shardcollection','dbname.comments',{...'key':{'node_id':1,'slug':1}}){ "collectionsharded" : "dbname.comments", "ok" : 1 }
In the case of comments that are fully embedded in parent content, the comments will just participate in the sharding of their parent document.
For hybrid documents, we can use the page number of the comment page in the
shard key along with the node_id to prevent a single discussion from creating
a giant, unsplittable chunk of comments. The appropriate command for this is as follows:
>>>db.command('shardcollection','dbname.comment_pages',{...key:{'node_id':1,'page':1}}){ "collectionsharded" : "dbname.comment_pages", "ok" : 1 }