
4
BLOCK CIPHER
TANVEER AHMED, MOHAMMAD ABUL KASHEM, AND SAIFUL AZAD
Contents
4.2 The Feistel Block Structure
4.3.1 Electronic Codebook (ECB) Mode
4.3.2 Cipher Block Chaining (CBC)
4.3.3 Cipher Feedback (CFB) Mode
4.3.4 Output Feedback (OFB) Mode
Keywords
Block cipher
Cipher block chaining
Cipher feedback
Counter
Electronic code block
Feistel cipher
Output feedback
A stream cipher is one that encrypts/decrypts a data stream character by character, i.e., one character at a time. All the ciphers discussed in Chapter 3 are stream ciphers. On the other hand, a block cipher encrypts/decrypts a block of n characters and produces an output of similar length. The Data Encryption Standard (DES), Advanced Encryption Standard (AES), etc., are examples of block ciphers. Most of the symmetric key-based block cipher algorithms currently in use are based on a structure known as Feistel block cipher [1]. It is worth mentioning that although this structure was proposed several years ago, it is still utilized by many significant symmetric block ciphers currently in operation. In general, block cipher algorithms ensure higher security over stream cipher algorithms. In this chapter, we discuss the basic principles behind block cipher algorithms and Feistel block cipher in detail.
4.1 Block Cipher Principles
To enhance the security of symmetric key algorithms, Calude Shannon introduced two principles: confusion and diffusion [2]. He argued that these principles should be followed to design any secure cryptographic system. They are detailed below:
• Confusion: Shannon said confusion makes the relation between the key and the ciphertext as complex as possible. Actually, every character in the key influences every other character of the ciphertext block. This relationship needs to be loosened in such a way that even though the attacker gets some grip on the statistics of the ciphertext, he or she may not be able to deduce the key. A good confusion could be achieved if each character of the ciphertext depends on several parts of the key. For any attacker, it must appear that this dependence is random. This could be achieved by utilizing complex substitution techniques in the algorithm.
• Diffusion: This refers to the property that the statistical structure of the plaintext is dissipated into long-range statistics of the ciphertext [3]. In contrast to confusion, diffusion spreads the influence of a single plaintext character over many ciphertext characters, or in other words, each ciphertext character is affected by many ciphertext characters. In binary block cipher, an algorithm must be designed with a combination of permutation and should be followed by a function. The binary block is permuted repeatedly, followed by applying a function to that permuted block.
4.2 The Feistel Block Structure
In Figure 4.1, the Feistel block structure is depicted. As can be observed from the figure, a plaintext of length n bits and a key K are passed as input to the structure. This n-bit plaintext block is then divided into two halves, LE0 and RE0, i.e., LE0 = RE0 = n/2. These two halves of data blocks are passed through r rounds. In each round, a separate key Ki is utilized that is generally derived from K. All the subkeys that are derived from K are different from each other, i.e., K ≠ Ki ≠ Kj. A round i receives two inputs, LEi–1 and REi–1, from the previous round i – 1. Each round comprises both substitution and permutation operations. A substitution is performed on the left half of the block by XORing it with the output of a round function F.
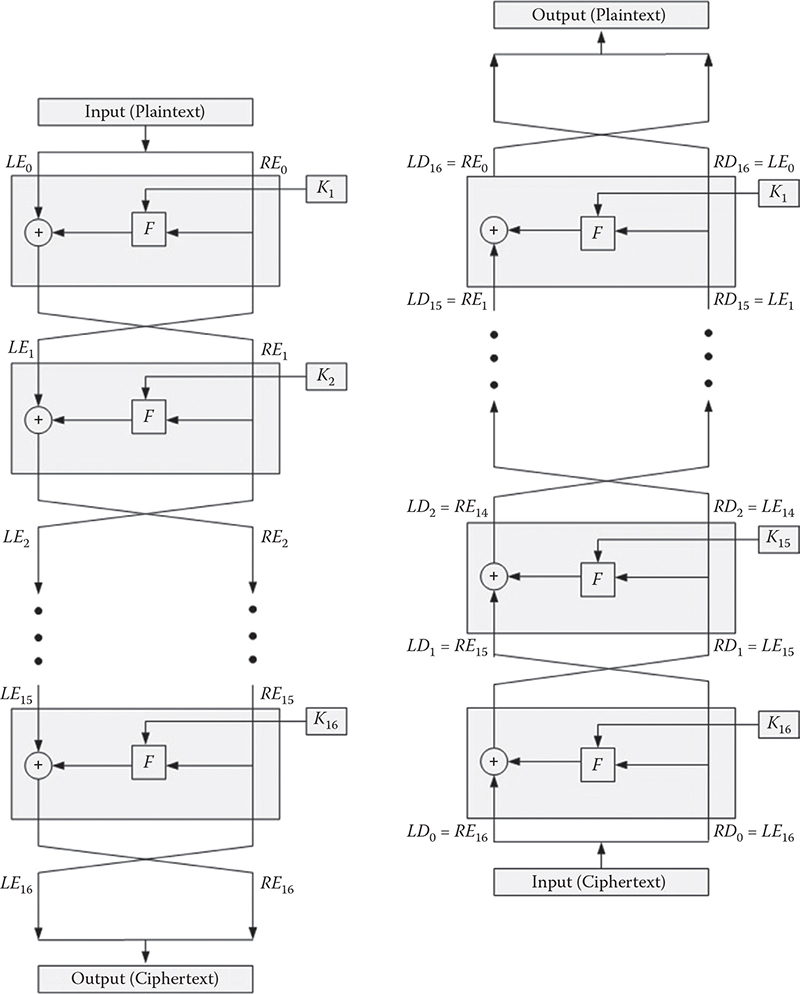
Figure 4.1 Encryption and decryption of the Feistel network.
Each F takes the right half block and a subkey Ki as input and produces an output of the same size. These activities can be expressed using the following expressions:
LEi = REi–1
REi = LEi–1 ⊗ F(REi–1, Ki)
Following the substitution, the two halves are interchanged to achieve permutation. After the last round, the two halves are combined to produce the ciphertext block. In the case of decryption, similar procedures are followed, but in opposite order, i.e.,
REi–1 = LEi
LEi–1 = REi ⊗ F(REi–1, Ki) = REi ⊗ F(LEi, Ki)
The strength of a Feistel network depends on the selection of the following parameters:
• Block size: The larger the block, the greater the security. However, a larger block size reduces the speed of the encryption/decryption technique. Therefore, a reasonable trade-off is considered in terms of choosing the size of a block.
• Key size: Like the block size, larger is better. Again, a larger key may increase the processing time, and hence reduce the encryption/decryption speed.
• Number of rounds: In general, a single round is inadequate to assure a required level of security. But, multiple rounds offer increasing security.
• Subkey generation algorithm: For greater security, a subkey generation algorithm also plays an important role. A complex algorithm makes the cryptanalysis difficult. All the subkeys must be generated in such a way that they have greater resistance to brute-force attacks and greater confusion.
• Round function: Again, a greater complex round function makes the cryptanalysis difficult, and hence increases the security.
4.3 Block Cipher Modes
What if the size of a message is longer than the considered block size? To resolve this issue, there are five block cipher modes that have been defined by the National Institute of Standards and Technology (NIST). All these modes of operation are briefly described below.
4.3.1 Electronic Codebook (ECB) Mode
This is the simplest mode of operation. In this mode, a plaintext is divided into blocks of n bits and every block is encrypted/decrypted separately using a similar secret key. This is depicted in Figure 4.2. A plaintext is divided into m different blocks, i.e., P1, P2, P3, …, Pm. After encryption, it produces m blocks of ciphertext, namely, C1, C2, C3, …, Cm. The ECB encryption and decryption can be defined as follows:
Encryption:
C1 = EK (P1)
Decryption:
P1 = DK (C1)= EK-1 (EK (P1 ))
In this scheme, since all the blocks are independent of each other, it does not suffer any propagation error. There are a couple of problems with this approach, which is absent in the single-block case. If a plaintext block contains two identical n-bit blocks, the corresponding ciphertext blocks will be also identical. These regularities provide sufficient hints to a cryptoanalyst to decipher the message.
Figure 4.2 Electronic codebook (ECB) mode.
4.3.2 Cipher Block Chaining (CBC)
To overcome the deficiencies of the ECB, IBM invented the CBC mode in 1976. In this mode, every block of the plaintext is XORed with the previous ciphertext block. Therefore, identical blocks in the plaintext would not produce identical ciphertext blocks. Since the decryption is dependent on the previous block, a single bit error in a block will cause the failure. Since there is no previous ciphertext block for the first plaintext block, a fixed initialization vector (IV) is XORed with this block. The IV is not secret and must be known to the receiver. To make every message unique, a different IV could be utilized for every plaintext, which must be generated in such a way that a malicious user has no influence on it. The encryption/decryption of CBC can be expressed as follows:
Encryption:
C1 |
= EK (P1 ⊕ IV) |
Ci |
= EK (Pi ⊕ Ci−1), where i ≥ 2 |
Decryption:
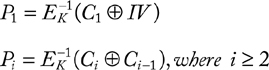
Figure 4.3 illustrates the CBC scheme. The CBC also suffers from a couple of problems. For instance, if someone predictably changes bits in IV intentionally, the corresponding bits of the received value of P1 can be changed.
4.3.3 Cipher Feedback (CFB) Mode
All the modes discussed previously require a fixed data block. If there are not enough bits to fill up a block, the padding bits are affixed to make it of a desirable size. Unlike the ECB and CBC, the CFB mode is a stream cipher. One desirable property of a stream cipher is that it produces the ciphertext of the same length as the plaintext. Like the CBC, the CFB requires an IV for the initial input block that is n bits long. It also requires an integer value, denoted by s, that is assumed to be the unit of transmission. Figure 4.4 illustrates the CFB scheme. As can be observed from the figure, the first input block is the IV, and the forward cipher operation is performed over it to produce the first output block. Keeping the s most significant bits, the remaining n – s bits are discarded. Then, s bits are XORed with the first plaintext segment of s bits to produce a first ciphertext segment of s bits. To produce the second input block, the IV is circularly shifted s bits to the left and the recently produced ciphertext segment is placed in the least significant s bits. This process continues until all the plaintext segments produce the relative ciphertext segment.
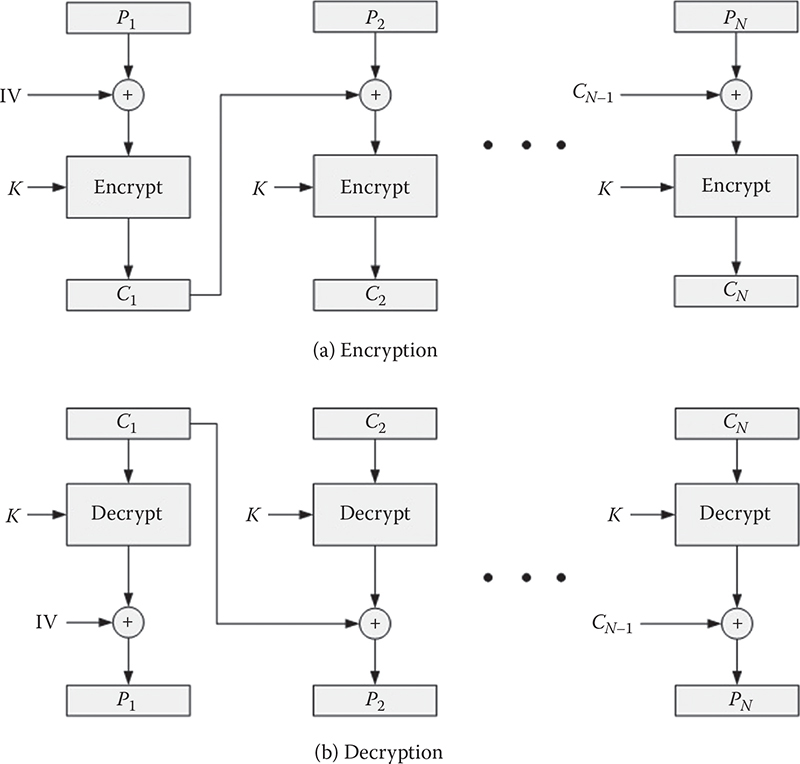
Figure 4.3 Cipher block chaining (CBC) mode.
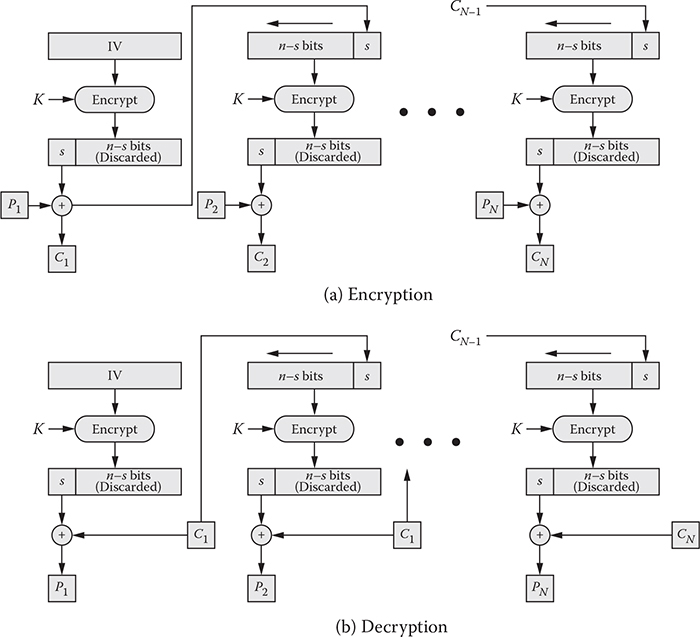
Figure 4.4 Cipher feedback (CFB) mode.
The decryption utilizes a scheme similar to that for encryption, except that the received ciphertext segment is XORed with the output block of the encryption function. Note that there is no decryption function utilized to decrypt a ciphertext, but an encryption function is used. All the operations can be expressed as below:
Encryption:
C1 |
= EK (IV) ⊕ P1 |
Ci |
= EK (Ci−1) ⊕ P1, where i ≥ 2 |
Decryption:
P1 |
= EK (IV) ⊕ C1 |
Pi |
= EK (Ci−1) ⊕ C1, where i ≥ 2 |
The CFB suffers from error propagation since all the ciphertext segments are related to each other.
4.3.4 Output Feedback (OFB) Mode
The OFB mode is similar in terms of structure to that of the CFB. Like the CFB, the first input block requires the IV, which is then encrypted with a secret key to produce an output block of n bits. Unlike the CFB, the ciphertext segment is not fed back to the next input block. Instead, the output of the encryption function is fed back to the next input block. In the first input block, the IV and a secret key are required by an encryption function that produces an output block. All the bits except the most significant s bits are discarded. These bits are fed back to the next input block. These s bits are also XORed with the plaintext to produce a ciphertext segment of s bits. To produce the second input block, the IV is circularly left shifted to s number of bits, and the least significant s bits are replaced by the s bits received from the previous output block. The OFB mode is illustrated in Figure 4.5. In case of decryption, no ciphertext segment is required, unlike CFB. The encryption/decryption operations can be expressed as follows:
Encryption:
s1 |
= EK (IV) and C1 = (s1 ⊕ P1) |
si |
= EK (si−1) and Ci = (si ⊕ Pi), where i ≥ 2 |
Decryption:
s1 |
= EK (IV) and C1 = (s1 ⊕ C1) |
si |
= EK (si−1) and Ci = (si ⊕ Ci), where i ≥ 2 |
Since all the ciphertext segments are independent of each other, this mode is more vulnerable to a message stream modification attack than CFB.
4.3.5 Counter (CTR) Mode
In this mode, a counter equal to the plaintext block is used to produce an output block. If there is a sequence of plaintext blocks, in that case, a sequence of counters is utilized. Each counter is distinct from the other. In general, the counter is initialized to some value that is then incremented by 1 for every subsequent block. Every block receives a counter and a key, and produces an output block. The resultant output block is XORed with the corresponding plaintext block to produce the ciphertext block. The encryption/decryption scheme can be expressed as below:
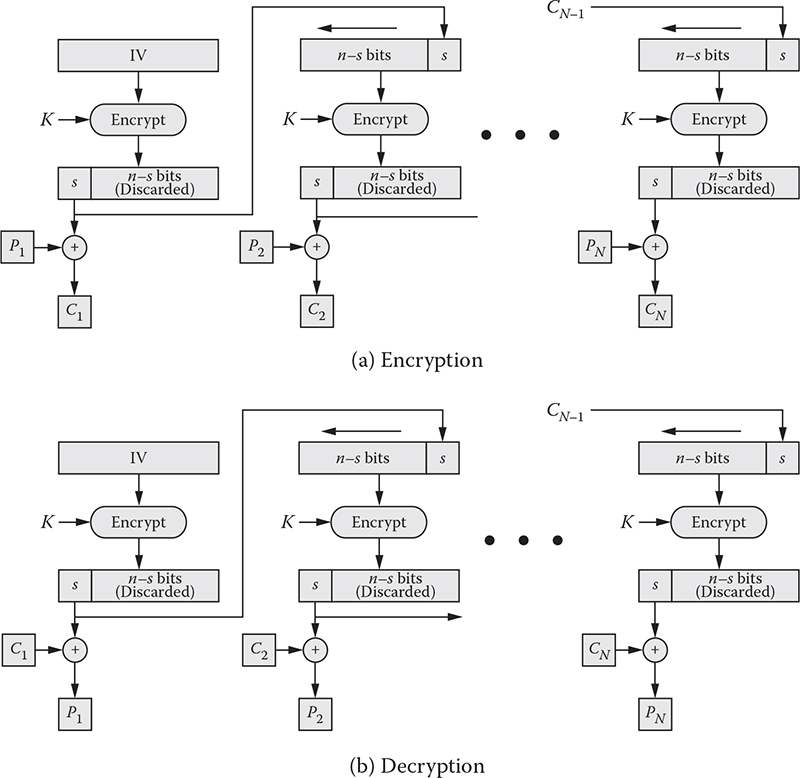
Figure 4.5 Output feedback (OFB) mode.
Encryption:
Ci = EK (CTRi) ⊕ Pi
Decryption:
Pi = EK (CTRi) ⊕ Ci
One notable advantage of this technique is that unlike the CFB and OFB modes, both the CTR encryption and the CTR decryption can be parallelized since the second encryption can begin before the first one has finished. Moreover, if necessary, any particular ciphertext block/plaintext block can be recovered independently if the corresponding counter block can be determined. Figure 4.6 illustrates the CTR mode.
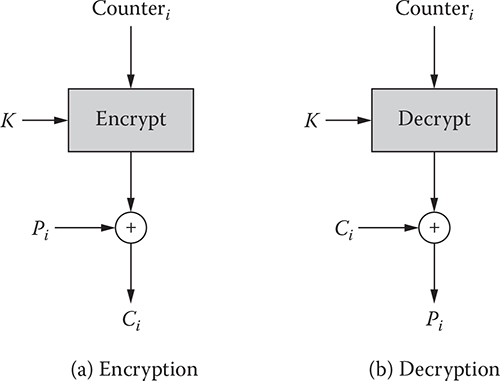
Figure 4.6 Counter (CTR) mode.
References
1. H. Feistel. Cryptography and computer privacy. Scientific American, May 1973.
2. C. Shannon. Communication theory of secrecy systems. Bell Systems Technical Journal, No. 4, 1949.
3. W. Stallings. Cryptography and network security, 4th ed. Pearson, India, 2006.