
11
SECURE HASH ALGORITHM
SADDAM HOSSAIN MUKTA AND SAIFUL AZAD
Contents
11.1 Basic Hash Function Concept
11.3.1 Appending Original Message Lengths and Padding
Keywords
Authentication check
Hash function
Integrity check
Secure Hash Algorithm
SHA-1
In 1990, Ron Rivest invented an algorithm utilizing the concept of hash function, called Message Digest 4 (MD4). He extended that algorithm in 1992, and named it Message Digest 5 (MD5). Later in 1993, the National Institute of Standards and Technology (NIST) developed and published an algorithm as a Federal Information Processing Standard (FIPS 180) that is analogous to the MD5 algorithm, called Secure Hash Algorithm (SHA). It is now often named SHA-0. After discovering some weaknesses in the SHA, the National Security Agency (NSA) shortly withdrew the publication. Then, in 1995, the NSA issued a revised version of the SHA that is commonly designated SHA-1. In the SHA-1algorithm, a single bitwise rotation is introduced in the message schedule of its compression functions over SHA.
11.1 Basic Hash Function Concept
A hash function is a procedure that maps data of arbitrary length to data of a fixed length. The values returned by a hash function are often known as hash values, hash codes, hash sums, checksums, or simply hashes. Generally, a hash function compresses data to a fixed size, which could be considered a shortened reference to the original data. For compression, hash functions usually utilize a one-way function of number theory; hence, they are irreversible. Consequently, it is infeasible to reconstruct particular data when a hash value is known. Utilizing this basic concept, there are some hash algorithms that have been proposed: SHA, SHA-1, SHA-224, SHA-256, SHA-384, SHA-512, SHA-512/224, and SHA-512/256. Each algorithm is different from the others in terms of one or more parameters. Table 11.1illustrates various parameters of different algorithms.
There are a couple of applications where these irreversible hash values are utilized. They are discussed in detail in the next section.
11.2 Applications
One realistic application of a hash function is a hash table in data structure. It is tedious to search particular data in a list linearly; instead, a hash value could be computed utilizing the key part of the data to keep an indication of the entire data. Now, a simple data comparison can be utilized to find out desired data, which accelerates the searching mechanism. Another application of the hash function is in cryptography, the science of encoding and protecting data. This is the application in which we are interested. A hash function can be utilized to check the integrity of a piece of data, and often a resultant hash value is affixed to the original data. After receiving the data at the destination, a receiver utilizes a similar hash function to create a hash value. Then, two hash values are compared to check the equality. If they are similar, the receiver can presume that the integrity is preserved in the data. If anyone changes the data, in that case two hash values cannot be similar. Hash functions are also utilized for authentication and verification.
Table 11.1 Comparison of Various Secure Hash Algorithms
ALGORITHM |
MESSAGE SIZE, MI (BITS) |
BLOCK SIZE, BI (BITS) |
WORD SIZE, WI (BITS) |
MESSAGE DIGEST SIZE, DI (BITS) |
SHA-1 |
<264 |
512 |
32 |
160 |
SHA-224 |
<264 |
512 |
32 |
224 |
SHA-256 |
<264 |
512 |
32 |
256 |
SHA-384 |
<2128 |
1024 |
64 |
384 |
SHA-512 |
<2128 |
1024 |
64 |
512 |
SHA-512/224 |
<2128 |
1024 |
64 |
224 |
SHA-512/256 |
<2128 |
1024 |
64 |
256 |
11.3 Steps of SHA-1
The processing steps of the SHA-1 are discussed below.
11.3.1 Appending Original Message Lengths and Padding
Before starting to process the message, M, it is padded first so that its length becomes congruent to 448 modulo 512. If the message is already of the desired length, padding is still performed. Thus, the number of padding bits could range from 1 to 512 bits. The padding starts with 1 bit and is followed by the consecutive number of zeros. The last 64 bits are kept empty. These bits are utilized to store the length of the original message. These operations are illustrated in Figure 11.1.
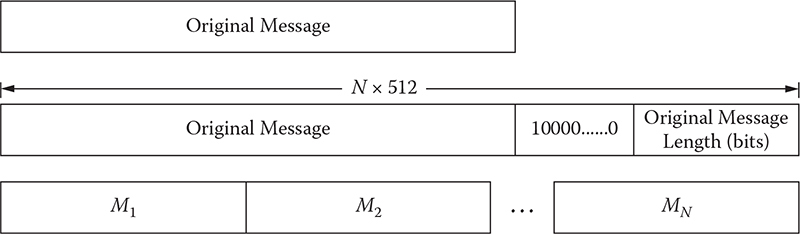
Figure 11.1 Message format after padding and appending original message length.
11.3.2 Initialization
SHA-1 generates a 160-bit message digest that consists of five 32-bit words. Let us call those h0, h1, h2, h3, and h4. Before utilizing these words in the processing, they are initialized with the following values:
h0 = 0x67452301
h1 = 0xefcdab89
h2 = 0x98badcfe
h3 = 0x10325476
h4 = 0xc3d2e1f0
These values are stored according to big-endian format, which means that the most significant byte of a word is placed in the low-address byte position. These values change when they are passed through different rounds. There are 80 rounds in the SHA-1. After the last round, the value of h0|h1|h2|h3|h4 is considered the message digest of the entire message. Details of these rounds are discussed later in this chapter.
11.3.3 Message Processing
As mentioned previously, every message passes through 80 different rounds before generating the final message digest, which is shown in Figure 11.2. It can be observed from the figure that in every round, one word is passed, and from the message, Mi, only 16 words can be found. The rest of the words are generated using the following expression:
![]() is then rotated 1 bit to the left to generate Wi. Along with a word, one constant, Ki, is passed to the ith round. The value of K varies with rounds as follows:
is then rotated 1 bit to the left to generate Wi. Along with a word, one constant, Ki, is passed to the ith round. The value of K varies with rounds as follows:
Ki = 0x5a827999 |
(0 ≤ t ≤ 19) |
K i = 0x6ed9eba1 |
(20 ≤ t ≤ 39) |
K i = 0x8f1bbcdc |
(40 ≤ t ≤ 59) |
K i = 0xca62c1d6 |
(60 ≤ t ≤ 79) |
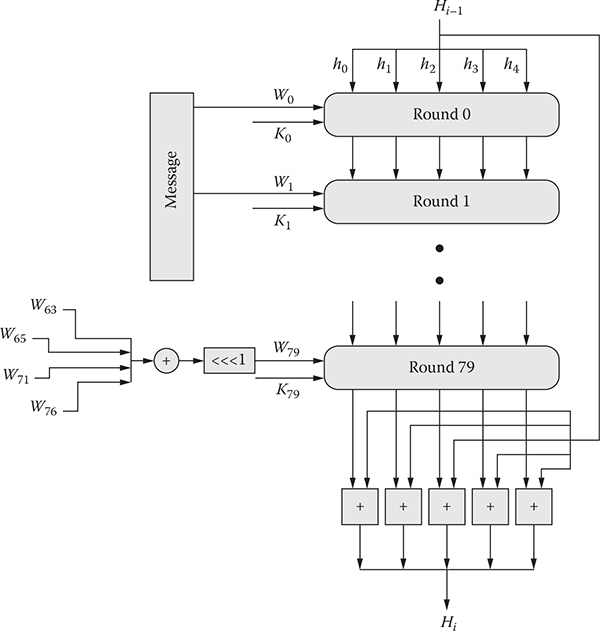
Figure 11.2 Processing of a 512-bit block.
Every round acquires a 160-bit or 5-word buffer value from the previous round, except the initial one, which acquires this value from the initialization technique discussed in the previous subsection. All the operations involved in a round are depicted in Figure 11.3. Each round utilizes a function, F, which is calculated as follows:
Assume,
A |
= |
h(i − 1, 1) |
B |
= |
h(i − 1, 2) |
C |
= |
h(i − 1, 3) |
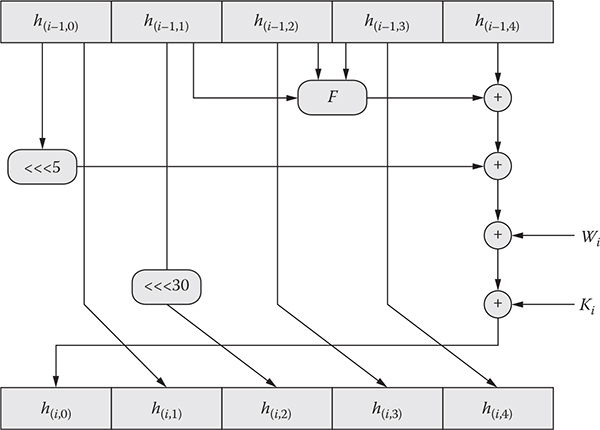
Figure 11.3 Operations of a single round.
F = f(i, A,B, C, |
= |
(A ∧ B) ∨ (− A ∧ C ) |
(0 <= i 19) |
|
= |
A⊕B⊕C |
(20 <= i <= 39) |
|
= |
(A ∧ B) ∨ (A ∧ C) ∨ (B ∧ C) |
(40 <= i <= 59) |
|
= |
A ⊕ B ⊕ C |
(60 <= i <= 79) |
Again, a function could be defined by the following set of expressions:
h (i,1) |
= |
h (i −1,0) |
h(i,2) |
= |
LS30 (h(i −1,1)) |
h(i,3) |
= |
h(i −1,2) |
h(i,4) |
= |
h(i −1,3) |
h(i,0) |
= |
(((h(i−1,4) ⊕ F) ⊕ LS5(h(i − 1, 0))) ⊕Wi) ⊕ Ki |
where LSj is rotating j number of bits to the left and i is the round number.
11.3.4 Output
A 160-bit output is produced after completing all the rounds as follows:
Hi = sum (H(i − 1), h79)
In this process, all the blocks are processed. The final 160-bit resultant output is considered the message digest. An example is given below to understand the SHA-1 in detail.
11.4 An Example
The following example demonstrates the procedures followed by the SHA-1 algorithm to generate a 160-bit message digest.
Let us assume that the message for which a user wants to find the message digest is: The quick fox jumps over the lazy dog.
Following is the bit-level representation of the above message:
01010100 01101000 01100101 00100000 01110001
01110101 01101001 01100011 0110101100100000
01100110 01101111 01111000 00100000 01101010
01110101 01101101 0111000001110011 00100000
01101111 01110110 01100101 01110010 00100000
01110100 0110100001100101 00100000 01101100
01100001 01111010 0111100100100000 01100100
0110111101100111 00101110The message contains 304 bits. Therefore, it is necessary to pad the message so that its length becomes congruent to 448 modulo 512. Since the entered message is 304 bits long, 144 bits padding is necessary. The first bit is 1 and the remaining 143 bits are zeros. At the end, a 64-bit value appends that represents the original size of the message. For this specific example, we could find the following message after padding and appending the length of the original message:
01010100 01101000 01100101 00100000 01110001
01110101 01101001 01100011 0110101100100000
01100110 01101111 01111000 00100000 01101010
01110101 01101101 0111000001110011 00100000
01101111 01110110 01100101 01110010
0010000001110100 0110100001100101 00100000
01101100 01100001 01111010 01111001 00100000
01100100 0110111101100111 00101110 10000000
00000000 00000000 00000000 00000000 00000000
0000000000000000 00000000 00000000 00000000
00000000 00000000 00000000 00000000
0000000000000000 00000000 0000000000000000
00000000 00000000 00000000 00000000
0000000100110000The above message is now divided into 16 words and utilized in 16 different rounds ranging from 0 to 15. The first 32 bits are stored in W0 and the last 32 bits are stored in W15. How to calculate the other words that could be acquired from the message is already discussed above. A 160-bit buffer is used to store the result of the hash function. In this example, W0 = 01010100 01101000 01100101 00100000. K0 is also known, which is 0x5a827999, or 01011010100000100111100110011001 (in binary). Initially, a 160-bit buffer is initialized as the following:
h0: 00000001 00100011 01000101 01100111
h1: 10001001 10101011 11001101 11101111
h2: 11111110 11011100 10111010 10011000
h3: 01110110 01010100 00110010 00010000
h4: 11110000 11100001 11010010 11000011
After round 0:
h0: 11010011 11111101 00011100 11110100
h1: 00000001 00100011 01000101 01100111
h2: 11100010 01101010 11110011 01111011
h3: 11111110 11011100 10111010 10011000
h4: 01110110 01010100 00110010 00010000
After round 1:
h0: 11101110 11110000 11000101 01011011
h1: 11010011 11111101 00011100 11110100
h2: 11000000 01001000 11010001 01011001
h3: 11100010 01101010 11110011 01111011
h4: 11111110 11011100 10111010 10011000
After round 2:
h0: 10110001 00100101 00001111 00110011
h1: 11101110 11110000 11000101 01011011
h2: 01110100 00111111 00000111 11111101
h3: 11000000 01001000 11010001 01011001
h4: 11100010 01101010 11110011 01111011
After round 3:
h0: 01111010 00111101 10010000 00001001
h1: 10110001 00100101 00001111 00110011
h2: 00111011 01111100 11110001 10010110
h3: 01110100 00111111 00000111 11111101
h4: 11000000 01001000 11010001 01011001
After round 4:
h0: 00101111 00100011 11001101 00110001
h1: 01111010 00111101 10010000 00001001
h2: 01101100 11001001 11000011 01001100
h3: 00111011 01111100 11110001 10010110
h4: 01110100 00111111 00000111 11111101
.
.
.
After final round (i.e., 79):
h0: 10100110 11101101 10001111 00011011
h1: 11011100 01010111 10011001 10111010
h2: 01000000 01000111 11111110 00000110
h3: 01000011 11001000 00111000 00101110
h4: 00010100 00111010 00100010 11100001
Since the message is less than 512 bits, a single block processing is enough to find out the final message digest. In case of a larger block, this procedure needs to continue again until all the blocks are processed.
Therefore, the final message digest would be
h0: 10100111 00010000 11010101 10000010
h1: 01100101 00000011 01100111 10101010
h2: 00111110 00100100 10111001 10011111
h3: 10111001 00011100 01101011 00111110
h4: 00000100 00011100 11110101 10100100
The message digest (in hex):
82d510a7aa6703659fb9243e3e6b1cb9a4f51c04
11.5 Implementation
All the codes (and program files) related to the SHA-1 algorithm are included below with relevant comments.
/** SHA1.h file **/
#ifndef SHA1_H_
#define SHA1_H_
#include <stdint.h>
#include <vector>
#include <iostream>
#include <stdio.h>
#include <bitset>
#include <climits>
using namespace std;
#define MB 64//size of the message block in bytes
#define AB 8//appended bytes where the length of the
message is stored
#define Byte 8
template<typename T>
voidshow_binrep(const T& a)
{
const char* beg = reinterpret_cast<const char*>(&a);
const char* end = beg + size of(a);
while(beg ! = end)
std::cout<<std::bitset<CHAR_BIT>(*beg++) << ' ';
std::cout<< ' ';
}
class SHA1 {
public:
SHA1();
~SHA1();
void Reset();
voidSetMessage();
voidMessageBlockProcessing(uint8_t* MessageBlock);
voidMessagePadding();
void Rounds (uint32_t *DB, uint32_t W, uint32_t K,
intround_num);
void Result();
voidClearMessageBlock();
voidClearDigestBlock();
voidShowMessageDigest();
private:
uint8_tMessageBlock[64];
uint32_tDigestBlock[5];
uint8_t *Message;
vector<char>InputMessage;
uint64_tMessageSize;
uint64_tMessageSizeAfterPadding;
};
#endif//SHA1_H_
/**SHA1.cpp file **/
#include <cstdlib>
#include "sha.h"
#define LeftCircularShift(bits,word) (((word) <<
(bits)) | ((word) >> (32-(bits))))
SHA1 :: SHA1 ()
{
Reset();
}
SHA1 :: ~SHA1 () {}
void SHA1 :: ClearMessageBlock()
{
for (inti = 0; i< MB; i++) {
MessageBlock[i] = 0;
}
}
void SHA1 :: ClearDigestBlock()
{
for (inti = 0; i< 5; i++) {
DigestBlock[i] = 0;
}
}
void SHA1 :: Reset ()
{
ClearMessageBlock();
ClearDigestBlock();
DigestBlock[0] = 0x67452301;
DigestBlock[1] = 0xEFCDAB89;
DigestBlock[2] = 0x98BADCFE;
DigestBlock[3] = 0x10325476;
DigestBlock[4] = 0xC3D2E1F0;
}
void SHA1 :: ShowMessageDigest ()
{
cout<< "h0: "; show_binrep(DigestBlock[0]); cout<<endl;
cout<< "h1: "; show_binrep(DigestBlock[1]); cout<<endl;
cout<< "h2: "; show_binrep(DigestBlock[2]); cout<<endl;
cout<< "h3: "; show_binrep(DigestBlock[3]); cout<<endl;
cout<< "h4: "; show_binrep(DigestBlock[4]); cout<<endl;
}
void SHA1 :: SetMessage() {
cout<< "Put a message (press enter to finish): ";
char c = getchar();
while (c ! = ' ') {
InputMessage.push_back(c);
c = getchar();
}
MessagePadding();
}
void SHA1 :: MessagePadding()
{
uint64_tMessageSize = (uint64_t)InputMessage.size();
uint64_t n = ((MessageSize + AB)/MB) + 1;
MessageSizeAfterPadding = n * MB;
Message = new uint8_t[MessageSizeAfterPadding];
in tpadding_bytes = MessageSizeAfterPadding -
(MessageSize + AB);
cout<<dec<< "Number of padding bytes are: " <<padding_
bytes<<endl;
for (uint64_t i = 0; i<MessageSize; i++) {
Message[i] = InputMessage[i];
}
Message[MessageSize] = 0x80;
for (int i = MessageSize + 1;
i<MessageSizeAfterPadding; i++) {
Message[i] = 0;
}
uint64_tMessageSizeInBit = MessageSize * Byte;
Message[56] = (MessageSizeInBit& 0x000000000000ff00)
>> 56;
Message[57] = (MessageSizeInBit& 0x000000000000ff00)
>> 48;
Message[58] = (MessageSizeInBit& 0x000000000000ff00)
>> 40;
Message[59] = (MessageSizeInBit& 0x000000000000ff00)
>> 32;
Message[60] = (MessageSizeInBit& 0x000000000000ff00)
>> 24;
Message[61] = (MessageSizeInBit& 0x000000000000ff00)
>> 16;
Message[62] = (MessageSizeInBit& 0x000000000000ff00)
>> 8;
Message[63] = MessageSizeInBit& 0x00000000000000ff;
for (int i = 0; i<MessageSizeAfterPadding; i++) {
show_binrep(Message[i]);
}
}
void SHA1 :: Rounds (uint32_t *DB, uint32_t W,
uint32_t K, intround_num)
{
uint32_t temp; /* Temporary word value */
cout<<endl;
if (round_num> = 0 &&round_num< 20) {
temp = LeftCircularShift(5,DB[0]) +
((DB[1] & DB[2]) | ((~DB[1]) & DB[3])) +
DB[4] + W + K;
DB[4] = DB[3];
DB[3] = DB[2];
DB[2] = LeftCircularShift(30,DB[1]);
DB[1] = DB[0];
DB[0] = temp;
cout<< "Round: " <<round_num<<endl;
ShowMessageDigest();
}
else if (round_num> = 20 &&round_num< 40) {
temp = LeftCircularShift(5,DB[0]) + (DB[1] ^ DB[2] ^
DB[3]) + DB[4] + W + K;
DB[4] = DB[3];
DB[3] = DB[2];
DB[2] = LeftCircularShift(30,DB[1]);
DB[1] = DB[0];
DB[0] = temp;
cout<< "Round: " <<round_num<<endl;
ShowMessageDigest();
}
else if (round_num> = 40 &&round_num< 60) {
temp = LeftCircularShift(5,DB[0]) +
((DB[1] & DB[2]) | (DB[1] & DB[3]) |
(DB[2] & DB[3])) + DB[4] + W + K;
DB[4] = DB[3];
DB[3] = DB[2];
DB[2] = LeftCircularShift(30,DB[1]);
DB[1] = DB[0];
DB[0] = temp;
cout<< "Round: " <<round_num<<endl;
ShowMessageDigest();
}
else if (round_num> = 60 &&round_num< 80) {
temp = LeftCircularShift(5,DB[0]) + (DB[1] ^ DB[2] ^
DB[3]) + DB[4] + W + K;
DB[4] = DB[3];
DB[3] = DB[2];
DB[2] = LeftCircularShift(30,DB[1]);
DB[1] = DB[0];
DB[0] = temp;
cout<< "Round: " <<round_num<<endl;
ShowMessageDigest();
}
else {
cout<< "Wrong round is put" <<endl;
exit(1);
}
}
void SHA1 :: MessageBlockProcessing (uint8_t*
MessageBlock)
{
uint32_t K[4] = {0x5A827999,
0x6ED9EBA1,
0x8F1BBCDC,
0xCA62C1D6
};
uint32_t W[80]; /* Word sequence */
uint32_t A = DigestBlock[0],
B = DigestBlock[1],
C = DigestBlock[2],
D = DigestBlock[3],
E = DigestBlock[4]; /* Word buffers */
//Initialize the first 16 words in the array W
uint8_t t;
for(t = 0; t < 16; t++)
{
W[t] = MessageBlock[t * 4] << 24;
W[t] | = MessageBlock[t * 4 + 1] << 16;
W[t] | = MessageBlock[t * 4 + 2] << 8;
W[t] | = MessageBlock[t * 4 + 3];
}
//Storing other 64 words in the array W
for(t = 16; t < 80; t++)
{
W[t] = LeftCircularShift(1, W[t-3] ^ W[t-8] ^ W[t-14]
^ W[t-16]);
}
//round function calling
for(t = 0; t < 20; t++)
{
Rounds(DigestBlock, W[t], K[0], t);
}
for(t = 20; t < 40; t++)
{
Rounds(DigestBlock, W[t], K[1], t);
}
for(t = 40; t < 60; t++)
{
Rounds(DigestBlock, W[t], K[2], t);
}
for(t = 60; t < 80; t++)
{
Rounds(DigestBlock, W[t], K[3], t);
}
//final addition
DigestBlock[0] + = A;
DigestBlock[1] + = B;
DigestBlock[2] + = C;
DigestBlock[3] + = D;
DigestBlock[4] + = E;
cout<< "Message Digest: " <<endl;
ShowMessageDigest();
}
void SHA1 :: Result () {
for (uint64_t i = 0; i<MessageSizeAfterPadding; i = i
+ 64) {
uint8_t temp[64];
for (uint64_t j = i; j <i + MB; j++) {
temp[j - i] = Message[j];
}
MessageBlockProcessing (temp);
}
cout<< "Final Message Digest: " <<endl;
ShowMessageDigest();
cout<< "In hex: " <<endl;
for (inti = 0; i< 5; i++)
cout<< hex <<DigestBlock[i];
cout<<endl;
}
/** main.cpp **/
#include "sha.h"
int main()
{
SHA1 sha;
sha.ShowMessageDigest();
sha.SetMessage();
sha.Result();
return 0;
}
11.6 Conclusion
The SHA-1 is considered one of the most secure hash algorithms. Therefore, it is utilized is various applications, like Secure Sockets Layer (SSL), Pretty Good Privacy (PGP), Extensible Markup Language (XML) signatures, in the Microsoft® Xbox, and in hundreds of other applications (including from IBM, Cisco, Nokia, etc.). After a thorough cryptanalysis over the SHA-1 in 2005, it has been observed that in practice, it is weaker than its theoretical strength. Consequently, NIST made a recommendation to all federal agencies to migrate to the SHA-2 algorithm by 2010.