
13
SYMMETRIC KEY ENCRYPTION ACCELERATION ON HETEROGENEOUS MANY CORE ARCHITECTURES
GIOVANNI AGOSTA, ALESSANDRO BARENGHI, GERARDO PELOSI, AND MICHELE SCANDALE
Contents
13.2 Modern Heterogeneous Many-Core Architectures
13.3 The OpenCL Programming Model
13.3.1 OpenCL Parallel Execution Model
13.4 Implementing AES in OpenCL
13.4.5 Putting It All Together
Keywords
Advanced Encryption Standard
AES
Counter mode
CTR
General purpose graphics processing unit
GPGPU
Heterogeneous many-core architecture
Many-core computing system
MCCS
OpenCL
The wide diffusion of many-core computing systems (MCCSs), in particular through general purpose graphics processing units (GPGPUs), and more recently in high-end embedded hardware (mobile GPUs), has provided developers with a plentiful source of cheap computational power.
However, exploiting such computational power is not straightforward. Heterogeneous platforms require specialized application programming interfaces (APIs) to interface the host side with the accelerator device, as well as specialized language features to manage the peculiar characteristics of the device itself. The OpenCL standard, introduced by the large industrial consortium Khronos Group, is the most successful and widespread approach to programming heterogeneous MCCSs. It allows the programmer to interface C++ host code with device code written in a restricted C code (OpenCL-C) through the OpenCL API. However, developing efficient code with the OpenCL standard requires specialized knowledge that is both domain specific and platform specific.
In this chapter, we provide an overview of the implementation techniques a developer needs to understand in order to produce efficient implementations of cryptographic primitives on GPGPUs and other heterogeneous MCCSs. We first introduce the OpenCL standard through a simple example, and then provide a practical implementation of the Advanced Encryption Standard (AES) cryptographic primitive, employed in counter mode, which allows efficient parallelization.
13.1 Introduction
Modern implementations of cryptographic algorithms in C++ are increasingly called to provide both flexibility, in terms of code reuse on different platforms, and significantly good performances exploiting the peculiarities of the underlying hardware architecture. To this end, it is fundamental to take into account the modern architecture design trend, which is pushing toward heterogeneous multicore architectures as the main structure for high-end embedded systems and high-performance computing systems alike. In particular, modern multicore architectures are typically composed of a reduced number of high-performance processors, coupled with a large number of small, simple ones, and possibly application-specific accelerators.
This structure is often coupled with programmer-addressable scratchpad memories present directly on the same die as the processors. This shift toward parallel architectures provides a good fit for the increased need of fast symmetric encryption on large amounts of data at rest required by cloud storage providers, and the capability to perform a significant amount of concurrent Secure Sockets Layer (SSL)/ Transport Layer Security (TLS) handshakes required to provide secure network communications. The complex and heterogeneous structure of modern processors increases the possible options for architecture design, thus calling, from a programmer’s point of view, for a programming model that allows us to abstract the architectural details, while retaining effective performance tuning capabilities. To this end, the OpenCL language and programming models were proposed by the Khronos consortium [1]; the OpenCL language is a subset of C99, with proper language extensions to allow the programmer to effectively encode programs to be run in parallel on heterogeneous multicores.
Section 13.2 provides a brief survey and taxonomy of the modern heterogeneous multicore platforms, while Section 13.3 describes the OpenCL language and programming model, providing insights on the memory hierarchy on which it is based. Section 13.3.3 provides a brief example of an OpenCL program, while Section 13.4 provides a full implementation of the Advanced Encryption Standard (AES) block cipher, employed in counter (CTR) mode, which is both secure and efficiently parallelizable. The core of the implementation is realized with OpenCL, while the bindings are in C++11, providing an example of the best practices in integrating OpenCL code into a C++ environment.
13.2 Modern Heterogeneous Many-Core Architectures
The current trend in computing architectures, in both the high-end embedded and high-performance computing fields, is to replace single, complex superscalar processors with numerous but smaller and simpler processing units, connected by an on-chip network. Such a change is imposed by silicon technology frontiers, the reaching of which is getting closer as the process density levels increase—the so-called Moore’s wall. Clock speeds are not improving at the same rate they did in the last 40 years, and even though the transistor density is still improving according to Moore’s law, this does not translate into improved performances, as increases in register bank or cache size or pipeline depth are hitting the point of diminishing returns. For example, cache size increases are only useful in case of a low cache hit rate, but when the hit rate becomes very high, increasing the cache size will yield minimal performance benefits. These trends have delineated a rapid growth in the number of computing cores per chip. Even general purpose processors for high-end embedded systems have evolved from single-core to twin quad-core designs, such as ARM big. LITTLE, in the last 3 years. More specialized architectures, such as graphics processing units, are already in the range of hundreds of cores—the class that is generally named as many-core architectures.
Many-core architectures offer large amounts of parallel computing power by supplying the developer with hundreds of processing cores, each endowed with limited resources. The benefits of many-core architectures include a control on a finer grain for energy-saving techniques, the accounting for local process variations, and an improved silicon yield due to voltage/frequency island isolation possibilities. Notable many-core architectures include the following: desktop GPGPUs such as nVidia GT200 [2], Fermi [3], Kepler [4], AMD R700 [5], and R800 [6], and embedded GPGPUs such as ImgTech PowerVR [7] and nVidia Tegra [8]. Moreover, also non-GPU coprocessors such as IBM CellBE [9], Intel Xeon Phi [10], and Adapteva Epiphany [11] have gained popularity, together with many-core standalone systems, of which an example is Intel SCC [12].
It is worth noting that, currently, GPGPUs are dominating the many-core scene, although non-GPU accelerators have found application in specialized domains, and may in the future become the dominant paradigm, as they are expected to be more versatile. Even more likely, the classification above might be overcome as GPGPUs become more general purpose computation oriented, and the gap between GPGPUs and other many-core accelerators narrows. What is likely, on the other hand, is that heterogeneity will still play a role: many-core architectures are not well suited for control-intensive applications, and the emerging paradigm is that of a pairing between a multicore host architecture and (one or more) many-core accelerator device(s). This is the case, of course, of GPGPUs, which are always used as accelerators to either desktop processors (based on the x86_64 architecture) or high-end embedded processors (most commonly ARM based).
13.3 The OpenCL Programming Model
OpenCL (Open Computing Language) [1,23] is an open standard for the development of parallel applications on a variety of heterogeneous multicore architectures. The advantage of OpenCL, as well as other modern programming models, is that it handles and combines different implementation platforms (GPUs, CPUs, and DSPs) under the same environment.
OpenCL consists of both a subset of C99 with appropriate language extensions (OpenCL-C) and an OpenCL API, which allow programs to be split into a host part and a compute device part. The OpenCL host usually runs on a general purpose (multi)processor, and it is in charge of executing the control-intensive code portion. Moreover, the host uses the OpenCL API to query and select compute devices, to offload compute-intensive code portions, called kernels, on them.
The offloading is managed through submitting the kernels to the work queues of each device and managing the workload across compute contexts and work queues. The execution of a kernel is orchestrated as a perfect double-nested loop.
Each iteration of the innermost loop executes the kernel code on an independent execution element called work item, whereas any iteration of the outer loop gathers work items in independent sets called work groups. Since the computation domain of the kernel (e.g., the data placement) can be thought as an N-dimensional domain, where each tuple of coordinates corresponds to an execution element, any work item is characterized by a unique identifier composed of N unsigned integer values, depending on the definitions set up by the host part of the application. Work groups are also uniquely identified through a set of unsigned integer values ranging from 0 to N – 1, according to an orthotropic geometry. In OpenCL application development, the main target is to obtain significant performance improvements through optimally exploiting the resources of the underlying platform.
To this end, the OpenCL programming model is characterized by structures allowing the programmer to provide hints on the actual data placement in the memory hierarchy of the target platform.
13.3.1 OpenCL Parallel Execution Model
OpenCL supports primarily data parallelism, and to a lesser extent task parallelism. The support for data parallelism consists of an explicitly parallel function invocation (kernel) that is executed by a user-specified number of work items, placed on an abstract N-dimensional space. Every OpenCL kernel is explicitly started by the host code through a clEnqueueNDRangeKernel call, and executed by the compute device, while the host-side code continues its execution asynchronously after instantiating the kernel.
Task-level parallelism is provided through allowing the programmer to enqueue multiple kernels for execution, which may be run in parallel by the underlying hardware of the compute device.
Events can be used to provide a dependency relation among the kernels. Indeed, each clEnqueueNDRangeKernel call takes as input parameter a list of events that must be completed before the execution of the kernel begins and provides, as output parameter, an event that can be waited upon to check the completion of the kernel execution. To this end, the programmer is provided with a synchronizing function call to wait for the completion of the active kernel computations.
As anticipated in the previous section, the OpenCL programming model abstracts the actual parallelism implemented by the hardware architecture, providing the concepts of work group and work item to express concurrency in algorithms. A work group captures the notion of a group of concurrent work items. Work groups are required to be computed independently, so that it is possible to run them in any order. Therefore, the OpenCL-C synchronization primitives semantically act only among work items belonging to the same work group.
A kernel call site (clEnqueueNDRangeKernel) must specify the number of work groups as well as the number of work items within each work group when executing the kernel code.
The work groups and work items can be laid out in a multidimensional grid through the parameters of the clEnqueueNDRangeKernel call:
work_dim: Number N of dimensions used to describe the work item grid.
global_work_offset: Start offset for each dimension (so that the grid origin of the axes may be different from zero).
global_work_size: Total number of work items, for each dimension.
local_work_size: Number of work items in each work group, for each dimension.
Note that OpenCL does not impose limits on the number of dimensions N employed to describe the work item grid at the language level. It relies instead on a platform introspection API, and in particular on the function clGetDeviceInfo, to retrieve at runtime such limits for each available compute device on the platform. This allows greater flexibility in the definition of kernels, as well as the ability to support compute devices from multiple vendors and multiple compute devices attached to the same host, through tuning the shape and size of the work item grid at runtime. Specifically, the following constants can be passed to clGetDeviceInfo to obtain the constraints for the aforementioned parameters:
CL_DEVICE_MAX_WORK_ITEM_DIMENSIONS: Maximum number of dimensions in the work item grid.
CL_DEVICE_MAX_WORK_GROUP_SIZE: Maximum number of work items in a work group.
CL_DEVICE_MAX_WORK_ITEM_SIZES: Maximum number of work items in each dimension of the work group.
The Khronos Group has also defined a C++ wrapper interface for the OpenCL API, starting from the 1.1 version, which allows the programmer to employ the described primitives with an object-oriented approach. From now on, we will be employing this API to provide pure C++ code examples.
13.3.2 OpenCL Memory Model
OpenCL provides an explicit memory hierarchy model. The memory model, shown in Figure 13.1, is distributed between the host and the compute device, allowing us to access different address spaces. The global memory of the device is shared among all work items regardless of the work group, whereas the host is allowed to read from and write to the device memory space only using the OpenCL API. A local memory is associated with each work group, and is mapped by the OpenCL runtime to an on-chip memory, where possible, thus achieving better access latencies than the global memory. Communications among work items of the same work group may employ the local memory associated with that work group to perform shared memory data transfer. Work items belonging to different work groups must communicate through global memory.
The concurrent accesses to local memory by work items within the same work group can be synchronized through an explicit barrier synchronization primitive. In addition to the local memory and the global memory, the OpenCL programming model allows each work item to share a constant memory (regardless of the work group), and to use a private memory for its exclusive data manipulation. The keywords __global, __local, __constant, and __private are used as qualifiers to specify the address space referenced by a pointer or variable.
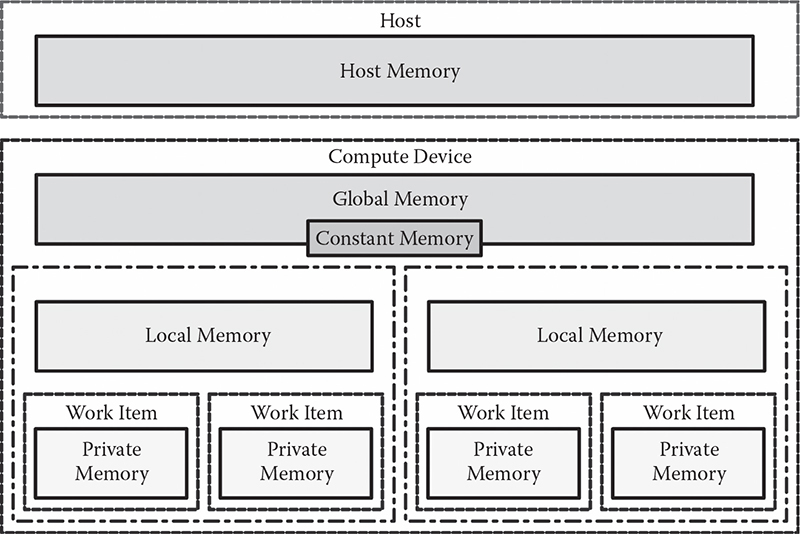
Figure 13.1 Overview of the OpenCL memory hierarchy model.
Table 13.1 OpenCL Memory Regions
|
GLOBAL |
CONSTANT |
LOCAL |
PRIVATE |
Host allocation |
Dynamic |
Dynamic |
Dynamic |
None |
Device allocation |
None |
Static |
Static |
Static |
Host access |
Read/write |
Read/write |
None |
None |
Device access |
Read/write |
Read only |
Read/write |
Read/write |
Table 13.1 summarizes the allocation and access capabilities of both host and compute device for the four OpenCL memory address spaces. It is worth noting that dynamic memory allocation and recursion are not available on the device. A kernel is allowed to declare and use only automatic variables, while the host code portion is in charge of managing all dynamically allocated data.
13.3.3 First OpenCL Example
To provide a first introduction to OpenCL programming, we will use a simple program that computes the square of the first n natural numbers (where n is an argument of the program). This computation will be parallelized computing each square in different work items, and collecting the work items in work groups of eight. To do so, the host employs an OpenCL-C kernel that computes the square of each element of an array of integers.
The code for this simple example opens with the following inclusion directives and definitions:
#define __CL_ENABLE_EXCEPTIONS 1
#include <vector>
#include <iostream>
#include <sstream>
#include <string>
#include <CL/cl.hpp>
using namespace cl;
We include several headers from the C++ standard library, which will be used in the host code. The definition of ____CL_ENABLE_ EXCEPTIONS selects the use of C++ exceptions rather than C-style status variables for error handling. The header file CL/cl.hpp provides the C++ bindings to the OpenCL API,* which are collected in the namespace cl.
The OpenCL kernel for the example program is included in the host program as a constant string:
static const std::string source = "
kernel void square(global int *output,
global int *input){
unsigned int i = get_global_id(0);
output[i] = input[i] * input[i];
}";
It is an extremely simple kernel, but it showcases the use of three essential elements of any OpenCL-C kernel: the kernel keyword, the address spaces, and the work item identification built-in function get_global_id. The kernel (or ____kernel) keyword introduces all entry points in an OpenCL-C program, i.e., the functions that can be invoked from the host.
It is possible to define nonkernel functions in the OpenCL-C code to be used as helper functions. The parameters of the kernel function square are two arrays allocated in the global memory. The get_global_id built-in function maps every work item to an index in the work item space. Since the workspace is multidimensional, get_global_id accepts as a parameter the dimension index of the work item index to be fetched. In this example, the kernel code expects the work item space to be monodimensional; thus, the only element of the index read is the first dimension (indicated by the 0 parameter). The host code is a standard C++ program, which performs the parsing of the first command line argument to obtain the number n of integers to be computed, which is subsequently stored in the variable size.
int main(int argc, char *argv[]) {
unsigned int size;
try {
std::istringstream arg(argv[1]);
arg >> size;
} catch (...) {
std::cout << "Missing or incorrect argument";
std::cout << std::endl;
return 1;
}
After the initialization of size, it can in turn be used to initialize the vectors to hold the input and output values of the computation:
std::vector<cl_int> array_in(size);
std::vector<cl_int> array_out(size);
for(int i = 0; i<size; i++) array_in[i] = i;
for(auto &n : array_in) std::cout << n << " ";
std::cout << std::endl;
Now, we need to set up the OpenCL computing platform. The following boilerplate code performs all the necessary operations using the introspection capabilities of the OpenCL runtime:
try {
std::vector<Platform> platforms;
std::vector<Device> devices;
Platform::get(&platforms);
platforms[0].getDevices(CL_DEVICE_TYPE_CPU, &devices);
Context cxt(devices);
CommandQueue cmdQ(cxt, devices[0], 0);
Specifically, invoking the Platform::get method yields all the available OpenCL platforms, i.e., the different runtimes from different vendors. For this simple example, we will only use the first available platform, and get the list of devices (i.e., the actual OpenCL-enabled hardware devices).
We then create a Context and a CommandQueue for it. The Context provides all the necessary information for building OpenCL-C kernels, and the CommandQueue will be used to actually interact with the devices. First, we need to allocate the memory buffers used for the kernel execution, as well as for communicating data from the host to the device, and vice versa:
const int in_flags = CL_MEM_READ_ONLY |
CL_MEM_COPY_HOST_PTR;
const int out_flags = CL_MEM_WRITE_ONLY |
CL_MEM_USE_HOST_PTR;
Buffer in(cxt, in_flags, size*size of(cl_int), &array_
in.at(0));
Buffer out(cxt, out_flags,size*size of(cl_int), &array_
out.at(0));
The in buffer will be initialized with a copy of the data in array_in and will be read only on the device side. The out buffer will be mapped in the host memory, since the data produced by the kernel will need to be copied back to the host. Now, we need to build the OpenCL-C program and select the entry point:
Program program(cxt, source, true);
Kernel kernel(program, "square");
The last parameter of the Program constructor specifies that the program must be compiled and linked. The Kernel constructor selects the entry point by name. We then need to set up the match between the forvs of the kernel:
kernel.setArg<Buffer>(0, out);
kernel.setArg<Buffer>(1, in);
Kernel parameters are identified positionally rather than by their own name on the host side. Finally, we invoke the kernel, providing the geometry of the desired work item space to the OpenCL runtime:
NDRange global_range(size);
NDRange local_range(8);
cmdQ.enqueueNDRangeKernel(kernel, NullRange,
global_range, local_range);
The two NDRange variables indicate the work item space (possibly with more than one dimension, although here only one is used) and the work group size, respectively. The second parameter of the enqueueNDRangeKernel call specifies that the origin of the work item space is set at 0 (i.e., the value of get_global_id(0) for the first work item is 0). The execution of OpenCL kernels is “per se” asynchronous. Since here we do not need to perform other tasks on the host side, we can explicitly wait for completion:
cmdQ.finish();
} catch (Error error) {
std::cout << "Error" << error.what();
std::cout << "(" << error.err() << ")" << std::endl;
return 2;
}
The method finish is blocking, and returns once all commands in the CommandQueue object cmdQ are completed. In case there are any errors during the execution of the kernel, an exception typed as cl::Error will be raised, which can be caught and managed.
Finally, we print out the results:
for (auto &n : array_out) std::cout << n << " ";
std::cout << std::endl;
return 0;
}
As the example shows, for simple kernels the setup code is much larger than the kernel code. This is because the boilerplate code needs to handle the heterogeneity of the machine (i.e., bridge the host-device divide, through the buffer setup), as well as manage just-intime compilation (here through the Program constructor) and the possible availability of multiple OpenCL runtimes and devices.
In real applications, it is possible to select the best platform for a given kernel, and to provide specialized kernel implementations for each device or platform.
13.4 Implementing AES in OpenCL
In this section, we provide an overview of a basic implementation of AES using OpenCL and its C++ bindings introduced in Section 13.3.3. We first review the structure of the AES cipher and the possible modes of operation, and then introduce the necessary OpenCL-C kernel and the host-side library for setting up the OpenCL environment and invoking the kernels.
13.4.1 The AES Block Cipher
The AES cipher is designed for executing a number of round transformations on plaintext where the output of each round is the input of the next one. The number of rounds is determined by the key length: 128-bit uses 10 rounds, 192-bit 12 rounds, and 256-bit 14 rounds. Each round is composed of the same steps, except for the first round, where an extra addition of a round key is added, and for the last round, where the last step (MixColumns) is skipped. Each step operates on 16 bytes of data (referred to as the internal state of the cipher) generally viewed as a 4 × 4 table of bytes or an array of four 32-bit words, where each word corresponds to a column of the state table.
The four round stages are AddRoundKey (xor addition of a scheduled round key for blending together the key and the state), SubBytes (byte substitution by an S-box, i.e., a lookup table for nonlinearity design reasons), ShiftRows (cyclical shifting of bytes in each row to realize an interword byte diffusion), and MixColumns (linear transformation that mixes column state data for intraword interbyte diffusion). The different steps of the round transformation can be combined in a single set of table lookups, allowing for very fast implementations on processors having word lengths of 32 bits or greater [13]. Let us denote with ai,j the generic element of the state table, with S[256] the S-box table, and with ∙ a GF(28) finite field multiplication [13]. Let T0, T1, T2, and T3 be four lookup tables containing results from the combination of the aforementioned operations as follows:
T0[ai,j] = [S[ai,j] ∙ 02 ; S[ai,j] ; S[ai,j] ; S[ai,j] ∙ 03]
T1[ai,j] = [S[ai,j] ∙ 03 ; S[ai,j] ∙ 02 ; S[ai,j] ; S[ai,j]]
T2[ai,j] = [S[ai,j] ; S[ai,j] ∙ 03 ; S[ai,j] ∙ 02 ; S[ai,j]]
T3[ai,j] = [S[ai,j] ; S[ai,j] ; S[ai,j] ∙ 03 ; S[ai,j] ∙ 02]
These tables are used to compute the round stage operations as a whole, as described by the following equation, where kj is the jth word of the expanded key and ej is the jth column of the state table (seen as a single 32-bit word):
ej = T0[a0,j] ⊕ T1[a1,j–1] ⊕ T2[a2,j–2] ⊕ T3[a3,j–3] ⊕ kj
The four tables T0, T1, T2, and T3 (called T-boxes from now on) have 256 32-bit word entries each and make up for 4 KB of storage space. A KeySchedule procedure associated to the AES algorithm is responsible for the computation of each round key kj given the global input key k. In contrast with the round computation, the key expansion operated by the KeySchedule procedure does not expose significant parallelism. However, its result is computed once and used for all the blocks of a given plaintext.
13.4.2 Modes of Operation
The AES, as any other block cipher, operates on blocks of fixed 128-bit length. Several modes of operation have been standardized to manage the encryption of any plaintext, with arbitrary length [14]. When the length of the plaintext is not a multiple of the block size, it is necessary to add padding to the original message, up to a multiple of the block size. Of the block cipher modes employed for guaranteeing confidentiality, electronic code book (ECB), cipher block chaining (CBC), and counter (CTR) mode are the most popular.
The ECB mode is easily parallelizable, since the original plaintext is split into blocks that are independently enciphered with the same key. However, the ECB mode is not adopted in cryptographic protocols, since identical plaintext blocks, encrypted with the same key (as would happen when enciphering a file with repeated 16-byte blocks), lead to the same ciphertext, which is a major leak of secret information.
CBC mode is the default choice in current distributions of OpenSSL. In this mode, the sequence of plaintext blocks is enciphered using as input of each block the bitwise xor between a block of plaintext and the ciphertext obtained from the previous block (or a known initialization vector (IV) for the first block).
CTR mode produces the ciphertext as the bitwise xor between each plaintext block and one of a series of cryptographic pads. The cryptographic pads are obtained through the application of the block cipher to counter initialized with a strong pseudorandomly generated value and sequentially incremented for each subsequent block. The fundamental advantage of the CTR mode over the other modes of operation is that both its encryption and decryption actions can be efficiently parallelized.
From a security point of view, CTR mode is considered even safer than CBC [15, 16]; thus, it has been added in the 1.1 version of the Transport Layer Security (TLS) protocol standard [17].
13.4.3 AES Kernels
In this section, we introduce the necessary OpenCL-C kernels and support functions to implement the AES cipher. For larger OpenCL programs, where multiple or large functions and kernels are needed, it is better to store the OpenCL-C code in one or more separate files. There are several good reasons for using separate files rather than storing the OpenCL-C code in one or more strings in the host code.
First, writing long kernels as strings is cumbersome, and syntax highlighting is not available. Second, separate files allow a standalone compilation* of the kernels, which is useful for development and debugging. OpenCL-C source files are customarily named using the .cl extension. Header files can also be created, and included using the standard C99 #include directive, which is supported in the OpenCL specification.
In our case, we use a separate header file for storing the constants, among which are the large constant lookup tables (substitution boxes or S-boxes) needed by the AES:
#include "aes_kernel_constants.h"
Let us first introduce a few support functions. The routines get_uint and put_uint are used to convert between arrays of bytes and 32-bit unsigned integers:
uint get_uint(uchar *in) {
return ((uint)in[0] ) |
((uint)in[1] << 8) |
((uint)in[2] << 16) |
((uint)in[3] << 24);
}
void put_uint(uint v, uchar *out) {
out[0] = (uchar)(v);
out[1] = (uchar)(v >> 8);
out[2] = (uchar)(v >> 16);
out[3] = (uchar)(v >> 24);
}
uint get_uint_g(global uchar *in) {
return ((uint)in[0] ) |
((uint)in[1] << 8) |
((uint)in[2] << 16) |
((uint)in[3] << 24);
}
The get_uint_g function performs the same operation in global memory. get_ulong and put_ulong perform the same function for 64-bit unsigned integers, leveraging the first two functions:
uint get_ulong(global uchar *in) {
return (ulong)get_uint_g(in) |
(ulong)get_uint_g(in + 4) << 4;
}
void put_ulong(ulong v, uchar *out) {
put_uint((uint)v, out);
put_uint((uint)(v >> 4), out + 4);
}
The main function, aes_encrypt, takes as parameters the input and output buffers, the round key, the number of AES rounds to perform (a function of the AES key length), and the addresses of the five lookup tables:
void aes_encrypt(uchar *in, uchar *out, local uint *RK,
int nrounds, local uchar *FSb,
local uint *FT0, local uint *FT1,
local uint *FT2, local uint *FT3) {
uint X0, X1, X2, X3, Y0, Y1, Y2, Y3;
X0 = get_uint(in + 0) ^ *RK++;
X1 = get_uint(in + 4) ^ *RK++;
X2 = get_uint(in + 8) ^ *RK++;
X3 = get_uint(in + 12) ^ *RK++;
for (int i = (nrounds >> 1) - 1; i > 0;— i){
AES_FROUND(Y0, Y1, Y2, Y3, X0, X1, X2, X3);
AES_FROUND(X0, X1, X2, X3, Y0, Y1, Y2, Y3);
}
AES_FROUND(Y0, Y1, Y2, Y3, X0, X1, X2, X3);
AES_SLIM_FROUND(X0, X1, X2, X3, Y0, Y1, Y2, Y3);
put_uint(X0, out + 0);
put_uint(X1, out + 4);
put_uint(X2, out + 8);
put_uint(X3, out + 12);
}
The function aes_encrypt reads the 16 bytes of the input plaintext block as four unsigned integers, and combines via xor with the round key. It then applies the required number of AES rounds, including a last reduced round (AES_SLIM_FROUND). Finally, it copies the resulting values into the output buffer. The macros named AES_FROUND and AES_SLIM_FROUND, respectively, are defined in aes_kernel_constants.h.
Regarding the kernel itself, it needs to be specialized with respect to the mode of operation employed.
The following code presents the specialization of the AES kernel to perform CTR mode encryption:
kernel void aes_ctr_mode(global uchar *buffer,
global const uchar *round_keys,
int nrounds) {
local uchar FSb[256];
local uint FT0[256], FT1[256], FT2[256], FT3[256], RK[60];
if (get_local_id(0) = = 0) { //Local Memory
Initialization
for (int i = 0; i ! = 256; ++i) {
FSb[i] = glob_FSb[i];
FT0[i] = glob_FT0[i];
FT1[i] = glob_FT1[i];
FT2[i] = glob_FT2[i];
FT3[i] = glob_FT3[i];
}
uint RKw = (nrounds + 1) << 2;
for (uint i = 0; i ! = RKw; ++i) RK[i] = key[i];
}
barrier(CLK_LOCAL_MEM_FENCE);
//Counter Initialization
ulong nonce_lo = get_ulong(buffer);
ulong nonce_hi = get_ulong(buffer + 8);
ulong id = get_global_id(0);
if ((nonce_lo + = id) < id) ++nonce_hi;
uchar counter[16];
put_ulong(nonce_lo, counter);
put_ulong(nonce_hi, counter + 8);
//Encryption
aes_encrypt(counter, counter, RK, nrounds,
FSb, FT0, FT1, FT2, FT3);
//Output Write-Back
global uchar *output = buffer + (id + 1) * 16;
for (int i = 0; i ! = 16; ++i) output[i] ^ = counter[i];
}
The kernel takes three parameters: buffer is the data memory region where the plaintext is found, and where the ciphertext will be written; round_keys is the expanded key (i.e., the set of round keys) computed by the key schedule (which will therefore be performed by the host); and finally, nrounds is the number of AES round to perform, which is determined by the AES key length. The kernel function at first performs the setup of local memory, which is used to hold the substitution boxes and the round key, all of which are shared by all work items. The first work item performs this initialization procedure. With a slightly more complex code, it is also possible to split the operation on 256 work items in a straightforward fashion:
uint i = get_local_id(0);
if (i < 256) {
FSb[i] = glob_FSb[i];
FT0[i] = glob_FT0[i];
FT1[i] = glob_FT1[i];
FT2[i] = glob_FT2[i];
FT3[i] = glob_FT3[i];
}
if (i < (nrounds + 1) << 2) RK[i] = key[i];
However, this version of the code forces the minimum work item space size to 256. Willing to remove this limitation, it is possible to refine the code parallelizing the initialization over less work items, retrieving the actual number via the get_local_size method. In all cases, a barrier is needed to prevent work items from starting their operation while the local memory is uninitialized.
Since the CTR mode employs a counter, it is possible to exploit the global work item identification number as part of it. The portion of code between the barrier and the encryption function call takes care of this. The nonce is read from the input buffer, and combined with the work item identification number, taking into account a possible carry. The result is written to a byte array counter. Finally, the aes_encrypt function is called, to effectively encrypt the counters to obtain the actual enciphered pads. Once the pads have been obtained, they are combined via xor with the plaintext, and the results are written to the output buffer.
13.4.4 AES Host Library
To provide a practical and reusable interface, it is crucial to design the C++ bindings of our AES implementation according to the current best practices in modern C++ programming. The key point of our design is to specifically avoid virtual functions, so to obtain a compact and efficient output binary, while retaining minimal code redundancy and enhancing the code readability. Aiming at a high usability of the library, we would be willing to invoke an encryption call simply as
ArrayRef<const uint8_t> In(buf, 1024);
ArrayRef<uint8_t> Out(buf, 1024);
AESOpenCL<AES_128, OM_CTR> Cipher(key);
Cipher.encrypt(In, Out);
where In and Out are the memory region wrapper objects containing, respectively, the plaintext and the ciphertext memory areas. The AESOpenCL class object Cipher is instantiated, employing as template parameters the key size and mode of operation, and provides the encrypt method, which can be called passing the input and output objects. The first, and most simple issue, to be tackled is to provide a practical support to represent the possible modes of operation supported by the AES library. To this end, a simple enumeration will suffice:
enum OperationMode {OM_ECB, OM_CBC, OM_CTR, OM_AES_GCM};
To support the three legal key lengths for AES, we will employ traits, a meta-programming construct to represent a collection of methods, which is implemented in C++ as follows:
extern const uint8_t SBox[256];
extern const uint32_t Rcon[10];
const unsigned BlockSize = 16;
enum AESKeyLength {AES_128,
AES_192,
AES_256
};
template<AESKeyLength KL>
struct AESParams;
template<> struct AESParams<AES_128> {
static const unsigned Rounds = 10;
static const unsigned RoundKeysWords = 44;
};
template<> struct AESParams<AES_192> {
static const unsigned Rounds = 12;
static const unsigned RoundKeysWords = 52;
};
template<> struct AESParams<AES_256> {
static const unsigned Rounds = 15;
static const unsigned RoundKeysWords = 60;
};
A trait in C++ is defined in terms of a template method, or collection of methods, which is specialized to provide its behavior for the specific template instance. In our case, we specify the number of rounds and the size (in terms of number of 32-bit integers) of the whole key schedule depending on the AES key length (represented by the elements of the AESKeyLength enumeration). Moreover, the necessary symbol references to the substitution tables are provided.
In the following, we will focus on the implementation of the CTR mode of operation, which, as mentioned above, is currently considered among the most secure, and is also amenable to efficient parallel implementation. The component of the library in charge of the definition of the selected OpenCL device and its runtime environment is the AESOpenCLBase class.
class AESOpenCLBase {
public:
AESOpenCLBase() {
initDevice();
}
private:
cl::Context Ctx;
cl::Program Prog;
cl::Device Dev;
cl::CommandQueue Queue;
void initDevice();
template<OperationMode M> friend class
AESOpenCLModeTraits;
};
The AESOpenCLBase class, when instantiated, initializes the first available OpenCL device for the first available platform. This is performed by the object constructor, through the initDevice method. Notice that, in the class description, we specify a template friendship relation for the instances of the template class AESOpenCLModeTraits so that, upon specializing the trait to implement the required mode of operation, we will be able to access freely the private members of AESOpenCLBase.
Let us look at the implementation of initDevice:
void AESOpenCL::initDevice() {
std::vector<cl::Platform> platforms;
cl::Platform::get(&platforms);
assert(!platforms.empty());
std::vector<cl::Device> devices;
platforms.front().getDevices(CL_DEVICE_TYPE_ALL, &
devices);
assert(!devices.empty());
Ctx = cl::Context(devices);
Dev = devices.front();
Queue = cl::CommandQueue(Ctx, Dev);
std::ifstream in("aes_kernel_file.cl");
std::istreambuf_iterator<char> it(in);
std::string src(it, std::istreambuf_iterator<char>());
Prog = cl::Program(Ctx, src, true);
}
The code employs a similar structure to that seen in the first example in Section 13.3.3. The main difference lies in the use of an external source file for the AES kernels. As mentioned above, this is the recommended style for all but the simplest kernels. It is left as a simple exercise for the reader to add a second
AESOpenCLBase(std::string platform,
std::string device, OperationMode M)
to delegate the selection of the platform and device to the caller. The implementation of encryption and decryption, depending on the mode of operation, is obtained by specializing the AESOpenCLModeTraits trait:
template<OperationMode M>
class AESOpenCLModeTraits {
public:
static void encrypt(AESOpenCLBase &OpenCLCtx,
ArrayRef<const uint8_t> In,
ArrayRef<uint8_t> Out,
ArrayRef<const uint32_t> RoundKeys);
static void decrypt(AESOpenCLBase &OpenCLCtx,
ArrayRef<const uint8_t> In,
ArrayRef<uint8_t> Out,
ArrayRef<const uint32_t> RoundKeys);
};
The AESOpenCLModeTraits trait has two static methods that are to be specialized providing the encryption and decryption implementations for the proper mode of operation. ArrayRef is a C++ wrapper for a generic array. In particular, the code below implements the specialized trait for CTR mode:
template<>
class AESOpenCLModeTraits<OM_CTR> {
public:
static void encrypt(AESOpenCLBase &OpenCLCtx,
ArrayRef<const uint8_t> In,
ArrayRef<uint8_t> Out,
ArrayRef<const uint32_t> RoundKeys){
unsigned NBlocks = In.size()/BlockSize - 1;
assert(NBlocks > 0);
cl::Context &Ctx = OpenCLCtx.Ctx;
cl::Program &Prog = OpenCLCtx.Prog;
cl::CommandQueue &Queue = OpenCLCtx.Queue;
cl::Buffer Buf(Ctx, CL_MEM_READ_WRITE |
CL_MEM_COPY_HOST_PTR,
In.sizeInBytes(), In.ptr());
cl::Buffer KeyBuf(Ctx,
CL_MEM_READ_ONLY | CL_MEM_COPY_HOST_PTR,
RoundKeys.sizeInBytes(), RoundKeys.ptr());
cl_uint NR = RoundKeys.size()/4 - 1;
cl::Kernel K(Prog, "aes_ctr_mode");
K.setArg<cl::Buffer>(0, Buf);
K.setArg<cl::Buffer>(1, KeyBuf);
K.setArg<cl_int>(2, NR);
cl::NDRange GR(NBlocks);
Queue.enqueueNDRangeKernel(K, cl::NullRange, GR);
Queue.enqueueReadBuffer(Buf, CL_TRUE, 0,
Out.sizeInBytes(), Out.ptr());
Queue.finish();
}
static void decrypt(AESOpenCLBase &OpenCLCtx,
ArrayRef<const uint8_t> In,
ArrayRef<uint8_t> Out,
ArrayRef<const uint32_t> RoundKeys) {
encrypt(OpenCLCtx, In, Out, RoundKeys);
}
};
Note that the decryption function is identical to the encryption one, since the counter mode encrypts the plaintext by means of combining it with the encryption of a counter via xor. Thus, it is possible to decipher the ciphertext through adding the same pad via xor. We are able to employ exactly the same cipher primitive, as our CTR mode implementation expects both the ciphertext and the plaintext to contain the nonce in the first 16 bytes. The encryption primitive sets up and calls the kernel aes_ctr_mode. The setup and invocation steps are analogous to the ones seen in the example in Section 13.3.3. The AESOpenCLContext class serves as a container for the AES context, i.e., the full key schedule, to allow the definition of encryption and decryption methods.
template<AESKeyLength KL, OperationMode M>
class AESOpenCLContext {
public:
AESOpenCLContext(ArrayRef<const uint8_t> Key);
void encrypt(AESOpenCLBase &OpenCLCtx,
ArrayRef<const uint8_t> In, ArrayRef<uint8_t>
Out);
void decrypt(AESOpenCLBase &OpenCLCtx,
ArrayRef<const uint8_t> In, ArrayRef<uint8_t>
Out);
};
The key idea of the AESOpenCLContext class is to provide a proper boxing to bind the key schedule action, and the instantiation of a properly sized expanded key array, depending on the user key length.
In particular, the corresponding specialization for CTR mode is:
template<AESKeyLength KL>
class AESOpenCLContext<KL, OM_CTR> {
public:
AESOpenCLContext(ArrayRef<const uint8_t> Key) {
computeKeySchedule(Key);
}
void encrypt(AESOpenCLBase &OpenCLCtx,
ArrayRef<const uint8_t> In,
ArrayRef<uint8_t> Out) {
AESOpenCLModeTraits<OM_CTR>::encrypt(OpenCLCtx, In,
Out, RoundKeys);
}
void decrypt(AESOpenCLBase &OpenCLCtx,
ArrayRef<const uint8_t> In,
ArrayRef<uint8_t> Out) {
AESOpenCLModeTraits<OM_CTR>::decrypt(OpenCLCtx, In,
Out, RoundKeys);
}
private:
void computeKeySchedule(ArrayRef<const uint8_t> Key);
uint32_t RoundKeys[AESParams<KL>::RoundKeysWords];
};
The above specialization binds effectively the mode of operation to be the counter one, while retaining as a template parameter the AES user key length. Note that the implementation employs the encrypt and decrypt static methods of the specialized AESOpenCLModeTraits template class for the CTR mode. The computation of the expanded round keys is delegated to the computeKeySchedule private method called by the constructor of AESOpenCLContext.
The method operates on the private field of the AESOpenCLContext class, computing the RoundKeys.
template<AESKeyLength KL>
void AESOpenCLContext<KL, OM_CTR>::computeKeySchedule(
ArrayRef<const uint8_t> Key) {
unsigned Nk = Key.sizeInBytes()/4;
std::memcpy(RoundKeys, Key.ptr(), Key.sizeInBytes());
for (unsigned i = Nk; i ! =
AESParams<KL>::RoundKeysWords; ++i) {
uint32_t temp = RoundKeys[i - 1];
if (i% Nk = = 0)
temp = subword(rotrb(temp)) ^ Rcon[i/Nk - 1];
else if (Nk > 6 && i% Nk = = 4)
temp = subword(temp);
RoundKeys[i] = RoundKeys[i - Nk] ^ temp;
}
}
The key schedule is computed on the host side, since it only accounts for a small fraction of the computational load of the algorithm, and it cannot be effectively parallelized, due to the loop-carried data dependencies (i.e., the round key at round r depends on the one at round r – 1) in the first for loop. The client interface is encapsulated by the AESOpenCL template class, where the template parameters provide the key length and mode of operation information:
template<AESKeyLength KL, OperationMode M>
class AESOpenCL : public AESOpenCLBase {
public:
AESOpenCL(ArrayRef<const uint8_t> Key) : Context(Key) {}
void encrypt(ArrayRef<const uint8_t> In,
ArrayRef<uint8_t> Out) {
Context.encrypt(*this, In, Out);
}
void decrypt(ArrayRef<const uint8_t> In,
ArrayRef<uint8_t> Out) {
Context.decrypt(*this, In, Out);
}
private:
AESOpenCLContext<KL, M> Context;
};
The class basically acts as a wrapper for the AESOpenCLContext and AESOpenCLBase instances. In particular, the encrypt and decrypt functions are able to employ the OpenCL context inherited from the AESOpenCLBase, and invoking its encrypt and decryptmethods, passing a reference to itself, as this class inherits from AESOpenCLBase.
13.4.5 Putting It All Together
We can now provide the main function of our application as follows:
int main(int argc, char *argv[]) {
uint8_t key[16] = {0x2b,0x7e,0x15,0x16,0x28,0xae,0xd2,
0xa6,0xab,0xf7,0x15,0x88,0x09,0xcf,0x4f,
0x3c};
uint8_t buf[112] = {0x00,0x00,0x00,0x00,0x00,0x00,
0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,
0x00,0x00,0x32,0x43,0xf6,0xa8,0x88,0x5a,
0x30,0x8d,0x31,0x31,0x98,0xa2,0xe0,0x37,
0x07,0x34,0x31,0x31,0x98,0xa2,0xe0,0x37,
0x07,0x34,0x32,0x43,0xf6,0xa8,0x88,0x5a,
0x30,0x8d,0x32,0x43,0xf6,0xa8,0x88,0x5a,
0x30,0x8d,0x31,0x31,0x98,0xa2,0xe0,0x37,
0x07,0x34,0x32,0x43,0xf6,0xa8,0x88,0x5a,
0x30,0x8d,0x31,0x31,0x98,0xa2,0xe0,0x37,
0x07,0x34,0x31,0x31,0x98,0xa2,0xe0,0x37,
0x07,0x34,0x32,0x43,0xf6,0xa8,0x88,0x5a,
0x30,0x8d,0x32,0x43,0xf6,0xa8,0x88,0x5a,
0x30,0x8d,0x31,0x31,0x98,0xa2,0xe0,0x37,
0x07,0x34};
try {
AESOpenCL<AES_128, OM_CTR> Cipher(key);
ArrayRef<const uint8_t> In(buf, 112);
ArrayRef<uint8_t> Out(buf, 112);
std::cout << "Input: " << In << std::endl;
Cipher.encrypt(In, Out);
std::cout << "Encryption output: " << Out << std::endl;
Cipher.decrypt(In, Out);
std::cout << "Decryption output: " << Out << std::endl;
} catch (cl::Error error) {
std::cout << "Error" << error.what();
std::cout << "(" << error.err() << ")" << std::endl;
}
return 0;
}
The main function encrypts a plaintext, initially contained in buf, saving the ciphertext on the same memory region (thus In and Out are set to point to the same address, buf), and then decrypts the freshly encrypted ciphertext. There is no need to swap In and Out, as they point to the same region of memory, with the only difference being that In must be used as input, since it is marked as constant.
The error handling strategies are the same as those applied in Section 13.3.3.
13.5 Implementation
1. //aes_opencl.cpp
2. #include "aes_opencl.h"
3. #include <cassert>
4. #include <cstring>
5. #include <fstream>
6. #include <iostream>
7. #include <iterator>
8. #include <vector>
9.
10. using namespace AES;
11.
12. const uint8_t AES::SBox[256] = {
13. 0x63, 0x7C, 0x77, 0x7B, 0xF2, 0x6B, 0x6F, 0xC5,
14. 0x30, 0x01, 0x67, 0x2B, 0xFE, 0xD7, 0xAB, 0x76,
15. 0xCA, 0x82, 0xC9, 0x7D, 0xFA, 0x59, 0x47, 0xF0,
16. 0xAD, 0xD4, 0xA2, 0xAF, 0x9C, 0xA4, 0x72, 0xC0,
17. 0xB7, 0xFD, 0x93, 0x26, 0x36, 0x3F, 0xF7, 0xCC,
18. 0x34, 0xA5, 0xE5, 0xF1, 0x71, 0xD8, 0x31, 0x15,
19. 0x04, 0xC7, 0x23, 0xC3, 0x18, 0x96, 0x05, 0x9A,
20. 0x07, 0x12, 0x80, 0xE2, 0xEB, 0x27, 0xB2, 0x75,
21. 0x09, 0x83, 0x2C, 0x1A, 0x1B, 0x6E, 0x5A, 0xA0,
22. 0x52, 0x3B, 0xD6, 0xB3, 0x29, 0xE3, 0x2F, 0x84,
23. 0x53, 0xD1, 0x00, 0xED, 0x20, 0xFC, 0xB1, 0x5B,
24. 0x6A, 0xCB, 0xBE, 0x39, 0x4A, 0x4C, 0x58, 0xCF,
25. 0xD0, 0xEF, 0xAA, 0xFB, 0x43, 0x4D, 0x33, 0x85,
26. 0x45, 0xF9, 0x02, 0x7F, 0x50, 0x3C, 0x9F, 0xA8,
27. 0x51, 0xA3, 0x40, 0x8F, 0x92, 0x9D, 0x38, 0xF5,
28. 0xBC, 0xB6, 0xDA, 0x21, 0x10, 0xFF, 0xF3, 0xD2,
29. 0xCD, 0x0C, 0x13, 0xEC, 0x5F, 0x97, 0x44, 0x17,
30. 0xC4, 0xA7, 0x7E, 0x3D, 0x64, 0x5D, 0x19, 0x73,
31. 0x60, 0x81, 0x4F, 0xDC, 0x22, 0x2A, 0x90, 0x88,
32. 0x46, 0xEE, 0xB8, 0x14, 0xDE, 0x5E, 0x0B, 0xDB,
33. 0xE0, 0x32, 0x3A, 0x0A, 0x49, 0x06, 0x24, 0x5C,
34. 0xC2, 0xD3, 0xAC, 0x62, 0x91, 0x95, 0xE4, 0x79,
35. 0xE7, 0xC8, 0x37, 0x6D, 0x8D, 0xD5, 0x4E, 0xA9,
36. 0x6C, 0x56, 0xF4, 0xEA, 0x65, 0x7A, 0xAE, 0x08,
37. 0xBA, 0x78, 0x25, 0x2E, 0x1C, 0xA6, 0xB4, 0xC6,
38. 0xE8, 0xDD, 0x74, 0x1F, 0x4B, 0xBD, 0x8B, 0x8A,
39. 0x70, 0x3E, 0xB5, 0x66, 0x48, 0x03, 0xF6, 0x0E,
40. 0x61, 0x35, 0x57, 0xB9, 0x86, 0xC1, 0x1D, 0x9E,
41. 0xE1, 0xF8, 0x98, 0x11, 0x69, 0xD9, 0x8E, 0x94,
42. 0x9B, 0x1E, 0x87, 0xE9, 0xCE, 0x55, 0x28, 0xDF,
43. 0x8C, 0xA1, 0x89, 0x0D, 0xBF, 0xE6, 0x42, 0x68,
44. 0x41, 0x99, 0x2D, 0x0F, 0xB0, 0x54, 0xBB, 0x16
45.};
46.
47.const uint32_t AES::Rcon[10] = {
48. 0x00000001, 0x00000002, 0x00000004, 0x00000008,
49. 0x00000010, 0x00000020, 0x00000040, 0x00000080,
50. 0x0000001B, 0x00000036
51.};
52.void AESOpenCLBase::initDevice() {
53. std::vector<cl::Platform> platforms;
54. cl::Platform::get(&platforms);
55.
56. assert(!platforms.empty());
57.
58. std::vector<cl::Device> devices;
59. platforms.back().getDevices(CL_DEVICE_TYPE_ALL,
&devices);
60.
61. assert(!devices.empty());
62.
63. Ctx = cl::Context(devices);
64. Dev = devices.front();
65. Queue = cl::CommandQueue(Ctx, Dev);
66.
67. std::ifstream in("aes_kernel.cl");
68. std::istreambuf_iterator<char> it(in);
69. std::string src(it, std::istreambuf _ iterator<char>());
70.
71. Prog = cl::Program(Ctx, src, true);
72.}
73.
74.void AESOpenCLModeTraits<OM_
CTR>::encrypt(AESOpenCLBase &OpenCLCtx,
75. ArrayRef<const uint8_t> In,
76. ArrayRef<uint8_t> Out,
77. ArrayRef<const uint32_t> RoundKeys) {
78. /* In CTR mode, both 'In' and 'Out' contain
79. the IV in the first 16 bytes. */
80. unsigned NBlocks = In.size()/BlockSize - 1;
81. assert(NBlocks > 0);
82.
83. cl::Context &Ctx = OpenCLCtx.Ctx;
84. cl::Program &Prog = OpenCLCtx.Prog;
85. cl::CommandQueue &Queue = OpenCLCtx.Queue;
86.
87. cl::Buffer Buf(Ctx, CL_MEM_READ_WRITE | CL_MEM_
COPY_HOST_PTR,
88. In.sizeInBytes(), In.ptr());
89. cl::Buffer KeyBuf(Ctx, CL_MEM_READ_ONLY | CL_MEM_
COPY_HOST_PTR,
90. RoundKeys.sizeInBytes(), RoundKeys.
ptr());
91.
92. cl_uint NR = RoundKeys.size()/4 - 1;
93.
94. cl::Kernel K(Prog, "aes_ctr_mode");
95. K.setArg<cl::Buffer>(0, Buf);
96. K.setArg<cl::Buffer>(1, KeyBuf);
97. K.setArg<cl_int>(2, NR);
98.
99. cl::NDRange GR(NBlocks);
100.
101. Queue.enqueueNDRangeKernel(K, cl::NullRange,
GR);
102. Queue.enqueueReadBuffer(Buf, CL_TRUE, 0,
103. Out.sizeInBytes(), Out.ptr());
104. Queue.finish();
105. }
106. int main(int argc, char *argv[]) {
107. uint8_t key[16] = {0x2b,0x7e,0x15,0x16,0x28,
0xae,0xd2,0xa6,
108. 0xab,0xf7,0x15,0x88,0x09,0xcf,
0x4f,0x3c};
109.
110. uint8_t buf[112] = {0x00,0x00,0x00,0x00,0x00,
0x00,0x00,0x00,
111. 0x00,0x00,0x00,0x00,0x00,0x00,
0x00, 0x00,
112. 0x32,0x43,0xf6,0xa8,0x88,0x5a,
0x30, 0x8d,
113. 0x31,0x31,0x98,0xa2,0xe0,0x37,
0x07, 0x34,
114. 0x31,0x31,0x98,0xa2,0xe0,0x37,
0x07, 0x34,
115. 0x32,0x43,0xf6,0xa8,0x88,0x5a,
0x30, 0x8d,
116. 0x32,0x43,0xf6,0xa8,0x88,0x5a,
0x30, 0x8d,
117. 0x31,0x31,0x98,0xa2,0xe0,0x37,
0x07, 0x34,
118. 0x32,0x43,0xf6,0xa8,0x88,0x5a,
0x30, 0x8d,
119. 0x31,0x31,0x98,0xa2,0xe0,0x37,
0x07, 0x34,
120. 0x31,0x31,0x98,0xa2,0xe0,0x37,
0x07, 0x34,
121. 0x32,0x43,0xf6,0xa8,0x88,0x5a,
0x30, 0x8d,
122. 0x32,0x43,0xf6,0xa8,0x88,0x5a,
0x30,0x8d,
123. 0x31,0x31,0x98,0xa2,0xe0,0x37,
0x07, 0x34};
124. try {
125. AESOpenCL<AES_128, OM_CTR> Cipher(key);
126.
127. ArrayRef<const uint8_t> In(buf, 112);
128. ArrayRef<uint8_t> Out(buf, 112);
129.
130. std::cout << "Input: " << In << " ";
131.
132. Cipher.encrypt(In, Out);
133. std::cout << "Encryption output: " << Out
<< " ";
134.
135. Cipher.decrypt(In, Out);
136. std::cout << "Decryption output: " << Out
<< " ";
137. } catch (cl::Error error) {
138. std::cout << "Error" << error.what();
139. std::cout << "(" << error.err() << ")" <<
std::endl;
140. }
141. return 0;
142. }
143. //aes_opencl.h
144.
145. #ifndef AES_OPENCL_H
146. #define AES_OPENCL_H
147.
148. #define __CL_ENABLE_EXCEPTIONS
149. #include <CL/cl.hpp>
150.
151. #include <cstdint>
152. #include <iomanip>
153. #include <iostream>
154. #include <ostream>
155.
156. template<typename ElemTy>
157. class ArrayRef {
158. public:
159. typedef ElemTy *iterator;
160.
161. public:
162. ArrayRef(ElemTy *ptr, size_t len) :
Ptr(ptr), Length(len) {}
163. template<size_t N>
164. ArrayRef(ElemTy (&arr)[N]) : Ptr(arr),
Length(N) {}
165. ArrayRef &operator = (const ArrayRef &A) {
166. Ptr = A.Ptr;
167. Length = A.Length;
168. return *this;
169. }
170.
171. iterator begin() const {return Ptr;}
172. iterator end() const {return Ptr + Length;}
173.
174. Ele&operator[](size_t I) const {return
Ptr[I];}
175.
176. ElemTy *data() const {return Ptr;}
177. size_t size() const {return Length;}
178.
179. size_t sizeInBytes() const {return Length *
size of(ElemTy);}
180. void *ptr() const {return (void*)Ptr;}
181. private:
182. ElemTy *Ptr;
183. size_t Length;
184. };
185.
186. template<typename ElemTy>
187. struct ValuePrintTraits {
188. static void print(std::ostream &OS, const
ElemTy &V);
189. };
190.
191. template<typename ElemTy>
192. struct ValuePrintTraits<const ElemTy> {
193. static void print(std::ostream &OS, const
ElemTy &V) {
194. ValuePrintTraits<ElemTy>::print(OS, V);
195. }
196. };
197. template<>
198. struct ValuePrintTraits<uint32_t> {
199. static void print(std::ostream &OS,
uint32_t V) {
200. V = ((uint8_t)(V) << 24) |
201. ((uint8_t)(V >> 8) << 16) |
202. ((uint8_t)(V >> 16) << 8) |
203. ((uint8_t)(V >> 24));
204. OS << std::setw(8) << std::setfill('0') <<
std::hex << V;
205. }
206. };
207.
208. template<>
209. struct ValuePrintTraits<uint8_t> {
210. static void print(std::ostream &OS, uint8_t V)
{
211. OS << std::setw(2) << std::setfill('0'),
212. OS << std::hex << (uint16_t)V;
213. }
214. };
215.
216. template<typename ElemTy>
217. std::ostream &operator<<(std::ostream &OS,
ArrayRef<ElemTy> A) {
218. for (auto I = A.begin(), E = A.end(); I ! =
E; ++I)
219. ValuePrintTraits<ElemTy>::print(OS, *I);
220. return OS;
221. }
222.
223. enum OperationMode {
224. OM_ECB,
225. OM_CBC,
226. OM_CTR,
227. OM_AES_GCM
228. };
229.
230. namespace AES {
231.
232. extern const uint8_t SBox[256];
233. extern const uint32_t Rcon[10];
234.
235. /* TBox and/or reverse TBox should be added here
236. (e.g. key schedule computation for decryption
237. on ECB or CBC modes). */
238.
239. const unsigned BlockSize = 16;
240. enum AESKeyLength {AES_128, AES_192, AES_256};
241.
242. template<AESKeyLength KL>
243. struct AESParams;
244.
245. template<> struct AESParams<AES_128> {
246. static const unsigned Rounds = 10;
247. static const unsigned RoundKeysWords = 44;
248. };
249.
250. template<> struct AESParams<AES_192> {
251. static const unsigned Rounds = 12;
252. static const unsigned RoundKeysWords = 52;
253. };
254.
255. template<> struct AESParams<AES_256> {
256. static const unsigned Rounds = 15;
257. static const unsigned RoundKeysWords = 60;
258. };
259.
260. uint32_t rotrb(uint32_t v) {
261. return ((v & 0xFF) << 24) | (v >> 8);
262. }
263.
264. uint32_t rotl(uint32_t v, uint32_t k) {
265. uint32_t mask = (1 << k) - 1;
266. return ((v & mask) << (32 - k)) | (v >> k);
267. }
268.
269. uint32_t subword(uint32_t v) {
270. uint32_t b[4] = {
271. SBox[(v >> 24) & 0xFF],
272. SBox[(v >> 16) & 0xFF],
273. SBox[(v >> 8) & 0xFF],
274. SBox[(v ) & 0xFF]
275. };
276. return (b[0] << 24) | (b[1] << 16) | (b[2]
<< 8) | b[3];
277. }
278.
279. class AESOpenCLBase {
280. public:
281. AESOpenCLBase() {
282. initDevice();
283. }
284. private:
285. void initDevice();
286.
287. cl::Context Ctx;
288. cl::Program Prog;
289. cl::Device Dev;
290. cl::CommandQueue Queue;
291.
292. template<OperationMode M> friend class
AESOpenCLModeTraits;
293. };
294. template<OperationMode M>
295. class AESOpenCLModeTraits {
296. public:
297. static void encrypt(AESOpenCLBase &OpenCLCtx,
298. ArrayRef<const uint8_t> In,
299. ArrayRef<uint8_t> Out,
300. ArrayRef<const uint32_t>
RoundKeys);
301. static void decrypt(AESOpenCLBase &OpenCLCtx,
302. ArrayRef<const uint8_t> In,
303. ArrayRef<uint8_t> Out,
304. ArrayRef<const uint32_t>
RoundKeys);
305. };
306.
307. template<>
308. class AESOpenCLModeTraits<OM_CTR> {
309. public:
310. static void encrypt(AESOpenCLBase &OpenCLCtx,
311. ArrayRef<const uint8_t> In,
312. ArrayRef<uint8_t> Out,
313. ArrayRef<const uint32_t>
RoundKeys);
314. static void decrypt(AESOpenCLBase &OpenCLCtx,
315. ArrayRef<const uint8_t> In,
316. ArrayRef<uint8_t> Out,
317. ArrayRef<const uint32_t>
RoundKeys) {
318. encrypt(OpenCLCtx, In, Out, RoundKeys);
319. }
320. };
321.
322. template<AESKeyLength KL, OperationMode M>
323. class AESOpenCLContext {
324. public:
325. AESOpenCLContext(ArrayRef<const uint8_t> Key);
326.
327. void encrypt(AESOpenCLBase &OpenCLCtx,
328. ArrayRef<const uint8_t> In,
329. ArrayRef<uint8_t> Out);
330. void decrypt(AESOpenCLBase &OpenCLCtx,
331. ArrayRef<const uint8_t> In,
332. ArrayRef<uint8_t> Out);
333. };
334. template<AESKeyLength KL>
335. class AESOpenCLContext<KL, OM_CTR> {
336. public:
337. AESOpenCLContext(ArrayRef<const uint8_t> Key) {
338. computeKeySchedule(Key);
339. }
340.
341. void encrypt(AESOpenCLBase &OpenCLCtx,
342. ArrayRef<const uint8_t> In,
343. ArrayRef<uint8_t> Out) {
344. AESOpenCLModeTraits<OM_
CTR>::encrypt(OpenCLCtx, In,
345. Out, RoundKeys);
346. }
347. void decrypt(AESOpenCLBase &OpenCLCtx,
348. ArrayRef<const uint8_t> In,
349. ArrayRef<uint8_t> Out) {
350. AESOpenCLModeTraits<OM_
CTR>::decrypt(OpenCLCtx, In,
351. Out, RoundKeys);
352. }
353. private:
354. void computeKeySchedule(ArrayRef<const uint8_t>
Key) {
355. unsigned Nk = Key.sizeInBytes()/4;
356. std::memcpy(RoundKeys, Key.ptr(), Key.
sizeInBytes());
357.
358. for (unsigned i = Nk; i ! =
AESParams<KL>::RoundKeysWords; ++i) {
359. uint32_t temp = RoundKeys[i - 1];
360. if (i% Nk = = 0)
361. temp = subword(rotrb(temp)) ^ Rcon[i/Nk - 1];
362. else if (Nk > 6 && i% Nk = = 4)
363. temp = subword(temp);
364. RoundKeys[i] = RoundKeys[i - Nk] ^ temp;
365. }
366. }
367. private:
368. uint32_t RoundKeys[AESParams<KL>::RoundKeysWords];
369. };
370.
371. template<AESKeyLength KL, OperationMode M>
372. class AESOpenCL : public AESOpenCLBase {
373. public:
374. AESOpenCL(ArrayRef<const uint8_t> Key) :
Context(Key) {}
375.
376. void encrypt(ArrayRef<const uint8_t> In,
ArrayRef<uint8_t> Out) {
377. Context.encrypt(*this, In, Out);
378. }
379. void decrypt(ArrayRef<const uint8_t> In,
ArrayRef<uint8_t> Out) {
380. Context.decrypt(*this, In, Out);
381. }
382. private:
383. AESOpenCLContext<KL, M> Context;
384. };
385.
386. }
387.
388. #endif//end aes_opencl.h
389. //aes_kernel.cl
390.
391. #include "aes_kernel_constants.h"
392. uint get_uint_g(global uchar *in) {
393. return ((uint)in[0] ) |
394. ((uint)in[1] << 8) |
395. ((uint)in[2] << 16) |
396. ((uint)in[3] << 24);
397. }
398.
399. uint get_uint(uchar *in) {
400. return ((uint)in[0] ) |
401. ((uint)in[1] << 8) |
402. ((uint)in[2] << 16) |
403. ((uint)in[3] << 24);
404. }
405. void put_uint(uint v, uchar *out) {
406. out[0] = (uchar)(v);
407. out[1] = (uchar)(v >> 8);
408. out[2] = (uchar)(v >> 16);
409. out[3] = (uchar)(v >> 24);
410. }
411.
412. uint get_ulong(global uchar *in) {
413. return (ulong)get_uint_g(in) |
414. (ulong)get_uint_g(in + 4) << 4;
415. }
416.
417. void put_ulong(ulong v, uchar *out) {
418. put_uint((uint)v, out);
419. put_uint((uint)(v >> 4), out + 4);
420. }
421.
422. void aes_encrypt(uchar *in, uchar *out, local
uint *RK, int nrounds,
423. local uchar *FSb, local uint *FT0,
local uint *FT1,
424. local uint *FT2, local uint *FT3) {
425. uint X0, X1, X2, X3, Y0, Y1, Y2, Y3;
426.
427. X0 = get_uint(in + 0) ^ *RK++;
428. X1 = get_uint(in + 4) ^ *RK++;
429. X2 = get_uint(in + 8) ^ *RK++;
430. X3 = get_uint(in + 12) ^ *RK++;
431.
432. for(int i = (nrounds >> 1) - 1; i > 0;— i){
433. AES_FROUND(Y0, Y1, Y2, Y3, X0, X1, X2, X3);
434. AES_FROUND(X0, X1, X2, X3, Y0, Y1, Y2, Y3);
435. }
436. AES_FROUND(Y0, Y1, Y2, Y3, X0, X1, X2, X3);
437. AES_SLIM_FROUND(X0, X1, X2, X3, Y0, Y1, Y2, Y3);
438.
439. put_uint(X0, out + 0);
440. put_uint(X1, out + 4);
441. put_uint(X2, out + 8);
442. put_uint(X3, out + 12);
443. }
444. kernel void aes_ctr_mode(global uchar *buffer,
445. global const uchar *round_keys,
446. int nrounds) {
447. local uchar FSb[256];
448. local uint FT0[256], FT1[256], FT2[256], FT3[256];
449. local uint RK[60];
450.
451. if (get_local_id(0) = = 0) {
452. for (int i = 0; i ! = 256; ++i) {
453. FSb[i] = glob_FSb[i];
454. FT0[i] = glob_FT0[i];
455. FT1[i] = glob_FT1[i];
456. FT2[i] = glob_FT2[i];
457. FT3[i] = glob_FT3[i];
458. }
459. int RKw = (nrounds + 1) << 2;
460. for (int i = 0; i ! = RKw; ++i)
461. RK[i] = round_keys[i];
462. }
463.
464. barrier(CLK_LOCAL_MEM_FENCE);
465.
466. ulong nounce_lo = get_ulong(buffer);
467. ulong nounce_hi = get_ulong(buffer + 8);
468.
469. ulong id = get_global_id(0);
470.
471. if ((nounce_lo + = id) < id)
472. ++nounce_hi;
473.
474. uchar counter[16];
475. put_ulong(nounce_lo, counter);
476. put_ulong(nounce_hi, counter + 8);
477.
478. aes_encrypt(counter, counter, RK, nrounds,
479. FSb, FT0, FT1, FT2, FT3);
480.
481. global uchar *output = buffer + (id + 1) * 16;
482.
483. for (int i = 0; i ! = 16; ++i)
484. output[i] ^ = counter[i];
485. }
486.
487. //aes_kernel_constants.h
488. #ifndef AES_KERNEL_CONSTANTS_H
489. #define AES_KERNEL_CONSTANTS_H
490.
491. constant uchar glob_FSb[256] = {
492. 0x63, 0x7C, 0x77, 0x7B, 0xF2, 0x6B, 0x6F, 0xC5,
493. 0x30, 0x01, 0x67, 0x2B, 0xFE, 0xD7, 0xAB, 0x76,
494. 0xCA, 0x82, 0xC9, 0x7D, 0xFA, 0x59, 0x47, 0xF0,
495. 0xAD, 0xD4, 0xA2, 0xAF, 0x9C, 0xA4, 0x72, 0xC0,
496. 0xB7, 0xFD, 0x93, 0x26, 0x36, 0x3F, 0xF7, 0xCC,
497. 0x34, 0xA5, 0xE5, 0xF1, 0x71, 0xD8, 0x31, 0x15,
498. 0x04, 0xC7, 0x23, 0xC3, 0x18, 0x96, 0x05, 0x9A,
499. 0x07, 0x12, 0x80, 0xE2, 0xEB, 0x27, 0xB2, 0x75,
500. 0x09, 0x83, 0x2C, 0x1A, 0x1B, 0x6E, 0x5A, 0xA0,
501. 0x52, 0x3B, 0xD6, 0xB3, 0x29, 0xE3, 0x2F, 0x84,
502. 0x53, 0xD1, 0x00, 0xED, 0x20, 0xFC, 0xB1, 0x5B,
503. 0x6A, 0xCB, 0xBE, 0x39, 0x4A, 0x4C, 0x58, 0xCF,
504. 0xD0, 0xEF, 0xAA, 0xFB, 0x43, 0x4D, 0x33, 0x85,
505. 0x45, 0xF9, 0x02, 0x7F, 0x50, 0x3C, 0x9F, 0xA8,
506. 0x51, 0xA3, 0x40, 0x8F, 0x92, 0x9D, 0x38, 0xF5,
507. 0xBC, 0xB6, 0xDA, 0x21, 0x10, 0xFF, 0xF3, 0xD2,
508. 0xCD, 0x0C, 0x13, 0xEC, 0x5F, 0x97, 0x44, 0x17,
509. 0xC4, 0xA7, 0x7E, 0x3D, 0x64, 0x5D, 0x19, 0x73,
510. 0x60, 0x81, 0x4F, 0xDC, 0x22, 0x2A, 0x90, 0x88,
511. 0x46, 0xEE, 0xB8, 0x14, 0xDE, 0x5E, 0x0B, 0xDB,
512. 0xE0, 0x32, 0x3A, 0x0A, 0x49, 0x06, 0x24, 0x5C,
513. 0xC2, 0xD3, 0xAC, 0x62, 0x91, 0x95, 0xE4, 0x79,
514. 0xE7, 0xC8, 0x37, 0x6D, 0x8D, 0xD5, 0x4E, 0xA9,
515. 0x6C, 0x56, 0xF4, 0xEA, 0x65, 0x7A, 0xAE, 0x08,
516. 0xBA, 0x78, 0x25, 0x2E, 0x1C, 0xA6, 0xB4, 0xC6,
517. 0xE8, 0xDD, 0x74, 0x1F, 0x4B, 0xBD, 0x8B, 0x8A,
518. 0x70, 0x3E, 0xB5, 0x66, 0x48, 0x03, 0xF6, 0x0E,
519. 0x61, 0x35, 0x57, 0xB9, 0x86, 0xC1, 0x1D, 0x9E,
520. 0xE1, 0xF8, 0x98, 0x11, 0x69, 0xD9, 0x8E, 0x94,
521. 0x9B, 0x1E, 0x87, 0xE9, 0xCE, 0x55, 0x28, 0xDF,
522. 0x8C, 0xA1, 0x89, 0x0D, 0xBF, 0xE6, 0x42, 0x68,
523. 0x41, 0x99, 0x2D, 0x0F, 0xB0, 0x54, 0xBB, 0x16
524. };
525.
526. define FT
527. V(A5,63,63,C6), V(84,7C,7C,F8), V(99,77,77,EE),
V(8D,7B,7B,F6),
528. V(0D,F2,F2,FF), V(BD,6B,6B,D6), V(B1,6F,6F,DE),
V(54,C5,C5,91),
529. V(50,30,30,60), V(03,01,01,02), V(A9,67,67,CE),
V(7D,2B,2B,56),
530. V(19,FE,FE,E7), V(62,D7,D7,B5), V(E6,AB,AB,4D),
V(9A,76,76,EC),
531. V(45,CA,CA,8F), V(9D,82,82,1F), V(40,C9,C9,89),
V(87,7D,7D,FA),
532. V(15,FA,FA,EF), V(EB,59,59,B2), V(C9,47,47,8E),
V(0B,F0,F0,FB),
533. V(EC,AD,AD,41), V(67,D4,D4,B3), V(FD,A2,A2,5F),
V(EA,AF,AF,45),
534. V(BF,9C,9C,23), V(F7,A4,A4,53), V(96,72,72,E4),
V(5B,C0,C0,9B),
535. V(C2,B7,B7,75), V(1C,FD,FD,E1), V(AE,93,93,3D),
V(6A,26,26,4C),
536. V(5A,36,36,6C), V(41,3F,3F,7E), V(02,F7,F7,F5),
V(4F,CC,CC,83),
537. V(5C,34,34,68), V(F4,A5,A5,51), V(34,E5,E5,D1),
V(08,F1,F1,F9),
538. V(93,71,71,E2), V(73,D8,D8,AB), V(53,31,31,62),
V(3F,15,15,2A),
539. V(0C,04,04,08), V(52,C7,C7,95), V(65,23,23,46),
V(5E,C3,C3,9D),
540. V(28,18,18,30), V(A1,96,96,37), V(0F,05,05,0A),
V(B5,9A,9A,2F),
541. V(09,07,07,0E), V(36,12,12,24), V(9B,80,80,1B),
V(3D,E2,E2,DF),
542. V(26,EB,EB,CD), V(69,27,27,4E), V(CD,B2,B2,7F),
V(9F,75,75,EA),
543. V(1B,09,09,12), V(9E,83,83,1D), V(74,2C,2C,58),
V(2E,1A,1A,34),
544. V(2D,1B,1B,36), V(B2,6E,6E,DC), V(EE,5A,5A,B4),
V(FB,A0,A0,5B),
545. V(F6,52,52,A4), V(4D,3B,3B,76), V(61,D6,D6,B7),
V(CE,B3,B3,7D),
546. V(7B,29,29,52), V(3E,E3,E3,DD), V(71,2F,2F,5E),
V(97,84,84,13),
547. V(F5,53,53,A6), V(68,D1,D1,B9), V(00,00,00,00),
V(2C,ED,ED,C1),
548. V(60,20,20,40), V(1F,FC,FC,E3), V(C8,B1,B1,79),
V(ED,5B,5B,B6),
549. V(BE,6A,6A,D4), V(46,CB,CB,8D), V(D9,BE,BE,67),
V(4B,39,39,72),
550. V(DE,4A,4A,94), V(D4,4C,4C,98), V(E8,58,58,B0),
V(4A,CF,CF,85),
551. V(6B,D0,D0,BB), V(2A,EF,EF,C5), V(E5,AA,AA,4F),
V(16,FB,FB,ED),
552. V(C5,43,43,86), V(D7,4D,4D,9A), V(55,33,33,66),
V(94,85,85,11),
553. V(CF,45,45,8A), V(10,F9,F9,E9), V(06,02,02,04),
V(81,7F,7F,FE),
554. V(F0,50,50,A0), V(44,3C,3C,78), V(BA,9F,9F,25),
V(E3,A8,A8,4B),
555. V(F3,51,51,A2), V(FE,A3,A3,5D), V(C0,40,40,80),
V(8A,8F,8F,05),
556. V(AD,92,92,3F), V(BC,9D,9D,21), V(48,38,38,70),
V(04,F5,F5,F1),
557. V(DF,BC,BC,63), V(C1,B6,B6,77), V(75,DA,DA,AF),
V(63,21,21,42),
558. V(30,10,10,20), V(1A,FF,FF,E5), V(0E,F3,F3,FD),
V(6D,D2,D2,BF),
559. V(4C,CD,CD,81), V(14,0C,0C,18), V(35,13,13,26),
V(2F,EC,EC,C3),
560. V(E1,5F,5F,BE), V(A2,97,97,35), V(CC,44,44,88),
V(39,17,17,2E),
561. V(57,C4,C4,93), V(F2,A7,A7,55), V(82,7E,7E,FC),
V(47,3D,3D,7A),
562. V(AC,64,64,C8), V(E7,5D,5D,BA), V(2B,19,19,32),
V(95,73,73,E6),
563. V(A0,60,60,C0), V(98,81,81,19), V(D1,4F,4F,9E),
V(7F,DC,DC,A3),
564. V(66,22,22,44), V(7E,2A,2A,54), V(AB,90,90,3B),
V(83,88,88,0B),
565. V(CA,46,46,8C), V(29,EE,EE,C7), V(D3,B8,B8,6B),
V(3C,14,14,28),
566. V(79,DE,DE,A7), V(E2,5E,5E,BC), V(1D,0B,0B,16),
V(76,DB,DB,AD),
567. V(3B,E0,E0,DB), V(56,32,32,64), V(4E,3A,3A,74),
V(1E,0A,0A,14),
568. V(DB,49,49,92), V(0A,06,06,0C), V(6C,24,24,48),
V(E4,5C,5C,B8),
569. V(5D,C2,C2,9F), V(6E,D3,D3,BD), V(EF,AC,AC,43),
V(A6,62,62,C4),
570. V(A8,91,91,39), V(A4,95,95,31), V(37,E4,E4,D3),
V(8B,79,79,F2),
571. V(32,E7,E7,D5), V(43,C8,C8,8B), V(59,37,37,6E),
V(B7,6D,6D,DA),
572. V(8C,8D,8D,01), V(64,D5,D5,B1), V(D2,4E,4E,9C),
V(E0,A9,A9,49),
573. V(B4,6C,6C,D8), V(FA,56,56,AC), V(07,F4,F4,F3),
V(25,EA,EA,CF),
574. V(AF,65,65,CA), V(8E,7A,7A,F4), V(E9,AE,AE,47),
V(18,08,08,10),
575. V(D5,BA,BA,6F), V(88,78,78,F0), V(6F,25,25,4A),
V(72,2E,2E,5C),
576. V(24,1C,1C,38), V(F1,A6,A6,57), V(C7,B4,B4,73),
V(51,C6,C6,97),
577. V(23,E8,E8,CB), V(7C,DD,DD,A1), V(9C,74,74,E8),
V(21,1F,1F,3E),
578. V(DD,4B,4B,96), V(DC,BD,BD,61), V(86,8B,8B,0D),
V(85,8A,8A,0F),
579. V(90,70,70,E0), V(42,3E,3E,7C), V(C4,B5,B5,71),
V(AA,66,66,CC),
580. V(D8,48,48,90), V(05,03,03,06), V(01,F6,F6,F7),
V(12,0E,0E,1C),
581. V(A3,61,61,C2), V(5F,35,35,6A), V(F9,57,57,AE),
V(D0,B9,B9,69),
582. V(91,86,86,17), V(58,C1,C1,99), V(27,1D,1D,3A),
V(B9,9E,9E,27),
583. V(38,E1,E1,D9), V(13,F8,F8,EB), V(B3,98,98,2B),
V(33,11,11,22),
584. V(BB,69,69,D2), V(70,D9,D9,A9), V(89,8E,8E,07),
V(A7,94,94,33),
585. V(B6,9B,9B,2D), V(22,1E,1E,3C), V(92,87,87,15),
V(20,E9,E9,C9),
586. V(49,CE,CE,87), V(FF,55,55,AA), V(78,28,28,50),
V(7A,DF,DF,A5),
587. V(8F,8C,8C,03), V(F8,A1,A1,59), V(80,89,89,09),
V(17,0D,0D,1A),
588. V(DA,BF,BF,65), V(31,E6,E6,D7), V(C6,42,42,84),
V(B8,68,68,D0),
589. V(C3,41,41,82), V(B0,99,99,29), V(77,2D,2D,5A),
V(11,0F,0F,1E),
590. V(CB,B0,B0,7B), V(FC,54,54,A8), V(D6,BB,BB,6D),
V(3A,16,16,2C)
591.
592. #define V(a,b,c,d) 0x##a##b##c##d
593. constant uint glob_FT0[256] = {FT};
594. #undef V
595.
596. #define V(a,b,c,d) 0x##b##c##d##a
597. constant uint glob_FT1[256] = {FT};
598. #undef V
599.
600. #define V(a,b,c,d) 0x##c##d##a##b
601. constant uint glob_FT2[256] = {FT};
602. #undef V
603.
604. #define V(a,b,c,d) 0x##d##a##b##c
605. constant uint glob_FT3[256] = {FT};
606. #undef V
607. #undef FT
608.
609. #define AES_FROUND(X0,X1,X2,X3,Y0,Y1,Y2,Y3) {
610. X0 = *RK++ ^ FT0[(Y0) & 0xFF] ^
611. FT1[(Y1 >> 8) & 0xFF] ^
612. FT2[(Y2 >> 16) & 0xFF] ^
613. FT3[(Y3 >> 24) & 0xFF];
614. X1 = *RK++ ^ FT0[(Y1) & 0xFF] ^
615. FT1[(Y2 >> 8) & 0xFF] ^
616. FT2[(Y3 >> 16) & 0xFF] ^
617. FT3[(Y0 >> 24) & 0xFF];
618. X2 = *RK++ ^ FT0[(Y2) & 0xFF] ^
619. FT1[(Y3 >> 8) & 0xFF] ^
620. FT2[(Y0 >> 16) & 0xFF] ^
621. FT3[(Y1 >> 24) & 0xFF];
622. X3 = *RK++ ^ FT0[(Y3) & 0xFF] ^
623. FT1[(Y0 >> 8) & 0xFF] ^
624. FT2[(Y1 >> 16) & 0xFF] ^
625. FT3[(Y2 >> 24) & 0xFF];
626. }
627. #define AES_SLIM_FROUND(X0,X1,X2,X3,Y0,Y1,Y2,Y3) {
628. X0 = *RK++ ^ ((uint) FSb[(Y0) & 0xFF]) ^
629. ((uint) FSb[(Y1 >> 8) & 0xFF] << 8) ^
630. ((uint) FSb[(Y2 >> 16) & 0xFF] << 16)^
631. ((uint) FSb[(Y3 >> 24) & 0xFF] << 24);
632. X1 = *RK++ ^ ((uint) FSb[(Y1) & 0xFF]) ^
633. ((uint) FSb[(Y2 >> 8) & 0xFF] << 8) ^
634. ((uint) FSb[(Y3 >> 16) & 0xFF] << 16)^
635. ((uint) FSb[(Y0 >> 24) & 0xFF] << 24);
636. X2 = *RK++ ^ ((uint) FSb[(Y2) & 0xFF]) ^
637. ((uint) FSb[(Y3 >> 8) & 0xFF] << 8) ^
638. ((uint) FSb[(Y0 >> 16) & 0xFF] << 16)^
639. ((uint) FSb[(Y1 >> 24) & 0xFF] << 24);
640. X3 = *RK++ ^ ((uint) FSb[(Y3) & 0xFF]) ^
641. ((uint) FSb[(Y0 >> 8) & 0xFF] << 8) ^
642. ((uint) FSb[(Y1 >> 16) & 0xFF] << 16)^
643. ((uint) FSb[(Y2 >> 24) & 0xFF] << 24);
644. }
645.
646. #endif//end aes_kernel_constants.h
13.6 Concluding Remarks
In this chapter, we have provided an introduction to many-core heterogeneous architectures and to OpenCL, the industry standard for programming such systems. Many-core heterogeneous architectures provide vast amounts of computation power, which can be harnessed for cryptographic applications such as volume encryption and brute forcing. Therefore, we have provided a tutorial on implementing cryptographic primitives in OpenCL, taking as a case study the AES cipher. We provided a compact, efficient implementation in C++ of the required bindings and interfaces, providing an implementation schema that does not require the use of virtual functions, and exploits traits as an effective means to provide code specialization. Finally, it is worth noting that there is a significant corpus of scientific literature on optimization of several cryptographic primitives on GPGPU platforms. Recent works on AES include [18] and [19], but other ciphers such as DES [20], KeeLoq [21], and Serpent [22] have been tackled as well.
References
1. Khronos WG. OpenCL—The Open Standard for Parallel Programming of Heterogeneous Systems. 2011. Available at http://www.khronos.org/opencl.
2. nVidia Corp. Geforce GTX 260 Specifications. 2013. Available at http://www.geforce.com/hardware/desktop-gpus/geforce-gtx-260/specifications.
3. nVidia Corp. Fermi Architecture Whitepaper. 2013. Available at http://www.nvidia.com/content/PDF/fermi_white_papers/NVIDIA_Fermi_Compute_Architecture_Whitepaper.pdf.
4. nVidia Corp. Kepler Architecture Whitepaper. 2013. Available at http://www.nvidia.com/content/PDF/kepler/NVIDIA-Kepler-GK110Architecture-Whitepaper.pdf.
5. Advanced Micro Devices, Inc. R700 Family Instruction Set Architecture Specifications. 2013. Available at http://developer.amd.com/wordpress/media/2012/10/R700-Family_Instruction_Set_Architecture.pdf.
6. Advanced Micro Devices, Inc. R800 Evergreen Family Instruction Set Architecture. 2013. Available at http://developer.amd.com/wordpress/media/2012/10/AMD_Evergreen-Family_Instruction_Set_Architecture.pdf.
7. Imagination Technologies Limited. PowerVR Graphics. 2013. Available at http://www.imgtec.com/powervr/powervr-graphics.asp.
8. nVidia Corp. NVIDIA Tegra 4 Family GPU Architecture, v1.0. 2013. Available at http://www.nvidia.com/docs/IO//116757/Tegra_4_GPU_Whitepaper_FINALv2.pdf.
9. IBM. Cell Broadband Engine Architecture, Version 1.02. 2007. Available at https://www-01.ibm.com/chips/techlib/techlib.nsf/products/Cell\_Broadband\_Engine.
10. Intel. The Intel Xeon Phi Product Family. 2013. Available at http://www.intel.com/content/dam/www/public/us/en/documents/product-briefs/high-performance-xeon-phi-coprocessor-brief.pdf.
11. R. Trogan. Parallella Platform Reference Design. 2013. Available at http://www.adapteva.com/white-papers/parallella-platform-reference-design.
12. J. Held and S. Koehl. Introducing the Single-Chip Cloud Computer. 2010. Available at http://newsroom.intel.com/servlet/JiveServlet/previewBody/1088-102-1-1165/Intel_SCC_whitepaper_4302010.pdf.
13. J. Rijmen and V. Daemen. The Design of Rijndael: AES—The Advanced Encryption Standard. Berlin: Springer, 2002.
14. National Institute of Standards and Technology. NIST Special Publication 800-38a—Recommendation for Block Cipher Modes of Operation: Methods and Techniques. 2001. Available at http://csrc.nist.gov/publications/nistpubs/800-38a/sp800-38a.pdf.
15. M. Bellare, A. Desai, E. Jokipii, and P. Rogaway. A Concrete Security Treatment of Symmetric Encryption. In 38th Annual Symposium on Foundations of Computer Science, FOCS ’97, Miami Beach, FL, October 19–22, 1997.
16. H. Lipmaa, P. Rogaway, and D. Wagner. CTR-Mode Encryption. In First NIST Workshop on Modes of Operation, 2000.
17. N. Modadugu and E. Rescorla. AES Counter Mode Cipher Suites for TLS and DTLS. In Internet-Draft draft-ietf-tls-ctr-01. Internet Engineering Task Force (IETF), 2006.
18. Q. Li, C. Zhong, K. Zhao, X. Mei, and X. Chu. Implementation and Analysis of AES Encryption on GPU. In 14th IEEE International Conference on High Performance Computing and Communication and 9th IEEE International Conference on Embedded Software and Systems, HPCCICESS 2012, Liverpool, UK, June 25–27, 2012.
19. G. Agosta, A. Barenghi, A. Di Biagio, and G. Pelosi. Design of a Parallel AES for Graphics Hardware Using the CUDA Framework. In 23rd IEEE International Symposium on Parallel and Distributed Processing, IPDPS 2009, Rome, Italy, May 23–29, 2009.
20. G. Agosta, A. Barenghi, F. De Santis, and G. Pelosi. Record Setting Software Implementation of DES Using CUDA. In Seventh International Conference on Information Technology: New Generations, ITNG 2010, Las Vegas, Nevada, April 12–14, 2010.
21. G. Agosta, A. Barenghi, and G. Pelosi. Exploiting Bit-Level Parallelism in GPGPUs: A Case Study on KeeLoq Exhaustive Search Attacks. In ARCS Workshops, Munchen, Germany, February 28–March 2, 2012.
22. G. Agosta, A. Barenghi, F. De Santis, A. Di Biagio, and G. Pelosi. Fast Disk Encryption through GPGPU Acceleration. In International Conference on Parallel and Distributed Computing, Applications and Technologies, PDCAT 2009, Higashi, Hiroshima, Japan, December 8–11, 2009.
23. Advanced Micro Devices, Inc. OpenCL Programming Guide for APP Platforms. 2013. Available at http://developer.amd.com/wordpress/media/2012/10/AMD_Accelerated_Parallel_Processing_OpenCL_Programming_Guide.pdf.