
![]()
Schema Design and Text Analysis
Search engine development in Solr initially follows four sequential steps: Solr setup, schema design, indexing documents, and searching for results. Schema design is the process of defining the structure of data and is a prerequisite for the process of indexing and searching.
This chapter covers defining fields, specifying types, and other features.
The role of text analysis is vital in information retrieval. It’s the text analysis process that determines the terms (the smallest piece of information, to be used for matching and scoring of documents). This chapter covers the text analysis process, including what analyzers do, the various analyzers/tokenizers available in Solr, and chaining them together.
In this chapter, you will learn about running Solr in schemaless mode, using a managed schema, and working with REST APIs.
This chapter is divided into the following sections:
- Schema design
- Text analysis
- Going schemaless
- REST API for managing schema
- solrconfig.xml file
- Frequently asked questions
Schema Design
Schema design is one of the most fundamental steps for building an effective search engine. It is the process of defining the structure of data and applying text analysis to control the matching behavior.
Before defining the schema, you should understand the problem you are trying to solve and get your strategy in place. You should be able to answer a few questions, including these: What are you using Solr for? What search experiences will you be offering? Which portion of data should be searchable? What information is to be retrieved?
Solr is generally used to index denormalized data. If your data is normalized, you might want to flatten it and define the structure before indexing. If total denormalization is a challenge, Solr allows you to join indexes. But a join in Solr is different from database joins and has its own limitations. Solr also supports indexing hierarchical data, with parent-child relationships. Chapter 7 covers these advanced search features.
All search engines are unique in their own ways, either because of the domain, nature of data, or other factor. Searches can be on full-text or metadata. Also, Solr is not just limited to being a text search engine and is being widely used as a NoSQL datastore and for performing analytics; many new innovative use cases have been seen. A project called Lucene Image Retrieval (LIRE), for example, uses Solr for image searches.
If you are using Solr as a NoSQL datastore or want to get started quickly or don’t have complete visibility of the data or are working with a data structure that’s dynamic, you can choose to go schemaless and leave it to Solr to automatically detect the fieldType and index documents. As of release 5.0, Solr creates a core in schemaless mode by default. You’ll learn more about this topic at the end of this chapter.
Documents
In Solr, each search result corresponds to a document. This basic unit of information is analogous to a record in a database table. When developing a search engine, the first step in schema design is to determine what makes a document for your search engine. The same data can be represented and indexed differently, and the definition of a document can be different depending on the result you expect from the engine and its purpose.
For example, in the Indian film industry, most movies have five to ten songs. If you are building a movie search engine, each movie is a document. Each document then contains multiple songs, indexed as a multiValued field. In contrast, if you were building a music search engine, each song name would be a unique document, and the movie name is redundant in those documents.
Similarly, if you are developing an online bookstore, each book or journal will be a document, which contains information such as ISBN, book name, author, and publisher. But if you are developing a search engine for researchers, perhaps each chapter, topic, or article of the book or journal can be a document.
schema.xml File
The schema.xml file defines the document structure and the fields that it contains. These fields are used when adding data to Solr or querying for results. You will learn about fields in Solr in the next section.
In Solr, schema.xml and solrconfig.xml are the two primary configuration files. Usually you will be playing with them to modify your search strategy and enhance the user experience. These files can be located in the conf directory of the cores in $SOLR_HOME or in named configsets.
The schema.xml file has a well-defined purpose, and the solrconfig.xml file is for all other configurations. The following is the list of configurations supported in schema.xml:
- Define field types and the text analysis, if supported
- Define each field and its applicable properties
- Define dynamic fields
- Specify the scoring algorithm
- Copy data from one field to another
- Specify other field-related definitions such as identification of a unique field or a default field
![]() Note The solrconfig.xml file is discussed at the end of this chapter.
Note The solrconfig.xml file is discussed at the end of this chapter.
As the file extension of schema.xml states, the configuration is specified in XML format, where <schema> is the root element. This element supports two attributes: name and version. The name attribute assigns a name to the schema that can be used for display. The version attribute states the version number of supported syntax and behavior. The latest version as of Solr 5.3.1 is 1.5. The following is a sample schema.xml file:
<schema name="example" version="1.5">
<field name="title" type="string" indexed="true" stored="true"/>
<field name="isbn" type="string" indexed="true" stored="true"/>
..
<fieldType name="string" class="solr.StrField" sortMissingLast="true"/>
<fieldType name="int" class="solr.TrieIntField" precisionStep="0" positionIncrementGap="0"/>
..
</schema>
The core should be reloaded to reflect any changes in this file. If any change has been made in the index-time processing, the documents should be reindexed after reloading the core.
Fields
Each section of information in a document (for example, ISBN, book name, author, and publisher) is a field and is analogous to a column in database tables. The following is a sample definition of a field in schema.xml:
<field name="title" type="string" indexed="true" stored="true"/>
<field name="isbn" type="string" indexed="true" stored="true"/>
..
Solr supports a set of attributes to configure the behavior of a field. Among the attributes, type defines the fieldType, which is similar to Java’s data types but is much more powerful. It links the field to the chain of analysis to be performed on its data while indexing and querying.
![]() Note Earlier versions of Solr required fields to be defined inside the <fields> element. Recent releases have flattened the structure, and you can directly specify fields inside the <schema> element.
Note Earlier versions of Solr required fields to be defined inside the <fields> element. Recent releases have flattened the structure, and you can directly specify fields inside the <schema> element.
Field Attributes
The following are descriptions of attributes supported by a field. You can also define the attributes of fieldType in the field element, which will override the value specified in the fieldType element.
name
This mandatory parameter assigns a name to the field, which is referenced when performing any operation on it such as indexing, querying, and highlighting.
You can use only alphabetic characters, numbers, and underscores to name a field. The names are case sensitive. Names starting and ending with an underscore (such as _version_ and _root_) are reserved.
There is no other specification for naming fields, but it’s advised to follow one convention—for example, keep all words in lowercase and separate them with an underscore, or follow camel casing for readability.
type
This mandatory parameter specifies the name of the fieldType. You will learn more about fieldType in the next section.
default
This parameter specifies the default value for a field when no value is provided while indexing a document.
This parameter is also useful when you want to automatically index a value for a field instead of specifying it in every document. One classical example is the index timestamp, which indicates the time that the document was added to Solr. Here is an example field definition for indexing the timestamp:
<field name="timestamp" type="date" indexed="true" stored="true" default="NOW" />
In this example, the type="date" attribute specifies the fieldType as TrieDateField, and NOW is provided as the value for the default attribute, which specifies the current timestamp.
The example also contains indexed and stored attributes, which are attributes of fieldType that have been overridden in our field definition. Some fieldType parameters are generally overridden by the field, and this occurs so frequently that you may feel that they are properties of the field instead of the fieldType.
Reserved Field Names
Solr reserves field names starting and ending with an underscore for special purposes. The following are some of the reserved field names:
- _version_: Solr uses this field for transaction logging, to support optimistic locking of documents in SolrCloud and for real-time get operations.
- _root_: This field is required to support nested documents (hierarchical data). It identifies the root document in a block of nested documents.
- _text_: This field is a predefined catchall field, to enable single field searching in schemaless mode.
fieldType
The fieldType element determines the type of value a field can hold, how the value should be interpreted, operations that can be performed on it, and the text analysis the field will go through.
The significance of the field type is critical in Solr. It’s the field type and the specified analysis chain that determine the text analysis pipeline to be applied while indexing and querying documents. The matching strategy can be expressed as a sequence of analyzers, tokenizers, and token filters in the field definition. Whenever you want to tune your search for a query term to match or not match an indexed term, you will usually be changing the fieldType definition or its analysis chain.
The following is an example of a fieldType element, where name is the fieldType identifier, class is the Solr’s implementation class name, and sortMissingLast is the property needed by the implementation class:
<fieldType name="string" class="solr.StrField" sortMissingLast="true" />
![]() Note Earlier versions of Solr required field types to be defined inside the <types> element. Recent releases have flattened the structure, and field types can directly be specified inside the <schema> element.
Note Earlier versions of Solr required field types to be defined inside the <types> element. Recent releases have flattened the structure, and field types can directly be specified inside the <schema> element.
The type of value supported, the field’s behavior, and the text analysis to be performed on the field depend on three types of configuration:
- Implementation class
- Attributes
- Text analysis
Each is described next.
Implementation Class
The implementation class implements the features of the field type. It determines the type of values the field can hold and how the values should be interpreted. To customize the text processing, the implementation class usually supports a set of attributes, some of which are marked mandatory.
Based on the data and the type of operation to be performed on the field, you need to choose a fieldType. Suppose your data is Boolean; you will choose the implementation class solr.BoolField. If your data is of the type Integer, you might choose the implementation class solr.TrieIntField. Table 4-1 shows the data types and supported implementation classes provided by Solr.
Table 4-1. Primary Data Types Provided and Their Implementation Classes
Data | Implementation Class |
|---|---|
String | solr.StrField solr.TextField |
Boolean | solr.BoolField |
Number | solr.TrieIntField solr.TrieLongField |
Float | solr.TrieFloatField solr.TrieDoubleField |
Date | solr.TrieDateField solr.DateRangeField |
Binary data | solr.BinaryField |
Spatial data | solr.LatLonType solr.PointType solr.SpatialRecursivePrefixTreeFieldType |
Closed set of values | solr.EnumField |
Random unique ID | solr.UUIDField |
Value from external source | solr.ExternalFileField |
Here are some key points to note about the implementation classes:
- The text added to solr.StrField is indexed and queried as it is. No analysis (no modification) can be applied to it. If you want to split the incoming text by whitespace or change it to lowercase, solr.StrField is not the appropriate fieldType for you. It is suitable if you want to index the text as it is—for example, in the case of a document identifier such as product SKU.
- The solr.TextField allows to you perform custom analysis on the text by applying a chain containing an analyzer or a tokenizer and list of token filters that can be applied while indexing or querying documents. While performing the analysis, you can transform the text in any desired way; for example, you can split a token, introduce a new token, remove a token, or replace a token with another token.
- solr.DateRangeField provides additional provisions for expressing date ranges in the query. Another difference from solr.TrieDateField is that the response format is String instead of Date.
Refer to the Solr official guide at https://cwiki.apache.org/confluence/display/solr/Field+Types+Included+with+Solr for a complete list of field types available in Solr.
![]() Note Class names starting with solr refer to Java classes in a standard package (such as org.apache.solr.analysis), and you don’t need to provide the complete package name.
Note Class names starting with solr refer to Java classes in a standard package (such as org.apache.solr.analysis), and you don’t need to provide the complete package name.
fieldType Attributes
Additional attributes can be specified as part of the element while defining the fieldType. These attributes can be generic and can be applied on any fieldType, or can be specific to the implementing class.
The following is a sample fieldType definition for numeric data having a different value for the precisionStep attribute. The precisionStep attribute enables faster-range queries but increases the index size. If you need to execute range queries on a field, use the fieldType tint. Otherwise, use the fieldType int. The precisionStep="0" disables indexing data at various levels of precision.
<fieldType name="int" class="solr.TrieIntField"
precisionStep="0" positionIncrementGap="0" sortMissingLast="true"/>
<fieldType name="tint" class="solr.TrieIntField"
precisionStep="8" positionIncrementGap="0" sortMissingLast="true"/>
In this example, sortMissingLast is the generic attribute that can be applied on any fieldType, and precisionStep is the attribute of the implementation class TrieIntField.
The following are the primary fieldType attributes provided by Solr.
indexed
For a field to be searchable, it must be indexed. If you will be querying a field for matching documents, it must be indexed by setting the attribute indexed="true". Only when this attribute is enabled, can the generated tokens be indexed and the terms become searchable. If you set indexed="false", the query operation on this field will not fetch any result, as no terms are indexed.
You may set indexed="false" when you are adding a field for display that will never be queried upon.
stored
Only stored fields can be displayed. If you set stored="false", the data in this field cannot be displayed.
You may set stored="false" when you know that you will never return the value of this field back to the user. Also, if you are indexing the same text to multiple fields for performing different analysis, in that case, you can set all copies as indexed="true" and store only one copy of it. Whenever you need to display the value, you get it from the stored field. Here is an example schema definition for such a scenario:
<field name="title" type="string" indexed="true" stored="true"/>
<field name="title_ws" type="text_ws" indexed="true" stored="false"/>
<field name="title_gen" type="text_general" indexed="true" stored="false"/>
Suppose you want to query and display the title_gen field. In that case, query the title_gen field and display the title field. Here is a sample query for such a scenario:
$ curl http://localhost:8983/solr/hellosolr/select?q=user+query&qf=title_gen&fl=title&defType=edismax
If possible, set stored="false", as it would provide better performance and reduced index size (size of stored information). Stored fields of larger size are even costlier to retrieve.
The following are possible combinations of indexed and stored parameters:
- indexed="true" & stored="true": When you are interested in both querying and displaying the value of a field.
- indexed="true" & stored="false": When you want to query on a field but don’t need its value to be displayed. For example, you may want to only query on the extracted metadata but display the source field from which it was extracted.
- indexed="false" & stored="true": If you are never going to query on a field and only display its value.
- indexed="false" & stored="false": Ignore input values for a field. If the document being indexed or Lucene query contains a field that doesn’t exist, Solr may report an exception. You can handle this exception by creating an ignored field (a field with both these attributes disabled). Now, suppose that you have an update processor that extracts metadata from a field, and you are interested in only the extracted metadata and not the value of the unstructured field. This attribute can be quite useful for ignoring such fields.
![]() Note It’s important to note that the value stored in the field is the original value received by it and not the analyzed value. If you want to transform the value before storing it, the transformation should be done using either transformers or preprocessors. Chapter 5 covers this topic.
Note It’s important to note that the value stored in the field is the original value received by it and not the analyzed value. If you want to transform the value before storing it, the transformation should be done using either transformers or preprocessors. Chapter 5 covers this topic.
required
Setting this attribute as true specifies a field as mandatory. If the document being indexed doesn’t contain any value for the field, it will not be indexed. By default, all fields are set as required="false".
multiValued
This Boolean parameter specifies whether the field can store multiple values. For example, a song can have multiple singers, a journal can have multiple authors, and so forth. You might want to set the singer and author fields as multiValued="true". Here is a sample definition in schema.xml for the singer and author fields:
<field name="singer" type="string" indexed="true" stored="true" multiValued="true"/>
<field name="actor" type="string" indexed="true" stored="true" multiValued="true"/>
Because you generally index denormalized data, it’s quite common to have few multiValued fields in schema.xml. If you are copying data from multiple source fields into one destination field, ensure that you define the destination field as multiValued, as Solr won’t allow copying multiple values to a single valued field. If the source field is multiValued, in that case also, the destination field should be defined as multiValued. By default, all fields are single valued.
docValues
docValues is an interesting feature introduced in Solr 4.0. If this Boolean parameter is set to true, a forward index is created for the field. An inverted index is not efficient for sorting, faceting, and highlighting, and this approach promises to make it faster and also free up the fieldCache. The following is an example field definition with docValues enabled:
<field name="language" type="string" indexed="true" stored="false" docValues="true"/>
Enabling docValues requires all the documents to be reindexed.
sortMissingFirst/sortMissingLast
Both these attributes are helpful in handling a scenario in sorting, where the field being sorted doesn’t contain any value for some of the documents. Specifying the sortMissingLast="true" attribute on a field sorts the documents without a value for the field last (after the documents containing a value for the field). On the contrary, specifying sortMissingFirst="true" sorts the documents without a value for the field at the top of the result set. This position is maintained regardless of the sorting order being either ascending or descending.
By default, both these attributes are set to false, and in that case sorting in ascending order places all documents with missing values first, and sorting in descending order places all documents with missing values last.
positionIncrementGap
Internally, the multiValued field is implemented by padding spaces between values (between the last token of a value and the first token of the next value). The optional attribute positionIncrementGap specifies the number of virtual spaces to put between values to avoid false phrase matching.
Suppose a document has two values, bob marley and elvis presley, for the multiValued field singer. If you specify positionIncrementGap="0", the phrase query marley elvis will match the document, as there is no padding and it is treated as part of the same token stream. If you specify positionIncrementGap="100", even phrases with moderate slop will not match, as marley and elvis are a hundred spaces apart.
precisionStep
This is an advanced topic for executing faster range queries on numeric and date fields. Range queries are search requests for documents with values of a field in a specified range, such as products in the price range of $500 to $1,000. Range query is covered in more detail in Chapter 6.
The default precision step specified by Solr for a numeric field is 4, which is optimal for executing faster range queries. If you don’t need to execute range queries on a numeric field, specify precisionStep="0", which offers more-efficient sorting. The schema.xml provided with Solr contains numeric fields such as int and float for general purposes, and precisionStep="0" and fields prefixed with t such as tint, tfloat with precisionStep="8" for numeric fields that need range queries.
Lower step values generate more tokens and speed up range queries but consume more disk space. Generally, the value should be kept between 1 and 8. Refer to the Lucene Javadoc at http://lucene.apache.org/core/5_3_1/core/org/apache/lucene/search/NumericRangeQuery.html#precisionStepDesc for the implementation details.
omitNorms
Fields have norms associated with them, which holds additional information such as index-time boost and length normalization. Specifying omitNorms="true" discards this information, saving some memory.
Length normalization allows Solr to give lower weight to longer fields. If a length norm is not important in your ranking algorithm (such as metadata fields) and you are not providing an index-time boost, you can set omitNorms="true". By default, Solr disables norms for primitive fields.
omitTermFreqAndPositions
The index postings also store information such as term frequency, position information, and payloads, if any. You can disable this additional information by setting omitTermFreqAndPositions="true". Disabling this attribute saves memory, reduces index size, and provides better performance. If you need to support queries such as a phrase query or span query on the field, you shouldn’t disable omitTermFreqAndPositions, as these queries rely on position information. Query terms that are more frequent in a document are usually considered more relevant in full-text fields, and that information is maintained by term frequency. Hence, you might not want to disable it in full-text fields.
omitPosition
Specifying the Boolean attribute omitPosition="true" omits the position information but retains the term frequency.
termVectors
Specifying the Boolean attribute termVectors="true" retains the complete term vectors information. This attribute is generally used with termPositions and termOffsets. These are used by features such as highlighting and “more like this” to offer better performance; otherwise, the field would be reanalyzed by using the stored value.
termPositions
Specifying the Boolean parameter termPositions="true" retains the position of the term in the document.
termOffsets
Specifying the Boolean parameter termOffsets="true" retains the offset information of the term in the document.
termPayloads
Specifying the Boolean parameter termPayloads="true" retains the payload information for the term in the document. Payloads allow you to add a numeric value to a term, which you can use in scoring. This feature is useful when you want to give a high weight to a term (such as nouns or correlated words).
![]() Tip If remembering class implementations, attributes, and the (yet-to-be-covered) text analysis seems too much to digest, don’t worry! The best approach to designing your own schema is to take the full-fledged schema.xml provided in the Solr distribution and edit it. In Solr 5.x, the schema.xml file provided in the named configset sample_techproducts_configs can be the reference point for designing your schema.
Tip If remembering class implementations, attributes, and the (yet-to-be-covered) text analysis seems too much to digest, don’t worry! The best approach to designing your own schema is to take the full-fledged schema.xml provided in the Solr distribution and edit it. In Solr 5.x, the schema.xml file provided in the named configset sample_techproducts_configs can be the reference point for designing your schema.
Text Analysis, If Applicable
Table 4-1 introduced the field type solr.TextField for string data. TextField is a special implementation of a field type that supports analyzers with a configurable chain of a single tokenizer and multiple token filters for text analysis. Analyzers can break the input text into tokens, which is used for matching instead of performing an exact match on the whole text. In turn, solr.StrField performs only an exact match, and analyzers cannot be applied.
Text analysis on TextField is covered in more detail in an upcoming section.
copyField
You may want to analyze the same text in multiple ways or copy the text from multiple fields into a single field. The copyField element in schema.xml provides the provision to copy the data from one field to another. You specify the copy-from field name in the source attribute and the copy-to field name in the dest attribute, and whenever you add documents containing a source field, Solr will automatically copy the data to the destination fields. The following is an example of copyField, which copies the text of the album field to multiple fields for different analysis:
<copyField source="album" dest="album_tokenized"/>
<copyField source="album" dest="album_gram"/>
<copyField source="album" dest="album_phonetic"/>
If you are copying data from multiple sources to a single destination, or any of the source fields is multiValued, ensure that the destination field is also defined as multiValued="true". Otherwise, Solr will throw an exception while indexing documents.
The following are attributes supported by copyField.
source
The source attribute specifies the field from which the data is to be copied. The source field must exist. The field name can start and end with asterisk to copy from all the source fields matching the pattern.
dest
The dest attribute specifies the destination field to which the data is to be copied. The destination field must exist. The field name can start and end with asterisk to copy the text to all the destination fields matching the pattern. You can specify a wildcard in the destination field only if it is specified in the source field also.
maxChars
This optional integer attribute allows you to keep a check on the field size and prevent the index from growing drastically. If the number of characters indexed to the destination field outgrows the maxChars value, those extra characters will be skipped.
Define the Unique Key
The element <uniqueKey> in schema.xml is analogous to a primary key in databases. This element specifies the field name that uniquely identifies a document. Here is a sample definition that specifies isbn of a book as a unique identifier for documents.
<uniqueKey>isbn</uniqueKey>
It’s not mandatory to declare a uniqueKey, but defining it is strongly recommended. It’s also highly likely that your application will have one. The following are rules and suggestions for defining a uniqueKey field:
- The field should be of type String or UUID.
- Any index-time analysis on this field might break document replacement or document routing in SolrCloud and should be avoided.
- A field with multiple tokens is not allowed as a uniqueKey.
- A dynamic field cannot be used to declare a uniqueKey.
- The value of this field cannot be populated by using copyField.
If you index a document and if another document already exists with the same unique key, the existing document will be overwritten. To update a document instead of replacing it, use the Atomic Update feature of Solr. Chapter 5 provides more details on atomic updates.
Dynamic Fields
Instead of declaring all the fields explicitly, Solr allows you to define dynamic fields by specifying patterns for creating fields. While indexing a document, if any of the specified fields isn’t defined in schema.xml, Solr looks for a matching dynamic field pattern. If a pattern exists, Solr creates a new field of the fieldType defined in the <dynamicField> element.
If you want to perform a similar analysis on multiple fields, then instead of declaring them explicitly, you could define a dynamicField for that fieldType. Suppose you want to create N-grams for the fields movie name, actor, and director. Instead of explicitly defining fields for each one of them, you can create dynamic fields as shown here:
<dynamicField name="*_gram" type="ngrams" indexed="true" stored="false"/>
Similarly, if you are performing a multilingual operation, a dynamic field can be useful for storing language-specific information:
<dynamicField name="*_ut_en" type="ngrams" indexed="true" stored="true"/>
<dynamicField name="*_ut_fr" type="ngrams" indexed="true" stored="true"/>
<dynamicField name="*_ut_sp" type="ngrams" indexed="true" stored="true"/>
At times, you don’t know the field type until the document is indexed—for example, while extracting metadata from a rich document. Dynamic fields are useful in such scenarios.
The dynamicField element supports the same attribute as the field definition, and all behavior remains the same.
defaultSearchField
If a search request doesn’t contain the field name to be queried upon, Solr searches on the default field. This element specifies the default field to query. The following is an example query that doesn’t contain a field name, and Solr uses the default field to query.
This element has been deprecated in Solr 3.6 and should not be used as fallback. Instead, the df request parameter should be used.
solrQueryParser
This element specifies the default operator to be used by the query parsers, if an operator is not specified in the query. A sample solrQueryParser definition is provided here:
<solrQueryParser defaultOperator="OR"/>
This element has been deprecated since Solr 3.6, and the q.op request parameter should be used instead.
Similarity
Lucene uses the Similarity class implementation for scoring a document. To use an implementation other than the default implementation, you can declare it by using this element and specifying the class name in the class attribute. Here is the specification for the default similarity in schema.xml:
<similarity class="solr.DefaultSimilarityFactory"/>
A different similarity algorithm can be applied on all the fields or on a specific field. Here is an example for specifying a different similarity on a specific field:
<fieldType name="text_ib">
<analyzer/>
<similarity class="solr.IBSimilarityFactory">
<str name="distribution">SPL</str>
<str name="lambda">DF</str>
<str name="normalization">H2</str>
</similarity>
</fieldType>
<similarity class="solr.SchemaSimilarityFactory"/>
Similarity implementations are covered in more detail in Chapter 8.
Text Analysis
Our discussion of schema design provided an overview of text analysis. In this section, you will learn about the process in more detail.
Analysis is the phase of converting a text stream into terms. Terms are the smallest unit of information used by Lucene for matching and computing the score of documents. A term is not necessarily the words in the input text; the definition of a term depends on how you analyze the text stream. A term can be the whole input text, a sequence of two or more words, a single word, or a sequence of any characters in the text stream.
Figure 4-1 depicts an example: different terms are emitted for the same input text stream because of different analysis. As you can see, the KeywordTokenizerFactory doesn’t make any changes to the stream, and the emitted term is the whole input text; in contrast, the WhitespaceTokenizerFactory splits on whitespace and multiple terms are emitted. You will learn about analyzers and tokenizers later in this chapter.

Figure 4-1. Text stream and the emitted terms
To understand the matching behavior, Table 4-2 provides few simple user queries that are searched on (or matched against) fields with this analysis. For simplicity, the table provides queries of one word, and you can assume that no analysis is being performed at query time.
Table 4-2. Query Match Status
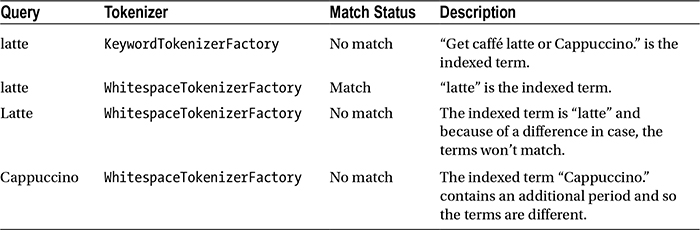
If you had applied PatternReplaceCharFilterFactory to remove the special characters after tokenization, the Cappuccino query in Table 4-2 would have matched.
These are simple examples, and you can apply other processing (such as for lowercasing, converting to the nearest ASCII character, or removing special characters and symbols) as needed. The processing you perform depends on your matching requirements; it’s not that the analysis performed using KeywordTokenizerFactory is wrong, but that it’s meant for a different purpose.
Lucene uses the Boolean model (BM) and vector space model (VSM) together to determine the relevancy of documents with respect to a query. The combination works as follows: Documents matched by the BM are ranked by the VSM. The BM determines whether a term matches in a field. There the text analysis then comes into action, to control the matching behavior and determine the query terms that match the terms in the index. The analysis chain plays a crucial role in document matching.
![]() Note The query parser also play important roles in determining the matching documents. You will learn about it in Chapter 6.
Note The query parser also play important roles in determining the matching documents. You will learn about it in Chapter 6.
An analyzer defines a chain of processes, each of which performs a specific operation such as splitting on whitespace, removing stop words, adding synonyms, or converting to lowercase. The output of each of these processes is called a token. Tokens that are generated by the last process in the analysis chain (which either gets indexed or is used for querying) are called terms, and only indexed terms are searchable. Tokens that are filtered out, such as by stop-word removal, have no significance in searching and are totally discarded.
Figure 4-1 oversimplified an example of a term in Solr. Solr allows you to perform the same or a different analysis on the token stream while indexing and querying. Query-time analysis is also needed in most cases. For example, even if you perform lowercasing at index time, the Latte query in Table 4-2 will lead to no match, as the query token itself starts with an uppercase letter. You generally perform the same analysis while indexing and searching, but you may want to apply some of the analysis either only while indexing or only while searching, as in the case of synonym expansion.
Figure 4-2 depicts a typical analyzer that executes a chain of analysis on the text stream. The first process in the chain receives the input stream, splits it on whitespace, and emits a set of tokens. The next process checks the tokens for non-ASCII characters; if any exist, they are converted to the nearest ASCII equivalent. The converted tokens are input to the process for removing stop words, which filters out the keywords present in the stop-words list. The next process converts all tokens to lowercase, and then the stemmer converts the tokens to their base format. Finally, the tokens are trimmed, and the terms emitted by this last process are finally indexed or used for querying.
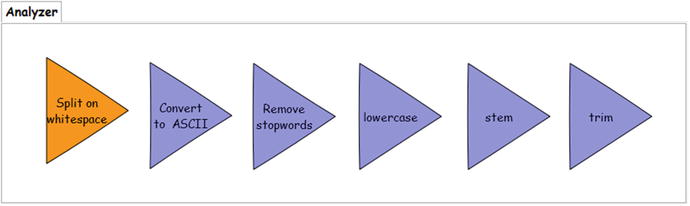
Figure 4-2. A typical analysis chain
The following is a sample fieldType definition to build the analysis chain specified in figure 4-2:
<fieldType name="text_analysis" class="solr.TextField" positionIncrementGap="100">
<analyzer>
<tokenizer class="solr.WhitespaceTokenizerFactory"/>
<filter class="solr.AsciiFoldingFilterFactory"/>
<filter class="solr.StopFilterFactory" ignoreCase="true" words="stopwords.txt" />
<filter class="solr.LowerCaseFilterFactory"/>
<filter class="solr.PorterStemFilterFactory"/>
<filter class="solr.TrimFilterFactory"/>
</analyzer>
</fieldType>
Figure 4-3 depicts an example of the text analysis of this fieldType definition. Suppose you are building a movie search engine that discovers movies for the user, even if the query partially matches. The system uses the preceding text analysis and indexes the movie name as To Kill a Mockíngbird, with the letter í in Mockingbird mistakenly having an accent, as you can see. You will see how the matching works when a user who hardly remembers the correct movie name searches kills the mockingbird. Also note that a majority of users, like this one, generally provide queries in lowercase. The following steps indicate how the analysis chain results in the user finding the movie To Kill a Mockíngbird:
- WhitespaceTokenizerFactory splits the text stream on whitespace. In the English language, whitespace separates words, and this tokenizer fits well for such text analysis. Had it been an unstructured text containing sentences, a tokenizer that also splits on symbols would have been a better fit, such as for the “Cappuccino.” example in Figure 4-1.
- AsciiFoldingFilterFactory removes the accent as the user query or content might contain it.
- StopFilterFactory removes the common words in the English language that don’t have much significance in the context and adds to the recall.
- LowerCaseFilterFactory normalizes the tokens to lowercase, without which the query term mockingbird would not match the term in the movie name.
- PorterStemFilterFactory converts the terms to their base form without which the tokens kill and kills would have not matched.
- TrimFilterFactory finally trims the tokens.
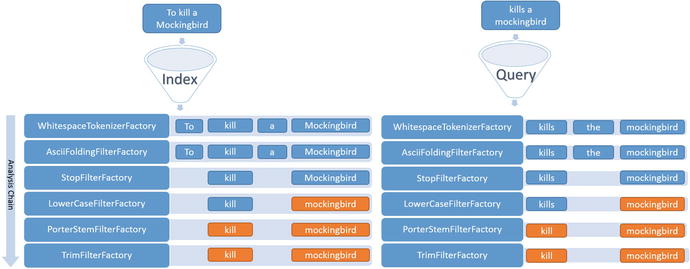
Figure 4-3. Text analysis and term matching
Tokens
The token stores the text and the additional metadata, including the start and end offset of the text, token type, position increment information, application-defined bit flag, and byte payload.
If you are writing your custom implementation for text analysis, the additional metadata should not be ignored, as some of the components require this additional information to function. The offset value is used by features such as highlighting. The position increment value identifies the position of each token in the field and plays an important role in phrase and span queries. A position increment value greater than 1 indicates a gap (a word from that position has been removed)—for instance, stop-word removal leaves a gap. A value of 0 places a token in the same position as the previous token; for example, synonym enrichment places synonyms in the same position. The default value for position increment is 1.
Terms
Terms are the output of the analysis process, each of which is indexed and used for matching. A term holds the same information as a token, except the token type and the flag.
![]() Note The terms token and term are used interchangeably at times to refer to the emitted tokens.
Note The terms token and term are used interchangeably at times to refer to the emitted tokens.
Analyzers
The analysis process is defined by the analyzer, which is specified as a child element of <fieldType> in schema.xml. It analyzes the input text and optionally runs it through an analysis chain. Analyzers can perform two types of analysis, as described next.
Simple Analysis
The analyzer element specifies the name of the class implementing the analysis. For example:
<fieldType name="text_simple" class="solr.TextField">
<analyzer class="org.apache.lucene.analysis.WhitespaceAnalyzer"/>
</fieldType>
The preceding fieldType definition for simple analysis emits terms by splitting the input token stream on whitespace. If the input stream is Bob Marley, the analyzed terms of a field of type text_simple will be Bob and Marley.
Analysis Chain
Instead of specifying the class implementing the analysis, the analyzer element contains a series of child elements called tokenizer and filter. These elements chained together form a pipeline for processing and analyzing the input text. The sequence in which the elements are specified in the chain matters: they should be specified in the order you want them to run. At a high level, the analysis chain can be used to perform the following operations:
- Splitting the text on whitespace, symbols, or case change
- Normalizing
- Removing the junks
- Performing enrichment
The fieldType definition in Figure 4-2 provides an example of an analysis chain. You will notice that the fieldType definition of this analyzer doesn’t contain the classname attribute, as in the case of simple analysis. Instead it contains a set of child elements, each of which corresponds to a text analysis process in the chain.
Analysis Phases
In the preceding examples, we performed the same analysis for indexing and querying documents. Solr allows you to perform a different analysis during both phases (indexing and querying), and one phase can have even no analysis at all. For example, if you want the term inc to match incorporated, you may need to do synonym expansion, and doing it during one phase, either indexing or querying, will match both the terms.
The following are some important points about text analysis:
- The scope of the analyzer is limited to the field it is applied on. It cannot create a new field, and the terms emitted by one field cannot be copied to another field.
- copyField copies the stored value of the field and not the terms emitted by the analysis chain.
A description of both analysis phases follows.
Indexing
Index-time analysis applies when a document is added to Solr. Each field has a type. If the fieldType has an analyzer defined, the text stream is analyzed and the emitted terms are indexed along with posting information such as position and frequency. Figure 4-4 depicts an index-time analysis process. It’s important to note that the analysis process affects only the indexed term, and the value stored is always the original text received by the field. The transformed text can only be queried upon and cannot be retrieved.
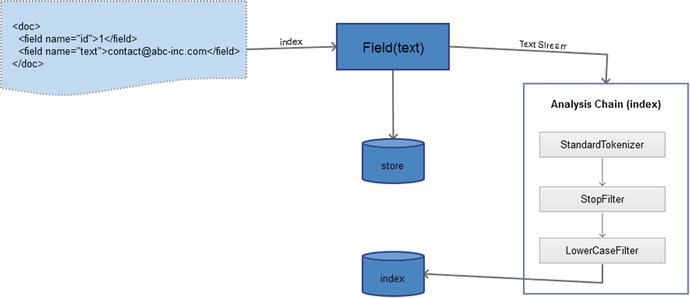
Figure 4-4. Index-time analysis
A different analysis can be performed at index time by specifying the analyzer element with the type="index" attribute, as shown here:
<fieldType name="text_analysis" class="solr.TextField" positionIncrementGap="100">
<analyzer type="index">
<tokenizer class="solr.WhitespaceTokenizerFactory"/>
<filter class="solr.AsciiFoldingFilterFactory"/>
...
</analyzer>
<analyzer type="query">
<tokenizer class="solr.WhitespaceTokenizerFactory"/>
<filter class="solr.AsciiFoldingFilterFactory"/>
...
</analyzer>
</fieldType>
![]() Note Any change in the index-time analyzer or its analysis chain requires a core reload and reindexing of all documents.
Note Any change in the index-time analyzer or its analysis chain requires a core reload and reindexing of all documents.
Querying
Query-time analysis on the field is invoked by the query parser for a user query. Figure 4-5 depicts a query-time analysis process. You can see that the analysis differs from index-time analysis.
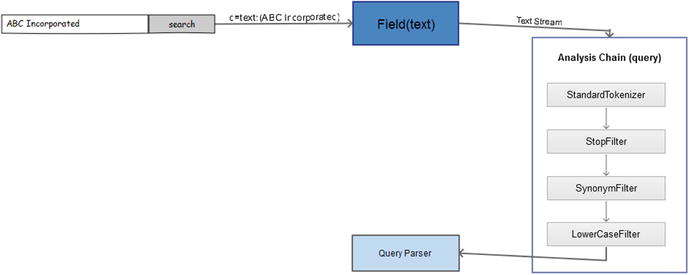
Figure 4-5. Query-time analysis
A different analysis can be performed at query time by specifying the analyzer element with the type="query" attribute for the fieldType.
![]() Note Any change in the query-time analyzer or its analysis chain requires only the core to be reloaded, and reindexing is not required.
Note Any change in the query-time analyzer or its analysis chain requires only the core to be reloaded, and reindexing is not required.
Analysis Tools
For examining the fields and the analysis process, the following tools can be used.
Solr Admin Console
To examine the fields and fieldTypes defined in schema.xml, Solr provides the Analysis tab in the admin console. The associated page provides separate fields for index-time and query-time analysis. You need to input the text to be analyzed, select the field or fieldType, and click Analyze Values. If values are supplied in both text boxes, the process highlights the matching tokens. If you are interested only in terms emitted by the analyzer, you can disable the Verbose Output option.
On the Analysis screen, you can find a question-mark symbol beside the Analyze Fieldname drop-down list, which will take you to the Schema Browser screen. This screen allows you to view the properties of fields and examine the indexed terms. Figure 4-6 shows the Schema Browser screen for a field. It shows field properties and the top terms indexed to that field along with term frequency.
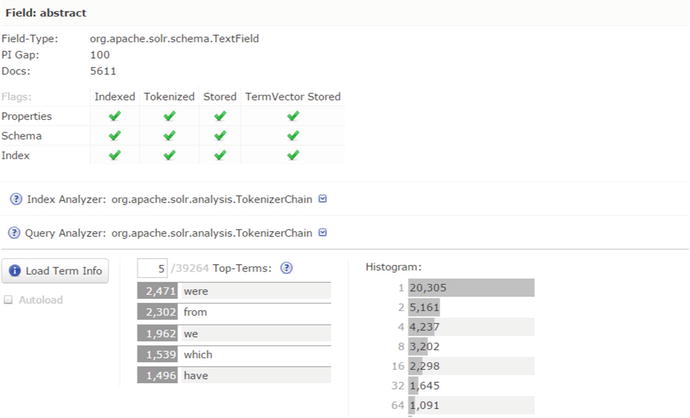
Figure 4-6. Schema Browser
Luke
The Lucene Index Toolbox (Luke) is a wonderful open source tool for examining as well as modifying the index. You should use the same version of Luke as the Lucene libraries. You can find the tool at https://github.com/DmitryKey/luke.
Analyzer Components
The analysis chain is specified inside the <analyzer> element and is composed of a combination of three types of components described next. Figure 4-7 depicts how a text stream flows through the analyzer and tokens are emitted.

Figure 4-7. Analyzer components chaining
CharFilters
This component cleans up and preprocesses the characters before being processed by the tokenizer. Multiple CharFilters can be chained together and should always be configured before Tokenizer.
Tokenizers
Tokenizer accepts the text stream, processes the characters, and emits a sequence of tokens. It can break the text stream based on characters such as whitespace or symbols. An adjacent sequence of characters forms tokens. It can also add, remove, or replace characters.
Tokenizers should always be specified before TokenFilters and can be specified only once in an analyzer. Also, the tokenizer has no information about the field it is specified in. Table 4-3 specifies the tokenizer implementations provided by Solr.
Table 4-3. Tokenizer Implementations
Implementation | Description |
|---|---|
KeywordTokenizerFactory | Does no tokenization. Creates a single token for the entire text. Preferred for exact matching on fields such as metadata. Input: “Bob Marley is a legendary singer.” Output: “Bob Marley is a legendary singer.” |
StandardTokenizerFactory | Sophisticated and smart general-purpose Tokenizer. It splits on whitespace and punctuations, identifies sentence boundaries and URLs. It uses the Unicode standard word-boundary rule. Input: “Bob Marley is a legendary singer.” Output: “Bob” “Marley” “is” “a” “legendary” “singer” |
WhitespaceTokenizerFactory | It simply splits on whitespace. Input: “Bob Marley is a legendary singer.” Output: “Bob” “Marley” “is” “a” “legendary” “singer.” |
ClassicTokenizerFactory | It supports the behavior of StandardTokenizer as in Solr 3.1. It recognizes e-mail IDs and keeps them intact (the current StandardTokenizer splits the ID because of the @ symbol). Input: “Bob’s id is [email protected]” Output: “Bob’s” “id” “is” “[email protected]” |
LetterTokenizerFactory | It treats contiguous letters as tokens, and everything else is discarded. Input: “Bob’s id is [email protected]” Output: “Bob” “s” “id” “is” “contact” “bob” “com” |
TokenFilters
TokenFilter processes the tokens produced by Tokenizer. The important difference between Tokenizers and TokenFilters is that the Tokenizer input is Reader, whereas the TokenFilter input is another TokenStream.
TokenFilters should always be specified after a Tokenizer and can be specified any number of times. Also, the TokenFilter has no information about the field it is processing for.
Solr provides a wide range of token filter factories. The next section covers the primary filter factories. Refer to the Solr official reference guide at https://cwiki.apache.org/confluence/display/solr/Filter+Descriptions for a complete list of filters provided by Solr.
Common Text Analysis Techniques
Solr out-of-the-box provides a wide variety of analyzers, tokenizers and token filters to quickly and easily build an effective search engine. In this section, you will learn about the text processing techniques which can be applied using these field analyzers to achieve the desired search behavior.
Synonym Matching
Before exploring synonym matching, let’s consider an example. Synonyms for the word define include describe, detail, explain, illustrate, and specify. Before performing a search, the end user thinks about which keywords to use to express the intent and formulate the query. Suppose the user is looking for the definition of the word synonym; his query could be define synonym, describe synonym, or any other synonym for the word define. Hence, it’s really crucial to maintain synonyms for terms. Otherwise, even if your corpus contains the information the user is looking for, the system will fail to retrieve it.
Solr provides SynonymFilterFactory to perform dictionary-based synonym matching. Synonyms can be configured in a text file with a list of keywords and their matching synonyms. The following is a sample definition of SynonymFilterFactory in schema.xml:
<fieldType name="text_synonyms" class="solr.TextField">
<analyzer>
<tokenizer class="solr.WhitespaceTokenizerFactory"/>
<filter class="solr.SynonymFilterFactory" synonyms="synonyms.txt"
ignoreCase="true" expand="false"/>
</analyzer>
</fieldType>
Refer to the sample synonyms.txt file provided in the named configsets for the file format.
Parameters
The following parameters are supported by SynonymFilterFactory:
- synonyms: Specifies the name of the external text file that contains the synonym mapping.
- ignoreCase: If set to true, the case of keywords will be ignored during lookup.
- expand: If true, the tokens will be expanded. If false, the synonyms will collapse to the keyword.
Given the need of having a generic synonym (applicable to the language) and specific synonym (specific to your domain), you can configure multiple SynonymFilters in an analysis chain. Basically, any TokenFilter can be configured multiple times, if needed.
SynonymFilterFactory can be applied at both index time and query time, but is usually applied at either of the two. Index-time synonym expansion results in a bigger index size, and any change in the list requires reindexing. But it also has benefits. The expanded tokens will contribute to inverse document frequency (IDF), which gives higher importance to rarer words.
The query-time synonym expansion doesn’t increase the index size and saves you from reindexing after changing the synonym list, but it increases the query response time. The problem in query-time expansion is with synonyms containing multiple words, such as movie star. Such words are already tokenized by the QueryParser into movie and star before being processed by the analyzer. Another problem is with phrase queries: the tokens in the phrase would get expanded, which results in the phrase having multiple tokens that could end up being a no-match. For example, movie star can expand to "(movie | cinema) (star | actor | cast)" and end up not matching documents containing movie star.
Phonetic Matching
Phonetic matching algorithms are for matching words that sound alike and are pronounced similarly. Edit distance and N-grams are particularly suitable when words are misspelled, but phonetics is suitable when a word is written differently but is always pronounced the same.
Name matching is a typical example: a name can have multiple spellings but be pronounced the same. For matching a person’s name, phonetic algorithms become even more crucial, as there is no standard definition or dictionary for names. A name can have multiple variations that are pronounced the same. For example, Christy and Christie are phonemes for the same name, and both are correct.
Phonetic matching may not work well for typographical errors, which are unintentional and typically include letters in the wrong order (for example, good typed as godo). However, phonetic matching can be effective if the error is intentional, as in the case of tweets or short messages where the user might replace good with gud, or you with u.
The purpose of phonetic matching is to increase recall and ensure that no terms are missed that could have matched. It’s advised to give low boost to the phonetic field, as this may end up matching totally unrelated words either due to words being phonetically similar but representing different concepts or due to the limitations of the algorithm.
Phonetics are highly language specific, and most of the algorithms are developed for English. The algorithms encode the tokens and are supposed to be the same for phonetically similar words. Table 4-4 provides a list of phonetic algorithms supported by Solr and sample definitions.
Table 4-4. Phonetic Algorithms
Algorithm | Definition |
|---|---|
Beider-Morse Phonetic Matching (BMPM) | Provides much better codes for first name and last name. Configuration: <filter class="solr.BeiderMorseFilterFactory" nameType="GENERIC" ruleType="APPROX" concat="true" languageSet="auto"/> |
Soundex | Developed to match phonetically similar surnames. It generates codes of four characters, starting with a letter and followed by three numbers. Configuration: <filter class="solr.PhoneticFilterFactory" encoder="Soundex"/> |
Metaphone | It is used generally for matching similar-sounding words and is not limited to surnames. Configuration: <filter class="solr.PhoneticFilterFactory" encoder="Metaphone"/> |
Double Metaphone | This extension of Metaphone addresses peculiarities in languages other than English. Configuration: <filter class="solr.DoubleMetaphoneFilterFactory"/> <filter class="solr.PhoneticFilterFactory" encoder="DoubleMetaphone"/> |
Refined Soundex | Refined version of Soundex, which matches fewer names to the same code. Configuration: <filter class="solr.PhoneticFilterFactory" encoder="RefinedSoundex"/> |
Daitch-Mokotoff Soundex | Refinement of Soundex. It provides high accuracy for matching names, especially Slavic and European. It generates codes of six numeric digits. Configuration: <filter class="solr.DaitchMokotoffSoundexFilterFactory" inject="true"/> |
Caverphone | Optimized for accents in New Zealand. Configuration: <filter class="solr.PhoneticFilterFactory" encoder="Caverphone"/> |
Kölner Phonetik (a.k.a. Cologne Phonetic) | It is suitable for German words. Configuration: <filter class="solr.PhoneticFilterFactory" encoder="ColognePhonetic"/> |
New York State Identification and Intelligence System (NYSIIS) | Provides a better result than Soundex, using a more sophisticated rule for code generation. Configuration: <filter class="solr.PhoneticFilterFactory" encoder="Nysiis"/> |
N-Grams
N-Gram breaks the input token into multiple subtokens called grams. For example, grams for the input token hellosolr of size 4 will be hell, ello, llos, loso, osol, and solr. If the user query is solr, you can see that the last gram generated will match.
N-grams are useful for matching substrings and misspelled words. It is also useful for features such as autocompletion, prefix and postfix queries, and wildcard searches. N-grams increase the recall and match tokens that would otherwise be missed.
Solr provides Tokenizers as well as TokenFilters for N-grams. If you want to generate grams on the tokenized text, you can use TokenFilter; otherwise, the Tokenizer can be used. Table 4-5 lists the implementations provided by Solr for N-gram.
Table 4-5. N-Gram Implementations
Implementation | Definition | Example |
|---|---|---|
NGramTokenizerFactory NGramFilterFactory | Generates N-grams from all character positions and of all sizes in the specified range Attributes: minGramSize: Minimum gram size maxGramSize: Maximum gram size Configuration: <tokenizer class="solr.NGramTokenizerFactory" minGramSize="3" maxGramSize="4"/> <filter class="solr.NGramFilterFactory" minGramSize="3" maxGramSize="4"/> | Input: hellosolr Output: hel, ell, llo, los, oso, sol, olr, hell, ello, llos, loso, osol, solr |
EdgeNGramTokenizerFactory EdgeNGramFilterFactory | Generates N-grams from the specified edge and of all sizes in the specified range Attributes: minGramSize: Minimum gram size maxGramSize: Maximum gram size side: Edge from which grams should be generated. Value can be front or back. Default is front. Configuration: <tokenizer class="solr.EdgeNGramTokenizerFactory" minGramSize="4" maxGramSize="5"/> <filter class="solr.EdgeNGramFilterFactory" minGramSize="4" maxGramSize="5" side="front"/> | Input: hellosolr Output: hell, hello |
The edge N-gram generates fewer tokens and provides better performance than N-gram. N-gram offers better recall but should be used carefully, as it can lead to overmatching.
If you keep the minGramSize small, lots of tokens will be generated and the index size and indexing time will increase and will have performance implications. You should generate N-grams only for a few fields and try to keep the minGramSize high and maxGramSize low.
Shingling
Shingling generates grams on the basis of words instead of on the basis of characters. For the input stream apache solr rocks, the shingles generated would be apache solr and solr rocks.
Shingling provides a mechanism to improve relevance ranking and precision, by allowing you to match subphrases. Phrase queries match the entire sequence of tokens, token-based matching matches an emitted term, and shingles fit between both. Shingling provides better query-time performance than phrases with a trade-off of additional tokens generated.
Shingles are generally applied while indexing, but can be applied both while indexing and querying. Also, the shingle fields are usually given a high boost.
The following is a sample definition of SynonymFilterFactory in schema.xml:
<fieldType name="text_shingles" class="solr.TextField">
<analyzer>
<tokenizer class="solr.WhitespaceTokenizerFactory"/>
<filter class="solr.ShingleFilterFactory" minShingleSize="2" maxShingleSize="3" outputUnigrams="false"/>
</analyzer>
</fieldType>
Parameters
The following parameters are supported by ShingleFilterFactory:
- minShingleSize: The minimum number of tokens per shingle. The default value is 2.
- maxShingleSize: The maximum number of tokens per shingle. The default value is 2.
- outputUnigrams: This Boolean parameter specifies whether the individual tokens should be generated. By default, this is set to true. If this parameter is true and you are giving a high boost to the field, evaluate that the boost doesn’t adversely affect the relevancy, as your general intention would be to give higher boost to shingles constituted of multiple tokens.
- outputUnigramsIfNoShingles: This Boolean parameter specifies whether individual tokens should be generated if no shingle is generated. By default, this is set to false.
- tokenSeparator: This specifies the separator for joining the tokens that form the shingles. The default value is " ".
Stemming
Stemming is the process of converting words to their base form in order to match different tenses, moods, and other inflections of a word. The base word is also called a stem. It’s important to note that in information retrieval, the purpose of stemming is to match different inflections on a word; stems are not necessarily the morphological root.
Stemmers are generally language specific. A wide range of stemmers are available for English. For other languages, stemmers are also available. Table 4-6 specifies the primary stemmers supported in Solr.
Table 4-6. Stemming Algorithms
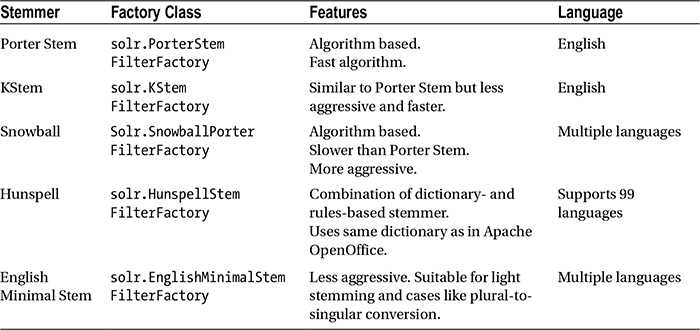
Figure 4-8 shows the result of stemming for words whose base is travel. We applied PorterStemFilter at index time and EnglishMinimalStemFilter at query time, to illustrate the difference in results and level of aggressiveness of both algorithms. PorterStemFilter is more aggressive and converts all inflections of travel to its base word, while EnglishMinimalStemFilter does it only for a few inflections.
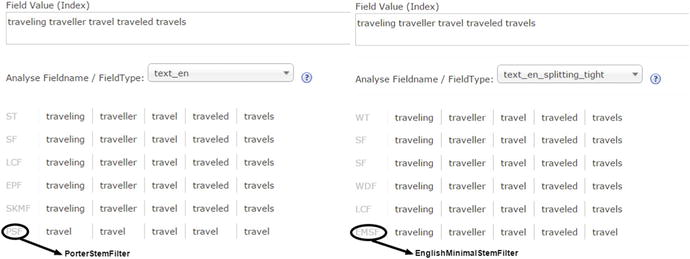
Figure 4-8. Stemming algorithm comparison
![]() Caution In Figure 4-8, a different stemmer has been configured at index time and query time for comparison. Rarely will there be a scenario where you would want to configure this way.
Caution In Figure 4-8, a different stemmer has been configured at index time and query time for comparison. Rarely will there be a scenario where you would want to configure this way.
While stemming the tokens, the problem of overstemming and understemming can occur, so the stemming algorithm should be chosen considering these error measurements. In overstemming, two totally unrelated words are stemmed to the same root, though they shouldn’t be (a false positive). In understemming, two related words are not stemmed to the same root, though they should be (a true negative). For example, EnglishMinimalStemFilter not stemming traveling to travel is a case of understemming, and PorterStemFilter stemming university and universe both to univers is a case of overstemming.
Stemming should generally be applied both while indexing and querying. Stemming doesn’t increase the size of the index.
Solr provides provisions to solve the problem of overstemming and understemming with KeywordMarkerFilter and StemmerOverrideFilter, respectively.
KeywordMarkerFilter
KeywordMarkerFilter prevents words from being stemmed, by specifying the protected words in a file. The filename should be specified in the protected attribute of the filter factory.
KeywordMarkerFilter makes an effective solution for blacklisting words that result in false positives due to overstemming. In the previous example, you saw university being overstemmed. Suppose you don’t want a term to be stemmed; you can add it to the protected words file and configure KeywordMarkerFilter. The following is a sample fieldType configuration in schema.xml:
<fieldType name="text_stem" class="solr.TextField">
<analyzer>
<tokenizer class="solr.WhitespaceTokenizerFactory"/>
<filter class="solr.KeywordMarkerFilterFactory" protected="protwords.txt" />
<filter class="solr.PorterStemFilterFactory" />
</analyzer>
</fieldType>
KeywordMarkerFilterFactory should always be configured before the factory for the stemmer. If you configure it after the stemmer, it will have no effect.
StemmerOverrideFilter
To address the problem of understemming, Solr provides StemmerOverrideFilter. It overrides the stemming done by the configured stemmer, with the stem mapped to the word in the stemming override file.
The stemming override filename is configured in the dictionary attribute of the filter factory, which contains the mapping of words to its stems in a tab-separated file. The following is a sample fieldType configuration in schema.xml:
<fieldType name="text_stem" class="solr.TextField">
<analyzer>
<tokenizer class="solr.WhitespaceTokenizerFactory"/>
<filter class="solr.StemmerOverrideFilterFactory" dictionary="stemdict.txt" />
<filter class="solr.PorterStemFilterFactory" />
</analyzer>
</fieldType>
StemmerOverrideFilterFactory should always be configured before the factory for the stemmer. If you configure it after the stemmer, it will have no effect.
Blacklist (Stop Words)
Some of the terms are of no importance to your search engine. For example, words such as a, an, and the add to the bag of words and end up increasing the false positives. You might want to stop such words from being indexed and queried. Solr provides StopFilterFactory to blacklist and discard the words specified in the stop-words file from the field tokens. Here is an example configuration:
<analyzer>
<tokenizer class="solr.WhitespaceTokenizerFactory"/>
<filter class="solr.StopFilterFactory" words="stopwords.txt"/>
</analyzer>
Figure 4-9 illustrates stop-word removal with an example of a movie search engine; the word movie is assumed to be a stop word. We added the keyword movie to the stop-words file and analyzed the text review of movie shawshank redemption. The stop-words filter removes the token movie from the token stream. Also, it creates a gap in the stream that can be determined by the token metadata, such as the position and start and end offsets.
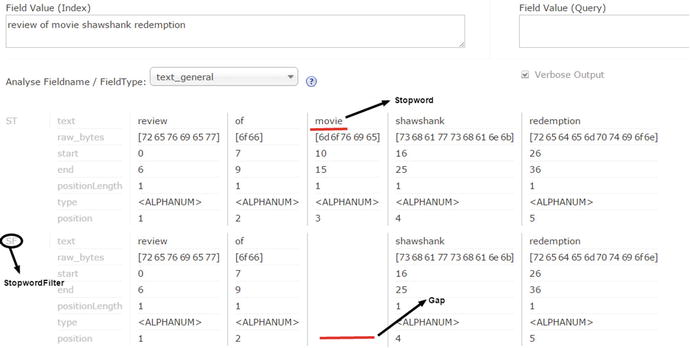
Figure 4-9. Stop-words removal
The stopwords.txt file provided in the sample_techproducts_configs configset is blank and it contains no entries. Common English words such as a, an, and the generally make good candidates for the stopwords.txt file. To find stop words specific to your content, the Schema Browser in the Solr admin console is a good place to start. You can select a field and load the terms with highest frequency by clicking the Load Term Info button. You can then review these high-frequency terms to determine whether some of them can be stop words.
Whitelist (Keep Words)
Whitelisting is the opposite of stop-word removal or blacklisting. This allows only those tokens to pass through that are present in the specified list, and all other tokens are discarded. Suppose your application supports a specified set of languages; in that case, you might want to apply a filter that keeps only the supported language and discards all other text.
You can achieve this in Solr by using the KeepWordFilterFactory class. This filter is generally applied while indexing. The following is an example configuration:
<analyzer>
<tokenizer class="solr.WhitespaceTokenizerFactory"/>
<filter class="solr.KeepWordFilterFactory" words="keepwords.txt"/>
</analyzer>
The following are the supported parameters:
- words: Path of the text file containing the allowed words. The file-definition rule is the same as the stop-words file.
- ignoreCase: This Boolean parameter, if set to true, makes the filter insensitive to case changes. The default value is false.
Other Normalization
In the previous section, you learned about stemming, which is one form of text normalization. Similarly, you may need to perform other text normalizations, by adding token filters to the analysis chain. The following are other frequently used normalizers.
User queries typically don’t adhere to language casing conventions and are mostly provided in lowercase. Therefore,, you might want your search to be insensitive to case. The best way to achieve this is follow one convention of having all tokens in the same case. Solr provides LowerCaseFilterFactory to convert all the letters in the token to lowercase, if they are not. For example, Bob Marley must match bob marley. The following is an example configuration:
<analyzer>
<tokenizer class="solr.WhitespaceTokenizerFactory"/>
<filter class="solr.LowerCaseFilterFactory"/>
</analyzer>
This is generally applied both while indexing and querying.
Convert to Closest ASCII Character
If you want your search experience to be insensitive to accents, so that both accented and nonaccented characters match the same documents, you should add ASCIIFoldingFilterFactory to the analysis chain. This filter converts Unicode characters to their closest ASCII equivalents, if available. For example, Bełżec should match Belzec. Here is an example configuration:
<analyzer>
<tokenizer class="solr.WhitespaceTokenizerFactory"/>
<filter class="solr.ASCIIFoldingFilterFactory"/>
</analyzer>
This is generally applied both while indexing and querying.
Remove Duplicate Tokens
After performing a series of operations on the text, the chain might end up generating duplicate tokens, such as performing enrichments or synonym expansion followed by stemming. Solr provides the RemoveDuplicatesTokenFilterFactory implementation to remove the duplicate tokens at the same position. The following is an example configuration:
<analyzer>
<tokenizer class="solr.WhitespaceTokenizerFactory"/>
<filter class="solr.RemoveDuplicatesTokenFilterFactory"/>
</analyzer>
This is generally applied while indexing.
Multilingual Support
The text analysis you perform depends a lot on the language you need to support. You may be developing a search engine for a specific language or you may need to support multiple languages. To support a specific language, you can define all fieldTypes as per the linguistics of that language. If you need to support multiple languages, you can define different fieldTypes for each language and copy the text to the corresponding field. The named configsets provided by Solr contain fieldType definitions for a wide range of languages, a sample of which is provided here:
<!-- German -->
<fieldType name="text_de" class="solr.TextField" positionIncrementGap="100">
<analyzer>
<tokenizer class="solr.StandardTokenizerFactory"/>
<filter class="solr.LowerCaseFilterFactory"/>
<filter class="solr.StopFilterFactory" ignoreCase="true"
words="lang/stopwords_de.txt" format="snowball" />
<filter class="solr.GermanNormalizationFilterFactory"/>
<filter class="solr.GermanLightStemFilterFactory"/>
<!-- less aggressive: <filter class="solr.GermanMinimalStemFilterFactory"/> -->
<!-- more aggressive: <filter class="solr.SnowballPorterFilterFactory" language="German2"/> -->
</analyzer>
</fieldType>
The preceding fieldType definition is for the German language. You can see that Solr provides factories specific to it. Among the provided factories, it offers multiple implementations for stemmers, and you can use the one that works well for your needs.
The alphabets of many languages use diacritical marks, such as French scripts, to change the sounds of letters to which they are added. A simple way to normalize is to use ASCIIFoldingFilterFactory, which we discussed in the previous section, to convert words with accents to the closest ASCII character. But this doesn’t work for languages such as Arabic, whose diacritics cannot be converted to ASCII characters.
For some languages, Solr provides specific tokenizers and filter factories such as ElisionFilterFactory to handle the elision symbol that applies to a selected language. Also, some filter factories accept a different input file that contains the content specific to that language. For example, stop words in English are different from those in Bulgarian. Solr provides a lang subdirectory in conf that contains a list of language-specific files that can be used by the factories.
In a language like English, you can easily identify the words on the basis of whitespace, but some languages (for example, Japanese) don’t separate words with whitespace. In these cases, it’s difficult to identify which tokens to index. The following is an example of Japanese script for the sentence, “What will you have, beer or coffee?”
![]()
Solr provides CJKTokenizerFactory, which breaks Chinese, Japanese, and Korean language text into tokens. The tokens generated are doubles, overlapping pairs of CJK characters found in the text stream. It also provides JapaneseTokenizerFactory and other filters for Japanese language, which are defined in the fieldType text_ja in the schema.xml file bundled with Solr. The example in Figure 4-10 shows the analysis performed by text_ja for text in the Japanese language.
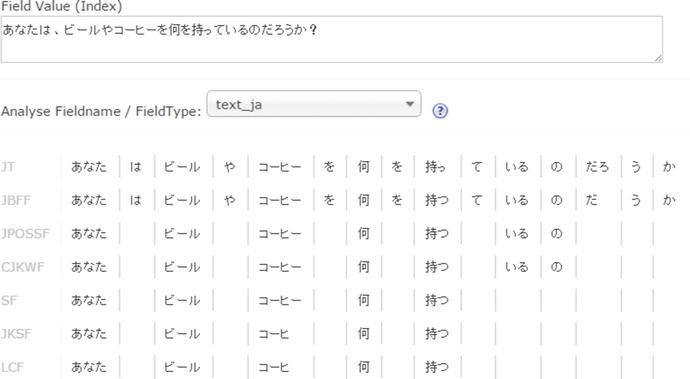
Figure 4-10. Text analysis example for Japanese language
You can refer to the official guide at https://cwiki.apache.org/confluence/display/solr/Language+Analysis for the complete list of language-specific factories provided by Solr.
Going Schemaless
Schemaless mode is the quickest way of getting started with Solr. It allows you to start Solr with zero schema handcrafting and simply index documents without worrying about field definitions. In schemaless mode, you can initially bypass whatever you read early in this chapter. If you want finer control over field definitions or other schema configurations, you can use a managed schema and REST APIs.
Schemaless mode is essentially the proper packaging of a set of Solr features that enables easy setup and creating fields on-the-fly. The following are the features that can be used together to support such a dynamic schema.
- Automatic field type identification
- Automatic field creation
- Managed schema and REST APIs
- Dynamic fields
Schemaless mode is useful if you are new to Solr or you don’t know the document structure or the structure changes frequently.
Solr bundles an example configset for schemaless mode. You can test it by running the Solr script as follows:
$ ./solr start -e schemaless
If you want to create a schemaless core, you can either create a core/collection without any configuration information or specify the prebundled configset data_driven_schema_configs. Here is an example for creating a schemaless core:
$ ./solr create -c schemaless -d data_driven_schema_configs
$ ./solr create -c schemaless // by default uses data_driven_schema_configs
What Makes Solr Schemaless
As you learnt, Solr goes schemaless by bundling a set of features together. The following are features that can be leveraged to go schemaless.
Automatic Field Type Identification
Whenever Solr encounters a new field that is not defined in the schema, it run a set of parsers on the field content, to identify the field type. Currently, Solr provides field type guessing only for the primitive fieldTypes: Integer, Long, Float, Double, Boolean, and Date.
Remember, the field type guess using a dynamic field is based on the field name pattern, but here it is based on field content. Solr implements this feature by providing the update processor factories starting with name Parse*, which identifies the field type while preprocessing. You will read about update processor factories in more detail in Chapter 5.
Automatic Field Addition
For unknown fields, if Solr successfully guesses the fieldType, it adds that field to the schema. The field addition is handled by AddSchemaFieldsUpdateProcessorFactory configured subsequent to the processor for field-type guessing.
Managed Schema and REST API
Automatic field type identification and field addition is limited to primitive field types. If you want to specify a fieldType for any field or define text analysis on it, you might want to add a field and/or fieldType. You can do this on-the-fly by using the managed schema and REST APIs. We discuss this in more detail in the next section.
Dynamic Fields
A dynamic field is supported in Solr since early releases and supports a limited yet powerful schemaless capability. It allows you to assign a complex fieldType to a new field that matches the field-naming pattern.
Configuration
This section specifies the steps that configure Solr to go schemaless. If you are creating a core using the data_driven_schema_configs configset, Solr has the configurations already in place, and you just need to start indexing documents. If you want to manually define or modify the existing schemaless core, the following are the steps to be followed:
- Define the following updateRequestProcessorChain with the update processor factories specified in sequence in solrconfig.xml. All the defined factories starting with Parse* perform the fieldType identification. The AddSchemaFieldsUpdateProcessorFactory is responsible for creating fields automatically, and the UUIDUpdateProcessorFactory generates unique identifiers for the document. The RemoveBlankFieldUpdateProcessorFactory and FieldNameMutatingUpdateProcessorFactory are for normalization of a field and its value.
<updateRequestProcessorChain name="add-unknown-fields-to-the-schema">
<!-- UUIDUpdateProcessorFactory will generate an id if
none is present in the incoming document -->
<processor class="solr.UUIDUpdateProcessorFactory" />
<processor class="solr.LogUpdateProcessorFactory"/>
<processor class="solr.DistributedUpdateProcessorFactory"/>
<processor class="solr.RemoveBlankFieldUpdateProcessorFactory"/>
<processor class="solr.FieldNameMutatingUpdateProcessorFactory">
<str name="pattern">[^w-.]</str>
<str name="replacement">_</str>
</processor>
<processor class="solr.ParseBooleanFieldUpdateProcessorFactory"/>
<processor class="solr.ParseLongFieldUpdateProcessorFactory"/>
<processor class="solr.ParseDoubleFieldUpdateProcessorFactory"/>
<processor class="solr.ParseDateFieldUpdateProcessorFactory">
<arr name="format">
<str>yyyy-MM-dd'T'HH:mm:ss.SSSZ</str>
<str>yyyy-MM-dd'T'HH:mm:ss,SSSZ</str>
<str>yyyy-MM-dd'T'HH:mm:ss.SSS</str>
<str>yyyy-MM-dd'T'HH:mm:ss,SSS</str>
<str>yyyy-MM-dd'T'HH:mm:ssZ</str>
<str>yyyy-MM-dd'T'HH:mm:ss</str>
<str>yyyy-MM-dd'T'HH:mmZ</str>
<str>yyyy-MM-dd'T'HH:mm</str>
<str>yyyy-MM-dd HH:mm:ss.SSSZ</str>
<str>yyyy-MM-dd HH:mm:ss,SSSZ</str>
<str>yyyy-MM-dd HH:mm:ss.SSS</str>
<str>yyyy-MM-dd HH:mm:ss,SSS</str>
<str>yyyy-MM-dd HH:mm:ssZ</str>
<str>yyyy-MM-dd HH:mm:ss</str>
<str>yyyy-MM-dd HH:mmZ</str>
<str>yyyy-MM-dd HH:mm</str>
<str>yyyy-MM-dd</str>
</arr>
</processor>
<processor class="solr.AddSchemaFieldsUpdateProcessorFactory">
<str name="defaultFieldType">strings</str>
<lst name="typeMapping">
<str name="valueClass">java.lang.Boolean</str>
<str name="fieldType">booleans</str>
</lst>
<lst name="typeMapping">
<str name="valueClass">java.util.Date</str>
<str name="fieldType">tdates</str>
</lst>
<lst name="typeMapping">
<str name="valueClass">java.lang.Long</str>
<str name="valueClass">java.lang.Integer</str>
<str name="fieldType">tlongs</str>
</lst>
<lst name="typeMapping">
<str name="valueClass">java.lang.Number</str>
<str name="fieldType">tdoubles</str>
</lst>
</processor>
<processor class="solr.RunUpdateProcessorFactory"/>
</updateRequestProcessorChain> - For the chain to be usable, UpdateRequestProcessorChain should be registered in the update handler that gets invoked for indexing the documents:
<initParams path="/update/**">
<lst name="defaults">
<str name="update.chain">add-unknown-fields-to-the-schema</str>
</lst>
</initParams> - Enable support for the managed schema in solrconfig.xml:
<schemaFactory class="ManagedIndexSchemaFactory">
<bool name="mutable">true</bool>
<str name="managedSchemaResourceName">managed-schema</str>
</schemaFactory> - After making the preceding changes, you are all set to index documents without worrying about whether the field is defined in schema.xml.
Limitations
Running Solr in full schemaless mode has limitations. The following are the important ones to be noted:
- A limited set of Primitive fieldTypes is supported by automatic field addition and doesn’t allow you to apply an analyzer or perform a specific set of text analysis.
- Field Type identification can lead to wrong fieldType guessing, as Solr cascades through the processors to identify the fieldType. If the document being indexed contains a number, Solr will create a field of type TrieIntField. Now, if the next document contains a floating-point number, Solr would fail to index this document because it has already defined the fieldType of this field as TrieIntField, and a field once defined cannot be changed automatically.
- While defining a field, you may want to fine-tune it by specifying additional attributes such as precisionStep. An automatic fieldType definition ignores that perspective.
![]() Tip The schema should not be manually modified when running Solr in schemaless mode.
Tip The schema should not be manually modified when running Solr in schemaless mode.
REST API for Managing Schema
Before discussing schemaless mode, we used schema.xml, to define the schema. Any changes in the schema require you to manually edit schema.xml and reload the core. Since the inception of Solr, this is the way schema.xml has been used. But recent releases of Solr allow you to manage the schema through REST APIs. Solr provides REST APIs to read, add, remove, and update elements for managing field, fieldType, copyField, and dynamicField elements.
Solr provides two implementations of the base class IndexSchemaFactory to manage schema. You need to define the implementation class in the schemaFactory element in solrconfig.xml:
- ClassicIndexSchemaFactory: This is the default implementation, in which you define the schema manually. The schema.xml file must be present in the conf directory and should be manually modified. This implementation doesn’t support managing the schema through REST APIs.
- ManagedIndexSchemaFactory: This is the implementation to manage a schema through REST APIs.
Configuration
The following are the steps to configure a managed schema for using the REST APIs.
- Define the schemaFactory element in solrconfig.xml and provide the implementation class as ManagedIndexSchemaFactory:
<schemaFactory class="ManagedIndexSchemaFactory">
<bool name="mutable">true</bool>
<str name="managedSchemaResourceName">managed-schema</str>
</schemaFactory>In Solr 5.x, if you create a core without specifying the configuration directory, it will by default use the data_driven_schema_configs configset, which creates a managed schema to support REST calls. The data_driven_schema_configs configset is provided with the Solr distribution and can be located in the $SOLR_DIST/server/solr/configsets directory.
The following is the schemaFactory element in solrconfig.xml for the traditional approach to a schema definition:
<schemaFactory class="ClassicIndexSchemaFactory"/> - The default file for a managed schema definition is managed-schema. You can change the filename by modifying the managedSchemaResourceName parameter. On creating a core, if the schema.xml exists but the managed-schema file doesn’t exist, in that case Solr will copy schema.xml to the managed-schema file and rename schema.xml to schema.xml.bak. Solr doesn’t allow you to change the name of managed schema file to schema.xml. The following is the property to be set for specifying the managed schema file name:
<str name="managedSchemaResourceName">managed-schema</str> - If your schema is finalized, you may be interested in disallowing all future edits. To limit the REST APIs to support only read access, set the mutable Boolean parameter to false:
<bool name="mutable">false</bool>
It’s good to disable the mutable setting in production.
REST Endpoints
Once you have managed-schema set up, you can start performing read and write operations using the REST API. All write requests automatically trigger core reload internally, and so should not be invoked by you in order for the changes to reflect. Table 4-7 lists the operations supported over the REST API, the endpoints to invoke, and the examples.
Table 4-7. REST Endpoints for Managing Schema
Operation | Endpoints & Commands | Example |
|---|---|---|
Read schema | GET /core/schema | curl http://localhost:8983/solr/core/schema?wt=json |
Read field(s) | GET /core/schema/fields GET /core/schema/fields/fieldname | curl http://localhost:8983/solr/core/schema/fields?wt=json |
Modify field | POST /core/schema Commands: add-field delete-field replace-field | curl -X POST -H 'Content-type:application/json' --data-binary '{ "add-field":{ "name":"title", "type":"text_general", "stored":true } }' http://localhost:8983/solr/core/schema |
Read field type | GET /core/schema/fieldtypes GET /core/schema/fieldtypes/name | curl http://localhost:8983/solr/core/schema/fieldtypes?wt=json |
Modify field type | POST /core/schema Commands: add-field-type delete-field-type replace-field-type | curl -X POST -H 'Content-type:application/json' --data-binary '{ "add-field-type" : { "name":"text_ws", "class":"solr.TextField", "positionIncrementGap":"100", "analyzer" : { "tokenizer":{ "class":"solr.WhitespaceTokenizerFactory" }}} }' http://localhost:8983/solr/core/schema |
Read dynamic field(s) | GET /core/schema/dynamicfields GET /core/schema/dynamicfields/name | curl http://localhost:8983/solr/core/schema/dynamicfields?wt=json |
Modify dynamic field | POST /core/schema Commands: add-dynamic-field delete-dynamic-field replace-dynamic-field | curl -X POST -H 'Content-type:application/json' --data-binary '{ "add-dynamic-field":{ "name":"*_en", "type":"text_general", "stored":true } }' http://localhost:8983/solr/core/schema |
Read copy fields | GET /core/schema/copyfields | curl http://localhost:8983/solr/core/schema/copyfields?wt=json |
Modify copy field | POST /core/schema Commands: add-copy-field delete-copy-field replace-copy-field | curl -X POST -H 'Content-type:application/json' --data-binary '{ "add-copy-field":{ "source":"title", "dest":[ "title_ut", "title_pn" ]} }' http://localhost:8983/solr/core/schema |
Other Managed Resources
Solr offers provisions to manage other resources such as stop words and synonyms using the REST APIs.
Usage Steps
The following are the steps for managing stop words and synonyms using the REST APIs.
- Add the implementing filter factory to the analysis chain
<filter class="solr.ManagedStopFilterFactory" managed="product" /> // stopwords
<filter class="solr.ManagedSynonymFilterFactory" managed="product" /> // synonyms - Assign a name to the managed resource
The managed attribute assigns a name to the resource, as shown in the preceding example. This is useful if you want to support multiple stop words or synonyms, such as for the domain, feature, or language.
- Access the resource over REST endpoint
/core/schema/analysis/stopwords/<name> // syntax
/core/schema/analysis/stopwords/product // example
Refer to the Solr manual at https://cwiki.apache.org/confluence/display/solr/Managed+Resources for its complete list of REST endpoints and the usage information.
solrconfig.xml File
Solr supports innumerable features and allows a wide set of customization and control over those features. You can use solrconfig.xml to define and configure the features you want to offer in your search solution and manage its behavior and properties by changing the XML. The important features that can be configured in solrconfig.xml are as follows:
- Define the request handler that specifies the REST endpoint and the corresponding Solr feature to expose over it. For example, all requests to the /select endpoint handle the search request, and the /update endpoint handles the indexing requests.
- Define the search components, update request processors, and query parsers, and configure them to a handler or other component that they can be chained with. Suppose you want to enable the hit-highlighting feature in your search engine. You can do this by defining the highlighting component, configuring the parameters to achieve the desired behavior, and finally chaining it to the search handler.
- Configure paths and files used by the Solr core, such as name of the schema file.
- Configure other core-level properties such as caching, included libraries, auto commit, index merging behavior, and replication.
solrconfig.xml provides a high degree of flexibility in defining and exposing a feature. You define and configure the components provided by Solr or the custom components you developed by extending the Solr base classes, and then you assemble them together to quickly expose a feature.
![]() Note No single chapter is dedicated to the definitions and configurations supported by solrconfig.xml. Instead, you will learn about them as and we discuss a feature or search capability offered by Solr.
Note No single chapter is dedicated to the definitions and configurations supported by solrconfig.xml. Instead, you will learn about them as and we discuss a feature or search capability offered by Solr.
Frequently Asked Questions
This section provides answers to some of the questions that developers often ask while defining schema.xml.
How do I handle the exception indicating that the _version_ field must exist in the schema?
The _version_ field is required for optimistic concurrency in SolrCloud, and it enables a real-time get operation. Solr expects it to be defined in schema.xml as follows:
<field name="_version_" type="long" indexed="true" stored="true" />
It’s recommended to have this field in schema.xml, but if you still want to disable it, you can comment out the updateLog declaration in the updateHandler section in solrconfig.xml.
<!--updateLog>
<str name="dir">${solr.ulog.dir:}</str>
<int name="numVersionBuckets">${solr.ulog.numVersionBuckets:65536}</int>
</updateLog-->
Why is my Schema Change Not Reflected in Solr?
For the changes in schema.xml to be reflected, the core should be reloaded. If any change has been made in index-time processing of a field, all the documents should also be reindexed.
I Have Created a Core in Solr 5.0, but Schema.xml is Missing. Where Can I find it?
By default, the core created by Solr 5.0 is schemaless. It uses managed-schema for all schema definitions. If you want to create a core that contains schema.xml for manual handcrafting, do it as follows:
solr create -c corename -d sample_techproducts_configs
Summary
Good schema design is one of the fundamental steps in building a search engine that really works. If you know the structure of your data, schema design should always precede the indexing process. Though you may need to come back and tune the schema later as your search engine evolves, it’s always good to get it right the first time.
Solr provides a set of fieldTypes that work for most cases, but we all have our unique challenges and that may require us to configure our own analysis chains. As you have seen, configuring a process to the chain is simple, as all Solr configurations are defined in XML files and you need to only add new elements and map them appropriately.
Some of the text analysis process is costly, both in terms of processing time and index size, so chains should be defined carefully. Also, whenever you make a change to the index-time processing for a field, reindexing is mandatory for the changes to reflect.
This chapter focused primarily on designing schema and text analysis. You looked at various analysis processes, their uses, and scenarios where they can be used. Going schemaless was covered in a separate section.
With this chapter, you are good to dive into the much awaited concepts of indexing and searching. The next chapter covers the indexing process, and then the following chapters take up searching along with advanced capabilities.